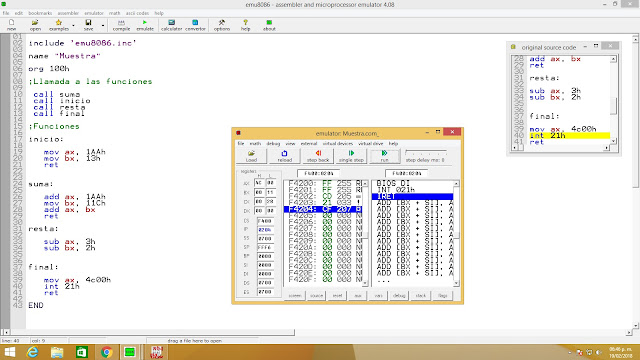
Трясём стариной — или как вспомнить Ассемблер, если ты его учил 20 лет назад / Хабр
Это — тёплая, ламповая статья об Ассемблере и разработке ПО. Здесь мы не будем пытаться писать убийцу Майкрософта или Андроида. Мы будем писать убийцу 2048. Здесь не будет докера и терраформа с кубером. Зато здесь вы сможете найти большое количество материалов по Ассемблеру, которые помогут вам вновь погрузиться в мир трёхбуквенных инструкций. Доставайте пивко, и поехали. (Саундтреком к этой статье можно считать IBM 1401 a system manual)
Недавно, было дело, сидел и ждал результатов какой-то конференции на одном из предприятий. Сидеть было скучно, и я вытащил мобильник, чтобы погрузиться в мир убивания времени. Но, к моему огорчению, мы были в месте с нереально слабым сигналом, и я понял, что нахожусь в том странном и непонятном мире, когда интернета нету. Ничего путного на мобиле у меня установлено не было, посему я переключил своё внимание на гостевой лаптоп. Внутрикорпоративный прокси спрашивал логин и пароль для интернета, коих у меня не имелось. Ступор. Я вспомнил 1990-е, когда интернет был только по модему и добывать его надо было через поход на почту или в «Интернет-кафе». Странное чувство.
Внутрикорпоративный прокси спрашивал логин и пароль для интернета, коих у меня не имелось. Ступор. Я вспомнил 1990-е, когда интернет был только по модему и добывать его надо было через поход на почту или в «Интернет-кафе». Странное чувство.
К счастью, на вышеозначенном компьютере была обнаружена игрушка под названием 2048. Замечательно, подумал я, и погрузился в складывание кубиков на целых 30 минут. Время было убито чётко и резко. Когда пришла пора уходить, я попытался закрыть игрушку, и увидел, что она подвисла. Я по привычке запустил менеджер задач и хотел уже было убить несчастную, когда вдруг мои глаза увидели потребление 250-ти мегабайт оперативной памяти. Волосы встали дыбом под мышками, пока я пристреливал кобылку. Страшные 250 мегабайт оперативки не хотели вылезать из моей головы.
Я сел в машину и поехал домой. Во время поездки я только и думал о том, как можно было так раскормить 2048 до состояния, когда она будет пожирать 250 мегабайт оперативки. Ответ был достаточно прост.
И я подумал, а почему-бы не сделать всё намного более компактно? Сколько битов тебе на самом деле надо, для того, чтобы хранить цифровое поле 2048?
Для начала обратимся к интернетам. Учитывая, что мы играем абсолютно правильную игру и все ставки на нас, то при самом хорошем расходе, мы не сможем набрать больше 65536. Ну, или если всё будет в нашу пользу, и мы будем получать блоки с четвёрками в 100 процентах случаев, то мы можем закончить с тайлом в 131072. Но это на грани фантастики.
Итак, у нас есть поле из 16-ти тайлов, размером до 131072, который умещается в Int. В зависимости от битности системы, int может быть 4 или 8 байт. То есть, 16*4 = 64 байта, хватило бы для хранения всего игрового поля.
Хотя, на самом деле, это тоже жутко много. Мы ведь можем хранить степени двойки, так ведь?
;00 = nothing
;01 = 2
;02 = 4
;03 = 8
;04 = 16
;05 = 32
;06 = 64
;07 = 128
;08 = 256
;09 = 512
;0a = 1024
;0b = 2048
;0c = 4096
;0d = 8192
;0e = 16384
;0f = 32768
;10 = 65536 - maximum with the highest number is 2
;11 = 131072 - maximum with the highest number 4
;12 = 262144 - impossible
Ага, мы можем запихнуть каждую клетку поля в один байт. На самом деле, нам нужно всего лишь 16 байт, на то, чтобы хранить всё игровое поле. Можно пойти немного дальше и сказать, что случай, когда кто-то соберёт что-то больше 32768 — это граничный случай, и такого быть не может. Посему можно было бы запихнуть всё поле в полубайты, и сократить размер всего поля до восьми байт. Но это не очень удобно. (Если вы реально забыли бинарное и шестнадцатеричное счисление, то тут нужно просто сесть, погуглить и вспомнить его)
На самом деле, нам нужно всего лишь 16 байт, на то, чтобы хранить всё игровое поле. Можно пойти немного дальше и сказать, что случай, когда кто-то соберёт что-то больше 32768 — это граничный случай, и такого быть не может. Посему можно было бы запихнуть всё поле в полубайты, и сократить размер всего поля до восьми байт. Но это не очень удобно. (Если вы реально забыли бинарное и шестнадцатеричное счисление, то тут нужно просто сесть, погуглить и вспомнить его)
Итак, подумал я, если всё это можно запихнуть в 16 байт, то чего бы этим не заняться. И как же можно отказаться от возможности вспомнить мой первый язык программирования — Ассемблер.
