Извлечение шрифтов из PDF / Хабр
Сразу следует сказать, что лучшей информации по формату, чем много мегабайтный PDFReference с сайта Adobe не существует. Для тех, кто пишет на С++ есть готовое решение — XPDF. В линуксе это самая полнофункциональная замена продуктам Adobe. Русскоязычные материалы на эту тему поверхностны и служат лишь для ознакомления, а не для практической работы. Но я рассчитываю, что с ними, а лучше с PDFReference вы уже знакомы. Я решил описать конкретный упрощенный пример извлечения из файла PDF truetype шрифтов, потому что этот вопрос очень часто звучит в сети и остается без ответа. Мне известна только одна такая программа, которая работает с ошибками и без исходников. Напоминаю, что пользоваться извлеченными шрифтами не всегда законно, можно только выводить встроенным шрифтом текст из документа.
Кто интересовался вопросом, то знают, что PDF состоит из заголовка, таблицы перекрестных ссылок (XRef), тела и трайлера (прицепа).
Вот пример конца файла:
startxref
173
%%EOF
число 173 — это смещение от начала данных файла к началу первой таблицы XRef. Переместившись в эту точку, мы видим что-то вроде этого:
xref
7628 42
0000000016 00000 n
0000001195 00000 f
и тд.
На 7628 пока не будем обращать внимание (это имя первого объекта, где записана информация о количестве страниц, например, а так же много чего другого). А 42 — это количество записей в данной части таблицы. Далее совсем просто: считываем в 10 байтный буфер первое слово, пропускаем пробел и считываем 5 байтный буфер, читаем отдельный символ.
/Prev 4025745
Таким образом прочитываем все таблицы, если их больше одной. Закончить чтение можно, если в следующем трайлере будет отсутствовать ключ /Prev. Признаком последней таблицы может служить и то, что она начинается с записи 0000000000 65535 f. Надо сказать, что мы читаем таблицы задом наперед, последняя при чтении является первой, которая появилась при создании самого документа, а первая при чтении возникла после последнего редактирования.
Используя полученные данные мы можем перемещаться к любому ссылочному объекту документа. Правда есть еще прямые объекты, адреса которых не внесены в XRef, но об этом позже. Теперь мы можем перебирать объекты документа, проверяя их тип и делая с ними, что душе угодно. Объект начинается так:
Правда есть еще прямые объекты, адреса которых не внесены в XRef, но об этом позже. Теперь мы можем перебирать объекты документа, проверяя их тип и делая с ними, что душе угодно. Объект начинается так:
7626 0 obj
содержимое объекта
endobj
7626 — номер (имя) объекта, а 0 — номер генерации, который должен совпадать с подобным значением в таблице ссылок для этого объекта. Как я понял, если объект меняется, редактируется, то и номер генерации увеличивается. Мы собрались искать шрифты, для этого надо прочитать словарь объекта, который представляет собой лексему, заключенную в теги <<… >>. Если элементы словаря имеют такую структуру, например:
/FirstChar 32
где слово после слеша — ключ, а необязательное значение после пробела — значение. При парсинге надо помнить, что значение может содержать любые данные, любой вложенности, в том числе и другие словари. Так что рекурсию вам в руки, впрочем, можно и без рекурсии, если мы работаем над конкретной задачей извлечения шрифтов. Указанное значение может также включать вложенные или не вложенные элементы следующих типов:
Указанное значение может также включать вложенные или не вложенные элементы следующих типов:
(… ) -текстовые строки
<… > — hex-строки
[… ] — массивы
Строка значения продолжается до следующего слеша или до перевода строки. Чтобы идентифицировать объект шрифта надо найти в словаре комбинацию:
/Type /Font
Теперь фильтруем Truetype шрифты по содержанию в словаре последовательности:
/Subtype /TrueType
Остальные ключи игнорируем, потому что мы просто хотим извлечь шрифты. Но самого шрифта мы в этом объекте, скорее всего не найдем. Только набор ненужных нам ключей. Читаем один из них:
/FontDescriptor 1675 0 R
Если такой ключ отсутствует, то шрифт внешний и не встроен в документ. Далее номер генерации этого объекта, а символ R обозначает, что это ссылка. Таблицу XRef мы уже прочитали и теперь можем переместиться к данным шрифта, через поиск смещения для объекта с номером 1675. Правда, возможен такой вариант:
/FontDescriptor << словарь и (или) данные шрифта >>
Будем считать, что мы переместились по ссылке к прямому объекту. В его словаре должны быть такие ключи:
В его словаре должны быть такие ключи:
/Type /FontDescriptor
В этом объекте тоже много полезных сведений о шрифте, но самого шрифта опять нет. Не моя вина — все претензии к компании Adobe. Нам нужен такой ключ
/FontFile2 1676 0 R
Знакомая конструкция. Переходим к следующему объекту. Если мы все сделали правильно, то это потоковый объект. Он состоит из словаря потока и из бинарных данных, заключенных между тегами stream… endstream. Вот тут надо сказать, что наличие бинарных данных не дает использовать готовые текстовые парсеры. Перепробовал много и пришлось написать свой с нуля. Бинарные данные можно считывать разом, так как в словаре потока имеется ключ /Length с длиной потока. Если попробовать сохранить извлеченный поток в файл с расширением TTF, то система объявит, что это никакой не шрифт. Все правильно, надо его разжать.
