Механизм запросов
Механизм запросов — это один из способов доступа к данным, которые поддерживает платформа. Используя этот механизм, разработчик может читать и обрабатывать данные, хранящиеся в информационной базе; изменение данных с помощью запросов невозможно. Это объясняется тем, что запросы специально предназначены для быстрого получения и обработки некоторой выборки из больших массивов данных, которые могут храниться в базе данных.
Табличный способ доступа к данным
Запросы реализуют табличный способ доступа к данным, которые хранятся в базе данных. Это означает, что все данные представляются в виде совокупности связанных между собой таблиц, к которым можно обращаться как по-отдельности, так и к нескольким таблицам во взаимосвязи:
Такой способ работы с данными позволяет получать сложные выборки данных, сгруппированные и отсортированные определенным образом. Для этих выборок могут быть рассчитаны общие и промежуточные итоги, наложены ограничения на количество или состав записей и пр.
Язык запросов
Для того чтобы разработчик имел возможность использовать запросы для реализации собственных алгоритмов, в платформе реализован язык запросов. Этот язык основан на SQL, но при этом содержит значительное количество расширений, ориентированных на отражение специфики финансово-экономических задач и на максимальное сокращение усилий по разработке прикладных решений. Можно перечислить наиболее существенные возможности, реализуемые языком запросов:
Обращение к полям через точку (».»)
Если поля какой-либо таблицы имеют ссылочный тип (хранят ссылки на объекты другой таблицы), разработчик может в тексте запроса ссылаться на них через «.», при этом количество уровней вложенности таких ссылок система не ограничивает.
Обращение к вложенным таблицам (табличным частям документов и элементов справочников)
Система поддерживает обращения к вложенным табличным частям и как к отдельным таблицам, и как к целым полям одной таблицы.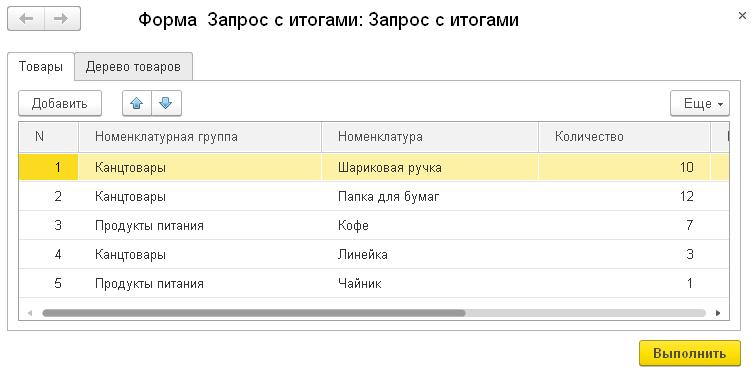 Например, при обращении к документу Реализация товаров (содержащему табличную часть Товары с составом отгружаемых товаров), мы можем считать табличную часть как отдельную таблицу:
Например, при обращении к документу Реализация товаров (содержащему табличную часть Товары с составом отгружаемых товаров), мы можем считать табличную часть как отдельную таблицу:
Но также мы можем считать заголовочную запись документа, в которой значением поля Товары будут все записи вложенной таблицы, подчиненные этому объекту (документу):
Автоматическое упорядочивание
Для выбора наиболее правильного («естественного») порядка вывода информации на экран или в отчет разработчику в большинстве случаев достаточно задать режим автоматического упорядочивания.
Многомерное и многоуровневое формирование итогов
Итоги и подитоги формируются с учетом группировки и иерархии, обход уровней может выполняться в произвольном порядке с подведением подитогов, обеспечивается корректное построение итогов по временным измерениям.
Поддержка виртуальных таблиц
Виртуальные таблицы, предоставляемые системой, позволяют получить практически готовые данные для большинства прикладных решений без необходимости составления сложных запросов. Например, такая виртуальная таблица может предоставить данные по остаткам товаров в разрезе периодов на какой-то момент времени. При этом виртуальные таблицы максимально используют хранимую информацию, например, ранее рассчитанные итоги и т. д.
Стандартные SQL операции
В языке запросов поддерживаются стандартные для SQL операции, такие, как объединение (Union), соединение (Join) и т. д.
Временные таблицы
Язык запросов позволяет использовать в запросах временные таблицы. С их помощью можно повысить производительность запросов, в некоторых случаях снизить количество блокировок и сделать текст запроса более легким для восприятия.
Предположим, нужно получить данные из двух регистров накопления. Данные из одного регистра поместим во временную таблицу:
Запрос, использующий временную таблицу, будет иметь вид:
Пакетные запросы
Для более удобной работы с временными таблицами в языке запросов поддерживается работа с пакетными запросами — таким образом, создание временной таблицы и ее использование помещаются в один запрос. Пакетный запрос представляет собой последовательность запросов, разделенных символом «;». Запросы исполняются один за другим. Результатом выполнения пакетного запроса в зависимости от используемого метода будет являться либо результат, возвращаемый последним запросом пакета, либо массив результатов всех запросов пакета в той последовательности, в которой следуют запросы в пакете.
