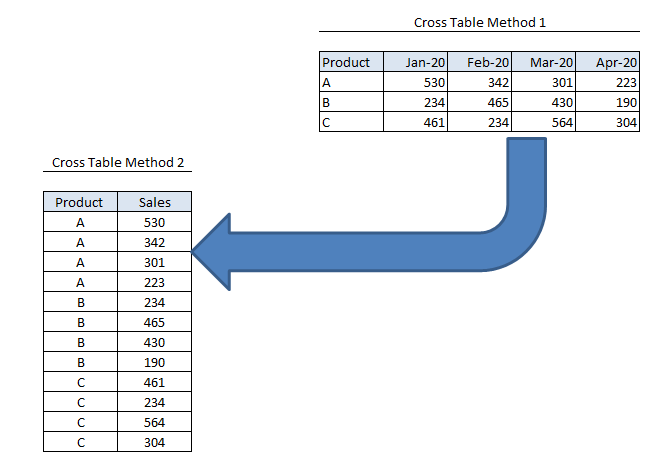
Кросс-таблица · Loginom Help
Обработчик создает сводную таблицу на основе исходного набора. При создании таблицы:
Пример: Исходная таблица:
Преобразуем исходную таблицу со следующими параметрами: колонки — Товар, строки — Дата, факты — Количество продаж. По полю Количество продаж выберем функцию агрегации Сумма. Выходной набор данных:
После обработки значения поля Товар перешли в заголовки новых столбцов, значения поля Дата остались в строках, а значения поля Количество продаж просуммированы по датам.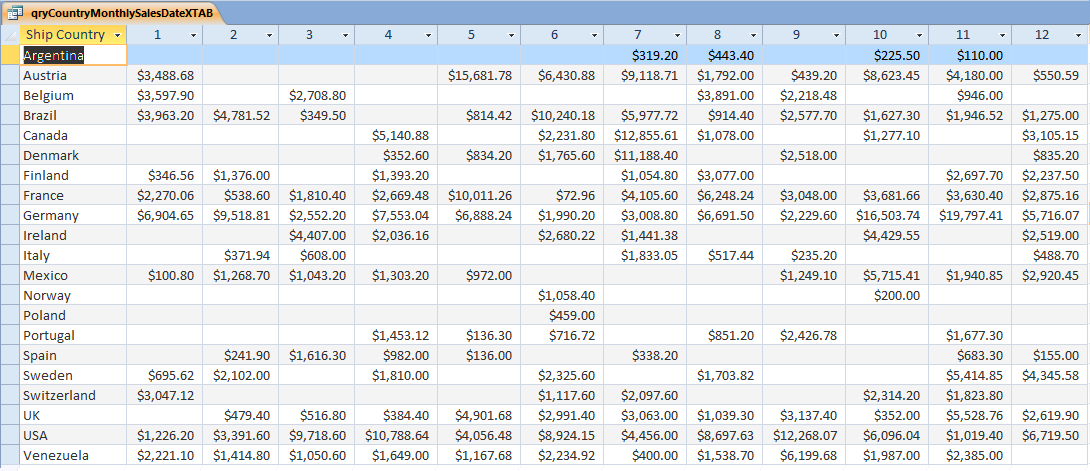 Вход Вход
Окно мастера поделено на две области: доступные поля (слева) и выбранные поля (справа).
