Обработка изображений — Работаем с фото и видео / Хабр
Работаем с фото и видео
Статьи Авторы Компании
Сначала показывать
Порог рейтинга
OlegSivchenko
Информационная безопасность *Обработка изображений *Машинное обучение *Научно-популярное
В эпоху всеобщей виртуальности и общения через аватары, а также бурно развивающейся биометрической идентификации и дипфейков становится исключительно важно отличать живого человека от неживой подделки, например, от фотографии.
Читать далее
Всего голосов 20: ↑18 и ↓2 +16
Просмотры1.9K
Комментарии 6
datist
Обработка изображений *Машинное обучение *Искусственный интеллект
Tutorial
SVTR — state-of-the-art модель-трансформер для решения задачи OCR.
Авторами статьи была предложена архитектура с одним «зрительным» модулем для эффективного распознавания текста. Основная идея работы заключается в обработке признаков разного уровня, то есть локальных, которые представляют собой признаки отдельных частей символов, и глобальных, признаков целого изображения.
Читать далее
Всего голосов 5: ↑5 и ↓0 +5
Просмотры728
Комментарии 2
Clickru
Блог компании Click.ru Обработка изображений *Графический дизайн *Повышение конверсии *
Если вы занимаетесь интернет-маркетингом, вам потребуются качественные изображения. Они влияют на эффективность рекламы ничуть не меньше, чем правильно подобранные ключи, составленное объявление или выбранная аудитория, помогают лучше воспринимать информацию из текста, хорошо запоминаются.
Они влияют на эффективность рекламы ничуть не меньше, чем правильно подобранные ключи, составленное объявление или выбранная аудитория, помогают лучше воспринимать информацию из текста, хорошо запоминаются.
Мы подготовили подборку из 19 популярных фотостоков, на которых вы без проблем сможете найти изображения для любых целей. Почти все фотобанки бесплатные, а платные легко оплатить из России.
Читать далее
Всего голосов 13: ↑12 и ↓1 +11
Просмотры2.2K
Комментарии 1
ZlodeiBaalБлог компании Recognitor Обработка изображений *Машинное обучение *Компьютерное железо DIY или Сделай сам
Выбор платформы для работы с Computer Vision on the Edge — непростая задача. На рынке десятки плат. И одна другой краше. Но на практике все оказывается не так хорошо.
Я попробовал сравнить дешевые платы которые есть на рынке. И сделал это не только в по скорости. Я попробовал сравнить платформы по “удобству” их использования. Насколько просто будет портировать сети, насколько хорошая поддержка. И насколько просто работать. И актуализировал это для 2022 года (один и тот же Coral из 2020 и из 2022 — две разные платы).
Читать далее
Всего голосов 26: ↑24 и ↓2 +22
Просмотры3.9K
Комментарии 12
kucev
Data Mining *Обработка изображений *Big Data *Машинное обучение *Искусственный интеллект
Перевод
Обычно эту задачу решают при помощи глубокого обучения.
Это одна из самых интересных областей исследований, получившая популярность благодаря своей полезности и универсальности — она находит применение в широком спектре сфер, в том числе в гейминге, здравоохранении, AR и спорте.
В этой статье приведён исчерпывающий обзор определения положения тела человека (Human Pose Estimation, HPE) и того, как оно работает. Также в ней рассматриваются различные подходы к решению задачи HPE — классические методы и методы на основе глубокого обучения, метрики и способы оценки, а также многое другое.
Читать дальше →
Всего голосов 19: ↑17 и ↓2 +15
Просмотры2.9K
Комментарии 6
megabax
Python *Обработка изображений *
Tutorial
Читать далее
Всего голосов 17: ↑15 и ↓2 +13
Просмотры4.3K
Комментарии 3
arch2baald
Обработка изображений *Машинное обучение *Искусственный интеллект Natural Language Processing *
Tutorial
Вероятно вы уже слышали про успехи нейросетей в генерации картинок по текстовому описанию.
Я решил разобраться, и заодно сделать небольшой туториал, по архитектуре модели Stable Diffusion. Сегодня мы не будем глубоко погружаться в математику и процесс тренировки. Вместо этого сфокусируемся на применении и устройстве основных компонент: UNet, VAE, CLIP.
Читать далее
Всего голосов 70: ↑70 и ↓0 +70
Просмотры5.9K
Комментарии 10
Atmyre
Обработка изображений *Машинное обучение *Искусственный интеллект
В этой статье я расскажу об одном из самых важных отличий человеческого мышления от того, как работают нейросети: о структурном восприятии мира. Мы поймем, как это отличие мешает ИИ эффективно решать многие задачи, а также поговорим об идеях, с помощью которых можно внедрить в нейросети понимание структуры. В том числе обсудим недавние работы таких известных в области AI людей, как Джеффри Хинтон и Ян ЛеКун.
Начнем мы с понимания того, что вообще такое “структурное мышление” и почему люди им обладают:
Читать далее
Всего голосов 38: ↑37 и ↓1 +36
Просмотры7.1K
Комментарии 50
ElenaVolchenko
Блог компании Финолаб Data Mining *Обработка изображений *
⚒️ Cезон Data Mining
Добрый день, коллеги! Меня зовут Елена Волченко. В компании Финолаб я являюсь руководителем отдела машинного обучения и анализа данных. Этой статьей я хочу начать цикл публикаций о создании нашей командой сервиса дистанционной оценки технического состояния автомобилей на основе технологий искусственного интеллекта.
Мой рассказ будет разделен на две части. В первой расскажу о потребностях и проблемах в дистанционной оценке повреждений автомобилей. Во второй — о том, как мы решали эту задачу с помощью нейронных сетей и классического machine learning, с какими проблемами сталкивались, каких результатов достигли и что еще предстоит сделать.
Во второй — о том, как мы решали эту задачу с помощью нейронных сетей и классического machine learning, с какими проблемами сталкивались, каких результатов достигли и что еще предстоит сделать.
Читать далее
Всего голосов 23: ↑23 и ↓0 +23
Просмотры3.9K
Комментарии 15
phillennium
Блог компании JUG Ru Group Обработка изображений *Машинное обучение *Будущее здесь
Перевод
Генерация изображений с помощью AI пришла по-настоящему. Опенсорсная модель для синтеза изображений Stable Diffusion позволяет любому обладателю компьютера с хорошей видеокартой творить практически любую визуальную реальность, какую сможет выдумать. Она может имитировать практически любой визуальный стиль, и если задать ей фразу-описание, результаты возникают на экране словно магия.
Одни художники восхищаются открывшимися возможностями, другие недовольны, а общество в целом пока вроде бы не курсе той стремительно развивающейся технологической революции, которая происходит в сообществах на Twitter, Discord и GitHub. Возможно, синтез изображений приносит настолько же большие возможности, как изобретение камеры — или даже создание самого визуального искусства. Даже наше восприятие истории
Читать далее
Всего голосов 81: ↑79 и ↓2 +77
Просмотры30K
Комментарии 81
NewTechAudit
Обработка изображений *Big Data *Машинное обучение *
Tutorial
Привет, Хабр!
При автоматизации работы с документацией иногда приходится иметь дело со сканами плохого качества. Особенно удручает ситуация, при которой вместо сканированного документа предоставляется фото с телефона.
Особенно удручает ситуация, при которой вместо сканированного документа предоставляется фото с телефона.
В области обработки документов существует целый ряд задач, которые решаются с помощью машинного обучения. С примерным списком можно ознакомиться в данной статье. В этом руководстве я предлагаю решение проблемы различных помех на фото документа, которые могут возникнуть при плохом качестве съемки или плохом качестве самого документа.
Читать далее
Всего голосов 7: ↑7 и ↓0 +7
Просмотры4.2K
Комментарии 3
honyaki
Блог компании SkillFactory Open source *Обработка изображений *Искусственный интеллект
Перевод
Компания Stability.ai объявила о публичном релизе модели графической нейросети Stable Diffusion. Можно подумать, что это лишь очередная новость о том, что в мире искусства появилась ещё одна рядовая нейросеть. Но это далеко не так по двум причинам, одну из которых вы видите в хабах. Подробности — к старту нашего флагманского курса по Data Science.
Но это далеко не так по двум причинам, одну из которых вы видите в хабах. Подробности — к старту нашего флагманского курса по Data Science.
Узнать больше
Всего голосов 36: ↑32 и ↓4 +28
Просмотры17K
Комментарии 39
GermanZvezdin
Блог компании Constanta C++ *Обработка изображений *Математика *Машинное обучение *
Tutorial
Привет, Хабр!
Перед вами продолжение статьи про рендеринг. В первой части, которую вы, кстати, можете найти по ссылке (link), мы поговорили о трассировке лучей и маршевом методе, а в этой части мы с вами получим фотографию мыльного пузыря. Будет интересно 🙂
Читать далее
Всего голосов 27: ↑27 и ↓0 +27
Просмотры2.7K
Комментарии 6
honyaki
Блог компании SkillFactory Обработка изображений *Машинное обучение *Лайфхаки для гиков
Перевод
Посты блогов с изображениями — это в 2,3 раза больше вовлечённости. Но проблема вот в чём — мы делаем движок запросов для потоковых таблиц. И как же выбирать изображения для технических тем?
Читать дальше →
Всего голосов 23: ↑23 и ↓0 +23
Просмотры4.8K
Комментарии 16
SvetBolgova
Блог компании Leader-ID Обработка изображений *Машинное обучение *Искусственный интеллект
Пару лет назад мы делали интервью с Михаилом Бурцевым из МФТИ — создателем системы разговорного ИИ iPavlov. Очень интересный человек, который в 2015 году удачно скрестил свой талант с программами госфинансирования через «Сбер» и НТИ (АСИ). Все началось с библиотеки DeepPavlov, которую в итоге скачали больше миллиона раз. Затем проект расползся по соседним нишам, причем мне кажется, что скоро появится целая корпорация iPavlov с целым пакетом ИИ-продуктов федерального масштаба. Насколько это хорошо или плохо, не могу сказать. Иногда случается так, что быстрый успех может вскружить голову.
Все началось с библиотеки DeepPavlov, которую в итоге скачали больше миллиона раз. Затем проект расползся по соседним нишам, причем мне кажется, что скоро появится целая корпорация iPavlov с целым пакетом ИИ-продуктов федерального масштаба. Насколько это хорошо или плохо, не могу сказать. Иногда случается так, что быстрый успех может вскружить голову.
Под катом — интервью с нынешним директором iPavlov Лораном Акопяном про то, какое место российские технологии занимают в мировой ИИ-индустрии, изменится ли что-то из-за сложностей с поставками «железа» и в каком направлении развивается сам iPavlov.
Если все пойдет по плану, самый массовый и функциональный голосовой помощник в стране будет в приложении Госуслуг.
Читать далее
Всего голосов 22: ↑21 и ↓1 +20
Просмотры2.8K
Комментарии 2
PereslavlFoto
Обработка изображений *Управление проектами *Копирайт Научно-популярное Краудсорсинг
Главархив Москвы принимает у москвичей фотоплёнки и киноплёнки, чтобы сохранять их на долгие годы. Плюс: сдать исторические материалы можно в центрах госуслуг «Мои документы». Минус: сразу возникает очень неприятная ситуация с авторским правом.
Подробно о проблеме.
Всего голосов 195: ↑189 и ↓6 +183
Просмотры27K
Комментарии 206
kucev
Data Mining *Обработка изображений *Big Data *Машинное обучение *Искусственный интеллект
Перевод
Данные становятся движущей силой современного мира, поэтому почти каждый уже сталкивался с такими терминами, как data science, «машинное обучение», «искусственный интеллект», «глубокое обучение» и data mining. Но что же обозначают эти понятия? Какие различия и связи между ними существуют?
Но что же обозначают эти понятия? Какие различия и связи между ними существуют?
Все перечисленные выше термины, несмотря на их взаимосвязь, нельзя использовать в качестве синонимов. Эта статья поможет вам не только понять, какие исследования и опыт позволяют извлекать знания из данных, чтобы делать машины умнее, но и как конкретно это происходит.
Читать дальше →
Всего голосов 11: ↑8 и ↓3 +5
Просмотры11K
Комментарии 5
NewTechAudit
Алгоритмы *Обработка изображений *Машинное обучение *
Сегодня расскажу о решении важной для многих из нас и ставшей уже классической задачи ― детектировании позы человека на изображении. Решать её я предлагаю с использованием библиотеки OpenPose. Всё самое интересное ― под катом. Сразу скажу, что статья небольшая, но наглядная ― я постаралась без лишних слов показать возможности библиотеки.![]() В первую очередь она предназначена для начинающих специалистов, но, возможно, и профи найдут что-то полезное для себя.
В первую очередь она предназначена для начинающих специалистов, но, возможно, и профи найдут что-то полезное для себя.
Вперёд!
Всего голосов 2: ↑2 и ↓0 +2
Просмотры1.4K
Комментарии 0
VolinNilov
Блог компании RUVDS.com Python *Обработка изображений *Big Data *
Tutorial
Это вторая статья из серии введения в «Нейронные сети для начинающих». Здесь и далее мы постараемся разобраться с таким понятием — как обработка графических данных, визуализация данных, а также на практике решим пару простых задач. Предыдущая статья — #1 Нейронные сети для начинающих. Решение задачи классификации Ирисов Фишера
Маленький совет из будущего: «В данной статье будут затронуты некоторые понятия, о которых я писал раньше, так что для полного понимания темы, советую прочитать и предыдущую статью»
На самом деле, на хабре было множество публикаций по этой теме, но все они говорят о разных вещах. Давайте разберёмся и соберём всё в одну кучку, для полноценного понимания картины мира.
Давайте разберёмся и соберём всё в одну кучку, для полноценного понимания картины мира.