Конструкторы запроса
Для облегчения труда разработчика технологическая платформа содержит два специальных конструктора. Они служат для того, чтобы помочь разработчику составить правильный текст запроса, используя только визуальные средства. Выбирая мышью нужные поля таблиц, разработчик может составить работоспособный запрос, даже не зная синтаксиса языка запросов.
Они служат для того, чтобы помочь разработчику составить правильный текст запроса, используя только визуальные средства. Выбирая мышью нужные поля таблиц, разработчик может составить работоспособный запрос, даже не зная синтаксиса языка запросов.
- Конструктор запроса позволяет составить только текст запроса. Подробнее…
- Конструктор запроса с обработкой результата помимо текста запроса формирует фрагмент программного кода, который исполняет запрос и выводит результаты в табличный документ или диаграмму. Подробнее…
Консоль запросов
Инструмент «Консоль запросов» позволяет разработчикам конфигураций и специалистам по внедрению отлаживать запросы и просматривать результаты их выполнения в режиме «1С:Предприятие 8». Подробнее…
Язык запросов «1С:Предприятия 8» (+диск)
Авторы: Е.Ю. Хрусталева
15 лучших практик SQL после 20 лет программирования
Данная статья является переводом. Автор: Brandon Southern. Ссылка на оригинал.
Автор: Brandon Southern. Ссылка на оригинал.
Обратите внимание, что, хотя все эти советы можно считать «мнениями», эти методы я использовал после 20 лет совершения ошибок, проблем с эффективным чтением, редактированием и пониманием кода и наблюдения за тем, как члены моей команды сталкиваются с теми же проблемами. Я постараюсь рассказать вам о практике и логике их использования и оставлю вам возможность рассмотреть эти методы и посмотреть, что актуально для вас и вашей команды.
1. Форматирование
Первое, о чем я хотел бы поговорить, это форматирование. Код должен быть хорошо отформатирован и визуально привлекателен, чтобы его было легко читать. Создавая правильно отформатированный код, мы упрощаем себе жизнь, когда дело доходит до отладки, устранения неполадок и модификации нашего кода.
При форматировании следует учитывать ряд вещей, таких как цели, выравнивание, позиции запятых и регистр текста. Если вы зашли так далеко в чтении, вы, вероятно, заметили, насколько хорошо выровнен мой код и что большинство элементов находятся в одной строке. Это имеет огромное значение в читабельности.
Если вы зашли так далеко в чтении, вы, вероятно, заметили, насколько хорошо выровнен мой код и что большинство элементов находятся в одной строке. Это имеет огромное значение в читабельности.
Ниже приведен пример кода, который был написан и совершенно нечитаем. В этом примере вы заметите, что ряд вещей идет вразрез с лучшими практиками, например:
- количество элементов в строке;
- проблемы с выравниванием;
- конечные запятые;
- слабый алиасинг или его отсутствие;
- отсутствие комментариев;
- группировка по номеру вместо имени;
- положение агрегатных функций в операторе select;
- несколько трудно обнаруживаемых ошибок.
1.1. Плохая практика — много проблем
Лучшие практики
Посмотрите на код ниже и сравните с кодом выше.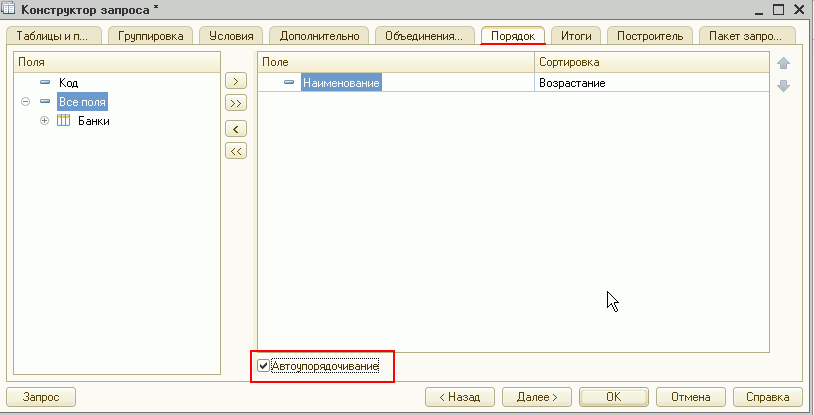 Какой из них легче читать? Какая версия обеспечивает более чистый пользовательский интерфейс, который позволит вам быстро обнаруживать ошибки или избегать ошибок в целом? Я надеюсь, что вы согласились с тем, что приведенный ниже код служит для преодоления всех проблем, обнаруженных в приведенном выше коде.
