Поиск в документах PDF, Adobe Acrobat
Обычно используются следующие логические операторы.
AND
Ставится между двумя словами для поиска документов, содержащих оба слова в любом порядке. Например, введите Париж AND Франция для поиска документов, содержащих оба слова: Париж и Франция. Поиск только с одним логическим оператором «AND» дает такие же результаты, как если бы параметр Совпадение всех слов был выбран.
NOT
Ставится перед искомым словом, чтобы исключить все документы, в которых оно содержится. Например, введите NOT Кентукки для поиска всех документов, не содержащих слово Кентукки. Или введите Париж NOT Кентукки для поиска всех документов, содержащих слово Париж, но не слово Кентукки.
OR
Используется для поиска всех вхождений любого из слов. Например, введите электронная почта OR эл. почта, чтобы найти все документы, содержащие любое из этих слов или оба слова в любой комбинации. Поиск только с одним логическим оператором «OR» дает такие же результаты, как если бы параметр «Совпадение любого из слов» был выбран.
^ (исключающее OR)
Используется для поиска всех вхождений, в которых присутствует одно из слов, но не оба слова сразу. Например, введите кошка ^ собака, чтобы найти все документы, содержащие либо слово кошка, либо собака, но не оба слова кошка и собака сразу.
( )
Круглые скобки используются, чтобы задать порядок оценки слов. Например, введите белый AND (кит ORахав), чтобы найти все документы, содержащие либо слова белый и кит, либо слова белый и ахав. (Обработчик запросов сначала выполняет запрос OR для слов кит и ахав, а затем выполняет запрос AND со словом белый и результатом предыдущего запроса).
Чтобы узнать больше о логических запросах, синтаксисе и других логических операторах, которые можно использовать при поиске, ознакомьтесь с информацией в соответствующей литературе, на веб-сайтах или в других источниках с более полными сведениями по математической логике.
helpx.adobe.com
Как найти слово или фразу в документе PDF Как? Так!
Содержимое:
3 метода:
Из данной статьи вы узнаете, как найти конкретное слово или фразу в PDF документе в приложении Adobe Reader DC, браузере Google Chrome (на компьютерах Mac и Windows) и в приложении «Просмотр» на Мас.
Шаги
Метод 1 Adobe Reader DC
- 1 Откройте файл PDF в Adobe Acrobat Pro. Иконка программы имеет вид красной иконки Adobe Reader со стилизованной буквой «А». Когда программа откроется, нажмите «Файл», а затем «Открыть». После этого выберите файл PDF и нажмите «Открыть».
- Если у вас нет Adobe Reader DC, его можно скачать бесплатно, пройдя по этой ссылке и нажав на кнопку «Установить сейчас».
- 2 Нажмите Редактирование на панели меню.
- 3 Нажмите Найти.
- 4 Введите в диалоговое окно «Найти» искомое слово или фразу.
- 5 Нажмите Далее. Следующее упоминание искомого слова или фразы будет выделено в документе.
- Нажмите «Далее» или «Назад», чтобы найти все места, где искомое слово или фраза встречается в документе.
Метод 2 Google Chrome
- 1 Откройте PDF документ в Google Chrome. В Google Chrome можно найти веб-версию файла или открыть PDF на компьютере. Для этого нажмите на PDF правой кнопкой мыши, нажмите «Открыть с помощью…» и выберите «Google Chrome».
- На компьютере Mac с однокнопочной мышью необходимо зажать клавишу ^ Control и нажать на сенсорную панель двумя пальцами.
- 2 Нажмите на ⋮ в правом верхнем углу браузера.
- 3 Выберите Найти почти в самом низу выпадающего меню.
- 4 Введите слово или фразу, которую необходимо найти. В процессе печати браузер начнет выделять появившиеся результаты.
- Желтые полоски на правой полосе прокрутки определяют местоположение результатов поиска на странице.
- 5 Нажмите на или , чтобы перейти к следующему или предыдущему результату в документе.
Метод 3 Просмотр на Mac
- 1 Откройте PDF документ в приложении «Просмотр». Для этого дважды нажмите на синюю иконку приложения, которая выглядит как два снимка, расположенных друг на друге. Затем нажмите на «Файл» на панели меню и выберите в выпадающем меню опцию «Открыть». Выберите в диалоговом окне нужный файл и нажмите «Открыть».