Агрегация фактов и возможные типы данных:
В области Доступные поля помимо полей входного набора данных всегда присутствует синтетическое поле Количество, оно может быть добавлено только в группу Факты. Значения этих полей станут заголовками столбцов. Поля в данной группе обязательно должны иметь дискретный вид данных. Измерение в колонкахДанная панель может быть открыта следующими способами:
При работе с кросс-таблицей может возникнуть ситуация, когда в полях, по которым были сформированы колонки, появляются новые значения. В обработчике имеется два подхода к решению этой проблемы:
Пример: Входная таблица:
Кросс-таблица с колонкой: Товар. Результирующая таблица:
Если во входной набор добавился ещё один товар:
И настройки кросс-таблицы не изменились, то результирующий набор будет следующим:
Общие настройки для колонок Рисунок 2. Общие настройки для колонокРасположены в нижней части мастера и имеют следующие параметры:
С помощью кнопок и можно менять порядок полей в группе. То, в каком порядке расположены поля, влияет на структуру результирующей таблицы. Пример: Исходная таблица:
Кросс-таблица с порядком колонок: Товар, Точка продажи. Фактом: Сумма продажи (Сумма). И параметром Разделитель частей меток полей:
Кросс-таблица с порядком колонок: Точка продажи, Товар. Фактом: Сумма продажи (Сумма). И параметром Разделитель частей меток полей:
Строки Из значений полей сформируются строки в кросс-таблице. Одинаковые значения поля (полей) будут сгруппированы таким же образом, как это происходит в обработчике Группировка. Порядок полей в данной группе влияет на порядок сортировки данных в результирующей таблице по этим полям. Пример: Исходная таблица:
Кросс-таблица с порядком строк: Точка продажи, Дата. Фактом: Сумма продажи (Сумма).
Данные полей в этой группе обрабатываются в соответствии с функциями агрегации. Получившиеся значения отображаются на пересечении колонок и строк. По умолчанию для числовых типов выбрана функция Сумма, а для всех остальных Количество. Чтобы выбрать другие функции агрегации, необходимо дважды кликнуть по полю. При выборе нескольких вариантов функций каждая из них будет рассчитана в отдельном столбце. В группе Факты порядок полей не имеет значения. |
 02.2022
02.2022 В нем будет подсчитано, сколько раз в исходном наборе данных встречается каждая комбинация из колонок и строк.
В нем будет подсчитано, сколько раз в исходном наборе данных встречается каждая комбинация из колонок и строк. Также можно установить минимальное число значений поля, из которых будут созданы колонки. Но в этом случае в результирующей таблице сохранится столбец с оставшимися значениями.
Также можно установить минимальное число значений поля, из которых будут созданы колонки. Но в этом случае в результирующей таблице сохранится столбец с оставшимися значениями. Установленный флаг Пропущенные обеспечивает отображение в выходном наборе данных полей с пропущенными значениями. Факты для них будут агрегироваться в столбце Пропущенные значения.
Установленный флаг Пропущенные обеспечивает отображение в выходном наборе данных полей с пропущенными значениями. Факты для них будут агрегироваться в столбце Пропущенные значения.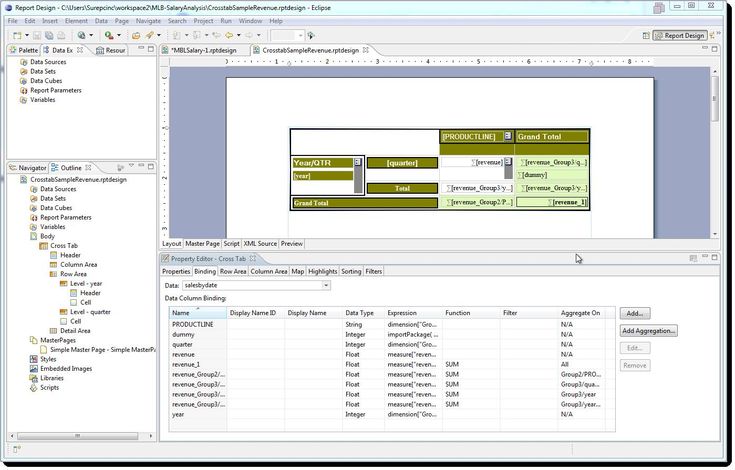
 04.2022
04.2022 Обои
Обои 04.2022
04.2022 04.2022
04.2022Кросс таблица в запросе 1С: что это такое?
Главная » База знаний
На чтение 3 мин Просмотров 940 Опубликовано
Кросс-таблица 1С – это отчет с группой данных в строчках и в столбцах. Он бывает выстроен для любого накопительного регистра, что имеется в конфигурации.