Какой из них легче читать? Какая версия обеспечивает более чистый пользовательский интерфейс, который позволит вам быстро обнаруживать ошибки или избегать ошибок в целом? Я надеюсь, что вы согласились с тем, что приведенный ниже код служит для преодоления всех проблем, обнаруженных в приведенном выше коде.
Встречный аргумент, который я слышал от людей, звучит так: «Ну, вам пришлось написать больше строк кода». Это не имеет значения. Компьютеру все равно, и достаточно пары нажатий клавиш, чтобы получить возврат строки и пробелы или табуляцию.
В следующих разделах я рассмотрю каждый из этих вопросов и приведу примеры хороших и плохих практик.
1.2. Выравнивание
Если вы посмотрите на приведенный выше код «лучшей практики», то обратите внимание, насколько хорошо все выровнено по левому краю. Все запятые, пробелы и отступы делают код очень удобным для чтения.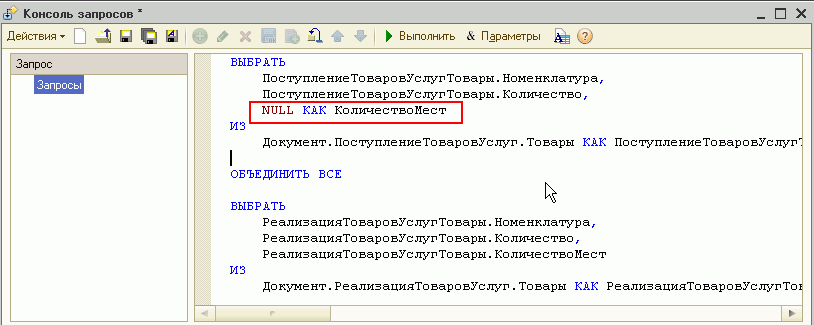
1.3. Один элемент в строке
Мое общее правило — один элемент в строке, например, один элемент в вашем select, одно условие в join или один case. Посмотрите на приведенный выше код, чтобы увидеть разницу в удобочитаемости при написании с одним элементом в строке. Здесь главное — быть последовательным. Я видел код, который написан с одним элементом в строке, но затем время от времени будет встречаться предложение *join*, в котором операторы and и or находятся в одной строке. Это может быть очень неприятно при чтении и отладке, так как очень легко пропустить условие добавления, потому что оно было записано в той же строке.
1.4. Плохая практика — несколько условий case в одной строке
Здесь мы видим оператор case, который помещается в одной строке. Это плохая практика, потому что код становится трудночитаемым и сложно быстро проанализировать все условия. Кроме того, действительно сложно, правильно прокомментировать код. Я знаю, что в этом примере
Кроме того, действительно сложно, правильно прокомментировать код. Я знаю, что в этом примере main_reporting не является описательным и не соответствует другим значениям, но иногда вам говорят выводить значения таким образом, и вы не можете объяснить логику для других.
Лучшая практика — несколько условий case на нескольких строках
Здесь мы видим оператор case, который написан на нескольких строках с комментариями.
Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста»
Интересно, перейти к каналу
2. Комментирование кода
Пожалуйста, комментируйте свой код. Мне кажется, что я каждый день вижу посты на LinkedIn или каком-либо другом сайте, где кто-то говорит что-то вроде: «Вам не нужны комментарии к коду. Код представляет собой комментарий. Ты что, не умеешь читать код?». Серьезно, я слышал такое в течение многих лет. Хотя код — это язык, и если программист хорошо владеет языком, читатель может понять, что делает код. Но код никогда не сообщает читателю, почему кто-то хотел, чтобы код функционировал таким образом. Возможности безграничны. Почему кто-то хотел, чтобы код работал определенным образом?
Хотя код — это язык, и если программист хорошо владеет языком, читатель может понять, что делает код. Но код никогда не сообщает читателю, почему кто-то хотел, чтобы код функционировал таким образом. Возможности безграничны. Почему кто-то хотел, чтобы код работал определенным образом?
Конечно, вы можете прочитать код и, возможно, ознакомиться с документацией, но это займет намного больше времени, чем написание комментариев. Ниже приведены несколько примеров хороших и плохих практик комментирования.
2.1. Плохие комментарии — их отсутствие
Посмотрите на код ниже. Мы видим, что код хочет возвращать результаты только там, где u.id > 1000. Это довольно очевидно в этом очень простом примере. Но более важный вопрос: почему кто-то это сделал?
Возможно, это тестовые пользователи до u.id = 1000. А может быть, код отфильтровывает всех пользователей из Мичигана, потому что кто-то почему-то думал, что все пользователи с u. меньше 1000 из штата Мичиган. Это может показаться ужасной идеей писать код таким образом, но он все равно будет выполняться. Дело в том, что мы, новые пользователи, не знаем об этом, и есть вероятность, что через шесть месяцев вы, вероятно, тоже не будете знать. id
id
2.2. Лучшее комментирование — встроенные комментарии
Здесь у нас есть встроенный комментарий, который говорит нам немного больше о том, почему мы добавили условие u.id > 1000. Очевидно, у нас есть тестовые пользователи, которых следует вычеркнуть из набора результатов.
