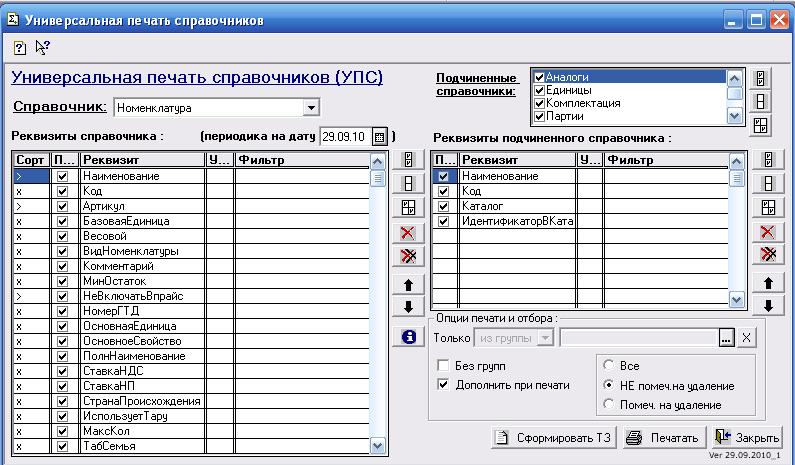
Делопроизводство в 1С 8.3 и документооборот
Раздел \ СЭД Корпоративный документооборот \ Пресс-релизы о СЭД Корпоративный документооборот \ Статья «1С и Документооборот»
Наш документооборот
Внимание! СЭД «Корпоративный документооборот» заменен на новый продукт СЭД «Наш документооборот» оптимизированный и переписанный «с нуля».
Перейти к описанию СЭД «Наш документооборот»
Описание на этой странице потеряло актуальность.
С помощью программы «1С:Документооборот» осуществляется учет движения официальной документации организации, основывающийся на положения законодательства РФ, требованиях ГОСТ, а также традициях, сложившихся в области делопроизводства в России и за рубежом.
Виды документов
В программе осуществляется обработка входящей, исходящей и внутренней корреспонденции.
К любому документу может быть прикреплен 1 и более файлов, в том числе фотография или отсканированный документ.
Входящая документация 1С:8.2
В программе регистрируются входящие документы и от юридических, и от физических лиц. Регистрация осуществляется согласно требованиям ГОСТ и установившимся в РФ правилам в области делопроизводства. При регистрации документ проходит три этапа – первичную регистрацию, рассмотрение уполномоченным лицом и исполнение документа.
Исходящая корреспонденция 1С:8.2
Исходящий документ может создаваться как в ответ на входящий, так и самостоятельно.
Регистрационный номер исходящему документу присваивает секретарь организации после его согласования и утверждения уполномоченным лицом.
Если исходящий документ создается в ответ на входящий, то программа автоматически присвоит входящему отметку – Отправлен ответ.
В процессе обработки исходящая документация проходит этапы, включающие в себя непосредственное создание, согласование, утверждение уполномоченным лицом и регистрацию.
Входящая и исходящая корреспонденция составляется программой в цепочки.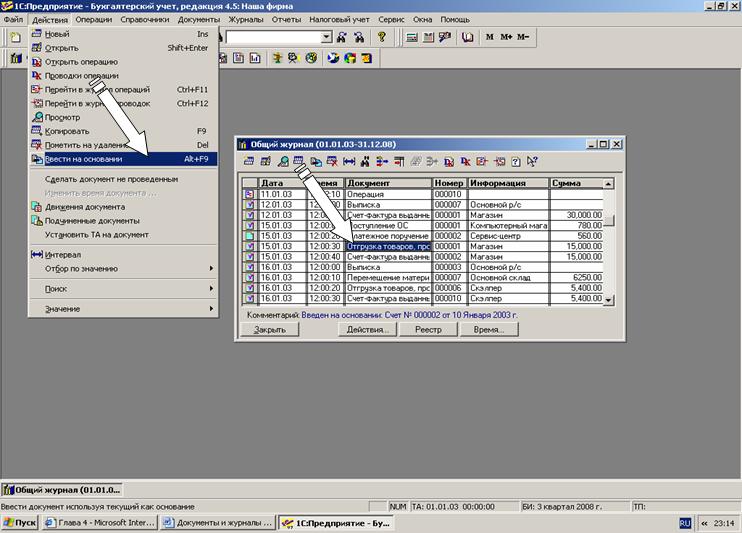
Внутренняя документация
Под внутренними документами принято понимать организационно-распорядительные и информационно-справочные официальные документы. Сюда относятся приказы, документы кадровой службы, служебные записки и др.
Внутренний документ, как и исходящий, регистрируется секретарем организации с присвоением номера после согласования документа и утверждения уполномоченным лицом.
Виды документации 8.2
В качестве одной из главных характеристик документа выступает его вид, согласно которому определяется срок исполнения этого документа, маршрут его обработки и правила присвоения номера при регистрации.
Программа самостоятельно ведет списки для входящей, исходящей и внутренней документации в отдельности.
Присвоение регистрационного номера
В программе осуществляется регистрация документа в зависимости от его даты, вида, подразделения и корреспондента (для входящих/исходящих). Для отдельного вида документации можно создать отдельный нумератор.
Карточка документа делопроизводства
На каждый вновь созданный документ программа автоматически создает учетно-регистрационную карточку, внешнее оформление и список полей которой пользователь может подобрать самостоятельно. Доступна также функция удаления или добавления полей учетной карточки. Учетно-регистрационную карточку можно распечатать.
Карточка учета движения входящей/исходящей корреспонденции предназначена также для просмотра общей переписки с тем или иным корреспондентом.
Дополнительные параметры
К дополнительным параметрам относят реквизиты и сведения, настроить их может администратор или пользователь, ответственный за нормативно-справочные документы. Дополнительные свойства могут быть настроены индивидуально в зависимости от типа или вида документа. В программе используются также наборы свойств, применяемые при определенных данных.
В качестве примера использования дополнительных параметров можно обозначить возможность сделать документ актуальным/неактуальным и пометить его, как «информационно-справочный».
Прочие возможности
Программа может осуществлять учет обращений физических лиц. Можно настроить ограничение доступа к личной информации этих граждан или к входящей документации.
Хранение внутренних документов осуществляется в структуре папок, что помогает упорядочить документооборот и определить права доступа к данной информации.