- Просмотр – это стандартная программа для просмотра изображений от компании Apple, идущая в комплекте со всеми последними версиями Mac OS.
- 2 Нажмите Правка на панели меню.
- 3 Выберите Поиск.
- 4 Нажмите на Найти….
- 5 Введите слово или фразу в поле «Найти» в правом верхнем углу окна.
- 6 Нажмите Далее. В документе будут выделены все упоминания искомого слова или фразы.
- Нажмите < или > под поисковым полем, чтобы перейти к следующему или предыдущему результату в документе.
Прислал: Давыдова Юлия . 2017-11-06 17:27:01
kak-otvet.imysite.ru
Удаление конфиденциального содержимого из документов PDF в Adobe Acrobat DC
Метаданные
Метаданные содержат сведения о документе и его содержимом, такие как имя автора, ключевые слова и сведения об авторских правах. Для просмотра метаданных выберите Файл > Свойства.
Вложенные файлы
К документу PDF можно присоединить в качестве вложения файл любого формата. Чтобы просмотреть вложения, выберите Просмотр > Показать/Скрыть > Области навигации > Вложенные файлы.
Закладки
Закладки – это ссылки с поясняющим текстом, с помощью которых можно открывать заданные страницы документа PDF. Чтобы просмотреть закладки, выберите Просмотр > Показать/Скрыть > Области навигации > Закладки.
Комментарии и пометки
Этот элемент включает все комментарии, добавленные в файл PDF с помощью инструментов комментирования и разметки, в том числе файлы, вложенные как комментарии. Для просмотра комментариев выберите Инструменты > Комментарии
Поля форм
К этому типу элементов относятся поля форм (в том числе поля подписей), а также все действия и расчеты, связанные с полями форм. При удалении этого элемента все поля формы объединяются, и их нельзя будет заполнять, изменять или подписывать.
Скрытый текст
Этот элемент соответствует прозрачному тексту документа PDF, тексту, закрытому другим содержимым, либо тексту того же цвета, что и фон документа.
Скрытые слои
Документ PDF может содержать несколько слоев, которые могут быть видимыми или скрытыми. При удалении из документа PDF скрытых слоев оставшиеся слои объединяются в один. Чтобы просмотреть слои, выберите Просмотр > Показать/Скрыть > Области навигации > Слои.
Встроенный поисковый индекс
Встроенный поисковый индекс позволяет ускорить поиск в файле PDF. Чтобы определить, содержит ли файл PDF поисковый индекс, выберите Инструменты > Указатель, затем на дополнительной панели инструментов нажмите Управление встроенным указателем. Удаление индексов позволяет уменьшить размер файла, но увеличивает время поиска в документе PDF.
Удаленное или обрезанное содержимое
В документах PDF иногда содержится информация, которая была удалена и теперь невидима, например удаленные изображения и усеченные или удаленные страницы.
Ссылки, операции и JavaScript
Этот элемент включает в себя веб-ссылки, операции, добавленные с помощью мастера операций и сценарии JavaScript во всем документе.
Перекрывающиеся объекты
Этот элемент включает объекты, наложенные друг на друга. Объекты могут быть изображениями (состоят из пикселей), векторной графикой (состоят из контуров), градиентами или узорами.
Найти ваши любимые PDF файлы с помощью поиска Google – Multilizer Translation Blog
В настоящее время вы можете использовать Google для поиска много информации. Эта поисковая система может помочь вам искать более чем 10 различных типов файлов. Google может также использоваться для поиска PDF-файлов в дополнение к стандартным HTML документацию. Это легко найти ваши любимые файлы PDF с помощью инструмента поиска Google.
