«РИБ в 1С простыми словами» и «Как подчиненную базу 1С сделать самостоятельной» / Хабр
Оговорка: Предполагается, что читатель знает что такое синхронизация баз в 1С.
ПЕРЕД ЛЮБЫМИ ОПАСНЫМИ ДЕЙСТВИЯМИ/ОПЕРАЦИЯМИ С БАЗАМИ 1С ВСЕГДА ДЕЛАЙТЕ РЕЗЕРВНУЮ КОПИЮ
И вообще всегда делайте резервную копию.
Резервных копий много не бывает.
В любой непонятной ситуации делайте резервную копию.
=======================================================================
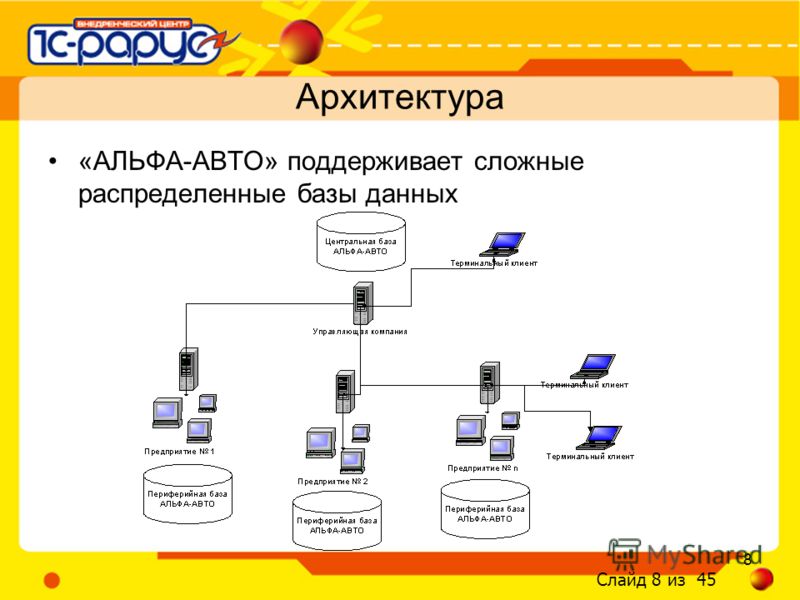
Механизм РИБ — механизм распределенных информационных баз — это когда у вас есть главная база и подчиненная(ые). Главная база может быть только одна, подчиненных может быть много. Каждая подчиненная база может иметь свои подчиненные базы, для которых она будет главной.
Вот посмотрим на картинку из первой ссылки по запросу в Яндексе:
Зачем это надо?
РИБ используется для обмена данными. Причем не только теми данными, с которыми работает пользователь, но и данными изменения конфигурации. То есть РИБ позволяет передавать изменения конфигурации. Но изменить конфигурацию можно только в главной базе!
Причем не только теми данными, с которыми работает пользователь, но и данными изменения конфигурации. То есть РИБ позволяет передавать изменения конфигурации. Но изменить конфигурацию можно только в главной базе!
Визуализируем:
У нас большая компания и много филиалов. Есть доработанная УНФ, которую мы гордо называем УБФ(Управление Большой Фирмой). Но мы решили, что хватит терпеть то, что все филиалы имеют доступ к документам всех филиалов и каждому филиалу решили сделать отдельную базу, которую синхронизировать с нашей основной базой для передачи данных. Что ж, можно. Сделали.
И внезапно мы решили изменить картинку, которая появляется при входе в базу, захотели поместить туда логотип нашей фирмы, а почему бы и нет?
Как запилить картинку во все базы всех филиалов? Ну при текущем варианте, что у всех филиалов отдельная база, только руками… Руками специалистов, которые умеют заходить в конфигуратор и знают что нужно там нажать.
А вот если бы мы сделали подчиненные базы для филиалов, то есть использовали РИБ, то и данными бы обменивались, как при обычной синхронизации, и картинка бы сама добавилась во все «базы-дочки». Однако, в конфигуратор зайти бы все-таки пришлось, но только чтобы нажать кнопочку «Обновить конфигурацию базы данных», вот картинка:
Как создать подчиненную базу, на пальцах:
я буду использовать Управление торговлей, редакция 11 (11.4.13.275), но способ, в целом, одинаковый во всех типовых конфигурациях.
1) Сначала проделаем шаги, как при настройке обычной синхронизации:
2) …поставим галочку, нажмем…
3) еще нажмем…
4) тут ознакомимся с описанием. Я выберу обычную настройку, но если бы мы следовали примеру выше, то нужно было бы выбрать «с фильтром» и там одним кликом выбрать нужный филиал.
5) Укажем каталог, где будут храниться файлы обмена — это файлы, которые создают конфигурации при синхронизации через файл… Сначала первая база создает файл обмена, куда записывает информацию о том, что она выгрузила (выгрузка зарегистрированных изменений), вторая база подгружает этот файл себе, на основании информации в нем создает у себя новые данные (или изменяет существующие) и создает свой файл, который предназначен для первой базы, где, в общем случае, записана информация о том, что база приняла изменения и выложила то, что изменилось у нее.
6) Указываем префикс — он будет подставляться к номерам документов, чтобы можно было отличить документы дочки и основной базы.
7) в общем случае, тут ничего не надо нажимать, кроме «Записать и закрыть».
8) А вот теперь создаем нашу новую подчиненную базу:
9) указываем место, куда ее покладем…
Дождемся окончания:
10) Зайдем в нашу новую подчиненную базу и закончим настройки синхронизации(синхронизация уже создалась, так как использовали РИБ, но нужно указать каталог для обмена выбрав «Настройки подключения»)
(обратите внимание на верхний левый угол окна программы, там название базы, он отличается от предыдущих, так как это «дочка»)
Кстати, в новой базе все пользователи будут выключены, пароли сброшены, нужно включить руками:
В общем-то ВСЕ.
Подчиненная база создана!
Теперь, когда наши программисты что-нибудь улучшат, эти улучшения прилетят в подчиненные базы сами…
Пример:
Вот что-то изменили в основной базе:
нам нужно перенести изменения в базы-дочки.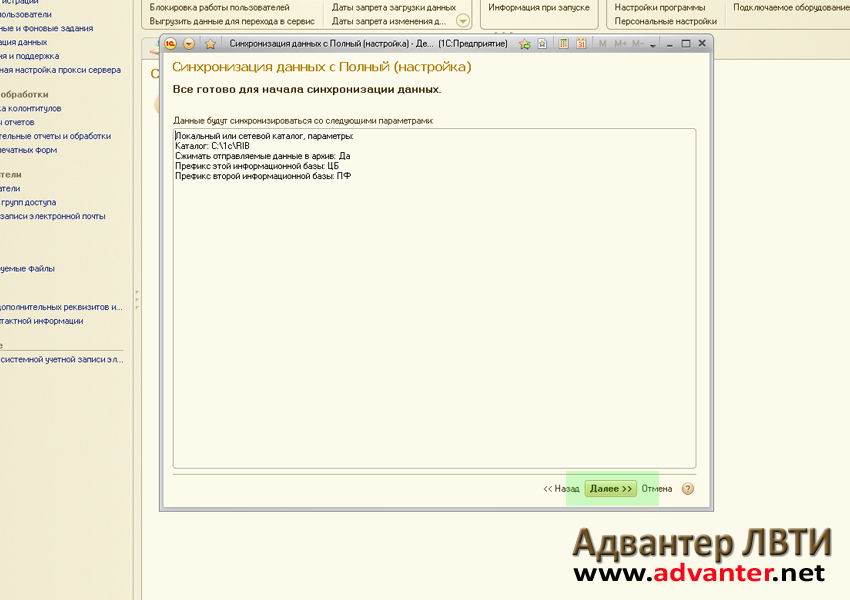
Для этого запускаем главную базу в режиме 1С:Предприятие, то есть в пользовательском интерфейсе, заходим в настройки синхронизации, жмем выделенную кнопку:
После того, как синхронизация закончится, заходим в базу дочку и так же жмем «Синхронизировать», база загрузит данные и напишет:
Устанавливаем!
После нажатия на Далее база закроется и начнет устанавливать обновления.
Когда обновы установятся, база начнет запускаться и сообщит нам следующее:
Это означает, что не обновлена конфигурация базы данных. Та самая маленькая кнопка в конфигураторе и это именно та причина, почему придется ОДИН раз зайти в конфигуратор. Что ж, зайдем в конфигуратор базы-дочки и нажмем эту кнопку, заодно вообще посмотрим что-да-как там, мы ж там еще не были…
Откроем конфигурацию и вот что увидим
Нажмем на «Обновить конфигурацию базы данных».
Увидим список изменений, которые прилетели с обновлениями:
Нажмем «Принять».
И вот эти обновления появились в подчиненной базе.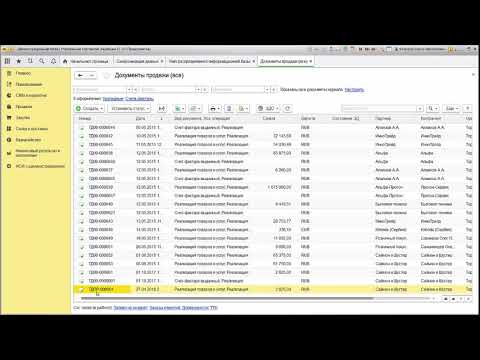
Теперь необходимо запустить базу в пользовательском режиме, чтобы выполнились обработчики обновления.
Несколько правил:
1) Все узлы, кроме одного, должны иметь по одному главному узлу и один узел не будет иметь главного узла — это корневой узел.
2) Конфигурация может быть изменена только в узле, не имеющем главного узла (то есть в корневом).
3) Изменения конфигурации будут передаваться от главного к подчиненным узлам.
4) Разрешение коллизий так же будет производиться исходя из отношений «главный — подчиненный» — если изменения сделаны одновременно и в главном и в подчиненном узлах, то приняты будут изменения главного узла.
5) Сделать подчиненный узел в распределенной базе можно разными способами, но создание начального образа является рекомендуемым.
А теперь то, ради чего все писалось…
Я опишу только тот способ, которым пользуюсь.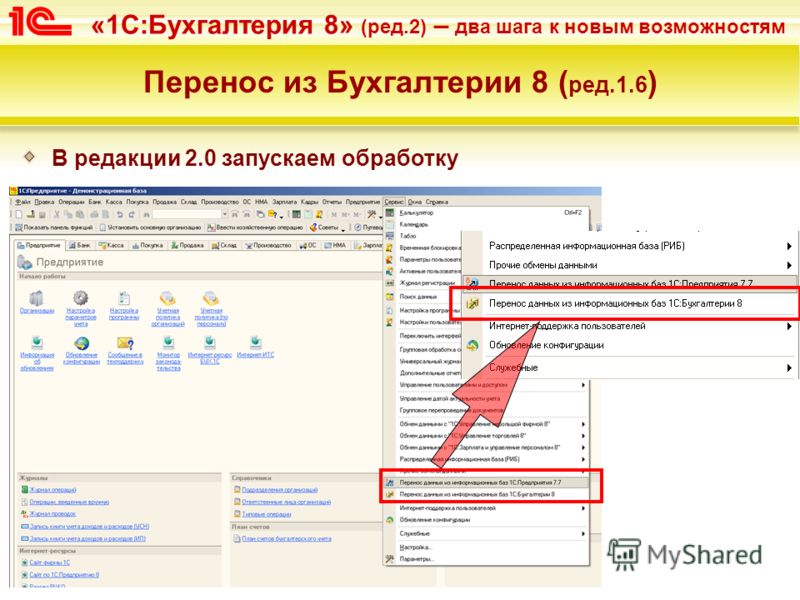 Это моя шпаргалка. Но он не единственный.
Это моя шпаргалка. Но он не единственный.
1) Заходим в свойства ярлыка запуска окна 1С:Предприятие:
2) В поле «Объект» дописываем:
DESIGNER /F»Путь до базы» /N»Имя Пользователя в базе» /P»Пароль пользователя» /ResetMasterNode
В итоге у меня получится:
«C:\Program Files\1cv8\common\1cestart.exe» DESIGNER /F»C:\Users\79119\Desktop\РИБ» /N»» /P»» /ResetMasterNode
логин и пароль пустые, ведь пользователи у меня все выключены.
3) Сохраняем изменения в ярлыке и запускаем его.
4) Не забываем удалить добавленный текст из ярлыка.
5) Готово 🙂 при запуске база сообщит:
Кликаем «Отключить» — база теперь самостоятельная!
Вот и все! Успехов хорошим людям желаю! Спасибо!
