Функции ссылок и массивов — Excel.su
Перейти к содержимому
| Функция | Описание |
|---|---|
| АДРЕС | Возвращает ссылку в виде текста на отдельную ячейку листа |
| ВПР | Ищет значение в первом столбце массива и возвращает значение из ячейки в найденной строке и указанном столбце |
| ВЫБОР | Выбирает значение из списка значений по индексу |
| ГИПЕРССЫЛКА | Создает ссылку, открывающую документ, находящийся на жестком диске, сервере, сети или в Интернете |
| ГПР | Ищет значение в первой строке массива и выдает значение из ячейки в найденном столбце и указанной строке |
| ДВССЫЛ | Определяет ссылку, заданную текстовым значением |
| ДРВ | Извлекает данные реального времени из программ, поддерживающих автоматизацию COM |
| ИНДЕКС | По индексу получает значение из ссылки или массива |
| ОБЛАСТИ | Определяет количество областей в ссылке |
| ПОИСКПОЗ | Ищет значения в ссылке или массиве |
| ПРОСМОТР | Ищет значения в векторе или массиве |
| СМЕЩ | Определяет смещение ссылки относительно заданной ссылки |
| СТОЛБЕЦ | Определяет номер столбца, на который указывает ссылка |
| СТРОКА | Определяет номер строки, определяемой ссылкой |
| ТРАНСП | Выдает транспонированный массив |
| ЧИСЛСТОЛБ | Определяет количество столбцов в массиве или ссылке |
| ЧСТРОК | Определяет количество строк в ссылке |
Как снять пароль в Excel? Три рабочих способа снятия пароля.

Способ 1. (Используем программу) Ищем в поисковике и загружаем программу
Как собрать несколько книг Excel в одну?
Например, мы имеем много рабочих книг Excel, и мы хотим
Что такое макрос и куда его вставлять в Excel?
Нам в работе иногда не хватает стандартных возможностей Эксель и приходится напрягать
Как добавить абзац в ячейке Excel?
Достаточно часто при заполнении ячейки текстом, возникает необходимость ввести текст
Как посчитать количество уникальных значений в колонке Excel?
Иногда в работе нам нужно посчитать уникальные значения в определенной
Отсортировать уникальные значения в Excel
Предположим, что у нас есть такая таблица с перечнем соглашений,
Как сделать и добавить выпадающий список в Excel?
В Excel есть одна интересная особенность, а именно возможность вводить
Как быстро перейти в нужный лист книги Excel?
Многие сталкивались с файлами Ексель, в которых создано огромное количество
PrevПредыдущаяФинансовые функции
СледующаяКак объединить ячейки в Excel?Next
Как снять пароль в Excel? Три рабочих способа снятия пароля.
Способ 1. (Используем программу) Ищем в поисковике и загружаем программу…
Как собрать несколько книг Excel в одну?
Например, мы имеем много рабочих книг Excel, и мы хотим…
Что такое макрос и куда его вставлять в Excel?
Нам в работе иногда не хватает стандартных возможностей Эксель и приходится напрягать…
Как добавить абзац в ячейке Excel?
Достаточно часто при заполнении ячейки текстом, возникает необходимость ввести текст…
Как посчитать количество уникальных значений в колонке Excel?
Иногда в работе нам нужно посчитать уникальные значения в определенной…
Отсортировать уникальные значения в Excel
Предположим, что у нас есть такая таблица с перечнем соглашений,…
Поддержка и продвижение проекта — студия BusinessTerra
Ссылка на элемент массива. VBA для чайников
Ссылка на элемент массива. VBA для чайниковВикиЧтение
VBA для чайников
Каммингс Стив
Содержание
Ссылка на элемент массива
Каждый массив в VBA имеет имя, т. е. аналог заголовка списка на листе бумаги. Чтобы работать с отдельным элементом массива, нужно сослаться на него по имени массива и индексу — целому числу, соответствующему месту элемента в массиве. Например, выражение intLottoArray ( 3 ) ссылается на третий (или четвертый, в зависимости от системы нумерации) элемент массива с именем intLottoArray. Как вы, наверное, догадались, intв начале имени массива говорит о том, что в этом массиве предполагается хранить целые значения. Поэтому можно утверждать, что данные, хранящиеся в intLottoArray (3), представляют собой целое число.
е. аналог заголовка списка на листе бумаги. Чтобы работать с отдельным элементом массива, нужно сослаться на него по имени массива и индексу — целому числу, соответствующему месту элемента в массиве. Например, выражение intLottoArray ( 3 ) ссылается на третий (или четвертый, в зависимости от системы нумерации) элемент массива с именем intLottoArray. Как вы, наверное, догадались, intв начале имени массива говорит о том, что в этом массиве предполагается хранить целые значения. Поэтому можно утверждать, что данные, хранящиеся в intLottoArray (3), представляют собой целое число.
Создание массива
Создание массива
arrayСоздание и инициализация массива.Синтаксис:array array([mixed …])Функция возвращает созданный массив. Индексы и значения в массиве разделяются оператором =. Пары index=value разделяются запятыми, они определяют индекс и значение. Индекс может быть как числовым, так
Индекс может быть как числовым, так
Неразрешимая символическая ссылка при загрузке ztdummy
Неразрешимая символическая ссылка при загрузке ztdummy Драйвер ztdummy требует наличия доступного контроллера UHCI USB в ядрах Linux 2.4 (USB-котроллер не является обязательным требованием для ядер Linux 2.6, потому что они способны генерировать опорный синхросигнал частотой 1 кГц).Ссылка на главную страницу
Ссылка на главную страницу Да, вы не ошиблись, на главной странице иногда есть ссылка на… главную страницу. С точки зрения логики ссылаться на самого себя – серьезная ошибка. Ведь если нажать на такую ссылку, окажешься там же.Запутанная проблема, которой следует избегать.
