Как мы научили ABBYY FineReader PDF редактировать целые абзацы / Хабр
Сегодня мы обновили ABBYY FineReader 15 и выпустили его под брендом ABBYY FineReader PDF, потому что он объединяет все инструменты для работы с PDF. По этому поводу публикуем первый пост из серии материалов о фичах программы. В нем мы расскажем об одной интересной возможности, которая не первый месяц есть в программе, но, возможно, не все о ней знали.
Давно ли вы открывали PDF-файлы? Готовы поспорить, что совсем недавно. Скорее всего, на вашем компьютере точно найдется пара сканов, а может, еще и макет презентации, аналитическое исследование или техническая инструкция. Для каких задач обычно используют эти документы? По данным опроса ABBYY, 62% респондентов ищут информацию в PDF, 60% — копируют текст из документа, а 52% — редактируют: вносят в файл правки, исправляют ошибки и опечатки.
Даже сейчас не все знают, что можно редактировать текст в PDF. Да, изменение таких файлов устроено не так, как редактирование обычного текстового документа.
В этом посте мы раскроем технические подробности редактирования многострочных фрагментов текста в FineReader: как мы изменили движок программы, как редактирование устроено изнутри и как оно выглядит для пользователя. Поехали!
Форматом PDF пользуются по всему миру: его содержимое одинаково отображается на любых компьютерах, смартфонах и планшетах с разными операционными системами. Это удобно и помогает избежать неловких ситуаций. Например, когда вы написали текст в MS Word, отправили коллегам, а они открывают его LibreOffice’ом или Wordpad’ом, и все поехало
 В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.Поговорим сначала о PDF, в которых текст есть. Чтобы редактировать PDF, надо понимать, как в нем записан текст. Открывали когда-нибудь PDF в блокноте? Если да, то вы видели такое:
Чтобы все это отображалось понятно для пользователя, нужно проделать большую работу.
Задача: понять PDF
Содержимое каждой страницы в PDF-файле хранится в виде потоков команд для отрисовки документа – это могут быть текст, изображения или векторная графика. Структуру файла определяют PDF-объекты, например, страница, картинка, комментарий (а абзацы, строчки текста и буквы – это всего лишь части объекта). Символ в PDF представляется  Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
В PDF нет ни строк, ни абзацев, которые есть в документах текстовых форматов. Даже порядок текста не всегда определен. То есть вы видите текст, но на самом деле текста не существует. Это хаос из трудно понятных инструкций (как на изображении выше), которые нужно правильно отобразить в конкретных местах документа, с соответствующим форматированием.
«А как же текст?» – спросите вы.
Текст в PDF все же существует, и его даже получится редактировать. Для этого мы учим наши технологии понимать структуру текста, например, определять и выделять строки. Расскажем об этом подробнее.
Библиотеки PDF и как мы их поменяли
Чтобы сделать возможным редактирование целых абзацев, мы сильно поменяли нашу внутреннюю подсистему (библиотеку), которую мы называем PdfTools. Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Подсистема PdfTools содержит все необходимые инструменты, чтобы прочитать содержимое и обернуть его в объекты (страница, картинка, комментарий), с которыми удобно работать программе. С этими объектами уже могут работать наши продукты, в частности ABBYY FineReader PDF и другие.
Как было раньше. В FineReader 14 мы умели редактировать текст только в рамках одной строчки. После редактирования необходимо было выполнить «рендеринг» — расставить глифы на свои новые места.
Вообще рендеринг — это визуализация. Но мы вкладываем в это слово иное понятие — расположение объектов в PDF на своих местах. Для PDF-специалистов это и есть визуализация, которую больше никто не видит. Когда мы говорим о визуализации в привычном понимании, то используем слово «растеризация».

Весь этот процесс располагался в подсистеме PdfTools. Она помогала нам собирать содержимое PDF в строчки и редактировать их. Например, надо поставить на 5-ое месте глиф «А». FineReader передавал подсистеме PdfTools, что на пятое место нужно поставить глиф «А» с заданным размером и шрифтом, а PdfTools вставляла «А» и перемещала на нужное место в строчке все глифы, которые следовали за буквой «А». Построчное редактирование довольно легкое: текст просто смещался вправо или, например, влево, если он записан на иврите или арабском языке. Это позволяло внести небольшие корректировки, например, исправить опечатку, но не давало возможность сделать более глобальные изменения в тексте PDF-документа.
Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую.
Document Analysis и Synthesis
Чтобы определять в тексте блоки, ABBYY FineReader PDF использует технологию Document Analysis. Она позволяет найти абзацы, таблицы, картинки. Программа подсвечивает найденные блоки небольшими бледными рамками, чтобы пользователю удобнее было вносить правки:
Далее мы усовершенствовали другую подсистему нашей программы – Synthesis. Мы уже рассказывали на Хабре, зачем она нужна. Если вкратце, именно она определяет структуру и все характеристики распознанного текста: какие используются шрифты и размеры, какое начертание (bold, italic, underline), где заголовки, списки, отступы и многие другие параметры, которые можно настраивать в том же MS Word. Мы доработали Synthesis для того, чтобы при распознавании и воссоздании страницы очень точно восстанавливать исходные параметры текста.
Особенности подчеркнутого текста
В PDF нет такого атрибута текста как подчеркивание, привычного, например, пользователям MS Word. Подчеркивание в PDF – это векторная графика, никак не связанная с текстом. Без дополнительной доработки продукта при редактировании «подчеркнутого» текста символы бы перемещались привычным образом, а линии, обозначающие подчеркивания, оставались бы на месте. ABBYY FineReader PDF умеет определять и редактировать подчеркнутый текст привычным пользователю образом.
Редактирование таблиц в PDF
Изменилось и редактирование таблиц. Раньше программа «видела» таблицу, как отдельные строки, и редактировала ее так же. Теперь при работе с таблицами ABBYY FineReader PDF определяет содержимое каждой ячейки, умеет извлекать из них текст и работать с ним. Это удобно, когда надо исправить ошибку в цифре, поменять точку на запятую и при этом сохранить структуру таблицы, сделать это быстро и без конвертации PDF-документа в другие форматы.
Как отредактировать скан?
Возможность многострочного редактирования доступна и для сканов. Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.
В программе скан сначала распознается, а потом происходит подготовка к редактированию. Когда скан распознали, то текст получается не в нашем исходном документе, а в его виртуальном «двойнике». И именно в нем происходят все операции по редактированию.
Когда пользователь закончил редактировать документ, программа автоматически собирает все изменения со страницы и заменяет эти фрагменты в исходном документе. Наша задача — встроить текст обратно в PDF-документ, не повредив все то остальное, что уже есть в нем.
Редактирование скана позволяет не тратить время на конвертацию документа в другие форматы и обратно. Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Пример многострочного редактирования. Текст автоматически перераспределяется по строкам по мере добавления слов и предложений внутри абзаца.
Вместо заключения
Исправить опечатку в листовке, поменять местами текстовые блоки в инструкции, изменить целый абзац в скане договора или добавить несколько новых, поправить форматирование всего текста – все эти задачи теперь возможно решить:
- быстро,
- с помощью одной программы.
Попробовать можно прямо сейчас – скачайте триал-версию ABBYY FineReader PDF бесплатно.
В следующем посте через неделю мы расскажем о том, как научили ABBYY FineReader PDF еще одной интересной фиче и для чего может пригодиться новая функциональность.
Пишите в комментариях, о каких еще технологических особенностях нашей программы вам было бы интересно узнать?
Как мы сделали ABBYY FineReader, или история, произошедшая 20 лет назад / Хабр
ABBYY FineReader – программа для распознавания текстов, которая в России известна многим ещё со студенческих времён. В этом году FineReader исполняется 22 года, он немного моложе нашего словаря Lingvo. Как так вышло, что вместе со словарём молодые программисты из BIT Software (в то время ABBYY называлась именно так) занялись распознаванием текстов? И что помогло Файну стать одной из самых узнаваемых на рынке программ?
В этом году FineReader исполняется 22 года, он немного моложе нашего словаря Lingvo. Как так вышло, что вместе со словарём молодые программисты из BIT Software (в то время ABBYY называлась именно так) занялись распознаванием текстов? И что помогло Файну стать одной из самых узнаваемых на рынке программ?
