Обьясните кто то про регистры в Ассемблере? — Хабр Q&A
У меня нет линукса, чтобы проверить, но, кажется, программа в корне неверна. Вы используете 32-битное соглашение вызова на 64-битной машине.
https://www.informatik.htw-dresden.de/~beck/ASM/sy…
https://blog.rchapman.org/posts/Linux_System_Call_…
Откуда 32-битный вызов на x64 — дайте пруфлинк, может, в вашем линуксе так и есть.
Регистры — это маленькие и очень быстрые ячейки памяти, встроенные в процессор. Их ограниченное количество, и у них конкретные чётко зафиксированные названия.
Часто для работы с данными малых разрядностей и совместимости с ранним кодом процессор даёт доступ и к половинкам регистров. Так, нижняя половина регистра rax — eax, нижняя четверть — ax, половины ax (соответственно восьмушки rax) называются al и ah. Сами понимаете: когда процессор был 16 бит, регистр назывался ax = al + ah. Сделали 32 бита — стал eax. Сделали 64 бита — стал rax.
Для вызова системных функций Linux используется такое соглашение вызова. Все функции висят на прерывании 0x80, rax — название функции, остальные параметры рассовываются по регистрам.
Насчёт int, char, double. Знаковость (signed/unsigned) определяется инструкциями ассемблера (например, ja = jump if above для unsigned, jg = jump if greater для signed). Длина — задействованным куском регистра (rax = long long, eax = int/long, ax = short, al = char). С дробными числами работает отдельный блок процессора, т.н. сопроцессор, со своими регистрами (в первых x86 он был отдельной микросхемой, существовавшей не во всех компьютерах, отсюда название).
Ответ написан
Регистр — это аппаратная ячейка статической памяти внутри процессора, которой присвоено имя. И есть команды или подпрограммы, которые что-то делают с значением из этого регистра.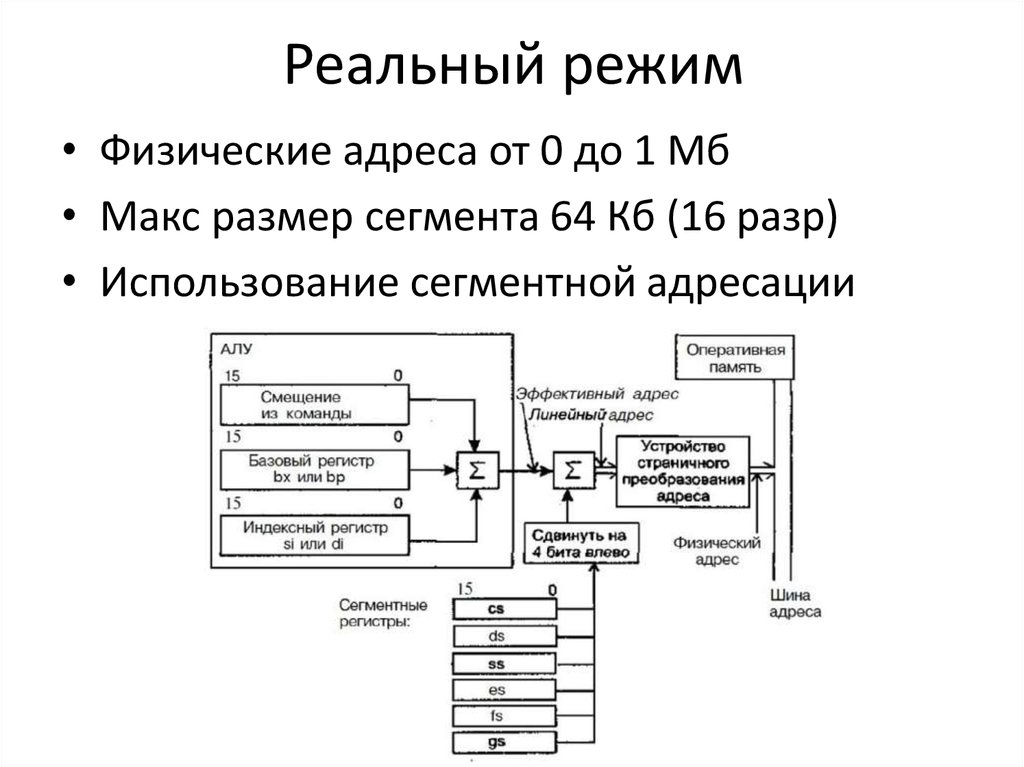
Ответ написан
Регистры — это не переменные. Это ячейки памяти в процессоре. Их нельзя именовать от балды, как переменные в языках высокого уровня. Потому что это конкретные физические ячейки, за которыми закреплены некие буквенные названия.
Они могут использоваться с самыми разными целями, и от того, с какой целью используются в конкретный момент, в них нужно «класть» самое разное.

Что именно и куда именно класть — написано, сюрприз, в документации. Путем переписывания кода от балды, вы Ассемблер никогда выучить не сможете, там нужно сначала понимать, что вы делаете, а потом — делать.
Ответ написан
Комментировать
Проще понять что такое регистры МП на примере человека. Регистр — это рука, в которую процессор берет число, чтобы потом что-то с ним сделать (сложить, умножить или просто записать куда-то). У современных микропроцессоров таких регистров очень приблизительно от 5 до 50.