32. Ссылка
32. Ссылка
Ссылка – это другое имя объекта. Главное применение ссылок заключается в спецификации операций для типов, определяе-мых пользователем. Их можно также применять как параметры функции. Запись x& представляет собой ссылку на x.К примеру:int i = 1;int& r = i; // r и i теперь
Главное применение ссылок заключается в спецификации операций для типов, определяе-мых пользователем. Их можно также применять как параметры функции. Запись x& представляет собой ссылку на x.К примеру:int i = 1;int& r = i; // r и i теперь
Данные массива
Данные массива При работе с массивами нужно помнить следующее.* Можно создавать массивы данных любых типов. VBA с успехом хранит в массивах строки, даты, денежные значения и данные любых числовых типов.* В одном массиве могут храниться данные только одного типа. Нельзя
8.1.5. Сортировка массива
8.1.5. Сортировка массива Самый простой способ отсортировать массив — воспользоваться встроенным методом sort:words = %w(the quick brown fox)list = words.sort # [«brown», «fox», «quick», «the»]# Или отсортировать на месте:words.sort! # [«brown», «fox», «quick», «the»]Здесь предполагается, что все элементы массива сравнимы
8.
 1.10. Рандомизация массива
1.10. Рандомизация массива8.1.10. Рандомизация массива Иногда нужно переставить элементы массива в случайном порядке. Первое, что приходит на ум, — тасование карточной колоды, но есть и другие применения — например, случайная сортировка списка вопросов.Для решения этой задачи пригодится метод rand из
8.1.18. Обход массива
8.1.18. Обход массива Как и следовало ожидать, в классе Array есть стандартный итератор each. Но имеются и другие полезные итераторы.Метод reverse_each обходит массив в обратном порядке. Результат такой же, как если бы мы вызвали сначала метод reverse, а потом each, но работает быстрее.words =
8.1.20. Обращение массива
8.1.20. Обращение массива
Чтобы переставить элементы массива в обратном порядке, воспользуйтесь методами reverse или reverse!:inputs = [«red», «green», «blue»]outputs = inputs.
Использование массива
Использование массива Предположим, у нас есть массив структур. Имя массива является синонимом его адреса, поэтому его можно передать функции. С другой стороны, функции будет необходим доступ к структурному шаблону. Чтобы показать, как такая программа работает (рис.
Объявление массива
Объявление массива Синтаксис:[<спецификация типа]> <описатель> [<константное выражение>];[<спецификация типа]> <описатель> [];Квадратные скобки, следующие за описателем, являются элементом языка Си, а не признаком необязательности синтаксической
Ссылка на себя
Ссылка на себя
Ничто не препятствует объекту O1 в определенный момент выполнения системы содержать ссылку, присоединенную к самому O1.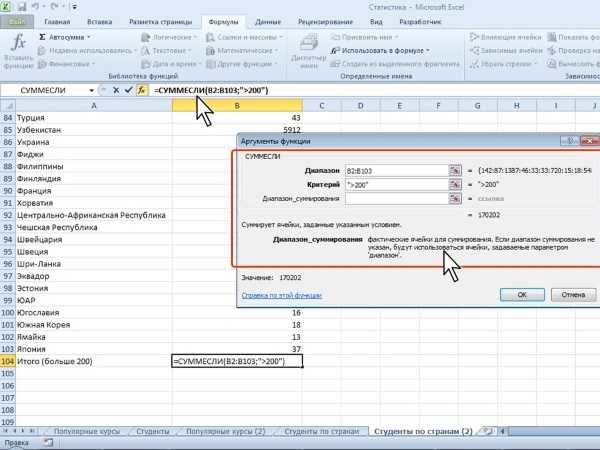 Такая ссылка на себя может быть косвенной. В ситуации на рис.8.7 объект, имеющий значением поля name: «Almaviva», сам является своим лендлордом
Такая ссылка на себя может быть косвенной. В ситуации на рис.8.7 объект, имеющий значением поля name: «Almaviva», сам является своим лендлордом
Свойства массива
Свойства массива Некоторые замечания о классе.[x]. Подобные классы существуют для массивов большей размерности: ARRAY2 и т. д.[x]. Компонент Count может быть реализован и как атрибут и как функция, поскольку count = upper — lower+1. В реальном классе это выражается инвариантом, как
Ссылка на Chrome Web Store появилась в Chromium Евгений Крестников
Новые функции Excel для формирования массивов • My Online Training Hub
Microsoft недавно выпустила 11 новых функций Excel для формирования массивов (данных). Я уже рассказывал о суперпопулярных VSTACK и HSTACK, и в этом посте я собираюсь использовать некоторые другие новые функции, чтобы делать то, что раньше требовало перебора функций на уровне ниндзя.
Я уже рассказывал о суперпопулярных VSTACK и HSTACK, и в этом посте я собираюсь использовать некоторые другие новые функции, чтобы делать то, что раньше требовало перебора функций на уровне ниндзя.
Вы можете посмотреть отдельные уроки, представленные в видео, или прочитать о них по ссылкам ниже:
| Функция РАСШИРЕНИЯ | Расширяет или дополняет массив до указанного количества строк и столбцов. |
| ТОРОВ Функция | Возвращает массив в одну строку. Полезно для объединения данных из нескольких столбцов и строк в одну строку. |
| Функция TOCOL | Возвращает массив в один столбец. Полезно для объединения данных из нескольких столбцов и строк в один столбец. |
| WRAPROWS Функция | Позволяет оборачивать (преобразовывать) строку или столбец значений в строки, вы указываете количество значений в каждой строке. |
| Функция WRAPCOLS | Позволяет оборачивать (преобразовывать) строку или столбец значений в столбцы, вы указываете количество значений в каждом столбце. |
| Функция DROP | Удалить указанное количество смежных строк или столбцов из начала или конца массива. |
| ПРИНЯТЬ Функция | Извлечь указанное количество смежных строк или столбцов из начала или конца массива. |
| ВЫБОР Функция | Извлечь строки из указанного столбца или столбцов. |
| ВЫБОР Функция | Извлечь столбцы из указанных строк или строк. |
| Функция VSTACK | Объединить массивы, расположенные вертикально (VSTACK), в новый единый массив. |
| Функция HSTACK | Объединить массивы, расположенные горизонтально (HSTACK), в новый единый массив. |
Примечание. эти функции доступны только пользователям Microsoft 365.
Посмотреть видео
Загрузить рабочую тетрадь
Введите адрес электронной почты ниже, чтобы загрузить образец рабочей тетради.
Отправляя свой адрес электронной почты, вы соглашаетесь с тем, что мы можем отправить вам наш информационный бюллетень Excel по электронной почте.
