Ассемблер с нуля — просто о сложном языке программирования.
mr.Аsm
Просто о сложном.
Для начала уясним цели и задачи, которые будут рассматриваться в цикле статей в рамках рубрики «Ассемблер с нуля», определим потенциальную аудиторию.
«Ассемблер с нуля» заинтересует тех, кто желает научиться программировать на языке ассемблер, не будучи профессиональным математиком.
Информация излагается понятной для любого начинающего, не обладающего никакими (совершенно никакими) дополнительными знаниями выше уровня школьника седьмого — восьмого класса среднеобразовательной школы.
Дополнительная, но не менее важная цель — наработать общий подход к изучению любого языка программирования. Показать, насколько просто научиться программировать самостоятельно при наличии времени и желания.
Статьи заинтересуют преподавателей программирования с практической направленностью изложения материала.
Несомненную пользу в излагаемом материале найдут студенты, изучающие ассемблер — лишними знания не бывают, к тому же форма изложения материала проста и общедоступна.
Опытных гуру программирования может возмутить наш подход к форме подачи материала. Ох как любят программисты считать себя избранными, обладающими недоступными для других способностями. Ох как любят усложнять простые вещи, чтобы пустить пыль в глаза и набить себе цену! Призываю всех не становиться на тёмную сторону силы — знаниями нужно делиться, рассказывая просто о сложном и избегая усложнения простых вещей!
Ассемблер с нуля — практический подход.
Чтобы не показаться полными теоретиками, оторванными от практического применения знаний и умений, мы постараемся не отходить от конкретики, создавать и изучать конкретный код. Будут приводиться ссылки на литературу, позволяющую более глубоко проникнуть в конкретные языки, на примере которых мы стараемся изложить наш подход к программированию. При этом основы современного программирования будут играть роль своеобразного скелета, на который будут накладываться отдельные строки программного кода.
В качестве примеров будет рассмотрено написание конкретных простейших программ «хакерской» направленности, а также изучены основы крекинга (взлома программных защит), использования дизассемблированного кода в сторонних программах.
Заранее оговоримся, что информация будет излагаться в ознакомительных целях. Чтобы обеспечивать компьютерную безопасность, защищать свой код, предотвращать возможные риски утраты интеллектуальной собственности, необходимо знать потенциальные угрозы, а также способы их реализации.
Наш план действий.
Изучать ассемблер мы будем по следующему плану :
1. Суть программирования.
2. Понятие кода и данных на примере разработки простейших MS-DOS программы на Ассемблере с учётом возможностей простой, с точки зрения современности, операционной системы.
3. Программирование Windows приложений на ассемблере и Си.
4. Основы вирусологии — просто о сложном. Создание простейшего вируса и антивируса для Windows.
5. Основы крэкинга. Исследование программ.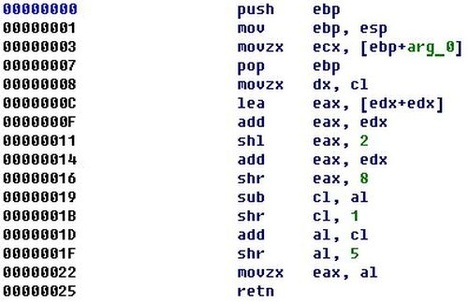
6. Дизассемблирование — ассемблирование. Сложно ли «украсть» чужой код.
7. Применение ассемблера и Си для создания современных Windows приложений.
8. Итоги, выводы, применение полученных знаний и умений на практике.
Как вы видите, мы уделим внимание не только ассемблеру, но и языкам программирования Си и С++, как наиболее близким по сути и форме. Вы помните, одна из целей цикла статей — дать заинтересованному читателю основы современного программирования, которые позволят изучить любой язык с нуля за достаточно сжатые сроки.
Updated:
Categories: Ассемблер с нуляTags: обучение программированию
Assembler с нуля — Мы знаем всё о сети!
Мы знаем
Автор adm-pcst На чтение 3 мин Просмотров 155 Опубликовано
Содержание
- Где можно писать на ассемблере?
- Что можно написать на ассемблере?
- Где учить ассемблер?
- Что такое ассемблер простыми словами?
- Где используется ассемблер в 2021?
- На каком языке написан процессор?
- Зачем программисту ассемблер?
- Что такое высокоуровневый и низкоуровневый язык программирования?
- Как очистить регистр в ассемблере?
- Какой из языков программирования низкоуровневый?
Где можно писать на ассемблере?
Поэтому чаще всего на ассемблере пишут отдельно взятые хорошо оптимизированные функции, которые затем вызываются из языков более высокого уровня, таких как с++ и c#. Исходя из этого, наиболее удобной средой для программирования будет Visual Studio, в состав которой уже входит MASM….
Исходя из этого, наиболее удобной средой для программирования будет Visual Studio, в состав которой уже входит MASM….
- assembler.
- masm.
- 64-bit.
- visual studio.
- c#
Что можно написать на ассемблере?
На ассемблере пишут драйверы устройств и некоторые компоненты операционных систем — например, ядро или загрузчик. Любительские операционные системы MenuetOS и KolibriOS полностью написаны на ассемблере. Ассемблерный код есть в программах для игровых приставок и мультимедийных кодеков.
Где учить ассемблер?
Ресурсы
- wasm.ru — наверное, самый крупный русскоязычный ресурс по Ассемблеру. …
- cracklab.ru — огромный ресурс по исследованию/крэкингу программ
- www.insidepro.com/rus/doc.shtml — огромнейшее собрание статей Криса Касперски
- programmersclub.ru/assembler — курс asm&&win32.
Что такое ассемблер простыми словами?
Ассемблер — программа, которая транслирует эти команды в машинный код.![]() Т. е. команды, понятные человеку (язык ассемблера) превращаются в команды, понятные машине (двоичный код).
