1.4.5 Классификация и агрегирование « Все об электронных архивах на ЭлАрхиво.РУ
В MoReq2010 введено несколько новых понятий, например, было проведено различие между классификацией и агрегированием. Стандарт ISO 15489 определяет классификацию как «систематическую идентификацию и упорядочение видов деловой деятельности и/или записей по категориям в соответствии с логически структурированными соглашениями, методами и процедурными правилами, представленными в системе классификации» (ISO 15489‑1:2001, 3.5).
В то время как классификация рассматривает обеспечение бизнес-контекста для записи и устанавливает связи между записью и транзакционным действием, в результате которого данная запись была создана, агрегирование описывает действие по сбору связанных между собой записей . В отличие от классификации, агрегирование может основываться на любом организационном требовании или критерии, не обязательно только бизнес-контексте. Агрегирование разделено на уровни с более высокими уровнями агрегации, представляющими собой объединение более низких уровней агрегации. Вся служба записей, пожалуй, может рассматриваться как единая агрегация высокого уровня.
Вся служба записей, пожалуй, может рассматриваться как единая агрегация высокого уровня.
Исторически некоторые спецификации управления записями сочетают в себе иерархические схемы классификации, устанавливая их над уровнями агрегации таким образом, что каждая запись всегда наследует свой класс посредством своей агрегации. Данный подход показан на Рис. 1i с использованием классов вместо агрегаций на более высоком уровне. Подобная организация данных, несмотря на то, что она является желательной благодаря собственной простоте, если она может быть достигнута, также является негибкой и не всегда является пригодной для использования в условиях реальных ситуаций. Ограничения, накладываемые данным подходом, во многих случаях привели к смешению организационных и тематических элементов с функциональной схемой бизнес-классификации для создания локализованного гибрида.
Рисунок 1i. Традиционная иерархическая модель классификации и агрегирования, в которой большинство классов и агрегаций объединены вместе в единую структуру (данный подход может быть применен при использовании MoReq-совместимых систем, однако MoReq2010 также позволяет большую гибкость)
Многие организации практикуют совместную работу в команде, работу по изучению конкретных случаев или работу по проектам. Когда возникают такие ситуации, естественной тенденцией внутри организаций является агрегирование записей на основе главной темы, такой как конкретный проект, а не исключительно на основе деловой деятельности или процессов, которые и создали данные записи.
Когда возникают такие ситуации, естественной тенденцией внутри организаций является агрегирование записей на основе главной темы, такой как конкретный проект, а не исключительно на основе деловой деятельности или процессов, которые и создали данные записи.
Например, небольшая ассоциация может хранить записи о каждом из своих членов в отдельной агрегации. В рамках каждой такой агрегации можно найти:
• исходную форму регистрации, ее оценку и одобрение;
• идентификационные данные, банковскую и контактную информацию, включая различные уведомления об изменениях;
• ежегодные обновления, подписки и членства;
• заявки, деловые встречи и представительства внутри ассоциации;
• корреспонденцию и другую информацию по различным видам деятельности ассоциации, проводимой данным членом;
• затраты и заявления на возмещение;
• контракты, сертификаты, юридические документы и отказы;
• другое.
В данном примере записи агрегации для конкретного члена ассоциации связаны с различными функциями, видами деятельности и транзакциями и должны, таким образом, привлекать различные бизнес-классификации. Некоторые записи из агрегации по каждому члену должны хранится в течение относительно долгого периода времени, тогда как другие записи в данном агрегировании должны храниться только в течение короткого промежутка времени и затем удаляться по причинам юридического, нормативного или практического характера исходя из данных классификаций.
Некоторые записи из агрегации по каждому члену должны хранится в течение относительно долгого периода времени, тогда как другие записи в данном агрегировании должны храниться только в течение короткого промежутка времени и затем удаляться по причинам юридического, нормативного или практического характера исходя из данных классификаций.
Схема записей, подобная данной, даже несмотря на то, что она обычно используется в организациях, сложна для встраивания в структуру, основанную на традиционной иерархической классификации, показанной на Рис. 1i. Это происходит потому, что в традиционной схеме агрегация по члену целиком должна подходить под отдельный класс в схеме классификации.
