Курсы 1С управление торговлей | Обучение 1С торговля и склад
Логистика и управление торговлей
Бухгалтерский учет и 1С
Компания «1С» рекомендует Центр «Специалист»!
Крупнейший в России учебный центр 1С «Специалист» при МГТУ имени Баумана, обладающий статусами Авторизованного Учебного центра 1С (ЦСО), Центра сертифицированного обучения 1С и Центра тестирования 1С, предлагает Вам курсы 1С Управление торговлей 11.5.
1С:Управление торговлей 11.5 — новейшая версия комплексного решения для автоматизации бизнес-процессов на торговых предприятиях. С ее помощью все подразделения предприятия будут взаимодействовать в четком и слаженном ритме единой команды. Приложение 1С:Управление торговлей 11.5 реализует ряд возможностей для интерактивного анализа текущей ситуации, регулярного получения управленческой информации (опция «Рапорт руководителю»), а также для работы с использованием серверных и интернет-ресурсов.
Обучение 1С Управление торговлей строится не просто на демонстрации работы программы. С помощью наших преподавателей Вы на примере реальных практических задач научитесь работать в 1С:Управление торговлей 11.5.
По окончании обучения Вы получаете фирменный сертификат 1C и можете сразу приступать к работе.
Мы не продаем программное обеспечение, мы учим правильно и эффективно работать в 1С!
Наши преимущества:
- Мы являемся Центром Сертифицированного Обучения (ЦСО).
- Нас рекомендует компания «1С».
- Мы преподаем курсы 1С с 1993 г.
- Наши преподаватели — признанные эксперты и практики в области 1С.
- Практикоориентированность курсов: Вы получите знания и навыки, необходимые Вам для работы.
- Точное расписание на год вперед.
- Большой выбор режимов обучения: утро, утро-день, вечер.
- Есть группы выходного дня.
- Виды обучения: очное, онлайн, открытое обучение, свободное обучение.
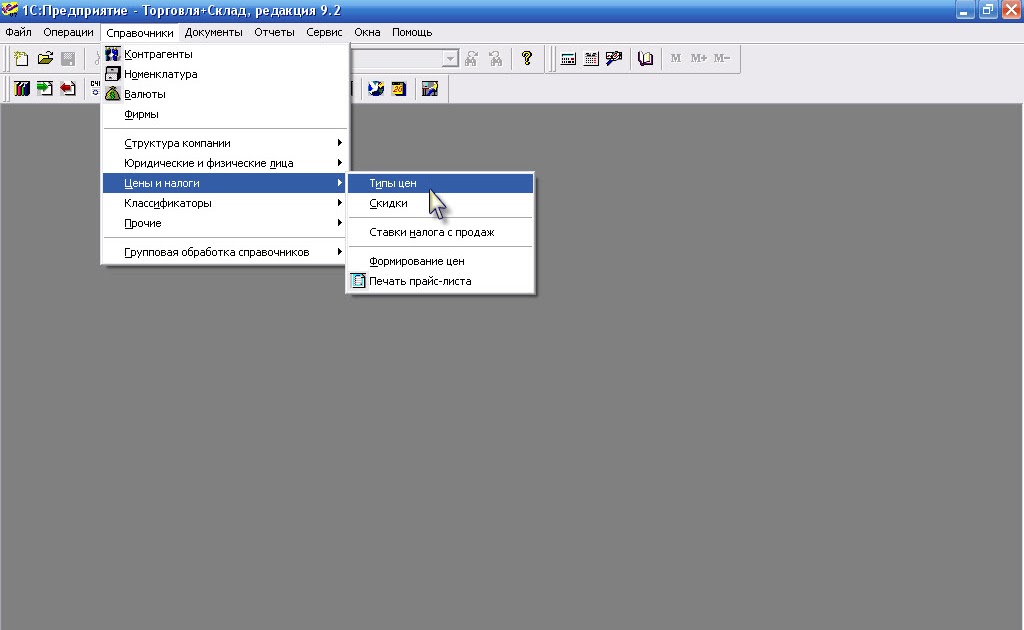
- По окончании сертифицированных курсов Вы получаете свидетельство 1С.
- У нас Вы можете сдать экзамен 1С:Профессионал и подготовиться к нему.
- Гарантия качества обучения.
-
24.10.2022
Другие даты
Дипломная программа — 288 ак.ч
Логистика и управление цепями поставок
Продолжительность: от 3 до 6 месяцев
Хрущ
Игорь
Валерьевич
140 890 ₽
187 930 ₽
150 690 ₽
200 930 ₽
-
01.
 10.2022
10.2022
Другие даты
Комплексная программа — 56 ак.ч
Специалист по 1С:Предприятие 8. Управление торговлей
Вы экономите 32% стоимости второго курса!
Гречко
Елена
Валериевна
Читать отзывы
28 790 ₽
33 980 ₽
31 390 ₽
36 980 ₽
-
01.10.2022
Другие даты
Комплексная программа — 128 ак.ч
Эксперт по 1С:Предприятие 8.
 Управление торговлей
Управление торговлей
Вы экономите 55% стоимости четвёртого курса!
Гречко
Елена
Валериевна
Читать отзывы
64 490 ₽
75 960 ₽
70 490 ₽
82 960 ₽
-
01.10.2022
Другие даты
Комплексная программа — 68 ак.ч
Управление логистикой в 1C
Вы экономите 28% стоимости второго курса!
Гречко
Елена
Валериевна
Читать отзывы
33 090 ₽
38 980 ₽
35 590 ₽
41 980 ₽
-
24.
 10.2022
10.2022
Другие даты
Комплексная программа — 140 ак.ч
Менеджер по логистике (управление материальными потоками) со знанием 1С:Предприятие 8. Управление торговлей
Вы экономите 72% стоимости третьего курса!
Хрущ
Игорь
Валерьевич
Читать отзывы
72 990 ₽
85 970 ₽
79 790 ₽
93 970 ₽
-
01.10.2022
Другие даты
Курс — 32 ак.
 ч
ч
1C:Управление торговлей (редакция 11.5). Оператор 1С
Гречко
Елена
Валериевна
Читать отзывы
17 990 ₽
19 990 ₽
-
01.10.2022
Другие даты
Курс — 24 ак.ч
1С: Управление торговлей (ред. 11.5). Уровень 2. Управленческий учет
Гречко
ЕленаВалериевна
Читать отзывы
15 990 ₽
16 990 ₽
-
01.
 10.2022
10.2022
Другие даты
Курс — 36 ак.ч
1С: Управление торговлей (ред. 11.4). Уровень 2. Расширенные возможности
Гречко
Елена
Валериевна
Читать отзывы
20 990 ₽
23 990 ₽
-
01.10.2022
Другие даты
Курс — 36 ак.ч
 11.5). Логистика»>
1С: Управление торговлей (ред. 11.5). Логистика
11.5). Логистика»>
1С: Управление торговлей (ред. 11.5). Логистика
Гречко
Елена
Валериевна
Читать отзывы
20 990 ₽
21 990 ₽
1C:Управление торговлей 8, Учебные курсы 1С
Все Интернет-обучение и самоучители Очное обучение
1С:Управление торговлей 8: Первые шаги
10 ак.ч.
- Рекомендуемая подготовка: Курс предназначен для пользователей, владеющих основными навыками работы с компьютером, а также имеющим опыт в ведении торговых операций и ведении торгового учета.
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c. ru
ru
1С:Управление торговлей 8. Углубленное изучение возможностей программы
40 ак.ч.
- Рекомендуемая подготовка: Курс предназначен для пользователей, владеющих основными навыками работы с компьютером, а также имеющим опыт в ведении торговых операций и ведении торгового учета.
- Уровень получаемых знаний: Навыки использования средств типовой конфигурации для решения сложных и специфических задач автоматизации оперативного и управленческого учета.
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c. ru
ru
1C:Предприятие 8. Управление торговлей. Основные принципы работы с программой
40 ак.ч., 30 дней
- Рекомендуемая подготовка: знакомство с предметной областью организации документооборота при оптовой и розничной торговле
- Уровень получаемых знаний: 1C:Профессионал по 1С:Предприятие 8. Управление торговлей»
Подробнее на edu.1c.ru
1С:Управление торговлей 8. Основные принципы работы с программой. Редакция 11 и торговый функционал в «1С: Комплексная автоматизация 2»
40 ак.ч., 5 дней
- Рекомендуемая подготовка: знакомство с предметной областью организации документооборота при оптовой и розничной торговле
-
Уровень получаемых знаний: 1C:Профессионал по «1С: Предприятие 8.
 Управление торговлей»
Управление торговлей»
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c.ru
1С:Управление торговлей 8. Основные принципы работы с программой. Редакция 11 и торговый функционал в «1С: Комплексная автоматизация 2»
40 ак.ч., 5 дней
- Рекомендуемая подготовка: знакомство с предметной областью организации документооборота при оптовой и розничной торговле
- Уровень получаемых знаний: 1C:Профессионал по «1С: Предприятие 8. Управление торговлей»
- Место проведения: Учебный центр №1
Подробнее на 1c. ru
ru
Внедрение и адаптация прикладного решения «1С: Управление торговлей 8»
32 ак.ч., 4 дня
- Рекомендуемая подготовка: 1С: Профессионал по «1С: Предприятие 8. Управление торговлей»
- Уровень получаемых знаний: 1С: Специалист-консультант по по внедрению прикладного решения «1С: Управление торговлей 8»
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c.ru
«1С: Управление торговлей 8» для организаций ведущих оптовую, розничную и комиссионную торговлю
30 ак. ч
ч
- Рекомендуемая подготовка: опыт в ведения торговых операций и ведения торгового учета
- Уровень получаемых знаний: опыт в ведения торговых операций и ведения торгового учета
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c.ru
«1С: Предприятие 8. Управление торговлей для Казахстана». Практическое применение типовой конфигурации
40 ак.ч., 5 дней
- Рекомендуемая подготовка: опыт в ведения торговых операций и ведения торгового учета
- Уровень получаемых знаний: ознакомление с «1 °C: Управление Торговлей 8 для Казахстана»
- Место проведения: Центры сертифицированного обучения
Подробнее на 1c. ru
ru
Курсы 1С Торговля и склад. Обучение по курсу 1С Управление торговлей 8. Ред. 10.3 или 11
15.08.2022, Бычек Яна Николаевна
Дистанционное обучение «1С Управление торговлей 8». Очень понравился представленный учебный материал, также интересные видеоматериалы. Очень удобно прохождение тестирования — сразу же получаешь оценку. Самое главное, что учиться можно в удобное для себя время, не прерывая свою трудовую деятельность. Выражаю свою огромную признательность и благодарность организаторам и кураторам курсов за прекрасное педагогическое сопровождение. Отдельное спасибо выражаю Галине Викторовне Улич за чуткое, внимательное, терпеливое и бережное отношение. В целом, за месяц получила большой поток информации. Изложен понятно. Буду применять на практике.
