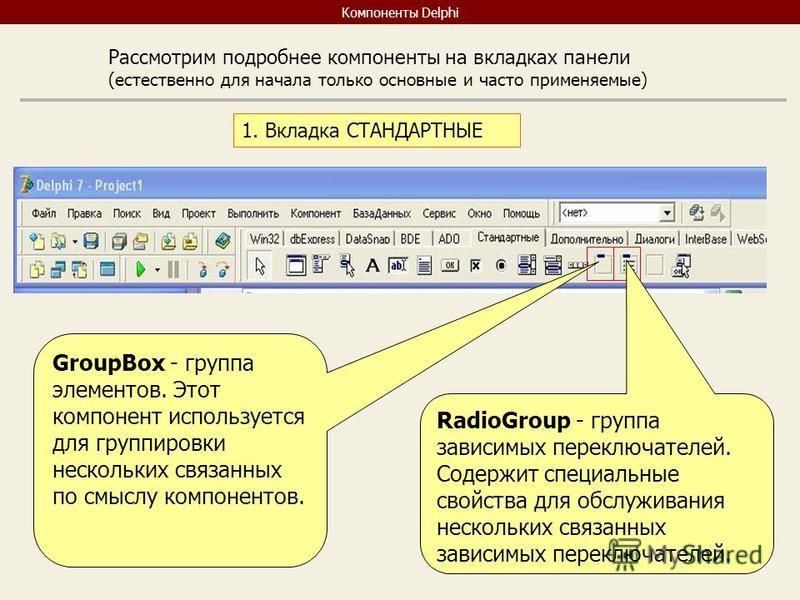
Агрегирование и группировка данных
В данном разделе рассматривается применение в запросе агрегирующих функций- функций вычисляющих результат по набору значений группы, либо всех записей БД. Например, функция sum возвращает сумму значений заданного поля, а функция count — общее число записей.
Агрегирующая функция может применяться ко всем записям БД слоя, к выборке по заданным условиям и, кроме того, возможно группирование записей слоя в несколько групп, и применение агрегирующей функции к каждой группе («Группировка записей»).
Применяемые агрегирующие функции записываются после ключевого слова SELECT. Также допускается использовать агрегирующие функции в составе
выражений, включающих функции, арифметические и побитовые операции. В одном запросе может
перечисляться несколько выражений с агрегирующими функциями. Не допускается в запросе
одновременно с агрегирующими функциями запрашивать значения полей записей БД, либо
использовать в аргументах неагрегирующих функций обращения к полям записей БД .
SELECT SQRT(Area), SUM(Perimeter) FROM Здания не допускается,
поскольку аргументом функции SQRT является название поля данных.Общая запись агрегирующих функций:
<Функция>([DISTINCT]<выражение>)
В качестве аргумента агрегирующей функции обычно используется название поля, над значениями которого проводятся вычисления. Также допускается в качестве аргумента использовать выражения, включающие в себя произвольную комбинацию названий полей, констант, функций и подзапросов, объединенных арифметическими и побитовыми операциями.
Остальная часть запроса задается стандартным образом.
Перед аргументом функции (кроме функций MAX и MIN)может указываться ключевое слово DISTINCT. В этом
случае итоговое значение вычисляется только для различающихся значений аргумента. При
использовании ключевого слова DISTINCT в качестве аргумента агрегирующей
функции нельзя использовать арифметические выражения, — только названия полей.
В языке SQL используются следующие агрегирующие функции:
SUM([DISTINCT] <выражение>)
Выводит в итоговой таблице сумму значений для выражения по полям выборки. Выражение должно возвращать числовое значение.
AVG([DISTINCT] <выражение>)
Среднее значение для выражения. Выражение должно возвращать числовое значение.
COUNT([DISTINCT] <выражение> |*)
Подсчитывает число записей, в который выражение не имеет значение Null (поля имеют значение Null, когда никакое значение для них не задано).
Выражение может возвращать произвольное значение.
При используемом формате функции COUNT(*) возвращает общее количество записей в БД слоя.
MAX( <выражение>)
Возвращает максимальное значение выражения для выборки.
MIN(<выражение>)
Возвращает минимальное значение выражения из выборки.
Применение агрегирующих функций
Простой пример
SELECT SUM(Perimeter) FROM Здания
Выводит сумму периметров зданий.
Одновременное применение нескольких функций
SELECT AVG(Area), Count(*) FROM Здания
Выводит среднюю площадь здания и общее количество зданий.
Применение функций совместно с условиями отбора
SELECT SUM(Area) FROM Здания WHERE Улица='Нахимова'
Возвращает сумму площадей зданий расположенных на улице Нахимова.
Применение выражений в качестве аргументов агрегирующих функций
SELECT SUM(Area/Perimeter*2) FROM Здания
Для каждого здания рассчитывается величина равная Площадь/Периметр*2 и
суммируется.
Применение агрегирующих функций в составе выражений
SELECT SQRT(SUM(Area)), "Общий периметр" + SUM(Perimeter) FROM Здания
Возвращает квадратный корень от суммарной площади всех зданий и фразу вида «Общий
периметр XXX», где XXX — суммарный периметр всех зданий.
Использование ключевого слова DISTINCT
SELECT COUNT(DISTINCT Улица) FROM Здания
Возвращает количество разных названий улиц в БД слоя.
28. Агрегирующие функции. Группировка кортежей. Примеры.
Агрегирующие
функции:
работают с набором строк и предоставляют
один результат в группе. Примеры
функций:
AVG,
COUNT,
MAX,
MIN,
SUM.
AVG
и SUM
используются только для числовых
значений. MIN
и MAX
для числовых значений и дат. COUNT(*)
возвращает количество строк в таблице,
COUNT(выражение) возвращает количество
строк с не пустым (не NULL) значением
выражения. COUNT(DISTINCT выражение) возвращает
количество уникальных не null значений
выражения.
COUNT(DISTINCT выражение) возвращает
количество уникальных не null значений
выражения.
Синтаксис:
SELECT [column,]Групповая_функция(column), …
FROM таблица
[WHERE условие]
[GROUP BY column]
[ORDER BY column];
Есть возможность применять агрегирующие функции к группам данных. Для этого используется GROUP BY столбец (пример на рисунке, группировка идёт по номеру отдела). Группировку можно делать по нескольким колонкам.
Агрегирующие функции не могут использоваться в части WHERE! При выводе нескольких колонок, для тех, которые не обрабатываются агрегирующей функцией, должен быть установлен GROUP BY. При выводе одной колонки допускается не писать GROUP BY, тогда результат запроса будет рассматриваться как одна группа.
Использование HAVING. Выражение нужно для: накладывания дополнительных условий на результаты агрегирующих функций.
Пример:
SELECT
отдел.
FROM отдел
GROUP BY номер_отдела
HAVING MAX(зарплата)>150; — будут выведены только те результаты, у которых значения соответствуют условию.
Представление это объект БД на основе одной или нескольких таблиц и/или других представлений.( виртуальная (логическая) таблица, результат запроса из базы данных.)
Преимущества представлений:
+ Ограниченный доступ к данным
+ Независимость от данных
+ Упрощение создания сложных запросов
+ Представление по разному одних и тех же данных
Создание представлений
CREATE VIEW имя_представления [(имя_колонки, …)] AS запрос
Имя_представления – именует представление. Имя_колонки – именует колонку представления.
AS
– указывает начало определения
представления. Запрос – определяет
представление.
Запрос – определяет
представление.
Причины использования View:
Использование представлений не даёт каких-то совершенно новых возможностей в работе с БД, но может быть очень удобно.
1) Представления скрывают от прикладной программы сложность запросов и саму структуру таблиц БД. Когда прикладной программе требуется таблица с определённым набором данных, она делает простейший запрос из подготовленного представления. При этом даже если для получения этих данных требуется чрезвычайно сложный запрос, сама программа этого запроса не содержит.
2)
Использование представлений позволяет
отделить прикладную схему представления
данных от схемы хранения. С точки зрения
прикладной программы структура данных
соответствует тем представлениям, из
которых программа эти данные извлекает.
В действительности данные могут храниться
совершенно иным образом, достаточно
лишь создать представления, отвечающие
потребностям программы.
3) С помощью представлений обеспечивается ещё один уровень защиты данных. Пользователю могут предоставляться права только на представление, благодаря чему он не будет иметь доступа к данным, находящимся в тех же таблицах, но не предназначенных для него.
4) Поскольку SQL-запрос, выбирающий данные представления, зафиксирован на момент его создания, СУБД получает возможность применить к этому запросу оптимизацию или предварительную компиляцию, что положительно сказывается на скорости обращения к представлению, по сравнению с прямым выполнением того же запроса из прикладной программы.
Пример
1. CREATE VIEW sum_zakaz AS
CREATE VIEW sum_zakaz AS
SELECT SUM (WorkTable.WorkPrice) AS Summa, SalesID
FROM WorkSalesTable
INNER JOIN WorkTable On WorkTable.WorkId=WorkSalesTable.WorkId
GROUP By WorkSalesTable.SalesId
Пример 2. CREATE VIEW dept_sum_v (name, minsal, maxsal, avgsal)
AS
SELECT d.department_name, MIN(e.salary),MAX(e.salary),
AVG(e.salary)
ON (e.department_id = d.department_id)
GROUP BY d.department_name
2.2. Агрегирующие функции языка sql
При
статистическом
анализе
баз
данных
необходимо
получать
такую
ин-
формацию,
как
общее
количество
записей,
наибольшее
и
наименьшее
значения заданного
поля
записи,
усредненное
значение
поля
и
т.
д.
Данная
задача
выпол-
няется
с
помощью
запросов,
содержащих
так
называемые
агрегирующие
функ-
ции.
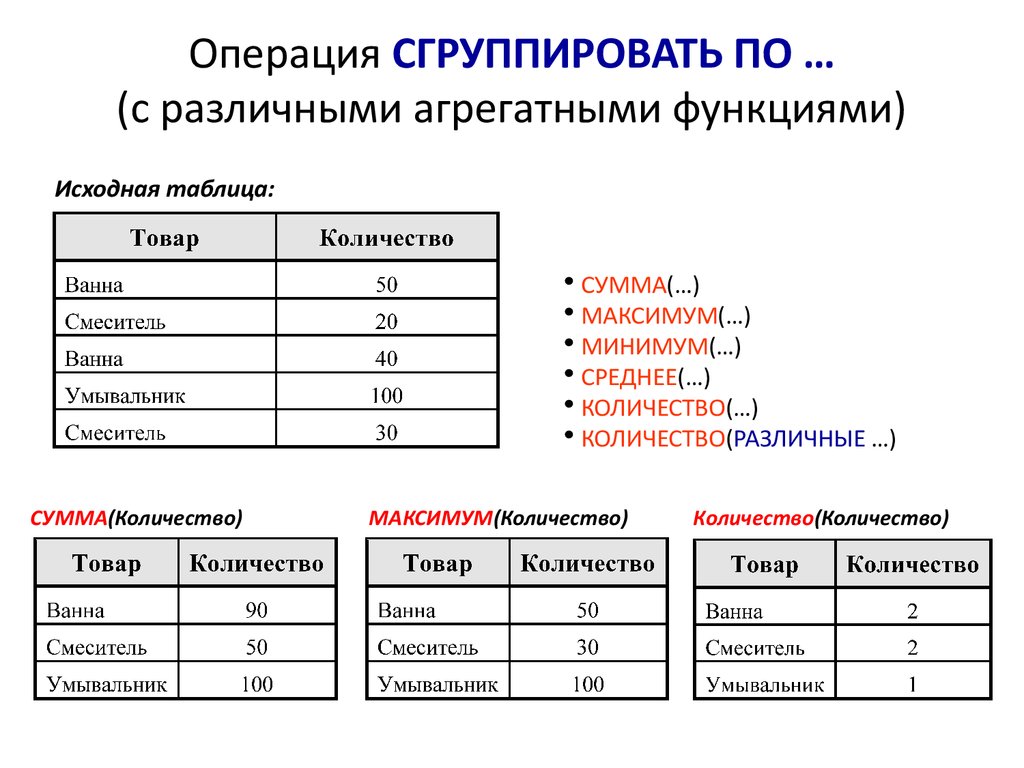
Агрегирующие функции производят вычисление одного «собирающего» значения (суммы, среднего, максимального, минимального значения и т. п.) для заданных групп строк таблицы. Группы строк определяются различными зна- чениями заданного поля (полей) таблицы. Разбиение на группы выполняется с помощью предложения group by.