|
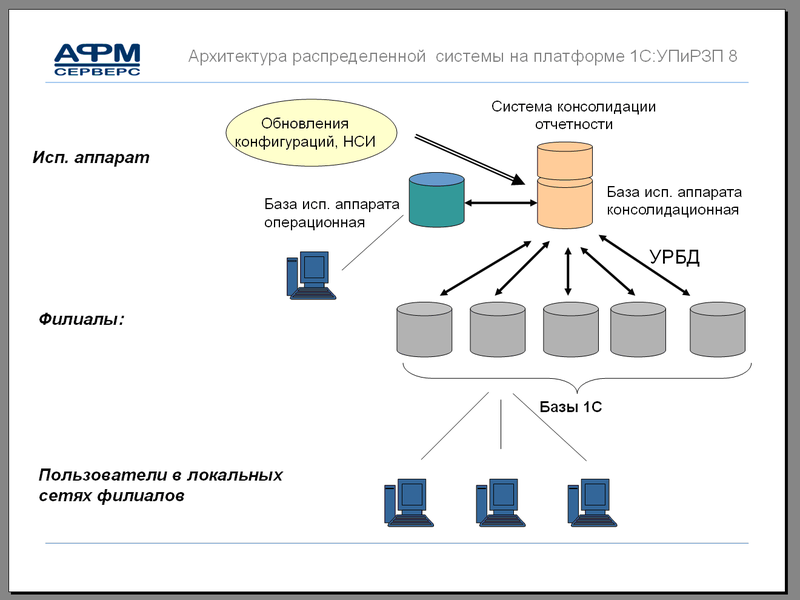
Главная » Статьи 1с » Риб что это 1с Настройка распределенной информационной базы (РИБ) в 1С 8.3Создание и настройка распределенной базы данных (РИБ) в 1С 8.3 Бухгалтерия (и других конфигурациях) необходимы в случаях, когда нет возможности работать нескольким пользователям, одновременно подключаясь к одной базе данных. Но тем не менее бывают ситуации, когда просто-напросто нет интернета. А данные должны в итоге оказаться в одной информационной базе. Для этого и создается распределенная база данных. Обычно главную базу называют центральной, а остальные — периферийными. Суть в том, что либо в ручном, либо в автоматическом режиме (зависит от настройки) базы данных объединяются в одну. Чтобы номера вновь введенных документов и коды справочников не дублировались, каждой базе данных назначается префикс. В этой инструкции мы на примере создадим центральную и периферийную базы данных, проверим обмен между ними. Это пособие подойдет как для 1С 8.3 Бухгалтерия, так и для 1С Управление торговлей (УТ) и других конфигураций. Настройка главной (центральной) распределенной базы РИБЗайдем в меню 1С «Администрирование», далее по ссылке «Настройки синхронизации данных». Заходим по ссылке «Синхронизация данных», откроется окно с кнопкой «Настроить синхронизацию данных». При нажатии на эту кнопку откроется выпадающий список, где нужно выбрать режим «Полный». Если требуется синхронизация только по одной организации, нужно выбрать «По организации…». В следующем окне нам программа предложит сделать резервную копию. Настоятельно рекомендую сделать это, так как следующие шаги настройки могут быть необратимы. После создания резервной копии нажимаем кнопку «Далее». На следующем шаге нам следует определиться, как будет происходить синхронизация:
Получите 267 видеоуроков по 1С бесплатно: Для простоты и наглядности примера выберем локальный каталог. Следующие шаги с настройкой синхронизации по FTP и электронной почте пропускаем. Останавливаемся на настройках названий главной и периферийной баз данных. Здесь же зададим префикс для периферийной базы: Не забывайте, что префиксы каждой базы должны быть уникальны. В противном случае Вы получите ошибку «Значение префикса первой информационной базы не уникально». Жмем «Далее», проверяем введенную информацию и опять нажимаем «Далее», затем — «Готово». В поле «Полное имя файловой базы» указываем файл 1Cv8.1CD в каталоге, который создали для синхронизации. Создаем начальный образ распределенной базы 1С: После создания начального образа РИБ в 1С можно задать расписание синхронизации или синхронизировать вручную: После синхронизации можно подключиться к новой базе данных и убедиться, что туда выгрузилась информация из центральной базы: Только сразу в новой периферийной базе заведите хотя бы одного пользователя с правами Администратора. Настройка синхронизации в периферийной базе данныхВ периферийной базе 1С настройка намного проще. Достаточно установить флажок «Синхронизация данных» и перейти по одноименной ссылке. И мы почти сразу попадаем в окно с кнопкой «Синхронизировать». Попробуем создать тестовую номенклатуру в периферийной базе и выгрузить ее в основную с помощью РИБ: Как видно, идет полноценный двухсторонний обмен информации с префиксами информационных баз. В заключение хочется добавить важное замечание. Изменения в конфигурации можно производить только в центральной базе данных. Эти изменения потом автоматически будут транслированы в периферийные базы. В заключение рекомендуем видеоинструкцию по настройке РИБ в 1С на примере Управление Торговлей: [youtube]https://www.youtube.com/watch?v=C7k-Y7w0LEU[/youtube] Если Вы начинаете изучать 1С программирование, рекомендуем наш бесплатный курс (не забудьте подписаться на YouTube — регулярно выходят новые видео): К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области. programmist1s.ru Настройка распределенной информационной базы (РИБ) в 1С 8.3Зачастую на практике встречаются такие ситуации, когда различные подразделения или филиалы территориально располагаются в разных местах. При этом данные, заносимые в программу в удаленных подразделениях должны как-то попадать в головной офис, чтобы велся общий учет. Зачем нужна РИБ в 1С?В настоящее время данная проблема зачастую решается предоставлением территориально удаленным сотрудникам удаленный доступ к общей базе. Он может быть осуществлен посредством публикации базы на веб-сервере, через удаленный рабочий стол и проч. Однако, не редки и такие ситуации, когда в территориально удаленном офисе попросту нет интернета, либо он не достаточно стабилен для работы в общей информационной базе. Для этого в 1С существует механизм настройки распределенной базы. Проще говоря, в головном офисе располагается главная база. В удаленном подразделении используется подчиненная. Таких подчиненных баз может быть и несколько. В результате такая распределенная база объединяется в одну посредством синхронизации. Ее можно производить как в автоматическом режиме по расписанию, так и вручную. В данной статье мы рассмотрим настройку распределенной базы данных для 1С:Бухгалтерия 3.0. Несмотря на это, инструкция подойдет и для большинства других конфигураций 1С 8.3. Обратите внимание, что все необходимые доработки конфигурации должны производиться только в главной базе РИБ. При синхронизации эти изменения передадутся во все подчиненные базы и вступят в силу. Главная информационная базаПри использовании распределенной базы данных основные настройки приходятся на главную базу. В открывшемся окне сразу же установите галку «Синхронизация данных». В нижней части укажите префикс главной (текущей базы). Он может состоять не более чем из двух символов. В нашем случае префиксом будет «БГ», так как мы подразумеваем, что эта РИБ 1С «Бухгалтерия главная». Теперь можно приступить к настройке самой синхронизации, а именно к указанию того, с какой базой (или базами) будет производиться обмен данными. Для этого перейдите по гиперссылке «Настройки синхронизации данных». Она будет доступна для перехода только при установленной галке слева. В открывшемся окне из меню выберем пункт «Полный…». Он позволит нам указать любую информационную базу 1С для произведения синхронизации. В первом окне подключения подчиненной базы, которая расположена в территориально удаленном офисе, отметим флагом, что подключение будет производиться через локальный или сетевой каталог. Далее уточним, какая РИБ будет подчиненной. В качестве префикса мы указали «БП», что в нашем случае означает «Бухгалтерия подчиненная». Вы в свою очередь можете выбрать любое другое имя. Обязательно указывайте разные префиксы для разных баз. Дело в том, что при синхронизации данных для данных, перегруженных из каждой базы, устанавливается свой префикс. При их дублировании работа будет некорректной, поэтому программа не даст вам такой возможности. Когда программа предложит вам создать начальный образ, выберите эту опцию. Данная процедура займет некоторое время, после чего сохраните его на компьютер с именем «1Cv8.1CD». Сама синхронизация может производиться как автоматически по расписанию, которое вы можете настроить самостоятельно, так и вручную. Во втором случае достаточно нажать на кнопку «Синхронизировать» в удобное для вас время. Подчиненный узел РИБКоличество производимых настроек в подчиненной базы значительно меньше. В рамках нашего примера в главную базу были добавлены две номенклатурные позиции: «Брус» и «Доска». После синхронизации они попали в подчиненную базу. Как вы можете увидеть на рисунке ниже, им присвоился префикс «БГ». Остальным двум позициям («Токарный станок» и «Поддон») присвоен префикс «БП», так как они были заведены непосредственно в подчиненной базе. Обратите внимание, что нумерация элементов в нашем случае сквозная, но только в пределах одного и того же префикса. 1s83.info Создание распределенной информационной базы (РИБ) 1С:ПредприятиеЧасто возникает ситуация, когда организация имеет несколько филиалов или торговых точек, территориально удаленных друг от друга. Тем не менее остается необходимость вести единый учет по всей организации. Одним из вариантов решения этой задачи является создание единой сети, в которую будут включены автоматизированные рабочие места всех филиалов, и размещение информационной базы 1С на общедоступном сервере. Второй вариант — создание распределенной информационной базы (РИБ). Распределенная информационная база представляет собой иерархическую структуру, состоящих из отдельных информационных баз на платформе 1С:Предприятие, между которыми организован обмен данными с целью синхронизации конфигурации и данных. Эти отдельные информационные базы называются узлами РИБ. Распределенная информационная база может быть создана на основе различных конфигураций системы 1С:Предприятие. Рассмотрим ее создание на примере 1С:Управление торговлей 10.3. Допустим, в торговой организации открывается дополнительная торговая точка, в которой необходимо иметь доступ к общей торговой системе организации. Для создания РИБ необходимо выполнить следующие шаги:
На этом создание распределенной информационной базы завершено. Для обмена информацией необходимо запустить обмен данных в Центральной базе (выгрузятся изменения, которые произошли в ней), затем — в магазине (загрузятся изменения из центральной базы и выгрузятся изменения, произошедшие в магазине), и снова — в центральной базе (в нее загрузятся изменения, произошедшие в магазине). Распределенные информационные базы имеют свой механизм разрешения коллизий. Так, если при проведении обмена выясняется, что какой-либо объект (документ, справочник и т.д.) был изменен и в главной, и в подчиненной базе, то приоритет будет иметь изменение, сделанное в главной базе. При необходимости изменить конфигурацию распределенной информационной базы, это нужно делать в корневом узле (см. первый рисунок статьи), конфигурации остальных узлов заблокированы. После проведения необходимых изменений, их можно передать в подчиненные узлы с помощью стандартной процедуры обмена данными между узлами РИБ. После проведения обмена в конфигураторе подчиненного узла необходимо выполнить обновление конфигурации информационной базы. Если у вас возникли проблемы с настройкой распределенной информационной базы, наши специалисты помогут вам настроить обмен данными и подробно объяснят, как его использовать. chel1c.ru Распределенные информационные базы, известные как РИБПри расширении организации, либо когда предприятие сосредоточено не в едином офисе, а имеет филиалы в разных частях города или разных городах, ведение единой системы учета становится не простой задачей, как ее решить? Сотрудникам, которые находятся в разных местах, нужно иметь доступ к единой базе данных, а также иметь возможность работы с этой базой, вносить изменения, получать данные, распечатывать их. Для решения подобной задачи разработан и уже давно используется компонент под названием «Управление распределенными Информационными Базами». С помощью этого компонента представляется возможным создать и организовать двухуровневую структуру из информационных баз 1С Предприятия, которая состоит из центральной и нескольких периферийных ИБ (информационных баз). Основная суть этой системы в том, что все периферийные базы работают с конфигурацией центральной базы, при этом данная система поддерживает идентичное состояние объектов данных на всех узлах этой РИБ. Данные информационных баз синхронизируются методом переноса измененных объектов данных из периферийных баз к центральной и между собой. Для обмена данными используются файлы, называемые — файлами переноса данных. Но есть такой момент, что изменения переносятся только между центральной информационной базой и периферийными, тоесть перенос данных чисто между периферийными базами невозможен. Поэтому все внесенные изменения в периферийных базах, попадают к остальным периферийным базам только через центральную. Далее пойдет обьяснение на языке программирования, если вы не хотите заморачиваться, можете пропустить этот пункт. По умолчанию область распространения изменений для каждого из объектов – это вся распределенная информационная база. Поэтому, если через определенное время изменения данных системы не будут производиться, и одновременно будут произведены все нужные действия для обмена изменениями между всеми узлами ИБ, тогда все узлы системы будут содержать идентичные данные. Иногда возникает необходимость того, чтобы объекты определенного класса не попадали в некоторые узлы распределенной ИБ, или никогда не выходили из места, где были созданы. Чтобы такие действия были доступны, существует механизм настройки параметров миграции объектов. Он позволяет ограничить распространение изменений объектов определенных классов. Также в версии 1С:Предприятие7,7 можно создавать такие периферийные информационные базы, которые будут принимать данные об измененных объектах из центральной информационной базы, но не будут передавать те изменения, которые сделаны с ними. Механизмы распространения всех изменений объектов полностью автоматизированы. Разработчик конфигурации не наделен правами вмешиваться в работу данных механизмов. Чтобы они начали работать, не нужно делать никаких действий, связанных с конфигурированием этой системы. Но для того, чтобы документы, блоки справочников, и остальные объекты, созданные на разных узлах распределенной информационной базы, имели заведомо непересекающиеся пространства кодов, номеров и прочих данных, возможно будет нужно внести изменение в конфигурацию; также нужно изменять конфигурацию для того, чтобы обеспечить специальные ограничения по работе пользователей на периферийных РИБ. Для того, чтобы переносить измененные объекты в распределенной информационной базе, а также для первичного создания периферийной информационной базы используются файлы переноса данных. Они являются сжатыми файлами, которые содержат объекты из РИБ – если периферийная база только создается, тогда все, если передаются изменение, тогда только измененные объекты ИБ . В отличии от серверной базы 1С, терминального доступа к одной базе, это совершенно иное решение, требующее создание отдельных баз (периферийных) и настройка по обмену данными между центральной и периферийной (периферийными) базами данных. Теги: риб, распределенная информационная база, 1С риб, распределенные базы данных, распределенные базы данных 1с, распределенная база данных 1с 8 www.compline-ufa.ru |
 В настоящее время это довольно редкое явление, так как прекрасно работает стандартный удаленный рабочий стол и есть другие программы, которые обеспечивают удаленное подключение к центральному компьютеру, где расположена база данных.
В настоящее время это довольно редкое явление, так как прекрасно работает стандартный удаленный рабочий стол и есть другие программы, которые обеспечивают удаленное подключение к центральному компьютеру, где расположена база данных. В открывшемся окне нужно установить флажок «Синхронизация данных». Станет активной ссылка «Синхронизация данных». Сразу здесь же установим префикс для главной информационной базы – например, «ЦБ»:
В открывшемся окне нужно установить флажок «Синхронизация данных». Станет активной ссылка «Синхронизация данных». Сразу здесь же установим префикс для главной информационной базы – например, «ЦБ»: Я указал следующий путь: «D:\Базы 1С\Синхронизация». Не лишней будет проверка записи в данный каталог, для этого есть специальная кнопка:
Я указал следующий путь: «D:\Базы 1С\Синхронизация». Не лишней будет проверка записи в данный каталог, для этого есть специальная кнопка:
 Производить их нужно в разделе «Администрирование», как показано на изображении ниже.
Производить их нужно в разделе «Администрирование», как показано на изображении ниже.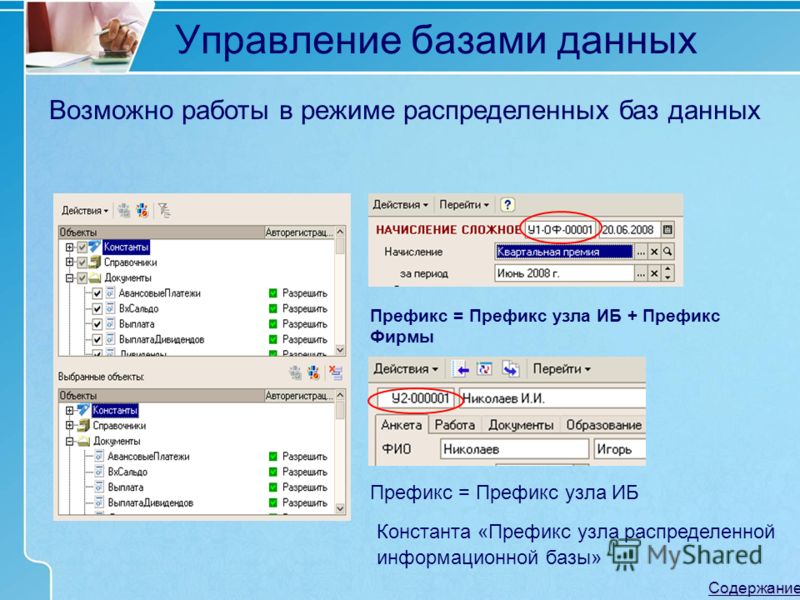 В нашем случае это «D:\DB\InfoBase». Так же заранее проверим возможность записи в него.
