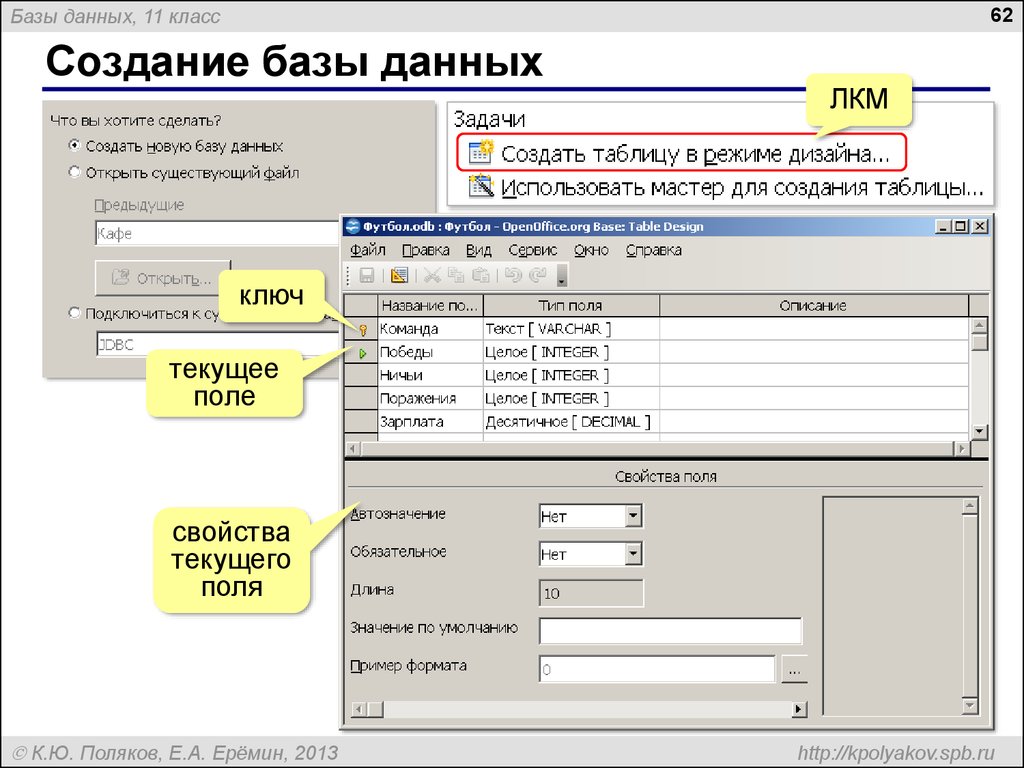
создание базы данных рабочего стола в Access
Создание базы данных Access
Обучение работе с Access
Создание базы данных Access
Создание базы данных Access
Создание классической базы данных в Access
-
Классическая база данных или веб-приложение
Статья -
Создание классической базы данных в Access
Видео -
Создание веб-приложения Access
Видео
Далее: Добавление таблиц
Проверьте, как это работает!
Чтобы быстро создать базу данных рабочего стола, вы можете воспользоваться одним из доступных шаблонов Access.
Создание базы данных из шаблона
Самый простой и быстрый способ создать базу данных — воспользоваться шаблоном Access, который создает готовую к использованию базу данных с таблицами, формами, отчетами, запросами, макросами и связями, которые нужно сразу же приступить к работе. Если оно вам не соответствует, настройте его.
Когда вы запустите Access, отобразятся доступные шаблоны. В Интернете можно найти и другие варианты.
Совет: Если у вас открыта база данных, выберите Файл > Закрыть, чтобы закрыть ее.
-
Откройте Access (или выберите Файл > )и выберите шаблон базы данных рабочего стола.

Совет: Если нужный шаблон не видна, наймем его на сайте Office.com. Под полем Поиск шаблонов в сети выберите Базы данных. Затем в поле Поиск введите одно или несколько ключевых слов.
-
Введите имя новой базы данных и выберите ее расположение. Нажмите кнопку Создать.
Возможные сообщения
Если при создании базы данных отобразится одно из указанных ниже окон, выполните соответствующие действия.
|
Окно |
Действие |
|---|---|
|
Диалоговое окно входа с пустым списком пользователей. |
|
|
Страница Приступая к работе |
Перейдите по ссылкам на этой странице, чтобы узнать больше о базе данных, или изучите ее, нажимая на кнопки и выбирая вкладки. |


Создание базы данных с нуля
Если необходимый шаблон отсутствует, создайте базу данных с нуля.
-
Запустите Access (или выберите Файл > Создать) и выберите пункт Пустая база данных рабочего стола.
-
Введите имя файла и нажмите кнопку Создать. Чтобы сохранить файл в определенном расположении, нажмите кнопку Поиск расположения для размещения базы данных. Access создаст базу данных с пустой таблицей «Таблица1» и откроет ее в режиме таблицы.
В качестве первичного ключа в ней будет автоматически создан столбец «Код».
-
Таблица «Таблица1» не сохранится автоматически, поэтому сделать это следует вручную, даже если вы не вносили в нее изменений.
Уже скоро можно будет ввести в таблицу данные, но сначала для нее следует определить поля. С помощью Access вы можете добавить в базу данных другие таблицы с полями, а затем создать между ними связи. Инструкции см. в модуле этого курса под названием Создание таблиц и назначение типов данных.
Вам нужны дополнительные возможности?
Основные сведения о создании баз данных
Обучение работе с Excel
Обучение работе с Outlook
Видео курс SQL Essential.
 Проектирование БД
Проектирование БДЗдравствуйте, сегодня наша тема называется «Проектирование баз данных». Сегодня мы будем рассматривать нормализацию БД и рассматриваем три первые нормальные формы. В различных источниках вы сможете увидеть различные определения термина нормализации. Вы можете встретить например такое определение: Нормализация- это процесс разработки оптимальной организации информации в базе данных. Или допустим такое определение: Нормализация – это процесс разбивки информации в БД на отдельные таблицы с целью создания эффективной структуры хранения данных. Или же вы можете встретить определение, которое у нас в презентации. Какое бы вы не выбрали для себя определение нормализации вы должны четко понимать что из себя представляют различные нормальные формы. Потому как формально нормализация как раз и представляет собой процесс преобразования БД к виду нормальной формы. Это нужно для обеспечения минимальной минимальной логической избыточности данных.
Устранение избыточности производиться как правило за счет организации по таблицам таким образом что бы в каждой таблице хранились только первичные факты, то есть факты не выводимые из других фактов. Каждая из нормальных форм характеризуется определенными правилами организации данных. Каждой нормальной форме соответствует какой либо номер, таким образом существует первая, вторая, третья и так далее нормальные формы, каждая последующая НФ должна включать в себя правила предыдущей. То есть данные соответствующие третьей нормальной форме автоматически соответствуют первой и второй НФ (нормальной форме). В нашем уроке мы будем изучать первые три нормальные формы. Это 3 НФ были предложены британским ученым Эдгаром Франком Коддом. Кстати, именно этот ученый работая в компании IBM создал реляционную модель БД. Но сегодняшний наш урок не биография Эдгара Кодда поэтому давайте пойдем дальше и попробуем рассмотреть сначала первую НФ, вторую и третью. Можно описывать НФ с помощью каких то абстрактных теоретический понятий но проще всего разобраться в этом процессе на примерах что мы и сделаем. Сперва рассмотрим первую НФ.
Каждая из нормальных форм характеризуется определенными правилами организации данных. Каждой нормальной форме соответствует какой либо номер, таким образом существует первая, вторая, третья и так далее нормальные формы, каждая последующая НФ должна включать в себя правила предыдущей. То есть данные соответствующие третьей нормальной форме автоматически соответствуют первой и второй НФ (нормальной форме). В нашем уроке мы будем изучать первые три нормальные формы. Это 3 НФ были предложены британским ученым Эдгаром Франком Коддом. Кстати, именно этот ученый работая в компании IBM создал реляционную модель БД. Но сегодняшний наш урок не биография Эдгара Кодда поэтому давайте пойдем дальше и попробуем рассмотреть сначала первую НФ, вторую и третью. Можно описывать НФ с помощью каких то абстрактных теоретический понятий но проще всего разобраться в этом процессе на примерах что мы и сделаем. Сперва рассмотрим первую НФ.
Первая нормальная форма требует отсутствия повторяющихся данных и требует что бы любое поле любой записи хранило только одно значение. Давай рассмотрим нашу БД, которую нужно привести в нормальную форму. Пока что в нашей БД есть только одна табличка- это табличка Orders, она содержит в себе все данные, которые касаются нашего бизнеса. Вот допустим есть поля : OrderNo, OrderDate, CustomerNo, CustomerName, CustomerAdress, itemsOrdered. Первые два поля отвечают за заказ, за номер и дату заказа. Следующие три поля содержат информацию о клиентах и последнее поле содержит информацию о продукте, который был заказан. Сперва давайте избавимся от повторяющихся данных, которые есть у нас в табличке. Если мы просто посмотрим на таблицу то сразу увидим какие данные у нас дублируются – это данные в полях CustomerNo, CustomerName, CustomerAdress. Как и все остальные правила нормализации приведение БД к нормальной форме является вопросом здравого смысла, то есть следует обращать внимание не только на формальную часть а и на сценарий использования этих данных. Это говорит о том что даже не имея данных в табличке Orders мы должны были догадаться что эти три поля должны хранить дублирующие данные потому что у нас есть несколько заказов и они могут быть созданы одним и тем же клиентом так же как и в нашем случае.