Т. е. команды, понятные человеку (язык ассемблера) превращаются в команды, понятные машине (двоичный код).
Где используется ассемблер в 2021?
Где используют ассемблер в 2021 году
- Операционные системы и компиляторы. Современные операционные системы, например дистрибутивы Linux, пишут на C/C++, но там есть фрагменты на ассемблере. …
- Встроенные системы и драйверы. …
- Кибербезопасность и хакинг. …
- Виртуальные машины / эмуляторы.
На каком языке написан процессор?
язык ассемблераКаждая модель (или семейство) процессоров имеет свой набор команд (систему команд) и соответствующий ей язык ассемблера.
Зачем программисту ассемблер?
Стоит освоить ассемблер, если ты хочешь: разобраться, как работают компьютерные программы. Разобраться в деталях, на всех уровнях, вплоть до машинного кода; разрабатывать программы для микроскопических встраиваемых систем.
Что такое высокоуровневый и низкоуровневый язык программирования?
Низкоуровневые языки являются менее портируемыми, поскольку их инструкции «машинозависимы». То есть, каждая инструкция написана для конкретной машины. Код, написанный для конкретной машины, не запустится на на компьютере с другой архитектурой. Высокоуровневые языки не зависят от аппаратной части
То есть, каждая инструкция написана для конкретной машины. Код, написанный для конкретной машины, не запустится на на компьютере с другой архитектурой. Высокоуровневые языки не зависят от аппаратной части
Как очистить регистр в ассемблере?
Команды очистки регистров F и W (обнуления)
- ; установить в 0 все биты регистра KLOP.
- CLRW ; очистить аккумулятор W.
- ; установить в 0 все биты регистра W.
Какой из языков программирования низкоуровневый?
язык ассемблераОбщеизвестный пример низкоуровневого языка — язык ассемблера, хотя правильнее говорить о группе языков ассемблера. Более того, для одного и того же процессора существует несколько видов языка ассемблера. Они совпадают в машинных командах, но различаются набором дополнительных функций (директив и макросов).
Сборка— Хочу создать простой ассемблер на C. С чего начать?
Я сам написал несколько (ассемблеры и дизассемблеры) и с х86 не стал бы начинать. Если вы знаете x86 или любой другой набор инструкций, вы можете подобрать и изучить синтаксис для другого набора инструкций в короткие сроки (вечер/день), по крайней мере, львиную его долю. Процесс написания ассемблера (или дизассемблера) определенно быстро научит вас набору инструкций, и вы будете знать этот набор инструкций лучше, чем многие опытные программисты на ассемблере для этого набора инструкций, которые не изучали микрокод на этом уровне. msp430, pdp11 и thumb (не расширения thumb2) (или mips или openrisc) — все это хорошие места для начала, не так много инструкций, не слишком сложно и т. д.
Если вы знаете x86 или любой другой набор инструкций, вы можете подобрать и изучить синтаксис для другого набора инструкций в короткие сроки (вечер/день), по крайней мере, львиную его долю. Процесс написания ассемблера (или дизассемблера) определенно быстро научит вас набору инструкций, и вы будете знать этот набор инструкций лучше, чем многие опытные программисты на ассемблере для этого набора инструкций, которые не изучали микрокод на этом уровне. msp430, pdp11 и thumb (не расширения thumb2) (или mips или openrisc) — все это хорошие места для начала, не так много инструкций, не слишком сложно и т. д.
Сначала я рекомендую дизассемблер, а вместе с ним набор инструкций фиксированной длины, например, arm или thumb, mips или openrisc и т. д. Если нет, то по крайней мере используйте дизассемблер (обязательно выберите набор инструкций, для которого у вас уже есть ассемблер, компоновщик , и дизассемблер) и с помощью карандаша и бумаги понять взаимосвязь между машинным кодом и сборкой, в частности ответвлениями, у них обычно есть одна или несколько причуд, например счетчик программ опережает на одну-две инструкции при добавлении смещения, чтобы получить другой бит они иногда измеряют целыми инструкциями, а не байтами.
Довольно легко проанализировать текст с помощью программы на C, чтобы прочитать инструкции. Более сложной задачей, но, возможно, поучительной, было бы использование bison/flex и изучение этого языка программирования, чтобы позволить этим инструментам создавать (еще более грубая сила) синтаксический анализатор, который затем взаимодействует с вашим кодом, чтобы сообщить вам, что и где было найдено.
Сам ассемблер довольно прост, просто прочитайте ascii и установите биты в машинном коде. Ветви и другие инструкции, относящиеся к ПК, немного более болезненны, поскольку для их полного разрешения может потребоваться несколько проходов через исходный код/таблицы.
мов r0,r1 мов р2, #1
ассемблер начинает синтаксический анализ текста для строки (определяется как байты, следующие за возвратом каретки 0xD или переводом строки 0xA), отбрасывает пробелы (пробелы и табуляции), пока не дойдет до чего-то не пробела, затем strncmp, который с известной мнемоникой.
как минимум вам понадобится таблица/массив, который накапливает машинный код/данные по мере их создания, а также какой-то метод пометки инструкций как неполных, инструкции, относящиеся к ПК, которые должны быть завершены в будущем проходе. вам также понадобится таблица/массив, который собирает найденные вами метки и адрес/смещение в таблице машинных кодов, где они были найдены. А также метки, используемые в инструкции в качестве пункта назначения/источника, и смещение в таблице/массиве, содержащее частично завершенную инструкцию, с которой они идут. после первого прохода, затем возвращайтесь к этим таблицам, пока не сопоставите все определения меток с метками, используемыми в качестве источника или назначения, используя адрес/смещение определения метки для вычисления расстояния до рассматриваемой инструкции, а затем завершите создание машинный код этой инструкции. (может потребоваться некоторая дизассемблирование и/или использование какого-либо другого метода для запоминания того, какая это была кодировка, когда вы вернетесь к ней позже, чтобы закончить создание машинного кода).
