Ассемблер для чайников
Главная / Ассемблер /
Эта книга рассчитана на начинающих изучать язык ассемблера. Двольно часто можно увидеть книги и статьи с заголовками типа Ассемблер это просто. Как бы не так. Подобные лозунги ни что иное, как маркетинговый ход — надо же как то завлекать клиентов (читателей). Конечно, научиться писать простые программки и в самом деле легко (в этом вы убедитесь, прочитав первые главы представленной ниже книги). Но всё зависит от задач, которые вы перед собой ставите. Научиться водить автомобиль — это просто. Однако Шумахер только один.
Представленная ниже книга не ответит на все ваши вопросы. Но, надеюсь, научит вас искать ответы на вопросы
самостоятельно. Книгу Assembler для чайников можно скачать бесплатно вместе с
исходными кодами программ, которые рассматриваются в книге в качестве примеров.
| Скачать бесплатно книгу Ассемблер для начинающих (с исходными кодами) можно ЗДЕСЬ |
- ПРЕДИСЛОВИЕ
- ВВЕДЕНИЕ
- Немного о процессорах
- БЫСТРЫЙ СТАРТ
- Первая программа
- Emu8086
- Debug
- MASM, TASM и WASM
- Ассемблирование в TASM
- Ассемблирование в MASM
- Ассемблирование в WASM
- Выполнение программы
- Использование BAT-файлов
- Шестнадцатеричный редактор
- Резюме
- ВВЕДЕНИЕ В АССЕМБЛЕР
- Hello World на Ассемблере
- Комментарии в Ассемблере
- Как устроен компьютер
- Структура процессора
- Регистры процессора
- Регистры-указатели
- Сегментные регистры
- Цикл выполнения команды
- Организация памяти
- Реальный режим
- Защищённый режим
- Системы счисления
- Двоичная система счисления
- Шестнадцатеричная система счисления
- Другие системы
- Представление данных в памяти компьютера
- Положительные числа
- Отрицательные числа
- Что такое переполнение
- Регистр флагов
- Коды символов
- Вещественные числа
- Первая попытка
- Нормализованная запись числа
- Представление вещественных чисел в памяти компьютера
- Числа с фиксированной точкой
- Числа с плавающей точкой
- Что такое BCD
- Условный и безусловный переход
- Процедуры в Ассемблере
- Как вызывается процедура
- Инкремент и декремент в Ассемблере
Ассемблер для начинающих / Хабр
В любом деле главное — начать. Или вот еще хорошая поговорка: «Начало — половина дела». Но иногда даже не знаешь как подступиться к интересующему вопросу. В связи с тем, что воспоминания мои еще свежи, спешу поделиться своими соображениями с интересующимися.
Или вот еще хорошая поговорка: «Начало — половина дела». Но иногда даже не знаешь как подступиться к интересующему вопросу. В связи с тем, что воспоминания мои еще свежи, спешу поделиться своими соображениями с интересующимися.
Скажу сразу, что лично я ассемблирую не под PC, а под микроконтроллеры. Но это не имеет большого значения, ибо (в отличие от микроконтроллеров AVR) система команд данных микроконтроллеров с PC крайне схожа. Да и, собственно говоря, ассемблер он и в Африке ассемблер.
Конечно, я не ставлю своей целью описать в этой статье всё необходимое от начала и до конца. Благо, по ассемблеру написано уже невообразимое число литературы. И да, мой опыт может отличаться от опыта других программистов, но я считаю не лишним изложить основную концепцию этого вопроса в моем понимании.
Для начала успокою любознательных новобранцев: ассемблер — это совсем не сложно, вопреки стереотипному мнению. Просто он ближе к «земле», то бишь к архитектуре. На самом деле, он очень прост, если ухватить основную идею. В отличие от языков высокого уровня и разнообразных специализированных платформ для программирования (под всем перечисленным я понимаю всякое вроде C++, MatLAB и прочих подобных штук, где требуются программерские навыки), команд тут раз-два и обчелся. По началу даже, когда мне нужно было посчитать двойной интеграл, эта задача вызывала лишь недоумение: как при помощи такого скудного количества операций можно совершить подобную процедуру? Ведь образно говоря, на ассемблере можно разве что складывать, вычитать и сдвигать числа. Но с помощью ассемблера можно совершать сколь угодно сложные операции, а код будет выходить крайне лёгкий. Вот даже для примера, нужно вам зажечь светодиод, который подключен, например, к нулевому контакту порта номер 2, вы просто пишете:
В отличие от языков высокого уровня и разнообразных специализированных платформ для программирования (под всем перечисленным я понимаю всякое вроде C++, MatLAB и прочих подобных штук, где требуются программерские навыки), команд тут раз-два и обчелся. По началу даже, когда мне нужно было посчитать двойной интеграл, эта задача вызывала лишь недоумение: как при помощи такого скудного количества операций можно совершить подобную процедуру? Ведь образно говоря, на ассемблере можно разве что складывать, вычитать и сдвигать числа. Но с помощью ассемблера можно совершать сколь угодно сложные операции, а код будет выходить крайне лёгкий. Вот даже для примера, нужно вам зажечь светодиод, который подключен, например, к нулевому контакту порта номер 2, вы просто пишете:
И, как говорится, никаких проблем. Нужно включить сразу штуки четыре, подключенных последовательно? Да запросто:
mov P2, #000fh
Да, тут я подразумеваю, что начинающий боец уже знаком хотя бы со системами счисления.