Ниже регистров по быстродействию идет кеш-память процессора, к кешу программист не имеет прямой возможности обратиться, это просто хранения часто используемой информации. Еще ниже по быстродействию — оперативная память, к ней можно обращаться из программы, например записать число из регистра в ячейку оперативной памяти. Еще ниже т.н. «внешнаяя» память. Это там где храняться файлы — жесткий диск, флешки, и т.д.
Ответ написан
Комментировать
Использование и сохранение регистров во встроенном коде на языке ассемблера
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Блок, относящийся только к системам Microsoft
В общем случае в начале блока __asm не следует предполагать, что регистр будет иметь какое-либо определенное значение. Сохранение значений регистров между разными блоками
Сохранение значений регистров между разными блоками __asm не гарантируется. Когда заканчивается один блок встроенного кода и начинается следующий блок, не следует полагать, что регистры во втором блоке сохраняют свои значения из первого блока. Блок __asm наследует значения регистров, получающиеся в процессе обычного потока управления.
Если используется соглашение о вызовах __fastcall, компилятор передает аргументы функций в регистрах, а не в стеке. Это может создавать проблемы в функциях с блоками __asm, поскольку для функции не существует способа определить, как параметры распределены по регистрам. Если функция получила параметр в регистре EAX и сразу же записала в регистр EAX какое-то другое значение, исходный параметр будет потерян. Кроме того, необходимо сохранять значение регистра ECX в любой функции, объявленной с атрибутом __fastcall.
Чтобы избежать подобных конфликтов регистров, не используйте соглашение __fastcall для функций, которые содержат блок __asm. Если соглашение __fastcall задано глобально с помощью параметра компилятора /Gr, объявляйте каждую функцию, содержащую блок __asm, с атрибутом __cdecl или __stdcall. (Атрибут __cdecl указывает компилятору использовать соглашение о вызовах C для этой функции.) Если вы не компилируется с помощью /Gr, не объявляйте функцию с атрибутом __fastcall .
При использовании блока __asm для написания кода на языке ассемблера в функциях C/C++ нет необходимости сохранять значения регистров EAX, EBX, ECX, EDX, ESI и EDI. Например, в POWER2. Пример C при написании функций с помощью встроенной сборки функция power2 не сохраняет значение в регистре EAX.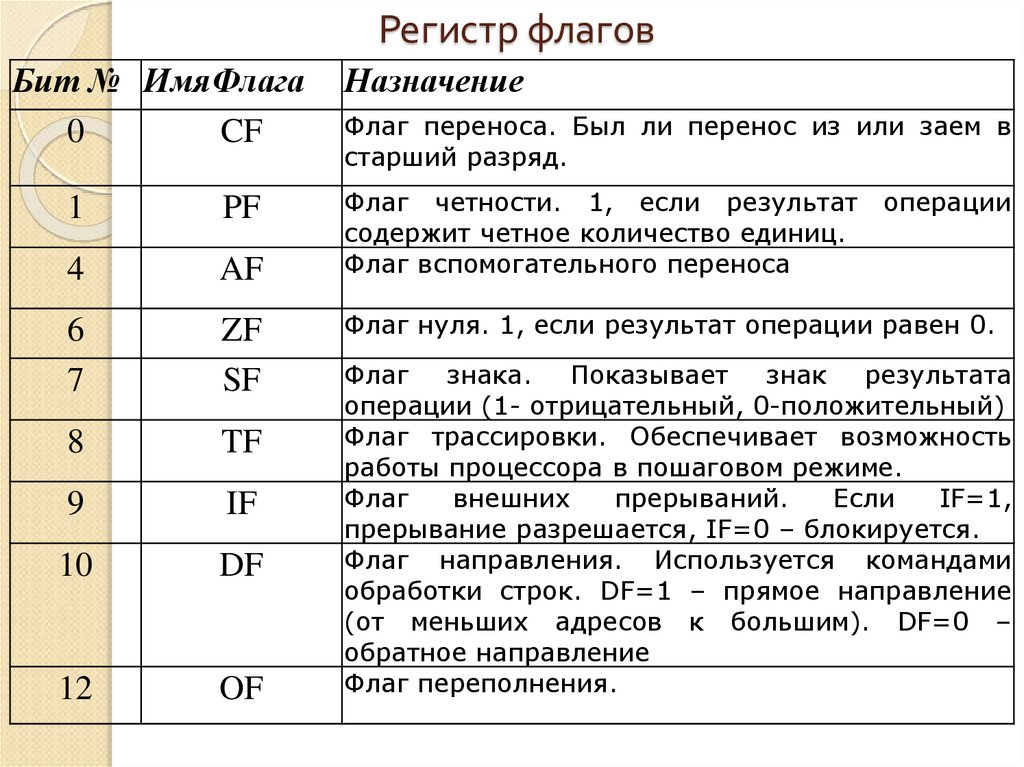 Однако использование этих регистров влияет на качество кода, поскольку распределитель регистров не может использовать их для хранения значений между блоками
Однако использование этих регистров влияет на качество кода, поскольку распределитель регистров не может использовать их для хранения значений между блоками __asm. Кроме того, если во встроенном коде на языке ассемблера используется регистр EBX, ESI или EDI, компилятор вынужден сохранять и восстанавливать значения этих регистров в прологе и эпилоге функции.
Необходимо сохранять значения остальных используемых регистров (например, DS, SS, SP, BP и флаговые регистры) в пределах области блока __asm. Необходимо сохранять значения регистров ESP и EBP, если только нет определенной причины для их изменения (переключение стека, например). Кроме того, см. раздел «Оптимизация встроенной сборки».
