Выделение фрагментов таблицы
⇐ ПредыдущаяСтр 8 из 13Следующая ⇒Если планируется копировать или перемещать строки, столбцы или ячейки таблицы, то их вначале нужно выделить. В таблице 5 приведены некоторые методы выделения фрагментов таблицы.
Таблица 5 — Методы выделения фрагментов таблицы
| Область выделения | Способ выделения |
| Вся таблица | Щелкните на таблице и затем – на маркере перемещения в левом верхнем углу таблицы |
| Одна строка | Щелкните левее начала строки, вне таблицы Двойной щелчок по левой границе таблицы напротив строки (курсор в виде черной стрелки) |
| Один столбец | Щелчок по верхней границе таблицы напротив столбца (курсор в виде черной стрелки) |
| Одна ячейка | Щелчок по левой границе нужной ячейки (курсор в виде черной стрелки) |
| Несколько ячеек, строк или столбцов | Поставьте курсор в один элемент и перетащите указатель мыши на остальные |
Добавление строк и столбцов
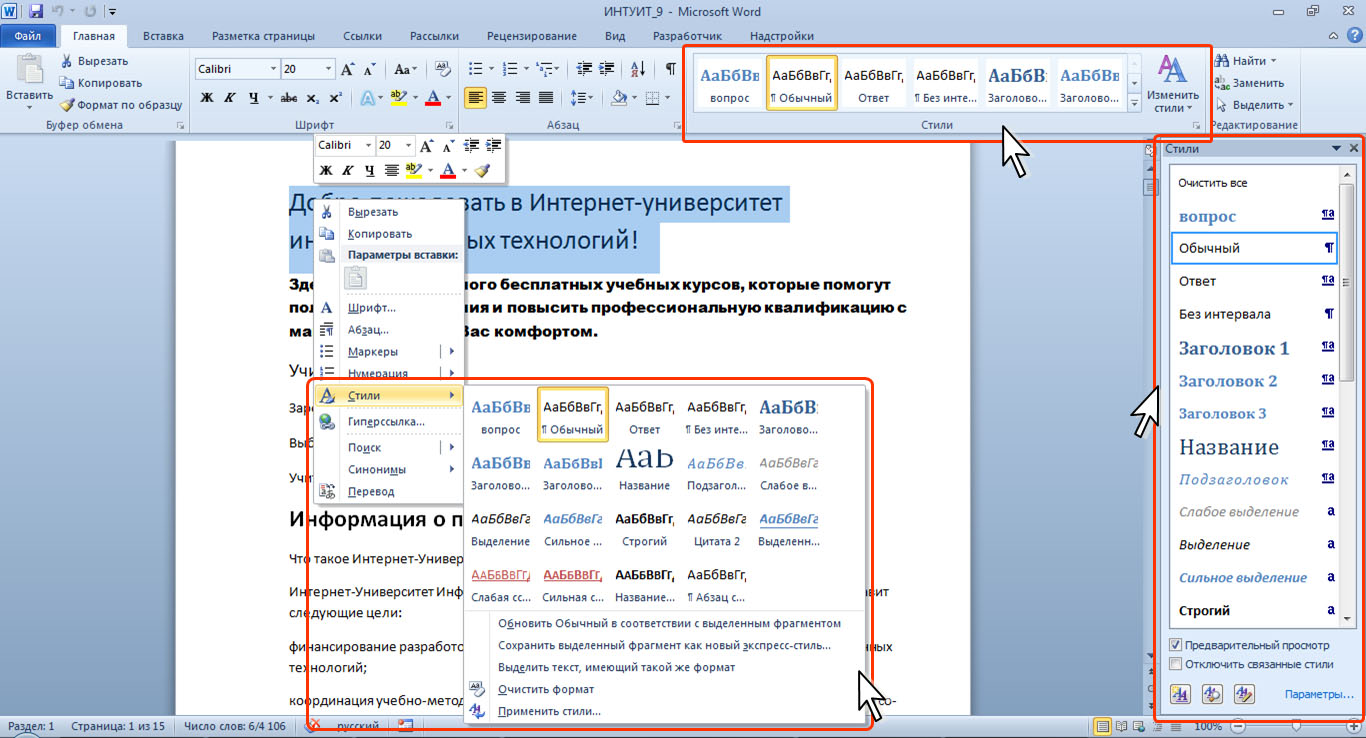
Для добавления строк в таблицу можно воспользоваться контекстной вкладкой Макет. Курсор устанавливается в нужное место таблицы и редактирование осуществляется с помощью кнопок в группе Столбцы и строки на контекстной вкладке Макет (Рис. 33А).
Курсор устанавливается в нужное место таблицы и редактирование осуществляется с помощью кнопок в группе Столбцы и строки на контекстной вкладке Макет (Рис. 33А).
Рис. 33. Контекстное меню Макет
Также для редактирования таблицы можно воспользоваться контекстным меню. Для этого необходимо щелкнуть правой кнопкой мыши по любой ячейке строки таблицы, выше или ниже которой требуется вставить новую строку, и выбрать нужную команду Вставить или Удалить ячейку. Если в таблицу требуется вставить сразу несколько новых строк, то следует выделить в таблице такое же число строк, а затем воспользоваться любым из описанных выше способов.
При работе с клавиатурой для вставки строки можно поставить курсор справа от самой правой ячейки строки (вне таблицы) и нажать клавишу Enter.
Новую строку в конце таблицы можно добавить, если, находясь в последней ячейке последней строки таблицы, нажать клавишу Tab.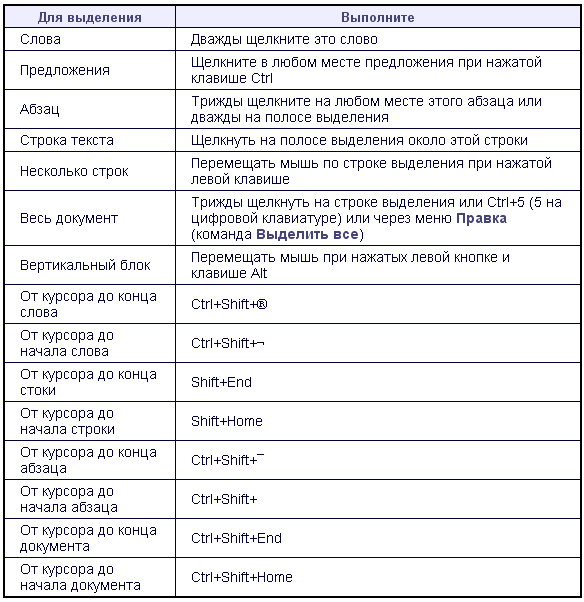
Для редактирования таблицы служит группа Объединить вкладки Макет. С её помощью можно объединить несколько строк (столбцов, ячеек) в одну, разбить одну строку (столбец, ячейку) на несколько, разбить одну таблицу на две отдельные (Рис. 33Б).
Для вставки ячеек надо нажать кнопку запуска окна диалога в группе
Рис. 34. Вызов диалогового окна Добавление ячеек
Изменение ширины столбца и высоты строки
Размеры строки или столбца можно быстро изменить перетаскиванием границы, для чего необходимо навести указатель мыши на границу так, чтобы он превратился в двунаправленную стрелку. Нажать левую кнопку мыши и перетащите маркер.
Для одновременного изменения высоты всех строк и ширины всех столбцов таблицы надо навести курсор на маркер конца таблицы, расположенный около ее правого нижнего угла так, чтобы он превратился в двунаправленную стрелку.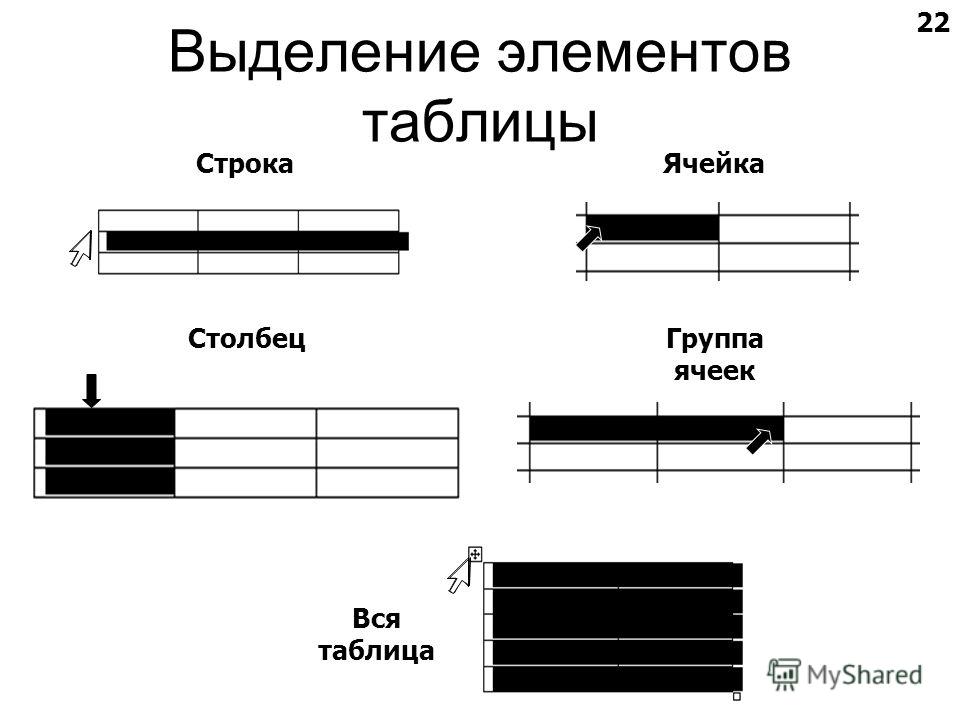 В процессе перетаскивания указатель мыши примет вид крестика, а граница таблицы будет отображаться пунктиром.
В процессе перетаскивания указатель мыши примет вид крестика, а граница таблицы будет отображаться пунктиром.
Форматирование данных
Для выполнения форматирования данных (распределение данных, изменение направления текста, добавление границ или заливки и т.д.) используются команды с контекстных вкладок Конструктор и Макет (Рис. 35).
Все те же операции можно выполнить через контекстное меню если поставить курсор в любую ячейку таблицы и нажать правую клавишу мыши.
Рис. 35. Команды для форматирования данных в таблице
Сортировка данных
Сортировка — расположение строк в таблице в определенном порядке. Чаще всего необходимо сортировать строки по данным какого-либо одного или нескольких столбцов. Сортировку можно производить как по возрастанию, так и по убыванию.
Сортировку таблицы можно выполнять при работе во вкладке Главная или Макет (кнопка Сортировка).