Функции формирования вложенных массивов
Новые функции формирования массивов по отдельности великолепны, но объединив их, вы сможете создать несколько очень полезных формул.
В приведенной ниже таблице у меня есть список почтовых индексов и соответствующих пригородов:
Я могу повернуть макет с помощью WRAPCOLS и TOROW, чтобы почтовые индексы теперь были в столбце следующим образом:
Или я могу отформатировать это в виде таблицы со столбцом для почтового индекса и столбцом для пригорода с HSTACK, TOCOL и CHOOSEROWS:
Обратите внимание, как я дважды использовал CHOOSEROWS для возврата списка почтовых индексов, отсюда и 1,1 в формуле CHOOSEROWS:
=HSTACK(TOCOL(CHOOSEROWS(C6:G6,1,1)),TOCOL(C7: G8))
Обработка отсутствующих данных
Если количество пригородов для каждого почтового индекса нечетное, в результате вы получите пробелы:
Мы можем отфильтровать пробелы с помощью функции ФИЛЬТР:
ФИЛЬТР проверяет для пробелов повторением второго массива в HSTACK, возвращаемого TOCOL:
=ФИЛЬТР(HSTACK(TOCOL(CHOOSEROWS(C31:G31,1,1,1,1)),TOCOL(C32:G35)), TOCOL(C32:G35)»»)
Как создать устойчивую модель Excel использование растекающихся формул динамического массива
Когда дело доходит до программирования, большинство кодеров или программистов признают, что код и данные должны быть разделены.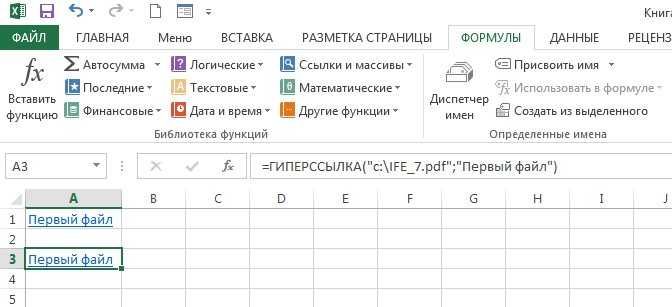 «Избегание жесткого кодирования» — общепринятая передовая практика в этом отношении. К сожалению, когда дело доходит до Excel, эта идея еще не восторжествовала. Даже когда дело доходит до кодирования VBA в Excel, многие разработчики по-прежнему полагаются на смешанный код в огромных файлах XLSB, задаваясь вопросом, почему производительность и удобство сопровождения настолько плохи. Однако этот пост не о написании надстроек VBA для Excel (с использованием файлов XLAM).
«Избегание жесткого кодирования» — общепринятая передовая практика в этом отношении. К сожалению, когда дело доходит до Excel, эта идея еще не восторжествовала. Даже когда дело доходит до кодирования VBA в Excel, многие разработчики по-прежнему полагаются на смешанный код в огромных файлах XLSB, задаваясь вопросом, почему производительность и удобство сопровождения настолько плохи. Однако этот пост не о написании надстроек VBA для Excel (с использованием файлов XLAM).
Этот пост посвящен раздельному хранению данных и логики вычислений (вместо кода) в простых файлах Excel. По сути, возмутительная идея, поскольку «перетаскивание формул» и «адаптация диапазонов» — это мгновенные ассоциации для большинства пользователей Excel после изменения входных данных. Я объясню, как формулы динамического массива помогут построить высоконадежные модели Excel, которые будут автоматически адаптироваться к изменениям в необработанных данных.
Соответственно, концепции, представленные здесь, идеально подходят для вычислений в Excel, которые должны длиться долго, например, оценки опросов или корпоративная отчетность. Общим для обоих является то, что структура данных остается довольно похожей, в то время как новые опросы или новые месяцы не за горами, соответственно.
Общим для обоих является то, что структура данных остается довольно похожей, в то время как новые опросы или новые месяцы не за горами, соответственно.
Отказ от ответственности. Здесь вы найдете мое личное мнение, основанное на более чем 10-летнем опыте работы с Excel и VBA. У вас может быть другое мнение. Но, возможно, вы все же узнаете что-то новое 😉
Классические способы построения модели Excel на основе файлов данных, например. из инструментов опроса или дампов данных программного обеспечения для бизнеса
Предположим, что есть необработанные данные, которые подпитывают некоторые расчеты. Эти данные могут быть таблицей результатов из веб-инструмента опроса или некоторыми бизнес-данными, такими как список статей расходов, связанных с поставщиками. Эти данные могут служить для какой-то задачи автоматизации. Это может быть создание слайдов PowerPoint с помощью SlideFab. Но это также может быть сценарий VBA, который разбивает данные на несколько файлов, например. один файл для каждого поставщика. Такая задача является отправной точкой для представленных здесь идей.
один файл для каждого поставщика. Такая задача является отправной точкой для представленных здесь идей.
Типичные подходы к структурированию логики и необработанных данных в модели Excel
Исходя из моего опыта, обычно существует три подхода к построению модели Excel в этой ситуации.
Базовый подход: работать непосредственно с необработанными данными
Многие пользователи Excel открывают файл данных, а затем добавляют столбцы с формулами и поисками, где это необходимо. Опытные пользователи знают, что разумно добавлять столбцы только слева и справа от исходных данных. Если есть новые необработанные данные, они вставляют их только в то место, где были старые данные. Если количество строк изменится, они будут перетаскивать формулы.
Промежуточный подход: использование промежуточной области для необработанных данных
Некоторые пользователи Excel создают рабочую книгу Excel для расчетов, которая содержит своего рода рабочую таблицу «промежуточной области», куда можно заранее вставить необработанные данные. Затем расчеты располагаются на отдельных листах, относящихся к этапу. Это не так уж плохо, так как еще больше отделяет данные от логики (то есть формул). Это чище, чем базовый подход, поскольку упрощает поиск местоположений необработанных данных.
Затем расчеты располагаются на отдельных листах, относящихся к этапу. Это не так уж плохо, так как еще больше отделяет данные от логики (то есть формул). Это чище, чем базовый подход, поскольку упрощает поиск местоположений необработанных данных.