Давай рассмотрим нашу БД, которую нужно привести в нормальную форму. Пока что в нашей БД есть только одна табличка- это табличка Orders, она содержит в себе все данные, которые касаются нашего бизнеса. Вот допустим есть поля : OrderNo, OrderDate, CustomerNo, CustomerName, CustomerAdress, itemsOrdered. Первые два поля отвечают за заказ, за номер и дату заказа. Следующие три поля содержат информацию о клиентах и последнее поле содержит информацию о продукте, который был заказан. Сперва давайте избавимся от повторяющихся данных, которые есть у нас в табличке. Если мы просто посмотрим на таблицу то сразу увидим какие данные у нас дублируются – это данные в полях CustomerNo, CustomerName, CustomerAdress. Как и все остальные правила нормализации приведение БД к нормальной форме является вопросом здравого смысла, то есть следует обращать внимание не только на формальную часть а и на сценарий использования этих данных. Это говорит о том что даже не имея данных в табличке Orders мы должны были догадаться что эти три поля должны хранить дублирующие данные потому что у нас есть несколько заказов и они могут быть созданы одним и тем же клиентом так же как и в нашем случае. Давайте разберемся каким образом избавиться от этой проблемы. Мы на прошлом уроке рассматривали что такое связь между таблицами, рассматривали первичные и внешние ключи и так же рассматривали каким образом обеспечить ссылочную целостность между таблицами нашей БД. Мы это все знаем и можем взять нашу БД и таблицу Orders и разделить на две таблички, которые связать между собой с помощью пары внешнего и первичного ключа. Давайте создадим отдельную табличку, которая будет хранить данные о клиентах. Давайте перейдем на следующий слайд.
Давайте разберемся каким образом избавиться от этой проблемы. Мы на прошлом уроке рассматривали что такое связь между таблицами, рассматривали первичные и внешние ключи и так же рассматривали каким образом обеспечить ссылочную целостность между таблицами нашей БД. Мы это все знаем и можем взять нашу БД и таблицу Orders и разделить на две таблички, которые связать между собой с помощью пары внешнего и первичного ключа. Давайте создадим отдельную табличку, которая будет хранить данные о клиентах. Давайте перейдем на следующий слайд.
Мы сделали следующее: создали эти три поля CustomerNo, CustomerName, CustomerAdress и вынесли в отдельную табличку Customers и между табличками Orders Customers мы наладили связь с помощью пары внешнего в первичного ключей. Тем самым мы обеспечили ссылочную целостность для этих таблиц. При этом таблицы связаны по полю CustomerNo. То есть теперь одно из требований приведения к первой нормальной форме мы выполнили. Так же есть второе условие, которое говорит о том что любое поле любой записи должно хранить только одно значение. Давайте рассмотрим поле itemsOrdered, это поле хранит у нас сразу же несколько различных данных. То есть это поле не является атомарным. Теперь давайте рассмотрим значение значение атомарности в нашем случае. Значение поля является атомарным если его значение имеет смысл при любом разбиении его на части. Давайте попробуем взять данные в поле itemsOrdered и попробуем разделить их на более мелкие. Например после разбиения одна из частей это «75$». Давайте определим теряется ли смысл каждой из частей. «75$» это значение, которое не потеряло смысл, то есть если после разделения поле не потеряло смысл значит оно является не атомарным. itemsOrdered не является атомарным. Поэтому давайте поле itemsOrdered разделим на несколько частей, каждое из который будет содержать уже точно атомарные данные. Давайте перейдем на следующий слайд. После разбиения поля itemsOrdered наша табличка приняла следующий вид. Кроме полей CustomerNo, CustomerName, CustomerAdress у нас появились еще 6 полей: PartNo, Description, Qty, UnitPrice, TotalPrice, Wt.
Давайте рассмотрим поле itemsOrdered, это поле хранит у нас сразу же несколько различных данных. То есть это поле не является атомарным. Теперь давайте рассмотрим значение значение атомарности в нашем случае. Значение поля является атомарным если его значение имеет смысл при любом разбиении его на части. Давайте попробуем взять данные в поле itemsOrdered и попробуем разделить их на более мелкие. Например после разбиения одна из частей это «75$». Давайте определим теряется ли смысл каждой из частей. «75$» это значение, которое не потеряло смысл, то есть если после разделения поле не потеряло смысл значит оно является не атомарным. itemsOrdered не является атомарным. Поэтому давайте поле itemsOrdered разделим на несколько частей, каждое из который будет содержать уже точно атомарные данные. Давайте перейдем на следующий слайд. После разбиения поля itemsOrdered наша табличка приняла следующий вид. Кроме полей CustomerNo, CustomerName, CustomerAdress у нас появились еще 6 полей: PartNo, Description, Qty, UnitPrice, TotalPrice, Wt. Теперь давайте попробуем разделить значения этих полей на какие то составные части. Допустим если мы разобьем значение Flange то у нас получится два значения Fla и nge. Две эти части теряют смысл поэтому мы можем говорить что поле является атомарным. Если мы попробуем разбить значения других полей на какие то более мелкие части то мы увидим что они потеряют смысл, потому эти поля можно считать атомарными.
Теперь давайте попробуем разделить значения этих полей на какие то составные части. Допустим если мы разобьем значение Flange то у нас получится два значения Fla и nge. Две эти части теряют смысл поэтому мы можем говорить что поле является атомарным. Если мы попробуем разбить значения других полей на какие то более мелкие части то мы увидим что они потеряют смысл, потому эти поля можно считать атомарными.
Но мы встретились с новой проблемой – поле OrderNo таблицы Orders нельзя считать первичным ключем потому что данные первичного ключа нельзя считать уникальными, но теперь у нас есть несколько дублирующихся значений потому это поле не может быть полем первичного ключа. Давайте рассмотрим нашу таблицу и попробуем найти ключ-кандидат для нашей таблицы. Ключом-кандидатом можно называть любой набор столбцов, которые могут использоваться первичным ключем, набор каких то данных, кторые по своей природе могут уникальным образом идентифицировать любую строку в таблице. Но если мы посмотрим на нашу табличку то увидим что набор таких столбцов будет найти сложно, поэтому нужно создать сурогатный уникальный ключ для нашей таблицы. Суррогатным ключем называют ключ, который не является исходной частью данных. То есть в нашу табличку мы добавим еще одно поле, которое в паре с полем OrderNo будет уникальным образом идентифицировать любую строку нашей таблички. Давайте перейдем к слебующему слайду и видим что мы сделали с табличкой Orders. Мы добавили новое поле Line Item, тем самым мы определили суррогатный ключ для нашей таблицы. Это будет ключ, который состоит из двух столбцов OrderNo и Line Item.
Суррогатным ключем называют ключ, который не является исходной частью данных. То есть в нашу табличку мы добавим еще одно поле, которое в паре с полем OrderNo будет уникальным образом идентифицировать любую строку нашей таблички. Давайте перейдем к слебующему слайду и видим что мы сделали с табличкой Orders. Мы добавили новое поле Line Item, тем самым мы определили суррогатный ключ для нашей таблицы. Это будет ключ, который состоит из двух столбцов OrderNo и Line Item.
Теперь абсолютно любая строка нашей таблицы может быть определена уникально с помощью пар значений OrderNo и Line Item. При этом OrderNo в этом поле указывает номер заказа а поле Line Item указывает позицию в заказе. То есть в одном заказе у нас может быть куплено несколько единиц продукции, вот например в заказе 98 у нас был куплен Flange, Injector, Injector и Head. И покупка каждой новой единицы продукции это новая позиция в нашем заказе. Тем самым можно считать что нашу БД мы привели к первой нормальной форме. Мы избавились от повторяющихся данных и мы разбили составные поля нашей таблицы на атомарные. Теперь давайте перейдем к приведению нашей БД ко второй нормальной форме. Как мы уже говорили каждая последующая НФ включает в себя правила предыдущей НФ, поэтому перед тем как приводит к первой НФ нужно предварительно привести исходные таблицы БД к первой нормальной форме, что мы и сделали. Так же вторая нормальная форма требует чтобы каждый неключевой столбец таблицы находящийся в первой НФ был зависим от всего ключа, то есть приводить БД к НФ имеет смысл если в таблице содержится составной ключ, как и в нашем случае. Если в таблица не содержит составного ключа то можно считать что таблица уже приведена ко второй НФ. Давайте перейдем к нашей табличке и посмотрим есть ли у нас неключевые столбцы, которые зависят не от всего ключа а только от его части. В нашей табличке есть два неключевых столбца, которые зависят только от части ключа – это поле OrderDate и поле CustomerNo. Давайте посмотрим от какой части первичного ключа зависят эти два поля.