Шрифт чаще сжат с помощью zip, но для верности можно это проверить по наличию ключа /FlateDecode. Если работаем в Delphi, то используем стандартный ZLib. Мы можем получить размер буфера для разжатых данных из словаря потока по ключу /Length2. Ну и нужно знать, что встроенный в документ шрифт содержит только те глифы, которые в документе используются.
Мы можем получить размер буфера для разжатых данных из словаря потока по ключу /Length2. Ну и нужно знать, что встроенный в документ шрифт содержит только те глифы, которые в документе используются.
Думаю, что после этих наметок можно брать в одну руку hex-вьвер, в другую — PDFReference и стоить собственный АкробатРидер.
Извлечение шрифта из PDF | Render.ru
Guest
#1
#1
Господа, сабж.
Можно ли в принципе извлечь из ПДФа встроенный в него шрифт? Интересует извлечение либо в виде шрифтового файла, либо как просто вектор.
Guest
#2
#2
В Акробате есть Text Select Tool [V] нажимаешь, выжеляешь, копируешь. ..
..
Guest
#3
#3
>>> нажимаешь, выжеляешь, копируешь
Зачем, что, куда??? Вопрос то о другом совсем.
=====================================
Повторяю. Есть файл ПДФ. В него встроен шрифт. В системе, да и вообще у меня такого шрифта нет. Единственный способ, до которого я дошел — растеризация в Шопе, втягивание в Илл и трассировка по средством «Силуэта»… Но, сами понимаете, не супергуд это… Есть ли другой способ выдрать этот шрифт в виде шрифтового файла, либо, просто вектора.
=====================================
Ну а про Text Select Tool [V] я, извини, знаю и сам. Тем более, как надо было читать вопрос, что бы дать такой ответ?..
Тем более, как надо было читать вопрос, что бы дать такой ответ?..
Guest
#4
#4
У меня недавно сходная проблема была:
http://www.graphics.ru/forum/read.php?f=26&i=5446&t=5446
Есть такая штука — TransverterPro:
www.techpool.com
Экспортирует в том числе и в формат *.ai. При этом теряет оригинальные установки оверпринт.
Доступная к скачиванию версия работает 7 дней
Насчет Illustrator CS — не проверял, не знаю.
Guest
#5
#5
Ну извини!
Не понял!
Guest
#6
#6
Блин, вроде писал, куда-то сообщение делось. ..
..
Ну да ладно. Короче моя вина, недочитал, панику поднял…
Vldmr, спасибо, но в свете описанного и прочитанного — не слишком и даже для моей конкретной задачи не в оверпринтах дело… Идеально подошел вариант http://graphics.ru/forum/read.php?f=5&i=14897&t=14896. Вобчем супер.
СПАСИБО NETIK! Решение ну просто-таки… Век живи, блин… и все равно дураком помрешь… )))
СПАСИБО! Ну и Акробат Ридер 3 — форева!!!
netik
Активный участник
#7
#7
Благодарности принял
Guest
#8
#8
А если файл не для Акробат 3, что делать будешь?
Как я понимаю он сможет открыть, а следовательно и вытащить шрифт, если сохранен в PostScript 1, а из более поздних версиях ничего не получится.