Рассмотрим перечень агрегирующих функций.
• count определяет количество записей данного поля в группе строк.
• sum вычисляет арифметическую сумму всех выбранных значений данного поля.
• avg рассчитывает арифметическое среднее (усреднение) всех выбранных значений данного поля.
• max находит наибольшее из всех выбранных значений данного поля.
• min находит наименьшее из всех выбранных значений данного поля.
Для определения общего числа запи- сей в таблице Туристы используем запрос select count (*) from Туристы;
Результат выполнения запроса пред-
ставленнарисунке34.
Отметим, что результатом запроса яв- ляется одно число, содержащееся в поле с отсутствующим именем.
Рис. 34. Результат запроса с функцией count
А если мы захотим посчитать однофамильцев (то есть разбить набор за- писей-результатов запроса на группы с одинаковыми фамилиями), то запрос будет выглядеть так:
select Фамилия, count (Фамилия) from Туристы group by Фамилия;
Синтаксис использования других операторов одинаков – следующие за- просы извлекают сумму, арифметическое среднее, наибольшее и наименьшее значения поля «Цена» таблицы «Туры» (здесь заданной группой записей, как и в первом примере с функцией count, являются все записи таблицы).
select sum(Цена) from Туры select avg(Цена) from Туры select max(Цена) from Туры select min(Цена) from Туры
Если
значение
поля
может
быть
незаполненным,
то
для
обращения
к
та-
ким
полям
необходимо
использовать
оператор
null. Отметим,
что
величина
null
не
означает,
что
в
поле
стоит
число
0
(нуль)
или
пустая
текстовая
строка.
Су-
ществует
два
способа
образования
таких
значений:
Отметим,
что
величина
null
не
означает,
что
в
поле
стоит
число
0
(нуль)
или
пустая
текстовая
строка.
Су-
ществует
два
способа
образования
таких
значений:
1) Microsoft SQL Server автоматически подставляет значение null, если в зна- чение поля не было введено никаких значений и тип данных для этого поля не препятствует присвоению значения null;
2) или если пользователь явным образом вводит значение null.
Оператор сравнения like нужен для поиска записей по заданному шабло- ну. Эта задача является одной из наиболее часто встречаемых задач – например, поиск клиента с известной фамилией в базе данных.
Рис. 35. Запрос с оператором like
Предположим, что в таблице «Тури-
сты», содержащей поля «Фамилия», «Имя» и
«Отчество»,
требуется
найти
записи
клиентов
с
фамилиями,
начинающимися
на
букву
«И». select
Фамилия,
Имя,
Отчество
from
Туристы
where
Фамилия
Like
‘И%’
select
Фамилия,
Имя,
Отчество
from
Туристы
where
Фамилия
Like
‘И%’
Результатом этого запроса будет таблица, представленная на рисунке 35.
Оператор like содержит шаблоны, позволяющие получать различные ре-
зультаты(таблица7).
Таблица 7
Шаблоны оператора like
Шаблон
Значение
like ‘5[%]’
5%
like ‘[_]n’
_n
like ‘[a–cdf]’
a, b, c, d, или f
like ‘[–acdf]’
–, a, c, d, или f
like ‘[ [ ]’
[
like ‘]’
]
like ‘abc[_]d%’
abc_d и abc_de
like ‘abc[def]’
abcd, abce, и abcf
Агрегирующие функции в dplyr / Хабр
summarise() используется с агрегирующими функциями, которые принимают на вход вектор значений, а возвращают одно. Функция summarise_each() предлагает другой подход к summarise() с такими же результатами.
Цель этой статьи — сравнить поведение summarise() и summarise_each(), учитывая два фактора, которыми мы можем управлять:
1. Сколькими переменными оперировать
- 1А, одна переменная
- 1В, более одной переменной
2. Сколько функций применять к каждой переменной
- 2А, одна функция
- 2В, более одной функции
Получается четыре варианта:
- Вариант 1: применить одну функцию к одной переменной
- Вариант 2: применить много функций к одной переменной
- Вариант 3: применить одну функцию к многим переменным
- Вариант 4: применить много функций к многим переменным
Также проверим эти четыре случая с и без опции group_by().
Пакет данных
mtcars
Для этой статьи мы используем хорошо известный пакет данных mtcars.
Сначала мы преобразуем его в объект tbl_df. Со стандартным объектом data.frame ничего не произойдет, зато будет доступен гораздо лучший метод вывода.
Наконец, для того, чтобы было легко ориентироваться, выделим только четыре переменных, с которыми будем работать:
mtcars <- mtcars %>% tbl_df() %>% select(cyl , mpg, disp)
Вариант 1: применить одну функцию к одной переменной
В этом случае summarise() выдаст простой результат:
# без группировки mtcars %>% summarise (mean_mpg = mean(mpg))
## Source: local data frame [1 x 1] ## ## mean_mpg ## (dbl) ## 1 20.09062
# с группировкой mtcars %>% group_by(cyl) %>% summarise (mean_mpg = mean(mpg))
## Source: local data frame [3 x 2] ## ## cyl mean_mpg ## (dbl) (dbl) ## 1 4 26.66364 ## 2 6 19.74286 ## 3 8 15.10000
Можно было использовать и функцию summarise_each(), но ее использование менее обоснованно с точки зрения понятности кода.
# без группировки mtcars %>% summarise_each (funs(mean) , mean_mpg = mpg)
## Source: local data frame [1 x 1] ## ## mean_mpg ## (dbl) ## 1 20.09062
# с группировкой mtcars %>% group_by(cyl) %>% summarise_each (funs(mean) , mean_mpg = mpg)
## Source: local data frame [3 x 2] ## ## cyl mean_mpg ## (dbl) (dbl) ## 1 4 26.66364 ## 2 6 19.74286 ## 3 8 15.10000
Вариант 2: применить много функций к одной переменной
В этом случае можно применить обе функции, и summarise(), и summarise_each().
У функции summarise() более интуитивно понятный синтаксис:
# без группировки mtcars %>% summarise (min_mpg = min(mpg), max_mpg = max(mpg))
## Source: local data frame [1 x 2] ## ## min_mpg max_mpg ## (dbl) (dbl) ## 1 10.
# с группировкой mtcars %>% group_by(cyl) %>% summarise (min_mpg = min(mpg), max_mpg = max(mpg))
## Source: local data frame [3 x 3] ## ## cyl min_mpg max_mpg ## (dbl) (dbl) (dbl) ## 1 4 21.4 33.9 ## 2 6 17.8 21.4 ## 3 8 10.4 19.2
Можно просто задавать имена выходных переменных:
max_mpg = max(mpg)
Когда к одной переменной применяется много функций, summarise_each() использует более компактный и аккуратный синтаксис:
# без группировки mtcars %>% summarise_each (funs(min, max), mpg)
## Source: local data frame [1 x 2] ## ## min max ## (dbl) (dbl) ## 1 10.4 33.9
# с группировкой mtcars %>% group_by(cyl) %>% summarise_each (funs(min, max), mpg)
## Source: local data frame [3 x 3] ## ## cyl min max ## (dbl) (dbl) (dbl) ## 1 4 21.
Имена выходных переменных задаются именами функций: min и max. В этом случае мы теряем имя переменной, к которой применяется функция. Если нужно что-то вроде min_mpg и max_mpg, нужно переименовать функции внутри funs():
# без группировки mtcars %>% summarise_each (funs(min_mpg = min, max_mpg = max), mpg)
## Source: local data frame [1 x 2] ## ## min_mpg max_mpg ## (dbl) (dbl) ## 1 10.4 33.9
# с группировкой mtcars %>% group_by(cyl) %>% summarise_each (funs(min_mpg = min, max_mpg = max), mpg)
## Source: local data frame [3 x 3] ## ## cyl min_mpg max_mpg ## (dbl) (dbl) (dbl) ## 1 4 21.4 33.9 ## 2 6 17.8 21.4 ## 3 8 10.4 19.2
Вариант 3: применить одну функцию к многим переменным
Этот вариант очень похож на предыдущий. Можно использовать обе функции: и summarise(), и summarise_each().
Функция summarise() снова имеет более интуитивный синтаксис, и имена выходных переменных можно задавать в обычной простой форме:
max_mpg = max(mpg)
# без группировки mtcars %>% summarise(mean_mpg = mean(mpg), mean_disp = mean(disp))
## Source: local data frame [1 x 2] ## ## mean_mpg mean_disp ## (dbl) (dbl) ## 1 20.09062 230.7219
# с группировкой mtcars %>% group_by(cyl) %>% summarise(mean_mpg = mean(mpg), mean_disp = mean(disp))
## Source: local data frame [3 x 3] ## ## cyl mean_mpg mean_disp ## (dbl) (dbl) (dbl) ## 1 4 26.66364 105.1364 ## 2 6 19.74286 183.3143 ## 3 8 15.10000 353.1000
Когда ко многим переменным применяется одна функция, summarise_each() использует более компактный и аккуратный синтаксис:
# без группировки mtcars %>% summarise_each(funs(mean) , mpg, disp)
## Source: local data frame [1 x 2] ## ## mpg disp ## (dbl) (dbl) ## 1 20.09062 230.7219
# с группировкой mtcars %>% group_by(cyl) %>% summarise_each (funs(mean), mpg, disp)
## Source: local data frame [3 x 3] ## ## cyl mpg disp ## (dbl) (dbl) (dbl) ## 1 4 26.66364 105.1364 ## 2 6 19.74286 183.3143 ## 3 8 15.10000 353.1000
Имена выходных переменных определяется именами переменных: mpg и disp. В этом случае мы теряем имя функции, примененной к переменным — mean(). Вероятно, хотелось бы что-то вроде mean_mpg и mean_disp. Для того, чтобы этого достичь, нужно соответственно переименовать переменные, передающиеся в «…» внутри summarise_each():
# без группировки mtcars %>% summarise_each(funs(mean) , mean_mpg = mpg, mean_disp = disp)
## Source: local data frame [1 x 2] ## ## mean_mpg mean_disp ## (dbl) (dbl) ## 1 20.09062 230.7219
# с группировкой mtcars %>% group_by(cyl) %>% summarise_each(funs(mean) , mean_mpg = mpg, mean_disp = disp)
## Source: local data frame [3 x 3] ## ## cyl mean_mpg mean_disp ## (dbl) (dbl) (dbl) ## 1 4 26.66364 105.1364 ## 2 6 19.74286 183.3143 ## 3 8 15.10000 353.1000
Вариант 4: применить много функций к многим переменным
Как и в предыдущих случаях, обе функции, и summarise(), и summarise_each(), имеют свои преимущества.
