- пробельные символы: пробел, символы табуляции, символы перехода на новую строку.
Из символов алфавита формируются лексемы языка:
- идентификаторы;
- ключевые (зарезервированные) слова;
- знаки операций;
- константы;
- разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими, как разделители или знаки операций.
Идентификаторы
Идентификатор — это имя программного объекта. В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания. Прописные и строчные буквы различаются, например, sysop, SySoP и SYSOP — три различных имени. Первым символом идентификатора может быть буква или знак подчеркивания, но не цифра. Пробелы внутри имен не допускаются.
СоветДля улучшения читаемости программы следует давать объектам осмысленные имена. Существует соглашение о правилах создания имен, называемое венгерской нотацией (поскольку предложил ее сотрудник компании Microsoft венгр по национальности), по которому каждое слово, составляющее идентификатор, начинается с прописной буквы, а вначале ставится префикс, соответствующий типу величины, например, iMaxLength, IpfnSetFirstDialog.
Другая традиция — разделять слова, составляющие имя, знаками подчеркивания: maxjength, number_of_galosh.
Длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения. Идентификатор создается на этапе объявления переменной, функции, типа и т. п., после этого его можно использовать в последующих операторах программы. При выборе идентификатора необходимо иметь в виду следующее:
- идентификатор не должен совпадать с ключевыми словами и именами используемых стандартных объектов языка;
- не рекомендуется начинать идентификаторы с символа подчеркивания, поскольку они могут совпасть с именами системных функций или переменных, и, кроме того, это снижает мобильность программы;
- на идентификаторы, используемые для определения внешних переменных, налагаются ограничения компоновщика (использование различных компоновщиков или версий компоновщика накладывает разные требования на имена внешних переменных).
Ключевые слова
Ключевые слова — это зарезервированные идентификаторы, которые имеют специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены. Список ключевых слов C++ приведен в таблице ниже.
Их можно использовать только в том смысле, в котором они определены. Список ключевых слов C++ приведен в таблице ниже.
| Список ключевых слов C++ | |||
| asm | else | new | this |
| auto | enum | operator | throw |
| bool | explicit | private | |
| break | export | protected | try |
| case | extern | public | typedef |
| catch | false | register | typeid |
| char | float | reinterpret_cast | typename |
| class | for | return | union |
| const | friend | short | unsigned |
| const_cast | goto | signed | using |
| continue | if | sizeof | virtual |
| default | inline | static | void |
| delete | int | static__cast | volatile |
| do | long | struct | wchar_t |
| double | mutable | switch | while |
| dynamic_cast | namespace | template | |
Знаки операций
Знак операции — это один или более символов, определяющих действие над операндами.
Один и тот же знак может интерпретироваться по-разному в зависимости от контекста. Все знаки операций за исключением [ ], ( ) и ? : представляют собой отдельные лексемы.
Большинство стандартных операций может быть переопределено (перегружено).
Константы
Константами называют неизменяемые величины. Различаются целые, вещественные, символьные и строковые константы. Компилятор, выделив константу в качестве лексемы, относит ее к одному из типов по ее внешнему виду (формат константы можно указать самостоятельно).
Форматы констант, соответствующие каждому типу, приведены в таблице ниже.
| Константа | Формат | Константа |
| Целая | Десятичный: последовательностьдесятичных цифр, начинающаясяне с нуля, если это не число нуль Восьмеричный: нуль, за которым следуют восьмеричные цифры (0,1,2,3,4,5,6,7)
Шестнадцатеричный: 0х или 0Х, за которым следуют шестнадцатеричные цифры (0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F) | 8, 0, 199226 01, 020, 07155
0хА, 0x1B8, 0X00FF |
| Вещественная | Десятичный:[цифры]. [цифры]Экспоненциальный: [цифры]Экспоненциальный:[цифры][.][цифры]{Е¦е}[+¦ -][цифры] | 5.7, .001, 35.0.2Е6, .11е-З, 5Е10 |
| Символьная | Один или два символа, заключенных в апострофы | ‘А’, ‘ю’, ‘*’, ‘db’, ‘ |
Алфавит языка программирования Java и Unicode
Мне кажется, что этот вопрос скорее из плоскости философии, но всё равно было бы неплохо разобраться. Итак, начну немного издалека, чтобы была понятна суть. Абсолютно любой язык программирования, в том числе и упомянутый в заголовке Java, является формой формального языка, который предназначен для записи компьютерных программ. Если говорить грубо, то формальный язык представляет собой математическую модель реального языка и содержит набор правил, которые позволяют определить язык, в том числе множество грамматик (в иерархии Хомского выделено 4 типа формальных грамматик), предназначенных для этих целей. Разумеется, что каждый язык имеет свой алфавит, так что формальные языки не выпадают из этого правила и также подразумевают наличие некоторого множества атомарных символов, которые позволят выстраивать слова на этом языке и выступать в качестве основы терминальных символов.
Как только мы начинаем знакомиться с JLS, то уже во второй главе узнаём о том, что Java относится к формальным языкам с контекстно-свободной грамматикой, что и не сильно удивляет, так как подавляющее большинство языков программирования описывается именно при помощи этого типа формальной грамматики. Какую основную мысль мы можем выделить из этого для себя? Если мы имеем дело с КС-грамматикой, то любую лексическую и синтаксическую структуру, мы будем описывать при помощи продукций, в левой части которых всегда будет находиться исключительно один нетерминальный символ (отсутствует окружающий его контекст), который может быть выражен через некоторое сочетание, как терминальных, так и нетерминальных символов, начиная с целевого символа.
Чтобы понять, чем ограничен алфавит языка программирования Java, давайте обратим внимание на одну из продукций, которая представлена в разделе3.3. Unicode Escapes. Приведу её полностью.
UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter
UnicodeEscape:
\ UnicodeMarker HexDigit HexDigit HexDigit HexDigit
UnicodeMarker:
u {u}
HexDigit:
(one of)
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
RawInputCharacter:
any Unicode character
Здесь нас больше всего интересует фраза any Unicode character, которая чётко даёт понять, что в качестве необработанного входного символа может выступать совершенно любой символ стандарта Unicode. И вот тут напрашивается вопрос. Любой Unicode-символ? Что именно подразумевалось в данном контексте под словом «любой»? Все символы, которые описаны стандартом по состоянию на сегодняшний день? Или же всё то кодовое пространство, которое описывается в общем и целом?