Читать дальше →
Всего голосов 43: ↑41 и ↓2 +39
Просмотры7.5K
Комментарии 8
kucev
Data Mining *Обработка изображений *Big Data *Машинное обучение *Искусственный интеллект
Перевод
В 2019 году компания OpenAI опубликовала статью о точной настройке GPT-2, в которой она использовала Scale AI для сбора мнений живых разметчиков с целью совершенствования своих языковых моделей. Хотя в то время мы уже размечали миллионы задач обработки текста и computer vision, уникальные требованиях к срокам и субъективная природа задач OpenAI создали для нас новую сложность. В частности, трудность заключалась в следующем: как поддерживать качество меток в больших масштабах без возможности проверки чужой работы разметчиками? Сегодня мы подробно расскажем о своём подходе к решению этой проблемы, о системе автоматического майнинга бенчмарков, которую мы для этого создали, а также об уроках, которые получили в процессе. Этой статьёй мы хотим проиллюстрировать небольшую часть тех сложностей, делающих масштабируемую разметку данных такой интересной сферой работы.
Этой статьёй мы хотим проиллюстрировать небольшую часть тех сложностей, делающих масштабируемую разметку данных такой интересной сферой работы.
Читать дальше →
Всего голосов 4: ↑4 и ↓0 +4
Просмотры1.1K
Комментарии 0
Обработка изображений | это… Что такое Обработка изображений?
Монохромное черно-белое изображение.
Обработка изображений — любая форма обработки информации, для которой входные данные представлены изображением, например, фотографиями или видеокадрами. Обработка изображений может осуществляться как для получения изображения на выходе (например, подготовка к полиграфическому тиражированию, к телетрансляции и т. д.), так и для получения другой информации (например, распознание текста, подсчёт числа и типа клеток в поле микроскопа и т. д.). Кроме статичных двухмерных изображений, обрабатывать требуется также изображения, изменяющиеся со временем, например видео.
Содержание
|
История
Ещё в середине XX века обработка изображений была по большей части аналоговой и выполнялась оптическими устройствами. Подобные оптические методы до сих пор важны, в таких областях как, например, голография. Тем не менее, с резким ростом производительности компьютеров, эти методы всё в большей мере вытеснялись методами цифровой обработки изображений. Методы цифровой обработки изображений обычно являются более точными, надёжными, гибкими и простыми в реализации, нежели аналоговые методы. В цифровой обработке изображений широко применяется специализированное оборудование, такое как процессоры с конвейерной обработкой инструкций и многопроцессорные системы. В особенной мере это касается систем обработки видео. Обработка изображений выполняется также с помощью программных средств компьютерной математики, например, MATLAB, Mathcad, Maple, Mathematica и др. Для этого в них используются как базовые средства, так и пакеты расширения Image Processing.
В особенной мере это касается систем обработки видео. Обработка изображений выполняется также с помощью программных средств компьютерной математики, например, MATLAB, Mathcad, Maple, Mathematica и др. Для этого в них используются как базовые средства, так и пакеты расширения Image Processing.
Основные методы обработки сигналов
Большинство методов обработки одномерных сигналов (например, медианный фильтр) применимы и к двухмерным сигналам, которыми являются изображения. Некоторые из этих одномерных методов значительно усложняются с переходом к двухмерному сигналу. Обработка изображений вносит сюда несколько новых понятий, таких как связность и ротационная инвариантность, которые имеют смысл только для двухмерных сигналов. В обработке сигналов широко используются преобразование Фурье, а также вейвлет-преобразование и фильтр Габора. Обработку изображений разделяют на обработку в пространственной области (преобразование яркости, гамма коррекция и т. д.) и частотной (преобразование Фурье, и т. д.). Преобразование Фурье дискретной функции (изображения) пространственных координат является периодическим по пространственным частотам с периодом 2pi.
д.). Преобразование Фурье дискретной функции (изображения) пространственных координат является периодическим по пространственным частотам с периодом 2pi.
Обработка изображений для воспроизведения
Основная статья: Редактирование изображений
Типичные задачи
- Геометрические преобразования, такие как вращение и масштабирование.
- Цветовая коррекция: изменение яркости и контраста, квантование цвета, преобразование в другое цветовое пространство.
- Сравнение двух и более изображений. Как частный случай — нахождение корреляции между изображением и образцом, например, в детекторе банкнот.
- Комбинирование изображений различными способами.
- Интерполяция и сглаживание.
- Разделение изображения на области (сегментация изображений).
- Редактирование и ретуширование.
- Расширение динамического диапазона путём комбинирования изображений с разной экспозицией (HDR).
- Компенсация потери резкости, например, путём нерезкого маскирования.

Обработка изображений в прикладных и научных целях
Типичные задачи
- Распознавание текста
- Обработка спутниковых снимков
- Машинное зрение
- Обработка данных для выделения различных характеристик
- Обработка изображений в медицине
- Идентификация личности (по лицу, радужке, дактилоскопическим данным)
- Автоматическое управление автомобилями
- Определение формы интересующего нас объекта
- Определение перемещения объекта
- Наложение фильтров
См. также
- Редактирование изображений
- Алгоритм сбалансированного порогового отсечения гистограммы
Литература
- Потапов А. А., Пахомов А. А., Никитин С. А., Гуляев Ю. В., Новейшие методы обработки изображений. — M.: Физматлит, 2008. — 496 с. ISBN 9785922108416
- К. Айсманн, У. Палмер, Ретуширование и обработка изображений в Photoshop, 3-е издание. M: Вильямс, 2008. — 560 с. ISBN 978-5-8459-1078-3
- Степаненко О.
 С., Сканеры и сканирование. Краткое руководство. — M.: Диалектика, 2005. — 288 с. ISBN 5-8459-0617-2
С., Сканеры и сканирование. Краткое руководство. — M.: Диалектика, 2005. — 288 с. ISBN 5-8459-0617-2 - Д. В. Иванов, А. А. Хропов, Е. П. Кузьмин, А. С. Карпов, В. С. Лемпицкий, Алгоритмические основы растровой графики, 2007. Учебное пособие.
- Дьяконов В. П., MATLAB 6.5 SP1/7/7 SP1/ Работа с изображениями и видеопотоками. — M.: СОЛОН-Пресс, 2010. — 400 с. ISBN 5-98003-205-2
- Гонсалес Р., Вудс Р., Цифровая обработка изображений. — М.: Техносфера, 2005, 2006. — 1072 с. ISBN 5-94836-028-8
Ссылки
- Ident Smart Studio (экспертная система предметно-независимого распознавания образов)
Цифровая обработка изображений | Altamisoft.ru
Для проведения анализа цифровых изображений и устранения с них различных технических изъянов, возникших при съемке, например, из-за неправильной настройки устройства захвата или дефектов (царапины, пылинки и т.д.) объектива видео- или фотокамеры, часто требуется обработка изображений с целью повышения информативности и качества полученных снимков.
Такие операции, как удаление/подавление шумов, настройка яркости, контраста, резкости фотографий, цветокоррекция, сглаживание, компенсация дисторсии и многие другие, позволяют отредактировать изображение и подготовить его к печати или публикации. Существуют и специальные операции для работы с изображениями: получение негатива, бинаризация (преобразование снимка в черно-белые цвета), конвертирование в серый и т. д.
Цифровая обработка изображений включает в себя также создание панорамных изображений, полученных соединением нескольких кадров.
Программа для обработки изображений
Для ввода цифровых изображений с устройства захвата (видео-, веб- или фотокамеры) в компьютер и их последующего редактирования требуется определенная система для обработки изображений. В идеальном случае такая система должна также управлять параметрами съемки, как например, значением выдержки и экспозиции, такими настройками изображения, как яркость, контраст, гамма, насыщенность и др.
Программа Altami Studio разработана специально для управления устройствами захвата изображений (или захвата видео), а также для анализа и обработки полученных кадров. Это кроссплатформенное приложение, которое может работать с различными моделями камер в большинстве популярных операционных систем (например, с Canon PowerShot и Canon EOS в ОС линейки Windows, в ОС на базе ядра Linux, а также в Mac OS). Для обработки полученных кадров в программе имеется множество фильтров и операций, работающих как с формой изображений, так и с цветом. Все действия, выполняемые в данном приложении над статичной картинкой, можно также выполнять и в режиме реального времени.
Методы обработки изображений
Для редактирования цифровых изображений существуют различные алгоритмы обработки изображений, реализованные в современных программах. Их применение позволяет получить высокое качество изображения, а также устранить большинство возникших при съемке дефектов на фотографиях.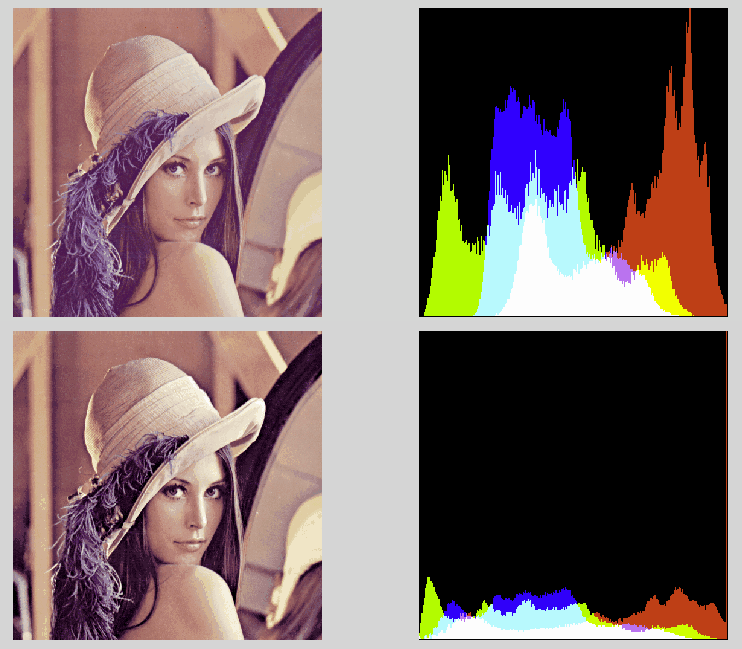
В программе Altami Studio разработаны такие методы обработки изображений, как: геометрические (например, поворот, масштаб, обрезание), морфологические (дилатация, эрозия), преобразования цветных изображений (негатив, гамма, сглаживание), изображений в градациях серого (преобразование Лапласа, пороговое, нахождение границ), а также операции по работе с измерениями (поиск контуров) и с фоном (выравнивание освещенности, восстановление, удаление фона). Кроме того, программное обеспечение для обработки изображений Altami Studio имеет такую функцию, как автоматический поиск объектов на изображении. Все операции могут быть последовательно применены к одному изображению, что позволяет откорректировать изображение.
Обработка рентгеновского изображения
Для анализа рентгеновского снимка часто требуется предварительно его отредактировать. В основном для этого настраивают яркость и контраст фотографии, используют операцию гамма-коррекции, а также алгоритмы обработки полутоновых изображений и многое другое.
В основном для этого настраивают яркость и контраст фотографии, используют операцию гамма-коррекции, а также алгоритмы обработки полутоновых изображений и многое другое.
Данные методы обработки изображений можно применить в программе Altami Studio. К тому же, с помощью преобразований для работы с фоном, предлагаемых этой системой, с рентгеновского изображения можно удалять артефакты, а фильтр Автоматический поиск объектов позволяет найти и выделить интересующие области на изображении. Помимо перечисленного, в программе Altami Studio реализовано такое преобразование, как Псевдоцвета, идеально подходящее для работы с рентгеновскими снимками. Применяя его, можно «раскрасить» изображение, присвоив пикселям те или иные цвета в результате квантования их по уровням яркости. Таким образом становятся различимы области с близкими по значению яркостями.
Читать другие материалы по теме:
Вам не подходят существующие решения?
Контроль качества зерна
Анализ изображений
Захват изображения
Компенсация дисторсии изображения
Техническое (машинное) зрение
Обработка изображения в реальном времени
Панорамные изображения
Определение размера частиц
Контроль качества труб
Расширенная обработка изображения — 2017
| и смещений | Предусмотрено несколько способов представления данных об изображении для их объективного анализа в процессе корректировки.
|
||||||
| Канал уровней | Определяет данные каналов, отображаемые на мониторе. Цвета, Яркость, Красный, Зеленый или Синий. Цвета, Яркость, Красный, Зеленый или Синий. |
||||||
| Яркость изображения | Регулировка яркости изображения на мониторах, позволяющая просмотреть уровни яркости для областей изображения с недостаточным шагом дискретизации. | ||||||
| Диапазон отображения | Задание диапазона мониторов. Диапазон по умолчанию: от 0 до 1. | ||||||
| Смещение уровня | Сдвиг всех цветовых значений вверх или вниз по шкале значений на одну и ту же величину в отрисованном изображении. Например, при наличии в изображении черного пиксела со значением 0% и серого пиксела со значением 50% смещение значений на 50% приводит к превращению черного пиксела в серый со значением 50%, а серого – в белый со значением 100%; на ту же величину изменяются и все другие значения. |
||||||
| Входной уровень черного | Задание порога, по достижении которого область изображения считается черной. По умолчанию пикселы со значением 0,0 Вт/ср-м2 являются черными. При регулировке параметра Входной уровень черного в сторону увеличения некоторые пикселы со значениями, превышающими 0,0, начинают считаться черными, что приводит к затенению изображения в целом. | ||||||
| Входной уровень серого | Нелинейная регулировка освещенности, при которой к пикселам применяется функция в виде кривой: сильнее всего изменяются значения в среднем диапазоне, в меньшей степени – значения, близкие к заданным точкам черного и белого. Значения, большие 1, соответствуют осветлению среднего диапазона, а значения, меньшие 1 – его затенению. | ||||||
| Входной уровень белого | Задание порога, по достижении которого область изображения считается белой. По умолчанию пикселы со значением освещенности 1,0 Вт/ср-м2 и выше являются белыми. При регулировке параметра Входной уровень белого в сторону уменьшения некоторые пикселы с более низкими значениями начинают считаться белыми, что приводит к возрастанию общей яркости изображения. При регулировке параметра Входной уровень белого в сторону увеличения некоторые пикселы с более высокими значениями перестают считаться белыми, что приводит к снижению общей яркости изображения. По умолчанию пикселы со значением освещенности 1,0 Вт/ср-м2 и выше являются белыми. При регулировке параметра Входной уровень белого в сторону уменьшения некоторые пикселы с более низкими значениями начинают считаться белыми, что приводит к возрастанию общей яркости изображения. При регулировке параметра Входной уровень белого в сторону увеличения некоторые пикселы с более высокими значениями перестают считаться белыми, что приводит к снижению общей яркости изображения. |
||||||
| Тональное отображение | Позволяет сжать динамический диапазон изображения. В программу PhotoView 360 поступают данные из полного диапазона светлых и темных участков изображения (динамического диапазона). Однако на мониторе отображение полного динамического диапазона не поддерживается, поэтому на очень светлых или очень темных участках могут быть не видны детали, что создает впечатление изображения с чрезмерной или недостаточной экспозицией. Во многих случаях для достижения наилучших результатов требуется согласованное задание параметров Уровень белого, Тональная компрессия и Выходное значение гамма-коррекции. |
||||||
| Смещение оттенка | Настройка цветовых значений отрисованного изображения независимо от значений яркости, их последовательное смещение по всему спектру. Например, значения красного цвета смещаются к оранжевому, оранжевого – к желтому и т. д. Значение оттенков можно мысленно представить в виде колеса, поворот которого на 180° соответствует обращению цветов, а угол поворота 0° – исходному состоянию. |
 При сжатии динамического диапазона с помощью функции Тональная компрессия становятся видимыми детали на самых темных и самых светлых участках изображения.