Функция summarise() снова имеет более интуитивный синтаксис, и имена выходных переменных можно задавать в обычной простой форме:
max_mpg = max(mpg)
# без группировки mtcars %>% summarise(min_mpg = min(mpg) , min_disp = min(disp), max_mpg = max(mpg) , max_disp = max(disp))
## Source: local data frame [1 x 4] ## ## min_mpg min_disp max_mpg max_disp ## (dbl) (dbl) (dbl) (dbl) ## 1 10.4 71.1 33.9 472
# с одной группой mtcars %>% group_by(cyl) %>% summarise(min_mpg = min(mpg) , min_disp = min(disp), max_mpg = max(mpg) , max_disp = max(disp))
## Source: local data frame [3 x 5] ## ## cyl min_mpg min_disp max_mpg max_disp ## (dbl) (dbl) (dbl) (dbl) (dbl) ## 1 4 21.4 71.1 33.9 146.7 ## 2 6 17.8 145.0 21.4 258.0 ## 3 8 10.4 275.8 19.2 472.0
Когда ко многим переменным применяется много функций, summarise_each() использует более компактный и аккуратный синтаксис:
# без группировки mtcars %>% summarise_each(funs(min, max) , mpg, disp)
## Source: local data frame [1 x 4] ## ## mpg_min disp_min mpg_max disp_max ## (dbl) (dbl) (dbl) (dbl) ## 1 10.4 71.1 33.9 472
# с одной группой mtcars %>% group_by(cyl) %>% summarise_each(funs(min, max) , mpg, disp)
## Source: local data frame [3 x 5] ## ## cyl mpg_min disp_min mpg_max disp_max ## (dbl) (dbl) (dbl) (dbl) (dbl) ## 1 4 21.4 71.1 33.9 146.7 ## 2 6 17.8 145.0 21.4 258.0 ## 3 8 10.4 275.8 19.2 472.0
Имена выходных переменных можно задать так: variable_function, т. е.
е. mpg_min, disp_min и т.д.
Обратное именование переменных, т.е. function_variable, невозможно при вызове summarise_each(). Это можно реализовать с помощью отдельной команды.
# без группировки
mtcars %>%
summarise_each(funs(min, max) , mpg, disp) %>%
setNames(c("min_mpg", "min_disp", "max_mpg", "max_disp"))
## Source: local data frame [1 x 4] ## ## min_mpg min_disp max_mpg max_disp ## (dbl) (dbl) (dbl) (dbl) ## 1 10.4 71.1 33.9 472
# с группировкой
mtcars %>%
group_by(cyl) %>%
summarise_each(funs(min, max) , mpg, disp) %>%
setNames(c("gear", "min_mpg", "min_disp", "max_mpg", "max_disp"))
## Source: local data frame [3 x 5] ## ## gear min_mpg min_disp max_mpg max_disp ## (dbl) (dbl) (dbl) (dbl) (dbl) ## 1 4 21.4 71.1 33.9 146.7 ## 2 6 17.8 145.0 21.4 258.0 ## 3 8 10.4 275.8 19.2 472.0
Выводы
При использовании функций, возвращающих результат единичной длины, есть два основных кандидата:
summarise()summarise_each()
Функция summarise() имеет более простой синтаксис, а функция summarise_each() — более компактный.
Вследствие этого, summarise() больше подходит для одной переменной единственной функции. Чем больше количество переменных или функций, тем более оправдано применение summarise_each().
У функции summarise_each() свой способ именования выходных переменных:
Вариант 2: применить много функций к одной переменной
Имена выходных переменных определяются именами функций. В этом случае мы теряем имя переменной, к которой применяются функции.
Вариант 3: применить одну функцию к многим переменным
Имена выходных переменных определяются именами переменных. В этом случае мы теряем имя функции, применяемой к переменным.
В этом случае мы теряем имя функции, применяемой к переменным.
Вариант 4: применить много функций к многим переменным
Имена выходных переменных определяются нотацией variable_function. Внутри вызова summarise_each() другое именование невозможно.
Виды функций агрегирования ‒ Qlik Sense Enterprise на Kubernetes
Функции агрегирования — это функции «многие к одному». Они используют в качестве входных данных значения из многих записей и сворачивают их в одно значение, которое суммирует все записи. Sum(), Count(), Avg(), Min(), и Only() это всё функции агрегирования.
В большинстве формул Qlik Sense нужен именно один уровень функции агрегирования. К этим формулам относятся выражения диаграммы, текстовые поля и метки. Если не включить функцию агрегирования в выражение, Qlik Sense автоматически назначит для этого функцию Only().
- Функция агрегирования — это функция, которая возвращает одно значение, описывающее некоторое свойство нескольких записей данных.

- Все выражения, кроме вычисляемых измерений, вычисляются как агрегирования.
- Все ссылки на поле в выражениях необходимо заключать в функцию агрегирования.
Примечание об информацииДля создания и изменения выражений в Qlik Sense используется редактор выражения. Для получения дополнительной информации о функциях редактора выражения см.: Редактор выражения.
Консолидация сумм с помощью Sum()
Sum() вычисляет итоговое значение агрегированных данных, выданное выражением или полем.
Давайте вычислим общий объем продаж по каждому менеджеру, а также общий объем продаж всех менеджеров.
В приложении на листе Which Aggregations? находятся две таблицы — Sum(), Max(), Min() и Count(). Каждая из них будет использоваться для создания функций агрегирования.
Выполните следующие действия.
- Выберите доступную таблицу Sum(), Max(), Min().

Откроется панель свойств. - Щелкните команду Добавить столбец и выберите параметр Мера.
- Щелкните символ .
Откроется редактор выражения. - Введите следующее: Sum(Sales)
- Щелкните Применить.
Таблица показывает общий объем продаж по менеджеру
Можно просмотреть общий объем продаж по каждому менеджеру, а также общий объем продаж всех менеджеров.
Примечание об информацииРекомендуется убедиться, что данные отформатированы правильно. В этом случае установите в поле Формат чисел значение Денежный, а в поле Образец формата — $ #,##0;-$ #,##0.
Для получения дополнительной информации см. Sum.
Вычисление наибольшего значения объема продаж с помощью Max()
Max() находит наибольшее значение для каждой строки агрегированных данных.
Выполните следующие действия.
- Щелкните команду Добавить столбец и выберите параметр Мера.
- Щелкните символ .
Откроется редактор выражения. - Введите следующее: Max (Sales)
- Щелкните Применить.
Таблица показывает общий объем продаж и наибольшее значение объема продаж по менеджеру
Можно просмотреть наибольшее значение объема продаж по каждому менеджеру, а также наибольший общий объем продаж.
Для получения дополнительной информации см. Max.
Вычисление наименьшего значения объема продаж с помощью Min()
Min() находит наименьшее значение для каждой строки агрегированных данных.
Выполните следующие действия.
- Щелкните команду Добавить столбец и выберите параметр Мера.
- Щелкните символ .

Откроется редактор выражения. - Введите следующее: Min (Sales)
- Щелкните Применить.
Таблица показывает общий объем продаж, наибольшее и наименьшее значение объема продаж по менеджеру
Можно просмотреть наименьшее значение объема продаж по каждому менеджеру, а также наименьший общий объем продаж.
Для получения дополнительной информации см. Min.
Подсчет количества элементов с помощью Count()
Count() используется для подсчета текстовых и числовых значений в каждом измерении диаграммы.
В наших данных каждый менеджер отвечает за нескольких торговых представителей (Sales Rep Name). Давайте вычислим количество торговых представителей.
Выполните следующие действия.
- Выберите доступную таблицу Count().
Откроется панель свойств. - Щелкните команду Добавить столбец и выберите параметр Мера.

- Щелкните символ .
Откроется редактор выражения. - Введите следующее: Count([Sales Rep Name])
- Щелкните Применить.
Таблица показывает торговых представителей и общее их количество.
Общее количество торговых представителей равно 64.
Различие между Count() и Count(distinct )
Давайте вычислим количество менеджеров.
Выполните следующие действия.
- Добавьте новое измерение в таблицу: Manager.
Один менеджер обрабатывает нескольких торговых представителей, поэтому имя менеджера появляется несколько раз в таблице. - Щелкните команду Добавить столбец и выберите параметр Мера.
- Щелкните символ .
Откроется редактор выражения. - Введите следующее: Count(Manager)
Добавьте еще одну меру с выражением: Count(distinct Manager)
- Щелкните Применить.

Таблица показывает торговых представителей, общее количество торговых представителей, менеджера, отвечающего за каждого торгового представителя, неправильное общее количество менеджеров и правильное общее количество менеджеров.
Видно, что общее количество менеджеров в столбце, вычисленное с помощью Count(Manager) в качестве выражения, равно 64. Это неверно. Правильное общее количество менеджеров равно 18 при использовании выражения Count(distinct Manager). Каждый менеджер посчитан только один раз независимо от того, сколько раз его имя встречается в списке.
Для получения дополнительной информации см. Count.
Аннотирование и агрегация | Python: Django ORM
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Базы данных призваны не только хранить и накапливать данные. И даже если добавить к хранению выдачу данных по запросу, останется не упомянутой ещё одна обязанность, возлагаемая на СУБД: анализ накопленных данных.
Представим классический пример предметной области — «Книжный магазин». Главной сущностью в проекте, работающем в данной области, будет «книга»:
class Book(models.Model):
# цену часто хранят в числовом поле фиксированной точности
price = models.DecimalField(max_digits=10, decimal_places=2)
# ...
Когда имеешь дело с некоторыми товарами, часто приходится вычислять суммарную цену наборов товаров и среднюю цену товаров набора. Python — язык достаточно выразительный, он позволяет ту же сумму посчитать прямо на месте:
total_price = sum(book.price for book in Book.objects.all())
Средняя цена вычисляется ненамного сложнее. Однако будет ли такое решение оправданным?
ORM честно запросит все книги из базы и поместит данные каждой книги в объект класса Book. А затем в коде потребуется только цена — это уже выглядит как лишняя работа! И СУБД тоже потратит лишние ресурсы на загрузку всех столбцов таблицы, вместо того, чтобы достать ровно один. Когда дело касается крупного магазина книг, подобное использование БД неприемлемо.
Когда дело касается крупного магазина книг, подобное использование БД неприемлемо.