Смотрите также:
- Хранение информации
- Основные возможности
- Ведение безбумажного документооборота
- Переход с «1С:Документооборот» на СЭД «Корпоративный документооборот»
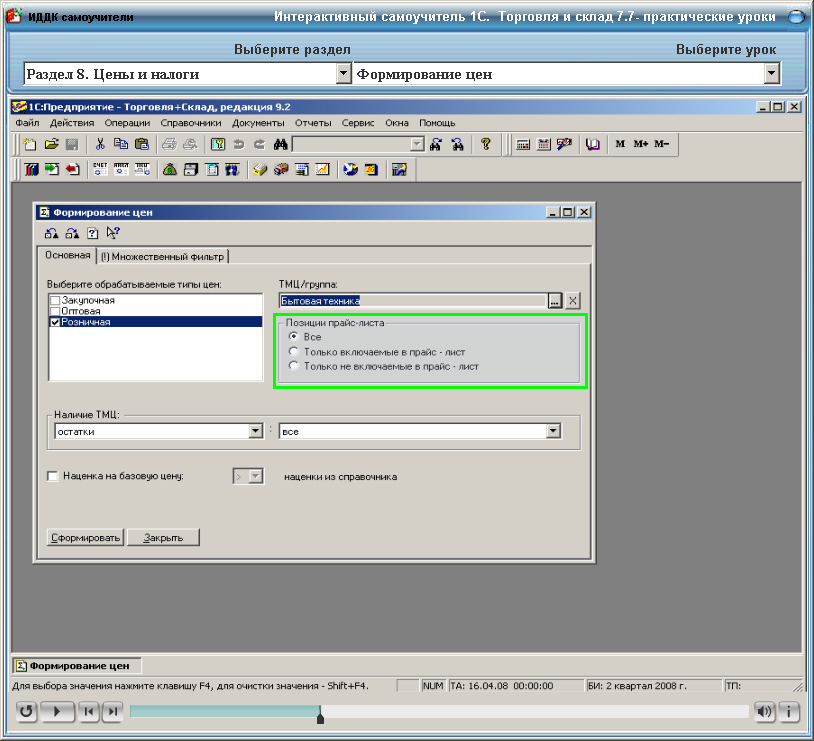
Программа 1С Бухгалтерия – Профессиональный бухгалтер
admin Комментариев нет 1С Бухгалтерия 3.0, Бухгалтерия, Программа 1С Бухгалтерия
Смотрите запись вебинара про изменения в учете с 2017 года.
Продолжить чтение
admin Комментариев нет
1С Бухгалтерия 3. 0, 1С ЗУП 2.5, Программа 1С Бухгалтерия
0, 1С ЗУП 2.5, Программа 1С Бухгалтерия
14 октября 2015 года партнерами 1С был проведен очередной бесплатный семинар, где рассказывалось про изменения и новости в программах 1С, а также учете и налогообложении. Первый доклад был посвящен работе с программами 1С в облаке. Эта же тема уже освящалась в предыдущем семинаре, который проходил весной, я об этом тоже рассказывала в этой статье.
Продолжить чтение
admin Один комментарий 1С Бухгалтерия 3.0, 1С ЗУП 2.5, 1С Управление торговлей 10.3, 1С Управление торговлей 11, Программа 1С Бухгалтерия
Вопрос архивирования баз 1С стоит очень остро. Особенно если в программой работа ведется часто или несколькими пользователями. Можно делать архивацию стандартными средствами 1С, через конфигуратор. Но лучше эту задачу автоматизировать. Для этого прекрасно подходит программа Effector Saver 3. Разберем, как настроить автоматическое архивирование баз 1С с ее помощью.
Разберем, как настроить автоматическое архивирование баз 1С с ее помощью.
Продолжить чтение
admin Комментариев нет 1С Бухгалтерия 3.0, 1С ЗУП 2.5, Программа 1С Бухгалтерия
17 декабря 2014 года прошел очередной единый семинар, который был проведен партнерами фирмы 1С по всей России. Первый доклад был посвящен сервису «1С-Отчетность». Сервис доступен всем пользователям программы 1С, включая тех, кто арендует программу или использует ее через Интернет.
Продолжить чтение
admin 2 комментария 1С Бухгалтерия 3.0, 1С ЗУП 2.5, Программа 1С Бухгалтерия
08 октября 2014 года был проведен очередной единый семинар, который проводился партнерами фирмы 1С во многих городах России. В начале семинара было рассказано о новых функциях программы 1С Бухгалтерия 8 ред. 3.0. Также было сказано, что ред. 2.0 будет поддерживаться только до конца года, поэтому сейчас самое время переходить на ред. 3.0.
В начале семинара было рассказано о новых функциях программы 1С Бухгалтерия 8 ред. 3.0. Также было сказано, что ред. 2.0 будет поддерживаться только до конца года, поэтому сейчас самое время переходить на ред. 3.0.
Продолжить чтение
admin Комментариев нет 1С Бухгалтерия 3.0, Программа 1С Бухгалтерия
В одной из предыдущих статей я уже рассказывала о нескольких полезных обучающих материалах по 1С, которые подойдут для новичков. А сегодня хотелось бы рассказать о том, какая книга по программе 1с подойдет для более подробного обучения. Я сделаю обзор нескольких книг, которые помогают лучше разобраться в программе 1С Бухгалтерия 8.
Продолжить чтение
admin Один комментарий
1С Бухгалтерия 3.0, 1С ЗУП 2. 5, Программа 1С Бухгалтерия
5, Программа 1С Бухгалтерия
02 апреля 2014 года в 100 городах России одновременно партнерами 1С был проведен очередной семинар. Большое внимание на семинаре было уделено заполнению новой формы РСВ-1, которая представляется, начиная с 1 квартала 2014 года. Были рассмотрены наиболее сложные вопросы заполнения данной формы, такие как заполнение строки 100 в первом разделе, заполнение раздела 6 и другие.
Продолжить чтение
admin Комментариев нет 1С Бухгалтерия 3.0, 1С ЗУП 2.5, 1С Управление торговлей 11, Программа 1С Бухгалтерия
09 октября 2013 прошел очередной единый семинар, который проводится партнерами фирмами 1С в более 100 городах России. Я опять посетила семинар, который проводила компания Онлайн в городе Уфа и хотела бы поделиться основными новостями.
Продолжить чтение
admin Комментариев нет Программа 1С Бухгалтерия
Простой – это время, в течение которого работник находился на рабочем месте, но не участвовал в производственном процессе, оплата времени простоя зависит от того, по чьей вине он произошел. Простой может быть: по вине работника, такой простой не оплачивается по вине работодателя, оплачивается в размере не менее 2/3 средней заработной платы работника не зависеть от […]
Простой может быть: по вине работника, такой простой не оплачивается по вине работодателя, оплачивается в размере не менее 2/3 средней заработной платы работника не зависеть от […]
Продолжить чтение
admin 2 комментария Программа 1С Бухгалтерия
Взносы в пенсионный фонд начисляются с зарплаты всех сотрудников предприятия, однако многие работники принимают решение уплачивать еще и добровольные взносы, рассмотрим, как сделать начисление дополнительных страховых взносов на накопительную часть в 1С Бухгалтерия 8. В программе 1с Бухгалтерия 8 редакция 2.0 начисление дополнительных страховых взносов осуществляется в несколько этапов.
