Распознавание текста в ABBYY FineReader (1/2) / Хабр
Содержание
Распознавание текста в ABBYY FineReader (1/2)
Распознавание текста в ABBYY FineReader (2/2)
Систему распознавания текста в FineReader можно описать очень просто.
У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы.
Выглядит очень просто, но дьявол, как обычно, кроется в деталях.
Про уровень от документа до строки текста поговорим как-нибудь в следующий раз. Это большая система, в которой есть много своих сложностей. В качестве некоторого введения, пожалуй, можно оставить здесь вот такую иллюстрацию к алгоритму выделения строк.
В этой статье мы начнём рассказ про распознавание текста от уровня строки и ниже.
Небольшое предупреждение: система распознавания FineReader – очень большая и постоянно дорабатывается в течение многих лет. Описывать эту систему целиком со всеми ее нюансами, во-первых, лучше кодом, во-вторых, займет очень-очень много места, в-третьих, почитайте это. Поэтому к написанному далее рекомендуем относиться как к некой очень обобщенной теории, стоящей за практической системой. То есть общие идеи и направления в технологии примерно похожи на правду, но чтобы понять до мелочей, что же там на практике происходит, лучше не читать эту статью, а работать у нас над разработкой этой системы.
Граф линейного деления
Итак, у нас есть черно-белое изображение строки текста. На самом деле изображение, конечно, серое или цветное, а черно-белым становится после бинаризации (про бинаризацию тоже нужно писать отдельную статью, а пока отчасти может помочь вот это).
Так вот, пусть есть черно-белое изображение строки текста. Нужно его поделить на слова, а слова — на символы для распознавания.
Идея замечательная, но в реальной жизни ширина пробелов может быть очень неоднозначным показателем, к примеру, для текста с наклоном или неудачного сочетания символов или слипшегося текста.
Решений у проблемы, в общем, два. Решение первое – считать некую «видимую» ширину просветов. Человек может практически любой текст, даже на незнакомом языке, точно поделить на слова, а слова — на символы. Это происходит потому, что мозг фиксирует не вертикальное расстояние между символами, а некий видимый объем пустого пространства между ними. Решение хорошее, мы его, конечно, используем, только работает оно не всегда. К примеру, текст может быть повреждён при сканировании и некоторые нужные просветы могут уменьшиться или, наоборот, сильно увеличиться.
Это приводит нас ко второму решению – графу линейного деления. Идея в следующем – если есть несколько вариантов, где поделить строку на слова, а слова на буквы, то давайте отметим все возможные точки деления, которые мы смогли придумать. Кусок изображения между двумя отмеченными точками будем считать кандидатом буквы (или слова). Вариант графа линейного может быть простым, если текст хороший и нет проблем с определением точек деления или сложным, если изображение было плохое.
Идея в следующем – если есть несколько вариантов, где поделить строку на слова, а слова на буквы, то давайте отметим все возможные точки деления, которые мы смогли придумать. Кусок изображения между двумя отмеченными точками будем считать кандидатом буквы (или слова). Вариант графа линейного может быть простым, если текст хороший и нет проблем с определением точек деления или сложным, если изображение было плохое.
Теперь задача. Есть множества вершин графа, нужно найти путь от первой вершины до последней, проходящий через какое-то количество промежуточных вершин (не обязательно все) с наилучшим качеством. Начинаем думать, что это напоминает. Вспоминаем курс оптимального управления из института, понимаем, что это подозрительно похоже на задачи динамического программирования.
Давайте подумаем, что нам нужно, чтобы алгоритм перебора всех вариантов не взорвался.
Для каждой дуги в графе нужно определить её качество. Если мы работаем с графом линейного деления слова на символы, то каждая дуга у нас – это символ. В роли качества дуги мы используем уверенность распознавания символа (как её посчитать — поговорим позднее). А если работаем с ГЛД на уровне строки, то каждая дуга этого ГЛД – вариант распознавания слова, который в свою очередь был получен из символьного графа. То есть нам нужно уметь оценивать общее качество полного пути в графе линейного деления.
В роли качества дуги мы используем уверенность распознавания символа (как её посчитать — поговорим позднее). А если работаем с ГЛД на уровне строки, то каждая дуга этого ГЛД – вариант распознавания слова, который в свою очередь был получен из символьного графа. То есть нам нужно уметь оценивать общее качество полного пути в графе линейного деления.
Качество полного пути в графе мы будем определять как сумму качества всех дуг МИНУС штраф за весь вариант. Почему именно минус? Это дает нам возможность быстро оценить максимально возможное качество варианта пути по сумме качества дуг этого пути, а это значит, что большинство вариантов мы будем отсекать еще до подсчета общего качества варианта.
