Загрузка классификаторов в 1С (адреса КЛАДР, банки, единицы измерения)
Здравствуйте, уважаемые коллеги!
В этой статье я расскажу, каким образом загружать классификаторы банков, адресов (КЛАДР) и единиц измерения (ОКЕИ) в программе 1С: Управление производственным предприятием (1С:УПП) из программы 1С.
Для того, чтобы все прошло корректно — убедитесь, что на вашем компьютере есть доступ к интернету. Если все хорошо, и доступ есть — следуйте инструкции:
1. Обновление или загрузка классификаторов Банков.
Открываем меню Операции >> Справочники >> Банки
Рис.1. Справочник «Банки»
Выбираем источник, из которого будем загружать информацию. В нашем примере — у нас нет диска ИТС, но на компьютере есть интернет, поэтому я выбираю «Загрузка с сайта «РосБизнесКонсалт»
Рис.2. Загрузка с сайта «РосБизнесКонсалт»
Выбираем регион, в котором находится банк.
Рис.3. Выбор региона для банка.
Нажать на кнопку «Далее» и далее программа осуществит запись данных (перезапишет неактуальные реквизиты существующих банков, добавит новые банки и банковские счета ,которых раньше не было).
Готово!
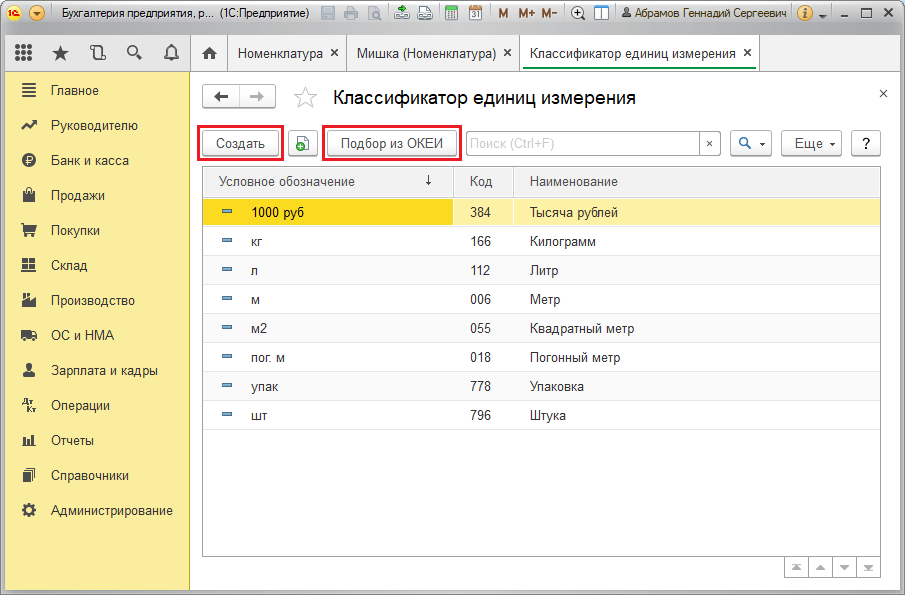
2. Обновление (загрузка) единиц измерения
Открываем меню Операции >> Справочники >>Единицы измерения и нажимаем кнопку «Подбор из ОКЕИ»
Рис. 4. Справочник «Единицы измерения»
Выбираем нужную единицу и нажимаем «Записать»
Рис.5. Запись новой единицы измерения
3. Обновление (загрузка) Классификатора адресов
Для загрузки классификатора адресов необходимо скачать и распаковать актуальные файлы КЛАДР.
Актуальные данные можно скачать по ссылке с nalog. ru (Архив том 1 и Архив том 2).
ru (Архив том 1 и Архив том 2).
Далее в меню Операции >> Справочники >>Классификаторы >> Адресный классификатор нажимаем «Загрузить классификатор»
Рис.6. Загрузка КЛАДР
В открывшемся окне выбираем распакованные файлы и регион, адреса которого необходимо загрузить. Путь нужно указать по аналогии с тем, как указано на скриншоте (у вас может быть свой пусть в зависимости от того, куда скачан классификатор, но конечные папки нужно указать также, как указано на скриншоте)
Рис.7. Подбор нужных папок с данными в КЛАДР
Загрузить классификатор можно по кнопке Загрузить.
Все готово, желаю удачи в работе!)
___________________________________________
Автор статьи: Специалист отдела сопровождения Вершинина Ирина
Подпишитесь на нашу рассылку
и получите еще больше статей от экспертов по 1С!
По мере публикации статей, но не чаще
одного раза в неделю.
Порядок загрузки адресного классификатора (КЛАДР) в программы 1С
- Общие сведения об адресном классификаторе.
- Где найти файлы КЛАДР?
- Порядок загрузки в 1С:Бухгалтерии 8.1 редакции 1.6, 1С:Управление торговлей редакции 10.3
- Порядок загрузки в 1С:Зарплата и Управление Персоналом, редакция 2.5
Общие сведения об адресном классификаторе.
При осуществлении хозяйственной деятельности для некоторых объектов необходимо хранить адресную информацию. Например, чтобы правильно отправлять грузы, необходимо знать адрес контрагента, для заполнения различных кадровых справок, необходимо знать адрес сотрудника.
Адресный классификатор предназначен для правильного и быстрого заполнения адреса. При заполнении адресов, например, в контактной информации, из адресного классификатора можно выбрать необходимые адресные элементы и на основе них заполнить адресные поля.
Где найти файлы КЛАДР?
Адресный классификатор, предназначенный для загрузки в программы 1С, поставляется в виде файлов DBF и состоит из 4 основных файлов:
- KLADR.
 DBF — классификатор адресов
DBF — классификатор адресов - STREET.DBF — классификатор улиц
- DOMA.DBF — классификатор домов
- SOCRBASE.DBF — классификатор сокращений
Последнюю версию КЛАДР можно найти на сайтах налоговых органов российской федерации. Так же КЛАДР можно найти на дисках ИТС:
- Диск ИТС-Проф (DVD) — располагается в папке [Путь к дисководу]:\1CIts\EXE\KLADR;
- Диск ИТС (CD) — диск «Работаем с программами», располагается в папке [Путь к дисководу]:\1CIts\EXE\KLADR.