вам также понадобится таблица/массив, который собирает найденные вами метки и адрес/смещение в таблице машинных кодов, где они были найдены. А также метки, используемые в инструкции в качестве пункта назначения/источника, и смещение в таблице/массиве, содержащее частично завершенную инструкцию, с которой они идут. после первого прохода, затем возвращайтесь к этим таблицам, пока не сопоставите все определения меток с метками, используемыми в качестве источника или назначения, используя адрес/смещение определения метки для вычисления расстояния до рассматриваемой инструкции, а затем завершите создание машинный код этой инструкции. (может потребоваться некоторая дизассемблирование и/или использование какого-либо другого метода для запоминания того, какая это была кодировка, когда вы вернетесь к ней позже, чтобы закончить создание машинного кода).
Следующий шаг — разрешить несколько исходных файлов, если вы хотите это разрешить. Теперь у вас должны быть метки, которые не разрешаются ассемблером, поэтому вам нужно оставить заполнители в выводе и внести некоторую разновидность самой длинной инструкции перехода/ветвления, потому что вы не знаете, как далеко будет пункт назначения, ожидайте худшего. Затем есть формат выходного файла, который вы выбираете для создания/использования, затем есть компоновщик, который в основном прост, но вы должны не забыть заполнить машинный код для окончательных инструкций относительно ПК, не сложнее, чем это было в ассемблере сам.
Затем есть формат выходного файла, который вы выбираете для создания/использования, затем есть компоновщик, который в основном прост, но вы должны не забыть заполнить машинный код для окончательных инструкций относительно ПК, не сложнее, чем это было в ассемблере сам.
Заметьте, написание ассемблера не обязательно связано с созданием языка программирования и последующим написанием для него компилятора, отдельная вещь, разные проблемы. На самом деле, если вы хотите создать новый язык программирования, просто используйте существующий ассемблер для существующего набора инструкций. Не обязательно, конечно, но большинство учений и учебных пособий будут использовать подход bison/flex для языков программирования, и есть много заметок/ресурсов лекций колледжа для начинающих классов компилятора, которые вы можете просто использовать, чтобы начать, а затем изменить скрипт для добавления возможностей вашего языка. Середина и задняя часть представляют собой более сложную задачу, чем передняя часть.
Ассемблер в Ink, часть I: процессы, сборка и файлы ELF
Содержание
На каникулах я решил изучить компоненты нижнего уровня программ, написав ассемблер и компоновщик с нуля. Сборка и компоновка — два последних шага типичного процесса «компиляции», который генерирует исполняемый файл из ассемблерной программы. Прохождение процесса создания базового ассемблера x86 открыло много нового о внутренней работе программ и операционных систем, которых я раньше не знал.
Мини-ассемблер/компоновщик, который я построил, конечно, написан на Ink и называется August , как осенний месяц. Он содержит некоторые внутренние библиотеки для работы с файлами ELF и сборки текста инструкций x86, но в остальном это довольно простой учебный проект.
См. август на GitHub →
В следующих двух блогах я хочу поделиться своим процессом сборки ассемблера и пролить свет на аспекты компьютеров, которые я изучил в процессе сборки, от внутреннего устройства операционной системы до интересных фактов о программах на ассемблере и машинном коде.
Мы начнем с того, с чего начал я, выяснив, что именно входит в ассемблер.
Что такое ассемблер?
Когда я начинал, я действительно хотел преодолеть разрыв между самой низкоуровневой частью программ, о которых я знал, исходным кодом на ассемблере и базовым процессором, работающим в компьютере. Оказывается, нам нужно выполнить два разных шага, чтобы преобразовать исходный код сборки в исполняемый машинный код для процессора, и они обозначены как 9.0039 собрать и связать шагов соответственно. В зависимости от инструмента некоторые ассемблеры могут выполнять обе задачи (например, August), в то время как другие, такие как NASM, выполняют только этап сборки и полагаются на компоновщики , такие как ld , для выполнения второго этапа.
Вот наша дорожная карта высокого уровня. Нам нужно перейти от сборки x86, которая для программы Hello World выглядит так:
(Если вы уже писали на ассемблере x86, вы могли заметить, что это нестандартный синтаксис. Поскольку август — игрушечный ассемблер, я начал с синтаксиса Intel, но сделал некоторые субъективные эстетические выборы, чтобы сделать синтаксический анализ немного проще, а синтаксис немного лучше, но это не должно мешать чтению кода.В частности, у нас нет запятых, разделяющих аргументы, у нас нет глобальная директива , потому что каждый символ является глобальным, а синтаксис сегмента данных немного отличается.)
