Поддержка G-буфера
Поддержка G-буфераHome | V‑Ray и 3ds Max | Примеры |
Обзор
Поддерживаемые каналы G-буфера
Замечания
Search keywords: g-buffer, RLA, RPF, render effects
Обзор
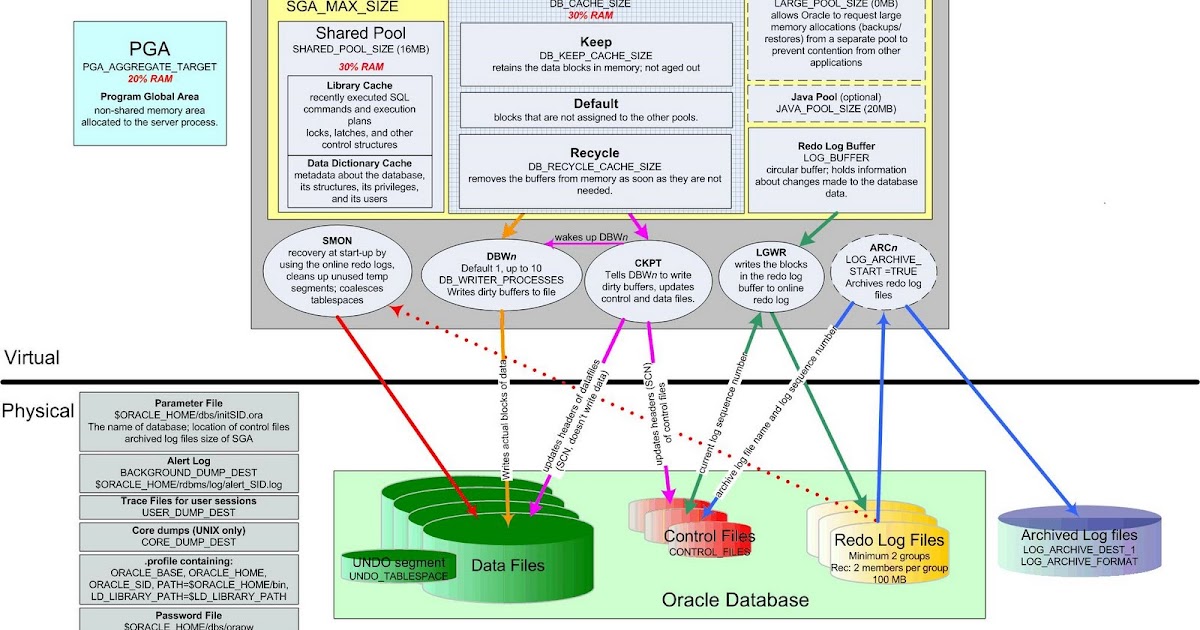
V-Ray поддерживает вывод в многослойный G-буфер, необходимый для создания файлов .rla и .rpf, также хорошо, как и многие эффекты 3dsmax. V-Ray будет автоматически генерировать каналы G-буфера, необходимые для вывода изображения и эффектов визуализации, и нет необходимости выбирать их вручную.
Поддерживаемые каналы G-буфера
Это список поддерживаемых каналов G-буфера 3ds Max.
Название канала 3ds Max Поддержка V-Ray Описание Z yes Буфер глубины. Заметим, что в отличие от встроенного визуализатора (scanline renderer), V-Ray хранит в этом канале расстояние до камеры, а не до плоскости камеры.
Material Effects yes ID материала. Object yes ID узла объекта, назначенный через диалог Properties объекта. UV Coordinates yes UV-координаты поверхности. Заметим, что V-Ray будет всегда выводить UV-координаты для канала преобразования номер 1. Normal yes Нормаль к поверхности относительно камеры. Non-Clamped Color yes Реальный несжатый цвет пикселя. Заметим, что этот канал хранит пиксели до применений любых преобразований цвета. Так же как и со встроенным визуализатором, этот канал не хранит атмосферные эффекты. Coverage yes Вклад объекта в пиксель изображения. Node Render ID yes Уникальный ID, назначенный визуализатором каждому узлу. Color yes Цвет материала объекта. Так же как и со встроенным визуализатором, этот канал не хранит атмосферные эффекты. Transparency yes Прозрачность материала для объекта. Так же как и со встроенным визуализатором, этот канал не хранит атмосферные эффекты. Velocity yes Скорость поверхности относительно камеры. Sub-Pixel Weight yes Вклад объекта в пиксель изображения, включая прозрачность. Sub-Pixel Mask no Битовая маска для вклада объекта в пиксель. Канал Sub-Pixel Mask не имеет смысла, когда принимаются во внимание фильтры антиалиазинга, глубина резкости или смазывание при движении. Поэтому V-Ray не поддерживает этот канал.
 Заметим, что в отличие от встроенного визуализатора (scanline renderer), V-Ray хранит в этом канале расстояние до камеры, а не до плоскости камеры.
Заметим, что в отличие от встроенного визуализатора (scanline renderer), V-Ray хранит в этом канале расстояние до камеры, а не до плоскости камеры.