В этой статье есть два основных метода, которые вы можете последовать за для того чтобы найти PDF файлов через Google search. Эти советы помогут вам легко найти документы, которые вы ищете. Вот эти два основных метода для вас, чтобы использовать при поиске файлов PDF на поиск в Google:
1. Расширенный поиск
Расширенный поиск вариантов это расширенная функция, созданные Google, чтобы помочь всем клиентам легко найти свои любимые файлы с помощью этого параметра. Есть много людей, используя этот вариант, потому что это часто самый простой вариант для поиска PDF-файлов с помощью поиска Google. Вы должны нажать «Расширенный поиск», расположенный на домашней странице Google. Затем следует ввести запрос или ключевое слово, которое требуется выполнить поиск. Вы можете искать много типов ключевых слов, которые вы хотите. Попробуйте включить некоторые конкретные слова или фразы, которые вы хотите в поле поиска. Если вы хотите исключить некоторые слова или фразы, вы также можете сделать это, используя функцию расширенного поиска.
Затем после написания вниз ваш запрос, необходимо щелкнуть раскрывающийся список тип файлов вариант. Выберите «Adobe Acrobat PDF файлы». Нажав на этот вариант, вы сказать Google для поиска любой PDF файлы, которые связаны с ключевыми словами или запрос. После управления все варианты, вы должны нажать «Расширенный поиск». Google принесет вам все PDF-файлы, которые соответствуют вашему запросу.
2. Поиск PDF-файлов с помощью поискового запроса
Вы также можете использовать для поиска запрос, чтобы найти все Google PDF файлы, которые хранятся в системе Google. Во-первых вам необходимо посетить главную страницу Google. Затем вы можете включить этот текст «filetype.pdf» на запрос поиска. Например если вы хотите для поиска PDF-файлов, связанных с бейсбол, можно ввести бейсбол filetype.pdf на Google поисковый запрос. Можно просто нажать «Enter» или нажмите кнопку «Поиск». Подождите несколько секунд, прежде чем Google может показать все PDF-файлы, которые связаны с ключевыми словами, слова или фразы.
Это два основных метода, которые можно использовать для поиска PDF-файлов с помощью поиска Google. В настоящее время вы сможете найти ваши любимые PDF файлы легко с Google. Google является важным инструментом, который можно использовать для легко найти ваши любимые файлы PDF. В большинстве случаев эта поисковая система может показать все результаты в течение нескольких секунд.
Перевести документы PDF автоматически на 27 языков.
translation-blog.multilizer.com
Поиск в PDF файлах, поиск в нескольких PDF документах в Adobe Acrobat – видео TeachVideo
Поиск в PDF документах в Adobe Acrobat
Можно запустить поиск в PDF документах, используя либо окно «Поиск», либо панель инструментов «Найти».
По умолчанию панель инструментов «Найти» всегда открыта. Если она закрыта, ее можно открыть, выбрав «Редактирование» > «Поиск». Для открытия окна «Поиск», выберите меню «Редактирование» > «Поиск». Затем на панели инструментов «Найти» щелкните стрелку и выберите команду «Открыть полный поиск Acrobat».
Окно «Поиск» появляется в виде отдельного окна. При этом его можно перемещать, изменять его размер, сворачивать или располагать частично или полностью за окном PDF-документа.
Для размещения окна PDF-документа и окна «Поиск», в окне «Поиск» щелкните кнопку «Упорядочить окна». Изменяются размеры или два окна размещаются рядом друг с другом.
Повторное нажатие кнопки «Упорядочить окна» изменяет размер окна документа, но оставляет без изменений окно «Поиск». Если вы хотите увеличить или уменьшить размер окна «Поиск», перетащите его угол или край.
Панель инструментов «Найти» производит поиск текста в открытом в данный момент PDF-документе. Напечатайте текст, который нужно искать, в текстовом поле панели инструментов «Найти». Затем щелкните стрелку рядом с текстовым полем и выберите необходимый вариант.
Нажмите клавишу «Enter».
Еще раз нажмите клавишу «Enter» для перехода к следующему вхождению.
Окно «Поиск» позволяет производить поиск в нескольких PDF-документах. Например, можно выполнить поиск во всех файлах PDF в определенном месте или во всех файлах в открытом портфолио PDF. При поиске в нескольких документах поиск в зашифрованных документах не производится. Необходимо сначала открыть эти документы и последовательно выполнить в них поиск.
На панели инструментов «Найти» введите текст для поиска, затем выберите «Открыть полный поиск Acrobat» в выпадающем меню.