2.3. Плохие комментарии — без блочных комментариев
Посмотрите на код ниже. Здесь мы видим, что запрос будет возвращать пользователей, которые считаются непроверенными пользователями. Встроенный комментарий помогает нам понять, что мы хотим удалить этих тестовых пользователей из набора результатов. Но нам пришлось прочитать несколько строк кода.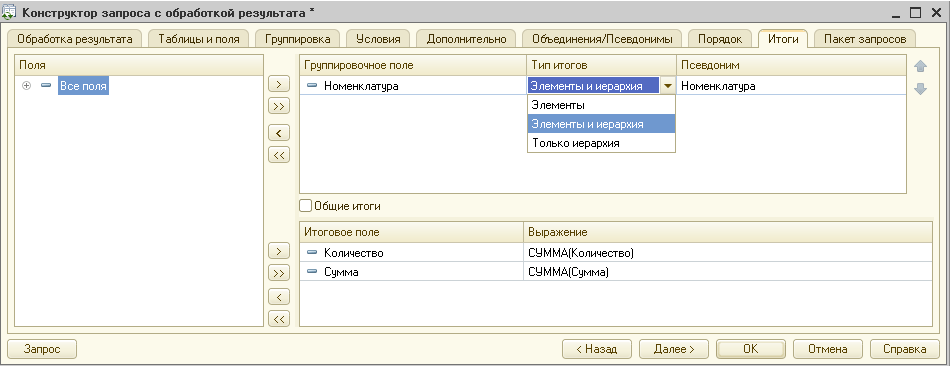 Вы можете сказать, ну, это не стоит блока комментариев вверху. Всего 8 строк кода, и понятно, что происходит. Просто или нет, но читатель не знает, почему этот код работает. Но что, если код был бы не таким простым?
Вы можете сказать, ну, это не стоит блока комментариев вверху. Всего 8 строк кода, и понятно, что происходит. Просто или нет, но читатель не знает, почему этот код работает. Но что, если код был бы не таким простым?
Лучший способ комментирования — блочные комментарии
Ниже приведен тот же код, который мы только что рассмотрели, теперь мы сообщаем пользователю, почему мы хотим запустить этот код и на что обратить внимание.
3. Общие табличные выражения (CTE)
Общие табличные выражения или CTE — это способ создания в памяти таблицы результатов вашего запроса. Затем эту таблицу можно использовать во всем остальном сценарии SQL. Преимущество использования CTE заключается в том, что вы можете уменьшить дублирование кода, сделать его более читабельным и расширить возможности выполнения проверок качества результатов.
Также обратите внимание на действительно хороший блочный комментарий.
3.1. Пример кода, не использующего CTE
В приведенном ниже коде мы видим, что есть два подзапроса, которые возвращают результаты. Затем эти два подзапроса объединяются для получения окончательного набора результатов. Хотя этот код будет выполняться, есть несколько проблем:
1. Очень сложно выполнить контроль качества подзапросов и проверить результаты. Например, что, если мы хотим запустить некоторые подсчеты количества пользователей, у которых есть несколько записей для экранов по умолчанию? Мы не можем просто выполнить некоторый sql для подзапроса. Нам пришлось бы скопировать/вставить подзапрос, а затем изменить его, чтобы выполнить проверку качества. Было бы намного лучше, если бы мы могли избежать изменения кода в процессе проверки качества.
2. Если нам нужно использовать этот users подзапрос в другом месте нашего кода, нам придется переписать или скопировать/вставить этот блок кода в другие места нашего скрипта. Это не будет DRY (не повторяйтесь) процесс и может привести к ошибкам.
Это не будет DRY (не повторяйтесь) процесс и может привести к ошибкам.
Как так? Предположим на мгновение, что вы использовали подзапрос users в 5 местах вашего скрипта. Также предположим, что код, с которым вы работаете, нелегко читать, поскольку он не соответствует лучшим практикам. Если вас попросят обновить код, чтобы добавить еще одно условие для удаления дополнительных тестовых пользователей, есть большая вероятность, что вы можете пропустить добавление этого условия хотя бы для одного из 5 вариантов использования подзапроса.
