Функция Len (Visual Basic для приложений)
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Возвращает элемент Long, содержащий число символов в стоке или число байтов, необходимое для хранения переменной.
Синтаксис
Len (stringvarname | )
Синтаксис функции Len состоит из следующих элементов:
| Part | Описание |
|---|---|
| строка | Любое допустимое строковое выражение. Если строка содержит значение NULL, возвращается NULL. |
| varname | Любое допустимое имя переменной. Если varname содержит Null, возвращается Null. Если varname — Variant, функция Len обрабатывает этот элемент так же, как String, и всегда возвращает число символов, которые он содержит. |
Должен быть указан один (и только один) из двух возможных аргументов. При использовании с определяемыми пользователем типами функция Len возвращает размер в том виде, в котором он будет записан в файл.
Примечание
Используйте функцию LenB с байтовыми данными, содержащимися в строке, как в языках с двухбайтовой кодировкой.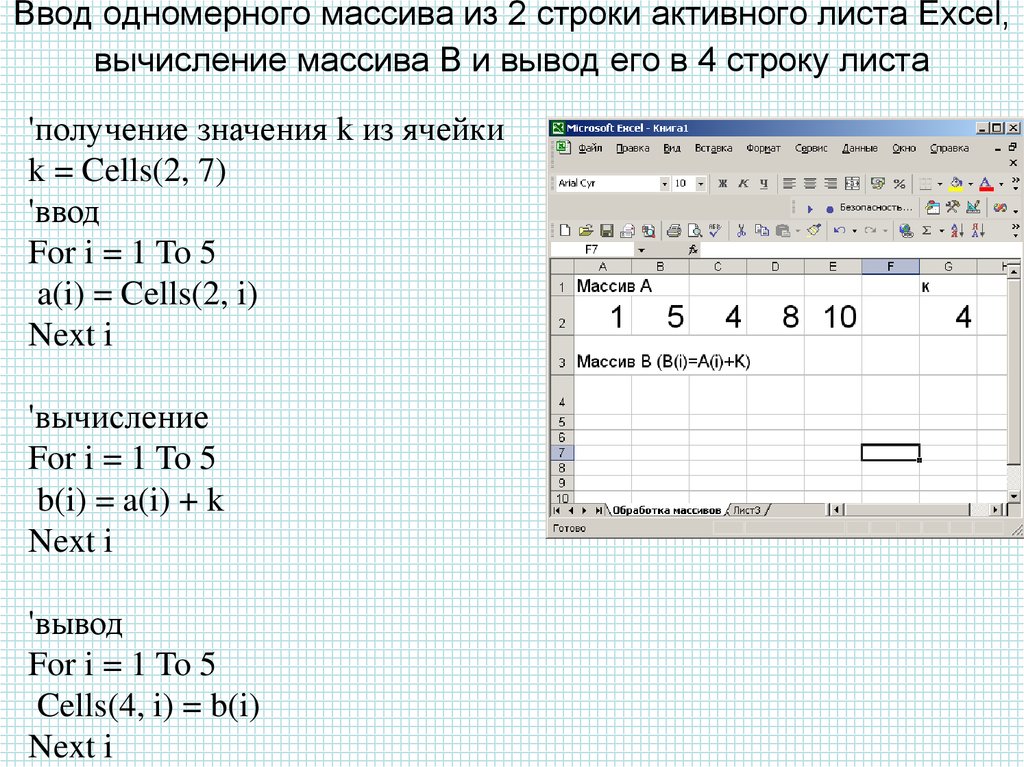 Вместо числа символов в строке функция LenB возвращает число байтов, используемых для представления этой строки. При использовании с определяемыми пользователем типами функция LenB возвращает размер внутренней памяти, включая любое заполнение между элементами. Пример кода, использующего LenB, см. во втором примере в разделе примеров.
