Как мы научили ABBYY FineReader PDF редактировать целые абзацы / Блог компании ABBYY / Хабр
Сегодня мы обновили ABBYY FineReader 15 и выпустили его под брендом ABBYY FineReader PDF, потому что он объединяет все инструменты для работы с PDF. По этому поводу публикуем первый пост из серии материалов о фичах программы. В нем мы расскажем об одной интересной возможности, которая не первый месяц есть в программе, но, возможно, не все о ней знали.
Давно ли вы открывали PDF-файлы? Готовы поспорить, что совсем недавно. Скорее всего, на вашем компьютере точно найдется пара сканов, а может, еще и макет презентации, аналитическое исследование или техническая инструкция. Для каких задач обычно используют эти документы? По данным опроса ABBYY, 62% респондентов ищут информацию в PDF, 60% — копируют текст из документа, а 52% — редактируют: вносят в файл правки, исправляют ошибки и опечатки.
Даже сейчас не все знают, что можно редактировать текст в PDF. Да, изменение таких файлов устроено не так, как редактирование обычного текстового документа.
В этом посте мы раскроем технические подробности редактирования многострочных фрагментов текста в FineReader: как мы изменили движок программы, как редактирование устроено изнутри и как оно выглядит для пользователя. Поехали!
Форматом PDF пользуются по всему миру: его содержимое одинаково отображается на любых компьютерах, смартфонах и планшетах с разными операционными системами. Это удобно и помогает избежать неловких ситуаций. Например, когда вы написали текст в MS Word, отправили коллегам, а они открывают его LibreOffice’ом или Wordpad’ом, и все поехало и начинается веселье. PDF, конечно, в этом плане удобнее, но с текстом здесь все сложно. В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
Поговорим сначала о PDF, в которых текст есть. Чтобы редактировать PDF, надо понимать, как в нем записан текст. Открывали когда-нибудь PDF в блокноте? Если да, то вы видели такое:
Чтобы все это отображалось понятно для пользователя, нужно проделать большую работу.
Задача: понять PDF
Содержимое каждой страницы в PDF-файле хранится в виде потоков команд для отрисовки документа – это могут быть текст, изображения или векторная графика. Структуру файла определяют PDF-объекты, например, страница, картинка, комментарий (а абзацы, строчки текста и буквы – это всего лишь части объекта). Символ в PDF представляется
 То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.В PDF нет ни строк, ни абзацев, которые есть в документах текстовых форматов. Даже порядок текста не всегда определен. То есть вы видите текст, но на самом деле текста не существует. Это хаос из трудно понятных инструкций (как на изображении выше), которые нужно правильно отобразить в конкретных местах документа, с соответствующим форматированием.
«А как же текст?» – спросите вы.
Текст в PDF все же существует, и его даже получится редактировать. Для этого мы учим наши технологии понимать структуру текста, например, определять и выделять строки. Расскажем об этом подробнее.
Библиотеки PDF и как мы их поменяли
Чтобы сделать возможным редактирование целых абзацев, мы сильно поменяли нашу внутреннюю подсистему (библиотеку), которую мы называем PdfTools. Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.
 е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.Подсистема PdfTools содержит все необходимые инструменты, чтобы прочитать содержимое и обернуть его в объекты (страница, картинка, комментарий), с которыми удобно работать программе. С этими объектами уже могут работать наши продукты, в частности ABBYY FineReader PDF и другие.
Как было раньше. В FineReader 14 мы умели редактировать текст только в рамках одной строчки. После редактирования необходимо было выполнить «рендеринг» — расставить глифы на свои новые места.
Вообще рендеринг — это визуализация. Но мы вкладываем в это слово иное понятие — расположение объектов в PDF на своих местах. Для PDF-специалистов это и есть визуализация, которую больше никто не видит. Когда мы говорим о визуализации в привычном понимании, то используем слово «растеризация».
Весь этот процесс располагался в подсистеме PdfTools.
 Она помогала нам собирать содержимое PDF в строчки и редактировать их. Например, надо поставить на 5-ое месте глиф «А». FineReader передавал подсистеме PdfTools, что на пятое место нужно поставить глиф «А» с заданным размером и шрифтом, а PdfTools вставляла «А» и перемещала на нужное место в строчке все глифы, которые следовали за буквой «А». Построчное редактирование довольно легкое: текст просто смещался вправо или, например, влево, если он записан на иврите или арабском языке. Это позволяло внести небольшие корректировки, например, исправить опечатку, но не давало возможность сделать более глобальные изменения в тексте PDF-документа. Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую.
Она помогала нам собирать содержимое PDF в строчки и редактировать их. Например, надо поставить на 5-ое месте глиф «А». FineReader передавал подсистеме PdfTools, что на пятое место нужно поставить глиф «А» с заданным размером и шрифтом, а PdfTools вставляла «А» и перемещала на нужное место в строчке все глифы, которые следовали за буквой «А». Построчное редактирование довольно легкое: текст просто смещался вправо или, например, влево, если он записан на иврите или арабском языке. Это позволяло внести небольшие корректировки, например, исправить опечатку, но не давало возможность сделать более глобальные изменения в тексте PDF-документа. Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую. Чтобы определить все эти параметры, мы решили привлечь для решения этой задачи и другие наши OCR-технологии — Document Analysis (DA) и Synthesis, которые умеют строить структуру документа.
Чтобы определить все эти параметры, мы решили привлечь для решения этой задачи и другие наши OCR-технологии — Document Analysis (DA) и Synthesis, которые умеют строить структуру документа.Document Analysis и Synthesis
Чтобы определять в тексте блоки, ABBYY FineReader PDF использует технологию Document Analysis. Она позволяет найти абзацы, таблицы, картинки. Программа подсвечивает найденные блоки небольшими бледными рамками, чтобы пользователю удобнее было вносить правки:

Особенности подчеркнутого текста
В PDF нет такого атрибута текста как подчеркивание, привычного, например, пользователям MS Word. Подчеркивание в PDF – это векторная графика, никак не связанная с текстом. Без дополнительной доработки продукта при редактировании «подчеркнутого» текста символы бы перемещались привычным образом, а линии, обозначающие подчеркивания, оставались бы на месте. ABBYY FineReader PDF умеет определять и редактировать подчеркнутый текст привычным пользователю образом.
Редактирование таблиц в PDF
Изменилось и редактирование таблиц. Раньше программа «видела» таблицу, как отдельные строки, и редактировала ее так же. Теперь при работе с таблицами ABBYY FineReader PDF определяет содержимое каждой ячейки, умеет извлекать из них текст и работать с ним. Это удобно, когда надо исправить ошибку в цифре, поменять точку на запятую и при этом сохранить структуру таблицы, сделать это быстро и без конвертации PDF-документа в другие форматы.
Как отредактировать скан?
Возможность многострочного редактирования доступна и для сканов.
 Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.
Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.Когда пользователь закончил редактировать документ, программа автоматически собирает все изменения со страницы и заменяет эти фрагменты в исходном документе. Наша задача — встроить текст обратно в PDF-документ, не повредив все то остальное, что уже есть в нем.
Редактирование скана позволяет не тратить время на конвертацию документа в другие форматы и обратно. Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Пример многострочного редактирования. Текст автоматически перераспределяется по строкам по мере добавления слов и предложений внутри абзаца.
Вместо заключения
Исправить опечатку в листовке, поменять местами текстовые блоки в инструкции, изменить целый абзац в скане договора или добавить несколько новых, поправить форматирование всего текста – все эти задачи теперь возможно решить:
- быстро,
- без конвертации документа,
- с помощью одной программы.
Попробовать можно прямо сейчас – скачайте триал-версию ABBYY FineReader PDF бесплатно.
В следующем посте через неделю мы расскажем о том, как научили ABBYY FineReader PDF еще одной интересной фиче и для чего может пригодиться новая функциональность.
как сделать дизайн и передать исходники верстальщику — статьи на Skillbox
Начинающие дизайнеры часто не знают, в какой программе можно сделать макет. Изучают разные графические редакторы, выбирают удобный для себя.
Изучают разные графические редакторы, выбирают удобный для себя.
Популярный редактор — Adobe Photoshop. Это универсальный инструмент для работы с любой графикой: фотографы обрабатывают там снимки, иллюстраторы занимаются рисунками, а веб-дизайнеры делают макеты. Файл, в который сохраняется макет в Photoshop, имеет расширение .psd. Его отправляют разработчикам как PSD-макет для сайта.