Порядок загрузки в 1С:Бухгалтерии 8.1 редакции 1.6, 1С:Управление торговлей редакции 10.3
Файлы КЛАДР скопировать с диска на компьютер, разархивировать (файлы KLADR.EXE, STREET.EXE, DOMA.EXE, SOCRBASE.EXE являются самораспаковывающимися архивами, для извлечения необходимо запустить их на выполнение). Работа по загрузке ведется в рабочем режиме «Предприятие». Необходимо зайти в меню «Операции» — «Регистры сведений» — «Адресный классификатор»
Если адресный классификатор абсолютно пуст то появится окно с предложением загрузки классификатора, в ином случае откроется форма списка регистра сведений
Для загрузки из формы списка регистра сведений необходимо нажать кнопку «Загрузить классификатор» на командной панели окна
В форме загрузки необходимо указать путь к файлам КЛАДР и выбрать регионы, по которым необходимо произвести загрузку адресов. После всех настроек нажать кнопку «Загрузить», начнется процесс загрузки
После всех настроек нажать кнопку «Загрузить», начнется процесс загрузки
После окончания загрузки классификатор готов к работе.
Порядок загрузки в 1С:Зарплата и Управление Персоналом, редакция 2.5
Пункты 1-5 аналогично загрузке в 1С:Бухгалтерия предприятия
В форме загрузки необходимо указать путь к файлам КЛАДР. Кодировку поставляемых таблиц установить в «Кодировка DOS (866)», Формат поставляемых таблиц «2003 года»
Нажать кнопку «Загрузить регионы»
Перейти на закладку «Фильтр по регионам» и выбрать необходимые для загрузки регионы. После выбора нажать кнопку «Загрузить» и дождаться окончания загрузки.
После окончания загрузки классификатор готов к работе.
Рекомендуем ознакомиться
Загрузка КЛАДР на платформу 1С :Бухгалтерия 3.0 (8.3)
ТОП ПРОДАЖ
- 1С:Бухгалтерия 8
- 1С:Управление нашей фирмой 8
- 1С:Управление торговлей 8
- 1С:Управление предприятием 2
- 1С:ЗУП 8
- 1C:Учет путевых листов и ГСМ
- 1С:Учет в управляющих компаниях
- Электронные поставки 1С
Облачные сервисы
- 1С:Фреш
- 1С:Готовое рабочее место
- 1С:ЭДО
- Маркировка товаров
- 1С:Отчетность
- 1C:Товары
- 1C-Ритейл Чекер
Машинное обучение 1.
 0.1. — Что такое классификатор?
0.1. — Что такое классификатор?Я уже упоминал в одном из своих предыдущих сообщений в блоге, что существуют различные типы классификаторов, которые мы можем использовать для практического применения машинного обучения. Многие делят их на следующие категории: наивный байесовский классификатор, регуляризованные линейные регрессии, машины опорных векторов, деревья решений, k-ближайшие соседи, а также искусственные нейронные сети (источник). классификатор в первую очередь, во всяком случае?
Классификатор и алгоритмы
Итак, прежде всего, давайте вернемся к изучению некоторых важных терминов, используемых в области машинного обучения. Прежде всего, что такое классификатор? Классификатор, как уже можно предположить из этого термина, классифицирует информацию по разным категориям. Одним из примеров является наша знаменитая газетная статья, в которой мы пытаемся классифицировать 500 газетных статей по 5 различным категориям. Другой пример — классификация писем на спам и не спам (подробнее об этом ниже). Следовательно, это всего лишь один конкретный тип алгоритма (подкатегория алгоритма). Алгоритмы, с другой стороны, могут иметь в виду множество различных целей, таких как структурирование данных, их анализ, сортировка, разделение и многие другие.
Следовательно, это всего лишь один конкретный тип алгоритма (подкатегория алгоритма). Алгоритмы, с другой стороны, могут иметь в виду множество различных целей, таких как структурирование данных, их анализ, сортировка, разделение и многие другие.
Алгоритмы, с другой стороны, можно рассматривать как большой «набор правил», которым машины следуют при решении задач или расчетов (Источник. Алгоритм живет на основе входных данных и правил и создает выходные данные. Например, мы могли бы Скармливаем компьютеру информацию о погоде в течение следующих 7 дней. Точнее говоря, мы скармливаем ему двоичную информацию о том, идет ли дождь или нет (это наш ввод). в дождливые дни Мы в основном говорим компьютеру применить следующие правило : Если идет дождь, отправьте сообщение «Возьми зонт». Это наше правило. Затем сообщение представляет собой результат , сгенерированный алгоритмом. Мы можем легко применить это к нашей задаче о газетной статье. В этом случае наш ввод состоит из 500 газетных статей и всех записанных там слов. Затем мы говорим машине классифицировать статью как «политическую», если она содержит слово «политика» более 5 раз. Это наше правило. Затем алгоритм создает классификацию наших газетных статей, которая является результатом. Затем эта проблема становится алгоритм машинного обучения , когда данные обучаются на обучающем наборе данных (обучение с учителем) или сами по себе (обучение без учителя). Более конкретно, мы бы
Затем мы говорим машине классифицировать статью как «политическую», если она содержит слово «политика» более 5 раз. Это наше правило. Затем алгоритм создает классификацию наших газетных статей, которая является результатом. Затем эта проблема становится алгоритм машинного обучения , когда данные обучаются на обучающем наборе данных (обучение с учителем) или сами по себе (обучение без учителя). Более конкретно, мы бы
Теперь разница между алгоритмом и моделью заключается в том, что модель является конечным результатом вашего алгоритма (Источник. Другими словами, путем обучения нашего алгоритма на этапе обучения нашего упражнения по машинному обучению , мы оцениваем параметры нашего метода машинного обучения (Источник. Например, может быть, что нам нужна линейная или нелинейная модель, но мы не знаем этого с самого начала. Во время обучения мы находим кривую, которая предположительно лучше всего соответствует нашим данным, что приводит к нашей окончательной модели. На втором этапе мы тестируем метод машинного обучения.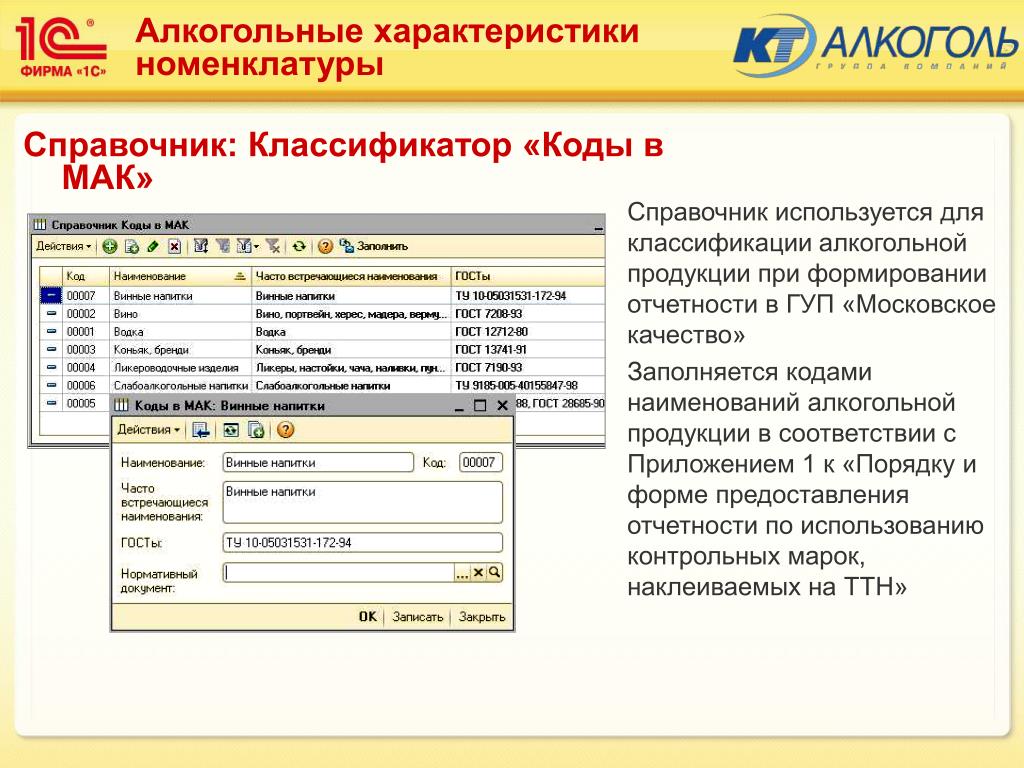 Более подробное объяснение этого см. В моем предыдущем блоге.