[flashback mode on]
Картинки детства. Выпуск №45
Именно в этой статье я вычитал про разные компиляторы, нашёл мануалы и попробовал писать. Писалось плохо, потому что я понимал, что мне не хватает понимания основ, и нужен был какой-то фундамент, который позволил бы работать более стабильно.
Ужасы детства. Ссылка на издание
Ссылка на издание
Из всех сайтов, приведённых в примерах журнала Хакер, в живых не осталось ни одного. Но, не бойтесь, дело живо и инструкции публикуются. Вот здесь, например, есть одно из самых подробных описаний работы с Ассемблером.
[flashback mode off]
Когда я добрался домой и сел за свой компьютер, я понял, пошёл вспоминать молодость. Как скомпилировать ассемблер? В своё время, когда мы всему этому учились, у нас был TASM, MASM и MASM32. Я лично пользовался последними двумя. В каждом ассемблере был линкер и сам компилятор. Из этих трёх проектов в живых остался только оригинальный MASM.
Для того чтобы его установить в 2021 году, надо сливать Visual Studio и устанавливать кучу оснасток, включая линкер. А для этого надо качать полтора гигабайта оснасток. И хотя я, конечно, нашёл статьи о том, как использовать llvm-link вместо link при работе с Ассемблером, там нужно то ещё скрещивание ужей с ежами и альбатросами. Такими непотребностями мы заниматься не будем.
Хорошо, в таком случае, что? С удивлением обнаружил, что большое количество курсов по Ассемблеру х64 написано для линукса. YASM и NASM там правят бал и работают просто прекрасно. Что хорошо для нас, NASM отлично запускается и работает на Windows. Типа того.
Запускается-то он, запускается, но линкера у него в комплекте нету. (По-русски этот линкер должен называться компоновщиком, но мне это непривычно и звать я его буду линкером или линковщиком). Придётся использовать Майкрософтский линковщик, а как мы знаем, для его использования нам нужно качать гигабайты MSVS2021. Есть ещё FASM, но он какой-то непривычный, а в NASM бонусом идёт отличная система макросов.
Опять же, дружить всё это с llvm-link мне было очень занудно, потому что ни одна из инструкций не описывала того, как эту сакральную магию правильно применять.
Весь интернет пестрит рассказами про то, как прекрасен MinGW. Я же, будучи ленивым, пошёл по упрощённому пути и слил систему разработки CodeBlocks. Это IDE со всякими свистопипелками и, самое главное, наличием установленного MinGW.
Отлично, устанавливаем всё, добавляем в PATH и теперь мы можем компилировать, запуская:
nasm -f win64 -gcv8 -l test.lst test.asm gcc test.obj -o test.exe -ggdb
Отлично! Давайте теперь сохраним данные в памяти:
stor db 0x00, 0x00, 0x00, 0x01, 0x00, 0x01, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00 fmt db "%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa,"%c %c %c %c", 0xd, 0xa, "-------",0xd, 0xa, 0
Вот наше игровое поле stor, а вот — беспощадное разбазаривание оперативной памяти — строка форматирования fmt, которая будет выводить это игровое поле на экран.
Соответственно, для того, чтобы обратиться к какой-либо клетке поля, мы можем считать байты следующим образом:
; byte addressing ; 00 00 00 00 [stor] [stor+1] [stor+2] [stor+3] ; 00 01 00 00 [stor+4] [stor+5] [stor+6] [stor+7] ; 00 01 00 00 [stor+8] [stor+9] [stor+a] [stor+b] ; 00 00 00 00 [stor+c] [stor+d] [stor+e] [stor+f]
Тут начинаем втягиваться в разницу того самого 16-ти битного ассемблера под ДОСом из страшного Хакера 2002 года и нашего 64х битного ассемблера прямиком из 2021.
У нас были регистры ax, bx и так далее, помните? Все они делились на две части: _l _h, типа al, ah для записи байта в верхнюю часть ax или в нижнюю его часть. Соответственно, al был восьми битовым, ax был 16-ти битовым, а если вы были счастливым обладателем нормального процессора, то вам был доступен eax для целых 32х бит. Хаха! Добро пожаловать в новые процессоры. У нас теперь есть rax для записи 64х бит.
Что, страшно читать про регистры? Теряетесь и вообще не понимаете о чём идёт речь? Обратитесь к ответу frosty7777777 по адресу qna.habr.com/q/197637. Он приводит список книг по Ассемблеру на русском языке.
Более того, в мире 64х битных процессоров у нас в распоряжении есть не только EAX, EBX, EDX и ECX (не будем забывать про EDI, EBP, ESP и ESI, но и играться с ними тоже не будем). Нам даны R8 – R15 – это замечательные 64х битные регистры. Зубодробилка начинается, если вы хотите считывать данные из этих регистров. Байты можно считать обращаясь к r10b, слова находятся по адресу r10w, двойные слова можно найти по r10d, а ко всем 64ти четырём битам можно обратиться через к10. Почему всё это не назвать так же, как и предыдущие регистры — чёрт его знает. Но ничего, привыкнем.