Составление отчетной документации кросс-таблицы
При выстраивании отчетности существуют задачи, решая которые «в лоб» приходится писать сложные запросы или вводить табличные данных от руки. К примеру:
- нахождение объема нарастания месячных продаж, для выведения в качестве диаграммы;
- высчитывание разницы реализации товара текущего и прошедшего времени – для всех отчетных строчек;
- сравнивание объема реализации товаров каждого специалиста со значением эталоном, что находится в процессе, когда отчетность формируется;
- результат нарастания в кросс-таблицах по столбцам и по строкам.
Данные задачи можно решить просто, воспользовавшись функционалом СКД – понадобится совсем немного времени. Не нужно цикловых запрашиваемых данных и кривого кодирования.

Получение суммы итогом нарастания
Такого рода задачи нередко можно встретить на деле. Например, – в отчетность должны быть выведены реализации по периодам, нужно знать сумму проданного за месяц, а также итог нарастания. Вопрос можно разрешить посредством запроса (без функционала СКД), но есть пара проблематичных моментов запроса:
- он тяжелый – его надо долго разрабатывать и отлаживать;
- перегружает систему – и чем большее количество данных, тем дольше его работа.
С функционалом СКД проблема будет решена 1 кодовой строкой, и отчет заработает по максимуму быстро.
Получение значения из предыдущей отчетной строчки
Функции принесут пользу, когда надо следить за трендом ресурса – идет сокращение или повышение от прошлого состояния, обязательно высчитываться дельта.
Изучение дебиторского долга по датам – получают тренд и полное повышение или сокращение долга от предыдущего периода.
Изучение валютных курсов и дохода или трат от их разницы – надо найти дельту между курсами и выполнить умножение на остаток денег.
Сравнение итоговых данных по текущей строчке со значением эталоном
Функция может принести пользу. В системе учитываются продажи работниками. Руководство проводит продажи параллельно с ними. Надо выводить отчетность по реализацию в разрезе рабочих. В него также нужно вывести дельту от продажного объема руководящего лица. Это означает, что надо сравнить каждую строчку реализаций менеджера и руководителя.
Они могут, к примеру, применяться, когда начисляются премиальные деньги.
Результат может высчитываться по строчкам, так и по столбцам.
Вывод части таблицы в отчетной ячейке
Когда нужно создать отчет, выводящий сведения о документации, в ячейке должна присутствовать его часть в таблице.
Для решения задачи по стандартному запросу, требуется написать ручной вывод итога в документ таблицу.
В СКД поможет всего одна функция. Чтобы не изобретать велосипед при создании отчетной документации 1С, важно изучить все функции СКД.
Оцените автора
Кросс-таблица с примером | Кросс-таблица и анализ хи-квадрат
Анализ помогает вам принимать обоснованные решения относительно вашего рациона питания и потребления калорий.
Кросс-табуляция — это статистическая модель мэйнфрейма, построенная по тому же принципу. Это помогает вам принимать обоснованные решения относительно вашего исследования, определяя закономерности, тенденции и корреляцию между параметрами вашего исследования.![]() При проведении исследования необработанные данные обычно могут быть пугающими. Они всегда будут указывать на несколько хаотических возможных исходов. В такой ситуации кросс-таблица помогает вам сфокусироваться на одной теории, вне всяких сомнений, рисуя тенденции, сравнения и корреляции между взаимовключающими факторами в вашем исследовании.
При проведении исследования необработанные данные обычно могут быть пугающими. Они всегда будут указывать на несколько хаотических возможных исходов. В такой ситуации кросс-таблица помогает вам сфокусироваться на одной теории, вне всяких сомнений, рисуя тенденции, сравнения и корреляции между взаимовключающими факторами в вашем исследовании.
Например, рассмотрим ваше заявление в колледж. Вы, вероятно, не осознавали этого тогда, но вы мысленно сопоставляли факторы, связанные с этим, чтобы прийти к сознательному решению относительно колледжей, в которые вы хотели бы поступить и в которых у вас были лучшие шансы при подаче заявления. Давайте рассмотрим процесс принятия решений по одному фактору за раз.