Более подробное объяснение этого см. В моем предыдущем блоге.
K-Классификация ближайших соседей
Классификация KNN основана на базовой идее о том, что вы классифицируете точку данных на основе ее сходства с ее непосредственными соседями. Предположим, у вас есть набор данных, содержащий данные о весе и росте людей, и вы хотите разделить их на людей с ожирением и без него. Часть вашего набора данных уже помечена, и вы можете взять этот набор данных для обучения своего классификатора. Предположим теперь, что у вас есть 5 точек данных: 3 человека ростом 1,70 метра и весом 60, 65 и 80 кг и два человека ростом 1,50 и весом 50 и 70 кг. Мы определяем человека 1, 2 и 4 как не страдающего ожирением, а человека 3 и 5 — страдающего ожирением. Если теперь вы добавите шестую немаркированную точку данных с размерами 1, 60 и 70 кг и скажете нашему KNN-классификатору пометить ее на основе 5 соседних значений, алгоритм пометит ее как не страдающую ожирением. Почему? Потому что KNN-классификатор следует правилу выбора класса большинства среди всех достаточно близких точек данных. Ну, это облом, поскольку мы, вероятно, подумали бы, что кто-то ростом 1,60 и весом 70 кг имеет немного избыточный вес. К счастью, есть решение этой проблемы: увеличьте количество точек данных, с которыми следует сравнивать нашего нового человека без метки. Предположим, что есть еще 3 тучных человека со следующими показателями: рост 1,50 и 100 кг, рост 1,55 и 100 кг и рост 1,80 и 100 кг. Затем есть еще один человек, не страдающий ожирением, ростом 1,80 и весом 80 кг. Если мы теперь скажем нашему алгоритму сравнить новую немаркированную точку данных со всеми 9других людей, большинство из которых страдают ожирением, алгоритм пометит нашего нового человека как страдающего ожирением.
Ну, это облом, поскольку мы, вероятно, подумали бы, что кто-то ростом 1,60 и весом 70 кг имеет немного избыточный вес. К счастью, есть решение этой проблемы: увеличьте количество точек данных, с которыми следует сравнивать нашего нового человека без метки. Предположим, что есть еще 3 тучных человека со следующими показателями: рост 1,50 и 100 кг, рост 1,55 и 100 кг и рост 1,80 и 100 кг. Затем есть еще один человек, не страдающий ожирением, ростом 1,80 и весом 80 кг. Если мы теперь скажем нашему алгоритму сравнить новую немаркированную точку данных со всеми 9других людей, большинство из которых страдают ожирением, алгоритм пометит нашего нового человека как страдающего ожирением.
Как теперь найти ближайших соседей ? Чтобы идентифицировать точки данных, ближайшие к нашей непомеченной точке, мы (или наш алгоритм) вычислили евклидово расстояние. На основе этого расстояния мы можем затем определить ближайших K соседей, с которыми мы хотим сравнить наши немаркированные данные. И как мы выбираем правильное количество соседей? Ну, это настройка параметров. Есть несколько вариантов, как выбрать K , но это может быть совершенно случайно. Некоторые используют квадратный корень из числа наблюдений, например, как здесь.
И как мы выбираем правильное количество соседей? Ну, это настройка параметров. Есть несколько вариантов, как выбрать K , но это может быть совершенно случайно. Некоторые используют квадратный корень из числа наблюдений, например, как здесь.
KNN работает хорошо, когда мы пометили данные с небольшим шумом. Выборка также не должна быть слишком большой (Источник). Не рекомендуется использовать KNN со сложными наборами данных. В целом, запуск классификатора KNN может занять довольно много времени, особенно при наличии большого количества соседей.
Дерево решений
Деревья решений относятся к категории обучения с учителем (Источник). Они также носят название CART или деревья классификации и регрессии. Одна из его наиболее известных и прикладных вариаций называется Random Forest. Дерево решений состоит из узлов, представляющих соответствующие входные переменные, и конечных узлов с выходной переменной. Предположим, у вас есть три фрукта, яблоко, банан и киви, и вы хотите научить свою машину различать их по цвету. Набор правил, которые мы можем вывести из нашего дерева, выглядит следующим образом:
Набор правил, которые мы можем вывести из нашего дерева, выглядит следующим образом:
Если цвет=желтый, то банан
Если цвет!=желтый и диаметр<2, то киви
Если цвет!=желтый и диаметр>2, то яблоко
В приведенном выше примере показано, что дерево решений состоит из ветвей. На каждом филиале мы принимаем решение . Так называемое решение также может быть реакцией или событием (Источником). Последний этап в нижней части дерева решений называется конечным листом и содержит окончательную классификацию упражнения. Точно так же первая стадия наверху дерева называется 9.0013 корневой узел . Глубина дерева — это количество стадий (слоев), а листьев дерева — это количество категорий (ящиков) в корневом узле (нижний слой).
