Что такое Elasticsearch: Учебник для начинающих
#Примечание. Elastic недавно объявила о внедрении лицензирования с закрытым исходным кодом для новых версий Elasticsearch и Kibana после версии 7.9. Для получения более подробной информации прочитайте комментарии нашего генерального директора Томера Леви к статье «Истинное удвоение усилий с открытым исходным кодом».
Elasticsearch — это живое сердце самой популярной на сегодняшний день платформы для анализа журналов — стека ELK (Elasticsearch, Logstash и Kibana). Роль Elasticsearch настолько велика, что стала синонимом названия самого стека. В первую очередь для поиска и анализа журналов Elasticsearch является одной из самых популярных систем баз данных, доступных сегодня. Это руководство по Elasticsearch предоставляет новым пользователям необходимые знания и инструменты для начала работы с Elasticsearch. Он включает инструкции по установке, а также инструкции по начальной индексации и обработке данных.
Стоит отметить, что Elasticsearch больше не является компонентом с открытым исходным кодом, как это было раньше. В январе 2021 года Elastic объявила, что Elasticsearch и Kibana (начиная с версии 7.11) перейдут на проприетарную двойную лицензию (в рамках лицензии SSPL) и откажутся от лицензии Apache-2.0 с открытым исходным кодом.
В январе 2021 года Elastic объявила, что Elasticsearch и Kibana (начиная с версии 7.11) перейдут на проприетарную двойную лицензию (в рамках лицензии SSPL) и откажутся от лицензии Apache-2.0 с открытым исходным кодом.
Это побудило AWS разветвить Elasticsearch и Kibana на OpenSearch и OpenSearch Dashboards, которые выполняют те же варианты использования стека ELK под лицензией Apache 2.0 с открытым исходным кодом.
Elasticsearch: краткое введениеПервоначально выпущенная в 2010 году, Elasticsearch (иногда называемая ES) — это современная система поиска и аналитики, основанная на Apache Lucene. Elasticsearch, построенный на Java, представляет собой базу данных NoSQL. Это означает, что он хранит данные неструктурированным образом, и вы не можете использовать SQL для запросов к ним.
Это руководство по Elasticsearch также можно рассматривать как руководство по NoSQL. Однако, в отличие от большинства баз данных NoSQL, Elasticsearch уделяет большое внимание возможностям и функциям поиска — фактически настолько, что самый простой способ получить данные из ES — выполнить их поиск с помощью расширенного API Elasticsearch.
В контексте анализа данных Elasticsearch используется вместе с другими компонентами стека ELK, Logstash и Kibana и играет роль индексации и хранения данных. В наши дни Logstash обычно заменяют меньшими и более легкими компонентами, такими как Fluentd или FluentBit, которые могут выполнять большую часть того, что может Logstash, без больших вычислительных ресурсов и общих проблем.
Как вы увидите в этом руководстве, начать работу с Elasticsearch не сложно. Особенно, когда вы настраиваете небольшой кластер, реализовать конвейер ведения журналов ELK несложно.
Однако, как только вы начнете отправлять больше данных, управление ELK потребует больше усилий. Вам нужно будет управлять большими кластерами и масштабировать их, внедрять больше синтаксического анализа данных, устанавливать и управлять очередями данных, такими как Kafka, для буферизации ваших журналов, возможно, обновлять компоненты ELK, а также отслеживать и настраивать свой стек для устранения проблем с производительностью.
Для тех, кто не хочет самостоятельно управлять этими задачами и нуждается в дополнительных функциях, таких как RBAC, Logz.io создал инструмент управления журналами, который предоставляет ELK как услугу (теперь OpenSearch как услугу! ), поэтому вы можете воспользоваться ведущей в мире платформой ведения журналов, не запуская ее самостоятельно. Logz.io также поддерживает аналитику метрик и трассировки. Узнайте здесь о том, как Logz.io объединяет и совершенствует ведущие технологии наблюдения с открытым исходным кодом.
При всем при этом, с небольшими кластерами запуск Elasticsearch самостоятельно — отличный выбор. Давайте посмотрим, как начать.
Установка Elasticsearch
Требования к Elasticsearch просты: Java 8 (рекомендуется конкретная версия: Oracle JDK версии 1.8.0_131). Взгляните на этот учебник по Logstash, чтобы убедиться, что вы настроены. Кроме того, вам нужно убедиться, что ваша операционная система находится в матрице поддержки Elastic, иначе вы можете столкнуться со странными и непредсказуемыми проблемами. Как только это будет сделано, вы можете начать с установки Elasticsearch.
Как только это будет сделано, вы можете начать с установки Elasticsearch.
Вы можете загрузить Elasticsearch как отдельный дистрибутив или установить его с помощью репозиториев apt и yum . Мы установим Elasticsearch на машину с Ubuntu 16.04, работающую на AWS EC2, используя apt .