Строго говоря, Django ORM умеет запрашивать только часть данных. Как это делается, будет рассказано в последующем уроке про эффективную работу с БД.
Ещё один минус подобной обработки на стороне Python заключается в том, что мы при этом не используем часть возможностей СУБД. Как уже было сказано, подсчёт сумм и средних значений — часто встречающиеся задачи. Поэтому большинство СУБД умеет выполнять такой анализ данных на своей стороне и сам язык SQL содержит средства для описания того, что же СУБД должна вычислить или, как ещё говорят, выполнить агрегацию. И разработчики СУБД вкладывают много сил в то, чтобы агрегация работала быстро. Осталось научиться описывать агрегацию с использованием Django ORM
Агрегация и агрегирующие функции
Для того, чтобы получить уже агрегированные данные, нужно воспользоваться методом .aggregate(), вызвав его у имеющегося менеджера или QuerySet. Этот метод принимает в качестве параметров так называемые агрегирующие функции. Функций этих достаточно много, но все они используются примерно одинаково, поэтому рассмотрим для примера функцию
Этот метод принимает в качестве параметров так называемые агрегирующие функции. Функций этих достаточно много, но все они используются примерно одинаково, поэтому рассмотрим для примера функцию Avg:
from django.db.models import Avg
# Получение средней цены среди всех книг магазина
Book.objects.aggregate(Avg('price'))
# {'price__avg': 34.35}
# Можно задать имя ключа результирующего словаря явно
Book.objects.aggregate(average_price=Avg('price'))
# {'average_price': 34.35}
Если аргументы указываются как позиционные, то имена для ключей генерирует Django ORM на основе имени поля и имени агрегирующей функции. Аргументов можно указать сразу несколько и генерируемые имена не дадут запутаться:
from django.db.models import Avg, Max, Min
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
# {'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
Как можно заметить, каждый запрос на агрегацию возвращает не сами книги, а только итоговый результат. Таким образом со стороны Python никаких промежуточных объектов создавать не приходится!
Таким образом со стороны Python никаких промежуточных объектов создавать не приходится!
Вернёмся к учебному проекту, который моделирует платформу для ведения блогов. Никаких «цен» в этом проекте нет, но задачи для анализа найдутся. Предположим, что нужно для каждой записи в блоге некоторого автора узнать количество комментариев. Агрегация на первый взгляд не подходит: сами посты тоже нужны. Можно решить задачу «в лоб», написав:
author = User.objects.get(id=1) posts = [(p, p.postcomment_set.count()) for p in author.post_set.all()]
Такое решение имеет своё собственное название – «N+1 запросов» – поскольку будет выполнен один запрос N постов, а затем N запросов комментариев к каждому. Легко представить, насколько это неэффективно.
Для того, чтобы для каждой возвращаемой сущности вычислить некоторое значение в рамках одного запроса, Django ORM предоставляет механизм аннотирования.
Аннотирование
Процесс аннотирования описывается вызовом метода . применительно к менеджеру или QuerySet. Этот метод принимает те же агрегирующие функции. А возвращает метод QuerySet, объекты которого будут всё теми же экземплярами класса модели, но каждый объект будет иметь дополнительные атрибуты. Каждый атрибут будет хранить результат соответствующей агрегации относительно текущего объекта. Например,  annotate()
annotate().aggregate(Count('postcomment')) подсчитает количество всех комментариев, а .annotate(Count('postcomment')) даст количество комментариев к каждому посту. Так выглядит подсчёт количества тегов, которыми помечен каждый пост:
posts = Post.objects.annotate(Count('tags'))
posts[0].tags__count # только тут финализируется запрос!
# SELECT "blog_post"."id",
# ...
# COUNT("blog_post_tags"."tag_id") AS "tags__count"
# FROM "blog_post"
# LEFT OUTER JOIN "blog_post_tags"
# ON ("blog_post"."id" = "blog_post_tags"."post_id")
# GROUP BY ...
# LIMIT 1
# Execution time: 0.000563s [Database: default]
# => 2
Здесь новый атрибут получил имя «tags__count», но имя можно было указать вручную, как и в случае обычной агрегации.
Аннотирование и дубликаты в выдаче
Если вы уже имеете некоторый опыт в SQL, вы можете задаться вопросом: а не добавляет ли OUTER JOIN, который можно заметить в примере выше, в выборку дублирующиеся элементы, если присовокупляемые сущности соотносится с текущей как «многие к одному»? Добавляет! Более того, агрегация в таких случаях даёт неверные результаты, так как учитывает и повторяющиеся строки. И тем больше дублей вы увидите, чем больше разных связей «многие к одному» задействуете (и даже одну и ту же, но несколько раз).
Увы, в общем виде эту проблему не решить. Но конкретно агрегирующая функция Count имеет опцию distinct=True, которая убирает дублирование, пока вы используете только этот вид аннотаций и каждый Count используете с distinct=True.
Агрегация аннотированных значений
Аннотирование позволяет добавить вычислимые данные к каждому элементу запроса, а это значит, что можно выполнить итоговую агрегацию с использованием этих значений! Получение среднего количества тегов среди всех постов будет выглядеть так:
Post.objects.annotate(Count('tags')).aggregate(Avg('tags__count')) # SELECT AVG("tags__count") # FROM ( # SELECT COUNT("blog_post_tags"."tag_id") AS "tags__count" # FROM "blog_post" # LEFT OUTER JOIN "blog_post_tags" # ON ("blog_post"."id" = "blog_post_tags"."post_id") # GROUP BY "blog_post"."id" # ) subquery # Execution time: 0.000361s [Database: default] # => {'tags__count__avg': 1.5}
VAR (Transact-SQL) — SQL Server
Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL Аналитика синапсов Azure Система аналитической платформы (PDW)
Возвращает статистическую дисперсию всех значений в указанном выражении. Может сопровождаться предложением OVER.
Может сопровождаться предложением OVER.
Соглашения о синтаксисе Transact-SQL
Синтаксис
-- Синтаксис агрегатных функций VAR ([ALL | DISTINCT] выражение) -- Синтаксис аналитической функции VAR (выражение [ALL]) OVER ([partition_by_clause] order_by_clause)
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
Аргументы
ВСЕ
Применяет функцию ко всем значениям. ВСЕ по умолчанию.
DISTINCT
Указывает, что учитывается каждое уникальное значение.
выражение
Является выражением категории точного или приблизительного числового типа данных, за исключением типа данных бит . Агрегатные функции и подзапросы не допускаются.
БОЛЕЕ ( [ раздел_по_пункту ] порядок_по_пункту )
partition_by_clause делит набор результатов, созданный предложением FROM, на разделы, к которым применяется функция.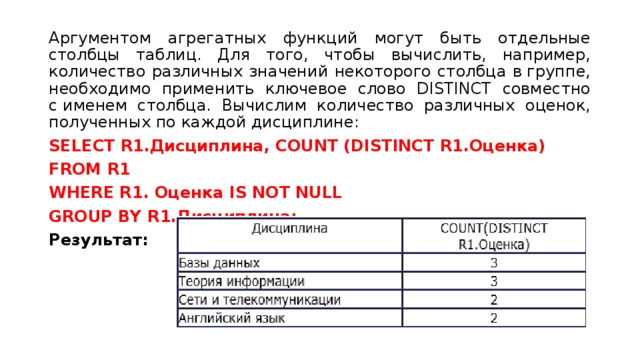 Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет логический порядок выполнения операции. Требуется order_by_clause . Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет логический порядок выполнения операции. Требуется order_by_clause . Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Типы возврата
Плавающая
Если VAR используется для всех элементов в операторе SELECT, каждое значение в результирующем наборе включается в расчет. VAR можно использовать только с числовыми столбцами. Нулевые значения игнорируются.
VAR является детерминированной функцией при использовании без предложений OVER и ORDER BY. Он недетерминирован, если указан с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A: Использование VAR
В следующем примере возвращается дисперсия для всех значений бонусов в 9Таблица 0083 SalesPerson в базе данных AdventureWorks2019.
ВЫБЕРИТЕ ПЕРЕМЕННУЮ (БОНУС) ОТ Sales.SalesPerson; ИДТИ
Примеры: Azure Synapse Analytics and Analytics Platform System (PDW)
B: Использование VAR
В следующем примере возвращается статистическая дисперсия значений квоты продаж в таблице dbo.FactSalesQuota . Первый столбец содержит дисперсию всех различных значений, а второй столбец содержит дисперсию всех значений, включая любые повторяющиеся значения.
-- использует AdventureWorks ВЫБРАТЬ VAR(DISTINCTSalesAmountQuota)AS Distinct_Values, VAR(SalesAmountQuota)AS All_Values ОТ dbo.FactSalesQuota;
Вот набор результатов.
Отдельные_значения Все_значения ---------------- ---------------- 1569909,18 158762853821,10 C. Использование VAR с OVER
В следующем примере возвращается статистическая дисперсия значений квоты продаж для каждого квартала календарного года.
Обратите внимание, что ORDER BY в предложении OVER упорядочивает статистическую дисперсию, а ORDER BY оператора SELECT упорядочивает набор результатов.
-- использует AdventureWorks ВЫБЕРИТЕ CalendarYear AS Year, CalendarQuarter AS Quarter, SalesAmountQuota AS SalesQuota, VAR(SalesAmountQuota) OVER (ORDER BY CalendarYear, CalendarQuarter) AS Variance ОТ dbo.FactSalesQuota ГДЕ EmployeeKey = 272 И CalendarYear = 2002 ЗАКАЗАТЬ ПО CalendarQuarter;Вот набор результатов.
Отклонение квоты продаж за квартал за год ---- ------- ---------------------- ----------------- -- 2002 1 .0000 ноль 2002 2 140000,0000 1200500000,00 2002 3 70000,0000 12333.33 2002 4 154000,0000 1580250000,00
См. также
Агрегированные функции (Transact-SQL)
Предложение OVER (Transact-SQL)AVG (Transact-SQL) — SQL Server
- Статья
- 5 минут на чтение
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL Аналитика синапсов Azure Analytics Platform System (PDW)
Эта функция возвращает среднее значение в группе. Он игнорирует нулевые значения.
Соглашения о синтаксисе Transact-SQL
Синтаксис
AVG ([ALL | DISTINCT] выражение) [ ПЕРЕД ( [ раздел_по_пункту ] заказ_по_пункту ) ]Примечание
Для просмотра синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий см. документацию по предыдущим версиям.
Аргументы
ВСЕ
Применяет агрегатную функцию ко всем значениям. ВСЕ по умолчанию.DISTINCT
Указывает, что AVG работает только с одним уникальным экземпляром каждого значения, независимо от того, сколько раз встречается это значение.выражение
Выражение категории точного или приблизительного числового типа данных, за исключением категории бит тип данных.Агрегатные функции и подзапросы не допускаются.
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause делит результирующий набор, созданный предложением FROM, на разделы, к которым применяется функция. Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет логический порядок, в котором выполняется операция. 9Требуется 0045 order_by_clause . Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).Типы возвращаемых значений
Результат вычисления выражения определяет тип возвращаемого значения.