Введите искомый текст в окне «Поиск».
Затем в окне «Поиск» выберите «Во всех документах PDF». Во всплывающем меню прямо под этим параметром выберите пункт «Обзор».
Выберите место поиска, на компьютере или в сети, затем нажмите «OK».
Чтобы задать дополнительные критерии поиска, щелкните «Использовать расширенные параметры поиска» и укажите параметры.
Нажмите
Во время поиска можно щелкнуть результат или использовать сочетания клавиш для перемещения по результатам, не прерывая при этом поиск. Нажатие кнопки «Стоп», расположенной под индикатором хода поиска, отменяет дальнейший поиск, и результаты поиска ограничиваются теми, которые уже найдены. Это не приводит к закрытию окна «Поиск» или к удалению списка результатов. Для просмотра дополнительных результатов запустите новый поиск.
После запуска поиска из окна «Поиск» результаты будут появляться под именем документа, в котором ведется поиск, в том порядке, в котором они расположены на страницах документа При необходимости разверните результаты поиска. Затем выберите одно из вхождений для его просмотра в PDF-документе.
Чтобы просмотреть другие вхождения, выберите меню «Редактирование» > «Результаты поиска», затем выберите команды «Следующий результат» или «Предыдущий результат».
www.teachvideo.ru
как найти в компе PDF файлы по содержимому?
если вин 7 то пиши в поиске текст, который нужно найти. семерка сама попробует найти файлы где это есть
Пуск—>поиск—> Вбиваешь *.pdf (поиск всех файлов в формате ПДФ)
ищи Total Commander -ом
Самое простое решение: <img data-big=»1″ data-lsrc=»//otvet.imgsmail.ru/download/230542562_d612c1ceb147e074a31e57a77e536de5_120x120.png» alt=»» src=»//otvet.imgsmail.ru/download/230542562_d612c1ceb147e074a31e57a77e536de5_800.png»>
touch.otvet.mail.ru
Создание архива документов в формате PDF с возможностью поиска по содержимому средствами ОС Windows 7 : Документные сканеры
 При работе с большим количеством фалов и папок, содержащих текстовую информацию, пользователю ПК неоднократно приходилось сталкиваться с такой ситуацией: не удается найти на компьютере нужный файл, не известно где и когда его сохранили, какое имя было присвоено при сохранении, не запомнилось в каком формате он был — офисном, текстовом или графическом. А в этом файле содержатся данные, которые именно сейчас крайне необходимы. На компьютере столько много всего накопилось, что на поиск нужного файла открытием просмотром всех файлов подряд может уйти не один час.
При работе с большим количеством фалов и папок, содержащих текстовую информацию, пользователю ПК неоднократно приходилось сталкиваться с такой ситуацией: не удается найти на компьютере нужный файл, не известно где и когда его сохранили, какое имя было присвоено при сохранении, не запомнилось в каком формате он был — офисном, текстовом или графическом. А в этом файле содержатся данные, которые именно сейчас крайне необходимы. На компьютере столько много всего накопилось, что на поиск нужного файла открытием просмотром всех файлов подряд может уйти не один час.
В данной статье мы рассмотрим вопросы создания архива документов в формате PDF и возможность простой организации поиска по тексту, содержащемуся в этих документах.
Portable Document Format (PDF) — межплатформенный формат электронных документов, разработанный в 1993 году компанией Adobe Systems с использованием ряда возможностей языка PostScript. В первую очередь предназначен для представления полиграфической продукции в электронном виде. Для просмотра файлов данного формата существует официальная программа Adobe Reader, а так же множество программ сторонних разработчиков.
После того, как Adobe выпустила бесплатную версию Acrobat Reader (позднее переименованную в Adobe Reader) для чтения PDF-документов, популярность этого формата стала возрастать. Формат PDF-файлов несколько раз изменялся и продолжает эволюционировать. Существует несколько спецификаций формата, последовательно расширяющих друг друга.
Формат PDF с 1 июля 2008 года является открытым стандартом ISO 32000.