25.02.2021г. Дедова И.А.
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Искренне благодарю за организацию и проведение обучения по программе «1С Управление торговлей 8». И персональная благодарность Галине Викторовне за подробное объяснение материала, за терпение и высокий профессионализм! Желаю всему Центру образования процветания и финансового благополучия!
13.
 11.2020г. Свахчян С.
11.2020г. Свахчян С.Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Впечатления о курсе замечательные! Преподаватель Улич Галина Викторовна профессионал в своем деле! Все объясняла четко и понятно! Благодарны за ваш познавательный и интересный курс!
13.11.2020г. Финкельштейн М.
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Закончила курс «1С Управление торговлей». Все понравилось, хорошие преподаватели, всё доступно и быстро!
05.11.2020г. Хайдурова М.М.
Курс «1С Бухгалтерия предприятия 8», «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Закончила дистанционно два курса у преподавателя Улич Галины Викторовны. Очень довольна курсами, отличная подача материала, интересные задания, быстрая проверка заданий и обратная связь! Спасибо большое, Галина Викторовна!
28.10.2020 г. Говорина М.Г.
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Хочу сказать огромное спасибо за обучение по программе «1С Управление торговлей». Очень хороший преподаватель Улич Г.В., объясняет все доступно, с примерами из жизни.
Очень хороший преподаватель Улич Г.В., объясняет все доступно, с примерами из жизни.
02.08.2020 г. Сергеева Е.В.
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Уважаемая Галина Викторовна! Вы замечательный преподаватель! Спасибо Вам за Ваше терпение и понимание! С огромным уважением. Всех Вам благ!!!
20.12.2019г. Барткова Инга
Курс «Оператор 1С». Преподаватель Улич Галина Викторовна С огромным удовольствием посещала занятия в Центре образования. Очень уютное помещение, комфортные условия для обучения и отдыха. Очень обаятельный внимательный персонал и преподавательский состав. Огромное спасибо за внимание, обучение и уютную, комфортную обстановку в центре. Успехов и процветания, а также здоровьяи всех благ всему персоналу.
11.11.2019г. Верхотурова Наталия
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Выражаю большую благодарность и уважение преподавателю Галине Викторовне за предоставленные знания! Также хочу отметить компетентную работу всего Центра образования и дружелюбную обстановку в нем. Было очень приятно посещать занятия и получать новые знания! Есть большое желание вернуться сюда за новыми знаниями! Спасибо! Желаю успехов и процветания!
Было очень приятно посещать занятия и получать новые знания! Есть большое желание вернуться сюда за новыми знаниями! Спасибо! Желаю успехов и процветания!
11.11.2019г. Стефаненко Екатерина
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна По окончании курса остается приятное впечатление. Очень уютный и комфортный офис. Здесь работают исключительно приятные люди. Отдельное спасибо хочется выразить Галине Викторовне. Приятный человек, который доступно объясняет и умеет научить нужному.
05.04.2019г. Марченко Софья
Курс «Оператор 1С». Преподаватель Улич Галина Викторовна Я закончила курс «Оператор 1С», освоила программу «1С Управление торговлей», Excel и слепой десятипальцевый метод печати. Преподаватели очень хорошие, открытые и добрые, всегда помогут. Занятия проходят быстро и интересно. Улич Галина Викторовна и Карелина Ольга Валерьевна – высококвалифицированные специалисты, знающие свое дело. Очень приятно было работать с ними! Большое спасибо!
29.
 03.2019 г. Гладких Светлана
03.2019 г. Гладких СветланаКурс «1С:Предприятие». Преподаватель Улич Галина Викторовна Хочется оставить слова благодарности Байкальскому Центру образования в лице Улич Г.В., Васильковской А.Н. после успешного прохождения двух курсов: 1С Предприятие и Пользователь ПК. Спасибо за личный подход, доступное объяснение материала и комфортную обстановку, как дома! Желаю дальнейших успехов и процветания!!!
28.03.2018 г. Карпович Ольга (группа ЦЗН г. Иркутска)
Курс «1С:Предприятие». Преподаватель Улич Галина Викторовна Я получила большие практические знания программы. Обучение проходило в доброжелательной комфортной атмосфере. Выражаю огромную благодарность преподавателю Улич Галине Викторовне. Буду рекомендовать центр обучения друзьям!
06.03.2019 г. Директор ООО «БСМ-групп» Данилова Н.М.
Курс «1С Управление торговлей 8». Преподаватель Улич Галина Викторовна Выражаю огромную благодарность Улич Галине Викторовне за прекрасное, понятное, доброжелательное преподавание курса по 1С.
Концепции, проектирование и интеграция хранилищ данных
Об этом курсе
34 986 недавних просмотров
Это второй курс специализации Data Warehousing for Business Intelligence. В идеале курсы следует проходить последовательно.
Гибкие сроки К концу курса у вас будет опыт проектирования, опыт работы с программным обеспечением и организационный контекст, который подготовит вас к успеху в проектах по разработке хранилищ данных.
В этом курсе вы создадите проекты хранилищ данных и рабочие процессы интеграции данных, которые удовлетворят потребности организаций в бизнес-аналитике. Когда вы закончите этот курс, вы сможете:
* Оценить организацию на предмет зрелости хранилища данных и согласования бизнес-архитектуры;
* Создайте дизайн хранилища данных и подумайте об альтернативных методологиях проектирования и целях проектирования;
* Создание рабочих процессов интеграции данных с использованием известного программного обеспечения с открытым исходным кодом;
* Подумайте о роли данных об изменениях, ограничениях обновления, компромиссах частоты обновления и целях качества данных при разработке процесса интеграции данных; а также
* Выполнение операций со сводными таблицами для удовлетворения типичных запросов бизнес-анализа с использованием известного программного обеспечения с открытым исходным кодом
К концу курса у вас будет опыт проектирования, опыт работы с программным обеспечением и организационный контекст, который подготовит вас к успеху в проектах по разработке хранилищ данных.
В этом курсе вы создадите проекты хранилищ данных и рабочие процессы интеграции данных, которые удовлетворят потребности организаций в бизнес-аналитике. Когда вы закончите этот курс, вы сможете:
* Оценить организацию на предмет зрелости хранилища данных и согласования бизнес-архитектуры;
* Создайте дизайн хранилища данных и подумайте об альтернативных методологиях проектирования и целях проектирования;
* Создание рабочих процессов интеграции данных с использованием известного программного обеспечения с открытым исходным кодом;
* Подумайте о роли данных об изменениях, ограничениях обновления, компромиссах частоты обновления и целях качества данных при разработке процесса интеграции данных; а также
* Выполнение операций со сводными таблицами для удовлетворения типичных запросов бизнес-анализа с использованием известного программного обеспечения с открытым исходным кодомГибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 2 из 5 в рамках специализации
Data Warehousing for Business Intelligence
Часов для прохожденияПрибл. 22 часа на прохождение
Доступные языкианглийский
субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, немецкий, русский, английский, испанский
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификатОбщий сертификат
Получение сертификата по завершении
100 % онлайн100 % онлайн
Начните сразу и учитесь по собственному расписанию.
СпециализацияКурс 2 из 5 в рамках специализации
Data Warehousing for Business Intelligence
Часов для прохожденияПрибл. 22 часа
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, немецкий, русский, английский, испанский
Преподаватель
Майкл Маннино
Ассоциированный профессор
Бизнес-школа Университета Колорадо Денвер
203,967 Учащиеся
4 Курсы
Предлагает
Система Университета Колорадо
является признанным лидером в сфере высшего образования в Колорадо . Мы сотрудничаем, чтобы удовлетворить разнообразные потребности наших студентов и сообществ. Мы продвигаем инновации, поощряем открытия и поддерживаем расширение знаний способами, уникальными для штата Колорадо и за его пределами.
Мы сотрудничаем, чтобы удовлетворить разнообразные потребности наших студентов и сообществ. Мы продвигаем инновации, поощряем открытия и поддерживаем расширение знаний способами, уникальными для штата Колорадо и за его пределами.
Reviews
4.4
Filled StarFilled StarFilled StarFilled StarHalf Filled Star206 reviews
5 stars
61.17%
4 stars
28.14%
3 stars
5.68%
2 звезды
1,99%
1 Star
2,99%
Лучшие обзоры из хранилища данных, дизайн и интеграция данных
Заполненные звезды StarFiled StarFiled Star.0004 от AN 30 мая 2016 г.Для меня этот курс является одним из самых важных в BI. У нас были хорошие учителя, которые помогали нам разобраться в важных вопросах.
Filled StarFilled StarFilled StarFilled StarStarот EM17 июня 2020 г.
Курс был очень хорошим, но в середине он чувствовал себя немного поспешным. В разделе дизайна хранилища данных должно быть еще несколько примеров и пояснений. В целом отличное качество материала
В разделе дизайна хранилища данных должно быть еще несколько примеров и пояснений. В целом отличное качество материала
от RAF 18 февраля 2017 г.
Лучший курс для начинающих, чтобы учиться и развивать свою карьеру в области хранилищ данных. Также Coursera является лучшим источником обучения. Спасибо всем
Filled StarFilled StarFilled StarFilled StarStarот HD 16 января 2016 г.
В целом хороший класс, однако видеолекции не предоставляют достаточной справочной информации для выполнения некоторых заданий. Ожидайте потратить гораздо больше времени, чем предполагаемые 30 минут, чтобы завершить.
Просмотреть все отзывы
О специализации Data Warehousing for Business Intelligence
Оценка потребностей бизнеса, разработка хранилища данных, а также интеграция и визуализация данных с помощью информационных панелей и средств визуальной аналитики.
 Вы изучите основы моделирования структурированных данных, получите практический опыт кодирования SQL и получите глубокое понимание проектирования хранилища данных и управления данными. У вас будет возможность работать с большими наборами данных в среде хранилища данных для создания информационных панелей и визуальной аналитики. Вы будете использовать MicroStrategy, ведущий инструмент бизнес-аналитики, OLAP (онлайн-аналитическая обработка) и возможности Visual Insights для создания информационных панелей и визуальной аналитики. В финальном проекте Capstone вы примените свои навыки для создания небольшого базового хранилища данных, заполнения его данными и создания информационных панелей и других визуализаций для анализа и передачи данных широкой аудитории.
Вы изучите основы моделирования структурированных данных, получите практический опыт кодирования SQL и получите глубокое понимание проектирования хранилища данных и управления данными. У вас будет возможность работать с большими наборами данных в среде хранилища данных для создания информационных панелей и визуальной аналитики. Вы будете использовать MicroStrategy, ведущий инструмент бизнес-аналитики, OLAP (онлайн-аналитическая обработка) и возможности Visual Insights для создания информационных панелей и визуальной аналитики. В финальном проекте Capstone вы примените свои навыки для создания небольшого базового хранилища данных, заполнения его данными и создания информационных панелей и других визуализаций для анализа и передачи данных широкой аудитории.Часто задаваемые вопросы
Когда я получу доступ к лекциям и заданиям?