Вычисления в таблицах
В таблицах Word можно выполнять несложные вычисления с использованием формул. Для этого необходимо установить курсор в ячейку, в которой требуется получить результат вычисления. Во вкладке Макет в группе Данные нажать кнопку Формула. В окне Формула в поле Формула ввести формулу (Рис. 36). Формула начинается со знака = (равно) и может содержать адреса ячеек, операторы (знаки действий) и функции. При желании в списке поля Формат числа можно выбрать числовой результата вычисления (числовой с разделителем разрядов, денежный, процентный).
В Word 2007 можно использовать 18 функций. Их можно вводить с клавиатуры или выбрать в раскрывающемся списке Вставить функцию. Наиболее часто используют функции:
ABS( ) — абсолютное значение;
AVERAGE( )— среднее значение;
MIN( ) — наименьшее значение;
MAX( ) — наибольшее значение;
SUM( ) — сумма.
В круглых скобках записывается аргумент функции. Аргументом может быть число, адрес ячейки или диапазон ячеек, имя закладки, функция. Если в формуле присутствует слово ABOVE, например, =SUM(ABOVE), то оно означает выбор значений из диапазона ячеек, расположенных выше ячейки, в которой находится формула. При изменении данных результат вычислений автоматически не меняется, для этого надо выделить результат, правой клавишей открыть контекстное меню и выбрать 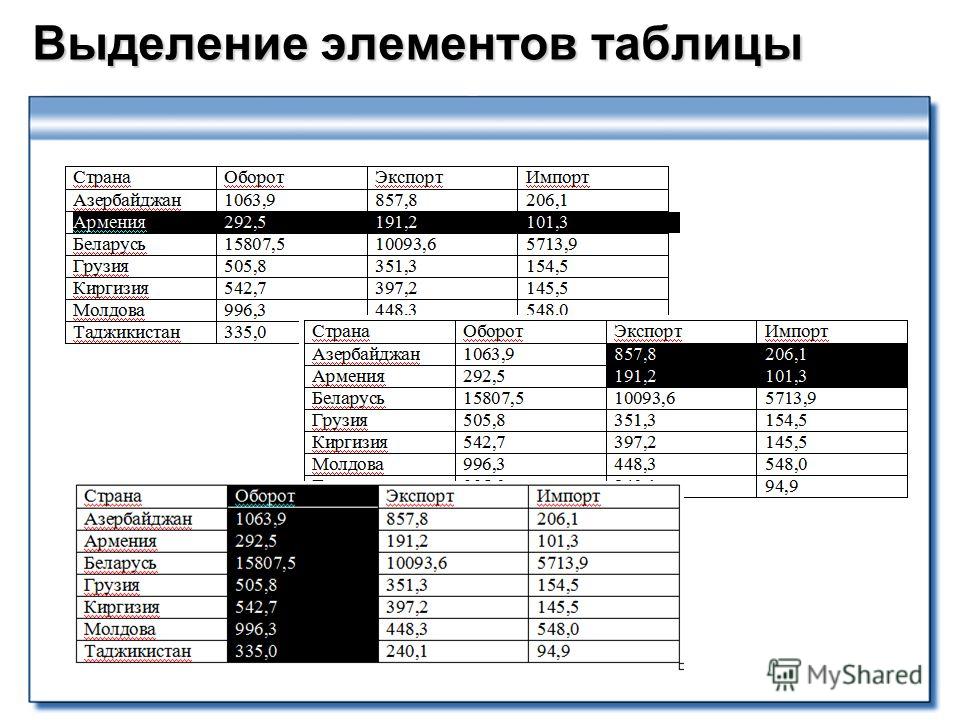
Рис. 36. Диалоговое окно Формула
ДИАГРАММЫ
Создание простых диаграмм
Кроме графических файлов, в документы Word можно вставлять диаграммы. При помощи диаграмм можно наглядно представить числовые данные, например проследить, как из, меняются данные, увидеть развитие того или иного проекта в динамике. Для создания диаграммы необходимо:
1. Установить курсор в место, куда нужно вставить диаграмму.
2. Перейти на вкладку Вставка, в группе Иллюстрации нажать кнопку Диаграмма.
3. В появившемся окне Вставка диаграммы выбрать в списке слева тип диаграммы, а в списке справа — вид диаграммы указанного типа (Рис. 37).
Рис. 37. Диалоговое окно Вставка диаграммы
В документе появится диаграмма и откроется окно Excel c таблицей для ввода данных. В эту таблицу необходимо ввести числовые значения и пояснения к ним. Чтобы изменения, внесенные в ячейку таблицы данных, отобразились на диаграмме, необходимо нажать клавишу Enter. После ввода данных необходимо закрыть окно Exсel (Рис. 38).
В эту таблицу необходимо ввести числовые значения и пояснения к ним. Чтобы изменения, внесенные в ячейку таблицы данных, отобразились на диаграмме, необходимо нажать клавишу Enter. После ввода данных необходимо закрыть окно Exсel (Рис. 38).
Рис. 38. Диаграмма и таблица данных
При построении диаграммы этим способом никакие исходные данные не используются. Таблица, которая открывается в Excel содержит произвольные данные, которые необходимо менять вручную. Если уже в Word уже имеется таблица с данными, то можно построить диаграмму по уже имеющимся данным.
Первый способ: Скопировать таблицу в Excel, построить там диаграмму, скопировать готовую диаграмму обратно в Word.
Второй способ: Выделить всю таблицу или ее часть. Воспользоваться надстройкой Microsoft Graph (Вставка ® Объект ® Объект… ® Диаграмма Microsoft Graph). После запуска Microsoft Graph будет создана диаграмма, основанная на содержимом выделенной таблицы (части таблицы).
После запуска Microsoft Graph будет создана диаграмма, основанная на содержимом выделенной таблицы (части таблицы).
Вместе с диаграммой на экране отобразится таблица данных (таблица, на основе которой была создана диаграмма). Если диаграмма создавалась без предварительного выделения таблицы или ее элементов, то на экране появится стандартная таблица данных и диаграмма. При необходимости можно менять данные в таблице данных, что автоматически приведет к изменению диаграммы.
Читайте также:
Способы выделения объектов таблицы — Студопедия
После того как мы создали новую книгу Excel, сохранили ее и убедились в том, что можем снова открыть, обратимся к инструментам форматирования. Все они собраны на соответствующей панели.
Однако для того чтобы совершить любую операцию по форматированию или редактированию ячеек при помощи инструментов, программе Excel необходимо указать, к чему относится отдаваемая вами команда. Для указания объекта, над которым вы производите действие, его нужно пометить (выделить).
Для указания объекта, над которым вы производите действие, его нужно пометить (выделить).
ВНИМАНИЕ
Если вы щелкаете мышью, а команда не выполняется, то в 99% случаев это значит, что вы не указали Excel, над чем именно должно быть произведено желаемое вами действие. По умолчанию в Excel всегда выделена какая-либо одна ячейка.
Выделение можно выполнять при помощи мыши.
О Щелчок мышью на заголовке столбца выделяет целиком столбец (рис. 3.2).
Рис. 3.2.Выделение столбца
О Щелчок мышью на номере строки выделяет целиком строку (рис. 3.3).
Рис. 3.3.Выделение строки
О Несколько ячеек по вертикали, горизонтали или в прямоугольном блоке можно выделить тем же приемом, который используется при перетаскивании объектов, то есть нажав кнопку мыши в начале выделяемого фрагмента и отпустив в его конце (рис.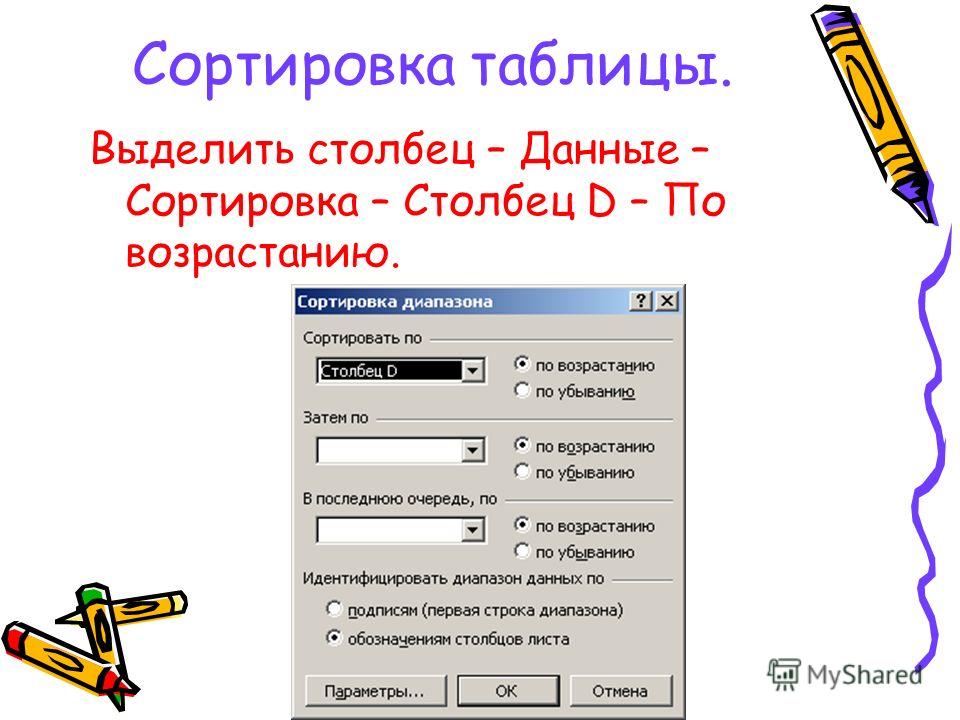 3.4).
3.4).
Рис. 3.4.Выделение прямоугольного блока
О Несколько строк можно выделить, нажав кнопку мыши на первом выделяемом номере строки и отпустив на последнем. Несколько столбцов можно выделить, нажав кнопку мыши на первом выделяемом заголовке столбца и отпустив на последнем.
О Нажав и удерживая клавишу Ctrl, можно выделить одновременно и столбец, и строку (рис. 3.5). Точно так же можно выделять несмежные ячейки или блоки ячеек (рис. 3.6).
Рис. 3.5.Одновременное выделение строки и столбца
О Щелчок на верхнем левом углу таблицы (пустой прямоугольник на пересечении названий столбцов и номеров строк) выделяет всю таблицу целиком.
Для того чтобы убрать выделение, достаточно щелкнуть мышью на любом свободном месте листа.
При помощи клавиатуры выделение фрагментов производится передвижением курсора клавишами со стрелками при нажатой клавише Shift.
Рис. 3.6.Выделение несмежных прямоугольных блоков
3.6.Выделение несмежных прямоугольных блоков
Выделение фрагментов — Студопедия
Для выполнения каких-либо операций над ячейкой или группой ячеек должен быть выделен соответствующий фрагмент таблицы. Выделяемый фрагмент может содержатьодну или несколько прямоугольных групп смежных ячеек таблицы.