Различные спецификации формата
PDF/X−1a — это стандартный формат файлов, специально предназначенный для обмена готовыми к печати документами (для передачи в типографию) в виде электронных данных, при котором отправителю и получателю не требуется дополнительной договоренности для обработки информации и получения требуемых результатов в тираже. Применение PDF/X−1a устраняет наиболее распространенные ошибки при подготовке файлов для печати.
PDF/A — стандарт ISO 19005-1:2005 (опубликован 1 октября 2005 г.) для долгосрочного архивного хранения электронных документов и базируется на описании стандарта PDF версии 1.4 от Adobe Systems (использовался в Adobe Acrobat 5). В действительности, PDF/A является подмножеством формата PDF, из которого исключены некоторые особенности, не подходящие для долгосрочного архивного хранения.
Почему для архивации удобнее выбирать именно PDF-формат
Одной из проблем, с которой сталкиваются крупные промышленные предприятия, государственные учреждения, страховые компании, издательства и архивы, является надежная архивация больших объемов данных.
Традиционные способы, например, хранение информации на бумаге или микрофильмах, безнадежно устарели, так как они не обеспечивают компактности данных, а также возможностей эффективного поиска и передачи информации. Поэтому в последние годы для архивации используются цифровые форматы представления данных. Одним из таких популярных графических форматов стал TIFF.
TIFF (англ. Tagged Image File Format) — формат хранения растровых графических изображений. TIFF стал популярным форматом для хранения изображений с большой глубиной цвета. Он используется при сканировании, отправке факсов, распознавании текста, в полиграфии, широко поддерживается графическими приложениями.
Однако формат TIFF в свою очередь имеет существенные недостатки — невозможность поиска текстовой информации без применения средств распознавания знаков (OCR), а также потребность в больших объемах памяти для хранения ТIFF- файлов. Формат PDF лишен этих недостатков — файлы имеют компактный размер, возможен поиск по тексту, обеспечивается высокое качество визуализации как графических, так и текстовых данных. По этой причине для создания электронных архивов целесообразно использовать формат PDF, в частности спецификацию PDF/A. Именно по этому стандартизировать PDF/А было предложено еще в 2002 г.
Понятия Searchable PDF и OCR
Searchable PDF (так же иногда называют PDF+text) — файлы формата PDF с включенным распознанным текстовым слоем с возможностью поиска по тексту. Именно файлы такого формата интересны для создания архива документов, ведь в случае отсутствия текста в документе поиск по содержимому попросту теряет смысл. Текстовый слой в файле создается непосредственным включением текста из текстового редактора, либо методом OCR.
OCR (optical character recognition) — оптическое распознавание символов , механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные — последовательность кодов, использующихся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь.
Традиционным способом создания PDF-документов является виртуальный принтер, то есть документ как таковой готовится в своей специализированной программе — графической программе или текстовом редакторе, САПР и т. д., а затем экспортируется в формат PDF для распространения в электронном виде, передачи в типографию и т. п.
Современные офисные пакеты (например Microsoft Office) умеют сохранять файлы в формате PDF напрямую, без использования виртуального принтера. Весь содержащийся в документе текст при сохранении в формате PDF включается в виде текстового слоя (Searchable PDF — с возможностью поиска по тексту.)
Существует множество специализированных программ для создания Searchable PDF. В основном это программы, имеющие функции получения изображения документа (работа со сканером, импорт изображения из файла), функции обработки, оптимизации, улучшения качества изображения, функции OCR, функции сохранения, экспорта в популярные текстовые редакторы.
В качестве примера таких программ можно привести ABBYY FineReader, IRIS Readiris.
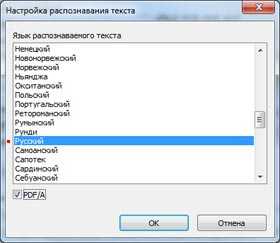
Современная версия платного пакета Adobe Acrobat XI так же имеет встроенную функцию оптического распознавания текста и включения в файл текстового слоя. Поддерживается более 40 языков, включая Русский.