Вместо числа символов в строке функция LenB возвращает число байтов, используемых для представления этой строки. При использовании с определяемыми пользователем типами функция LenB возвращает размер внутренней памяти, включая любое заполнение между элементами. Пример кода, использующего LenB, см. во втором примере в разделе примеров.
Примечание
Len может не определить фактическое число байтов хранилища, необходимых при использовании со строками переменной длины в определяемых пользователем типах данных.
Пример
В первом примере используется Len для возвращения числа символов в строке или числа байтов, необходимых для хранения переменной. Тип … Определению блока end Type CustomerRecord должно предшествовать ключевое слово Private , если оно отображается в модуле класса. В стандартном модуле оператор Type может иметь значение Public.
Type CustomerRecord ' Define user-defined type.
ID As Integer ' Place this definition in a
Name As String * 10 ' standard module.
Address As String * 30
End Type
Dim Customer As CustomerRecord ' Declare variables.
Dim MyInt As Integer, MyCur As Currency
Dim MyString, MyLen
MyString = "Hello World" ' Initialize variable.
MyLen = Len(MyInt) ' Returns 2.
MyLen = Len(Customer) ' Returns 42.
MyLen = Len(MyString) ' Returns 11.
MyLen = Len(MyCur) ' Returns 8.
Во втором примере используется LenB и определяемая пользователем функция (LenMbcs) для возвращения символов кодировки в строке, если ANSI используется для представления строки.
Function LenMbcs (ByVal str as String)
LenMbcs = LenB(StrConv(str, vbFromUnicode))
End Function
Dim MyString, MyLen
MyString = "ABc"
' Where "A" and "B" are DBCS and "c" is SBCS.
MyLen = Len(MyString)
' Returns 3 - 3 characters in the string.
MyLen = LenB(MyString)
' Returns 6 - 6 bytes used for Unicode. MyLen = LenMbcs(MyString)
' Returns 5 - 5 bytes used for ANSI.
MyLen = LenMbcs(MyString)
' Returns 5 - 5 bytes used for ANSI.
См. также
- Функции (Visual Basic для приложений)
Поддержка и обратная связь
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.
Анализ текста регулярными выражениями (RegExp) в Excel
21428 11.02.2018 Скачать пример
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.
 д.
д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
 д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти.
| Паттерн | Описание | |
| . |
Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
|
| \s |
Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
|
|
\S |
Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
|
|
\d |
Любая цифра |
|
|
\D |
Анти-вариант предыдущего, т.е. любая НЕ цифра |
|
| \w |
Любой символ латиницы (A-Z), цифра или знак подчеркивания |
|
| \W |
Анти-вариант предыдущего, т.
|
Начало строки |
| $ |
Конец строки |
|
| \b |
Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? |
Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + |
Одно или более вхождений. Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * |
Ноль или более вхождений, т.е. любое количество. Так \s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например \d{6} означает строго шесть цифр, а шаблон \s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:
Логика работы регулярного выражения тут простая: \d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол \d для цифры и квантор {6} для количества знаков:
Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:
Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор \b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):
Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т. д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой \d{11} вытаскивать 11 цифр подряд:
д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой \d{11} вытаскивать 11 цифр подряд:
ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой \d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):
Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:
То есть после срабатывания первого условия дальнейшая проверка уже не производится:
Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:
Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце \d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС. ..) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
..) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
Паттерн \d с квантором + ищет любое число до дефиса, а \d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:
Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:
Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:
Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:
После двоеточия фрагмент [0-5]\d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]\d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. ) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:
) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:
Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:
Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г\. если ищем плюсик, то \+ и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т. е. любое название города.