В результате оказывается невозможным избежать трудностей, возникающих между практической и операционной эффективностью и потребностями в управлении записями. И схема классификации становится совмещенной, например, посредством внедрения классификации, охватывающей несколько типов, таких как «конкретная ситуация», «клиенты», «проекты», «персонал» и «события», и естественным образом происходящее агрегирование, которое разделяется таким образом, что, например, записи о регистрации всех членом хранятся в месте в одном классе/агрегировании, таком как «заявление на членство», а ежегодные подписки для всех членов собраны в совершенно отдельном классе/агрегировании, таком как «обновления членства 2011 года». Никакие компромиссы не будут считаться полностью приемлемыми.
Никакие компромиссы не будут считаться полностью приемлемыми.
Обеспечивая четкое различие между взаимосвязанными понятиями классификации и агрегирования, MoReq2010 позволяет большую гибкость при принятии решений в отношении планирования о том, какие записи должны храниться вместе, с какой схемой классификации их следует комбинировать и как ее применить. Это, в свою очередь, делает MoReq2010 более адаптируемым к ситуациям, возникающим на практике. Спецификация позволяет основывать агрегирование на операционных критериях, тогда как классификация может применяться на любом уровне агрегирования, включая даже отдельное привязывание классов к записям при необходимости (это показано на Рис. 5d и подробно разъяснено далее в п. 5, «Служба классификации»). В тоже самое время поддерживается совместимость с предыдущими версиями, использующими традиционный подход, показанный на Рис. 1i.
Иллюстрированный самоучитель по SPSS > Модификация данных > Агрегирование данных | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 gif»/> gif»/> | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
8.6. Агрегирование данных На базе значений одной или нескольких группирующих переменных (переменных разбиения) можно объединить наблюдения в группы (агрегировать) и создать новый файл данных, содержащий по одному наблюдению для каждой группы разбиения. Для этого SPSS предоставляет большое количество функций агрегирования. В сельскохозяйственном исследовании рассматривалось содержание свиней в двух различных типах свинарников. При этом в каждом из двух свинарников осуществлялся мониторинг поведения восьми свиней в течение двадцатидневного периода. На протяжении этого периода фиксировалась длительность определенных действий животных (то есть сколько времени свиньи рылись, ели, чесали голову и туловище). Данные хранятся в файле schwein.sav, содержащем следующие переменные:
Следует выяснить, значительно ли различается по длительности эти три действия в свинарниках обоих типов, для чего необходимо применить соответствующий статистический текст, например, тест Стьюдента (см. В каждой из двух выборок для каждого из трех действий имеется по 8 + 20=160 измерений. Однако выполнение статистического тест на основе этих данных будет не совсем корректно, так как они относятся к восьми особям, для каждой из которых было проведено по двадцать измерений. Поэтому мы просуммируем длительности для каждой отдельной свиньи и для каждого отдельного действия. Затем полученные наборы сумм мы сравним при помощи теста Стьюдента. Это типичный пример агрегирования данных. Откроется диалоговое окно Aggregate Data (Агрегировать данные).
Будут показаны три новые переменные wuehle_l, fresse_l и massag_l, имена которых состоят из первых шести букв имен соответствующих переменных агрегирования и комбинации символов _1. Можно выбрать одну из шестнадцати функций агрегирования, имена которых не требуют особых пояснений.
Рис. 8.8: Диалоговое окно Aggregate Data Рис. 8.9: Диалоговое окно Aggregate Data: Aggregate Function После щелчка на кнопке Отбудет создан новый файл, содержащий 2 х 8=16 наблюдений и переменные stall, nr, wuehle_l, fresse_l и massag_l.
Group Statistics (Статистика группы)
Independent Samples Test (Тест для независимых выборок)
В первом свинарнике свиньи ели в продолжение наблюдаемого периода в среднем 339,0 секунд в день, а в другом — только 231,7 секунд. Это различие является почти статистически значимым (р= 0,058). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 главу 13).