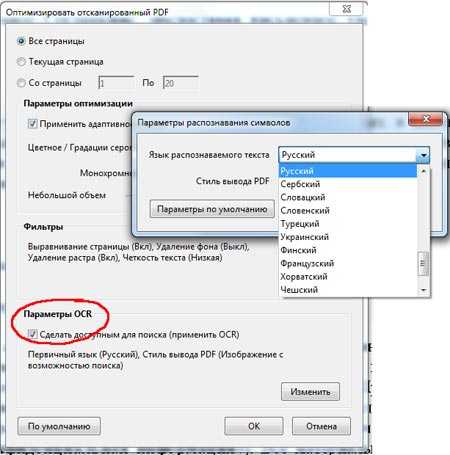
Сегодня сканирование документов в производственном масштабе с использованием поточных сканеров осуществляется с помощью специально разработанных программных систем для скоростного сканирования и обработки документов. Данное ПО позволяет выполнять такие операции как разделение сканируемого потока на отдельные документы (по различным признакам), классификацию (определение типа) документа и последующую его обработку, сохранение либо перенаправление, в зависимости от установленных действий для каждого типа. Данное ПО, как правило, весьма дорогостоящее и требует специализированных навыков (а зачастую и сертифицированных специалистов) для его настройки и работы. Несомненно, применение подобного рода решений целесообразно и оправданно только при весьма значительных масштабах системы документооборота и больших объемах обрабатываемых документов.
Но что делать пользователям, чьи объемы документации не столь значительны и применение дорогостоящих специализированных решений не рентабельно, а задача создания структурированного хранилища с возможностью поиска актуальна и должна как то решаться.

Производители поточных сканеров постепенно начали осознавать потребность своих клиентов, которые приобретают сканеры начального уровня. Современные поточные сканеры поставляются не только в виде «железа» и драйверов, но и включают в комплект поставки программное обеспечение для сканирования. И данное ПО в последнее время способно предоставлять пользователю не только средство для выполнения базовых операций по сканированию, но и весьма продвинутые функции, для выполнения которых ранее нужно было приобретать дополнительное ПО, либо расширенную версию ПО идущего в комплекте.
Таким образом, современный поточный сканер — это как правило комплексное, готовое аппаратно-программное решение, которое является самодостаточным инструментом для решения широкого круга задач.
К таким задачам относится и сканирование документа в PDF-файл с распознанным текстом. Современные новинки от ведущих производителей имеют, как правило, все необходимое для решения данной задачи в комплекте. Причем включается возможность распознавания широкого набора языков. К слову, не так давно средств получения OCR (оптического распознавания текста) непосредственно «из коробки» сканера производителями не предоставлялось (за исключением, разве что, поставок-бандлов, то есть комплектов включающих стороннее ПО для распознавания на OEM основе).
Рассмотрим один из таких примеров — новинка от компании Kodak Alaris: персональный сканер документов Kodak ScanMate i1150 (вышел во 2-ом квартале 2014 года). Подробное описание сканера смотрите здесь.
Входящий в комплект поставки стандартный новый менеджер профилей Kodak SmartTouch позволяет настроить профиль сканирования в формат PDF с включениям функции оптического распознавания текста (возможен выбор более 40 языков включая Русский). ПО так же способно распознавать штрих-кодов, встречающихся на страницах документов, разделять поток страниц на отдельные документы и именовать файлы в соответствии с данными, извлеченными из штрих-кода. Могут быть обнаружены следующие штрих-коды: Interleaved 2 из 5; Код 3 из 9; Код 128; Codabar; UPC-A; UPC-E; EAN-13; EAN-8; PDF417. Программа распознает только первый штрих-код, встретившийся на листе. Причем расположение штрих-кода (под наклоном, вертикально либо перевернутый по отношению к ориентации текста) на качество обнаружения не влияет, штрих-код распознается стабильно.
SmartTouch поддерживает сохранение в формате PDF спецификации PDF/A.