Как мне сказал один знакомый полиграф. Адобе наоборот стремится к тому, что из пдф ничего нельзя было достать!
Guest
#9
#9
Предупреждаю сразу, писал не я.
Достать отттуда шрифты можно, но вау как непросто. Вряд ли стоит браться, если дальнейшее не понятно. Имеенно чтобы не было легко достать шрифты и придумали абобцы пдф.
А так:
— напечатать PDF в PS
— выкусить текстовым редактором ресурс шрифта. Сохранить с расширением .pfa (PS Font ASCII)
— преобразовать в . pfb (PS Font Bin) — есть утилиты
pfb (PS Font Bin) — есть утилиты
— открыть шрифтовым редактором и сгенерить новые .pfm и прочее. Вся инфа о трекингеи кернинге будет потеряна.
Так что не советую. Сам баловался из любознательности, получить так полноценный шрифт не удастся. Лучше найти/купить родной/близкий.
Была идея наглее. Ведь АТМ создает все эти виртуальные шрифты в своей временной папке. А потом стирает. Возможно, стертое можно восстановить. Проще, но не пробовал. Стоит помнить, что в публикацию могут включаться не все символы используемого шрифта…
Отвечал Mike Kouvchinov
Guest
#10
#10
>>> Адобе наоборот стремится к тому, что из пдф ничего нельзя было достать!
Дык это и ежу понятно. Тут и «знакомый полиграф» не нужен. Однако в этом мои стремления несколько с адобовскими расходятся.
Тут и «знакомый полиграф» не нужен. Однако в этом мои стремления несколько с адобовскими расходятся.
>>> ничего не получится.
Всё, что требуется, получается великолепно.
ЗЫ. «Полиграф», кстати, есть т.н. детектор лжи.
fasimba
Пользователь сайта
#11
#11
все классно тока ссылки на графикс не работают — очень интересно что это был за вариант который идеально подошел? (http://graphics.ru/forum/read.php?f=5&i=14897&t=14896)
если автор случайно забредет в этот форум снова — было бы здорово оживить тени давно ушедших лет
alexdoors
Пользователь сайта
#12
#12
///Интересует извлечение либо в виде шрифтового файла, либо как просто вектор. /// Не знаю актуален ли еще вопрос, но
/// Не знаю актуален ли еще вопрос, но
насчет шрифтового файла, конечно проблематично будет, а вот простым вектором можно. Лично я в таких случаях курвлю тексты в акробате, после чего ПДФку можно спокойно открыть в Иллюстраторе CS3, а там уже работать как с обычной аишкой, убивая все лишнее, оставляя текст.
Как извлечь встроенные шрифты из PDF-файла как допустимые файлы шрифтов?
У вас есть несколько вариантов. Все эти методы работают в Linux, а также в Windows или Mac OS X. Однако имейте в виду, что большинство PDF-файлов не включают полный шрифт, если в них встроен шрифт. В основном они включают только подмножества глифов, используемых в документе.
Использование
pdftops Один из наиболее часто используемых способов сделать это в системах *nix состоит из следующих шагов:
- Преобразование PDF в PostScript, например, с помощью вспомогательной программы XPDF
pdftops(в Windows:pdftops.. exe
exe - Теперь шрифты будут встроены в формате
.pfa(PostScript) + их можно извлечь с помощью текстового редактора . - Возможно, вам потребуется преобразовать файл
.pfa(ASCII) в файл.pfb(двоичный) с помощьюt1utilsиpfa2pfb. - В PDF-файлах никогда не бывает 9Встроенные файлы 0008 .pfm или
.afm(файлы метрик шрифта) (поскольку средство просмотра PDF имеет внутреннюю информацию о них). Без них файлы шрифтов вряд ли можно будет использовать в визуально приятном виде.
Использование
fontforge Другим способом является использование бесплатного редактора шрифтов FontForge :
- Используйте диалоговое окно «Открыть шрифт» , используемое при открытии файлов.
- Затем выберите «Извлечь из PDF» в разделе фильтра диалогового окна.
- Выберите файл PDF со шрифтом, который необходимо извлечь.

- A «Выберите шрифт» открывается диалоговое окно — выберите здесь, какой шрифт открыть.