главу 13).

 600
600 1
1 390
390 4760 596 ,8594
4760 596 ,8594Что такое агрегация данных?
Управление даннымиОт
- Крейг С. Маллинз, Маллинз Консалтинг
Агрегация данных – это любой процесс, посредством которого данные собираются и представляются в сводной форме. При агрегировании данных ряды атомарных данных, обычно собираемые из нескольких источников, заменяются итоговыми значениями или сводной статистикой. Группы наблюдаемых агрегатов заменяются сводной статистикой, основанной на этих наблюдениях. Агрегированные данные обычно находятся в хранилище данных, поскольку они могут дать ответы на аналитические вопросы, а также значительно сократить время на запросы к большим наборам данных.
Агрегирование данных часто используется для предоставления статистического анализа для групп людей и для создания полезных сводных данных для бизнес-анализа. Агрегация часто выполняется в больших масштабах с помощью программных средств, известных как агрегаторы данных . Агрегаторы данных обычно включают в себя функции для сбора, обработки и представления совокупных данных.
Агрегация данных может позволить аналитикам получать доступ и анализировать большие объемы данных в разумные сроки. Строка совокупных данных может представлять собой сотни, тысячи или даже больше записей атомарных данных. Когда данные агрегированы, их можно быстро запрашивать, вместо того чтобы требовать, чтобы все циклы обработки обращались к каждой базовой атомарной строке данных и агрегировали их в режиме реального времени при запросе или доступе к ним.
Поскольку объем данных, хранящихся в организациях, продолжает расти, наиболее важные и часто используемые данные могут выиграть от агрегирования, что делает возможным эффективный доступ.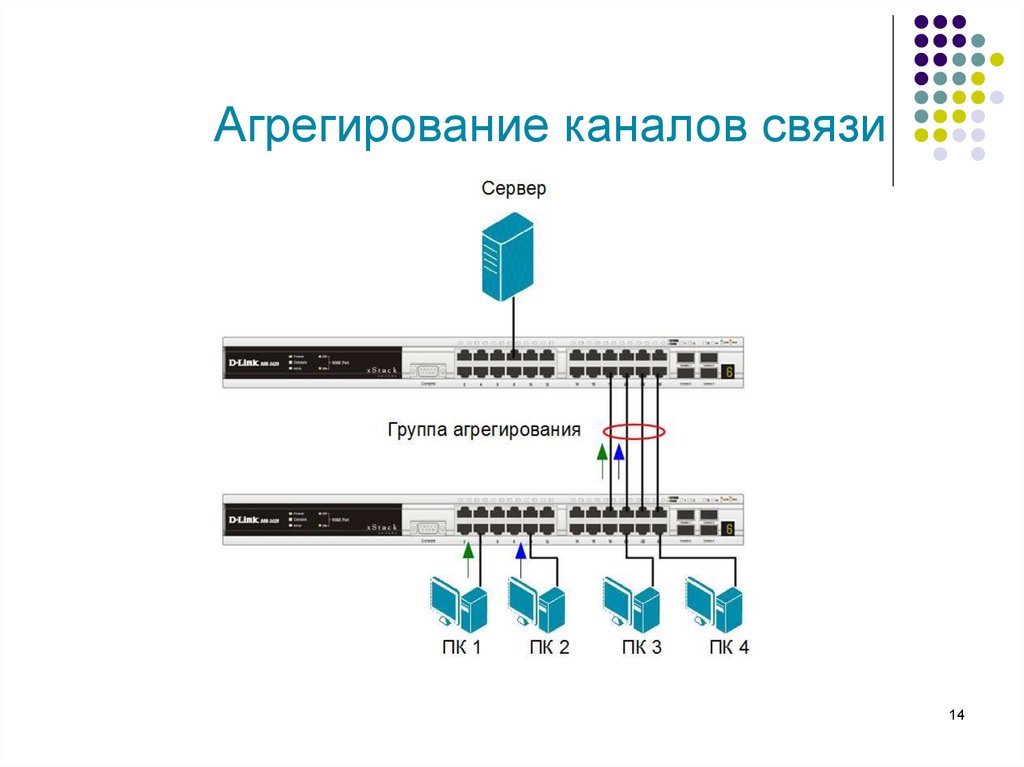
Агрегаторы данных суммируют данные из нескольких источников. Они предоставляют возможности для нескольких совокупных измерений, таких как сумма, среднее значение и подсчет.