При оценке деревьев решений нам необходимо знать о ряде других концепций. Во-первых, энтропия : Энтропия измеряет степень случайности или непредсказуемости в наборе данных. Тогда есть прироста информации . Прирост информации измеряет снижение энтропия за счет разделения нашего набора данных. Алгоритм дерева решений — это не что иное, как решение другой задачи оптимизации. Что мы пытаемся сделать, так это минимизировать нашу знаменитую функцию потерь (или функцию стоимости), которая в данном случае представляет собой энтропию . Или, другими словами, мы пытаемся максимизировать прирост информации . Формулу энтропии смотрите в этом видео.
Тогда есть прироста информации . Прирост информации измеряет снижение энтропия за счет разделения нашего набора данных. Алгоритм дерева решений — это не что иное, как решение другой задачи оптимизации. Что мы пытаемся сделать, так это минимизировать нашу знаменитую функцию потерь (или функцию стоимости), которая в данном случае представляет собой энтропию . Или, другими словами, мы пытаемся максимизировать прирост информации . Формулу энтропии смотрите в этом видео.
Итак, как мы можем применить эти деревья решений в машинном обучении? Предположим, вы хотите предсказать, зарабатывает ли кто-то более 100 000 долларов США, исходя из компании, должности человека, а также степени, как в этом примере. В домашинные времена мы делали это вручную, создавая дерево решений вручную. Вероятно, мы бы начали с компании, затем продолжили бы работу и, наконец, степень. Это может быть довольно просто, но во многих случаях вы можете столкнуться с сотнями атрибутов и тысячами сотрудников. Поэтому выполнение задачи вручную стало бы довольно сложным и заняло бы безумное количество времени. Теперь хорошо то, что мы можем управлять машинами, которые делают за нас жадную и жадную работу. Поэтому мы, как и во всех других примерах машинного обучения, обучаем нашу машину на обучающих данных, а это означает, что у нас есть набор данных, для которого мы уже наблюдаем заработную плату для каждого сотрудника.
Поэтому выполнение задачи вручную стало бы довольно сложным и заняло бы безумное количество времени. Теперь хорошо то, что мы можем управлять машинами, которые делают за нас жадную и жадную работу. Поэтому мы, как и во всех других примерах машинного обучения, обучаем нашу машину на обучающих данных, а это означает, что у нас есть набор данных, для которого мы уже наблюдаем заработную плату для каждого сотрудника.
Вы передаете алгоритму некоторые предопределенные параметры, такие как максимальное количество слоев (глубина) и минимальное количество листьев (конечные категории). Это необходимо, так как алгоритм должен знать, когда остановиться. Вы можете определить оптимальное количество шпагатов путем обрезки. Основная идея обрезки заключается в том, что вы после каждого дополнительного разделения спрашиваете себя, действительно ли это разделение было необходимо (привело ли оно к каким-либо значительным улучшениям или падению функции затрат). Более сложный метод сокращения называется сокращением сложности стоимости и учитывает параметр обучения для принятия решения об удалении узлов или нет. Затем мы запускаем алгоритм на наших обучающих данных (скажем, 30 процентов нашего предварительно размеченного набора данных) и прогнозируем заработную плату на наших тестовых данных (оставшиеся 70 процентов нашего предварительно размеченного набора данных). Мы можем оценить производительность модели благодаря нашей знаменитой точности. Если нам нравится то, что мы видим, мы можем сделать прогноз на основе новых, невидимых и немаркированных данных.
Затем мы запускаем алгоритм на наших обучающих данных (скажем, 30 процентов нашего предварительно размеченного набора данных) и прогнозируем заработную плату на наших тестовых данных (оставшиеся 70 процентов нашего предварительно размеченного набора данных). Мы можем оценить производительность модели благодаря нашей знаменитой точности. Если нам нравится то, что мы видим, мы можем сделать прогноз на основе новых, невидимых и немаркированных данных.
Деревья решений легко визуализировать и интерпретировать. Нам также нужно немного подготовить данные при работе с деревьями решений, и они хорошо работают при нелинейных параметрах. К сожалению, деревья решений часто страдают от переобучения и высокой дисперсии. Кроме того, в случае низкого смещения модель может плохо работать с невидимыми данными. Чтобы узнать о кодах Python, стоящих за всем этим, посмотрите это видео.
Наивный байесовский классификатор
Наивный байесовский классификатор представляет собой модель условной вероятности.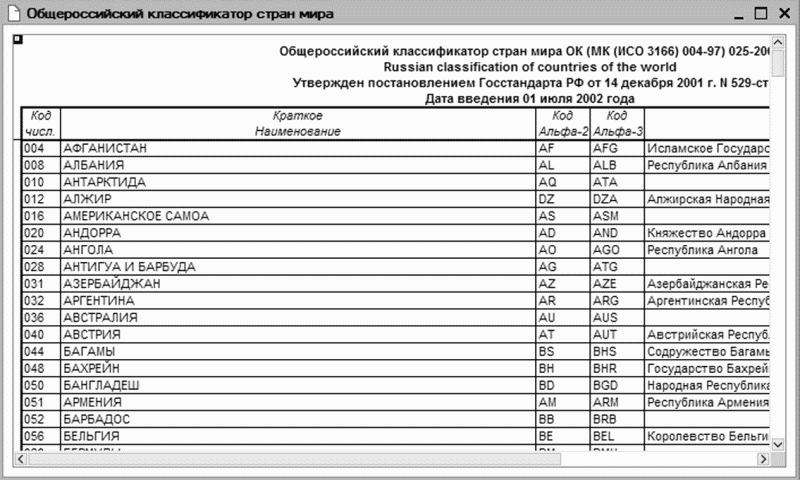
Чтобы проиллюстрировать это, давайте рассмотрим конкретный пример, классификацию электронных писем на спам и не спам. У нас есть обучающий набор электронных писем, которые мы вручную классифицировали как спам и не спам.
 здесь. Для практического применения следуйте этому коду.
здесь. Для практического применения следуйте этому коду. Проблема с наивным байесовским классификатором заключается в предположении о его независимости. Предположение, что все предикторы (или признаки) независимы, в реальной жизни крайне маловероятно. Кроме того, алгоритм страдает от проблемы нулевой частоты . Допустим, слово «солнечный» не появилось в ваших тренировочных данных, но появилось в ваших тестовых данных. Наивный байесовский классификатор присвоит всем этим случаям нулевую вероятность (Источник. Он просто игнорирует неизвестные слова (Источник) и не может классифицировать невидимые новые слова. Это можно решить с помощью методов сглаживания, таких как оценка Лапласа. Для лежащего в основе рационального см. это обсуждение, а сводку плюсов и минусов этой модели см. здесь.