При сжатии динамического диапазона с помощью функции Тональная компрессия становятся видимыми детали на самых темных и самых светлых участках изображения.Обработка изображений -Публикации
Обработка данных в виде изображения возможна с помощью нескольких методов. Изображение обычно интерпретируется как двумерный массив значений яркости, и наиболее часто встречаемыми являются такие модели, как фотографии, слайды. Изображение может быть обработано оптическим способом или цифровым при помощи компьютера.
Изображение обычно интерпретируется как двумерный массив значений яркости, и наиболее часто встречаемыми являются такие модели, как фотографии, слайды. Изображение может быть обработано оптическим способом или цифровым при помощи компьютера.
Для цифровой обработки изображений, в первую очередь, необходимо представить фотографию в виде ряда цифр, которые обрабатываются с помощью компьютера. Каждое число, представляющее значение яркости изображения в определенном месте, называется элементом изображения или пикселем. Стандартный размер оцифрованных изображений равен 512х512 или примерно 250 000 пикселей, хотя и гораздо большие изображения становятся распространенными. После оцифровки образа, используются три основных операции. Для точечной операции значение пикселя в выходном изображении зависит от одного значения пикселя в исходном изображении. Для локальных операций несколько соседних пикселей в исходном изображении определяют значение пикселя выходного изображения. В глобальной операции все пиксели исходного изображения вкладываются в значение пикселя выходного изображения. Эти операции, взятые по отдельности или в сочетании, являются средством, с помощью которого изображения усиливаются, восстанавливаются или сжимаются.
Эти операции, взятые по отдельности или в сочетании, являются средством, с помощью которого изображения усиливаются, восстанавливаются или сжимаются.
Качество изображения возрастает, когда оно изменяется так, что содержащаяся в нем информация становится более достоверной, но повышение качества может также включать в себя способ, при котором изображение становится более привлекательным визуально. Например, сглаживание шумов. Для сглаживания зашумленного изображения, применяется медианная фильтрация с окном 3?3 пикселя. Это означает, что значение каждого пикселя в зашумленном изображении записывается, а также значения его ближайших восьми соседей. Эти девять пикселей затем упорядочиваются в соответствии с размером, а пиксель со средним значением выбирается в качестве значения пикселя в новом образе. Окно 3?3 перемещается на один пиксель за единицу времени через зашумленный образ, так формируется отфильтрованное изображение.
Другим примером является изменение контраста, где значение каждого пикселя в новом образе зависит только от значения этого пикселя в старом образе, другими словами, это точечная операция. Изменение контраста обычно проводится путем настройки яркости и контрастности на телевизоре или путем настроек экспозиции и времени разработки в графике. Еще одним моментом данной операции является то, что псевдоокрашенное черно-белое изображение появляется путем присвоения произвольного цвета оттенкам серого. Этот метод популярен в термографии (тепловое изображение), т.е. где наиболее горячему месту объекта (с высоким значением пикселя) присваиваются оттенки одного цвета (например, красного), а прохладному месту объекта (с низкими значениями пикселей) — оттенки другого цвета (например, синего), другие места объекта окрашиваются иным цветом, соответствующим промежуточным значениям.
Изменение контраста обычно проводится путем настройки яркости и контрастности на телевизоре или путем настроек экспозиции и времени разработки в графике. Еще одним моментом данной операции является то, что псевдоокрашенное черно-белое изображение появляется путем присвоения произвольного цвета оттенкам серого. Этот метод популярен в термографии (тепловое изображение), т.е. где наиболее горячему месту объекта (с высоким значением пикселя) присваиваются оттенки одного цвета (например, красного), а прохладному месту объекта (с низкими значениями пикселей) — оттенки другого цвета (например, синего), другие места объекта окрашиваются иным цветом, соответствующим промежуточным значениям.
Основой восстановления и улучшения изображения является знание того, как был сформирован образ. Это знание используется в попытке получить идеальное изображение. Любое изображение, формируемое системой, не является совершенным, и содержит артефакты (например, размытие, аберрации) в окончательном изображении, что уже не будет являться идеальным образом. Функция рассеивания точки является фильтром, наличие которого отменяет размытие. С помощью фильтра происходит восстановление изображения. Функции рассеивания точки более распространены, чем функции размытия точки, в результате чего большая часть пикселей в процессе восстановления получает усредненное значение. Это пример глобальной операции, так как, возможно, все пиксели размытого изображения могут способствовать значению одного пикселя в восстановленном изображении. Этот тип устранения размытости называется обратной фильтрацией, и он чувствителен к наличию шума в размытом изображении.
Функция рассеивания точки является фильтром, наличие которого отменяет размытие. С помощью фильтра происходит восстановление изображения. Функции рассеивания точки более распространены, чем функции размытия точки, в результате чего большая часть пикселей в процессе восстановления получает усредненное значение. Это пример глобальной операции, так как, возможно, все пиксели размытого изображения могут способствовать значению одного пикселя в восстановленном изображении. Этот тип устранения размытости называется обратной фильтрацией, и он чувствителен к наличию шума в размытом изображении.
Сжатие — способ представления изображения меньшего размера, но, в то же время, сведения к минимуму деградации информации, содержащейся в изображении. Сжатие играет важную роль при большом количестве цифровых снимков, которые обрабатываются и хранятся в электронном виде. Цифровое телевидение высокой четкости в значительной мере опирается на сжатие изображений для включения их в передачу и отображения изображений большого формата. После того, как изображение было сжато для хранения или передачи, оно должно быть распаковано для использования путем операции обратной сжатию. Существует компромисс между степенью сжатия и качеством несжатого изображения. Высокий уровень сжатия является приемлемым, например, для телевизионных изображений. Однако там, где высокое качество изображения должно быть сохранено (как в диагностических медицинских изображениях), степень сжатия очень низка, приемлемым является сжатие 3:57.
После того, как изображение было сжато для хранения или передачи, оно должно быть распаковано для использования путем операции обратной сжатию. Существует компромисс между степенью сжатия и качеством несжатого изображения. Высокий уровень сжатия является приемлемым, например, для телевизионных изображений. Однако там, где высокое качество изображения должно быть сохранено (как в диагностических медицинских изображениях), степень сжатия очень низка, приемлемым является сжатие 3:57.
Обработка изображений является активной областью исследований в таких разнообразных областях, как медицина, астрономия, микроскопия, сейсмология, промышленный контроль, а также в публикации и индустрии развлечений. Восприятие изображения расширяется за счет включения трехмерных изображений (объёмные изображения), и даже четырехмерного набора данных с учетом времени. Примером последнего является объемный образ бьющегося сердца, получаемый с рентгеновской компьютерной томографии (КТ). КТ, ПЭТ, однофотонная эмиссионная компьютерная томография (ОФЭКТ), МРТ, УЗИ, ЮАР, конфокальная микроскопия, сканирующая туннельная микроскопия, атомно-силовая микроскопия, а также другие направления были разработаны с помощью оцифровки изображений.
ЭБ СПбПУ — Низкоуровневая обработка изображений в компьютерном зрении
|
Разрешенные действия: Прочитать Группа: Анонимные пользователи Сеть: Интернет |
 93’1
93’1
 18720/SPBPU/5/tr21-13
18720/SPBPU/5/tr21-13
Аннотация
В монографии излагаются вопросы низкоуровневой обработки изображений, которые представлены в рамках методологии распределенной обработки изображений в видеосистемах. Рассматриваются алгоритмы, которые можно осуществлять как в компьютере, так в фотоприемнике и видеопроцессоре. Приводятся примеры реализации алгоритмов, в том числе и с применением функций OpenCV. В книге представлен материал, который является дальнейшим развитием вопросов, рассмотренных в монографии «Проектирование специализированных цифровых видеокамер» ISBN 978-5-7422-5334-1
Книга предназначена для специалистов в области проектирования и применения видеосистем для обработки сигналов и изображений. Она может быть полезна студентам, проходящим подготовку по направлениям 09.03.01 «Информатика и вычислительная техника», 09.03.04 «Программная инженерия»,12.03.01 «Приборостроение».
Приводятся примеры реализации алгоритмов, в том числе и с применением функций OpenCV. В книге представлен материал, который является дальнейшим развитием вопросов, рассмотренных в монографии «Проектирование специализированных цифровых видеокамер» ISBN 978-5-7422-5334-1
Книга предназначена для специалистов в области проектирования и применения видеосистем для обработки сигналов и изображений. Она может быть полезна студентам, проходящим подготовку по направлениям 09.03.01 «Информатика и вычислительная техника», 09.03.04 «Программная инженерия»,12.03.01 «Приборостроение».
Права на использование объекта хранения
| Место доступа | Группа пользователей | Действие | ||||
|---|---|---|---|---|---|---|
| Локальная сеть ИБК СПбПУ | Все | |||||
| Интернет | Все |
Оглавление
- Оглавление
- Введение.
 Особенности низкоуровневой обработки изображений
Особенности низкоуровневой обработки изображений - Глава 1. Видеосистемы и распределенная обработка изображений
- 1.1. Архитектуры видеосистем
- 1.1.1. Простая видеосистема
- 1.1.2. Видеосистема с распределенными камерами
- 1.1.3. Специализированная видеосистема
- 1.2. Элементы видеосистем (фотоприемники, камеры, видеопроцессоры, элементы сопряжения)
- 1.2.1. Необходимость обработки сигналов в фотоприемниках
- 1.2.2. Принципы работы ПЗС-фотоприемников
- 1.2.3. Рассмотрение ПЗС-элементов как элементов цифрового процессора
- 1.2.4. КМОП-фотоприемники. Принципы работы
- 1.2.5. Видеокамеры и их параметры
- 1.2.6. Интерфейсы видеосистем
- 1.3. Распределенная обработка изображений в видеосистемах
- Глава 2. Алгоритмы низкоуровневой обработки изображений
- 2.1. Классификация алгоритмов
- 2.2. Низкоуровневые алгоритмы для улучшения изображений
- 2.
 3. Алгоритмы конвейерной, векторной и параллельной обработки видео
3. Алгоритмы конвейерной, векторной и параллельной обработки видео - 2.4. Алгоритмы для оптоэлектронных процессоров
- Глава 3. Алгоритмы обработки изображений, реализуемые в ПЗС-фотоприемниках
- 3.1. Классификация алгоритмов
- 3.2. Виртуальные светочувствительные элементы
- 3.3. Фрагментирование
- 3.4. Синхронное накопление
- 3.5. Использование антиблюминговой защиты
- 3.6. Режим временной задержки и накопления
- Глава 4. Алгоритмы низкоуровневой обработки и примеры программ с функциями OpenCV
- 4.1. Библиотеки функций компьютерного зрения. OpenCV
- 4.2. Вычисление гистограмм
- 4.3. Пиксельные преобразования. Подмена пикселей
- 4.4. Фильтрация в пространственной области
- 4.5. Фильтрация в частотной области. Поиск объекта на изображении методом поиска по шаблону
- 4.6. Изменение палитры цветов, псевдо раскраска
- 4.
 7. Пороговые преобразования
7. Пороговые преобразования - 4.8. Сегментация на основе цвета
- 4.9. Сегментация. Метод морфологического водораздела (watershed)
- 4.10. Отслеживание объекта. Трекеры
- Глава 5. Примеры использования низкоуровневых алгоритмов обработки в задачах распознавания
- 5.1. Детектирование и анализ клеточных ядер
- 5.2. Распознавание рельсовой колеи
- 5.3. Добавление водяного знака на видео
- Заключение
- Список литературы
Статистика использования
Основы цифровой обработки изображений — GeeksforGeeks
Цифровая обработка изображений означает обработку цифрового изображения с помощью цифрового компьютера. Мы также можем сказать, что это использование компьютерных алгоритмов для получения улучшенного изображения или для извлечения некоторой полезной информации.
Обработка изображения в основном включает следующие этапы:
1. Импорт изображения с помощью инструментов получения изображения;
2. Анализ и обработка изображения;
Анализ и обработка изображения;
3.Вывод, результатом которого может быть измененное изображение или отчет, основанный на анализе этого изображения.
Что такое изображение?
Изображение определяется как двумерная функция F(x,y) , где x и y — пространственные координаты, а амплитуда F в любой паре координат (x,y) называется интенсивность этого изображения в этой точке. Когда значения x, y и амплитуды F конечны, мы называем это цифровым изображением .