Расширенный подход: поместить необработанные данные в таблицу Excel этапы
Меньшая часть пользователей Excel может следовать идее промежуточного подхода, но использовать таблицы Excel в качестве промежуточных областей. Это действительно полезно, поскольку создает четкие формулы, основанные на именах таблиц и столбцов, а не на обычных листах и адресах ячеек. Таблицы обеспечивают уникальные заголовки таблиц (т. е. имена столбцов). Кроме того, это также в некоторой степени снижает потребность в перетаскивании формул.
Все эти подходы объединяет то, что они смешивают данные и логику вычислений в одной рабочей книге. Даже трезво и надежно структурированная модель Excel не может избежать этого недостатка. Соответственно, эти модели Excel не обязательно должны быть плохими все время, но есть возможности для улучшения. Кроме того, глядя на большинство примеров, представленных здесь, на SlideFab.com, вы обнаружите, что они следуют продвинутому подходу. Это был лучший подход, который я придумал, когда кодирование VBA не было частью игры.
Кроме того, глядя на большинство примеров, представленных здесь, на SlideFab.com, вы обнаружите, что они следуют продвинутому подходу. Это был лучший подход, который я придумал, когда кодирование VBA не было частью игры.
Давайте посмотрим на что-то другое, но родственное: ссылки на данные.
Случайное связывание внешних файлов Excel происходит довольно часто: пользователи копируют и вставляют формулы между двумя книгами, а затем появляется ссылка: вставленная формула ссылается не только на листы и диапазоны, но и на исходную книгу. Довольно раздражает, чтобы избавиться, большую часть времени.
Когда я вижу, что пользователи ссылаются на другие файлы Excel, они часто создают здесь и там ссылки на определенные ячейки или диапазоны в какой-либо другой книге. Это работает. Но это довольно хрупко, потому что изменения в связанных данных могут не отражаться в связывающей книге. Соответственно, я не был поклонником такого подхода к моделированию в Excel. На мой взгляд, это довольно плохая практика в большинстве ситуаций. Разбросанные ссылки по книге могут привести к беспорядку.
Разбросанные ссылки по книге могут привести к беспорядку.
Но прежде чем обсуждать идеи по улучшению внешних ссылок на данные Excel, следует упомянуть о новой функциональности Excel. Большинство даже более опытных пользователей Excel, которых я знаю, не знали об этих формулах. Так что здесь имеет смысл быстро подвести итоги.
Что такое формулы динамического массива и почему они так удобны?
Microsoft представила динамические массивы и формулы динамических массивов в сентябре 2018 года. Они ввели так называемое «поведение с разлитым массивом». Это означает, что формула теперь может ссылаться на диапазон, в котором раньше ожидалась только одна ячейка. В этих ситуациях одна формула может повлиять не только на первую ячейку, но и на другие. Результат его вычисления «растекается» и по другим ячейкам. Я знаю, довольно искусственное описание, ниже приведены несколько примеров, чтобы пролить больше света на то, как они работают.
Это само по себе неплохо, но становится еще лучше: Excel позволяет ссылаться на формулы в расширенном диапазоне, а не только на ячейку, содержащую формулу. А когда разбросанный диапазон изменится, то все формулы ссылок будут отражать это без ручного вмешательства.
А когда разбросанный диапазон изменится, то все формулы ссылок будут отражать это без ручного вмешательства.
Рассмотрим простой пример формул динамического массива
На следующем снимке экрана показан пример. Формулы суммируют результаты на игрока и в целом. В то время как подход с формулой «старого стиля» требует одной уникальной формулы для каждого игрока (столбцы E и F), «стиль разбрызгивания» с формулами динамического массива требует только одной формулы для всех игроков (столбцы 9).0173 G и H ). Хотя на скриншоте этого не видно: Диапазон G4:G10 пуст. Результаты распределяются от G3 вниз, поскольку суммируются диапазоны, а не ячейки. Также обратите внимание на # в конце формулы =СУММ(G3#) в ячейке h21 . Этот хэштег гарантирует, что здесь рассматривается весь диапазон разлива (например, G3:G10 ) (подробнее об обозначении # будет следовать ниже).
 Использование старого стиля формулы в столбцах E и F и стиля заполнения в столбцах G и H.
Использование старого стиля формулы в столбцах E и F и стиля заполнения в столбцах G и H. Вдобавок к этому поведению с разливом теперь доступно несколько новых функций, которые делают работу с Excel намного проще, чем раньше. Например, новые функции, такие как SORT , UNIQUE или FILTER , чрезвычайно полезны. Причина в том, что без них для достижения той же функциональности требуется значительная работа (пусть это будет написание формул Excel или кодирование VBA). И все они играют роль, когда речь идет о создании надежных моделей Excel для задач автоматизации.
Другой пример дает представление о силе Dynamic Array Formulas
На следующем снимке экрана показан еще один пример, основанный на предыдущем. Он иллюстрирует, как извлечь 3 лучших игроков с их общими результатами в правильном порядке. И все это возможно с помощью всего одной формулы. Краткое объяснение этой формулы в K3 : SORTBY используется для сортировки диапазона A3:E10 по значениям общего диапазона результатов E3:E10 по убыванию.
ИНДЕКС затем используется для выбора 3 верхних строк с помощью ТРАНСП({1,2,3}) и столбцы для имени игрока и общего результата с использованием {1,5} . Ячейки K4,K5,L3,L4,L5 не имеют формулы.
Легко понять, что классические функции Excel намного слабее по сравнению с ними. Несколько диапазонов расчета позволяют пошагово рассчитать этот результат.