Во-первых, нужно учитывать академический фактор: ваши оценки в старшей школе, результаты SAT, область, в которой вы хотите специализироваться, и эссе, которое вам нужно будет написать. Во-вторых, финансовый фактор, который будет учитывать плату за обучение и возможности получения стипендии.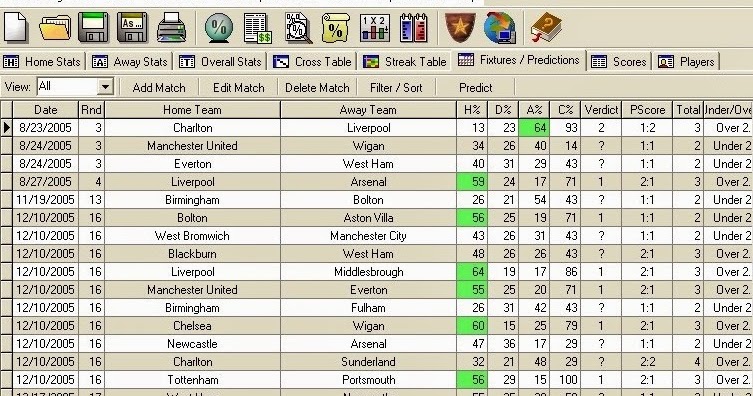 Наконец, это будет эмоциональный фактор, который будет учитывать вашу удаленность от дома и то, как далеко находятся университеты, которые рассматривают ваши друзья, поэтому встречи не будут проблемой. Другими словами, перекрестная таблица «Академики + финансы + эмоции» привела вас к уточненному списку университетов, один из которых является или скоро станет вашей альма-матер.
Наконец, это будет эмоциональный фактор, который будет учитывать вашу удаленность от дома и то, как далеко находятся университеты, которые рассматривают ваши друзья, поэтому встречи не будут проблемой. Другими словами, перекрестная таблица «Академики + финансы + эмоции» привела вас к уточненному списку университетов, один из которых является или скоро станет вашей альма-матер.
Кросс-таблица, также известная как кросс-таблица или таблица непредвиденных обстоятельств, представляет собой статистический инструмент, используемый для категорийных данных. Категориальные данные включают значения, которые исключают друг друга. Данные всегда собираются в числах, но числа не имеют значения, если они что-то не значат. 4,7,9 являются просто числами, если не указано иное, например, 4 яблока, 7 бананов и 9 киви.
Исследователи используют кросс-табулирование для изучения взаимосвязи в данных, которая не очевидна. Это весьма полезно в маркетинговых исследованиях и опросах. В перекрестном отчете показана связь между двумя или более вопросами, заданными в исследовании.
Понимание кросс-таблицы на примере
Кросс-таблица является популярным выбором для статистического анализа данных. Поскольку это инструмент отчетности/анализа, его можно использовать с любым уровнем данных: порядковым или номинальным. Он обрабатывает все данные как номинальные данные (номинальные данные не измеряются. Они классифицируются). Например, вы можете проанализировать связь между двумя категориальными переменными, такими как возраст и покупка электронных гаджетов.
Здесь задаются два вопроса:
В этом примере вы можете увидеть отчетливую связь между возрастом и покупкой электронных гаджетов. Неудивительно, но интересно видеть корреляцию между двумя переменными через собранные данные.
В обзорных исследованиях перекрестная таблица позволяет нам глубоко погрузиться и проанализировать предполагаемые данные, упрощая определение тенденций и возможностей, не перегружаясь всеми данными, собранными из ответов.
Перекрестная таблица и хи-квадрат
Хи-квадрат или критерий хи-квадрат Пирсона — это любая статистическая гипотеза, которую исследователи используют для определения того, существует ли значительная разница между ожидаемыми частотами и наблюдаемыми частотами в одной или нескольких категориях.