 Ну хотя бы с десятичной. 😉
Ну хотя бы с десятичной. 😉Итак, для достижения успеха в деле ассемблирования, следует разбираться в архитектуре (в моем случае) микроконтроллера. Это раз.
Кстати, одно из больных мест в познании архитектуры — это организация памяти. Тут на Хабре я видела соответствующую статью: habrahabr.ru/blogs/programming/128991. Еще могу упомянуть ключевые болевые точки: прерывания. Штука не сложная, но по началу (почему-то) тяжелая для восприятия.
Если перед вами стоит сложная задача и вы даже не знаете как по началу к ней подступиться, лучше всего написать алгоритм. Это воистину спасает. А по началу, даже если программа совершенно не сложная, лучше всё же начать с алгоритма, ибо этот процесс помогает разложить всё в голове по местам. Возвращаясь к примеру с вычислением двойного интеграла по экспериментальным данным, обдумывала алгоритм я весь день, но зато потом программку по нему написала всего за 20 минут. Плюс алгоритм будет полезен при дальнейшей модернизации и/или эксплуатации программы, а то ассемблерный код, временами, если и будет понятен построчно, то чтобы разобраться в чем же общая идея, придется немало потрудиться.
Итак, второй ключ к успеху — подробно написанный и хорошо продуманный алгоритм. Настоятельно рекомендую не садиться сразу за аппарат и писать программу. Ничего дельного вы с ходу не напишете. Это два.
Собственно, хотелось бы как Фандорин написать: «Это т-т-три»… Но, боюсь, на этом пока можно остановиться. Хотя хотелось бы добавить еще несколько рекомендаций и пряников.
Подводя итог моему несколько сумбурному монологу, ключевые моменты в программировании на ассемблере — это знание архитектуры и связное построение мыслей. Конечно, не обязательно сразу с головой кидаться в штудировании литературы с описанием внутренностей того же PC, но общее представление (повторюсь, хотя бы для начала) будет очень нужно.
А теперь обещанные пряники! Вот я тут распинаюсь о каком-то непонятном ассемблере, а что же в нем, собственно говоря, хорошего? Да много всего! Во-первых, конечно, не нужно запоминать много команд, используемых библиотек и прочей сопутствующей дребедени. Всего парочка команд и, считайте, вы во всеоружии. Во-вторых, в связи с крайней близостью к машинным кодам, вы можете делать практически всё, что душе угодно (в отличие от тех же языков высокого уровня)! В-третьих, ассемблерный код, по причине максимальной лаконичности в формулировках, выполняется крайне быстро.
Всего парочка команд и, считайте, вы во всеоружии. Во-вторых, в связи с крайней близостью к машинным кодам, вы можете делать практически всё, что душе угодно (в отличие от тех же языков высокого уровня)! В-третьих, ассемблерный код, по причине максимальной лаконичности в формулировках, выполняется крайне быстро.
В общем, сплошные плюсы. На этой оптимистической ноте разрешите откланяться.
Сборка. Часть 1. Изучаем сборку! | Программа инженерного образования (EngEd)
Вначале были перфокарты. В конце концов, кому-то пришла в голову блестящая идея сделать компьютер программируемым. Просто введите шестнадцатеричный код и запустите его. Проблема в том, что очень сложно посмотреть на шестнадцатеричный код и понять, что он делает.
Войдите в сборку
Сборка по-прежнему очень проста, и каждая деталь того, как компьютер выполняет свою задачу, должна быть указана. Разница в том, что ассемблер делает эти инструкции удобочитаемыми для человека.
Следующим шагом выше будет использование языка программирования, такого как C, Java или Typescript. Это, безусловно, проще, чем использование ассемблера, но и по сей день все еще существуют задачи, которые не могут решить языки системного программирования. Вот некоторые примеры:
Это, безусловно, проще, чем использование ассемблера, но и по сей день все еще существуют задачи, которые не могут решить языки системного программирования. Вот некоторые примеры:
- Агрессивная оптимизация (C и Rust уже очень быстры, но не идеальны) Сборка
- упрощает расчет точного времени выполнения программы
- Программы, которые должны работать напрямую с оборудованием, например драйверы
- Загрузка операционной системы
Требования
К сожалению, сборка не одинакова для всех систем. Разным компьютерам для работы нужен разный код. Вот что вам нужно для этого урока:
- Компьютер x86 (например, он не будет работать на Raspberry Pi)
- 32-битная или 64-битная операционная система (предпочтительно Linux)
- Ассемблер (NASM в Linux или MASM в Windows)
- Опыт низкоуровневого программирования (C, C++, Rust и Go — хорошие языки для изучения)
Разделы
Исполняемые программы можно разделить на три раздела (вы можете использовать больше, но в этом руководстве мы будем придерживаться трех). Вот они:
Вот они:
- текст — Этот раздел содержит фактические инструкции, которые будет выполнять ваш код.
- bss — Здесь хранятся все глобальные переменные. Сюда помещается любая статическая переменная
- data — Этот раздел используется для постоянных глобальных переменных.
Разделы объявляются простым вводом section .name . Например, раздел данных будет объявлен с использованием:
section .data
Переменные
Переменные, как мы уже говорили, хранятся в секции bss . Мы не можем просто объявить их значение, как в обычном языке. Вместо этого мы можем точно сказать ассемблеру, сколько байтов нужно зарезервировать.