Что я получу, подписавшись на эту специализацию?
Доступна ли финансовая помощь?
Есть вопросы? Посетите Справочный центр для учащихся.
Учебное пособие по хранилищу данных для начинающих: изучение основных понятий
Хранилище данных. Краткое изложение руководства
Хранилище данных — это набор программных инструментов, помогающих анализировать большие объемы разрозненных данных. Цель состоит в том, чтобы извлечь выгодные идеи из данных. Этот курс охватывает дополнительные темы, такие как витрины данных, озера данных, схемы и другие.
Что я должен знать?
Учебные пособия предназначены для начинающих с небольшим опытом работы с хранилищем данных или без него. Хотя базовое понимание базы данных и SQL является плюсом.
Введение
| 👉 Урок 1 | Что такое хранилище данных? — Типы, определение и пример |
| 👉 Урок 2 | База данных и хранилище данных — ключевые отличия |
| 👉 Урок 3 | Архитектура хранилища данных — Изучение архитектуры, концепций и компонентов |
| 👉 Урок 4 | Что такое ETL? — Процесс ETL (извлечение, преобразование и загрузка) в хранилище данных |
| 👉 Урок 5 | ETL против ELT — необходимо знать различия |
| 👉 Урок 6 | Руководство по тестированию хранилища данных или ETL — Что такое, типы и пример |
Дополнительные материалы
| 👉 Урок 1 | Моделирование данных — Концептуальные, логические и физические типы моделей данных |
| 👉 Урок 2 | Что такое OLAP? — Куб, операции и типы в хранилище данных |
| 👉 Урок 3 | MOLAP — Многомерный OLAP в хранилище данных |
| 👉 Урок 4 | Что такое OLTP? — определение, архитектура, пример |
| 👉 Урок 5 | OLTP и OLAP — Разница между OLTP и OLAP |
| 👉 Урок 6 | Что такое объемное моделирование? — Что такое, типы и преимущества |
| 👉 Урок 7 | Что такое звездная схема? — Что такое схема «звезда» в моделировании хранилища данных? |
| 👉 Урок 8 | Схема снежинки — Схема снежинки в модели хранилища данных |
| 👉 Урок 9 | Схема «звезда и снежинка» — обучение на примерах |
| 👉 Урок 10 | Что такое киоск данных в хранилище данных? — Типы и пример |
| 👉 Урок 11 | Хранилище данных и Data Mart — Знайте разницу |
| 👉 Урок 12 | Что такое озеро данных? — Это архитектура |
| 👉 Урок 13 | Озеро данных и хранилище данных — в чем разница? |
| 👉 Урок 14 | Что такое бизнес-аналитика? — Определение и пример |
| 👉 Урок 15 | Учебное пособие по интеллектуальному анализу данных — Что такое | процесс | Методы и примеры |
| 👉 Урок 16 | Учебное пособие по DataStage для начинающих — Обучение IBM DataStage (инструмент ETL) |
| 👉 Урок 17 | Что такое согласование данных? — Определение, процесс, инструменты |
Ключевое отличие!
| 👉 Урок 1 | Интеллектуальный анализ данных и хранилище данных — в чем разница? |
| 👉 Урок 2 | Таблица фактов и таблица размеров — в чем разница? |
| 👉 Урок 3 | Информация и данные — в чем разница? |
| 👉 Урок 4 | Информация и знания — ключевые отличия |
Должен знать!
| 👉 Урок 1 | Лучшие инструменты для хранилищ данных — 25 ЛУЧШИХ инструментов для хранилищ данных |
| 👉 Урок 2 | Лучшие инструменты ETL — 25 ЛУЧШИХ инструментов ETL (бесплатных и платных) |
| 👉 Урок 3 | Лучшие инструменты интеграции данных — 15 лучших программ для интеграции данных (бесплатно + платно) |
| 👉 Урок 4 | Лучшие инструменты непрерывной интеграции — 20 лучших инструментов непрерывной интеграции (CI/CD) |
| 👉 Урок 5 | Лучшие инструменты для тестирования автоматизации ETL — 5 лучших инструментов для тестирования автоматизации ETL |
| 👉 Урок 6 | Лучшие инструменты бизнес-аналитики — 24 лучших программного обеспечения для бизнес-аналитики |
| 👉 Урок 7 | ЛУЧШИЕ инструменты моделирования данных — 20 ЛУЧШИХ инструментов моделирования данных: проектирование базы данных |
| 👉 Урок 8 | ЛУЧШИЕ инструменты интеллектуального анализа данных — 25 ЛУЧШИХ инструментов и программного обеспечения для интеллектуального анализа данных |
| 👉 Урок 9 | ЛУЧШИЕ инструменты визуализации данных — 20 ЛУЧШИХ инструментов визуализации данных [бесплатно и платно] |
| 👉 Урок 10 | ЛУЧШИЕ инструменты анализа данных — 14 ЛУЧШИХ инструментов анализа данных |
| 👉 Урок 11 | ЛУЧШИЕ системы программного обеспечения для управления складом — 10 ЛУЧШИЕ системы программного обеспечения для управления складом |
| 👉 Урок 12 | ЛУЧШИЕ инструменты отчетности — 18 ЛУЧШИЕ инструменты отчетности и программное обеспечение |
| 👉 Урок 13 | ЛУЧШАЯ программа для работы с блок-схемами — 20 лучших бесплатных программ для работы с блок-схемами | Создатель блок-схем |
| 👉 Урок 14 | ЛУЧШИЕ инструменты управления журналами — 30 ЛУЧШИЕ инструменты и программное обеспечение для управления журналами |
| 👉 Урок 15 | ЛУЧШИЕ серверы системного журнала — 15 ЛУЧШИХ серверов системного журнала для Windows и Linux |
| 👉 Урок 16 | ЛУЧШИЕ инструменты SIEM — 20 ЛУЧШИХ инструментов и программных решений SIEM |
| 👉 Урок 17 | Вопросы для интервью по тестированию ETL — 25 лучших вопросов для интервью по тестированию ETL |
| 👉 Урок 18 | Учебное пособие по Teradata — Что такое? Базовый SQL базы данных Teradata |
| 👉 Урок 19 | Вопросы для интервью с Teradata — 50 лучших вопросов и ответов для интервью с Teradata |
| 👉 Урок 20 | Вопросы интервью по моделированию данных — 88 лучших вопросов интервью по моделированию данных |
| 👉 Урок 21 | Хранилище данных в формате PDF — Скачать учебник по хранилищу данных в формате PDF для начинающих |
MicroStrategy
| 👉 Урок 1 | Учебное пособие по MicroStrategy — Что такое средство создания отчетов MSTR? |
| 👉 Урок 2 | Вопросы для интервью по микростратегии — Топ 42 вопросов и ответов для интервью по микростратегии |
| 👉 Урок 3 | Учебное пособие по Power BI — Что такое Power BI? Зачем использовать? Примеры DAX |
| 👉 Урок 4 | Вопросы на собеседовании по Power BI — Топ-100 вопросов и ответов на собеседовании по Power BI |
| 👉 Урок 5 | Учебное пособие по Qlikview — Что такое QlikView? Как установить инструмент QlikView |
| 👉 Урок 6 | Qlikview Interview Questions — Top 100 Qlikview Interview Q & A |
Ab Initio Tutorial | Полный обзор Ab Initio
AB Initio Introduction
Программное обеспечение Ab initio — это американское многонациональное предприятие, расположенное в Лексингтоне, штат Массачусетс. Ab initio также известен как инструмент тестирования ETL, он состоит из шести основных компонентов, таких как взаимодействующие системы, библиотека компонентов, графическая среда разработки, метасреда предприятия, профилировщик данных и настройка среды поведения. Это один из мощных инструментов параллельного процесса на основе графического интерфейса, разработанный для инструментов управления и анализа данных ETL. Инструмент ETL в основном используется для загрузки разнородных источников данных в приложения хранилища данных. Ab initio ETL выполняет следующие три операции:
Ab initio также известен как инструмент тестирования ETL, он состоит из шести основных компонентов, таких как взаимодействующие системы, библиотека компонентов, графическая среда разработки, метасреда предприятия, профилировщик данных и настройка среды поведения. Это один из мощных инструментов параллельного процесса на основе графического интерфейса, разработанный для инструментов управления и анализа данных ETL. Инструмент ETL в основном используется для загрузки разнородных источников данных в приложения хранилища данных. Ab initio ETL выполняет следующие три операции:
1. Инструмент ETL извлекает данные из транзакционной системы. Включенное программное обеспечение: Oracle, IBM и Microsoft.
2. Используется для преобразования данных в систему хранилища данных путем выполнения операций очистки данных.
3. Наконец загружает данные в систему хранилища данных OLTP.
Чтобы получить глубокие знания и практический опыт, изучите Ab Initio Training
Обзор AB Initio:
Ab initio — это набор приложений для работы с данными, который содержит различные компоненты хранилища данных. Обычно, когда люди называют это «Ab initio», это означает взаимодействующую систему Ab Initio. Это также известно как инструмент ETL на основе приложения с графическим пользовательским интерфейсом. Это дает возможность перетаскивать различные компоненты и присоединять их. Ab initio — это прикладной инструмент для параллельной обработки ETL, используемый для обработки большого объема данных.
Обычно, когда люди называют это «Ab initio», это означает взаимодействующую систему Ab Initio. Это также известно как инструмент ETL на основе приложения с графическим пользовательским интерфейсом. Это дает возможность перетаскивать различные компоненты и присоединять их. Ab initio — это прикладной инструмент для параллельной обработки ETL, используемый для обработки большого объема данных.
Включены следующие компоненты:
1. Система совместной работы
2. Метасреда предприятия (EME)
3. Дополнительные инструменты обработки данных
4. Приложение для профилирования данных
5. Система информационных технологий PLAN.