раздел .текст
_начинать:
перемещение еах 0x1 ; написать системный вызов
мов эди 0x1 ; стандартный вывод
mov esi msg ; строка для печати
mov edx len ; длина
системный вызов
Выход:
движение еах 60 ; выход из системного вызова
движение эди 0 ; код выхода
системный вызов
раздел .rodata
сообщение:
дб "Привет, мир!" 0xa
Лен:
уравнение 14
… в бинарный файл, который операционная система (в моем случае Linux) может понять и запустить в процесс. Если я скомпилирую вышеописанное с последней версией августа и дамп полученного файла с
Если я скомпилирую вышеописанное с последней версией августа и дамп полученного файла с xxd , я получаю файл размером в несколько килобайт:
$ август ./hello-world.asm ./hello-world $ xxd -a ./привет-мир 00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............ 00000010: 0200 3e00 0100 0000 0010 4000 0000 0000 ..>.......@..... 00000020: 4000 0000 0000 0000 8320 0000 0000 0000 @........ ...... 00000030: 0000 0000 4000 3800 0200 4000 0500 0400 [email protected]...@..... 00000040: 0100 0000 0500 0000 0010 0000 0000 0000 ................ 00000050: 0010 4000 0000 0000 0010 4000 0000 0000 ..@.......@..... 00000060: 0010 0000 0000 0000 0010 0000 0000 0000 ................ 00000070: 0010 0000 0000 0000 0100 0000 0400 0000 ................ 00000080: 0020 0000 0000 0000 0050 6b00 0000 0000 . .......Пк..... 00000090:0050 6b00 0000 0000 0e00 0000 0000 0000 .Pk.............. 000000a0: 0e00 0000 0000 0000 0010 0000 0000 0000 ................ 000000b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ * 00001000: b801 0000 00bf 0100 0000 be00 506b 00ba ............Pk.. 00001010: 0e00 0000 0f05 b83c 0000 00bf 0000 0000 .......<........ 00001020: 0f05 0000 0000 0000 0000 0000 0000 0000 ................ 00001030: 0000 0000 0000 0000 0000 0000 0000 0000 ................ * 00002000: 4865 6c6c 6f2c 2057 6f72 6c64 210a 0000 Привет, мир!... 00002010: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00002020: 0000 0000 0000 0100 0000 0200 0100 0010 ................ 00002030: 4000 0000 0000 0000 0000 0000 0000 0800 @............ 00002040: 0000 0200 0100 1610 4000 0000 0000 0000 ........@......... 00002050: 0000 0000 0000 005f 7374 6172 7400 6578 ......._start.ex 00002060:6974 002e 7465 7874 002e 726f 6461 7461 ит..текст..родата 00002070: 002e 7379 6d74 6162 002e 7368 7374 7274 ..symtab..shstrt 00002080: 6162 0000 0000 0000 0000 0000 0000 0000 аб............. 00002090: 0000 0000 0000 0000 0000 0000 1000 0000 ................ 000020a0: 0000 0000 0000 0000 0000 0000 0000 0000 .
............... 000020b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000020c0: 0000 000d 0000 0001 0000 0006 0000 0000 ................ 000020d0: 0000 0000 1040 0000 0000 0000 1000 0000 .....@......... 000020e0: 0000 0000 1000 0000 0000 0000 0000 0000 ................ 000020f0: 0000 0010 0000 0000 0000 0000 0000 0000 ................ 00002100: 0000 0013 0000 0001 0000 0002 0000 0000 ................ 00002110: 0000 0000 506b 0000 0000 0000 2000 0000 ....пк...... ... 00002120: 0000 000e 0000 0000 0000 0000 0000 0000 ................ 00002130: 0000 0001 0000 0000 0000 0000 0000 0000 ................ 00002140: 0000 001b 0000 0002 0000 0000 0000 0000 ................ 00002150: 0000 0000 0000 0000 0000 000e 2000 0000 ............ ... 00002160: 0000 0048 0000 0000 0000 0004 0000 0003 ...Ч............ 00002170: 0000 0001 0000 0000 0000 0018 0000 0000 ................ 00002180: 0000 0023 0000 0003 0000 0000 0000 0000 ...#............ 00002190: 0000 0000 0000 0000 0000 0056 2000 0000 .
..........В ... 000021a0: 0000 002d 0000 0000 0000 0000 0000 0000 ...-............ 000021b0: 0000 0001 0000 0000 0000 0000 0000 0000 ................ 000021c0:0000 00...
Итак, это наша конечная цель. В файле первая порция данных — это заголовок исполняемого файла, содержащий метаданные и некоторое описание формата, а следующие части содержат машинный код, символы отладки и данные, содержащиеся в программе. Работа ассемблера состоит в том, чтобы перейти от ассемблерного кода к этому сгенерированному файлу, и мы доведем его до конечного результата в этом и следующем постах блога.
В большинстве цепочек инструментов существует формат файла, который находится между этими двумя представлениями программы и называется объектным файлом . Объектный файл — это упакованный пакет машинного кода и данных, необходимых для запуска программы. Но объектный файл может быть не исполняемым напрямую. Например, объектный файл для библиотеки libc может содержать код для реализации printf , но запускать библиотеку как исполняемый файл не имеет смысла, поэтому вы не можете этого сделать.
На большинстве этапов компиляции компилятор или ассемблер создает объектные файлы для каждой «единицы компиляции» кода — обычно это файл или библиотека — а затем компоновщик связывает различные части разных объектных файлов вместе в один окончательный исполняемый файл. . Например, если бы у нас был объектный файл, содержащий программу Hello World, которая затем ссылалась бы на функцию printf во внешней библиотеке C, мы бы скомпилировали каждый из двух компонентов, а затем соединили их вместе с компоновщиком для создания окончательного исполняемого файла. бинарный файл.