раздел .bss вар резб 4
Это создает переменную с именем var и резервирует для него четыре байта. Если бы мы хотели зарезервировать два байта, мы бы поставили в конце 2 . Чтобы получить доступ к значению
Чтобы получить доступ к значению var , мы заключаем его имя в квадратные скобки: [var] .
Операторы
Операторы на ассемблере имеют следующий формат:
Мнемоника [операнды] [;комментарий]
Давайте разберемся.
Мнемоника является фактической для запуска. Некоторые операции принимают один параметр. Некоторые берут несколько. В ассемблере много инструкций, но мы остановимся на следующих.
| Мнемоника | Операнд 1 | Операнд 2 | Описание |
|---|---|---|---|
| мов | местоположение | значение | Устанавливает операнд 1 в операнд 2 |
| вкл. | местоположение | Добавляет единицу к местоположению | |
| дек | местоположение | Вычитает единицу из местоположения | |
| добавить | местоположение | значение | Добавляет значение в ячейку |
| суб | местоположение | значение | Вычитает значение из местоположения |
| джмп | этикетка | Переход к части программы | |
| смп | значение1 | значение2 | Сравнивает два значения |
| и | этикетка | Переход к части программы, если два значения равны | |
| целое число | прерывание | Создает программное прерывание |
Комментарии в ассемблере — это все, что идет после точки с запятой ( ; ). Вы уже должны быть знакомы с тем, что они делают — они помогают объяснить ваш код другим людям, которые его читают.
Вы уже должны быть знакомы с тем, что они делают — они помогают объяснить ваш код другим людям, которые его читают.
Подробнее об этих инструкциях мы поговорим позже. А пока вот несколько примеров:
mov [var], 5 ; переменная = 5 дек [вар] ; вар -- добавить [вар], 3 ; переменная += 3 ; Посмотрим, сможешь ли ты придумать свое!
Метки
Рассмотрим следующий код C
void main() {
интервал переменная = 0;
в то время как (1) {
вар++;
}
}
Этот код использует цикл while для бесконечного повторения. Однако в сборке нет таких простых циклов. В сборке вам нужно сделать что-то более похожее на следующее
void main() {
интервал переменная = 0;
петля:
вар++;
перейти в петлю;
}
Простите, если вы не знаете, что это допустимый код C. (Это довольно плохая практика.) Но в ассемблере это все, что у вас есть. Попробуем перевести это на Ассемблер.
Давайте настроим нашу программу. Нам нужен раздел text для хранения инструкций программы и раздел bss для хранения нашей переменной.
раздел .текст раздел .bss
Мы еще не говорили об этом, но нам нужно сказать программе, с чего начать в нашей программе. Мы создадим метку с именем _start и начнем с нее. Мы можем указать компоновщику, с чего начать, используя global _start .
раздел .текст глобальный _start _Начало:
Теперь нам нужно создать нашу переменную. Мы будем использовать 32-битное целое число, для которого требуется четыре байта.
раздел .bss вар резб 4
Теперь нам нужно инициализировать переменную. Именно для этого и предназначена инструкция mov .
_старт: mov двойное слово [вар], 0 ; Здесь у нас есть «dword», потому что это 32-битная операция.
Теперь нам нужен цикл. Мы создадим метку, назовем ее loop и безоговорочно перейдем к ней.
_старт: mov двойное слово [вар], 0 петля: джмп петля
Наконец, нам нужно увеличить нашу переменную.
раздел .текст глобальный _start _Начало: mov двойное слово [вар], 0 петля: inc двойное слово [var] джмп петля раздел .bss вар резб 4
Вероятно, я должен упомянуть, как вы можете запустить это. Предположим, что файл называется incrementor.asm и вы используете NASM:
nasm -f elf incrementor.asm ld -m elf_i386 -s -o инкрементатор incrementor.o ./инкрементор
Регистры
Знаете ли вы, что ваш процессор имеет встроенную память? 😲 Регистры — это память, встроенная в ЦП. Из-за этого можно молниеносно использовать регистры вместо хранения значений в оперативной памяти.
Так почему бы нам просто не использовать регистры для всего?
Вот в чем проблема. У нас не так много регистров. В этом уроке будут использоваться только четыре. Это станет проблемой позже, но пока нам нужно меньше четырех переменных, это должно работать для нас. Мы будем использовать четыре:
Мы будем использовать четыре: eax , ebx , ecx и edx . Мы будем использовать эти четыре, потому что их очень легко запомнить. Все они имеют формат e_x . Каждый из этих регистров может хранить одно 32-битное число.
Мы можем переписать наш бесконечный цикл, чтобы использовать раздел регистра
.text глобальный _start _Начало: движение акс, 0 петля: вкл. джмп петля
Теперь нам вообще не нужна оперативная память!… кроме как для хранения фактической программы в памяти. Нам также не нужно указывать размер операции. Размер eax всегда равен четырем байтам.
Заключение
На этом основы сборки закончены. Прочтите мою следующую статью о том, как написать настоящую программу с помощью ассемблера.
Основы написания ассемблера. Хотите научиться ассемблеру? Начните здесь! | by Emmett Boudreau
Хотите изучать ассемблер? Начните здесь!