Продолжить чтение
admin Комментариев нет Бухгалтерия, Программа 1С Бухгалтерия
Если вы начинаете работу с программными продуктами от фирмы 1С и вам нужен самоучитель программы 1с, например, по 1С Бухгалтерия, то в этой подборке вы найдете подходящие материалы для обучения. Первое, что хотелось бы рекомендовать – это даже ни одна книга, а целый комплект книг плюс учебная платформа 1С Предприятия 8, которая к тому же […]
Первое, что хотелось бы рекомендовать – это даже ни одна книга, а целый комплект книг плюс учебная платформа 1С Предприятия 8, которая к тому же […]
Продолжить чтение
admin 3 комментария Бухгалтерия, Программа 1С Бухгалтерия
Многим предприятиям приходится уплачивать пошлины различного вида, от этого зависит и учет госпошлины в бухгалтерском учете. В соответствие со статьей 13 Налогового кодекса Российской Федерации государственная пошлина является федеральным сбором. Она отражается на счете 68 «Расчеты по налогам и сборам».
Продолжить чтение
admin Комментариев нет Программа 1С Бухгалтерия
Тара – это вид материалов, предназначенная для упаковки, хранения и транспортировки продукции, товаров и других ценностей, учет тары в 1с зависит от ее вида. Тара бывает возвратная и невозвратная. Счет для учета тары зависит от вида деятельности предприятия. У производственных предприятий тара учитывается на счете 10 субсчет 4 «Тара и тарные материалы», у предприятий, которые […]
Тара бывает возвратная и невозвратная. Счет для учета тары зависит от вида деятельности предприятия. У производственных предприятий тара учитывается на счете 10 субсчет 4 «Тара и тарные материалы», у предприятий, которые […]
Продолжить чтение
admin Комментариев нет Бухгалтерия, Программа 1С Бухгалтерия
Назначение спецодежды – это защита работников от вредного воздействия, налоговый и бухгалтерский учет спецодежды может различаться в зависимости от ее вида и срока использования. Бухгалтерский учет спецодежды регулируется Методическим указаниями по бухгалтерскому учету специального инструмента, специальных приспособлений, специального оборудования и специальной одежды (утверждены приказом Минфина России от 26.12.2002 № 135н).
Продолжить чтение
admin 2 комментария Программа 1С Бухгалтерия
Дивиденды сотрудникам предприятия – это их доход, полученный от организации, в которой они владеют акциями и долями. Выплата дивидендов производится из прибыли, оставшейся после налогообложения. Доход может выплачиваться как сотрудникам организации, так и физическим лицам, не являющимися сотрудниками, и юридическим лицам. В этой статье будет рассмотрено, как отражаются дивиденды сотрудникам в 1С Бухгалтерия 8 редакция […]
Выплата дивидендов производится из прибыли, оставшейся после налогообложения. Доход может выплачиваться как сотрудникам организации, так и физическим лицам, не являющимися сотрудниками, и юридическим лицам. В этой статье будет рассмотрено, как отражаются дивиденды сотрудникам в 1С Бухгалтерия 8 редакция […]
Продолжить чтение
Учебник C1
Учебник C1Анализ RMSD в CPPTRAJ
Дэниел Р. Роу, июль 2014 г.
Примечание. Это руководство было разработано для использования с CPPTRAJ из AmberTools 14.
ВведениеРасчет RMSD
Загрузка эталонной структуры
Расчет RMSD для эталона
RMSD для эталона с различной топологией
Связанные файлы
В этом учебном пособии рассматривается один из самых основных типов выполняемого анализа после моделирования МД: координатное среднеквадратичное отклонение (RMSD). Это также будет охватывать «пометку» загруженной топологии и эталонных файлов в CPPTRAJ.
RMSD измеряет отклонение целевого набора координат (т. е. конструкции)
к эталонному набору координат, где RMSD=0,0 указывает на идеальное
перекрывать. RMSD определяется как:
е. конструкции)
к эталонному набору координат, где RMSD=0,0 указывает на идеальное
перекрывать. RMSD определяется как:
При расчете среднеквадратичного стандартного отклонения цели относительно эталонной конструкции есть два
очень важные требования:
Предпосылки
В этом руководстве предполагается, что вы установили и протестировали AmberTools и
что вы прошли первое руководство по CPPTRAJ.
Кроме того, xmgrace будет
требуется для просмотра некоторых выходных данных. Просмотр молекулярной графики
программа (такая как VMD или
Химера) рекомендуется
для просмотра структур/траекторий.
Просмотр молекулярной графики
программа (такая как VMD или
Химера) рекомендуется
для просмотра структур/траекторий.
На протяжении всего этого урока приводится краткий пример траектории бета-шпильки. trpzip2 будет использоваться. Траектория находится в формате NetCDF, т.е. быстрее обрабатывать, компактнее, точнее и надежнее, чем формат ASCII. NetCDF включен по умолчанию в Amber, но если вы обнаружите, что что ваш CPPTRAJ не может прочитать эту траекторию, обратитесь в Янтарный список рассылки для помощи. Траекторию, соответствующую топологию и другие файлы можно скачать здесь:
- trpzip2.gb.nc ¦ Сумма MD5: 059435cfe1fcd57c327d46711da9ceff
- trpzip2.ff10.mbondi.parm7 ¦ Сумма MD5: 140044a45c683612da3431dfd0697e22
- trpzip2.1LE1.1.rst7 ¦ Сумма MD5: 9d4a64e65c77e9833ff38a424b4669d0
- trpzip2.1LE1.10.rst7 ¦ Сумма MD5: 6ea49fa08bae5fd92fb4246ee7ec34ca
- 2GB1.pdb ¦ Сумма MD5: 69fd269e026f25aef2a5e94654296ae5
Более подробную информацию о CPPTRAJ см. здесь:
здесь:
Дэниел Р. Роу и Томас Э. Читэм, III,
«PTRAJ и CPPTRAJ: программное обеспечение для обработки и анализа траекторных данных молекулярной динамики».
J. Chem. Теория вычислений., 2013, 9 (7), стр. 3084-3095.
Чтобы запустить CPPTRAJ, введите «cpptraj» в командной строке:
[пользователь@компьютер ~]$ cpptraj
CPPTRAJ: Анализ траектории. V14.05
___ ___ ___ ___
| \/ | \/ | \/ |
_|_/\_|_/\_|_/\_|_
>
Загрузить файл топологии и траектории:
> парм trpzip2.ff10.mbondi.parm7 Чтение «trpzip2.ff10.mbondi.parm7» как Amber Topology > траджин trpzip2.gb.nc Чтение «trpzip2.gb.nc» как Amber NetCDF
Укажите команду RMSD:
> rms ToFirst :1-13&!@H= первый выход rmsd1.agr масса
RMSD: (:1-13&!@H*), эталоном является первый кадр (:1-13&!@H*), с подгонкой, взвешенный по массе.