August, будучи небольшим проектом, не может связать несколько объектных файлов (пока?). Вместо этого он принимает одну ассемблерную программу, генерирует внутреннее представление машинного кода и данных программы, а затем просто выводит исполняемый файл. В случае моей системы этот исполняемый файл должен быть файлом ELF, потому что на моем компьютере работает ядро Linux, которое ожидает, что исполняемые двоичные файлы будут файлами ELF.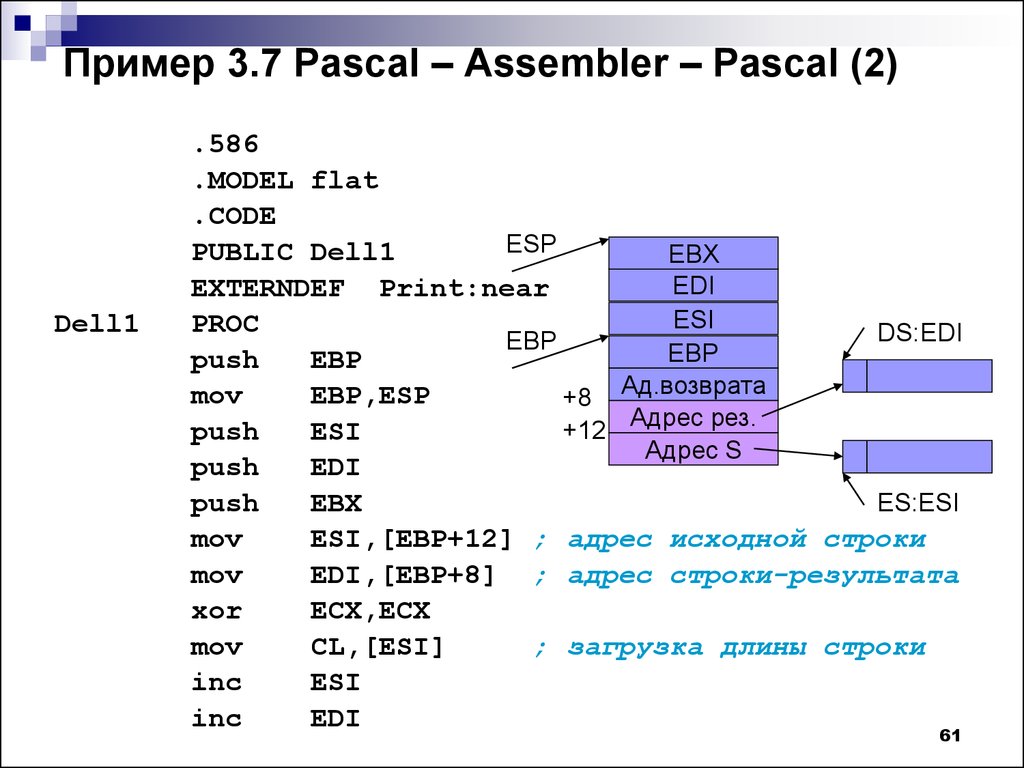
С этой приблизительной картой того, куда мы направляемся, давайте начнем с того, с чего начал я.
Подделка под MVP
Первым фрагментом кода, который я написал для ассемблера, была программа, которая просто выводила жестко закодированный двоичный файл и помечала его как исполняемый (здесь вы можете найти diff коммита). Я хотел начать с программы, которая работала для очень специфического ввода и вывода (базовая программа Hello World), и постепенно обобщать ее по мере того, как я понимал больше частей ассемблера.
Первая версия этого «фальшивого» ассемблера выводит двоичный код для этой ассемблерной программы, жестко запрограммированный в самой программе:
мов еакс 0x1 ; номер системного вызова "выход" мов ebx 0x2a ; аргумент для выхода() интервал 0x80; сделать системный вызов
Все, что делает эта программа, это выполняет системный вызов «выход», так что программа завершается с кодом состояния выхода 42 ( 0x2a ). Это самая простая валидная программа на ассемблере, которую я мог сделать на x86 — она использует две инструкции, mov и int , два регистра, eax и ebx , и несколько непосредственных целочисленных значений.
Как только у меня заработал этот «фальшивый» ассемблер, я начал разбивать большой жестко закодированный двоичный файл на множество более мелких частей, которые я мог понять и обобщить для любой ассемблерной программы. Однако для этого нам нужно сначала понять формат файлов ELF, которые являются собственными форматами исполняемых файлов для Linux и других систем UNIX, таких как BSD.
Деконструкция формата ELF
ELF — это формат исполняемых двоичных файлов и объектных файлов. Это общепринятый стандарт, используемый большинством UNIX-подобных систем, таких как Linux и BSD. Досадно, что ни macOS, ни Windows не поддерживают исполняемые файлы ELF.
Структура файла ELF довольно хорошо описана на странице руководства ELF, и она достаточно гибкая. Если вы хотите следовать диаграмме, эта диаграмма @corkami кажется лучшей. Файл ELF:
- Начинается с небольшого раздела заголовка, определяющего тип и размер различных частей файла ELF, за которым следует
- Любое количество «разделов», которые могут содержать что угодно, от машинного кода программы до данных, отладочной информации или чего-то еще
- Где некоторые из разделов также могут быть «сегментами», которые загружаются в память при выполнении программы
Все исполняемые двоичные файлы в системах Linux являются файлами ELF, и вы можете заглянуть во внутреннюю структуру любого файла ELF, используя readelf или elfdump (в зависимости от вашей операционной системы). Где-то в файле ELF также есть таблица заголовков программы и таблица заголовков раздела . Эти таблицы могут находиться где угодно в файле и сообщать тому, кто интерпретирует файл ELF, где найти все сегменты и разделы в файле ELF. Поскольку эти таблицы могут быть расположены в любом месте файла, заголовок ELF в начале файла указывает на смещение в байтах в файле, где находятся эти две таблицы.
Где-то в файле ELF также есть таблица заголовков программы и таблица заголовков раздела . Эти таблицы могут находиться где угодно в файле и сообщать тому, кто интерпретирует файл ELF, где найти все сегменты и разделы в файле ELF. Поскольку эти таблицы могут быть расположены в любом месте файла, заголовок ELF в начале файла указывает на смещение в байтах в файле, где находятся эти две таблицы.