Выделение группы смежных фрагментов с помощью мыши
· Выделение отдельной ячейки осуществляется с помощью щелчка клавишей мыши на ячейке.
· Выделение произвольной группы подряд расположенных ячеек осуществляется буксировкой выделения от первой к последней ячейке группы.
· Выделение произвольной группы подряд расположенных ячеек можно выполнить и по-другому: выполняется щелчок клавишей мыши на первой ячейке группы, затем нажимается клавиша Shift и выполняется щелчок на последней ячейке группы.
· Выделение одной строки таблицы осуществляется с помощью щелчка на ее заголовке.
· Для выделения группы строк следует описанным выше способом выделить первую строку группы и отбуксировать выделение к последней строке или после выделения первой строки нажать кнопку Shift и затем выполнить щелчок на названии последней строки.
· Выделение одного столбца таблицы осуществляется с помощью щелчка мыши на его заголовке.
· Выделение группы столбцов производится аналогично выделению группы строк, то есть вначале нужно только что описанным способом выделить первый столбец группы, затем выделение буксируется к последнему столбцу или же, после нажатия клавиши Shift, выполняется щелчок на заголовке последнего столбца группы.
Клавиатурные способы выделения группы смежных фрагментов
· Выделение одной ячейки таблицы, находящейся справа от текущей, можно выполнить, нажав клавишу Tab или клавишу направления ->;
· Выделение одной ячейки таблицы, находящейся слева от текущей, можно выполнить, используя сочетание клавиш Shift+Tab или нажав клавишу направления <-;
· Выделение одной ячейки таблицы, находящейся над текущей, можно выполнить, нажав клавишу направления стрелка вверх;
· Выделение одной ячейки таблицы, находящейся пой текущей, можно выполнить, нажав клавишу направления стрелка вниз;
· Выделение произвольной группы ячеек можно осуществить следующим способом. Вначале произвольным способом выделяется одна ячейка, затем нажимается и удерживается в нажатом состоянии клавиша Shift. Выделение продолжается в любом направлении от уже выделенной ячейки нажатием на клавиши соответствующих направлений. Если использовать клавиши стрелки вверх и вниз (Shift+стрелки), то выделение будет распространяться по столбцу, а при использовании клавиш <- и -> (Shjft+<- и Shlft+->) выделение будет расширяться по строке.
Вначале произвольным способом выделяется одна ячейка, затем нажимается и удерживается в нажатом состоянии клавиша Shift. Выделение продолжается в любом направлении от уже выделенной ячейки нажатием на клавиши соответствующих направлений. Если использовать клавиши стрелки вверх и вниз (Shift+стрелки), то выделение будет распространяться по столбцу, а при использовании клавиш <- и -> (Shjft+<- и Shlft+->) выделение будет расширяться по строке.
Выделение несмежных фрагментов
Несмежными считаются такие участки таблицы, которые разделены хотя бы одним столбцом или хотя бы одной строкой, не входящей в рассматриваемые участки. Таким образом, несмежный фрагмент фактически представляет собой несколько смежных фрагментов. Для выделения несмежного фрагмента можно использовать все только что описанные приемы, но во время выделения необходимо удерживать в нажатом состоянии клавишу Ctrl.
Снятие выделения
Если во время выделения фрагмента в него случайно попали какие-либо не принадлежащие ему ячейки, строки или столбцы, то выделение нужно снять и более аккуратно повторить процесс выделения фрагмента. Снятие выделения осуществляется щелчком на любой не принадлежащей фрагменту ячейке, нажатием на одну из клавиш направлений или же клавиши Home, End, PageUp, PageDown.
Снятие выделения осуществляется щелчком на любой не принадлежащей фрагменту ячейке, нажатием на одну из клавиш направлений или же клавиши Home, End, PageUp, PageDown.
совет ———————————————————————————————
Выполнять запланированное действие над фрагментом лучше всего сразу же после его выделения, так как любое случайное нажатие клавиши мыши или указанные клавиши клавиатуры может снять выделение и все действия по выделению фрагмента придется повторить сначала.
———————————————————————————————————
Выделение таблицы Word с помощью мышки и клавиш
Для редактирования и форматирования таблиц нужно сначала выделить то, что нужно поменять. При этом нужно учесть, что в отличие от выделения фрагмента текста, при выделении таблицы есть, так сказать, два направления:
- выделение содержимого таблицы;
- выделение элемента таблицы.

А определить, что выделено можно по внешнему виду.
Можно выделять, просто потянув мышку по таблице. Кроме этого метода выделения, Word предлагает простые и очень удобные возможности для выделения. Об этих возможностях Ворда эта статья.
Попробуйте все варианты и выберите самый удобный для Вас.
Для снятия выделения нужно:
- щелкнуть мышкой
- нажать клавишу перемещения курсора.
Кстати. Если, выделив текст, нажать какую-нибудь клавишу, то текст заменится на этот знак. Не сотрите нужное. 🙂
ВЫДЕЛЕНИЕ ЭЛЕМЕНТА ТАБЛИЦЫ С ПОМОЩЬЮ ЛЕНТЫ
- Поставьте курсор в нужную ячейку таблицы. На ленте появится комплект вкладок Работа с таблицами.
- На вкладке Макет нажмите кнопку Выделить.
- Выберите в списке нужное.
ВЫДЕЛЕНИЕ ТАБЛИЦЫ С ПОМОЩЬЮ МЫШКИ
- Основной метод выделения мышкой.
Поставив курсор в начало, нажать на левую кнопку и тянуть мышь до окончания фрагмента. Так выделять не очень удобно.
Так выделять не очень удобно.
А можете попробовать так
- Основной метод выделения мышкой.
| Выделение текста и элемента таблицы | Мышка |
|---|---|
| wordprogram.ru | |
| Выделение содержимого таблицы | |
| Слово | Двойной щелчок по нужному слову |
| Предложение | CTRL+ щелчок по предложению |
| От курсора до нужного места в ячейке | Очень удобный метод для выделения длинного фрагмента Поставив курсор в начало, нажать SHIFT и щелкнуть на окончании фрагмента. На Веб-странице сначала нужно выделить начало фрагмента, а после нажать SHIFT и щелкнуть на окончании. |
| Выделение элемента таблицы | |
| Ячейка | Тройной щелчок по тексту в ячейке |
- Курсор слева от таблицы и на левой линии рамки столбца примет вид стрелки. С её помощью тоже можно выделять.
- Курсор слева от таблицы и на левой линии рамки столбца примет вид стрелки. С её помощью тоже можно выделять.
| Выделение элемента таблицы | Эскиз курсора | Одинарный щелчок мышкой |
|---|---|---|
| wordprogram.ru | ||
| Строка* таблицы | Левее строки таблицы | |
| Ячейка* | По левой линии рамки ячейки | |
| Столбец* | Сверху столбца | |
| Таблица | По квадрату со стрелками в левом верхнем углу таблицы | |
*Если, щелкнув, не отпустить кнопки и потянуть мышку, станут выделяться следующие строки ячейки и столбцы.
- Выделение несмежных фрагментов.
Теперь можно мышкой выделять несмежные элементы таблицы, а так же снять выделение, нажав при выделении клавишу CTRL.
- Выделение несмежных фрагментов.
А при выделении только текста, даже в соседних ячейках, тоже нажмите клавишу CTRL.
ВЫДЕЛЕНИЕ ТАБЛИЦЫ С ПОМОЩЬЮ СОЧЕТАНИЙ КЛАВИШ
| Выделение текста и элемента таблицы | Сочетание клавиш |
|---|---|
wordprogram. ru ru | |
| Выделение текста в одной ячейке | |
| Выделение текста в ячейке перед ячейкой, в которой стоит курсор | SHIFT+TAB |
| Выделение текста в ячейке после ячейки, в которой стоит курсор | TAB |
| Выделение ячейки | |
| Выделение нескольких соседних ячеек рядом с выделенной ячейкой | При нажатой клавише SHIFT несколько раз нажмите соответствующую клавишу СТРЕЛКА |
| По строкам | |
| Выделение строк выше выделенной строки | При нажатой клавише SHIFT несколько раз нажмите клавишу СТРЕЛКА ВВЕРХ |
| Выделение строк ниже выделенной строки | При нажатой клавише SHIFT несколько раз нажмите клавишу СТРЕЛКА ВНИЗ |
| Перенести всю строку на одну строку вверх с выделением содержимого | ALT+SHIFT+СТРЕЛКА ВВЕРХ |
| Перенести всю строку на одну строку вниз с выделением содержимого | ALT+SHIFT+СТРЕЛКА ВНИЗ |
| По столбцам | |
| Выделение столбца от курсора до верхней ячейки | SHIFT+ALT+PAGE UP |
| Выделение столбца от курсора до нижней ячейки | SHIFT+ALT+PAGE DOWN |
| Выделение всего столбца, если курсор стоит в верхней ячейке | SHIFT+ALT+PAGE DOWN |
| Выделение всего столбца, если курсор стоит в нижней ячейке | SHIFT+ALT+PAGE UP |
| Таблица | |
| Выделение всей таблицы | ALT+5 на цифровой клавиатуре (при выключенном индикаторе NUM LOCK) |
РЕЖИМ ВЫДЕЛЕНИЯ
Для удобства пользования этим методом нужно нажать правой кнопкой мышки на строке состояния и в контекстном меню поставить напротив Режим выделения галочку. Тогда при включении выделения будет видно название.
Тогда при включении выделения будет видно название.
Если передумали форматировать текст, не забудьте отключить режим выделения.
Расширяемое выделение
- Включение расширяемого выделения.
Нажмите клавишу F8. В строке состояния появится надпись Режим выделения. - Выделение текста.
Выделять текст от курсора до нужного места в документе можно мышкой, а можно клавишами.Выделение текста Клавиша wordprogram.ru Клавишами перемещения курсора По знакам СТРЕЛКА ВЛЕВО
СТРЕЛКА ВПРАВОПо строкам СТРЕЛКА ВВЕРХ
СТРЕЛКА ВНИЗКлавишей F8 Слово с курсором Второй раз нажать клавишу F8 Предложение Третий раз нажать клавишу F8 Абзац Четвертый раз нажать клавишу F8 Весь текст Пятый раз нажать клавишу F8 - Уменьшение и отключение режима выделения.

Для уменьшения выделения нажмите SHIFT+F8.
Для отключения режима выделения.- Нажмите клавишу ESC.
- Щелкнув мышкой на названии Расширяемое выделение в строке состояния.
Как выделить ячейки в Эксель
Прежде, чем приступить к выполнению действий с ячейками в таблицах Эксель, для начала нужно их выделить. В программе есть возможность сделать это разными методами, которые позволяют отметить как отдельные ячейки, так и целые строки, столбца, а также произвольные диапазоны элементов. Ниже мы разберем все методы, пользуясь которыми можно выполнить данные процедуры.