В этом случае мы вычисляем средневзвешенное среднеквадратичное отклонение, сохраняя в наборе данных
названный «ToFirst», используя все неводородные атомы в остатках с 1 по 13, используя
первый кадр в качестве ссылки и запись в файл с именем «rmsd1..png) agr»
(который будет записан в формате xmgrace из-за расширения .agr). Примечание
что по умолчанию команда ‘rms’ в CPPTRAJ вычисляет наиболее подходящее RMSD, что означает, что каждый
структура поворачивается и перемещается так, чтобы минимизировать среднеквадратичное отклонение до
опорная структура (в данном случае первый кадр). Как таковой, команда ‘rms’ изменяет
координаты для всех последующих команд, если не указано «nofit» (об этом позже).
agr»
(который будет записан в формате xmgrace из-за расширения .agr). Примечание
что по умолчанию команда ‘rms’ в CPPTRAJ вычисляет наиболее подходящее RMSD, что означает, что каждый
структура поворачивается и перемещается так, чтобы минимизировать среднеквадратичное отклонение до
опорная структура (в данном случае первый кадр). Как таковой, команда ‘rms’ изменяет
координаты для всех последующих команд, если не указано «nofit» (об этом позже).
Запустите обработку траектории, набрав «run». Как только прогон завершится, если xmgrace установлен, вы можете просмотреть вывод прямо из CPPTRAJ командная строка:
> xmgrace rmsd1.agr
На этом рисунке ось X — это номер кадра, а ось Y — координата RMSD относительно первого кадра (в ангстремах).
Хотя среднеквадратичное отклонение для первого кадра может быть полезным индикатором того, насколько структура
отклоняется от своей начальной конфигурации, как правило, также интересует вычисление
отклонение от конкретной эталонной структуры, такой как полученная в результате экспериментального
метод (например, рентгеновская кристаллография или ЯМР). Запись PDB для trpzip2, изученная с помощью ЯМР,
1ЛЕ1. Янтарь
файл перезапуска ‘trpzip2.1LE1.1.rst7’ содержит координаты первого члена
ансамбля ЯМР. Эта структура может быть загружена как ссылка с помощью ‘reference’
команда.
Запись PDB для trpzip2, изученная с помощью ЯМР,
1ЛЕ1. Янтарь
файл перезапуска ‘trpzip2.1LE1.1.rst7’ содержит координаты первого члена
ансамбля ЯМР. Эта структура может быть загружена как ссылка с помощью ‘reference’
команда.
Поскольку этот файл имеет ту же топологию, что и наша траектория (220 атомов), мы не необходимо загрузить новый файл топологии.
> ссылка trpzip2.1LE1.1.rst7 Чтение «trpzip2.1LE1.1.rst7» как Amber Restart 'trpzip2.1LE1.1.rst7' - это файл перезапуска AMBER, без скоростей, Parm trpzip2.ff10.mbondi.parm7 (чтение 1 из 1)
Аналогично, файл перезапуска Amber ‘trpzip2.1LE1.10.rst7’ содержит координаты для 10-й участник ансамбля ЯМР:
> ссылка trpzip2.1LE1.10.rst7 [десятый_член] Чтение «trpzip2.1LE1.10.rst7» как Amber Restart 'trpzip2.1LE1.10.rst7' - это файл перезапуска AMBER, без скоростей, Parm trpzip2.ff10.mbondi.parm7 (чтение 1 из 1)
В этом случае у нас есть тегированная ссылка с ‘[десятым_членом]’. В cpptraj тегами могут быть отмечены как ссылочные структуры, так и файлы топологии.
они загружаются путем предоставления имени в квадратных скобках, т. е. [<имя>].
к файлам можно обращаться по имени файла, по индексу (т. е. в том порядке, в котором они
загружается, начиная с 0), или по тегу.
В cpptraj тегами могут быть отмечены как ссылочные структуры, так и файлы топологии.
они загружаются путем предоставления имени в квадратных скобках, т. е. [<имя>].
к файлам можно обращаться по имени файла, по индексу (т. е. в том порядке, в котором они
загружается, начиная с 0), или по тегу.
Любой файл траектории, который CPPTRAJ может нормально прочитать, может использоваться как ссылочная структура, указав желаемый номер кадра или «последний кадр» чтобы явно выбрать окончательный кадр траектории. Например, скажем, мы хотели использовать конечный кадр траектории в качестве опорной структуры. Мы можем используйте ключевое слово ‘lastframe’ и пометьте его [последний] следующим образом:
> ссылка trpzip2.gb.nc lastframe [последний] Чтение «trpzip2.gb.nc» как Amber NetCDF 'trpzip2.gb.nc' - это траектория NetCDF AMBER, Parm trpzip2.ff10.mbondi.parm7 (чтение 1 из 1201)
Команда list может предоставить информацию о загруженных в данный момент опорных структурах:
> список ссылок
Опорные кадры (всего 3):
0: 'trpzip2. 1LE1.1.rst7', кадр 1
1: [десятый_член] 'trpzip2.1LE1.10.rst7', кадр 1
2: [последний] 'trpzip2.gb.nc', кадр 1201
Активная система отсчета для масок равна 0
1LE1.1.rst7', кадр 1
1: [десятый_член] 'trpzip2.1LE1.10.rst7', кадр 1
2: [последний] 'trpzip2.gb.nc', кадр 1201
Активная система отсчета для масок равна 0
Здесь мы видим три загруженные ссылочные структуры, а также с их индексами, именами и тегами (если тег был указан).
После того, как все загруженные в данный момент ссылочные структуры будут напечатаны, является сообщение «Активная система отсчета для масок равна 0». Это значит, что Маски на основе расстояния будут использовать опорный индекс 0 для определения того, что выбираются атомы. Единственное действие в CPPTRAJ, которое обновляет данные о расстоянии. маски на основе текущего кадра — это действие маски.
Теперь, когда мы загрузили некоторые эталонные структуры, мы можем рассчитать RMSD для каждый. Есть три ключевых слова, которые можно использовать для выбора ссылочных структур:
- ссылка: Используйте первую загруженную структуру ссылки.
- refindex <#>: Использовать номер индекса ссылки <#> (так что «ссылка» похожа на «refindex 0»).

- ссылка <имя | tag>: Использовать ссылку, указанную именем файла или тегом.
> rms ToMember1 :1-13&!@H= ссылка на rmsd2.agr
Маска [:1-13&!@H*] соответствует 116 атомам.
