Голосовой DeepFake, или Как работает технология клонирования голоса
Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
- Resemble.AI (предоставляется демоверсия программы).

- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
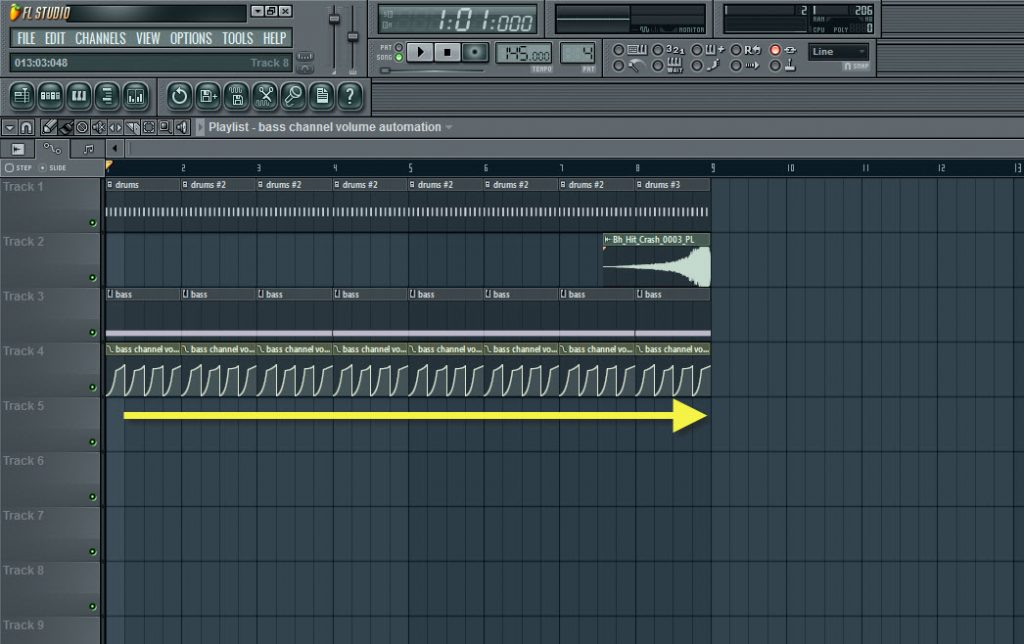
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.
С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.

- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS, создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных
train-other-500(извлеките какLibriSpeech/train-other-500). - VoxCeleb1: наборы данных
Dev A–D,в том числе набор метаданных (извлеките какVoxCeleb1/wavиVoxCeleb1/vox1_meta.csv). - VoxCeleb2: наборы данных
Dev A–H(извлеките какVoxCeleb2/dev).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как
LibriSpeech/train-clean-100andLibriSpeech/train-clean-360 - LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr. org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
pip install audiodatasets
Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
- Librispeech (60 Гб)
- TEDLIUM_release2 (35 Гб)
- VCTK-Corpus (11 Гб)
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
- Корпус речи англоговорящих людей CSTR VCTK
- Набор данных M-AILABS: имеются примеры речи на русском, украинском, немецком, английском, испанском, итальянском, французском и польском языках
- Корпуса звучащей русской речи
- Мультимедийный корпус русского языка: преимущественно фрагменты кинофильмов с распознанным текстом
- Подборка различных речевых датасетов
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине. Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
pip3 install -r requirements.txt
Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
python3 demo_cli.py
Если все тесты пройдены (вы увидите строку All tests passed), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
python3 demo_toolbox.py
Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
python3 demo_toolbox.py -d <путь_к_директории_датасетов>
Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:
Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load, чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите
Чтобы услышать как звучит отрывок, просто нажмите Synthesize and vocode. С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h.
Начинаем с подготовки данных для обучения кодера:
python3 encoder_preprocess.py <datasets_root>
Для обучения кодер использует окружение visdom. Инструменты окружения выглядят следующим образом:
Инструменты окружения выглядят следующим образом:
При необходимости вы можете отключить окружение с помощью аргумента --no_visdom .
Обучаем кодер:
python3 encoder_train.py my_run <datasets_root>
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py <datasets_root>
Затем вложения:
python3 synthesizer_preprocess_embeds.py <datasets_root>/synthesizer
Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run <datasets_root>/synthesizer
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py <datasets_root>
Наконец, обучаем вокодер:
python3 vocoder_train.py <datasets_root>
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Интересны ли вам проекты, связанные с дипфейками лиц и голоса? Будем рады вашим ответам в комментариях.
Turlington 1317 – Language Studio
Turlington 1317
Turlington 1317, «Языковая студия», может быть зарезервирована полностью или частично для небольших языковых занятий, репетиторства, клубных встреч или разговорных групп.
Если группы относительно небольшие (или тихие, как в случае с американским жестовым языком), пространство могут делить несколько групп.
Учащиеся могут работать индивидуально или совместно с группами.
Импровизированные группы по изучению языка приветствуются, но следует учитывать потребности классов и разговорных групп.
Нажмите здесь для формы бронирования комнаты
(см. Текущие бронирование по графику ниже)
Spring 2023
| март | 6 Связь Таблица КЛУБЫ | 29 6-0709 7 Разговор Таблица | 8 Связь Таблица CLUBS | 9 TABLE TABLE Клубы | 10 Стол для переговоров |
|---|---|---|---|---|---|
| март | 13 Закрытый весенний перерыв | 14 Закрытая пружинная каникулы | 15 Закрытый перерыв | 9000 .0002 ЗАКРЫТЫЙ ПЕРЕРЫВ | 17 ЗАКРЫТЫЙ ПЕРЕРЫВ |
| март | 20 Разговор Таблица КЛУБЫ | 21 90 Стол для разговоров0028 Клубы Клубы | 23 TABLE CLUBS | 24 Conversation Table | |
| март | 27 Разговор Таблица КЛУБЫ | 28 Разговор Таблица | 29 Table CLUBS | 30 Conversation Table CLUBS | 31 Разговор Таблица |
| апреля | 3 Разговор Таблица CLUBS | 4 Conversation Table CLUBS | 5 Стол для разговоров Клубы | 6 Разговор Таблица Клубы | 7 Table |
| Апрель | 10 Стол для переговоров Итальянский 19-027 КЛУБЫ | 11 Conversation Table CLUBS | 12 Разговор Таблица CLUBS | 13 Conversation Table CLUBS | 14 Стол для переговоров |
| апрель | 17 Беседовать Таблица Клубы | 18 TABLE CLUBS | 19 Conversation Table | 20 TABLE TABLE Клубы 9009 . 6 вечера корейский | 21 Разговор Таблица |
| апреля | 24 Разговор Таблица CLUBS | 25 Conversation Table Клубы КЛУБЫ | 27 Связь Таблица Клубы | 28 Table |
 18:00–19:00 Японский Кайва
18:00–19:00 Японский Кайва 15-7 часов. Испанский
15-7 часов. Испанский  -15:00 немецкий
-15:00 немецкий 
 2-4pm Chinese
2-4pm Chinese 