Выделение отдельной ячейки
Пожалуй, это одно из самых простых и базовых действий, выполняемых в Эксель. Чтобы выделить конкретную ячейку щелкаем по ней левой кнопкой мыши.
Чтобы отметить нужную ячейку можно использовать навигационные клавиши на клавиатуре: “вправо”, “влево”, вверх”, “вниз”.
Выделяем столбец
Выделить столбец в Эксель можно несколькими способами:
- Зажав левую кнопку мыши тянем ее указатель от первой ячейки до последней, после чего отпускаем кнопку. Действие можно выполнять как сверху вниз (первая ячейка – самая верхняя, последняя – самая нижняя), так и снизу вверх (первая ячейка – самая нижняя, последняя – самая верхняя).
- Щелкаем по первой ячейке столбца, далее зажав клавишу Shift, кликаем по последней ячейке столбца, после чего отпускаем клавишу Shift. Как и в первом способе, выделение можно выполнять в обе стороны: и вверх, и вниз.
- Также, вместо мыши вместе с Shift мы можем использовать клавиши навигации. Щелкаем по первой ячейке столбца, далее зажимаем Shift, после чего нажимаем клавишу вверх (или вниз в зависимости от того, какую ячейку мы выбрали в качестве первой – самую верхнюю или самую нижнюю) ровно столько раз, сколько ячеек мы хотим добавить в выделяемый диапазон.
 Одно нажатие на клавишу – одна ячейка. После того, как все нужные элементы отмечены, отпускаем клавишу Shift.
Одно нажатие на клавишу – одна ячейка. После того, как все нужные элементы отмечены, отпускаем клавишу Shift. - Кликаем по первой ячейка столбца, после чего нажимаем сочетание клавиш Ctrl+Shif+стрелка вниз. В результате будет выделен весь столбец, охватив все ячейки, в которых есть данные. Если мы хотим выполнить выделение снизу вверх, то соответственно, нажимаем комбинацию Ctrl+Shif+стрелка вверх, предварительно встав в самую нижнюю ячейку.Тут есть один нюанс. При использовании данного способа нужно убедиться в том, что в отмечаемом столбце нет пустых элементов, иначе выделение будет произведено лишь до первой незаполненной ячейки.
- Когда вместо выделения столбца таблицы нужно отметить весь столбец книги, щелкаем по его обозначению на координатной панели (курсор должен изменить свой привычный вид на стрелку, направленную вниз):
- если выбран стиль A1, то в качестве названия столбцов используются латинские буквы.
- при стиле R1C1 для обозначения столбцов используются их порядковые номера.
- если выбран стиль A1, то в качестве названия столбцов используются латинские буквы.
- В случае, когда требуется одновременное выделение нескольких столбцов книги, расположенных подряд, зажав левую кнопку мыши проводим курсором по всем нужным наименованиям столбцов на координатной панели.
- Также для этих целей можно воспользоваться клавишей Shift. Щелкаем по первому столбцу на панели координат, затем, зажав клавишу Shift, кликаем по последнему, после чего отпускаем клавишу.
- В случаях, когда столбцы расположены не подряд, зажав клавишу Ctrl на клавиатуре щелкаем на координатной панели по наименованиям всех нужных столбцов, после чего отпускаем клавишу.
Выделяем строку
По такому же алгоритму производится выделение строк в Excel. Выполнить это можно разными способами:
- Чтобы выделить одну строку в таблице, зажав левую кнопку мыши, проходим по всем нужным ячейкам (слева направо или наоборот), после чего отпускаем кнопку.

- Кликаем по первой ячейки строки, затем, зажав клавишу Shift, щелкаем по последней ячейке, и отпускаем клавишу. Выполнять данную процедуру можно в обе стороны.
- Совместно с клавишей Shift вместо левой кнопки мыши можно использовать клавиши навигации. Кликаем по первой ячейке строки, зажимаем клавишу Shift и жмем клавишу вправо (или влево, в зависимости от того, какую ячейку мы выбрали в качестве первой – самую левую или самую правую). При таком выделении одно нажатие навигационной клавиши равно одной выделенной ячейке. Как только мы выделили все требуемые элементы, можно опускать клавишу Shift.
- Щелкаем по первой ячейке строки, затем жмем сочетание клавиш Ctrl+Shif+стрелка вправо.Таким образом, будет выделена вся строка с охватом всех заполненных ячеек, но с важной оговоркой – выделение будет выполнено до первой пустой ячейки. Если мы хотим выполнить выделение справа налево, следует нажать сочетание клавиш Ctrl+Shif+стрелка влево.

- Чтобы выделить строку не только таблицы, но и всей книги, кликаем по ее порядковому номеру на координатной панели (вид курсора при наведении на панель должен смениться на стрелку, направленную вправо).
- Когда требуется одновременное выделение нескольких соседних строк, зажав левую кнопку мыши проходим на координатной панели по всем требуемым порядковым номерам.
- Когда нужно сразу выделить несколько соседних строк книги, можно использовать клавишу Shift. Для этого кликаем на координатной панели по номеру первой строки, затем зажимаем клавишу Shift, кликаем по последней строке и отпускаем клавишу.
- Когда требуется выделение строк книги, расположенных не по соседству, зажав клавишу Ctrl на клавиатуре, поочередно щелкаем по обозначениям всех нужных строк на координатной панели.
Выделяем диапазон ячеек
В данной процедуре как и в тех, что были описаны ранее, нет ничего сложного, и она также выполняется разными способами:
- Зажав левую кнопку мыши проходим по всем ячейкам требуемой области, двигаясь по диагонали:
- от самой верхней левой ячейки до самой нижней правой
- от самой нижней правой ячейки до самой верхней левой
- от самой верхней правой ячейки до самой нижней левой
- от самой нижней левой ячейки до самой верхней правой
- Зажав клавишу Shift, кликаем по первой, а затем – по последней ячейкам требуемого диапазона.
 Направления выделения – те же, что и в первом способе.
Направления выделения – те же, что и в первом способе. - Встаем в первую ячейку требуемого диапазона, и зажав клавишу Shift, используем клавиши для навигации на клавиатуре, чтобы “дойти” таким образом до последней ячейки.
- Если нужно одновременно выделить как отдельные ячейки, так и диапазоны, причем, находящиеся не рядом, зажимаем клавишу Ctrl и левой кнопкой мыши выделяем требуемые элементы.
Выделяем все ячейки листа
Чтобы осуществить данную задачу, можно воспользоваться двумя разными способами:
- Щелкаем по небольшому треугольнику, направленному по диагонали вправо вниз, который расположен на пересечении координатных панелей. В результате будут выделены все элементы книги.
- Также можно применить горячие клавиши – Ctrl+A. Однако, тут есть один нюанс. Прежде, чем нажимать данную комбинацию, нужно перейти в любую ячейку за пределами таблицы. Если же мы будем находиться в пределах таблицы, то нажав на клавиши Ctrl+A, мы сначала выделим все ячейки именно самой таблицы.
 И только повторное нажатие комбинации приведет к выделению всего листа.
И только повторное нажатие комбинации приведет к выделению всего листа.
Горячие клавиши для выделения ячеек
Ниже приведен перечень комбинаций (помимо тех, что ранее уже были рассмотрены), пользуясь которыми можно производить выделение элементов в таблице:
- Ctrl+Shift+End – выделение элементов с перемещением в самую первую ячейку листа;
- Ctrl+Shift+Home – выделение элементов с перемещением до последней используемой ячейки;
- Ctrl+End – выделение последней используемой ячейки;
- Ctrl+Home – выделение первой ячейки с данными.
Ознакомиться с более расширенным список комбинаций клавиш вы можете в нашей статье – “Горячие клавиши в Эксель“.
Заключение
Итак, мы разобрали различные способы, пользуясь которыми можно выделить отдельные ячейки таблицы Эксель, а также столбцы, строки, диапазоны элементов и даже целый лист. Каждый из этих способов прекрасно справляется с поставленной задачей, поэтому, пользователь может выбрать тот, который ему больше нравится и кажется наиболее удобным в применении.
Каждый из этих способов прекрасно справляется с поставленной задачей, поэтому, пользователь может выбрать тот, который ему больше нравится и кажется наиболее удобным в применении.
Выделение фрагмента таблицы
Выделение ячейки
Поместите курсор мышки на невидимое поле выделения ячейки, находящееся у левого края каждой ячейки. При этом мышиный курсор превратится в черную стрелку указывающую вправо вверх. Щелкните один раз для выделения ячейки.
Выделение диапазона ячеек
Щелкните мышкой по левой верхней ячейке и, не отпуская её, протащите мышиный курсор вправо вниз. Можно начинать выделение диапазона снизу справа.
Обратите внимание на то как Word выделяет ячейки: как только вы протащили мышиный курсор через символ конца ячейки(см. Рис. 5 .99),тут же выделяется следующая ячейка.
Выделение строк
Строка/строки выделяются с помощью
колонки выделения (как обычный текст).
Выделение столбцов
Чтобы выделить столбец, наведите мышиный курсор на верхнюю границу нужного вам столбца, – курсор должен превратиться в черную стрелку . Щелкните левой кнопкой мышки*.
Для выделения нескольких столбцов вместо щелчка нажмите левую кнопку мышки и, не отпуская её, двигаясь вправо или влево, выделите нужные столбцы.
Выделение таблицы
Для выделения всей таблицы щелкните по маркеру перемещения таблицы (см. Рис. 5 .99) или, нажав и удерживая клавишу [Alt], дважды щелкните в любом месте таблицы.
Кроме перечисленных способов, фрагмент таблицы можно выделить с помощью команд меню Таблица(Таблица/Выделить/Ячейка,Таблица/Выделить/Столбец, Таблица/Выделить/Строка, Таблица/Выделить/Таблица).
Маркеры и непечатаемые символы
Для
управления таблицей и хранимой в ней
информацией используются различные
маркеры. Для того чтобы их увидеть (Рис. 5 .99)
щелкните по инструменту Непечатаемыезнаки.
5 .99)
щелкните по инструменту Непечатаемыезнаки.
Рис. 5.99.Маркеры и специальные символы таблицы
Маркер перемещения таблицы используется для перемещения таблицы на новое место. Чтобы выполнить эту операцию:
Наведите мышиный курсор на таблицу и подождите, пока в верхнем левом углу таблицы не появится маркер перемещения таблицы.
Наведите на него мышку и подождите, пока мышиный курсор не превратится в четырехнаправленную стрелку.
Нажмите левую кнопку мышки и перетащите таблицу на новое место.
Задание: переместите таблицу на несколько абзацев вверх, затем верните её обратно; подвигайте таблицу вправо, влево.
ОБРАТИТЕ ВНИМАНИЕ: последние операции
(передвижение таблицы по горизонтали)
можно выполнить также с помощью
инструментов УменьшитьотступиУвеличитьотступ.