е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:
В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:
Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:
Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т. к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
vb6 — Подсчет вхождений символа в строку
спросил
Изменено 5 лет, 9 месяцев назад
Просмотрено 32к раз
Ищем лучший способ сделать это в VB6. Как правило, я бы использовал этот подход…
'количество пробелов
Для i = 1 To Len(текст)
Если Mid$(text, i, 1) = " ", то count = count + 1
Следующий
11
Не говорю, что это лучший способ, но вы делаете код:
DifferentChr = " " count = Len(текст) - Len(Replace(текст, DifferentChr, ""))
3
Используйте команду разделения, как эта
Dim TempS As String TempS = "Это сплит-тест" Dim V как вариант V = Разделить (TempS, "") Клс Печать UBound(V) '7 V = Разделить (TempS, "i") Печать UBound(V) '3 V = Разделить (TempS, "e") Печать UBound(V) '1
Можно объединить в одну строку.
Печать UBound(Split(TempS, "i"))
Я сделал на нем грубый тайминг. Строка из 40 000 символов со всеми пробелами, кажется, работает за 17 миллисекунд на процессоре Intel Core 2 с тактовой частотой 2,4 ГГц.
Функция может выглядеть так
Функция CountChar(ByVal Text As String, ByVal Char As String) As Long
Dim V как вариант
V = Разделить (Текст, Символ)
CountChar = UBound(V)
Конечная функция
1
Я бы использовал модифицированную сортировку:
Dim i as Integer
Dim индекс как целое число
Dim count как Integer
Dim FoundByAscii (от 0 до 255) как логическое значение
Для i = 1 To Len(текст)
индекс = Asc (Mid $ (текст, i, 1))
FoundByAscii(индекс) = Истина
Далее я
количество = 0
Для я = 0 до 255
Если НайденоByAscii(i) Тогда
количество = количество + 1
Конец, если
Далее я
…и ваш результат подсчитайте . Производительность O(N) — если Mid$ равно O(1).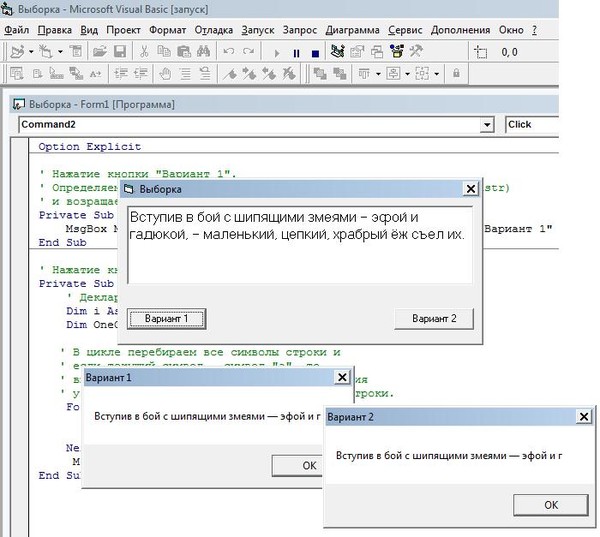
Редактировать :
Основываясь на вашем разъяснении, сделайте следующее:
' считать пробелы
Dim asciiToSearchFor As Integer
asciiToSearchFor = Asc(" ")
Для i = 1 To Len(текст)
Если Asc(Mid$(text, i, 1)) = asciiToSearchFor, то count = count + 1
Следующий
Поскольку сравнение ascii должно быть быстрее, чем сравнение строк. Я бы профилировал его на всякий случай, но я почти уверен.
2
Непонятно, что вы имеете в виду под лучший способ сделать это.
Если вам нужно что-то очень быстрое, но совершенно необслуживаемое, адаптируйте этот ужасный код, который копается в базовой памяти строки VB6 для подсчета количества слов. Предоставлено VBspeed.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как считать символы в строках в vb6
спросил
Изменено 8 лет, 10 месяцев назад
Просмотрено 7к раз
Добрый день! У меня проблема с Visual Basic 6. 0
Цель состоит в том, чтобы подсчитать, сколько слов и символов.
0
Цель состоит в том, чтобы подсчитать, сколько слов и символов.
Например:
Электровентилятор
Слов : 2 Символов: 11
Я уже сделал код для слова.
Но я понятия не имею, как считать символы. Спасибо!