Главная | Кафедра русского языка
Главные новости
Представляем новых преподавателей Дартмута
Татьяна Филимонова – одна из 29 новых преподавателей Дартмута в этом году.
 Она доцент кафедры русского языка. Каждый год впечатляющая группа ученых-преподавателей пополняет ряды профессорско-преподавательского состава Дартмута, и этот год не стал исключением.
Она доцент кафедры русского языка. Каждый год впечатляющая группа ученых-преподавателей пополняет ряды профессорско-преподавательского состава Дартмута, и этот год не стал исключением.Новый курс весна 2023: воображая Сибирь
RUSS 38.23/NAIS 30.27 @ 2A/Филимонова, Без предварительных условий, обучение на английском языке. С шумными промышленными городами, бездонными шахтными стволами, обширными равнинами и бескрайними лесами Сибирь составляет почти 80% территории России. Сибирь, известная своими суровыми зимами, могучими реками, чистыми озерами и тюремными комплексами, также является местом значительных экологических изменений.
Save the Date: Павел Суляндзига Лекция Весна 2023
4 апреля 2023 г., 17:00, место: Moore B03 (*возможны изменения), лектор: Павел Суляндзига, правозащитник. Доступно и открыто для публики.
Русский А.
 Т. Даты проб студентов
Т. Даты проб студентов3-27-23 Ориентация, Комната: TBD, 17:30, Практические занятия: 3-27-23, 3-28-23, 3-29-23, Жюри 3-30-23, Комнаты: Reed 107, время: 16:30 — 17:30 все три дня. Все кандидаты должны посетить все вышеуказанные сессии.
Украина на карте языковых баталий
RUSS 38/COLT 19 представили студенты: Украина на карте языковых баталий, среда, 8 марта 2023 г.
«Микстейп перевода»: чтение Эйнсли Морс
3 декабря 2022 г., 16:30, Атриум Института Гарримана, 12-й этаж, Здание международных отношений, 420 W 118th St New York, NY 10027 United States, Columbia University, требуется регистрация.
Ученые из Украины нашли убежище в Дартмуте
Несмотря на войну, «украинские музы не молчат».
Лекция Любы Гольбурт
Люба Голбурт, Калифорнийский университет в Беркли прочитала лекцию 26 октября 2022 г.
 Ян Сатуновский: личность и биография, от войны до лирики.
Ян Сатуновский: личность и биография, от войны до лирики.Смотреть «Гнев Кана: антрополог советского происхождения о сталинском ГУЛАГе».
Часы «Гнев Кана: антрополог советского происхождения о сталинском ГУЛАГе». 15 апреля 2022 года профессор антропологии Сергей Кан, сотрудник Русского отделения, дал интервью Питеру Робинсону из Института Гувера для своей программы «Необычные знания».
Заявление Российского ведомства по поводу войны России против Украины
Факультет кафедры русского языка и литературы Дартмутского колледжа осуждает российскую агрессию против Украины, начавшуюся в 2014 году с аннексии Крыма и переросшую в широкомасштабное вторжение России в Украину.
Последние публикации
просмотреть всеПрекрасные подвиги банды пяти петушков Югославская марксистско-сюрреалистическая эпическая поэма для детей
Александр Бошкович, Эйнсли Э.
 Морс
МорсBrill.Series: Avant-Garde Critical Studies, Volume: 40, 15 марта 2022
Юлия Аверкиева и Франц Боас: взаимная симпатия и идеологические разногласия
Кан Сергей Александрович
Этнографическое обозрение. 2018. №. 3
Достоевский Провокатор
Линн Эллен Патик
(издательство Северо-Западного университета, январь 2023 г.) 240 стр.
Филантропия, политика и общественное действие: Екатерина Пешкова в годы войны и революции
Стюарт Д. Финкель
(Блумингтон, Индиана: Slavica Publishers, 2022), стр.