(src = https://pixabay. com/images/id-424812/)
com/images/id-424812/)Компьютеры — это технологические инновации, которые полностью изменили весь мир и то, как мы делаем практически все, всего за полвека. . Вычислительные технологии настолько важны для современной эпохи, что мы даже назвали ту часть времени, которую мы живем, «информационной эрой» из-за распространения Интернета и компьютеров во всем мире. Излишне говорить, что компьютерная теория — очень важный предмет, особенно в контексте науки о данных. В основе компьютерной теории лежит очень важный компонент аппаратного обеспечения, центральный процессор или ЦП.
Центральный процессор
Центральный процессор часто можно метафорически сравнить с человеческим мозгом, так как он, по сути, является мозгом операции, когда речь идет о компьютере. Я думаю, что более точной метафорой могла бы быть сама кора головного мозга, поскольку процессоры не обязательно делают все, что делает мозг, например, хранят память, но я отвлекся, эта метафора все еще выполняет свою работу. Процессор — это прежде всего устройство ввода-вывода, которое может временно хранить биты внутри регистров для вычислений. Единственными другими компонентами внутри ЦП являются блок управления, который направляет поток данных в регистры и из них, и, наконец, комбинационное логическое ядро. Комбинационное логическое ядро используется для очень быстрой обработки команд с данными и даже может использоваться для битов, хранящихся в памяти, а не только в регистрах. Другими словами, если бы у нас было 8 битов в стеке, а затем 8 битов в регистре процессора, оба из которых были целыми числами, и мы хотели бы сложить числа, мы могли бы использовать команду add. Сборка для этого, которую вы пока можете игнорировать, будет выглядеть так:
Процессор — это прежде всего устройство ввода-вывода, которое может временно хранить биты внутри регистров для вычислений. Единственными другими компонентами внутри ЦП являются блок управления, который направляет поток данных в регистры и из них, и, наконец, комбинационное логическое ядро. Комбинационное логическое ядро используется для очень быстрой обработки команд с данными и даже может использоваться для битов, хранящихся в памяти, а не только в регистрах. Другими словами, если бы у нас было 8 битов в стеке, а затем 8 битов в регистре процессора, оба из которых были целыми числами, и мы хотели бы сложить числа, мы могли бы использовать команду add. Сборка для этого, которую вы пока можете игнорировать, будет выглядеть так:
mov rsi, example_data1
add rsi, example_data2
Это, конечно, предполагает, что обе эти части стека являются псевдонимами, которые зарезервированы или назначены ранее. Конечно, с таким сложным аппаратным компонентом всегда должен быть какой-то способ взаимодействия программного обеспечения с ним, и именно здесь в игру вступает ассемблер или машинный код.
Что такое сборка?
Сборка — это система меток регистров, разделов и команд, которые процессор может использовать для выполнения определенных операций на аппаратной стороне. Если процессор — это мозг компьютера, то Assembly — это его спинной мозг. Ассемблер позволяет ЦП передавать информацию между памятью и ядром, чтобы компьютер действительно делал то, что от него хочет человек.
Зачем изучать ассемблер?
Сборка, безусловно, потеряла многих пользователей из-за того, что C был гораздо более доступным и универсальным, хотя и немного медленнее. Тем не менее, я думаю, что веская причина получить хотя бы минимальное образование в области ассемблера заключается в том, что это действительно может помочь вам узнать о компьютерах больше, чем вы когда-либо могли бы писать на таких языках, как Python, C++ или даже C. Даже если вы новичок, Я думаю, что базовое понимание ассемблера действительно может помочь понять концепции ввода и вывода на очень низком уровне.
Кроме того, есть много очень хорошо оплачиваемых вакансий по программированию на ассемблере, поэтому я думаю, что это может быть даже полезно для получения денег. Излишне говорить, что если никакие другие языки вы не изучили достаточно хорошо, чтобы написать код, который вы хотите, ассемблер всегда может быть точкой отката. Тем не менее, я думаю, что основная причина, по которой я хотел написать статью о программировании на ассемблере, была в интересах образования, так как это, вероятно, большая часть того, что будет сделано в этой статье. Специалисты по обработке данных действительно имеют довольно большую часть своей работы, посвященной компьютерному программированию, поэтому понимание компьютера может иметь жизненно важное значение для написания лучшего кода.
Теперь, когда у нас есть базовое понимание ассемблера, мы можем заняться написанием нашей первой программы на этом языке! Конечно, для того, чтобы написать ассемблер, вам понадобится скомпилированный ассемблер. Иногда вы можете слышать, как программисты называют язык ассемблера ассемблером, это технически неправильно, поскольку ассемблер больше похож на компилятор, а не на сам язык. Например, язык Python и компилятор Python — это не одно и то же. Это странная вещь, которая меня раздражает, поэтому я полагаю, что хотел бы объяснить, что на самом деле между этими двумя терминами есть разница!
Иногда вы можете слышать, как программисты называют язык ассемблера ассемблером, это технически неправильно, поскольку ассемблер больше похож на компилятор, а не на сам язык. Например, язык Python и компилятор Python — это не одно и то же. Это странная вещь, которая меня раздражает, поэтому я полагаю, что хотел бы объяснить, что на самом деле между этими двумя терминами есть разница!