Замечания
- При генерации каналов G-буфера, в отличие от встроенного визуализатора 3ds Max, V-Ray берет в расчет фильтры антиалиазинга. Это может приводить к различиям в работе некоторых эффектов. Если это создает проблемы, то выключите фильтр антиалиазинга в свитке Image sampler. Также не используйте фильтры антиалиазинга с отрицательными компонентами (Catmull-Rom, Mitchell-Netravali) при генерации G-буфера — 3ds Max не поддерживает слои с отрицательными границами, и V-Ray будет их игнорировать при создании G-буфера 3ds Max.
- Генерация корректного многослойного G-буфера требует дополнительной памяти. G-буфер 3ds Max поддерживает запись только в стиле встроенного визуализатора. Но V-Ray визуализирует изображение бакитами и не может обеспечить порядок данных как для scanline. Поэтому V-Ray в процессе визуализации сохраняет в памяти данные для G-буфера, и затем уже записывает их за раз в окончательное изображение.

- Слои G-буфера таперь генерируются корректно и в режиме распределенной визуализации. Это означает, что эффекты типа смазывания при движении будут теперь работать и в режиме распределенной визуализации.
Перевод © Black Sphinx, 2008-2010. All rights reserved.
Хостинг от uCoz
G-Buffer support
G-Buffer supportHome | V‑Ray and 3ds Max | Examples |
General
Supported G-Buffer channels
Notes
Search keywords: g-buffer, RLA, RPF, render effects
General
V-Ray supports multi-layered G-Buffer output required for writing .rla and .rpf files, as well as by many 3dsmax render effects. V-Ray will automatically generate the g-buffer channels requested by the image output and the render effects and there is no need to select these manually.

Supported G-Buffer channels
This is a list of supported G-Buffer channels in 3ds Max.
3ds Max channel name Supported by V-Ray Description Z yes Depth buffer. Note that in difference from the scanline renderer, V-Ray stores in this channel the distance to the camera, and not to the camera plane. Material Effects yes The material ID. Object yes The object node id that is set through the Properties dialog of an object. UV Coordinates yes The surface UV coordinates. Note that V-Ray will always output the UV coordinates for mapping channel 1. Normal yes The surface normal relative to the camera. Non-Clamped Color yes The real unclamped pixel color. Note that this channel stores the pixels before any color mapping is applied. Like with the scanline renderer, this channel does not store atmospheric effects. Coverage yes The contribution of an object to the image pixel. Node Render ID yes A unique ID assigned by the renderer to each node. Color yes The material color for the object. Like with the scaneline renderer, this does not include any atmospheric effects. Transparency yes The material transparency for the object. Like with the scanline renderer, this does not include atmospherics. Velocity yes The surface velocity relative to the camera. Sub-Pixel Weight yes The contribution of an object to the image pixel including transparencies. Sub-Pixel Mask no A bit mask for the contribution of an object to a pixel. The Sub-Pixel Mask channel is meaningless when AA filters, depth of field and motion blur are taken into consideration, which is why V-Ray does not support it.

Notes
- V-Ray takes antialiasing filters into account when
generating the g-buffer channels, in contrast with the default scanline
renderer of 3ds Max. This may cause differences in the way some render
effects work. If this is a problem, turn off
the AA filter from the Image
sampler rollout. Also, avoid using AA filters with negative
components (Catmull-Rom, Mitchell-Netravali) when
generating a g-buffer — 3ds Max cannot handle layers with negative
coverage and V-Ray will ignore those when creating the 3ds Max g-buffer.

- Generating a correct multi-layer g-buffer requires extra memory. This is because the 3ds Max g-buffer supports only scanline-style writing. However, V-Ray renders in buckets and cannot provide the data in scanline order. That’s why V-Ray stores all the g-buffer data while rendering, and then writes it at once into the final image.
- G-Buffer layers are now generated correctly in Distributed rendering mode. This means that render effects like image motion blur will now work in DR mode too.
Хостинг от uCoz
javascript — В чем разница между ND-буфером и G-буфером?
спросил
Изменено 6 лет, 9 месяцев назад
Просмотрено 4к раз
Я новичок в WebGL. Я читал в нескольких сообщениях о ND-Buffers и G-Buffers, как будто это был стратегический выбор для разработки WebGL.
Как ND-буферы и G-буферы связаны с конвейерами рендеринга? Используются ли ND-буферы только при прямом рендеринге, а G-буферы — только при отложенном рендеринге?
Пример кода JavaScript, как реализовать оба, был бы полезен для меня, чтобы понять разницу.
- javascript
- webgl
- отложенный рендеринг
- webgl-расширения
- webgl2
2
G-буферы — это просто набор буферов, обычно используемых при отложенном рендеринге.
Википедия дает хороший пример данных, часто встречающихся в g-буфере
Информация о диффузном цвете
Нормали мирового пространства или экранного пространства из этих 3 буферов называется «g-буфером»
Генерируя эти 3 буфера из данных геометрии и материалов, вы можете затем запустить шейдер, чтобы объединить их для создания окончательного изображения.