Почему всё это не назвать так же, как и предыдущие регистры — чёрт его знает. Но ничего, привыкнем.
Более того, благодаря SSE, SSSE и AVX у нас на руках ещё есть 15 регистров по 128 или 256 бит. Они названы XMM0-XMM15 для 128 бит и YMM0-YMM15 для 256 бит. С ними можно вытворять интересные вещи. Но статья не об этом.
Идём дальше. Как выводить данные на экран. Помните ДОС и те замечательные времена, когда мы делали:
mov dx, msg ; the address of or message in dx mov ah, 9 ; ah=9 - "print string" sub-function int 0x21 ; call dos services
Теперь забудьте. Прямой вызов прерываний нынче не в моде, и делать этого мы больше не сможем. Если вы ассемблируете под линуксом, вы сможете дёргать системные вызовы, или пользоваться прерыванием 80, которое, отвечает за выплёвывание данных на экран. А вот под Windows у вас нет иных вариантов, кроме как воспользоваться printf. (Нет, конечно, можно было бы получить дескриптор консоли и писать напрямую, но тут уже совсем было бы неприлично). В принципе, это не так-то плохо. Printf это часть стандартной библиотеки Си, и вызывать его можно на чём угодно.
В принципе, это не так-то плохо. Printf это часть стандартной библиотеки Си, и вызывать его можно на чём угодно.
Посему программу мы начнём с пары объявлений для компилятора и линкера:
bits 64
default rel
global main
extern printf
extern getch
extern ExitProcessПервая строка указывает, что мы работаем на настоящем, ламповом 64х битном процессоре. Последние 3 строки говорят, что нам нужно будет импортировать 3 внешних функции. Две printf и getch для печатания и читания данных и ExitProcess из стандартной библиотеки Windows для завершения приложения.
Соответственно, для того чтоб нам воспользоваться какой-либо из вышеперечисленных функций, нам нужно сделать следующее:
push rbp mov rbp, rsp sub rsp, 32 lea rcx, [lost] ;Load the format string into memory call printf
Сохраняем текущую позицию стека, выравниваем стек и даём ему дополнительные 32 байта. Про магию выравнивания стека можно читать вот здесь. (Статья на английском, как и многие из рекомендованных мною материалов. Комментируйте, если есть на русском, мы добавим.) Загружаем в регистр CX адрес строки под названием
Про магию выравнивания стека можно читать вот здесь. (Статья на английском, как и многие из рекомендованных мною материалов. Комментируйте, если есть на русском, мы добавим.) Загружаем в регистр CX адрес строки под названием lost, которая определена как lost db "You are done!",0xd, 0xa, 0 и вызываем printf, которая эту строку и выведет на экран.
Два основных момента, о которых надо знать — это как выравнивать стек, и как передавать параметры в функции. В примере чуть выше, мы передаём только один параметр. А вот для показа значения всех 16 полей в командной строке мы должны передать 16 параметров, для этого нам нужно будет грузить часть их них в регистры, а часть записывать в стек. Вот — очень запутанный пример того, как программа вызывает printf с 16-ю параметрами для того, чтобы отобразить игровое поле на экране.
Хорошо, что мы уже умеем? Можем грузить данные в память и из памяти, перекладывать в многочисленные регистры и запускать функции из стандартной библиотеки.
Будем использовать getch для того, чтобы считать ввод с клавиатуры. Управление будет вимовским, то есть, hjkl для того, чтобы двигать тайлы. Просто пока не будем мучиться со стрелочками.
Что осталось сделать? Написать саму логику программы.
И тут вот в чём прикол. Можно было бы делать математику и прибавлять значения и всё такое, но это всё очень уж сложно. Давайте посмотрим, на наше игровое поле, и на то, что с ним происходит каждый раз, когда пользователь нажимает на кнопку в любом направлении.
Во первых, направление неважно. Что бы пользователь не нажимал на клавиатуре, мы всегда можем это развернуть и сказать что это просто сжимание 16ти байт слева направо. Но так как ряды у нас не пересекаются, то мы можем сказать, что вся логика-это сжимание четырёх байт слева направо, повторённое четыре раза.
А так как у нас всего лишь четыре байта, то мы можем просто написать логику на граничных кейсах. Какая разница?
Посему считываем направление, проходимся по всем значениям в одной строке и загружаем их в регистры r10 – r14. С этими регистрами и будем работать.
С этими регистрами и будем работать.
Чтобы облегчить нам жизнь, мы воспользуемся макросами NASM. Пишем два макроса, один для считывания памяти в регистры, другой для переписывания регистров в память. В данном объявлении макроса мы говорим, что у нас будут 4 параметра — 4 адреса в памяти. Их то мы и двигаем в регистры или из регистров. (Все параметры позиционные, % обращается к конкретной позиции)
%macro memtoreg 4 xor r10, r10 mov r10b, byte [stor + %4] xor r11, r11 mov r11b, byte [stor + %3] xor r12, r12 mov r12b, byte [stor + %2] xor r13, r13 mov r13b, byte [stor + %1] %endmacro %macro regtomem 4 mov [stor + %4], r10b mov [stor + %3], r11b mov [stor + %2], r12b mov [stor + %1], r13b %endmacro
Тут всё просто.