В нашем случае это «D:\DB\InfoBase». Так же заранее проверим возможность записи в него.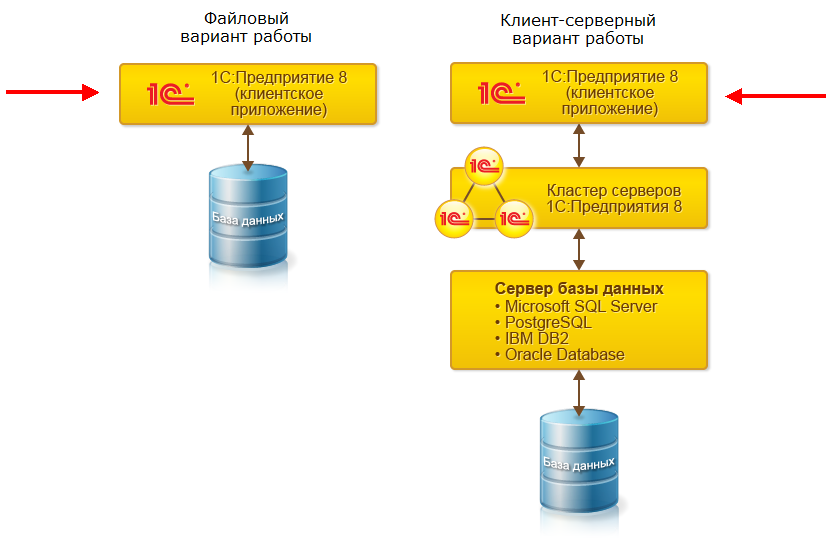 В том же разделе установите флаг «Синхронизация данных» и перейдя по соответствующей ссылке будет доступна кнопка «Синхронизировать».
В том же разделе установите флаг «Синхронизация данных» и перейдя по соответствующей ссылке будет доступна кнопка «Синхронизировать».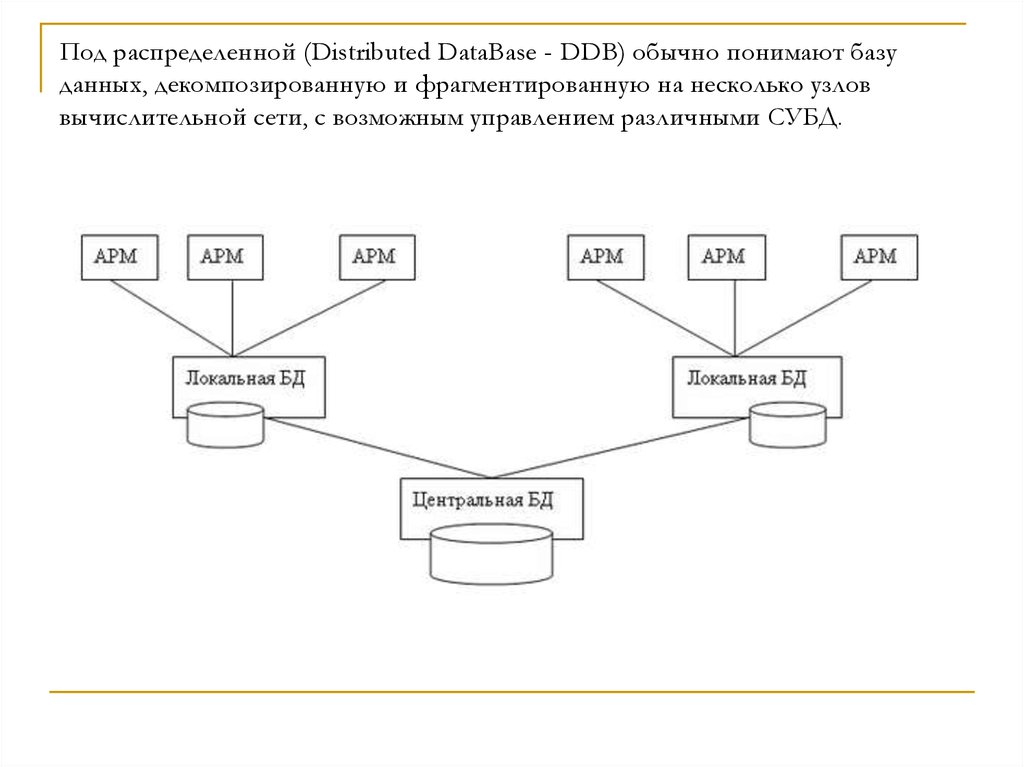 Этот способ может быть технически сложен и затратен. Кроме того, возникает ряд вопросов, связанных с информационной безопасностью.
Этот способ может быть технически сложен и затратен. Кроме того, возникает ряд вопросов, связанных с информационной безопасностью.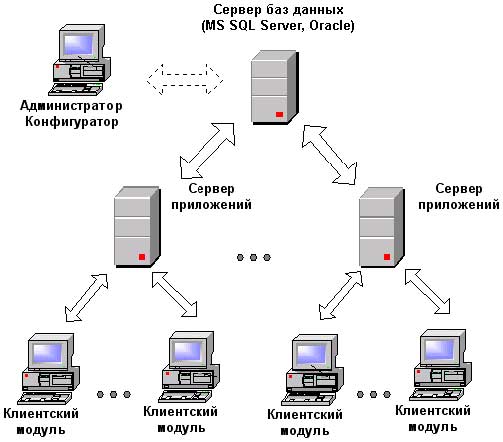


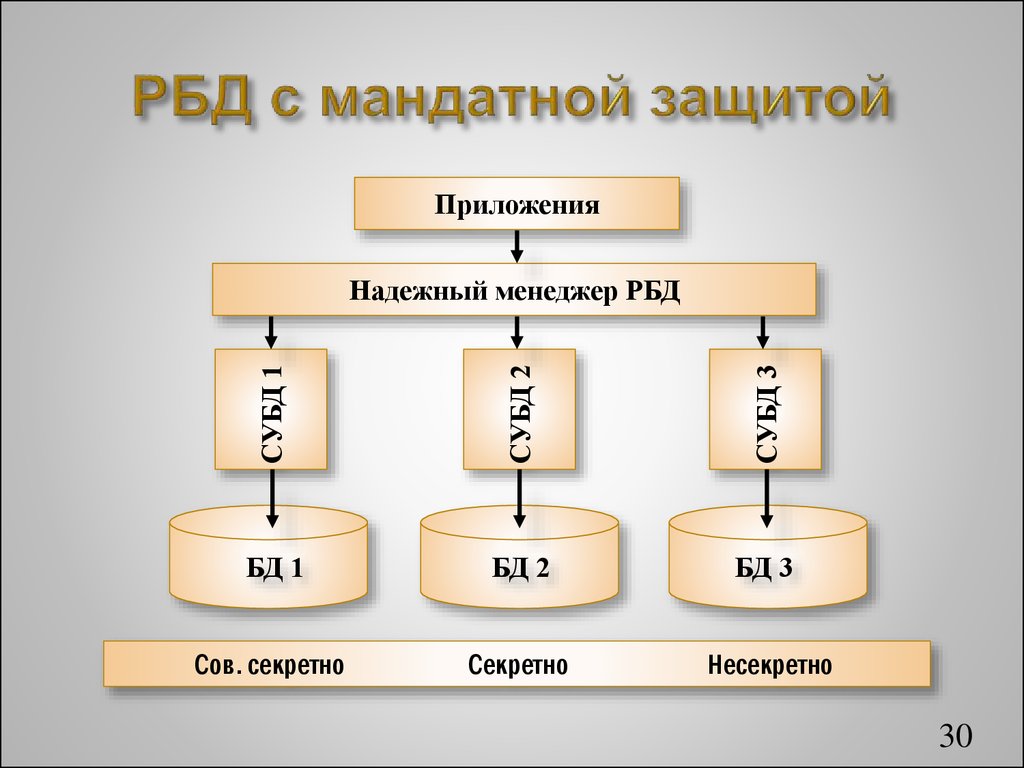
 Формат этого файла предназначен только для того, для чего он используется, то есть для передачи информации об изменениях; он не зависит от формата базы данных, поэтому имеет универсальное использование.
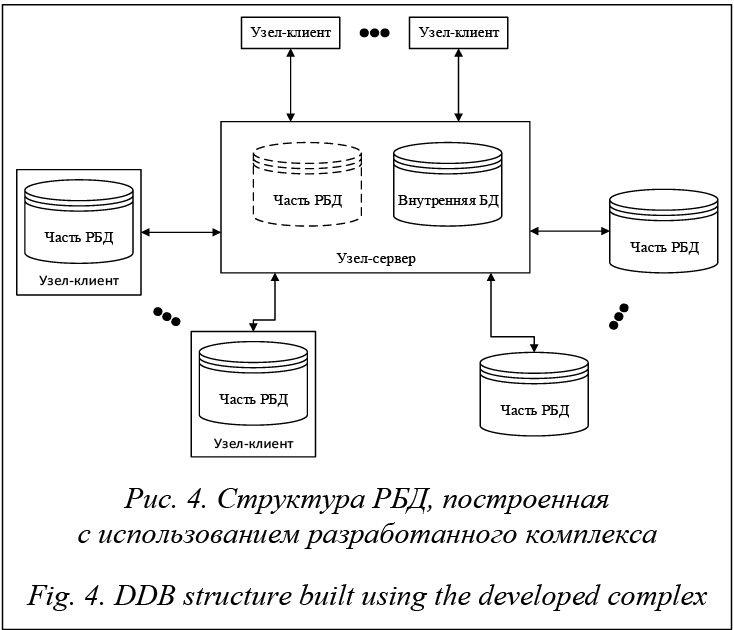
Формат этого файла предназначен только для того, для чего он используется, то есть для передачи информации об изменениях; он не зависит от формата базы данных, поэтому имеет универсальное использование.Статья: Инструкция по созданию УРБД (УРИБ) 1С 7.
 7 и обмену в РБД
7 и обмену в РБДИнструкция по созданию и настройке распределенных баз с помощью компоненты УРБД (УРИБ)
Компонента УРБД (Управление распределенными базами данных) применяется для обмена информацией между двумя идентичными базами 1С. Если конфигурации разные, то применять ее также можно, об этом написано в другой статье. Для работы компоненты необходимо наличие файла DistrDB.dll в папке BIN программы 1С: Предприятие.
Рассмотрим действия по созданию распределенных баз данных. Например, у нас есть рабочая база в каталоге D:\base1. Требуется сделать ее центральной и создать периферийную базу.
1. Создаем каталог D:\base2 для периферийной базы.
2. В каталогах D:\base1 и D:\base2 создаем папки CP и PC (используем латинские буквы).
3. Запускаем конфигуратор центральной базы (D:\base1) и выбираем Меню — Администрирование — Распределенная ИБ — Управление.
4. Нажимаем кнопку «Центральная ИБ», в появившемся окне вводим код и наименование базы.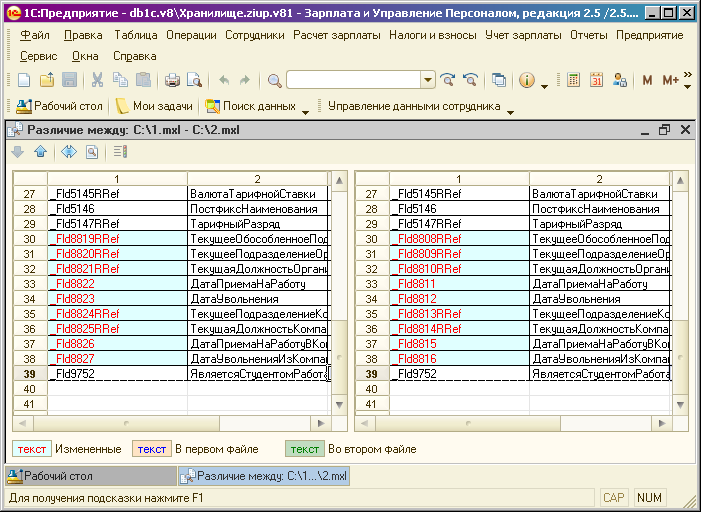 Для кода лучше использовать цифры или латинские буквы. Вводим, например, 001 и «Центральная база», подтверждаем нажатием кнопки «ОК».
Для кода лучше использовать цифры или латинские буквы. Вводим, например, 001 и «Центральная база», подтверждаем нажатием кнопки «ОК».
5. Нажимаем кнопку «Новая периф. ИБ» для того чтобы создать периферийную базу. Вводим для нее параметры: 002 и «Периферийная база 1».
6. Курсором выделяем базу «Периферийная база 1» и нажимаем кнопку «Настр. автообмена». В настройках меняем ручной режим на автоматический. Будьте внимательны, это важно.
7. Курсором выделяем базу «Периферийная база 1» и нажимаем кнопку «Выгрузить данные», затем кнопку «ОК». В результате выгрузки появится файл D:\base1\CP\020.zip.
8. Запускаем 1С в режиме конфигуратора, добавляем в окне запуска 1С новую базу «Периферийная база 1», указываем для нее ранее созданный каталог D:\base2.
9. Выбираем Меню — Администрирование – Распределенная ИБ – Управление. На заданный вопрос «Информационная база не обнаружена. Выполнить загрузку данных?» нажимаем кнопку «Да» и указываем имя файла «D:\base1\CP\020.zip», нажимаем кнопку «ОК». После окончания загрузки процесс создания периферийной базы можно считать законченным.
После окончания загрузки процесс создания периферийной базы можно считать законченным.
В статье и еще в одной приведены способы создания периферийной базы путем восстановления из бэкапа копии центральной базы либо приаттачивания файлов копии центральной базы для формата SQL и выполнения скрипта. Это будет полезно при больших объемах данных, когда выгрузки-загрузки растягиваются на часы или вообще нереальны.
Инструкция по обмену между распределенными базами с помощью компоненты УРБД (УРИБ)
Рассмотрим упрощенный пример, выполнять обмен будем вручную, запуская конфигуратор. Можно использовать пакетный режим конфигуратора, для доставки пакетов обмена можно использовать почту, ftp, автоматическое копирование файлов.
Для выполнения обмена необходимо выбирать Меню — Администрирование — Распределенная ИБ — Автообмен. Если обмен автоматический (см. пункт 6 предыдущей инструкции), то все у нас получится.
1. Итак, изменяем либо создаем какие-то объекты, которые мигрируют в периферийную базу. Правила миграции объектов задаются на вкладке «Миграция» в свойствах объекта (см. дерево объектов в конфигураторе).
Правила миграции объектов задаются на вкладке «Миграция» в свойствах объекта (см. дерево объектов в конфигураторе).
2. Запускаем конфигуратор центральной базы, выбираем Меню — Администрирование — Распределенная ИБ — Автообмен, нажимаем кнопку «Выполнить».
3. Полученный файл D:\base1\CP\020.zip перемещаем в папку D:\base2\CP\
4. Изменяем какие-то объекты периферийной базе данных. Желательно не те, которые менялись до этого в центральной базе, т.к. центральная база имеет приоритет изменений объектов при обмене.
5. Запускаем конфигуратор периферийной базы, выбираем Меню — Администрирование — Распределенная ИБ — Автообмен, нажимаем кнопку «Выполнить».