То, что на самом деле входит в g-буфер, зависит от конкретного движка/рендерера. Например, один из отложенных рендеров Unity3D содержит диффузный цвет, окклюзию, зеркальный цвет, шероховатость, нормаль, глубину, трафарет, эмиссию, освещение, карту освещения, пробы отражения.
Например, один из отложенных рендеров Unity3D содержит диффузный цвет, окклюзию, зеркальный цвет, шероховатость, нормаль, глубину, трафарет, эмиссию, освещение, карту освещения, пробы отражения.
Буфер ND означает «нормальный буфер глубины», что делает его подмножеством того, что обычно находится в типичном g-буфере.
Что касается образца, который, возможно, слишком велик для SO, но есть статья об отложенном рендеринге в WebGL на MDN
0
Выбор пути рендеринга является важным архитектурным решением для модуля 3D-рендеринга, независимо от того, какой API он использует. Этот выбор сильно зависит от набора функций, которые должен поддерживать модуль визуализации, и требований к производительности.
Существенный набор указанных функций состоит из так называемых эффектов экранного пространства. Это означает, что мы визуализируем некоторые важные данные о каждом пикселе экрана в набор буферов рендеринга, а затем используем эти данные (не геометрию) для вычисления некоторых новых данных, необходимых для кадра.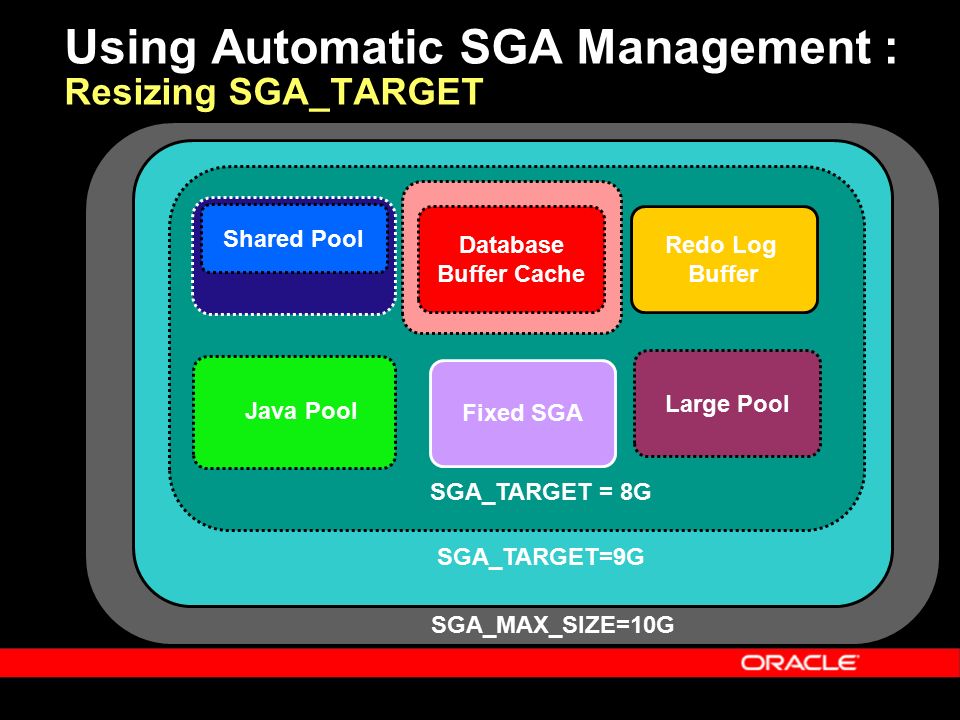 Ambient Occlusion — отличный пример такого эффекта. Основываясь на некоторых пространственных значениях пикселей, мы вычисляем «маску», которую позже можем использовать для правильного затенения каждого пикселя.
Ambient Occlusion — отличный пример такого эффекта. Основываясь на некоторых пространственных значениях пикселей, мы вычисляем «маску», которую позже можем использовать для правильного затенения каждого пикселя.
Кроме того, существует этап рендеринга, который почти полностью зависит от вычислений экранного пространства. И это действительно Deferred Shading. И вот здесь на помощь приходит G-буфер. Все данные, необходимые для вычисления цвета пикселя, передаются в G-буфер: набор буферов рендеринга, хранящих эти данные. Сами данные (и, следовательно, значения буферов рендеринга G-буфера) могут быть разными: диффузный компонент, зеркальный компонент, блеск, нормаль, положение, глубина и т. д. А в рамках рендеринга кадра современные движки отложенного шейдинга используют экранное пространство. Ambient occlusion (SSAO), которые используют данные из нескольких буферов рендеринга G-буфера (обычно это положение, нормаль и глубина).
О ND-буферах. Мне кажется, что это не широко используемый термин (Google не смог найти никакой соответствующей информации о них, кроме этого вопроса). Я считаю, что ND означает нормальную глубину. Это просто частный случай G-буфера для конкретного алгоритма и эффекта (в диссертации это SSAO).