Теперь давайте перейдем к приведению нашей БД ко второй нормальной форме. Как мы уже говорили каждая последующая НФ включает в себя правила предыдущей НФ, поэтому перед тем как приводит к первой НФ нужно предварительно привести исходные таблицы БД к первой нормальной форме, что мы и сделали. Так же вторая нормальная форма требует чтобы каждый неключевой столбец таблицы находящийся в первой НФ был зависим от всего ключа, то есть приводить БД к НФ имеет смысл если в таблице содержится составной ключ, как и в нашем случае. Если в таблица не содержит составного ключа то можно считать что таблица уже приведена ко второй НФ. Давайте перейдем к нашей табличке и посмотрим есть ли у нас неключевые столбцы, которые зависят не от всего ключа а только от его части. В нашей табличке есть два неключевых столбца, которые зависят только от части ключа – это поле OrderDate и поле CustomerNo. Давайте посмотрим от какой части первичного ключа зависят эти два поля.
Если мы просто посмотрим то сразу сможем определить что они зависят только от поля Number. То есть один заказ занимает один день и ним распологает один пользователь, поэтому эти поля зависят только от поля OrderNo. Поэтому давайте перейдем к следующему слайду и посмотрим что нам нужно сделать что бы привести нашу таблицу ко второй нормальной форме. Мы можем взять эти два поля OrderDate и CustomerNo, которые зависят только от части ключа мы можем взять эти данные и перенести в другую табличку. Давайте посмотрим на ту ситуацию, которая сейчас есть в нашей БД. В таблице Orders мы оставили только поля OrderNo, OrderDate, CustomerNo. Табличка Orders как и в предыдущем состоянии зависит от таблички Customers. Данные, которые касаются непосредственно каждого заказа мы вынесли в отдельную табличку, которую назвали OrderDetails и конечно же мы создали связь между табличкой Orders и OrderDetails. Из таблички Orders можем узнать когда появился заказ и кто его разместил. Из таблички OrderDetails можем увидеть дополнительные данные о каждом из заказов. Например мы можем посмотреть что в заказе №98 у нас было 4 позиции: Flange, Ingector, Injector и Head.
То есть один заказ занимает один день и ним распологает один пользователь, поэтому эти поля зависят только от поля OrderNo. Поэтому давайте перейдем к следующему слайду и посмотрим что нам нужно сделать что бы привести нашу таблицу ко второй нормальной форме. Мы можем взять эти два поля OrderDate и CustomerNo, которые зависят только от части ключа мы можем взять эти данные и перенести в другую табличку. Давайте посмотрим на ту ситуацию, которая сейчас есть в нашей БД. В таблице Orders мы оставили только поля OrderNo, OrderDate, CustomerNo. Табличка Orders как и в предыдущем состоянии зависит от таблички Customers. Данные, которые касаются непосредственно каждого заказа мы вынесли в отдельную табличку, которую назвали OrderDetails и конечно же мы создали связь между табличкой Orders и OrderDetails. Из таблички Orders можем узнать когда появился заказ и кто его разместил. Из таблички OrderDetails можем увидеть дополнительные данные о каждом из заказов. Например мы можем посмотреть что в заказе №98 у нас было 4 позиции: Flange, Ingector, Injector и Head. То есть теперь можно считать что мы привели табличку ко второй нормальной форме. Мы определили табличку с составным ключом в нашей БД, нашли поля, которые зависят от части ключа и сделали так что б такой ситуации не было, то есть вынесли некоторые поля в отдельную табличку.
То есть теперь можно считать что мы привели табличку ко второй нормальной форме. Мы определили табличку с составным ключом в нашей БД, нашли поля, которые зависят от части ключа и сделали так что б такой ситуации не было, то есть вынесли некоторые поля в отдельную табличку.
Теперь давайте перейдем дальше и приведем нашу БД к НФ3. Третья НФ требует приведения нашей таблицы ко второй НФ а так же ни в одном неключевом столбце не может быть зависимости от другого неключевого столбца. Так же не допускается наличие в таблице производных данных. Сперва давайте избавимся от производных данных, которые есть у нас в БД. Если мы внимательно посмотрим на табличку OrderDetails нашей БД, то увидим что поле TotalPrice у нас является вычисляемым, то есть его значение можно вычислить путем перемножением полей Qty и UnitPrice. Давайте проверим: 4*15=75, 4*27=108 и так далее. То есть это поле можно просто напросто убрать из нашей таблицы. А когда нам потребуется значение мы можем взять калькулятор и посчитать эти значения или же взять UserFace приложение, которое будет работать в этой БД. Получив данные из источника данных, то есть из нашей таблицы наше приложение может само посчитать значение этого столбца, поэтому хранить и дублировать эти данные нет никакого смысла, их можно высчитать когда нужно. Поэтому удаляем этот столбец из OrderDetails. Также мы говорили, что третья НФ требует что бы ни в одном ключевом столбце не было зависимости от другого неключевого столбца. Давайте внимательно посмотрим на табличку OrderDetails и определим возможно у нас есть в нашей таблице такие поля, которые зависят друг от друга а не от ключа. Действительно есть такие поля, это поля : PartNo, Description и поле Wt. Эти поля касаются продукции и зависят друг от друга поэтому их нужно вынести в отдельную табличку. Давайте перейдем на следующий слайд, мы в нашей БД создали еще одну табличку, которое имеет имя Product. В этой табличке мы создали первичный ключ в поле PartNo, то есть идентификационный номер детали. И в табличке Orders мы оставили поле PartNo с ограничением внешнего ключа и оно нужно для связи с таблицей Product.
Получив данные из источника данных, то есть из нашей таблицы наше приложение может само посчитать значение этого столбца, поэтому хранить и дублировать эти данные нет никакого смысла, их можно высчитать когда нужно. Поэтому удаляем этот столбец из OrderDetails. Также мы говорили, что третья НФ требует что бы ни в одном ключевом столбце не было зависимости от другого неключевого столбца. Давайте внимательно посмотрим на табличку OrderDetails и определим возможно у нас есть в нашей таблице такие поля, которые зависят друг от друга а не от ключа. Действительно есть такие поля, это поля : PartNo, Description и поле Wt. Эти поля касаются продукции и зависят друг от друга поэтому их нужно вынести в отдельную табличку. Давайте перейдем на следующий слайд, мы в нашей БД создали еще одну табличку, которое имеет имя Product. В этой табличке мы создали первичный ключ в поле PartNo, то есть идентификационный номер детали. И в табличке Orders мы оставили поле PartNo с ограничением внешнего ключа и оно нужно для связи с таблицей Product. Теперь можно считать что ограничение третей нормальной формы обеспечивается, то есть тем самым можно считать что три НФ мы реализовали в нашей БД.
Теперь можно считать что ограничение третей нормальной формы обеспечивается, то есть тем самым можно считать что три НФ мы реализовали в нашей БД.
Как мы уже говорили что нормализация это процесс разбивки данных в нашей БД с целью избавления от избыточности данных. Так же существует и денормализация, это обратный процесс, который вносит избыточность в БД. С теоретической точки зрения денормализация выполняться никогда не должна, но на практике не все так просто. Иногда денормализовать БД нужно в интересах производительности. Слишком нормализованая БД замедляет работу в сети так как из-за многочисленых связей между таблицами серверу приходиться выполнять большее число операций. Если у нас есть такая операция, то есть если наша нормализованая БД приводит к ухудшению пракического использования то мы можем денормализовать её. То есть можно понизить форму. У нас была БД третей НФ а можно понизить до второй. Что касается нашей БД и таблицы Details. Для того чтобы было удобно и повысить скорость вычислений возможно вернуть вычесляемый столбец TotalPrice. Для этого нужно понизить третью НФ нашей таблицы и ввести столбец TotalPrice. Денормализовывать или нет это вы должны решать сами. Если вы хотите повысить производительность работы БД за счет памяти тогда можно денормализововать.
Для этого нужно понизить третью НФ нашей таблицы и ввести столбец TotalPrice. Денормализовывать или нет это вы должны решать сами. Если вы хотите повысить производительность работы БД за счет памяти тогда можно денормализововать.
Если мы не хотим денормализововать то нам прийдется пожертвовать производительностью. Теперь давайте перейдем на примеры и попробуем нормальзовать некую БД. Переходим к примерам и давайте попробуем нормализовать некую БД, которую мы сами с вами создадим. Первая строка давайте подключимся к БД Shopdb. Сперва её удалим. Создадим её заново и после подключимся. И давайте создадим табличку Orders и в этой табличке у нас будет хранится вся информация, которая касается нашего интернет-магазина, тут же у нас информация о клиентах, дата продаж, какие то детали продаж и так же данные о наших сотрудниках. Мы создали таблицу и давайте её заполним её данными. На 18-й строке у нас есть оператор INSERT, который вставит наши данные в таблицу Orders. Давайте выберем все данные из таблицы и вот мы видим что в таблице есть куча данных и разобраться в них не так уж просто но тем не менее наша таблица содержит всю инфу, которая нам нужно. И что бы хранить эти данные и с ними работать нам прийдется эту БД привести к НФ. И начем мы конечно же с первой НФ. Для того что бы привести её к первой НФ нужно избавить её от составных данных в таблице. Давайте посмотрим на таблицу Orders, которую мы сами создали. Явно те данные, которые находятся в различных полях нашей таблице это не атомарные данные. То есть мы можем разбить наши ячейки на более атомарные данные. И первое что мы сделаем это возьмем нашу табличку, и 4 поля которые в ней есть мы разобьем на несколько полей. Вот апример «Имя, Фамилия и Отчество» можно разбить на три поля, что мы и сделаем. Мы создадим поле CustFName, CustMName и CustLName. Дальше можно в отдельное поле вынести город, в котором живет наш клиент и так же в отдельное поле адрес по которому проживает наш клиент. Также в отдельное поле мы выносим номер телефона и пока что это все столбцы, которые касаются наших клиентов. То есть одно поле мы разбили на шесть. Дальше, поле OrderDate, ну тут у нас атомарные данные и разбивать их нет смысла.