Photoshop — универсальный редактор, и поэтому его довольно непросто освоить. Чтобы не тратить много времени на изучение функций, можно использовать новое поколение программ, предназначенных специально для веб-дизайна: Adobe XD, Figma, Sketch.
Некоторые дизайнеры рисуют макеты в других редакторах. Кто-то пользуется Adobe Illustrator или Adobe InDesign.
Перед тем как выбрать программу для создания макетов, поговорите с верстальщиком. Удобно ли ему будет пользоваться Photoshop или лучше нарисовать всё в Sketch? Или он пользуется Zeplin, поэтому неважно, в какой программе вы рисуете?
Создавайте макет по правилам. Это упростит работу над внешним видом и облегчит процесс вёрстки.
Это упростит работу над внешним видом и облегчит процесс вёрстки.
- Выберите цветовую модель RGB перед созданием макета. Это стандарт для мониторов и экранов.
- Пользуйтесь сеткой, чтобы выравнивать контент внутри макета.
- Не увеличивайте маленькие картинки.
- Изменяйте размер изображений с зажатой клавишей Shift, чтобы сохранять пропорции.
- Если нужен наклонный или жирный текст, выбирайте одно из начертаний шрифта. Не пользуйтесь псевдостилями, чтобы изменить внешний вид букв в Photoshop и других редакторах.
Проверьте все элементы макета и посмотрите на расстояния и отступы. Все размеры должны быть выражены целыми чётными числами. Не используйте нечётные числа и дроби.
Во время работы над макетом дизайнер располагает слои в хаотичном порядке, не переименовывает их, скрывает неподходящие варианты. С таким макетом сложно работать верстальщику и другим специалистам, в нём нет структуры.
С таким макетом сложно работать верстальщику и другим специалистам, в нём нет структуры.
Чтобы создать порядок в слоях:
- удалите скрытые и пустые,
- сгруппируйте по смыслу,
- напишите для каждого название.
Назовите осмысленно все артборды. Это поможет разработчику понять логику макета, и ему легче будет ориентироваться в структуре.
Все элементы, которые нельзя отобразить с помощью HTML и CSS, необходимо вынести на отдельную страницу макета. Обычно так поступают с иконками, карточками и некоторыми кнопками. Чтобы сэкономить время верстальщику, элементы можно сразу экспортировать в формат PNG или SVG.
На этом артборде также покажите все позиции элементов. Скопируйте кнопку из макета и нарисуйте все её состояния: обычное, при наведении мыши, при нажатии. Укажите все цвета и шрифты, которые присутствуют в макете.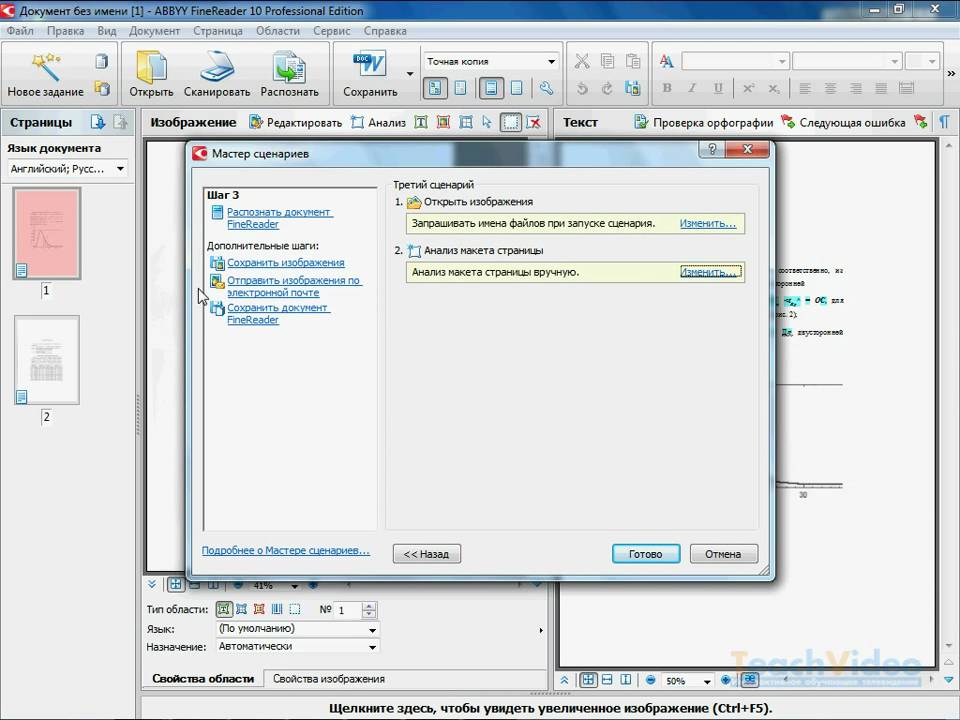 Приведите примеры с параметрами и размерами заголовков, подзаголовков и основного текста.
Приведите примеры с параметрами и размерами заголовков, подзаголовков и основного текста.
Если в макете используются нестандартные шрифты, то отправьте файл с ними вместе с макетом.
Если шрифт есть в сервисе Google Fonts, то дайте разработчику ссылку на него. В этом случае файл не понадобится, потому что на сайт его подключают через этот сервис.
В архив к макету приложите все элементы, которые вы экспортировали из артборда. Если эти файлы — в формате PNG, то нужно сделать версии в нескольких разрешениях.
Анимированные макеты используют не только для демонстрации сайта в портфолио или презентации заказчику.
Если нужно, чтобы элементы двигались и взаимодействовали друг с другом, нарисуйте интерактивный прототип и покажите верстальщику. Лучше продемонстрировать, чем описывать словами.
Распознавание FineReader
Автор:
Тип лицензии:
Крякнутая
Языки:
Мульти
ОС:
Windows 8, 8 64-bit, 7, 7 64-bit, Vista, Vista 64-bit, XP, XP 64-bit
Просмотров:
1387
Скачано:
555
Предлагаю на рассмотрение восьмую версию ресурса, ведь я сама его использую.
Распознание
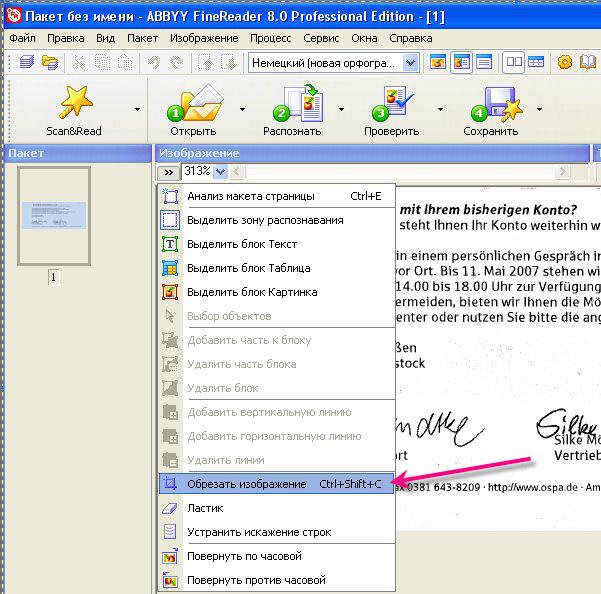
Воспользуйтесь функцией «Сканировать», то есть открыть в определенном источнике, для начала сканирования. Появляется окошко ресурса сканирования. В основном приемлемым разрешением является 300pi, процесс сканирования более оптимально установить, если следить за различными элементами в документе: это может быть «голый» текст, текст и графики, а также текст с картинками.
Если вам необходимо отсканировать одновременно несколько страниц, выберите стрелку справа от клавиши «Скан», а затем команду опции, в появившимся окне опции требуется нажать «Скан несколько страниц». В случае большого количества страниц, как в PDF- и TIFF-документах, необходимо активировать только часть страниц, необходимых вам. Чтобы это сделать, нужно написать номер страниц через запятую, к примеру: 3,5,7-11.
Затем сканированное фото нужно распознать. Это можно сделать с текущим фото, и с набором фото, которые введены в границах этой сессии в ресурс со сканера.
Также нужно учитывать, что языки, предназначенные для распознания и написания документа должны совпадать. Есть также функция указания нескольких языков для распознания (для многоязычных док). Но лучше не использовать больше трех языков.