Для этого таблицу предварительно
необходимо выделить (щелкнув по маркеру
перемещения таблицы или выполнив командуТаблица/Выделить/Таблица).
Маркер изменения размеровтаблицыиспользуется для изменения размеров таблицы. При этом пропорционально изменяется ширина столбцов и высота строк. Чтобы выполнить эту операцию:
Наведите мышиный курсор на таблицу и подождите, пока в нижнем правом углу таблицы не появится маркер изменения размера таблицы.
Наведите мышку на этот маркер и подождите, пока он не примет вид двусторонней стрелки.
Перетаскивайте границу таблицы до достижения нужных размеров.
Задание: измените размеры таблицы, обратив внимание на то, как изменяется ширина столбцов и высота строк. Верните таблицу к прежним размерам.
Для лучшей ориентации в таблице имеются концевые символы. Различаютконцевой символ ячейкииконцевой символ строки, которые обозначают, соответственно, конец ячейки и конец строки. Часто их называютконцевыми маркерами.
Изучение фрагментации таблиц MySQL
Недавно я работал с заказчиком, которому нужно было быстро разогреться — как можно быстрее получить таблицу Innodb в памяти, чтобы добиться хорошей производительности доступа к памяти.
Для этого я запускаю запрос: «SELECT count (*) FROM tbl WHERE non_idx_col = 0» Я использую эту конкретную форму запроса, потому что он будет выполнять полное сканирование таблицы — текущий счетчик (*) без условия where может выбрать вместо этого сканировать небольшой индекс.
Если ваша таблица не фрагментирована, должно произойти одно из двух: либо вы должны читать со скоростью последовательного чтения вашего жесткого диска, либо вы увидите, что MySQL становится зависимым от ЦП, если подсистема ввода-вывода работает слишком быстро.
В этом случае, однако, я ничего не увидел — vmstat показал скорость чтения менее 10 МБ / с , что очень мало для этой системы, в которой было 6 жестких дисков SAS 15K в RAID10.
Еще одним признаком плохой фрагментации был средний размер ввода-вывода, отображаемый в выводе SHOW INNODB STATUS . Его размер составлял около 20 КБ, что означает, что большинство операций чтения — это одна страница (16 КБ). В случае нефрагментированной таблицы вы увидите последовательное упреждающее чтение Innodb, в котором чтение выполняется блоками по 1 МБ, и поэтому вы увидите средний размер ввода-вывода в сотнях КБ.
В случае нефрагментированной таблицы вы увидите последовательное упреждающее чтение Innodb, в котором чтение выполняется блоками по 1 МБ, и поэтому вы увидите средний размер ввода-вывода в сотнях КБ.
Теперь стоит заметить, что вы можете увидеть низкую производительность последовательного сканирования, даже если таблица не является логически фрагментированной, а Innodb читает данные большими блоками — это может произойти, если файл таблицы Innodb сам фрагментирован.
Чтобы проверить, так ли это, я обычно выполняю « cat table.ibd> / dev / null » и смотрю статистику ввода-вывода. Если вы видите небольшие размеры запросов ввода-вывода в iostat и просто скорость чтения. Как и в случае с клиентом, о котором идет речь, я видел скорость чтения файла около 50 МБ / с , что, конечно, намного лучше, чем 10 МБ / с , но намного ниже емкости RAID-массива.
Чтобы проверить, является ли проблема фрагментацией файлов, плохой или неправильной настроенной подсистемой ввода-вывода, я провожу еще одну проверку, запустив cat / dev / sdb1> / dev / null — Физический жесткий диск никогда не должен подвергаться фрагментации, поэтому вы можете получить как столько последовательных операций ввода-вывода, сколько вы можете получить (с использованием шаблона ввода-вывода, который использует «кошка»). В этом случае я получил около 300 МБ / сек , что подтверждало, что фрагментация файла также является проблемой.
В этом случае я получил около 300 МБ / сек , что подтверждало, что фрагментация файла также является проблемой.
Достаточно интересно, что «лекарство» от обеих проблем фрагментации одно и то же — OPTIMIZE TABLE tbl — эта команда воссоздает таблицу, записывая новую.ibd (если вы используете innodb_file_per_table = 1 ), который обычно был бы гораздо менее фрагментированным, поскольку он записывается сразу. Жаль, но это требует, чтобы таблица была заблокирована, пока она перестраивается, а также дефрагментирует только кластерный ключ, но не индекс.
P.S Было бы здорово получить статистику фрагментации объектов Innodb (данных и индекса), которую на самом деле не должно быть так сложно реализовать.
Связанные
Фрагментация таблиц Oracle
Вопрос: Меня беспокоит, что таблица из-за фрагментации мой SQL может работать медленнее.Как могу ли я определить, фрагментированы ли мои таблицы? Если у меня есть стол фрагментация, как я могу реорганизовать таблицу, чтобы предотвратить дальнейшее фрагментация?
Ответ: Oracle — высокий
двигатель производительности, и он может допускать тысячи одновременных
задачи для вставки в несмежные блоки данных, перебрасывание строк таблицы
беспорядок через экстенты таблицы.
Существует множество названий типов таблиц и фрагментация табличного пространства с именами типа «соты фрагментация »и« пузырьковая фрагментация ».Это также различия между фрагментацией, которая напрямую связана с таблицы, а также фрагментация табличного пространства, что происходит, когда некоторые «карманы» свободного места существует в табличном пространстве.
Теоретическое примечание: Когда Кодд и Дэйт написали манифест базы данных, они были непреклонны, что физическое размещение Строки таблиц на дисках не имели отношения к базе данных. Однако с прагматической точки зрения Oracle предлагает несколько типов инструментов (секционированные таблицы, отсортированные хеш-кластеры) для группировки одинаковые строки на соседние блоки данных.
Вот удобный скрипт для поиска сильно фрагментированных таблиц:
выберите
table_name, round ((блоки * 8), 2)
«размер (кб)»,
раунд ((num_rows * avg_row_len / 1024), 2)
«фактические_данные (кб)»,
(раунд ((блоки * 8), 2) —
round ((num_rows * avg_row_len / 1024), 2)) «wasted_space (kb)»
из
dba_tables
, где
(round ((блоки * 8), 2)>
round ((num_rows * avg_row_len / 1024), 2))
упорядочить по 4 убыванию;
Чтобы понять фрагментацию таблицы, давайте начнем с наблюдения
таблица в «первозданном» нефрагментированном состоянии. Когда только для чтения
таблицы архивируются в табличное пространство только для чтения, администратор базы данных
реорганизовать строки таблицы, чтобы плотно упаковать строки в таблицу
блоки, регулируя параметры объекта (например, PCTFREE), и перестраивать
индексы в первозданное дерево.
Когда только для чтения
таблицы архивируются в табличное пространство только для чтения, администратор базы данных
реорганизовать строки таблицы, чтобы плотно упаковать строки в таблицу
блоки, регулируя параметры объекта (например, PCTFREE), и перестраивать
индексы в первозданное дерево.
Это действие DML, которое фрагментирует строки таблицы Oracle, и несколько параметры контролируют степень фрагментации таблицы:
- Параметр pctfree (если не
с использованием ASM): pctfree Параметр используется во время вставки для определения
когда таблица логически заполнена, и отсоедините блок данных от
фрилист, тем самым лишив блок права на получение новых
ряды.Использование табличных пространств ASM для автоматизации управления списками фрилансеров
и убрать возможность указывать pctfree, pctused,
freelists и freelist групп параметров хранения.
- следующий параметр (если не используется локально управляемые табличные пространства): следующий параметр
управлять, когда стол расширяется.

- Фрилисты и группы фрилистов (если не использовать ASSM): во время вставки несколько одновременных задач могут одновременно вставить в таблицу Oracle, каждый из которых использует разные несмежные блоки данных.
Когда таблица становится фрагментированной, администратор базы данных может выбрать реорганизация таблиц с использованием Oracle dbms_redefinition утилита.
Итак, как устроены эти карманы свободного места появляются? Если таблицы реорганизованы, удаляются и создаются заново, или если отдельные таблицы экспортируются и импортируются, пространство, которое когда-то было зарезервированный для экстента таблицы теперь будет пустым.
Кому понять, как строки фрагментируются между блоками данных, мы должны знать, что внутри табличного пространства объекты разбросаны по табличному пространству и соответствующие файлы данных. Существует несколько типов фрагментации таблиц, чаще всего
фрагментация «соты» и фрагментация «пузыря», где
труднее восстановить потраченное впустую дисковое пространство. Обратите внимание, что вы
можно удалить фрагментацию пузыря с помощью локально управляемых табличных пространств, и см. эти примечания по Фрагментация файлов данных Oracle.
Обратите внимание, что вы
можно удалить фрагментацию пузыря с помощью локально управляемых табличных пространств, и см. эти примечания по Фрагментация файлов данных Oracle.
В принципе, таблица Oracle может фрагментироваться в несколько способов:
Таблица расширяется (без строки цепочка): Вопреки распространенному мнению, это не проблема и производительность не пострадает.Во многих случаях таблица с несколькими экстентами будет работать быстрее, чем таблица в единственная степень.
Фрагмент строк таблицы внутри табличное пространство (из-за нескольких свободных списков и одновременных DML): это вызывает серьезные проблемы с производительностью, и Таблицы-нарушители должны быть экспортированы, удалены и повторно импортированы.
Фрагментация High Water Mark: После массовых операций удаления SQL высокий водяной знак (HWM) остается высоким, что приводит к полному сканированию таблицы дольше, чем следовало бы.

Фрагментация таблиц Oracle
По мере добавления строк в таблицы таблица расширяется до неиспользуемого пространства в пространстве. И наоборот, когда строки удаляются, таблица может объединить экстенты, освободив неиспользуемое пространство обратно в табличное пространство. Когда происходит активность DML, возможно, что несмежные куски или фрагменты неиспользуемого пространства внутри табличное пространство и фрагментация в строках таблицы.
Таблицы, индексы и табличные пространства естественным образом фрагментируются в зависимости от активность обновления, и у Oracle есть много методов для восстановления диска пространство и советник по сегментам, который будет рекомендовать, когда таблицы и индексы выиграют от реорганизации, чтобы освободить место на диске.
Во время вставки таблицы с несколькими списками или списками фрилансеров
группы будут естественно фрагментироваться, поскольку несмежные блоки данных
получено для получения новых строк.
Есть только два случая, когда фрагментация таблицы может вызвать проблемы, медленное сканирование и потерю дискового пространства. С точки зрения производительности важно понимать, что SQL который запрашивает отдельные строки, никогда не пострадает от фрагментированной таблицы в то время как SQL, который выполняет полное сканирование и сканирование большого диапазона индексов, может работать медленнее в фрагментированной таблице.