И что бы хранить эти данные и с ними работать нам прийдется эту БД привести к НФ. И начем мы конечно же с первой НФ. Для того что бы привести её к первой НФ нужно избавить её от составных данных в таблице. Давайте посмотрим на таблицу Orders, которую мы сами создали. Явно те данные, которые находятся в различных полях нашей таблице это не атомарные данные. То есть мы можем разбить наши ячейки на более атомарные данные. И первое что мы сделаем это возьмем нашу табличку, и 4 поля которые в ней есть мы разобьем на несколько полей. Вот апример «Имя, Фамилия и Отчество» можно разбить на три поля, что мы и сделаем. Мы создадим поле CustFName, CustMName и CustLName. Дальше можно в отдельное поле вынести город, в котором живет наш клиент и так же в отдельное поле адрес по которому проживает наш клиент. Также в отдельное поле мы выносим номер телефона и пока что это все столбцы, которые касаются наших клиентов. То есть одно поле мы разбили на шесть. Дальше, поле OrderDate, ну тут у нас атомарные данные и разбивать их нет смысла. Смотрим дальше. Поле OrderDetails можно так же разбить на несколько полей. То есть у нас будет айди продукта, его описание, цена, количество и общая цена за заказ. Тем самым мы разбиваем наше поле на несколько: ProductID, ProductDescription, UnitPrice, Qty, TotalPrice. И так же нам осталось разбить поле Employee так же на несколько полей, тут мы разделим на 3 поля. Поле для имени, отчества и фамилии. И так же на поле Phone мы поставим пользовательское ограничение на допустимость символов с шаблоном.
Смотрим дальше. Поле OrderDetails можно так же разбить на несколько полей. То есть у нас будет айди продукта, его описание, цена, количество и общая цена за заказ. Тем самым мы разбиваем наше поле на несколько: ProductID, ProductDescription, UnitPrice, Qty, TotalPrice. И так же нам осталось разбить поле Employee так же на несколько полей, тут мы разделим на 3 поля. Поле для имени, отчества и фамилии. И так же на поле Phone мы поставим пользовательское ограничение на допустимость символов с шаблоном.
Давайте удалим старуби создадим новую таблицу. Удалили старую и переносим данные из старой в новую. Выполняем запрос INSERT с 72-й по 109-й строку. И давайте выберем данные из таблицы Orders. Вот теперь табличка читается намного проще и работать с ней будет намного легче. И вот сейчас можно считать что мы нашу табличку привели к первой НФ, потому как во всех полях таблицы имеются только атомарные данные и вряд ли их можно поделить на более мелкие что бы не терялся их смысл. И в принципе можно переходить к приведению нашей таблицы ко второй НФ. Но перед тем как перейти к рассмотрению второй НФ нужно будет обеспечить сущностную целостность для нашей таблицы, то есть определить для неё первичный ключ, поэтому мы удалим таблицу Orders и создадим её заново.В нашей таблице можно поискать кандидатов на пароль первичного ключа, но мы не будем этого делать а просто создадим для нашей таблицы суррогатный первичный ключ, то есть создадим еще одно поле с OrderID и на это поле мы поставим ограничение первичного ключа. Давайте выполним с 118-й по 140-ю строку но до этого нужно удалить таблицу Orders и создать новую. И давайте перенесем данные из старой таблицы в новую. Выполним запрос с 142-й по 179-ю строку и выполняем 181-ю строку. Вот теперь наша таблица имеет первичный ключ. И вот обратите внимание на то что наша таблица имеет первичный ключ из двух полей, это поля: OrderId Line Item. Нам пришлось создать такой ключ потому что одно поле не может уникальным образом идентифицировать любую строку из нашей таблицы потому как у нас может быть несколько продаж и заказов в которых может быть заказано несколько различных единиц продукции.
Но перед тем как перейти к рассмотрению второй НФ нужно будет обеспечить сущностную целостность для нашей таблицы, то есть определить для неё первичный ключ, поэтому мы удалим таблицу Orders и создадим её заново.В нашей таблице можно поискать кандидатов на пароль первичного ключа, но мы не будем этого делать а просто создадим для нашей таблицы суррогатный первичный ключ, то есть создадим еще одно поле с OrderID и на это поле мы поставим ограничение первичного ключа. Давайте выполним с 118-й по 140-ю строку но до этого нужно удалить таблицу Orders и создать новую. И давайте перенесем данные из старой таблицы в новую. Выполним запрос с 142-й по 179-ю строку и выполняем 181-ю строку. Вот теперь наша таблица имеет первичный ключ. И вот обратите внимание на то что наша таблица имеет первичный ключ из двух полей, это поля: OrderId Line Item. Нам пришлось создать такой ключ потому что одно поле не может уникальным образом идентифицировать любую строку из нашей таблицы потому как у нас может быть несколько продаж и заказов в которых может быть заказано несколько различных единиц продукции. Вот поэтому нам пришлось разделить столбец на два, вот у нас есть ID заказа и второй столбец это позиция в заказе.
Вот поэтому нам пришлось разделить столбец на два, вот у нас есть ID заказа и второй столбец это позиция в заказе.
Вот теперь можно переходить к приведению нашей таблицы ко второй нормальной форме. Для того что бы привести таблицу ко второй НФ она должна удовлетворять критерии первой НФ. Ну как раз к первой НФ мы нашу таблицу привели. И для того чтобы привести таблицу ко второй НФ нужно что бы каждый столбец зависел от первичного ключа. Давайте разберемся какие столбцы нашей таблицы зависят не от всего ключа а только от части. Поле Order-Date, CustFName, CustMName, CustLName, CustomerCty, CustomerAddress и Phone. Все эти поля зависят только от части ключа. Все они зависят от айди заказа но никак не от позиции в заказе. Поэтому нужно будет все эти поля вынести в отдельную таблицу. Поле ProductID зависит от всего ключа, поле ProductDescription так же от всего ключа, UnitPrice, Qty, TotalPrice- зависят от всего ключа.И еще есть три ключа EmpFName, EmpMName, EmpLName, которые зависят от части ключа. Эти поля зависят так же только от ID заказа но никак не от позиции в заказе. Давайте создадим еще две таблички Customers Employees и вынесим данные из этих полей в отдельные таблицы. Давайте создадим табличку Employees и в ней будет содержаться информация только о наших сотрудниках. В этой таблицах будет поле EmployeeID с автоинкриментом и с первичным ключем. Так же будут поля с именем фомилией и отчеством, так поле зарплаты, поле премии, поле принятия на работу, поле увольнения, поле менеджера, то есть вся информация, которая нужна для описания любого нашего сотрудника. У нас такая табличка есть потому давайте удалим все таблички и создадим их заново.
Эти поля зависят так же только от ID заказа но никак не от позиции в заказе. Давайте создадим еще две таблички Customers Employees и вынесим данные из этих полей в отдельные таблицы. Давайте создадим табличку Employees и в ней будет содержаться информация только о наших сотрудниках. В этой таблицах будет поле EmployeeID с автоинкриментом и с первичным ключем. Так же будут поля с именем фомилией и отчеством, так поле зарплаты, поле премии, поле принятия на работу, поле увольнения, поле менеджера, то есть вся информация, которая нужна для описания любого нашего сотрудника. У нас такая табличка есть потому давайте удалим все таблички и создадим их заново.
Создаем таблицу Employees и так же мы говорим что нам нужно вынести в отдельную таблицу данные о клиентах. Поэтому мы создали еще одну табличку Customers и в ней создали все поля, которые нужны для описания любого нашего клиента. Создали табличку Customers, табличку Orders мы так же разделили на две Orders и OrderDetails. Для чего мы это сделали? Для того что бы в одну таблицу помещать все данные о айди заказа и в табличку OrderDetails мы будем помещать все данные, которые зависят от всего ключа нашей старой таблички Orders. То есть айди заказа и позиции в заказе. Создаем табличку Orders и у неё будут следующие поля: OrderID- это поле первичного ключа, OrderDate-инф. О дате заказа, информация о клиенте- CustomerNo который разместил заказ, и о сотруднике, который принял этот заказ – Employeed. И конечно же наша таблица имеет два внешних ключа, это связи с таблицами Customers и Employees и ихними полями CustomerNo EmployeeID соответственно. Давайте создадим табличку Orders и идем дальше. Вторая часть нашей таблички имеет имя OrderDetails, тут у нас сосредоточены все данные, которые зависят и от самого заказа и от конкретной позиции в заказе. Это такие данные как айди продукта, описание продукта, цена за еденицу, количество заказаных единиц и общая сумма за заказ. Создаем эту таблицу и она будет иметь кроме первичного ключа составного а еще и будет иметь внешний ключ, то есть связь с табличкрй Orders, то есть мы сможем перейти к заказу, посмотреть на его дату из таблицы Orders, посмотреть информацию о клиенте и о сотруднике.