Есть также функция указания нескольких языков для распознания (для многоязычных док). Но лучше не использовать больше трех языков.
Клиенты, у которых есть желание использовать лишь сегменты документа, которые им необходимы, могут использовать функцию «Анализа макета страницы».
Проверить можно собственноручно используя встроенный WYSIWYG-редактор, он обеспечить наиболее точный процесс распознания всех элементов файла: разметки текста, таблички, фото, они появляются в окне редактирования тем же действием, если они были размещены в исходном изображении.
Вы можете использовать функцию для диалога «Проверка», где вы увидите слово с допущенной ошибкой, его скрин в исходном файле и способы замены. В этих действиях следует просчитать, что распознаются и показываются в диалоге «Проверка» исключительно слова, где присутствуют некорректно замеченные символы, или те, которым придана оценка в самой лучшей из гипотез в плане уверенности программы, менее определенной ошибки указанного уровня. И совсем не обязательно, что ошибки, указанные неуверенно действительно ошибки.
И совсем не обязательно, что ошибки, указанные неуверенно действительно ошибки.
В случае необходимости в сохранении результата распознаваний в документ, требуется кликнуть по функции справа от клавиши «Сохранить», а затем использовать функцию «Сохранить страницы». Проверенный текст следует сохранять в таких форматах, как: RTF, DOC, Word XML, XLS, PDF, HTML,PPT, TXT, DBF, CSV, LIT. Есть также функция переформирования проверенного файла в исходное приложение для того, чтобы можно было завершить работу с файлом, но уже в привычном для вас виде.
Каждый формат имеет функцию настройки сохранения. Вы можете их отыскать в определенной вкладке диалога «форматы», для настаивания в формате PDF есть в вкладке PDF, к примеру, и так с каждым форматом. Чтобы активировать диалог «Форматы», требуется кликнуть клавишу справа от функции «Сохранить», а затем, использовать функцию опции. В появившимся диалоге кликните по клавише «Форматы».
Все, что было указано выше, скорее всего не является новой информацией, но все равно мне следует остановиться на двух моментах.
1. В ABBYY FineReader вы можете, обладая фото в формате pdf, переформатировать в документ word, чтобы в последующем плане иметь возможность редактировать его. Представим ситуацию: вы нашли в интернете файл в pdf, но вам необходим текст из изображения, чтобы вытащить его, требуется воспользоваться FineReader, затем выбрать документ, сохранить его в word, после чего вы уже можете отредактировать файл как вам угодно.
2. Мало кто знает, что в FineReader (правда не в версии демо) существует функция Screenshot Reader. Эта функция для того, чтобы вычитывать тексты с изображений прямо с экрана монитора. Используется она очень просто: нужно нажать (на клавиатуре) клавишу PrintScreen, затем FineReader берет это фото из буфера обмена и начинает вычитывать текст. Вы можете это совершить и собственноручно, ноScreenshot Reader дает возможность это сделать быстрее. О необходимости данного ресурса можно долго рассуждать, в любом случае, она приносит пользу. В первую очередь, она вычитывает текст быстрее, чем это можете сделать вы))), также, это великолепный вариант взять текст из защищенных текстовых документов.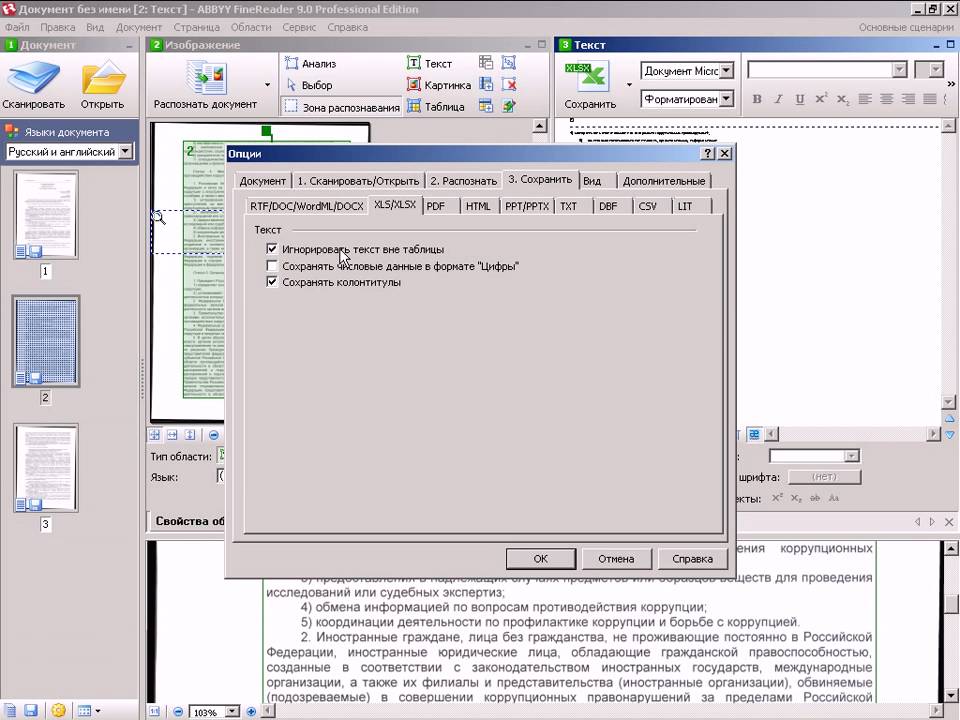
Запуск происходит очень закономерно: Запускаете программу ABBYY FineReader, и функцию ABBYYScreenshot Reader.
Обличие программы неимоверно просто.
После кликанья клавши «Снимок», вы увидите сетку захвата, и сможете выбрать место на экране для последующего копирования на свой ПК но уже в виде файла.
Экспериментируйте с программой, я уверена, это принесет Вам массу удовольствия.
Работа с макетами страниц, столбцами и разделами — Wiki Help
Если вы хотите добавить структуру к информации на странице, часто бывает полезно разбить информацию на столбцы. Под «столбцом» мы подразумеваем вертикальный блок контента. Вам может понадобиться более одного столбца по ширине страницы.
Вы также можете использовать общую структуру на нескольких страницах, чтобы читатели знали, где найти информацию на каждой странице.Помимо столбцов здесь полезны разделы. Под «разделом» мы подразумеваем область страницы. Раздел может содержать один или несколько столбцов.
Confluence предоставляет следующие способы создания столбцов и разделов на странице:
- Макеты страниц предлагают набор предварительно определенных столбцов и разделов.
- Макросы раздела и столбца обеспечивают большую гибкость. Вы можете установить ширину столбцов и разместить разделы и столбцы в любой части страницы.
На этой странице:
Связанные страницы:
Использование макетов страниц
Редактор Confluence предлагает набор предварительно определенных макетов страниц.Каждый макет содержит один или несколько столбцов. Некоторые макеты также содержат горизонтальный блок вверху и внизу страницы. Выбранный вами макет определяет положение разделов и столбцов на странице, а также относительную ширину столбцов. Содержимое страницы ограничено рамками макета. Вы не можете добавлять контент выше или ниже разделов и столбцов, предусмотренных макетом.
Чтобы выбрать макет страницы:
- Во время редактирования страницы щелкните значок макета страницы.
 Появится раскрывающийся список со значками, иллюстрирующими доступные макеты.
Появится раскрывающийся список со значками, иллюстрирующими доступные макеты. - Выберите макет.
Снимок экрана: Выбор макета страницы
Если на вашей странице уже есть контент, Confluence поместит существующий контент в левый столбец нового макета. Если на странице использовался другой макет, Confluence поместит контент в соответствующие разделы и столбцы нового макета.
Снимок экрана: страница с макетом из трех столбцов в режиме редактирования
Примечания о макете страниц
- Очень широкие таблицы. Ширина каждого столбца устанавливается в процентах от ширины страницы. Значки в раскрывающемся меню указывают относительную ширину для каждого макета. В большинстве случаев Confluence адаптирует ширину столбцов к ширине страницы. Если столбец включает большую таблицу, содержимое может не умещаться по ширине страницы. При просмотре страницы вы увидите горизонтальную полосу прокрутки.

- Смешивание и согласование. Вы можете поместить макросы разделов и столбцов в макеты страниц. Вы также можете размещать таблицы внутри макетов страниц.