Таким образом, для ГЛД мы приходим к стандартному алгоритму динамического программирования – находим точки линейного деления, строим путь от начала до конца по дугам с наибольшим качеством, высчитываем итоговую стоимость построенного варианта. А дальше перебираем пути в ГЛД в порядке уменьшения суммарного качества элементов с постоянным обновлением найденного лучшего варианта, пока не поймем, что все необработанные варианты заведомо хуже, чем текущий лучший вариант.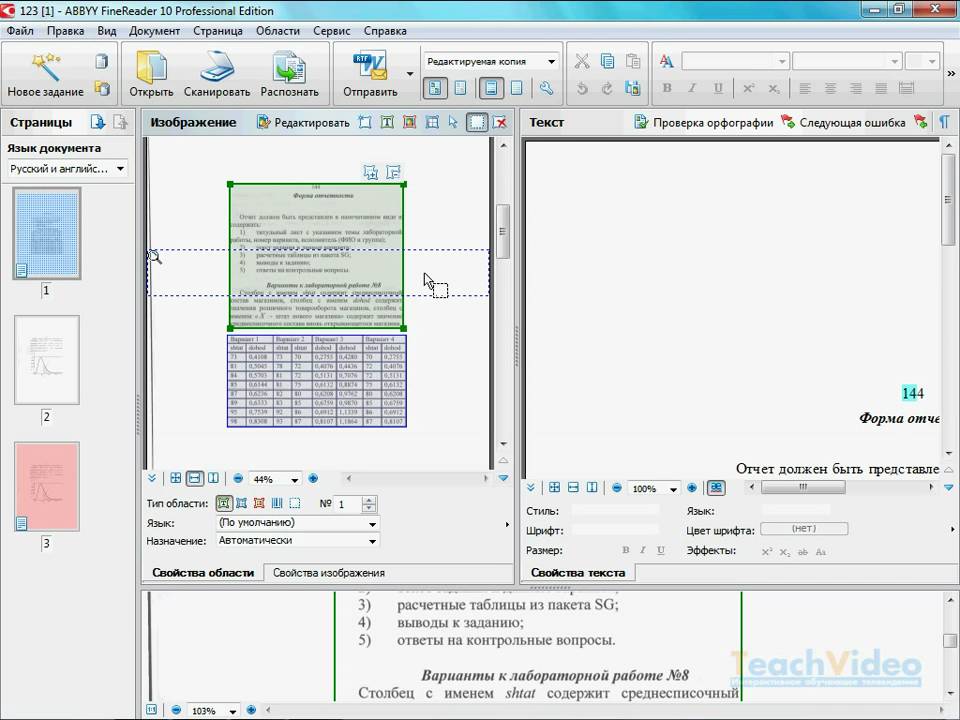
Гипотезы изображения
Прежде чем мы спустимся на уровень распознавания отдельных слов, у нас есть еще одна тема, которая не обсуждалась, – гипотезы изображения фрагмента.
Идея в следующем – у нас есть изображение текста, с которым мы собираемся работать. Очень хочется все изображения обрабатывать одинаковым образом, но правда в том, что в реальном мире изображения все разные – они могут быть получены из разных источников, они могут быть разного качества, они могут быть по-разному отсканированы.
С одной стороны, кажется, что разнообразие возможных искажений должно быть очень велико, но если начать разбираться, обнаруживается только ограниченный набор возможных искажений. Поэтому мы используем систему гипотез текста.
У нас есть предопределенный набор возможных гипотез проблемного текста. Для каждой гипотезы нужно определить:
- Быстрый способ выяснить, применима ли данная гипотеза к текущему изображению, причем сделать это только на основе характеристик изображения, до распознавания.
- Метод для исправления на изображении проблем конкретной гипотезы.
- Критерий качества правильности выбора гипотезы по итогам распознавания изображения, плюс, возможно, рекомендации для следующих гипотез.
На изображении выше можно увидеть гипотезы для различной бинаризации и контрастности исходного изображения.
В результате обработка гипотез выглядит так:
- По изображению сгенерировать наиболее подходящую гипотезу.
- Исправить искажения от выбранной гипотезы.
- Распознать полученное изображение.
- Оценить качество распознавания.
- Если качество распознавания улучшилось, то оценить, нужно ли применять новые гипотезы к измененному изображению.
- Если качество ухудшилось, то вернуться к исходному изображению и попробовать применить к нему какую-либо другую гипотезу.
На изображениях показано последовательное применение гипотез белого шума и сжатого текста.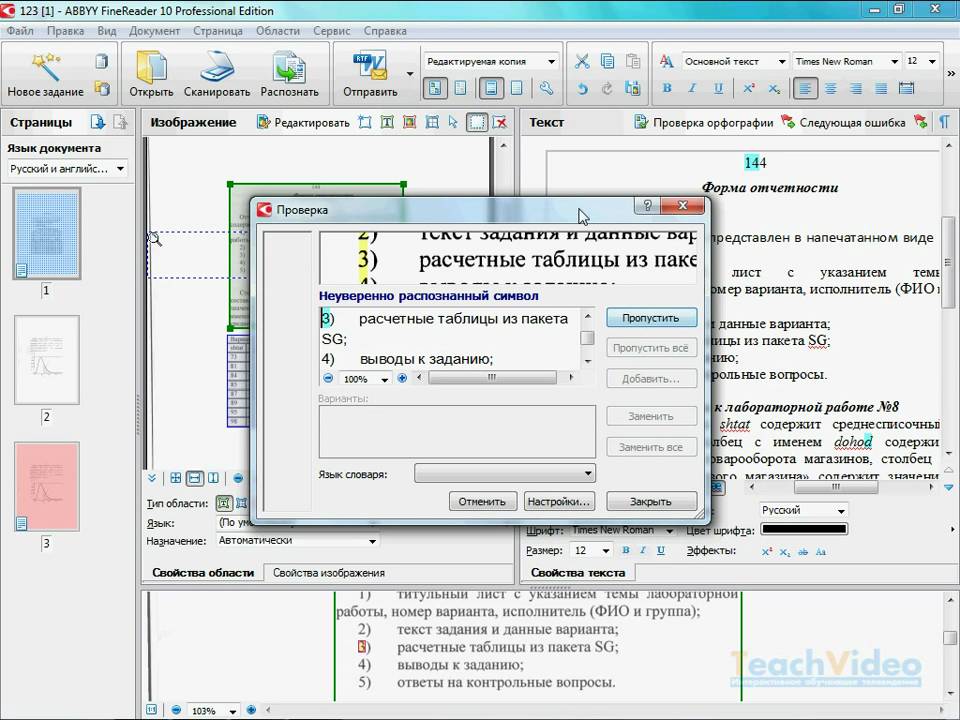
Оценка качества слова
Остались нераскрытыми две важных темы: оценка общего качества распознавания слова и распознавание символов. Распознавание символа – тема на несколько разделов, поэтому сначала обсудим оценку качества распознанного слова.