Во-первых, вам нужно добавить ключ подписи Elastic, чтобы вы могли проверить загруженный пакет (пропустите этот шаг, если вы уже установили пакеты из Elastic):
wget -qO - https://artifacts.elastic.co/GPG -KEY-эластичный поиск | sudo apt-ключ добавить -
Для Debian нам нужно установить пакет apt-transport-https :
sudo apt-get install apt-transport-https
Следующим шагом является добавление определения репозитория в вашу систему:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Осталось обновить репозитории и установить Elasticsearch:
sudo apt-get update sudo apt-get установить elasticsearch
Настройка Elasticsearch
Конфигурация Elasticsearch выполняется с помощью файла конфигурации, расположение которого зависит от вашей операционной системы. В этом файле вы можете настроить общие параметры (например, имя узла), а также сетевые параметры (например, хост и порт), где хранятся данные, память, файлы журналов и многое другое.
В этом файле вы можете настроить общие параметры (например, имя узла), а также сетевые параметры (например, хост и порт), где хранятся данные, память, файлы журналов и многое другое.
В целях разработки и тестирования настроек по умолчанию будет достаточно, однако рекомендуется изучить, какие настройки следует задать вручную перед запуском в производство.
Например, особенно при установке Elasticsearch в облаке, рекомендуется привязать Elasticsearch либо к частному IP-адресу, либо к локальному хосту:
sudo vim /etc/elasticsearch/elasticsearch.yml network.host: "локальный хост" http.port:9200
Запуск Elasticsearch
Elasticsearch не запустится автоматически после установки, и вам нужно будет запустить его вручную. То, как вы запускаете Elasticsearch, будет зависеть от вашей конкретной системы. В большинстве систем на базе Linux и Unix вы можете использовать эту команду:
sudo service elasticsearch start
Вот и все! Чтобы убедиться, что все работает нормально, просто укажите в curl или браузере адрес http://localhost:9200 , и вы должны увидеть что-то вроде следующего:
{
"имя": "33QdmXw",
"имя_кластера": "эластичный поиск",
"cluster_uuid": "mTkBe_AlSZGbX-vDIe_vZQ",
"версия": {
"номер": "6.
1.2",
"build_hash": "5b1fea5",
"build_date": "2018-01-10T02:35:59.208Z",
"build_snapshot": ложь,
"lucene_version": "7.1.0",
"минимальная_версия_совместимости_провода": "5.6.0",
"минимальная_индексная_совместимая_версия": "5.0.0"
},
«слоган»: «Знаешь, для поиска»
} Для отладки процесса запуска Elasticsearch используйте файлы журнала Elasticsearch, расположенные (в Deb) в /var/log/elasticsearch/.
Создание индекса Elasticsearch
Индексирование — это процесс добавления данных в Elasticsearch. Это связано с тем, что когда вы вводите данные в Elasticsearch, они помещаются в индексы Apache Lucene. Это имеет смысл, поскольку Elasticsearch использует индексы Lucene для хранения и извлечения своих данных. Хотя вам не нужно много знать о Lucene, полезно знать, как он работает, когда вы начинаете серьезно относиться к Elasticsearch.
POST или PUT для добавления в него данных. Вы используете
Вы используете PUT , когда знаете или хотите указать id элемента данных, или POST , если вы хотите, чтобы Elasticsearch сгенерировал id для элемента данных: curl -XPOST 'localhost:9200 /logs/my_app' -H 'Тип содержимого: приложение/json' -d'
{
"отметка времени": "2018-01-24 12:34:56",
"message": "Пользователь вошел в систему",
"user_id": 4,
"админ": ложь
}
'
curl -X ПОСТАВИТЬ 'localhost:9200/приложение/пользователи/4' -H 'Тип содержимого: приложение/json' -d '
{
"идентификатор": 4,
"имя пользователя": "Джон",
"last_login": "2018-01-25 12:34:56"
}
' И ответ:
{"_index":"logs","_type":"my_app","_id":"ZsWdJ2EBir6MIbMWSMyF","_version":1,"result":"created","_shards ":{"всего":2,"успешно":1,"не удалось":0},"_seq_no":0,"_primary_term":1}
{"_index":"приложение","_тип":"пользователи","_id":"4","_версия":1,"результат":"создано","_shards":{"всего":2, «успешно»: 1, «не удалось»: 0}, «_seq_no»: 0, «_primary_term»: 1} Данные для документа отправляются как объект JSON. Вам может быть интересно, как мы можем индексировать данные, не определяя структуру данных. Что ж, с Elasticsearch, как и с любой другой базой данных NoSQL, нет необходимости заранее определять структуру данных. Однако для обеспечения оптимальной производительности вы можете определить сопоставления Elasticsearch в соответствии с типами данных. Подробнее об этом позже.
Вам может быть интересно, как мы можем индексировать данные, не определяя структуру данных. Что ж, с Elasticsearch, как и с любой другой базой данных NoSQL, нет необходимости заранее определять структуру данных. Однако для обеспечения оптимальной производительности вы можете определить сопоставления Elasticsearch в соответствии с типами данных. Подробнее об этом позже.
Если вы используете какой-либо из поставщиков Beats (например, Filebeat или Metricbeat) или Logstash, эти части стека ELK автоматически создадут индексы.