Примеры агрегированных данных включают следующее:
- Явка избирателей по штатам или округам. Индивидуальные списки избирателей не представлены, только итоги голосования по кандидатам в конкретном регионе.
- Средний возраст покупателя по продукту. Каждый отдельный покупатель не идентифицируется, но для каждого товара сохраняется средний возраст покупателя.
- Количество клиентов по странам. Вместо изучения каждого клиента представлено количество клиентов в каждой стране.
Агрегирование данных также может привести к эффекту, аналогичному анонимизации данных, поскольку отдельные элементы данных с персональными данными объединяются и заменяются сводкой, представляющей группу в целом. Примером этого является создание сводки, показывающей совокупную среднюю заработную плату сотрудников по отделам, а не просмотр записей отдельных сотрудников с данными о зарплате.
Агрегированные данные не обязательно должны быть числовыми. Вы можете, например, подсчитать количество любого нечислового элемента данных.
Перед агрегированием крайне важно, чтобы атомарные данные были проанализированы на предмет точности и чтобы было достаточно данных, чтобы агрегирование было полезным. Например, подсчет голосов, когда доступно только 5% результатов, вряд ли даст релевантную совокупность для прогнозирования.
Как работают агрегаторы данных?Агрегаторы данных работают, комбинируя атомарные данные из нескольких источников, обрабатывая данные для получения новой информации и представляя совокупные данные в сводном представлении. Кроме того, агрегаторы данных обычно предоставляют возможность отслеживать происхождение данных и могут отслеживать базовые атомарные данные, которые были агрегированы.
Коллекция. Во-первых, инструменты агрегации данных могут извлекать данные из нескольких источников, сохраняя их в больших базах данных как атомарные данные. Данные могут быть извлечены из источников Интернета вещей (IoT), таких как:
Данные могут быть извлечены из источников Интернета вещей (IoT), таких как:
- общение в социальных сетях;
- заголовка новостей;
- личных данных и истории просмотров с IoT-устройств; и
- колл-центры, подкасты и т. д. (через распознавание речи).
Обработка. Когда данные извлечены, они обрабатываются. Агрегатор данных идентифицирует атомарные данные, которые должны быть агрегированы. Агрегатор данных может применять прогнозную аналитику, искусственный интеллект (ИИ) или алгоритмы машинного обучения к собранным данным для получения новой информации. Затем агрегатор применяет указанные статистические функции для агрегирования данных.
Презентация. Пользователи могут представлять агрегированные данные в обобщенном формате, который сам по себе предоставляет новые данные. Статистические результаты полны и высокого качества.
Агрегирование данных может выполняться вручную или с помощью агрегаторов данных. Однако агрегирование данных часто выполняется на крупномасштабной основе, что делает ручное агрегирование менее осуществимым. Кроме того, при ручной агрегации существует риск случайного пропуска важных источников данных и шаблонов.
Однако агрегирование данных часто выполняется на крупномасштабной основе, что делает ручное агрегирование менее осуществимым. Кроме того, при ручной агрегации существует риск случайного пропуска важных источников данных и шаблонов.
Агрегация данных может быть полезна для многих дисциплин, таких как принятие решений по финансам и бизнес-стратегии, планирование продуктов, ценообразование продуктов и услуг, оптимизация операций и создание маркетинговой стратегии. Пользователи могут быть аналитиками данных, исследователями данных, администраторами хранилища данных и экспертами в предметной области.
Агрегированные данные обычно используются для статистического анализа для получения информации о конкретных группах на основе конкретных демографических или поведенческих переменных, таких как возраст, профессия, уровень образования или доход.