Как объяснялось выше, простое связывание некоторых внешних диапазонов в других книгах на самом деле не меняет правила игры, но на самом деле это еще более вредно. Вместо этого вся область данных на листе будет связана с помощью формул динамического массива. Но не грубой силой, такой как 1:1048576 ссылка, которая в основном извлекает все значения из другого рабочего листа.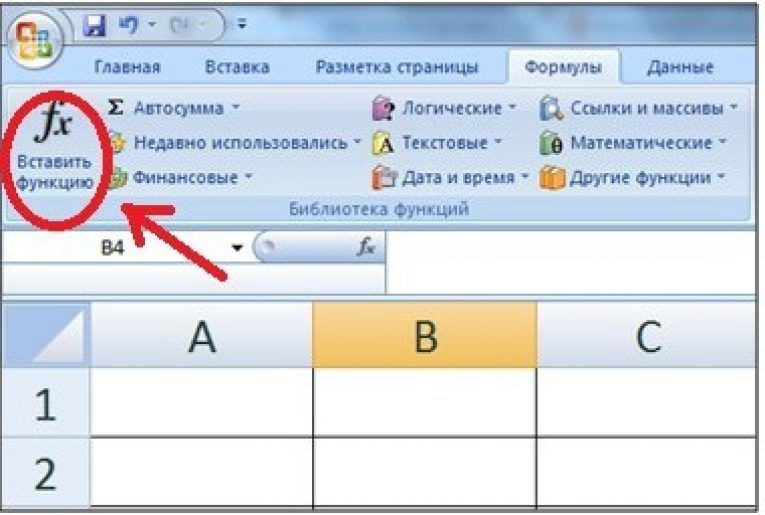 Этот способ действительно плох, так как снижает производительность без какой-либо выгоды. Хуже того, следующий подход будет поврежден. Итак, давайте посмотрим на более разумный способ.
Этот способ действительно плох, так как снижает производительность без какой-либо выгоды. Хуже того, следующий подход будет поврежден. Итак, давайте посмотрим на более разумный способ.
Идея состоит в том, чтобы связать только диапазон, в котором действительно находятся данные. С помощью динамической формулы это позволяет автоматически отражать изменения в количестве данных (пусть это будет больше/меньше строк или столбцов). Итак, как это можно сделать? Для простоты мы предполагаем, что данные начинаются в A1 и имеет заголовок столбца в строке 1:1 и заголовки строк в столбцах A:C . В остальной части этого документа будут использоваться некоторые фиктивные финансовые данные. Эти данные содержат четыре ключевых показателя эффективности (то есть выручку, себестоимость проданных товаров (COGS), маржу и единицы) для стран, сгруппированных по регионам в период с января 2020 г. по декабрь 2021 г.
Таким образом, примерные данные выглядят следующим образом:
Это примерные внешние данные. файл, содержащий различные ключевые показатели эффективности бизнеса за несколько месяцев.
файл, содержащий различные ключевые показатели эффективности бизнеса за несколько месяцев.Теперь вопрос: сколько там строк и столбцов?
К счастью, на этот вопрос ответит следующая формула:
=OFFSET('[ExternalFile.xlsx]данные'!$A$1,0,0,
ПРОСМОТР(2,1/('[ExternalFile.xlsx]данные'!$A:$A<>""),
ROW('[ExternalFile.xlsx]данные'!$A:$A)
),
ПРОСМОТР(2,1/('[ExternalFile.xlsx]данные'!$1:$1<>""),
COLUMN('[ExternalFile.xlsx]данные'!$1:$1)
)
)
Идея этой формулы заключается в использовании OFFSET , начиная с A1 внешнего рабочего листа. А затем измените размер диапазона, чтобы охватить последнюю запись в строке 1 и столбце 1. Эти последние записи находятся с помощью ПРОСМОТР – СТРОКА / СТОЛБЦ функций.
Результатом этой формулы является диапазон, охватывающий все данные на внешнем рабочем листе. В соответствии с поведением сброса эта формула перетащит все внешние данные и поместит их на свой рабочий лист.
В качестве примечания: Формула OFFSET иногда комбинируется с COUNTA для получения количества непустых записей. Когда пробелов нет, это тоже сработает. Там, где они есть, он будет недооценивать количество строк или столбцов соответственно. Соответственно, приведенная выше формула является рекомендуемой версией.
Чтобы быть точным, можно немного улучшить идею выше: вместо того, чтобы связывать все, что начинается в ячейке A1 , разумнее разделить заголовки столбцов в один поиск и данные в другой.
Итак, формула заголовка столбца входит в datasheet_loading_improved!A1 . Он работает аналогичным образом, но учитывает только первую строку связанного рабочего листа:
=OFFSET('[ExternalFile.xlsx]данные'!$A$1,0,0,
ПРОСМОТР(2,1/('[ExternalFile. xlsx]данные'!$1:$1<>""),
COLUMN('[ExternalFile.xlsx]данные'!$1:$1)
)
)
xlsx]данные'!$1:$1<>""),
COLUMN('[ExternalFile.xlsx]данные'!$1:$1)
)
)
Формула связывания тела данных переходит в и просто начинает ссылаться ниже строки заголовка столбца следующим образом: datasheet_loading_improved!A2
=OFFSET('[ExternalFile.xlsx]данные'!$A$2,0,0,
ПРОСМОТР(2,1/('[ExternalFile.xlsx]данные'!$A:$A<>""),
ROW('[ExternalFile.xlsx]данные'!$A:$A)
) - 1,
ПРОСМОТР(2,1/('[ExternalFile.xlsx]данные'!$1:$1<>""),
COLUMN('[ExternalFile.xlsx]данные'!$1:$1)
)
)
Рабочая книга CalculationLogic.xlsx связывает рабочую таблицу «таблица данных» в рабочей книге ExternalFile.xlsx, используя 2 формулы динамического массива в ячейках A1 (для строки заголовка) и A2 (для остальных строк).Итак, в чем преимущество такого связывания данных с помощью формул динамического массива?
Этот подход имеет несколько преимуществ.
- При связывании всех необработанных данных можно отделить все данные от логики.
 Итак, данные — это один файл (или несколько файлов, в зависимости от данных), а в другом файле — логика, т.е. формулы и структура. Таким образом, когда появляются новые данные, необходимо только обновить связи между логической книгой Excel и файлом (файлами) новых данных. Кроме того, при внесении изменений в логическую книгу Excel нет проблем с внесением в нее данных. Опять же, речь идет только об обновлении каналов передачи данных.
Итак, данные — это один файл (или несколько файлов, в зависимости от данных), а в другом файле — логика, т.е. формулы и структура. Таким образом, когда появляются новые данные, необходимо только обновить связи между логической книгой Excel и файлом (файлами) новых данных. Кроме того, при внесении изменений в логическую книгу Excel нет проблем с внесением в нее данных. Опять же, речь идет только об обновлении каналов передачи данных. - Теперь данные можно найти по новому адресу рабочего листа с использованием записи расширения, заканчивающейся хэштегом, например.