Для некоторых типов SSE требуется 8-байтовое выравнивание стека, в результате чего компилятор вынужден создавать код динамического выравнивания стека. Чтобы иметь возможность доступа к локальным переменным и параметрам функций после выравнивания, компилятор поддерживает два указателя фреймов.
Примечание
Если встроенный код на языке ассемблера изменяет флаг направления с помощью инструкций STD или CLD, необходимо восстановить исходное значение этого флага.
Завершение блока, относящегося только к системам Майкрософт
Встроенный ассемблер
— Сколько способов обнулить регистр?
См. этот ответ для лучшего способа обнуления регистров: xor eax,eax (преимущества в производительности и меньшее кодирование).
Я рассмотрю только способы, которыми одна инструкция может обнулить регистр. Существует слишком много способов разрешить загрузку нуля из памяти, поэтому мы в основном исключаем инструкции, которые загружаются из памяти.
Я нашел 10 различных отдельных инструкций, которые обнуляют 32-битный регистр (и, следовательно, полный 64-битный регистр в длинном режиме), без предварительных условий или загрузки из какой-либо другой памяти. Это не считая разных кодировок одного и того же insn или разных форм 9.0005 мов . Если вы считаете загрузку из памяти, которая, как известно, содержит ноль, или из сегментных регистров или чего-то еще, существует множество способов. Существует также миллион способов обнуления векторных регистров.
Для большинства из них версии eax и rax представляют собой разные кодировки для одной и той же функциональности, обе обнуляют полные 64-битные регистры, либо неявно обнуляют верхнюю половину, либо явно записывают полный регистр с префиксом REX.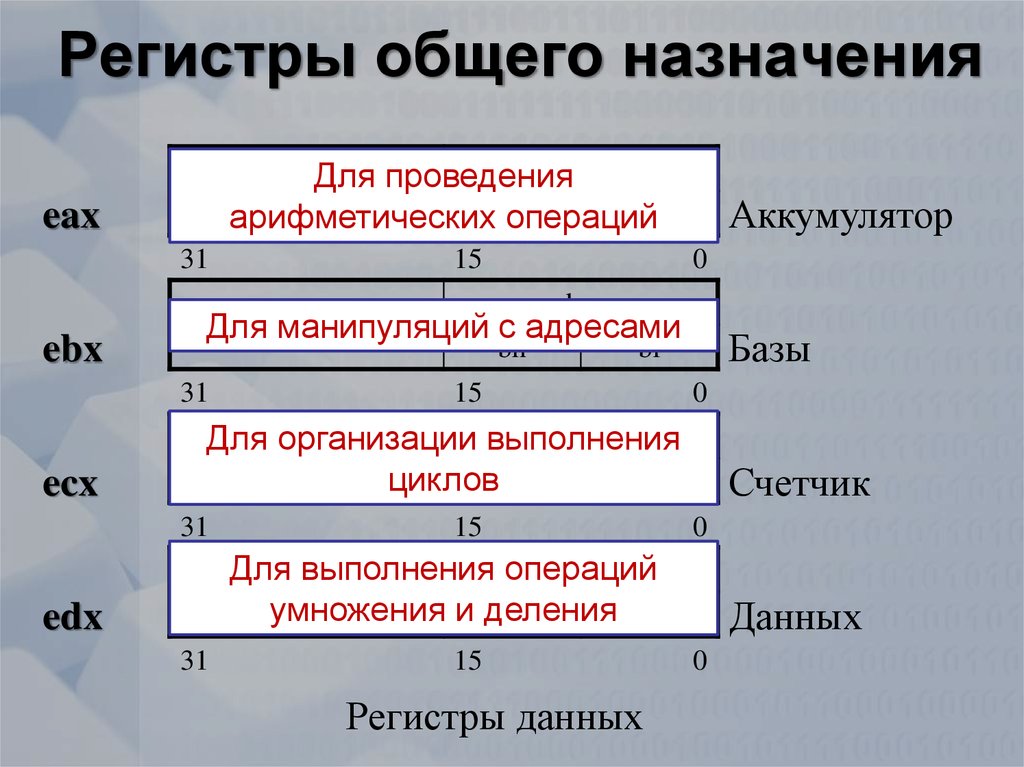 W.
W.