На самом деле, всё очень логично. Если бы не Lingvo, FineReader’а могло бы и не быть. Началось всё с масштабного и амбициозного комплекса под названием Lingvo Systems. С его помощью человек мог отсканировать текст на одном языке, пропустить его через программу и получить перевод, правда, черновой, но для понимания смысла его было достаточно.
В Lingvo Systems были объединены четыре программы: от сторонних компаний — распознавалка символов, корректор, переводчик, а также наш словарь Lingvo. И самым слабым звеном было как раз распознавание: программу нужно было долго обучать каждому шрифту, но даже после этого качество оставляло желать лучшего. Программа должна была встретить по крайней мере несколько экземпляров одной буквы и каждый раз нуждалась в подсказке. Понемногу она «прозревала» и начинала понимать все больше символов. Так проходил процесс обучения. Но как только менялся шрифт или хотя бы его размер, все приходилось повторять сначала.
Понемногу она «прозревала» и начинала понимать все больше символов. Так проходил процесс обучения. Но как только менялся шрифт или хотя бы его размер, все приходилось повторять сначала.
Стоит сказать, что тогда, в начале 90-х, в организациях, отпочковавшихся от различных НИИ, уже начали разрабатывать свои OCR-системы (оптическое распознавание символов). Это была довольно востребованная технология – качественное распознавание было нужно не только нам для нашей Lingvo Systems, но и рынку. И у нас был выбор – ждать, пока кто-то другой сделает крутую программу, или разработать свою собственную.
Мы решили не ждать. Конечно, задача казалась нетривиальной: проблемой распознавания символов занимались целые научные институты, а у нас такого опыта не было. Но мы были молоды и амбициозны, считали, что любые задачи нам по плечу, поэтому с энтузиазмом взялись за разработку качественной программы.
Начали создавать программу мы в ноябре 1992 года, а закончить планировали к маю 1993. Отсутствие качественной программы распознавания существенно мешало продажам, конкуренты не дремали, поэтому нам надо было спешить. Понимая, что разработать всю технологию с нуля в такой срок невозможно, приобрели некоторые наработки у молодого учёного, который в свободное время дома работал над похожей программой – без особой цели, просто из личного интереса к предмету.
Отсутствие качественной программы распознавания существенно мешало продажам, конкуренты не дремали, поэтому нам надо было спешить. Понимая, что разработать всю технологию с нуля в такой срок невозможно, приобрели некоторые наработки у молодого учёного, который в свободное время дома работал над похожей программой – без особой цели, просто из личного интереса к предмету.
Его технология была в состоянии, далёком от коммерческого применения, и мы приложили массу усилий, чтобы программа научилась выдавать полезный результат. Одно дело – экспериментальная разработка, другое – работающий продукт. Исходно код программы был разработан под MS DOS, а нам нужно было перенести все под Windows. Кроме того, технология поддерживала лишь один простейший формат изображений (несжатый BMP), а от коммерческого продукта требовалась поддержка всех основных на тот момент форматов – хотя бы формата TIFF. Но в те времена это был очень неустоявшийся формат, каждый его писал, как хотел: то с выравниванием, причем разным, то без, то в прямом варианте, то в негативе. В общем, пришлось повозиться, и все равно еще долго находились файлы TIFF, которые вызывали проблемы с чтением.
В общем, пришлось повозиться, и все равно еще долго находились файлы TIFF, которые вызывали проблемы с чтением.
Ну и самое главное: в системе практически не было готовых описаний символов, а инструменты для создания этих описаний отсутствовали вовсе. В качестве такого инструмента использовался набор больших текстовых файлов, в которых в псевдографическом виде были прочерчены обобщенные контуры символов. Их полагалось править и улучшать прямо в этом файле в обычном текстовом редакторе. В какой-то момент Давид Ян лично сел за подготовку данных для системы – до этого несколько девушек, нанятых на эту работу, отказались от неё, очень тяжело было. Инструмент был очень неудобный, а работа была большая, сложная и очень нудная. Надо было часами листать огромные текстовые файлы, что-то там высматривать и править, изучая результаты тестовых прогонов. Работа казалась вечной, прогресс происходил мелкими шажками. Нужна была крепкая психика, чтобы справляться с этим. И Давид два месяца без выходных каждый день по 12-14 часов доводил до ума базу распознавания.
Параллельно с этим мы начали вникать в предметную область. Общались со специалистами, познакомились с Александром Львовичем Шамисом – выдающимся учёным, который занимался практическими и теоретическими проблемами искусственного интеллекта, разрабатывал прикладные технологии в области машинного восприятия (Александр Львович до сих пор работает научным консультантом в ABBYY). И к моменту выпуска FineReader 1.0 мы уже знали, какой должна быть следующая версия. Вы спросите, почему всё то хорошее, что мы придумали, не вошло в первую версию – мы ответим, что первую версию нужно было делать быстро. Компании нужны были деньги – без первой версии у нас бы не хватило денег на разработку следующей. Следующая версия была существенно лучше первой – даже не на голову, а на много голов. Она делала значительно меньше ошибок, намного лучше справлялась со сложными проблемами, существенно лучше сохраняла форматирование и по тем временам имела просто рекордную точность работы.
Конечно, мы подошли к разработке с умом, представили себе, как должна выглядеть идеальная программа. И у нас сразу сложилось два преимущества – независимость от шрифта и многоязычность.
И у нас сразу сложилось два преимущества – независимость от шрифта и многоязычность.
С многоязычностью всё просто: очевидно, что многие технические тексты, даже написанные на русском, содержат довольно много слов и терминов на латинице, чаще всего на английском. Но в то время об этом почему-то никто не задумывался, и первые системы распознавания понимали только один язык. А мы специально включили в программу поддержку русского и английского языков, чтобы такие тексты можно было качественно обработать. Здесь нам помогло наличие в команде Владимира Селегея, который имел значительный опыт в разработке средств проверки правописания для различных языков. Вообще, с тех пор и поныне словарная поддержка является сильной стороной нашей технологии распознавания.
Независимость от шрифта (омнифонтовость) означает, что программу не нужно было настраивать для распознавания каждого нового шрифта, то есть она распознаёт символы практически любых размеров и начертаний. Наш FineReader был первой омнифонтовой программой, поддерживающей кириллицу. Сейчас-то мы уже привыкли, что, если программа не распознала шрифт, значит, он какой-то очень сложный или причудливый, а тогда даже для обычных книжных шрифтов приходилось проводить обучение. Шаг влево, шаг вправо – и программа не может воспринять даже тот шрифт, который вообще-то знает. Например, если он другого размера или качество изображения хуже.
Сейчас-то мы уже привыкли, что, если программа не распознала шрифт, значит, он какой-то очень сложный или причудливый, а тогда даже для обычных книжных шрифтов приходилось проводить обучение. Шаг влево, шаг вправо – и программа не может воспринять даже тот шрифт, который вообще-то знает. Например, если он другого размера или качество изображения хуже.
Так выглядела коробка первого FineReader:
Сразу же после выпуска программы к ней возник огромный интерес. Спрос был большой, и существовавшие до появления FineReader программы его не удовлетворяли. Нам повезло — мы оказались в правильном месте и в правильное время.
Первая версия FineReader’а вышла тиражом 500 экземпляров. В первый месяц мы продали больше сотни копий – для тех времён это было эпохальное число! Даже продажи Lingvo, уже очень популярного в то время и стоившего в несколько раз дешевле, редко доходили до 100 экземпляров в месяц.
Конечно, нам предстояла еще большая работа, чтобы довести программу до высочайшего уровня. И, кстати, помогла нам в этом конкурентная борьба с одной из российских компаний. В результате в пылу жаркой конкуренции мы создали продукт, оказавшийся лучше многих иностранных аналогов.
И, кстати, помогла нам в этом конкурентная борьба с одной из российских компаний. В результате в пылу жаркой конкуренции мы создали продукт, оказавшийся лучше многих иностранных аналогов.
Выпуск второй версии FineReader сопровождался ещё одной интересной историей. FineReader 2.0 был 32-битным приложением. Мы запланировали его выпуск на весну 1995 года, и собирались подгадать прямо под выпуск Windows 95 (ранее Microsoft объявляла, что новая версия Windows выйдет именно в апреле). Новая Windows выгодно отличалась от старой, мы понимали, что люди станут сразу делать апргейд и наши продажи пойдут в гору. Но при этом мы имели «запасной аэродром» в виде компоненты Win32s – дополнения к 16-битной Windows 3.1x, которая позволяла запускать под нее специально адаптированные 32-битные приложения. Но тут возникло одновременно две проблемы: Microsoft перенесла выпуск Windows 95 на август, а в Win32s версии 1.2 обнаружилась ошибка с поддержкой Unicode, из-за которой русские буквы в интерфейсе не отображались. Пришлось срочно связываться с Microsoft, что в то время было делом практически невозможным, – это был крупнейший монополист на рынке ПО, от которого зависело почти все в индустрии, и ожидать от него реакции на нужды небольшой компании в далекой России с мизерным для Microsoft рынком сбыта было бы безумием.