Я считаю, что ND означает нормальную глубину. Это просто частный случай G-буфера для конкретного алгоритма и эффекта (в диссертации это SSAO).
Таким образом, использование G-буферов (и ND-буферов как подмножества G-буферов) и exa зависит от алгоритмов затенения и эффектов, которые вы реализуете. Но все вычисления экранного пространства потребуют некоторой формы G-буфера.
P.S. Тезис, на который вы ссылаетесь, содержит неточность. В качестве преимущества метода автор называет возможность реализации ND-буферов на GLES 2.0. Однако на самом деле это невозможно, так как GLES 2.0 не имеет текстур глубины (они были добавлены в расширении OES_depth_texture ).
3
Я хотел бы добавить еще немного информации к предыдущим ответам.
Я читал в нескольких сообщениях о ND-Buffers и G-Buffers, как будто это стратегический выбор для разработки WebGL.
Одной из наиболее важных частей отложенного рендеринга является поддержка данной платформой MRT (несколько целей рендеринга). Если это не так, вы не сможете разделить частичные вычисления в шейдерах между каждым рендерингом, а также заставит вас запускать рендеринг столько раз, сколько у вас есть «слоев» (в случае единства 3D это может быть до 11 раз). ?). Это может сильно замедлить вашу программу.
Если это не так, вы не сможете разделить частичные вычисления в шейдерах между каждым рендерингом, а также заставит вас запускать рендеринг столько раз, сколько у вас есть «слоев» (в случае единства 3D это может быть до 11 раз). ?). Это может сильно замедлить вашу программу.
Подробнее в этом вопросе Возможен ли отложенный рендеринг/затенение в OpenGL ES 2.0?
Webgl не поддерживает MRT, но имеет расширение: https://www.khronos.org/registry/webgl/extensions/WEBGL_draw_buffers/
Также есть расширение для текстур глубины: https://www.khronos.org/registry/webgl/extensions/WEBGL_depth_texture/
Таким образом, должна быть возможность использовать технику отложенного рендеринга, но ее скорость трудно угадать.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Обучение компьютерной графике — отложенный рендеринг
Стандартный способ графического конвейера, который мы изучали на курсе компьютерной графики, назывался опережающий рендеринг . GPU создан для этого. Мы отправили данные и команды в конвейер и получили результат.
GPU создан для этого. Мы отправили данные и команды в конвейер и получили результат.
Однако у прямого рендеринга есть некоторые проблемы. Примечательно, что тест глубины является последним шагом в конвейере, поэтому многие заштрихованные фрагменты могут быть перезаписаны. Когда у нас есть сложный фрагментный шейдер, это приведет к потере производительности. Кроме того, если у нас много источников света, то в шейдере у нас будет цикл по всем из них. Вклады от каждого источника света будут вычисляться и складываться вместе, даже если они очень малы (т.е. источник света на самом деле находится далеко).
Пример справа включает такую сцену. Вокруг перемещается 120 точечных источников света, и фрагментный шейдер зацикливается на них всех. Вы можете настроить параметры затухания, чтобы увидеть, что часто точечные источники света имеют довольно ограниченную область действия. В зависимости от вашего графического процессора пример может быть довольно медленным. Пример включает статистику, поэтому вы также можете проверить милли- или микросекунды, необходимые для рендеринга одного кадра и обновления сцены. Нажав на статистику, вы переключитесь между различными представлениями. Просмотр примера в полноэкранном режиме с режимом рендеринга будет более затратным, так как количество отображаемых пикселей будет больше.
Нажав на статистику, вы переключитесь между различными представлениями. Просмотр примера в полноэкранном режиме с режимом рендеринга будет более затратным, так как количество отображаемых пикселей будет больше.
Отложенный рендеринг (также называемый отложенным затенением ) может решить эти проблемы. Основная идея заключается в том, что мы делаем 2 прохода и не затеняем наши фрагменты в первом. Вместо этого мы записываем в промежуточную цель рендеринга только все значения (например, нормали, цвета, глубины), необходимые для второго прохода для затенения фрагментов. Таким образом, при первом проходе будут перезаписаны фрагменты, не прошедшие проверку глубины, без лишних затрат ресурсов. Во втором проходе мы используем результаты первого прохода, чтобы закрасить только видимые пиксели.
Несмотря на то, что основная идея проста для понимания, необходимо учитывать несколько моментов. Например, как получить положение из глубины, можем ли мы оптимизировать его для рендеринга областей, затронутых только светом и т. д. У отложенного рендеринга есть свои плюсы и минусы по сравнению с прямым рендерингом. В зависимости от сцены или приложения, которое вы создаете, одно может быть более подходящим, чем другое.
д. У отложенного рендеринга есть свои плюсы и минусы по сравнению с прямым рендерингом. В зависимости от сцены или приложения, которое вы создаете, одно может быть более подходящим, чем другое.