Целочисленные регистры (синтаксис NASM):
# Работает на любом регистре, если не указано иное, обычно любого размера. eax/ax/al в качестве заполнителей и еакс, 0; три кодировки: imm8, imm32 и imm32 только для eax и eax, eax, eax ; Набор инструкций BMI1: назначение = ~s1 & s2 imul eax, любой,0 ; eax = что-то * 0. две кодировки: imm8, imm32 lea eax, [0] ; абсолютная кодировка (disp32 без базы или индекса). Используйте [abs 0] в NASM, если вы использовали DEFAULT REL lea eax, [отн. 0] ; YASM поддерживает это, а NASM — нет: использует относительное RIP кодирование для обращения к определенному абсолютному адресу, создавая код, зависящий от положения. мов акс, 0 ; 5 байт для кодирования (B8 imm32) mov rax, строгое двойное слово 0 ; 7 байт: REX mov r/m64, расширенный знак-imm32. NASM оптимизирует mov rax,0 до версии 5B, но dword или strict dword его почему-то останавливает mov rax, строгое qword 0 ; 10 байт для кодирования (REX B8 imm64). Мнемоника movabs для AT&T. обычно ассемблеры выбирают меньшие кодировки, если операнд подходит, но строгое qword принудительно использует imm64.суб акс, экз ; распознается как идиома обнуления на некоторых, но, возможно, не на всех процессорах xor eax, eax ; Предпочтительная идиома: распознается на всех процессорах. ; 2 кодировки одинакового размера: r/m, r vs. r, r/m @movzx: movzx eax, byte ptr[@movzx + 6] //Предположим, что старший байт абсолютного адреса равен 0. Не зависит от позиции, и x86-64 RIP+rel32 загрузит 0xFF .l: цикл .l ; очищает e/rcx... в конце концов. из ответа И. Дж. Кеннеди. Чтобы работать только с ECX, используйте префикс размера адреса. ; представитель lodsb ; не считается, потому что это небезопасно (потенциальные segfaults), но и нули ecx

Инструкции типа xor reg,reg могут быть закодированы двумя разными способами. В синтаксисе GAS AT&T мы можем запросить код операции, который выбирает ассемблер. Это относится только к целочисленным инструкциям reg, reg, которые допускают обе формы, т. е. восходят к 8086. Так что не SSE/AVX.
{загрузка} xor %eax, %eax # 31 c0
{store} xor %eax, %eax # 33 c0
«Сдвинуть все биты с одного конца» невозможно для регистров GP обычного размера, только для частичных регистров.
shl и shr счетчики смен маскируются (на 286 и выше): count & 31; т. е. мод 32.
(сдвиги с немедленным подсчетом были новыми в 186 (ранее только CL и неявный-1), поэтому есть процессоры с немаскированными немедленными сдвигами (включая NEC V30). Кроме того, 286 и более ранние версии являются только 16-битными , так что x является «полным» регистром. Были процессоры, в которых сдвиг может обнулить полный целочисленный регистр.)
Также обратите внимание, что счетчики сдвига для векторов насыщаются, а не переносятся.
# Методы обнуления, которые работают только с 16-битными или 8-битными регистрами: шл топор, 16 ; счетчик сдвига по-прежнему маскируется до 0x1F для любого размера операнда менее 64b. т. е. количество% = 32 шр аль, 16 ; поэтому сдвиги 8b и 16b могут обнулять регистры. # обнуление ah/bh/ch/dh: Младший байт регистра = любой мусор, который был в регистре high26 movxz eax, ах ; Из ответа Джерри Коффина
В зависимости от других существующих условий (кроме наличия нуля в другом регистре):
bextr eax, любой, eax ; если al >= 32 или ah = 0.ИМТ1 BLSR eax, src ; если src имеет только один установленный бит CDQ ; edx = расширение знака (eax) sbb eax, eax ; если КФ=0. (Распознается только на процессорах AMD как зависящий только от флагов (не eax)) setcc al ; с условием, которое даст ноль на основе известного состояния флагов PSHUFB xmm0, все единицы ; Байты xmm0 очищаются, когда байты маски имеют установленный старший бит
Векторные регистры
Некоторые из этих целочисленных инструкций SSE2 также могут использоваться в регистрах MMX ( mm0 — mm7 ). Отдельно показывать не буду.
Опять же, лучшим выбором является некоторая форма xor. Либо PXOR / VPXOR , либо XORPS / VXORPS . См. Как лучше всего обнулить регистр в сборке x86: xor, mov или and? для деталей.
AVX vxorps xmm0,xmm0,xmm0 обнуляет полные ymm0/zmm0 и лучше, чем vxorps ymm0,ymm0,ymm0 на процессорах AMD.
Каждая из этих инструкций обнуления имеет три кодировки : устаревшие SSE, AVX (префикс VEX) и AVX512 (префикс EVEX), хотя версия SSE обнуляет только нижние 128, что не является полным регистром на процессорах, поддерживающих AVX. или AVX512. В любом случае, в зависимости от того, как вы считаете, каждая запись может быть тремя разными инструкциями (один и тот же код операции, только разные префиксы). Кроме vzeroall , который AVX512 не менял (и не обнуляет zmm16-31).