Это высокоуровневая структура файла ELF: заголовок, указывающий на программу и таблицы заголовков разделов, которые, в свою очередь, указывают на остальные сегменты и разделы в файле. Разделы предназначены для хранения произвольных данных, но сегменты предназначены специально для хранения данных, полезных при фактической загрузке программы для выполнения, таких как машинный код, пул констант и любые глобальные переменные.
Операционная система, пытающаяся запустить двоичный файл ELF , ищет только программные сегменты и игнорирует любые разделы и заголовки разделов, но другие инструменты, такие как дизассемблер objdump и отладчик gdb , полагаются на эти разделы, содержащие значимые данные для работы. Если вы связываете несколько объектных файлов вместе, эти разделы, содержащие данные символов и тому подобное, также становятся полезными.
Если вы связываете несколько объектных файлов вместе, эти разделы, содержащие данные символов и тому подобное, также становятся полезными.
Для сборки августа, поскольку я хотел вывести исполняемые файлы, которые можно было бы разобрать и изучить, я решил включить следующие разделы и сегменты.
Секции…
- A нулевой раздел , просто запись в таблице заголовков разделов всех нулевых байтов, которая должна быть первой секцией в любом файле ELF
- Текстовый раздел , условно обозначенный
.text, содержащий машинный код, также обычно называемый «текстом» программы - Раздел только для чтения , условно называемый
.rodata, содержащий любые константы для программы, такие как строка"Hello, World!" - Раздел таблицы символов , условно обозначенный
.symtab, который содержит таблицу «символов» в программе, таких как имена функций - Таблица строк , в которой нам нужно хранить имена других разделов в этом списке и другие элементы, такие как символы.
 Обычно это обозначено
Обычно это обозначено .shstrtab, что означает «Таблица строк заголовка раздела».
Сегменты…
- Один, указывающий на текстовую часть, содержащий машинный код, необходимый для запуска программы
- Один указывает на раздел данных только для чтения, содержащий константы, на которые машинный код будет ссылаться при выполнении, например строковые литералы
Когда мы сгенерируем этот ELF-файл и передадим его операционной системе, операционная система запустит новый процесс, в котором сможет работать наша программа. ОС просмотрит два сегмента, содержащих наш машинный код и константы, и обратится к таблице заголовков программы, чтобы выяснить, где в виртуальном адресном пространстве процесса должны быть размещены эти сегменты, и назначит сегментам их правильные места в виртуальной памяти процесса. Затем он перемещает счетчик программ ЦП или регистр указателя инструкций на начальный адрес исполняемого файла, указанный в заголовке ELF. Наконец, задача ОС переключается на новый процесс, где процессор начинает выполнять наш машинный код!
Наконец, задача ОС переключается на новый процесс, где процессор начинает выполнять наш машинный код!
Это простейшая модель исполняемого файла ELF. Большинство языков и компиляторов будут создавать двоичные файлы, которые включают более сложные движущиеся части, такие как ссылки на интерпретаторы или libc, загрузка в другие динамически подключаемые библиотеки или ссылки на отладочную информацию, встроенную в двоичные файлы. Двоичные файлы, которые включают большие среды выполнения, такие как среда выполнения языка программирования Go, могут иметь много сегментов, загруженных в память, которые отвечают за разные задачи или данные в программе.
Однако для простого игрушечного ассемблера, такого как August, этих нескольких разделов и сегментов достаточно, чтобы получить работающий исполняемый файл, который мы можем заглянуть внутрь.
Анализ файлов ELF с помощью
readelf Чтобы начать писать программу, которая может генерировать нужный нам файл ELF, нам нужны две вещи. Во-первых, нам нужна подробная спецификация того, какие именно биты и байты нам нужно поместить в наш файл ELF для представления наших разделов и сегментов. Мы можем найти эту информацию на странице руководства (в Linux простой 9команда 0045 man elf доставит нас туда), или в различных закоулках мира низкоуровневого программирования онлайн, некоторые из которых я связал в файле readme августовского проекта. Во-вторых, нам нужно иметь возможность легко проверять структуру ELF любого файла, который мы выводим. Теоретически мы можем сделать это, используя инструмент для дампа двоичных файлов, такой как
Во-первых, нам нужна подробная спецификация того, какие именно биты и байты нам нужно поместить в наш файл ELF для представления наших разделов и сегментов. Мы можем найти эту информацию на странице руководства (в Linux простой 9команда 0045 man elf доставит нас туда), или в различных закоулках мира низкоуровневого программирования онлайн, некоторые из которых я связал в файле readme августовского проекта. Во-вторых, нам нужно иметь возможность легко проверять структуру ELF любого файла, который мы выводим. Теоретически мы можем сделать это, используя инструмент для дампа двоичных файлов, такой как hexdump , и читая байты, но это болезненно и требует много времени. Я решил использовать readelf , чтобы получить непрерывное считывание данных в файлах ELF, выводимых моей программой, чтобы убедиться, что мой код создает действительный файл ELF.
Вывод readelf вполне читаем. Давайте разберем это для программы Hello World, которую я использовал для открытия этого блога.
$ readelf --all ./hello-world Заголовок ЭЛЬФ: Магия: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Класс: ЭЛЬФ64 Данные: дополнение до 2, обратный порядок байтов Версия: 1 (текущая) ОС/ABI: UNIX - System V Версия АБИ: 0 Тип: EXEC (исполняемый файл) Машина: Advanced Micro Devices X86-64 Версия: 0x1 Адрес точки входа: 0x401000 Начало заголовков программы: 64 (байт в файле) Начало заголовков разделов: 8323 (байт в файл) Флаги: 0x0 Размер этого заголовка: 64 (байта) Размер заголовков программы: 56 (байт) Количество заголовков программ: 2 Размер заголовков разделов: 64 (байта) Количество заголовков разделов: 5 Индекс таблицы строк заголовков разделов: 4
Первый набор информации — это расшифровка заголовка ELF в начале нашего файла. Он содержит метаданные об архитектуре целевой машины этого исполняемого файла, а также различную информацию о версии, а также о размерах и расположении заголовков программ и разделов в этом файле ELF.