Наивный байесовский метод хорош тем, что его очень просто и легко реализовать, он требует меньше обучающих данных, относительно быстр и хорошо масштабируется, может работать как с непрерывными, так и с категориальными переменными и не чувствителен к нерелевантным функциям (Источник).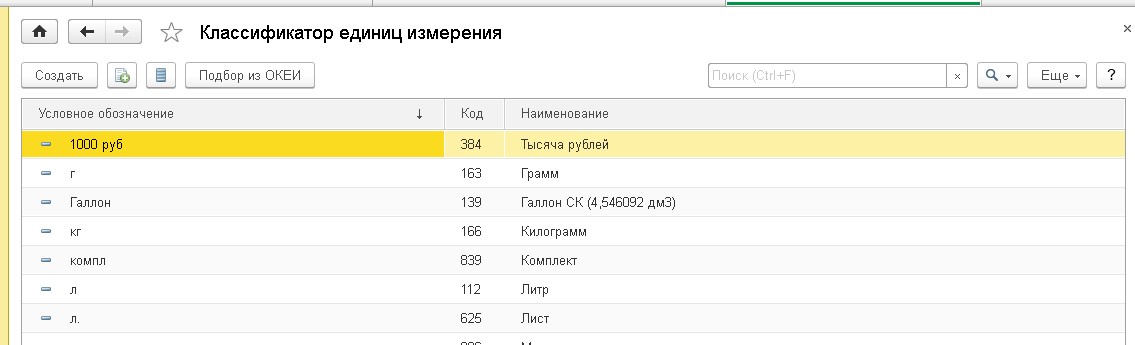
Регуляризованные линейные и логистические модели
Регуляризованные линейные модели — один из самых популярных алгоритмов для задач обучения с учителем. В моем предыдущем сообщении в блоге я немного напомнил вам о простых линейных регрессиях и OLS (обычный метод наименьших квадратов). Чтобы просмотреть основные математические аннотации, стоящие за этим, см. здесь. Проблема в том, что в некоторых случаях это не работает. Одной из проблем является мультиколлинеарность. Мультиколлинеарность — это когда наши объясняющие переменные зависят друг от друга (имеют некоторую форму отношений друг с другом). Помните приведенный выше пример с ростом, весом и размером ноги? Мой вес определенно зависит от моего роста, поэтому предположение, что они независимо влияют на пол человека, может быть сильным предположением, которое не соответствует действительности. Другая проблема заключается в том, что теперь, с большими данными, у нас часто бывают случаи, когда у нас больше объясняющих переменных, чем точек данных.

Для начала давайте напомним себе о важном понятии, компромиссе смещения и дисперсии. Чтобы напомнить себе, о чем идет речь, давайте вернемся к практическому примеру. Предположим, ваш вес составляет 60,34 кг. Давайте теперь представим, что нам нужно выбрать между 4 различными балансами. Чтобы проверить их точность, мы трижды взвешиваемся на каждом из трех сбалансированных весов. Вы записываете следующие результаты:
- Баланс 1: 60,2, 60,5, 60,4, 60,4: Этот баланс имеет низкую дисперсию (отклонения) и низкую погрешность (дает правильное среднее значение, равное 60,34 кг).
- Баланс 2: 58,2, 57,9, 58,0, 59,0: Этот баланс имеет низкую дисперсию (отклонения), но смещение (среднее значение 58,3 кг и слишком низкое).
- Баланс 3: 55,9, 65,8, 57,2, 63,2: Этот баланс имеет высокую дисперсию (отклонения), но низкое смещение (среднее значение равно 60,5 и близко к нашему фактическому весу).
Теперь вы, очевидно, захотите выбрать Баланс 1. Дело в том, что этот вариант не существует при коллинеарности. Вам нужно выбрать между смещением (баланс 2 или регрессия хребта) или высокой дисперсией (баланс 3 или регрессия МНК). Еще один способ начать это — подумать об ограничениях анализа данных. Вернемся к нашему фактическому весу. Каков наш фактический вес, в конце концов? Должны ли мы взвешиваться первым делом утром, перед тем, как выпить стакан воды, или после? До или после завтрака? Перед туалетом или после? До или после похода в спортзал и выпитого с потом пол-литра жидкости? Так что на самом деле вы можете искать какой-то супер-баланс, который учитывает все эти факторы, играющие роль в вашем окончательном весе. Этот новый супербаланс, возможно, будет основываться на такой информации, как время дня и ваш вес за прошлые дни. Если супербаланс заметит, что ваш вес в 6 утра на 0,5 кг ниже среднего веса прошлых дней около 10 утра и на 0,5 кг тяжелее в 7 вечера, он может догадаться, что это связано с вашей одеждой. или потребление воды и пищи, и сократить наблюдения с 6 утра и 7 вечера до наблюдаемого среднего значения за прошлые дни.
Дело в том, что этот вариант не существует при коллинеарности. Вам нужно выбрать между смещением (баланс 2 или регрессия хребта) или высокой дисперсией (баланс 3 или регрессия МНК). Еще один способ начать это — подумать об ограничениях анализа данных. Вернемся к нашему фактическому весу. Каков наш фактический вес, в конце концов? Должны ли мы взвешиваться первым делом утром, перед тем, как выпить стакан воды, или после? До или после завтрака? Перед туалетом или после? До или после похода в спортзал и выпитого с потом пол-литра жидкости? Так что на самом деле вы можете искать какой-то супер-баланс, который учитывает все эти факторы, играющие роль в вашем окончательном весе. Этот новый супербаланс, возможно, будет основываться на такой информации, как время дня и ваш вес за прошлые дни. Если супербаланс заметит, что ваш вес в 6 утра на 0,5 кг ниже среднего веса прошлых дней около 10 утра и на 0,5 кг тяжелее в 7 вечера, он может догадаться, что это связано с вашей одеждой. или потребление воды и пищи, и сократить наблюдения с 6 утра и 7 вечера до наблюдаемого среднего значения за прошлые дни. Тогда у нас будет меньше дисперсии, но также и систематическая ошибка, поскольку мы можем не получить точное среднее значение или сообщить о фактических изменениях веса в задержках.
Это как раз и есть основная концепция гребень регресс. Помните наш пример с образованием и заработной платой и тем фактом, что некоторые работники имели удивительно высокую для своего уровня образования заработную плату (так называемые выбросы). Что ж, гребневая регрессия добавит несколько искусственных сотрудников, что сведет на нет эти выбросы.
Тогда у нас будет меньше дисперсии, но также и систематическая ошибка, поскольку мы можем не получить точное среднее значение или сообщить о фактических изменениях веса в задержках.
Это как раз и есть основная концепция гребень регресс. Помните наш пример с образованием и заработной платой и тем фактом, что некоторые работники имели удивительно высокую для своего уровня образования заработную плату (так называемые выбросы). Что ж, гребневая регрессия добавит несколько искусственных сотрудников, что сведет на нет эти выбросы.