Другими словами, изображение может быть определено двумерным массивом, специально упорядоченным по строкам и столбцам.
Цифровое изображение состоит из конечного числа элементов, каждый из которых имеет определенное значение в определенном месте. Эти элементы называются элементами изображения, элементами изображения и пикселями . Пиксель используется наиболее широко. для обозначения элементов цифрового изображения.
Типы изображения
- ДВОИЧНОЕ ИЗОБРАЖЕНИЕ — Двоичное изображение, как следует из его названия, содержит только два пиксельных элемента, т. е. 0 и 1, где 0 относится к черному цвету, а 1 — к белому. Это изображение также известно как монохромный.
- ЧЕРНО-БЕЛОЕ ИЗОБРАЖЕНИЕ – Изображение, состоящее только из черного и белого цветов, называется ЧЕРНО-БЕЛОЕ ИЗОБРАЖЕНИЕ.
- 8-битный ЦВЕТНОЙ ФОРМАТ — это самый известный формат изображения. Он имеет 256 различных оттенков цветов и широко известен как изображение в градациях серого. В этом формате 0 означает черный, 255 — белый, а 127 — серый.
- 16-битный ЦВЕТНОЙ ФОРМАТ – это формат цветного изображения. Он имеет 65 536 различных цветов. Он также известен как формат высокого цвета. В этом формате распределение цвета не такое, как в изображении в градациях серого.
16-битный формат фактически делится на три дополнительных формата: красный, зеленый и синий. Знаменитый формат RGB.
Знаменитый формат RGB.
Изображение как матрица
Как мы знаем, изображения представлены в строках и столбцах, у нас есть следующий синтаксис представления изображений:
Правая часть этого уравнения является цифровым изображением по определению. Каждый элемент этой матрицы называется элементом изображения, элементом изображения или пикселем.
ЦИФРОВОЕ ПРЕДСТАВЛЕНИЕ ИЗОБРАЖЕНИЯ В MATLAB:
В MATLAB начальный индекс равен 1 вместо 0. Следовательно, f(1,1) = f(0,0).
впредь два представления изображения идентичны, за исключением смещения начала координат.
В MATLAB матрицы хранятся в переменной, т.е. X,x,input_image и т.д. Переменные должны быть буквой, как и в других языках программирования.
ЭТАПЫ ОБРАБОТКИ ИЗОБРАЖЕНИЯ:
1. ПОЛУЧЕНИЕ — Это может быть так же просто, как получить изображение в цифровой форме. Основная работа включает в себя:
a) Масштабирование
b) Преобразование цвета (RGB в серый или наоборот)
2. УЛУЧШЕНИЕ ИЗОБРАЖЕНИЯ – Это один из самых простых и привлекательных способов обработки изображений, который также используется для извлечения некоторые скрытые детали изображения и является субъективным.
УЛУЧШЕНИЕ ИЗОБРАЖЕНИЯ – Это один из самых простых и привлекательных способов обработки изображений, который также используется для извлечения некоторые скрытые детали изображения и является субъективным.
3. ВОССТАНОВЛЕНИЕ ИЗОБРАЖЕНИЯ – Это также касается привлекательности изображения, но оно объективно (Восстановление основано на математической или вероятностной модели или ухудшении изображения).
4. ОБРАБОТКА ЦВЕТНЫХ ИЗОБРАЖЕНИЙ – относится к обработке псевдоцветных и полноцветных изображений. Цветовые модели применимы к цифровой обработке изображений.
5. ВЕЙВЛЕТЫ И ОБРАБОТКА С МНОЖЕСТВЕННЫМ РАЗРЕШЕНИЕМ – Это основа представления изображений в различных степенях.
6. СЖАТИЕ ИЗОБРАЖЕНИЯ — Требуется разработка некоторых функций для выполнения этой операции. В основном это касается размера или разрешения изображения.
7. МОРФОЛОГИЧЕСКАЯ ОБРАБОТКА — Он касается инструментов для извлечения компонентов изображения, которые полезны при представлении и описании формы.
8. ПРОЦЕДУРА СЕГМЕНТАЦИИ — Включает разделение изображения на составные части или объекты. Автономная сегментация — самая сложная задача в обработке изображений.
9. ПРЕДСТАВЛЕНИЕ И ОПИСАНИЕ — Это следует за результатом этапа сегментации, выбор представления является только частью решения для преобразования необработанных данных в обработанные данные.
10. ОБНАРУЖЕНИЕ И РАСПОЗНАВАНИЕ ОБЪЕКТА — Это процесс, который присваивает метку объекту на основе его дескриптора.
ПЕРЕКРЫВАЮЩИЕСЯ ПОЛЯ ПРИ ОБРАБОТКЕ ИЗОБРАЖЕНИЙ
В соответствии с блоком 1 , если на вход поступает изображение, а на выходе мы получаем изображение, то это называется цифровой обработкой изображения.
Согласно блоку 2 , если на вход подается изображение, а на выходе мы получаем некоторую информацию или описание, то это называется компьютерным зрением.
Согласно блоку 3 , если на вход подается какое-то описание или код, а на выходе мы получаем изображение, то это называется компьютерной графикой.
В соответствии с блоком 4 , если входными данными является описание, некоторые ключевые слова или некоторый код, а на выходе мы получаем описание или некоторые ключевые слова, то это называется искусственным интеллектом
ССЫЛКИ
Цифровая обработка изображений (Рафаэль ок. gonzalez)
Что такое обработка изображений? Значение, методы, сегментация и важные факты, которые необходимо знать
За последние несколько лет глубокое обучение оказало огромное влияние на различные области технологий. Одной из самых горячих тем, обсуждаемых в этой отрасли, является компьютерное зрение, способность компьютеров самостоятельно понимать изображения и видео. Самоуправляемые автомобили, биометрия и распознавание лиц — все они полагаются на компьютерное зрение. В основе компьютерного зрения лежит обработка изображений.
Что такое изображение?
Прежде чем мы перейдем к обработке изображений, нам нужно сначала понять, что именно представляет собой изображение. Изображение представлено своими размерами (высота и ширина) в зависимости от количества пикселей. Например, если размеры изображения составляют 500 x 400 (ширина x высота), общее количество пикселей в изображении составляет 200 000.
Изображение представлено своими размерами (высота и ширина) в зависимости от количества пикселей. Например, если размеры изображения составляют 500 x 400 (ширина x высота), общее количество пикселей в изображении составляет 200 000.
Этот пиксель представляет собой точку на изображении, которая приобретает определенный оттенок, непрозрачность или цвет. Обычно это представлено в одном из следующих:
- Оттенки серого — пиксель — это целое число со значением от 0 до 255 (0 — полностью черный, а 255 — полностью белый).
- RGB — пиксель состоит из 3 целых чисел от 0 до 255 (целые числа представляют интенсивность красного, зеленого и синего).
- RGBA — это расширение RGB с добавленным альфа-полем, которое представляет непрозрачность изображения.
Для обработки изображений требуется фиксированная последовательность операций, выполняемых над каждым пикселем изображения. Процессор изображения выполняет первую последовательность операций над изображением, пиксель за пикселем. Как только это будет полностью сделано, он начнет выполнять вторую операцию и так далее. Выходное значение этих операций может быть вычислено для любого пикселя изображения.
Как только это будет полностью сделано, он начнет выполнять вторую операцию и так далее. Выходное значение этих операций может быть вычислено для любого пикселя изображения.
Что такое обработка изображений?
Обработка изображений — это процесс преобразования изображения в цифровую форму и выполнения определенных операций для получения из него некоторой полезной информации. Система обработки изображений обычно обрабатывает все изображения как 2D-сигналы при применении определенных предопределенных методов обработки сигналов.
Существует пять основных типов обработки изображений:
- Визуализация — поиск объектов, которые не видны на изображении
- Распознавание — Различать или обнаруживать объекты на изображении
- Повышение резкости и восстановление — создание улучшенного изображения из исходного изображения
- Распознавание образов. Измерение различных узоров вокруг объектов на изображении
- Извлечение — просмотр и поиск изображений в большой базе данных цифровых изображений, которые похожи на исходное изображение
Основные этапы обработки изображения
Получение изображения
Получение изображения — это первый шаг в обработке изображения. Этот шаг также известен как предварительная обработка при обработке изображений. Он включает получение изображения из источника, обычно аппаратного источника.
Этот шаг также известен как предварительная обработка при обработке изображений. Он включает получение изображения из источника, обычно аппаратного источника.
Улучшение изображения
Улучшение изображения — это процесс выявления и выделения определенных интересных деталей на скрытом изображении. Это может включать изменение яркости, контрастности и т. д.
Восстановление изображения
Восстановление изображения — это процесс улучшения внешнего вида изображения. Однако, в отличие от улучшения изображения, восстановление изображения выполняется с использованием определенных математических или вероятностных моделей.
Обработка цветных изображений
Обработка цветных изображений включает ряд методов цветового моделирования в цифровой области. Этот шаг получил известность из-за значительного использования цифровых изображений в Интернете.
Вейвлеты и обработка с несколькими разрешениями
Вейвлеты используются для представления изображений с различной степенью разрешения. Изображения подразделяются на вейвлеты или меньшие области для сжатия данных и пирамидального представления.
Изображения подразделяются на вейвлеты или меньшие области для сжатия данных и пирамидального представления.
Сжатие
Сжатие — это процесс, используемый для уменьшения памяти, необходимой для сохранения изображения, или пропускной способности, необходимой для его передачи. Это делается, в частности, когда изображение предназначено для использования в Интернете.
Морфологическая обработка
Морфологическая обработка представляет собой набор операций обработки для преобразования изображений на основе их формы.
Сегментация
Сегментация — один из самых сложных этапов обработки изображений. Он включает в себя разделение изображения на составные части или объекты.
Изображение и описание
После сегментации изображения на области в процессе сегментации каждая область представляется и описывается в форме, подходящей для дальнейшей компьютерной обработки. Репрезентация имеет дело с характеристиками изображения и региональными свойствами. Описание связано с извлечением количественной информации, которая помогает отличить один класс объектов от другого.
Описание связано с извлечением количественной информации, которая помогает отличить один класс объектов от другого.
Признание
Распознавание присваивает объекту метку на основе его описания.
Применение обработки изображений
Получение медицинских изображений
Обработка изображений широко используется в медицинских исследованиях и позволяет создавать более эффективные и точные планы лечения. Например, его можно использовать для раннего выявления рака молочной железы с помощью сложного алгоритма обнаружения узлов при сканировании молочной железы. Поскольку медицинское использование требует хорошо обученных процессоров изображений, эти приложения требуют серьезной реализации и оценки, прежде чем они могут быть приняты для использования.
Технологии определения трафика
В случае датчиков дорожного движения мы используем систему обработки видеоизображения или VIPS. Он состоит из а) системы захвата изображения, б) телекоммуникационной системы и в) системы обработки изображений. При захвате видео VIPS имеет несколько зон обнаружения, которые выдают сигнал «включено» всякий раз, когда транспортное средство входит в зону, а затем выводят сигнал «выключено», когда транспортное средство выходит из зоны обнаружения. Эти зоны обнаружения могут быть настроены для нескольких полос и могут использоваться для обнаружения трафика на конкретной станции.
При захвате видео VIPS имеет несколько зон обнаружения, которые выдают сигнал «включено» всякий раз, когда транспортное средство входит в зону, а затем выводят сигнал «выключено», когда транспортное средство выходит из зоны обнаружения. Эти зоны обнаружения могут быть настроены для нескольких полос и могут использоваться для обнаружения трафика на конкретной станции.
Слева — нормальное дорожное изображение | Справа — изображение VIPS с зонами обнаружения (источник)
Помимо этого, он может автоматически записывать номерной знак транспортного средства, различать тип транспортного средства, контролировать скорость водителя на шоссе и многое другое.
Реконструкция изображения
Обработку изображения можно использовать для восстановления и заполнения отсутствующих или поврежденных частей изображения. Это включает в себя использование систем обработки изображений, которые были тщательно обучены с использованием существующих наборов данных фотографий, для создания новых версий старых и поврежденных фотографий.
Рис. Реконструкция поврежденных изображений с помощью обработки изображений (источник)
Распознавание лиц
Одно из наиболее распространенных применений обработки изображений, которые мы используем сегодня, — это распознавание лиц. Он следует алгоритмам глубокого обучения, когда машина сначала обучается конкретным чертам человеческого лица, таким как форма лица, расстояние между глазами и т. д. После обучения машины этим чертам человеческого лица она начнет принимать все объекты на изображении, напоминающие человеческое лицо. Распознавание лиц является жизненно важным инструментом, используемым в безопасности, биометрии и даже фильтрах, доступных в настоящее время в большинстве приложений для социальных сетей.
Преимущества обработки изображений
Внедрение методов обработки изображений оказало огромное влияние на многие технологические организации. Вот некоторые из наиболее полезных преимуществ обработки изображений, независимо от области применения:
- Цифровое изображение может быть доступно в любом желаемом формате (улучшенное изображение, рентгеновский снимок, фотонегатив и т.
 д.)
д.) - Помогает улучшить изображения для интерпретации человеком
- Информация может быть обработана и извлечена из изображений для машинной интерпретации
- Пикселями изображения можно управлять с любой желаемой плотностью и контрастностью
- Изображения можно легко сохранять и извлекать
- Позволяет легко передавать изображения в электронном виде сторонним поставщикам
Изучите концепции глубокого обучения и платформу с открытым исходным кодом TensorFlow с помощью учебного курса по глубокому обучению. Получите мастерство сегодня!
Вот что вы можете сделать дальше
Рост технологий глубокого обучения привел к быстрому ускорению компьютерного зрения в проектах с открытым исходным кодом, что только увеличило потребность в инструментах обработки изображений. Спрос на специалистов, обладающих ключевыми навыками в технологиях глубокого обучения, с каждым годом растет стремительными темпами. Если вы хотите узнать больше об обработке изображений и преимуществах глубокого обучения, сертификационный курс Simplilearn Best Deep Learning Course (с Keras и TensorFlow) — идеальный способ направить вас на правильный путь. Вы освоите все концепции и модели глубокого обучения с использованием фреймворков Keras и TensorFlow и реализуете алгоритмы глубокого обучения. Начните с этого курса сегодня, чтобы начать успешную карьеру в области глубокого обучения.