Заголовок ELF для этого двоичного файла также содержит важную информацию, «адрес точки входа», который в данном случае равен 0x401000 . Запомните этот адрес, потому что мы еще увидим его внизу.
Заголовки разделов:
[Nr] Имя Тип Адрес Смещение
Размер EntSize Флаги Информация о ссылке Выровнять
[0] NULL 0000000000000000 00001000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000401000 00001000
0000000000001000 0000000000000000 АХ 0 0 16
[ 2] .rodata PROGBITS 00000000006b5000 00002000
000000000000000e 0000000000000000 А 0 0 1
[ 3] .symtab SYMTAB 0000000000000000 0000200e
0000000000000048 0000000000000018 4 3 1
[ 4] .shstrtab STRTAB 0000000000000000 00002056
000000000000002d 0000000000000000 0 0 1
Ключ к флагам:
W (запись), A (распределение), X (выполнение), M (объединение), S (строки), I (информация),
L (порядок ссылок), O (требуется дополнительная обработка ОС), G (группа), T (TLS),
C (сжато), x (неизвестно), o (зависит от ОС), E (исключить),
l (большой), p (зависит от процессора)
В этом файле нет групп разделов.
Далее следует список разделов readelf , найденных в заголовке раздела этого файла. Он нашел наши пять разделов, которые я описал выше: нулевой раздел, .text , .rodata , таблицу символов и таблицу строк. Мы также можем увидеть некоторые дополнительные метаданные, например, в разделе .text установлены биты флага AX (выделение и выполнение), а в разделах .symtab и .shstrtab установлен «тип» соответствующие типы, чтобы другая программа, например отладчик, могла их распознать.
readelf также сообщает нам, что в этом файле нет «групп разделов». Группы разделов не особенно полезны в исполняемых файлах, но иногда они используются в объектных файлах для группировки связанных разделов для отдельного шага компоновки.
Заголовки программ:
Тип Смещение VirtAddr PhysAddr
Выравнивание флагов FileSiz MemSiz
ЗАГРУЗКА 0x0000000000001000 0x0000000000401000 0x0000000000401000
0x0000000000001000 0x0000000000001000 ЧТ 0x1000
ЗАГРУЗКА 0x0000000000002000 0x00000000006b5000 0x00000000006b5000
0x000000000000000e 0x0000000000000000e R 0x1000
Сопоставление раздела с сегментом:
Разделы сегмента. ..
00 .текст
01 .родата
..
00 .текст
01 .родата
Вот два заголовка наших программ: один указывает на наш машинный код, помеченный флагами R (чтение) и E (выполнение), а другой указывает на наши данные (строка «Hello, World!»), только с установленным флагом чтения. readelf также помог нам сопоставить наши разделы и сегменты на основе их расположения в файле ELF.
Одна интересная информация здесь — столбец VirtAddr в нашем текстовом сегменте, содержащий код программы. это 0x401000 , тот же адрес, что и «адрес точки входа», указанный в ELF-заголовке выше. Когда этот исполняемый файл запустится, он начнет выполнять код, расположенный по адресу 0x401000 , который начинается в начале нашего сегмента машинного кода.
В этом файле нет динамического раздела. В этом файле нет перемещений. Декодирование секций раскрутки для машин типа Advanced Micro Devices X86-64 в настоящее время не поддерживается.
Поскольку наш исполняемый файл не является ни динамически компонуемым, ни библиотечным объектным файлом, у нас нет динамических разделов или перемещений.
Таблица символов '.symtab' содержит 3 записи:
Num: Значение Размер Тип Bind Vis Ndx Имя
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000401000 0 FUNC ЛОКАЛЬНАЯ ПО УМОЛЧАНИЮ 1 _start
2: 0000000000401016 0 FUNC ЛОКАЛЬНАЯ ПО УМОЛЧАНИЮ 1 выход
В этом файле не найдена информация о версии.
Наконец, мы получаем нашу таблицу символов, которая сообщает дизассемблерам и отладчикам, где в нашем коде находятся различные символы в нашей программе. В случае этой программы, которая была собрана из ассемблерного кода, эти символы соответствуют меткам в нашем ассемблерном коде. _start , например, является нашей точкой входа в программу и находится по виртуальному адресу 0x401000 , началу нашего текстового сегмента.
Если у вас есть система Linux или BSD, попробуйте использовать readelf для взлома других программ, с которыми вы знакомы, например bash или vi . Вы увидите дополнительные разделы, дополнительные символы отладки и более сложные структуры времени компоновки, но базовая высокоуровневая структура сегментов и разделов будет одинаковой для всех файлов ELF.
Вы увидите дополнительные разделы, дополнительные символы отладки и более сложные структуры времени компоновки, но базовая высокоуровневая структура сегментов и разделов будет одинаковой для всех файлов ELF.
Первая часть нашего ассемблера — это программа, которая может брать данные, необходимые для каждой секции, и создавать простой файл ELF, подобный тому, который мы только что разобрали.
Генерация двоичного файла ELF в августе
Если немного упростить, создание ELF-файла в основном сводится к перемещению байтов данных, чтобы они располагались в нужных местах в файле. Поскольку мы придерживаемся простой структуры, мы можем заранее определить множество констант, чтобы упростить наш процесс. Библиотека ELF августа предполагает следующее.