G-буфер
Неотъемлемой частью отложенного рендеринга является G-буфер. Именно здесь должны храниться все данные, необходимые для затенения фрагмента. Мы также хотим сделать его как можно меньше, чтобы не тратить слишком много памяти графического процессора. Обратите внимание, что G-буфер не копируется на сторону процессора.
Посмотрите на некоторые из самых простых моделей освещения. Для затенения фрагмента минимально необходимым вводом является цвет материала, нормаль поверхности и положение фрагмента. Например, диффузная модель Ламберта $color \cdot \max(0, n \cdot l)$. У нас явно есть цвет и нормаль к поверхности. Цвет, который мы можем просто записать в целевой G-буфер, так как его значения варьируются от $[0, 1]$. Нормаль, которую мы можем преобразовать из $[-1, 1] \rightarrow [0, 1]$, просто добавив $1$ и умножив на $0,5$.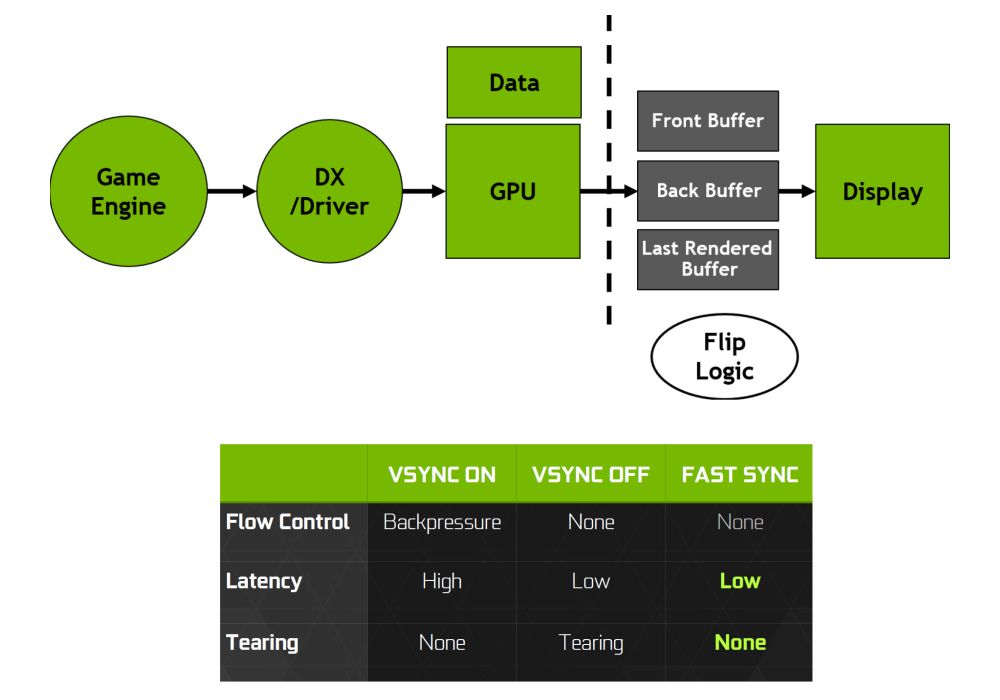
Чтобы найти $l$, нам нужно $l = normalize(lightPosition — fragmentPosition)$. $lightPosition$ мы отправляем во второй проход как юниформу. Чтобы получить $fragmentPosition$, у нас есть 2 варианта: 1) Сохранить позицию в одной из целей, 2) Сохранить линейную глубину и вычислить позицию по ней позже.
С вариантом 1) наша проблема в том, что нам понадобится 3-канальный буфер, где каждый канал имеет либо 16 (половина с плавающей запятой), либо 32 (с плавающей запятой) бит. Это приведет к нормальному хранению наших координат. Тем не менее, он будет использовать как минимум $16 \cdot 3 = 48$ или $32 \cdot 3 =9.6$ бит памяти на пиксель. Вместо этого мы можем использовать вариант 2) и сохранить значение глубины фрагмента. Это зависит от вашей реализации, используете ли вы фактическое значение глубины (которое вы также можете взять вместо этого из буфера глубины) или сохранили расстояние по оси от камеры (координата $-z$), нормализованную в фурстуме или нет. Если вы используете слишком мало битов для хранения глубины, то позже вы можете получить полосы в значениях, а затем и в вычислениях цвета:
Если вы используете слишком мало битов для хранения глубины, то позже вы можете получить полосы в значениях, а затем и в вычислениях цвета:
Обвязка на месте. | Полосатость в рендере. | Отсутствие полос при визуализации. |
В нашем примере мы сохранили координату $-z$ и нормализовали ее на основе усеченной пирамиды.
Возникает сложный вопрос: как нам вернуть положение фрагмента пространства камеры только по глубине?
Для этого нужно вспомнить, как мы проецировали пространственные точки камеры на ближнюю плоскость в курсе компьютерной графики. Мы находили проекционные координаты $x_p$ и $y_p$ по некоторым $x$ и $y$.