Если вы хотите узнать больше об обработке изображений и преимуществах глубокого обучения, сертификационный курс Simplilearn Best Deep Learning Course (с Keras и TensorFlow) — идеальный способ направить вас на правильный путь. Вы освоите все концепции и модели глубокого обучения с использованием фреймворков Keras и TensorFlow и реализуете алгоритмы глубокого обучения. Начните с этого курса сегодня, чтобы начать успешную карьеру в области глубокого обучения.
Image Processing Toolbox — MATLAB
Выполнение обработки, визуализации и анализа изображений
Получить бесплатную пробную версию
Посмотреть цены
Image Processing Toolbox™ предоставляет полный набор эталонных стандартных алгоритмов и приложений рабочего процесса для обработки изображений, анализа, визуализации и разработки алгоритмов. Вы можете выполнять сегментацию изображения, улучшение изображения, шумоподавление, геометрические преобразования и регистрацию изображений, используя методы глубокого обучения и традиционные методы обработки изображений. Инструментарий поддерживает обработку 2D, 3D и произвольно больших изображений.
Инструментарий поддерживает обработку 2D, 3D и произвольно больших изображений.
Приложения Image Processing Toolbox позволяют автоматизировать стандартные рабочие процессы обработки изображений. Вы можете в интерактивном режиме сегментировать данные изображений, сравнивать методы совмещения изображений и выполнять пакетную обработку больших наборов данных. Функции и приложения визуализации позволяют просматривать изображения, трехмерные объемы и видео; настроить контраст; создавать гистограммы; и управлять областями интереса (ROI).
Вы можете ускорить свои алгоритмы, запустив их на многоядерных процессорах и графических процессорах. Многие функции набора инструментов поддерживают генерацию кода C/C++ для создания прототипов настольных компьютеров и развертывания встроенных систем машинного зрения.
Что такое Image Processing Toolbox?2:12 Продолжительность видео 2:12.
Что такое панель инструментов обработки изображений?
Анализ изображений
Извлечение значимой информации из изображений, например нахождение форм, подсчет объектов, определение цветов или измерение свойств объектов.
Документация | Примеры
Сегментация изображения
Определение границ областей на изображении с использованием различных подходов, включая автоматическое определение порога, методы на основе границ и методы на основе морфологии.
Документация | Примеры
Регистрация изображений
Выравнивание изображений для проведения количественного анализа или качественного сравнения с использованием мультимодальных и нежестких методов регистрации на основе интенсивности.
Документация | Примеры
К сожалению, ваш браузер не поддерживает встроенные видео.К сожалению, ваш браузер не поддерживает встроенные видео.
Рабочие процессы обработки 3D-изображений
Визуализируйте и выполняйте полные рабочие процессы обработки изображений на 3D-объемах.
Документация | Примеры
К сожалению, ваш браузер не поддерживает встроенные видео.К сожалению, ваш браузер не поддерживает встроенные видео.
Обработка гиперспектральных изображений
Чтение, запись и визуализация гиперспектральных данных в различных форматах файлов и обработка данных с использованием таких алгоритмов, как Smile Reduction, NDVI или определение спектральных индексов.
Документация | Примеры
Глубокое обучение обработке изображений
Выполнение задач обработки изображений, таких как удаление шума изображения и выполнение преобразования изображения в изображение, с использованием глубоких нейронных сетей.
Документация | Примеры
Предварительная обработка изображений
Повышение контрастности, удаление шума и устранение размытия с помощью настройки контрастности, морфологических операторов и пользовательских или предустановленных фильтров.
Документация | Примеры
Приложения для исследований и открытий
Используйте приложения для изучения и открытия различных алгоритмических подходов. С помощью приложения Color Thresholder вы можете сегментировать изображение на основе различных цветовых пространств. Приложение Image Region Analyzer позволяет вычислять свойства регионов в бинарных изображениях.
Документация | Примеры
Ускорение и развертывание
Автоматическое создание кода C/C++, CUDA ® и HDL для прототипирования и развертывания алгоритмов обработки изображений на ЦП, графических процессорах, ПЛИС и ASIC.
Документация | Примеры
Ресурсы продукта:
Документация Примеры кода Видео Требования к продукту Примечания к выпуску
«Вскоре после запуска ForWarn в производство были обнаружены ранее незамеченные повреждения градом, которые представляли угрозу для водораздела. Без MATLAB мы не смогли бы выполнить эту работу столь же эффективно».
Дуэйн Армстронг, Космический центр Стеннис НАСА
Посмотреть больше историй клиентов
Получите бесплатную пробную версию
30 дней исследования в ваших руках.
Начинай сейчас
Готов купить?
Получите информацию о ценах и изучите сопутствующие товары.
Посмотреть цены Связаться с отделом продаж
Вы студент?
Ваше учебное заведение уже может предоставлять доступ к MATLAB, Simulink и дополнительным продуктам через лицензию для всего кампуса.
Что дальше?
Учебник
Обработка изображений Onramp
Видео
Обработка изображений Made Easy
Особенности выпуска
Что нового в последней версии MATLAB и Simulink
Выберите сеть Сайт
Выберите веб-сайт, чтобы получить переведенный контент, где он доступен, и посмотреть местные события и предложения. На основе ваше местоположение, мы рекомендуем вам выбрать: .
Вы также можете выбрать веб-сайт из следующего списка:
Европа
Свяжитесь с местным офисом
ImageProcessingPlace
ImageProcessingPlace
|
|
|
 ..
..  (DIP/3e)
(DIP/3e) 

Обработка изображений 101
Зачем это было написано
В Recurse Center я некоторое время обучался обработке изображений. Когда я начинал, я понятия не имел, что это повлечет за собой. Я просто знал, что это может помочь мне распознавать текст, формы и узоры и делать с ними интересные вещи.
Моими источниками в основном были страницы Википедии, книги и общедоступные университетские конспекты лекций. По мере того, как я лучше знакомился с материалом, мне захотелось статьи «Обработка изображений 101», которая могла бы дать любому мягкое введение в мир обработки изображений.
Это моя попытка написать эту статью.
Предпосылки
Эта статья предназначена для тех, кто хорошо знаком с Python. Никаких других предварительных знаний не требуется, хотя некоторое знакомство с операциями numpy и matrix будет полезно.
Начало работы
Мы будем использовать OpenCV для Python, Python 2.7 1 и iPython Notebook. Инструкции по настройке OpenCV на MacOS можно найти здесь.
Весь используемый код и изображения доступны в виде записной книжки iPython на Github. Вы также можете посмотреть блокнот iPython в Интернете.
Я настоятельно рекомендую изучать работу по обработке изображений на ноутбуке iPython, так как он позволяет отображать изображения во встроенном виде, что упрощает получение отзывов о том, что на самом деле делает ваш код.
Что такое обработка изображений?
Обработка изображений — это процесс манипулирования изображениями или выполнения операций с ними для достижения определенного эффекта (например, создание изображения в градациях серого) или получения некоторой информации из изображения с помощью компьютера (например, подсчет количества кругов в нем). .
.
Обработка изображений также очень тесно связана с компьютерным зрением, и мы сильно стираем грань между ними. Не беспокойтесь об этом слишком сильно — вам просто нужно помнить, что мы собираемся узнать о методах манипулирования изображениями и о том, как мы можем использовать эти методы для сбора информации о них.
В этой статье я расскажу о некоторых основных строительных блоках обработки изображений и поделюсь кодом и подходами к базовым инструкциям. Весь написанный код написан на Python и использует OpenCV, мощную библиотеку обработки изображений и компьютерного зрения.
Строительные блоки
Начнем с импорта. Мы используем cv2 , numpy и немного matplotlib (в основном как удобный способ отображения изображений).
импорт cv2, matplotlib импортировать numpy как np импортировать matplotlib.pyplot как plt
Формат изображения
Хорошо! Давайте начнем. Во-первых, нам нужно читать изображения и понимать формат, в котором они нам представлены.
В OpenCV изображения представлены в виде трехмерных массивов Numpy. Изображение состоит из строк пикселей, и каждый пиксель представлен массивом значений, представляющих его цвет.
Учитывая изображение выше, его представление в виде массива будет:
# прочитать изображение
img = cv2.imread('images/noguchi02.jpg')
# показать формат изображения (в основном трехмерный массив информации о цвете пикселей в формате BGR)
печать (изображение)
Результаты:
[
[[72 99 143] [76 103 147] [78 106 147] ..., [159 186 207] [160 187 213] [157 187 212]]
[[74 101 145] [77 104 148] [77 105 146] ..., [160 187 208] [158 186 210] [153 183 208]]
[[76 103 147] [77 104 148] [76 104 145] ..., [157 181 203] [160 188 212] [158 186 210]]
...,
[[3978 130] [39 78 130] [40 79 131] ..., [193 210 223] [195 212 225] [197 214 227]]
[[32 71 123] [32 71 123] [32 71 123] ..., [198 215 228] [200 217 230] [200 217 230]]
[[39 78 130] [39 78 130] [39 78 130] . .., [199 216 229] [200 217 230] [201 218 231]]
]
.., [199 216 229] [200 217 230] [201 218 231]]
]
Где [72 99 143] и т. д. — значения синего, зеленого и красного (BGR) этого одного пикселя. Обратите внимание, что OpenCV по умолчанию загружает изображение в формате BGR. Однако Matplotlib считывает изображения как RGB. Чтобы отобразить изображение в matplotlib, нам нужно будет преобразовать формат BGR в RGB. Я дам вам понять, что произойдет, если вы забудете выполнить преобразование перед передачей изображения в matplotlib.
# преобразовать изображение в цвет RGB для matplotlib img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # показать изображение с помощью matplotlib plt.imshow (изображение)
Цвета
Подожди, подожди, подожди. К чему все эти дела с BGR и RGB?
Красный, зеленый и синий (RGB)
В цифровом мире цвета обычно представляются с использованием цветовой модели RGB . В этой цветовой модели красный, зеленый и синий свет могут быть объединены различными способами для получения диапазона цветов в видимом спектре. Каждый из этих цветов называется 9.0014 канал . Это работает немного иначе, чем, скажем, смешивание цветов краски. В цветовой модели RGB:
Каждый из этих цветов называется 9.0014 канал . Это работает немного иначе, чем, скажем, смешивание цветов краски. В цветовой модели RGB:
Изображение из Википедии 3
- красный + зеленый = желтый
- синий + зеленый = голубой
- красный + синий = пурпурный
- красный + синий + зеленый = белый
Не буду вдаваться в технические подробности, но в Википедии есть раздел о том, как работают цветовые комбинации.
В большинстве систем значения RGB представлены в виде значений в диапазоне от 0 до 255, причем более высокие значения соответствуют более высокой интенсивности этого цветового канала. Например, мы можем предположить, что [255, 51, 0] , вероятно, имеет красноватый цвет, потому что его канал R является самым высоким, а [51, 102, 0] , вероятно, имеет зеленоватый цвет, а канал G является самым высоким.
Оттенок, насыщенность и значение (HSV)
Другой полезной цветовой моделью является цветовая модель HSV . Вместо того, чтобы представлять цвета с помощью красного, зеленого и синего, мы представляем их с помощью оттенков (где он находится в диапазоне радуги), насыщенности («красочности» цвета) и значение (также известное как яркость или количество воспринимаемого света).
Вместо того, чтобы представлять цвета с помощью красного, зеленого и синего, мы представляем их с помощью оттенков (где он находится в диапазоне радуги), насыщенности («красочности» цвета) и значение (также известное как яркость или количество воспринимаемого света).
Изображение из Википедии 4
Цветовая модель HSV особенно полезна, когда вы хотите думать о цвете изображения в любом из этих каналов, например. поиск частей изображения, попадающих в диапазон оттенков синего.
Разновидностью HSV является цветовая модель HSL , которая состоит из оттенка, насыщенности и яркости. Он похож на HSV, но отличается определением насыщенности и третьего канала (яркость против яркости) 2 .
Оттенки серого
Мы также будем работать с изображениями в оттенках серого . Изображения в градациях серого имеют только один цветовой канал по шкале от 0 до 255, представляющий яркость этого пикселя, где 0 означает полностью темный (черный), а 255 — полностью яркий (белый).
Преобразование изображения, которое у нас есть, в оттенки серого дает нам этот двумерный массив:
# преобразовать изображение в оттенки серого grey_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # изображение в градациях серого, представленное в виде двумерного массива печать (серый_img)
Результат:
[[109 113 115 ..., 189 192 191] [111 114 114 ..., 190 190 187] [113 114 113 ..., 185 192 190] ..., [89 89 90 ..., 212 214 216] [ 82 82 82 ..., 217 219 219 ] [ 89 89 89 ..., 218 219 220]]
Я рекомендую поиграть с палитрой цветов, чтобы лучше понять, как меняются цвета при их изменении. Особенно интересно наблюдать, как меняются значения RGB при изменении одного из каналов HSV.
Упражнение:
Зная это, теперь мы можем найти средний цвет изображения! Если мы усредним каждый из каналов R, G и B, это даст нам значение RGB, которое является средним цветом пикселя. Вот пример того, как это можно сделать с помощью np. . average()
average()
# найти среднее значение для каждой строки, при условии, что изображение уже находится в формате RGB. # np.average() принимает аргумент оси, который находит среднее значение по этой оси. medium_color_per_row = np.average (изображение, ось = 0) # найти среднее значение по среднему значению в строке medium_color = np.average (average_color_per_row, ось = 0) # преобразовать обратно в uint8 средний_цвет = np.uint8 (средний_цвет) печать (средний_цвет)
Результат:
[179 146 123]
Чтобы отобразить цвет на matplotlb, нам нужно создать небольшое изображение размером 100×100 пикселей, заполненное этим значением RGB.