Так мы избегаем переоснащения . С математической точки зрения это означает добавление штрафа за регуляризацию к нашей функции потерь (Источник). В случае OLS мы добавили бы штраф к сумме квадратов ошибок. Штраф состоит из параметра настройки (лямбда) и штрафа (в случае ребро часто называют L2 ). L2 является линейной функцией квадратов коэффициентов, составляющих часть модели. Важно отметить, что в гребневых регрессиях мы только уменьшаем коэффициенты параметров, но не исключаем их полностью (Источник).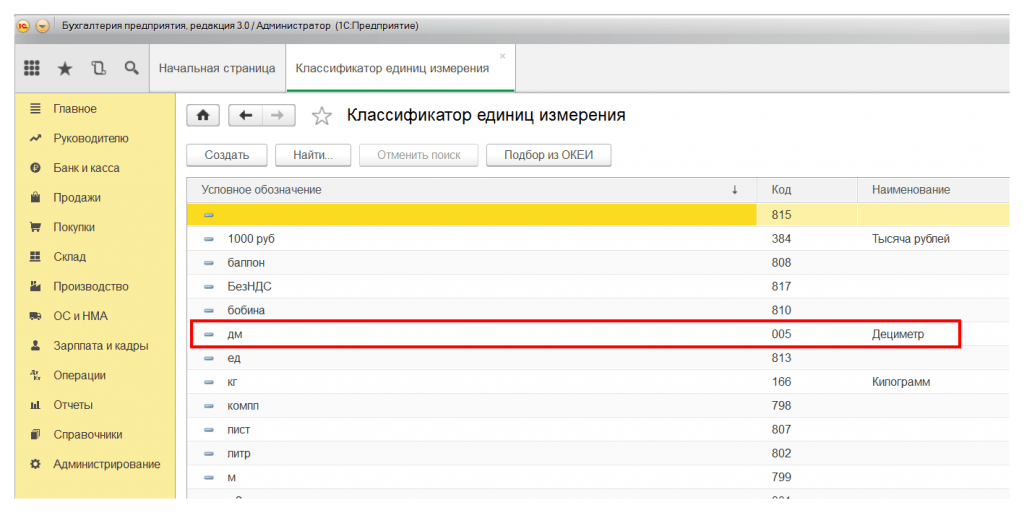 Вот почему все независимые переменные являются частью модели. Это главное отличие от регрессий лассо , которые мы рассмотрим далее.
Вот почему все независимые переменные являются частью модели. Это главное отличие от регрессий лассо , которые мы рассмотрим далее.
Ну, это звучит очень абстрактно, так что давайте посмотрим на конкретный пример. Предположим, мы хотим предсказать заработную плату людей на основе их лет образования. Предположим, что наши обучающие данные состоят только из двух точек данных: один сотрудник с 10-летним образованием и заработком 2000 валют, а другой с 13-летним образованием и заработком 4000 валют. МНК из этого уравнения предполагает, что влияние образования на заработную плату составляет 500. Глядя на наш график ниже, при добавлении данных тестирования, состоящего из дополнительных 3 сотрудников, это завышенная оценка. OLS завысил самую высокую зарплату, которая на самом деле была своего рода выбросом. Фактическое отношение намного ниже с 440. Ридж (оранжевая линия на правом графике) пытается объяснить это, вводя небольшое смещение, но уменьшая дисперсию и риск переобучения. Если концепция еще не ясна, посмотрите это видео, которое дает очень четкое объяснение. На практическом примере применения ridge с Python, посмотрите здесь.
Если концепция еще не ясна, посмотрите это видео, которое дает очень четкое объяснение. На практическом примере применения ridge с Python, посмотрите здесь.
Лассо работает аналогично ребру регрессий, но вместо штрафа L2 применяется штраф L1. Это означает, что он добавляет штраф, равный взвешенной сумме коэффициентов моделей (Источник). Это означает, что, в отличие от ребра , некоторые из коэффициентов будут равны нулю, что приводит к тому, что известно под термином выбор признака . Таким образом, модель будет проще и будет включать меньше независимых переменных. Математические подробности, стоящие за этим, см. здесь. Для практического применения Lasso на Python, см. здесь.
Итак, теперь, когда мы знаем, как выглядят Ridge и Lasso , мы можем взглянуть на их общего потомка, Elastic Net . Эластичная сетка сочетает в себе штрафы от хребта и лассо, включая их оба и взвешивая их дополнительным параметром (альфа).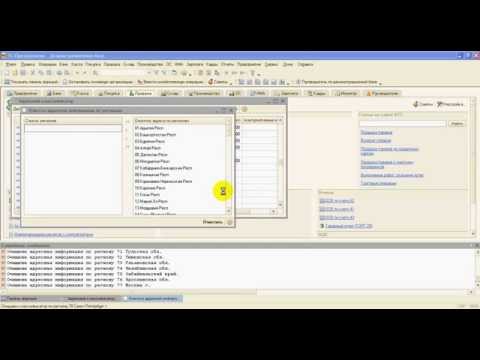 Здесь вы можете увидеть, как это выглядит с точки зрения формулы, и это хороший практический пример на Python (видеоурок см. в этом примере от Simplilearn.
Здесь вы можете увидеть, как это выглядит с точки зрения формулы, и это хороший практический пример на Python (видеоурок см. в этом примере от Simplilearn.
Кстати, параметр настройки (лямбда) очень важен в линейных регрессиях. Лассо, параметр настройки, равный нулю, будет равен регрессии OLS, а лямбда бесконечного значения будет равен модели, состоящей только из перехвата Мы можем найти оптимальный параметр настройки с помощью перекрестной проверки (CV) или просмотра других параметров , такие как AIC (информационный критерий Акаике) и BIC (байесовский информационный критерий).