Результат выражения Тип возврата крошечный внутр. маленький внутр. инт внутр. 
большое число большой десятичный разряд (р, с) десятичное (38, макс.(s,6)) деньги и мелкие деньги категория деньги плавающая и реальная категория поплавок Если тип данных выражения является типом данных псевдонима, возвращаемый тип также относится к типу данных псевдонима. Однако если базовый тип данных псевдонима повышается, например, с tinyint до int , возвращаемое значение будет принимать повышенный тип данных, а не псевдоним.
AVG () вычисляет среднее значение набора значений путем деления суммы этих значений на число ненулевых значений. Если сумма превышает максимальное значение для типа данных возвращаемого значения, AVG() вернет ошибку.
AVG является детерминированной функцией при использовании без предложений OVER и ORDER BY. Он недетерминирован, если указан с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A. Использование функций SUM и AVG для вычислений
В этом примере вычисляется среднее количество часов отпуска и сумма отпусков по болезни, которые использовали вице-президенты Adventure Works Cycles. Каждая из этих агрегатных функций создает одно итоговое значение для всех извлеченных строк. В примере используется AdventureWorks2019база данных.
ВЫБЕРИТЕ AVG(VacationHours)AS 'Среднее количество часов отпуска', SUM(SickLeaveHours) AS 'Общее количество часов отпуска по болезни' ОТ HumanResources.Employee ГДЕ JobTitle НРАВИТСЯ «Вице-президент%»;Вот набор результатов.
Среднее количество часов отпуска Всего часов отпуска по болезни ---------------------- ---------------------- 25 97 (затронуты 1 ряд)B.
Использование функций SUM и AVG с предложением GROUP BY
При использовании с
GROUP BY, каждая агрегатная функция создает одно значение, охватывающее каждую группу, вместо одного значения, охватывающего всю таблицу. В следующем примере создаются сводные значения для каждой территории продаж в базе данных AdventureWorks2019. В сводке перечислены средние бонусы, полученные продавцами в каждой территории, и сумма продаж с начала года для каждой территории.SELECT TerritoryID, AVG(Bonus) как «Средний бонус», SUM(SalesYTD) как «Продажи с начала года» ОТ Sales.SalesPerson СГРУППИРОВАТЬ ПО TerritoryID; ИДТИВот набор результатов.
TerritoryID Средний бонус продаж с начала года ------------------------- ------------------------------------ ------------------ --- НУЛЕВОЕ 0,00 1252127,9471 1 4133.3333 4502152.2674 2 4100.00 3763178.1787 3 2500.00 3189418.3662 4 2775.00 6709904.1666 5 6700.00 2315185.611 6 2750.00 4058260.1825 7 985.00 3121616.3202 8 75.00 1827066.7118 9 5650.00 1421810.9242 10 5150.00 4116871.2277 (затронуты 11 рядов)
C. Использование AVG с DISTINCT
Этот оператор возвращает среднюю прейскурантную цену продуктов в базе данных AdventureWorks2019. Благодаря использованию DISTINCT при расчете учитываются только уникальные значения.
ВЫБЕРИТЕ СРЕДНЕЕ (DISTINCT ListPrice) ОТ Производство.Продукт;Вот набор результатов.
--------------------------------------------- 437.4042 (затронуты 1 ряд)D. Использование AVG без DISTINCT
Без DISTINCT функция
AVGнаходит среднюю прейскурантную цену всех продуктов в таблицеProductв базе данных AdventureWorks2019, включая все повторяющиеся значения.ВЫБЕРИТЕ СРЕДНЮЮ (списочная цена) ОТ Производство.Продукт;Вот набор результатов.
--------------------------------------------- 438,6662 (затронуты 1 ряд)E. Использование предложения OVER
В следующем примере используется функция AVG с предложением OVER для получения скользящего среднего годового объема продаж для каждой территории в таблице
Sales.в базе данных AdventureWorks2019. Данные разделены поSalesPerson
TerritoryIDи логически упорядочены поSalesYTD. Это означает, что функция AVG вычисляется для каждой территории на основе года продаж. Обратите внимание, что дляTerritoryID1 есть две строки для 2005 года продаж, которые представляют двух продавцов с продажами в этом году. Рассчитывается средний объем продаж для этих двух строк, а затем в расчет включается третья строка, представляющая продажи за 2006 год.ВЫБЕРИТЕ BusinessEntityID, TerritoryID ,DATEPART(yy,ModifiedDate) AS SalesYear ,Преобразовать(VARCHAR(20),ПродажиYTD,1) КАК ПродажиYTD ,CONVERT(VARCHAR(20),AVG(SalesYTD) OVER (PARTITION BY TerritoryID ORDER BY DATEPART(yy,ModifiedDate) ),1) AS MovingAvg ,CONVERT(VARCHAR(20),SUM(SalesYTD) OVER (PARTITION BY TerritoryID ORDER BY DATEPART(yy,ModifiedDate) ),1) AS CumulativeTotal ОТ Sales.SalesPerson ГДЕ TerritoryID равен NULL ИЛИ TerritoryID < 5 ЗАКАЗАТЬ ПО TerritoryID,SalesYear;
Вот набор результатов.
BusinessEntityID TerritoryID SalesYear SalesYTD MovingAvg CumulativeTotal ---------------- ----------- ----------- ------------ -------- -------------------- -------------------- 274 НЕТ 2005 559 697,56 559 697,56 559 697,56 287 НЕТ 2006 519 905,93 539 801,75 1 079 603,50 285 НЕТ 2007 172 524,45 417 375,98 1 252 127,95 283 1 2005 1 573 012,94 1 462 795,04 2 925 590,07 280 1 2005 1 352 577,13 1 462 795,04 2 925 590,07 284 1 2006 1 576 562,20 1 500 717,42 4 502 152,27 275 2 2005 3 763 178,18 3 763 178,18 3 763 178,18 277 3 2005 3 189 418,37 3 189 418,37 3 189,418,37 276 4 2005 4 251 368,55 3 354 952,08 6 709 904,17 281 4 2005 2 458 535,62 3 354 952,08 6 709 904,17 (затронуты 10 строк)В этом примере предложение OVER не включает PARTITION BY. Это означает, что функция будет применяться ко всем строкам, возвращаемым запросом. Предложение ORDER BY, указанное в предложении OVER, определяет логический порядок, к которому применяется функция AVG.
Запрос возвращает скользящее среднее продаж по годам для всех территорий продаж, указанных в предложении WHERE. Предложение ORDER BY, указанное в инструкции SELECT, определяет порядок, в котором инструкция SELECT отображает строки запроса.
ВЫБЕРИТЕ BusinessEntityID, TerritoryID ,DATEPART(yy,ModifiedDate) AS SalesYear ,Преобразовать(VARCHAR(20),ПродажиYTD,1) КАК ПродажиYTD ,CONVERT(VARCHAR(20),AVG(SalesYTD) OVER (ORDER BY DATEPART(yy,ModifiedDate) ),1) AS MovingAvg ,CONVERT(VARCHAR(20),SUM(SalesYTD) OVER (ORDER BY DATEPART(yy,ModifiedDate) ),1) AS CumulativeTotal ОТ Sales.SalesPerson ГДЕ TerritoryID равен NULL ИЛИ TerritoryID < 5 ЗАКАЗАТЬ ПО Году продаж;Вот набор результатов.
BusinessEntityID TerritoryID SalesYear SalesYTD MovingAvg CumulativeTotal ---------------- ----------- ----------- ------------ -------- -------------------- -------------------- 274 НЕТ 2005 559 697,56 2 449 684,05 17 147 788,35 275 2 2005 3 763 178,18 2 449 684,05 17 147 788,35 276 4 2005 4 251 368,55 2 449684,05 17 147 788,35 277 3 2005 3 189 418,37 2 449 684,05 17 147 788,35 280 1 2005 1 352 577,13 2 449 684,05 17 147 788,35 281 4 2005 2 458 535,62 2 449 684,05 17 147 788,35 283 1 2005 1 573 012,94 2 449 684,05 17 147 788,35 284 1 2006 1 576 562,20 2 138 250,72 19244 256,47 287 НЕТ 2006 519 905,93 2 138 250,72 19 244 256,47 285 НЕТ 2007 172 524,45 1 941 678,09 19 416 780,93 (затронуты 10 строк)См.
также
Агрегированные функции (Transact-SQL)
Предложение OVER (Transact-SQL)Функция AGGREGATE
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel Web App Excel 2010 Excel для Mac 2011 Excel Starter 2010 Дополнительно... Меньше
Возвращает агрегат в списке или базе данных. Функция АГРЕГАТ может применять различные агрегатные функции к списку или базе данных с возможностью игнорировать скрытые строки и значения ошибок.
Синтаксис
Справочная форма
АГРЕГАТ(номер_функции, опции, ссылка1, [ссылка2], …)
Форма массива
АГРЕГАТ(номер_функции, параметры, массив, [k])
Синтаксис функции АГРЕГАТ имеет следующие аргументы:
Function_num
Функция
1
СРЕДНЕЕ
2
СЧЕТ
3
СЧЁТ
4
МАКС
5
МИН
6
ПРОДУКТ
7
СТАНДОТКЛОН.
S
8
СТАНДОТКЛОН.P
9
СУММА
10
ВАР.С
11
ВАР.П
12
МЕДИАНА
13
РЕЖИМ.
SNGL
14
БОЛЬШОЙ
15
МАЛЕНЬКИЙ
16
ПРОЦЕНТИЛЬ.ВКЛ
17
КВАРТИЛЬ.ВКЛ
18
ПРОЦЕНТИЛЬ.
ИСКЛ
19
КВАРТИЛЬ.ИСКЛ
Опции Обязательно. Числовое значение, определяющее, какие значения игнорировать в диапазоне оценки функции.
Примечание. Функция не будет игнорировать скрытые строки, вложенные промежуточные итоги или вложенные агрегаты, если аргумент массива включает вычисление, например: =ОБЪЕДИНЕНИЕ(14,3,A1:A100*(A1:A100>0),1)
Опция
Поведение
0 или опущено
Игнорировать вложенные функции ПРОМЕЖУТОЧНЫЙ ИТОГ и АГРЕГАТ
1
Игнорировать скрытые строки, вложенные функции ПРОМЕЖУТОЧНЫЙ ИТОГ и АГРЕГАТ
2
Игнорировать значения ошибок, вложенные функции ПРОМЕЖУТОЧНЫЙ ИТОГ и АГРЕГАТ
3
Игнорировать скрытые строки, значения ошибок, вложенные функции ПРОМЕЖУТОЧНЫЕ.
ИТОГИ и АГРЕГАТ
4
Ничего не игнорировать
5
Игнорировать скрытые строки
6
Игнорировать значения ошибок
7
Игнорировать скрытые строки и значения ошибок
org/ListItem">
Ref1 Обязательно. Первый числовой аргумент для функций, принимающих несколько числовых аргументов, для которых требуется совокупное значение.
Ref2,... Необязательно. Числовые аргументы от 2 до 253, для которых требуется совокупное значение.