# создать изображение размером 100 x 100 пикселей со средним значением цвета medium_color_img = np.array([[average_color]*100]*100, np.uint8) plt.imshow (средний_цвет_img)
Каков средний цвет изображения?
Сегментация
Когда мы пытаемся собрать информацию об изображении, нам сначала нужно разбить его на интересующие нас функции. Это называется сегментация . Сегментация изображения — это процесс представления изображения в виде сегментов, чтобы сделать его более осмысленным для облегчения анализа 3 .
Это называется сегментация . Сегментация изображения — это процесс представления изображения в виде сегментов, чтобы сделать его более осмысленным для облегчения анализа 3 .
Порог
Одним из самых простых способов сегментации изображения является определение порога . Основная идея пороговой обработки заключается в замене каждого пикселя изображения белым пикселем, если значение канала этого пикселя превышает определенный порог, и черным пикселем, если это не так. Обычно мы конвертируем изображение в бинарное изображение 9.0015 , то есть одноканальное изображение. Изображения в градациях серого являются примерами одноканальных изображений.
# порог для изображения, с порогом 60 _, threshold_img = cv2.threshold (grey_img, 60, 255, cv2.THRESH_BINARY) # показать изображение threshold_img = cv2.cvtColor (threshold_img, cv2.COLOR_GRAY2RGB) plt.imshow (порог_img)
Результат:
Это позволяет легко выделить части изображения с разной яркостью. Это относится не только к версиям изображений в градациях серого. Мы также можем сегментировать части изображений по цветовым каналам. Цветовой порог лучше всего работает с HSV. Мы говорили о том, что у HSV есть канал оттенка, то есть по шкале от красного к зеленому, к синему и к пурпурному, где лежит цвет пикселя?
Это относится не только к версиям изображений в градациях серого. Мы также можем сегментировать части изображений по цветовым каналам. Цветовой порог лучше всего работает с HSV. Мы говорили о том, что у HSV есть канал оттенка, то есть по шкале от красного к зеленому, к синему и к пурпурному, где лежит цвет пикселя?
Вместо того, чтобы находить значение ниже порогового значения, мы можем найти части изображения с оттенками, которые находятся в пределах диапазона с помощью cv2.inRange() .
# открыть новое фото картины Мондриана Пита
пиет = cv2.imread('images/piet.png')
piet_hsv = cv2.cvtColor(piet, cv2.COLOR_BGR2HSV)
# порог для канала оттенка в синем диапазоне
blue_min = np.array([100, 100, 100], np.uint8)
blue_max = np.array([140, 255, 255], np.uint8)
threshold_blue_img = cv2.inRange (piet_hsv, blue_min, blue_max)
threshold_blue_img = cv2.cvtColor (threshold_blue_img, cv2.COLOR_GRAY2RGB)
plt.imshow (threshold_blue_img)
Результат:
Исходное изображение
Порог синего оттенка
Упражнение: Как бы мы извлекли красные или желтые части этой картины? Какие диапазоны мы используем для красного или желтого, если весь оттенок цвета представлен по шкале от 0 до 255?
Маскировка с двоичным порогом
Теперь, когда мы можем идентифицировать цвета, мы можем делать интересные вещи, например использовать бинарное изображение в качестве маски . Маска — это матрица нулевых и ненулевых значений, используемая для побитовой операции. Маски можно использовать для вырезания или «маскирования» определенных частей изображения. Маска обычно представляет собой матрицу нулей (для частей, которые нужно исключить) и ненулевых (для частей, которые мы хотим сохранить).
Маска — это матрица нулевых и ненулевых значений, используемая для побитовой операции. Маски можно использовать для вырезания или «маскирования» определенных частей изображения. Маска обычно представляет собой матрицу нулей (для частей, которые нужно исключить) и ненулевых (для частей, которые мы хотим сохранить).
Допустим, мне нужна версия изображения открытого пейзажа без неба. Сначала мы можем найти пиксели, которые находятся в диапазоне синего оттенка, что позволит идентифицировать части изображения с голубым небом. Чтобы получить части изображения, которые не являются небом, мы можем инвертировать значения с помощью bitwise_not , что оставляет нам части, которые не синие, давая нам нашу маску. Выполнение bitwise_and на этой маске с изображением оставит только те части, которые не синие.
upstate = cv2.imread('images/upstate-ny.jpg')
upstate_hsv = cv2.cvtColor (upstate, cv2.COLOR_BGR2HSV)
plt.imshow (cv2. cvtColor (upstate_hsv, cv2.COLOR_HSV2RGB))
# получаем маску пикселей, находящихся в синем диапазоне
mask_inverse = cv2.inRange (upstate_hsv, blue_min, blue_max)
# обратная маска, чтобы получить части, которые не синие
маска = cv2.bitwise_not (mask_inverse)
plt.imshow (cv2.cvtColor (маска, cv2.COLOR_GRAY2RGB))
# преобразовать маску одного канала обратно в 3 канала
mask_rgb = cv2.cvtColor (маска, cv2.COLOR_GRAY2RGB)
# выполнить побитовое и по маске, чтобы получить вырезанное изображение, которое не является синим
masked_upstate = cv2.bitwise_and (upstate, mask_rgb)
# заменить вырезанные части на белые
masked_replace_white = cv2.addWeighted (masked_upstate, 1, \
cv2.cvtColor(mask_inverse, cv2.COLOR_GRAY2RGB), 1, 0)
plt.imshow (cv2.cvtColor (masked_replace_white, cv2.COLOR_BGR2RGB))
cvtColor (upstate_hsv, cv2.COLOR_HSV2RGB))
# получаем маску пикселей, находящихся в синем диапазоне
mask_inverse = cv2.inRange (upstate_hsv, blue_min, blue_max)
# обратная маска, чтобы получить части, которые не синие
маска = cv2.bitwise_not (mask_inverse)
plt.imshow (cv2.cvtColor (маска, cv2.COLOR_GRAY2RGB))
# преобразовать маску одного канала обратно в 3 канала
mask_rgb = cv2.cvtColor (маска, cv2.COLOR_GRAY2RGB)
# выполнить побитовое и по маске, чтобы получить вырезанное изображение, которое не является синим
masked_upstate = cv2.bitwise_and (upstate, mask_rgb)
# заменить вырезанные части на белые
masked_replace_white = cv2.addWeighted (masked_upstate, 1, \
cv2.cvtColor(mask_inverse, cv2.COLOR_GRAY2RGB), 1, 0)
plt.imshow (cv2.cvtColor (masked_replace_white, cv2.COLOR_BGR2RGB))
Результаты:
Исходное изображение
Порог (маска)
Маскированное изображение
Дальнейшее чтение
- Для получения дополнительной информации о различных типах более надежных пороговых значений и о том, как они работают, ознакомьтесь с документацией OpenCV3.
Размытие
Фотографии могут быть довольно шумными, что означает, что могут быть небольшие неровности, которые могут мешать сегментации изображения. Обычный способ избавиться от зашумленных битов — предварительно обработать изображение с помощью Размытие по Гауссу . Вы можете думать о размытии как о способе сглаживания высокой интенсивности или резких изменений между пикселями.
Размытие по Гауссу работает путем применения преобразований к каждому пикселю изображения. Это делается путем свертки изображения с ядром размера n x n . Вы можете думать о свертке как о применении операции к пикселю в зависимости от значений n x n пикселей вокруг него. Операция определяется ядром. Таким образом, при размытии по Гауссу с ядром 5 x 5 для каждого пикселя учитываются окружающие пиксели 5 x 5, и выполняется вычисление усреднения, которое дает нам новый размытый цвет пикселей. Чем больше размер ядра Гаусса, тем более размытым будет изображение.
img = cv2.imread('images/oy.jpg')
# размытие по Гауссу с ядром 5x5
img_blur_small = cv2.Размытие по Гауссу (img, (5,5), 0)
Исходное изображение (600 на 450 пикселей)
Размытие с ядром 5×5
Размытие с ядром 15×15
Размытие по Гауссуособенно полезно, когда у вас есть зашумленное изображение и вы хотите сгладить все эти неровности перед выполнением пороговой обработки.
Результаты:
Пороговое исходное изображение
Пороговое изображение 5×5 с размытым ядром
Выше приведен пример выполнения порога для неразмытого изображения по сравнению с изображением, размытым ядром 5×5. Размытие дает нам более четкие линии на наших пороговых участках, что упрощает работу с ними.
Дальнейшее чтение
- Размытие по Гауссу объяснено в Википедии
- Сглаживание изображений объясняется на OpenCV
Контуры и ограничивающие прямоугольники
Теперь, когда у нас есть упрощенные двоичные версии этих изображений, мы можем использовать их для определения интересующих объектов. В качестве примера давайте посмотрим, как мы можем идентифицировать отдельные монеты на изображении.
В этом разделе мы увидим, как мы можем использовать контуры и ограничивающие прямоугольники для сегментации объектов.
Исходное изображение
Образ предварительной обработки
Сначала мы преобразуем изображение в оттенки серого и применим к нему размытие по Гауссу, чтобы упростить его и удалить шум. Это распространенная форма предварительной обработки и часто первый шаг в работе с изображением.
Затем мы выполним двоичный порог на предварительно обработанном изображении. Поскольку монеты находятся на светлом фоне, порог будет воспринимать более светлый фон как интересующий объект. Мы инвертируем бинарное изображение, чтобы подобрать монеты.
# получить бинарное изображение и применить размытие по Гауссу
монеты = cv2.imread('images/coins. jpg')
монеты_серый = cv2.cvtColor (монеты, cv2.COLOR_BGR2GRAY)
Coins_preprocessed = cv2.GaussianBlur(coins_gray, (5, 5), 0)
# получить бинарное изображение
_,coins_binary = cv2.threshold(coins_preprocessed, 130, 255, cv2.THRESH_BINARY)
# инвертировать изображение, чтобы получить монеты
монеты_бинарные = cv2.bitwise_not (монеты_бинарные)
Результаты:
Предварительно обработанное бинарное изображение
Найти контуры
Контуры — это кривые, соединяющие все непрерывные точки, имеющие одинаковый цвет или интенсивность вдоль границы. Они полезны для обнаружения объектов или особенностей, а также для анализа формы 4 . Используя cv2.findContours() , мы найдем контур каждой монеты. Передача флага cv2.RETR_EXTERNAL в функцию возвращает только внешние контуры, поэтому она не будет подбирать контуры для более мелких деталей на поверхности монеты.
Из этих контуров мы найдем площадь каждого и отфильтруем те, которые слишком малы, чтобы быть монетами. Изображения из реальной жизни редко бывают идеальными, и такие проверки часто необходимы для фильтрации шума и выбросов. Чтобы получить площадь контура, мы используем cv2.contourArea() .
# найти контуры
coins_contours, _ = cv2.findContours (coins_binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# сделать копию изображения
монеты_и_контуры = np.copy(монеты)
# найти контуры достаточно большой площади
min_coin_area = 60
large_contours = [cnt для cnt в монетах_контуров, если cv2.contourArea(cnt) > min_coin_area]
# рисуем контуры
cv2.drawContours (coins_and_contours, large_contours, -1, (255,0,0))
# вывести количество контуров
print('количество монет: %d' % len(large_contours))
количество монет: 8
Результаты:
Контуры монет из бинарного изображения
Найти ограничивающие прямоугольники
Ограничивающий прямоугольник — это наименьший прямоугольник, который может содержать контур. Мы можем использовать их для сегментации отдельных монет на нашем изображении. Обратите внимание, что метод cv2.boundingRect() возвращает ограничивающий прямоугольник как координаты x и y верхнего левого угла прямоугольника, а также его ширину и высоту. Мы также можем использовать ограничивающие прямоугольники, чтобы обрезать восемь отдельных монет.
# создать копию изображения для рисования ограничивающих рамок
bounding_img = np.copy (монеты)
# для каждого контура найти ограничивающую рамку и нарисовать прямоугольник
для контура в large_contours:
х, у, ш, ч = cv2.boundingRect (контур)
cv2.rectangle (bounding_img, (x, y), (x + w, y + h), (0, 255, 0), 3)
Результаты:
Ограничивающие рамки контуров
Дальнейшее чтение
- Понимание контуров и иерархии контуров
- Другие типы элементов контура, включая область контура и ограничивающие прямоугольники
Обнаружение края
Иногда сегментации по цвету или интенсивности, как мы делали с бинарным пороговым значением, недостаточно. Что, если бы нам нужно было выделить разноцветный объект? Представьте чашу в сине-желтую полоску при неравномерном освещении — ее цвет неоднороден по всей поверхности.
Входит обнаружение краев , способ нахождения краев в изображении. Края определяются как точки на изображении, в которых происходит изменение яркости или интенсивности, что обычно означает границу между различными объектами. Обнаружение краев является фундаментальной частью обработки изображений и часто является отправной точкой для обнаружения элементов и работы с ними 5 .
Обнаружение краев связано с некоторой математикой, но мы не будем вдаваться в это здесь. Основная идея обнаружения границ заключается в том, что мы можем измерять изменения яркости областей изображения, которые мы называем градиентом . Мы можем измерить как величину (насколько резкое изменение), так и направление градиента. Если величина изменения в наборе точек превышает заданный порог, то это можно считать краем.
Алгоритм обнаружения краев Canny — это популярный алгоритм обнаружения краев, который создает точные и четкие края. Ниже приведен пример его реализации OpenCV в действии по сравнению с двоичным порогом того же изображения. Обратите внимание, что неравномерное освещение на изображении не позволяет выделить и миску, и чашки с помощью простого определения порога.
Исходное изображение
Двоичный порог
В качестве стандартной практики мы предварительно обработаем изображение с помощью оттенков серого и размытия перед выполнением пороговой обработки. Обратите внимание, что самая верхняя чашка не может быть захвачена простым пороговым значением. Даже если мы настроим пороговое значение намного выше, чтобы захватить чашку, чаша будет исключена.