См. руководство FontForge. Возможно, вам придется выполнить несколько конкретных шагов, которые не обязательно являются простыми, чтобы сохранить извлеченные данные шрифта в виде файла, который можно использовать повторно.
Используя
mupdf Далее, MuPDF . Это приложение поставляется с утилитой под названием pdfextract 9.0009 (в Windows: pdfextract.exe ), который может извлекать шрифты и изображения из PDF-файлов. (Если вы не знаете о MuPDF, который все еще относительно неизвестен и нов: «MuPDF — это бесплатная облегченная программа для просмотра PDF и набор инструментов, написанный на портативном языке C». , написанный разработчиками Artifex Software, той же компанией, которая предоставила нам Ghostscript.)
( Обновление: В более новых версиях MuPDF прежняя функциональность 'pdfextract' перемещена в команду 'mutool Extract' . Загрузите его здесь: mupdf.com/downloads )
Загрузите его здесь: mupdf.com/downloads )
Примечание: pdfextract.exe — это программа командной строки. Чтобы использовать его, выполните следующие действия:
c:\> pdfextract.exe c:\path\to\filename.pdf # (в Windows) $> pdfextract /path/tofilename.pdf # (в Linux, Unix, Mac OS X)
Эта команда создаст дамп всех извлекаемых файлов из файла pdf, на который есть ссылка, в текущий каталог. Как правило, вы увидите множество файлов: изображения, а также шрифты. К ним относятся PNG, TTF, CFF, CID и т. д. Имена изображений будут примерно такими, как 9.0003 img-0412.png , если номер объекта PDF изображения был 412. Названия шрифтов будут такими, как FGETYK+LinLibertineI-0966.ttf , если номер объекта PDF шрифта был 966.
CFF ( Compact Font Format ) являются распознаваемым форматом, который можно преобразовать в другие форматы с помощью различных конвертеров для использования в различных операционных системах.
Еще раз: имейте в виду, что большинство этих файлов шрифтов могут иметь только подмножества символов и могут не представлять полный шрифт.
Обновление: (июль 2013 г.) Последние версии mupdf претерпели внутреннюю перетасовку и переименование своих двоичных файлов не один раз, а несколько раз. Основной утилитой был похожий на «швейцарский нож» бинарный файл под названием mubusy (название вдохновлено busybox?), который недавно был переименован в mutool . Они поддерживают подкоманды info , clean , Extract , poster и show . К сожалению, официальная документация по этим инструментам устарела (пока). Если вы используете «MacPorts» на Mac: утилита была переименована, чтобы избежать конфликтов имен с другими утилитами, использующими одинаковые имена, и вам может потребоваться использовать mupdfextract .
Чтобы получить (примерно) эквивалентные результаты с помощью mutool , как это делал его предыдущий инструмент pdfextract , просто запустите mubusy Extract . .* ..
..
Таким образом, для извлечения шрифтов и изображений вам может потребоваться запустить один из следующие командные строки:
c:\> mutool.exe extract filename.pdf # (в Windows) $> mutool extract filename.pdf # (в Linux, Unix, Mac OS X)
Загрузки здесь: mupdf.com/downloads
Использование
gs (Ghostscript) Затем Ghostscript также может извлекать шрифты непосредственно из PDF-файлов. Однако для этого требуется помощь специальной служебной программы с именем extractFonts.ps , написанной на языке PostScript, которая доступна в репозитории исходного кода Ghostscript.
Теперь используйте его, вам нужно запустить оба, этот файл extractFonts.ps и ваш файл PDF. Затем Ghostscript будет использовать инструкции программы PostScript для извлечения шрифтов из PDF. В Windows это выглядит так (да, Ghostscript понимает косую черту, / как разделитель пути и в Windows!): 9-c "(c:/путь/к/вашему/PDFFile. pdf) извлечьШрифты выйти"
pdf) извлечьШрифты выйти"
или в Linux, Unix или Mac OS X:
gs \ -q -dNODISPLAY \ /путь/к/extractFonts.ps \ -c "(/path/to/your/PDFFile.pdf) ExtractFonts выйти"
Я тестировал метод Ghostscript несколько лет назад. В то время он отлично извлекал *.ttf (TrueType). Я не знаю, будут ли вообще извлекаться другие типы шрифтов, и если да, то повторно используемым способом. Я не знаю, блокирует ли утилита извлечение шрифтов, помеченных как защищенные.