Итак, у нас есть некий вариант распознавания слова. Первое, что приходит на ум, – проверить его по словарю и дать ему штраф, если оно в словаре не нашлось. Идея хорошая, но не все языки есть словари, не все слова в тексте могут быть словарными (имена собственные, к примеру), и, если уж мы углубляемся в сложности, – не всё в тексте вообще может быть словами в стандартном понимании этого термина.
Чуть раньше мы говорили, что любые оценки за слово целиком должны быть отрицательными, чтобы у нас нормально работал перебор по ГЛД. Сейчас нам это начнет активно мешать, поэтому давайте зафиксируем, что у нас есть некая заранее определенная максимальная положительная оценка слова, слову мы даем положительные бонусы, а финальный отрицательный штраф определяем как разность набранных бонусов и максимальной оценки.
Ок, пусть мы распознаём фразу «Вася прилетает рейсом SU106 в 23.55 20/07/2015». Мы, конечно, можем оценивать здесь качество каждого слова по общим правилам, но это будет достаточно странно. Скажем, и SU106 и Вася вполне понятные в данной строке слова, но очевидно, что правила образования у них разные и, по идее, верификация тоже должна быть разной
Отсюда появляется идея моделей. Модель слова – это некое обобщенное описание конкретного типа слов в языке. У нас, конечно, будет модель стандартного слова в языке, но также будут модели чисел, аббревиатур, дат, сокращений, имен собственных, URL и т.д.
Что нам дают модели и как их нормально использовать? Фактически мы обращаем в обратную сторону нашу систему проверки слова – вместо того чтобы для варианта слова долго узнавать, что же это такое, мы даем каждой модели решать, подходит ли ей данный вариант слова и насколько хорошо она его оценивает.
Из самой постановки задачи формируются наши требования к архитектуре модели. Модель должна уметь:
Модель должна уметь:
- Быстро сказать, подходит или нет для нее вариант слова. Стандартная проверка включает все проверки разрешенных наборов символов для каждой буквы в слове. Скажем, в словарном слове пунктуация должна быть только в начале или в конце, а в середине слова набор пунктуации сильно ограничен, и сочетание пунктуации сильно ограничено (супер-способность?!), а в модели числа в основном должны быть цифры, кроме разрешенного в данном языке символьного суффикса (10-ое, 10th).
- Уметь по своей внутренней логике оценить качество распознаваемого слова. К примеру, слово из словаря должно явно оцениваться выше, чем просто набор символов.
При оценке качества модели не стоит забывать, что наша задача в итоге – сравнивать модели между собой, поэтому их оценки должны быть согласованы. Более-менее нормальный способ этого добиться – это относиться к оценке модели как к оценке вероятности построить слово по данной модели. Скажем, словарных слов в обычном языке достаточно много, и получить словарное слово при неправильном распознавании несложно.
В итоге при распознавании некоторого фрагмента строки у нас получается примерно такая схема:
Отдельным пунктом при оценке вариантов распознавания идут дополнительные эмпирические штрафы, не вписывающиеся ни в концепцию моделей, ни в оценку распознавания. Скажем, «ООО Рога и копыта» и «000 Рога и копыта» выглядят как два одинаково нормальных варианта (особенно если в шрифте 0 (ноль) и О (буква О) слабо отличаются пропорциями). Но при этом достаточно очевидно, какой вариант распознавания должен быть правильным. Для таких небольших конкретных знаний о мире сделана отдельная система правил, которая может дополнительно штрафовать не понравившиеся ей варианты после оценок моделей.
Про само распознавание поговорим уже в следующей части этого поста. Подписывайтесь на блог компании, чтобы не пропустить 🙂
Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция
Содержание:
 org/ListItem»> СКАНИРОВАНИЕ в PDF
org/ListItem»> СКАНИРОВАНИЕ в PDF- РАСПОЗНАВАНИЕ ТЕКСТА
[contents]
В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
Произойдет сканирование и появится предложение сохранить файл. Выбираем место, пишем название файла и сохраняем.