Использование макросов разделов и столбцов
Вы можете использовать макросы раздела и столбца, чтобы добавить на страницу набор столбцов. Макрос раздела определяет область, которая будет содержать столбцы. Вы можете иметь столько разделов, сколько захотите. В каждом разделе вы можете иметь столько столбцов, сколько захотите.
Чтобы добавить раздел и несколько столбцов на страницу:
- В редакторе Confluence выберите Insert (значок плюса) > Other Macros .
- Найдите макрос Section путем поиска или просмотра доступных макросов, выберите его и вставьте на страницу.
- Снова выберите Вставить > Другие макросы .
- Найдите и вставьте макрос столбца .

- Добавьте свое содержимое в столбец.
- Вставьте в раздел столько столбцов, сколько хотите.
Снимок экрана: раздел и два столбца в редакторе
Когда вы видите страницу в режиме просмотра, макет выше отображается следующим образом:
Содержимое столбца 1 находится здесь
Содержимое столбца 2 идет сюда
Параметры макроса раздела
Параметр | По умолчанию | Описание |
|---|---|---|
Показать границу Примечание: Без макроса столбца граница не будет отображаться правильно. |
Параметры макроса столбца
Параметр | По умолчанию | Описание | % | Укажите ширину столбца в пикселях (например, |
|---|

Примечания к разделам и столбцам
- Все содержимое раздела должно быть заключено в макрос столбца, иначе макет раздела не будет работать должным образом.
- Таблицы можно размещать внутри столбцов.
- Экспорт PDF не обрабатывает макеты страниц.
Примеры кода
См .:
| Составление корпусов для использования в качестве переводческих ресурсов Майкл Уилкинсон, Майкл. Станьте участником TranslationDirectory.com всего за 8 долларов в месяц (оплачивается в год) дюйм предыдущие выпуски журнала переводов (Июль 2005; Октябрь 2005) Я показал, как инструмент анализа корпуса может быть полезным подспорьем при переводе.Однако, прежде чем вы начнете использовать анализ корпуса инструмент, вам необходимо иметь корпус или корпус для него Анализировать. У вас есть две альтернативы: либо приобрести готовые корпуса, или сделать самостоятельно («сделай сам») корпуса. A
большой выбор корпусов на английском и других языках
составлены в электронном формате для различных
целей за последние несколько десятилетий. Однако
большинство англоязычных корпусов, упомянутых на
сайт «Gateway», хотя и представляет большую ценность для лингвистической
исследователи, не очень полезны как средства перевода
поскольку они, как правило, носят слишком общий характер
или несколько устаревшие; кроме того, некоторые коллекции
состоят из устных текстов или исторических текстов, и эти
мало помогают при переводе современной письменной
язык. На сайте «Шлюз» упоминается несколько многомиллионных слов
«мега-корпуса». Некоторые из них были использованы в словаре
компиляции, в то время как другие использовались для лингвистических
исследование.Один из самых известных мегакорпусов британских
Английский — это Британский национальный корпус (BNC), 100
коллекция из миллионов слов образцов письменной и
разговорный язык из широкого спектра источников, разработанный
представлять широкий круг современных британских
Английский. Bowker & Pearson (2002, стр. 46-47) являются хорошим примером.
этого. Если вы переводили текст на механический
инженерии и хотел исследовать термин «орех»
и его различных словосочетаний, 100-миллионное слово
BNC произведет 670 вхождений. Bowker & Pearson сообщает, что поиск
термин «орех» в корпусе из 10 000 слов, содержащем каталоги,
описания продуктов и инструкции по сборке из
компаний обрабатывающей промышленности сформировали
49 находок. Оксфорд Контроллер WordSmith Tools Таким образом
это корпуса, которые являются специализированными в том смысле, что
они ограничены языком определенного
специальные поля, которые больше всего нужны переводчику. Сделай сам специализированный корпус К сожалению
в настоящее время доступно очень мало готовых корпусов LSP — либо
бесплатно или на коммерческой основе — поэтому переводчики должны
уметь составлять свои собственные специализированные корпуса,
изготовленные на заказ в соответствии с их собственными требованиями.В этом
уважение, ряд преподавателей-переводчиков сообщили
об использовании составленных студентами «специальных» корпусов (также
называемые «виртуальными», «сделай сам» или «одноразовыми» корпусами)
в своих курсах. Например, Варантола (2003) описывает
на кафедре проведен семинар-эксперимент
переводческих исследований Университета Тампере,
Финляндия, используя Интернет как ресурс для сопоставимых
корпуса. Мост инструменты анализа корпуса предпочитают обрабатываемые тексты быть в текстовом формате (* .txt), хотя некоторые могут также обрабатывать тексты в других форматах. Тем не мение, первый шаг в составлении вашего корпуса — найти подходящие источники по интересующей вас теме, а затем преобразовать их в обычный текст.Есть ряд способов сделать это. Назначения как корпус Если
вы профессиональный переводчик, возможно
что вы получаете многие свои задания в электронном виде
формат. Например, если вы переводите с финского
на английский и наоборот, весьма вероятно, что
вы постепенно накопите большое количество аутентичных
исходные тексты на английском и финском языках в формате Word. Мой
жена, Арья, профессиональный переводчик,
специализируется на переводе туристических брошюр.
с финского на английский.Недавно я собрал 70 000
словесный корпус финляндского туризма с использованием ее источника
тексты. Это было сделано всего за несколько часов, поскольку
практически все ее задания приходят в электронном виде
формат. Этот корпус можно использовать при переводе с
Финский на другие языки, чтобы узнать, например,
насколько распространен термин в исходном языке, и
найти контексты, которые проливают свет на его значение. Сканирование Вы
может искать печатные материалы, такие как книги, журналы,
брошюры и журналы, и преобразовать текст из них
с помощью сканера (устройства, связанного с оптическим
программное обеспечение для распознавания, позволяющее печатать документы
конвертировать в электронный текст; плоские сканеры
чем-то похож на копировальный аппарат). http://www.aarp.org/learntech/computers/howto/Articles/a2002-07-16-scan.html http://www.ehow.com/how_3668_scanner-capture-text.html Однако Недостатком этого метода является то, что он относительно медленный по сравнению с некоторыми другими методами. Онлайн литература Есть доступен ряд газет и журналов онлайн. Некоторым требуется годовая подписка для доступа их, некоторые предлагают товары на продажу, а другие предоставляют бесплатный доступ. Веб-страница со ссылками на англоязычный газеты можно найти по адресу: http: // www. пока веб-страница со ссылками на англоязычные журналы можно найти по адресу: http://www.uk250.co.uk/Magazine/ следующий шаг — определить интересующие вас статьи, а затем скопируйте и вставьте их в документ Word с использованием Paste Special → Unformatted Текст , а затем сохраните их как обычный текст. Мост
профессиональные и академические журналы требуют ежегодного
подпишитесь на них, или предложите статьи для
продажа. Однако студенты и сотрудники академических институтов
часто имеют бесплатный онлайн-доступ к широкому спектру
журналы через сеть своего института. Многие образовательные учреждения также позволяют студентам и оперативный доступ сотрудников к большому количеству справочных материалов книги и энциклопедии, такие как энциклопедия Британника, Словарь искусств Grove и Словарь Grove музыки и музыкантов, где вы можете искать релевантные статьи для включения в ваш корпус. Сбор урожая Интернет Интернет предоставляет обширный источник потенциальных материалов для
составление корпуса в дополнение к интернет-газетам,
журналы, журналы и книги, упомянутые выше. Компиляция Корпус по туризму на английском языке A
описание того, как я составил корпус из 670 000 слов
текстов туристических брошюр на английском языке может предоставить
вам с некоторыми рекомендациями относительно того, как скомпилировать ваш
собственный корпус специального поля. тексты Корпуса по туризму в основном заимствованы из
туристические брошюры, которые появляются в Интернете в формате PDF
формат. Во многих случаях преобразование их в простые
текстовый формат был довольно простым, хотя в большинстве случаев осторожным
необходимо было выполнить постредактирование, поскольку заголовки и
титулы часто имели тенденцию к смене позиций.В некоторых
параграфы дел также имели тенденцию менять позиции,
и хотя это не проблема при просмотре
Отображение KWIC, где размер совместного текста («промежуток»)
ограничено четырьмя или пятью словами с каждой стороны
шаблона поиска исправлен порядок абзацев
чтобы пользователи могли смотреть на строки соответствия в
более широкий контекст. Однако
некоторые брошюры, особенно те, которые содержат несколько столбцов
и сложные макеты, было очень трудно преобразовать
в текстовый формат из-за графики, используемой в их
дизайн.Очень часто более изысканные и привлекательные
брошюру, тем сложнее было преобразовать ее в
текстовый формат. Строки из одного столбца перепутались
с теми из другого столбца или раздела страницы.