То есть айди заказа и позиции в заказе. Создаем табличку Orders и у неё будут следующие поля: OrderID- это поле первичного ключа, OrderDate-инф. О дате заказа, информация о клиенте- CustomerNo который разместил заказ, и о сотруднике, который принял этот заказ – Employeed. И конечно же наша таблица имеет два внешних ключа, это связи с таблицами Customers и Employees и ихними полями CustomerNo EmployeeID соответственно. Давайте создадим табличку Orders и идем дальше. Вторая часть нашей таблички имеет имя OrderDetails, тут у нас сосредоточены все данные, которые зависят и от самого заказа и от конкретной позиции в заказе. Это такие данные как айди продукта, описание продукта, цена за еденицу, количество заказаных единиц и общая сумма за заказ. Создаем эту таблицу и она будет иметь кроме первичного ключа составного а еще и будет иметь внешний ключ, то есть связь с табличкрй Orders, то есть мы сможем перейти к заказу, посмотреть на его дату из таблицы Orders, посмотреть информацию о клиенте и о сотруднике.
Если мы захотим увидеть более детальную информацию о заказе тогда мы сможем перейти к табличке OrderDetails по связи внешнего ключа и тогда уже увидеть более детальную инфу о том что купили, сколько единиц, на какую общую сумму и так далее. Создаем табличку OrderDetails и теперь можем заполнять нашу БД информацией. На 254-й строке заполняем таблицу Employees, вставляем туда инфу о наших сотрудниках. Дальше заполняем табличку Customers, это информация о клиентах. Ошибка. Проблема была в том что я был подключен к БД Master, но я подключился к Shopdb, создал заново таблички и пробую подключится. Создал таблицу Customers и поместил в неё информацию о моих клиентах. Дальше я заполняю таблицу Orders, это таблица заказов. Сюда помещаю несколько заказов которые ссылаются на существующего клиента и существующего сотрудника. Дальше с 279-й по 187-ю строку я заполняю таблицу OrderDetails. Ниже на 290-й строке делаю выборку данных из всех наших таблиц: Customers, Employees, Orders и OrderDetails. И так же для того что бы более абстрактно посмотреть на нашу БД, посмотреть какие у нас есть таблицы и какие связи у этих таблиц то можно создать диаграму БД. Я выбираю меню New Database Diagram на папке диаграмм баз данных. У меня появляется окошко, которое требует выбрать какие таблички я хочу поместить в окошко моей диаграмы. Ну я выберу все таблицы. И вот теперь я могу посмотреть на самом деле что ж я создал. Вот как выглядит моя БД. У меня есть таблица Orders, которая ссылается на таблицу Customers и на таблицу Employees и также есть таблица OrderDetails, которая позволяет нам узнать более детальную информацию о наших заказах. Теперь можно считать что мы привели нашу БД ко второй НФ. И если мы посмотрим на все таблицы то мы не найдем каких либо полей, которые зависят только от части ключей. Есть смысл искать такие поля только в таблице OrderDetails потому что если таблица не имеет составного ключа то она автоматически приведена ко второй НФ. У нас есть таблица с составным ключем, но если мы посмотрим на поля этой таблицы то каждое значение зависит от всего ключа, то есть от заказа и от позиции в заказе.
И так же для того что бы более абстрактно посмотреть на нашу БД, посмотреть какие у нас есть таблицы и какие связи у этих таблиц то можно создать диаграму БД. Я выбираю меню New Database Diagram на папке диаграмм баз данных. У меня появляется окошко, которое требует выбрать какие таблички я хочу поместить в окошко моей диаграмы. Ну я выберу все таблицы. И вот теперь я могу посмотреть на самом деле что ж я создал. Вот как выглядит моя БД. У меня есть таблица Orders, которая ссылается на таблицу Customers и на таблицу Employees и также есть таблица OrderDetails, которая позволяет нам узнать более детальную информацию о наших заказах. Теперь можно считать что мы привели нашу БД ко второй НФ. И если мы посмотрим на все таблицы то мы не найдем каких либо полей, которые зависят только от части ключей. Есть смысл искать такие поля только в таблице OrderDetails потому что если таблица не имеет составного ключа то она автоматически приведена ко второй НФ. У нас есть таблица с составным ключем, но если мы посмотрим на поля этой таблицы то каждое значение зависит от всего ключа, то есть от заказа и от позиции в заказе. Давайте перейдем дальше и попробуем привести нашу таблицу к третей НФ. Третья НФ требует что бы наша БД уже была приведена ко второй нормальной форме, так же требуется что бы ни в одном ключевом столбце не было зависимости ни от одного из ключевых столбцов. Так же наличие в столбцах непроизводных данных не допускается. Давайте попробуем удалить таблицы OrderDetails и Products и попробуем создать их заново. Ну что касается того что при приведении к третьей НФ ни в одном неключевом столбце не может быть зависимости от другого неключевого столбца. Если мы рассмотрим таблицу OrderDetails то мы поймем что некоторые поля в этой таблице зависят друг от друга но никак не от ключа. Это такие поля как ProductId, ProductDescription и UnitPrice.
Давайте перейдем дальше и попробуем привести нашу таблицу к третей НФ. Третья НФ требует что бы наша БД уже была приведена ко второй нормальной форме, так же требуется что бы ни в одном ключевом столбце не было зависимости ни от одного из ключевых столбцов. Так же наличие в столбцах непроизводных данных не допускается. Давайте попробуем удалить таблицы OrderDetails и Products и попробуем создать их заново. Ну что касается того что при приведении к третьей НФ ни в одном неключевом столбце не может быть зависимости от другого неключевого столбца. Если мы рассмотрим таблицу OrderDetails то мы поймем что некоторые поля в этой таблице зависят друг от друга но никак не от ключа. Это такие поля как ProductId, ProductDescription и UnitPrice.
Все это касается продуктов и в принципе это никак не взаимосвязано с заказом и с позицией заказа. Во второй НФ мы говорили что не должно зависить от части ключа но мы не говорили о том, что поле вообще может не зависеть от ключа, то есть разные поля могут зависеть друг от друга. И мы понимаем что в таблице OrderDetails поля ProductId, ProductDescription и UnitPrice, эти поля мы вынесем в отдельную таблицу, которую назовем Products. На 306-й строке я создаю таблицу Products, и в ней будет находится айди продукта, его описание, цена за единицу и какой то параметр Weight. Я создаю таблицу Products и заново создаю таблицу OrderDetails. Ну понятно что в таблице OrderDetails не будет полей Description, UnitPrice и Weight . Но таблица OrderDetails будет содержать поле внешнего ключа, которое будет ссылаться на строки на строки из таблицы Products и иметь имя поля ProductID. Это поле у нас с внешним ключом, который ссылается на поле ProductID из таблицы Products. Теперь давайте вставим данные в таблицы Products и OrderDetails и посмотрим что же у нас получилось. Производим поиск по всем данным нашей таблицы и получаем следующие данные. Так же можно построить диаграмму БД что бы посмотреть что там на самом деле происходит. Я добавляю таблицы и вижу вот что происходит: теперь таблица PrderDetails имеет еще связь с таблицей Products.
И мы понимаем что в таблице OrderDetails поля ProductId, ProductDescription и UnitPrice, эти поля мы вынесем в отдельную таблицу, которую назовем Products. На 306-й строке я создаю таблицу Products, и в ней будет находится айди продукта, его описание, цена за единицу и какой то параметр Weight. Я создаю таблицу Products и заново создаю таблицу OrderDetails. Ну понятно что в таблице OrderDetails не будет полей Description, UnitPrice и Weight . Но таблица OrderDetails будет содержать поле внешнего ключа, которое будет ссылаться на строки на строки из таблицы Products и иметь имя поля ProductID. Это поле у нас с внешним ключом, который ссылается на поле ProductID из таблицы Products. Теперь давайте вставим данные в таблицы Products и OrderDetails и посмотрим что же у нас получилось. Производим поиск по всем данным нашей таблицы и получаем следующие данные. Так же можно построить диаграмму БД что бы посмотреть что там на самом деле происходит. Я добавляю таблицы и вижу вот что происходит: теперь таблица PrderDetails имеет еще связь с таблицей Products. И вот теперь наша таблица приведена к трем нормальным формам и работать с ней будет более удобно чем с той версией, которую мы смотрели в самом начале этого примера.
И вот теперь наша таблица приведена к трем нормальным формам и работать с ней будет более удобно чем с той версией, которую мы смотрели в самом начале этого примера.