RMSD: (:1-13&!@H*), эталоном является система отсчета trpzip2.1LE1.1.rst7 (:1-13&!@H*), с подгонкой.
> rms ToMember10 :1-13&!@H= refindex 1 из rmsd2.agr
Маска [:1-13&!@H*] соответствует 116 атомам.
RMSD: (:1-13&!@H*), эталоном является система отсчета trpzip2.1LE1.10.rst7 (:1-13&!@H*), с подгонкой.
> rms ToLast :1-13&!@H= ref [последний] из rmsd2.agr
Маска [:1-13&!@H*] соответствует 116 атомам.
RMSD: (:1-13&!@H*), эталоном является система отсчета trpzip2.gb.nc (:1-13&!@H*), с подгонкой.
Обратите внимание, что данные команд ‘rms’ будут выводиться в один файл
потому что мы указали один и тот же выходной файл для каждой команды. Это относится к
почти каждая команда, использующая ключевое слово «out» в CPPTRAJ.
Запустите обработку траектории, набрав «run». Как только прогон завершится, если xmgrace установлен, вы можете просмотреть вывод прямо из CPPTRAJ командная строка:
> xmgrace rmsd2.agr
Здесь мы видим, что траектория начинается немного ближе к элементу 1. чем член 10.
Часто бывает полезно посмотреть на среднеквадратичное отклонение между конструкциями, которые могут не
имеют одинаковую топологию. Например, связанной структурой шпильки является структура
IgG-связывающий домен B1 белка G (GB1, PDB ID: 2GB1), который имеет аналогичное расположение
гидрофобные остатки в его нитях. Однако у него другой мотив поворота.
а также два дополнительных остатка в области поворота. Кому-то может быть интересно
с тем, насколько нити trpzip2 похожи на нити GB1, или хотят
выровняйте структуру trpzip2 со шпилькой GB1. Это можно сделать, загрузив
GB1 в качестве эталонной структуры, а затем выбор целевой маски для trpzip2 и
эталонная маска для GB1, чтобы они перекрывались. Осмотр двух структур
показывает, что остатки с 1 по 6 и с 7 по 12 trpzip2 перекрываются с остатками с 42 по 47.
и от 50 до 55 GB1.
Осмотр двух структур
показывает, что остатки с 1 по 6 и с 7 по 12 trpzip2 перекрываются с остатками с 42 по 47.
и от 50 до 55 GB1.
Trpzip2 (слева) рядом со второй шпилькой GB1 (справа, PDB ID: 2GB1). Мотив гидрофобного остатка в trpzip2 соответствует найденному в GB1. выделено красным цветом. Рисунок создан с помощью VMD 1.9.1.
Поскольку топология GB1 отличается от топологии trpzip2, нам нужно загрузить ее как новую топологию.
> парм 2GB1.pdb Чтение «2GB1.pdb» как файла PDB 2GB1.pdb: определение информации об облигациях на расстоянии. Предупреждение: 2GB1.pdb: Определение расстояния связи по умолчанию от типов элементов.
Обратите внимание, что, поскольку файлы PDB не содержат соединения, CPPTRAJ автоматически пытается определить связность на основе межатомных расстояния и типы элементов.
Теперь мы можем загрузить 2GB1 в качестве ссылочной структуры. Однако, поскольку 2GB1 не использует
первая загруженная топология, нам нужно указать топологию для использования. Похожий на
ссылочные структуры, топологии могут быть указаны по индексу, имени или тегу.
Похожий на
ссылочные структуры, топологии могут быть указаны по индексу, имени или тегу.
- parmindex <#>: Использовать номер индекса топологии <#>.
- параметр <имя | tag>: Использовать топологию, указанную именем файла или тегом.
> ссылка 2GB1.pdb параметр 2GB1.pdb [GB1] Чтение «2GB1.pdb» как PDB «2GB1.pdb» — это файл PDB, Parm 2GB1.pdb (чтение 1 из 1)
Теперь мы указываем команду ‘rms’, но с небольшими отличиями от предыдущие команды. Во-первых, так как остатки в основном разные между двумя цепями, и порядок атомов в PDB может быть другим чем в нашей топологии, мы будем использовать только альфа-углероды. Во-вторых, мы необходимо указать две маски: одна описывает атомы для выбора в trpzip2, и тот, который описывает атомы для выбора в GB1.
> rms ToGB1 ref [GB1] :1-12@CA :42-47,50-55@CA out rmsd3.agr
Маска [:42-47,50-55@CA] соответствует 12 атомам.
RMSD: (:1-12@CA), система отсчета 2GB1. pdb (:42-47,50-55@CA), с подгонкой.
pdb (:42-47,50-55@CA), с подгонкой.
Мы также укажем CPPTRAJ записать первый кадр trpzip2 после него. был наиболее подходящим RMS с использованием ключевого слова onlyframes.
> trajout trpzip2.overlap.mol2 только кадры 1 Запись «trpzip2.overlap.mol2» как Mol2 Сохранение кадров 1
Введите «run», чтобы обработать траекторию. Вы можете видеть в выводе, что количество атомов мишени, выбранных во время обработки траектории, совпадает количество атомов, выбранных для эталона.
НАСТРОЙКА ДЕЙСТВИЯ ДЛЯ PARM 'trpzip2.ff10.mbondi.parm7' (1 действие): 0: [rms ToGB1 ref [GB1] :1-12@CA :42-47,50-55@CA out rmsd3.agr] Маска [:1-12@CA] соответствует 12 атомам.
После завершения выполнения, если xmgrace установлен, вы можете просмотреть вывод прямо из командной строки CPPTRAJ:
> xmgrace rmsd3.agr
Если вы визуализируете структуру вывода, вы увидите, что файл trpzip2
координаты лучше всего подходят для указанных нитей в GB1.
Пряди trpzip2 (синего цвета), наложенные внахлест на шпильку GB1 (голубого цвета).
Эти файлы можно использовать для проверки вывода.
rmsd1.inrmsd1.agr
rmsd2.in
rmsd2.agr
rmsd3.in
rmsd3.agr
trpzip2.overlap.mol2
Copyright Daniel R. Roe, 2014
Алгоритм кластеризации K-средних: приложения, типы и демонстрации [обновлено]
Каждый инженер по машинному обучению хочет получать точные прогнозы с помощью своих алгоритмов. Такие алгоритмы обучения обычно делятся на два типа — с учителем и без учителя. Кластеризация K-средних — это один из неконтролируемых алгоритмов, в котором доступные входные данные не имеют помеченного ответа.
Типы кластеризации
Кластеризация — это тип обучения без учителя, при котором точки данных группируются в разные наборы в зависимости от степени их сходства.