В целях бизнес-анализа данные можно объединять в сводки, которые помогают руководителям принимать взвешенные решения. Пользовательские данные могут быть собраны из нескольких источников, таких как общение в социальных сетях, история просмотров с устройств IoT и другие личные данные, чтобы дать компаниям критическое представление о потребителях.
Пользовательские данные могут быть собраны из нескольких источников, таких как общение в социальных сетях, история просмотров с устройств IoT и другие личные данные, чтобы дать компаниям критическое представление о потребителях.
Последнее обновление: июнь 2020 г.
Продолжить чтение Об агрегации данных- Следует ли размещать озеро данных в облаке?
- Руководство по инструментам анализа больших данных, тенденциям и лучшим практикам
- Концепция больших данных вышла далеко за рамки своего крошечного начала
- Хранилище данных, озеро данных и киоск данных: помимо СУБД
- Центр знаний IBM: объединение данных
атом
Автор: Бен Луткевич
атомная единица массы (АМД или а.е.м.)
Автор: Рахул Авати
Следуйте этим примерам, чтобы использовать CloudWatch Logs Insights
Автор: Крис Мойер
ИТ-компания одерживает победу в проекте технологии стадионов
Автор: Пол Корженёвски
Бизнес-аналитика
- Расширенная интеграция AtScale и Databricks добавляет функциональность
Инструменты поставщика платформы семантического уровня теперь перечислены в Databricks Partner Connect, и существующие клиенты теперь могут подключаться .
 ..
.. - Платформы потоковой передачи данных способствуют быстрому принятию решений
Анализ в режиме реального времени имеет решающее значение, поскольку организации пытаются конкурировать в условиях экономической неопределенности. Непрерывная потоковая передача разведывательных данных…
- Пространственный анализ — портал для более глубокого понимания данных
В сочетании с другими типами данных информация о местоположении может добавить важный контекст, который приводит к хорошо обоснованным выводам …
ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных.
 Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу… - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
Управление контентом
- Как перейти на систему управления медиаактивами
Что такое управление медиаактивами и что оно может сделать для вашей организации? Это похоже на управление цифровыми активами, но оно нацелено на …
- Какие бывают системы управления знаниями?
Чтобы понять различные типы систем управления знаниями, организации должны знать о различных типах …
- 10 лучших программных продуктов PIM в 2023 году
PIM-системы могут поставляться как отдельные продукты, но многие из них подходят для более крупных цифровых платформ.
 Лучшие продукты PIM включают …
Лучшие продукты PIM включают …
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, положив конец …
ПоискSAP
- Увольнения коснулись 2,5% сотрудников SAP; Qualtrics выставлен на продажу
SAP сокращает штат в рамках «целевой реструктуризации» и продажи Qualtrics.
 Увольнения имитируют других продавцов, а продажи …
Увольнения имитируют других продавцов, а продажи … - Руководство SAP получает хорошую оценку, но есть возможности для улучшения
По словам наблюдателей, генеральный директор SAP Кристиан Кляйн хорошо показал себя в сложных условиях, но ему все еще приходится сталкиваться с такими проблемами, как …
- Будущее SAP зависит от открытия своего ИТ-стека
Первые 50 лет SAP сосредоточилась на основных ERP-системах для внутренних бизнес-операций, но в предстоящие годы необходимо сосредоточиться на расширении …
Определение сводных данных
Агрегированные данные относятся к числовой или нечисловой информации, которая (1) собирается из нескольких источников и/или по нескольким показателям, переменным или отдельным лицам и (2) компилируется в сводки данных или сводные отчеты, как правило, для целей публичной отчетности или статистического анализа, т. е. изучения тенденций, проведения сравнений или раскрытия информации и выводов, которые нельзя было бы наблюдать, если бы элементы данных рассматривались изолированно. Например, информация о том, закончили ли отдельные учащиеся среднюю школу, может быть объединил , то есть скомпилировал и обобщил, в единый процент выпускников для выпускного класса или школы, а годовые показатели выпускников школ затем можно агрегировать в коэффициенты выпускников для округов, штатов и стран.