В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.
Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ
Получаем отсканированный документ
Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF
В итоге получаем готовый многостраничный документ в виде файла в формате PDF.
Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)
2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)
Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки).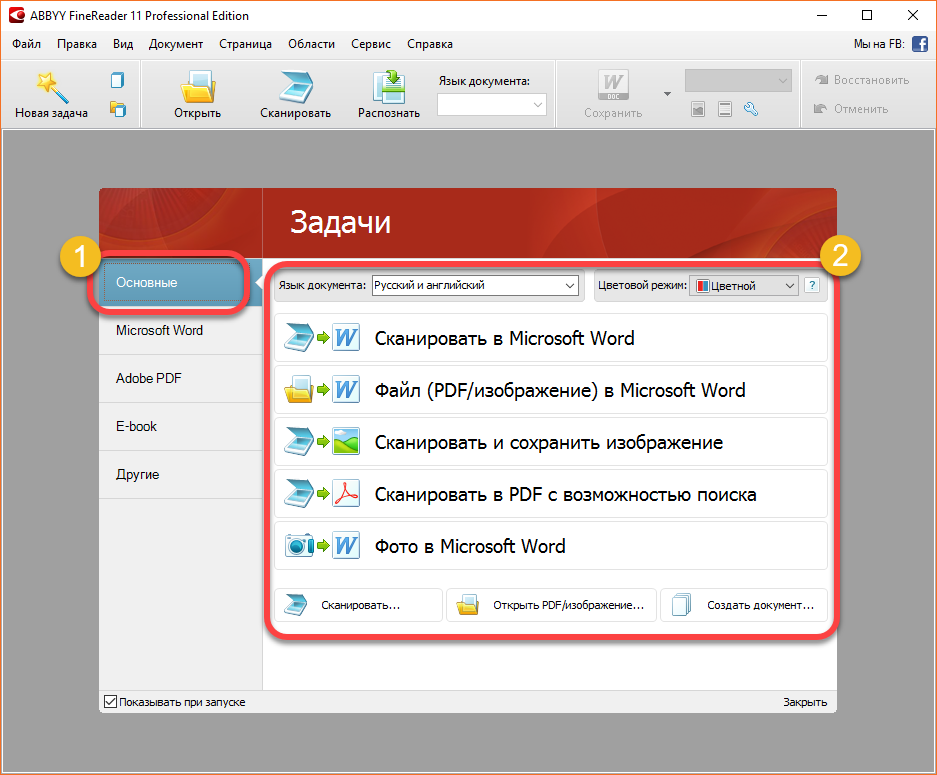 Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD
Получаем
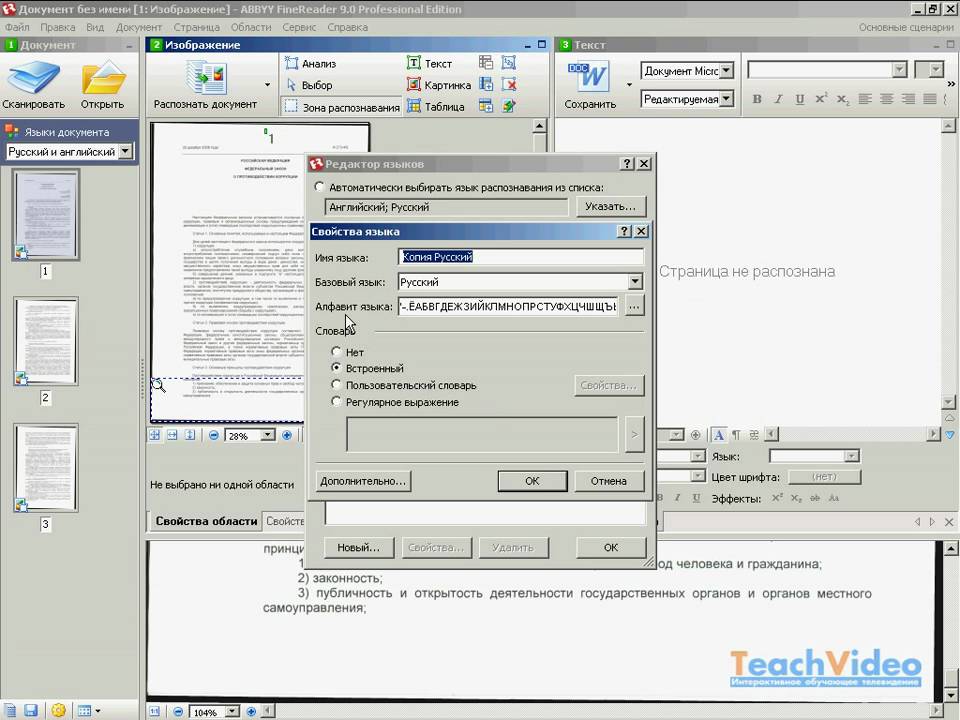
Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.
Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.
Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).
В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
Преобразование отсканированных документов в редактируемый текст
Главная > Сканирование специальных проектов
Окна
Mac OS X
Вы можете отсканировать документ и преобразовать его в редактируемый текст с помощью программы оптического распознавания символов (OCR), такой как ABBYY FineReader.