Для функций, принимающих массив, ref1 — это массив, формула массива или ссылка на диапазон ячеек, для которых требуется агрегированное значение. Ref2 — это второй аргумент, необходимый для некоторых функций. Следующие функции требуют аргумент ref2:
Функция
БОЛЬШОЙ(массив,k)
МАЛЕНЬКИЙ (массив, k)
ПРОЦЕНТИЛЬ.
ВКЛ(массив,k)
КВАРТИЛЬ.ВКЛ(массив,кварта)
ПРОЦЕНТИЛЬ.ИСКЛ(массив,k)
КВАРТИЛЬ.ИСКЛ(массив,кварта)
Примечания
Function_num :
Ошибки:
Если требуется второй аргумент ref, но он не указан, функция АГРЕГАТ возвращает #ЗНАЧ! ошибка.
Если одна или несколько ссылок являются трехмерными ссылками, функция АГРЕГАТ возвращает ошибку #ЗНАЧ! значение ошибки.
Тип диапазона:
Функция АГРЕГАТ предназначена для столбцов данных или вертикальных диапазонов. Он не предназначен для строк данных или горизонтальных диапазонов. Например, когда вы подытоживаете горизонтальный диапазон с помощью параметра 1, такого как АГРЕГАТ(1, 1, ссылка1), скрытие столбца не влияет на итоговое значение суммы. Но скрытие строки в вертикальном диапазоне влияет на агрегат.
Пример
Скопируйте данные примера из следующей таблицы и вставьте их в ячейку A1 нового рабочего листа Excel. Чтобы формулы отображали результаты, выберите их, нажмите F2, а затем нажмите клавишу ВВОД. При необходимости вы можете настроить ширину столбцов, чтобы увидеть все данные.
#ДЕЛ/0!
82
72
65
30
95
#ЧИСЛО!
63
31
53
96
71
32
55
81
83
33
100
53
91
34
89
Формула
Описание
Результат
=ОБЪЕДИНИТЬ(4, 6, A1:A11)
Вычисляет максимальное значение, игнорируя значения ошибок в диапазоне
96
=ОБЪЕДИНЕНИЕ(14, 6, A1:A11, 3)
Вычисляет третье по величине значение, игнорируя значения ошибок в диапазоне
72
=ОБЪЕДИНЕНИЕ(15, 6, A1:A11)
вернет #ЗНАЧ! ошибка.
Это связано с тем, что AGGREGATE ожидает второй аргумент ref, так как функция (SMALL) требует его.
#ЗНАЧ!
=ОБЪЕДИНЕНИЕ(12, 6, A1:A11, B1:B11)
Вычисляет медиану, игнорируя значения ошибок в диапазоне
68
=МАКС(А1:А2)
Возвращает значение ошибки, так как в диапазоне оценки есть значения ошибки.
#ДЕЛ/0!
Определение агрегатной функции
По
Адам Хейс
Полная биография
Адам Хейс, доктор философии, CFA, финансовый писатель с более чем 15-летним опытом работы на Уолл-стрит в качестве трейдера деривативов.
Помимо своего обширного опыта торговли деривативами, Адам является экспертом в области экономики и поведенческих финансов. Адам получил степень магистра экономики в Новой школе социальных исследований и докторскую степень. из Университета Висконсин-Мэдисон по социологии. Он является обладателем сертификата CFA, а также лицензий FINRA Series 7, 55 и 63. В настоящее время он занимается исследованиями и преподает экономическую социологию и социальные исследования финансов в Еврейском университете в Иерусалиме.
Узнайте о нашем редакционная политика
Обновлено 30 июня 2022 г.
Рассмотрено
Хадиджа Хартит
Рассмотрено Хадиджа Хартит
Полная биография
Хадиджа Хартит — эксперт по стратегии, инвестициям и финансированию, а также преподаватель финансовых технологий и стратегических финансов в ведущих университетах. Она была инвестором, предпринимателем и консультантом более 25 лет.
Она является держателем лицензий FINRA Series 7, 63 и 66.
Узнайте о нашем Совет по финансовому обзору
Что такое агрегатная функция?
Агрегатная функция — это математическое вычисление, включающее диапазон значений, в результате которого получается только одно значение, выражающее значимость накопленных данных, из которых оно получено. Агрегированные функции часто используются для получения описательной статистики.
Агрегированные функции часто используются в базах данных, электронных таблицах и пакетах статистического программного обеспечения, которые теперь широко используются на рабочем месте. Агрегированные функции широко используются в экономике и финансах для получения ключевых чисел, отражающих экономическое здоровье или эффективность рынка.
Ключевые выводы
- Агрегированные функции предоставляют одно число для представления большего набора данных. Используемые числа сами могут быть произведениями агрегатных функций.
- Многие описательные статистики являются результатом агрегатных функций.
- Экономисты используют результаты агрегирования данных, чтобы отображать изменения во времени и прогнозировать будущие тенденции.
- Модели, созданные на основе агрегированных данных, можно использовать для влияния на политику и бизнес-решения.
Понимание агрегатной функции
Агрегатная функция просто относится к вычислениям, выполняемым с набором данных, чтобы получить одно число, которое точно представляет базовые данные. Использование компьютеров улучшило выполнение этих расчетов, позволяя агрегатным функциям очень быстро выдавать результаты и даже корректировать веса в зависимости от уверенности пользователя в данных. Благодаря компьютерам агрегатные функции могут обрабатывать все более крупные и сложные наборы данных.
Некоторые общие агрегатные функции включают в себя:
- Среднее (также называемое средним арифметическим)
- Счет
- Максимум
- Минимум
- Диапазон
- NaNmean (среднее значение без учета значений NaN, также известное как «нулевое» или «нулевое»)
- Медиана
- Режим
- Сумма
Агрегированные функции в экономическом моделировании
Математика для агрегатных функций может быть довольно простой, например, найти средний рост валового внутреннего продукта (ВВП) США за последние 10 лет.
Имея список показателей ВВП, который сам по себе является продуктом агрегированной функции набора данных, вы должны найти разницу по годам, а затем суммировать разницу и разделить на 10. Математика выполнима с карандашом и бумагой, но представьте, что вы пытаетесь сделать такой расчет для набора данных, содержащего цифры ВВП для каждой страны мира. В этом случае лист Excel значительно сокращает время обработки, а программное решение, такое как программное обеспечение для моделирования, даже лучше. Этот тип вычислительной мощности очень помог экономистам в выполнении наборов агрегатных функций на массивных наборах данных.
Эконометрика и другие дисциплины ежедневно используют агрегированные функции, и они иногда узнают это в названии результирующей цифры. Совокупный спрос и предложение — это визуальное представление результатов двух агрегированных функций, одна из которых выполняется для набора данных о производстве, а другая — для набора данных о расходах. Кривая совокупного спроса создается на основе аналогичного набора данных о расходах и показывает совокупное количество подмножеств, нанесенных на график за период, чтобы получить кривую, показывающую изменения во временном ряду.
Этот тип визуализации или моделирования помогает показать текущее состояние экономики и может использоваться для информирования о реальных политических и деловых решениях.
Агрегированные функции в бизнесе
Очевидно, что в бизнесе есть много агрегатных функций — совокупные затраты, совокупный доход, совокупные часы и так далее. Тем не менее, одним из наиболее интересных способов использования функции агрегирования в финансах является моделирование совокупного риска.
Финансовые учреждения, в частности, должны предоставлять понятные сводки своих рисков. Это означает суммирование их конкретных рисков контрагента, а также совокупной стоимости, подверженной риску. Расчеты, используемые для получения этих цифр, должны точно отражать риски, которые сами по себе являются вероятностями, основанными на наборах данных.
При высоком уровне сложности солнечное предположение не в том месте может подорвать всю модель. Именно эта проблема сыграла роль в последствиях краха Lehman Brothers.
Агрегированные функции SQL: руководство
Агрегированные функции SQL очень полезны и являются одними из наиболее часто используемых функций. Узнайте все о агрегатных функциях SQL и о том, что они делают, в этой статье.
Что такое агрегатные функции SQL?
Агрегированные функции — это функции, которые позволяют просматривать один фрагмент данных из нескольких фрагментов данных.
Большинство функций в SQL работают с одной строкой или одной записью, например, DECODE или LENGTH.
Однако агрегатные функции отличаются тем, что их можно использовать для нескольких строк и в результате получить одно значение.
Примером агрегатной функции является SUM. Эта функция позволяет вам вводить диапазон значений, например, в столбце, и получать общую сумму этих чисел.
Если бы у вас была таблица, которая выглядела бы так:
SELECT * FROM student;
STUDENT_ID ИМЯ ФАМИЛИЯ FEES_REQUIRED FEES_PAID АДРЕС_СОСТОЯНИЕ 1 Джон Смит 500 100 Нью-Йорк 2 Сьюзан Джонсон 150 150 Колорадо 3 Том Крышка 350 320 Невада 4 Марка Холлоуэй 500 410 Нью-Йорк 5 Стивен Уэббер 100 80 Нью-Йорк 6 Джули Армстронг 100 0 Техас 7 Мишель Рэндалл 250 (пусто) Флорида 8 Андрей Купер 800 400 Техас 9 Роберт Пикеринг 110 100 Колорадо 10 Таня Зал 150 150 Техас Затем вы можете использовать агрегатную функцию, такую как SUM, чтобы получить сумму всех значений в столбце fee_paid.
ВЫБЕРИТЕ СУММУ (сборы_оплачены) ОТ студента;
СУММА (ОПЛАЧЕННЫЕ СБОРЫ) 1710 Эта функция сворачивает множество строк таблицы в одну строку, представляющую агрегатную функцию SUM.
Есть еще множество агрегатных функций, которые мы рассмотрим в этой статье.
Вы также можете делать некоторые интересные вещи с агрегатными функциями, например выбирать все строки, которые соответствуют максимальному значению или выбирать максимальное значение на основе подгруппы.
Что такое предложение GROUP BY?
В SQL есть нечто, называемое предложением «группировать по». Что это значит? Что оно делает?
Предложение GROUP BY позволяет вам использовать агрегатных функций для частей ваших данных .
В приведенном выше примере показана СУММА всех значений Feas_paid в таблице.
Но что, если вы хотите увидеть СУММУ оплаченных сборов для каждого адреса_состояния?
ВЫБРАТЬ адрес_состояние, СУММ(сборы_уплачены) ОТ студента;Результат зависит от того, в какой базе данных вы запускаете это:
Oracle:
ORA-00937: не групповая функция с одной группой
включить все неагрегированные функции из предложения SELECT в предложение GROUP BY;
SQL Server:
Столбец «student.address_state» недействителен в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
MySQL:
MySQL действительно покажет вам результат. Однако он показывает первый адрес_состояние и сумму всех записей оплаченных сборов. Это кажется правильным, но это не так.
PostgreSQL:
ОШИБКА: столбец «student.
address_state» должен присутствовать в предложении GROUP BY или использоваться в агрегатной функции Позиция: 8
Вы получите эти ошибки, потому что мы не сгруппировали наши данные.
Здесь на помощь приходит предложение GROUP BY.
Предложение GROUP BY позволяет группировать агрегатную функцию по другим значениям.