Используя похожие треугольники, мы нашли ответы: $x_p = \frac{x \cdot near}{-z}$ и $y_p = \frac{y \cdot near}{-z}$.
Теперь, для нашего второго прохода отложенного рендеринга, мы используем квадроцикл и ортогональную камеру, чтобы просмотреть все пиксели экрана. Мы можем расположить этот четырехугольник так, чтобы он точно соответствовал ближней плоскости. Это означает, что четырехугольные углы будут $(-верхний, левый)$ и $(верхний, -левый)$.
Мы можем расположить этот четырехугольник так, чтобы он точно соответствовал ближней плоскости. Это означает, что четырехугольные углы будут $(-верхний, левый)$ и $(верхний, -левый)$.
При рендеринге одного пикселя координаты фрагмента $x$ и $y$ теперь будут соответствовать проецируемым координатам нашей точки $A$. Чтобы найти пространственные координаты камеры сцены $A$, мы просто делаем тот же вывод с подобными треугольниками, что и раньше (или просто обращаем ранее полученные формулы). Результат: $x = \frac{-x_p \cdot z}{near}$ и $y = \frac{-y_p \cdot z}{near}$. Здесь нужно быть осторожным со знаком. В зависимости от того, каким образом вы сохранили значение глубины в G-буфере, знак $z$ может отличаться. В нашем случае это на самом деле просто $z$, а не $-z$, поскольку мы включили отрицание в значения глубины (поэтому более высокие значения будут дальше).
Таким образом, чтобы получить положение из глубины, учитывая орфографическую визуализацию почти плоского четырехугольника и координату $z$, полученную из значения G-буфера, формула просто:
$$A = \left( \frac{ -x_p \cdot z}{near}, \frac{-y_p \cdot z}{near}, z \right). $$
$$
Теперь это охватывает все минимально необходимые данные. Однако вы, возможно, сейчас подумали, что насчет альфа-канала? Цвет и нормаль занимают 3 канала, но у нас может быть и 4-канальная текстура. Также на иллюстрации у нас было 4 цели рендеринга. В основном все сводится к конкретной реализации. Естественно, нам потребуется больше значений на фрагмент для разных моделей освещения. Фонгу, например, потребуется зеркальный цвет (или, по крайней мере, интенсивность) и значения блеска.
Прямо сейчас мы использовали другую цель рендеринга для хранения, например, значения эмиссии в одном канале. Позже мы сохраним излучение в красном цвете, а интенсивность зеркального отражения — в зеленом.
Как правило, да, вы должны оптимизировать свои значения и буферы, чтобы не тратить слишком много памяти графического процессора.
В примере справа показаны 4 цели рендеринга и их значения. Цели рендеринга выбираются в размере 1/4 размера, чтобы они все поместились на экране. На самом деле они имеют тот же размер, что и окно просмотра.
На самом деле они имеют тот же размер, что и окно просмотра.
Ссылки
- Изучите главу OpenGL об отложенном рендеринге
Обзор отложенного рендеринга - Создание G-буфера (2008 г.) – Каталин Зима-Зегреану
Соображения относительно того, какой размер использовать для разных значений. - Метод отложенного затенения в DirectX9 (2019) – DreamAndDead
Подробный обзор отложенного рендеринга от теории ослабления света до позиционирования четырехугольника ближней плоскости. - Отложенный рендеринг: делаем игры более реалистичными (2020) – Copperpod
Еще один обзор с примерами реальных игр.
Отложенное освещение
Основным преимуществом отложенного рендеринга является рендеринг с множеством источников света. Для такого рендеринга у нас может быть квадрат для каждого источника света . Эти четырехугольники визуализируются за один проход, а значения аддитивно смешиваются друг с другом. Это имитирует добавление различных источников света, которые мы бы закодировали в шейдере фрагментов прямого рендеринга. Когда мы хотим добавить рассеянный свет, мы добавляем еще один четырехугольник с материалом, который добавляет небольшой постоянный вклад. 9с$.
Это имитирует добавление различных источников света, которые мы бы закодировали в шейдере фрагментов прямого рендеринга. Когда мы хотим добавить рассеянный свет, мы добавляем еще один четырехугольник с материалом, который добавляет небольшой постоянный вклад. 9с$.
Однако сейчас мы только увеличили производительность за счет перерасхода. Это означает, что хотя мы затеняем только видимые пиксели (не все пиксели, обращенные вперед, как при прямом рендеринге), мы все равно пытаемся учесть все источники света для всех пикселей. Даже если у нас есть пиксели, не освещенные никаким источником света (затухание будет около 0), мы все равно пытаемся рассчитать затенение. Следующим шагом в оптимизации отложенного рендеринга является использование 90 119 90 120 объемов света 90 121 вместо четырехугольников 9.0122 . Это объемы, в которых затухание не будет слишком маленьким, т. е. в которых присутствует значимый вклад света.
Аддитивное смешение света. | Световые объемы. |

Теперь для рендеринга результата мы можем использовать перспективную камеру и визуализировать сцену световых объемов.