Пришлось срочно связываться с Microsoft, что в то время было делом практически невозможным, – это был крупнейший монополист на рынке ПО, от которого зависело почти все в индустрии, и ожидать от него реакции на нужды небольшой компании в далекой России с мизерным для Microsoft рынком сбыта было бы безумием.
Но случилось чудо: та же проблема оказалась у компании Autodesk, которая была стратегическим партнером Microsoft. В результате нас с Autodesk объединили в один кейз и выделили специального менеджера, который вступил с нами в переписку. В результате удалось договориться, чтобы в версии 1.3, которая, правда, вышла одновременно с Windows 95, эту ошибку исправили. А до того мы нашли обходной вариант – полученная версия не работала корректно под Windows 95, зато работала до поры до времени в Windows 3.1x.
Так выглядел FineReader 1.3:
Вообще, наша рисковая затея с выпуском 32-битного коробочного продукта испортила нам много крови. 16-битная Windows была еще широко распространена, а Win32s не отличалась стабильностью. Помню, как почти неделю мы ловили какую-то жуткую ошибку в недрах самой Win32s с помощью отладчика ядра (kernel debugger) через com-порт в командно-строчном режиме. Нашли проблему – что-то неправильно работало в системном аллокаторе памяти, и смогли придумать обход. Зато новый FineReader блистал на Windows 95, будучи родным для него приложением, а 32-битный режим был очень важен для программы OCR, так как позволял значительно оптимизировать работу с большими данными в памяти, что типично для задач распознавания. Это дало нам фору на много лет вперед перед конкурентами и во многом предопределило наш успех на рынке лицензирования технологии распознавания.
Помню, как почти неделю мы ловили какую-то жуткую ошибку в недрах самой Win32s с помощью отладчика ядра (kernel debugger) через com-порт в командно-строчном режиме. Нашли проблему – что-то неправильно работало в системном аллокаторе памяти, и смогли придумать обход. Зато новый FineReader блистал на Windows 95, будучи родным для него приложением, а 32-битный режим был очень важен для программы OCR, так как позволял значительно оптимизировать работу с большими данными в памяти, что типично для задач распознавания. Это дало нам фору на много лет вперед перед конкурентами и во многом предопределило наш успех на рынке лицензирования технологии распознавания.
А вот FineReader 2.0:
Программа загружалась с четырёх дискет:
Руководство пользователя:
Конечно, вы ждёте скриншотов. Вот как выглядел интерфейс FineReader 3.0:
FineReader стал знаковой программой для нас. Именно с ним мы вышли на международный рынок. Сегодня эту программу используют более 20 миллионов людей в мире. А технологию распознавания текстов, лежащую в основе FineReader, лицензируют крупнейшие мировые компании – Microsoft, Samsung, Fujitsu, Panasonic и многие другие.
А технологию распознавания текстов, лежащую в основе FineReader, лицензируют крупнейшие мировые компании – Microsoft, Samsung, Fujitsu, Panasonic и многие другие.
Тогда, 22 года назад, мы и предположить не могли, куда все зайдет. А сегодня понимаем, что добиться такого впечатляющего результата смогли благодаря:
• Большой и упорной работе. Да-да, из последних сил, но с колоссальным драйвом (помните про 12-14 часов в день без выходных ).
• Умению найти и создать конкурентные преимущества – те самые многоязычность и независимость от шрифта.
• И смелости. Теперь-то мы понимаем, как важно не бояться преград на пути.
3DNews Новости Software программное обеспечение ABBYY FineReader 15 выводит редактирован… Самое интересное в обзорах 27.08.2019 [11:00], Андрей Крупин Компания ABBYY объявила о выпуске FineReader 15 — новой версии своего флагманского продукта, объединяющего все необходимые инструменты для работы с PDF и бумажными документами. ABBYY FineReader является универсальным программным решением. Помимо OCR-системы оптического распознавания текста, обеспечивающей конвертирование отсканированных изображений, фотографий, документов или PDF-файлов в редактируемые электронные форматы, в составе приложения представлены PDF-редактор, инструмент для сравнения документов различных форматов, включая бумажные и электронные, а также средства автоматизации задач по конвертации документов. Пользователи могут создавать новый PDF из нескольких документов в разных форматах, добавлять цифровую подпись или водяные знаки, вносить комментарии, защищать файл с помощью пароля, скрывать в тексте конфиденциальные данные, менять форматирование документов и решать прочие задачи. ABBYY FineReader 15 предоставляет широкий спектр возможностей в одной программе Сравнение документов Отличительной особенностью обновлённого FineReader 15 является поддержка технологий машинного обучения и искусственного интеллекта на базе нейронных сетей. Комментирование PDF-документов Значительным доработкам в FineReader 15 подверглись средства просмотра, редактирования и конвертирования PDF-документов. В частности, появились возможности многострочного редактирования PDF в пределах абзаца (теперь текст автоматически перераспределяется по строкам по мере добавления или удаления слов и фрагментов), изменения оформления любых страниц в PDF-документе, форматирования текста в пределах абзаца или какого-либо его фрагмента, а также редактирования отдельных ячеек в таблицах. Благодаря разработкам в области ИИ, FineReader 15 позволяет редактировать целые абзацы в PDF, это при том условии, что данный формат изначально не предназначен для внесения правок. Программа определяет, где находятся заголовки, подзаголовки, отдельные абзацы, ячейки таблиц, колонтитулы, обводит их в специальные рамки и позволяет редактировать. Редактирование текста в ячейках таблицы Немало в FineReader 15 реализовано других полезных нововведений. Из наиболее интересных стоит отметить улучшения OCR-движка, расширенные возможности для системных администраторов и доработанный модуль сравнения документов, теперь позволяющий экспортировать результаты сравнения в документ Word и отображать их в режиме отслеживания изменений, который часто используется, например, при работе с юридическими документами. С полным списком внесённых в продукт изменений можно ознакомиться по ссылке abbyy.com/finereader/15/user_guide/newfeatures. ABBYY FineReader 15 распознает документы на 192 мировых языках и любых их комбинациях. Программа поставляется разработчиком в трёх редакциях — Standard, Business и Сorporate, разнящихся набором включённых инструментов, формами поставки и условиями лицензирования. Получить подробную информацию о продукте и узнать о системных требованиях можно на сайте abbyy. Источник: Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER. Материалы по теме Постоянный URL: https://3dnews.ru/993043 Рубрики: Новости Software, программное обеспечение, Теги: abbyy, finereader, pdf, ocr, документооборот, редактирование, сканирование, искусственный интеллект ← В прошлое В будущее → |

 Благодаря этому к минимуму сведены ошибки распознавания PDF, созданных из других приложений, в том числе PDF-документов с битыми кодировками или некачественным текстовым слоем. Улучшено распознавание таблиц и колонтитулов. Благодаря новой версии технологии оптического распознавания символов FineReader 15 ещё точнее конвертирует тексты на японском и корейском языках, воспроизводит таблицы в Excel на языках, на которых текст пишется и читается справа налево, и расставляет автоматические теги при сохранении в PDF (в том числе в PDF/UA).
Благодаря этому к минимуму сведены ошибки распознавания PDF, созданных из других приложений, в том числе PDF-документов с битыми кодировками или некачественным текстовым слоем. Улучшено распознавание таблиц и колонтитулов. Благодаря новой версии технологии оптического распознавания символов FineReader 15 ещё точнее конвертирует тексты на японском и корейском языках, воспроизводит таблицы в Excel на языках, на которых текст пишется и читается справа налево, и расставляет автоматические теги при сохранении в PDF (в том числе в PDF/UA). По заверениям разработчиков, новая версия программы открывает любые файлы, даже объёмные PDF с изображениями, диаграммами и таблицами, на 40 % быстрее, чем раньше. Кроме того, появился специальный механизм извлечения текста из полей интерактивных PDF-форм и комментариев типа «Текстовый блок», а также добавлена функция интеллектуальной оценки качества текстового слоя в PDF-документах. В случае проблем с текстовым слоем (текст повреждён, имеет неверную кодировку и т.п.) программа применит технологию оптического распознавания символов вместо того, чтобы извлекать проблемный текст. Таким образом повышается качество конвертирования PDF-документов в редактируемые форматы.