чашек = cv2.imread('images/cups.jpg')
# предварительная обработка с помощью размытия и оттенков серого
cups_preprocessed = cv2.cvtColor(cv2. Размытие по Гауссу(чашки, (7,7), 0), cv2.COLOR_BGR2GRAY)
# найти бинарное изображение с пороговым значением
_, cups_thresh = cv2.threshold(cups_preprocessed, 80, 255, cv2.THRESH_BINARY)
plt.imshow (cv2.cvtColor (cups_thresh, cv2.COLOR_GRAY2RGB))
Результат:
Бинарное изображение с пороговым значением 80. Чашка не захвачена.
Двоичное изображение с пороговым значением 200. Захвачена чашка, но не миска.
Осторожные края
Вместо пороговой обработки давайте выполним обнаружение края изображения Канни. Обратите внимание, что функция cv2.Canny() принимает два пороговых значения — алгоритм делает то, что называется двойным пороговым значением. Если величина градиента выше threshold2 , принимается за сильное ребро. Если оно ниже threshold2 , но выше threshold1 , оно также будет считаться ребром, хотя и слабым, если оно соединено с другим сильным ребром.
# найти бинарное изображение с краями
cups_edges = cv2.Canny (cups_preprocessed, порог 1 = 90, порог 2 = 110)
plt.imshow (cv2.cvtColor (cups_edges, cv2.COLOR_GRAY2RGB))
cv2.imwrite('cups-edges.jpg', cups_edges)
Результаты:
Обнаружены хитрые грани
Обнаружение краев Canny намного лучше справляется с выделением особенностей изображения, которые в противном случае не обнаруживаются простым двоичным порогом.
Краядовольно круты и создают интересные эффекты, но что с ними делать?
Распознавание линий и форм
Если интересующие нас объекты имеют правильную форму, такую как линии и круги, мы можем использовать преобразования Хафа для их обнаружения.
Обнаружение линии
Преобразование линии Хафа работает, составляя список вероятных линий, на которых могут быть точки, где каждая линия определяется в терминах полярных координат r и тета как r = x * cos (тета) + y * sin (тета) . Если на вероятной прямой имеется достаточно других точек, то она считается линией.
Вот пример преобразования линии Хафа в действии.
# копия изображения для рисования линий
cups_lines = np.copy (чашки)
# найти линии
num_pix_threshold = 110 # минимальное количество пикселей, которое должно быть в строке
линии = cv2.HoughLines (cups_edges, 1, np.pi/180, num_pix_threshold)
для ро, тета в строках [0]:
# преобразовать уравнение линии в начальную и конечную точки линии
а = np.cos (тета)
б = np.sin (тета)
х0 = а * ро
у0 = б * ро
х1 = целое (х0 + 1000 * (-b))
у1 = интервал (у0 + 1000 * (а))
x2 = целое число (x0 - 1000 * (-b))
у2 = интервал (у0 - 1000 * (а))
cv2.line (cups_lines, (x1, y1), (x2, y2), (0,0,255), 1)
92 . Поскольку у них очень большие пространства поиска, в идеале мы должны установить границы для пространства поиска (например, установить минимальные или максимальные значения радиуса).
Вот пример преобразования Круга-Хафа в действии:
# найти круги
круги = cv2. HoughCircles(cups_edges, cv2.cv.CV_HOUGH_GRADIENT, dp=1.5, minDist=50, minRadius=20, maxRadius=130)
cups_circles = np.copy (чашки)
# если круги обнаружены, рисуем их
если круги не равны None и len(circles) > 0:
# примечание: cv2.HoughCircles возвращает круги, вложенные в массив.
# документация OpenCV не объясняет этот формат возвращаемого значения
круги = круги[0]
для (x, y, r) в кружках:
х, у, г = интервал (х), интервал (у), интервал (г)
cv2.circle (cups_circles, (x, y), r, (255, 255, 0), 4)
plt.imshow (cv2.cvtColor (cups_circles, cv2.COLOR_BGR2RGB))
print('количество обнаруженных кругов: %d' % len(круги[0]))
количество обнаруженных кругов: 3
Результаты:
Края
Окружности, обнаруженные по краям
Обратите внимание, что для чаши обнаружен только один круг, так как мы указали, что минимальное расстояние minDist между кругами должно быть не менее 50 пикселей.
Дополнительное чтение
- Преобразования Хафа объяснены и продемонстрированы в документации OpenCV
Что дальше?
Круто! Теперь, когда вы знаете некоторые основы, вы, надеюсь, должны быть в хорошей форме, чтобы начать думать о своих собственных проектах обработки изображений. И даже если у вас нет проекта, просто поэкспериментируйте с различными функциями OpenCV с разными параметрами — это отличный способ познакомиться с ним поближе.
Если вы хотите глубже понять, как работают эти функции (например, как на самом деле происходит обнаружение границ?), их реализация на выбранном вами языке может оказаться полезным опытом обучения. Например, я не полностью понимал обнаружение границ, пока не начал работать над реализацией JavaScript. Пусть вас не пугает математика! Чтение псевдокода часто дает вам довольно хорошее понимание логики алгоритмов.
Дальнейшее чтение
- Учебные ресурсы по обработке изображений HIPR2 9В 0015 есть объяснения того, как работают различные алгоритмы, а также хорошие учебники по ним.
- Страницы Википедии , посвященные концепциям обработки изображений, часто содержат понятный псевдокод, подробное описание того, как они работают на практике, а также стоящие за ними математические расчеты. В этой статье я дал ссылки на некоторые из них, которые показались мне полезными, и их гораздо больше.
- Практика OpenCV от Samarth Brahmbhatt содержит отличные примеры различных подходов к обработке изображений в OpenCV.
- Автоматизация карточных игр с использованием OpenCV и Python В есть отличное изложение того, как вы можете использовать OpenCV для выполнения чего-то вроде обнаружения карт.
Кредиты
Спасибо Джону Воркману, фасилитатору Recurse Center, который увлек меня обработкой изображений, а также Джесси Гонсалесу и Мириам Шиффман, которые вместе работали над Set Solver, из которого я узнал много методов обработки изображений.
Фотографии, используемые в этой статье, являются моими собственными, если не указано иное.
На момент написания этой статьи поддержка OpenCV на Python3 все еще находилась в стадии бета-тестирования ↩
.Статья в Википедии о цветовой модели HSL и HSV, объясняющая разницу между HSV и HSL. ↩
Определение взято из статьи Википедии для сегментации изображения ↩
.Определение взято из документации OpenCV по контурам ↩
Статья в Википедии об обнаружении границ ↩
Обработка изображений в Python: алгоритмы, инструменты и методы, которые вы должны знать
Изображения определяют мир, каждое изображение имеет свою историю, оно содержит много важной информации, которая может быть полезна во многих отношениях. Эта информация может быть получена с помощью метода, известного как Обработка изображений .
Это основная часть компьютерного зрения, играющая решающую роль во многих реальных примерах, таких как робототехника, беспилотные автомобили и обнаружение объектов. Обработка изображений позволяет нам одновременно преобразовывать и обрабатывать тысячи изображений и извлекать из них полезную информацию. Он имеет широкий спектр применения практически во всех областях.
Python — один из широко используемых языков программирования для этой цели. Его удивительные библиотеки и инструменты помогают очень эффективно решать задачу обработки изображений.
В этой статье вы узнаете о классических алгоритмах, методах и инструментах для обработки изображения и получения желаемого результата.
Давайте приступим!
Что такое обработка изображений?
Как следует из названия, обработка изображения означает обработку изображения, и это может включать множество различных методов, пока мы не достигнем нашей цели.
Конечный результат может быть либо в виде изображения, либо в виде соответствующей функции этого изображения. Это можно использовать для дальнейшего анализа и принятия решений.
Но что такое образ?
Изображение может быть представлено в виде 2D-функции F(x,y), где x и y — пространственные координаты. Амплитуда F при определенном значении x, y известна как интенсивность изображения в этой точке. Если x, y и значение амплитуды конечно, то мы называем это цифровым изображением. Это массив пикселей, расположенных в столбцах и строках. Пиксели — это элементы изображения, которые содержат информацию об интенсивности и цвете. Изображение также может быть представлено в 3D, где x, y и z становятся пространственными координатами. Пиксели расположены в виде матрицы. Это известно как Изображение RGB .
Существуют различные типы изображений:
- Изображение RGB: Содержит три слоя 2D-изображения, эти слои представляют собой каналы красного, зеленого и синего цветов.
- Изображение в градациях серого. Эти изображения содержат оттенки черного и белого и содержат только один канал.
Классические алгоритмы обработки изображений
1. Морфологическая обработка изображений
Морфологическая обработка изображений пытается удалить дефекты из бинарных изображений, поскольку бинарные области, созданные простой пороговой обработкой, могут быть искажены шумом. Это также помогает сглаживать изображение с помощью операций открытия и закрытия.
Морфологические операции можно распространить на изображения в градациях серого. Он состоит из нелинейных операций, связанных со структурой признаков изображения. Это зависит не только от связанного порядка пикселей, но и от их числовых значений. Этот метод анализирует изображение с использованием небольшого шаблона, известного как структурирующий элемент , который размещается в различных возможных местах изображения и сравнивается с соответствующими соседними пикселями. Элемент структурирования представляет собой небольшую матрицу со значениями 0 и 1.
Рассмотрим две основные операции морфологической обработки изображения, Расширение и стирание:
- расширение операция добавление пикселей к границам объекта на изображении от границ объекта.
Количество удаленных или добавленных пикселей к исходному изображению зависит от размера элемента структурирования.
В этот момент вы можете подумать: «Что такое структурирующий элемент?» Поясню:
Структурирующий элемент — это матрица, состоящая только из нулей и единиц, которая может иметь произвольную форму и размер. Он размещается во всех возможных местах изображения и сравнивается с соответствующей окрестностью пикселей.
ИсточникКвадратный структурирующий элемент «A» вписывается в объект, который мы хотим выделить, «B» пересекает объект, а «C» находится вне объекта.
Шаблон ноль-единица определяет конфигурацию элемента структурирования. Это соответствует форме объекта, который мы хотим выделить. Центр структурирующего элемента идентифицирует обрабатываемый пиксель.
Источник Расширение | Источник Эрозия | Источник 2. Обработка изображения по Гауссу Размытие по Гауссу, также известное как сглаживание по Гауссу, является результатом размытия изображения с помощью функции Гаусса .
Это используется для уменьшения шума изображения и уменьшения деталей . Визуальный эффект от этой техники размытия подобен просмотру изображения через полупрозрачный экран. Иногда он используется в компьютерном зрении для улучшения изображения в разных масштабах или в качестве метода увеличения данных в глубоком обучении.
Основная гауссовская функция выглядит так:
На практике лучше всего воспользоваться свойством отделимости гауссовского размытия, разделив процесс на два прохода. В первом проходе одномерное ядро используется для размытия изображения только в горизонтальном или вертикальном направлении. Во втором проходе то же одномерное ядро используется для размытия в оставшемся направлении. Полученный эффект такой же, как при свертывании двумерного ядра за один проход. Давайте посмотрим на пример, чтобы понять, что фильтры Гаусса делают с изображением.
Если у нас есть нормально распределенный фильтр, то при его применении к изображению результаты выглядят следующим образом: иметь немного меньше деталей. Фильтр придает больший вес пикселям в центре, чем пикселям вдали от центра. Фильтры Гаусса являются фильтрами нижних частот, т.е. ослабляют высокие частоты. Он обычно используется для обнаружения краев.
3. Преобразование Фурье при обработке изображений
Преобразование Фурье разбивает изображение на синусоидальную и косинусоидальную составляющие.
Он имеет несколько приложений, таких как реконструкция изображения, сжатие изображения или фильтрация изображения.
Поскольку мы говорим об изображениях, мы будем учитывать дискретное преобразование Фурье.
Давайте рассмотрим синусоиду, она состоит из трех вещей:
- Величина — связана с контрастом
- Пространственная частота — связана с яркостью
- Фаза – связана с информацией о цвете
Изображение в частотной области выглядит следующим образом:
ИсточникФормула для двумерного дискретного преобразования Фурье:
В приведенной выше формуле f(x,y) обозначает изображение.
Обратное преобразование Фурье преобразует преобразование обратно в изображение. Формула для двумерного обратного дискретного преобразования Фурье:
4. Обнаружение краев при обработке изображений
Обнаружение краев — это метод обработки изображений для нахождения границ объектов на изображениях. Он работает, обнаруживая разрывы в яркости.
Это может быть очень полезно при извлечении полезной информации из изображения, поскольку большая часть информации о форме заключена в краях. Классические методы обнаружения краев работают путем обнаружения неоднородностей яркости.
Он может быстро реагировать, если на изображении обнаружен шум при обнаружении изменений уровня серого. Края определяются как локальные максимумы градиента.
Наиболее распространенным алгоритмом обнаружения границ является алгоритм обнаружения границ Собеля . Оператор обнаружения Собеля состоит из 3*3 сверточных ядер. Простое ядро Gx и ядро Gy, повернутое на 90 градусов. Отдельные измерения производятся путем применения обоих ядер отдельно к изображению.
И,
* обозначает операцию свертки при обработке 2D-сигнала.
Результирующий градиент можно рассчитать как:
Источник5. Вейвлет-обработка изображения
Мы видели преобразование Фурье, но оно ограничено только частотой. Вейвлеты принимают во внимание как время, так и частоту. Это преобразование подходит для нестационарных сигналов.
Мы знаем, что края являются одной из важных частей изображения, при применении традиционных фильтров было замечено, что шум удаляется, но изображение становится размытым. Вейвлет-преобразование разработано таким образом, что мы получаем хорошее частотное разрешение для низкочастотных составляющих. Ниже приведен пример двухмерного вейвлет-преобразования:
ИсточникОбработка изображений с использованием нейронных сетей
Нейронные сети представляют собой многослойные сети, состоящие из нейронов или узлов. Эти нейроны являются основными процессорами нейронной сети. Они созданы для того, чтобы действовать подобно человеческому мозгу. Они получают данные, тренируются распознавать закономерности в данных, а затем предсказывают результат.