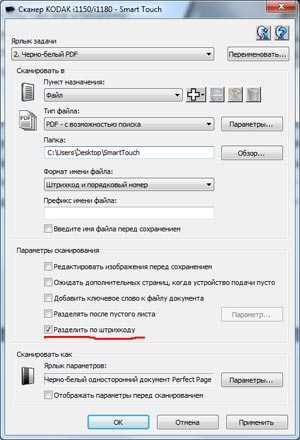
Таким образом, установив пачку листов в приемный лоток автоподатчика сканера Kodak ScanMate i1150, выбрав на панели сканера предварительно настроенный профиль и нажав кнопку запуска сканирования мы получаем на компьютере в указанном месте (диске или папке) надлежащим образом поименованный набор PDF-файлов, содержащих отсканированные документы, с возможностью поиска по содержимому документа. Никаких дополнительных действий не требуется.
Согласитесь, решение задачи получения searchable PDF никогда не было на столько простым. В этом свете задача создания электронного архива (хранилища) документов в формате PDF с возможностью поиска так же не выглядит сложной.
По вопросам приобретения новинки от Kodak Alaris, а так же других документных сканеров ведущих производителей вы всегда можете обратиться в компанию ПИРИТ, являющейся официальным дистрибутором сканеров Canon, Kodak, Fujitsu, Avision на территории России. Сайт отдела сканеров: http://www.docscan.ru.
Итак, теперь мы с вами знаем как создать систему файлов и папок, содержащих наш архив файлов PDF. Теперь выясним, каким несложным образом можно осуществлять поиск необходимой нам информации по содержимому файлов (по словам), находящихся в этом архиве.
На сегодняшний день, несмотря на относительно недавний (2012 г.) выход системы Windows 8, наиболее распространенной в среднестатистических офисах является ОС Windows 7 (редакцию упоминать здесь не будем, т.к. для наших целей это не принципиально). Кое где, конечно, еще остается в работе проверенная годами старушка XP, но все таки с началом эпохи беспроводных сетей в конце 2000-х данная ОС постепенно (и повсеместно) уходит в прошлое.
Поэтому рассмотрим как обстоит дело с поисковой подсистемой в ОС Windows 7.
Чтобы Операционная система Windows 7 смогла найти файл по его содержимому, сперва необходимо включить данную опцию в настройках ОС.
1. Включение поиска в Windows 7 Search по содержимому
По умолчанию ОС Windows 7 настроена на поиск только по именам файлов. Для включения возможности поиска по содержимому нужно в Проводнике Windows выбрать Упорядочить -> Параметры папок и поиска. Закладка Поиск — выбрать ВТОРОЙ вариант поиска «Всегда искать по именам файлов и содержимому».
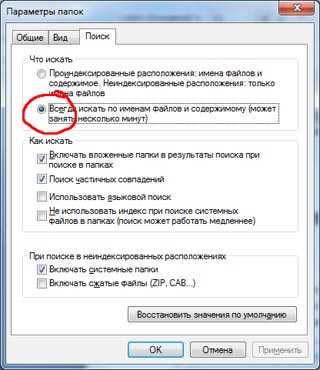
Теперь при поиске система будет просматривать не только имена файлов, но и их содержимое, если для данного типа файлов указана возможность поиска по содержимому (об этом узнаем в следующем разделе статьи).
2. Индексирование
Далее необходимо проиндексировать файлы и папки, в которых предполагается осуществлять поиск. Поиск в проиндексированных папках осуществляется значительно быстрее.
Для того чтобы ваш ПК проиндексировал папки вашего архива, необходимо в параметрах индексирования добавить в список мест индексирования папку(папки) где будут храниться PDF-файлы, либо указать букву диска, если точное местонахождение архива не определено.
Кроме того, по умолчанию, для поиска по содержимому, в индексе включены только популярные форматы файлов, все остальные файлы надо активировать вручную.
В нашей редакции Windows 7 формат файлов PDF уже оказался включен для поиска по содержимому. В вашей версии возможен другой вариант, по этому вот подробная инструкция по решению этой проблемы (Русская версия Windows 7).
- ПУСК (Start). (Нижний, левый угол, Флажок)
- Внизу, в поле: «Найти программы и файлы» (Run) вписываем эту строку: «Параметры индексирования» (Enter)
- В появившемся окошке убедитесь, что буква диска, на котором находятся файлы вашего архива, присутствует в списке «Включенные расположения». Если нет, нужно добавить нужный диск (либо указать определенную папку или несколько папок, где будут храниться файлы PDF-архива), нажав кнопку «Изменить».