Настройка ассемблера
С самого начала нам нужно посмотреть на наши системы, чтобы понять, какой ассемблер нам понадобится. Обычно вы можете ассемблировать для других ядер и процессоров, но вы не сможете эффективно отлаживать, если у вас нет подходящего ассемблера для вашей операционной системы и процессора. Поскольку я на Linux, в настоящее время POP! ОС, производной от Ubuntu и имею процессор Intel, я буду использовать Netwide Assembler или NASM. Для систем Windows Intel вам понадобится Microsoft Macro Assembler или MASM. Если у вас какая-то другая система, вы всегда можете погуглить
(ОС) (производитель ЦП) Ассемблер
Следует также отметить, что некоторые системные вызовы потенциально могут отличаться от примеров, следующих от ассемблера к ассемблеру. В примере из этой статьи существуют огромные различия между разными ядрами, поэтому я не могу точно учесть их все. Имея это в виду, статья, вероятно, по-прежнему полезна для чтения, даже если вы не будете следовать ей, поскольку основная цель здесь — узнать больше о компьютерах. Тем не менее, я могу, по крайней мере, указать вам правильное направление, с чего начать поиск в Google, независимо от того, на какой системе вы работаете, и что именно вам нужно будет установить:
В примере из этой статьи существуют огромные различия между разными ядрами, поэтому я не могу точно учесть их все. Имея это в виду, статья, вероятно, по-прежнему полезна для чтения, даже если вы не будете следовать ей, поскольку основная цель здесь — узнать больше о компьютерах. Тем не менее, я могу, по крайней мере, указать вам правильное направление, с чего начать поиск в Google, независимо от того, на какой системе вы работаете, и что именно вам нужно будет установить:
- Windows — Нажмите кнопку «Пуск» Windows, затем нажмите «Настройки» (значок шестеренки). В меню «Настройки» нажмите «Система». Прокрутите вниз и нажмите «О программе».
- OSX — щелкните меню Apple > «Об этом Mac».
- Linux — Если вы не знаете, как это сделать, я предполагаю, что вы используете Gnome. На большинстве DE это все еще будет работать. Нажмите кнопку действий (или кнопку Windows), а затем введите about и нажмите Enter.
В Linux вы можете установить NASM напрямую через менеджеры пакетов. Например, Apt:
Например, Apt:
sudo apt-get install nasm
Я уверен, что в Windows вы сможете установить MASM с помощью стандартного мастера установки. В MacOS, должен признаться, я вообще не знаю, как установить Ассемблер. Я предполагаю, что это, вероятно, будет сделано через Brew.
Наш код
Сегодня для нашего проекта мы напишем простую программу Hello «Name». По сути, это Hello World! приложение, которое также покажет, как резервировать байты для ввода и тому подобное. Хотя я обычно думаю, что Hello World! это слишком просто для первого проекта, так как в большинстве языков высокого уровня это что-то вроде print("Привет, мир!") , на примере ассемблера, я думаю, это отличный пример для обучения! Кроме того, этот код будет доступен на Github, так что вы можете свободно скачать его, собрать или просто посмотреть здесь:
GitHub — emmettgb/Assembly-Intro: Некоторые вводные примеры в сборке NASM
Некоторые вводные примеры в Сборка НАСМ.
 Внесите свой вклад в разработку emmettgb/Assembly-Intro, создав учетную запись…
Внесите свой вклад в разработку emmettgb/Assembly-Intro, создав учетную запись…github.com
Разделы
Первое, что нам нужно обсудить и понять основы сборки для этого проекта, — это концепция секций. Разделы используются для определения данных, которые процессор должен будет выделить или зарезервировать в стеке, или дать процессору важные директивы в виде текста. Есть несколько разделов, но сейчас мы сосредоточимся на разделе .data. Чтобы определить раздел, вы просто пишете раздел, а затем раздел, который мы хотим создать. Например, раздел .data:
section .data
Кроме того, для разделов не нужно использовать двоеточие, как для функций. В любом случае, мы также определим еще один раздел под ним, называемый разделом .bss, а затем разделом .text. После этого наши разделы должны выглядеть так:
section .datasection .bsssection .text
Aliasing Stack
Во-первых, раздел .data используется для определения статических данных. Это означает, что мы будем помещать эти данные непосредственно в стек с псевдонимом, который их вызывает. Эта команда называется определить байты, для краткости мы пишем db. Перед db мы хотим указать псевдоним этой части стека. Скажем, наш стек начинается с 0, всякий раз, когда мы пишем этот псевдоним, он сохраняет для нас только начальную точку наших байтов, 0, в этом примере мы будем писать привет _____. Это будет 6 байтов, по одному на каждый символ в приветствии и один на пробел в конце. Я также собираюсь зарезервировать еще больше памяти для конца, с пояснением и возвратом. Хотя мы привыкли к красивым и причудливым регулярным выражениям с ядром внутри ядра, у процессора их нет, поэтому вместо \n мы будем использовать число 10. Это просто число, которое по сути работает как регулярное выражение для добавление новой строки.