Лист1!A1#. Этот диапазон имеет как раз правильный размер в соответствии с приведенной выше формулой. Поэтому очень удобно ссылаться на этот диапазон. Ни строки, ни столбцы не будут пропущены. Отсутствие лишних строк и столбцов не снизит производительность. - Этот подход очень чистый. Существует только 1 формула сброса, ссылающаяся на внешние данные (или, может быть, 2, когда строка заголовка и тело данных связаны отдельно).
 Никакая логика расчета не будет напрямую ссылаться на внешние данные, а вместо этого будет ссылаться на эти связывающие области данных. Это делает формулы более разборчивыми, когда они не содержат информацию о пути и имени файла сверху. А еще лучше, в тех случаях, когда ссылка обрывается, нет поиска по
Никакая логика расчета не будет напрямую ссылаться на внешние данные, а вместо этого будет ссылаться на эти связывающие области данных. Это делает формулы более разборчивыми, когда они не содержат информацию о пути и имени файла сверху. А еще лучше, в тех случаях, когда ссылка обрывается, нет поиска по #ССЫЛКА!ошибки формулы во всей книге Excel. Соответственно, битые ссылки будет легко исправить.
После связывания внешних данных открывается огромный спектр возможностей. Какие будут следующие задачи, зависит от данных и целей. К счастью, есть несколько шаблонов, полезных во многих ситуациях. Следующие разделы прольют свет, по крайней мере, на некоторые возможности.
Поиск нужного номера столбца по имени его заголовка
Может случиться так, что внешний файл данных имеет другой порядок столбцов.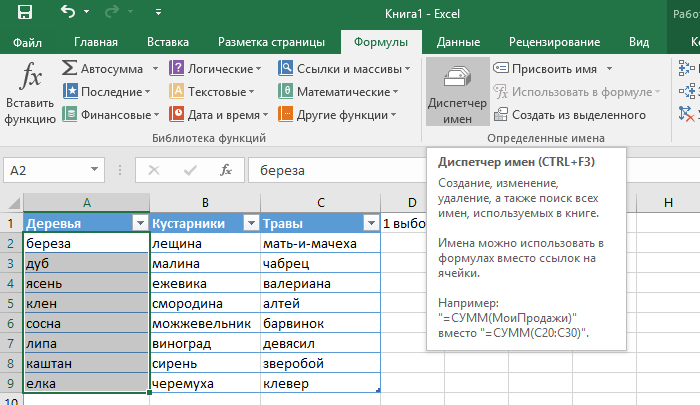 Или, может быть, была формула, получающая имя вычисляемого столбца. Или, может быть, каждый месяц добавляются новые столбцы. Итак, вопрос: как получить данные столбца для дальнейшей обработки.
Или, может быть, была формула, получающая имя вычисляемого столбца. Или, может быть, каждый месяц добавляются новые столбцы. Итак, вопрос: как получить данные столбца для дальнейшей обработки.
Поскольку предполагается, что заголовок столбца и данные находятся в двух разных диапазонах переноса, формулу для получения номера столбца построить довольно просто.
=XMATCH(Номера столбцов[[#Заголовки],[КПЭ]],datasheet_loading_improved!$A$1#)
Это простой поиск заголовка столбца (здесь адресовано через таблицу Excel ColumnNumbers[[#Headers],[KPI]] ) в пределах диапазона заголовков datasheet_loading_improved!$A$1# .
Таблица Excel с удобным доступом к номеру столбца для дальнейшего использования.
Таблица Excel «ColumnNumbers» позволяет легко получить номера столбцов.Получение уникального отсортированного списка записей для агрегирования или итерации
Как только номер столбца станет ясным, как объяснялось ранее, можно извлечь весь столбец с помощью функции ИНДЕКС . Для упрощения обработки имеет смысл создать рабочий лист, содержащий все уникальные списки, которые предполагается использовать для целей агрегирования или итерации. В примере имеет смысл иметь уникальный список имен KPI и названий регионов.
Для упрощения обработки имеет смысл создать рабочий лист, содержащий все уникальные списки, которые предполагается использовать для целей агрегирования или итерации. В примере имеет смысл иметь уникальный список имен KPI и названий регионов.
=УНИКАЛЬНЫЙ(ИНДЕКС(datasheet_loading_improved!A2#,Номера столбцов[KPI]))
Функция INDEX возвращает весь столбец KPI из диапазона данных, используя номер столбца, определенный в таблице ColumnNumbers , ср. выше. В отличие от классических формул Excel, функция ИНДЕКС теперь может возвращать более одной ячейки. Соответственно, когда параметр строки оставлен пустым (двойная запятая, между которой ничего нет, это не опечатка), он просто вернет все строки. После этого функция UNIQUE удаляет все дубликаты. Хотя здесь это не показано: Как обернуть SORT вокруг этого, не должно быть слишком сложно, когда это необходимо.

Заполнение раскрывающихся списков с помощью формул динамического массива
На самом деле, для создания надежной модели Excel для автоматизации раскрывающиеся списки не требуются. Тем не менее, они делают тестирование и ручное использование намного более удобным. К счастью, уникальные списки, как определено выше, отлично справляются со своей задачей, когда дело доходит до динамического подпитки выпадающих списков. Наличие выпадающего списка динамических длин не требует громоздких OFFSET / COUNTA Функциональные конструкции больше.
Например, построение динамического селектора KPI очень просто (обратите внимание на # в конце формулы): не назовешь его «громоздким». Однако наградой является то, что формулы, относящиеся к этим диапазонам сброса, очень надежны и не требуют обслуживания после изменения входных данных, как уже объяснялось выше.
Следующие примерные ситуации и их решения могут дать некоторое вдохновение.
Когда требуются только определенные строки или столбцы из диапазона разлива, функция ФИЛЬТР отлично справляется со своей задачей. В своей базовой форме он возвращает строки/столбцы из предоставленного диапазона, которые соответствуют определенному условию. Например, когда предполагается отображать только доходы, функция
В своей базовой форме он возвращает строки/столбцы из предоставленного диапазона, которые соответствуют определенному условию. Например, когда предполагается отображать только доходы, функция ФИЛЬТР отлично справляется со своей задачей.