3. Больше циклов по базе. Каждый раз, когда выполняется подзапрос, он выполняет сканирование таблицы для возврата результатов. С подзапросом наших пользователей, содержащим подстановочные знаки, базе данных предстоит выполнить изрядный объем работы. Гораздо дешевле (говоря о циклах ЦП и затраченных деньгах, если вы используете облачные базы данных) выполнить подзапрос один раз, сохранить его в памяти, а затем просто повторно использовать набор результатов по мере необходимости в своем коде.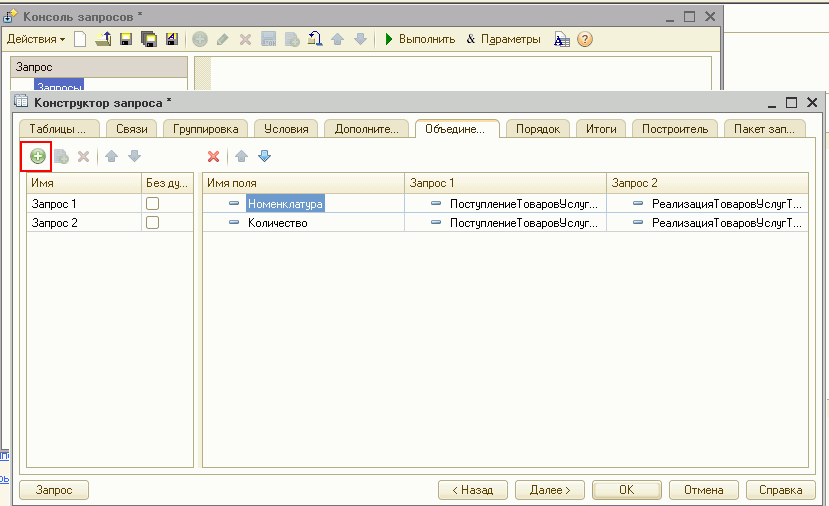
4. Сложнее прочитать весь блок кода и понять, что и зачем выполняется. Хотя можно прокручивать код, может быть трудно понять, что происходит. Если вам приходится вертикально прокручивать свой код на мониторе и ваш код слишком длинный, то следует реорганизовать для более мелких компонентов.
Пример использования CTE
Ниже мы видим пример использования CTE. Хотя CTE могут помочь преодолеть некоторые из проблем, которые мы ранее указывали, CTE обычно не остаются в памяти после отображения окончательного набора результатов.
Например, если бы вы запустили весь этот блок кода, он бы выполнился. Но если через несколько минут вы захотите выбрать все результаты CTE пользователей, эти данные будут недоступны для запроса. Чтобы обойти эту проблему, вы можете использовать временные таблицы или временные таблицы в памяти, которые обычно существуют, пока ваш сеанс (подключение к базе данных) остается активным. Подробнее на эту тему поговорим позже.
Подробнее на эту тему поговорим позже.
4. Использование “select *”
Вы никогда не должны писать запросы с “select *”. Я думаю, что единственным исключением из этого правила является случай, когда вы пытаетесь проверить таблицу, и в таком случае вы всегда должны ограничивать количество возвращаемых результатов. Написание запросов таким образом — плохая идея по многим причинам:
1. Производительность базы данных. Возврат ненужных столбцов обходится дороже, чем запрос только тех столбцов, которые вам нужны.
2. Проблемы с отладкой. Предполагая, что вы используете CTE, как описано в предыдущем разделе, может быть очень сложно отследить происхождение определенных атрибутов.
3. Таблицы меняются. Даже если вам действительно нужно выбрать все столбцы, нет никакой гарантии, что ваша таблица не изменится со временем. И по мере изменения таблицы вы будете запрашивать новые данные, что может привести к нарушению кода в другом месте, вызвать путаницу или повлиять на производительность базы данных и затраты.
4.1. Плохая практика — использование Select *
Лучшая практика — выбор только нужных элементов
5. Псевдонимы (Aliasing)
Псевдонимы очень важны, чтобы помочь читателям понять, где находятся элементы и какие таблицы используются. Когда псевдонимы не используются или используются плохие соглашения об именах, сложность увеличивается, а чтение/понимание кода уменьшается.
5.1. Плохая практика — в полях не используется псевдонимы (alias)
Ниже вы можете видеть, что таблицы имеют псевдонимы u и p, но выбранные элементы не используют псевдоним. Это может быть очень неприятно и может вызвать ошибки во время выполнения, если несколько таблиц содержат поле с одинаковым именем. Например, user_id находится как в таблице users, так и в таблице preferences.
Лучшая практика — псевдоним, используемый в полях
Ниже вы можете видеть, что таблицы и выбранные элементы используют псевдоним таблицы. Это делает код очень читаемым для конечного пользователя. Даже если у вас есть только одна таблица, рекомендуется использовать псевдоним для таблицы и имени поля.
5.2. Плохая практика — общий псевдоним на CTE
Ниже у нас есть CTE, который был создан, но имя таблицы, которое было назначено, называется cte. Это очень общее имя, которое абсолютно ничего не говорит конечному пользователю о данных в таблице. Если бы вы были пользователем, читающим оператор select, у вас не было бы никаких указаний на то, какая таблица используется.