Во всяком случае, это мой код для подсчета слов:
Dim Counter As Integer
Dim StartPos как целое число
Если Обрезать(Текст1) = "" Тогда
Количество слов = 0
Выйти из подпрограммы
Конец, если
Text1 = Trim(Text1) 'Удалить все пробелы
Количество слов = 1
Для счетчика = 1 в Len(Text1)
Если Середина(Текст1, Счетчик, 1) = " " Тогда
Кол-во слов = Кол-во слов + 1
Конец, если
Следующий счетчик
Text2.Text = ЧислоСлов
Текст3.Текст = Индекс
6
В вашем примере вы используете только пробел в качестве разделения между словами, поэтому вы можете использовать следующий код:
'1 форма с: ' 1 текстовое поле: name=Text1 ' 2 командные кнопки: name=Command1 name=Command2 Опция явная Частная подпрограмма Command1_Click() Dim lngWord As Long Dim lngWords As Long, lngChars As Long Dim strWord() как строка 'разделить текст по каждому пробелу strWord = Разделить (Text1.Text, "") считать слова lngWords = UBound(strWord) 'перебрать все слова и подсчитать символы lngChars = 0 Для lngWord = 0 В lngWords lngChars = lngChars + Len(strWord(lngWord)) Следующее длинное слово 'показать результаты Показать результаты lngWords + 1, lngChars Конец сабвуфера Частная подпрограмма Command2_Click() Dim lngWords As Long, lngChars As Long Dim strText как строка стрТекст = Текст1.Текст считать пробелы lngWords = Len(strText) - Len(Replace(strText, " ", "")) 'посчитать все, кроме пробелов lngChars = Len(strText) - lngWords 'показать результаты Показать результаты lngWords + 1, lngChars Конец сабвуфера Частная подпрограмма Form_Load() Text1.Text = "Электрический вентилятор" Конец сабвуфера Private Sub ShowResults (lngWords As Long, lngChars As Long) MsgBox "Words: " & CStr(lngWords) & vbCrLf & "Chars: " & CStr(lngChars), vbInformation, "Count" Конец сабвуфера
Command1 и Command2 должны дать одинаковый результат.
Команда Command1, вероятно, более проста для понимания и в конце дает массив, содержащий все слова. Command2 меньше кода 🙂
Command2 меньше кода 🙂
Некоторые замечания:
- слова также могут быть разделены ,.:;() и многое другое
- слов также можно разделить, если текст продолжается на новой строке
- может быть 2 разделительных символа без слова между ними, например, случайно 2 пробела
- слов могут быть продолжены на следующей строке. это должно считаться 1 словом, но между ними есть новая строка и, вероятно, —
Если вы хотите учитывать другие символы, вам, возможно, придется написать свои собственные функции split() или replace()
2
Вот функция, которая это делает. Было не так очевидно писать это, как я ожидал. Здесь я предполагаю, что вы хотите только считать буквы. Но это может быть не так. См. http://www.vb6.us/tutorials/vb6-string-functions для кодов символов ASCII и измените код в соответствии с тем, что вы подразумеваете под словом «символ».
Частная функция countLetters(str As String) As Integer
Дим и пока
Затемнение символа в виде строки
количество букв = 0
Для i = 1 To Len(str)
символ = Середина (ул, я, 1)
Если Буква(символ) Тогда
количество букв = количество букв + 1
Конец, если
Следующий
Конечная функция
Частная функция isLetter (символ как строка) как логическое значение
isLetter = (Asc(символ) >= 65 И Asc(символ) <= 90) Или (Asc(символ) >= 97 И Asc(символ) <= 122) Или Asc(символ) >= 161
Конечная функция
Вы можете использовать регулярные выражения, чтобы приблизиться к счетчикам MS Word, как это
lNumOfWords = CountWords(TextToCount)
Частная функция CountWords (текст в виде строки, необязательный шаблон в виде строки = "\S+") As Long
С CreateObject("VBScript.