Архитектура AB Initio:
Архитектура Ab initio объясняет характер работы и общую структуру инструмента ETL:
На приведенной ниже диаграмме подробно объясняется архитектура Ab initio:
Ab initio означает «начинается с самого начала». Это программное обеспечение хорошо работает с моделью клиент-сервер. Здесь клиентская система называется графической средой разработки или GDE; это находится на вашем рабочем столе. Сервер или внутренняя система известна как взаимодействующая система. Этот системный инструмент взаимодействия на стороне сервера расположен на мэйнфрейме или удаленной машине UNIX. В общем, код ab initio также известен как граф, который имеет расширение .mp. Этот граф GDE необходим для развертывания версии .ksh или K-shell. Взаимодействующая система используется для запуска файлов .ksh для выполнения необходимых задач. Как я уже говорил ранее, ab initio является поставщиком инструментов ETL и постепенно становится самым сильным игроком в системе интеграции данных приложений с критически важными компонентами. Их:
Здесь клиентская система называется графической средой разработки или GDE; это находится на вашем рабочем столе. Сервер или внутренняя система известна как взаимодействующая система. Этот системный инструмент взаимодействия на стороне сервера расположен на мэйнфрейме или удаленной машине UNIX. В общем, код ab initio также известен как граф, который имеет расширение .mp. Этот граф GDE необходим для развертывания версии .ksh или K-shell. Взаимодействующая система используется для запуска файлов .ksh для выполнения необходимых задач. Как я уже говорил ранее, ab initio является поставщиком инструментов ETL и постепенно становится самым сильным игроком в системе интеграции данных приложений с критически важными компонентами. Их:
1. ETL или система хранения данных
2. Инструмент для анализа данных в режиме реального времени
3. CRM или управление взаимоотношениями с клиентами
4. EAI или интеграция корпоративных приложений
Ab initio предлагает надежную модель архитектуры, которая обеспечивает простая, быстрая и высокозащищенная прикладная система интеграции данных. Этот инструмент также объединяет разнообразные, непрерывные и сложные потоки данных, которые могут варьироваться от гигабайт до терабайт.
Этот инструмент также объединяет разнообразные, непрерывные и сложные потоки данных, которые могут варьироваться от гигабайт до терабайт.
Ab Initio Обучение
- Мастер своего дела
- Пожизненная LMS и доступ преподавателей
- Круглосуточная экспертная онлайн-поддержка
- Реальное и проектное обучение
Изучение учебного плана
Различия между ETL и BI:
1. Инструмент ETL в основном используется для извлечения данных из различных источников данных, преобразования извлеченных данных и загрузки их в систему хранилища данных.
2. Инструмент бизнес-интеграции используется для создания интерактивных и специальных отчетов с данными для конечных пользователей, информационных панелей, визуализации данных и управления данными на высшем уровне.
3. Наиболее распространенными включенными инструментами ETL являются технология службы данных SAP BO (BODS), Data Informatica, Power Center, MSIS, инструмент ODI интегратора данных Oracle и инструмент ETL с открытым исходным кодом clover.
4. Некоторые популярные инструменты BI включают бизнес-объекты SAP, IBM Cognos, SAP lumira, Jasper soft, платформы Microsoft BI, платформу бизнес-аналитики Oracle и многие другие.
Реализация интеграции приложений с помощью AB Initio:
В этом разделе мы объясним процесс интеграции приложений с помощью ab initio. На приведенной ниже диаграмме поясняется архитектура проекта и общая структура, используемые для интеграции данных из разрозненного источника в хранилище данных и загрузки их в инструмент приложения CRM.
Основные проблемы включают:
1. Несколько источников: здесь доступны данные из разных источников, таких как мэйнфреймы или таблицы оракула, использующие разные методы и форматы данных с разной частотой загрузки.
2. Сложная бизнес-логика: здесь вы получите формат данных с целевыми системами, методами очистки данных и общими объектами.
3. Избыточность: несколько источников данных из-за дублирования данных.
С помощью ab initio экономичное системное решение может предложить механизмы пакетного выполнения или выполнения в реальном времени. Здесь масштабируемое решение, которое извлекает данные из распределенных систем, преобразует несколько форматов данных в общий формат, создает хранилище данных, оперативные хранилища данных, агрегацию или получение бизнес-аналитики и загружает данные в целевые системы.
Функции системного инструмента AB Initio:
Ниже перечислены основные ключевые функции системного инструмента Ab:
1. Загружает данные в оперативные хранилища данных.
2. Используйте механизм правил на основе метаданных для создания различных кодов.
3. Предоставляет средство PAI для выполнения операций запроса.
4. Графический интерфейс с базой данных для извлечения данных и загрузки данных.
5. Предлагает дельту и изображения данных до и после.
6. Подает целевую систему и средства отчетности или очереди сообщений.
Преимущества методов AB Initio:
Ниже приведены преимущества методов Ab initio:
1. Ab initio может дать представление о механизмах складывания.
2. Помогает понять неправильное свертывание белка.
3. Не требует методик гомологов.
4. Единственный способ смоделировать новые складки данных.
5. Модель Ab initio полезна для дизайна белков de novo.
Обзор процесса ETL:
Расскажите нам немного больше о процессе ETL:
Процедуры следующие:
На приведенной ниже диаграмме поясняется процесс ETL:
1. Извлечение данных:
На этом этапе вам будет разрешено извлекать данные из нескольких разнородных источников данных. Процесс извлечения данных варьируется в зависимости от требований организации. Этот тип извлечения данных можно выполнить, запустив различные расписания заданий в нерабочее время, например, если вы выполняете задание ночью или в выходные дни.
2. Преобразование данных:
На этом этапе вы сможете преобразовать данные в подходящий формат, чтобы их можно было легко загрузить в систему хранилища данных. Включены различные типы преобразования данных: применение вычислений данных, операции объединения и указание первичных и внешних ключей. Эти типы задействованных преобразований данных включают исправление данных, удаление неверных данных, неполное формирование данных и исправление ошибок данных. Это также выполняет интеграцию данных и форматирует загрузку несовместимых данных в систему хранилища данных.
3. Загрузка данных в различные системы хранения данных:
На этом этапе вам будет разрешено загружать данные в различные системы хранения данных для выполнения аналитических отчетов и информации. Целевая система может хранить плоские файлы и информацию хранилища данных.
Функции инструмента ETL:
Инструмент ETL состоит из трехуровневой архитектуры, которая использует промежуточную область, уровни доступа и интеграцию данных для выполнения операций ETL (извлечение, передача и загрузка).
1. Промежуточный уровень: промежуточный уровень или промежуточная база данных используется для хранения данных, извлеченных из различных систем-источников данных.
2. Уровень интеграции данных: Уровень интеграции данных преобразует различные данные из промежуточного уровня и передает их в базу данных, здесь данные будут организованы в иерархическую группу, известную как измерения, и преобразованы в факты или совокупные факты. Эта комбинация агрегированных фактов и таблиц измерений в таблице хранилища данных называется схемой.
3. Уровень доступа: этот уровень доступа в основном используется конечным пользователем для извлечения данных для аналитической отчетности и хранения информации.
На приведенной ниже диаграмме поясняются функции инструмента ETL:
Тестирование ETL – задачи, которые необходимо выполнить:
Тестирование ETL выполняется перед передачей данных в производственную складскую систему. Этот процесс известен как балансировка таблиц или согласование продуктов. Тестирование ETL отличается от тестирования других баз данных с точки зрения объема и важных шагов, которые необходимо предпринять.
При тестировании ETL необходимо выполнить важные задачи:
1. Понимание данных, которые будут использоваться для целей анализа и отчетности.
2. Обзор архитектуры модели данных
3. Источник для выполнения целевого сопоставления
4. Помогает проверять данные из различных источников.
5. Проверка схемы и упаковки
6. Помогает выполнять проверку данных в целевой системе источника данных
7. Проверка передачи данных, расчетов и правил агрегирования.
8. Пример сравнения данных между любой исходной системой и целевой системой
9. Интеграция данных и проверка качества данных в целевой системе-источнике.
10. Помогает выполнить различные тестирование данных
Часто задаваемые вопросы интервью ab initio
Подпишитесь на наш канал на YouTube, чтобы получить новые обновления ..!
Подписаться
Теперь пришло время узнать разницу между тестированием ETL и тестированием базы данных:
И тестирование ETL, и тестирование базы данных включают операции проверки данных. Но эти два метода тестирования не одинаковы. Тестирование ETL в основном используется для работы с источниками данных в системе хранилища данных. Тестирование базы данных выполняется в источнике транзакционной системы. Здесь данные поступают из различных приложений в транзакционную базу данных.
Тестирование ETL включает следующие операции:
1. Выполните перемещения проверки данных из исходной системы в целевую систему.
2. Проверка нескольких счетчиков данных в исходной и целевой системах.
3. Проверяет извлечение данных, передачу данных в соответствии с требованиями.
4. Проверка того, что отношения таблиц, такие как соединения и ключи, сохраняются во время преобразования данных.
Тестирование базы данных выполняет следующие операции:
1. Проверяет и поддерживает первичный и внешний ключи.
2. Проверка столбца данных в таблице базы данных, содержащего действительные значения данных.
3. Проверка точности данных в столбцах данных. Например: столбец количества месяцев не должен превышать значение, превышающее 12 месяцев.
4. Проверка отсутствующих значений данных в столбце. Это используется для проверки наличия нулевых значений.
Категории тестирования AB Initio-ETL:
Тестирование Ab initio ETL можно разделить на категории на основе целей тестирования и представления данных. Тестирование ETL классифицируется по следующим пунктам.
1. Тестирование исходного и целевого количества:
Этот тип категории тестирования включает сопоставление количества записей данных как в исходной, так и в целевой системах.
2. Тестирование исходных и целевых данных:
Этот тип категории тестирования включает проверку данных между исходной и целевой системами. Здесь это помогает выполнить интеграцию данных и проверку пороговых значений данных, а также устранить повторяющиеся значения данных в целевой системе.
3. Тестирование сопоставления данных или преобразования данных:
Этот тип категории тестирования подтверждает сопоставление данных любого объекта как в исходной, так и в целевой системах. Это также включает проверку функциональности данных в целевой системе.
4. Тестирование конечным пользователем:
Это включает создание отчетов данных для конечных пользователей, чтобы проверить, соответствуют ли доступные данные в отчетах вашим требованиям. С помощью этого тестирования вы также можете найти отклонения в отчете и провести перекрестную проверку данных в целевой системе для проверки отчета.
5. Повторное тестирование:
Оно включает в себя исправление ошибок и дефектов данных в целевой системе и создание отчетов о данных для проверки данных.
6. Тестирование системной интеграции:
Это включает в себя тестирование всех отдельных исходных систем, а затем объединение результатов для выявления каких-либо отклонений. Здесь доступны три основных подхода:
1. Нисходящий подход
2. Восходящий подход
3. Гибридный подход
Тестирование ETL также можно разделить на следующие категории:
1. Тестирование новой системы хранилища данных:
В этом типе тестирования ETL ваша новая система хранилища данных может быть построена и проверьте данные. Здесь входные данные могут быть получены от конечных пользователей или клиентов из различных источников данных, после чего создается новое хранилище данных.
2. Тестирование миграции:
В этом типе тестирования у клиентов будет существующее хранилище данных и инструмент ETL, но здесь они ищут новый инструмент ETL для повышения эффективности данных. Это тестирование включает перенос данных из существующей системы с использованием нового инструмента ETL.
3. Тестирование изменений:
В ходе этого тестирования изменений в существующую систему будут добавлены новые данные из различных источников данных. Здесь клиенты также могут изменить существующие правила ETL или добавить новые правила.