Здесь ведь вот какой интересный момент возникает. Я даже не буду брать пробельные символы (в том числе ограничители строк) и комментарии, они всё равно относятся к разряду незначащих и полностью игнорируются компилятором. Возьмём хотя бы лексические токены, которые составляют основу любой Java-программы. С ключевыми словами, операторами и разделителями всё понятно, их набор заранее определён и фиксирован спецификацией языка. А сколько тех же Unicode-символов можно использовать при составлении корректных идентификаторов? Выяснить это достаточно легко. Воспользовался методами
С ключевыми словами, операторами и разделителями всё понятно, их набор заранее определён и фиксирован спецификацией языка. А сколько тех же Unicode-символов можно использовать при составлении корректных идентификаторов? Выяснить это достаточно легко. Воспользовался методами Character.isJavaIdentifierPart(codepoint) и Character.isJavaIdentifierStart(codepoint), которые поместил в тело цикла и прогнал через них все возможные значения кодовых позиций. Итак, многих это может удивить, но в качестве начального символа нашего Java-идентификатора мы можем использовать 125,951 различный Unicode-символ! И это только результат работы метода Character.isJavaIdentifierStart(codepoint). К примеру, тот же Character.isJavaIdentifierPart(codepoint), сообщает нам, что частью корректного Java-идентификатора может быть уже 129,053 символа. Во всяком случае, эта информация достоверна для версии Java SE 14, которая официально поддерживает Unicode 12.1. Такое огромное количество связано с тем, что в составе идентификатора могут быть фактически любые буквы национальных алфавитов, куча иероглифов, валютные символы, форматирующие и даже управляющие, не говоря уже о многих других символах, типа различных разновидностей пробелов и других специальных символов (к примеру, U+2060 WORD JOINER, U+2061 FUNCTION APPLICATION, U+2062 INVISIBLE TIMES, U+2063 INVISIBLE SEPARATOR и даже некоторые дефисы, такие как мягкий дефис (U+00AD
U+00СA) и т. д).
д).А вот когда мы подбираемся к литералам, особенно к строковым, то понимаем, что раздолье наступает такое, что нас уже не остановить. Мы можем использовать фактически любой символ из UCS, а это 1,114,112 кодовых позиций, если брать суммарно. Здесь конечно можно возразить и сразу же вычесть верхние и нижние суррогаты (2,048 кодовых позиций), а там ещё порассуждать над целесообразностью учёта символов, которые помечены, как <not a character>, а также те, которые зарезервированы под частное использование. Хотя мы можем спокойно использовать любой codepoint в своих личных целях, даже те, которые выделены под суррогаты.
Так какую же величину имеет наш алфавит? 1,114,112 символов (если охватывать всё кодовое пространство Unicode)? 1,112,064, если вычесть из этого количества суррогаты? Или и вовсе 143,924 символа, если брать в расчёт исключительно символы, которые имеют графическое представление, а также форматирующие и управляющие. И то, это будет справедливо для Unicode 13. 0. А если учитывать тот факт, что класс java.lang.Character в Java SE 14 поддерживает лишь версию Unicode 12.1, то правильно ли говорить, что в нашем распоряжении ещё меньше символов, а точнее 137,994 (именно столько символов однозначно определено в этой версии Unicode)? Этот вопрос всегда волновал, так как неопределённость мне не очень нравится и всегда хочется дать чёткий ответ на поставленный вопрос. Лично я считаю, что мы можем использовать абсолютно все кодовые позиции так, как посчитаем нужным (такая возможность есть, но так лучше не делать). Именно поэтому, если мы больше говорим о теории, то мне кажется, что мы упираемся лишь в ограничения самого стандарта и кодировки UTF-16. Согласны со мной? Или я всё-таки не совсем верно рассуждаю и 1,114,112 символов далеки от истины? Интересно Ваше мнение по данному вопросу! 🙂
0. А если учитывать тот факт, что класс java.lang.Character в Java SE 14 поддерживает лишь версию Unicode 12.1, то правильно ли говорить, что в нашем распоряжении ещё меньше символов, а точнее 137,994 (именно столько символов однозначно определено в этой версии Unicode)? Этот вопрос всегда волновал, так как неопределённость мне не очень нравится и всегда хочется дать чёткий ответ на поставленный вопрос. Лично я считаю, что мы можем использовать абсолютно все кодовые позиции так, как посчитаем нужным (такая возможность есть, но так лучше не делать). Именно поэтому, если мы больше говорим о теории, то мне кажется, что мы упираемся лишь в ограничения самого стандарта и кодировки UTF-16. Согласны со мной? Или я всё-таки не совсем верно рассуждаю и 1,114,112 символов далеки от истины? Интересно Ваше мнение по данному вопросу! 🙂
Источник: https://ru.stackoverflow.com/questions/1113714/%D0%90%D0%BB%D1%84%D0%B0%D0%B2%D0%B8%D1%82-%D1%8F%D0%B7%D1%8B%D0%BA%D0%B0-%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-java-%D0%B8-unicode
Алфавит языка программирования Java и Unicode
Мне кажется, что этот вопрос скорее из плоскости философии, но всё равно было бы неплохо разобраться. Итак, начну немного издалека, чтобы была понятна суть. Абсолютно любой язык программирования, в том числе и упомянутый в заголовке Java, является формой формального языка, который предназначен для записи компьютерных программ. Если говорить грубо, то формальный язык представляет собой математическую модель реального языка и содержит набор правил, которые позволяют определить язык, в том числе множество грамматик (в иерархии Хомского выделено 4 типа формальных грамматик), предназначенных для этих целей. Разумеется, что каждый язык имеет свой алфавит, так что формальные языки не выпадают из этого правила и также подразумевают наличие некоторого множества атомарных символов, которые позволят выстраивать слова на этом языке и выступать в качестве основы терминальных символов. Запомним этот момент, так как он нам ещё пригодится.
Итак, начну немного издалека, чтобы была понятна суть. Абсолютно любой язык программирования, в том числе и упомянутый в заголовке Java, является формой формального языка, который предназначен для записи компьютерных программ. Если говорить грубо, то формальный язык представляет собой математическую модель реального языка и содержит набор правил, которые позволяют определить язык, в том числе множество грамматик (в иерархии Хомского выделено 4 типа формальных грамматик), предназначенных для этих целей. Разумеется, что каждый язык имеет свой алфавит, так что формальные языки не выпадают из этого правила и также подразумевают наличие некоторого множества атомарных символов, которые позволят выстраивать слова на этом языке и выступать в качестве основы терминальных символов. Запомним этот момент, так как он нам ещё пригодится.
Как только мы начинаем знакомиться с JLS, то уже во второй главе узнаём о том, что Java относится к формальным языкам с контекстно-свободной грамматикой, что и не сильно удивляет, так как подавляющее большинство языков программирования описывается именно при помощи этого типа формальной грамматики. Какую основную мысль мы можем выделить из этого для себя? Если мы имеем дело с КС-грамматикой, то любую лексическую и синтаксическую структуру, мы будем описывать при помощи продукций, в левой части которых всегда будет находиться исключительно один нетерминальный символ (отсутствует окружающий его контекст), который может быть выражен через некоторое сочетание, как терминальных, так и нетерминальных символов, начиная с целевого символа.
Какую основную мысль мы можем выделить из этого для себя? Если мы имеем дело с КС-грамматикой, то любую лексическую и синтаксическую структуру, мы будем описывать при помощи продукций, в левой части которых всегда будет находиться исключительно один нетерминальный символ (отсутствует окружающий его контекст), который может быть выражен через некоторое сочетание, как терминальных, так и нетерминальных символов, начиная с целевого символа.
Чтобы понять, чем ограничен алфавит языка программирования Java, давайте обратим внимание на одну из продукций, которая представлена в разделе 3.3. Unicode Escapes. Приведу её полностью.
UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter
UnicodeEscape:
\ UnicodeMarker HexDigit HexDigit HexDigit HexDigit
UnicodeMarker:
u {u}
HexDigit:
(one of)
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
RawInputCharacter:
any Unicode character
Здесь нас больше всего интересует фраза any Unicode character, которая чётко даёт понять, что в качестве необработанного входного символа может выступать совершенно любой символ стандарта Unicode. И вот тут напрашивается вопрос. Любой Unicode-символ? Что именно подразумевалось в данном контексте под словом «любой»? Все символы, которые описаны стандартом по состоянию на сегодняшний день? Или же всё то кодовое пространство, которое описывается в общем и целом?
И вот тут напрашивается вопрос. Любой Unicode-символ? Что именно подразумевалось в данном контексте под словом «любой»? Все символы, которые описаны стандартом по состоянию на сегодняшний день? Или же всё то кодовое пространство, которое описывается в общем и целом?
Здесь ведь вот какой интересный момент возникает. Я даже не буду брать пробельные символы (в том числе ограничители строк) и комментарии, они всё равно относятся к разряду незначащих и полностью игнорируются компилятором. Возьмём хотя бы лексические токены, которые составляют основу любой Java-программы. С ключевыми словами, операторами и разделителями всё понятно, их набор заранее определён и фиксирован спецификацией языка. А сколько тех же Unicode-символов можно использовать при составлении корректных идентификаторов? Выяснить это достаточно легко. Воспользовался методами Character.isJavaIdentifierPart(codepoint) и Character.isJavaIdentifierStart(codepoint), которые поместил в тело цикла и прогнал через них все возможные значения кодовых позиций. Итак, многих это может удивить, но в качестве начального символа нашего Java-идентификатора мы можем использовать 125,951 различный Unicode-символ! И это только результат работы метода
Итак, многих это может удивить, но в качестве начального символа нашего Java-идентификатора мы можем использовать 125,951 различный Unicode-символ! И это только результат работы метода Character.isJavaIdentifierStart(codepoint). К примеру, тот же Character.isJavaIdentifierPart(codepoint), сообщает нам, что частью корректного Java-идентификатора может быть уже 129,053 символа. Во всяком случае, эта информация достоверна для версии Java SE 14, которая официально поддерживает Unicode 12.1. Такое огромное количество связано с тем, что в составе идентификатора могут быть фактически любые буквы национальных алфавитов, куча иероглифов, валютные символы, форматирующие и даже управляющие, не говоря уже о многих других символах, типа различных разновидностей пробелов и других специальных символов (к примеру, U+2060 WORD JOINER, U+2061 FUNCTION APPLICATION, U+2062 INVISIBLE TIMES, U+2063 INVISIBLE SEPARATOR и даже некоторые дефисы, такие как мягкий дефис (U+00AD), дефис слога (U+00СA) и т. д).
д).
А вот когда мы подбираемся к литералам, особенно к строковым, то понимаем, что раздолье наступает такое, что нас уже не остановить. Мы можем использовать фактически любой символ из UCS, а это 1,114,112 кодовых позиций, если брать суммарно. Здесь конечно можно возразить и сразу же вычесть верхние и нижние суррогаты (2,048 кодовых позиций), а там ещё порассуждать над целесообразностью учёта символов, которые помечены, как <not a character>, а также те, которые зарезервированы под частное использование. Хотя мы можем спокойно использовать любой codepoint в своих личных целях, даже те, которые выделены под суррогаты.
Так какую же величину имеет наш алфавит? 1,114,112 символов (если охватывать всё кодовое пространство Unicode)? 1,112,064, если вычесть из этого количества суррогаты? Или и вовсе 143,924 символа, если брать в расчёт исключительно символы, которые имеют графическое представление, а также форматирующие и управляющие. И то, это будет справедливо для Unicode 13. 0. А если учитывать тот факт, что класс java.lang.Character в Java SE 14 поддерживает лишь версию Unicode 12.1, то правильно ли говорить, что в нашем распоряжении ещё меньше символов, а точнее 137,994 (именно столько символов однозначно определено в этой версии Unicode)? Этот вопрос всегда волновал, так как неопределённость мне не очень нравится и всегда хочется дать чёткий ответ на поставленный вопрос. Лично я считаю, что мы можем использовать абсолютно все кодовые позиции так, как посчитаем нужным (такая возможность есть, но так лучше не делать). Именно поэтому, если мы больше говорим о теории, то мне кажется, что мы упираемся лишь в ограничения самого стандарта и кодировки UTF-16. Согласны со мной? Или я всё-таки не совсем верно рассуждаю и 1,114,112 символов далеки от истины? Интересно Ваше мнение по данному вопросу! 🙂
Общие сведения о языке программирования Паскаль. Алфавит и словарь языка. Типы данных
Двадцать первый век – это
век высоких технологий. Очень быстро развивается техника. Мы уже с вами
привыкли, что год за годом появляются всё новые и новые изобретения, которые
влияют на нашу жизнь. В частности, это касается появления новых моделей
компьютеров, телефонов, планшетов и много другого.
Очень быстро развивается техника. Мы уже с вами
привыкли, что год за годом появляются всё новые и новые изобретения, которые
влияют на нашу жизнь. В частности, это касается появления новых моделей
компьютеров, телефонов, планшетов и много другого.
Сейчас человек не может себя представить без компьютера или телефона.
Мы привыкли, что с их помощью легко можно связаться с любым человеком, где бы мы не находились. А также зайти, например, в интернет и найти нужную вам информацию.
Но развитие такой техники не мыслимо без программирования. В наше время изучать и знать программирование престижно и полезно. С помощью программирования создаётся программное обеспечение компьютера: программы, игры, приложения.
Существует множество языков программирования. Например, С++, С#, Java, DELFI, Pascal и так далее. Можно перечислять очень долго.
Но для того, чтобы научиться
создавать программы на таких языках, как С# или Java,
необходимо изучить один из более простых. Например, тот, который преподают вам
в школе – Pascal. Так как после изучения
простого языка, вам будет легче понять более сложные языки программирования.
Например, тот, который преподают вам
в школе – Pascal. Так как после изучения
простого языка, вам будет легче понять более сложные языки программирования.
Итак, на этом уроке мы с вами узнаем, что такое языки программирования, программы, изучим алфавит и словарь языка Pascal, а также узнаем какие существуют типы данных.
Языки программирования – это формальные языки, предназначенные для записи алгоритмов, исполнителем которых будет компьютер. В свою очередь, программа – это запись алгоритма на языке программирования. То есть, когда мы с вами написали алгоритм действий компьютера на языке программирования Pascal – мы создали программу.
Pascal – один из наиболее известных языков программирования, а также является базой для ряда других языков.
Язык Pascal был создан в 1968–1969 годах швейцарским учёным, специалистом в области информатики Никлаусом Виртом.
Он получил своё название в
честь французского математика, физика, литератора и философа Блеза Паскаля,
который создал первую в мире механическую машину, умеющую складывать два числа.
Первая же публикация Никлауса Вирта о языке Pascal была сделана в 1970 году.
Pascal является одним из языков, на основе которых создавались и развивались другие языки программирования. К примерам можно отнести MODULA-2, который был также разработан Никлаусом Виртом в 1978 году.