Например, информация о том, закончили ли отдельные учащиеся среднюю школу, может быть объединил , то есть скомпилировал и обобщил, в единый процент выпускников для выпускного класса или школы, а годовые показатели выпускников школ затем можно агрегировать в коэффициенты выпускников для округов, штатов и стран.
Хотя большинство совокупных данных об образовании являются числовыми — например, количество выпускников и отсева, средние баллы по стандартизированным тестам для школы или округа, средний объем финансирования, потраченного на одного учащегося в штате, и т. д. — это возможно и распространено. агрегировать нечисловую информацию. Например, педагоги, учащиеся и родители в школьном округе могут быть опрошены по какой-либо теме, а информация и комментарии из этих опросов могут быть «объединены» в отчет, который показывает, что опрошенные в целом думают и думают по этому вопросу. . Информация, собранная в ходе опросов, интервью и фокус-групп, может быть агрегирована аналогичным образом.
Чтобы дополнительно проиллюстрировать концепцию агрегированных данных и то, как их можно использовать в государственном образовании, рассмотрим школу с 500 учащимися, что означает, что школа ведет записи 500 учащихся, каждая из которых содержит широкий спектр информации о зачисленных студентов — например, имя и фамилия, домашний адрес, дата рождения, идентификация пола, расы или этнической принадлежности, дата и период зачисления, пройденные и пройденные курсы, полученные оценки за курсы, результаты тестов и т. д. (собранная информация и поддерживается на отдельных студентах часто называется данные уровня студента , среди прочего). Один или два раза в год от школьного округа может потребоваться предоставление отчетов о зачислении учащихся в отдел образования штата. Затем каждая школа в округе составит отчет, в котором задокументировано количество учащихся, зачисленных в настоящее время в школу и на каждом уровне обучения, что требует от администраторов суммирования данных из всех их индивидуальных записей учащихся для создания отчетов о зачислении. Сейчас в районе агрегата информация о зачислении учащихся, посещающих его школы. В течение следующих пяти лет школьный округ может использовать эти ежегодные отчеты для анализа роста или снижения числа учащихся в округе, числа учащихся в каждой школе или числа учащихся в каждом классе. Однако округ не смог определить, произошло ли увеличение или уменьшение набора белых и небелых учащихся на основе совокупных данных, полученных от его школ. Чтобы подготовить отчет, показывающий четкие тенденции зачисления учащихся разных рас и этнических групп, окружным школам затем потребуется дезагрегировать информацию о зачислении по расовым и этническим подгруппам.
Сейчас в районе агрегата информация о зачислении учащихся, посещающих его школы. В течение следующих пяти лет школьный округ может использовать эти ежегодные отчеты для анализа роста или снижения числа учащихся в округе, числа учащихся в каждой школе или числа учащихся в каждом классе. Однако округ не смог определить, произошло ли увеличение или уменьшение набора белых и небелых учащихся на основе совокупных данных, полученных от его школ. Чтобы подготовить отчет, показывающий четкие тенденции зачисления учащихся разных рас и этнических групп, окружным школам затем потребуется дезагрегировать информацию о зачислении по расовым и этническим подгруппам.
Агрегированные и дезагрегированные данные
Агрегировать данные означает собирать и обобщать данные; дезагрегировать данные означает разбить агрегированные данные на составные части или более мелкие единицы данных. Хотя это различие между агрегированными и дезагрегированными данными может показаться очевидным, здесь есть нюанс, который стоит обсудить: многие «дезагрегированные» данные в образовании на самом деле представляют собой данные, которые технически0022 агрегировано на определенном уровне из записей, которые ведутся по отдельным учащимся.
Например, количество выпускников широко считается «агрегированными данными», в то время как количество выпускников, сообщаемых для различных подгрупп учащихся, например, для учащихся разных рас и этнических групп, обычно считается «дезагрегированными данными». Тем не менее, для составления отчетов, дезагрегирующих процент выпускников по расе и этнической принадлежности, данные по отдельным учащимся фактически должны быть «агрегированы» для получения сводных показателей выпускников для различных расовых подгрупп. Скорее всего, это различие между агрегированными и дезагрегированными данными возникло из-за того, что исторически только агрегированные данные об успеваемости в масштабах школы, округа или штата были доступны или общедоступны. При расследовании или сообщении по таким темам, как агрегированные данные или дезагрегированные данные важно точно определить, как термины используются в конкретном контексте.