Различные типы кластеризации:
- Иерархическая кластеризация
- Разделение кластера
Иерархическая кластеризация далее подразделяется на:
- Агломерационная кластеризация
- Разделительная кластеризация
Разделение на кластеры подразделяется на:
- Кластеризация K-средних
- Кластеризация нечетких C-средних
Иерархическая кластеризация
Иерархическая кластеризация использует древовидную структуру, например:
В агломеративной кластеризации используется восходящий подход. Мы начинаем с каждого элемента как отдельного кластера и последовательно объединяем их в более массивные кластеры, как показано ниже:
Мы начинаем с каждого элемента как отдельного кластера и последовательно объединяем их в более массивные кластеры, как показано ниже:
Разделительная кластеризация — это нисходящий подход. Мы начинаем со всего набора и продолжаем делить его на последовательно меньшие кластеры, как вы можете видеть ниже:
Разделение Кластеризация
Кластеризация секционирования делится на два подтипа — кластеризация K-средних и нечеткие C-средние.
При кластеризации k-средних объекты делятся на несколько кластеров, обозначенных номером «K». Поэтому, если мы говорим, что K = 2, объекты делятся на два кластера, c1 и c2, как показано:
Здесь свойства или характеристики сравниваются, и все объекты, имеющие схожие характеристики, группируются вместе.
Нечеткое c-среднее очень похоже на k-среднее в том смысле, что оно группирует вместе объекты со схожими характеристиками. В кластеризации k-средних один объект не может принадлежать двум разным кластерам. Но в c-средних объекты могут принадлежать более чем одному кластеру, как показано.
Но в c-средних объекты могут принадлежать более чем одному кластеру, как показано.
Что подразумевается под алгоритмом кластеризации K-средних?
Кластеризация K-средних — это алгоритм обучения без учителя. Для этой кластеризации нет размеченных данных, в отличие от обучения с учителем. K-Means выполняет разделение объектов на кластеры, которые имеют сходство и не похожи на объекты, принадлежащие другому кластеру.
Термин «К» — это число. Вам нужно сообщить системе, сколько кластеров вам нужно создать. Например, K = 2 относится к двум кластерам. Существует способ выяснить, какое значение K является лучшим или оптимальным для заданных данных.
Для лучшего понимания k-средних возьмем пример из крикета. Представьте, что вы получили данные о множестве игроков в крикет со всего мира, которые дают информацию о набранных игроком ранах и калитках, взятых им в последних десяти матчах. На основе этой информации нам нужно сгруппировать данные в два кластера, а именно игроков с битой и боулеров.
Давайте рассмотрим шаги по созданию этих кластеров.
Решение:
Назначить точки данных
Здесь у нас есть набор данных, построенный по координатам «x» и «y». Информация по оси y относится к забитым пробежкам, а по оси x — к калиткам, взятым игроками.
Если мы нанесем данные, это будет выглядеть так:
Выполнить кластеризацию
Нам нужно создать кластеры, как показано ниже:
Рассмотрим тот же набор данных, давайте решим задачу, используя кластеризацию K-средних (приняв K = 2).
Первым шагом в кластеризации k-средних является случайное распределение двух центроидов (при K=2). Две точки назначаются как центроиды. Обратите внимание, что точки могут быть где угодно, так как они являются случайными точками. Их называют центроидами, но изначально они не являются центральной точкой данного набора данных.
Следующим шагом является определение расстояния между точками данных случайно назначенных центроидов. Для каждой точки расстояние измеряется от обоих центроидов, и в зависимости от того, какое расстояние меньше, эта точка назначается этому центроиду. Вы можете видеть точки данных, прикрепленные к центроидам и представленные здесь синим и желтым цветом.
Для каждой точки расстояние измеряется от обоих центроидов, и в зависимости от того, какое расстояние меньше, эта точка назначается этому центроиду. Вы можете видеть точки данных, прикрепленные к центроидам и представленные здесь синим и желтым цветом.
Следующим шагом является определение фактического центроида для этих двух кластеров. Исходный случайно выделенный центроид должен быть перемещен в фактический центроид кластеров.
Этот процесс вычисления расстояния и изменения положения центроида продолжается до тех пор, пока мы не получим наш окончательный кластер. Затем репозиционирование центроида прекращается.
Как видно выше, центроид больше не нуждается в изменении положения, а это означает, что алгоритм сошелся, и у нас есть два кластера с центроидом.
Преимущества k-средних
- Простота и удобство реализации. Алгоритм k-средних прост для понимания и реализации, что делает его популярным выбором для задач кластеризации.
- Быстрота и эффективность: метод K-средних эффективен в вычислительном отношении и может обрабатывать большие наборы данных высокой размерности.
- Масштабируемость: K-средние могут обрабатывать большие наборы данных с большим количеством точек данных и могут быть легко масштабированы для обработки еще больших наборов данных.
- Гибкость: K-means легко адаптируется к различным приложениям и может использоваться с различными метриками расстояния и методами инициализации.
Недостатки K-средних:
- Чувствительность к начальным центроидам: K-средние чувствительны к начальному выбору центроидов и могут сходиться к субоптимальному решению.
- Требуется указать количество кластеров: Перед запуском алгоритма необходимо указать количество кластеров k, что может вызвать затруднения в некоторых приложениях.
- Чувствителен к выбросам: K-средние чувствительны к выбросам, которые могут оказать существенное влияние на результирующие кластеры.
Применение кластеризации K-средних
Кластеризация K-средних используется во множестве примеров или бизнес-кейсов в реальной жизни, например:
- Успеваемость
- Диагностические системы
- Поисковые системы
- Беспроводные сенсорные сети
Академическая успеваемость
На основании оценок учащиеся распределяются по классам, таким как A, B или C.
Системы диагностики
Медицинская профессия использует метод k-средних для создания более интеллектуальных систем поддержки принятия медицинских решений, особенно при лечении заболеваний печени.
Поисковые системы
Кластеризация является основой поисковых систем. При выполнении поиска результаты поиска необходимо сгруппировать, и поисковые системы очень часто используют для этого кластеризацию.
Беспроводные сенсорные сети
Алгоритм кластеризации играет роль поиска головок кластера, которые собирают все данные в соответствующем кластере.
Измерение расстояния
Мера расстояния определяет сходство между двумя элементами и влияет на форму кластеров.
Кластеризация K-средних поддерживает различные виды мер расстояния, например:
- Евклидова мера расстояния
- Манхэттенский дальномер
- Евклидова мера расстояния в квадрате
- Измерение косинусного расстояния
Евклидово расстояние
Самый распространенный случай — определение расстояния между двумя точками. Если у нас есть точка P и точка Q, евклидово расстояние представляет собой обычную прямую линию. Это расстояние между двумя точками в евклидовом пространстве.