Это означает, что мы будем помещать эти данные непосредственно в стек с псевдонимом, который их вызывает. Эта команда называется определить байты, для краткости мы пишем db. Перед db мы хотим указать псевдоним этой части стека. Скажем, наш стек начинается с 0, всякий раз, когда мы пишем этот псевдоним, он сохраняет для нас только начальную точку наших байтов, 0, в этом примере мы будем писать привет _____. Это будет 6 байтов, по одному на каждый символ в приветствии и один на пробел в конце. Я также собираюсь зарезервировать еще больше памяти для конца, с пояснением и возвратом. Хотя мы привыкли к красивым и причудливым регулярным выражениям с ядром внутри ядра, у процессора их нет, поэтому вместо \n мы будем использовать число 10. Это просто число, которое по сути работает как регулярное выражение для добавление новой строки.
section .data
hello: db "Hello"
окончание: db "!", 10
section .bsssection .text
Итак, теперь, если наш стек начинался с 0, у нас будет псевдоним hello, начинающийся с 0 и оканчивается на 6, а затем поверх него накладывается окончание псевдонима, начинающееся с 7 и заканчивающееся на 9 (один байт зарезервирован для 10).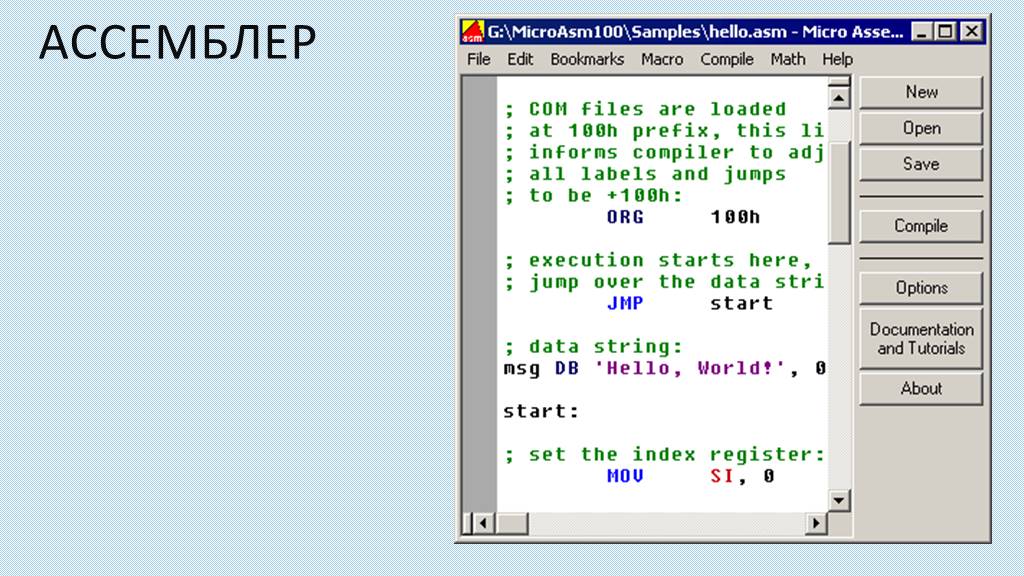 Теперь давайте перейдем к разделу .bss, который обычно используется для резервирования данных для чего-то, что будет использоваться внутри приложения. Конечно, мы собираемся зарезервировать байты для нашего пользовательского ввода, поэтому мы назовем наш новый псевдоним так. Имен длиннее 16 байт не так много, поэтому я выделю столько. Мы резервируем байты с помощью команды resb. Мы следуем за этим количеством байтов, которые мы хотели бы зарезервировать:
Теперь давайте перейдем к разделу .bss, который обычно используется для резервирования данных для чего-то, что будет использоваться внутри приложения. Конечно, мы собираемся зарезервировать байты для нашего пользовательского ввода, поэтому мы назовем наш новый псевдоним так. Имен длиннее 16 байт не так много, поэтому я выделю столько. Мы резервируем байты с помощью команды resb. Мы следуем за этим количеством байтов, которые мы хотели бы зарезервировать:
section .bss
input: resb 16
.text
Последний раздел, с которым мы собираемся работать сегодня, будет разделом .text. Этот раздел используется для предоставления процессору жизненно важной информации, а также для хранения всего кода для нашего программного обеспечения сборки. В этом случае _start будет точкой входа внутри нашего файла сборки, к которой должен обращаться процессор. Конечно, у него есть и другие цели, но в этом примере нам нужно будет использовать только эту часть. Все, что нам нужно сделать, это вызвать нашу стартовую функцию (которую мы еще не написали) с помощью глобальной команды:
section .text
global _start
Теперь раздел нашего кода будет выглядеть так:
; Разделы:
section .data
hello: db "Hello"
окончание: db "!", 10section .bss
input: resb 16section .text
global _start; Функции:
Вы также можете прокомментировать свой код с помощью ; как в Лиспе.
Функции
Чтобы написать функцию, мы просто введем псевдоним функции, за которым следует двоеточие, например наша стартовая функция:
_start:
Функции работают в ассемблере так же, как и в других языках. Имея это в виду, теперь нам нужно добавить команды в наши функции, и этому будет предшествовать МНОГО объяснений, так что будьте готовы.