С помощью языка Pascal можно создавать программы для решения вычислительных задач, обработки текстов, построения графических изображений и много другого.
То есть это универсальный язык программирования. Также он поддерживает процедурный стиль программирования, в соответствии с которым программа представляет собой последовательность операторов, задающих те или иные свойства. То есть компьютер последовательно выполняет написанный алгоритм действий.
А сейчас мы переходим к алфавиту и словарю языка Pascal.
Любой язык программирования базируется на алфавите языка.
Алфавит языка
– это набор допустимых символов, которые можно использовать для записи
программы. В алфавит языка Pascal
входят латинские прописные буквы, латинские строчные буквы, арабские цифры и
специальные символы. К специальным символам относятся знаки препинания, знак
подчёркивания, круглые, квадратные и фигурные скобки, знаки арифметических
действий и многое другое.
В алфавит языка Pascal
входят латинские прописные буквы, латинские строчные буквы, арабские цифры и
специальные символы. К специальным символам относятся знаки препинания, знак
подчёркивания, круглые, квадратные и фигурные скобки, знаки арифметических
действий и многое другое.
Также в алфавите языка есть неделимые элементы. Это составные символы, которые нельзя разрывать. К ним относятся знак операции присваивания (двоеточие равно), знаки больше либо равно и меньше либо равно. Для того, чтобы поставить этот знак в программе нужно поставить знак больше, а затем равно. А для знака меньше или равно, необходимо поставить знак меньше, затем равно. Всё знаки записываются без пробела. Также к составным символам относится начало и конец комментария. Сам комментарий, который вы ходите оставить, необходимо написать после знака «двойной слеш».
Помимо этого, в языке
программирование существует такое понятие как служебные слова.
Служебные слова – это цепочки символов, которые рассматриваются как единые смысловые элементы с фиксированным значением.
В таблице ниже приведены основные служебные слова, которые вы будете использовать при написании программы на языке Pascal.
Их все важно помнить наизусть. Давайте рассмотрим некоторые из них.
Например, в самом начале написания программы нужно указать, что это программа при помощи служебного слова program. Для того, чтобы начать записывать порядок действий, нужно записать служебное слово «Начало» («begin»). Слово же end с точкой в конце указывает на то, что это конец написанной нами программы. И так далее. Все служебные слова вы изучите в процессе обучения языку Pascal.
Для обозначения констант,
переменных, программ и других объектов используются имена. Имена – это
любые отличные от служебных слов последовательности букв, цифр и символов
подчёркивания. Следует запомнить, что при задании имени следует использовать
латинский алфавит, а имя должно начинаться с буквы или символа подчёркивания.
Прописные и строчные буквы в именах не различаются. Имя не должно совпадать ни
с одним служебным словом языка программирования.
Следует запомнить, что при задании имени следует использовать
латинский алфавит, а имя должно начинаться с буквы или символа подчёркивания.
Прописные и строчные буквы в именах не различаются. Имя не должно совпадать ни
с одним служебным словом языка программирования.
Давайте выполним задание.
Необходимо указать неверные имена и объяснить, почему они неверны.
Итак, первое имя «F». Это является верным, так как ничего лишнего нет, и оно написано латинской буквой.
Второе «d4» также является верным. Так как на первом месте стоит буква.
Третье «мама» является неверным, так как оно написано на русском языке.
Четвёртое «7а» является также неверным, так как на первом месте должна стоять буква или символ подчёркивания, а у нас стоит цифра.
Пятое имя «_nsw1»
является верным. Оно состоит из знака подчёркивания, латинских букв и цифры.
Знак подчёркивания можно ставить на первое место.
Идём дальше. Шестое имя «begin». Оно является неверным. Нельзя задавать такое имя, так как это служебное слово.
Седьмое – «a + b» является неверным, так как нельзя использовать в имени арифметические знаки.
Восьмое «mid_d» и девятое «min» являются верными.
И последнее, десятое «мин» – неверно, так как написано на русском языке.
Длина имени может быть любой. Но для удобства лучше пользоваться именами, длина которых не превышает восьми символов.
Также нам сегодня нужно узнать, какие типы данных существуют в языке Pascal.
Типы данных делятся на числовые, символьный, строковый и логический.
К числовым относятся следующие типы: integer, byte и real. Существуют и другие числовые типы. Но мы будем с вами рассматривать только эти.
Символьный тип char. Строковый – string и логический boolean.
Давайте рассмотрим их более подробно
с помощью таблицы.
С целочисленным типом (integer) вы уже знакомы. Это основной тип данных, он задаётся для переменных, которые будут содержать в себе целые числа в диапазоне, предоставленном в таблице. Но стоит заметить, что для переменных целого типа в различных версиях программы Pascal диапазон допустимых значений может быть различным. Так, например, в программе PascalABC.net тип integer будет иметь следующий диапазон: -2147483648 … 2147483647. А в Turbo Pascal он будет таким: -32768 … 32767.
Переменные данного типа будут занимать 2 байта вместе со знаком.
Второй тип данный – byte. Значение, которое принимает переменная будет занимать 1 байт. Сюда будут входить числа от 0 до 255 включительно.
Следующий тип данных – вещественный
(real). Он применяется в основном для
вещественных или дробных чисел. Важно помнить, что в вещественном числе в языке
программирования целая часть от дробной отделяется точкой. Также перед точкой и
после неё должно быть, по крайней мере, по одной цифре. Пробелы внутри числа
ставить нельзя. Допустимый диапазон вы можете видеть в третьем столбце.
Переменные данного типа будут занимать 6 байт.
Пробелы внутри числа
ставить нельзя. Допустимый диапазон вы можете видеть в третьем столбце.
Переменные данного типа будут занимать 6 байт.
Далее идёт символьный тип (char). Сюда может входить любой символ алфавита. Но только один. Это может быть, как строчная или прописная буква, так и цифра. Область памяти, которая выделена под этот тип равна 1 байту.
Следующий тип данных – строковый (string). Переменная может включать в себя любую последовательность символов, длинна которой не должна превышать 255 символов. Переменные данного типа будут занимать 1 байт на один символ.
И последний тип – логический (boolean). При этом типе данных переменная может принимать одно из двух значений: True или False. Область памяти для переменной этого типа равна 1 байту.
А сейчас давайте
соотнесём переменные с наиболее подходящими типами данных. Нам дано 6
переменных со значениями и 6
типов данных.
Итак, смотрим на переменную А. Она равна 356. Это целое число, значит тип данных целочисленный (integer).
B := 0.15. Это дробное число. Значит тип данных вещественный (real).
C := ‘B’. Переменная равна одному символу. Значит это символьный тип (char).
Далее, D := ‘Max’. Здесь у нас в переменной находится несколько символов, значит это уже строка. Соответственно тип данных – строковый (string).
E := true. Это логический тип (boolean).
F := 15. Это тип byte.
А сейчас пришла пора подвести итоги урока.
Сегодня мы с вами узнали, что такое языки программирования, кто и когда создал язык программирования Pascal. Изучили, что входит в алфавит этого языка, а также научились отличать верные имена от неверных. Ближе познакомились с типами данных и выполнили упражнение, с помощью которого научились различать типы данных.