Формула для расстояния между двумя точками показана ниже:
Евклидова дальномер в квадрате
Это идентично евклидову измерению расстояния, но не извлекает квадратный корень в конце. Формула показана ниже:
Манхэттенский дальномер
Манхэттенское расстояние — это простая сумма горизонтальной и вертикальной составляющих или расстояние между двумя точками, измеренное вдоль осей под прямым углом.
Обратите внимание, что мы берем абсолютное значение, чтобы не учитывать отрицательные значения.
Формула показана ниже:
Измерение косинусного расстояния
В этом случае мы берем угол между двумя векторами, образованными соединением исходной точки. Формула показана ниже:
K-средние значения сегментации извержений гейзеров
К-средних можно использовать для сегментации набора данных Geyser’s Eruptions, который регистрирует продолжительность и время ожидания между извержениями гейзера Old Faithful в Йеллоустонском национальном парке. Алгоритм можно использовать для группирования извержений по их продолжительности и времени ожидания, а также для выявления различных моделей извержений.
K-среднее для сжатия изображения
K-means также можно использовать для сжатия изображений, где его можно использовать для уменьшения количества цветов в изображении при сохранении его визуального качества. Алгоритм можно использовать для кластеризации цветов изображения и замены пикселей центроидным цветом каждого кластера, что приводит к сжатию изображения.
Методы оценки
Методы оценки используются для измерения производительности алгоритмов кластеризации. Общие методы оценки включают:
Сумма квадратов ошибок (SSE): измеряет сумму квадратов расстояний между каждой точкой данных и назначенным ей центром тяжести.
Коэффициент силуэта: измеряет сходство точки данных с собственным кластером по сравнению с другими кластерами. Высокий коэффициент силуэта указывает на то, что точка данных хорошо соответствует своему собственному кластеру и плохо соответствует соседним кластерам.
Анализ силуэта
Анализ силуэта — это графический метод, используемый для оценки качества кластеров, созданных алгоритмом кластеризации. Он включает в себя вычисление коэффициента силуэта для каждой точки данных и нанесение их на гистограмму. Ширина гистограммы указывает на качество кластеризации. Широкая гистограмма указывает на то, что кластеры хорошо разделены и различны, тогда как узкая гистограмма указывает на то, что кластеры плохо разделены и могут перекрываться.![]()
Как работает кластеризация K-средних?
На приведенной ниже блок-схеме показано, как работает кластеризация k-средних:
Целью алгоритма K-средних является поиск кластеров в заданных входных данных. Есть несколько способов сделать это. Мы можем использовать метод проб и ошибок, указав значение K (например, 3,4, 5). По мере продвижения мы продолжаем изменять значение, пока не получим лучшие кластеры.
Другой метод заключается в использовании метода локтя для определения значения K. Как только мы получим значение K, система случайным образом назначит столько центроидов и измерит расстояние каждой из точек данных от этих центроидов. Соответственно, он присваивает соответствующим центроидам те точки, расстояние от которых минимально. Таким образом, каждая точка данных будет привязана к ближайшему к ней центроиду. Таким образом, у нас есть K начальных кластеров.
Для вновь образованных кластеров вычисляет новую позицию центроида. Положение центроида перемещается по сравнению со случайно выделенным.
Еще раз, расстояние каждой точки измеряется от этой новой точки центра тяжести. При необходимости точки данных перемещаются в новые центроиды, и снова вычисляется среднее положение или новый центроид.
Если центроид перемещается, итерация продолжается, что указывает на отсутствие сходимости. Но как только центроид перестанет двигаться (что означает, что процесс кластеризации сошелся), он отразит результат.
Давайте используем пример визуализации, чтобы лучше понять это.
У нас есть набор данных для продуктового магазина, и мы хотим узнать, на сколько кластеров он должен быть распределен. Чтобы найти оптимальное количество кластеров, мы разобьем его на следующие шаги:
Шаг 1:
Метод локтя — лучший способ найти количество кластеров. Метод локтя представляет собой запуск кластеризации K-средних в наборе данных.
Затем мы используем сумму квадратов в качестве меры, чтобы найти оптимальное количество кластеров, которые могут быть сформированы для заданного набора данных.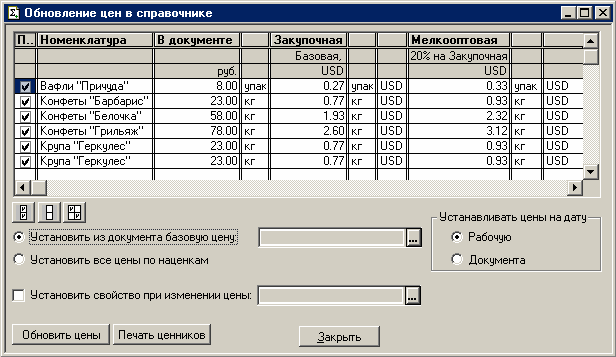 В пределах суммы квадратов (WSS) определяется как сумма квадратов расстояния между каждым членом кластера и его центроидом.
В пределах суммы квадратов (WSS) определяется как сумма квадратов расстояния между каждым членом кластера и его центроидом.
WSS измеряется для каждого значения K. Значение K, которое имеет наименьшее количество WSS, принимается за оптимальное значение.
Теперь нарисуем кривую между WSS и количеством кластеров.
Здесь WSS находится на оси y, а количество кластеров — на оси x.
Вы можете видеть очень постепенное изменение значения WSS по мере увеличения значения K от 2.
Итак, за оптимальное значение К можно взять значение точки локтя. Оно должно быть либо два, либо три, либо самое большее четыре. Но, кроме того, увеличение количества кластеров кардинально не меняет значения в WSS, оно стабилизируется.
Шаг 2:
Предположим, что это наши точки доставки:
Мы можем случайным образом инициализировать две точки, называемые центроидами кластера.
Здесь C1 и C2 — центроиды, назначенные случайным образом.
Шаг 3:
Теперь измеряется расстояние каждого местоположения от центроида, и каждая точка данных назначается ближайшему к ней центроиду.
Вот как выполняется начальная группировка:
Шаг 4:
Вычислите фактический центр тяжести точек данных для первой группы.
Шаг 5:
Переместите случайный центроид в фактический центроид.
Шаг 6:
Вычислите фактический центр тяжести точек данных для второй группы.
Шаг 7:
Переместите случайный центроид в фактический центроид.
Шаг 8:
Когда кластер становится статическим, считается, что алгоритм k-средних сошелся.
Окончательный кластер с центроидами c1 и c2 показан ниже:
Алгоритм кластеризации K-средних
Допустим, у нас есть x1, x2, x3……… x(n) в качестве входных данных, и мы хотим разбить их на K кластеров.
Шаги для формирования кластеров:
Шаг 1: Выберите K случайных точек в качестве центров кластеров, называемых центроидами.