Лучшая практика — конкретный псевдоним в CTE
Ниже у нас есть CTE, который был создан с более описательным именем. Имя дает пользователю некоторое представление о том, какие данные содержатся здесь.
6. Запятые в начале vs запятые в конце
В избранных утверждениях я предпочитаю ставить запятую в начале, а не в конце, и это один из тех случаев, когда я бы сказал, что это мое личное мнение. Я видел, как многие люди пишут свои выбранные элементы с завершающей запятой, а в других языках это обычная практика. Однако в других языках не принято передавать большое количество аргументов в функцию, тогда как в SQL довольно часто используется (и объявляется в коде) большое количество элементов. Вот несколько причин, по которым я считаю начальные запятые полезными.
1. Чистый пользовательский интерфейс. Когда вы посмотрите на пример лучшей практики, обратите внимание на то, как хорошо выровнены запятые. Очень легко увидеть, что запятая отсутствует, и избежать ошибки времени выполнения по сравнению с использованием завершающих запятых.
2. Отсутствие путаницы при работе с более длинными операторами case, переносящими строки. Глядя на приведенный ниже пример, трудно сказать, является ли конец строки концом элемента или оператора или же он указывает конец аргумента, который передается в функцию.
Чтобы добавить еще больше разочарования по поводу этой плохой практики замыкающих запятых, средство форматирования запросов BigQuery фактически переформатирует ваш код, чтобы отображать все, что заканчивается запятой 🙁
6.1. Плохая практика — запятая в конце
В этом примере мы видим, что начальные запятые не используются, что очень затрудняет поиск пропущенной запятой.
Лучшая практика — запятая в начале
В этом примере мы видим, что все запятые выровнены, что позволяет легко убедиться, что ни одна запятая не пропущена.
6.2. Плохая практика — путаница с запятой
В этом примере мы видим, что запятые в начале не используются. У нас есть разрыв строки, который заканчивается запятой, поэтому трудно сказать, действительно ли эта строка max является одним оператором или частью более длинного оператора. Кто-то может возразить, что вам не следует использовать такие разрывы строк в своем коде, и хотя я поддерживаю разрывы строк в нужных местах (потому что это облегчает чтение кода), вы все равно столкнетесь с той же проблемой при просмотре вашего текста с переносом слов в коде редакторе или в сравнении с Git diff.
Лучшая практика — запятая в начале с отступом в тексте с переносом
В приведенном ниже примере легко увидеть, что запятая отсутствует. Вы можете сразу же задаться вопросом, не забыл ли кто-то запятую, но поскольку код с начальными запятыми так легко читать, существует более высокая вероятность того, что ведущая запятая отсутствует по замыслу, и на самом деле запятая не должна стоять перед ‘cast’. Кроме того, добавление отступа к оператору приведения делает код более очевидным, поэтому запятая не нужна.
Если бы кто-то выполнил возврат каретки после desc) в строке 3, то у него было бы общее начало в строке 4. Обычно мы хотим, чтобы все запятые были ведущими символами. Но эта логика применима только в том случае, когда мы говорим о возвращаемом атрибуте (столбце). В нашем случае эта запятая в конце строки 3 является частью оператора case, поэтому все может сильно запутаться.
7. Капитализация
Во многих старых кодах SQL это было довольно распространенной практикой, и это могло быть связано с тем фактом, что SQL существует очень давно, возможно, дольше, чем большинство текстовых редакторов с подсветкой синтаксиса. Сегодня большинство людей используют (или должны использовать) подсветку синтаксиса в своих редакторах, поэтому использование заглавных букв не должно быть необходимым для определения зарезервированных слов.
Хотя у меня есть личное мнение не использовать заглавные буквы, вы можете не согласиться и иметь другое мнение. Вот мое обоснование:
1. Мне не нравится, когда мой код кричит на меня. В социальном контексте и письменном общении использование прописных букв является синонимом крика, поэтому я стараюсь не писать таким образом.
2. Код читается не так плавно. Психологические исследования показали, что слова в нижнем регистре распознаются легче, чем слова в верхнем регистре. Это связано с тем, что слова в нижнем регистре имеют больше вариаций формы по сравнению со словами в верхнем регистре. Скорость чтения может снизиться на 13–20% при использовании всех прописных букв.
3. Это дополнительные нажатия клавиш, чтобы удерживать нажатой клавишу Shift, пока я печатаю или блокирую/разблокирую клавишу Caps. Не лучший аргумент, я знаю.
7.1. Плохая практика — верхний регистр
В этом примере мы видим, что резервные слова написаны прописными буквами, а все остальные слова строчными.
Лучшая практика — нижний регистр
В этом примере мы видим, что все запятые выровнены, что позволяет легко убедиться, что ни одна запятая не пропущена.