PXOR xmm0, xmm0 ;; рекомендуемые XORPS xmm0, xmm0 ;; или это XORPD xmm0, xmm0 ;; более длинное кодирование с нулевой выгодой PXOR мм0, мм0 ;; MMX, не показывать для остальных целых insns ANDNPD xmm0, xmm0 ANDNPS xmm0, xmm0 ПАНДН xmm0, xmm0 ; пункт назначения = ~ пункт назначения и источник PCMPGTB xmm0, xmm0 ; n > n всегда ложно. PCMPGTW xmm0, xmm0 ; аналогично, pcmpeqd — хороший способ сделать _mm_set1_epi32(-1) PCMPGTD xmm0, xmm0 PCMPGTQ xmm0, xmm0 ; SSE4.2 и медленнее, чем byte/word/dword PSADBW xmm0, xmm0 ; сумма абсолютных разностей MPSADBW xmm0, xmm0, 0 ; ССЕ4.1. сумма абсолютных разностей, зарегистрируйтесь против себя без смещения. (imm8=0: то же, что и PSADBW) ; счетчики сдвига насыщают и обнуляют регистр, в отличие от сдвигов регистра GP PSLLDQ xmm0, 16 ; сдвиньте байты влево в xmm0 PSRLDQ xmm0, 16 ; сдвиньте вправо байты в xmm0 PSLLW xmm0, 16 ; сдвинуть влево биты в каждом слове PSLLD xmm0, 32 ; двойное слово PSLLQ xmm0, 64 ; четверное слово PSRLW/PSRLD/PSRLQ ; то же, но сдвиг вправо PSUBB/W/D/Q xmm0, xmm0 ; вычесть упакованные элементы, байт/слово/двойное слово/qword PSUBSB/Вт xmm0, xmm0 ; сабвуфер со знаком насыщения PSUBUSB/Вт xmm0, xmm0 ; сабвуфер с беззнаковой насыщенностью ;; SSE4.1 INSERTPS xmm0, xmm1, 0x0F ; imm[3:0] = zmask = все элементы обнулены. DPPS xmm0, xmm1, 0x00 ; imm[7:4] => inputs = рассматривать как ноль -> никаких исключений FP. imm[3:0] => outputs = 0, на всякий случай DPPD xmm0, xmm1, 0x00 ; входы = все обнулены -> нет исключений FP. выходы = 0 ВЗЕРОАЛЛ ; AVX1 x/y/zmm0..15 не zmm16..31 VPERM2I/F128 ymm0, ymm1, ymm2, 0x88 ; imm[3] и [7] обнуляют эту выходную дорожку # Может вызвать исключение в SNaN, поэтому его можно использовать только в том случае, если вы знаете, что исключения замаскированы CMPLTPD xmm0, xmm0 # исключение для QNaN или SNaN или денормальное VCMPLT_OQPD xmm0, xmm0,xmm0 # исключение только для SNaN или денормальных CMPLT_OQPS то же самое VCMPFALSE_OQPD xmm0, xmm0, xmm0 # На самом деле это просто другое значение предиката imm8 для той же инструкции VCMPPD xmm,xmm,xmm, imm8.
То же поведение исключения, что и LT_OQ.
SUBPS xmm0, xmm0 и подобные не будут работать, потому что NaN-NaN = NaN, а не ноль.
Кроме того, инструкции FP могут генерировать исключения для аргументов NaN, поэтому даже CMPPS/PD безопасен только в том случае, если вы знаете, что исключения маскируются, и вас не волнует возможность установки битов исключения в MXCSR. Даже версия AVX с расширенным набором предикатов поднимет #IA на SNaN. Предикаты «quiet» подавляют только #IA для QNaN. CMPPS/PD также может вызвать исключение Denormal. ( AVX512 Кодировки EVEX могут подавлять исключения FP для 512-битных векторов, а также переопределять режим округления)
(см. таблицу в записи insn set ref для CMPPD или, что предпочтительнее, в исходном PDF-файле Intel, поскольку HTML-выдержка искажает эту таблицу .)
AVX1/2 и AVX512 EVEX формы вышеперечисленных, только для PXOR: все они равны нулю для полного назначения ZMM. PXOR имеет две версии EVEX: VPXORD или VPXORQ, позволяющие маскировать элементы dword или qword. (XORPS/PD уже различает размер элемента в мнемонике, поэтому AVX512 не изменил этого. В устаревшей кодировке SSE XORPD всегда является бессмысленной тратой размера кода (более крупный код операции) по сравнению с XORPS на всех процессорах.)
PXOR имеет две версии EVEX: VPXORD или VPXORQ, позволяющие маскировать элементы dword или qword. (XORPS/PD уже различает размер элемента в мнемонике, поэтому AVX512 не изменил этого. В устаревшей кодировке SSE XORPD всегда является бессмысленной тратой размера кода (более крупный код операции) по сравнению с XORPS на всех процессорах.)
VPXOR xmm15, xmm0, xmm0 ; AVX1 VEX VPXOR ymm15, ymm0, ymm0 ; AVX2 VEX, менее эффективен на некоторых процессорах VPXORD xmm31, xmm0, xmm0 ; AVX512VL EVEX VPXORD ymm31, ymm0, ymm0 ; AVX512VL EVEX 256-бит VPXORD zmm31, zmm0, zmm0 ; AVX512F EVEX 512-бит VPXORQ xmm31, xmm0, xmm0 ; AVX512VL EVEX VPXORQ ymm31, ymm0, ymm0 ; AVX512VL EVEX 256-бит VPXORQ zmm31, zmm0, zmm0 ; AVX512F EVEX 512-бит
Различная ширина вектора указана отдельными записями в ручном вводе Intel PXOR.
Вы можете использовать нулевую маскировку (но не маскирование слиянием) с любым регистром маски, который вы хотите; не имеет значения, получаете ли вы ноль от маскирования или ноль от нормального вывода векторной инструкции. Но это не другая инструкция. например:
Но это не другая инструкция. например: VPXORD xmm16{k1}{z}, xmm0, xmm0
AVX512:
Вероятно, здесь есть несколько вариантов, но прямо сейчас мне не настолько любопытно, чтобы копаться в списке наборов инструкций в поисках всех их.
Однако есть один интересный момент, о котором стоит упомянуть: VPTERNLOGD/Q может установить регистр в вместо , с imm8 = 0xFF. (Но имеет ложную зависимость от старого значения, от текущих реализаций). Поскольку все инструкции сравнения сравниваются с маской, VPTERNLOGD кажется лучшим способом установить вектор на все единицы на Skylake-AVX512 в моем тестировании, хотя это не делает особый случай imm8 = 0xFF, чтобы избежать ложного зависимость.