Проблема с этими линейными регрессиями заключается в том, что они часто уступают более сложным алгоритмам, что приводит к лучшим прогнозам. Тем не менее, их легче понять и интерпретировать. Когда мы должны использовать Lasso и когда Ridge? Эмпирическое правило состоит в том, чтобы использовать регуляризацию хребта в случаях, когда у вас есть много переменных с относительно небольшим объемом данных, и использовать регуляризацию лассо в случаях, когда у вас меньше переменных (источник).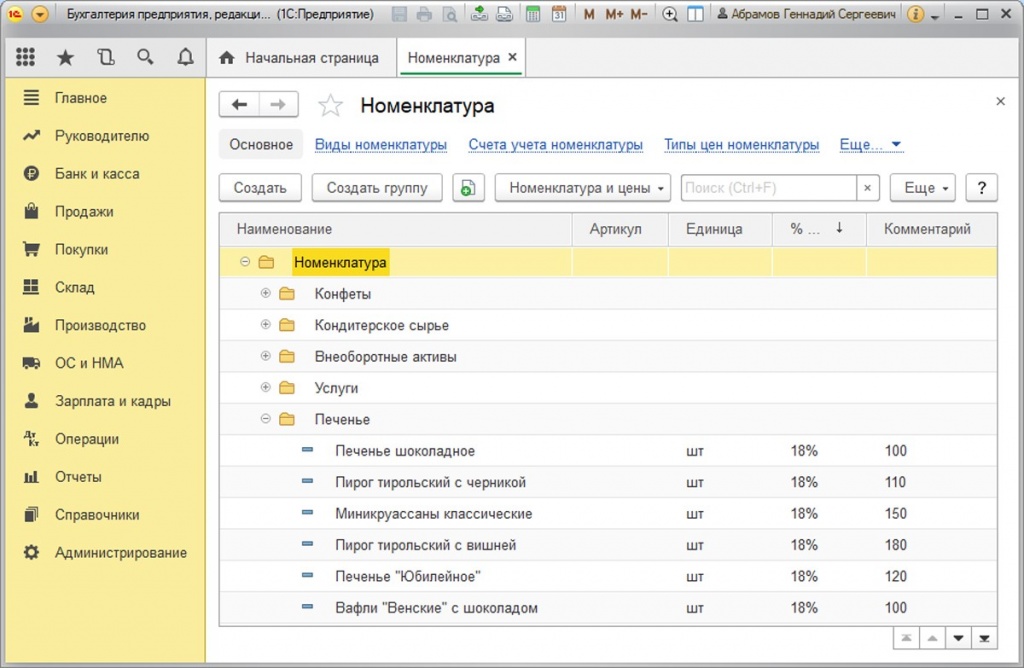
Машина опорных векторов
Я уже говорил об SVM в одной из своих предыдущих статей. Просто чтобы дать вам небольшое напоминание, основная идея SVM состоит в том, чтобы разделить точки данных на разные классы путем рисования линии, которая максимизирует пространство между ними, только то, что в SVM мы подходим к этому не через линию, а через гиперплоскость и опорные векторы . Возможно, вы помните, что размерность гиперплоскости зависит от количества объектов. SVM хорошо работает с многомерными данными, разреженными векторами документов и решает проблемы переобучения и смещения (Источник). Хороший пример смотрите в этом видео.
Случайные леса
Случайные леса — это один из самых продвинутых алгоритмов, входящий в состав так называемых ансамблевых классификаторов. Это классификаторы, которые объединяют оценки нескольких отдельных оценщиков, чтобы сделать лучший прогноз. В частности, они составляют часть группы параллельных ансамблевых методов (подробнее об этом позже).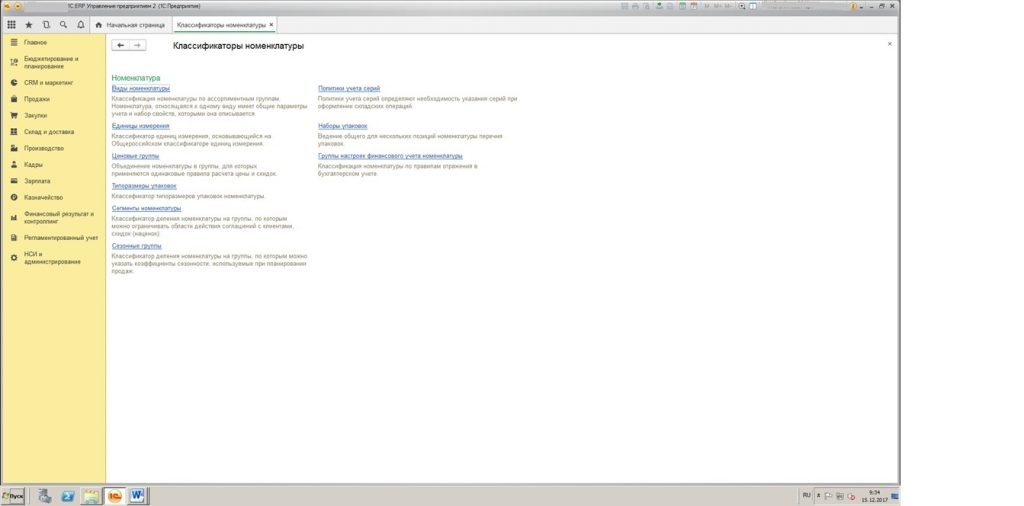 Случайные леса используются в различных приложениях, таких как дистанционное зондирование, обнаружение многоклассовых объектов, а также в технологиях игровых консолей (Source). Что делает случайный лес, так это оценивает несколько отдельных деревьев решений, а затем принимает большинство голосов в качестве окончательного решения. Возьмем пример ниже. Вы хотите предсказать, является ли животное кошкой или ягненком. Вы делаете 3 разных дерева решений, из которых 2 говорят вам, что это кошка, а одно говорит вам, что это ягненок. Алгоритм случайного леса рассматривает все деревья, так называемый лес, и принимает в качестве окончательного результата большинство голосов, в данном случае кошку.
Случайные леса используются в различных приложениях, таких как дистанционное зондирование, обнаружение многоклассовых объектов, а также в технологиях игровых консолей (Source). Что делает случайный лес, так это оценивает несколько отдельных деревьев решений, а затем принимает большинство голосов в качестве окончательного решения. Возьмем пример ниже. Вы хотите предсказать, является ли животное кошкой или ягненком. Вы делаете 3 разных дерева решений, из которых 2 говорят вам, что это кошка, а одно говорит вам, что это ягненок. Алгоритм случайного леса рассматривает все деревья, так называемый лес, и принимает в качестве окончательного результата большинство голосов, в данном случае кошку.
Но откуда берутся эти разные предсказания? Что ж, результат дерева зависит от порядка параметров решения. Ниже представлены 3 разных дерева с разным исходом. Теперь предположим, что у вас есть большая белая собака. Первое дерево скажет вам, что животное — ягненок, второе — что это кошка, а третье — что это ягненок. Таким образом, окончательное решение лесного дерева будет классифицировать белую большую копать как ягненка.
Таким образом, окончательное решение лесного дерева будет классифицировать белую большую копать как ягненка.
Как вы можете видеть на картинке выше, 3 дерева генерируются параллельно. Вот почему случайные леса являются частью методов параллельного ансамбля, а не методов последовательного ансамбля (подробнее об этом позже) (Источник). Благодаря объединению нескольких деревьев, а не просто просмотру одного дерева, общий прогноз модели будет более точным и надежным.