=ФИЛЬТР( datasheet_loading_improved!A2#, INDEX(datasheet_loading_improved!A2#,ColumnNumbers[KPI])=filterByKPI[Выбор KPI], "Ничего не найдено" )
В этом примере функция фильтрации принимает в качестве первого параметра диапазон разбросанных данных и фильтрует его во втором параметре, сравнивая столбец ключевого показателя эффективности INDEX(datasheet_loading_improved!A2#,ColumnNumbers[KPI]) с выбранным KPI filterByKPI [Селектор КПЭ] . Наконец, третий параметр содержит сообщение по умолчанию, если вообще ничего не найдено.
Двухмерное агрегирование данных с использованием функции MAKEARRAY и LAMBDA
Довольно сложной задачей является использование формул динамического массива для агрегирования двумерных данных без перетаскивания формулы. Например, при суммировании значений по KPI за все месяцы сразу. Хотя довольно просто охватить горизонтальную строку заголовка месяцами и вертикальный столбец заголовка уникальными ключевыми показателями эффективности, фактический расчет не является прямым. Фактически, для этого требуется решить как новые функции
Например, при суммировании значений по KPI за все месяцы сразу. Хотя довольно просто охватить горизонтальную строку заголовка месяцами и вертикальный столбец заголовка уникальными ключевыми показателями эффективности, фактический расчет не является прямым. Фактически, для этого требуется решить как новые функции MAKEARRAY , так и LAMBDA .
=СДЕЛАТЬСЯД(
РЯДЫ(A3#),
КОЛОННЫ(B1#),
ЛЯМБДА(
р,
в,
СУММ(
ЕСЛИОШИБКА(
datasheet_loading_improved!A2# *
--(INDEX(datasheet_loading_improved!A2#,ColumnNumbers[KPI])=INDEX(A3#,r)) *
--(datasheet_loading_improved!A1#=INDEX(B1#,1,c))
,0)
)
)
)
Формула MAKEARRAY охватывает массив с требуемым количеством строк и столбцов через первые два параметра ROWS(A3#) и КОЛОННЫ (B1#) .
Третий параметр MAKEARRAY берет функцию LAMBDA и предоставляет количество строк r и столбцов c для первых двух параметров.
Третий параметр LAMBDA принимает здесь функцию СУММ для имитации вычисления СУММЕСЛИМН . Он имеет три фактора:
- Диапазон данных
datasheet_loading_improved!A2# - Состояние строки
--(INDEX(datasheet_loading_improved!A2#,ColumnNumbers[KPI])=INDEX(A3#,r)) - Состояние столбца
--(datasheet_loading_improved!A1#=INDEX(B1# ,1,c))
Условия в 2) и 3) приводят к 1 или 0, когда они применимы или нет. Таким образом, SUM считает значение там, где оно совпадает, и 0, если оно не соответствует. Кроме того, формулы в 2) и 3) используют номер строки r и номер столбца c с ИНДЕКС для получения значений условий.
Как бороться с перекрывающимися областями разлива?
Зоны разлива займут столько места, сколько потребуется. Когда необработанные данные увеличиваются, диапазоны разлива также будут расти. Это может привести к ситуациям, когда диапазоны разлива перекрываются, и неприятный
Это может привести к ситуациям, когда диапазоны разлива перекрываются, и неприятный #SPILL! Возникает ошибка . Думать о том, сколько «запаса» нужно оставлять между расчетными областями, здесь соблазнительно. Это соответствует старой концепции, позволяющей формулам располагаться в диапазоне от строки 1 до 5000 (или числа по вашему выбору), потому что невозможно представить, чтобы строк было больше. А если строк больше, формулы будут пропускать данные. Альтернатива ручному изменению формулы также не столь привлекательна. Удачи с этим в больших моделях Excel, где так легко пропустить изменение формулы здесь и там.
Существует только одно надежное решение
Таким образом, в ситуациях, когда количество строк и количество столбцов являются динамическими, существует только одно надежное решение: одно вычисление на лист, которое теоретически может охватывать до миллиона строк и 16 384 столбцов. Выполнение сложных зависимых расчетов приведет к созданию ряда расчетных листов. Каждый из этих листов будет очень аккуратным и компактным, потому что в большинстве случаев не требуется слишком много рассыпающихся формул. Поэтому именование рабочих листов становится важным, чтобы избежать путаницы. Но при этом логика вычислений будет очень аккуратной и строгой.
Каждый из этих листов будет очень аккуратным и компактным, потому что в большинстве случаев не требуется слишком много рассыпающихся формул. Поэтому именование рабочих листов становится важным, чтобы избежать путаницы. Но при этом логика вычислений будет очень аккуратной и строгой.
Но не бывает правил без исключений
- Есть также проливные формулы, которые будут расти либо в строках, либо в столбцах. Здесь намного проще структурировать рабочий лист без перекрытий с несколькими вычислениями на нем.
- Если какая-то «основная» зона разлива растет как в правую сторону, так и вниз, то слева и сверху есть возможности для всех видов расчетов, которые не разливаются в сторону «основной» зоны разлива . Это приведет к обратному направлению, где этапы расчета идут справа налево или снизу вверх соответственно. Это, конечно, редкость, но позволяет избежать возможных перекрытий разливов.
Каковы недостатки этого подхода?