Использование
pdf-parser.py Наконец, pdf-parser.py Дидье Стивенса: этот, вероятно, не так прост в использовании, потому что вам нужно иметь некоторые знания о внутренних структурах PDF. pdf-parser.py — это скрипт Python, который также может делать много других вещей. Он также может распаковывать и извлекать произвольные потоки из объектов и, следовательно, также может извлекать встроенные файлы шрифтов.
Но нужно знать, что искать. Давайте посмотрим на это на примере. У меня есть файл с именем большой.pdf . В качестве первого шага я использую параметр
Давайте посмотрим на это на примере. У меня есть файл с именем большой.pdf . В качестве первого шага я использую параметр -s для поиска в PDF любого вхождения ключевого слова FontFile ( pdf-parser.py не требует поиска с учетом регистра):
pdf-parser. py -s файл шрифта большой.pdf
В моем случае для моего big1.pdf я получаю такой результат:
obj 9 0
Тип: /дескриптор шрифта
Ссылка: 15 0 Р
<<
/Восхождение 728
/CapHeight 716
/Спуск -210
/Флаги 32
/FontBBox [-665-325 2000 1006]
/FontFile2 15 0 R
/Название шрифта /ArialMT
/курсивный угол 0
/Ствол V 87
/Тип /Дескриптор шрифта
/XВысота 519>>
объект 11 0
Тип: /дескриптор шрифта
Ссылка: 16 0 R
<<
/Восхождение 728
/CapHeight 716
/Спуск -210
/Флаги 262176
/FontBBox [-628-376 2000 1018]
/FontFile2 16 0 R
/Название шрифта /Arial-BoldMT
/курсивный угол 0
/Ствол V 165
/Тип /Дескриптор шрифта
/XВысота 519
>>
Он говорит мне, что внутри PDF есть два экземпляра FontFile2 , и их в объектах PDF нет. 15 и нет. 16 соответственно. № объекта 15 держит
15 и нет. 16 соответственно. № объекта 15 держит /FontFile2 для шрифта /ArialMT , объект №. 16 содержит /FontFile2 для шрифта /Arial-BoldMT .
Чтобы показать это более ясно:
pdf-parser.py -s файл шрифта big1.pdf | grep -i файл шрифта /FontFile2 15 0 R /FontFile2 16 0 R
Быстрый взгляд на спецификацию PDF показывает, что ключевое слово /FontFile2 относится к «потоку, содержащему программу шрифтов TrueType» ( /FontFile относится к 'поток, содержащий программу шрифта Type 1' и /FontFile3 будет относиться к 'потоку, содержащему программу шрифта, формат которой указан записью Subtype в словаре потока' {следовательно, это либо Type1C , либо a CIDFontType0C подтип}.)
Чтобы посмотреть конкретно на номер объекта PDF. 15 (который содержит шрифт /ArialMT ), можно использовать параметр -o 15 :
pdf-parser.py -o 15 big1.pdf объект 15 0 Тип: Ссылка: Содержит поток << /Длина2 778552 /Длина 1581435 /Фильтр /ASCIIHexDecode >>
Этот вывод pdf-parser.py говорит нам, что этот объект содержит поток (который он не будет отображать напрямую), который имеет длину 1,581,435 байт и закодирован (== "сжатый") с помощью ASCIIHexEncode и требует для декодирования (== "распаковка" или "фильтрация") с помощью стандартного фильтра /ASCIIHexDecode .
Чтобы вывести любой поток из объекта, можно вызвать pdf-parser.py с параметром -d dumpname . Давайте сделаем:
pdf-parser.py -o 15 -d dumped-data.ext big1.pdf
Наш дамп извлеченных данных будет находиться в файле с именем dumped-data.ext . Давайте посмотрим, насколько он велик:
ls -l dumped-data.ext -rw-r--r-- 1 kurtpfeifle staff 1581435 11 апр 00:29 dumped-data.ext
Смотрите, это 1.581. 435 байт. Мы видели эту цифру в выводе предыдущей команды. Открытие этого файла в текстовом редакторе подтверждает, что его содержимое представляет собой данные в шестнадцатеричном коде ASCII.