8. Group By — числа vs явные поля
Я почти всегда выполняю свою группу с явными именами полей, а не с номером позиции в операторе select. Хотя это не имеет никакого отношения к результатам, я обнаружил, что это экономит мне время, когда дело доходит до набора текста и отладки. Обычно я предпочитаю просто использовать числа, потому что это занимает меньше текста на странице, но это вызывает слишком много проблем и времени, затрачиваемого на поиск ошибок во время выполнения.
8.
1. Плохая практика — группировать по номеру позицииЗдесь вы можете видеть, что мы выполняем группировку с номерами позиций на основе выбранных элементов. Что мне не нравится в этой практике, так это то, что:
1. Если кто-то помещает агрегатную функцию (функции) в любом месте, кроме первого или последнего элемента в операторе выбора, вам придется пропустить номер позиции в группе. Это может вас разочаровать, если вы позже решите изменить порядок выбранных элементов.
2. Вы должны подсчитать, сколько элементов у вас есть, за вычетом агрегированных элементов, а затем вручную ввести номер позиции.
Лучшая практика — группировка по имени поля
Здесь вы можете видеть, что мы выполняем группировку с явными именами полей. Хотя кажется, что печатать и работать будет намного сложнее, чем использовать номера позиций, на самом деле печатать быстрее, чем использовать числа. Как так? Потому что все, что вам нужно сделать, это скопировать то, что находится в операторе select (за вычетом агрегированного поля), и вставить эти значения в group-by.
***
Материалы по теме
- 🗄️ ✔️ 10 лучших практик написания SQL-запросов
- 📜 Основные SQL-команды и запросы с примерами, которые должен знать каждый разработчик
NYC CoolRoofs — NYC Business
NYC CoolRoofs предоставляет жителям Нью-Йорка оплачиваемое обучение и опыт работы по установке энергосберегающих отражающих крыш. Программа поддерживает цель города по достижению углеродной нейтральности к 2050 году. Эта инициатива представляет собой партнерство между Департаментом услуг малого бизнеса Нью-Йорка, его Центром карьеры Workforce1 Industrial & Transportation, Управлением мэрии по климату и экологической справедливости и программой HOPE.
Преимущества прохладных крыш для зданий | Поезд с NYC CoolRoofs | Заказать прохладную крышу | Сообщите о своей крутой крыше | Стать корпоративным спонсором | Станьте волонтером NYC CoolRoofs | Около
Преимущества прохладных крыш для зданий
Снижение температуры крыш
В обычный летний день плоские крыши из черного асфальта могут нагреваться до 190°F, что на 90° выше температуры окружающего воздуха!
Снижение температуры внутри здания
Прохладные крыши могут снизить внутреннюю температуру здания до 30 %, делая здание более прохладным и комфортным в жаркие летние месяцы.
Снижение эффекта городского острова тепла
В Нью-Йорке может быть на пять градусов жарче, чем в прилегающих районах, благодаря большему количеству темных поверхностей, таких как крыши и дороги, и меньшему затенению от растительности.
Сокращение выбросов углерода
Каждые 2500 квадратных футов крыши с покрытием могут уменьшить углеродный след города на 1 тонну CO2 и помочь в борьбе с изменением климата.
Улучшение качества воздуха
Прохладные крыши снижают загрязнение воздуха и выбросы парниковых газов за счет снижения энергопотребления.
Увеличение срока службы крыш и оборудования HVAC
Покрытие Cool Roof лучше регулирует температуру крыши по сравнению с обычными поверхностями
крыш. Снижая температуру крыши и охлаждающую нагрузку, можно продлить срок службы крыши и охлаждающего оборудования.
[Источник: Группа экспертов города Нью-Йорка по изменению климата, отчет за 2015 г. Глава 6: Показатели и мониторинг ]
Обучение с NYC CoolRoofs
NYC CoolRoofs предоставляет жителям Нью-Йорка, ищущим работу, возможность получить оплачиваемый опыт работы и получить квалификацию в строительном секторе.
Узнайте больше и подайте заявку
Запросите прохладную крышу
Это руководство поможет вам определить, имеете ли вы право на покрытие вашей крыши вместе с нами, и описывает дополнительные способы, с помощью которых вы можете поддержать и принять участие в этой программе и других инициативах. В любой момент мы также рады предоставить дополнительную техническую поддержку и ресурсы любому нью-йоркскому зданию, заинтересованному в установке прохладной крыши.
Rooftop Criteria
Ваше здание должно соответствовать всем следующим критериям , чтобы иметь право на покрытие в рамках программы NYC CoolRoofs Program.
- Крыша должна быть плоской
- Крыша должна быть в хорошем состоянии с минимальными трещинами
- Крыша должна быть легко доступна (без люка, лестницы или доступа к окну)
- На крыше не должно быть опасных механизмов или оборудования, которые могут помешать работе или подвергнуть рабочих риску
- Крыша должна иметь соответствующий парапет высотой 3 фута 8 дюймов
- Крыша должна быть одного из следующих типов:
- Гранулированный верхний лист
- Асфальт
- Модифицированный битум
- Битум
Стоимость
NYC CoolRoofs предлагает установку прохладных крыш по цене бесплатно или по низкой цене для выбора зданий, как указано ниже, при этом приоритет отдается некоммерческим организациям и доступному жилью.