Программное обеспечение OCR не распознает или с трудом распознает следующие типы документов или текста:
Рукописные символы
Страницы, скопированные с других копий
Факсы
Текст с короткими интервалами между символами или шагом строки
Текст в таблицах или подчеркнутый
Курсив или курсив, размер шрифта менее 8 пунктов
Выполните следующие действия, чтобы отсканировать и преобразовать текст с помощью ABBYY FineReader.
Windows
Примечание:
Параметры могут различаться в зависимости от используемой версии программного обеспечения. Подробности смотрите в справке ABBYY FineReader. |
Загрузите документы (до 75 страниц) во входной лоток стороной для печати вниз и верхним краем в устройство подачи. Инструкции см. в разделе Загрузка документов. |
Чтобы запустить ABBYY FineReader, выполните одно из следующих действий: |
Windows 8.x : Перейдите к экрану Apps и выберите ABBYY FineReader 9.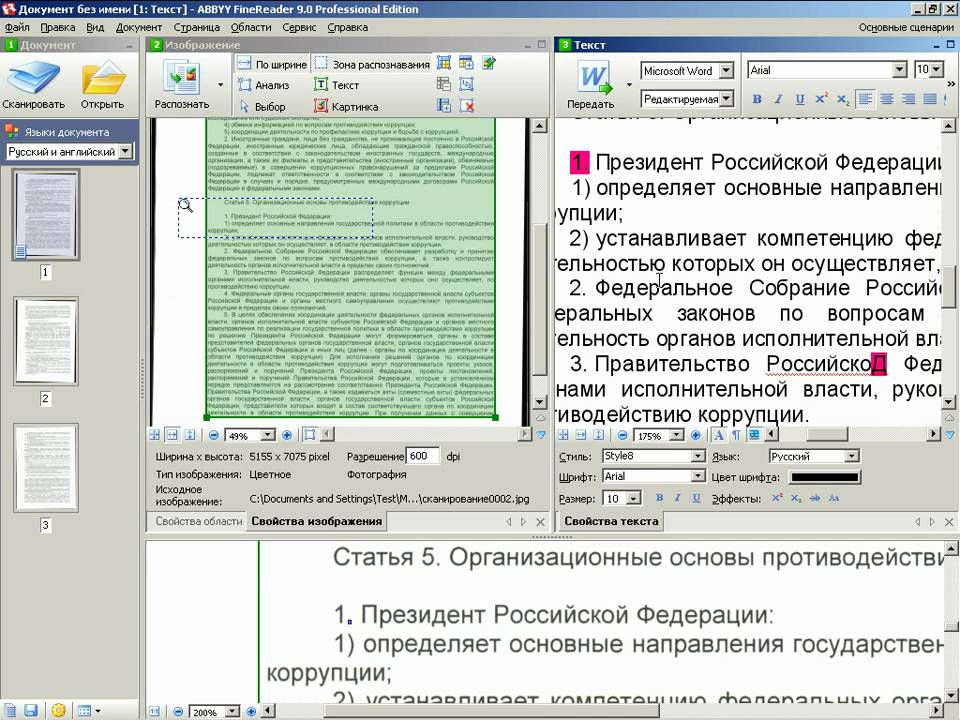 0 Sprint .
0 Sprint .
Windows (другие версии) : Щелкните значок кнопки «Пуск» или Пуск > Все программы или Программы > ABBYY FineReader 9.0 Sprint > ABBYY FineReader 9.0 Sprint .
Вы видите вот такое окно:
Выберите язык, используемый в документе, который вы собираетесь сканировать, в качестве параметра Язык документа . |
Щелкните значок Сканировать в другие форматы или значок, соответствующий программе, в которую вы хотите выполнить сканирование. |
Если вы видите окно Select Scanner, выберите свой продукт и нажмите OK . |

Примечание:
Не выбирайте вариант WIA для вашего продукта; это не будет работать правильно. |
Вы видите окно настроек сканирования.
Выберите параметры сканирования. |
Нажмите Предварительный просмотр и при необходимости отрегулируйте область сканирования. |
Снова вставьте документ и нажмите Сканировать . |

Когда вы закончите сканирование, нажмите Закрыть . Ваш документ будет отсканирован и преобразован в редактируемый текст, затем вы увидите окно «Сохранить как». |
Выберите имя и формат файла для документа и нажмите Сохранить . Файл сохраняется, а затем открывается в приложении, связанном с выбранным вами типом файла, если оно доступно в вашей системе. |
Mac OS X
Примечание:
Параметры могут различаться в зависимости от используемой версии программного обеспечения. |
 Подробности смотрите в справке ABBYY FineReader.