Реформа
До начала 2000-х годов большинство государственных образовательных учреждений и округов собирали только сводные данные об учащихся, зачисленных в государственные школы. Однако сегодня во всех 50 штатах США есть системы на уровне штатов, которые собирают и поддерживают данные на уровне учащихся, а не просто агрегированные записи, что позволяет агентствам штата по образованию составлять как агрегированные, так и дезагрегированные отчеты по школам и учащимся (государственные-школы). округа обычно собирают данные на уровне учащихся из школ, а штаты собирают данные на уровне учащихся из округов).
Однако сегодня во всех 50 штатах США есть системы на уровне штатов, которые собирают и поддерживают данные на уровне учащихся, а не просто агрегированные записи, что позволяет агентствам штата по образованию составлять как агрегированные, так и дезагрегированные отчеты по школам и учащимся (государственные-школы). округа обычно собирают данные на уровне учащихся из школ, а штаты собирают данные на уровне учащихся из округов).
В то время как агрегированные данные, такие как количество выпускников средних школ или средние результаты тестов, могут дать ряд важных сведений, значительное число школьных руководителей, исследователей, реформаторов образования и политиков в последние годы выступали за важность дезагрегирования данных для выявить основные тенденции и проблемы, такие как пробелы в достижениях , пробелы в возможностях , пробелы в обучении и другие неравенства в системе государственного образования. Если, например, единственными доступными данными об окончании школы являются годовые показатели по отдельным школам, эти агрегированные данные могут скрывать значительные различия в показателях выпуска для учащихся из семей с низким доходом, цветных учащихся, учащихся с ограниченными возможностями или учащихся, не владеющих английским языком. английский язык. Совокупный показатель выпускников школы в целом может оказаться высоким, скажем, 9.0 процентов, но когда данные дезагрегированы по разным группам учащихся, дезагрегация может показать, например, что более 50 процентов афроамериканцев и латиноамериканцев в школе не заканчивают учебу.
английский язык. Совокупный показатель выпускников школы в целом может оказаться высоким, скажем, 9.0 процентов, но когда данные дезагрегированы по разным группам учащихся, дезагрегация может показать, например, что более 50 процентов афроамериканцев и латиноамериканцев в школе не заканчивают учебу.
Вообще говоря, основная цель сбора и представления агрегированных данных состоит в том, чтобы предоставить полезную информацию об успеваемости государственных школ и учащихся государственных школ тем, кто следит за школами или работает над их улучшением. Хотя агрегированные данные необходимы для понимания того, как работает система государственного образования, отчеты по агрегированным данным обычно ограничиваются выявлением более широких тенденций и закономерностей в образовании; они не так полезны, когда дело доходит до диагностики более глубоких проблем, таких как различия в успеваемости среди учащихся разных рас и этнических групп.
Дебаты
В государственном образовании сводные данные широко собирались и публиковались на протяжении десятилетий. По большей части использование агрегированных данных не вызывало споров в государственном образовании, в первую очередь потому, что агрегированные данные вызывают гораздо меньше опасений в отношении безопасности и конфиденциальности учащихся, чем сбор, совместное использование и использование данных и личной информации о конкретных учащихся. Тем не менее, в последние годы возник ряд дебатов, связанных с использованием агрегированных данных в образовании, как правило, в ответ на (1) использование публичных отчетов, часто называемых «школьными табелями успеваемости», предназначенных для предоставления семьям и общественности с обобщенными оценками индивидуальной успеваемости в школе и (2) использованием средних результатов тестов учащихся и других совокупных показателей при оценке эффективности работы педагогов.