В этих случаях использовалась оптическая система FineReader. FineReader
может использоваться для сканирования и обработки печатных материалов,
но при составлении корпуса по туризму FineReader
в основном используется для обработки файлов PDF.FineReader в первую очередь
отсканировал PDF-файл, а затем «прочитал» его, т.е. распознал
блоки текста и изображений. В то время как преобразование из
Adobe Acrobat в формате Word вызывал проблемы в
форма перепутанных столбцов, с FineReader это можно было
для определения порядка заголовков и столбцов.
представлены в текстовой версии брошюры.Кроме того, вычитка казалась проще в
FineReader, потому что текст остался в исходном
макет и распознанный текст можно сравнить с
просмотр брошюры. В сравнение с конвертированием из Adobe Acrobat в Формат Word при использовании FineReader не был заметно быстрее.Это могло бы устранить некоторые проблемы прямого конвертировать, но в то же время нужно было быть осторожным с редкими лишними пробелами в словах или отсутствующими пробелы между двумя словами. Однако проверка FineReader Функция проверки орфографии оказалась очень полезной при обнаружении этих проблемы. Наконец, причины использования FineReader во многом было связано с его удобством использования, которое может быть важным фактором при очистке больших объемов текста в сложной компоновке. корпус с таким же успехом мог быть составлен путем концентрации
по тексту, появляющемуся на реальных веб-страницах туристической
маркетинговые организации или поставщики туристических услуг,
поскольку использование языка на веб-страницах, вероятно,
такой же, как в брошюрах, и действительно
тексты, используемые в брошюрах, иногда почти
идентичны тем, которые представлены на веб-сайте. А дальнейшая проблема с туристическими брошюрами — и действительно текст с веб-сайтов, это графика, макет и типографские особенности почти всегда важны части текста. При преобразовании брошюр в простые текст, эти нетекстовые элементы, особенно изображения, что может быть важно для понимания текста, потеряны. А лот зависит от корпуса В при составлении корпуса вам следует попробовать:
Будет это окупается? Все равно метод, который вы используете, составление собственного корпуса отнимает много времени процесс.Так что если вы студент-переводчик или профессионал переводчик работает над разовым, относительно коротким специального поля, вероятно, не будет целесообразно с точки зрения производительности собрать корпус текстов на целевом языке в рассматриваемой области чтобы помочь вам с переводом. Однако если у вас очень большой бриф на десятки или сотни страниц, потратив время на составление сопоставимого корпус целевого языка может окупиться.Более того, если вы работаете штатным переводчиком в компании если вы работаете в определенном секторе, вы можете сотрудничать с другими переводчиками и объединить тексты для создания суставной корпус. И если, как профессионал, вы регулярно перевод текстов, относящихся к одному или нескольким специальным поля, постепенно наращивая языковые корпуса в этих областях в конечном итоге может улучшить качество вашей работы и повышение вашей производительности. Артикул: Боукер,
Линн (2002). «Работаем вместе: сотрудничество
Подход к DIY корпусам ». Доклад представлен на
Первый международный семинар по языковым ресурсам
для переводческой работы и исследований , Гран-Канария,
28 мая 2002 г. Боукер, Линн и Пирсон, Дженнифер (2002). Работа с Специализированный язык: практическое руководство по использованию корпуса . Рутледж. Варантола, Криста (2003).«Переводчики и одноразовые корпуса» в Занеттине, Ф., Бернардини С. и Стюарте Д. (ред.) Корпуса переводчиков Манчестер: Святой Иероним, стр 55-70. Уилкинсон,
Майкл (2005). «Использование специализированного корпуса для улучшения
Качество перевода », в журнале переводов , ,
Том 9, № 3. Уилкинсон,
Майкл (2005a). «Обнаружение эквивалентов перевода
в корпусе туризма с помощью нечеткого поиска «,
в журнале переводов , том 9, №4. Занеттин,
Фредерико (2002).»Корпуса DIY: Интернет и
Переводчик «Ин Майя, Белинда / Халлер, Джонатан
/ Урлрих, Маргарита (ред.) Обучение языку
Поставщик услуг для нового тысячелетия , Порту:
Faculdade de Letras, Universidade do Porto, стр. 239-248. Эта статья изначально была опубликована в журнале переводов (http: // accurapid.com / journal). |
 Уилкинсон на uef.fi
Уилкинсон на uef.fi Сайт «Шлюз
в Corpus Linguistics в Интернете »на http://www.corpus-linguistics.de/
содержит полезный обзор многих наиболее известных
корпуса, включая информацию о том, когда и кем
они были составлены, а также их размер, содержание,
и доступность.
Сайт «Шлюз
в Corpus Linguistics в Интернете »на http://www.corpus-linguistics.de/
содержит полезный обзор многих наиболее известных
корпуса, включая информацию о том, когда и кем
они были составлены, а также их размер, содержание,
и доступность. Более того, некоторые из этих корпусов не
доступны для широкой публики, и большинство из них
доступные, довольно дорогие, требующие
что вы либо платите абонентскую плату, либо покупаете
компакт-диск.
Более того, некоторые из этих корпусов не
доступны для широкой публики, и большинство из них
доступные, довольно дорогие, требующие
что вы либо платите абонентскую плату, либо покупаете
компакт-диск. Впервые он был выпущен в 1995 году.
часть (90%) включает, например, выдержки из региональных
и национальные газеты, специализированные периодические издания и
журналы для всех возрастов и интересов, академические книги
и популярная художественная литература, опубликованные и неопубликованные письма
меморандумы, школьные и университетские эссе, среди
многие другие виды текста.Однако BNC, несмотря на
большой размер, серьезные ограничения как перевод
помощь, если вы переводите современные специализированные
тексты.
Впервые он был выпущен в 1995 году.
часть (90%) включает, например, выдержки из региональных
и национальные газеты, специализированные периодические издания и
журналы для всех возрастов и интересов, академические книги
и популярная художественная литература, опубликованные и неопубликованные письма
меморандумы, школьные и университетские эссе, среди
многие другие виды текста.Однако BNC, несмотря на
большой размер, серьезные ограничения как перевод
помощь, если вы переводите современные специализированные
тексты. Однако вы бы
обнаружил, что большинство строк соответствия бесполезны
вам, поскольку в большинстве контекстов показаны примеры
«орех» используется в других целях, например, как съедобный
типа или эксцентричный человек. Хотя некоторые из
вхождения описывают тип гаек, используемых в технике,
требуется время, чтобы их идентифицировать; есть чрезмерное
«шум» из-за того, что «орех» является омонимом — это
имеет разные значения — и поэтому разделение пшеницы
от половы — процесс трудоемкий.
Однако вы бы
обнаружил, что большинство строк соответствия бесполезны
вам, поскольку в большинстве контекстов показаны примеры
«орех» используется в других целях, например, как съедобный
типа или эксцентричный человек. Хотя некоторые из
вхождения описывают тип гаек, используемых в технике,
требуется время, чтобы их идентифицировать; есть чрезмерное
«шум» из-за того, что «орех» является омонимом — это
имеет разные значения — и поэтому разделение пшеницы
от половы — процесс трудоемкий. Хотя это было намного меньше, чем
Поиск BNC, результаты были гораздо более актуальными, поскольку
шум был значительно уменьшен, и это было легко
чтобы определить различные типы орехов, используемых в производстве
(е.г. гайка с буртиком, накидная гайка, накидная гайка, с накаткой
орех, крылатый орех), а также глаголы, которые сочетаются
гайкой (например, резьба, винт, затянуть, ослабить).
Хотя это было намного меньше, чем
Поиск BNC, результаты были гораздо более актуальными, поскольку
шум был значительно уменьшен, и это было легко
чтобы определить различные типы орехов, используемых в производстве
(е.г. гайка с буртиком, накидная гайка, накидная гайка, с накаткой
орех, крылатый орех), а также глаголы, которые сочетаются
гайкой (например, резьба, винт, затянуть, ослабить). Такие специализированные корпуса, которые сосредоточены на языке для
Специальные цели иногда называют LSP.