АЛФАВИТ (в программировании) — это.
 .. Что такое АЛФАВИТ (в программировании)?
.. Что такое АЛФАВИТ (в программировании)?- АЛФАВИТ (в программировании)
- АЛФАВИТ (в программировании)
АЛФАВИ́Т в программировании, система неразложимых, уверенно отличимых друг от друга символов (букв, цифр, знаков препинания и др. символов), используемых для построения языков программирования.
Энциклопедический словарь. 2009.
- АЛУНАНС Адольф
- АЛФАВИТ (газета)
Смотреть что такое «АЛФАВИТ (в программировании)» в других словарях:
алфавит в программировании — система неразложимых, уверенно отличимых друг от друга символов (букв, цифр, знаков препинания и др.), используемых для построения языков программирования … Энциклопедический словарь
АЛФАВИТ — в программировании система неразложимых, уверенно отличимых друг от друга символов (букв, цифр, знаков препинания и др.
 символов), используемых для построения языков программирования … Большой Энциклопедический словарь
символов), используемых для построения языков программирования … Большой Энциклопедический словарьАлфавит — (гр. – «альфа» и «бета» – первые буквы гр. алфавита) – совокупность знаков системы письма – букв, слоговых знаков и других графем, расположенных в определенном порядке. Качество букв зависит от звукового состава языка: в современном русском языке … Основы духовной культуры (энциклопедический словарь педагога)
АЛФАВИТ — в программировании, система неразложимых, уверенно отличимых друг от друга символов (букв, цифр, знаков препинания и др.), используемых для построения языков программирования … Естествознание. Энциклопедический словарь
Чешский алфавит — (чеш. Česká abeceda) вариант латиницы, который используется при написании на чешском языке. Основные принципы алфавита «один звук одна буква» и добавление диакритических знаков над буквами для обозначения звуков, далёких от латинского языка.
 … … Википедия
… … ВикипедияКОДИРОВАНИЕ — (от франц. code – свод законов, правил) – отображение (преобразование) нек рых объектов (событий, состояний) в систему конструктивных объектов (называемых кодовыми образами), совершаемое по определ. правилам, совокупность к рых наз. шифром К.,… … Философская энциклопедия
Йот — Запрос статьи «J#» перенапраляется сюда по техническим причинам; см. Visual J Sharp. Буква J (j) десятая буква латинского алфавита. Латинское название йот или йота, французское название (принятое также в русскоязычной математике) жи,… … Википедия
ДРАКОН — Эта статья предлагается к удалению. Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/28 сентября 2012. Пока процесс обсуждения не завершён, статью мож … Википедия
Венгерская нотация — Венгерская нотация в программировании соглашение об именовании переменных, констант и прочих идентификаторов в коде программ.
 Своё название венгерская нотация получила благодаря программисту компании Microsoft венгерского происхождения … Википедия
Своё название венгерская нотация получила благодаря программисту компании Microsoft венгерского происхождения … ВикипедияI (латиница) — Буква латиницы I, i Латинский алфавит A B C D E … Википедия
Ответы | § 2. Языки программирования — Информатика, 10 класс
1. Для чего предназначен транслятор?
Транслятор предназначен для преобразования текста программы, написанной на языке высокого уровня, в элементарные машинные команды.
2.
 Какие функции выполняет компилятор? Интерпретатор?
Какие функции выполняет компилятор? Интерпретатор?
Компилятор преобразует исходный код с какого-либо языка программирования на машинный. А интерпретатор читает код и исполняет его сразу либо читает код, создаёт в памяти промежуточное представление кода (байт-код или p-код) и выполняет промежуточное представление кода.
3. Что определяется парадигмой программирования?
Парадигмой программирования определяется стиль программирования, например, структурное, процедурное, функциональное, объектно-ориентированное программирование.
4. Из каких элементов может состоять алфавит языка программирования?
Алфавит языка программирования может состоять из букв латинского алфавита, цифр, знаков арифметических операций и сравнения, разделителей, служебных слов и комментариев.
5.
 Что представляет собой оператор языка программирования?
Что представляет собой оператор языка программирования?
Оператор языка программирования представляет собой законченную фразу языка, являясь предписанием на выполнение конкретных действий по обработке данных.
6. Какие типы данных вам известны?
Типы данных делятся на две группы: простые и структурированные. Структурированные типы данных: массив, строка. Простые: логические, символьные, целочисленные (знаковые, беззнаковые).
Структурированные типы данных: массив, строка. Простые: логические, символьные, целочисленные (знаковые, беззнаковые).
7. Для чего используются функции и процедуры?
Функции используются для описания процесса вычисления определенного значения, зависимого от некоторых аргументов. Процедуры используют в качестве самостоятельного этапа обработки данных, который не возвращает конкретные значения.
Присоединяйтесь к Telegram-группе @superresheba_10, делитесь своими решениями и пользуйтесь материалами, которые присылают другие участники группы!14.
 ; *; /; +; -; \; MOD.
; *; /; +; -; \; MOD.Знаки операций отношения: =; >; <; >=; <=; <>.
Разделители и прочие символы:
. – точка;
, — запятая;
; — точка с запятой;
: — двоеточие;
_ — пробел;
! – признак вещественной величины;
# — признак вещественной величины двойной точности;
% — признак целой величины;
& — признак длинной целой величины
$ — признак текстовой величины;
() – круглые скобки;
“ – кавычки;
‘ – апостроф.
Используются также буквы русского алфавита, но в текстовых константах или комментариях.
20. Прикладное программное обеспечение Оно определяет на компьютере прикладную среду правила работы в ней. Прикладные программы могут работать на компьютере только при условии, что на компьютере уже установлена операционная система.
Каждая
прикладная среда предназначена для
создания и исследования определенного
вида компьютерного объекта. Комплекс
прикладных программ в среде операционной
системы Windows называют приложением.
Нередко его называют также пакётом
прикладных программ (ППП).
Комплекс
прикладных программ в среде операционной
системы Windows называют приложением.
Нередко его называют также пакётом
прикладных программ (ППП).
Наибольшей популярностью пользуются следующие группы прикладного программного обеспечения:
текстовые процессоры — для создания текстовых документов;
табличные процессоры (электронные таблицы) — для вычислений и анализа информации, представленной в табличной форме;
базы данных — для организации и управления данными;
графические пакеты — для представления информации в виде рисунков и графиков; » коммуникационные программы — для обмена информацией между компьютерами;
интегрированные пакеты, включающие несколько прикладных программ разного назначения;
обучающие программы, электронные учебники, словари, энциклопедии, системы проектирования и дизайна;
игры. В
В
*, / умножение и деление А*В,А/В
\ целочисленное деление А\В
МОD остаток от целочисленного А МОD В
деления
+,- сложение и вычитание А+В,А-В
Размещение скобок в различных местах выражений приводит к разным результатам.