4. Тестирование отчетов:
В этом типе тестирования пользователь может создавать отчеты для проверки данных. Здесь отчеты являются конечным результатом работы любой системы хранилища данных. Тестирование отчетов может выполняться на основе макетов, отчетов с данными и расчетных значений.
Статья по теме: Сравнение AWS и Azure
Обзор методов тестирования AB Initio ETL:
Методы тестирования Ab Initio ETL играют жизненно важную роль, и вам необходимо применить эти методы перед выполнением фактического процесса тестирования. Эти методы тестирования должны применяться группой тестирования, и они должны быть осведомлены об этих методах. Доступны различные типы методов тестирования:
1. Проверка производства:
Этот тип метода тестирования используется для выполнения аналитических функций отчетности и анализа данных, а также для проверки создания данных проверки в системе. Тестирование производственной проверки может быть выполнено для данных, которые перемещаются в производственную систему. Этот метод считается важным этапом тестирования, поскольку он включает метод проверки данных и сравнение этих данных с исходной системой.
2. Тестирование исходного и целевого количества:
Этот тип тестирования может быть выполнен, когда у группы тестирования меньше возможностей для выполнения любого типа операций тестирования. Целевое тестирование проверяет количество данных как в исходной, так и в целевой системах. Еще один момент, который следует учитывать, заключается в том, что он не включает возрастание или убывание значений данных.
3. Тестирование исходных данных в целевые:
В этом типе тестирования команда тестировщиков включает проверку значений данных из исходной системы в целевую систему. Это проверяет соответствующие значения данных, также доступные в целевой системе. Этот тип техники тестирования также требует много времени и в основном используется для работы над банковскими проектами.
4. Тестирование проверки порогового значения сферы интеграции данных:
В этом типе тестирования группа тестирования проверяет диапазоны данных. Все пороговые значения данных в целевой системе будут проверены, если они ожидают действительный вывод. С помощью этого метода вы также можете выполнить интеграцию данных в целевой системе, где данные доступны из системы с несколькими источниками данных, после завершения операций передачи и загрузки данных.
5. Тестирование миграции приложений:
Тестирование миграции приложений обычно выполняется при переходе от старого приложения к новой системе приложений. Этот тип тестирования экономит много вашего времени, а также помогает извлекать данные из устаревших систем в новую прикладную систему.
6. Проверка данных и постоянное тестирование:
Это тестирование включает в себя различные типы проверок, такие как проверка типа данных, проверка индекса и проверка длины данных. Здесь инженер по тестированию выполняет следующие сценарии: проверки первичного ключа, внешнего ключа, NULL, Unique и NOT NULL.
7. Тестирование проверки дубликатов данных:
Этот метод тестирования включает проверку дубликатов данных, находящихся в целевой системе. Когда в целевой системе находится огромное количество данных. Также возможно, что в производственной системе имеются дубликаты данных.
Следующий оператор SQL используется для выполнения этого типа метода тестирования:
Выберите Customer_ID, Customer_NAME, Quantity, COUNT (*)
FROM Customer
СГРУППИРОВАТЬ ПО Customer_ID, Customer_NAME, количество, имеющее COUNT (*) > 1;
В целевой системе появляются повторяющиеся данные по следующим причинам:
1. Если первичный ключ не указан, могут появиться повторяющиеся значения.
2. Это также возникает из-за неправильного картирования и проблем с данными об окружающей среде.
3. Ручные ошибки возникают при переносе данных из исходной системы в целевую.
8. Тестирование преобразования данных:
Тестирование преобразования данных не выполняется с использованием какой-либо отдельной инструкции SQL. Этот метод тестирования требует много времени, а также помогает выполнять несколько запросов SQL для проверки правил преобразования. Здесь группа тестирования должна выполнить запросы операторов SQL, а затем сравнить результат.
Ab Initio Training
Пакеты рабочих дней/выходных дней
См. сведения о пакете
9. Тестирование качества данных:
Этот тип тестирования включает такие операции, как проверка числа, проверка даты, проверка нулевого числа, проверка точности и т. д. Здесь группа тестирования также выполняет тесты синтаксиса, чтобы проверить любые недопустимые символы и неправильный порядок в верхнем или нижнем регистре. Эталонные тесты также выполняются, чтобы проверить, доступны ли данные в соответствии с моделью данных.
10. Инкрементное тестирование:
Можно выполнить добавочное тестирование, чтобы проверить, вставляются ли данные и обновляются ли операторы SQL. Эти операторы SQL выполняются в соответствии с ожидаемыми результатами. Этот метод тестирования выполняется шаг за шагом со старыми и новыми значениями данных.
11. Регрессионное тестирование:
При внесении изменений в любые правила преобразования и агрегации данных, используемые для добавления новых функций. Это также помогает команде тестирования найти новую ошибку, которая называется регрессионным тестированием. Ошибка также возникает при регрессионном тестировании, и этот процесс известен как регрессия.
12. Повторное тестирование:
Когда команда тестировщиков запускает тесты после исправления ошибок, это называется повторным тестированием.
13. Системное интеграционное тестирование:
Системное интеграционное тестирование включает тестирование компонентов системы, а также интеграцию модулей. Доступны три способа системной интеграции, такие как подход «сверху вниз», «снизу вверх» и гибридный метод.
14. Навигационное тестирование:
Навигационное тестирование также называется тестированием интерфейсной системы. Это включает в себя тестирование точки зрения конечного пользователя, которое может быть выполнено путем проверки всех аспектов, таких как различные поля, агрегирование и вычисления.
Ab Initio – процесс ETL
Это тестирование Ab Initio включает жизненные циклы ETL, а также помогает лучше понять бизнес-требования.
Ниже приведены общие этапы жизненного цикла ETL:
1. Помогает понять бизнес-требования
2. Проверка процесса бизнес-требований.
3. Этап оценки теста используется для предоставления расчетного времени для выполнения тестовых случаев, а также для завершения сводного отчета о процессе тестирования.
4. Методы планирования тестирования включают поиск методов тестирования на основе входных данных в соответствии с бизнес-требованиями.
5. Помогает в создании тестовых сценариев и тестовых случаев.
6. После того, как тестовые наборы готовы к тестированию и одобрены, следующим шагом является выполнение любой проверки перед выполнением.
7. Позволяет выполнять все тестовые случаи.
8. Последний и заключительный шаг для создания полного сводного отчета о тестировании и регистрации процесса заключительного тестирования.
Ab initio-Процесс автоматизации
Тестирование ETL Ab initio можно выполнить с помощью сценариев SQL и сбора данных в электронных таблицах. Этот тип подхода делает тестирование ETL очень низким, трудоемким и подверженным ошибкам. Наиболее часто используемые инструменты тестирования ETL — это процесс проверки данных Query Surge и Informatica.
Процесс Query Surge:
Query Surge — это не что иное, как решение для тестирования данных, предназначенное для тестирования больших данных, тестирования хранилища данных и процесса ETL. Этот процесс может автоматизировать весь процесс тестирования и прекрасно вписывается в вашу стратегию DevOps.
Ключевая особенность всплеска запросов заключается в следующем:
1. Он состоит из мастеров запросов для быстрого и простого создания тестовых пар запросов без необходимости написания операторов SQL.
2. В нем есть библиотека дизайна с многократно используемыми фрагментами запросов. Кроме того, вы можете создавать собственные пары запросов.
3. Этот процесс может сравнивать значения данных из исходных файлов и данных, хранящихся в целевом хранилище больших данных.
4. Это также позволяет сравнивать миллионы строк и столбцов значений данных за считанные минуты.
5. Query Surge также позволяет пользователю планировать любые тесты для немедленного запуска в любое время и в любую дату.
6. Это также может создавать информативные отчеты с данными, просматривать обновления данных и автоматически отправлять результаты вашей команде по электронной почте.
Чтобы автоматизировать любой процесс, инструмент ETL должен запускаться с всплеска запросов с использованием командного API после завершения процесса загрузки программного обеспечения ETL. Процесс всплеска запросов запускается автоматически, а ООН посещает и выполняет все тестовые процессы.
Процесс проверки данных Informatica:
Проверка данных Informatica предлагает инструмент тестирования ETL, который помогает группе тестирования ускорить и автоматизировать процесс тестирования ETL во время разработки и производственной среды. Этот процесс проверки помогает вам предоставить, завершить, воспроизвести и проверить тестовое покрытие за меньшее время. И этот процесс проверки не требует каких-либо навыков программирования.
Заключение:
В этом вводном руководстве мы объяснили обзор архитектуры, определение, интеграцию, процесс автоматизации, инструмент функции ETL, характер работы ETL и методы тестирования. Изучение этого инструмента тестирования Ab initio поможет вам стать мастером в области автоматизации и инструментов ETL. Этот инструмент ab initio поможет вам исправить неверные поля данных и применить расчеты. Учебник ab initio специально разработан для тех, кто хочет начать свою карьеру в тестировании ETL. И это также полезно для тех специалистов по тестированию программного обеспечения, которые хотят выполнять анализ данных для извлечения процессов. Наша техническая команда обеспечивает круглосуточную онлайн-поддержку для решения этих вопросов, связанных с курсом.
Учебное пособие по потоковой обработке, часть 1.
Создание приложений для потоковой передачи событийПотоковая обработка — это технология обработки данных, используемая для сбора, хранения и управления непрерывными потоками данных по мере их создания или получения. Потоковая обработка (также известная как потоковая передача событий или обработка сложных событий) имеет множество вариантов использования и часто является внутренним процессом для выставления счетов, выполнения или обнаружения мошенничества, который, возможно, необходимо отделить от внешнего интерфейса, где пользователи нажимают кнопки и ожидают, что что-то произойдет. .
Преимущества Stream Processing
Модель, управляемая событиями, имеет множество преимуществ: она устраняет зависимости между службами, обеспечивает некоторый уровень подключаемости к архитектуре, позволяет службам развиваться независимо и т. д.
В своей книге Designing Event-Driven Systems , Бен Стопфорд объясняет, как архитектуры, управляемые событиями, можно использовать для создания критически важных для бизнеса систем. Он описывает ценность выворачивания баз данных «наизнанку» и обращения с потоками событий как с «источником правды». Помимо прочего, в книге показано, как применять шаблоны, включая совместную работу над событиями, поиск источников событий и CQRS для создания микросервисов и архитектур, ориентированных на события.
Такие системы обычно используют Apache Kafka ® в качестве основы. Kafka похожа на центральную плоскость данных, которая содержит общие события и синхронизирует сервисы. Его распределенная кластерная технология обеспечивает доступность, отказоустойчивость и производительность, укрепляющие архитектуру, позволяя программисту просто писать и развертывать клиентские приложения, которые будут работать с балансировкой нагрузки и будут высокодоступными.