А теперь давайте пойдем дальше и нам осталось рассмотреть только денормализацию. Как мы помним из презентации – денормализация это процесс понижения НФ и такой процесс осуществляется если последняя НФ приводит к ухудшению практического использования нашей БД. На самом деле когда мы приводили к третьей НФ мы из таблицы OrderDetails убрали поле TotalPrice. То есть если мы посмотрим на последнюю выборку то мы не увидим такого поля, то есть теперь нужно будет самому считать на какую сумму был произведен заказ. Нужно будет смотреть в таблицу Products UnitPrice, смотреть на цену продукции и умножать это значение на значение поля Qty какой либо позиции в заказе. Вот тут было бы неплохо денормализовать нашу таблицу и вернуть значение поля TotalPrice. Давайте удалим таблицы OrderDetails и Products и учетом денормализации. В таблице Products у нас ничего нового не будет, но вот таблица OrderDetails будет изменятся.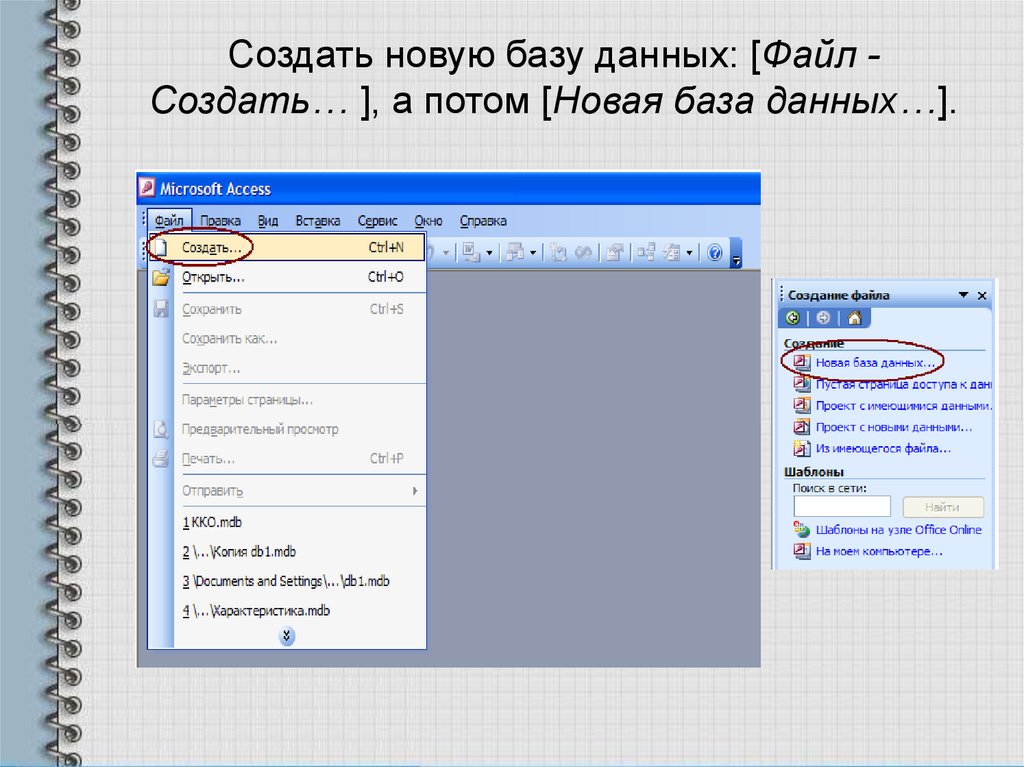 В таблице OrderDetails у нас будет появляться поле TotalPrice и в принципе все остальное такое же как и в предыдущей версии. И 337-я строка – мы вставляем данные в таблицу OrderDetails и при этом мы будем рассчитывать цену в нашем заказе при этом используя вложенные запросы. Давайте выполнимся. Да, сначала создадим таблицу, потом вставим в неё данные и выберем все данные из этой таблице. И видим что сервер сам посчитал значения для поля TotalPrice. Конечно неудобно умножать каждый раз Qty то есть количество купленных единиц на выборку. Ну в будущем мы будем знать что это можно реализовать с помощью хранимой процедуры или же с помощью триггера. На сегодня у нас все. Спасибо за внимание.
В таблице OrderDetails у нас будет появляться поле TotalPrice и в принципе все остальное такое же как и в предыдущей версии. И 337-я строка – мы вставляем данные в таблицу OrderDetails и при этом мы будем рассчитывать цену в нашем заказе при этом используя вложенные запросы. Давайте выполнимся. Да, сначала создадим таблицу, потом вставим в неё данные и выберем все данные из этой таблице. И видим что сервер сам посчитал значения для поля TotalPrice. Конечно неудобно умножать каждый раз Qty то есть количество купленных единиц на выборку. Ну в будущем мы будем знать что это можно реализовать с помощью хранимой процедуры или же с помощью триггера. На сегодня у нас все. Спасибо за внимание.
Создание успешной медиа-базы данных
Думайте о системе медиа-базы данных как о справочнике, написанном обо всех ваших проектах. С его помощью вы должны быть в состоянии найти любой выстрел и всю необходимую информацию об этом выстреле в любой момент. Простая база данных может содержать контент, исходное местоположение и продолжительность всех снимков в проекте, примерно так же, как ваши журналы мультимедиа сейчас. По-настоящему сложные предложения включают эскизы, превью, фильтр объектива и экспозицию, контактную информацию исполнителя… список бесконечен. Некоторые также могут быть интегрированы с вашей системой (системами) редактирования, чтобы они автоматически вводили весь контент, когда вы регистрируете свои клипы в инструменте захвата. Затем эти данные могут быть переданы, проанализированы и обработаны всеми остальными в вашей сети для использования в других проектах. Кроме того, бизнес-конец вашей компании может использовать его, чтобы подтвердить, что все важные моменты очищены от прав и контактов. Тем временем ваша съемочная группа может точно записать, как был сделан кадр. Это отличный способ собрать всех на одной волне.
По-настоящему сложные предложения включают эскизы, превью, фильтр объектива и экспозицию, контактную информацию исполнителя… список бесконечен. Некоторые также могут быть интегрированы с вашей системой (системами) редактирования, чтобы они автоматически вводили весь контент, когда вы регистрируете свои клипы в инструменте захвата. Затем эти данные могут быть переданы, проанализированы и обработаны всеми остальными в вашей сети для использования в других проектах. Кроме того, бизнес-конец вашей компании может использовать его, чтобы подтвердить, что все важные моменты очищены от прав и контактов. Тем временем ваша съемочная группа может точно записать, как был сделан кадр. Это отличный способ собрать всех на одной волне.
Существует три основных типа баз данных, имеющих отношение к видеоиндустрии. Нет никаких причин, по которым вы не можете смешивать и сочетать их, но успешные системы требуют тщательного ввода всех данных в любое время, поэтому иногда лучше сначала сосредоточиться на своих основных потребностях. Вы всегда можете расширить позже.
Вы всегда можете расширить позже.
Реклама
1. Простой каталог
Первый тип представляет собой подробный каталог, в котором представлено все, что вы когда-либо хотели знать (и многое, что вам никогда не было интересно) о вашей аудио- и видеобиблиотеке. С личной стороны вы можете использовать его в качестве каталога всех ваших Blu-ray, DVD и компакт-дисков. (Подумайте об интерфейсе просмотра Netflix, настроенном только на видео, которыми вы владеете). Вы можете просматривать свои фильмы, выполнять поиск по жанру, году выпуска и т. д. Если вам нравится актер в фильме, вы можете выбрать его имя, чтобы узнать, какие еще роли он сыграл (подумайте обо всех шести степенях игр Кевина Бэкона). Вы можете выиграть!) Это одна из самых простых баз данных для размещения, потому что многое из того, что вы получаете, может быть мгновенно и автоматически извлечено из Интернета (например, как музыкальные программы могут получать информацию с ваших скопированных компакт-дисков). Эти программы обычно строятся с определенным интерфейсом и уже установленными категориями, поэтому вам не нужно их настраивать. Однако они ограничены тем, что не поддерживают настройки общих программ базы данных. Вы можете ввести свою собственную информацию о медиа, но ваши категории будут в основном ограничены теми, которые имеют отношение к просмотру или прослушиванию. Возможно, нам нужна помощь в создании наших видео. Это приводит нас ко второму типу базы данных.
Эти программы обычно строятся с определенным интерфейсом и уже установленными категориями, поэтому вам не нужно их настраивать. Однако они ограничены тем, что не поддерживают настройки общих программ базы данных. Вы можете ввести свою собственную информацию о медиа, но ваши категории будут в основном ограничены теми, которые имеют отношение к просмотру или прослушиванию. Возможно, нам нужна помощь в создании наших видео. Это приводит нас ко второму типу базы данных.
2. Сдерживание контента
Бывают ситуации, когда вам может понадобиться система, которая будет поддерживать ваши усилия по постпродакшну. Эта система позволит вам искать исходный материал не только из вашего текущего проекта, но и из всех ваших проектов. Кинохроника, спорт и документальные фильмы — идеальные цели для такого бэкенда. Это жанры, в которых вы можете регулярно иметь дело с большим количеством архивных материалов и/или материалов, которые требуют, чтобы другая важная информация оставалась с клипом всякий раз, когда он используется. Как были получены эти кадры? Это правильный формат, разрешение или время суток? За какие права вы заплатили? Каковы ограничения? Вы можете поместить в него всю информацию, которую вам нужно будет предоставить своему вещателю. Когда придет время представить свою продукцию, вы можете ввести свой список решений по редактированию, и все ваши документы будут сгенерированы для вас. Это, конечно, прекрасно ведет к нашему третьему типу базы данных.