корпуса.
Такие специализированные корпуса, которые сосредоточены на языке для
Специальные цели иногда называют LSP.
корпуса. Однако ее ученики отметили, что открытие
соответствующий материал корпуса часто бывает затруднен и подвергается сомнению
рентабельность составления и использования специальных
корпуса. Аналогичным образом Занеттин (2002) описывает эксперимент
проводится в Школе переводчиков университета
Болоньи в Форли, где студентов поощряли
решать проблемы перевода с помощью DIY корпусов
собран из Интернета.Хотя многие студенты
сочли их корпуса полезными для поиска информации
по терминологии, фразеологии и словосочетаниям они
также отметил, что поиск на веб-страницах, создание
корпус и анализировать его с помощью конкордансера было
кропотливый. И действительно, это большая проблема —
время, необходимое для составления корпуса, вероятно,
чрезмерно с точки зрения производительности, если переводчик
предусматривает выполнение большого количества похожих переводов
в будущем.
Однако ее ученики отметили, что открытие
соответствующий материал корпуса часто бывает затруднен и подвергается сомнению
рентабельность составления и использования специальных
корпуса. Аналогичным образом Занеттин (2002) описывает эксперимент
проводится в Школе переводчиков университета
Болоньи в Форли, где студентов поощряли
решать проблемы перевода с помощью DIY корпусов
собран из Интернета.Хотя многие студенты
сочли их корпуса полезными для поиска информации
по терминологии, фразеологии и словосочетаниям они
также отметил, что поиск на веб-страницах, создание
корпус и анализировать его с помощью конкордансера было
кропотливый. И действительно, это большая проблема —
время, необходимое для составления корпуса, вероятно,
чрезмерно с точки зрения производительности, если переводчик
предусматривает выполнение большого количества похожих переводов
в будущем.
 В этом случае очень легко создать корпус из
ваши исходные тексты, повторно сохранив их в виде обычного текста
формат. Если вы студент, вы уже можете инициировать
этот процесс, поощряя своих учителей предоставлять
все ваши задания на перевод в виде документов Word.
В этом случае очень легко создать корпус из
ваши исходные тексты, повторно сохранив их в виде обычного текста
формат. Если вы студент, вы уже можете инициировать
этот процесс, поощряя своих учителей предоставлять
все ваши задания на перевод в виде документов Word. Его также можно использовать как помощь при переводе туристических
тексты с других языков на финский, особенно
если финский — L2 переводчика. (Например, те
студенты Савонлиннской школы переводоведения
чей L1 — русский, а L2 — финский, может использовать
этот корпус при переводе туристических брошюр с
С русского на финский).
Его также можно использовать как помощь при переводе туристических
тексты с других языков на финский, особенно
если финский — L2 переводчика. (Например, те
студенты Савонлиннской школы переводоведения
чей L1 — русский, а L2 — финский, может использовать
этот корпус при переводе туристических брошюр с
С русского на финский). Многочисленные гиды
об использовании сканеров можно найти в Интернете. Вы
можно посмотреть на следующее:
Многочисленные гиды
об использовании сканеров можно найти в Интернете. Вы
можно посмотреть на следующее: газетаwebsites.co.uk/
газетаwebsites.co.uk/ Многие из
статьи в этих журналах представлены в формате PDF,
можно загрузить и сохранить с помощью Acrobat Reader.Вы можете выделить текст и скопировать его в документ Word
и, наконец, сохраните его как обычный текст. Использование офиса
Буфер обмена для сбора отрывков текста для вставки
ускорит этот процесс.
Многие из
статьи в этих журналах представлены в формате PDF,
можно загрузить и сохранить с помощью Acrobat Reader.Вы можете выделить текст и скопировать его в документ Word
и, наконец, сохраните его как обычный текст. Использование офиса
Буфер обмена для сбора отрывков текста для вставки
ускорит этот процесс. В
хитрость — найти актуальные и достоверные тексты
включить в свой корпус из миллиардов
веб-страниц.И как только вы найдете подходящие тексты, «раскрасьте» их и скопируйте в свой документ Word.
занимает много времени. В общем, более сложные и
чем привлекательнее сайты, тем они трудоемки
захватывать и конвертировать, поскольку страницы часто
связаны между собой сложной системой гиперссылок.
Как утверждает Боукер (2002): «…хороший веб-дизайн — это не
способствует легкому построению корпуса! »
В
хитрость — найти актуальные и достоверные тексты
включить в свой корпус из миллиардов
веб-страниц.И как только вы найдете подходящие тексты, «раскрасьте» их и скопируйте в свой документ Word.
занимает много времени. В общем, более сложные и
чем привлекательнее сайты, тем они трудоемки
захватывать и конвертировать, поскольку страницы часто
связаны между собой сложной системой гиперссылок.
Как утверждает Боукер (2002): «…хороший веб-дизайн — это не
способствует легкому построению корпуса! »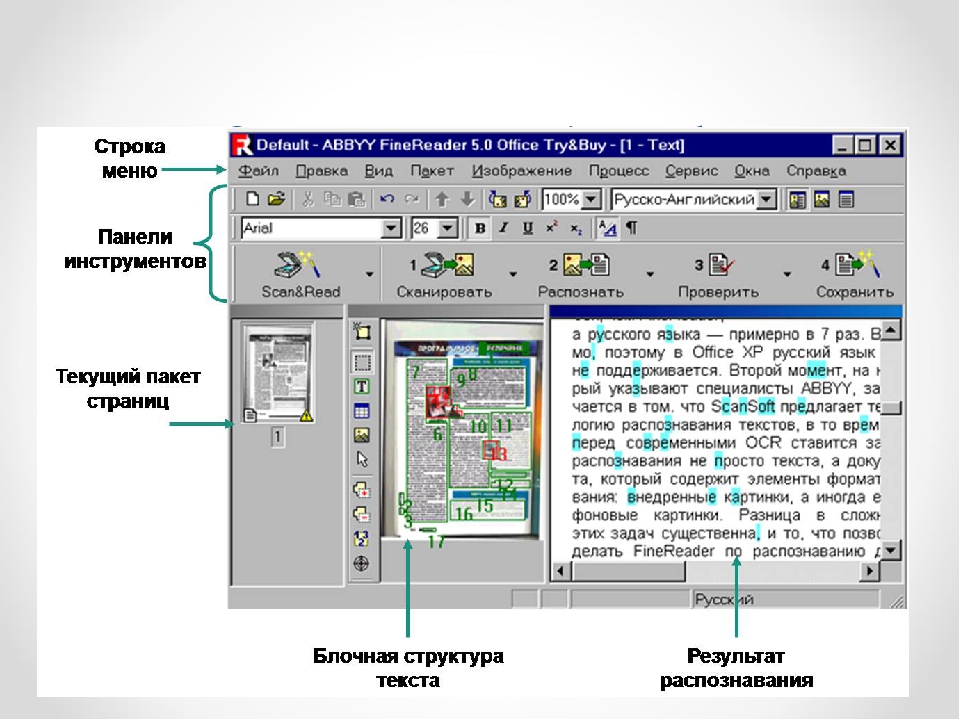
 Я бы рекомендовал сделать постредактирование
пока текст все еще находится в формате документа Word (* .doc),
так как легче читать, когда различные шрифты и
цвета все еще присутствуют, и только после редактирования
сохранить как текстовые файлы (* .txt).
Я бы рекомендовал сделать постредактирование
пока текст все еще находится в формате документа Word (* .doc),
так как легче читать, когда различные шрифты и
цвета все еще присутствуют, и только после редактирования
сохранить как текстовые файлы (* .txt). программное обеспечение для распознавания символов (OCR).
программное обеспечение для распознавания символов (OCR).

 Конечно не уроженцы
часто может писать так же хорошо, как носители языка,
если не лучше, но есть опасность, что СМС
не аборигены могут включать неидиоматические выражения.
Конечно не уроженцы
часто может писать так же хорошо, как носители языка,
если не лучше, но есть опасность, что СМС
не аборигены могут включать неидиоматические выражения.