По большей части использование агрегированных данных не вызывало споров в государственном образовании, в первую очередь потому, что агрегированные данные вызывают гораздо меньше опасений в отношении безопасности и конфиденциальности учащихся, чем сбор, совместное использование и использование данных и личной информации о конкретных учащихся. Тем не менее, в последние годы возник ряд дебатов, связанных с использованием агрегированных данных в образовании, как правило, в ответ на (1) использование публичных отчетов, часто называемых «школьными табелями успеваемости», предназначенных для предоставления семьям и общественности с обобщенными оценками индивидуальной успеваемости в школе и (2) использованием средних результатов тестов учащихся и других совокупных показателей при оценке эффективности работы педагогов.
Школьные табели успеваемости и другие формы отчетности по штату об успеваемости отдельных государственных школ могут стать предметом дискуссий или споров по целому ряду причин — их слишком много, чтобы всесторонне обсудить здесь. Однако, чтобы привести один иллюстративный пример, общим предметом разногласий является тенденция школ, расположенных в сообществах с высоким уровнем бедности или меньшинств, получать значительно более низкие оценки в государственных табелях успеваемости. Эти школы, как правило, обслуживают учащихся с более высокими потребностями и большим дефицитом знаний, недофинансируются (по сравнению с более богатыми районами), имеют менее опытных или менее квалифицированных учителей и сталкиваются с множеством дополнительных препятствий, которые способствуют снижению успеваемости. — тем не менее совокупные данные, представленные в государственных табелях успеваемости, могут не давать этой контекстуальной информации. Связанная с этим тема дискуссий заключается в том, является ли «пристыжение» школ, расположенных в районах с высоким уровнем бедности или меньшинств, лучшим способом улучшить эти школы или лучше обслуживать учащихся, которые их посещают, учитывая, что большая часть их результатов может быть объяснена факторами, которые находятся вне контроля воспитателей, работающих в школах.
Однако, чтобы привести один иллюстративный пример, общим предметом разногласий является тенденция школ, расположенных в сообществах с высоким уровнем бедности или меньшинств, получать значительно более низкие оценки в государственных табелях успеваемости. Эти школы, как правило, обслуживают учащихся с более высокими потребностями и большим дефицитом знаний, недофинансируются (по сравнению с более богатыми районами), имеют менее опытных или менее квалифицированных учителей и сталкиваются с множеством дополнительных препятствий, которые способствуют снижению успеваемости. — тем не менее совокупные данные, представленные в государственных табелях успеваемости, могут не давать этой контекстуальной информации. Связанная с этим тема дискуссий заключается в том, является ли «пристыжение» школ, расположенных в районах с высоким уровнем бедности или меньшинств, лучшим способом улучшить эти школы или лучше обслуживать учащихся, которые их посещают, учитывая, что большая часть их результатов может быть объяснена факторами, которые находятся вне контроля воспитателей, работающих в школах. Те, кто выступает за использование государственных табелей успеваемости, могут утверждать, что — независимо от проблем, с которыми сталкиваются школы — родители, семьи и широкая общественность имеют право на получение информации об успеваемости государственных школ в их штате и сообществе, и что повышение прозрачности, когда речь идет о школьной успеваемости, приведет к политике и реформам, которые в конечном итоге повысят качество образования для учащихся.
Те, кто выступает за использование государственных табелей успеваемости, могут утверждать, что — независимо от проблем, с которыми сталкиваются школы — родители, семьи и широкая общественность имеют право на получение информации об успеваемости государственных школ в их штате и сообществе, и что повышение прозрачности, когда речь идет о школьной успеваемости, приведет к политике и реформам, которые в конечном итоге повысят качество образования для учащихся.
Использование агрегированных данных при оценке эффективности работы администраторов и учителей также может стать предметом споров по целому ряду причин, многие из которых отражают дебаты, связанные со школьными табелями успеваемости. Например, многие профсоюзы работников образования и учителей утверждают, что учителя не должны рассчитывать на гарантии занятости или заработную плату в зависимости от успеваемости учащихся, потому что многие факторы, влияющие на академическую успеваемость, находятся вне их контроля: например, такие факторы, как низкий уровень образования родителей, неблагоприятная или неблагополучная домашняя среда.