Логические операции
Для сравнения двух величин служат операции отношения. Сравниваемые величины должны быть одинакового типа — либо обе число вые, либо обе строковые. Результатом операции отношения могут быть 1 (истина) или 0 (ложь). Сравнение строк символов осуществляется посимвольно слева направо. Допускается использование следующих операций отношения (в порядке приоритета выполнения):
= равно А=В
>< или <> не равно А><В или А<>В
< меньше А<В
> больше А>В
<= или =< меньше или равно А<=В
>= или => больше или равно А>=В
При
объединении в одном выражении
арифметических операций и операций
отношения первыми выполняются
арифметические операции.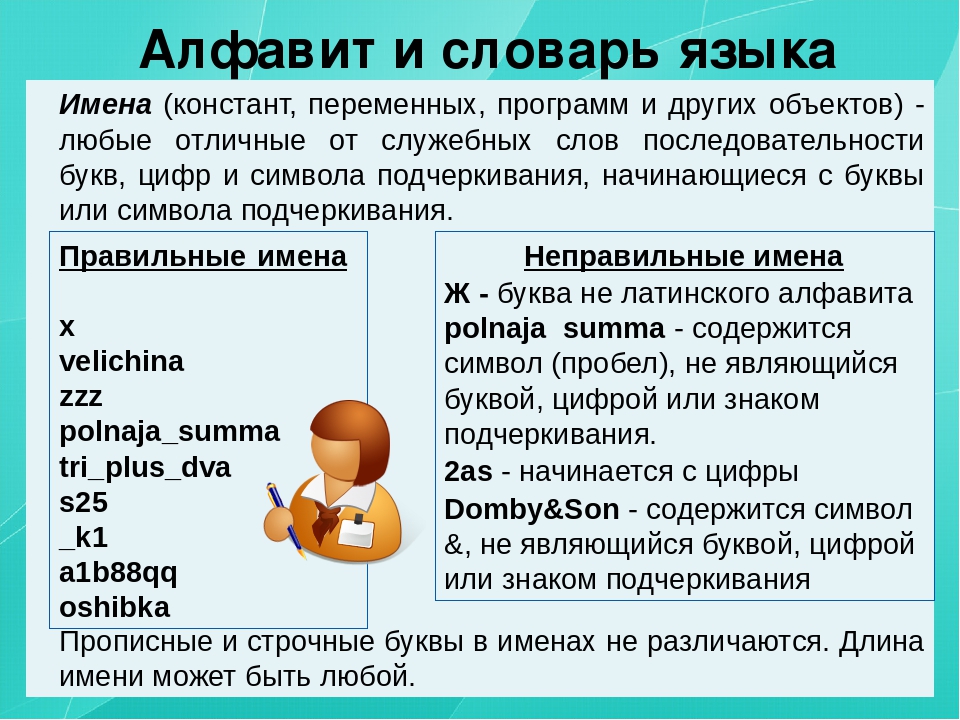
В языке BASIC используются следующие логические операции (в порядке приоритета их выполнения): NOT — не ; AND- и; OR — или.
NOT AND OR
R1 (NOT R1) R1 R2 (R1 AND R2) R1 R2 (R1 OR R2)
0 1 1 1 1 1 1 1
1 0 1 0 0 1 0 1
0 1 0 0 1 0
0 0 0 0 0 0
Операции одного уровня выполняются слева направо. Для изменения порядка выполнения операций применяются скобки.
Строковые операции
Операцией над строками, подобной операции сложения чисел, является конкатенация. Эта операция заключается в присоединении одной строки символов к концу другой строки символов. Для обо значения конкатенации строк используется символ “+” .
Например, «Высоко» + «урожайный»
Результирующая строка имеет вид: » Высокоурожайный «.
Для сравнения строк применяются операции отношения ( = , < , > , <= , >= , >< ).
The Programming Languages Alphabet — открытый исходный код для вас
Существует настоящий алфавитный суп из начальных букв названий языков программирования. Автор просматривает этот ассортимент, чтобы найти наиболее значимый язык программирования для представления каждой буквы алфавита.
Автор просматривает этот ассортимент, чтобы найти наиболее значимый язык программирования для представления каждой буквы алфавита.
Очень часто мы ограничиваем наши обсуждения языков программирования популярными языками, такими как Python, C, C ++, Java и т. Д. Мы не признаем, что существуют буквально тысячи языков программирования.В этой статье я стараюсь выделить изобилие вариантов, перечислив их в алфавитном порядке. Итак, у нас будет «A для Ada, B для BASIC…» и так далее. Выбирая конкретный язык программирования, я принимал во внимание факторы популярности, наличие компилятора с открытым исходным кодом и историческое значение. Помните, что любой инструмент, завершенный по Тьюрингу, можно назвать языком программирования, что, в общем, создает даже шаблоны C ++ и языки программирования препроцессора C.
А для Ada
На первую букву алфавита у меня претендуют ALGOL, AWK, AppleScript и Ada.Алгол — один из первых языков программирования, но он больше не широко используется в профессиональном плане, в то время как AppleScript используется исключительно с macOS. AWK — это язык обработки текста, который проигрывает войну Perl, другому языку обработки текста.
AWK — это язык обработки текста, который проигрывает войну Perl, другому языку обработки текста.
Ada — это язык программирования, который поддерживает как императивную, так и объектно-ориентированную парадигмы программирования, при этом безопасность и безопасность являются основными проблемами. GNAT — это компилятор с открытым исходным кодом для Ada, который является частью коллекций компиляторов GNU (GCC).Ада пользуется поддержкой небольшого, но стабильного сообщества разработчиков. Язык программирования Ada назван в честь Ады Лавлейс, дочери лорда Байрона (известного английского поэта). Ада Лавлейс считается пионером в области компьютерного программирования благодаря своей работе с Чарльзом Бэббиджем, когда она пыталась разработать свою незаконченную, но известную аналитическую машину. Хотя я выбрал Аду, помните, что языки ассемблера очень важны в программировании, но это не единственный язык программирования; скорее, это семейство языков программирования.
B для BASIC
Существуют языки программирования, называемые B и BCPL, которые повлияли на развитие языка программирования C, что делает их весьма важными. Но для буквы B я выбрал BASIC (Универсальный символический код инструкции для начинающих). BASIC повлиял на многие другие языки программирования, такие как Visual Basic, VB.NET и т. Д. Но самый большой вклад BASIC состоит в том, что впервые люди без научного фона могут начать программировать, используя его.
Но для буквы B я выбрал BASIC (Универсальный символический код инструкции для начинающих). BASIC повлиял на многие другие языки программирования, такие как Visual Basic, VB.NET и т. Д. Но самый большой вклад BASIC состоит в том, что впервые люди без научного фона могут начать программировать, используя его.
C для C
Это та буква, на которой число влиятельных языков программирования очень велико. Существуют такие языки программирования, как C ++, C #, Clojure, COBOL и т. Д. Но здесь выбор очевиден — это не что иное, как C, который был первоначально разработан в 1972 году Деннисом Ричи из Bell Labs. Даже после почти 50 лет существования C по-прежнему широко используется как в профессиональной, так и в академической среде. Таким образом, в обосновании выбора C нет необходимости.
D для Dart
Существует язык программирования D, на который сильно повлиял C ++.Но я выбрал Dart, объектно-ориентированный язык программирования с открытым исходным кодом, разработанный Google и выпущенный под лицензией BSD. Dart был отмечен как многообещающий язык программирования в статье в Open Source For You. Посетите веб-страницу.