После этого, передвижение всего поля в любом направлении будет простой задачей. Вот пример направления down. Мы просто выгружаем байты из памяти в регистры, вызываем процедуру, которая обсчитывает сдвиг и двигаем байты обратно в память.
down: push rbp mov rbp, rsp sub rsp, 32 memtoreg 0x0, 0x4, 0x8, 0xc call shift regtomem 0x0, 0x4, 0x8, 0xc memtoreg 0x1, 0x5, 0x9, 0xd call shift regtomem 0x1, 0x5, 0x9, 0xd memtoreg 0x2, 0x6, 0xa, 0xe call shift regtomem 0x2, 0x6, 0xa, 0xe memtoreg 0x3, 0x7, 0xb, 0xf call shift regtomem 0x3, 0x7, 0xb, 0xf leave ret
Если посмотреть на другие направления — происходит всё, то же самое, только мы берём байты в другой последовательности, чтобы симулировать «движение» влево, вправо, вниз и вверх.
Процедура самого сдвига находится в этом файле и является самой запутанной процедурой. Более того, точно вам могу сказать, в определённых кейсах она не работает. Надо искать и дебажить. Но, если вы посмотрите на сам код этой процедуры, она просто сравнивает кучу значений и делает кучу переходов. Математики в этой процедуре нет вообще. inc r11 — это единственная математика, которую вы увидите. Собственно говоря, единственное, что происходит в игре с математической точки зрения, это просто прибавление единицы к текущему значению клетки. Так что нам незачем грузить процессор чем-либо ещё.
Собственно говоря, единственное, что происходит в игре с математической точки зрения, это просто прибавление единицы к текущему значению клетки. Так что нам незачем грузить процессор чем-либо ещё.
Запускаем, пробуем — всё хорошо. Цифры прыгают по экрану, прибавляются друг к другу. Нужно дописать небольшой спаунер, который будет забрасывать новые значения на поле. Желания писать собственный рандомизатор прямо сию секунду у меня не было, так что будем просто запихивать значение в первую пустую клетку. А если оной не найдём, то скажем, что игра проиграна.
Складываем всё воедино, собираем, пробуем.
Красота исполнения -5 из десяти возможных. Мы, заразы такие, даже не потрудились конвертировать степени двойки обратно в числа. А могли бы. Если добавить табуляций в вывод, то всё может выглядеть даже поприличнее.
Смотрим в потребление оперативной памяти:
Итого — 2.5 мегабайта. Из них 1900 килобайт это общие ресурсы операционной системы. Почему так жирно? Потому что наш printf и ExitProcess используют очень много других системных вызовов. Если распотрошить программу с помощью x64dbg (кстати, замечательный бесплатный дебаггер, не IDA, но с задачей справляется), то можно увидеть, какие символы импортируются и потребляются.
Почему так жирно? Потому что наш printf и ExitProcess используют очень много других системных вызовов. Если распотрошить программу с помощью x64dbg (кстати, замечательный бесплатный дебаггер, не IDA, но с задачей справляется), то можно увидеть, какие символы импортируются и потребляются.
Сама же программа использует 300 килобайт памяти на всё про всё. Это можно было бы ужать, но статья не об этом.
▍ Итак, что же мы теперь знаем про Ассемблер в 2021 году
- Он всё ещё живой и люди им пользуются. Существует масса инструментов разработки для всех ОС. Вот, например, ассемблер для новых маковских чипов М1. А здесь можно слить более 5000 страниц документации по процессорам Intel. Ну а если у вас завалялась где-то Raspberry Pi (а у кого она не завалялась?), то вам сюда.
- Не всё так просто, как это было в наши стародавние времена, где надо было заучивать таблицу прерываний наизусть. Сегодня мануалов больше и они тяжеловеснее.
- Но и не всё так сложно.
 Опять же, сегодня мануалы найти проще, да и StackOverflow имеет достаточно данных про ассемблер. Да и на Хабре есть большое количество тёплых ламповых статей про Ассемблер.
Опять же, сегодня мануалы найти проще, да и StackOverflow имеет достаточно данных про ассемблер. Да и на Хабре есть большое количество тёплых ламповых статей про Ассемблер. - Скрещивать ассемблер и другие языки программирования не так-то сложно. Мы с вами в этом примере импортировали функции, а можем их экспортировать. Достаточно знать правила работы со стеком, чтобы передавать данные туда и обратно.
- Серьёзные системщики, которые могут раздебажить BSOD на лету и распотрошить любую программу с целью её пропатчить, могут читать подобный код без каких-либо проблем. Так что, если вам нужно серьёзно заняться системным программированием, то без ASM вы далеко не двинетесь. (Пусть даже вы не будете писать на асьме напрямую, а будете использовать C-ASM или читать листинги программ)
▍ Для чего вам это надо?
Для того чтобы вы понимали, как работают процессоры. В те старые, тёплые, ламповые времена, когда мне приходилось писать на ASM, я глубоко усвоил основополагающие данные о работе компьютера. После того как вы понимаете, как работать с памятью, что происходит в программе и, как и куда передаются ваши данные, у вас не будет проблем учить любые другие языки программирования. Система управления памяти в С и С++ покажется вам более удобной и приятной, а освоение Rust не займёт много времени.
После того как вы понимаете, как работать с памятью, что происходит в программе и, как и куда передаются ваши данные, у вас не будет проблем учить любые другие языки программирования. Система управления памяти в С и С++ покажется вам более удобной и приятной, а освоение Rust не займёт много времени.