Подробности смотрите в справке ABBYY FineReader.Загрузите документы (до 75 страниц) во входной лоток стороной для печати вниз и верхним краем в устройство подачи. Инструкции см. в разделе Загрузка документов. |
Выберите Приложения и дважды щелкните значок ABBYY FineReader Sprint . |
Примечание:
Если у вас еще нет ABBYY FineReader, вы можете получить его с помощью Epson Software Updater. Инструкции см. в разделе Обновление программного обеспечения для сканирования (только для Mac OS X). |

Вы видите вот такое окно:
Откройте всплывающее меню Get Images From и выберите свой продукт. |
Выберите язык, используемый в документе, который вы собираетесь сканировать, в качестве параметра Язык документа . |
Выберите тип документа, который вы собираетесь сканировать. Epson Scan запускается в последнем использовавшемся режиме сканирования. |
Выберите параметры сканирования и нажмите Сканировать . |
 Ваш документ отсканирован, и вы видите окно Epson Scan, пока ваш документ преобразуется в редактируемый текст.
Ваш документ отсканирован, и вы видите окно Epson Scan, пока ваш документ преобразуется в редактируемый текст.Щелкните Close , чтобы закрыть окно Epson Scan и окно предварительного просмотра, если это необходимо. Вы видите окно Сохранить преобразованный файл как: |
Нажмите кнопку Сохранить . Файл сохраняется, а затем открывается в приложении, связанном с выбранным вами типом файла, если оно доступно в вашей системе. |
Стоит ли оно того в 2023 году?
Abbyy Finereader PDF
Adrian Try
Эффективность : Точный OCR и экспорт
Цена : 117 долларов США в год для Windows, $ 69 в год для MAC
. Серстливый использование : Легкие в год. пользовательский интерфейс
Серстливый использование : Легкие в год. пользовательский интерфейс
Поддержка : Телефон, электронная почта и онлайн-документация
Резюме
ABBYY FineReader считается лучшим приложением для оптического распознавания текста. Он может распознавать блоки текста в отсканированных документах и точно преобразовывать их в печатный текст. Затем он может экспортировать полученный документ в ряд популярных форматов файлов, включая PDF и Microsoft Word, сохраняя исходный макет и форматирование. Если для вас важнее всего точное преобразование отсканированных документов и книг, то лучше FineReader PDF вам не найти.
Однако в версии программного обеспечения для Mac отсутствует возможность редактирования текста и совместной работы с другими пользователями, а приложение не содержит инструментов разметки. Если вы ищете более универсальное приложение, включающее эти функции, одно из приложений в разделе альтернатив этого обзора может подойти лучше.
Что мне нравится : Отличное оптическое распознавание символов отсканированных документов. Точное воспроизведение макета и форматирования исходного документа. Интуитивно понятный интерфейс, который не заставил меня искать руководство.
Что мне не нравится : Версия для Mac отстает от версии для Windows. Документации для версии для Mac немного не хватает.
Что делает ABBYY FineReader?
Это программа, которая берет отсканированный документ, выполняет на нем оптическое распознавание символов (OCR) для преобразования изображения страницы в фактический текст и преобразования результата в пригодный для использования тип документа, включая PDF, Microsoft Word и более.
Хорошо ли работает ABBYY OCR?
У ABBYY есть собственная технология оптического распознавания символов, которую они разрабатывают с 1989 года, и многие лидеры отрасли считают ее лучшей из существующих. OCR — сильная сторона FineReader. Если у вас есть другие приоритеты, такие как создание, редактирование и аннотирование PDF-файлов, ознакомьтесь с разделом альтернатив этого обзора для более подходящего приложения.
Если у вас есть другие приоритеты, такие как создание, редактирование и аннотирование PDF-файлов, ознакомьтесь с разделом альтернатив этого обзора для более подходящего приложения.
Является ли ABBYY FineReader бесплатным?
Нет, хотя у них есть 30-дневная бесплатная пробная версия, так что вы можете тщательно протестировать программу перед покупкой. Пробная версия содержит все функции полной версии.
Сколько стоит ABBYY FineReader?
FineReader PDF для Windows стоит 117 долларов в год (стандартная версия), он позволяет конвертировать PDF-файлы и сканы, редактировать и комментировать PDF-файлы. Для предприятий малого и среднего бизнеса, которым необходимо сравнивать документы и/или автоматизировать преобразование, ABBYY также предлагает корпоративную лицензию по цене 165 долларов США в год. FineReader PDF для Mac доступен на веб-сайте ABBYY за 69 долларов в год. Ознакомьтесь с последними ценами здесь.
Где я могу найти учебники FineReader PDF?
Справочную информацию по программе лучше всего найти в справочных файлах программы. Выберите в меню Справка / Справка FineReader, и вы найдете введение в программу, руководство по началу работы и другую полезную информацию.
Помимо краткого FAQ, вам может помочь учебный центр ABBYY. Есть также несколько полезных сторонних ресурсов, которые помогут вам понять OCR ABBYY и как использовать FineReader.
Содержание
- Почему доверяют мне для этого обзора?
- Подробный обзор ABBYY FineReader PDF
- 1. Распознавание отсканированных документов
- 2. Изменение порядка страниц и областей импортированного документа
- 3. Преобразование отсканированных документов в PDF и редактируемые типы документов
- Альтернативы ABBYY FineReader
- Заключение
Почему мне стоит доверять этот обзор?
Меня зовут Адриан Трий. Я пользуюсь компьютером с 19 лет88 и компьютеры Mac с 2009 года. Стремясь отказаться от бумаги, я приобрел сканер документов ScanSnap S1300 и преобразовал тысячи листов бумаги в PDF-файлы с возможностью поиска.