Как были получены эти кадры? Это правильный формат, разрешение или время суток? За какие права вы заплатили? Каковы ограничения? Вы можете поместить в него всю информацию, которую вам нужно будет предоставить своему вещателю. Когда придет время представить свою продукцию, вы можете ввести свой список решений по редактированию, и все ваши документы будут сгенерированы для вас. Это, конечно, прекрасно ведет к нашему третьему типу базы данных.
3. Управление метаданными
Представьте, что ваша контактная и адресная книга на стероидах. Что, если бы у вас была система, в которой вы могли бы выполнять поиск всех компаний, с которыми вы имеете дело и которые продают определенную услугу или часть оборудования? Затем вы могли бы сузить свой выбор, указав, кто работает по выходным, а у кого есть доставка на следующий день? Возможно, вместе с этим вы могли бы бронировать съемочные группы не только по имени которых вы помните, но и хорошо поработавшие на аналогичной съемке. Возможно, вы хотите сравнить показатели одного человека, которому вы поставили 8 из 10, и посмотреть, есть ли кто-то, кого вы оценили равным или лучше за меньшую стоимость. Если у вас есть огромные и постоянные исследовательские или подготовительные работы, база данных этого типа может сэкономить вам массу избыточных и лишних усилий с течением времени.
Возможно, вы хотите сравнить показатели одного человека, которому вы поставили 8 из 10, и посмотреть, есть ли кто-то, кого вы оценили равным или лучше за меньшую стоимость. Если у вас есть огромные и постоянные исследовательские или подготовительные работы, база данных этого типа может сэкономить вам массу избыточных и лишних усилий с течением времени.
Создание базы данных
Насколько эффективна будет ваша база данных в вашем бизнесе, зависит от того, как вы к ней подойдете. Ваша база данных будет настолько полезна, насколько полезна та информация, которую вы в нее поместите, и идеальный метод — получить как можно больше информации с минимальными усилиями. К счастью, в мире видео большая часть наших данных уже собрана в другом месте, нам просто нужно собрать их в одном месте.
Настоятельно рекомендуется систематизировать информацию в электронных таблицах, прежде чем заносить ее в базу данных. Это обеспечивает согласованность и плавный импорт, поэтому все идет туда, куда нужно. Это не означает, что вы должны начать вводить всю свою информацию в маленькие квадратики. Есть способы получить всю информацию о ваших mp3-тегах, например, в красивых аккуратных столбцах и строках. Хитрость заключается в том, чтобы найти общий интерфейс.
Это не означает, что вы должны начать вводить всю свою информацию в маленькие квадратики. Есть способы получить всю информацию о ваших mp3-тегах, например, в красивых аккуратных столбцах и строках. Хитрость заключается в том, чтобы найти общий интерфейс.
Перед этим, конечно, вам нужно получить информацию. Опять же, мы не хотим часами отмечать песни и пересматривать кассеты. Когда это возможно, мы хотим получить то, что нам нужно, из тех мест, где это уже есть.
Медиатека
Все ваши «потребительские» носители должны быть помечены и каталогизированы до того, как вы начнете интеграцию в базу данных. Это позволяет вам не только получать доступ к этой информации вне программы базы данных на основе отдельных файлов, но и позволяет вам использовать эти данные в медиаплеерах и других программах. Пользователям Mac следует использовать функции автоматической пометки iTunes для сбора информации о своих файлах. Для пользователей ПК есть отличная небольшая программа под названием MediaMonkey, которая обладает чрезмерным количеством возможностей тегов. Даже если формат файла не содержит метаданных, такие программы все равно позволят вам извлекать и сохранять информацию о них в своих списках воспроизведения, поэтому они идеально подходят для наших нужд.
Даже если формат файла не содержит метаданных, такие программы все равно позволят вам извлекать и сохранять информацию о них в своих списках воспроизведения, поэтому они идеально подходят для наших нужд.
Давайте пока поработаем с MediaMonkey. Укажите программе папку (папки), где хранятся ваши медиафайлы. После импорта программа волшебным образом классифицирует и сортирует файлы на основе того, что предоставлено. Затем вы можете настроить программу на доступ к Интернету и выполнить поиск любой недостающей информации, используя указанные вами онлайновые базы данных. Если он найдет более одного варианта, он даст вам возможность выбрать, какой из них лучше всего подходит для вашего файла. Затем он автоматически извлечет, свяжет и пометит носитель. Если нет информации о том или ином файле, вы можете ввести его самостоятельно. Иногда бывает достаточно ввести только название клипа, чтобы программа могла найти остальную связанную информацию.
Как только все ваши файлы будут размещены здесь, похлопайте себя по плечу. Вы только что создали свою первую базу данных мультимедиа. Однако мы не хотим останавливаться на достигнутом, поэтому давайте перейдем к следующему шагу. Большинство программ (включая Media Monkey и iTunes) могут экспортировать собранную информацию в виде текстового файла. В iTunes вы хотите выбрать свою аудиотеку (например). Затем в разделе «Файл» выберите «Экспорт> Список воспроизведения в виде текста». Этот текстовый файл представляет собой файл особого типа, который называется «значения, разделенные запятыми», что означает наличие набора небольших битов данных с запятыми (или иногда табуляцией или символами) между ними. Это наш «общий язык».
Вы только что создали свою первую базу данных мультимедиа. Однако мы не хотим останавливаться на достигнутом, поэтому давайте перейдем к следующему шагу. Большинство программ (включая Media Monkey и iTunes) могут экспортировать собранную информацию в виде текстового файла. В iTunes вы хотите выбрать свою аудиотеку (например). Затем в разделе «Файл» выберите «Экспорт> Список воспроизведения в виде текста». Этот текстовый файл представляет собой файл особого типа, который называется «значения, разделенные запятыми», что означает наличие набора небольших битов данных с запятыми (или иногда табуляцией или символами) между ними. Это наш «общий язык».
Внесите текст в программу для работы с электронными таблицами, такую как Excel или Calc. Увидев этот файл, программа проведет вас через мастер импорта, чтобы обеспечить правильное размещение данных.
Библиотека видеороликов
Теперь пришло время редактировать элементы. Большинство программ редактирования выше базового уровня позволяют вести журнал мультимедиа и упорядочивают ваши журналы вместе с таймингами, форматом и другой информацией о клипах, большая часть которой в наше время уже встроена в файл самой камерой. Вам следует обратиться к руководству, чтобы узнать, как именно происходит процесс, но экспорт журналов обычно так же прост, как процесс, описанный выше. Ищите функцию для экспорта ваших «корзин» или «журналов мультимедиа». Обратите внимание, что экспортируемая мультимедийная информация может основываться на отображении вашей корзины, поэтому убедитесь, что вы скрыли только те столбцы, которые не хотите передавать, и сделайте все, что хотите, видимым.
Вам следует обратиться к руководству, чтобы узнать, как именно происходит процесс, но экспорт журналов обычно так же прост, как процесс, описанный выше. Ищите функцию для экспорта ваших «корзин» или «журналов мультимедиа». Обратите внимание, что экспортируемая мультимедийная информация может основываться на отображении вашей корзины, поэтому убедитесь, что вы скрыли только те столбцы, которые не хотите передавать, и сделайте все, что хотите, видимым.
Опять же, теперь у вас есть формат файла, который вы можете импортировать в электронную таблицу для дальнейшего уточнения. После импорта убедитесь, что каждый лист выложен одинаковым образом. Возможно, вам придется вставить или переместить столбцы, чтобы они правильно совпадали с другими. Вы также можете добавлять отсутствующую информацию в массовом порядке и добавлять или удалять целые фрагменты данных по мере необходимости.
Последний шаг
Теперь вы готовы внести свою информацию в базу данных. Опять же, вы часто найдете мастер установки, который проведет вас через весь процесс. Если это так, он может даже создать соответствующие классификации данных. Поздравляем! Готово!
Если это так, он может даже создать соответствующие классификации данных. Поздравляем! Готово!
Теперь, когда у вас есть база данных, вам следует обратиться к руководству по ее эксплуатации, чтобы добиться максимальной полезности. Программы баз данных охватывают широкий спектр применений, и операции будут сильно различаться от программы к программе. Обратите внимание, однако, что поддерживать установленную базу данных можно по одной записи за раз или все сразу, добавляя новый столбец в вашу электронную таблицу, а затем повторно импортируя.