По заверениям разработчиков, новая версия программы открывает любые файлы, даже объёмные PDF с изображениями, диаграммами и таблицами, на 40 % быстрее, чем раньше. Кроме того, появился специальный механизм извлечения текста из полей интерактивных PDF-форм и комментариев типа «Текстовый блок», а также добавлена функция интеллектуальной оценки качества текстового слоя в PDF-документах. В случае проблем с текстовым слоем (текст повреждён, имеет неверную кодировку и т.п.) программа применит технологию оптического распознавания символов вместо того, чтобы извлекать проблемный текст. Таким образом повышается качество конвертирования PDF-документов в редактируемые форматы. Вносить правки в абзацы можно даже в сканы без готового текстового слоя
Вносить правки в абзацы можно даже в сканы без готового текстового слоя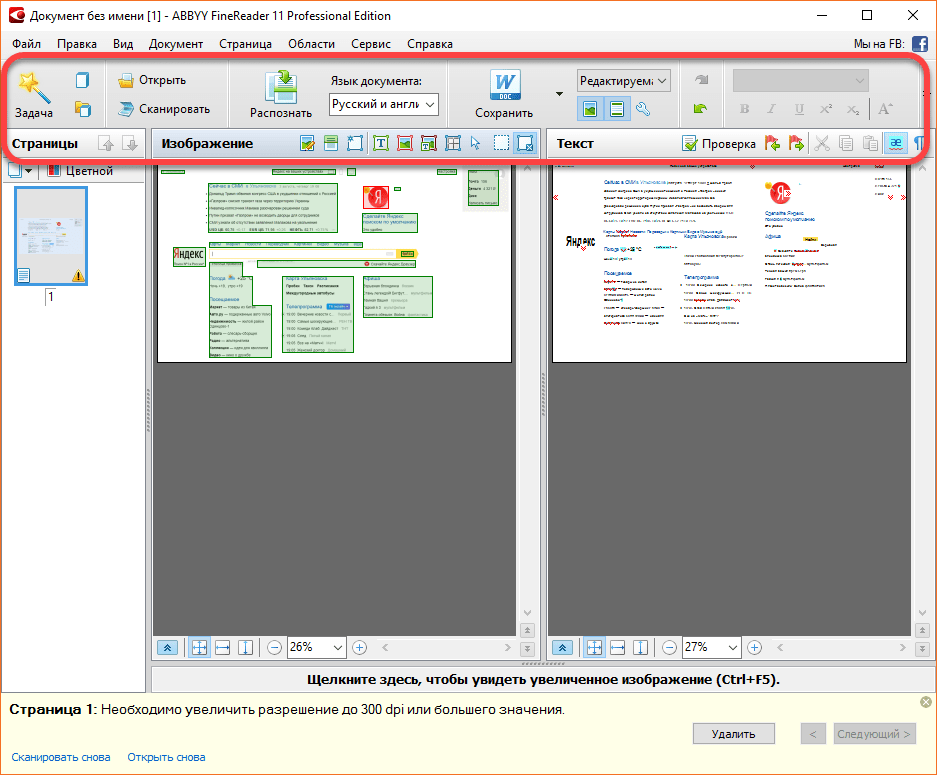 com/finereader.
com/finereader.PDF: открывайте, читайте и редактируйте PDF-файлы
Преобразование, редактирование, совместное использование и совместная работа над PDF-файлами и отсканированными файлами на цифровом рабочем месте.
Попробуйте бесплатно Купи сейчас Связаться с отделом продаж
FineReader PDF позволяет профессионалам максимально эффективно работать на цифровом рабочем месте. Благодаря новейшей технологии оптического распознавания символов ABBYY на основе искусственного интеллекта FineReader PDF упрощает оцифровку, извлечение, редактирование, защиту, совместное использование и совместную работу над всеми видами документов в рамках одного рабочего процесса. Теперь информационные работники могут еще больше сосредоточиться на своем опыте, а не на административных задачах.
Благодаря новейшей технологии оптического распознавания символов ABBYY на основе искусственного интеллекта FineReader PDF упрощает оцифровку, извлечение, редактирование, защиту, совместное использование и совместную работу над всеми видами документов в рамках одного рабочего процесса. Теперь информационные работники могут еще больше сосредоточиться на своем опыте, а не на административных задачах.
Основные возможности
FineReader PDF поможет вам выполнить работу
7 лучших возможностей FineReader PDF
Скачать электронную книгу
Ключевые факты
FineReader в цифрах
29
года на рынке
Подробнее
10
миллионов пользователей
4,5
из 5 – средний рейтинг продукта
Подробнее
200
корпоративные пользователи
Видеоотзыв от нашего бизнес-пользователя
«Я системный администратор в юридической сфере и ставлю ABBYY FineReader PDF пять баллов из пяти. Программное обеспечение фантастическое. Это очень быстро. Это очень точно, и нам это очень нравится».
Программное обеспечение фантастическое. Это очень быстро. Это очень точно, и нам это очень нравится».
Кевин Х .
Системный администратор
Прочитайте полный обзор на GetApp
Выберите ваши предпочтения: Бизнес или Индивидуальный?
Для организаций
Предоставьте сотрудникам возможность оптимизировать процессы PDF в организации с помощью гибких и простых вариантов лицензирования, начиная с пяти лицензий.
Узнать больше Связаться с отделом продаж
Для частных лиц
FineReader PDF интегрирует отсканированные документы в цифровые рабочие процессы и упрощает оцифровку, преобразование, извлечение, редактирование, защиту, совместное использование и совместную работу над всеми видами документов на цифровом рабочем месте.
Узнать больше
Что говорят наши клиенты
Миллионы клиентов по всему миру доверяют и полагаются на ABBYY FineReader PDF для Windows для эффективного выполнения задач по работе с документами.
«Великолепный инструмент для распознавания и преобразования документов»
Отличная цена, простота использования. Точность извлеченного текста (например, PDF в Word) превосходна — иногда ошеломляет, когда вы видите качество ввода. Инструмент сравнения особенно полезен для просмотра того, как кто-то мог изменить документ, отправленный, а затем распечатанный/отсканированный в PDF.
Джереми Б. Директор по малому бизнесу
Полный обзор на веб-сайте G2
«У FineReader 15 действительно нет конкурентов»
Он обладает сверхъестественной способностью точно разбирать документ и захватывать текст, нетекстовые элементы и макет. И он делает это на нескольких языках с одинаковой точностью. Считаю продукт непревзойденным.
Эли В. Президент, Малый бизнес
Подробнее
«Это облегчает мою работу»
ABBYY оцифровывает документы и изображения и позволяет мне сохранять их в различных форматах, сохраняя структуру указанных документов и изображений. Это просто потрясающе
Liliana A Programador, Government Administration
Читать дальше
«Это хорошо работает для извлечения текста из отсканированных документов»
Лучшее в ABBYY FineReader то, что когда вы импортируете отсканированный документ в OCR, вы можете видеть, как он сканирует перед вашими глазами. Это выглядит очень круто!
Кэрол Г. Администратор медицинской документации
Подробнее
«Незаменимая программа для моей работы»
FineReader помогает мне с распознаванием текста. Я не знаю, что делать без этого. Это экономит массу времени, при этом готовый текст почти не приходится редактировать.
Наталья С Консультант по персоналу
Читать далее
«ABBYY FineReader — мой повседневный партнер»
Я пользуюсь Abbby FineReader уже несколько лет, и это потрясающе, насколько это упрощает мою офисную жизнь. Я распознаю принтскрины, сканированные PDF-файлы, и это действительно может значительно ускорить мою работу.
Я распознаю принтскрины, сканированные PDF-файлы, и это действительно может значительно ускорить мою работу.
Томаш В. Директор отдела по работе с клиентами
Подробнее
«Надежное приложение в формате PDF»
Программные функции найти проще, чем Adobe, и это надежное приложение в формате PDF. Модель ценообразования хороша, не требует подписки. Характеристики хорошие.