435 байт. Мы видели эту цифру в выводе предыдущей команды. Открытие этого файла в текстовом редакторе подтверждает, что его содержимое представляет собой данные в шестнадцатеричном коде ASCII.
Открытие файла с помощью инструмента для чтения шрифтов, например otfinfo (это часть пакета lcdf-typetools ) поначалу вызовет некоторое разочарование:
otfinfo -i dumped-data.ext otfinfo: dumped-data.ext: не шрифт OpenType (неверный магический номер)
Хорошо, это потому, что мы (пока) не позволили pdf-parser.py использовать всю свою магию: выгрузить отфильтрованный, декодированный поток. Для этого мы должны добавить параметр -f :
pdf-parser.py -o 15 -f -d dumped-data-decoded.ext big1.pdf
Какого размера этот новый файл?
ls -l dumped-data-decoded.ext -rw-r--r-- 1 kurtpfeifle staff 778552 11 апр 00:39 dumped-data-decoded.ext
О, смотрите: этот точный номер уже был сохранен в объекте PDF №.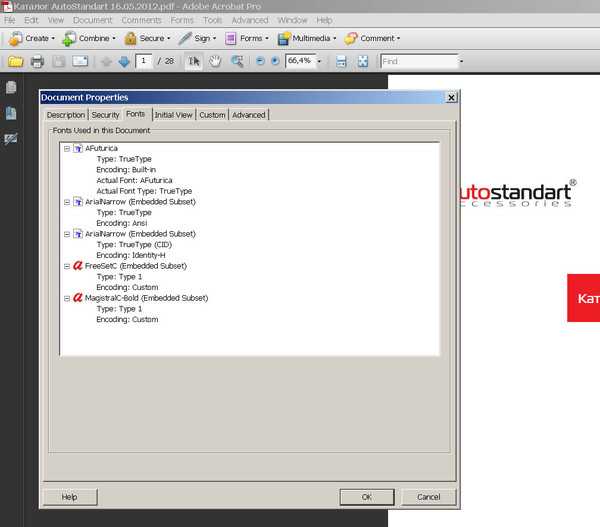 15 словарь как значение для ключа
15 словарь как значение для ключа /Length2 ...
Что думает файл ?
файл dumped-data-decoded.ext dumped-data-decoded.ext: данные шрифта TrueType
Что означает otfinfo расскажи нам об этом?
otfinfo -i дамп-данных-decoded.ext
Семья: Ариал
Подсемейство: Обычный
Полное имя: Ариал
Имя PostScript: ArialMT
Версия: Версия 5.10
Уникальный идентификатор: Monotype:Arial Regular:Version 5.10 (Microsoft)
Дизайнер: Чертежное бюро монотипного шрифта - Робин Николас, Патриция Сондерс, 1982 г.
Производитель: The Monotype Corporation
Товарный знак: Arial является товарным знаком The Monotype Corporation.
Авторское право: © 2011 Корпорация Monotype. Все права защищены.
Описание лицензии: вы можете использовать этот шрифт для отображения и печати контента, как это разрешено
условия лицензии для продукта, в который включен этот шрифт.
Вы можете (i) встраивать этот шрифт в контент только в том случае, если это разрешено
ограничения встраивания, включенные в этот шрифт; и (ii) временно
загрузите этот шрифт на принтер или другое устройство вывода, чтобы помочь
распечатать содержимое. Идентификатор поставщика: TMC
Идентификатор поставщика: TMC
Итак, Бинго!, у нас есть победитель: pdf-parser.py действительно извлек для нас допустимый файл шрифта. Учитывая размер этого файла (778,552 байта), похоже, что этот шрифт был встроен даже полностью в PDF...
Мы могли бы переименовать его в arial-regular.ttf и установить его как таковой и счастливо использовать его.
В любом случае вам необходимо следовать лицензии, применимой к шрифту. Некоторые лицензии на шрифты не допускают бесплатного использования и/или распространения. Пиратство шрифтов похоже на пиратство любого программного обеспечения или другого материала, защищенного авторским правом.
Большинство PDF-файлов, которые находятся в свободном доступе, в любом случае не встраивают полный шрифт, а только его подмножества. Извлечение подмножества шрифта полезно только в очень ограниченной области, если вообще полезно.