Чтобы просмотреть список ваших индексов Elasticsearch, используйте:
curl -XGET 'localhost:9200/_cat/indices?v&pretty' индекс состояния здоровья uuid pri rep docs.count docs.deleted store.size pri.store.size желтый открытый logstash-2018.01.23 y_-PguqyQ02qOqKiO6mkfA 5 1 17279 0 9.9mb 9.9mb желтый открытое приложение GhzBirb-TKSUFLCZTCy-xg 5 1 1 0 5.2kb 5.2kb желтый открытый .kibana Vne6TTWgTVeAHCSgSboa7Q 1 1 2 0 8.8kb 8.8kb желтые открытые бревна T9E6EdbMSxa8S_B7SDabTA 5 1 1 0 5,7 КБ 5,7 КБ
Список в этом случае включает индексы, которые мы создали выше, индекс Kibana и индекс, созданный конвейером Logstash.
Elasticsearch Querying
Проиндексировав данные в Elasticsearch, вы можете приступить к их поиску и анализу. Самый простой запрос, который вы можете сделать, — это получить один элемент. Прочтите нашу статью, посвященную исключительно запросам Elasticsearch.
Еще раз, через REST API Elasticsearch мы используем GET :
curl -XGET 'localhost:9200/app/users/4?pretty'
И ответ:
{
"_index": "приложение",
"_type": "пользователи",
"_id": "4",
"_версия": 1,
"найдено": правда,
"_источник" : {
"идентификатор": 4,
"имя пользователя": "Джон",
"last_login": "2018-01-25 12:34:56"
}
} Поля, начинающиеся со знака подчеркивания, являются всеми метаполями результата. Объект _source — это исходный документ, который был проиндексирован.
Мы также используем GET для поиска, вызывая _search конечная точка:
curl -XGET 'localhost:9200/_search?q=logged'
{"взял":173,"timed_out":false,"_shards":{"всего":16,"успешно":16,"пропущено":0,"не удалось":0},"попадания":{"всего ":1,"max_score":0,2876821,"hits":[{"_index":"журналы","_type":"my_app","_id":"ZsWdJ2EBir6MIbMWSMyF","_score":0,2876821,"_source":
{
"отметка времени": "2018-01-24 12:34:56",
"message": "Пользователь вошел в систему",
"user_id": 4,
"админ": ложь
}
}]}} Результат содержит ряд дополнительных полей, описывающих как поиск, так и результат. Вот краткое изложение:
Вот краткое изложение:
-
затрачено: время в миллисекундах, которое занял поиск -
timed_out: если время поиска истекло и коэффициенты отказов -
попаданий: Фактические результаты вместе с метаинформацией для результатов
Поиск, который мы сделали выше, известен как поиск URI и является самым простым способом запроса Elasticsearch. Предоставляя только слово, ES будет искать это слово во всех полях всех документов. Вы можете создавать более конкретные поиски, используя запросы Lucene:
-
- john* — ищет документы, содержащие термины, начинающиеся с john, за которыми следует ноль или более символов, например « джон», «джонб» и «джонсон»
- джон? — ищет документы, содержащие термины, начинающиеся с «джон», за которым следует только один символ.
 Соответствует «johnb» и «johns», но не «john».
Соответствует «johnb» и «johns», но не «john».
Существует множество других способов поиска, включая использование логической логики, усиление терминов, использование нечеткого поиска и поиска по близости, а также использование регулярных выражений.
Elasticsearch Query DSL
Поиск по URI — это только начало. Elasticsearch также предоставляет поиск по телу запроса с помощью Query DSL для более сложных поисков. Для таких видов поиска доступен широкий спектр параметров, и вы можете смешивать и сочетать различные параметры, чтобы получить требуемые результаты.
Он содержит два вида предложений: 1) листовые предложения запроса, которые ищут значение в определенном поле, и 2) составные предложения запроса (которые могут содержать одно или несколько конечных предложений запроса).
Типы запросов Elasticsearch
Для этих видов поиска доступен широкий набор параметров, и вы можете смешивать и сопоставлять различные параметры, чтобы получить требуемые результаты.
- Гео-запросы,
- Запросы типа «Больше похожих»
- Запросы со сценариями
- Полнотекстовые запросы
- Запросы Shape
- Запросы Span
- Запросы на уровне терминов
- Специализированные запросы
По состоянию на В Elasticsearch 6.8 стек ELK объединил запросы Elasticsearch и фильтры Elasticsearch, но ES по-прежнему различает их по контексту. DSL различает контекст фильтра и контекст запроса для предложений запроса. Предложения в контексте фильтра проверяют документы логическим способом: соответствует ли документ фильтру, «да» или «нет?» Фильтры также обычно быстрее, чем запросы, но запросы также могут вычислять показатель релевантности в зависимости от того, насколько близко документ соответствует запросу. Фильтры не используют показатель релевантности. Это определяет порядок и включение документов:
curl -XGET 'localhost:9200/logs/_search?pretty' -H 'Content-Type: application/json' -d'
{
"запрос": {
"match_phrase": {
"message": "Пользователь вошел в систему"
}
}
}
И результат:
{
"взял": 28,
"timed_out": ложь,
"_осколки": {
"всего" : 5,
"успешно" : 5,
"пропущено": 0,
"не удалось" : 0
},
"хиты" : {
"всего" : 1,
"max_score": 0,8630463,
"хиты" : [
{
"_index": "журналы",
"_тип": "мое_приложение",
"_id": "ZsWdJ2EBir6MIbMWSMyF",
"_score": 0,8630463,
"_источник" : {
"отметка времени": "2018-01-24 12:34:56",
"message": "Пользователь вошел в систему",
"user_id": 4,
"админ": ложь
}
}
]
}
}
'
Создание кластера Elasticsearch
Обслуживание кластера Elasticsearch может занять много времени, особенно если вы делаете ELK своими руками. Но, учитывая мощные поисковые и аналитические возможности Elasticsearch, такие кластеры незаменимы. У нас есть более глубокое погружение в эту тему в нашем руководстве по кластеру Elasticsearch, поэтому мы будем использовать его в качестве трамплина для более подробного изучения.