6. В результате автообмена у нас должны появиться изменения, поступившие из центральной базы данных. Также у нас должен появиться файл для передачи в центральную базу D:\base2\PC\021.zip
7. Копируем файл D:\base2\PC\021.zip в папку D:\base1\PC
8. Повторяем пункт 2. В результате в центральной базе появятся изменения, поступившие из периферийной базы.
Итак, общий принцип обмена: попеременное выполнение автообмена с одновременным перемещением файлов (пакетов обмена) из папки PC одной базы в папку PC другой базы и из папки CP одной базы в папку CP другой базы.
Изменение конфигурации производится только в центральной базе. При изменении конфигурации необходимо проведение обмена в периферийных базах в монопольном режиме. Для успешной обработки пакетов из периферийных баз в центральной базе конфигурация должна быть загружена в периферийные базы. Если вы запутались — ничего страшного, отвергнутый центральной базой пакет выгрузится повторно.
Другие статьи по УРБД:
Структура таблиц УРБД (УРИБ) 1С 7.7
Как использовать УРБД в отличающихся конфигурациях
Как из распределенной базы сделать обычную
Как из обычной базы сделать распределенную (SQL)?
УРБД 1С 7.7. Как быстро создать новую периферийную базу
Зачем и как использовать распределенные базы данных
Данные — это источник жизненной силы вашего бизнеса, поэтому вам нужна база данных в центре всего этого.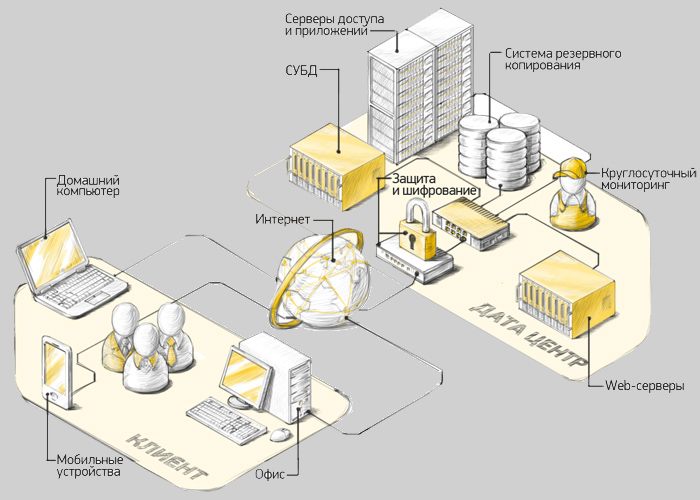 Однако не все базы данных могут удовлетворить растущие потребности современного бизнеса в данных. В частности, вам нужна распределенная система баз данных, позволяющая легко внедрять инновации и преобразовывать ее. В первой части этой серии, состоящей из двух частей, мы объясним, что такое распределенные базы данных, как они работают на высоком уровне, а также основные преимущества их использования для бизнеса. Во второй части мы сравним несколько распределенных баз данных, доступных сегодня на рынке, чтобы узнать, на что обращать внимание при выборе следующей базы данных. Итак, приступим…
Однако не все базы данных могут удовлетворить растущие потребности современного бизнеса в данных. В частности, вам нужна распределенная система баз данных, позволяющая легко внедрять инновации и преобразовывать ее. В первой части этой серии, состоящей из двух частей, мы объясним, что такое распределенные базы данных, как они работают на высоком уровне, а также основные преимущества их использования для бизнеса. Во второй части мы сравним несколько распределенных баз данных, доступных сегодня на рынке, чтобы узнать, на что обращать внимание при выборе следующей базы данных. Итак, приступим…
Как работают распределенные базы данных?
Распределенная система — это группа взаимосвязанных компьютеров, что делает ее похожей на единую систему. Как правило, в распределенной системе управления базами данных (СУБД) несколько « сайтов » управляются системой, которая выглядит как единая логическая база данных, хранящаяся на одном сайте. Распределенные базы данных обеспечивают прозрачность местоположения, а это означает, что приложениям не нужно знать точное местоположение сайта, где хранятся данные. Когда запрос выполняется в распределенной базе данных, коллективный набор сайтов в разных центрах обработки данных работает вместе, чтобы ответить на вопрос.
Когда запрос выполняется в распределенной базе данных, коллективный набор сайтов в разных центрах обработки данных работает вместе, чтобы ответить на вопрос.
Типы распределенных баз данных
Итак, все ли сайты в распределенной базе данных одинаковы? Это зависит от архитектуры — они бывают двух видов — гомогенные и гетерогенные. Если вы предпочитаете согласованность, вам следует использовать однородную архитектуру. В этом случае системные атрибуты, такие как физические ресурсы, операционная система и СУБД, одинаковы для всех сайтов. Благодаря однородной архитектуре развертывание сайтов баз данных и управление ими становятся проще.
Если ваш конкретный вариант использования требует дополнительной настройки, вам следует использовать гетерогенную архитектуру. Гетерогенные архитектуры баз данных позволяют различным сайтам иметь разные атрибуты. Сайты могут не знать друг о друге, и каждый сайт может использовать другой протокол связи, что требует дополнительной трансляции данных между сайтами.
Методы хранения данных для распределенных баз данных
Теперь предположим, что ваш начальник попросил вас найти лучший способ хранения данных в распределенной базе данных — какие у вас есть варианты? Вам придется выбирать между фрагментацией и репликацией. Но как узнать, какой из вариантов лучше? Ну, это зависит от вашего конкретного варианта использования и конкретных требований вашей организации.
Фрагментация или разделение включает разделение данных на более мелкие фрагменты и распределение этих фрагментов по разным узлам распределенной базы данных. Представьте, что вам нужно хранить предпочтения клиентов для розничного продавца в реляционной базе данных с идентификатором клиента в качестве первичного ключа. Как бы вы разделили и сохранили эти данные? Ну, вы можете нарезать и нарезать стол как по горизонтали, так и по вертикали.
При горизонтальном секционировании данные разбиваются по строкам, чтобы решить, к какому сайту принадлежат строки — либо с помощью диапазона, хэша, либо списка значений столбцов для секционирования. Столбец, используемый для разделения данных, называется «ключом разделения». При секционировании по диапазонам, которое является наиболее распространенным методом горизонтального секционирования, строки данных сопоставляются с секциями на основе предопределенных значений диапазона ключа секционирования. Например, предположим, что вы интернет-магазин, собирающий информацию о предпочтениях ваших клиентов, таких как цвет обуви, который им нравится. В этом сценарии вы можете горизонтально разбить данные по диапазонам идентификаторов клиентов: строки, соответствующие идентификаторам клиентов 1 и 2, принадлежат горизонтальному разделу 1 (HP1), а строки, соответствующие идентификаторам клиентов 3 и 4, принадлежат горизонтальному разделу 2 (HP2). ).
Столбец, используемый для разделения данных, называется «ключом разделения». При секционировании по диапазонам, которое является наиболее распространенным методом горизонтального секционирования, строки данных сопоставляются с секциями на основе предопределенных значений диапазона ключа секционирования. Например, предположим, что вы интернет-магазин, собирающий информацию о предпочтениях ваших клиентов, таких как цвет обуви, который им нравится. В этом сценарии вы можете горизонтально разбить данные по диапазонам идентификаторов клиентов: строки, соответствующие идентификаторам клиентов 1 и 2, принадлежат горизонтальному разделу 1 (HP1), а строки, соответствующие идентификаторам клиентов 3 и 4, принадлежат горизонтальному разделу 2 (HP2). ).
При горизонтальном разделении запрос данных, нацеленный на конкретный раздел, например оператор SELECT или UPDATE с предложением WHERE, содержащимся в разделе, может быстрее дать результаты — нерелевантные разделы могут быть пропущены из обработки запроса, что снижает время отклика. Независимый характер разделов также обеспечивает большую гибкость управления разделами без отключения всего набора данных. Для сравнения, секционирование списка основано на указании списка конкретных значений для ключа секционирования. Вы получаете очень точный контроль над тем, как строки сопоставляются с разделами, и предлагает естественный способ группировки данных. Наконец, хэш-разбиение хеширует ключ разбиения, а хеш-значение используется для определения того, какому сайту принадлежит строка.
Независимый характер разделов также обеспечивает большую гибкость управления разделами без отключения всего набора данных. Для сравнения, секционирование списка основано на указании списка конкретных значений для ключа секционирования. Вы получаете очень точный контроль над тем, как строки сопоставляются с разделами, и предлагает естественный способ группировки данных. Наконец, хэш-разбиение хеширует ключ разбиения, а хеш-значение используется для определения того, какому сайту принадлежит строка.
Теперь разделение данных не заслуживает внимания во всех случаях использования. Например, если вы подсчитываете долю людей, которым нравится каждый цвет, вам все равно нужно коснуться и просмотреть все разделы данных. Это означает, что никакие разделы не могут быть пропущены, и вы, возможно, не сможете сократить время ответа на запрос. В таких случаях вы можете рассмотреть возможность использования вертикального секционирования. Сохраняя все любимые цвета всех ваших клиентов в одной таблице, вертикальное секционирование может значительно снизить затраты на ввод-вывод и производительность, связанные с доступом к данным. Хотя вертикальное разбиение очень полезно, у него есть некоторые проблемы, которые нельзя упускать из виду. Например, при выполнении каждого оператора DELETE потребуется убедиться, что операция DELETE выполняется в каждом разделе для обеспечения целостности данных.
Хотя вертикальное разбиение очень полезно, у него есть некоторые проблемы, которые нельзя упускать из виду. Например, при выполнении каждого оператора DELETE потребуется убедиться, что операция DELETE выполняется в каждом разделе для обеспечения целостности данных.
Управление данными в распределенных базах данных
Репликация данных включает в себя создание копий элементов данных, которые могут находиться более чем на одном сайте в любой момент времени. Репликация приближает данные к пользователям, которые полагаются на них при принятии решений, а также гарантирует, что эти данные будут доступны, когда они потребуются. Распределенные базы данных делают это, назначая один из сайтов «основным сайтом» и периодически синхронизируя другие сайты с основным сайтом. Предположим, ваш основной сайт нуждается в обновлении или произошло незапланированное время простоя, затрагивающее ваш основной сайт — репликация позволяет вам переключать пользователей на другие сайты, чтобы ваши производственные данные оставались доступными. Вашим приложениям не нужно ждать, пока вы создадите новую копию всей базы данных, что означает, что вы не потеряете транзакции. Репликация также имеет свой собственный набор проблем — она требует высокой степени координации между различными сайтами в распределенной базе данных, чтобы гарантировать согласованность значений данных в распределенных копиях. Кроме того, при больших объемах данных требуется больше дискового пространства на разных сайтах, что увеличивает затраты.
Вашим приложениям не нужно ждать, пока вы создадите новую копию всей базы данных, что означает, что вы не потеряете транзакции. Репликация также имеет свой собственный набор проблем — она требует высокой степени координации между различными сайтами в распределенной базе данных, чтобы гарантировать согласованность значений данных в распределенных копиях. Кроме того, при больших объемах данных требуется больше дискового пространства на разных сайтах, что увеличивает затраты.
Что касается скорости репликации и гарантии согласованности, которую предлагает репликация, распределенные базы данных предлагают два типа вариантов репликации — синхронная и асинхронная . В модели синхронной репликации данные, записываемые приложением на первичный сайт, мгновенно копируются на все остальные сайты до того, как приложение получит уведомление. В модели асинхронной репликации приложение получает уведомление, как только данные записываются на основной сайт, а другие сайты лениво получают данные в фоновом режиме.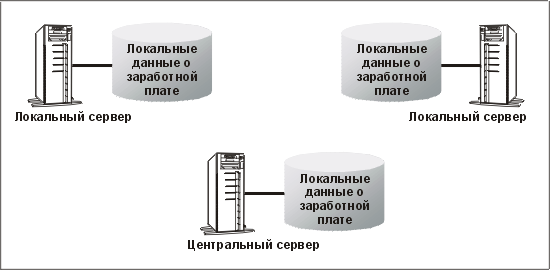 В конце концов, все сайты получают обновленные данные.
В конце концов, все сайты получают обновленные данные.
Давайте рассмотрим это на нашем предыдущем примере с розничной торговлей. Представьте, что у вас есть два покупателя, а на складе осталась только одна пара обуви. Что увидит на странице второй покупатель, если в тот же момент первый покупатель получит подтверждение покупки? При синхронной репликации второй покупатель увидит, что товар отсутствует на складе. Это обеспечивает целостность данных и снижает сложность определения того, где находится самая последняя копия данных, за счет медленного времени отклика. При асинхронной репликации второй клиент увидит, что элемент по-прежнему доступен. Операции асинхронной репликации занимают меньше времени, что делает ваше приложение более реактивным, но вы получаете некоторую степень временных несоответствий, таких как товары, которые появляются на складе, когда их нет.
Другой способ хранения ваших данных в нескольких местах — это использование специального программного обеспечения для создания копий данных и их хранения вне офиса на случай утери или повреждения оригинала.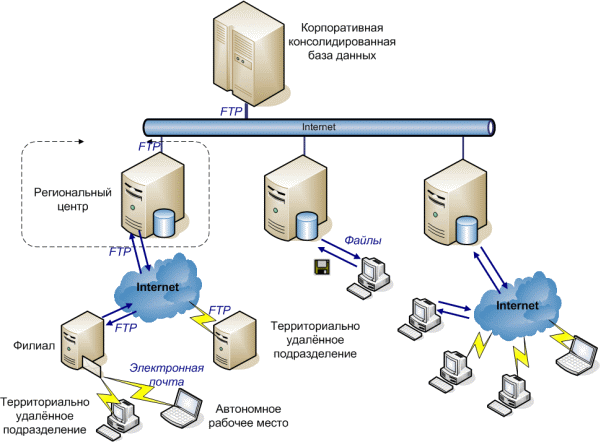 Обычно это называется дублированием (или «резервным копированием») и является хорошим вариантом для архивирования старых данных, которые не будут нужны слишком часто.
Обычно это называется дублированием (или «резервным копированием») и является хорошим вариантом для архивирования старых данных, которые не будут нужны слишком часто.
Ваши данные, ваши правила
Распределенные базы данных обеспечивают прозрачность местоположения данных с локальной автономией. Это означает, что даже если приложения могут не знать, где именно находятся данные, каждый сайт имеет возможность контролировать локальные данные, администрировать безопасность, отслеживать транзакции и восстанавливаться в случае сбоя локального сайта. Автономность доступна даже в случае сбоя подключения к другим узлам. Это обеспечивает большую гибкость, когда определенные данные, хранящиеся на определенных сайтах, могут нуждаться в дополнительных мерах безопасности и соответствия требованиям, а другие данные могут не требоваться. Например, информация о клиентах, хранящаяся для розничных клиентов из региона ЕС, должна соответствовать требованиям GDPR.
Преимущества использования архитектуры распределенной базы данных?
Поскольку данные становятся важным аспектом нашей жизни, распределенные базы данных лежат в основе инфраструктуры данных каждой организации. В большинстве случаев конечные пользователи, взаимодействующие с веб-службой или мобильным приложением, могут не видеть распределенную базу данных в действии — именно распределенная база данных активно работает в фоновом режиме, что обеспечивает многие из этих вариантов использования. Вот лишь несколько примеров важных преимуществ, которые приносят распределенные базы данных.