Пожалуйста, прочтите также следующее о плюсах и (больше) минусах усилий по извлечению шрифтов:
- http://typophile.com/node/34377 — больше не доступен , но его можно увидеть на Wayback Machine по адресу https ://web.archive.org/web/20110717120241/typophile.com/node/34377
Как извлечь цвет шрифта текста в PDF-файле на Python с помощью PDFMiner?
Я просмотрел весь исходный код PDFMiner (не поддерживается) и PDFMiner.Sixth (форк). Ни один модуль Python не позволяет извлекать цвет. В разделе проблем для обоих модулей извлечение цвета шрифта является общей проблемой.
Я также посмотрел PDFPlumber, который использует PDFMiner.Sixth. Модуль извлекает цвета шрифта. Извлеченные цветовые элементы включали stroking_color, — контур персонажа, non_stroking_color, — заливка персонажа. Я посмотрел на цвета, извлеченные из моего образца PDF, и они соответствовали цветам RGB.
импорт pdfplumber
pdf_file = pdfplumber.open('path_to_pdf')
для p, char в zip (pdf_file.pages, pdf_file.chars):
слова = p.extract_words (keep_blank_chars = True)
тексты = p.extract_text()
print(f"Номер страницы: {p.page_number}")
print(f"Имя шрифта: {char['имя_шрифта']}")
print(f"Размер шрифта: {char['size']}")
print(f"Цвет обводки: {char['stroking_color']}")
print(f"Цвет без поглаживания: {char['non_stroking_color']}")
печать (тексты.strip())
печать('\п')
Вопрос без ответа:
Как извлечь цвета шрифта и при этом использовать код PDFMiner?
Приведенный ниже код позволяет мне одновременно использовать PDFMiner.Sixth и PDFPlumber для извлечения различных элементов, таких как текст, имя шрифта, размер шрифта, stroking_color и non_stroking_color из исходного файла PDF.
импорт pdfplumber
из pdfminer.high_level импортировать extract_pages
из pdfminer.layout импортировать LTTextContainer, LTChar
с open('path_to_pdf', 'rb') как scr_file:
с pdfplumber. PDF(scr_file) как pdf_file:
для page_layout, char в zip (extract_pages (scr_file), pdf_file.chars):
для элемента в page_layout:
если экземпляр (элемент, LTTextContainer):
для text_line в элементе:
для символа в text_line:
если isinstance (персонаж, LTChar):
печать (элемент.get_text())
print(f"Имя шрифта: {character.fontname}")
print(f"Размер шрифта: {character.size}")
print(f"Цвет обводки: {char['stroking_color']}")
print(f"Цвет без поглаживания: {char['non_stroking_color']}")
печать('\n\n')
PDF(scr_file) как pdf_file:
для page_layout, char в zip (extract_pages (scr_file), pdf_file.chars):
для элемента в page_layout:
если экземпляр (элемент, LTTextContainer):
для text_line в элементе:
для символа в text_line:
если isinstance (персонаж, LTChar):
печать (элемент.get_text())
print(f"Имя шрифта: {character.fontname}")
print(f"Размер шрифта: {character.size}")
print(f"Цвет обводки: {char['stroking_color']}")
print(f"Цвет без поглаживания: {char['non_stroking_color']}")
печать('\n\n')
Я все еще работаю над объединением и синхронизацией этих функций. Я проверил их, и они, кажется, выводят правильные элементы.
импорт pdfplumber из pdfminer.high_level импортировать extract_pages из pdfminer.layout импортировать LTTextContainer, LTChar, LAParams def extract_character_characteristics (pdf_file): число_страниц = длина (список (извлечение_страниц (pdf_файл))) для page_layout в extract_pages(pdf_file, laparams=LAParams()): print(f'Страница обработки: {number_of_pages}') количество_страниц -= 1 для элемента в page_layout: если экземпляр (элемент, LTTextContainer): для text_line в элементе: для символа в text_line: если isinstance (персонаж, LTChar): если character.get_text() != ' ': print(f"Символ: {character.get_text()}") print(f"Имя шрифта: {character.fontname}") print(f"Размер шрифта: {character.size}") печать('\п') def extract_character_colors (pdf_file): с pdfplumber.PDF(pdf_file) в виде файла: для символа в файле.