Но, учитывая мощные поисковые и аналитические возможности Elasticsearch, такие кластеры незаменимы. У нас есть более глубокое погружение в эту тему в нашем руководстве по кластеру Elasticsearch, поэтому мы будем использовать его в качестве трамплина для более подробного изучения.
Что такое кластер Elasticsearch? Кластеры Elasticsearch объединяют несколько узлов и/или экземпляров Elasticsearch вместе. Конечно, вы всегда можете поддерживать один экземпляр или узел Elasticsearch внутри данного кластера. Суть такой группировки заключается в распределении кластером задач, поиска и индексации по его узлам. Варианты узла включают узлы данных, главные узлы, клиентские узлы и принимающие узлы.
Установка узлов может включать в себя множество конфигураций, которые рассматриваются в нашем вышеупомянутом руководстве. Но вот базовая установка узла кластера Elasticsearch:
Прежде всего, установите Java:
sudo apt-get install default-jre
Затем добавьте ключ входа в Elasticsearch:
wget -qO - https://artifacts .elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Затем установите новую версию Elasticsearch:
sudo apt-get update && apt-get install elasticsearch
Вам нужно будет создать и/или настроить собственный файл конфигурации elasticsearch.yml каждого узла Elasticsearch ( sudo vim /etc/elasticsearch/elasticsearch.yml ). Оттуда запустите Elasticsearch, а затем проверьте состояние своего кластера Elasticsearch. Ответы будут выглядеть примерно так:
{
"cluster_name": "elasticsearch-cluster-demo",
"compressed_size_in_bytes": 255,
"версия": 7,
"state_uuid": "50m3ranD0m54a531D",
"master_node": "IwEK2o1-Ss6mtx50MripkA",
«блоки»: {},
"узлы": {
"m4-aw350m3-n0D3": {
"имя": "es-узел-1",
"ephemeral_id": "x50m33F3mr--A11DnuM83r",
"transport_address": "172.31.50.123:9200",
"атрибуты": {}
},
},
}
Состояние кластера Elasticsearch будет следующим в вашем списке. Периодически проверяйте работоспособность вашего кластера с помощью следующего вызова API:
curl -X GET "localhost:9200/_cluster/health?wait_for_status=yellow&local=false&level=shards&pretty"
В этом примере параметр local показан как false , ( что на самом деле по умолчанию). Это покажет вам статус главного узла. Чтобы проверить локальный узел, измените на
Это покажет вам статус главного узла. Чтобы проверить локальный узел, измените на правда .
Параметр уровня по умолчанию показывает работоспособность кластера, но помимо этого ранги включают индексов и осколков (как в приведенном выше примере).
Существуют дополнительные необязательные параметры для тайм-аутов…
тайм-аут
master_timeout
…или для ожидания определенных событий:
wait_for_active_shards
wait_for_events 9 0093 wait_for_no_initializing_shards
wait_for_no_relocating_shards
wait_for_nodes
wait_for_status
Конечно, с помощью Logz.io создать кластер Elasticsearch (теперь OpenSearch) так же просто, как запустить бесплатную пробную версию. И масштабирование вашего кластера Elasticsearch ничего не требует от пользователя.
Удаление данных Elasticsearch
Удалить элементы из Elasticsearch так же просто, как ввести данные в Elasticsearch. Метод HTTP, который следует использовать на этот раз, — сюрприз, сюрприз —
Метод HTTP, который следует использовать на этот раз, — сюрприз, сюрприз — DELETE :
$ curl -XDELETE 'localhost:9200/приложение/пользователи/4? довольно'
{
"_index": "приложение",
"_type": "пользователи",
"_id": "4",
"_версия": 2,
"результат": "удалено",
"_осколки": {
"всего" : 2,
«успешно»: 1,
"не удалось" : 0
},
"_seq_no": 1,
"_primary_term" : 1
} Чтобы удалить индекс, используйте:
$ curl -XDELETE 'localhost:9200/logs?pretty'
Чтобы удалить все индекса (используйте с особой осторожностью), используйте:
$ curl -XDELETE 'localhost: 9200/_all?pretty'$
Ответ в обоих случаях должен быть:
{
"признано": правда
} Чтобы удалить один документ:
$ curl -XDELETE 'localhost:9200/index/type/document'
Что дальше?
Это руководство поможет новичкам в работе с Elasticsearch и, таким образом, содержит только основные этапы операций CRUD в Elasticsearch. Elasticsearch — это поисковая система, поэтому ее поисковые функции очень глубоки.
Elasticsearch — это поисковая система, поэтому ее поисковые функции очень глубоки.