Поскольку мы используем перспективную камеру, нам не нужно беспокоиться о размещении квадроцикла точно в ближней плоскости. Однако нам нужно преобразовать визуализированные координаты в него. Когда мы рендерим объем света, мы получаем координаты фрагмента объема света. Мы используем обратную сторону светового объема для его рендеринга, так как это часть оптимизации, которую мы сделаем позже.
Нам нужно спроецировать координаты фрагмента светового объема $A_{light} = (x_l, y_l, z_l)$ на ближнюю плоскость. Это делается так же, как и в обычной точечной проекции: $x_p = \frac{x_l \cdot near}{-z_l}$, $y_p = \frac{y_l \cdot near}{-z_l}$. Это оставит нам спроецированную точку на ближнюю плоскость, точно так же, как мы сделали с орфографической камерой и квадроциклами.
Последний шаг точно такой же, как и раньше. Мы проецируем координату ближней плоскости обратно в пространство камеры, но для этого используем глубину сцены из G-буфера. Это приведет нас к точке $A$, которую мы хотим визуализировать.
Мы проецируем координату ближней плоскости обратно в пространство камеры, но для этого используем глубину сцены из G-буфера. Это приведет нас к точке $A$, которую мы хотим визуализировать.
Если есть фрагменты сцены, которые не лежат на одном пути с некоторым фрагментом светового объема, то мы к ним не попадем. Но мы еще не устранили все фрагменты вне световых объемов. На изображении ниже наш алгоритм также попытается отобразить точку $B$, поскольку она находится на том же пути, что и световой объем. Однако она находится за пределами светового объема, и затухание будет близко к 0, поэтому точка не будет вносить значимого вклада света. Это будет пустой тратой расчета. Для точки $C$ алгоритм работает хорошо, потому что она не будет визуализирована.
Чтобы избавиться от таких случаев, как точка $B$, мы должны приближаться к этому одному источнику света за раз. Мы будем использовать оптимизацию отбраковки трафарета . Рассмотрим следующую сцену:
Очевидно, что на сцене фактически освещена только небольшая часть в правом верхнем углу. Световой объем слева не содержит никакой геометрии сцены. Световой объем в правом нижнем углу тоже не содержит ничего, но, что более важно, он перекрывается геометрией сцены. Так что даже если бы он что-то осветил, зритель этого не увидел бы.
Световой объем слева не содержит никакой геометрии сцены. Световой объем в правом нижнем углу тоже не содержит ничего, но, что более важно, он перекрывается геометрией сцены. Так что даже если бы он что-то осветил, зритель этого не увидел бы.
Чтобы обнаружить и обработать эти случаи, мы должны визуализировать каждый источник света отдельно и использовать тест трафарета. Получается, что нам понадобится 2 прохода на каждый источник света. Таким образом, количество проходов после прохода G-буфера будет равно $2 \cdot numberOfLights$. Хотя это кажется дорогим, в зависимости от сцены мы можем повысить производительность, отбрасывая множество ненужных в противном случае затененных фрагментов. Для каждого источника света в отдельности алгоритм работает так:
В первом проходе здесь мы рендерим лицевые стороны текущего объема света. Первый шаг — очистить буфер трафарета до 0. Это необходимо для того, чтобы другие источники света не влияли на текущий. В противном случае мы все равно будем рендерить некоторые игнорируемые фрагменты, если проходящий фрагмент окажется на том же проекционном луче. Или может случиться наоборот, что мы не рендерим проходящий фрагмент, потому что сбойный фрагмент находится на том же луче. В любом случае, мы очищаем только буфер трафарета. Мы не очищаем буфер цвета, так как он будет содержать накопленный окончательный рендер. Мы также не очищаем буфер глубины, так как он содержит глубину сцены из предыдущего прохода G-буфера.
Или может случиться наоборот, что мы не рендерим проходящий фрагмент, потому что сбойный фрагмент находится на том же луче. В любом случае, мы очищаем только буфер трафарета. Мы не очищаем буфер цвета, так как он будет содержать накопленный окончательный рендер. Мы также не очищаем буфер глубины, так как он содержит глубину сцены из предыдущего прохода G-буфера.
Затем на этом проходе пропускаем трафарет, но проверяем, меньше или равна ли глубина глубине сцены. Если это так, у нас есть потенциально видимый фрагмент, и мы сохраняем 0 в трафарете. Если это не так, то это означает, что лицевая сторона этого объема находится за какой-то геометрией сцены. Это означает, что геометрия сцены закрывает его, и мы не видим фрагмент или что-то за ним в финальном рендере. В этом случае мы записываем 1 в буфер трафарета.
Во втором проходе мы рендерим обратные стороны текущего объема света. Здесь мы также рендерим в цветовой буфер, накапливая окончательный рендер. Здесь мы используем тест трафарета для рендеринга только тех фрагментов, которые имеют 0 в буфере трафарета. Если передняя грань в предыдущем проходе была за какой-то геометрией сцены, то и все, что за ней, тоже, поэтому мы игнорируем фрагменты, получившие 1 в предыдущем проходе. Затем мы проверяем, больше ли глубина здесь или равна глубине сцены. Это означает, что задняя сторона объема находится за некоторой геометрией сцены. Если это так, мы знаем, что между передней и задней гранями объема есть геометрия сцены, поэтому мы визуализируем фрагмент задней грани этого светового объема.