В этой статье я привёл большое количество ссылок на материалы. Ещё раз обращу ваше внимание на вот эту страницу. Здесь автор собрал в одном файле замечательное руководство по Ассемблеру в Windows.
А вот здесь огромная документация для YASM на русском.
Я бы рекомендовал всем тем, кто только начинает писать программы на языках высокого уровня, взять небольшой пет-проект и написать его на Ассемблере. Так, чисто для себя, чтобы разобраться, на чём вы работаете.
▍ Тёплый, ламповый конкурс на пиво
В дополнение ко всему, вот вам конкурс на пиво. Весь код «работающего» приложения 2048 находится по адресу: github.com/nurked/2048-asm
Вот как выглядит игра на данный момент:
Играем чистыми степенями двойки
Слить скомпилированный бинарник можно по адресу .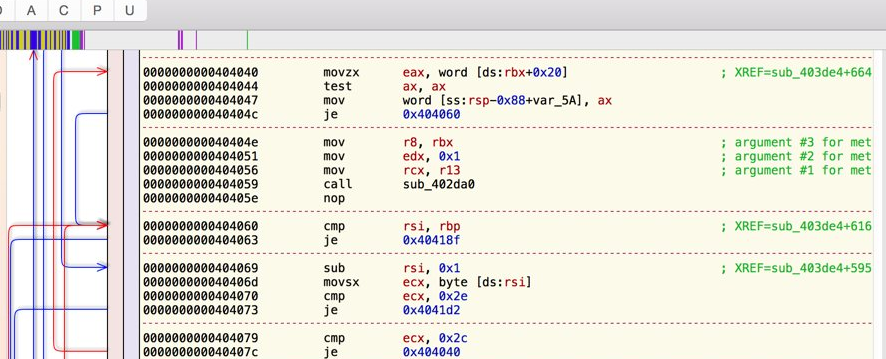 Играем нажатиями hjkl, выходим по нажатию s.
Играем нажатиями hjkl, выходим по нажатию s.
Для принятия участия в конкурсе вам надо будет сделать PRы, в которых:
Всем тем кто принимал участие — спасибо! Особенно tyomitch, который перепиарил весь проект. И Healer за работу с кнопками.
Переписан спаунер, и он на самом деле рандомно выбирает клетку на экране, в которой появляется новая фишка на поле.Переписан отображатель, и он выводит в консоль числа, а не степени двоек, возможно даже с подобием сетки.Добавлены цвета.Найдена и исправлена ошибка, когда мы сжимаем следующую строку: 7 6 6 1, она сожмётся до 8 1 0 0 за один раз, вместо 7 7 1 0, 8 1 0 0По нажатию на s игра должна закрываться, но сейчас она тихо падает, потому что стек обработан неправильно. Это нужно починить.Управление всё-таки нужно сделать стрелочками.
За первый работающий PR по каждому из этих пунктов я лично отправляю создателю денег на пиво пейпалом. Пишите в личку.
Пишите в личку.
Всем успешного учения ассемблера!
Урок 12. Преобразование типов — asmbase.ru
Часть команд процессор может обработать только со значениями одной разрядности. Процессор без колебаний перемножит байт на байт и слово на слово. Но никак не байт на слово, или двойное слово на слово. Чтобы складывать, перемножать и выполнять другие операции со значениями разных размеров, программист должен озаботиться преобразованием типов в своей программе.
Под преобразованием типов я подразумеваю изменение разрядности операнда от большего к меньшему (например, двойное слово в слово), или от меньшего к большему (например, байт в слово). Для преобразования больших типов в меньшие отбрасывается старшая часть значения. Операция может быть не безопасной, если утрачивается часть значения, хранимого в старшей части (например, беззнаковое слово хранит число 500, а его преобразование в байт отсекает всё выше 255). В таком случае преобразование приводит к ошибочному результату.
Преобразование типов без знака
Беззнаковое преобразовании с увеличением разряда происходит через добавление к исходному значению старшей части, биты которой заполняется нулями. На картинке показан пример расширения из байта в слово:
Преобразование беззнакового значения происходит просто. В программе на ассемблере для преобразования такого типа используется команда MOV:
mov dl,[a] mov dh,0 ;Другой вариант: mov dl,[a] xor dh,dh ;Вот еще один: mov dl,[a] sub dh,dh ;… a db 118
1 2 3 4 5 6 7 8 9 10 11 12 | mov dl,[a] mov dh,0
;Другой вариант: mov dl,[a] xor dh,dh
;Вот еще один: mov dl,[a] sub dh,dh ;… a db 118 |
Также для беззнаковых преобразований в ассемблере есть специальная команда MOVZX (move with Zero-Extend, т.е. переместить с нулевым расширением). Она копирует содержимое операнда источника (регистр или значение в памяти) в операнд назначения (регистр). Старшая часть расширения заполняется нулями. Операнд назначения определяет размер расширения.
Она копирует содержимое операнда источника (регистр или значение в памяти) в операнд назначения (регистр). Старшая часть расширения заполняется нулями. Операнд назначения определяет размер расширения.