Конечно, если вы не хотите делать что-либо самостоятельно, вы можете запустить бесплатную пробную версию Logz.io, чтобы начать ведение журнала с помощью OpenSearch, который на данный момент очень похож на Elasticsearch, без необходимости устанавливать что-либо вручную. или запустить что-нибудь на вашей собственной инфраструктуре.
Чтобы использовать альтернативу ELK с открытым исходным кодом, ознакомьтесь с нашим руководством по OpenSearch и панелям управления OpenSearch или с документацией AWS по OpenSearch.
Для дальнейших шагов с Elasticsearch рассмотрите возможность изучения официальной документации Elasticsearch, а также нашего руководства по Logstash и Kibana.
Учебное пособие: Как читать лесной участок
Опубликовано 11 июля 2016 г. автором Nathan Cantley
Учебные пособия и основы
По мере того, как мы приближаемся к вершине пирамиды доказательной медицины, иногда появляются странные графики. Лесной сюжет — это ключевой способ, с помощью которого исследователи могут обобщать данные из нескольких статей в одном изображении. [Если вам трудно прочитать текст на каком-либо из рисунков, щелкните изображение, чтобы увеличить его].
Лесной сюжет — это ключевой способ, с помощью которого исследователи могут обобщать данные из нескольких статей в одном изображении. [Если вам трудно прочитать текст на каком-либо из рисунков, щелкните изображение, чтобы увеличить его].
Рисунок 1. Пример лесного участка. Изображение адаптировано из Таблицы 4 Roberts et al. (2006). [1]
Будучи студентами, мы иногда думаем, что графики, подобные изображенному на рис. 1, немного сложно интерпретировать. Не бойтесь - следующий урок даст вам пошаговый способ интерпретации любого лесного участка!Учебная информация
Цели обучения.
К концу этого урока вы должны уметь:
- Понимать, какие лесные участки используются для
- Понять, как читать лесной график и что означают отображаемые результаты как на уровне отдельных исследований, так и на уровне усредненного результата
- Понять, почему лесные участки выглядят по-разному в зависимости от анализируемой статистики
- Понимать важность неоднородности на лесных участках и ее влияние на интерпретацию
Время прохождения обучения: 20–30 минут
Пример вопросов: Да
Ссылки все в открытом доступе: Да
Так зачем вообще делать лесной участок?
Попытка просмотреть множество различных статей, в которых задается один и тот же вопрос, может оказаться сложной задачей.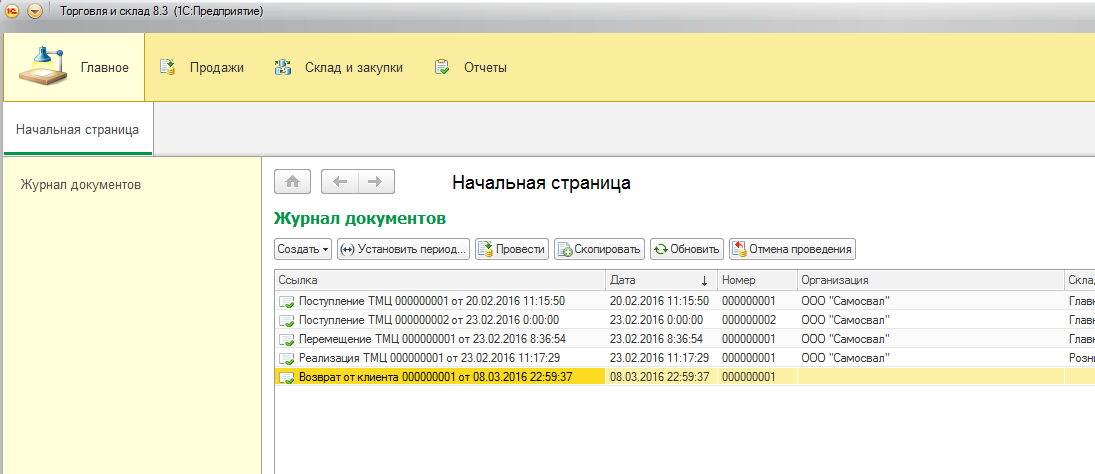 Это особенно верно, если проанализированные статьи приходят к разным выводам и имеют разную статистику как в пользу, так и против ассоциации.
Это особенно верно, если проанализированные статьи приходят к разным выводам и имеют разную статистику как в пользу, так и против ассоциации.
Что делает лесной участок, так это берет все соответствующие исследования, задающие один и тот же вопрос, определяет общую статистику в указанных документах и отображает их на одной оси. Это позволяет вам напрямую сравнивать то, что показывают исследования, и качество этого результата в одном месте.
Анализ лесного участка: основы
Часть 1: Ось.В этом учебном пособии в качестве примера мы возьмем рисунок 1 (показан выше), участок леса из Кокрейновского систематического обзора. По мере изучения руководства мы будем строить рисунок 1, исходя из первых принципов. В конце блога я раскрою значение именно этого лесного участка!
Рисунок 2. Давайте начнем с самого начала.