В большинстве случаев конечные пользователи, взаимодействующие с веб-службой или мобильным приложением, могут не видеть распределенную базу данных в действии — именно распределенная база данных активно работает в фоновом режиме, что обеспечивает многие из этих вариантов использования. Вот лишь несколько примеров важных преимуществ, которые приносят распределенные базы данных.
Повышение производительности
Конечные пользователи жалуются. Ваш босс расстроен, и пришло время исправить медленное приложение, от которого все зависят. С чего начать поиск? Во многих случаях снижение производительности происходит из-за узкого места в вашей централизованной базе данных. С помощью распределенных баз данных вы можете распределять данные по географическим регионам и приближать их к своим пользователям — эффективный доступ к данным и их передача приводят к сокращению времени отклика приложений. Распределенные базы данных также помогают лучше использовать параллельную обработку на обычных серверах, устраняя необходимость в специализированном или дорогостоящем оборудовании.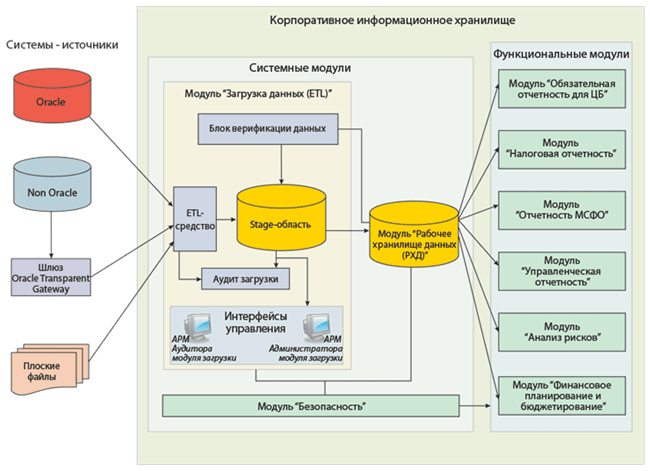
Включение массовой масштабируемости
Масштабируемость означает получение большего от вашей системы, когда система увеличивается за счет большего количества ресурсов. Кому не нужна система, которая может масштабироваться в соответствии с бизнес-требованиями и в любое время? Распределенные базы данных имеют модульную структуру и могут быть легко расширены по требованию. В отличие от централизованных баз данных, которые можно масштабировать только по вертикали за счет добавления дополнительных ресурсов (ЦП, памяти и диска), распределенные базы данных можно масштабировать как по вертикали, так и по горизонтали (за счет добавления дополнительных серверов). Это обеспечивает дополнительную степень гибкости для масштабирования вашей инфраструктуры. Например, из-за пандемии многие потребители обратились к онлайн-магазинам. Если вы интернет-магазин, вам необходимо быстро масштабировать свою инфраструктуру данных, чтобы справиться с наплывом новых онлайн-покупателей. Теперь представьте, как просто было бы, если бы вы работали с распределенной базой данных.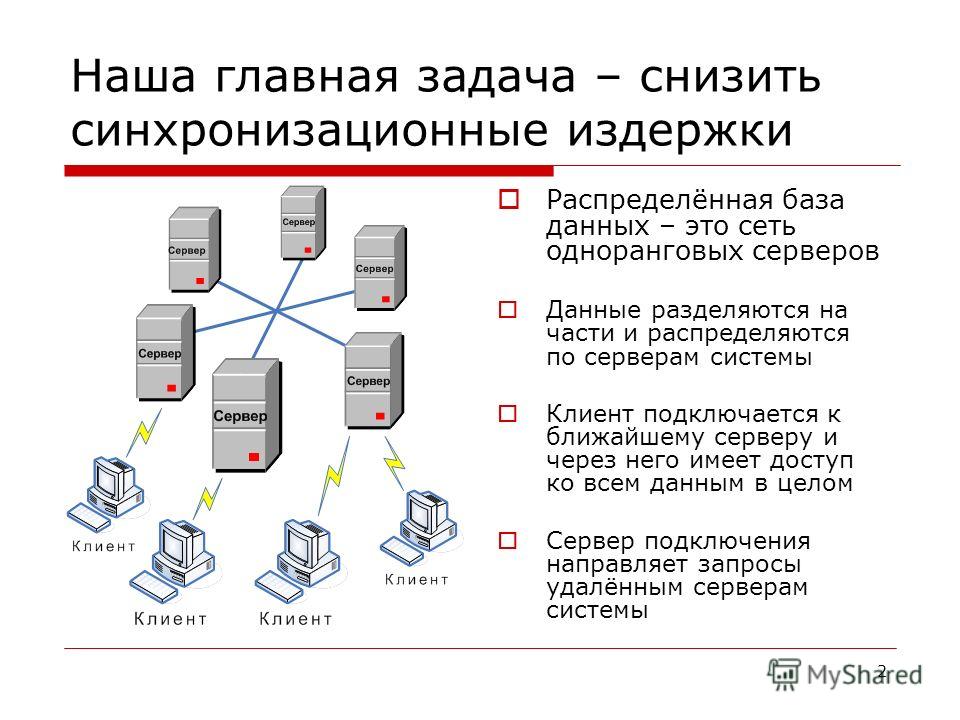
Обеспечение круглосуточной надежности
Возможность оставаться в сети круглосуточно и без выходных имеет решающее значение для современного цифрового бизнеса. Это означает, что если база данных недоступна, потребители данных, то есть приложения, клиенты и бизнес-пользователи, не могут получить доступ к критически важным данным для поддержания работы бизнеса. Автоматически реплицируя данные на несколько сайтов, распределенные базы данных обеспечивают избыточность данных. В случае сбоя эта настройка позволяет легко переключиться на сайт реплики, чтобы не возникало проблем с доступом к данным. Простои — дорогое удовольствие для бизнеса, и важно быстро реагировать на сбои, восстанавливать их и смягчать серьезность сбоя. Для многих бизнес-приложений распределенные базы данных обеспечивают экономию средств для обеспечения непрерывности бизнеса.
Это лишь некоторые из причин, по которым вам следует выбрать распределенную базу данных. Имея так много разных вариантов, важно знать, на какие характеристики обращать внимание и как они соотносятся с различными базами данных на рынке.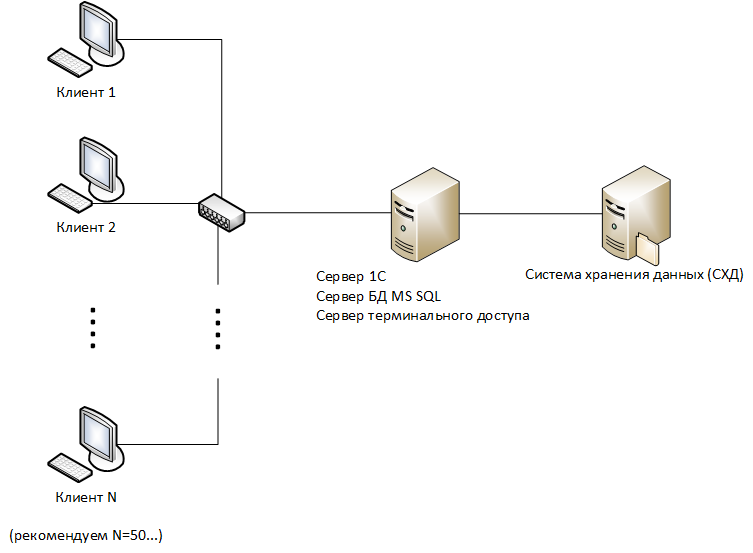 Оставайтесь с нами для части 2 этой серии, где мы объясним, что это за характеристики и почему они важны.
Оставайтесь с нами для части 2 этой серии, где мы объясним, что это за характеристики и почему они важны.
Итак, каковы проблемы традиционных распределенных СУБД?
За последние несколько десятилетий распределенные базы данных прошли долгий путь. Тем не менее, у них все еще есть несколько ключевых проблем, о которых стоит упомянуть —
Ограничения производительности в масштабе Интернета
Разрешение записи в географически распределенной базе данных, к которой имеют доступ миллионы пользователей, является сложной задачей. Однако это распространенный вариант использования среди современных современных приложений, включая IoT, электронную коммерцию и социальные сети. Многие традиционные распределенные базы данных решили эту проблему, создав один основной регион, отвечающий за организацию операций записи и приближение локальных данных к пользователям, доступных только для чтения, а не для обновлений. Такая конструкция может серьезно повлиять на производительность системы.
Масштабирование — это сложно
Разделение данных — это не панацея, а выбор ключа разделения — это искусство само по себе. Если вы выберете неправильный ключ разделения, вы можете нарушить балансировку нагрузки данных, сделав некоторые разделы более горячими, чем другие. Это снижает эффективность секционирования и чрезмерно усложняет управление базой данных и ее обслуживание.
Модель базы данных != модель программирования
Традиционные распределенные системы баз данных имеют только одну модель данных, и в большинстве случаев эта единственная модель данных плохо подходит для современных современных приложений. Несовместимость между типами данных приложения и тем, что предлагает модель базы данных, называется «несоответствием импеданса». Это требует дополнительных привязок к языку программирования и изменения базы данных при каждом изменении приложения.
Децентрализованное управление данными и безопасность
Серьезной проблемой при проектировании распределенной базы данных и управлении ею является отсутствие централизованного знания всей базы данных.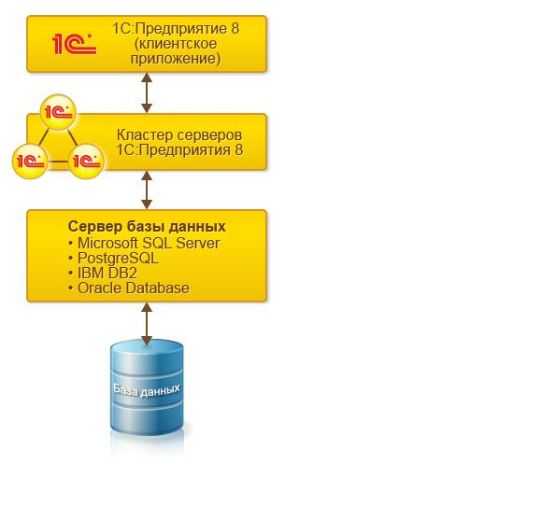 Это также относится к таким вещам, как управление данными и безопасность в распределенной базе данных. Отсутствие последовательного подхода к обоим этим аспектам создает риски, и любая утечка данных может быстро испортить имидж предприятия и дорого обойтись.
Это также относится к таким вещам, как управление данными и безопасность в распределенной базе данных. Отсутствие последовательного подхода к обоим этим аспектам создает риски, и любая утечка данных может быстро испортить имидж предприятия и дорого обойтись.
Высокая совокупная стоимость владения, требуется специальная рабочая группа
Распределенные базы данных сложны, и для управления вашей инфраструктурой данных требуется полностью специализированная рабочая группа. Затраты, связанные с эксплуатацией распределенной базы данных, такие как закупка оборудования, обслуживание и наем в разных регионах, складываются довольно быстро, что делает ее более дорогостоящей, чем обычная СУБД.
Итак, каковы же показатели Fauna по сравнению с другими распределенными СУБД на рынке?
Fauna — это гибкая, удобная для разработчиков транзакционная облачная база данных, предоставляемая вам в виде безопасного API данных, созданного для современных веб-приложений, использующих облако.