Преобразование командой MOVZX происходит так:
movzx cx,[b] ;CX = b ;… b db 193
movzx cx,[b] ;CX = b ;… b db 193 |
Преобразование типов со знаком
Существует нюанс, касающийся старшего бита, который, как мы помним из Урока 8. Числа со знаком и без, является знаковым битом, то есть битом, определяющим, стоит перед числом знак «минус» или нет. Поэтому преобразования знакового числа происходит через прибавление старшей части и её заполнением знаковым битом. Говоря проще, если число было отрицательным, то старшая часть заполняется единицами, а если положительным – то нулями:
В ассемблере за преобразование типов знаковых значений отвечает команда MOVSX (Move with Sign-Extension, т.е. переместить со знаковым расширением). Она копирует содержание операнда источника (регистр или значение в памяти) в операнд назначения (регистр), расширяя значение знаковым битом:
Она копирует содержание операнда источника (регистр или значение в памяти) в операнд назначения (регистр), расширяя значение знаковым битом:
movsx dx,[m] ;DX = m
movsx dx,[m] ;DX = m |
Дополнительно в ассемблере есть еще команды для преобразования знаковых операндов: CBW – преобразует байт в слово (Convert Byte to Word) и CWD – преобразует слово в двойное слово (Convert Word to Double word). Они не получают явных операндов. Вместо этого CBW расширяет значение-байт в регистре AL в слово в регистре AX. В свою очередь CWD преобразует значение-слово в AX в двойное слово DX:AX. На практике обе команды часто сопутствуют операциями на умножении и деление.
Пример программыНайдем решение формулы m = (a + 1) / (b – c). Все операнды со знаком. Размер m – слово, размер a – двойное слово, размер b – слово, размер c – байт.
use16 ;Генерировать 16-битный код org 100h ;Программа начинается с адреса 100h mov ax,[b] ;AX = b movsx cx,[c] ;CX = c sub ax,cx ;AX = (b — c) mov cx,ax ;Запоминаем результат в CX mov ax,word[a] ;AX = младшая часть a mov dx,word[a+2] ;DX = старшая часть a add ax,1 ;\ adc dx,0 ;/DX:AX = (a + 1) idiv cx ;AX = (a + 1) / (b — c), в DX остаток mov [m],ax ;m = AX, в DX остаток int 20h ;Завершение программы a dd 12299 b dw 128 c db -16 m dw ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | use16 ;Генерировать 16-битный код org 100h ;Программа начинается с адреса 100h
mov ax,[b] ;AX = b movsx cx,[c] ;CX = c sub ax,cx ;AX = (b — c) mov cx,ax ;Запоминаем результат в CX mov ax,word[a] ;AX = младшая часть a mov dx,word[a+2] ;DX = старшая часть a add ax,1 ;\ adc dx,0 ;/DX:AX = (a + 1) idiv cx ;AX = (a + 1) / (b — c), в DX остаток mov [m],ax ;m = AX, в DX остаток
int 20h ;Завершение программы
a dd 12299 b dw 128 c db -16 m dw ? |
Упражнение
Теперь упражнение для самостоятельной работы. 2 / (a + b). Все операнды со знаком. Размер a – слово, размеры b – байт, размер m – двойное слово. После компиляции откройте программу в Turbo Debugger, выполните все строки и проверьте, какое значение записалось по адресу переменной m. Результат отправьте в комментарии к уроку.
2 / (a + b). Все операнды со знаком. Размер a – слово, размеры b – байт, размер m – двойное слово. После компиляции откройте программу в Turbo Debugger, выполните все строки и проверьте, какое значение записалось по адресу переменной m. Результат отправьте в комментарии к уроку.
c++ — Компилятор генерирует дорогостоящую инструкцию MOVZX
Спасибо за хороший вопрос!
Очистка регистров и идиомы разрушения зависимостей
Цитата из архитектуры Intel® 64 и IA-32 Справочное руководство по оптимизации, раздел 3.5.1.8:
Кодовые последовательности, которые изменяют частичный регистр, могут иметь некоторую задержку в цепочке зависимостей, но этого можно избежать, используя идиомы, разрушающие зависимости. В процессорах на базе микроархитектуры Intel Core ряд инструкций может помочь устранить зависимость выполнения, когда программное обеспечение использует эти инструкции для очистки содержимого регистра до нуля. Устраните зависимости от частей регистров между инструкциями, работая с 32-битными регистрами вместо частичных регистров.
Для перемещений это можно сделать с помощью 32-битных перемещений или с помощью MOVZX.
Правило кодирования ассемблера/компилятора 37. (Влияние M, общность MH) : Разорвать зависимости от частей регистров между инструкциями, работая с 32-битными регистрами вместо частичных регистров. Для перемещений это можно сделать с помощью 32-битных перемещений или с помощью MOVZX.
movzx vs mov
Компилятор знает, что movzx не требует больших затрат, и использует его как можно чаще. Для кодирования movzx может потребоваться больше байтов, чем для mov, но его выполнение не требует больших затрат.
Вопреки логике, программа с movzx (которая заполняет все регистры) на самом деле работает быстрее, чем просто с mov, которая устанавливает только младшие части регистров.