Если вы готовы перейти от чтения этих фундаментальных концепций к более практическому обучению, Confluent предлагает несколько ресурсов:
- Серия видеороликов Kafka Streams
- Серия видеороликов KSQL
- Примеры Kafka Streams
- Документация Kafka Streams
Эта серия блогов, состоящая из двух частей, поможет вам разработать и проверить приложения для потоковой передачи в реальном времени. В части 1 мы представляем новый ресурс:
- Учебное пособие: Введение в разработку потоковых приложений
Во второй части мы проверяем эти потоковые приложения. А пока давайте поговорим об этом новом руководстве для разработчиков.
Учебное пособие по потоковой обработке для разработчиков
Это бесплатное учебное пособие для самостоятельного изучения является отличным введением для разработчиков, которые только начинают работать с потоковой обработкой. Вы изучите основы API Kafka Streams, который намного богаче, чем производитель Kafka или потребитель Kafka, а также общие шаблоны для разработки и создания приложений, управляемых событиями.
Учебное пособие основано на небольшой экосистеме микросервисов и демонстрирует рабочий процесс управления заказами, подобный тому, который вы можете найти в розничной торговле и интернет-магазинах. Он построен с использованием Kafka Streams, благодаря чему бизнес-события, описывающие рабочий процесс управления заказами, распространяются через эту экосистему. В сообщении блога Создание экосистемы микросервисов с помощью Kafka Streams и KSQL описан используемый подход.
В этом примере система сосредоточена на службе заказов, которая предоставляет интерфейс REST для заказов POST и GET. Публикация заказа создает событие в Kafka, которое записывается в теме заказов. Это определяется тремя различными механизмами проверки (служба мошенничества, служба инвентаризации и служба сведений о заказе), которые проверяют заказ параллельно, выдавая ПРОШЕЛ или НЕ ПРОШЕЛ в зависимости от того, прошла ли каждая проверка успешно.
Результат каждой проверки помещается в отдельный раздел «Проверки заказов», чтобы сохранить статус единственного автора службы заказов —> раздел заказов (в книге Бена Стопфорда обсуждается несколько вариантов управления согласованностью при совместной работе над событиями). Результаты различных проверок агрегируются в службе агрегатора проверки, которая затем переводит заказ в состояние «Проверено» или «Не выполнено» на основе объединенного результата.
Чтобы пользователи могли ПОЛУЧИТЬ любой заказ, служба заказов создает запрашиваемое материализованное представление (встроенное в службу заказов), используя хранилище состояний в каждом экземпляре службы, так что любой заказ может быть запрошен исторически. Также обратите внимание, что службу заказов можно масштабировать на несколько узлов, и в этом случае запросы GET должны направляться на правильный узел для получения определенного ключа. Это обрабатывается автоматически с помощью функции интерактивных запросов в Kafka Streams.
Служба заказов также включает блокировку HTTP GET, чтобы клиенты могли читать свои записи. Таким образом, мы соединяем синхронную, блокирующую парадигму интерфейса RESTful с асинхронной, неблокирующей обработкой, выполняемой на стороне сервера.
Существует простая служба, которая отправляет электронные письма, и другая, которая сопоставляет заказы и делает их доступными в поисковом индексе с помощью Elasticsearch.
Наконец, Confluent KSQL работает с постоянными запросами для обогащения потоков, а также для проверки мошеннического поведения.
Вот схема микросервисов и связанных тем Kafka:
Чтобы использовать учебник, сначала необходимо правильно настроить среду. Вы можете использовать локальную установку Confluent Platform или Docker.
Затем запустите полное комплексное рабочее решение, не требующее разработки кода, чтобы увидеть развертывание потокового приложения представителем клиента. Это обеспечивает контекст для каждого из упражнений, в которых вы будете разрабатывать части микросервисов.
После того, как вы успешно запустите полное решение, выполните отдельные упражнения в учебнике, чтобы лучше понять основные принципы потоковых приложений. Для каждого упражнения учебник предоставляет файл-заглушку, для которого вы должны завершить код. Работая над этими упражнениями, вы изучите шаблоны написания надежных потоковых приложений и получите опыт использования Kafka Streams API. Завершите код (есть подсказки, если они вам нужны!), скомпилируйте и запустите предоставленные тесты, чтобы убедиться, что он работает!
В учебнике рассматриваются следующие упражнения:
- Упражнение 1.
 Сохранение событий
Сохранение событий - Упражнение 2. Приложения, управляемые событиями
- Упражнение 3. Расширение потоков с помощью объединений
- Упражнение 4. Фильтрация и ветвление
- Упражнение 5. Операции с отслеживанием состояния
- Упражнение 6. Сохранение состояний
- Упражнение 7. Дополнение с помощью KSQL
Упражнение 1. Сохранение событий
В этом упражнении вы сохраните события в Kafka, создавая записи, представляющие заказы клиентов. событие — это просто то, что произошло или произошло. Событие в бизнесе — это какой-то факт, который произошел, например продажа, счет-фактура, сделка, взаимодействие с клиентом и т. д., и это источник истины. В событийно-ориентированных архитектурах события являются первоклассными гражданами, которые постоянно передают данные в приложения. Затем клиентские приложения могут реагировать на эти потоки событий в режиме реального времени и решать, что делать дальше.
Упражнение 2.
Приложения, управляемые событиямиВ этом упражнении вы позволите самому событию заказа запускать службу. В таком дизайне, управляемом событиями, поток событий — это взаимодействие между службами, которое приводит к меньшему количеству взаимодействий и запросов, позволяет службам пересекать границы развертывания и позволяет избежать синхронного выполнения. Напротив, архитектуры на основе служб часто разрабатываются для управления запросами, в которых службы отправляют команды другим службам, чтобы сообщить им, что делать, ждать ответа или отправлять запросы для получения результирующего состояния.
Визуальная сводка команд, событий и запросов
Упражнение 3. Расширение потоков с помощью объединений
В этом упражнении вы напишете службу, которая обогащает информацию о заказах потоковой передачи, объединяя ее с платежной информацией потоковой передачи и данными из клиентская база данных. Многие приложения потоковой обработки на практике кодируются как потоковые соединения. Например, приложениям, поддерживающим интернет-магазин, может потребоваться доступ к нескольким обновляемым таблицам базы данных (например, цены продажи, запасы, информация о клиентах), чтобы обогатить новую запись данных (например, транзакцию клиента) контекстной информацией. В этих сценариях может потребоваться выполнение поиска в таблице в очень большом масштабе и с малой задержкой обработки.
Служба потоковой передачи с отслеживанием состояния, которая объединяет два потока во время выполнения
Популярный шаблон — сделать информацию в базах данных доступной в Kafka с помощью так называемого захвата измененных данных (CDC) вместе с API Kafka Connect для извлечения данные из базы данных (подробнее см. в блоге Робина Моффатта No More Silos: How to Integration Your Databases with Apache Kafka and CDC). Когда данные находятся в Kafka, клиентские приложения могут выполнять очень быстрое и эффективное объединение таких таблиц и потоков, вместо того, чтобы требовать от приложения делать запрос к удаленной базе данных по сети для каждой записи.
Упражнение 4. Фильтрация и ветвление
Kafka может собрать много информации, связанной с событием, в одну тему Kafka. Затем клиентские приложения могут манипулировать этими данными на основе определенных пользователем критериев для создания новых потоков данных, с которыми они могут работать. В этом упражнении вы определите один набор критериев для фильтрации записей в потоке на основе некоторых критериев. Затем вы определите другой набор критериев для разделения записей на два разных потока.
Упражнение 5. Операции с отслеживанием состояния
В этом упражнении вы создадите окно сеанса для определения пятиминутных окон для обработки. Вы можете комбинировать значения текущей записи со значениями предыдущей записи, используя агрегаты. Это операции с отслеживанием состояния, поскольку они поддерживают данные во время обработки. Часто они сочетаются с возможностями работы с окнами, чтобы выполнять вычисления в реальном времени в течение окна времени. Кроме того, вы будете использовать операцию с отслеживанием состояния для свертывания повторяющихся записей в потоке.
Упражнение 6: Хранилища состояний
В этом упражнении вы создадите хранилище состояний, которое представляет собой резидентную на диске хэш-таблицу, хранящуюся внутри API для клиентского приложения. Хранилище состояний можно использовать в приложениях потоковой обработки для хранения и запроса данных, что является важной возможностью при реализации операций с отслеживанием состояния. Его можно использовать для запоминания недавно полученных входных записей, отслеживания скользящих агрегатов, дедупликации входных записей и т. д.
Хранилища состояний в Kafka Streams можно использовать для создания представлений для конкретных вариантов использования прямо внутри службы
Государственный магазин также поддерживается темой Kafka и поставляется со всеми гарантиями Kafka. Следовательно, другие приложения также могут интерактивно запрашивать хранилище состояний другого приложения. Запрос к хранилищам состояний всегда доступен только для чтения, чтобы гарантировать, что базовые хранилища состояний никогда не будут изменены вне диапазона (т. е. вы не можете добавлять новые записи).
Упражнение 7. Обогащение данных с помощью KSQL
Confluent KSQL — это механизм потокового SQL, который обеспечивает обработку данных в реальном времени с помощью Apache Kafka. Он предоставляет простой в использовании, но мощный интерактивный SQL-интерфейс для потоковой обработки в Kafka, не требуя написания кода на каком-либо языке программирования, таком как Java или Python.
KSQL является масштабируемым, гибким, отказоустойчивым и способным поддерживать широкий спектр потоковых операций, включая фильтрацию данных, преобразования, агрегирование, объединение, работу с окнами и создание сессий. В этом упражнении вы создадите один постоянный запрос, который обогащает поток заказов информацией о клиентах. Вы создадите еще один постоянный запрос, который выявляет мошеннические действия путем подсчета количества заказов в заданном окне.
Подробнее о потоковой обработке
Новое руководство Введение в разработку приложений для потоковой передачи — отличное введение для разработчиков, позволяющее изучить основы API Kafka Streams и применить их к примеру розничных микросервисов с архитектурой, управляемой событиями. С каждым из этих упражнений вы можете погрузиться и запустить сквозную автоматизированную демонстрацию.
Мы надеемся, что вы останетесь с нами во второй части этой серии блогов, которая поможет вам добиться успеха в проверке ваших потоковых приложений и охватит модульное тестирование, интеграционное тестирование, тестирование совместимости Avro и схемы, инструменты Confluent Cloud™ и мультицентр обработки данных. тестирование.
Подтверждение того, что решение работает, так же важно, как и его реализация. Это гарантирует, что приложение работает так, как задумано, может обрабатывать непредвиденные события и может развиваться без нарушения существующей функциональности.