- Адрес точки входа
0x401000 - Начало сегмента данных только для чтения по адресу
0x6b5000 - Предустановленный заказ деталей:
- Заголовок ELF
- Заголовок программы (таблица сегментов)
- Заполнение 0x00 байт до границы страницы размером 4 КБ
- Все разделы: null, текст, данные только для чтения, таблица символов и таблица строк, в указанном порядке
- Таблица заголовка раздела
Хотя ELF строго не соблюдает такой порядок, для простых двоичных файлов это кажется обычным. Особенно полезно, чтобы заголовок программы следовал сразу за заголовком ELF, потому что, когда операционная система выполняет этот двоичный файл, ей все равно придется загружать эту часть файла в память. Также обычно полезно иметь таблицу заголовков разделов в качестве последней части файла ELF, потому что это упрощает добавление разделов к этому файлу — вам нужно изменить только конец файла, а не весь файл.
Особенно полезно, чтобы заголовок программы следовал сразу за заголовком ELF, потому что, когда операционная система выполняет этот двоичный файл, ей все равно придется загружать эту часть файла в память. Также обычно полезно иметь таблицу заголовков разделов в качестве последней части файла ELF, потому что это упрощает добавление разделов к этому файлу — вам нужно изменить только конец файла, а не весь файл.
Эти предполагаемые константы произвольны, но их полезно иметь, потому что это значительно упрощает задачу написания ELF-заголовка. Такие числа, как «расположение заголовков разделов» и «количество сегментов», становятся константами, которые мы знаем с самого начала.
Исходя из этой более конкретной структуры, я начал планировать свою функцию по приему текста и данных программы и созданию двоичного файла ELF.
Вы можете увидеть структуру, которую я получил в ./src/elf.ink в репозитории. Например, вот немного логики в библиотеке для генерации каждого из разделов в файле ELF. Мое определение для 9Раздел 0045 .text выглядит так.
Мое определение для 9Раздел 0045 .text выглядит так.
TextSection := {
имя: toBytes (registerString ('.text'), 4)
тип: toBytes (SectionType.ProgBits, 4)
флаги: toBytes(SectionFlag.Alloc | SectionFlag.ExecInstr, 8)
адрес: toBytes (ExecStartAddr, 8)
смещение: toBytes(PageSize, 8)
выровнять: по байтам (16, 8)
основной текст
}
Большая часть этого напрямую соответствует метаданным раздела, которые мы видели в выводе readelf . Во время отладки этой части августа у меня была непрерывная readelf выводится рядом с моим редактором, чтобы я мог проверить, что то, что я написал на ассемблере, соответствует сгенерированным разделам.
Вот раздел данных только для чтения, где я обращу ваше внимание на биты флагов, которые отличаются от флагов в текстовом разделе (просто Alloc , а не Alloc | ExecInstr ).
RODataSection := {
имя: toBytes (registerString ('.rodata'), 4)
тип: toBytes (SectionType. ProgBits, 4)
флаги: toBytes (SectionFlag.Alloc, 8)
адрес: toBytes(ROStartAddr, 8)
смещение: toBytes (PageSize + len (текст), 8)
выровнять: по байтам (1, 8)
тело: родата
}
ProgBits, 4)
флаги: toBytes (SectionFlag.Alloc, 8)
адрес: toBytes(ROStartAddr, 8)
смещение: toBytes (PageSize + len (текст), 8)
выровнять: по байтам (1, 8)
тело: родата
}
Здесь я определяю соответствующие им сегменты
ТекстПрог := {
тип: toBytes(ProgType.Load, 4)
флаги: toBytes(ProgFlag.Read | ProgFlag.Execute, 4)
смещение: toBytes(PageSize, 8)
адрес: toBytes (ExecStartAddr, 8)
размер: toBytes (длина (текст), 8)
}
РОДатаПрог := {
тип: toBytes(ProgType.Load, 4)
флаги: toBytes(ProgFlag.Read, 4)
смещение: toBytes (PageSize + len (текст), 8)
адрес: toBytes(ROStartAddr, 8)
размер: toBytes(len(rodata), 8)
}
Эта функция генерации файлов ELF также создает таблицу символов. Учитывая словарь символов и их виртуальные адреса, Функция makeSymTab создает записи в разделе .symtab и связывает их вместе.
symtab: = makeSymTab (символы, строка регистра)
`... `
SymTabSection := {
имя: toBytes (registerString ('. symtab'), 4)
тип: toBytes(SectionType.SymTab, 4)
флаги: нули (8)
адрес: нули (8)
смещение: toBytes(PageSize + len(text) + len(rodata), 8)
выровнять: по байтам (1, 8)
тело: симтаб
`... `
}
symtab'), 4)
тип: toBytes(SectionType.SymTab, 4)
флаги: нули (8)
адрес: нули (8)
смещение: toBytes(PageSize + len(text) + len(rodata), 8)
выровнять: по байтам (1, 8)
тело: симтаб
`... `
}
Учитывая все эти разделы и сегменты, мы просто сопоставляем все описания разделов и сегментов, чтобы закодировать их в записи таблицы и расположить их рядом друг с другом, чтобы мы могли поместить их в наш результирующий файл ELF.
Последней задачей в библиотеке ELF является создание заголовка ELF. Этот шаг оставлен до конца, поэтому мы точно знаем, сколько разделов у нас есть, и насколько они велики в итоге. Нам нужна эта информация, чтобы сохранить макет всего нашего файла ELF в заголовке ELF.
Последняя строка кода генерации ELF объединяет все разделы вместе.
elfFile := padEndNull(ElfHeader + ProgHeaders, PageSize) +
Тела разделов + Заголовки разделов
Вот и все. Небольшая программа, которая берет некоторый закодированный блок машинного кода, некоторые отладочные символы и некоторые данные только для чтения и создает файл ELF, который может выполнить наша операционная система!
Итак, наше путешествие по сборке ассемблера наполовину завершено.