Шаг 2. Назначьте каждый x(i) ближайшему кластеру, реализуя евклидово расстояние (т. е. вычисляя его расстояние до каждого центроида)
Шаг 3: Определите новые центроиды, взяв среднее значение назначенных точек.
Шаг 4: Продолжайте повторять шаги 2 и 3, пока не будет достигнута конвергенция
Давайте подробно рассмотрим каждый из этих шагов.
Шаг 1:
Мы случайным образом выбираем K (центроиды). Назовем их c1,c2,….. ck, и мы можем сказать, что
Где C — множество всех центроидов.
Шаг 2:
Мы связываем каждую точку данных с ее ближайшим центром, что достигается путем вычисления евклидова расстояния.
Где dist() — евклидово расстояние.
Здесь мы вычисляем расстояние каждого значения x от каждого значения c, т. е. расстояние между x1-c1, x1-c2, x1-c3 и так далее. Затем мы находим наименьшее значение и присваиваем x1 этому конкретному центроиду.
Аналогично находим минимальное расстояние для x2, x3 и т. д.
д.
Шаг 3:
Мы идентифицируем фактический центр тяжести, взяв среднее значение всех точек, присвоенных этому кластеру.
Где Si — множество всех точек, присвоенных i-му кластеру.
Это означает, что исходная точка, которую мы считали центроидом, сместится в новое положение, которое является фактическим центроидом для каждой из этих групп.
Шаг 4:
Продолжайте повторять шаги 2 и 3, пока не будет достигнута сходимость.
Как выбрать значение «Количество кластеров K» в кластеризации K-средних?
Несмотря на то, что для выбора оптимального количества кластеров доступно множество вариантов, метод локтя является одним из самых популярных и подходящих методов. Метод локтя использует идею значения WCSS, что является сокращением от суммы квадратов внутри кластера. WCSS определяет общее количество вариаций в кластере. Это формула, используемая для расчета значения WCSS (для трех кластеров), предоставленная Javatpoint:
WCSS= ∑Pi на расстоянии Cluster1 (Pi C1)2 + ∑Pi на расстоянии Cluster2 (Pi C2)2 + ∑Pi на расстоянии Cluster3 (Pi C3)2
Python Реализация алгоритма кластеризации K-средних
Вот как использовать Python для реализации алгоритма кластеризации K-средних. Вот шаги, которые вам нужно предпринять:
Вот шаги, которые вам нужно предпринять:
- Предварительная обработка данных
- Нахождение оптимального количества кластеров методом локтя
- Обучение алгоритма K-средних на обучающем наборе данных
- Визуализация кластеров
1. Предварительная обработка данных. Импортируйте библиотеки, наборы данных и извлеките независимые переменные.
# импорт библиотек
импортировать numpy как nm
импортировать matplotlib.pyplot как mtp
импортировать панды как pd
# Импорт набора данных
Набор данных= pd.read_csv(‘Mall_Customers_data.csv’)
x = набор данных.iloc[:, [3, 4]].значения
2. Найдите оптимальное количество кластеров методом локтя. Вот код, который вы используете:
#нахождение оптимального количества кластеров методом локтя
из sklearn.cluster import KMeans
wcss_list= [] #Инициализация списка значений WCSS
#Использование цикла for для итераций с 1 по 10.
для i в диапазоне (1, 11):
kmeans = KMeans(n_clusters=i, init=’k-means++’, random_state= 42)
kmeans.fit(x)
wcss_list.append(kmeans.inertia_)
mtp.plot(диапазон(1, 11), wcss_list)
mtp.title(‘График метода Элобва’)
mtp.xlabel(‘Количество кластеров (k)’)
mtp.ylabel(‘wcss_list’)
mtp.show()
3. Обучите алгоритм К-средних на обучающем наборе данных. Используйте те же две строки кода, что и в предыдущем разделе. Однако вместо i используйте 5, потому что нужно сформировать 5 кластеров. Вот код:
#обучение модели K-средних на наборе данных
kmeans = KMeans(n_clusters=5, init=’k-means++’, random_state= 42)
y_predict= kmeans.fit_predict(x)
4. Визуализируйте кластеры. Поскольку в этой модели пять кластеров, нам нужно визуализировать каждый из них.
#визуализация кластеров
mtp.scatter(x[y_predict == 0, 0], x[y_predict == 0, 1], s = 100, c = ‘blue’, label = ‘Cluster 1’) #для первого кластера
mtp. scatter(x[y_predict == 1, 0], x[y_predict == 1, 1], s = 100, c = ‘green’, label = ‘Cluster 2’) #для второго кластера
scatter(x[y_predict == 1, 0], x[y_predict == 1, 1], s = 100, c = ‘green’, label = ‘Cluster 2’) #для второго кластера
mtp.scatter(x[y_predict== 2, 0], x[y_predict == 2, 1], s = 100, c = ‘red’, label = ‘Cluster 3’) #для третьего кластера
mtp.scatter(x[y_predict == 3, 0], x[y_predict == 3, 1], s = 100, c = ‘голубой’, label = ‘Cluster 4’) #для четвертого кластера
mtp.scatter(x[y_predict == 4, 0], x[y_predict == 4, 1], s = 100, c = ‘magenta’, label = ‘Cluster 5’) #for пятый кластер
mtp.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = ‘желтый’, label = ‘Центроид’)
mtp.title(‘Группы клиентов’)
mtp.xlabel(‘Годовой доход (тыс.$)’)
mtp.ylabel(‘Оценка расходов (1–100)’)
mtp.legend()
mtp.show()
Кодировка предоставлена Javatpoint.
Демонстрация: Кластеризация K-средних
Постановка задачи. Компания Walmart хочет открыть сеть магазинов по всему штату Флорида и найти оптимальное расположение магазинов для максимизации дохода.
Проблема здесь в том, что если они откроют слишком много магазинов близко друг к другу, они не получат прибыли. Но, если магазины находятся слишком далеко друг от друга, им не хватает охвата продаж.
Решение. Такая организация, как Walmart, является гигантом электронной коммерции. У них уже есть адреса их клиентов в их базе данных. Таким образом, они могут использовать эту информацию и выполнить кластеризацию K-средних, чтобы найти оптимальное местоположение.
Заключение
Инженеры по машинному обучению, которые считаются профессией будущего, востребованы и высокооплачиваемы. В отчете Marketwatch прогнозируется, что темпы роста машинного обучения превысят 45% в период с 2017 по 2025 год. Итак, зачем ограничивать свое обучение только алгоритмами кластеризации K-средних? Запишитесь на курс Simplilearn по машинному обучению и расширьте свои знания в более широких концепциях машинного обучения. Получите сертификацию и станьте частью таланта в области искусственного интеллекта, которого компании постоянно ждут.