Позвольте мне продемонстрировать вам этот вывод на следующем фрагменте кода. Это часть кода, реализующего вычисление CRC-32 с использованием алгоритма Slicing by-N. Вот он:
Вот он:
movzx ecx, bl
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
movzx ecx, бл
шр ебкс, 8
xor eax, двойное слово ptr [ecx * 4 + edi + 1024 * 2]
movzx ecx, бл
шр ебкс, 8
xor eax, двойное слово ptr [ecx * 4 + edi + 1024 * 1]
пропущено еще 6 подобных троек, которые делают movzx, shr, xor.
dec <<< регистр счетчика >>>>
jnz …… <<повторить весь цикл снова>>>
Вот второй фрагмент кода. Мы заранее очистили ecx, и теперь просто вместо «movzx ecx, bl» делаем «mov cl, bl»:
// здесь ecx уже очищен в 0
мов кл, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
мов кл, бл
шр ебкс, 8
xor eax, двойное слово ptr [ecx * 4 + edi + 1024 * 2]
мов кл, бл
шр ебкс, 8
xor eax, двойное слово ptr [ecx * 4 + edi + 1024 * 1]
<<< и так далее – как в примере №1>>>
Теперь угадайте, какой из двух приведенных выше фрагментов кода работает быстрее? Вы думали раньше, что скорость такая же, или версия movzx медленнее? На самом деле код movzx быстрее, потому что все процессоры, начиная с Pentium Pro, выполняют инструкции вне порядка и переименовывают регистры.
Переименование регистров
Переименование регистров — это метод, используемый внутри ЦП, который устраняет ложные зависимости данных, возникающие из-за повторного использования регистров последовательными инструкциями, между которыми нет реальных зависимостей данных.
Возьму первые 4 инструкции из первого фрагмента кода:
movzx ecx, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
movzx ecx, бл
Как видите, инструкция 4 зависит от инструкции 2. Инструкция 4 не зависит от результата инструкции 3.
Таким образом, процессор может выполнять инструкции 3 и 4 параллельно (вместе), но инструкция 3 использует регистр (читать -только) изменено инструкцией 4, поэтому инструкция 4 может начать выполнение только после полного завершения инструкции 3. Давайте тогда переименуем регистр ecx в edx после первого триплета, чтобы избежать этой зависимости:
movzx ecx, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
movzx edx, бл
шр ебкс, 8
xor eax, dword ptr [edx * 4 + edi + 1024 * 2]
movzx ecx, бл
шр ебкс, 8
xor eax, двойное слово ptr [ecx * 4 + edi + 1024 * 1]
Вот что мы имеем сейчас:
movzx ecx, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
movzx edx, бл
Теперь инструкция 4 никоим образом не использует регистр, необходимый для инструкции 3, и наоборот, так что инструкции 3 и 4 точно могут выполняться одновременно!
Это то, что делает для нас процессор. Центральный процессор при преобразовании инструкций в микрооперации (микрооперации), которые будет выполнять алгоритм вне очереди, внутренне переименовывает регистры, чтобы устранить эти зависимости, поэтому микрооперации имеют дело с переименованными внутренними регистрами, а не с настоящие, какими мы их знаем. Таким образом, нам не нужно самим переименовывать регистры, как я только что переименовал в приведенном выше примере — ЦП автоматически переименует все за нас, транслируя инструкции в микрооперации.
Центральный процессор при преобразовании инструкций в микрооперации (микрооперации), которые будет выполнять алгоритм вне очереди, внутренне переименовывает регистры, чтобы устранить эти зависимости, поэтому микрооперации имеют дело с переименованными внутренними регистрами, а не с настоящие, какими мы их знаем. Таким образом, нам не нужно самим переименовывать регистры, как я только что переименовал в приведенном выше примере — ЦП автоматически переименует все за нас, транслируя инструкции в микрооперации.
Микрооперации инструкции 3 и инструкции 4 будут выполняться параллельно, поскольку микрооперации инструкции 4 будут иметь дело с совершенно другим внутренним регистром (представленным снаружи как ecx), чем микрооперации инструкции 3, поэтому мы не не нужно ничего переименовывать.
Позвольте мне вернуть исходную версию кода. Вот он:
movzx ecx, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
movzx ecx, бл
(инструкции 3 и 4 выполняются параллельно, потому что ecx инструкции 3 — это не ecx инструкции 4, а другой, переименованный регистр — ЦП автоматически выделил для микроопераций инструкции 4 новый, свежий регистр из пула внутренних доступных регистров).
Теперь вернемся к movxz против mov.
Movzx полностью очищает регистр, поэтому ЦП точно знает, что мы не зависим ни от какого предыдущего значения, оставшегося в старших битах регистра. Когда ЦП видит инструкцию movxz, он знает, что может безопасно переименовать регистр внутри и выполнить инструкцию параллельно с предыдущими инструкциями. Теперь возьмем первые 4 инструкции из нашего примера №2, где мы используем mov, а не movzx:
мов кл, бл
шр ебкс, 8
mov eax, dword ptr [ecx * 4 + edi + 1024 * 3]
мов кл, бл
В этом случае инструкция 4, модифицируя cl, изменяет биты 0-7 ecx, оставляя биты 8-32 без изменений. Таким образом, ЦП не может просто переименовать регистр для инструкции 4 и выделить другой, свежий регистр, потому что инструкция 4 зависит от битов 8-32, оставшихся от предыдущих инструкций. ЦП должен сохранить биты 8-32, прежде чем он сможет выполнить инструкцию 4. Таким образом, он не может просто переименовать регистр. Он будет ждать завершения инструкции 3 перед выполнением инструкции 4. Инструкция 4 не стала полностью независимой — она зависит от предыдущего значения ECX 9.0014 и предыдущее значение бл. Так что это зависит от двух регистров сразу. Если бы мы использовали movzx, это зависело бы только от одного регистра — bl. Следовательно, инструкции 3 и 4 не будут выполняться параллельно из-за их взаимозависимости. Грустно, но верно.