Если передняя грань в предыдущем проходе была за какой-то геометрией сцены, то и все, что за ней, тоже, поэтому мы игнорируем фрагменты, получившие 1 в предыдущем проходе. Затем мы проверяем, больше ли глубина здесь или равна глубине сцены. Это означает, что задняя сторона объема находится за некоторой геометрией сцены. Если это так, мы знаем, что между передней и задней гранями объема есть геометрия сцены, поэтому мы визуализируем фрагмент задней грани этого светового объема.
Вам может быть интересно, что если тестирование глубины выполняется после затенения фрагментов в конвейере, то фрагменты, не прошедшие тест глубины во втором проходе, все равно будут визуализированы. Ответ обычно отрицательный, потому что современные графические процессоры фактически выполняют ранний тест глубины. Для этого есть некоторые условия, но в основном он проверяет глубину перед выполнением фрагментного шейдера. Таким образом, даже несмотря на то, что мы выполняем фрагментный шейдер и визуализируем в цветовой буфер, если тест глубины не проходит, фрагментный шейдер не запускается.
Возвращаясь к нашему примеру сцены, рассмотрим самый левый световой объем.
Первый проход. | Второй проход. |
При первом проходе фрагменты проходят тест ≤ глубины, поэтому мы сохраняем 0 в буфере трафарета. При втором проходе тест трафарета будет пройден, но тест ≥ глубины не пройден, так как перед задними гранями отсутствует геометрия сцены. Таким образом, мы ничего не будем рендерить в цветовой буфер.
Рассмотрим верхний правый том.
Первый проход. | Второй проход. |
В первом проходе мы сохраняем 0, как и раньше. Во втором проходе есть несколько задних граней, где тест глубины ≥ не проходит, как и раньше без крайнего левого объема. Но есть и обратные грани, где перед ними геометрия сцены, т.е. там, где пройдет тест глубины ≥. Эти фрагменты мы визуализируем, и фрагментный шейдер закрашивает освещенную часть сцены.
Рассмотрим нижний правый том.
Первый проход. | Второй проход. |
В этом случае первый проход не пройдет тест глубины ≤, так как перед передними гранями находится геометрия сцены. Мы записываем 1 в буфер трафарета. При втором проходе тест трафарета завершится ошибкой, так как в буфере нет нулевых значений. Таким образом, объем, перекрытый геометрией сцены, не будет визуализирован.
Справа у нас, наконец, пример отложенного рендеринга . У него та же сцена и те же 120 источников света, что и в примере прямого рендеринга, который у нас был в начале. Naive Result визуализирует один квадрат для каждого источника света. Оптимизированный результат использует легкие объемы и только что описанный алгоритм отбраковки трафарета.
Когда вы посмотрите на Фрагментов тома , то каждый отброшенный фрагмент внесет 10% красного цвета. Каждый переданный фрагмент устанавливает зеленый и синий цвета в 1, что приводит к голубому цвету. Если на том же луче, что и пройденный фрагмент, есть отброшенные фрагменты, цвет будет стремиться к белому.
Каждый переданный фрагмент устанавливает зеленый и синий цвета в 1, что приводит к голубому цвету. Если на том же луче, что и пройденный фрагмент, есть отброшенные фрагменты, цвет будет стремиться к белому.
| Нет фрагментов на пути | |
| Несколько выброшенных фрагментов. | Нет переданных фрагментов. |
| Не менее 10 отброшенных фрагментов. | |
| Отброшенных фрагментов нет. | Один пройденный фрагмент. |
| Несколько выброшенных фрагментов. | |
| Не менее 10 отброшенных фрагментов. | |
Заметный прирост производительности зависит от вашего графического процессора и экрана. Поскольку браузеры ограничивают частоту кадров до 60, мы также можем посмотреть на загрузку графического процессора. На моем компьютере получилось так:
На моем компьютере получилось так:
| Пример | Частота кадров | Загрузка графического процессора | ||
| Визуализация вперед | 48-60 | 87-99% | ||
| Отложенный рендеринг (наивный) | с крышкой | 90% | ||
| Отложенный рендеринг (оптимизированный ) | с крышкой | 64-81% | ||
Конечно, существуют и другие оптимизации. Некоторые алгоритмы, с которыми вы знакомы, используя подход с упреждающим рендерингом, имеют свои собственные реализации с отложенным рендерингом. Таким образом, всегда есть плюсы и минусы, которые следует учитывать при выборе между прямым и отложенным рендерингом.
Ссылки
- Позиция по глубине 3: Возвращение к привычке (2010) – Мэтт Петтинео
Объяснение того, как получить положение камеры в пространстве с учетом значения глубины.