Базовая нейронная сеть состоит из трех слоев:
- Входной слой
- Скрытый слой
- Выходной слой
Входные слои получают входные данные, выходной слой прогнозирует выходные данные, а скрытые слои выполняют большую часть вычислений. Количество скрытых слоев может быть изменено в соответствии с требованиями. В нейронной сети должен быть хотя бы один скрытый слой.
Основная работа нейронной сети выглядит следующим образом:
- Рассмотрим изображение, каждый пиксель подается на вход каждому нейрону первого слоя, нейроны одного слоя связаны с нейронами следующего слоя через каналы.
- Каждому из этих каналов присваивается числовое значение, известное как вес.
- Входные данные умножаются на соответствующие веса, и эта взвешенная сумма затем подается в качестве входных данных для скрытых слоев.
- Выходные данные скрытых слоев пропускаются через функцию активации, которая определяет, будет ли активирован конкретный нейрон или нет.
- Активированные нейроны передают данные на следующие скрытые слои. Таким образом данные распространяются по сети, это известно как прямое распространение.
- В выходном слое нейрон с наибольшим значением предсказывает выходные данные. Эти выходные данные являются значениями вероятности.
- Прогнозируемый вывод сравнивается с фактическим выводом для получения ошибки. Затем эта информация передается обратно по сети, этот процесс известен как обратное распространение.
- На основании этой информации корректируются веса. Этот цикл прямого и обратного распространения выполняется несколько раз для нескольких входных данных, пока сеть в большинстве случаев не будет правильно предсказывать выходные данные.
- На этом процесс обучения нейронной сети заканчивается. В некоторых случаях время, затрачиваемое на обучение нейронной сети, может быть большим.
На изображении ниже ai — это набор входных данных, wi’s — это веса, z — это выходные данные и g — любая функция активации.
Операции в одиночном нейроне | ИсточникВот несколько рекомендаций по подготовке данных для обработки изображений.
- Для получения лучших результатов в модель необходимо передать больше данных.
- Набор данных изображений должен быть высокого качества, чтобы получить более четкую информацию, но для их обработки могут потребоваться более глубокие нейронные сети.
- Во многих случаях изображения RGB преобразуются в оттенки серого перед их передачей в нейронную сеть.
Типы нейронной сети
Сверточная нейронная сеть
Сверточная нейронная сеть, сокращенно ConvNets, имеет три слоя:
- Сверточный слой ( CONV ): Они являются строительным блоком CNN. отвечает за выполнение операции свертки. Элемент, участвующий в выполнении операции свертки на этом уровне, называется ядром/фильтром (матрица). Ядро выполняет горизонтальные и вертикальные сдвиги на основе скорость шага , пока не будет пройдено все изображение.
- Уровень объединения ( POOL ): этот уровень отвечает за уменьшение размерности. Это помогает уменьшить вычислительную мощность, необходимую для обработки данных. Существует два типа объединения: максимальное объединение и среднее объединение. Максимальный пул возвращает максимальное значение из области, покрытой ядром на изображении. Объединение средних значений возвращает среднее значение всех значений в части изображения, покрываемой ядром.
- Полносвязный слой ( FC ): Полносвязный слой ( FC ) работает со сглаженным входом, где каждый вход подключен ко всем нейронам. Если они присутствуют, уровней FC обычно находятся ближе к концу архитектур CNN .
CNN в основном используется для извлечения признаков из изображения с помощью его слоев. CNN широко используются в классификации изображений, где каждое входное изображение проходит через серию слоев, чтобы получить вероятностное значение от 0 до 1.
ИсточникГенеративные состязательные сети
Генеративные модели используют подход к обучению без учителя (есть изображения, но нет меток).
GAN состоят из двух моделей Генератор и Дискриминатор. Генератор учится создавать поддельные изображения, которые выглядят реалистично, чтобы обмануть дискриминатор, а Дискриминатор учится отличать поддельные изображения от реальных (старается не дать себя обмануть).
Генератору не разрешено видеть реальные изображения, поэтому он может давать плохие результаты на начальном этапе, в то время как дискриминатору разрешено смотреть на реальные изображения, но они перемешаны с фальшивыми изображениями, созданными генератором, которые он должен классифицировать как оригинал или подделка.
На вход генератора подается некоторый шум, чтобы он мог каждый раз создавать разные примеры, а не изображения одного и того же типа. На основе оценок, предсказанных дискриминатором, генератор пытается улучшить свои результаты, через определенный момент времени генератор сможет создавать изображения, которые будет труднее различить, в этот момент времени пользователь будет удовлетворен его результаты. Дискриминатор также совершенствуется, получая от генератора все более и более реалистичные изображения на каждом раунде.
Популярными типами GAN являются Deep Convolutional GAN (DCGAN), Conditional GAN (cGAN), StyleGAN, CycleGAN, DiscoGAN, GauGAN и так далее.
Сети GAN отлично подходят для создания и обработки изображений. Некоторые приложения GAN включают в себя: старение лица, смешивание фотографий, суперразрешение, рисование фотографий, перевод одежды.
ИсточникСредства обработки изображений
1. OpenCV
Расшифровывается как библиотека компьютерного зрения с открытым исходным кодом. Эта библиотека состоит из более чем 2000 оптимизированных алгоритмов, полезных для компьютерного зрения и машинного обучения. Существует несколько способов использования opencv в обработке изображений, некоторые из них перечислены ниже:
- Преобразование изображений из одного цветового пространства в другое, т. е. между BGR и HSV, BGR и серым и т. д.
- Выполнение пороговой обработки изображений, например, простой пороговой обработки, адаптивной пороговой обработки и т. д.
- Сглаживание изображений, например, применение пользовательских фильтров к изображениям и размытие изображений.
- Выполнение морфологических операций над изображениями.
- Строительство пирамид изображений.
- Извлечение переднего плана из изображений с использованием алгоритма GrabCut.
- Сегментация изображения с использованием алгоритма водораздела.
Перейдите по этой ссылке для получения более подробной информации .
2.
Scikit-imageЭто библиотека с открытым исходным кодом, используемая для предварительной обработки изображений. Он использует машинное обучение со встроенными функциями и может выполнять сложные операции с изображениями с помощью всего нескольких функций.
Он работает с массивами numpy и является довольно простой библиотекой даже для тех, кто плохо знаком с Python. Некоторые операции, которые можно выполнить с помощью scikit image:
- Для реализации пороговых операций используйте Метод try_all_threshold() для изображения. Он будет использовать семь глобальных алгоритмов пороговой обработки. Это в модуле фильтров .
- Для реализации обнаружения границ используйте метод sobel() в модуле фильтров . Этот метод требует двумерного изображения в градациях серого в качестве входных данных, поэтому нам нужно преобразовать изображение в градации серого.
- Для реализации сглаживания по Гауссу используйте метод gaussian() в модуле фильтров .
- Чтобы применить выравнивание гистограммы, используйте экспозиция , чтобы применить нормальное выравнивание гистограммы к исходному изображению, используйте метод equalize_hist() , а для применения адаптивного выравнивания используйте метод equalize_adapthist() .
- Чтобы повернуть изображение, используйте функцию rotate() в модуле transform .
- Для масштабирования изображения используйте функцию rescale() из модуля transform .
- Для применения морфологических операций используйте binary_erosion() и функция binary_dilation() в модуле morphology .
3. PIL/pillow
PIL расшифровывается как библиотека изображений Python, а Pillow — дружественный форк PIL от Alex Clark and Contributors. Это одна из мощных библиотек. Он поддерживает широкий спектр форматов изображений, таких как PPM, JPEG, TIFF, GIF, PNG и BMP.
С его помощью можно выполнять несколько операций с изображениями, таких как поворот, изменение размера, кадрирование, градация серого и т. д. Рассмотрим некоторые из этих операций
Для выполнения манипуляций в этой библиотеке есть модуль под названием Image.
- Чтобы загрузить изображение, используйте метод open() .
- Для отображения изображения используйте метод show() .
- Чтобы узнать формат файла, используйте атрибут формата
- Чтобы узнать размер изображения, используйте атрибут размера
- Чтобы узнать формат пикселя, используйте атрибут режима .
- Чтобы сохранить файл изображения после требуемой обработки, используйте метод save() . Подушка сохраняет файл изображения в формате png .
- Чтобы изменить размер изображения, используйте метод resize() , который принимает два аргумента: ширину и высоту.
- Чтобы обрезать изображение, используйте метод crop() , который принимает один аргумент в виде кортежа поля, определяющего положение и размер обрезанной области.
- Чтобы повернуть изображение, используйте метод rotate() , который принимает один аргумент в виде целого числа или числа с плавающей запятой, представляющего градус поворота.
- Чтобы перевернуть изображение, используйте метод transform() , который принимает один аргумент из следующих: Image.FLIP_LEFT_RIGHT, Image.FLIP_TOP_BOTTOM, Image.ROTATE_90, Image.ROTATE_180, Image.ROTATE_270.
Читайте также
Учебное пособие по изображению Essential Pil (Pillow) (для людей, изучающих машинное обучение)
4. NumPy
С помощью этой библиотеки вы также можете выполнять простые методы работы с изображениями, такие как переворачивание изображений, извлечение признаков и их анализ.
Изображения могут быть представлены многомерными массивами numpy, поэтому их тип равен NdArrays . Цветное изображение представляет собой массив numpy с 3 измерениями. Нарезая многомерный массив, можно разделить каналы RGB.
Ниже приведены некоторые операции, которые можно выполнить с помощью NumPy над изображением (изображение загружается в переменную с именем test_img с помощью imread).
- Чтобы перевернуть изображение по вертикали, используйте np.flipud(test_img).
- Чтобы перевернуть изображение по горизонтали, используйте np.fliplr(test_img).
- Чтобы перевернуть изображение, используйте test_img[::-1] (изображение после его сохранения в виде массива numpy называется
). - Чтобы добавить фильтр к изображению, вы можете сделать это:
Пример: np.where(test_img > 150, 255, 0) , это говорит о том, что на этом изображении, если вы найдете что-нибудь с 150, то замените его на 255, иначе 0.
- Вы также можете отображать каналы RGB отдельно. Это можно сделать с помощью этого фрагмента кода:
Для получения красного канала выполните test_img[:,:,0] , для получения зеленого канала выполните test_img[:,:,1] и для получения синего канала выполните test_img[:, :,2].
5. Mahotas
Это библиотека компьютерного зрения и обработки изображений, имеющая более 100 функций. Многие его алгоритмы реализованы на C++. Mahotas сам по себе является независимым модулем, т.е. имеет минимальные зависимости.
В настоящее время он зависит только от компиляторов C++ для численных вычислений, нет необходимости в модуле NumPy, компилятор делает всю свою работу.
Вот названия некоторых замечательных алгоритмов, доступных в Mahotas:
- Watershed (https://mahotas.readthedocs.io/en/latest/distance.html)
- Морфологические операции (https://mahotas.readthedocs .io/en/latest/morphology.html)
- Случайно, истончение. (https://mahotas. readthedocs.io/en/latest/api.html#mahotas.hitmiss)
- Преобразование цветового пространства (https://mahotas.readthedocs.io/en/latest/color.html)
- Speeded- Up Robust Features (SURF), форма локальных признаков.
(https://mahotas.readthedocs.io/en/latest/surf.html) - Пороговое значение. (https://mahotas.readthedocs.io/en/latest/thresholding.html)
- Свертка. (https://mahotas.readthedocs.io/en/latest/api.html)
- Сплайн-интерполяция (https://mahotas.readthedocs.io/en/latest/api.html)
- Суперпиксели SLIC. (https://www.pyimagesearch.com/2014/07/28/a-slic-superpixel-tutorial-using-python/)
Давайте рассмотрим некоторые операции, которые можно выполнить с помощью Mahotas:
- Чтобы прочитать изображение, используйте метод imread() .
- Чтобы вычислить среднее значение изображения, используйте метод mean() .
- Эксцентриситет изображения измеряет кратчайшую длину пути от данной вершины v до любой другой вершины w связного графа. Чтобы найти эксцентриситет изображения, используйте метод eccentricity() в модуле features .
- Для расширения и эрозии изображения используйте dilate() 9Метод 0015 и erode() в модуле morph .
- Чтобы найти локальные максимумы изображения, используйте метод locmax() .
Резюме
В этой статье я кратко рассказал о классической обработке изображений, которую можно выполнить с помощью морфологической фильтрации, фильтра Гаусса, преобразования Фурье и вейвлет-преобразования .
Все это можно выполнить с помощью различных библиотек обработки изображений, таких как OpenCV, Mahotas, PIL, scikit-learn.
Я также обсудил популярные нейронные сети, такие как CNN и GAN , которые используются для компьютерного зрения.
Глубокое обучение меняет мир благодаря своей бродвейской терминологии и достижениям в области обработки изображений. Исследователи разрабатывают лучшие методы для точной настройки всей области обработки изображений, поэтому обучение на этом не заканчивается. Продолжайте продвигаться.
ЧИТАТЬ ДАЛЕЕ
Отслеживание экспериментов в машинном обучении: что это такое, почему это важно и как это реализовать
10 минут чтения | Автор Якуб Чакон | Обновлено 14 июля 2021 г.
Позвольте мне поделиться историей, которую я слышал слишком много раз.
”… Мы разрабатывали модель машинного обучения вместе с моей командой, мы провели много экспериментов и получили многообещающие результаты…
…к сожалению, мы не могли точно сказать, что работает лучше всего, потому что мы забыли сохранить некоторые модели параметры и версии наборов данных…
… через несколько недель мы даже не были уверены, что мы на самом деле пробовали, и нам нужно было перезапустить почти все»
— горе-исследователь машинного обучения.