Это стало возможным благодаря тому, что сканер включал ABBYY FineReader for ScanSnap , встроенное приложение для оптического распознавания символов, которое может превращать отсканированное изображение в печатный текст. Настроив профили в ScanSnap Manager, ABBYY может автоматически запускать и распознавать мои документы сразу после их сканирования.
Я очень доволен результатами, и теперь я могу найти именно тот документ, который мне нужен, с помощью простого поиска Spotlight. Я с нетерпением жду возможности попробовать автономную версию ABBYY FineReader PDF для Mac. ABBYY предоставила код NFR, чтобы я мог оценить полную версию программы, и за последние несколько дней я тщательно протестировал все ее функции.
Что я открыл? Содержимое приведенного выше сводного блока даст вам хорошее представление о моих выводах и выводах. Читайте дальше, чтобы узнать подробности обо всем, что мне понравилось и не понравилось в FineReader Pro.
Подробный обзор программы ABBYY FineReader PDF
Программа предназначена для преобразования отсканированных документов в доступный для поиска текст. Я расскажу о его основных функциях в следующих трех разделах, сначала изучив, что предлагает приложение, а затем поделюсь своим личным мнением.
Я расскажу о его основных функциях в следующих трех разделах, сначала изучив, что предлагает приложение, а затем поделюсь своим личным мнением.
Обратите внимание, что мое тестирование было основано на версии для Mac, и скриншоты ниже также основаны на этой версии, но я буду ссылаться на результаты версии для Windows из других авторитетных отраслевых журналов.
1. Оптическое распознавание ваших отсканированных документов
FineReader может преобразовывать бумажные документы, PDF-файлы и цифровые фотографии документов в редактируемый текст с возможностью поиска и даже в полностью отформатированные документы. Процесс распознавания символов на изображении и превращения их в настоящий текст называется OCR или оптическим распознаванием символов.
Если вам нужно преобразовать печатные документы в цифровые файлы или преобразовать печатную книгу в электронную книгу, это может сэкономить много времени при наборе текста. Кроме того, если ваш офис переходит на безбумажный документ, применение оптического распознавания символов к отсканированным документам сделает их доступными для поиска, что может быть очень полезно при поиске нужного документа среди сотен документов.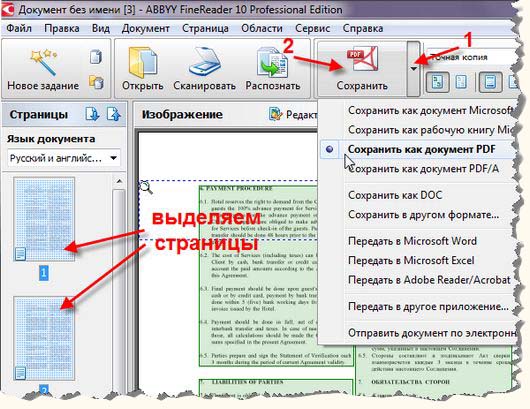
Мне очень хотелось оценить способность программы распознавать текст на бумаге. Сначала я отсканировал школьную заметку с помощью сканера ScanSnap S1300, а затем импортировал полученный JPG-файл в FineReader с помощью параметра Импорт изображений в новый документ в диалоговом окне Новый ….
FineReader ищет блоки текста в документе и распознает их.
Из того, что я могу сказать на данном этапе, документ выглядит идеально.
Для второго теста я взял несколько фотографий четырех страниц из книги о путешествиях на свой iPhone и таким же образом импортировал их в FineReader. К сожалению, фотографии были немного нечеткими, а также сильно перекошенными.
Я выбрал все четыре изображения (с помощью Command-щелчка). К сожалению, они были импортированы в неправильном порядке, но это можно исправить позже. В качестве альтернативы я мог бы добавлять страницы по одной.
Я уверен, что такой некачественный «скан» будет представлять гораздо большую проблему. Мы узнаем, когда приступим к экспорту документа — версия для Mac не позволяет вам увидеть его в документе.
Мы узнаем, когда приступим к экспорту документа — версия для Mac не позволяет вам увидеть его в документе.
Мое личное мнение : Сила FineReader в быстром и точном оптическом распознавании символов. Это широко признано в большинстве других обзоров, которые я читал, и ABBYY заявляет точность 99,8%. Во время моих экспериментов я обнаружил, что FineReader может обрабатывать и распознавать документы менее чем за 30 секунд.
2. Изменение порядка страниц и областей импортированного документа
Хотя вы не можете редактировать текст документа с помощью версии FineReader для Mac, мы можем вносить другие изменения, включая изменение порядка страниц. К счастью, в нашем проездном документе страницы расположены в неправильном порядке. Перетаскивая превью страниц на левой панели, мы можем это исправить.