Важным соображением при сопоставлении результатов вашего исследования является проверка того, является ли представление кросс-таблицы истинным или ложным. Это похоже на сомнения, которые возникают у нас после поступления в университет, когда мы задаемся вопросом, действительно ли это подходит нам или нет. Чтобы решить дилемму, кросс-таблица вычисляется вместе с анализом хи-квадрат, который помогает определить, являются ли переменные исследования независимыми или связанными друг с другом. Если два элемента независимы, табуляция называется незначительной, а исследование — нулевой гипотезой. Поскольку факторы не связаны друг с другом, результат исследования недостоверен. Наоборот, если между двумя элементами существует взаимосвязь, это подтверждает, что результаты табулирования значимы и на них можно положиться при принятии стратегических решений.
Важным соображением при сопоставлении результатов вашего исследования является проверка того, является ли представление кросс-таблицы истинным или ложным.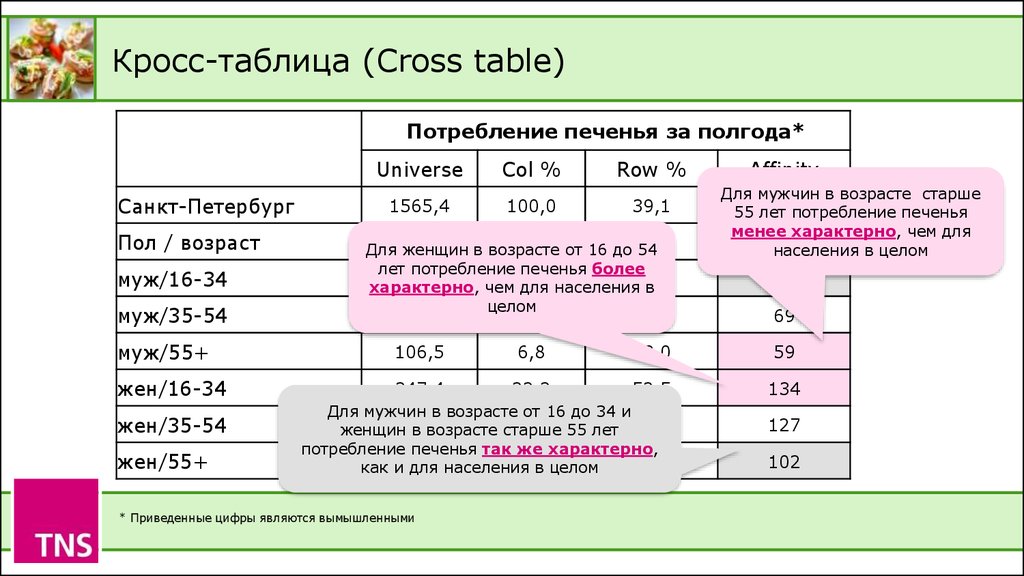 Это похоже на сомнения, которые возникают у нас после поступления в университет, когда мы задаемся вопросом, действительно ли это подходит нам или нет. Чтобы решить дилемму, кросс-таблица вычисляется вместе с анализом хи-квадрат, который помогает определить, являются ли переменные исследования независимыми или связанными друг с другом. Если два элемента независимы, табуляция называется незначительной, а исследование — нулевой гипотезой. Поскольку факторы не связаны друг с другом, результат исследования недостоверен. Наоборот, если между двумя элементами существует взаимосвязь, это подтверждает, что результаты табулирования значимы и на них можно положиться при принятии стратегических решений.
Это похоже на сомнения, которые возникают у нас после поступления в университет, когда мы задаемся вопросом, действительно ли это подходит нам или нет. Чтобы решить дилемму, кросс-таблица вычисляется вместе с анализом хи-квадрат, который помогает определить, являются ли переменные исследования независимыми или связанными друг с другом. Если два элемента независимы, табуляция называется незначительной, а исследование — нулевой гипотезой. Поскольку факторы не связаны друг с другом, результат исследования недостоверен. Наоборот, если между двумя элементами существует взаимосвязь, это подтверждает, что результаты табулирования значимы и на них можно положиться при принятии стратегических решений.