Dart был отмечен как многообещающий язык программирования в статье в Open Source For You. Посетите веб-страницу.
E для Erlang
Erlang — это язык программирования с открытым исходным кодом, разработанный Ericsson и работающий под лицензией Apache License 2.0. Erlang — это функциональный язык программирования. Есть также другие варианты, такие как Eiffel и Elixir.Eiffel — объектно-ориентированный язык программирования, тогда как Elixir — это функциональный язык программирования, на который сильно влияет сам Erlang. Поскольку у Erlang есть последние стабильные выпуски, я предпочел его Elixir. Кроме того, существует язык программирования с открытым исходным кодом Ezhil, который использует тамильский скрипт для написания программ.
F для Fortran
Существуют языки программирования, называемые F, F #, FoxPro и т. Д., Но я выбрал Фортран для обозначения буквы F. Это самый старый язык программирования, выбранный в этой статье, но он имел стабильную версию за последний год. Изначально Фортран использовался для научных и числовых вычислений. GFortran — это компилятор Fortran, предоставляемый GCC, что делает Fortran действительно языком программирования с открытым исходным кодом.
Изначально Фортран использовался для научных и числовых вычислений. GFortran — это компилятор Fortran, предоставляемый GCC, что делает Fortran действительно языком программирования с открытым исходным кодом.
G для Go
Go (также называемый Golang) разработан Google. Это популярный язык программирования, который входит в первую десятку многих рейтингов. Go похож на C, но с дополнительными функциями безопасности и сборки мусора. Go имеет несколько компиляторов с открытым исходным кодом с лицензиями BSD. Нет другого языка программирования, начинающегося с буквы G, достойного упоминания, кроме Groovy, объектно-ориентированного языка программирования, на который сильно повлияла Java.
H для Haskell
Haskell — это функциональный язык программирования, который был разработан в 1990 году. Glasgow Haskell Compiler (GHC) — популярный компилятор с открытым исходным кодом для Haskell, выпущенный под новой лицензией BSD. Haskell занимает относительно высокое место во многих рейтингах. Система программирования на хиндави — это набор языков программирования с открытым исходным кодом, в которых для написания программ используются сценарии хинди, бенгали и гуджарати.
Система программирования на хиндави — это набор языков программирования с открытым исходным кодом, в которых для написания программ используются сценарии хинди, бенгали и гуджарати.
I для Icon
Вряд ли есть какие-либо значимые языки программирования, начинающиеся с этой буквы.Я выбрал Icon, язык динамического программирования, созданный под влиянием SNOBOL, который намного старше. Но пока это единственная буква в алфавите наших языков программирования, удаление которой не сильно повлияет на мир программирования.
J для Java
Буква J в алфавите нашего языка программирования определенно зарезервирована для Java. Цитата: «Вы можете любить меня или ненавидеть, но вы не можете игнорировать меня» абсолютно верна для Java. Признательный или критический, настоящий программист не может игнорировать Java.Я не думаю, что мне нужно оправдывать свой выбор, и поэтому оставляю свою точку зрения. Но стоит упомянуть и JavaScript. JavaScript — это интерпретируемый язык сценариев, который постоянно входит в десятку самых рейтинговых списков.
K для Kotlin
Kotlin — относительно новый язык программирования. Его разработка началась в 2011 году, но он набирает популярность. Kotlin — это язык программирования со статической типизацией, который работает на виртуальной машине Java и широко используется для разработки приложений для Android.Kotlin выпущен под лицензией Apache. Поскольку оболочка Korn является полной по Тьюрингу, ее стоит упомянуть.
L для Lisp
Инженер-электрик мог бы выбрать LabVIEW, платформу для системного проектирования и среду разработки, для буквы L. Но я думаю, что Lisp, будучи исходным языком функционального программирования, должен представлять букву L. Lisp — один из старейших сохранившихся высокоуровневых языков. языки программирования. Но помните, что это не единственный язык программирования; вместо этого для Lisp существует ряд диалектов, таких как Clojure, Racket, Scheme и т. д.Здесь также стоит упомянуть Lua, язык программирования с несколькими парадигмами.
Буква M означает Maple, Magma, MATLAB, Maxima и Mathematica — языки программирования и математическое программное обеспечение, используемые для поддержки серьезной математики, а не, скажем, нахождения суммы двух небольших целых чисел и отображения результата на веб-странице. Несмотря на то, что Maxima является программным обеспечением с открытым исходным кодом, я выбрал MATLAB, проприетарное коммерческое ПО. Я считаю, что широкое использование MATLAB оправдывает его выбор.M — это также буква, которая напоминает нам о машинных языках и всех пионерах, которые писали программы на перфокартах.
Несмотря на то, что Maxima является программным обеспечением с открытым исходным кодом, я выбрал MATLAB, проприетарное коммерческое ПО. Я считаю, что широкое использование MATLAB оправдывает его выбор.M — это также буква, которая напоминает нам о машинных языках и всех пионерах, которые писали программы на перфокартах.
N для NASM
N — еще одна буква в этой последовательности, удаление которой не сильно повлияет на сообщество программистов. Я выбрал Netwide Assembler (NASM), ассемблер и дизассемблер для архитектуры Intel x86. NASM завершен по Тьюрингу; следовательно, его можно рассматривать как язык программирования. Он выпущен под лицензией BSD.
O для Objective-C
Objective-C — это объектно-ориентированный язык программирования, в котором есть компиляторы, реализованные как Clang, так и GCC.Он включен как один из десяти лучших языков программирования в упомянутой ранее статье Open Source For You. Objective-C поддерживается Apple для разработки приложений для macOS и iOS. Ocaml, язык программирования с несколькими парадигмами, и Octave, язык программирования для числовых вычислений, заняли второе место по представлению буквы O.
Ocaml, язык программирования с несколькими парадигмами, и Octave, язык программирования для числовых вычислений, заняли второе место по представлению буквы O.
P для Python
P — еще одна богатая буква в алфавите наших языков программирования, но, опять же, выбор был прост — это не что иное, как Python.Python — это интерпретируемый язык программирования общего назначения. В нашу эпоху искусственного интеллекта и машинного обучения Python — золотой ребенок в семье языков программирования. Приложения в самых разных областях делают Python абсолютно важным. Но в этой категории стоит упомянуть и другие важные языки программирования. Паскаль — важный процедурный язык программирования, разработанный в 1970 году. Perl — это универсальный интерпретируемый динамический язык программирования, часто используемый для обработки текста.PHP — это язык программирования общего назначения, который чаще всего используется для веб-разработки, а также стоит упомянуть Prolog, язык логического программирования, связанный с ИИ.
Q для Q #
В качестве буквы Q выбрана Q #, язык программирования, выпущенный Microsoft для разработки квантовых алгоритмов. Q # — это новейший язык программирования, включенный в наш список, первая версия которого выйдет в декабре 2017 года. На него влияют как C #, так и F #. Недавно мы узнали, что Google добился квантового превосходства и, как мы надеемся, в ближайшем будущем сделает квантовые компьютеры реальностью.Таким образом, возможно, что Q # или подобные языки программирования будут играть ключевую роль в мире программирования в не столь отдаленном будущем. Стоит упомянуть два других языка программирования в этой категории: QtScript и QBasic.