Вам нужно будет добавить GROUP BY, а затем имена всех остальных полей в предложении SELECT.
ВЫБРАТЬ адрес_состояние, СУММ(сборы_уплачены) ОТ студента СГРУППИРОВАТЬ ПО address_state;Результат:
АДРЕС_СОСТОЯНИЕ СУММА (FEES_PAID) Техас 550 Нью-Йорк 590 Колорадо 250 Невада 320 Флорида (пусто) Это сообщает базе данных, что вы хотите увидеть СУММУ уплаченных сборов, но сгруппировать по всем значениям address_state.
Что такое предложение HAVING?
Предложение HAVING — это еще одно предложение, относящееся к агрегатным функциям.
Позволяет вам ограничить результаты, возвращаемые на основе данных после того, как они были сгруппированы .
Что делать, если вы хотите увидеть СУММУ значений fee_paid для каждого штата, но только там, где сумма превышает 500?
Вы можете попробовать использовать предложение WHERE и сказать, WHERE fee_paid > 500.
SELECT address_state, СУММ(сборы_уплачены) ОТ студента ГДЕ fee_paid > 500 СГРУППИРОВАТЬ ПО address_state;Результат:
ADDRESS_STATE СУММА (FEES_PAID) Однако в этом случае вы не получите никаких результатов.
Почему это?
Это связано с тем, что сначала выполняется предложение WHERE, которое исключает строки, не соответствующие критериям. В этом случае из результирующего набора удаляются все строки, в которых fee_paid <= 500.
Затем выполняются SUM и GROUP BY. Однако в результирующем наборе нет строк, с которыми это можно было бы сделать.
Как мы можем получить желаемый результат?
Используйте предложение HAVING.
Предложение HAVING похоже на предложение WHERE, но оно работает с данными после их группировки.
Это важно помнить.
Предложение WHERE работает с данными до того, как они были сгруппированы, а предложение HAVING работает с данными после того, как они были сгруппированы.
Синтаксис аналогичен предложению WHERE.
ВЫБРАТЬ адрес_состояние, СУММ(сборы_уплачены) ОТ студента СГРУППИРОВАТЬ ПО address_state ИМЕЯ плату за оплату > 500;Вот что вы увидите.
Oracle:
ORA-00979: не выражение GROUP BY
SQL Server:
Столбец не содержится в агрегатном предложении 'student.fees_paid', поскольку он не содержится в агрегатном предложении 'student.fees_paid'. функцию или предложение GROUP BY.
MySQL:
Неизвестный столбец «fees_paid» в «условии наличия»
PostgreSQL:
ОШИБКА: столбец «student.fees_paid» должен присутствовать в предложении GROUP BY или использоваться в агрегатной функции. Позиция: 81
. также необходимо указать агрегатную функцию.
Таким образом, вместо того, чтобы говорить ИМЕТЬ плату_оплачиваемую, мне нужно сказать ИМЕТЬ СУММУ(оплата_платы), потому что это значение, которое мы проверяем.
ВЫБРАТЬ адрес_состояние, СУММ(сборы_уплачены) ОТ студента СГРУППИРОВАТЬ ПО address_state ПРИ СУММЕ(fees_paid) > 500;Результат:
ADDRESS_STATE СУММА (FEES_PAID) Техас 550 Нью-Йорк 590 Теперь это показывает результат, который мы хотим.
DISTINCT, UNIQUE и ALL с агрегатными функциями
SQL позволяет использовать несколько необязательных ключевых слов в агрегатных функциях, а именно:
- РАЗЛИЧНЫЙ
- УНИКАЛЬНЫЙ
- ВСЕ
DISTINCT и UNIQUE являются синонимами друг друга, поэтому в этой статье я буду называть его DISTINCT.
Они используются следующим образом:
SUM ( [ALL | DISTINCT ] выражение)Ключевое слово ALL используется по умолчанию и означает, что агрегатная функция будет учитывать все значения при выполнении своих вычислений.
Можно указать ключевое слово DISTINCT, и это означает, что агрегатная функция будет учитывать при расчете только различные или уникальные значения выражения. Эта функция предлагается Oracle, SQL Server, MySQL и PostgreSQL (и, возможно, другими).
Давайте посмотрим на пример.
ВЫБЕРИТЕ СУММУ (сборы_оплачены) ОТ студента;Результат:
СУММА(FEES_PAID) 1710 Это показывает обычную функцию SUM без DISTINCT или ALL.
ВЫБЕРИТЕ СУММУ (ВСЕ сборы_оплачены) ОТ студента;Результат:
СУММА(ALLFEES_PAID) 1710 Если мы добавим функцию ВСЕ, она покажет то же, что и в первом примере. Это потому, что ВСЕ по умолчанию.
Давайте добавим ключевое слово DISTINCT:
SELECT SUM(DISTINCT fee_paid) ОТ студента;
СУММА(DISTINCTFEES_PAID) 1460 Если мы добавим ключевое слово DISTINCT, СУММА уменьшится, поскольку учитываются только различные значения.
Как база данных обрабатывает значения NULL в агрегатных функциях?
В SQL почти все агрегатные функции игнорируют значения NULL.
Функции, учитывающие значения NULL:
- COUNT(*)
- ГРУППА
- GROUPING_ID
Если вы хотите включить записи со значениями NULL, вы можете преобразовать их в другое значение с помощью функции NVL.
Что произойдет, если в ваших данных есть значения NULL, и вы используете для них агрегатную функцию?
Если вы используете COUNT, вы получите либо число для количества записей, либо 0.
Если вы используете любую другую функцию и у вас есть только значения NULL в наборе данных, функция вернет NULL.
Можно ли использовать вложенные агрегатные функции?
Да, можно.
Допустим, у вас есть СУММА сборов за студентов в каждом штате, как мы упоминали ранее.
ВЫБРАТЬ адрес_состояние, СУММ(сборы_уплачены) ОТ студента СГРУППИРОВАТЬ ПО address_state;Результат:
ADDRESS_STATE СУММА (FEES_PAID) Техас 550 Нью-Йорк 590 Колорадо 250 Невада 320 Флорида (пусто) Что, если вы хотите найти среднюю СУММУ сборов, уплаченных в каждом штате?
Функцию СУММ можно поместить в другую агрегатную функцию, например AVG.
ВЫБОР СРЕДНЕЕ(СУММ(выплаченные сборы)) ОТ студента СГРУППИРОВАТЬ ПО address_state;Результат:
AVG(SUM(FEES_PAID) 427,5 Расчет здесь найдет СУММУ Fes_paid для каждого address_state, а затем получит AVG этих значений.
Однако, как вы могли заметить, вам нужно удалить это поле из предложения SELECT. Это потому, что вы пытаетесь получить общее среднее значение, а не среднее значение по штату.
Список агрегатных функций SQL
Ниже приведен список агрегатных функций SQL в Oracle, MySQL, SQL Server и PostgreSQL с кратким описанием того, что они делают.
Я написал подробные руководства по многим функциям, и там, где руководство существует, я привязал к нему название функции в этой таблице.
Итак, если вы нажмете на название функции, вы найдете больше информации о том, как ее использовать, и увидите несколько примеров.
Функция База данных Определение APPROX_COUNT_DISTINCT Оракул, SQL Server Находит приблизительное количество различных строк в выражении. МАССИВ_АГГ "}"> PostgreSQL
Собирает все входные значения в массив АВГ Oracle, SQL Server, MySQL, PostgreSQL Находит среднее значение выражения. БИТ_И MySQL, PostgreSQL Возвращает результат побитовой операции И БИТ_ИЛИ "}"> MySQL, PostgreSQL
Возвращает результат побитовой операции ИЛИ БИТ_ИСКЛЮЧАЮЩЕЕ ИЛИ MySQL Возвращает результат побитовой операции XOR BOOL_AND PostgreSQL Возвращает истину, если все ненулевые входные значения истинны, в противном случае возвращает ложь. BOOL_OR PostgreSQL Возвращает истину, если любое ненулевое входное значение истинно, в противном случае возвращает ложь. КОНТРОЛЬНАЯ СУММА_AGG SQL Server Находит контрольную сумму значений в группе. СБОР "}"> Оракул
Создает вложенную таблицу из предоставленного столбца. КОРР. Оракл, PostgreSQL Находит коэффициент корреляции набора пар чисел. КОРР_К Оракул "}"> Вычисляет коэффициент корреляции tau-b Кендалла.
КОРР_С Оракул Вычисляет коэффициент корреляции ро Спирмена. КОЛИЧЕСТВО Oracle, SQL Server, MySQL, PostgreSQL Находит количество строк, возвращенных запросом. COUNT_BIG "}"> SQL-сервер
Подсчитывает количество найденных значений. Аналогично COUNT, но возвращает BIGINT. COVAR_POP Оракл, PostgreSQL Находит ковариацию совокупности набора пар чисел. COVAR_SAMP Оракл, PostgreSQL "}"> Находит выборочную ковариацию набора пар чисел.
CUME_DIST Oracle, SQL Server, MySQL, PostgreSQL Находит кумулятивное распределение значения в группе значений. DENSE_RANK г. Oracle, MySQL, PostgreSQL "}"> Находит ранг строки в упорядоченной группе строк, и строки с одинаковым значением получают одинаковые ранги, но номера рангов не пропускаются. Это может привести к ранжированию 1, 2, 3, 3, 4 (ранг 4 по-прежнему используется, даже если для ранга 3 ничья).
КАЖДЫЙ PostgreSQL То же, что BOOL_AND ПЕРВЫЙ (Оракул) FIRST_VALUE (SQL Server, MySQL)
"}"> Oracle, SQL Server, MySQL
Используется с функциями ранжирования для получения первого значения. ГРУППА_КОНКАТ MySQL Объединяет строку значений. GROUP_ID Оракул "}"> Идентифицирует идентификатор уровня группировки в предложениях GROUP BY.
ГРУППИРОВКА Оракл, SQL Server Идентифицирует суперагрегированные строки из обычных сгруппированных строк. GROUPING_ID Оракул, SQL Server Указывает поле, которое было сгруппировано. JSON_ARRAYAGG (MySQL) JSON_AGG (PostgreSQL)
"}"> MySQL, PostgreSQL
Объединяет набор результатов в единый массив JSON. JSON_OBJECTAGG (MySQL) JSON_OBJECT_AGG (PostgreSQL)
MySQL Объединяет результирующий набор в виде набора пар ключ-значение. ПОСЛЕДНИЙ (Оракул) LAST_VALUE (SQL Server, MySQL)
Оракл, SQL Server, MySQL "}"> Используется с функциями ранжирования для получения последнего значения.
СПИСОК Оракул Упорядочивает данные в наборе данных, а затем объединяет их с указанным символом. МАКС Oracle, SQL Server, MySQL, PostgreSQL Находит максимальное значение выражения. СРЕДНЯЯ Оракул Находит среднее значение набора данных. РЕЖИМ PostgreSQL Находит наиболее часто используемое значение в наборе данных. МИН Oracle, SQL Server, MySQL, PostgreSQL "}"> Находит минимальное значение выражения.