Таблица может иметь внутреннюю фрагментацию по нескольким причинам. (Обратите внимание, что если вы используете ASSM, PCTFREE, PCTUSED FREELIST_GROUPS и FREELISTS являются игнорируется:
Пустые экстенты таблицы — Возможно, у вас было много удаляет, и высшая отметка была оставлена на высоком уровне.
После массового удаления SQL может быть много мегабайты неиспользуемого пространства между последними строками и верхним водяной знак.Это приведет к более медленному сканированию всей таблицы.
 производительность, поскольку Oracle должен читать до максимальной отметки.
производительность, поскольку Oracle должен читать до максимальной отметки.Неоптимальные вставки freelist unlink — Вы можете есть много операций вставки, которые оставили множество полупустых страниц из-за слишком низкой настройки PCTFREE.
Это вызывает страницу чтобы отсоединить себя от фрилистов, пока в нем еще много пространство для приема новых строк.
Неоптимальная повторная ссылка на фрилист — Возможно, у вас много страниц с небольшим количеством свободного места.но недостаточно, чтобы принять новые ряды
. Это происходит, когда для PCTUSED установлено значение
.Сцепление строк — У вас может быть цепочка строк / миграция строк вашего хранилища больших объектов LOB чем размер блока таблицы.
Редкие таблицы —
Разреженные таблицы обычно возникают, когда таблица SAP определяется с помощью
много свободных списков, и в таблице есть тяжелые вставки и удаления
деятельность. Это заставляет таблицу расширяться, даже если она может быть
в основном пусто. Расширение происходит, потому что каждый свободный список
не зная о содержимом других бесплатных списков внутри каждого бесплатного
список группы. Для более подробной информации см. Мои заметки на определение разреженных таблиц.
Это заставляет таблицу расширяться, даже если она может быть
в основном пусто. Расширение происходит, потому что каждый свободный список
не зная о содержимом других бесплатных списков внутри каждого бесплатного
список группы. Для более подробной информации см. Мои заметки на определение разреженных таблиц.
Смежность строк фрагментация — Некоторые магазины улучшат скорость SQL за счет развертывания сортированных хэш-кластеров, тем самым помещая связанные строки в один блок данных.
Для запросы, которые обращаются к общим строкам с таблицей (например,г. получить все предметы в порядок 123), неупорядоченные таблицы могут испытывать огромные объемы операций ввода-вывода в качестве индекса извлекает отдельный блок данных для каждой запрошенной строки.
Если мы
группировать похожие строки вместе (по данным clustering_factor в dba_indexes ) мы можем получить всю строку с помощью одного
блокировать чтение, потому что строки вместе. Вы можете использовать хэш размером 10 г
кластерные таблицы, одиночные кластеры таблицы или изменение последовательности строк вручную
(CTAS с ORDER BY) для достижения этой цели:
Вы можете использовать хэш размером 10 г
кластерные таблицы, одиночные кластеры таблицы или изменение последовательности строк вручную
(CTAS с ORDER BY) для достижения этой цели:
В Oracle было несколько методов для повторное упорядочение строк таблицы вместе, но лучше всего Oracle 10g отсортированный хэш-кластер:
Теперь, когда мы понимаем основы фрагментации таблиц, давайте изучить некоторые способы уменьшения фрагментации таблиц.
Если у вас медленный SQL (ТОЛЬКО для сканирования большого диапазона индексов и сканирование всей таблицы), или если вы хотите освободить дисковое пространство, Oracle предлагает несколько инструментов для реорганизовать таблицу для устранения фрагментации:
Oracle оставляет отметку максимума в покое после удаления строк, и вы можете освободить место на уровне стола с помощью этих методов, все это снижает максимальную отметку для стола, тем самым освобождение пространства:
В отличие от синтаксиса «освободить неиспользуемое пространство», который удаляет
пространство над высшей точкой, «coalesce» складывает вместе
несмежные фрагментированные экстенты. Есть два типа пространства
фрагментация в Oracle. Во-первых, это фрагментация сот,
когда бесплатные экстенты рядом, и «Швейцарский сыр»
фрагментация, когда экстенты разделены живыми сегментами.
Есть два типа пространства
фрагментация в Oracle. Во-первых, это фрагментация сот,
когда бесплатные экстенты рядом, и «Швейцарский сыр»
фрагментация, когда экстенты разделены живыми сегментами.
alter table xxx coalesce;
Вы
может освободить неиспользуемое пространство — Oracle отмечает, что «освободить
«неиспользованное пространство» используется для явного освобождения неиспользуемого пространства
пространство в «конце» сегмента и делает это пространство доступным для
другие сегменты в табличном пространстве.
изменить таблицу xxx
освободить неиспользуемое пространство;
изменить индекс xxx освободить неиспользуемое пространство;
Внутренне Oracle освобождает неиспользуемое пространство, начиная с
конец объектов (выделенное пространство) и движется вниз к
начало объекта, продолжая вниз, пока не достигнет максимума
водяной знак (HWM). Для индексов «освободить неиспользуемое пространство»
объединяет все блоки листьев в одной ветви b-дерева и быстро
освобождает листовые блоки индекса для использования.
Независимо от вашего подход к освобождению дискового пространства, вам нужно будет запустить сложный словарные скрипты для обнаружения областей фрагментации и эти сценарии также можно использовать для утилизации ненужного пространства.
SQL Server: что такое фрагментация? — Статьи TechNet — США (английский)
Фрагментированная таблица — это таблица, в которой некоторые из ее страниц данных указывают на страницы, которые не являются непосредственно следующими за страницами в экстенте, и если все ее страницы являются смежными как в плане распределения, так и в экстентах, то таблица не фрагментирована.
Пример для лучшего понимания:
Представьте, что есть 3 страницы данных для таблицы с кластерным индексом. Должна быть вставлена новая строка с первичным ключом «5», и поскольку это кластерный индекс, новая строка вставляется по порядку. Поскольку целевая страница достаточно полная, чтобы
новая строка не может быть вставлена, SQL Server делит страницу примерно на две и вставляет новые данные на новую страницу, как показано на рисунке выше.
Теперь логический порядок индекса не соответствует физическому порядку, и индекс стал фрагментированным.
Чтобы измерить фрагментацию индексов, вы можете выполнить следующий запрос в своей базе данных: ВЫБРАТЬ
I.index_id, I. имя ,
DM.avg_fragmentation_in_percent
ИЗ
Sys.dm_db_index_physical_stats (db_id (),
NULL , ПУСТО , ПУСТО , ПО УМОЛЧАНИЮ ) DM
ПРИСОЕДИНЯЙТЕСЬ sys.Индексы I
ПО I.object_id = DM.object_id
И I.Index_id = DM.index_id
Результат:
Чтобы уменьшить фрагментацию (дефрагментацию), вы можете использовать [ALTER INDEX] [REBUILD | REORGANIZE] команда: 1. Изменить реорганизацию индекса
Изменить реорганизацию индекса
- Переупорядочивает только конечные страницы и сжимает страницы индекса, удаляющие пустые страницы.
- Менее эффективен, чем восстановление индексов.
- Выполняется, когда 5% <= avg_fragmentation_in_percent <= 30% и количество страниц превышает 2000
- Предупреждение: не обновляет статистику.
Запрос T-SQL:
ЕГЭ AdventureWorks2012;
GO
- Реорганизовать все индексы в таблице HumanResources.Employee.
АЛЬТЕР ИНДЕКС ВСЕ НА Отдел кадров.Сотрудник
РЕОРГАНИЗАЦИЯ;
ГО
2. Изменить индекс, восстановить
- При воссоздании индекса, когда индекс кластеризован, таблица также реорганизуется.
- Внимание! При восстановлении кластерного индекса с помощью [ALTER INDEX REBUILD] некластеризованные индексы в таблице (v> = 7.
 0) не восстанавливаются, если не указано [ALL].
0) не восстанавливаются, если не указано [ALL]. - Выполняется, когда avg_fragmentation_in_percent> 30% и количество страниц превышает 2000 Параметр [ONLINE = ON] позволяет вам перестроить индекс, не блокируя активность.
Запрос T-SQL:
ЕГЭ AdventureWorks2012;
ГО
АЛЬТЕР ИНДЕКС PK_Employee_BusinessEntityID НА HumanResources.Сотрудник
ПЕРЕСТРОЙКА;
ГО
Чтобы понять, как SQL Server дефрагментирует индекс, рассмотрим упрощенный пример страниц после множества вставок, обновлений и удалений, как показано на следующем рисунке:
Нумерация страниц представляет собой логическую последовательность страниц.
Однако физическая последовательность, показанная на рисунке слева направо, не соответствует логической последовательности.
На следующем рисунке показано несколько проходов во время процесса дефрагментации и реорганизации, вызывающих перепланирование физических страниц путем замены первой логической страницы первой физической страницей и замены второй физической страницей и т. Д. на.
Во время первого прохода SQL Server находит первую физическую страницу (4) и первую логическую страницу (1), а затем обменивает эти страницы в отдельной транзакции.
На втором проходе SQL Server обменивает следующую физическую страницу (7) со следующей логической страницей (2).
На третьем проходе SQL Server обменивает следующую физическую страницу (4) со следующей логической страницей (3).
На четвертом проходе SQL Server обменивает следующую физическую страницу (5) со следующей логической страницей (4).
Сортировка завершена, поскольку все физические страницы соответствуют своим логическим позициям.
Что такое фрагмент предложения? (С примерами)
Никто не сбегает из школы английского без наказания за написание нечетного фрагмента предложения, но не все помнят, что это такое и как их исправить. Проще говоря, фрагмент предложения — это предложение, которое не соответствует истинному предложению, поскольку в нем отсутствует один из трех важных компонентов: подлежащее, глагол и законченная мысль.
Проще говоря, фрагмент предложения — это предложение, которое не соответствует истинному предложению, поскольку в нем отсутствует один из трех важных компонентов: подлежащее, глагол и законченная мысль.
Мы часто не можем распознать наши фрагменты предложений, потому что наши неполные мысли могут легко маскироваться под предложения. Все, что нужно для набора слов, — это заглавная буква в начале и конце, пунктуация и вуаля! Похоже на приговор. Тем не менее, чтобы предложение было действительно полным, оно должно содержать независимое предложение, в котором рассказывается вся история, даже если она изолирована от контекста.
Вот яркий пример фрагмента предложения:
Сам по себе из-за дождя не формирует целостную мысль. Это заставляет задуматься о том, что случилось из-за дождя. Для его завершения нам нужны дополнительные пояснения:
Теперь фрагмент стал зависимым предложением, присоединенным к предложению, имеющему подлежащее (сторона) и глагол (был отменен). Наша мысль завершена.
Наша мысль завершена.