Тем временем, чтобы получить более глубокое представление о Kafka Streams, ознакомьтесь с другими ресурсами:
- Серия видеороликов Kafka Streams
- Серия видеороликов KSQL
- Примеры Kafka Streams
- Документация Kafka Streams
Статьи по теме
- Простые способы создания тестовых данных в Kafka
- Начало работы с потоковой обработкой — часть 2: тестирование приложения для потоковой передачи
- Введение в ksqlDB — потоковая передача базы данных в реальном времени
Ева Байзек (Yeva Byzek) — архитектор интеграции в компании Confluent, разрабатывающая решения и создающая демонстрационные версии для разработчиков и операторов Apache Kafka. Она имеет многолетний опыт проверки и оптимизации комплексных решений для распределенных программных систем и сетей.
Учебное пособие по решателю Excel с пошаговыми примерами
В этом руководстве объясняется, как добавить и где найти решатель в различных версиях Excel с 2016 по 2003 год. В пошаговых примерах показано, как использовать решатель Excel для поиска оптимальные решения линейного программирования и других задач.
Всем известно, что Microsoft Excel содержит множество полезных функций и мощных инструментов, которые могут сэкономить часы вычислений. Но знаете ли вы, что у него также есть инструмент, который может помочь вам найти оптимальные решения для проблем принятия решений?
В этом руководстве мы рассмотрим все основные аспекты надстройки Excel Solver и предоставим пошаговое руководство по ее наиболее эффективному использованию.
- Что такое решатель в Excel?
- Как добавить решатель в Excel
- Как использовать Solver в Excel
- Примеры решения Excel
- Как сохранить и загрузить модели Excel Solver
- Алгоритмы Excel Solver
Что такое Excel Solver?
Решатель Excel принадлежит к специальному набору команд, часто называемых инструментами анализа «что, если». Он в первую очередь предназначен для моделирования и оптимизации различных бизнес-моделей и инженерных моделей.
Надстройка Excel Solver особенно полезна для решения задач линейного программирования, также называемых задачами линейной оптимизации, и поэтому иногда называется решателем линейного программирования . Кроме того, он может решать гладкие нелинейные и негладкие задачи. Дополнительные сведения см. в разделе Алгоритмы Excel Solver.
Хотя Solver не может решить каждую возможную проблему, он действительно полезен при решении всевозможных задач оптимизации, когда вам нужно принять наилучшее решение. Например, он может помочь вам максимизировать возврат инвестиций, подобрать оптимальный бюджет для вашей рекламной кампании, составить оптимальный график работы ваших сотрудников, минимизировать затраты на доставку и так далее.
Как добавить Solver в Excel
Надстройка Solver включена во все версии Microsoft Excel, начиная с 2003, но по умолчанию она не включена.
Чтобы добавить Solver в Excel, выполните следующие действия:
- В Excel 2010 — Excel 365 щелкните Файл > Параметры .
В Excel 2007 нажмите кнопку Microsoft Office и выберите Параметры Excel . - В диалоговом окне Параметры Excel нажмите Надстройки на левой боковой панели, убедитесь, что Надстройки Excel выбраны в поле Управление в нижней части окна, и нажмите Перейти .
- В диалоговом окне Надстройки установите флажок Надстройка Solver и нажмите OK :
Чтобы получить Solver для Excel 2003 , перейдите в меню Инструменты и щелкните Надстройки . В списке надстроек доступных установите флажок надстройка Solver и нажмите OK .
Примечание. Если Excel отображает сообщение о том, что надстройка Solver в настоящее время не установлена на вашем компьютере, нажмите Да для установки.
Где находится Solver в Excel?
В современных версиях Excel кнопка Solver появляется на вкладке Data , в группе Analysis :
Где находится Solver в Excel 2003?
После того, как надстройка Solver загружена в Excel 2003, ее команда добавляется в меню Tools :
Теперь, когда вы знаете, где найти Solver в Excel, откройте новый рабочий лист и приступим!
Примечание. В примерах, обсуждаемых в этом руководстве, используется Solver в Excel 2013. Если у вас есть другая версия Excel, снимки экрана могут не точно соответствовать вашей версии, хотя функциональность Solver в основном такая же.
Как использовать Solver в Excel
Перед запуском надстройки Excel Solver сформулируйте модель, которую вы хотите решить, на листе. В этом примере давайте найдем решение следующей простой задачи оптимизации.
Проблема . Предположим, вы владелец салона красоты и планируете предоставлять своим клиентам новую услугу. Для этого вам необходимо купить новое оборудование стоимостью 40 000 долларов США, которое необходимо оплатить в рассрочку в течение 12 месяцев.
Цель : Рассчитать минимальную стоимость услуги, которая позволит вам оплатить новое оборудование в указанные сроки.
Для этой задачи я создал следующую модель:
А теперь давайте посмотрим, как Excel Solver может найти решение этой проблемы.
1. Запустите Excel Solver
На вкладке Data в группе Analysis нажмите кнопку Solver .
2. Определите проблему
Solver Parameters откроется окно, в котором вы должны настроить 3 основных компонента:
- Целевая ячейка
- Переменные ячейки
- Ограничения
Что именно делает Excel Solver с указанными выше параметрами? Он находит оптимальное значение (максимальное, минимальное или заданное) для формулы в ячейке Цель путем изменения значений в ячейках Переменная и с учетом ограничений в ячейках Ограничения .
Цель
Ячейка Цель (ячейка Цель в более ранних версиях Excel) — это ячейка , содержащая формулу , которая представляет задачу или цель проблемы. Целью может быть максимизация, минимизация или достижение некоторого целевого значения.
В этом примере целевой ячейкой является B7, которая рассчитывает срок платежа по формуле =B3/(B4*B5) , и результат формулы должен быть равен 12:
Переменные ячейки
Переменные ячейки ( Изменяющиеся ячейки или Настраиваемые ячейки в более ранних версиях) — это ячейки, содержащие переменные данные, которые можно изменить для достижения цели. Excel Solver позволяет указать до 200 переменных ячеек.
В этом примере у нас есть пара ячеек, значения которых можно изменить:
- Прогнозируемое количество клиентов в месяц (B4), которое должно быть меньше или равно 50; и
- Стоимость услуги (B5), которую должен рассчитать Excel Solver.
Наконечник. Если переменные ячейки или диапазоны в вашей модели несмежные , выберите первую ячейку или диапазон, а затем нажмите и удерживайте клавишу Ctrl при выборе других ячеек и/или диапазонов. Или введите диапазоны вручную, разделив их запятыми.
Ограничения
Решатель Excel Ограничения — это ограничения или пределы возможных решений проблемы. Другими словами, ограничения — это условия, которые должны быть соблюдены.
Чтобы добавить ограничения, выполните следующие действия:
- Нажмите кнопку Добавить справа от поля « С учетом ограничений ».
- В окне Constraint введите ограничение.
- Нажмите кнопку Добавить , чтобы добавить ограничение в список.
- Продолжайте вводить другие ограничения.
- После того, как вы ввели окончательное ограничение, нажмите OK для возврата в главное окно Параметры .
Excel Solver позволяет указать следующие отношения между указанной ячейкой и ограничением.
- Меньше или равно , равно и больше или равно . Вы устанавливаете эти отношения, выбирая ячейку в поле Ссылка на ячейку , выбирая один из следующих знаков: <= , =, или >= , а затем введите число, ссылку на ячейку/имя ячейки или формулу в поле Constraint (см. скриншот выше).
- Целое число . Если указанная ячейка должна быть целым числом, выберите int , и слово integer появится в поле Constraint .
- Различные значения . Если каждая ячейка в указанном диапазоне должна содержать другое значение, выберите dif и слово 9.1407 AllDifferent появится в поле Constraint .
- Двоичный . Если вы хотите ограничить ссылочную ячейку значением 0 или 1, выберите bin , и слово binary появится в поле Constraint .
Примечание. Отношения int , bin и dif можно использовать только для ограничений переменных ячеек.
Чтобы отредактировать или удалить существующее ограничение, выполните следующие действия:
- В диалоговом окне Параметры решателя щелкните ограничение.
- Чтобы изменить выбранное ограничение, нажмите Изменить и внесите необходимые изменения.
- Чтобы удалить ограничение, нажмите кнопку Удалить .
В этом примере ограничения:
- B3=40000 — стоимость нового оборудования 40 000 долларов.
- B4<=50 - прогнозируемое количество пациентов в месяц в возрасте до 50 лет.
3. Решите проблему
После того, как вы настроили все параметры, нажмите кнопку Решить в нижней части окна Параметры решателя (см. снимок экрана выше) и дайте надстройке Excel Solver найти оптимальное решение вашей проблемы.
В зависимости от сложности модели, памяти компьютера и скорости процессора это может занять несколько секунд, несколько минут или даже несколько часов.
Когда Solver закончит обработку, он отобразит 9Диалоговое окно 0770 Solver Results , в котором вы выбираете Keep the Solver Solution и нажимаете OK :
Окно Solver Result закроется, и решение сразу появится на рабочем листе.
В этом примере в ячейке B5 отображается 66,67 доллара США, что является минимальной стоимостью за услугу, которая позволит вам оплатить новое оборудование через 12 месяцев при условии, что количество клиентов в месяц составляет не менее 50:
Чаевые:
- Если Excel Solver слишком долго обрабатывал определенную проблему, вы можете прервать процесс, нажав клавишу Esc. Excel пересчитает рабочий лист с последними значениями, найденными для ячеек Variable .
- Чтобы получить дополнительные сведения о решенной проблеме, щелкните тип отчета в поле Отчеты , а затем щелкните OK . Отчет будет создан на новом листе: .
Теперь, когда вы получили общее представление о том, как использовать Solver в Excel, давайте подробнее рассмотрим еще пару примеров, которые могут помочь вам лучше понять.
Примеры Excel Solver
Ниже вы найдете еще два примера использования надстройки Excel Solver. Сначала мы найдем решение известной головоломки, а затем решим реальную задачу линейного программирования.
Решатель Excel, пример 1 (магический квадрат)
Я думаю, все знакомы с головоломками «магический квадрат», где вам нужно поместить набор чисел в квадрат так, чтобы все строки, столбцы и диагонали в сумме давали определенное число.
Например, знаете ли вы решение для квадрата 3×3, содержащего числа от 1 до 9?где каждая строка, столбец и диагональ в сумме дают 15?
Вероятно, решить эту головоломку методом проб и ошибок не составит большого труда, но держу пари, что Решатель найдет решение быстрее. Наша часть работы состоит в том, чтобы правильно определить проблему.
Для начала введите числа от 1 до 9 в таблицу, состоящую из 3-х строк и 3-х столбцов. Решателю Excel на самом деле не нужны эти числа, но они помогут нам визуализировать проблему. Что действительно нужно надстройке Excel Solver, так это формулы SUM, которые суммируют каждую строку, столбец и 2 диагонали:
Со всеми формулами запустите Solver и настройте следующие параметры:
- Установить Цель . В этом примере нам не нужно устанавливать какую-либо цель, поэтому оставьте это поле пустым.