В приведенной ниже таблице мы рассмотрим несколько ключевых атрибутов СУБД разных поставщиков и объясним, почему они важны для вашего приложения —
| Атрибут | Фауна | АМС Аврора | ДинамоДБ | МонгоДБ | Почему это важно для вашего приложения? |
| Модель данных | Реляционный и документно-ориентированный | Относительный | Нереляционные (элементы данных без схемы в таблице) | Нереляционная модель данных на основе документов | Если модель данных идеально подходит для вашего варианта использования, у вашего приложения есть несколько преимуществ.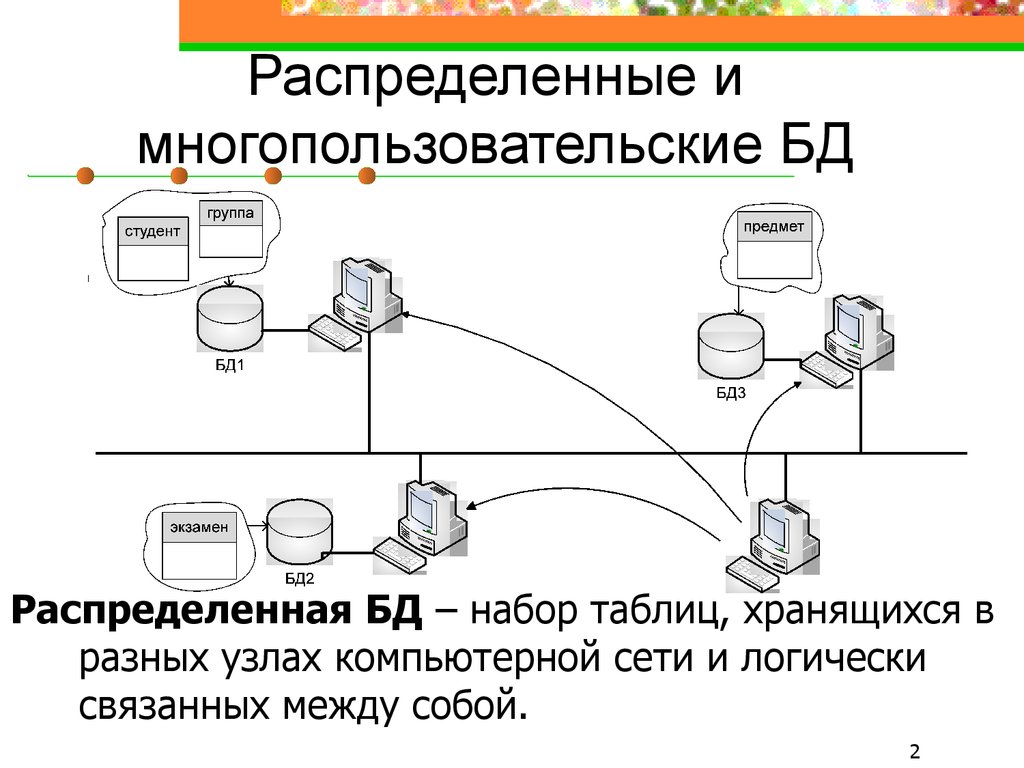 |
| Модель запроса | Модель запроса на основе API с использованием языка запросов Fauna (FQL) и GraphQL | Модель запросов на основе SQL аналогична популярным технологиям, таким как MySQL, Postgres. Также совместим с моделью запросов Amazon Redshift. | Использует PartiQL, язык запросов, совместимый с SQL, или классические API CRUD DynamoDB. | Язык запросов MongoDB (MQL), который представляет собой язык запросов на основе JavaScript. | Модель запроса определяет, как взаимодействуют приложения. Чтобы упростить разработку приложений, вам нужна современная и простая модель запросов. API соответствуют этим требованиям. |
| Транзакционная модель | Использует механику Calvin для поддержки строго сериализуемых, внешне согласованных транзакций в распределенной среде. | Транзакционная модель на основе ACID.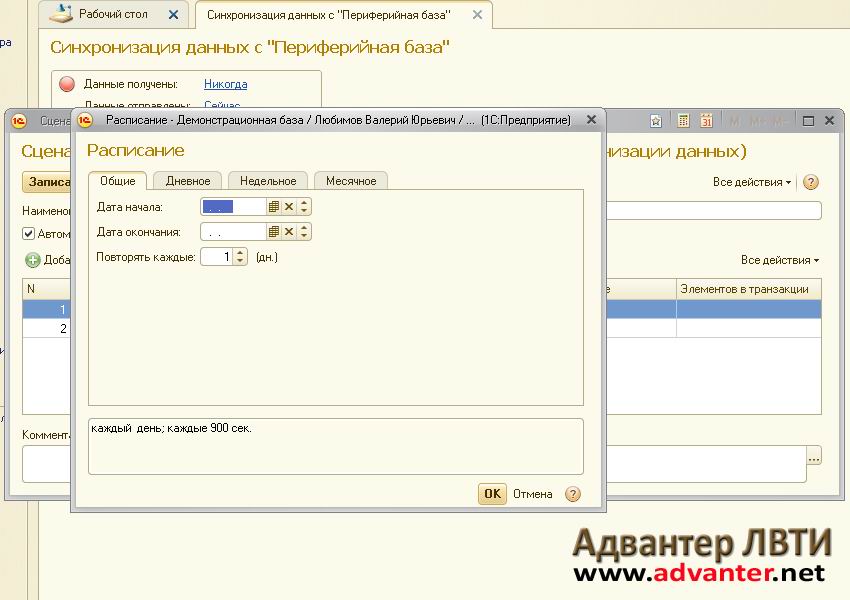 | Сериализуемые многоэлементные транзакции чтения и записи. Только совместимые с ACID в регионе, в котором они встречаются. | Многодокументные транзакции ACID | В зависимости от варианта использования одна модель транзакции может быть более желательной, чем другая. |
| Модель согласованности | Все запросы Fauna согласованы во всех моделях развертывания и предлагают строго сериализуемые уровни изоляции. | Общая кодовая база также ограничивает модель согласованности Aurora только первичной/вторичной репликацией. Невозможно выполнять транзакции записи или согласованные запросы только для чтения в неосновных процессах и регионах. | До некоторой степени возможна строгая согласованность, но только в контексте одного региона. | Чтобы обеспечить согласованность, разработчики должны предотвратить включение в запросы данных, которые можно откатить, и гарантировать, что во время чтения не будет выполняться запись. | База данных с моделью строгой согласованности предпочтительнее, чтобы гарантировать, что функциональность прецедентов не пострадает. |
| Индексация | Обеспечивает вторичное индексирование на основе полей. | AWS использует те же индексы, что и MySQL/InnoDB. Aurora также поддерживает пространственные индексы. | Поддерживает первичные и вторичные индексы (локальные и глобальные). | Обеспечивает первичное и вторичное индексирование, а также специализированные индексы, такие как хешированные индексы, индексы с подстановочными знаками и географические индексы. | Благодаря множеству вариантов индексирования появляется больше возможностей для настройки производительности базы данных по мере роста объема данных. Результатом является лучший пользовательский интерфейс для пользователей вашего приложения. |
| Отказоустойчивость | Базовая архитектура Fauna обеспечивает высокую доступность и отказоустойчивость.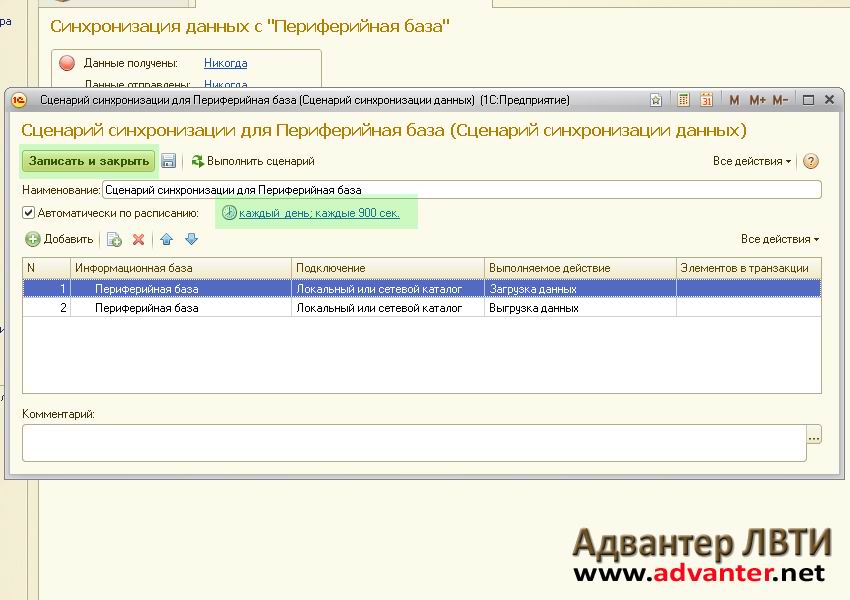 Базовая архитектура направляет запросы к доступным узлам обработки, которые находятся ближе всего к источнику. Протокол транзакций реплицирует данные как минимум в трех местах, гарантируя, что Fauna никогда не потеряет ваши данные. Базовая архитектура направляет запросы к доступным узлам обработки, которые находятся ближе всего к источнику. Протокол транзакций реплицирует данные как минимум в трех местах, гарантируя, что Fauna никогда не потеряет ваши данные. | Том кластера охватывает несколько зон доступности в одном регионе AWS, и каждая зона доступности содержит копию данных тома кластера. Эта функциональность означает, что ваш кластер БД может выдержать сбой зоны доступности без потери данных и только с кратковременным прерыванием обслуживания. | DynamoDB полагается на зоны доступности AWS (AZ), репликацию и долгосрочное хранилище для защиты от потери данных или сбоя службы. Узлы-лидеры являются потенциальными узкими местами, поскольку только они способны принимать записи и строго согласованные чтения. | Сбои узлов в MongoDB обрабатываются набором реплик. В случае сбоя основного узла оставшиеся узлы выбирают новый основной узел с приоритетной версией Raft, и система продолжает работать в обычном режиме.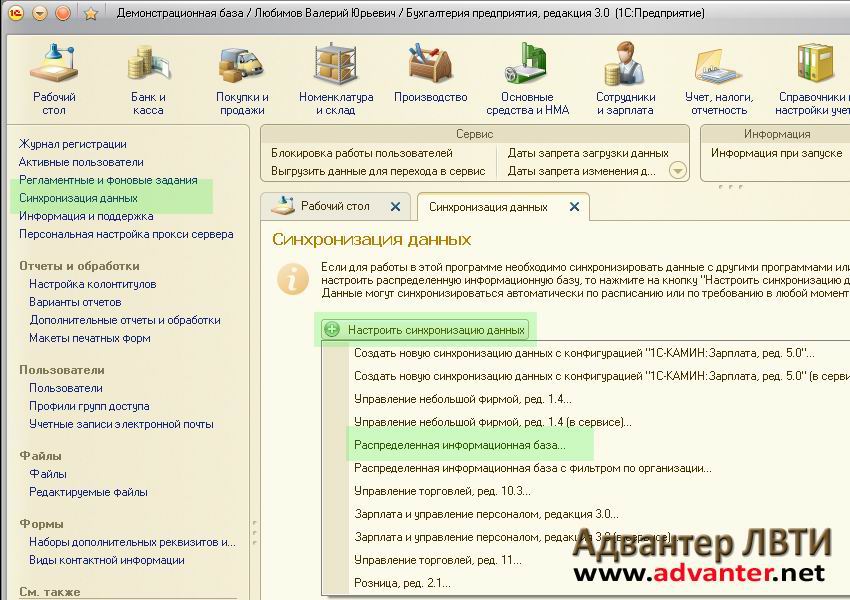 | Пользователи, создающие критически важные приложения, предпочитают систему базы данных с высокой степенью отказоустойчивости. |
| Безопасность | Fauna предлагает веб-модель безопасности. Это означает, что он предоставляет authN ключи и токены. Для authZ можно использовать управление доступом на основе атрибутов (ABAC) и предопределенные роли. TLS/SSL для сетевого шифрования между базой данных и клиентами, разделение клиентов и арендаторов с помощью иерархии баз данных, приоритетных рабочих нагрузок, а также маркеры безопасного доступа для прямого доступа клиентов к базе данных. Кластеры фауны требуют аутентификации и не могут быть случайно оставлены незащищенными. | AWS отвечает за защиту инфраструктуры, на которой работают сервисы AWS в облаке AWS. Вы также несете ответственность за другие факторы, включая конфиденциальность ваших данных, требования вашей организации и применимые законы и правила.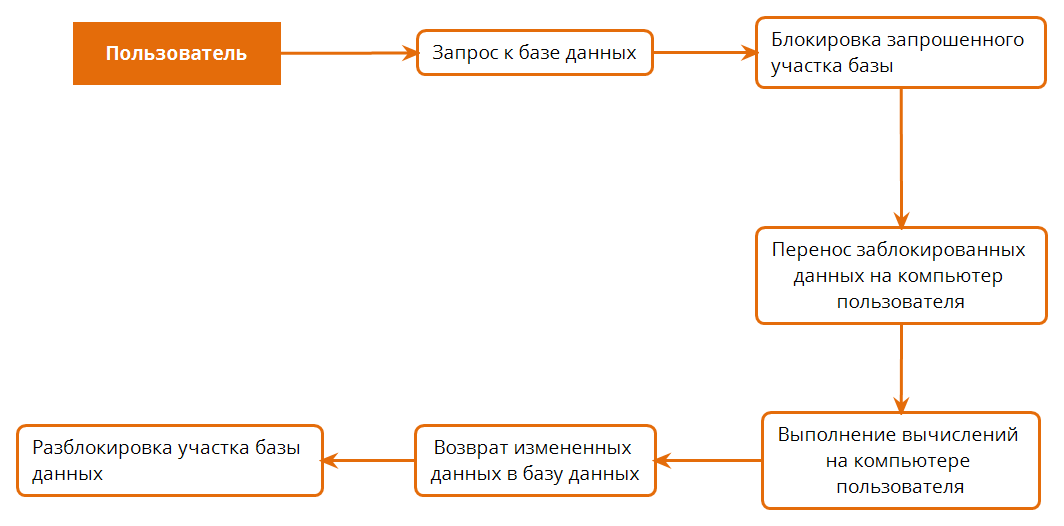 | Как и многие продукты AWS, DynamoDB унаследовал превосходную функцию AWS Identity and Access Management (IAM). С его помощью разработчики могут задавать грубые и детализированные разрешения пользователей, применимые ко всему API DynamoDB. | MongoDB предлагает поддержку проверки подлинности SCRAM, x509, LDAP и Kerberos, управление доступом на основе ролей с определяемыми пользователем ролями, разрешения на подмножества коллекций через нематериализованные представления, TLS/SSL для базы данных и клиентов, шифрование в состоянии покоя, аудит средства управления и разделение арендаторов через базы данных. | Если данные приложения взломаны, организация сталкивается с огромными рисками и штрафами. Отсутствие достаточных функций также означает, что база данных может не подходить для регулируемых отраслевых вариантов использования. |
| Масштабируемость | Fauna обеспечивает неограниченный масштаб без участия клиентов.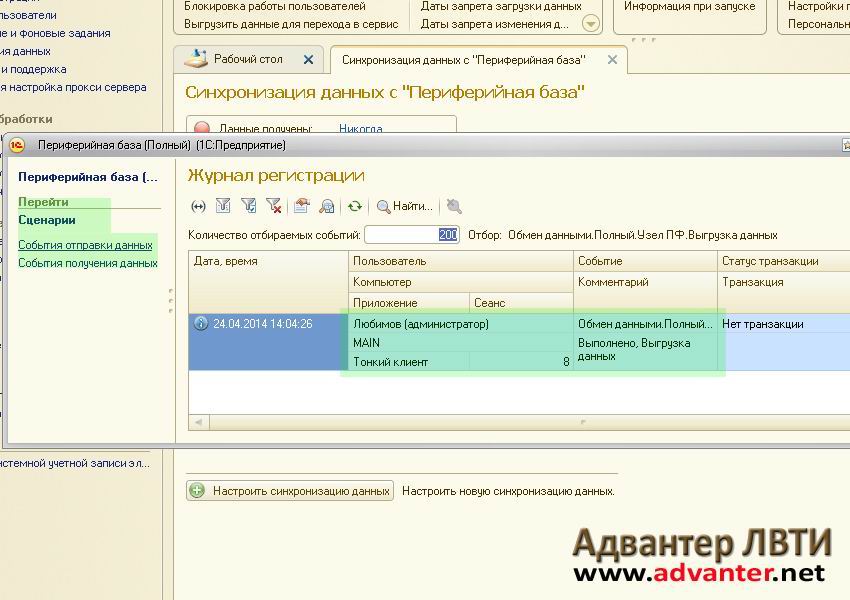 Fauna достигает этого, поддерживая несколько согласованных полных реплик данных клиентов и масштабируя свою инфраструктуру за кулисами. Fauna достигает этого, поддерживая несколько согласованных полных реплик данных клиентов и масштабируя свою инфраструктуру за кулисами. | Хранилище Aurora автоматически масштабируется с данными в томе вашего кластера. | DynamoDB стремится взять на себя ответственность за масштабирование в соответствии с потребностями клиентов. В отличие от Fauna, он по-прежнему требует значительной операционной работы и накладных расходов для клиентов, что делает его менее выгодным. | MongoDB предоставляет сегментированные кластеры как способ горизонтального масштабирования самых больших рабочих нагрузок во многих наборах реплик. Создание сегментированного кластера требует небольшого времени простоя для развертывания серверов конфигурации и для указания драйверов приложений на процессы «mongos», а не на узлы данных. | Если приложение сталкивается с притоком новых пользователей, простота масштабирования является обязательной.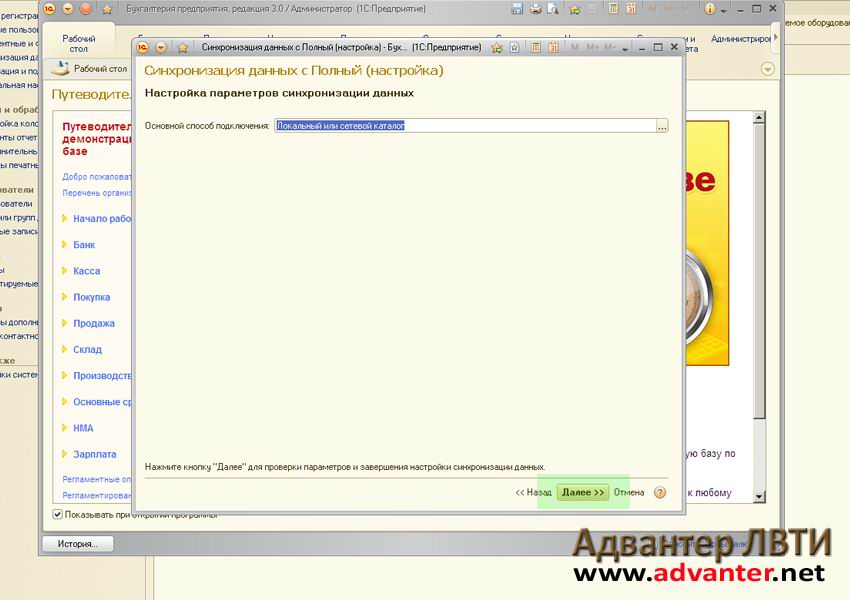 |
| Операции | Фауна не требует от пользователей никакой оперативной работы по управлению масштабируемостью и доступностью системы. Все происходит автоматически. Fauna предлагает CLI для пользователей, чтобы помочь в задачах администрирования схемы сценариев. | Amazon Aurora регулярно выпускает обновления. Обновления применяются к кластерам БД Aurora во время периодов обслуживания системы. Не требует от пользователей никакой оперативной работы по управлению масштабируемостью и доступностью системы. | Разработчики могут внедрять и настраивать развертывания DynamoDB через интерфейс командной строки AWS, Консоль управления AWS, AWS SDK, NoSQL Workbench или непосредственно через низкоуровневый API DynamoDB. | MongoDB использует Ops Manager, Cloud Manager или программное обеспечение MongoDB Atlas для внесения сложных изменений в базу данных. | Сокращение операционных издержек для запуска базы данных позволяет разработчикам уделять больше времени созданию своих приложений.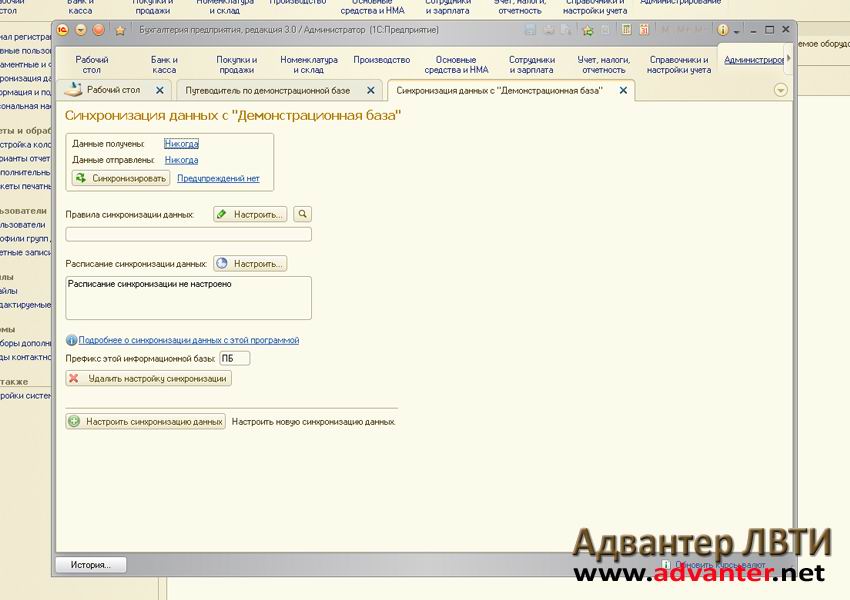 |
Начните работу с Fauna мгновенно и бесплатно
Бесплатная регистрация
API данных для современных приложений находится здесь. Зарегистрируйтесь бесплатно без кредитной карты и начните немедленно. Зарегистрироваться сейчас
Краткое руководство
Воспользуйтесь нашим кратким руководством, чтобы начать работу с вашей первой базой данных Fauna всего за 5 минут! Подробнее
25 лучших распределенных баз данных
Распределенные базы данных помогают более безопасно и надежно хранить данные и выполнять запросы. В этой статье рассматриваются лучшие открытые и коммерческие распределенные базы данных, которые помогут вам удовлетворить растущие потребности в хранении данных.