Слева вы видите базовый набор топоров, используемых на лесных участках. Горизонтальная ось обычно представляет собой статистику, которую показывают исследования. Это может быть либо «относительная» статистика, такая как отношение шансов (OR), либо относительный риск (RR). Или используемая статистика может быть «абсолютной», такой как абсолютное снижение риска (ARR) или стандартизированная средняя разница (SMD). Важно знать разницу между относительной и абсолютной статистикой, потому что она влияет на то, какое число находится на вертикальной линии.
Это может быть либо «относительная» статистика, такая как отношение шансов (OR), либо относительный риск (RR). Или используемая статистика может быть «абсолютной», такой как абсолютное снижение риска (ARR) или стандартизированная средняя разница (SMD). Важно знать разницу между относительной и абсолютной статистикой, потому что она влияет на то, какое число находится на вертикальной линии.
Вертикальная линия известна как «линия нулевого эффекта». Эта линия соответствует значению, при котором (как следует из названия) нет связи между воздействием и исходом или нет разницы между двумя вмешательствами. Если вы помните из своих классов статистики, относительная статистика, такая как OR или RR, имеет значение нулевого эффекта, равное 1. Для абсолютной статистики, такой как Абсолютный риск, ARR или SMD, значение нулевой разницы равно 0. Следовательно, почему значение в строке не влияет относится к используемой статистике. Если вы хотите освежить в памяти относительную и абсолютную статистику, почему бы не проверить этот блог S4BE.
Рисунок 3. Проведем несколько линий по этим осям.
Часть 2: Учебные линии.Итак, теперь, когда мы понимаем оси лесного участка, давайте установим некоторые значения. Каждая горизонтальная линия, нанесенная на лесной участок, представляет собой отдельное анализируемое исследование. На рисунке 3 представлены три исследования. Каждый «результат» исследования состоит из двух компонентов:
- Точечная оценка результата исследования, представленная черным прямоугольником. Этот черный ящик также дает представление о размере исследования. Чем больше коробка, тем больше участников исследования.
- Горизонтальная линия, представляющая 95% доверительные интервалы результата исследования, причем каждый конец линии представляет собой границы доверительного интервала.
То, что представляет каждая сторона линии с нулевым эффектом (т. е. в пользу контроля или вмешательства), также важно при рассмотрении отдельных исследований. Это будет отличаться в зависимости от того, какой вопрос вы задаете в своих исследованиях. Например, если вы смотрите на риск между воздействием и результатом, то, что представляет каждая сторона вертикальной линии, будет отличаться от случая, когда вы сравниваете вмешательство с контролем. Полезно, что для большинства лесных участков, опубликованных сегодня, авторы услужливо отмечают, что представляет каждая сторона линии. Если он не отмечен, не забывайте всегда возвращаться к своим первоначальным принципам статистики, которую вы используете.
Это будет отличаться в зависимости от того, какой вопрос вы задаете в своих исследованиях. Например, если вы смотрите на риск между воздействием и результатом, то, что представляет каждая сторона вертикальной линии, будет отличаться от случая, когда вы сравниваете вмешательство с контролем. Полезно, что для большинства лесных участков, опубликованных сегодня, авторы услужливо отмечают, что представляет каждая сторона линии. Если он не отмечен, не забывайте всегда возвращаться к своим первоначальным принципам статистики, которую вы используете.
Горизонтальная линия и то, пересекает ли она «линию нулевого эффекта», особенно важно учитывать для каждого исследования. Если вы помните, невероятно простое определение 95% доверительного интервала звучит так: « Диапазон значений, в пределах которого вы можете быть на 95% уверены, что истинное значение лежит ». Если горизонтальная линия пересекает линию нулевого эффекта, это фактически говорит о том, что нулевое значение находится в пределах вашего доверительного интервала и, следовательно, может быть истинным значением. Если бы я разложил это на самое простое объяснение: « любая линия исследования, которая пересекает линию нулевого эффекта, не иллюстрирует статистически значимый результат ».
Если бы я разложил это на самое простое объяснение: « любая линия исследования, которая пересекает линию нулевого эффекта, не иллюстрирует статистически значимый результат ».
В линейке есть еще один компонент, на который стоит обратить внимание. Хотя это не гарантируется, как правило, исследования с большим числом участников или пациентов обычно имеют более узкий доверительный интервал и, следовательно, меньшую горизонтальную линию. Итак, в общих чертах:
- больше исследование, меньше горизонтальная линия и больше черный ящик, представляющий точечную оценку. Это может означать, что менее вероятно, что эти исследования перейдут черту нулевого эффекта. Почему? Потому что ваши 95% доверительные интервалы должны иметь гораздо меньший диапазон.
- меньше исследование, шире горизонтальная линия и меньше черный ящик, представляющий точечную оценку.
 Это означает, что более вероятно, что эти исследования перейдут черту нулевого эффекта (поскольку ваши 95% доверительные интервалы будут намного больше).
Это означает, что более вероятно, что эти исследования перейдут черту нулевого эффекта (поскольку ваши 95% доверительные интервалы будут намного больше).
Теперь, когда вы прочитали приведенное выше описание, взгляните на исследование (A) и исследование (B) на рис. 3. Попробуйте интерпретировать то, что говорит вам каждое исследование, прежде чем искать ответ в нижней части веб-страницы. .