VPTERNLOGD zmm0, zmm0, zmm0, 0 ; входы могут быть любыми регистрами, которые вам нравятся.
Обнуление регистра маски (k0..k7): Инструкции маски и сравнение векторов с маской
kxorB/W/D/Q k0, k0, k0 ; узкие версии от нуля до max_kl kshiftlB/W/D/Q k0, k0, 100 ; kshifts не маскирует/переносит 8-битный счет kshiftrB/W/D/Q k0, k0, 100 kandnB/W/D/Q k0, k0, k0 ; х & ~ х ; сравнить с маской vpcmpB/W/D/Q k0, x/y/zmm0, x/y/zmm0, 3 ; предикат №3 = всегда ложно; другие предикаты также ложны на равных vpcmpuB/W/D/Q k0, x/y/zmm0, x/y/zmm0, 3 ; неподписанная версия vptestnmB/W/D/Q k0, x/y/zmm0, x/y/zmm0 ; x & ~x тест в маске
x87 FP:
Только один вариант (потому что sub не работает, если старое значение было бесконечностью или NaN).
ФЛДЗ ; нажать +0.0
Лекция по языку ассемблера и архитектуре компьютера (CS 301)
Лекция по языку ассемблера и архитектуре компьютера (CS 301) 301) CS 301: Сборка Лекция по языковому программированию, доктор ЛоулорКак C++ переменные, регистры на самом деле доступны в нескольких размерах:
- rax — это 64-битный регистр «длинного» размера. Он был добавлен в 2003 году во время
переход на 64-битные процессоры.
- eax — это 32-битный регистр размера «int». Он был добавлен в 1985 году. при переходе на 32-битные процессоры с 80386 ЦПУ. Я привык использовать этот размер регистра, так как они также работают в 32-битном режиме, хотя я пытаюсь использовать более длинные регистры rax для всего.
- axe — это 16-битный регистр «короткого» размера. Он был добавлен в 1979 году с
ЦП 8086, но по сей день используется в коде DOS или BIOS.

- al и ah — 8-битные регистры размера «char». все это младшие 8 бит, ах — старшие 8 бит. они красивые похож на старые 8-битные регистры 8008 еще в 1972 году.
Любопытно, вы может записать 64-битное значение в rax, а затем прочитать младшие 32 бита из eax, или младшие 16 битx из ax, или младшие 8 бит из al — это всего лишь один регистр, но они продолжают расширять его!
|
Например,
мов rcx,0xf00d00d2beefc03; загрузить большую 64-битную константу
mov eax,ecx; вытащить младшие 32 бита (0x2beefc03)
ret
(Попробуйте теперь это в NetRun!)
Вот
полный список регистров x86. Показаны 64-битные регистры.
в красном. «Скретч» регистрирует любую функцию, разрешенную для
перезапишите и используйте для чего угодно, не спрашивая
кто-нибудь. Регистры « Preserved » должны быть возвращены
(«сохранить» реестр), если вы их используете.
Показаны 64-битные регистры.
в красном. «Скретч» регистрирует любую функцию, разрешенную для
перезапишите и используйте для чего угодно, не спрашивая
кто-нибудь. Регистры « Preserved » должны быть возвращены
(«сохранить» реестр), если вы их используете.
| Имя | Примечания | Тип | 64-разрядная длинная | 32-разрядное целое число | 16-битный короткий | 8-бит символов |
| ракс | Значения возвращаются из
функции в этом регистре. | царапина | ракс | эакс | топор | ах и ал |
| РСХ | Типичная царапина