- Переменные ячейки . Мы хотим заполнить числами ячейки от B2 до D4, поэтому выберите диапазон B2:D4.
- Ограничения . Должны быть соблюдены следующие условия:
- $B$2:$D$4 = AllDifferent — все ячейки переменных должны содержать разные значения.
- $B$2:$D$4 = целое число — все ячейки переменных должны быть целыми числами.
- $B$5:$D$5 = 15 — сумма значений в каждом столбце должна быть равна 15.
- $E$2:$E$4 = 15 — сумма значений в каждой строке должна быть равна 15.
- $B$7:$B$8 = 15 — сумма обеих диагоналей должна быть равна 15.
Наконец, нажмите кнопку Решить , и решение уже готово!
Excel Solver, пример 2 (задача линейного программирования)
Это пример простой задачи оптимизации транспортировки с линейной целью. Более сложные модели оптимизации такого рода используются многими компаниями для ежегодной экономии тысяч долларов.
Проблема : Вы хотите минимизировать стоимость доставки товаров с 2 разных складов 4 различным клиентам. Каждый склад имеет ограниченное предложение, и у каждого клиента есть определенный спрос.
Цель : минимизировать общую стоимость доставки, не превышая количество, доступное на каждом складе, и удовлетворяя спрос каждого клиента.
Исходные данные
Вот как выглядит наша задача оптимизации транспортировки:
Формулировка модели
Чтобы определить нашу задачу линейного программирования для Excel Solver, давайте ответим на 3 основных вопроса:
- Какие решения должны быть сделанный? Мы хотим рассчитать оптимальное количество товара для доставки каждому покупателю с каждого склада. Это Variable ячеек (B7:E8).
- Каковы ограничения? Запасы, доступные на каждом складе (I7:I8), не могут быть превышены, и должно быть доставлено количество, заказанное каждым клиентом (B10:E10). это Ограничено ячеек.
- Какова цель? Минимальная общая стоимость доставки. А это наша ячейка Objective (C12).
Следующее, что вам нужно сделать, это рассчитать общее количество товаров, отгруженных с каждого склада (G7:G8), и общее количество товаров, полученных каждым клиентом (B9:E9). Вы можете сделать это с помощью простых формул суммы, показанных на снимке экрана ниже. Кроме того, вставьте формулу СУММПРОИЗВ в C12 для расчета общей стоимости доставки:
Чтобы облегчить понимание нашей модели оптимизации транспортировки, создайте следующие именованные диапазоны:
| Название диапазона | Клетки | Параметр решающей программы |
| Отгруженные товары | В7:Е8 | Переменные ячейки |
| В наличии | И7:И8 | Ограничение |
| Всего отправлено | G7:G8 | Ограничение |
| Заказ | Б10:Е10 | Ограничение |
| Всего_получено | В9:Е9 | Ограничение |
| Стоимость доставки | С12 | Цель |
Последнее, что вам осталось сделать, это настроить параметры Excel Solver:
- Цель: Shipping_cost установить на Min
- Переменные ячейки: Products_shipped
- Ограничения: Всего_получено = Заказано и Всего_отгружено <= Доступно
Обратите внимание, что в данном примере мы выбрали метод решения Simplex LP , потому что мы имеем дело с задачей линейного программирования. Если вы не уверены, какая у вас проблема, вы можете оставить метод решения GRG Nonlinear по умолчанию. Для получения дополнительной информации см. Алгоритмы Excel Solver.
Решение
Нажмите кнопку Решить в нижней части окна Параметры решателя , и вы получите ответ. В этом примере надстройка Excel Solver рассчитала оптимальное количество товаров для доставки каждому покупателю с каждого склада с минимальной общей стоимостью доставки:
Как сохранить и загрузить сценарии Excel Solver
При решении определенной модели может потребоваться сохранить значения ячеек Variable в качестве сценария, который можно просмотреть или повторно использовать позже.
Например, при расчете минимальной стоимости обслуживания в самом первом примере, обсуждаемом в этом руководстве, вы можете попробовать различное количество предполагаемых клиентов в месяц и посмотреть, как это повлияет на стоимость обслуживания. При этом вы можете захотеть сохранить уже просчитанный вами наиболее вероятный сценарий и восстановить его в любой момент.
Сохранение Сценарий решателя Excel сводится к выбору диапазона ячеек для сохранения данных. Загрузка модели решателя — это просто предоставление Excel диапазона ячеек, в которых сохраняется ваша модель. Подробные шаги следуют ниже.
Сохранение модели
Чтобы сохранить сценарий решателя Excel, выполните следующие действия:
- Откройте рабочий лист с рассчитанной моделью и запустите решатель Excel.
- В параметрах решателя , нажмите кнопку Загрузить/Сохранить .
- Excel Solver сообщит вам, сколько ячеек необходимо для сохранения вашего сценария. Выберите столько пустых ячеек и нажмите Сохранить :
- Excel сохранит вашу текущую модель, которая может выглядеть примерно так:
В то же время появится окно Параметры решателя , в котором можно изменить ограничения и попробовать различные варианты «что, если».
Загрузка сохраненной модели
Если вы решили восстановить сохраненный сценарий, сделайте следующее:
- В окне Параметры решателя нажмите кнопку Загрузить/Сохранить .
- На рабочем листе выберите диапазон ячеек, содержащих сохраненную модель, и нажмите Загрузить :
- В диалоговом окне Загрузить модель нажмите кнопку Заменить :
- Откроется главное окно Excel Solver с параметрами ранее сохраненной модели. Все, что вам нужно сделать, это нажать на Кнопка «Решить » для пересчета.
Алгоритмы решателя Excel
При определении задачи для решателя Excel можно выбрать один из следующих методов в раскрывающемся списке Выберите метод решения :
- GRG Нелинейный. Обобщенный редуцированный градиентный нелинейный алгоритм используется для задач, которые являются гладкими нелинейными, т.е. в которых хотя бы одно из ограничений является гладкой нелинейной функцией переменных решения. Более подробную информацию можно найти здесь.
- LP Симплекс . Метод Simplex LP Solving основан на алгоритме Simplex, созданном американским ученым-математиком Джорджем Данцигом. Он используется для решения так называемых задач Linear Programming — математических моделей, требования к которым характеризуются линейными отношениями, т.е. состоят из одной цели, представленной линейным уравнением, которое необходимо максимизировать или минимизировать. Для получения дополнительной информации, пожалуйста, посетите эту страницу.
- Эволюционный . Он используется для негладких задач, которые представляют собой наиболее сложный тип задач оптимизации, потому что некоторые функции не являются гладкими или даже прерывистыми, и поэтому трудно определить направление, в котором функция увеличивается или уменьшается. Для получения дополнительной информации см. эту страницу.
Чтобы изменить способ поиска решения Solver, нажмите кнопку Options в диалоговом окне Solver Parameters и настройте любые или все параметры в GRG Нелинейный , Все методы и Эволюционный вкладки.
Вот как вы можете использовать Solver в Excel, чтобы найти лучшие решения для ваших проблем принятия решений. А теперь вы можете загрузить примеры Excel Solver, обсуждаемые в этом руководстве, и перепроектировать их для лучшего понимания. Я благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе.
Вас также может заинтересовать
Перекрестная проверка в машинном обучении — Javatpoint
следующий → ← предыдущая Перекрестная проверка — это метод проверки эффективности модели путем ее обучения на подмножестве входных данных и тестирования на ранее невиданном подмножестве входных данных. Можно также сказать, что это метод проверки того, как статистическая модель обобщается на независимый набор данных . В машинном обучении всегда есть необходимость проверить стабильность модели. Это означает, что он основан только на обучающем наборе данных; мы не можем подогнать нашу модель к обучающему набору данных. Для этой цели мы резервируем определенный образец набора данных, который не был частью обучающего набора данных. Следовательно, основные этапы перекрестной проверки:
Методы перекрестной проверкиСуществует несколько распространенных методов перекрестной проверки. Эти методы приведены ниже:
Подход к набору валидации Мы разделяем наш входной набор данных на обучающий набор и тестовый или проверочный набор в подходе проверочного набора. Но у него есть один из больших недостатков, заключающийся в том, что мы используем только 50% набора данных для обучения нашей модели, поэтому модель может упустить важную информацию из набора данных. Это также имеет тенденцию давать недооснащенную модель. Перекрестная проверка без исключенияПри таком подходе наборы данных p исключаются из обучающих данных. Это означает, что если в исходном наборе входных данных всего n точек данных, то точки данных n-p будут использоваться в качестве набора обучающих данных, а точки данных p — в качестве проверочного набора. Этот полный процесс повторяется для всех образцов, и рассчитывается средняя ошибка, чтобы узнать эффективность модели. У этой техники есть недостаток; то есть это может быть сложно с точки зрения вычислений для большого p. Пропустить перекрестную проверку Этот метод похож на перекрестную проверку с пропуском p-out, но вместо p нам нужно исключить из обучения 1 набор данных.
K-кратная перекрестная проверка K-кратный метод перекрестной проверки делит входной набор данных на K групп выборок одинакового размера. Эти образцы называются складок . Для каждого обучающего набора функция прогнозирования использует k-1 сгибов, а остальные сгибы используются для тестового набора. Шаги для k-кратной перекрестной проверки:
Давайте рассмотрим пример 5-кратной перекрестной проверки. Итак, набор данных сгруппирован в 5 раз. На итерации 1 -й первая складка зарезервирована для тестирования модели, а остальные используются для обучения модели. На 2-й -й и -й итерациях вторая складка используется для тестирования модели, а остальные используются для обучения модели. Этот процесс будет продолжаться до тех пор, пока каждая складка не будет использована для тестовой складки. Рассмотрим приведенную ниже диаграмму: Стратифицированная k-кратная перекрестная проверкаЭтот метод похож на k-кратную перекрестную проверку с некоторыми небольшими изменениями. Этот подход работает на концепции стратификации, это процесс переупорядочения данных, чтобы гарантировать, что каждая складка или группа являются хорошим представителем полного набора данных. Чтобы справиться с предвзятостью и дисперсией, это один из лучших подходов. Это можно понять на примере цен на жилье, так как цена на одни дома может быть намного выше, чем на другие дома. Для решения таких ситуаций полезен метод стратифицированной k-кратной перекрестной проверки. Метод удержанияЭтот метод является самым простым среди всех методов перекрестной проверки. В этом методе нам нужно удалить подмножество обучающих данных и использовать его для получения результатов прогнозирования, обучая его на остальной части набора данных. Ошибка, возникающая в этом процессе, говорит о том, насколько хорошо наша модель будет работать с неизвестным набором данных. Сравнение перекрестной проверки с разделением обучения/тестирования в машинном обучении
Ограничения перекрестной проверкиСуществуют некоторые ограничения метода перекрестной проверки, которые приведены ниже:
|