Советы и приемы для решения распространенных проблем с преобразованием — Центр помощи Issuu
В этой статье представлено решение типичных проблем с преобразованием, ссылками, шрифтами, текстом и макетом при загрузке вашего контента на платформу Issuu.
ПРИМЕЧАНИЕ: Вам также необходимо следовать статье «Подготовка документов для загрузки», чтобы узнать больше об основных требованиях к документам.
Проблемы с конвертацией
Если преобразование завершилось неудачно, одна или несколько страниц могут быть слишком сложными (другими словами, они содержат слишком много векторных объектов).Для устранения неполадок выполните следующие действия:
- Определите эти сложные страницы, наблюдая, какие из них медленно загружаются в программе чтения PDF-файлов
- Удалите эти страницы и загрузите тест, чтобы проверить успешность преобразования
- Упростите дизайн сложных страниц или сведите их к растровой графике
ПРИМЕЧАНИЕ: На странице трудно увидеть подробную векторную графику. Обычно это делает дизайнерская программа, когда вы добавляете слишком много вещей на страницу.Вы можете попробовать создать свой PDF-файл как , оптимизированный для Интернета или линейный PDF . Это может быть достигнуто через диалоговое окно печати.
ПРИМЕЧАНИЕ. Если вы используете InDesign для создания своего содержимого, загрузите этот набор настроек экспорта Issuu, чтобы в процессе экспорта убедиться, что ваш PDF-файл готов к выпуску.
Проблемы со ссылками
Чтобы убедиться, что ваши ссылки работают правильно:
- Добавьте длинные ссылки перед загрузкой
- Ссылки должны иметь префикс www.или http (s): //
- Убедитесь, что ссылки в тексте не разделены переносом строки и не размещены непосредственно рядом с символами, не являющимися ссылками (добавьте пробелы с каждой стороны ссылки / адреса электронной почты)
- Если ссылки отображаются не в том месте , экспортируйте документ для просмотра на экране (не для печати)
- Если вы превращаете полные страницы в ссылки , например для полностраничных объявлений убедитесь, что область ссылки меньше фактической страницы. Наилучший подход — оставить место для поля вокруг области ссылки
Проблемы со шрифтами
Убедитесь, что ваши шрифты встроены в загружаемый документ путем экспорта со шрифтами.
ПРИМЕЧАНИЕ. Ваш документ может выглядеть правильно в настольной программе чтения PDF, поскольку программа чтения автоматически будет использовать правильные шрифты, доступные на локальном компьютере. Однако Issuu может потребоваться заменить отсутствующие шрифты другими, если вы не экспортируете правильные шрифты. Мы не сможем выполнять рендеринг шрифтов или извлечение текста.
ПРИМЕЧАНИЕ: Никогда не используйте лигатуры в своем документе. У них будут проблемы с рендерингом на Issuu.
Проблемы с текстом
Если на вашей странице нет четкого текста, убедитесь, что:
- У вас нет перекрывающихся изображений / графики в тексте.Это включает полупрозрачные или полностью прозрачные изображения / графику. Например, размещение текста под прозрачной частью изображения круга может вызвать проблемы с внешним видом текста. Чтобы исправить это, переупорядочьте слои в документе так, чтобы текст был поверх (даже если текст явно ничем не перекрывается).
- Вы не экспортируете текст в виде контуров
- Если вы загружаете документ PDF, текст можно выбрать при открытии документа в Adobe Reader.Если текст не может быть выделен, это означает, что он не будет четким на Issuu .
- Текст вставляется как текст, а не как изображение (например, как реклама). Если он вставлен как изображение, текст не всегда будет таким четким при увеличении, как в исходном документе
- В выходной PDF-файл включаются только видимые слои (см. Https://help.issuu.com/hc/en-us/articles/204815468-Exporting-from-InDesign-to-issuu-Ready-PDFs)
Все, что вам нравится | ABBYY FineReader 15.0.112.2130 Corporate Multilingual Pre-Activated
Компания ABBYY, ведущий поставщик технологий и услуг для распознавания документов, ввода данных, а также лингвистических технологий, анонсировала FineReader 12, новейшую версию отмеченного наградами приложения для оптического распознавания символов (OCR) и преобразования документов. FineReader 12 обеспечивает повышенную производительность для многих процессов и функций, включая более быстрое преобразование документов, возможность быстро открывать документы любой длины, в то время как обработка OCR выполняется в фоновом режиме, а также мгновенное распознавание области текста или таблицы, выбранной на странице.
Кроме того, FineReader 12 предлагает повышенную точность распознавания текста для деловых документов и с азиатскими языками, а также новые инструменты улучшения изображений, помогающие пользователям создавать цифровые копии документов с еще более высоким визуальным качеством, чем оригиналы. ABBYY FineReader® 12 Professional OCR точно преобразует бумажные и графические документы в редактируемые форматы, включая Microsoft Office и PDF-файлы с возможностью поиска, что позволяет повторно использовать их содержимое, более эффективно архивировать и получать более быстрое извлечение.FineReader избавляет от необходимости перепечатывать документы и обеспечивает постоянный доступ к важной информации. Он мгновенно обеспечивает доступ ко всему документу любого размера и поддерживает 190 языков в любых комбинациях.
ABBYY FineReader — это программа оптического распознавания символов (OCR), предназначенная для преобразования отсканированных документов, документов PDF и файлов изображений (включая цифровые фотографии) в редактируемые форматы.
Характеристики:
• Фоновое распознавание текста для максимальной эффективности — FineReader 12 предлагает инновационный подход к преобразованию документов, который позволяет пользователям открывать, просматривать и сразу же начинать работу с документом любого размера, пока он продолжает обрабатываться в фоновом режиме.В отличие от традиционных подходов, которые требуют, чтобы документ был полностью распознан до того, как он станет доступным для других действий, оптическое распознавание текста в FineReader 12 значительно экономит время, обеспечивая доступ ко всем страницам документа сразу. Кроме того, FineReader 12 увеличивает скорость обработки OCR до 15 процентов *.
• Простое извлечение данных и текстовое цитирование — FineReader 12 с оптимизированным интерфейсом и новыми элементами управления позволяет пользователям легко копировать таблицу или форматированный текст из любой выбранной области без необходимости распознавать весь документ.
• Повышенная точность деловых документов — FineReader 12 включает новый инструмент для удаления цветных штампов и следов пером на отсканированных или сфотографированных изображениях, обеспечивая лучшее качество распознавания и улучшая внешний вид деловых документов. Он также предлагает до 30% * более точное сохранение диаграмм и графиков и некоторых других элементов, типичных для деловых документов.
• Беспрепятственное преобразование таблиц — FineReader 12 улучшает преобразование таблиц до 40 процентов *, что позволяет инженерам, финансовым специалистам или другим специалистам значительно экономить время и силы при работе с числовыми данными.
• Повышенная точность для китайского, японского, корейского, арабского и иврита — FineReader 12 продолжает лидировать на рынке в области поддержки языков распознавания и предлагает до 15 процентов улучшения для арабского распознавания текста, до 10 процентов для распознавания текста на иврите и до 20 процентов. процентное повышение точности китайских, японских и корейских документов.
• Упрощенное сохранение и получение файлов из облака — FineReader 12 обеспечивает более легкий доступ к популярным облачным хранилищам, таким как Google Drive ™, Dropbox ™, SkyDrive® и другим. Кроме того, прямая интеграция с Microsoft SharePoint® Online / Office 365 ™ еще больше упрощает совместное использование документов.
• Улучшение визуального качества отсканированных изображений, фотографий и документов PDF — улучшенное распознавание текста ABBYY Camera OCR позволяет пользователям превращать фотографии документов в изображения сканерного качества и предлагает новые функции предварительной обработки фотографий, такие как автоматическая обрезка нескольких изображений и отбеливание оригинала. фон документа. Кроме того, новая технология PreciseScan от ABBYY сглаживает пиксельные символы в PDF-файлах с возможностью поиска, тем самым улучшая визуальное качество документов для облегчения чтения, архивирования или улучшения результатов печати.
• Более быстрая и простая проверка и исправление — расширенный инструмент проверки теперь позволяет пользователям вносить исправления как орфографии, так и форматирования с помощью интуитивно понятных горячих клавиш и элементов управления вкладками, которые упрощают навигацию по процессу проверки.