Таким образом, он не может просто переименовать регистр. Он будет ждать завершения инструкции 3 перед выполнением инструкции 4. Инструкция 4 не стала полностью независимой — она зависит от предыдущего значения ECX 9.0014 и предыдущее значение бл. Так что это зависит от двух регистров сразу. Если бы мы использовали movzx, это зависело бы только от одного регистра — bl. Следовательно, инструкции 3 и 4 не будут выполняться параллельно из-за их взаимозависимости. Грустно, но верно.
Вот почему всегда быстрее работать с полными регистрами. Предположим, нам нужно изменить только часть регистра. В этом случае всегда быстрее изменить весь регистр (например, использовать movzx) — чтобы ЦП точно знал, что регистр больше не зависит от своего предыдущего значения. Изменение полных регистров позволяет ЦП переименовать регистр и позволить алгоритму внеочередного выполнения выполнять эту инструкцию вместе с другими инструкциями, а не выполнять их одну за другой.
ассемблер — Почему MOVZX не работает, когда операнды имеют одинаковый размер?
Работает (в машинном коде), неэффективно.
Вот почему большинство ассемблеров мешают вам выстрелить себе в ногу.
Что может быть причиной создания такой инструкции?
Для выполнения нулевого расширения из узких исходных данных.
Вот что означает ZX в мнемонике.
Если у вас есть операнды одинакового размера, вы должны использовать mov ,
не пытаться использовать инструкцию копирования с расширением нуля или знака.
Как и в случае с MOVSXD, даже если можно использовать код операции MOVZX для кодирования инструкции, эквивалентной mov r, r/m16 , это не рекомендуется из соображений эффективности.
Как говорит Intel для MOVSXD: Использование MOVSXD без REX.W (которое будет кодировать movsxd r32, r/m32 ) не рекомендуется. Следует использовать обычный MOV вместо использования MOVSXD без REX.W. (Я убрал из цитаты «в 64-битном режиме», потому что это лишнее; movsxd существует только в 64-битном режиме; код операции означает что-то еще в других режимах. )
)
В любом случае да, это можно movzx axe, bx в машинном коде x86, но ассемблеры спасают вас от самого себя и отказываются ассемблировать эту неэффективную инструкцию. (2-байтовый опкод вместо 1 для mov ; movzx был новым в 386 и все 1-байтные опкоды уже были израсходованы до этого.)
Копирует содержимое операнда-источника (регистр или ячейка памяти) в операнд-назначение (регистр), и ноль расширяет значение. Размер преобразованного значения зависит от атрибута размера операнда.
https://www.felixcloutier.com/x86/movzx
Я протестировал его на своем процессоре Skylake со следующим исходным кодом NASM, написанным, вероятно, также для сборки с помощью MASM. (например, db 66h вместо использования префикса NASM o16 на movzx строка.)
mov edx, -1 xor eax,eax дб 66ч ; префикс размера операнда, о котором мы не сообщаем ассемблеру movzx eax, dx двигать топор, дх ; для сравнения
(суперминимальный, с использованием преимуществ набора инструментов по умолчанию для этой одноразовой программы, которая никогда не задумывалась как полноценная программа. )
)
$ nasm -felf64 movzx.asm && ld -o movzx movzx.o
ld: предупреждение: не удается найти символ входа _start; по умолчанию 0000000000401000
$ objdump -drwC -Mintel ./movzx
...
401000: ba ff ff ff ff mov edx,0xffffffff
401005: 48 b8 cc cc cc 44 33 22 11 movabs rax,0x11223344cccccccc
40100f: 66 0f b7 c2 movzx топор, dx
401013: 66 89d0 mov ax,dx # обратите внимание, что это короче.
# Забавный факт: мы видим, что NASM выбрал форму mov r/m16, r, поскольку байт ModRM отличается.
Интересно, что дизассемблер в GNU Binutils (objdump -d и GDB) декодирует его как movzx ax, dx или movzww %dx, %ax в синтаксисе AT&T.
Используя gdb ./movzx в статическом исполняемом файле, я использовал layout reg и starti / stepi , чтобы просмотреть изменения регистров:
66 0F B7 C2 AX MOVZX, DX Обычно выполняется и
изменяет RAX с 0x11223344CCCCCCC на 0x1123344CCCCCFFFFFF . (Включая неявное расширение нулями старших 32 битов RAX, как это было бы при записи в EAX.)
(Включая неявное расширение нулями старших 32 битов RAX, как это было бы при записи в EAX.)
(Затем выйти из GDB, потому что я не включил код для выхода, а только код, который я действительно хотел выполнить в один шаг. )
Это невозможно для movzx al, dl — 16-битный, 32-битный или 64-битный размер операнда выбирается с помощью 66 или префиксов REX для переопределения режима по умолчанию, но 8-битный размер операнда только устанавливается через опкод. Нет префикса, который может переопределить инструкцию до 8-битного размера операнда. И, конечно же, нет формы movzx с 8-битным операндом назначения. (Если вы хотите обнулить полубайт до байта, скопируйте и и зарегистрируйте, 0x0f .)
NASM и YASM отклоняют movzx ax, dx
Так же, как и clang (с .intel_syntax без префикса ).
Но llvm-objdump -d дизассемблирует его так же, как GNU Binutils.