В этом примере решением было удлинить предложение. Но это не значит, что короткие предложения не могут быть полными.Это крохотное предложение закончено:
«Я побежал» может быть короткой мыслью, но в ней есть подлежащее (I) и глагол (беги). Ничто в предложении не требует дополнительных пояснений. Другой известный пример короткого, но полного предложения — «Иисус плакал».
Вот совет: Хотите, чтобы ваш текст всегда выглядел великолепно? Grammarly может уберечь вас от орфографических ошибок, грамматических и пунктуационных ошибок и других проблем с написанием на всех ваших любимых веб-сайтах.
Избегание фрагментов предложений не только облегчает чтение, но также может сделать вашу вежливую переписку более изысканной.У всех нас были электронные письма, оканчивающиеся на:
В этом предложении отсутствует подлежащее. Добавление темы позволит составить более сильное и уверенно звучащее предложение:
Это тонкая психологическая разница, но если вы ведете переписку в формальной обстановке, стоит постараться написать полные предложения. Фрагменты могут звучать так, будто их выпалили по неосторожности.
Фрагменты могут звучать так, будто их выпалили по неосторожности.
Исправление фрагментов приговора
Исправление фрагмента предложения включает одно из двух: наделение его отсутствующими компонентами или закрепление его на независимом предложении.Обратите внимание на следующее:
Хотя у этого писателя есть отличные идеи, когда дело касается скрытности, это второе утверждение не является полным предложением. Нет предмета. Вам будет простительно, если вы подумаете, что это глагол, но «прятаться под своими кроватями и ждать темноты» — это предложная фраза.
Есть два способа исправить это предложение. Первый — привязать его к целому предложению перед ним. Точка с запятой отлично подходит для соединения зависимых предложений, начинающихся, например, с, но:
Если это кажется слишком формальным для ваших целей, вы можете дополнить фрагмент подлежащим (вы) и глаголами, над которыми нужно действовать.
Оба средства дают структурно здравые предложения.
ПОДРОБНЕЕ: Когда (и как) исправить фрагменты предложения
Стилистические фрагменты предложения
Без сомнения, вам следует избегать фрагментов предложений в формальных ситуациях и в академическом письме. Тем не менее, фрагмент в ясном контексте иногда может служить действенной драматической цели. Их часто используют журналисты, блогеры и писатели-фантасты. Например:
Ваш учитель английского языка в средней школе обнаружит, что в этом описании есть три ошибки. Неважно, что — это фрагмент предложения. И он сделал — это предложение, начинающееся со союза, и это абзац из одного предложения.
Ох!
Как всегда, судите сами, кто ваша аудитория и сколько у вас места для маневра, чтобы нарушить правила. Если вы рассказываете историю, несколько фрагментов могут хорошо соответствовать вашей цели и стилю, но если вы пишете эссе или составляете деловой документ, лучше от них держаться подальше.
Фрагменты документа
Фрагмент макета основан на файлах XDP, созданных в Designer. Для создания фрагментов макета необходимо создать XDP и загрузить их в формы AEM.
Для создания фрагментов макета необходимо создать XDP и загрузить их в формы AEM.
Один или несколько фрагментов макета могут составлять части письма и определять графическое расположение этих частей. Фрагмент макета может содержать типичные поля формы, такие как адрес и ссылочный номер, а также пустые подчиненные формы, обозначающие целевые области. Кроме того, фрагменты макета позволяют создавать таблицы и вставлять их по буквам.
Обычный вариант использования — найти в Letters многоразовые шаблоны макета и создать для них фрагменты макета.Например, приветствие, адрес и тема письма, которые появляются в одном и том же порядке из нескольких букв. Другим примером может быть таблица с таким же количеством строк и столбцов, которая используется несколькими буквами.
Вы можете создать фрагмент макета на основе существующего XDP. Фрагмент макета может состоять либо из полей и целевых областей, либо из одной или нескольких таблиц. Таблицы в макете могут быть статическими или динамическими.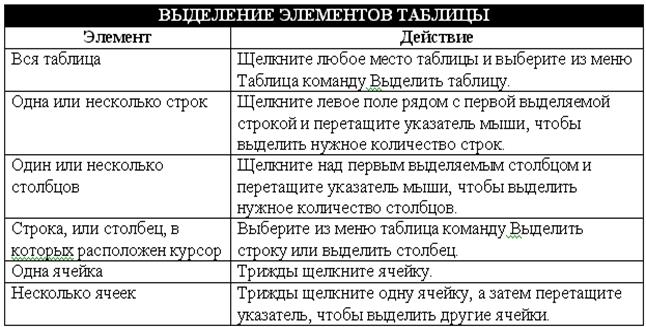 XDP создается в Designer и загружается в формы AEM. XDP может образовывать структуру либо фрагмента макета, либо письма.Дополнительная информация о дизайне макета.
XDP создается в Designer и загружается в формы AEM. XDP может образовывать структуру либо фрагмента макета, либо письма.Дополнительная информация о дизайне макета.
Использование фрагментов, привязанных к целевым областям, позволяет изменять букву во время разработки. Можно создать фрагмент макета с разными размерами и привязать соответствующий фрагмент к целевой области. Фрагменты макета также позволяют настраивать некоторые свойства таблицы:
- Вы можете увеличить количество строк и столбцов.
- Вы можете указать текст верхнего и нижнего колонтитула для большего количества строк и столбцов.
- Вы можете определить соотношение ширины столбца таблицы.Во время выполнения размер столбцов таблицы изменяется в соответствии с заданным соотношением и доступным пространством. Сумма отношения ширины должна быть 100. В противном случае это не применимо.
- Если таблица является заполнителем (содержит только одну пустую ячейку), вы можете определить тип (целевая область / поле) новых столбцов.

- Вы можете скрыть строки верхнего и нижнего колонтитула.
Запросы и мутации | GraphQL
На этой странице вы подробно узнаете о том, как запрашивать сервер GraphQL.
Fields #
В самом простом случае GraphQL запрашивает определенные поля для объектов.Давайте начнем с рассмотрения очень простого запроса и результата, который мы получим при его запуске:
Вы сразу увидите, что запрос имеет точно такую же форму, что и результат. Это важно для GraphQL, потому что вы всегда получаете то, что ожидаете, и сервер точно знает, какие поля запрашивает клиент.
Поле name возвращает тип String , в данном случае имя главного героя «Звездных войн», «R2-D2» .
О, еще одна вещь — запрос выше интерактивный .Это означает, что вы можете изменить его как хотите и увидеть новый результат. Попробуйте добавить поле
playsInк объектуheroв запросе и посмотрите новый результат.

В предыдущем примере мы просто запросили имя нашего героя, который вернул строку, но поля также могут ссылаться на объекты. В этом случае вы можете сделать подвыбор полей для этого объекта. Запросы GraphQL могут перемещаться по связанным объектам и их полям, позволяя клиентам извлекать множество связанных данных за один запрос, вместо того, чтобы выполнять несколько циклов туда и обратно, как это было бы необходимо в классической архитектуре REST.
Обратите внимание, что в этом примере поле друзей возвращает массив элементов. Запросы GraphQL выглядят одинаково как для отдельных элементов, так и для списков элементов, однако мы знаем, какой из них ожидать, исходя из того, что указано в схеме.
Аргументы #
Если бы мы могли только перемещаться по объектам и их полям, GraphQL уже был бы очень полезным языком для выборки данных. Но когда вы добавляете возможность передавать аргументы в поля, все становится намного интереснее.
В такой системе, как REST, вы можете передавать только один набор аргументов — параметры запроса и сегменты URL в вашем запросе. Но в GraphQL каждое поле и вложенный объект может получить свой собственный набор аргументов, что делает GraphQL полной заменой для выполнения множественных выборок API. Вы даже можете передавать аргументы в скалярные поля для реализации преобразования данных один раз на сервере, а не на каждом клиенте отдельно.
Аргументы могут быть разных типов. В приведенном выше примере мы использовали тип Enumeration, который представляет один из конечного набора параметров (в данном случае единицы длины: METER или FOOT ).GraphQL поставляется с набором типов по умолчанию, но сервер GraphQL также может объявлять свои собственные настраиваемые типы, если они могут быть сериализованы в ваш транспортный формат.
Подробнее о системе типов GraphQL здесь.
Псевдонимы #
Если у вас есть зоркий глаз, вы могли заметить, что, поскольку поля объекта результата соответствуют имени поля в запросе, но не содержат аргументов, вы не можете напрямую запросить то же поле. с разными аргументами. Вот почему вам нужны псевдонимы — они позволяют вам переименовывать результат поля во что угодно.
с разными аргументами. Вот почему вам нужны псевдонимы — они позволяют вам переименовывать результат поля во что угодно.
В приведенном выше примере два поля hero конфликтуют, но поскольку мы можем присвоить им разные имена, мы можем получить оба результата в одном запросе.
Fragments #
Допустим, у нас есть относительно сложная страница в нашем приложении, которая позволяет нам смотреть на двух героев бок о бок вместе с их друзьями. Вы можете себе представить, что такой запрос может быстро усложниться, потому что нам нужно будет повторить поля хотя бы один раз — по одному для каждой стороны сравнения.
Вот почему GraphQL включает многоразовые блоки, называемые фрагментами . Фрагменты позволяют создавать наборы полей, а затем включать их в запросы, когда это необходимо. Вот пример того, как вы могли бы решить вышеуказанную ситуацию, используя фрагменты:
Вы можете видеть, как вышеупомянутый запрос будет довольно часто повторяющимся, если бы поля повторялись. Концепция фрагментов часто используется для разделения сложных требований к данным приложения на более мелкие части, особенно когда вам нужно объединить множество компонентов пользовательского интерфейса с разными фрагментами в одну исходную выборку данных.
Концепция фрагментов часто используется для разделения сложных требований к данным приложения на более мелкие части, особенно когда вам нужно объединить множество компонентов пользовательского интерфейса с разными фрагментами в одну исходную выборку данных.
Использование переменных внутри фрагментов #
Для фрагментов возможен доступ к переменным, объявленным в запросе или мутации. См. Переменные.
Название операции #
До сих пор мы использовали сокращенный синтаксис, в котором мы опускали как ключевое слово запроса , так и имя запроса , но в производственных приложениях их полезно использовать, чтобы сделать наш код менее неоднозначным.
Вот пример, который включает ключевое слово , запрос как тип операции и HeroNameAndFriends как имя операции :
Тип операции либо запрос , мутация или подписка и описывает какой тип операции вы собираетесь делать.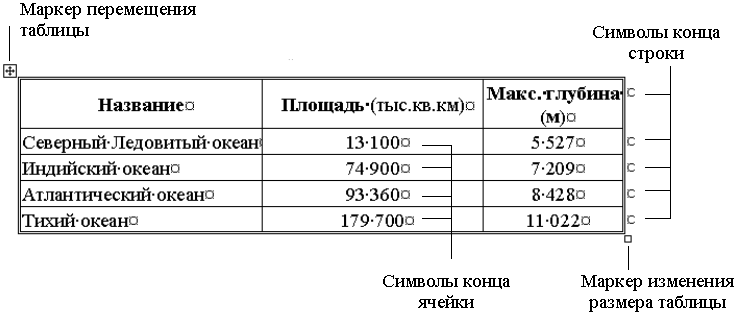 Тип операции является обязательным, если вы не используете сокращенный синтаксис запроса, и в этом случае вы не можете указать имя или определения переменных для своей операции.