PERCENT_RANK Oracle, SQL Server, MySQL, PostgreSQL Находит ранг строки в процентах, аналогично функции CUME_DIST. PERCENTILE_CONT Oracle, SQL Server, PostgreSQL "}"> Находит значение, попадающее в указанный диапазон, используя указанное процентное значение и метод сортировки.
ПРОЦЕНТИЛЬ_ДИСКА Oracle, SQL Server, PostgreSQL Находит значение, попадающее в указанный диапазон, используя указанное процентное значение и метод сортировки. РАНГ Оракл, MySQL, PostgreSQL Вычисляет ранг значения в группе значений, и строки с одинаковым значением получают одинаковый ранг, а номера рангов пропускаются. Это может привести к ранжированию 1, 2, 3, 3, 5 (ранг 4 пропускается из-за равенства).
REGR_ Функции Оракл, PostgreSQL Сопоставляет линию регрессии обычного метода наименьших квадратов с набором пар чисел. STATS_BINOMIAL_TEST Оракул "}"> Проверяет разницу между пропорцией выборки и заданной пропорцией.
STATS_CROSSTAB Оракул Использует метод для анализа двух переменных с помощью кросс-таблицы. STATS_F_TEST Оракул Проверяет, существенно ли различаются два значения. STATS_KS_TEST "}"> Оракул
Проверяет, относятся ли две выборки к одной совокупности или к разным совокупностям с одинаковым распределением. STATS_MODE Оракул Находит наиболее часто встречающееся значение. STATS_MW_TEST Оракул "}"> Выполняет тест Манна-Уитни на двух популяциях.
STATS_ONE_WAY_ANOVA Оракул Проверяет разницу средних значений для групп на статистическую значимость. STATS_T_TEST_* Оракул Проверяет значимость разницы средних. STATS_WSR_TEST "}"> Оракул
Выполняет критерий знаковых рангов Уилкоксона, чтобы определить, значительно ли медиана различий отличается от 0. СТАНДОТКЛОН (Oracle, MySQL, PostgreSQL) СТАНДОТКЛОН (SQL Server)
Oracle, SQL Server, MySQL, PostgreSQL Находит стандартное отклонение набора значений. STDDEV_POP (Oracle, MySQL, PostgreSQL) STDEVP (сервер SQL)
СТД (MySQL)
"}"> Oracle, SQL Server, MySQL, PostgreSQL
Находит стандартное отклонение генеральной совокупности для набора значений. STDDEV_SAMP Оракл, MySQL, PostgreSQL Находит кумулятивное стандартное отклонение выборки набора значений. STRING_AGG SQL-сервер, PostgreSQL "}"> Объединяет набор значений с указанным разделителем
СУММА Oracle, SQL Server, MySQL, PostgreSQL Находит сумму значений. SYS_OP_ZONE_ID Оракул Находит идентификатор зоны из указанного идентификатора строки SYS_XMLAGG "}"> Оракул
Объединяет XML-документы и создает один XML-документ. VAR_POP (Oracle, MySQL, PostgreSQL) ВАРП (сервер SQL)
Oracle, SQL Server, MySQL, PostgreSQL Находит дисперсию совокупности набора чисел. VAR_SAMP Оракл, MySQL, PostgreSQL "}"> Находит выборочную дисперсию набора чисел.
ДИСПЕРСИЯ (Oracle, MySQL, PostgreSQL) VAR (сервер SQL)
Oracle, SQL Server, MySQL, PostgreSQL Находит дисперсию набора чисел. XMLAGG Оракл, PostgreSQL Объединяет XML-документы и создает один XML-документ.
Итак, вот как вы используете агрегатные функции в SQL.
Если у вас есть какие-либо вопросы, пожалуйста, оставьте комментарий в конце этого поста.
Агрегированные функции SQL — как выполнять группировку в MySQL и PostgreSQL
В SQL агрегатные функции позволяют выполнять вычисления для нескольких данных и возвращать одно значение. Вот почему они называются «агрегатными» функциями.
Эти агрегатные функции:
AVG(),COUNT(),SUM(),MIN()иMAX().При выполнении запросов с агрегатными функциями их также можно использовать в сочетании с предложением
GROUP BYи операторомHAVINGв любой реляционной базе данных — MySQL, PostgreSQL и других.В этой статье вы узнаете, как использовать агрегатные функции сами по себе и с помощью
GROUP BY 9.Пункт 0084 и операторHAVING.Что мы рассмотрим
- Как использовать агрегатные функции
- Синтаксис агрегатных функций
- Как использовать агрегированную функцию
AVG()
- Как использовать функцию
AVG()сGROUP BYиHAVING- Как использовать агрегатную функцию
COUNT()
- Как использовать
COUNT()сGROUP BYиИМЕЮЩИЕ- Как использовать агрегатную функцию
MAX()
- Как использовать
MAX()сGROUP BYиHAVING- Как использовать агрегатную функцию
MIN()
- Как использовать
MIN()сGROUP BYиHAVING- Как использовать агрегатную функцию
SUM()
- Как использовать
СУММ()сГРУППА ПОиИМЕЮЩАЯ- Заключение
Как использовать агрегатные функции
Чтобы показать вам, как работают агрегатные функции, я буду работать с таблицей
сотрудниковв базе данныхemployee_data.Запуск
SELECT * FROM сотрудниковполучил у меня следующее:Синтаксис агрегатных функций
Синтаксис работы с агрегатными функциями выглядит так:
агрегатная_функция (МОДИФИКАТОР | выражение)
- агрегатная функция может быть
AVG,COUNT,MAX,MINилиSUM- модификатором могут быть все значения или значения в определенном столбце
Этот синтаксис будет иметь больше смысла на практике, поэтому давайте применим его к агрегатным функциям.
Как использовать функцию агрегации
AVG()
AVG()агрегатная функция получает общее количество данных и вычисляет их среднее значение.Мне удалось получить среднюю заработную плату сотрудников следующим образом:
ВЫБЕРИТЕ СРЕДНЕЕ (зарплата) ОТ сотрудниковПриведенный ниже запрос позволяет получить среднюю заработную плату младших разработчиков:
ВЫБЕРИТЕ СРЕДНЕЕ (зарплата) ОТ сотрудников ГДЕ роль = "Младший разработчик"Как использовать функцию
AVG()сGROUP BYиHAVINGВы можете получить среднее количество записей (строк) в определенном столбце с помощью предложения
GROUP BYи оператораHAVING.Это означает, что вы должны объединить эти два с
AVG().Например, я смог получить среднюю заработную плату, выплачиваемую сотрудникам в каждой строке, с помощью этого запроса:
ВЫБЕРИТЕ роль, AVG(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО ролиЯ также смог получить среднюю заработную плату старших разработчиков с помощью оператора HAVING:
ВЫБЕРИТЕ роль, AVG(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО роли ИМЕЕТ роль = "Старший разработчик"Как использовать функцию агрегации
COUNT()
COUNT()возвращает количество строк в таблице на основе примененного вами условия (или фильтра).Например, чтобы получить общее количество строк, я выполнил следующий запрос:
ВЫБЕРИТЕ СЧЕТ(*) ОТ сотрудниковА у меня получилось 20:
Чтобы получить общее количество сотрудников из США, я выполнил следующий запрос:
ВЫБЕРИТЕ СЧЕТ(*) ОТ сотрудников ГДЕ страна = "США"И чтобы получить сотрудников, которые являются техническими писателями, я сделал это:
ВЫБЕРИТЕ СЧЕТ(*) ОТ сотрудников ГДЕ роль = "Технический писатель"Как использовать
COUNT()сGROUP BYиHAVINGВ большой базе данных вы можете использовать предложение
GROUP BYи операторHAVINGв сочетании с COUNT(), чтобы получить общее количество записей (строк) в конкретном столбце.В базе данных, которую я использую в этой статье, я смог получить общее количество сотрудников в каждой строке с помощью предложения GROUP BY:
ВЫБЕРИТЕ роль, COUNT(*) ОТ сотрудников СГРУППИРОВАТЬ ПО ролиЧтобы получить количество только сотрудников, которые являются старшими разработчиками, я прикрепил
HAVING role = "Senior dev"к запросу:ВЫБЕРИТЕ роль, COUNT(*) ОТ сотрудников СГРУППИРОВАТЬ ПО роли ИМЕЕТ роль = "Старший разработчик"Как использовать
МАКС()Агрегатная функцияФункция
MAX()возвращает максимальное значение среди значений, отличных от NULL. Это означает, что он будет игнорировать поля, которые пусты, и будет возвращать наибольшее значение среди тех, которые не пусты.Например, чтобы получить самую высокую заработную плату в таблице
сотрудников, я использовал функциюMAX()следующим образом:ВЫБЕРИТЕ МАКС.(зарплата) ОТ сотрудников
Чтобы получить максимальную заработную плату для разработчиков среднего уровня, я использовал
ГДЕвыписка:ВЫБЕРИТЕ МАКС.(зарплата) ОТ сотрудников ГДЕ роль = "Разработчик среднего уровня"Как использовать
MAX()сGROUP BYиHAVINGЧтобы получить максимальную заработную плату в каждой роли, пригодится пункт
GROUP BY:ВЫБЕРИТЕ роль, MAX(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО ролиИ получить максимальную заработную плату в определенной роли, комбинируя оператор HAVING с
GROUP BYделает это:ВЫБЕРИТЕ роль, MAX(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО роли ИМЕЕТ роль = "Технический писатель"Как использовать функцию агрегации
MIN()Функция
MIN()является противоположностью функцииMAX()— она возвращает минимальное значение среди значений, отличных от NULL.Например, я получил самую низкую заработную плату в таблице
сотрудниковследующим образом:ВЫБЕРИТЕ МИН.(зарплата) ОТ сотрудниковКак использовать
MIN()сGROUP BYиHAVINGОпять же, чтобы получить минимальную заработную плату в каждой роли, можно выполнить пункт
GROUP BY:ВЫБЕРИТЕ роль, MIN(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО ролиИ чтобы получить минимальную заработную плату для определенной роли, нужно использовать оператор
HAVINGи пунктGROUP BY:ВЫБЕРИТЕ роль, MIN(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО роли ИМЕЕТ роль = "Младший разработчик"Как использовать функцию агрегации
SUM()Агрегатная функция SUM() суммирует количество записей в столбце на основе примененного фильтра.
Приведенный ниже запрос возвращает общее количество заработной платы, выплаченной сотрудникам:
ВЫБЕРИТЕ СУММУ(зарплата) ОТ сотрудниковКак использовать SUM() с
GROUP BYиHAVINGЧтобы получить сумму общей заработной платы, выплаченной сотрудникам в каждой роли, я выбрал роль, использовал
SUM()по заработной плате, и сгруппировать их по роли:ВЫБЕРИТЕ роль, СУММ(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО ролиЧтобы получить общую заработную плату, выплачиваемую только техническим писателям, я использовал оператор
HAVING:ВЫБЕРИТЕ роль, СУММ(зарплата) ОТ сотрудников СГРУППИРОВАТЬ ПО роли ИМЕЕТ роль = "Технический писатель"Заключение
В этой статье вы узнали, что такое агрегатные функции в SQL, их синтаксис и способы их использования.