Теодор А. Адвокат
Подробнее
Отличное решение для оптического распознавания текста PDF
Это программное обеспечение поставляется в комплекте с моим Fujitsu ScanSnap, и я использую его более 12 лет. Программное обеспечение по-прежнему работает отлично и конвертирует мои сканы в PDF и распознает их для дальнейшего использования.
Хесус П. Генеральный директор/президент, частный предприниматель
Подробнее
«Хорошая альтернатива обычному редактору PDF Adobe Acrobat»
На первый взгляд плавная интеграция с моим сканером Xerox. Очевидная маркировка и расположение кнопок, которые делают поиск действий интуитивно понятным. Низкий общий объем памяти при использовании, что очень удобно при одновременном запуске нескольких программ. Преобразование в различные документы Office также было очень приятным, чего я не ожидал.
Очевидная маркировка и расположение кнопок, которые делают поиск действий интуитивно понятным. Низкий общий объем памяти при использовании, что очень удобно при одновременном запуске нескольких программ. Преобразование в различные документы Office также было очень приятным, чего я не ожидал.
Джастин Р Старший инженер проекта
Подробнее
«Идеальная альтернатива удушающей хватке лидера отрасли»
FineReader PDF 15 предоставляет программную платформу, необходимую для 95% всего, что вам нужно делать. любые ваши документы, снимки экрана и документы Portable Document Format. Мне нравится возможность использовать это программное обеспечение на своем ноутбуке или настольном компьютере с тем же уровнем производительности. Сбор данных для обеспечения устойчивости PDF — это здорово.
Даг Б. Начальник отдела программ SSI
Читать далее
«Простота в использовании.
 Отличные функции. Относительно недорогая по сравнению с конкурирующими продуктами.»
Отличные функции. Относительно недорогая по сравнению с конкурирующими продуктами.»Простота использования/установки. Приятные черты. Относительно недорогой по сравнению с конкурирующими продуктами.
Администратор финансовых услуг
Подробнее
«Лучшее на рынке редактирование PDF и оптическое распознавание книг»
Возможность определять и изменять поля в макете отсканированной страницы. Разметка фото и текста самостоятельно. Правка без порчи макета. Вы даже можете перевести в ABBYY существующий макет и снова сохранить в формате PDF на новом языке.
Ойтун с Операции
Читать дальше
Важные улучшения
ABBYY FineReader 15 — это значительное улучшение по сравнению с предыдущими версиями. Я очень часто использую ABBYY FineReader для создания удобных и читаемых документов из технических руководств, для чтения которых нужен электронный микроскоп, а также способ их хранения и поиска.
FineReader PDF Пользователь Обзор в приложении
Мощный, но простой в использовании
Это продукт, который я искал. Он мощный, но простой в использовании; точно и быстро.
FineReader PDF пользователь Рецензирование в приложении
Готовы повысить эффективность документооборота?
Функция оптического распознавания символов ABBYY FineReader для ScanSnap
ScanSnap iX1600ScanSnap iX1500ScanSnap iX1400ScanSnap iX1300ScanSnap iX500ScanSnap iX100ScanSnap SV600ScanSnap S1300iScanSnap S1100iScanSnap S1100Для просмотра этого веб-сайта в настройках веб-браузера должны быть включены «JavaScript» и «таблица стилей».
Подробнее об их включении см. в справке вашего веб-браузера.
ABBYY FineReader для ScanSnap — это приложение, используемое исключительно со ScanSnap. Его можно использовать для распознавания текста текстовой информации в изображении в формате PDF документа, отсканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
Его можно использовать для распознавания текста текстовой информации в изображении в формате PDF документа, отсканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
В этом разделе описаны возможности и примечания к функции преобразования текстовой информации в изображение с помощью ABBYY FineReader for ScanSnap.
Особенности функции оптического распознавания символов ABBYY FineReader для ScanSnap
Параметры, которые нельзя воспроизвести в том виде, в каком они представлены в исходном документе
Документы и символы, которые могут быть неправильно распознаны
Прочие примечания
Особенности функции OCR программы ABBYY FineReader для ScanSnap
Функция OCR программы ABBYY FineReader для ScanSnap имеет следующие функции. Перед преобразованием изображения проверьте содержимое изображения, которое необходимо преобразовать.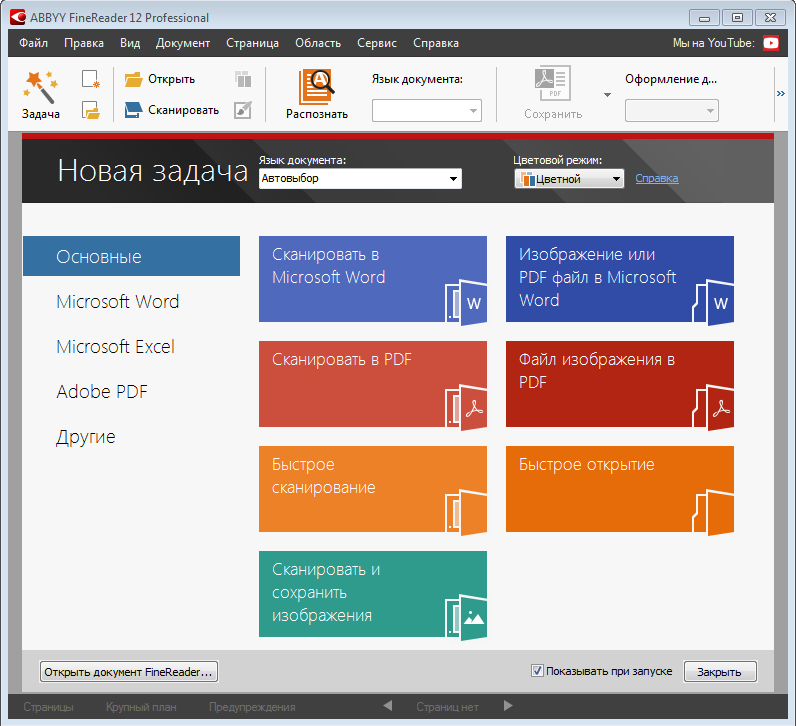
Приложение, используемое для преобразования | Документы, подходящие для преобразования | Документы, не подходящие для преобразования |
|---|---|---|
Сканировать в Word | Документы, созданные с использованием простого макета страницы с одним или двумя столбцами. | Документы, такие как брошюры, журналы и газеты, созданные с использованием сложной компоновки страниц, состоящей из следующего:
|
Сканировать в Excel | Документы с простыми таблицами, в которых каждая граница соединяется с внешней рамкой. | Документы, содержащие следующее:
|
Сканировать в PowerPoint(R) | Документы, состоящие только из символов и простых графиков или таблиц на белом или светлом одноцветном фоне. |
|

Параметры, которые не могут быть воспроизведены в исходном документе
Следующие параметры не могут быть воспроизведены в исходном документе. Проверьте преобразованные файлы с помощью Word, Excel или PowerPoint и при необходимости отредактируйте их.
Шрифт и размер символов
Междустрочный и межстрочный интервал
Подчеркнутые, полужирные и курсивные символы
Символы верхнего/нижнего индекса
Документы и символы, которые могут распознаваться неправильно
Следующие типы документов и символов могут распознаваться неправильно.
Их можно распознать, если отсканировать их, изменив цветовой режим или улучшив качество изображения в настройках профиля.
Документы, содержащие рукописные символы
Документы с мелкими символами размером менее 10 pt.
Перекошенные документы
Документы, написанные на языках, отличных от указанного языка
Документы с символами на неравномерно окрашенном фоне, например, с заштрихованными символами.
Документы с большим количеством декоративных символов, таких как рельефные или контурные символы
Документы с символами на узорчатом фоне, такими как символы, перекрывающие иллюстрации или диаграммы
Документы, в которых много символов касается подчеркивания или границ
Документы со сложной компоновкой и документы с шумом изображения (Может потребоваться дополнительное время для обработки распознавания текста для этих документов.
 )
)
Другие примечания
Когда документ большого размера на бумаге преобразуется в файл Word, он может быть преобразован в файл с максимальным размером бумаги, допустимым для Word.
При преобразовании документа в файл Excel, если результаты распознавания превышают 65536 строк, строки после 65536-й строки не сохраняются.
При преобразовании документа в файл Excel макет всего документа, диаграммы, графики, а также высота и ширина таблиц не воспроизводятся. Воспроизводятся только таблицы и символы.