Тип операции является обязательным, если вы не используете сокращенный синтаксис запроса, и в этом случае вы не можете указать имя или определения переменных для своей операции.
Имя операции — это понятное и явное имя для вашей операции. Он требуется только в многооперационных документах, но его использование приветствуется, поскольку он очень полезен для отладки и ведения журналов на стороне сервера.
Когда что-то идет не так (вы видите ошибки либо в сетевых журналах, либо в журналах вашего сервера GraphQL), проще идентифицировать запрос в вашей кодовой базе по имени, чем пытаться расшифровать содержимое.Думайте об этом как об имени функции на вашем любимом языке программирования.
Например, в JavaScript мы можем легко работать только с анонимными функциями, но когда мы даем функции имя, ее легче отследить, отладить наш код,
и записывать, когда он вызывается. Точно так же имена запросов и мутаций GraphQL, наряду с именами фрагментов, могут быть полезным инструментом отладки на стороне сервера для идентификации
разные запросы GraphQL.
Переменные #
До сих пор мы записывали все наши аргументы внутри строки запроса.Но в большинстве приложений аргументы для полей будут динамическими: например, может быть раскрывающийся список, который позволяет вам выбрать, какой эпизод «Звездных войн» вам интересен, или поле поиска, или набор фильтров.
Не рекомендуется передавать эти динамические аргументы непосредственно в строку запроса, потому что тогда нашему клиентскому коду потребуется динамически манипулировать строкой запроса во время выполнения и сериализовать ее в специфичный для GraphQL формат. Вместо этого в GraphQL есть первоклассный способ вычленить динамические значения из запроса и передать их как отдельный словарь.Эти значения называются переменными .
Когда мы начинаем работать с переменными, нам нужно сделать три вещи:
- Заменить статическое значение в запросе на
$ variableName - Объявить
$ variableNameкак одну из переменных, принимаемых запросом - Пройти
variableName: значениев отдельном, специфическом для транспорта (обычно JSON) словаре переменных
Вот как это выглядит все вместе:
Теперь в нашем клиентском коде мы можем просто передать другую переменную вместо того, чтобы создавать совершенно новый запрос. Это также в целом хорошая практика для обозначения того, какие аргументы в нашем запросе должны быть динамическими — мы никогда не должны выполнять интерполяцию строк для построения запросов из значений, предоставленных пользователем.
Это также в целом хорошая практика для обозначения того, какие аргументы в нашем запросе должны быть динамическими — мы никогда не должны выполнять интерполяцию строк для построения запросов из значений, предоставленных пользователем.
Определения переменных #
Определения переменных — это часть, которая в запросе выше выглядит как ($ Episode: Episode) . Он работает так же, как определения аргументов для функции на типизированном языке. В нем перечислены все переменные с префиксом $ , за которым следует их тип, в данном случае Episode .
Все объявленные переменные должны быть скалярами, перечислениями или типами входных объектов. Поэтому, если вы хотите передать сложный объект в поле, вам нужно знать, какой тип ввода соответствует на сервере. Узнайте больше о типах входных объектов на странице схемы.
Определения переменных могут быть необязательными или обязательными. В приведенном выше случае, поскольку ! рядом с типом Episode , это необязательно. Но если для поля, в которое вы передаете переменную, требуется ненулевой аргумент, то переменная также должна быть обязательной.
Но если для поля, в которое вы передаете переменную, требуется ненулевой аргумент, то переменная также должна быть обязательной.
Чтобы узнать больше о синтаксисе этих определений переменных, полезно изучить язык схем GraphQL. Язык схемы подробно объясняется на странице схемы.
Переменные по умолчанию #
Значения по умолчанию также могут быть присвоены переменным в запросе путем добавления значения по умолчанию после объявления типа.
предоставляется для всех переменных, вы можете вызывать запрос без передачи каких-либо переменных.Если какие-либо переменные передаются как часть словаря переменных, они отменяют значения по умолчанию.запрос HeroNameAndFriends ($ эпизод: эпизод = JEDI) {
герой (эпизод: $ эпизод) {
имя
друзья {
имя
}
}
}
Когда значения по умолчанию -
Директивы #
Выше мы обсуждали, как переменные позволяют нам избежать ручной интерполяции строк для создания динамических запросов. Передача переменных в аргументах решает довольно большой класс этих проблем, но нам также может потребоваться способ динамического изменения структуры и формы наших запросов с помощью переменных. Например, мы можем представить себе компонент пользовательского интерфейса, который имеет сводное и подробное представление, в котором одно включает больше полей, чем другое.
Передача переменных в аргументах решает довольно большой класс этих проблем, но нам также может потребоваться способ динамического изменения структуры и формы наших запросов с помощью переменных. Например, мы можем представить себе компонент пользовательского интерфейса, который имеет сводное и подробное представление, в котором одно включает больше полей, чем другое.
Давайте построим запрос для такого компонента:
Попробуйте отредактировать указанные выше переменные, чтобы вместо этого передать true для withFriends , и посмотрите, как изменится результат.
Нам нужно было использовать новую функцию в GraphQL под названием директива . Директива может быть прикреплена к полю или включению фрагмента и может влиять на выполнение запроса любым способом, который пожелает сервер. Базовая спецификация GraphQL включает ровно две директивы, которые должны поддерживаться любой соответствующей спецификацией реализацией сервера GraphQL:
-
@include (if: Boolean)Включать это поле в результат, только если аргументtrue.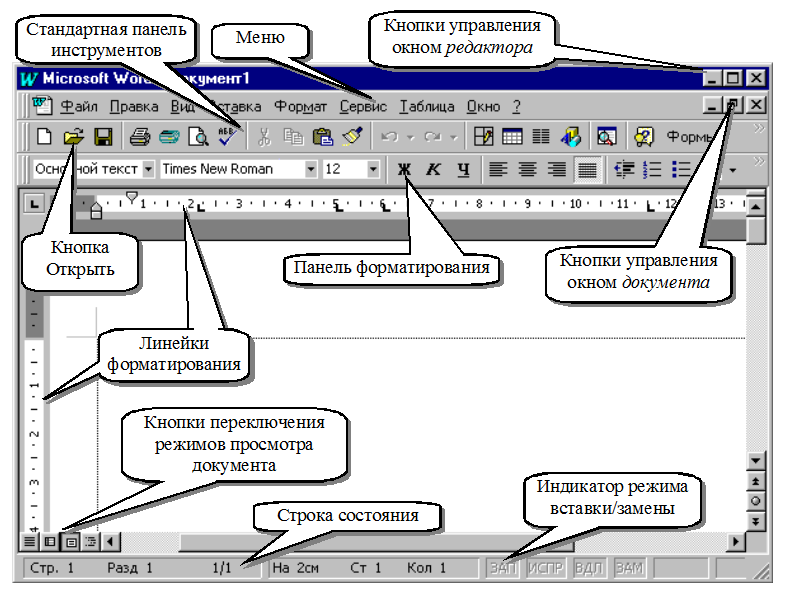
-
@skip (if: Boolean)Пропустить это поле, если аргументtrue.
Директивы могут быть полезны для выхода из ситуаций, когда вам в противном случае пришлось бы выполнять манипуляции со строками для добавления и удаления полей в вашем запросе. Реализации сервера могут также добавлять экспериментальные функции, определяя совершенно новые директивы.
Mutations #
Большинство обсуждений GraphQL сосредоточено на выборке данных, но любая полноценная платформа данных также нуждается в способе модификации данных на стороне сервера.
В REST любой запрос может в конечном итоге вызвать некоторые побочные эффекты на сервере, но по соглашению предлагается не использовать запросы GET для изменения данных. GraphQL похож — технически любой запрос может быть реализован, чтобы вызвать запись данных. Однако полезно установить соглашение о том, что любые операции, вызывающие запись, должны отправляться явно через мутацию.
Как и в запросах, если поле мутации возвращает тип объекта, вы можете запросить вложенные поля.Это может быть полезно для получения нового состояния объекта после обновления. Давайте посмотрим на простой пример мутации:
Обратите внимание, как поле createReview возвращает поля звезд, и комментариев, только что созданного обзора. Это особенно полезно при изменении существующих данных, например, при увеличении поля, поскольку мы можем изменять и запрашивать новое значение поля с помощью одного запроса.
Вы также можете заметить, что в этом примере переданная нами переменная review не является скаляром.Это входной объект типа , особый тип объекта, который может быть передан в качестве аргумента. Узнайте больше о типах ввода на странице схемы.
Несколько полей в мутациях #
Мутация может содержать несколько полей, как и запрос. Есть одно важное различие между запросами и мутациями, помимо имени:
В то время как поля запроса выполняются параллельно, поля мутаций выполняются последовательно, одно за другим.
Это означает, что если мы отправим две мутации incrementCredits в одном запросе, первая гарантированно завершится до начала второй, гарантируя, что мы не закончим с состоянием гонки с самими собой.
Встроенные фрагменты #
Как и многие другие системы типов, схемы GraphQL включают возможность определять интерфейсы и типы объединения. Узнайте о них в руководстве по схеме.
Если вы запрашиваете поле, которое возвращает интерфейс или тип объединения, вам нужно будет использовать встроенные фрагменты для доступа к данным базового конкретного типа. Это проще всего увидеть на примере:
В этом запросе поле hero возвращает тип Character , который может быть либо Human , либо Droid в зависимости от аргумента эпизода .При прямом выборе вы можете запрашивать только поля, которые существуют в интерфейсе символов , например, имя .
Чтобы запросить поле для конкретного типа, вам необходимо использовать встроенный фрагмент с условием типа. Поскольку первый фрагмент помечен как ... на Droid , поле primaryFunction будет выполняться только в том случае, если Character , возвращенный из hero , относится к типу Droid . Аналогично для поля height для типа Human .
Именованные фрагменты также могут использоваться таким же образом, поскольку именованный фрагмент всегда имеет присоединенный тип.
Мета-поля #
Учитывая, что в некоторых ситуациях вы не знаете, какой тип вы получите обратно от службы GraphQL, вам нужен способ определить, как обрабатывать эти данные на клиенте. GraphQL позволяет запрашивать мета-поле __typename в любой момент запроса, чтобы получить имя типа объекта в этой точке.
В приведенном выше запросе поиск возвращает тип объединения, который может быть одним из трех вариантов.