Бесплатная установка предлагается:
- Некоммерческие организации
- Доступное жилье для малоимущих
- Общественные или развлекательные центры
- Школы/колледжи/университеты
- Больницы или поликлиники
- Музеи/театры/другие культурные центры
- Выберите кооперативное жилье.
Недорогие установки предлагаются:
- Всем другим владельцам зданий, которые покрывают стоимость покрытия, которое предоставляется со скидкой через поставщиков, участвующих в программе NYC CoolRoofs. NYC CoolRoofs предоставит рабочую силу, техническую помощь и материалы (например, кисти, валики, перчатки и т. д.) бесплатно, если владелец (владельцы) здания оплатит покрытие.
Запросить прохладную крышу
Сообщить о своей прохладной крыше
Вы установили прохладную крышу? Расскажите нам об этом, чтобы мы могли учесть это в нашей годовой цели.
Стать корпоративным спонсором
Предприятия и сотрудники имеют возможность спонсировать корпоративный день добровольцев, чтобы установить прохладную крышу, а также получить уникальный опыт тимбилдинга. В связи с продолжающейся пандемией COVID-19 мы в настоящее время не предлагаем возможности корпоративного волонтерства. По дополнительным вопросам спонсорства, пожалуйста, свяжитесь с нами.
Станьте волонтером в NYC CoolRoofs
Из-за продолжающейся пандемии COVID-19 мы в настоящее время не предлагаем никаких возможностей для волонтерства. Пожалуйста, заполните эту форму, если вы хотите, чтобы мы связались с вами, как только мы начнем предлагать возможности волонтерства в будущем.
Информация о
NYC CoolRoofs была запущена в 2009 году как волонтерская программа для поддержки усилий города Нью-Йорка по борьбе с изменением климата. В 2015 году программа была преобразована в возможность обучения персонала, чтобы предоставить жителям Нью-Йорка, ищущим работу, возможность получить оплачиваемый опыт работы и дипломы в строительном секторе. Ежегодная цель программы — установить один миллион квадратных футов крыш, вовлекая в процесс местных владельцев собственности, общественных партнеров, организации по обучению персонала и волонтеров.
Отправка запроса на изменение уровня — Справочный центр Gradescope
Если ваш преподаватель разрешил это, вы можете отправить запрос на изменение уровня. Вам нужно будет отправить запрос на изменение рейтинга на уровне вопроса. Если ваш преподаватель активировал запросы на изменение оценки, на странице отправки задания есть кнопка
Чтобы отправить запрос на изменение уровня, выберите вопрос, для которого вы хотите отправить запрос на изменение уровня. Это отобразит рубрику для этого вопроса и выделит элементы рубрики, которые были применены. Выбрав вопрос, выберите Request Regrade на нижней панели действий. Откроется модальное окно Regrade Request for Question и введите в текстовое поле объяснение запроса на конкретный вопрос, который был выбран. Когда закончите, выберите Request a Regrade .
Совет: Инструкторы, скорее всего, ответят на запросы о повышении квалификации, если будут вежливы и лаконичны.
Запросы на переоценку составляют за вопрос. Если у вас есть несколько запросов, не забудьте отправить по одному для каждого вопроса, который необходимо просмотреть.
После отправки запроса ваш преподаватель(и) и оценщик(и), оценившие вопрос, получат электронное письмо с уведомлением о запросе. Затем оценщики могут повторно оценить вопрос, ответить ответом и закрыть запрос. После закрытия запроса вы получите электронное письмо с уведомлением о том, что запрос был решен.
Вы можете просмотреть все ожидающие и выполненные запросы на изменение уровня курса на странице Запросы на изменение уровня (на левой боковой панели). Вы также можете проверить статус вашего запроса на изменение рейтинга при просмотре отправленного материала. Вот что означает статус запроса на обновление:
- Если на значке рядом с вопросом написано IR , запрос на повышение класса находится на рассмотрении.
- Если на значке написано R , запрос на повышение класса разрешен.
- Если запрос на изменение уровня помечен как Completed , преподаватель рассмотрел запрос на изменение уровня, и вы сможете увидеть обновленную оценку по этому вопросу.
После того, как запрос на изменение рейтинга будет решен, вы можете сделать еще один запрос на этот вопрос, выбрав значок Запросить переоценку снова нажмите кнопку. Чтобы просмотреть всю ветку обсуждения для определенного запроса, выберите вопрос при просмотре оцененной отправки.
Была ли эта статья полезной?
Круто, рада, что полезно! 🙌 Есть идеи, как мы можем улучшить?
Жаль это слышать.