регистр.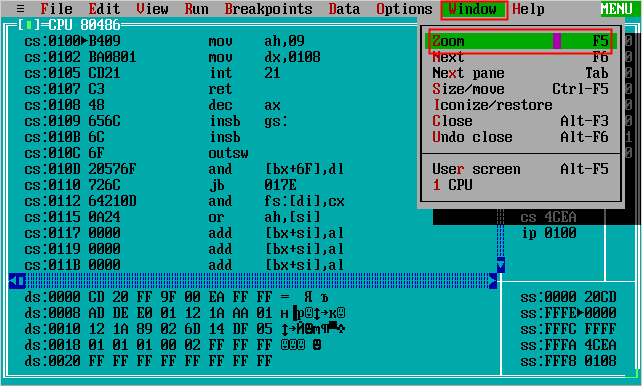 Некоторые инструкции также используют его в качестве счетчика. Некоторые инструкции также используют его в качестве счетчика. | царапина | РКС | ЕСХ | сх | ч. и кл. |
| RDX | Скретч-регистр. | царапина | РДС | эдкс | дх | дх и дл |
| рбкс | Сохранился зарегистрируйтесь: не используйте его без сохранения! | консервированный | рбкс | ebx | бх | бх и бл |
| рсп | указатель стека. Указывает на вершину стека (подробности скоро!) Указывает на вершину стека (подробности скоро!) | консервированный | рсп | исп | сп | спл |
| рбп | Сохранился регистр. Иногда используется для хранения старого значения указатель стека или «база». | консервированный | рбп | эбп | бп | баррель |
| доллар США | Скретч-регистр.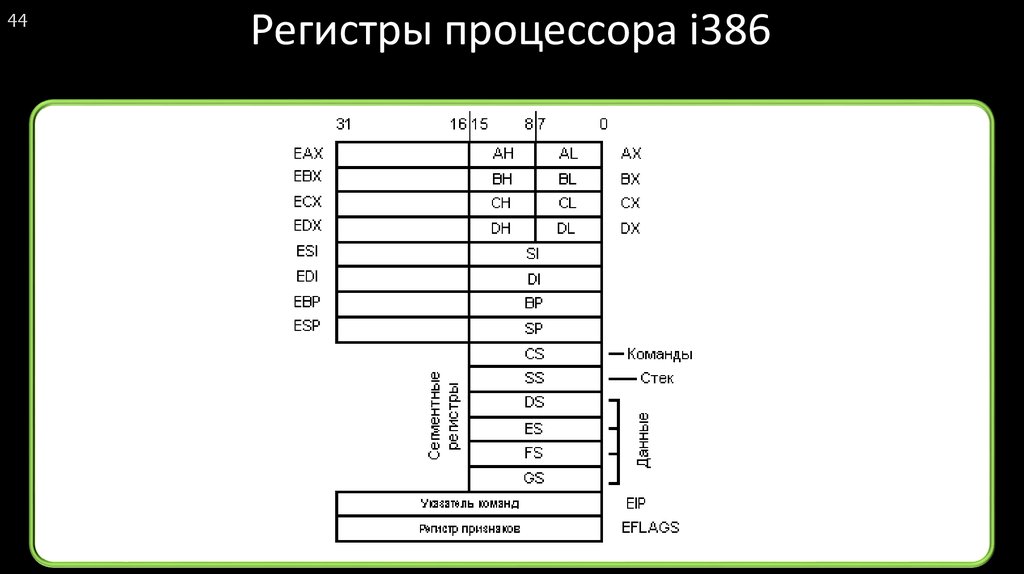 Также
используется для передачи аргумента функции #2 в 64-разрядной версии Linux Также
используется для передачи аргумента функции #2 в 64-разрядной версии Linux | царапина | рупий | ЕСИ | и | сил |
| рди | Скретч-регистр. Аргумент функции №1 в 64-битном Linux | царапина | рди | эди | по | до |
| р8 | Скретч-регистр. Эти
были добавлены в 64-битном режиме, поэтому у них есть номера, а не имена. | царапина | р8 | р8д | р8в | р8б |
| р9 | Скретч-регистр. | царапина | р9 | р9д | р9в | р9б |
| р10 | Скретч-регистр.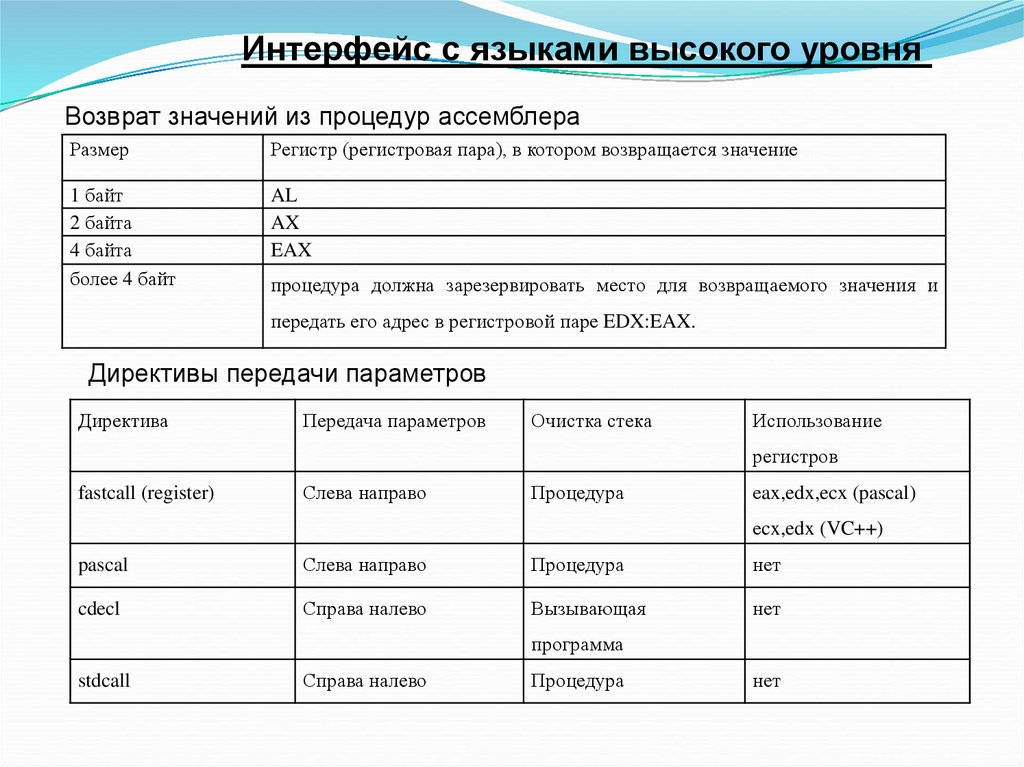 | царапина | р10 | р10д | р10в | р10б |
| р11 | Скретч-регистр. | царапина | р11 | р11д | р11в | р11б |
| р12 | Сохранился
регистр. Вы можете использовать его, но вам нужно сохранить и
восстановить его. | консервированный | р12 | р12д | р12в | р12б |
| р13 | Сохранился
регистр. | консервированный | р13 | р13д | р13в | р13б |
| р14 | Сохранился регистр. | консервированный | р14 | р14д | р14в | р14б |
| р15 | Сохранено регистр. | консервированный | р15 | р15д | р15в | р15б |
Вы можете преобразовать значения между различными размерами регистров, используя разные инструкции:
| | Источник
Размер | | |||
| | 64-битный RCX | 32-битный ecx | 16 бит сх | 8-битный класс | Примечания |
| 64-битный ракс | мов ракс, rcx | мовскд
ракс,экс | мовск
ракс,сх | мовск
ракс,кл | Запись во весь регистр |
| 32 бит EAX | мов акс, есх | мов акс, есх | мовск
еакс,сх | мовск
еакс,кл | Верхняя половина адресата обнуляется |
| 16-битный топор | мов топор, сх | мов топор, сх | мов топор, сх | мовск
топор,кл | Влияет только на младшие 16 бит, остальные без изменений. |
| 8 бит ал. | мов ал,кл | мов ал,кл | мов ал,кл | мов ал,кл | Влияет только на младшие 8 бит, остальные без изменений. |
Перелив
Дело в том, что переменные на компьютере имеют ограниченное количество битов. Если значение становится больше, чем может поместиться в этих битах, дополнительные биты сначала становятся отрицательными, а затем «переполняются». По умолчанию они потом полностью игнорировал.инт большой=1024*1024*1024; возврат большой*4;
(Попробуйте прямо сейчас в NetRun!)