Часть 3: Объединение всех исследований лесного участка.Рисунок 4. Бриллиант связки.
На рис. 4 вверху добавлены еще два исследования (попробуйте их интерпретировать), а также ромб. Сейчас бриллиант, пожалуй, самое главное, что вы увидите на лесном участке.
Ромб представляет точечную оценку и доверительные интервалы, когда вы объединяете и усредняете все отдельные исследования вместе. Если вы проведете вертикальную линию через вертикальные точки ромба, это будет точечная оценка усредненных исследований. Горизонтальные точки ромба представляют 95% доверительный интервал этой комбинированной точечной оценки. Если вы помните, что я сказал в части 2 о размере доверительных интервалов, потому что это комбинированное значение эффективно группирует всех участников из всех отдельных исследований, диапазон ДИ для этого результата должен быть наименьшим на лесном участке (и в 99% случаев это нормально).
Если вы помните, что я сказал в части 2 о размере доверительных интервалов, потому что это комбинированное значение эффективно группирует всех участников из всех отдельных исследований, диапазон ДИ для этого результата должен быть наименьшим на лесном участке (и в 99% случаев это нормально).
Правила пересечения линии нулевого эффекта здесь по-прежнему верны: если горизонтальные вершины ромба пересекают вертикальную линию, совокупный результат потенциально не является статистически значимым. Почему? Если вы помните, если доверительный интервал 95 % содержит нулевое значение, вы не можете быть уверены, что нулевое значение не является истинным значением.
Часть 4: Объединяем все вместе. Итак, мы поговорили о ряде элементов самого лесного участка. Давайте немного взглянем на весь, так сказать, «бамф», который находится вокруг лесного участка на графике. Вернемся к нашему исходному изображению. На рисунках 5-8 выделены различные элементы лесного участка, на которые стоит обратить внимание.
Рис. 5. Помимо самого сюжета имеется масса информации.
На Рисунке 5- в крайнем левом углу участка леса указано имя ведущего автора для каждого отдельного исследования, а также год публикации.
Непосредственно слева от участка леса находятся два столбца чисел, выделенных на рис. 6. В каждом столбце чисел есть два числа, разделенные знаком «/». Если вы посмотрите на заголовок каждого столбца, вы увидите, что числа организованы как «н/н». Что это значит? Проще говоря, «n» обозначает количество пациентов или лиц, у которых было событие/исход в этой конкретной группе, тогда как «N» обозначает общее количество людей в этой группе.
Рисунок 6. Имеет смысл сравнить цифры с графиком.
Итак, в нашем примере бумаги у нас есть два столбца чисел. Первый столбец предназначен для группы, получившей лечение (n = количество пролеченных людей, у которых был результат, N = общее количество людей в исследовании, которые получили лечение). Принимая во внимание, что второй столбец предназначен для группы, которая получила контрольную (n = количество людей в контрольной группе, у которых был результат, N = общее количество людей, которые были в контрольной группе).
Рисунок 7. Иногда проще просто сравнить цифры…
Рисунок 7 находится на другой стороне лесного участка. Крайний правый столбец в основном дает вам график леса в виде чисел (как точечная оценка, так и 95% доверительный интервал в скобках). Некоторым людям может быть проще просто смотреть прямо на эти цифры, чем смотреть на график и пытаться его интерпретировать.
Рис. 8. Если выделено жирным шрифтом, возможно, причина в этом!
Рисунок 8. Здесь просто выделены статистические данные, связанные с алмазом на участке леса. «Промежуточный итог» — это то, что написано на банке. Он сообщает вам общее количество участников в экспериментальной и контрольной группах по всем отдельным исследованиям, а также усредненную статистику и 95% доверительный интервал. Полезно смотреть на эту строку цифр и ромб, когда делаете выводы для вашего мета-анализа/систематического обзора.
Часть 5: Неоднородность статей.
Заключительная часть анализа лесного участка связана с рассмотрением того, что называется «гетерогенностью». В идеале, если разные испытания проверяют одно и то же, эффекты вмешательства/воздействия должны быть одинаковыми во всех исследованиях. К сожалению, это бывает редко. На результаты исследования могут повлиять многие факторы, такие как предвзятость исследователя или проблемы со сбором данных [2].
В идеале, если разные испытания проверяют одно и то же, эффекты вмешательства/воздействия должны быть одинаковыми во всех исследованиях. К сожалению, это бывает редко. На результаты исследования могут повлиять многие факторы, такие как предвзятость исследователя или проблемы со сбором данных [2].
Таким образом, помимо анализа результатов исследования, систематические обзоры или метаанализы предназначены для того, чтобы задать вопрос. Если все эти исследования проверяют одно и то же вмешательство, почему они не дают одинаковых результатов? Являются ли различия случайными, или здесь замешано что-то еще? Если это случайность, то нам не о чем беспокоиться. Если различия , а не являются результатом случайности, то нам нужно быть осторожными в том, как мы интерпретируем результаты. Чтобы упростить оценку согласованности проанализированных статей, была использована статистика под названием I 9.0480 2 используется («i-квадрат»).