Регистры и системные вызовы
Во многих отношениях программирование на ассемблере представляет собой связь между процессором и ядром. Мы осуществляем большую часть этого взаимодействия, перемещая данные в регистры, а затем используя системные вызовы для завершения операции на стороне ядра, чтобы обеспечить своего рода возврат фактическому человеку, использующему компьютер. Системные вызовы всегда будут работать таким образом, что данные сначала перемещаются в определенные позиции в регистрах, а затем выполняется системный вызов, когда ядро выполняет действие, помещенное в регистр. Регистры — это то, что мы можем считать временным хранилищем данных внутри процессора, и они невероятно изменчивы. Эти регистры названы с позициями, например, 1, 2, 3 …
Системные вызовы всегда будут работать таким образом, что данные сначала перемещаются в определенные позиции в регистрах, а затем выполняется системный вызов, когда ядро выполняет действие, помещенное в регистр. Регистры — это то, что мы можем считать временным хранилищем данных внутри процессора, и они невероятно изменчивы. Эти регистры названы с позициями, например, 1, 2, 3 …
Вот карта всех регистров для каждой архитектуры. Обратите внимание, что я не смог найти таблицу с атрибуцией Creative Commons, поэтому я взялся за изнурительную задачу создания своей собственной специально для вас.
(изображение автора) (Кстати, CREATIVE COMMONS, вы можете сохранить это изображение и поделиться им.)Чаще всего мы будем работать либо с системными вызовами, либо с командами процессора, используя эти регистры. Мы можем сделать это как из регистров, так и из памяти. Например, мы хотим добавить регистры rax и rbx:
add rax, rbx
Теперь поговорим о системных вызовах. Чтобы сделать системный вызов нашему ядру, нам нужно будет поместить данные в наши регистры. Обычно в позицию 1, регистр rax, мы помещаем команду для выполнения ядром с другими нашими регистрами. Конечно, вы можете найти полный список системных вызовов для ваших конкретных ядер.
Чтобы сделать системный вызов нашему ядру, нам нужно будет поместить данные в наши регистры. Обычно в позицию 1, регистр rax, мы помещаем команду для выполнения ядром с другими нашими регистрами. Конечно, вы можете найти полный список системных вызовов для ваших конкретных ядер.
Выполнение системных вызовов
Конечно, мне будет невыносимо много работы, чтобы пройти каждый системный вызов с вами, так как, например, в Linux их 313, поэтому вместо этого я просто покажу те, с которыми я буду работать. Cегодня. Вы можете просмотреть полный полный список системных вызовов Linux здесь:
Таблица системных вызовов Linux для x86 64
Linux 4.7 (взято с github.com/torvalds/linux 20 июля 2016 г.), x86_64
В любом случае, сегодня мы рассмотрим 3 вызова: sys_exit, sys_read и sys_write. Наша программа предназначена для чтения перед тем, как начать запись, так как она никогда не запрашивает наше имя (вы можете это заметить, потому что мы не зарезервировали для этого байты), поэтому первое, что нам нужно будет вызвать, это наш sys_write. Здесь я приведу небольшую таблицу для sys_read и sys_write:
Здесь я приведу небольшую таблицу для sys_read и sys_write:
Эти виды таблиц предоставят вам почти все, что вам нужно знать об этих системных вызовах. Мы можем думать о системных вызовах как о методах с регистрами в качестве аргументов. Мы будем использовать команду MOV для перемещения данных в регистры.
Чтобы начать демонстрацию системных вызовов, я думаю, было бы полезно использовать самый простой системный вызов, которым, конечно же, является системный вызов выхода. Это также поможет нам лучше понять, как выполнять системные вызовы, используя только регистры.
Выход
(Изображение автора) Как мы видим в нашей таблице, числовая метка для этого системного вызова будет 60. Это почти всегда будет находиться в регистре позиции 1, регистре rax, когда мы делаем системные вызовы. Итак, давайте теперь начнем с использования команды MOV для rax с целым числом без знака. Это целое число без знака является кодом выхода, в данном случае мы хотим, чтобы он был равен 0. В мире программирования код 0 означает, что с нашей программой все в порядке. Сначала мы начнем с перемещения 0 в 3 регистра rax:
В мире программирования код 0 означает, что с нашей программой все в порядке. Сначала мы начнем с перемещения 0 в 3 регистра rax:
_start:
mov rax, 60
Обратите внимание на синтаксис
[команда] (регистр), (регистр или данные)
Следуя тому же синтаксису, переместим 0 во вторую позицию регистра, rdi :
_start:
mov rax, 60
mov rdi, 0
Наконец, мы просто добавим системный вызов в конец, чтобы сделать системный вызов: Наш окончательный результат на данный момент должен выглядеть примерно так:
; Разделы:
section .data
hello: db "Hello"
окончание: db "!", 10section .bss
ввод: resb 16section .text
global _start; Функции: _start:
mov rax, 60
mov rdi, 0
syscall
Сборка!
Теперь соберем наше новое приложение. Конечно, это приложение не предназначено для каких-либо действий, кроме открытия и закрытия, но все же будет легко определить, если что-то пойдет не так, поскольку мы получим сообщение об ошибке сегментации. Теперь нам нужно перенести наш терминал в директорию с нашим файлом сборки и собрать его с помощью nasm:
Теперь нам нужно перенести наш терминал в директорию с нашим файлом сборки и собрать его с помощью nasm:
nasm -f elf64 hello_world.asm
Это даст нам файл .o, который мы теперь можем преобразовать в исполняемый двоичный файл:
ld hello_world.o -o hello
Затем мы можем выполнить этот двоичный файл с помощью ./:
./hello( Изображение автора)
Поздравляем!
Ваша первая программа на ассемблере официально собрана! Если вы в конечном итоге получите «Ошибка сегментации (основной дамп)», это в основном означает, что где-то в вашем коде что-то не так. Обнаружение этих ошибок может быть довольно сложной задачей, потому что дамп ядра действительно не содержит много информации о том, где возникает исключение.