Подведение итогов
Что ж, как вы видели, недостатка в классификаторах нет! Пытаясь решить проблему классификации, вы можете начать с выборочной проверки некоторых из них и сравнения их эффективности. Или вы можете сделать шаг назад, подумать о структуре ваших данных и решить, какой тип классификатора лучше всего подойдет для того вида или проблемы, с которой вы столкнулись! Логистическая регрессия отлично подходит для биномиальных результатов, K-ближайшие соседи хорошо работают для распознавания образов или интеллектуального анализа данных, SVM может быть лучшей моделью при работе с многомерными данными, а деревья решений следует использовать для анализа решений (Источник). Все вышеперечисленные алгоритмы имеют свои ограничения и недостатки. В то время как логистическая регрессия полагается на высокую представимость данных, KNN плохо работает с многомерными данными. С другой стороны, SVM и деревья решений плохо работают с большими наборами данных и наборами данных с большим количеством шума. Есть несколько методов и показателей, на которые вы можете обратить внимание, чтобы определить наилучший возможный классификатор среди всех, на которые вы смотрите, но это пища для будущей публикации в блоге. А пока получайте удовольствие, экспериментируя с некоторыми классификаторами ML!
Все вышеперечисленные алгоритмы имеют свои ограничения и недостатки. В то время как логистическая регрессия полагается на высокую представимость данных, KNN плохо работает с многомерными данными. С другой стороны, SVM и деревья решений плохо работают с большими наборами данных и наборами данных с большим количеством шума. Есть несколько методов и показателей, на которые вы можете обратить внимание, чтобы определить наилучший возможный классификатор среди всех, на которые вы смотрите, но это пища для будущей публикации в блоге. А пока получайте удовольствие, экспериментируя с некоторыми классификаторами ML!
Классификатор — C3 AI
Поиск:Что такое классификатор?
В науке о данных классификатор — это тип алгоритма машинного обучения, используемый для присвоения метки класса входным данным. Примером может служить классификатор распознавания изображений для маркировки изображения (например, «автомобиль», «грузовик» или «человек»). Алгоритмы классификатора обучаются на размеченных данных; например, в примере с распознаванием изображений классификатор получает обучающие данные, которые маркируют изображения.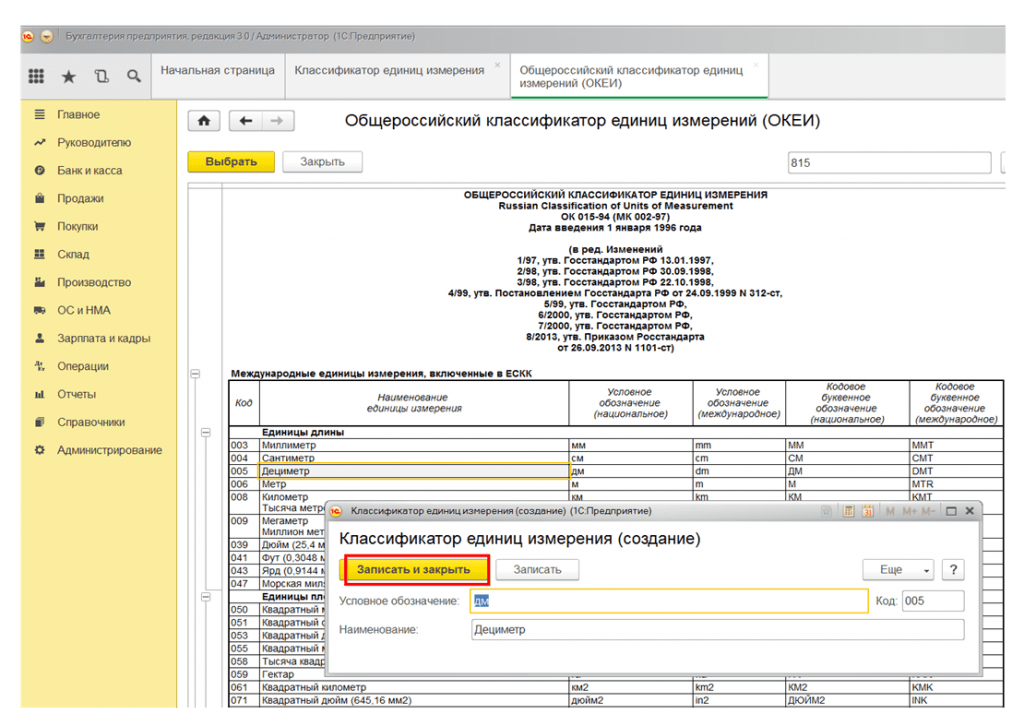 После достаточного обучения классификатор может получать немаркированные изображения в качестве входных данных и выводить классификационные метки для каждого изображения.
После достаточного обучения классификатор может получать немаркированные изображения в качестве входных данных и выводить классификационные метки для каждого изображения.
Алгоритмы классификатора используют сложные математические и статистические методы для прогнозирования вероятности того, что входные данные будут классифицированы определенным образом. В примере с распознаванием изображений классификатор статистически предсказывает, может ли изображение быть автомобилем, грузовиком или человеком, или какой-либо другой классификацией, которую классификатор обучен идентифицировать.
Почему важны классификаторы?
Классификация, то есть присвоение входным данным определенной метки класса, является фундаментальной функцией многих корпоративных приложений ИИ, и классификаторы являются ключевым элементом многих из этих приложений. Классификаторы широко используются для ряда распространенных случаев использования, таких как определение принадлежности клиента к определенному сегменту, определение того, является ли финансовая транзакция мошеннической, или определение того, находится ли часть полевого оборудования в рабочем состоянии на основе фото или видео. отснятый материал.
отснятый материал.
Классификация — это серьезная область постоянных исследований и инноваций в области машинного обучения. Значительные академические и коммерческие усилия были вложены в разработку разнообразного набора алгоритмов классификатора, оптимизированных для различных типов задач классификации. Были разработаны многочисленные надежные методы классификатора, и многие из них доступны через библиотеки с открытым исходным кодом, например, классификаторы Python от Pypi.org.
Как C3 AI позволяет организациям использовать классификаторы
Платформа C3 AI ® не только предоставляет богатую библиотеку классификаторов для использования при создании корпоративных приложений ИИ, но и полный набор возможностей для упрощения и ускорения использования классификаторов в корпоративных приложениях ИИ. Платформа C3 AI предоставляет и поддерживает обширную библиотеку алгоритмов машинного обучения для классификации, таких как древовидные модели, логистическая регрессия и глубокие нейронные сети.