Рисунок 9. Я подсматриваю своим маленьким глазом… что-то, начинающееся с h…
Я подсматриваю своим маленьким глазом… что-то, начинающееся с h…
Как показано на рисунке 9, статистика, связанная с неоднородностью, обычно находится внизу диаграммы. Эмпирическое правило заключается в том, что вы хотите, чтобы I 2 было меньше 50%. Все, что выше этого, и документы могут быть несовместимы по какой-то причине, кроме случайности (что плохо!). К счастью, для нашего примера I 2 составляет 38% — не идеально, но все еще в пределах нашего целевого диапазона. Вы заметите, что там есть и другие статистические данные, такие как Chi 9.0480 2 и я. Для целей этого руководства I 2 является наиболее полезным при интерпретации лесного участка.
Итоговое время
Надеюсь, изучение лесного участка от начала до конца помогло вам понять, что заставляет лесные участки работать. Я настоятельно рекомендую вам прокрутить вверх и посмотреть на рисунок 1, на котором нет никаких аннотаций, и выполнить 5 шагов, которые мы прошли.
Подводя итог тому, что мы рассмотрели:
- Каждая горизонтальная линия на лесном участке представляет собой отдельное исследование, результат которого отображается в виде прямоугольника, а доверительный интервал результата 95% отображается в виде линии.
- Значение каждого исследования, попадающего по одну или другую сторону вертикальной линии, зависит от используемой статистики.
- Если отдельное исследование пересекает вертикальную линию, это означает, что нулевое значение находится в пределах 95% доверительного интервала. Это означает, что результат исследования на самом деле является нулевым значением, и поэтому в исследовании не наблюдалось статистически значимой разницы между экспериментальной и контрольной группами.
- Ромб в нижней части графика леса показывает результат, когда все отдельные исследования объединяются и усредняются. Горизонтальные точки ромба являются пределами 95% доверительных интервалов и подлежат той же интерпретации, что и любые другие отдельные исследования на графике.

- Статистика I 2 дает представление о неоднородности исследований, то есть о том, насколько они последовательны. Если значение I 2 > 50%, это может означать, что исследования противоречивы по другой причине, чем случайность. Это может сделать выводы, которые вы сделаете из лесного участка, сомнительными.
Рис. 10. Еще один участок леса из той же бумаги для проработки. Изображение от Roberts et al. (2006) [1]
Имеет смысл? Я надеюсь, что это так! Если вы хотите проработать еще один пример, взгляните на рисунок 10 — лесной участок из статьи, из которой взят рисунок 1. Каково значение Кокрейновского обзора, на который я намекал в начале?И, наконец…
Ну, если вы когда-нибудь видели логотип Cochrane Collaboration, вы могли бы узнать горизонтальные линии и ромб.
Это потому, что логотип Cochrane Collaboration на самом деле представляет собой лесной участок. Лесной участок в логотипе Cochrane Collaboration из одного из первых когда-либо опубликованных систематических обзоров [3]. Статья, опубликованная в 1991 году, показала, что назначение стероидов матерям, чьи дети должны были родиться раньше срока, уменьшало осложнения, связанные с недоношенностью. Кокрановский обзор, из которого взяты рисунки 1 и 10, на самом деле является обновлением того первоначального обзора, который впоследствии сформировал логотип Кокрановского сотрудничества.
Статья, опубликованная в 1991 году, показала, что назначение стероидов матерям, чьи дети должны были родиться раньше срока, уменьшало осложнения, связанные с недоношенностью. Кокрановский обзор, из которого взяты рисунки 1 и 10, на самом деле является обновлением того первоначального обзора, который впоследствии сформировал логотип Кокрановского сотрудничества.
Ссылки:
[1] Робертс Д., Далзил С.Р. Антенатальные кортикостероиды для ускорения созревания легких плода у женщин с риском преждевременных родов. Кокрановская база данных систематических обзоров, 2006 г., выпуск 3. Ст. №: CD004454.
[2] «Как анализировать лесной участок: оценка неоднородности среди исследований». Центр вмешательства, основанного на доказательствах, Оксфордский университет. URL: http://www.cebi.ox.ac.uk/for-practitioners/what-is-good-evidence/how-to-interpret-the-sample-forest-plot.html#c56 Дата обращения: июнь 2016 г.
[3] «Наш логотип: Cochrane Collaboration». Кокрановское сотрудничество, 2016 г. URL: http://www.cochrane.org/about-us/our-logo. Доступ: июнь 2016 г.
URL: http://www.cochrane.org/about-us/our-logo. Доступ: июнь 2016 г.
Итак, как все прошло? То, что вы должны были найти, это:
- Для исследования A - оно имеет довольно широкую горизонтальную линию, которая пересекает линию нулевого эффекта с черным прямоугольником, который находится справа от вертикальной линии. Это, скорее всего, демонстрирует небольшое исследование с небольшим количеством участников, где результат точечной оценки благоприятствует контролю, использованному в исследовании. Но поскольку исследование содержит нулевое значение в своих 95% доверительный интервал, он, вероятно, будет иметь значение p> 0,05 и не будет статистически значимым.
- Для исследования B — довольно узкая линия, которая не пересекает линию нулевого эффекта, с черным прямоугольником, который находится слева от вертикальной линии и больше, чем исследование A. Это, скорее всего, демонстрирует более крупное исследование с большим количеством участников.