Чтение байтов
Следующее, что нам нужно сделать, это обработать некоторый простой стандартный ввод и вывести этот ввод вместе с нашим приветственным сообщением. Вернемся к таблице системных вызовов, содержащей необходимую для этого информацию:
Мы видим, что sys_read — это первый вызов, который равен нулю. Имея это в виду, мы продолжим и переместим это в регистр rax:
Имея это в виду, мы продолжим и переместим это в регистр rax:
mov rax, 0
Затем мы переместим 0 в регистр rdi. Этот регистр используется как описание используемого нами буфера. Конечно, для этого примера нам нужен STDIN, стандартный ввод — 0, стандартный вывод — 1.
mov rdi, 0
Затем мы поместим наши зарезервированные байты ввода в регистр rsi в позицию 3:
mov rsi, input
Когда мы это делаем, мы в основном говорим
«Сохранить ввод здесь!»
Это означает, что мы указываем на позицию в стеке, которая зарезервирована и имеет псевдоним в качестве входных данных. Наконец, нам нужно количество байтов, которое может занимать этот буфер, 16:
mov rax, 0
mov rdi, 0
mov rsi, input
mov rdx, 16
syscall
Output
Наконец, давайте теперь перейдем к печати этого вместе с остальной частью нашего сообщения на экране. Мы начнем с части «Привет» нашего сообщения. Во-первых, глядя на диаграмму выше, мы переместим 1 в регистр rax.
Во-первых, глядя на диаграмму выше, мы переместим 1 в регистр rax.
mov rax, 1
Поскольку это стандартный вывод, нам нужен этот дескриптор, также переместив 1 в rdi.
mov rdi, 1
Теперь нам нужно переместить псевдоним нашей памяти в rsi, hello, а затем переместить количество байтов, которое необходимо распечатать, в rdx. Чтобы продемонстрировать, как работает стек, я собираюсь изменить это число на 7, а затем собрать это, чтобы мы могли видеть, что происходит:
mov rdx, 7
Теперь наш окончательный результат выглядит примерно так.
mov rax, 1
mov rdi, 1
mov rsi, hello
mov rdx, 7
syscall
Давайте посмотрим, что произойдет, если мы скомпилируем это с одним дополнительным байтом в rdx:
(Изображение автора)Не обращайте внимания на f, это был мой ввод, но обратите внимание, что наш раздел .data не определяет наше приветственное сообщение с точкой объяснения?
раздел .data
hello: db "Hello"
окончание: db "!", 10
Стек не просто так называется стеком. Это последовательность байтов в памяти, расположенных друг над другом. Мы помещали «окончание» поверх «привет» всякий раз, когда выделяли эти части памяти. Длина приветствия неизвестна, и поэтому мы должны перемещать его в регистр rdx всякий раз, когда делаем этот системный вызов. В любом случае, теперь я верну это значение к шести, и мы продолжим, повторяя этот код, но вместо того, чтобы печатать привет, мы будем печатать ввод. После этого мы напечатаем окончание. Я также настоятельно рекомендую использовать правильное форматирование и разделение ваших системных вызовов, потому что это определенно может привести к путанице со всеми операциями, сгруппированными в одну. Вот наш конечный продукт:
Это последовательность байтов в памяти, расположенных друг над другом. Мы помещали «окончание» поверх «привет» всякий раз, когда выделяли эти части памяти. Длина приветствия неизвестна, и поэтому мы должны перемещать его в регистр rdx всякий раз, когда делаем этот системный вызов. В любом случае, теперь я верну это значение к шести, и мы продолжим, повторяя этот код, но вместо того, чтобы печатать привет, мы будем печатать ввод. После этого мы напечатаем окончание. Я также настоятельно рекомендую использовать правильное форматирование и разделение ваших системных вызовов, потому что это определенно может привести к путанице со всеми операциями, сгруппированными в одну. Вот наш конечный продукт:
; Разделы:
section .data
hello: db "Hello"
окончание: db "!", 10section .bss
input resb 16section .text
global _start
_start:
mov rax, 0
mov rdi, 0
, mov rsi Вход
MOV RDX, 16
SYSCALLMOV RAX, 1
MOV RDI, 1
MOV RSI, Hello
MOV RDX, 6
SYSCALLMOV RAX, 1
MOV RDI, 1
MOV RSI, вход
MOV RDX.1
mov rdi, 1
mov rsi, окончание
mov rdx, 2
системный вызовmov rax, 60
mov rdi, 0
системный вызов
; Функции:
Теперь соберем и запустим!
(изображение автора)Может показаться немного странным, что наш восклицательный знак оказался внизу. Это произошло потому, что мы зарезервировали 16 байт для STDOUT. Другими словами, мы еще не знаем длину имени. Это, безусловно, можно легко исправить с помощью сравнений, переходов и флагов, но это примерно то, что я хотел сделать в этой конкретной статье.
Я думаю, что навыки этого языка определенно могут быть применены к программированию более высокого уровня! Фактически, это почти единственная причина, по которой я лично научился писать на ассемблере. Кроме того, писать просто весело, потому что часто это может быть сложнее, чем писать на стандартных языках высокого уровня. Это действительно заставляет вас больше думать об оборудовании. Если и есть что-то, что мне лично нравится, так это взаимодействие с оборудованием с точки зрения программного обеспечения.