Изо дня в день предприятия генерируют петабайты данных. Однако не все базы данных обеспечивают гибкость, доступность и масштабируемость, необходимые для удовлетворения растущей потребности в хранении и доступе к этим данным.
Распределенная база данных хранит файлы и данные в разных физических местах в одной или разных сетях. Системы распределенных баз данных помогают внедрять инновации и справляться с растущими потребностями в данных за счет простого масштабирования.
Вместо того, чтобы ограничивать хранение данных и обработку транзакций одной машиной, распределенная база данных использует несколько машин в разных местах. Это, в свою очередь, увеличивает производительность, восстановление данных и общий пользовательский опыт.
В этом посте рассказывается о некоторых лучших базах данных, доступных для распределенного хранения данных.
Apache Ignite
Apache Ignite — это полнофункциональная распределенная база данных с открытым исходным кодом, быстродействующая в памяти и обладающая высокопроизводительными возможностями. Он известен своим использованием для кэширования данных и предлагает надежное, высокодоступное и последовательное сохранение данных с масштабируемой поддержкой SQL.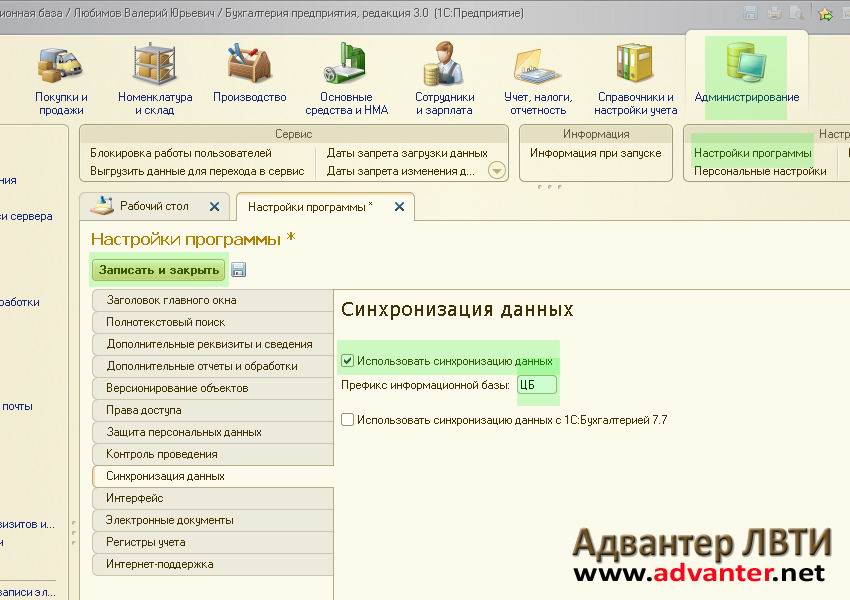 Это быстрое и интуитивно понятное решение для распределенной базы данных с полной поддержкой внешних баз данных, таких как Cassandra.
Это быстрое и интуитивно понятное решение для распределенной базы данных с полной поддержкой внешних баз данных, таких как Cassandra.
Apache Cassandra
Первоначально разработанная Facebook, Cassandra представляет собой распределенную базу данных NoSQL, которая предлагает высокодоступное и производительное хранилище данных. Это масштабируемое решение, используемое крупными технологическими компаниями, включая Netflix, eBay и Uber.
Это независимая от операционной системы и платформы система, обладающая устойчивостью, безопасностью и высокой доступностью, что позволяет обрабатывать запросы с малой задержкой. Это инструмент с открытым исходным кодом, но его также можно приобрести у сторонних поставщиков с коммерческими службами поддержки.
Apache HBase
Еще одна служба распределенной базы данных от Apache — это решение HBase-no-relational для Apache Hadoop. Это проект, созданный по образцу Google Bigtable для хранения больших наборов данных масштабируемым, согласованным и высокодоступным способом.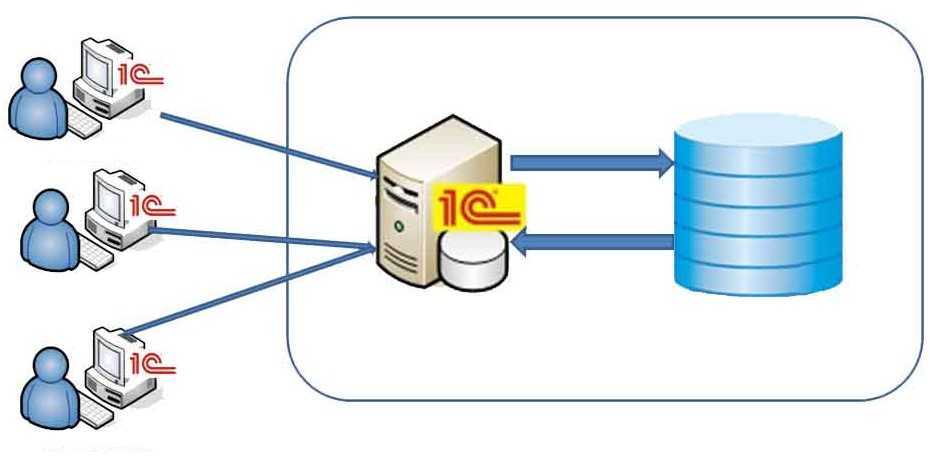
Couchbase Server
Couchbase — это распределенная база данных NoSQL масштаба предприятия. Это база данных с открытым исходным кодом, которая обеспечивает масштабируемость и гибкость, необходимые в распределенных облачных и пограничных средах. Его архитектура обеспечивает высокую производительность и идеально подходит для использования в облачных, мобильных и граничных вычислительных приложениях.
AWS SimpleDB
Являясь частью веб-сервисов Amazon, SimpleDB представляет собой распределенную базу данных, которая интегрируется с другими сервисами AWS, включая EC2 и Amazon S3. Некоторые из его функций включают высокую доступность, гибкость, эффективность, масштабируемость и, как и другие сервисы AWS, экономичность. Это устраняет сложность операций и использует простой API для доступа и хранения данных, которые автоматически индексируются, чтобы уменьшить административную нагрузку.
Однако он имеет более слабую согласованность и ограничение по объему памяти по сравнению с другими доступными службами распределенного хранения.
Он идеально подходит для хранения данных онлайн-игр, индексирования указателей на объекты Amazon S3, а также регистрации показателей аудита и анализа.
Clusterpoint
Clusterpoint — это решение интегрированной базы данных без схемы для распределенных данных. Это надежное решение для хранения данных и запросов, отличающееся гибкостью, масштабируемостью, высокой доступностью и экономичностью. Он идеально подходит для хранения данных в сфере финансовых услуг, здравоохранения, телекоммуникаций и других отраслей, требующих большого объема данных.
FoundationDB
FoundationDB — это распределенная база данных NoSQL с открытым исходным кодом и многомодельной архитектурой хранения данных, позволяющая хранить различные типы данных в одной базе данных. Это отказоустойчивое и хорошо масштабируемое решение с высокой производительностью для простых и тяжелых рабочих нагрузок. Благодаря мультимодельному хранилищу данных FoundationDB идеально подходит для многих случаев, включая облачные и пограничные приложения.
ETCD
ETCD — это решение для хранения данных типа «ключ-значение» с открытым исходным кодом для крупномасштабных распределенных систем. Он хранит конфигурации, состояние и метаданные для распределенных сред, таких как Kubernetes, согласованным и высокодоступным способом. Проект CNCF предлагает простой интерфейс, позволяющий выполнять чтение и запись с использованием стандартных инструментов, таких как curl. Он идеально подходит для хранения критически важной информации в производственных системах, таких как планировщики контейнеров, службы обнаружения служб и Kubernetes.
TiDB
TiDB — это совместимая с MySQL база данных с открытым исходным кодом для распределенных систем. Он поддерживает рабочие нагрузки гибридной транзакционной и аналитической обработки и обеспечивает горизонтальную масштабируемость, надежную согласованность и высокую доступность. Это облачная база данных с открытым исходным кодом, созданная для хранения данных SQL в масштабе и используемая различными компаниями, включая Xiaomi и Lenovo.
CockroachDB
CockroachDB — это облачная коммерческая распределенная база данных, разработанная Cockroach Labs. Это распределенная база данных SQL, созданная для транзакционных и согласованных хранилищ ключей и значений, хорошо совместимая с облачными приложениями со скоростью и масштабируемостью больших наборов данных. CockroachDB хранит операционные данные SpaceX и идеально подходит для отказоустойчивого хранилища с малой задержкой в глобальных приложениях.
Shardingsphere
Shardingsphere — это открытый проект базы данных Apache с несколькими компонентами для обеспечения распределенных транзакций, распределенного управления и доступного масштабирования данных в различных вариантах использования. Это гибкое и расширяемое решение для базы данных, которое интегрируется с подключаемыми модулями для расширенных функций, включая сегментирование данных, запросы реплик и протоколы базы данных.
Rqlite
Rqlite — это легкая распределенная реляционная база данных, построенная на SQLite. Это полностью реплицируемая система хранения, которую можно использовать в качестве центрального хранилища критически важных реляционных данных с межузловым шифрованием для обеспечения безопасности данных SQL производственного уровня.
Это полностью реплицируемая система хранения, которую можно использовать в качестве центрального хранилища критически важных реляционных данных с межузловым шифрованием для обеспечения безопасности данных SQL производственного уровня.
Yugabyte DB
YugabyteDB — это реляционная база данных с открытым исходным кодом для распределенного управления данными. Он способен хранить обширные данные в нескольких зонах доступности, чтобы упростить выполнение запросов с малой задержкой. Это облачная распределенная база данных, которая повторяет функции PostgreSQL с постоянной доступностью и горизонтальной масштабируемостью.
Citus
Citus — это расширение с открытым исходным кодом, которое помогает использовать PostgreSQL для предоставления решения для распределенной базы данных. Он распределяет обширные данные по нескольким узлам в PostgreSQL распределенным, высокопроизводительным и масштабируемым образом. Он с открытым исходным кодом, управляемый и использует все функции PostgreSQL.
Trino
Первоначально названный PrestoSQL, Trino представляет собой высокопроизводительный распределенный механизм запросов SQL, который позволяет запрашивать данные из нескольких баз данных, таких как Cassandra и MongoDB. Он предназначен для обеспечения высокой доступности и обслуживания данных с малой задержкой в любом масштабе. Он может использоваться в больших данных и других аналитических сценариях использования.
CrateDB
CrateDB — это высокооптимизированная распределенная база данных SQL с открытым исходным кодом. Он имеет системную архитектуру без общего доступа с гибридной моделью хранения данных. Его типичный вариант использования — приложения операционной аналитики и обработка данных IoT. Это коммерческая служба базы данных с бесплатной версией для сообщества.