Еще один важный термин, который мы здесь введем, — нулевая гипотеза. Нулевая гипотеза предполагает, что любое различие или важность, которые можно увидеть в наборе данных, являются случайными. Противоположность нулевой гипотезе называется альтернативной гипотезой.
Применение хи-квадрата к опросам обычно выполняется с помощью следующих типов вопросов:
Например, нам нужно выяснить, существует ли связь между поведением покупателя при покупке электронных устройств и регионом, где они продаются. Данные будут введены как в таблице ниже:
Данные будут введены как в таблице ниже:
Как упоминалось ранее, критерий хи-квадрат помогает определить, связаны ли две дискретные переменные. При наличии ассоциации распределение одной переменной будет отличаться в зависимости от значения второй переменной. Но если две переменные независимы, распределение первой переменной будет одинаковым для всех значений второй переменной.
Используя кросс-таблицу и хи-квадрат, мы получаем следующий вывод:
Применяя вычисление хи-квадрат к приведенным выше значениям — хи-квадрат Пирсона = 0,803, P-значение = 0,05. Итак, что это значит? Нам нужно обратить внимание на p-значение. Сравните p-значение с вашим альфа-уровнем, который обычно равен 0,05.
Если p-значение меньше или равно альфа-значению, то две переменные связаны.
Если p-значение больше альфа-значения, можно сделать вывод, что переменные независимы.
В этом примере статистика хи-квадрат Пирсона равна 0,803 (с p-значением 0,05). Таким образом, при значении альфа 0,05 мы делаем вывод, что корреляция отсутствует и незначительна.
Таким образом, при значении альфа 0,05 мы делаем вывод, что корреляция отсутствует и незначительна.
Кросс-таблица и хи-квадрат
Одним из существенных преимуществ использования перекрестных таблиц в опросе является простота вычислений и чрезвычайно легкое понимание. Даже если исследователь не обладает глубоким знанием концепции, интерпретировать результаты не составляет труда.
Устраняет путаницу, поскольку исходные данные иногда сложно понять и интерпретировать. Даже при наличии небольших наборов данных вы можете запутаться, если данные расположены неупорядоченно. Кросс-табуляция предлагает простой способ корреляции переменных, который помогает свести к минимуму путаницу, связанную с представлением данных.
С помощью перекрестных таблиц можно получить многочисленные сведения. Как упоминалось в примерах перекрестных таблиц в разделе выше, интерпретировать необработанные данные непросто. Кросс-таблица отображает корреляцию между переменными, ясно понимаются идеи, которые в противном случае могли быть упущены из виду.
 Легко понять выводы даже из сложной формы статистики.
Легко понять выводы даже из сложной формы статистики.С легкостью предоставляет квалифицированные или относительные данные по двум или более переменным для нескольких функций.
Наиболее важным преимуществом использования перекрестных таблиц для анализа опроса является простота использования любых данных, будь то номинальные, порядковые, интервальные или относительные.
Кросс-таблица с помощью QuestionPro
1. Войдите в свою учетную запись QuestionPro и выберите опрос, который хотите проанализировать.
2. В разделе «Аналитика» вы найдете опцию «Анализ». Щелкните Cross-Tabulation в разделе Analysis.
3. Выберите вопрос в строке и вопрос в столбце из раскрывающегося списка соответственно.
4. Таблица кросс-таблиц будет создана вместе с анализом хи-квадрат Пирсона.
5. После создания отчета его также можно загрузить.
Перекрестное табулирование: как оно работает и зачем его использовать — Atlan
Перекрестное табулирование — это метод количественного анализа взаимосвязи между несколькими переменными.

Также известные как таблицы непредвиденных обстоятельств или перекрестные таблицы, перекрестные таблицы группируют переменные для понимания корреляции между различными переменными. Он также показывает, как корреляции изменяются от одной группы переменных к другой. Обычно он используется в статистическом анализе для поиска закономерностей, тенденций и вероятностей в необработанных данных.