При преобразовании документа в файл PowerPoint фоновые цвета и узоры не воспроизводятся.
Если вы сканируете документ вверх ногами или боком, изображение не может быть правильно преобразовано. Установите [Поворот] в [Сканирование] в окне [Подробные настройки] или правильно загрузите документ, а затем отсканируйте документ.
Если включена функция уменьшения проступания, скорость распознавания текста может снизиться.
 Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] в окне [Параметры сканирования] в настройках профиля.
Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] в окне [Параметры сканирования] в настройках профиля.Если включена функция уменьшения проступания, скорость распознавания текста может снизиться. Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] на вкладке [Качество изображения] в окне [Параметры сканирования] в настройках профиля.
Fine Reader Professional версии 11 от ABBYY и Text Cloner Pro версии 11.5 от Premier Literacy: оценка и сравнение двух продуктов для оптического распознавания символов | Американский фонд помощи слепым
Слепые или слабовидящие люди имеют более широкий доступ к печатным материалам, чем когда-либо прежде, но огромное количество материалов по-прежнему недоступны в доступных форматах. Оптическое распознавание символов (OCR), процесс преобразования недоступных печатных и цифровых документов в доступный текст, позволяет слепым и слабовидящим людям получать доступ к материалам, которые в противном случае были бы им недоступны. Kurzweil 1000 и OpenBook, ранее оцененные в AccessWorld — два популярных продукта для оптического распознавания символов, каждый из которых стоит около 1000 долларов. В этой статье я рассматриваю две альтернативы дорогостоящему программному обеспечению для распознавания текста: ABBYY Fine Reader Professional версии 11 (169,99 долл. США) и Text Cloner Pro версии 11,5 (99,95 долл. США). Для обеих программ требуется один гигабайт оперативной памяти, и обе они совместимы с операционными системами Windows, начиная с Windows XP.
Kurzweil 1000 и OpenBook, ранее оцененные в AccessWorld — два популярных продукта для оптического распознавания символов, каждый из которых стоит около 1000 долларов. В этой статье я рассматриваю две альтернативы дорогостоящему программному обеспечению для распознавания текста: ABBYY Fine Reader Professional версии 11 (169,99 долл. США) и Text Cloner Pro версии 11,5 (99,95 долл. США). Для обеих программ требуется один гигабайт оперативной памяти, и обе они совместимы с операционными системами Windows, начиная с Windows XP.
Я тестировал каждую программу с использованием различных типов документов:
- Стандартные печатные документы, распечатанные из цифровых документов, созданных с помощью текстового процессора, на бумаге размером 8,5 на 11 дюймов (некоторые орфографические ошибки были намеренно включены в эти документы)
- Страницы только для текста из стандартной книги в мягкой обложке
- Журнальные статьи с колонками и изображениями
- Отсканированная таблица из книги
- Счет за коммунальные услуги, напечатанный на маленьком листе бумаги
В качестве сканера я использовал Plustek Opticbook 3800. Я тестировал каждую программу, используя NVDA, JAWS и Window Eyes.
Я тестировал каждую программу, используя NVDA, JAWS и Window Eyes.
ABBYY Fine Reader Professional
Установка
Чтобы установить ABBYY Fine Reader Professional, вы можете загрузить установочный файл с веб-сайта ABBYY Fine Reader или приобрести продукт на компакт-диске. Существует также 15-дневная бесплатная пробная версия, доступная для загрузки на веб-странице Fine Reader Professional. Вам нужно будет предоставить некоторую личную информацию (например, имя и профессию) перед загрузкой бесплатной пробной версии, и вы будете ограничены сохранением не более 50 страниц во время пробной версии. Программа установки очень доступна, так как это обычная программа установки Windows без каких-либо отклонений от стандартного формата. Программы чтения с экрана не вызывают проблем при установке программы.
Документация
Документацию для ABBYY Fine Reader можно найти в комплекте с программой (находится в папке программы в подпапке Guides) или загрузить с веб-страницы Fine Reader Guide в доступном формате PDF. Сама программа также содержит очень доступный файл справки Windows, содержащий содержимое руководства. Руководство предназначено для зрячих читателей, в нем часто упоминается расположение элементов и предлагается использовать мышь для выполнения задач. Однако оно не опирается на недоступные диаграммы для инструкций или изображения элементов управления, что делает руководство полезным для слабовидящих или слепых пользователей.
Сама программа также содержит очень доступный файл справки Windows, содержащий содержимое руководства. Руководство предназначено для зрячих читателей, в нем часто упоминается расположение элементов и предлагается использовать мышь для выполнения задач. Однако оно не опирается на недоступные диаграммы для инструкций или изображения элементов управления, что делает руководство полезным для слабовидящих или слепых пользователей.
Процесс сканирования
При первом запуске программы вам будет представлено диалоговое окно «Новая задача», в котором вы можете выбрать тип сканирования, которое хотите выполнить. Первый список позволяет вам выбрать выходной формат для отсканированного материала. Вы можете выбирать между несколькими форматами, включая DOC, PDF и форматы электронных книг. Документ будет открыт как в программе, отображающей выбранный вами формат, так и в самой программе Fine Reader.
После выбора формата необходимо выбрать несколько других параметров, включая язык и цветовой режим. Возможные варианты цветового режима: черно-белый и цветной. При выборе черно-белого изображения результаты возвращаются быстрее. Для форматов DOC, PDF и электронных книг необходимо также выбрать вариант типа документа. Например, вы можете выбирать между EPUB, FB2 и HTML для формата электронной книги. После того, как вы выбрали параметры, вы можете активировать кнопку «Сканировать», чтобы перейти в диалоговое окно «Сканирование».
Возможные варианты цветового режима: черно-белый и цветной. При выборе черно-белого изображения результаты возвращаются быстрее. Для форматов DOC, PDF и электронных книг необходимо также выбрать вариант типа документа. Например, вы можете выбирать между EPUB, FB2 и HTML для формата электронной книги. После того, как вы выбрали параметры, вы можете активировать кнопку «Сканировать», чтобы перейти в диалоговое окно «Сканирование».
Диалоговое окно «Сканирование» содержит несколько параметров для настройки параметров сканера. К ним относятся размер бумаги, яркость, цветовой режим и разрешение. Вы также можете указать, хотите ли вы, чтобы программа проверяла ориентацию сканируемой страницы, и хотите ли вы разделить лицевые страницы на отдельные страницы в выходном файле. После того, как вы сделали свой выбор, вы можете либо активировать предварительный просмотр, чтобы создать быстрое сканирование изображения, либо активировать кнопку «Сканировать», чтобы отсканировать изображение для обработки OCR. После завершения сканирования снова появится диалоговое окно «Сканирование», чтобы вы могли отсканировать другую страницу. Чтобы выйти и просмотреть результаты распознавания, вы можете нажать кнопку «Закрыть». В зависимости от того, какой тип выходного файла вы выбрали, вы либо попадете на экран редактирования Fine Reader, либо будет запущена программа, связанная с выбранным вами типом файла, с копией результатов OCR.
После завершения сканирования снова появится диалоговое окно «Сканирование», чтобы вы могли отсканировать другую страницу. Чтобы выйти и просмотреть результаты распознавания, вы можете нажать кнопку «Закрыть». В зависимости от того, какой тип выходного файла вы выбрали, вы либо попадете на экран редактирования Fine Reader, либо будет запущена программа, связанная с выбранным вами типом файла, с копией результатов OCR.
Результаты сканирования
В целом результаты сканирования для ABBYY были исключительно положительными. Документ, напечатанный на стандартной бумаге размером 8,5 на 11 дюймов, был воспроизведен идеально. Слова с ошибками (например, «tke» вместо «the») распознавались как написанные. Результаты сканирования также были почти идеальными при сканировании страниц из книги. Несколько ошибок в одном сканировании были вызваны смещением книги в процессе сканирования. Дальнейшее сканирование книги прошло без ошибок.
Журнальная статья с несколькими столбцами была представлена в виде одного столбца, при этом второй столбец следовал за первым. Текст был передан идеально. Текст журнальной статьи с изображением также был идеально воспроизведен с точным распознаванием изображения. Fine Reader очень хорошо работал при сканировании таблицы из книги. Когда документ был сохранен в форматах DOC и HTML, отдельные ячейки отображались в удобной для навигации форме программы чтения с экрана.