На моей машине «int» — это 32 бита, что составляет +-2 миллиарда в двоичном формате, так что на самом деле возвращает 0?!Программа завершена. Возврат 0 (0x0)
Вы можете извлечь значение каждого бита. Например:
Например:
целочисленное значение=1; /* значение для проверки, начиная с первого (младшего) бита */
for (целое число бит=0;бит<100;бит++) {
std::cout<<"в бите "< (Попробуйте
теперь это в NetRun!)
Потому что "целое"
в настоящее время имеет 32 бита, если вы начнете с одного и добавите переменную в
сам 32 раза, один переполняется и полностью теряется.
В сборе,
есть удобная инструкция "jo" (переход при переполнении) для проверки
переполнение из предыдущей инструкции. Компилятор С++
однако не удосуживается использовать jo!
мов эди,1 ; переменная цикла
дв акс,0 ; прилавок
Начало:
добавить eax,1 ; приращение битового счетчика
добавить эди, эди ; добавить переменную к себе
Джо нет ; проверьте наличие переполнения в приведенном выше добавлении
cmp эди,0
начало
рет
нет: ; призвал к переполнению
движение eax, 999
рет
(Попробуйте
это в NetRun сейчас!)
Обратите внимание на
приведенная выше программа возвращает 999 при переполнении, что кто-то другой
нужно проверить на. (Правильная реакция на переполнение
на самом деле довольно сложно - см., например, Ariane
5 взрыв, вызванный небрежным обращением с обнаруженным
переполнение. По иронии судьбы, игнорирование переполнения
проблем не вызвал!)
(Правильная реакция на переполнение
на самом деле довольно сложно - см., например, Ariane
5 взрыв, вызванный небрежным обращением с обнаруженным
переполнение. По иронии судьбы, игнорирование переполнения
проблем не вызвал!)
Подписано
по сравнению с числами без знака
Если вы смотрите
близко прямо перед переполнением вы видите, что происходит что-то смешное:
значение символа со знаком = 1; /* значение для проверки, начиная с первого (младшего) бита */
for (целое число бит=0;бит<100;бит++) {
std::cout<<"в бите "< (Попробуйте
теперь это в NetRun!)
Это печатает
вышло:
в бите 0 значение равно 1
в бите 1 значение равно 2
в бите 2 значение равно 4
в бите 3 значение равно 8
в бите 4 значение равно 16
в бите 5 значение равно 32
в бите 6 значение равно 64
в бите 7 значение равно -128
Программа завершена. Возврат 0 (0x0)
Возврат 0 (0x0)
Подожди, последний
значение бита равно -128? Да, это действительно так!
Этот негатив
старший бит называется "знаковым битом" и имеет отрицательное значение в двойках.
дополнение подписано
числа. Это означает, что для представления -1, например, вы устанавливаете
не только старший бит, но и все остальные биты: в
без знака, это максимально возможное значение. Причина
двоичный код 11111111 представляет -1 по той же причине, по которой вы можете выбрать
9999 для представления -1 на 4-значном одометре: если вы добавите единицу, вы
оберните вокруг и нажмите ноль.
Очень круто
что касается дополнения до двух, это сложение то же самое
операция ли
числа со знаком или без знака - мы просто интерпретируем результат
по-другому. Вычитание также идентично для знаков и
без подписи. Имена регистров идентичны в ассемблере для
подписанные и неподписанные. Однако при изменении размеров регистров
используя инструкцию типа "movsxd rax,eax", когда вы проверяете наличие
переполнение, когда вы сравниваете числа, умножаете или делите или сдвигаете
бит, вам нужно знать, является ли число подписанным (имеет знаковый бит) или
без знака (без знакового бита, без отрицательных чисел).
Однако при изменении размеров регистров
используя инструкцию типа "movsxd rax,eax", когда вы проверяете наличие
переполнение, когда вы сравниваете числа, умножаете или делите или сдвигаете
бит, вам нужно знать, является ли число подписанным (имеет знаковый бит) или
без знака (без знакового бита, без отрицательных чисел).
Подпись Без знака Язык Целое число Целое число без знака C++, int по умолчанию имеет знак. подписанный символ беззнаковый символ C++, char может быть подписанным или беззнаковым.