Когда можно использовать перекрестное табулирование
Перекрестное табулирование обычно выполняется на категориальных данных — данных, которые можно разделить на взаимоисключающие группы.
Примером категорийных данных является регион продаж продукта. Как правило, регион можно разделить на такие категории, как географическая область (север, юг, северо-восток, запад и т. д.) или штат (Андра-Прадеш, Раджастхан, Бихар и т. д.). Важно помнить о категориальных данных: точка категориальных данных не может принадлежать более чем к одной категории.
Перекрестные таблицы используются для изучения взаимосвязей в данных, которые могут быть неочевидными. Перекрестное табулирование особенно полезно при изучении маркетинговых исследований или ответов на опросы. Перекрестное табулирование категорийных данных может быть выполнено с помощью таких инструментов, как SPSS, SAS и Microsoft Excel.
Перекрестное табулирование особенно полезно при изучении маркетинговых исследований или ответов на опросы. Перекрестное табулирование категорийных данных может быть выполнено с помощью таких инструментов, как SPSS, SAS и Microsoft Excel.
Пример перекрестной таблицы
«Ни один другой инструмент в Excel не дает вам такой гибкости и аналитических возможностей, как сводная таблица».
Bill Jalen
Одним из простых способов составления перекрестных таблиц является функция сводной таблицы Microsoft Excel. Сводные таблицы — отличный способ поиска шаблонов, поскольку они помогают легко группировать необработанные данные.
Рассмотрим приведенный ниже пример набора данных в Excel. Он отображает сведения о коммерческих транзакциях для четырех категорий продуктов. Давайте используем этот набор данных, чтобы показать кросс-таблицу в действии.
Эти данные можно преобразовать в формат сводной таблицы, выбрав всю таблицу и вставив сводную таблицу в файл Excel. Таблица может сопоставлять различные переменные по строкам, по столбцам или по значениям как в формате таблицы, так и в формате диаграммы.
Таблица может сопоставлять различные переменные по строкам, по столбцам или по значениям как в формате таблицы, так и в формате диаграммы.
Воспользуемся кросс-табулированием для проверки связи между типом способа оплаты (например, Visa, MasterCard, PayPal и т. д.) и категорией продукта по отношению к региону продаж. Мы можем выбрать эти три категории в сводной таблице.
Затем результаты появляются в сводной таблице:
Теперь ясно, что самые высокие продажи были сделаны для P1 с использованием Master Card. Таким образом, мы можем сделать вывод, что платежный метод MasterCard и категория продукта P1 являются наиболее выгодным сочетанием.
Точно так же мы можем использовать перекрестную таблицу и найти связь между категорией продукта и типом способа оплаты в отношении количества транзакций.
Это можно сделать, сгруппировав способ оплаты, категорию продукта и количество проданных единиц:
По умолчанию сводная таблица Excel объединяет значения в виде суммы. Суммируя единицы, мы получим общее количество проданных единиц. Поскольку мы хотим сравнить количество транзакций, а не количество проданных единиц, нам нужно изменить настройку поля «Значение» с «Сумма» на «Подсчет единиц».
Суммируя единицы, мы получим общее количество проданных единиц. Поскольку мы хотим сравнить количество транзакций, а не количество проданных единиц, нам нужно изменить настройку поля «Значение» с «Сумма» на «Подсчет единиц».
Результаты сопоставления этой сводной таблицы показаны ниже. Это кросс-табличный анализ 3 переменных — он анализирует корреляцию между способом оплаты и категорией оплаты по количеству транзакций.
Для всех регионов мы можем наблюдать, что самой продаваемой категорией продуктов была P1, и наибольшее количество транзакций было совершено с использованием Master Card. Мы также можем увидеть предпочтительный способ оплаты в каждой из категорий продуктов. Например, American Express является предпочтительной картой для продуктов P2.