Текст был передан идеально. Текст журнальной статьи с изображением также был идеально воспроизведен с точным распознаванием изображения. Fine Reader очень хорошо работал при сканировании таблицы из книги. Когда документ был сохранен в форматах DOC и HTML, отдельные ячейки отображались в удобной для навигации форме программы чтения с экрана.
Единственным типом документа, который вызвал проблему, был счет за коммунальные услуги. Купюра была довольно маленькой и содержала штрих-код, который отображался как строка буквы «I» в результатах OCR.
Доступность программы чтения с экрана
Процесс сканирования — единственная полностью доступная часть Fine Reader. С другой стороны, основной интерфейс редактирования почти полностью недоступен. Несмотря на то, что можно войти в главное окно редактирования, где отображается текст, многие буквы будут отсутствовать в результате OCR, и нет доступного способа исправить текст. Поэтому я сосредоточу свою оценку на доступности процесса сканирования, так как есть возможность использовать Fine Reader, если вы сохраните свои результаты в другом формате.
У NVDA были лучшие результаты доступности. Почти все параметры в диалоговом окне «Новая задача» читались правильно, и NVDA даже читала пояснения к каждому варианту для тех форматов, в которых было несколько вариантов. Кнопка «Справка» не была помечена, и выбор в списке «Цветовой режим» не отображался, но в остальном все элементы управления отображались идеально. В диалоговом окне сканирования NVDA распознала все элементы. NVDA также правильно считывает диалоговые окна для сохранения документов.
JAWS не прочитал типы форматов в диалоговом окне «Новая задача». Он также не читал описание вариантов формата, когда они были выделены. Все остальные кнопки и параметры были правильно прочитаны, чтобы принять кнопку «Справка», которая снова не была помечена. Диалоговое окно «Сканирование» было правильно прочитано полностью, а также правильно прочитаны диалоговые окна сохранения файлов.
Window Eyes не читала формат, выбранный в диалоговом окне «Новая задача». Он также не читал кнопку «Помощь» или варианты выбора. Он прочитал метку в поле со списком для выбора «Цветной» или «Черно-белый», но не прочитал сами параметры. Он прочитал кнопку «Сканировать», кнопку «Закрыть» и флажок, который определяет, появляется ли диалоговое окно «Новая задача» при запуске программы. Window Eyes также боролась с диалоговым окном сканирования. Поле со списком, которое выбирает Разрешение, Режим сканирования, Яркость и Размер бумаги, читалось неправильно. Этикетки на этих коробках были прочитаны, но содержимое — нет. Window Eyes распознает кнопки «Сканировать», «Предварительный просмотр», «Восстановить значения по умолчанию» и «Закрыть». Он также правильно объявляет об изменениях в ползунке яркости. По сравнению с низкой производительностью в диалоговых окнах «Сканирование» и «Новая задача», Window Eyes отлично читается в диалоговых окнах «Сохранение».
Он прочитал метку в поле со списком для выбора «Цветной» или «Черно-белый», но не прочитал сами параметры. Он прочитал кнопку «Сканировать», кнопку «Закрыть» и флажок, который определяет, появляется ли диалоговое окно «Новая задача» при запуске программы. Window Eyes также боролась с диалоговым окном сканирования. Поле со списком, которое выбирает Разрешение, Режим сканирования, Яркость и Размер бумаги, читалось неправильно. Этикетки на этих коробках были прочитаны, но содержимое — нет. Window Eyes распознает кнопки «Сканировать», «Предварительный просмотр», «Восстановить значения по умолчанию» и «Закрыть». Он также правильно объявляет об изменениях в ползунке яркости. По сравнению с низкой производительностью в диалоговых окнах «Сканирование» и «Новая задача», Window Eyes отлично читается в диалоговых окнах «Сохранение».
Text Cloner Pro
Установка и интерфейс
Установочный пакет Text Cloner, использующий стандартный формат Windows, очень доступен при использовании программы чтения с экрана. Демонстрационную версию Text Cloner можно загрузить с веб-страницы бесплатных пробных версий Premier Literacy. Полную версию Text Cloner можно приобрести либо в виде загрузки, либо в виде компакт-диска на веб-странице продукта Text Cloner Pro.
Демонстрационную версию Text Cloner можно загрузить с веб-страницы бесплатных пробных версий Premier Literacy. Полную версию Text Cloner можно приобрести либо в виде загрузки, либо в виде компакт-диска на веб-странице продукта Text Cloner Pro.
Когда вы запустите программу, вам будет представлен пустой документ, который вы можете отсканировать или напечатать. Text Cloner действует аналогично основному текстовому редактору и предлагает список общих меню: «Файл», «Редактировать», «Просмотр» и т. д., а также специальные меню программы, такие как «Сканировать» и «Таблица». Существует очень мало горячих клавиш для конкретных программ, и они ограничены активацией процесса сканирования и функции суммирования документов.
Документация
Документация доступна из меню Справка. Доступ к нему можно получить в файле справки в стиле Windows или в виде документа Word, который можно открыть в Text Cloner. Вы также можете найти документ Word в папке установки Text Cloner Pro, где вы можете использовать свой процессор для его чтения. В документе содержится краткий справочник по сочетаниям клавиш; большинство перечисленных ярлыков являются стандартными в программах Windows. Например, Ctrl+N открывает новый документ, а Ctrl+C копирует выделенный текст. Единственными упоминаемыми горячими клавишами для конкретных программ являются клавиши сканирования: F5 для черно-белого сканирования и F6 для цветного сканирования, а также сочетание клавиш Ctrl+Shift+U для суммирования документов.
В документе содержится краткий справочник по сочетаниям клавиш; большинство перечисленных ярлыков являются стандартными в программах Windows. Например, Ctrl+N открывает новый документ, а Ctrl+C копирует выделенный текст. Единственными упоминаемыми горячими клавишами для конкретных программ являются клавиши сканирования: F5 для черно-белого сканирования и F6 для цветного сканирования, а также сочетание клавиш Ctrl+Shift+U для суммирования документов.
После раздела «Краткий справочник» в руководстве подробно описывается каждое меню. Документ довольно всеобъемлющий, в нем перечислены все варианты и их использование. Частые опечатки в документе, такие как пропущенные или добавленные слова, затрудняли понимание некоторых инструкций и портили профессиональный вид программы.
Сканирование
В Text Clone доступны два различных процесса сканирования. Черно-белый используется для книг и текстовых материалов. Цвет используется для более сложного материала, включающего изображения и таблицы. Вы можете начать сканирование, нажав F5 для черно-белого и F6 для цветного. Каждый из этих вариантов имеет собственный набор параметров, доступ к которым можно получить из меню «Сканирование». Параметры для каждого процесса сканирования оптимизируют сканирование для типа сканируемого материала. Например, черно-белое сканирование позволяет сканировать журнал, книгу или другой материал. Процесс цветного сканирования позволяет сканировать текст/изображения/таблицы, текст/изображения или только текст. В меню «Сканирование» также есть диалоговое окно выбора сканера с надписью «Выбор драйвера сканера», где вы можете выбрать сканер TWAIN по вашему выбору. При сканировании в черно-белом или цветном режиме программа автоматически начинает распознавание после завершения сканирования изображения. Вы также можете импортировать файл PDF или файл изображения для обработки, если материал, который вам нужно отсканировать, является цифровым. Поддерживаемые типы файлов изображений: GIF, TIF, BMP, JPG и FMF.