Полностраничное изображение выглядит не совсем правильно из-за кривизны книги, когда я сделал снимок. Я попробовал несколько вариантов, и обрезка страницы придала ей самый чистый вид.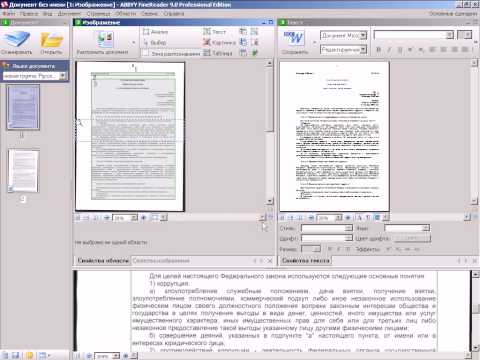
На второй странице немного пожелтело правое поле. На самом деле это часть исходного макета на бумаге, но я не хочу включать его в экспортированную версию документа. Вокруг него нет зеленой или розовой рамки, поэтому он не был распознан как изображение. Так что пока мы экспортируем без включенного фонового (отсканированного) изображения, это не проблема.
Четвертая страница такая же, однако третья страница имеет рамки вокруг желтого рисунка. Я могу выбрать их и нажать «удалить», чтобы удалить их. Я могу нарисовать прямоугольник вокруг номера страницы и изменить его на область изображения. Теперь он будет экспортироваться.
Мое личное мнение : Хотя версия FineReader для Windows имеет ряд функций редактирования и совместной работы, включая редактирование, комментирование, отслеживание изменений и сравнение документов, в версии для Mac в настоящее время их нет. Если эти функции важны для вас, вам нужно искать в другом месте. Однако FineReader для Mac позволит вам переупорядочивать, поворачивать, добавлять и удалять страницы, а также вносить коррективы в области, где программа распознает текст, таблицы и изображения.

3. Преобразование отсканированных документов в PDF-файлы и редактируемые типы документов
Я начал с экспорта школьной заметки в PDF.
Существует несколько режимов экспорта. Я хотел посмотреть, насколько точно FineReader может приблизиться к макету и форматированию исходного документа, поэтому я использовал опцию «Только текст и изображения», которая не будет включать исходное отсканированное изображение.
Экспортированный PDF-файл идеален. Исходный скан был очень чистым и имел высокое разрешение. Качественный вход — лучший способ обеспечить качественный результат. Я выделил некоторый текст, чтобы показать, что OCR было применено, и документ содержит фактический текст.
Я также экспортировал документ в редактируемый тип файла. На моем компьютере не установлен Microsoft Office, поэтому вместо этого я экспортировал в формат ODT OpenOffice.
И снова отличные результаты. Обратите внимание, что текстовые поля использовались везде, где текст определялся в FineReader с помощью «области».
Затем я попробовал отсканировать более низкое качество — четыре страницы из книги путешествий.
Несмотря на низкое качество исходного скана, результаты очень хорошие. Но не идеально. Обратите внимание на правом поле: «Велосипедная прогулка по Тоскане достаточно холмистая, чтобы оправдать трапезу».
Здесь должно быть написано «…оправдывать чрезмерное обильное питание». Нетрудно понять, откуда взялась ошибка. Исходный скан здесь очень неясен.
Точно так же на последней странице заголовок и большая часть текста искажены.
Опять же, исходный скан здесь очень плохой.
Здесь урок. Если вам нужна максимальная точность оптического распознавания символов, обязательно сканируйте документ с максимально возможным качеством.
Мой личный дубль : FineReader Pro может экспортировать отсканированные документы и документы, прошедшие распознавание, в ряд популярных форматов, включая типы файлов PDF, Microsoft и OpenOffice.
Эти экспорты могут сохранить исходный макет и форматирование исходного документа.
Причины моей оценки
Эффективность: 5/5
FineReader считается лучшим приложением для распознавания текста. Мои тесты подтвердили, что он способен точно распознавать текст в отсканированных документах и воспроизводить макет и формат этих документов при экспорте в различные типы файлов. Если вашим приоритетом является точное преобразование отсканированных документов в текст, это лучшее приложение.
Цена: 4,5/5
Его цена выгодно отличается от других продуктов OCR высшего уровня, включая Adobe Acrobat Pro. Доступны менее дорогие варианты, в том числе PDFpen и PDFelement, но если вы ищете лучшее, продукт ABBYY стоит своих денег.
Простота использования: 4,5/5
Я нашел интерфейс FineReader простым и смог выполнить все задачи, не обращаясь к документации. Чтобы получить максимальную отдачу от программы, стоит провести дополнительные исследования, а помощь FineReader довольно обширна и хорошо организована.
Поддержка: 4/5
Помимо справочной документации по приложению, на сайте ABBYY доступен раздел часто задаваемых вопросов. Однако по сравнению с приложениями компании для Windows документация отсутствует. Телефон, электронная почта и онлайн-поддержка доступны для FineReader в рабочее время, хотя у меня не было необходимости связываться со службой поддержки во время моей оценки программы.
Альтернативы ABBYY FineReader
FineReader может быть лучшим приложением для распознавания текста, но оно не для всех. Для некоторых людей это будет больше, чем им нужно. Если это не для вас, вот несколько альтернатив:
- Adobe Acrobat Pro DC (Mac, Windows) : Adobe Acrobat Pro был первым приложением для чтения, редактирования и распознавания документов PDF и до сих пор остается одним из лучших вариантов. Однако это довольно дорого. Прочтите наш обзор Acrobat Pro.
- PDFpen (Mac) : PDFpen — популярный редактор PDF для Mac с оптическим распознаванием символов.