• Улучшенная горячая папка в FineReader 12 Corporate — улучшенная функция горячей папки для пакетного преобразования документов теперь ускоряет общий процесс преобразования, а также обеспечивает поддержку двухъядерной обработки. Кроме того, он предлагает более гибкие параметры именования, позволяя пользователям добавлять префиксы и суффиксы к именам файлов или папок, чтобы лучше их организовать.
• Совместимость с Windows 8 — ABBYY FineReader 12 полностью совместима с Windows 8 и использует новые возможности операционной системы, в том числе возможность использовать базовые сенсорные жесты для прокрутки и масштабирования на ноутбуках с сенсорными экранами.
Преимущества ABBYY FineReader 12
• Быстрый и точный OCR
• Поддержка большинства языков мира
• Возможность проверки и настройки результатов OCR
• Интуитивно понятный пользовательский интерфейс
• Возможность распознавать фотографии документов
• Поддерживает несколько форматов сохранения и облачные сервисы хранения
• Бесплатная техническая поддержка (доступна только зарегистрированным пользователям)
Требования к ПК
Операционная система
• Microsoft® Windows® 10/8.1/8/7 / Vista® / XP
• Microsoft Windows Server® 2012/2012 R2 / 2008/2008 R2 / 2003
• Для работы с локализованными интерфейсами требуется соответствующая языковая поддержка
Аппаратное обеспечение
• ПК с тактовой частотой 1 ГГц или выше
• 1024 МБ ОЗУ
• В многопроцессорной системе дополнительно 512 МБ ОЗУ требуется для каждого дополнительного ядра процессора
• 850 МБ на жестком диске для стандартной установки программы и 850 МБ свободное место для оптимальной работы программы
• Видеокарта с разрешением 1280 × 1024 или выше
Другое оборудование
• FineReader поддерживает TWAIN- и WIA-совместимые сканеры, многофункциональные периферийные устройства (МФУ) и многофункциональные устройства.
• Рекомендуемые требования для цифровых фотоаппаратов:
— 5-мегапиксельный сенсор (минимум — 2-мегапиксельный)
— Функция отключения вспышки
— Ручное управление диафрагмой или режим приоритета диафрагмы
— Ручная фокусировка
— Система стабилизации или использование рекомендуется штатив
— Оптический зум
http://www.rarefile.net/mzyz91wihyo2/ABBYY.Fine.Reader.Corporate.15.0.112.2130.PreActivated.rar
http://www.rarefile.net/e52njon9yumd/ABBYY.FineReader.Corporate.14.0.107.232.part1.rar
http://www.rarefile.net/3lmt5v7n8e1i/ABBYY.FineReader.Corporate.14.0.107.232.part2.rar
http://www.rarefile.net/tg3mck3ke9lo/ABBYY.FineReader.Enterprise.14.0.107.232.part1.rar
http://www.rarefile.net/31ste508jm6g/ABBYY.FineReader.Enterprise.14.0. 107.232.part2.rar
http://www.rarefile.net/qjghkujlouaf/ABBYY.FineReader.Corporate.14.0.105.234.rar
http: // www.Redfile.net/013s3zpcps6u/ABBYFineR.12.0.101.496.Multilingual.part1.rar
http://www.rarefile.net/9h2y8z6znc8w/ABBYFineR.12.0.101.496.Multilingual.part2.rar
ПРЕДВАРИТЕЛЬНАЯ ПРОФИЛЬНАЯ РЕДАКЦИЯ
http://www.rarefile.net/ddcu0umtrnm9/ABBYYFineR.12.0.101.264.PREACTIVATED.rar
.
Топ-5 ABBYY Finereader для Mac OS X 10.15 Catalina Альтернативы
Откровенно говоря, вы не получите качественных преобразований с бесплатными программами распознавания текста.Мощные инструменты, такие как ABBYY Finereader Pro для Mac , справятся с задачей быстро и точно. С такими инструментами вы гарантированно вернете свои деньги. На рынке появилось много таких инструментов, что еще больше усложняет выбор. К счастью, в этом руководстве представлены другие альтернативы ABBYY Finereader для Mac.
5 Альтернатив ABBYY Finereader Pro для Mac
1. PDFelement
PDFelement — это программа, которая выполняет такие задачи PDF, как редактирование, преобразование файлов, оптическое распознавание символов (OCR) и водяные знаки.Он обеспечивает полное решение задач PDF, что сделало его уважаемым после Finereader для Mac.
Его установка отлично работает на Mac OS X Catalina, позволяя пользователям идти дальше и создавать заполняемые формы PDF, выполнять мощные задачи редактирования, среди прочего.
Плюсы
- Меню четко обозначены.
- Богатые инструменты для работы с PDF.
- Имеет пакетный процессор.
- Обладает удобным интерфейсом.
- Признана лучшей системой управления документами TrustRadius в 2019 году
2. Adobe Acrobat для Mac
Adobe Acrobat — один из ведущих инструментов для решения PDF, доступных на рынке. Он предлагает быстрые преобразования, отличный дисплей и позволяет пользователям выполнять свои задачи с его помощью в любом месте в любой момент времени. Существует версия, которая хорошо работает на мобильных устройствах и предоставляет пользователям платформу для заполнения и обмена файлами PDF.Формат хорошо работает на устройствах iOS, Mac и Windows.
Плюсы
- Совместим с продуктами и услугами Adobe.
- Обладает мощными инструментами редактирования.
- Точно выполняет задачи.
Минусы
- Сложный, затрудняющий использование новичками.
- Может быть довольно дорого.
- OCR не очень мощный по сравнению с Finereader Pro для Mac.
3. PDFpenPro
Этот инструмент хорошо работает в Mac OS X10.15 Catalina, обеспечивая качественные услуги оптического распознавания текста, что делает его одним из лучших программ оптического распознавания текста на данный момент. PDFpenPro был разработан таким образом, чтобы новичкам было легко использовать его при выполнении задач. А с помощью других дополнительных функций пользователи могут исправлять грамматику, проводить распознавание изображений и отсканированных документов, а также включать в документы тексты, изображения или цифровые подписи.
Плюсы
- Легко, так как обладает простым интерфейсом.
- Обладает базовыми возможностями редактирования благодаря своим текущим функциям.
Минусы
- Качество редактирования текстов и макета страницы оставляет желать лучшего.
- Поддерживает не все языки.
4. PDF Expert
Это приложение стало лучшим инструментом для обработки PDF в устройствах, поддерживаемых IOS. Когда в 2015 году была выпущена версия для Mac, она заслужила хорошую репутацию, благодаря чему ее широко рекомендовали редакторы.PDF Expert упростил пользователям профессиональное управление им, предоставив достойные инструменты для редактирования и отличную платформу для обмена документами.
Плюсы
- Простой и понятный интерфейс.
- Обеспечивает хорошее отображение документов.
Минусы
- Его можно еще больше интегрировать с другими платформами.
- Имеет несколько функций.
5.Предварительный просмотр
Preview — это приложение по умолчанию, присутствующее в Mac OS X 10.15 Catalina. Это приложение позволяет легко манипулировать документами PDF. Это может быть подходящий инструмент при поиске приложения для выполнения простых задач редактирования и чтения. Однако, если вы ищете что-то более надежное, вам лучше поискать более продвинутое программное обеспечение.
Плюсы
- Встроенный, поэтому доступен бесплатно.
- Может хорошо читать файлы.
Минусы
- Отсутствует профессиональный инструмент.
- У него очень низкие уровни совместимости.
Сравните 5 ABBYY Finereader Pro для Mac Альтернативы
PDFelement | Acrobat для Mac | PDFpenPro | PDF Эксперт | ABBYY Finereader | Предварительный просмотр | |
|---|---|---|---|---|---|---|
| Скорость | Высокая скорость | Быстро | Быстро | Быстро | Высокая скорость | Довольно быстро |
| Поддержка системы | Mac, Windows, iOS, Android | Windows, Mac, iOS | Mac, iOS | Mac, iOS | Mac, Windows | Mac |
| Стоимость | $ 129 | 179 долларов.88 | $ 124.95 | $ 59,99 | 14,99 $ / мес | Бесплатно |
| Элемент | Богатый | Круглый | Много | Много | Круглый | Базовый |
Загрузите или купите PDFelement бесплатно прямо сейчас!
Загрузите или купите PDFelement бесплатно прямо сейчас!
Купите PDFelement прямо сейчас!
Купите PDFelement прямо сейчас!
.