Вы можете начать сканирование, нажав F5 для черно-белого и F6 для цветного. Каждый из этих вариантов имеет собственный набор параметров, доступ к которым можно получить из меню «Сканирование». Параметры для каждого процесса сканирования оптимизируют сканирование для типа сканируемого материала. Например, черно-белое сканирование позволяет сканировать журнал, книгу или другой материал. Процесс цветного сканирования позволяет сканировать текст/изображения/таблицы, текст/изображения или только текст. В меню «Сканирование» также есть диалоговое окно выбора сканера с надписью «Выбор драйвера сканера», где вы можете выбрать сканер TWAIN по вашему выбору. При сканировании в черно-белом или цветном режиме программа автоматически начинает распознавание после завершения сканирования изображения. Вы также можете импортировать файл PDF или файл изображения для обработки, если материал, который вам нужно отсканировать, является цифровым. Поддерживаемые типы файлов изображений: GIF, TIF, BMP, JPG и FMF.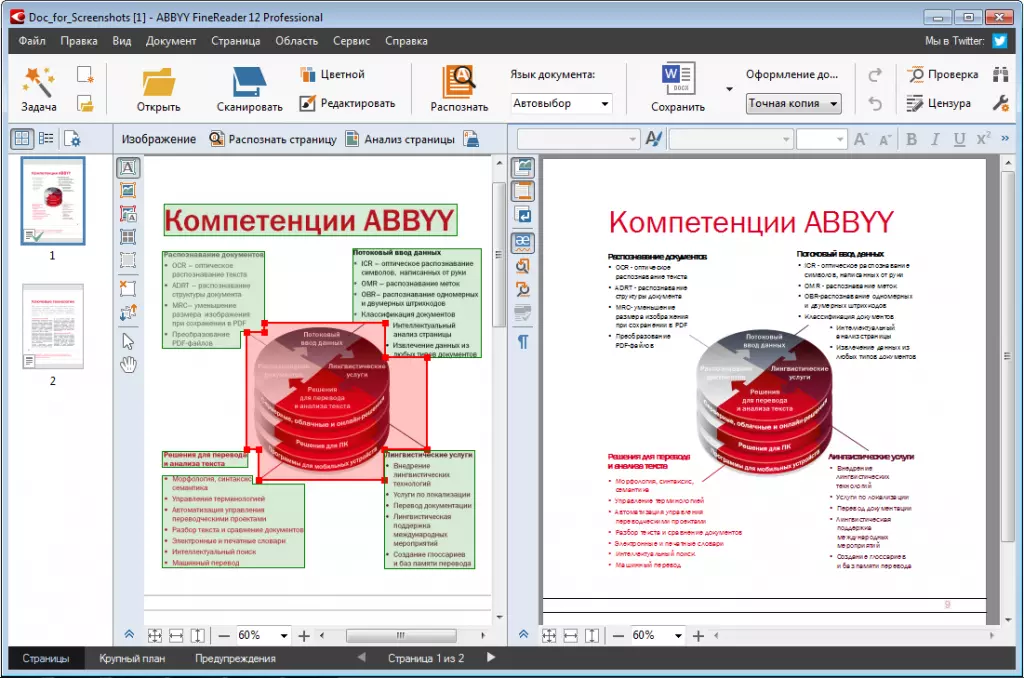
Результаты сканирования
Распечатанные документы на бумаге размером 8,5 на 11 дюймов сканируются довольно хорошо. Некоторые буквы не отображались должным образом, но все было разборчиво, и не было полных строк неузнаваемого текста. Документ с преднамеренными орфографическими ошибками был прекрасно обработан программой с неповрежденными орфографическими ошибками. Я использовал процесс черно-белого сканирования с включенным параметром «Другое» в подменю параметров материала. Сканирование книжных страниц дало сносные результаты. При каждом сканировании было несколько ошибок, из-за которых буквы не распознавались правильно. Повторные сканирования исправят ошибки в одной области, но внесут их в другую.
С таблицей сканирование прошло очень хорошо и почти без ошибок. Я смог сохранить таблицу в формате HTML и использовать функции навигации по таблицам программы чтения с экрана для навигации по ней. Для недорогого решения OCR Text Cloner Pro впечатляет своей способностью правильно отображать таблицы. Я использовал процесс цветного сканирования и опцию «Текст, таблицы и изображения» при сканировании этого материала.
Я использовал процесс цветного сканирования и опцию «Текст, таблицы и изображения» при сканировании этого материала.
Для журнальной статьи, состоящей из нескольких колонок, Text Cloner Pro обеспечил превосходный результат с правильным форматированием колонок, расположенной одна под другой для облегчения чтения, а также с правильным распознаванием и размещением изображения. Я использовал цветной процесс с выбранным параметром «Текст и изображения».
Счет за электричество был единственным типом материала, который вызывал серьезные проблемы. Содержимое купюры отображалось некорректно в надлежащем формате даже после нескольких сканирований для получения оптимального изображения. Часть счета, которая содержала только текст, отображалась правильно, но часть с суммой счета и другой соответствующей информацией отображалась крайне плохо. На этой стороне купюры действительно был штрих-код, который, возможно, способствовал возникновению этих проблем.
Редактирование
Text Cloner Pro — надежный текстовый редактор. Область, в которой содержимое появляется после ввода или сканирования, аналогично тому, что вы найдете в WordPad или Microsoft Word. В меню «Правка» включены многие распространенные параметры редактирования, такие как «Найти и заменить», «Тезаурус» и «Проверка орфографии». Программа поддерживает верхние и нижние колонтитулы, а также маркированные списки. Вы также можете создавать свои собственные таблицы с помощью меню «Таблица» и вставлять изображения и текст из других документов с помощью меню «Вставка». Программа также включает в себя возможность изменять шрифты и устанавливать специальные атрибуты на уровне абзаца.
Область, в которой содержимое появляется после ввода или сканирования, аналогично тому, что вы найдете в WordPad или Microsoft Word. В меню «Правка» включены многие распространенные параметры редактирования, такие как «Найти и заменить», «Тезаурус» и «Проверка орфографии». Программа поддерживает верхние и нижние колонтитулы, а также маркированные списки. Вы также можете создавать свои собственные таблицы с помощью меню «Таблица» и вставлять изображения и текст из других документов с помощью меню «Вставка». Программа также включает в себя возможность изменять шрифты и устанавливать специальные атрибуты на уровне абзаца.
Преобразование PDF и суммирование
Text Cloner Pro может выполнять распознавание текста в файлах PDF и суммировать документ. В меню «Сканирование» есть параметр «Импорт PDF», который позволяет импортировать PDF-файл для обработки. Сначала необходимо выбрать PDF-файл с помощью кнопки «Выбрать PDF» в диалоговом окне «Импорт PDF». Далее вы должны определить страницы, на которых вы хотите выполнять распознавание текста. После этого вы должны нажать кнопку «Обработать», чтобы начать распознавание текста в файле PDF. Диалоговое окно преобразования PDF остается на экране до завершения преобразования, после чего вы возвращаетесь в документ. Точность преобразования будет зависеть от качества вашего файла PDF. Я обнаружил, что некоторые PDF-файлы сканируются невероятно хорошо, а другие содержат ошибки.
После этого вы должны нажать кнопку «Обработать», чтобы начать распознавание текста в файле PDF. Диалоговое окно преобразования PDF остается на экране до завершения преобразования, после чего вы возвращаетесь в документ. Точность преобразования будет зависеть от качества вашего файла PDF. Я обнаружил, что некоторые PDF-файлы сканируются невероятно хорошо, а другие содержат ошибки.
Суммирование берет документ и удаляет большую часть содержимого, отображая процент от целого. Например, будут отображаться несколько предложений, за которыми следуют несколько предложений из абзаца на несколько страниц позже в документе. Диалоговое окно суммирования содержит кнопку для начала суммирования и ползунок для установки процента файла, который будет отображаться в сводке.
Доступность программы чтения с экрана
NVDA плохо работала при использовании Text Cloner. Он будет читать буквы несколько раз при редактировании буква за буквой или слово за словом. При чтении по строкам часто пропускались слова. Из-за этих проблем, если вы используете NVDA, необходимо сохранить документ, прежде чем вы сможете правильно его отредактировать. NVDA также не могла прочитать ползунок, определяющий отображаемый процент при суммировании файла, и метки в полях редактирования, определяющие ширину и высоту таблиц в диалоговом окне «Создание таблицы». В остальном NVDA показала себя хорошо; меню читались правильно, как и другие диалоговые окна.
Из-за этих проблем, если вы используете NVDA, необходимо сохранить документ, прежде чем вы сможете правильно его отредактировать. NVDA также не могла прочитать ползунок, определяющий отображаемый процент при суммировании файла, и метки в полях редактирования, определяющие ширину и высоту таблиц в диалоговом окне «Создание таблицы». В остальном NVDA показала себя хорошо; меню читались правильно, как и другие диалоговые окна.
Jaws и Window Eyes очень хорошо работали с Text Cloner Pro. Обе программы чтения с экрана позволяли навигацию по символам и словам без проблем, и все диалоговые окна читались правильно. Оба средства чтения с экрана объявляют элементы почти одинаково, поэтому использование любого из них работает одинаково хорошо.
Итоги
Text Cloner Pro и ABBYY Fine Reader обеспечивают оптическое распознавание символов за небольшую часть стоимости таких продуктов, как OpenBook и Kurzweil 1000. Однако у них есть ограничения, которых нет в более дорогих продуктах.