Итак, теперь, когда мы получили представление об объемах данных, которые может обрабатывать такая система, и рассмотрели, что необходимо для ее настройки, давайте вернемся к нашему давнему вопросу: подходит ли вам база данных? Честно говоря, при неправильном обращении такая система может стать огромной и ненужной тратой ресурсов. Вы не должны отказываться от этой статьи, думая, что вам абсолютно необходима медиа-база данных для вашего бизнеса; но для широко распространенной обработки данных их простота использования и богатство знаний непреодолимы. Ваш успех будет зависеть от того, насколько строго вы вводите данные, и будут предприятия, которые не смогут оправдать усилия по сравнению с преимуществами, которые предоставляет такая система. Однако, если вы регулярно используете или продаете стоковые видеоматериалы, ведете сериал с чрезмерным количеством роликов, производите вышеупомянутый документальный фильм или работаете в месте, где многие люди имеют доступ к одному и тому же материалу, вы, вероятно, обнаружите, что такая система облегчает много двойной работы и проблем с общением и в конечном счете бесценно.
Ваш успех будет зависеть от того, насколько строго вы вводите данные, и будут предприятия, которые не смогут оправдать усилия по сравнению с преимуществами, которые предоставляет такая система. Однако, если вы регулярно используете или продаете стоковые видеоматериалы, ведете сериал с чрезмерным количеством роликов, производите вышеупомянутый документальный фильм или работаете в месте, где многие люди имеют доступ к одному и тому же материалу, вы, вероятно, обнаружите, что такая система облегчает много двойной работы и проблем с общением и в конечном счете бесценно.
Боковая панель 1: Некоторые программы, на которые следует обратить внимание
Что касается электронных таблиц, вам действительно не нужно смотреть дальше, чем Microsoft Excel или LibreOffice Calc. Это одни из самых доступных программ с большей функциональностью, чем вам нужно, и они поддерживают популярные универсально совместимые форматы документов.
С другой стороны, программы баз данных — это совсем другая история. Общие программы баз данных, такие как Microsoft Access, Google Base и Filemaker Pro, предлагают беспрецедентную гибкость, но не предназначены специально для мультимедиа. Avid Interplay и Final Cut Pro Server — это лишь некоторые из доступных опций, специально предназначенных для кино- и видеоиндустрии. Некоторые предназначены в качестве браузера для просмотра вашего каталога (DVDpedia, Delicious Library 2, MediaMan). Такие системы, как Plex, предоставляют больше возможностей для медиасервера/просмотра. Другие помогут отслеживать мелкие детали производства (TeleScope Video Manager). Существует также множество программ с открытым исходным кодом и бесплатных программ (K Database Magic).
Общие программы баз данных, такие как Microsoft Access, Google Base и Filemaker Pro, предлагают беспрецедентную гибкость, но не предназначены специально для мультимедиа. Avid Interplay и Final Cut Pro Server — это лишь некоторые из доступных опций, специально предназначенных для кино- и видеоиндустрии. Некоторые предназначены в качестве браузера для просмотра вашего каталога (DVDpedia, Delicious Library 2, MediaMan). Такие системы, как Plex, предоставляют больше возможностей для медиасервера/просмотра. Другие помогут отслеживать мелкие детали производства (TeleScope Video Manager). Существует также множество программ с открытым исходным кодом и бесплатных программ (K Database Magic).
Боковая панель 2: Throwdown: База данных и электронная таблица
Электронная таблица также может содержать все эти данные. Это веский аргумент. Думайте о электронной таблице как о гигантском торговом центре. Все организовано по магазинам, затем по отделам, затем по категориям, ценовым диапазонам, брендам и цветам.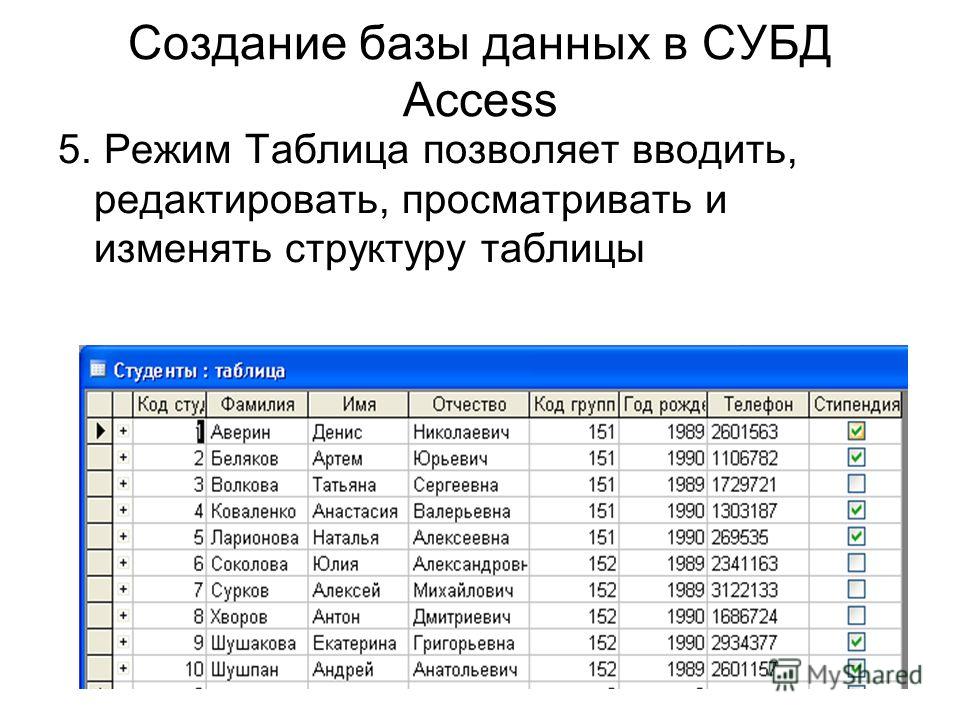 Вы можете часами ходить, сравнивая информацию, читая стороны коробок и т. д., просто чтобы найти в магазине единственный зеленый чайник стоимостью менее тридцати долларов с курком для носика. В качестве альтернативы вы можете инвестировать в компьютер и настроить его для подключения к Интернету. Затем вы можете зайти в Интернет и просто выполнить поиск одного и того же предмета, и сразу же появится двадцать вариантов покупки, отсортированных по релевантности. Это ваша база данных. Разница заключается в возможности запускать поиски, запросы (сравните стоимость выстрелов за день 1 и день 2) и переупорядочивать информацию любым удобным для вас способом без потери целостности взаимосвязей данных. Каждый отдел может одновременно вводить свою информацию об одном и том же клипе, и, в конце концов, все это находится в одном месте. Тем не менее, электронная таблица может быть составлена довольно просто. Эффективная база данных — это постоянное обязательство. (Поддержите своих местных розничных продавцов).
Вы можете часами ходить, сравнивая информацию, читая стороны коробок и т. д., просто чтобы найти в магазине единственный зеленый чайник стоимостью менее тридцати долларов с курком для носика. В качестве альтернативы вы можете инвестировать в компьютер и настроить его для подключения к Интернету. Затем вы можете зайти в Интернет и просто выполнить поиск одного и того же предмета, и сразу же появится двадцать вариантов покупки, отсортированных по релевантности. Это ваша база данных. Разница заключается в возможности запускать поиски, запросы (сравните стоимость выстрелов за день 1 и день 2) и переупорядочивать информацию любым удобным для вас способом без потери целостности взаимосвязей данных. Каждый отдел может одновременно вводить свою информацию об одном и том же клипе, и, в конце концов, все это находится в одном месте. Тем не менее, электронная таблица может быть составлена довольно просто. Эффективная база данных — это постоянное обязательство. (Поддержите своих местных розничных продавцов).
Боковая панель 3: Ключевые слова являются ключевыми
Если вы собираетесь использовать свою базу данных для поиска в отснятом материале, вам следует использовать ключевые слова. Это столбец, который сокращает описание до самых основных элементов. Поэтому, если в описании вашего выстрела написано «Игровая площадка — MWS Джек и Джилл от горки до качелей и бревна», вашими ключевыми словами могут быть «дети, Джек, Джилл, игра, детская площадка». Идея состоит в том, что если кому-то позже понадобится снимок детей, особенно Джека, или общие снимки игровых площадок, этот снимок появится в результатах. На самом деле это «Уловка 22», так как лучшее использование ключевых слов — это когда вы используете как можно меньше, но вам никогда не будет достаточно. Это сложно сделать, но практика и последовательность принесут положительные результаты.
Питер Цунич — менеджер по пост-продакшну и монтажер, работающий с любой системой, от 16-мм пленки до Avid Symphony, используя многие из современных передовых инструментов обработки и композитинга.
php — Как я могу хранить видео в базе данных?
спросил
Изменено 2 года, 5 месяцев назад
Просмотрено 11 тысяч раз
Недавно я установил xampp на Windows. Я хотел бы знать, как я могу хранить видео/клипы в базе данных. У меня есть видеоклип, хранящийся в папке htdocs, и там, где в базе данных xampp указано «значение», я помещаю каталог файлов, за которым следует имя файла (C:\xampp\htdocs\firstsite\check_php\helgo.mp4 , однако, когда Я обновляю и показываю свою работу в режиме предварительного просмотра, видео не появляется, а появляется только текстовая строка Тип установлен на VARCHAR(255)
У меня есть видео по следующему пути к файлу: C:\xampp\htdocs\ firstsite\helgo.mp4.В базе данных xampp запись имеет следующие свойства type=VARCHAR(255) function= я оставляю пустым и значение= C:\xampp\htdocs\firstsite\helgo.