R за
R Выбор языка для алфавита «R» также был относительно простым. R — еще один язык программирования из первой десятки, который присутствует почти во всех рейтингах. R — это язык программирования и бесплатная программная среда для статистических вычислений.Поскольку в настоящее время очень популярны большие данные и интеллектуальный анализ данных, популярность R, похоже, растет. В этой категории также стоит упомянуть Ruby, интерпретируемый язык программирования общего назначения, и Rust, язык программирования с несколькими парадигмами.
В этой категории также стоит упомянуть Ruby, интерпретируемый язык программирования общего назначения, и Rust, язык программирования с несколькими парадигмами.
S для Swift
S — еще одна богатая буква в алфавите языков программирования, но и здесь выбор был прост; это Свифт. К своему удивлению, я обнаружил, что существует также параллельный язык сценариев под названием Swift, но я имею в виду универсальный, многопарадигмальный язык программирования, разработанный Apple Inc.Он также входит в десятку лучших в большинстве рейтингов. В настоящее время Swift выпускается под лицензией Apache License 2.0, что делает его языком программирования с открытым исходным кодом. В этой категории есть ряд других языков программирования, о которых стоит упомянуть. Scala — это функциональный язык программирования общего назначения. Scilab — это пакет для числовых вычислений и язык числового программирования. Scratch — это визуальный язык программирования для обучения детей программированию. SQL (язык структурированных запросов) — это язык программирования, используемый для управления реляционными базами данных.Simula и Smalltalk, возможно, сегодня не актуальны, но они повлияли на развитие таких языков программирования, как C ++, Java и т. Д.
SQL (язык структурированных запросов) — это язык программирования, используемый для управления реляционными базами данных.Simula и Smalltalk, возможно, сегодня не актуальны, но они повлияли на развитие таких языков программирования, как C ++, Java и т. Д.
T для TypeScript
TypeScript — это язык программирования с открытым исходным кодом, выпущенный под лицензией Apache License 2.0 и разработанный Microsoft. Он имеет синтаксис и все функции JavaScript, с некоторыми дополнительными функциями, такими как статическая типизация. TypeScript набирает популярность в последние годы. В упомянутой ранее статье Open Source For You TypeScript был включен как многообещающий язык программирования.Tcl (Tool Command Language), интерпретируемый язык динамического программирования, также заслуживает упоминания в этой категории.
U для Umple
В этом письме тоже нечего предложить. Но для полноты картины Umple представляет букву U в нашем алфавите. Umple — это объектно-ориентированный язык программирования, используемый для моделирования с помощью диаграмм классов и диаграмм состояний. Впервые он был выпущен в 2008 году, а последний стабильный выпуск — в 2018. Но помните, что оболочка UNIX, полная по Тьюрингу, квалифицируется как язык программирования.
Впервые он был выпущен в 2008 году, а последний стабильный выпуск — в 2018. Но помните, что оболочка UNIX, полная по Тьюрингу, квалифицируется как язык программирования.
В для Verilog
Рассмотрите любой достойный язык программирования, у которого есть последователи, и поставьте перед термином слово «визуальный», и вы получите новый язык программирования! Я не шучу — у нас есть Visual Basic, Visual Basic.NET, Visual C ++, Visual FoxPro и многие другие в качестве доказательства. Несмотря на такой широкий выбор, я предпочитаю VHDL (язык описания оборудования для высокоскоростных интегральных схем) или Verilog, оба языка описания оборудования. Мое описание оборудования, часто ограниченное ценой, сделало выбор очень трудным.Беглый взгляд на несколько статей заставил меня поверить, что Verilog незначительно лидирует в гонке между ними и, следовательно, делает выбор. Но я буду очень рад перейти на другую сторону, если кто-нибудь сможет убедить меня, почему VHDL лучше, чем Verilog.
Вт для Wolfram Language
Wolfram language — еще один проприетарный коммерческий язык программирования в нашем списке. Но я считаю, что мой выбор оправдан, потому что другие языки программирования в этой категории почти не повлияли на мир программирования.Wolfram Language — это язык программирования с несколькими парадигмами, разработанный Wolfram Research, и язык программирования программы математических символьных вычислений Mathematica.
X для XOTcl
Мои дни симуляции ns-2 (сетевой симулятор-2) заставили меня выбрать XOTcl из незначительного в остальном списка языков программирования. XOTcl — это объектно-ориентированное расширение для языка команд инструментов (Tcl). XOTcl используется для генерации топологии в ns-2.
Y для Yorick
Y — наименее перспективная буква в алфавите наших языков программирования.Yoix, язык динамического программирования, и Yorick, интерпретируемый язык программирования, разработанный для числовых и научных вычислений, являются единственными претендентами в этой категории. Я выбрал Yorick вместо Yoix, потому что его последний стабильный выпуск был четыре года назад, по сравнению с семью годами для Yorick.
Я выбрал Yorick вместо Yoix, потому что его последний стабильный выпуск был четыре года назад, по сравнению с семью годами для Yorick.
Z для Zsh
Z — еще одна буква, в списке которой нет значимых языков программирования. Но поскольку любой инструмент, завершенный по Тьюрингу, квалифицируется как язык программирования, я номинирую Z Shell (Zsh).Оболочка Z — это интерактивная оболочка входа и интерпретатор команд для сценариев оболочки UNIX. В последней крупной версии для компьютеров Apple Macintosh в macOS Catalina в качестве оболочки используется Zsh вместо Bash.
Выбор конкретного языка программирования во многом основывается на личных предпочтениях автора, но были предприняты усилия, чтобы упомянуть все важные языки программирования. Насколько мне известно, существуют языки программирования с именами B, C, D, E, F, J, K, P, Q, R, S и T, но многие из них старые или малоизвестные и не имеют практического применения.Я буду рад, если кто-нибудь сможет указать на языки программирования, которые я, возможно, пропустил в этом списке. Тщательный анализ показывает, что C, J, M, P, R и S — самые важные буквы в алфавите наших языков программирования. Интересно отметить, что существуют языки программирования, названные в честь животных (Свинья, Питон и Кобра), мест (Java), известных людей (Ада, Бэббидж, Бертран, Оруэлл и Паскаль), вещей (Бумеранг, Дарт и Руби) и т. Д. Но помимо всего этого веселья, наш алфавит языков программирования ясно говорит нам, что возможности безграничны, когда дело доходит до создания приложений и карьеры.
Тщательный анализ показывает, что C, J, M, P, R и S — самые важные буквы в алфавите наших языков программирования. Интересно отметить, что существуют языки программирования, названные в честь животных (Свинья, Питон и Кобра), мест (Java), известных людей (Ада, Бэббидж, Бертран, Оруэлл и Паскаль), вещей (Бумеранг, Дарт и Руби) и т. Д. Но помимо всего этого веселья, наш алфавит языков программирования ясно говорит нам, что возможности безграничны, когда дело доходит до создания приложений и карьеры.
Алфавит языков программирования (инфографика)
От AWK к ЗИЛ: алфавит языков программирования
Алфавитный список известных языков программирования и изобретателей, их разработавших.
Вставить это изображение на свой сайт