Преимущества перекрестных таблиц
Теперь, когда мы поняли, как использовать перекрестные таблицы, давайте кратко рассмотрим преимущества использования перекрестных таблиц.
Исключает путаницу при интерпретации данных Необработанные данные могут быть трудны для интерпретации.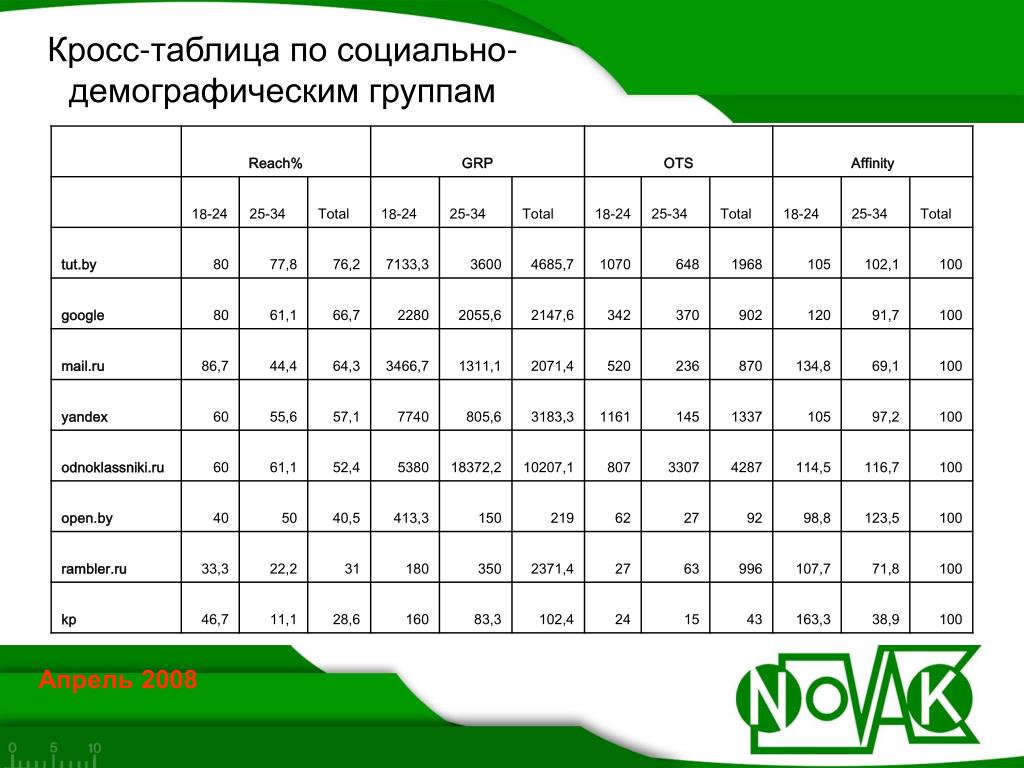 Даже для небольших наборов данных слишком легко получить неправильные результаты, просто взглянув на данные. Перекрестная таблица предлагает простой метод группировки переменных, который сводит к минимуму возможность путаницы или ошибки, предоставляя четкие результаты.
Даже для небольших наборов данных слишком легко получить неправильные результаты, просто взглянув на данные. Перекрестная таблица предлагает простой метод группировки переменных, который сводит к минимуму возможность путаницы или ошибки, предоставляя четкие результаты.
Как мы видели в нашем примере, перекрестное табулирование может помочь нам извлечь важные идеи из необработанных данных. Эти идеи нелегко увидеть, когда необработанные данные отформатированы в виде таблицы. Поскольку перекрестное табулирование четко отображает отношения между категориальными переменными, исследователи могут получить более качественные и более глубокие знания — идеи, которые в противном случае были бы упущены из виду или потребовалось бы много времени для расшифровки из более сложных форм статистического анализа.
Предлагает точки данных для планирования действий Перекрестная таблица облегчает интерпретацию данных, что полезно для исследователей, которые имеют ограниченные знания в области статистического анализа.