- Далее, жмем кнопку «Дополнительно», закладка «Типы файлов».
- В списке находим и устанавливаем курсор на расширение того файла, которое часто ищите: в нашем случае *.PDF.
- Обратите внимание, для большинства расширений в области «Как следует индексировать такие файлы?» выбрана опция «Индексировать только свойства». Для нужных нам файлов нам необходимо установить нижнюю опцию: «Индексировать свойства и содержимое файлов». Установите для типа PDF данную опцию (или убедитесь что она уже установлена).

Настоятельно НЕ рекомендуется выбирать много типов файлов для индексации по содержимому, а только те, что точно необходимо для будущего поиска.
При этом все изменения в настройках индексации файлов делайте перед периодом простоя компьютера, например на ночь (конечно, в том случае если ваш ПК на ночь не отключается), иначе в процессе работы вы почувствуете заторможенность вашего компьютера: процесс индексации весьма ресурсоемкий, не смотря на то, что система и будет пытаться давать вам приоритет в вашей активности.
3. Необходимо стороннее ПО, понимающее PDF-формат
На вашем ПК должен быть установлен Adobe Reader актуальной (или не слишком старой) версии. Adobe Reader распространяется бесплатно. Так же у Adobe есть более продвинутый продукт для работы с PDF — Adobe Acrobat (платный). Помимо программного обеспечения Adobe существует множество PDF-редакторов сторонних разработчиков (как бесплатных так и распространяемых на платной основе). В любом случае — выбор остается за пользователем.
Наличие ПО, работающего с форматом PDF позволит ОС Windows 7 «распознавать» и открывать файлы PDF-формата. По-умолчанию Windows данный формат не понимает.
Если вы являетесь обладателем 64-битной редакции Windows 7, необходимо дополнительно загрузить и уcтановить пакет PDF iFilter 64 (PDFFilter64Setup.msi)с сайта Adobe. Потребуется перезагрузить ПК.
Без данного пакета поиск по содержимому PDF-файлов в 64-битной системе работать не будет.
После проведения данной подготовки на вашем ПК должен работать поиск по содержимому PDF непосредственно из Проводника для текущей папки. Если нужно провести поиск по всему ПК — открываем диалог Поиска (Клавиша WIN + f).
4. Особенности работы Windows 7 Search
Поиск по содержимому в семерке независимо от того, проиндексированы файлы или нет осуществляется по целым словам или фразам, а не по фрагментам текста. Это объясняется тем, что проиндексировать фрагмент текста невозможно, т.к. индекс создаётся заранее, а знать заранее, с какого символа ты будешь искать и какой длины будет искомая строка, программа не может. В 7-ке поиск по содержимому изначально заявлялся для проиндексированных файлов как быстрый, а значит разработчикам нужно исполнять обещание хорошей скорости «индексированного» поиска, которую поиск по фрагменту не может достичь.
Текстовые файлы с разными расширениями
Система не может определять тип файлов иначе, кроме как по их расширениям. По этому для того чтобы любые текстовые файлы индексировались без переименования в txt, нужно зарегистрировать нужные расширения. Вручную в настройках службы индексирования, или внесением изменений непосредственно в реестре.
Теперь, прочитав данную статью, вы без труда сможете организовать PDF-архив и простой поиск по тексту. Естественно, это самый простой вариант поиска «по словам» (в качестве расширенного доступен только фильтр по: Виду файла, Дате изменения, Типу, Размеру и Имени).
Для организации расширенного поиска с применением различных фильтров, с учетом морфологии и т.п. необходимо использовать отдельное ПО. Например программа Архивариус 3000.
Программа Архивариус 3000 – это поиск документов и почтовых сообщений в Вашем компьютере, в локальной сети и в съёмных дисках (CD, DVD и др.). Поиск производится по содержимому документов, с учётом морфологии (смысловой поиск с морфологией на 18 языках).
Подробно о программе Архивариус и аналогичных можно прочитать на просторах интернета, а в данной статье мы ограничимся рассмотрением простого поискового решения стандартными средствами Windows, не требующего дополнительных вложений.
25.09.2014 Смирнов А.В., ПИРИТ
www.docscan.ru