Конечно, и у этой медали есть две стороны.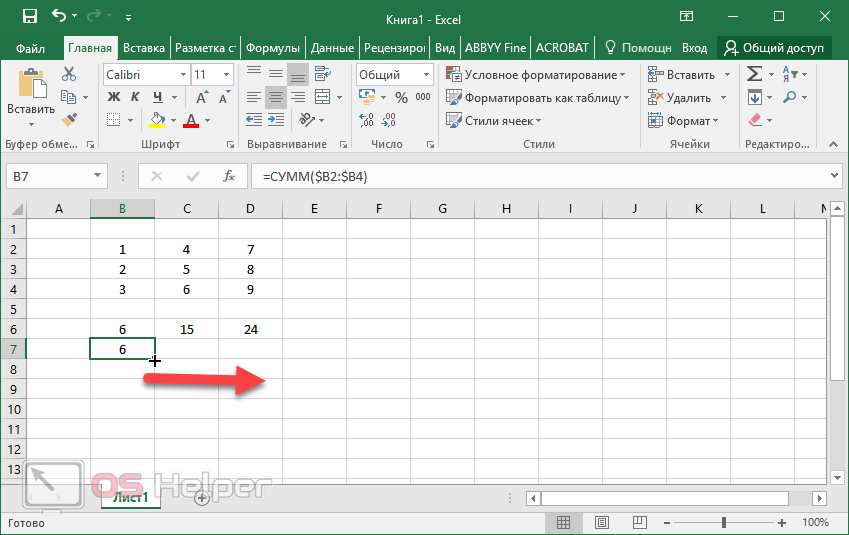 Хотя в большей части статьи описаны плюсы, здесь также должно быть место для минусов:
Хотя в большей части статьи описаны плюсы, здесь также должно быть место для минусов:
- Связывание внешних данных требует, чтобы связанные книги были открыты. Это может быть неприятно, когда слишком много связанных файлов Excel.
- Использование формул динамического массива и механизма переполнения не так разборчивы, как при использовании таблиц Excel. Это больше похоже на классический Excel: имена и адреса рабочих листов отображаются в формулах.
- Области разлива формулы возвращают только значения, но не форматы. В частности, отсутствующий числовой формат создает дополнительные усилия, например. применяя форматы вручную или используя для этого функцию
ТЕКСТ. - Модульность при отделении данных от логики расчета приводит к отдельным файлам. Некоторым людям это может не понравиться, и вместо этого они предпочитают «тяжелые» файлы Excel.
Обработка результатов вычисления формулы динамического массива для дальнейшего использования
Обеспечение числовых форматов
После создания расчетов пора подумать о представлении результатов.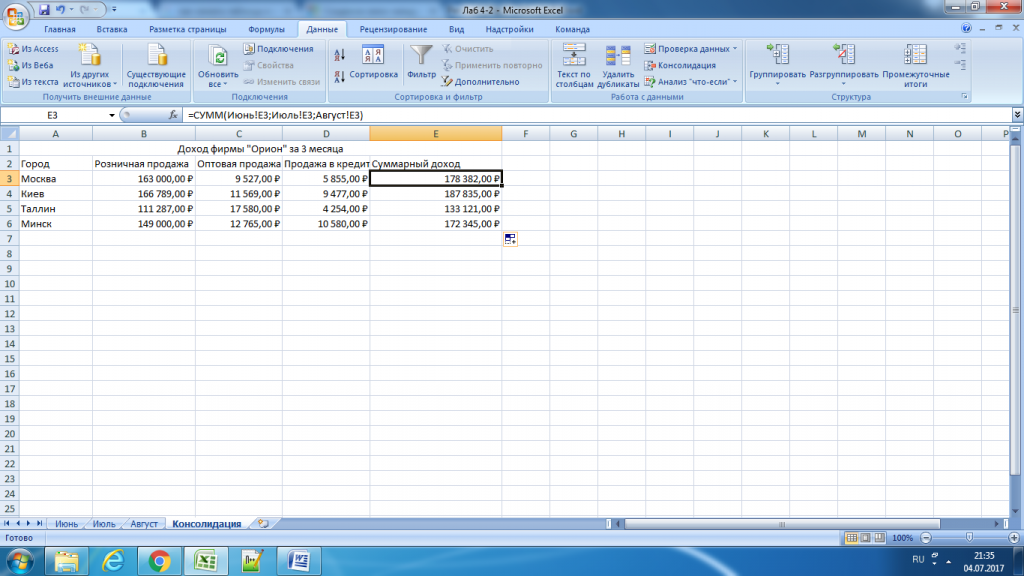 Это форматирование чисел, конечно. Поскольку диапазоны переноса не несут с собой исходный числовой формат, имеет смысл использовать функцию
Это форматирование чисел, конечно. Поскольку диапазоны переноса не несут с собой исходный числовой формат, имеет смысл использовать функцию ТЕКСТ для применения желаемого числового формата. Это также сохраняет идею разбрызгивания, которая пострадает при форматировании диапазонов вручную. Если это так, то хорошо отформатировать всю строку или столбец, чтобы никогда не исчерпать настройки формата при увеличении диапазона разлива.
Создание диаграмм на основе диапазонов разливов
Конечно, диаграммы имеют смысл показать некоторые результаты. Поскольку диаграммы не поддерживают формулы динамического массива, сработает небольшая хитрость: помогает перенос диапазона разлива в именованный диапазон. Тогда диаграммы будут гораздо лучше поддерживать функциональность разлива.
Резюме
В этой статье представлен довольно краткий обзор того, как создать отказоустойчивую книгу вычислений Excel. Представленные концепции основаны на новых формулах динамических массивов Excel и разделении логики вычислений и необработанных данных. Эти формулы помогли избежать перетаскивания диапазонов, повысив удобство сопровождения модели Excel для всех формул. Вместо этого эти новые формулы автоматически адаптируются к изменениям в необработанных данных, поскольку их область разлива занимает столько места, сколько требуется. В статье не было подробно описано, как построить автоматизацию SlideFab. Об этом будет рассказано в отдельных постах в блоге.
Эти формулы помогли избежать перетаскивания диапазонов, повысив удобство сопровождения модели Excel для всех формул. Вместо этого эти новые формулы автоматически адаптируются к изменениям в необработанных данных, поскольку их область разлива занимает столько места, сколько требуется. В статье не было подробно описано, как построить автоматизацию SlideFab. Об этом будет рассказано в отдельных постах в блоге.
Конечно, примеры файлов, показанные в этом сообщении в блоге, также доступны для скачивания:
Сделай сам вместо покупки услуг Excel и SlideFab
Личный комментарий в конце: В этом сообщении в блоге я поделился множеством деталей моего мыслительного процесса о том, как создавать устойчивые модели Excel. Тем не менее, для содержания здесь требуется опытный пользователь Excel. Если вам нравится то, что вы здесь видите, но у вас нет навыков или времени, чтобы сделать это самостоятельно, пожалуйста, свяжитесь с нами. Создание сложных моделей Excel — в частности, но не исключительно для SlideFab — является одним из наших предложений.