EventQL
EventQL — это распределенная база данных SQL для хранения крупномасштабных данных и аналитики. Это управляемая облачная система хранения для хранения и извлечения аналитических данных.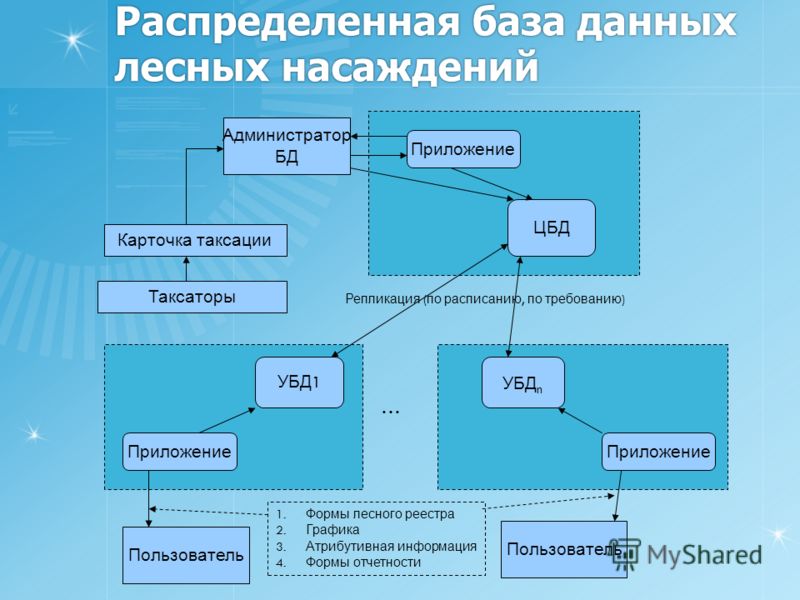 Благодаря дизайну хранилища, ориентированному на столбцы, он обеспечивает высокую доступность и масштабируемость данных.
Благодаря дизайну хранилища, ориентированному на столбцы, он обеспечивает высокую доступность и масштабируемость данных.
GhostDB
GhostDB — это быстрораспределенная база данных в памяти для хранения и запроса данных в масштабе. Он предназначен для доставки данных с высокой скоростью в динамических приложениях. Он хранит обширные данные в парах «ключ-значение» и реплицирует их в нескольких зонах доступности, чтобы обеспечить извлечение с малой задержкой.
Nebula Graph
Nebula Graph — это распределенная база данных с открытым исходным кодом, которая обеспечивает чтение и запись с малой задержкой, высокой пропускной способностью и высокой производительностью. Это SQL-подобная база данных, способная хранить крупномасштабные данные, сохраняя при этом безопасность, доступность и производительность.
CondensationDB
CondensationDB — это неизменяемая распределенная система хранения данных, построенная на основе криптографии. Он использует архитектуру с нулевым доверием для обеспечения высокой безопасности, доступности и надежности данных.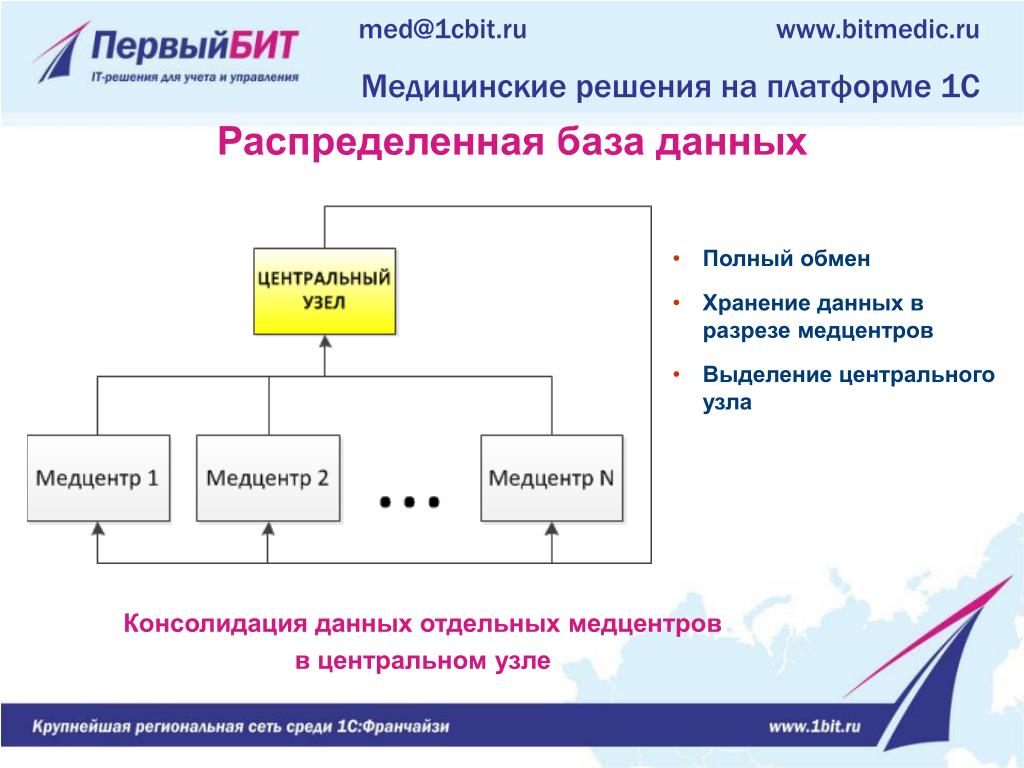 Он совместим с облаком и идеально подходит для хранения конфиденциальных данных и конфигураций.
Он совместим с облаком и идеально подходит для хранения конфиденциальных данных и конфигураций.
Hibari
Hibari — строго согласованная распределенная система хранения данных NoSQL с ключом и значением. Это готовая к работе база данных с высокой согласованностью и доступностью. Написанный на языке Erlang, он предназначен для быстрого и надежного запроса данных с репликациями, гарантирующими устойчивость данных в случае сбоя системы.
HerdDB
HerdDB — это встраиваемая распределенная база данных SQL, написанная на Java. Он предназначен для обеспечения масштабируемости, отказоустойчивости и репликации данных, обеспечивая при этом стабильную доступность данных с малой задержкой и высокой пропускной способностью.
Justin DB
Justin DB — это распределенная, согласованная база данных NoSQL с открытым исходным кодом, обеспечивающая доступность данных. Это улучшенная реализация Amazon DynamoDB с отказоустойчивостью и отказоустойчивостью. Он построен на Aka и использует его балансировку нагрузки, прозрачность местоположения и самообслуживание.
ZanredisDB
ZanredisDB — Redis-совместимая отказоустойчивая распределенная система баз данных «ключ-значение». Он обеспечивает высокую согласованность, масштабируемость и доступность данных.
Что такое распределенная база данных? {Возможности, преимущества и недостатки}
Введение
Распределенные базы данных используются для горизонтального масштабирования и предназначены для удовлетворения требований рабочей нагрузки без внесения изменений в приложение базы данных или вертикального масштабирования отдельной машины.
Распределенные базы данных решают различные проблемы , такие как доступность, отказоустойчивость, пропускная способность, задержка, масштабируемость и многие другие проблемы, которые могут возникнуть при использовании одной машины и одной базы данных.
В этой статье вы узнаете, что такое распределенные базы данных, их преимущества и недостатки.
Определение распределенной базы данных
Распределенная база данных представляет собой несколько взаимосвязанных баз данных, разбросанных по нескольким сайтам, соединенным сетью.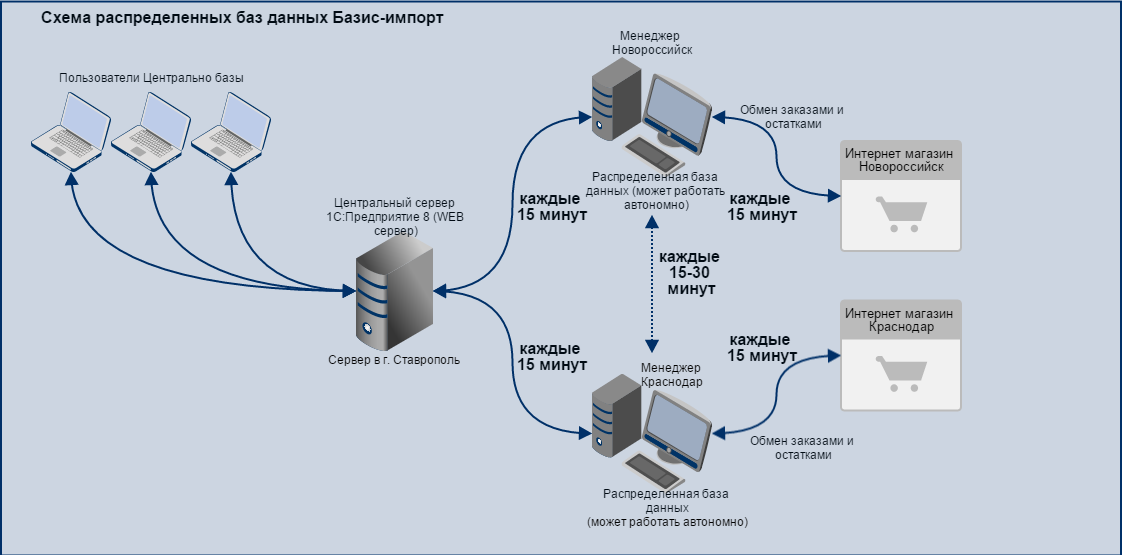 Поскольку все базы данных связаны, они отображаются для пользователей как единая база данных.
Поскольку все базы данных связаны, они отображаются для пользователей как единая база данных.
Распределенные базы данных используют несколько узлов. Они масштабируются горизонтально и развивают распределенную систему. Больше узлов в системе обеспечивает большую вычислительную мощность, обеспечивает большую доступность и решает проблему единой точки отказа.
Различные части распределенной базы данных хранятся в нескольких физических местах , а требования к обработке распределяются между процессорами на нескольких узлах базы данных.
Централизованная распределенная система управления базами данных ( DDBMS ) управляет распределенными данными, как если бы они хранились в одном физическом месте. DDBMS синхронизирует все операции с данными между базами данных и гарантирует, что обновления в одной базе данных автоматически отразятся на базах данных на других сайтах.
Функции распределенных баз данных
Некоторые общие характеристики распределенных баз данных:
- Независимость от местоположения — Данные физически хранятся на нескольких сайтах и управляются независимой СУБД.

- Распределенная обработка запросов — Распределенные базы данных отвечают на запросы в распределенной среде, которая управляет данными на нескольких сайтах. Запросы высокого уровня преобразуются в план выполнения запросов для более простого управления.
- Распределенное управление транзакциями — Обеспечивает согласованную распределенную базу данных с помощью протоколов фиксации, распределенных методов управления параллелизмом и распределенных методов восстановления в случае множества транзакций и сбоев.
- Полная интеграция — Базы данных в коллекции обычно представляют собой единую логическую базу данных, и они взаимосвязаны.
- Сетевое связывание — Все базы данных в коллекции связаны сетью и взаимодействуют друг с другом.
- Обработка транзакций — Распределенные базы данных включают обработку транзакций, которая представляет собой программу, включающую набор одной или нескольких операций с базой данных.
 Обработка транзакций — это атомарный процесс, который либо выполняется полностью, либо не выполняется вообще.
Обработка транзакций — это атомарный процесс, который либо выполняется полностью, либо не выполняется вообще.
Типы распределенных баз данных
Существует два типа распределенных баз данных:
- Однородные
- Гетерогенные
Однородные0044
Однородная распределенная база данных представляет собой сеть из идентичных баз данных, хранящихся на нескольких сайтах. Сайты имеют одинаковую операционную систему, DDBMS и структуру данных, что делает их легкоуправляемыми.
Однородные базы данных позволяют пользователям беспрепятственно получать доступ к данным из каждой из баз данных.
На следующей диаграмме показан пример однородной базы данных:
Гетерогенная
Гетерогенная распределенная база данных использует различных , операционные системы, DDBMS и различные модели данных.
В случае разнородной распределенной базы данных конкретный сайт может совершенно не знать о других сайтах, что приводит к ограниченному сотрудничеству в обработке запросов пользователей. Ограничение заключается в том, почему переводы необходимы для установления связи между сайтами.
Ограничение заключается в том, почему переводы необходимы для установления связи между сайтами.
На следующей диаграмме показан пример гетерогенной базы данных:
Хранилище распределенной базы данных
Хранилище распределенной базы данных управляется двумя способами:
- Репликация
- Фрагментация
Репликация
При репликации базы данных системы хранят копий данных на разных сайтах . Если вся база данных доступна на нескольких сайтах, это полностью избыточная база данных.
Преимущество репликации базы данных заключается в том, что она повышает доступность данных на различных сайтах и позволяет обрабатывать параллельные запросы.
Однако репликация базы данных означает, что данные требуют постоянного обновления и синхронизации с другими сайтами для поддержания точной копии базы данных. Любые изменения, сделанные на одном сайте, должны быть зарегистрированы на других сайтах, иначе возникнут несоответствия.
Постоянные обновления вызывают большую нагрузку на сервер и усложняют управление параллельным выполнением, так как множество одновременных запросов необходимо проверять на всех доступных сайтах.
Фрагментация
Когда дело доходит до фрагментации хранилища распределенной базы данных, отношения фрагментируются, что означает, что они разбиты на более мелкие части . Каждый из фрагментов хранится на разных сайтах, где это необходимо.
Условием фрагментации является уверенность в том, что фрагменты впоследствии могут быть реконструированы в исходное отношение без потери данных.
Преимущество фрагментации в том, что нет копий данных , что предотвращает несогласованность данных.
Существует два типа фрагментации:
- Горизонтальная фрагментация — Схема отношения фрагментирована на группы строк, и каждая группа (кортеж) относится к одному фрагменту.
- Вертикальная фрагментация — Схема отношения фрагментирована на более мелкие схемы, и каждый фрагмент содержит общий ключ-кандидат, чтобы гарантировать соединение без потерь.

Примечание: В некоторых случаях возможно сочетание фрагментации и репликации.
Distributed Database Advantages and Disadvantages
Below are some key advantages and disadvantages of distributed databases:
| Advantages | Disadvantages |
|---|---|
| Modular development | Costly software |
| Reliability | Large overhead |
| Снижение затрат на связь | Целостность данных |
| Лучший отклик | Неправильное распределение данных |
Преимущества и недостатки подробно описаны в следующих разделах.
Преимущества
- Модульная разработка . Модульная разработка распределенной базы данных подразумевает, что система может быть расширена за счет новых местоположений или единиц путем добавления новых серверов и данных к существующей установке и непрерывного подключения их к распределенной системе.
 Этот тип расширения не вызывает перерывов в работе распределенных баз данных.
Этот тип расширения не вызывает перерывов в работе распределенных баз данных.
- Надежность . Распределенные базы данных обеспечивают большую надежность по сравнению с централизованными базами данных. В случае сбоя базы данных в централизованной базе данных система полностью останавливается. В распределенной базе данных система работает даже при возникновении сбоев, снижая производительность только до тех пор, пока проблема не будет решена.
- Снижение стоимости связи . Локальное хранение данных снижает затраты на связь при манипулировании данными в распределенных базах данных. Локальное хранение данных невозможно в централизованных базах данных.
- Лучший ответ . Эффективное распределение данных в системе распределенной базы данных обеспечивает более быструю реакцию, когда запросы пользователей выполняются локально. В централизованных базах данных запросы пользователей проходят через центральную машину, которая обрабатывает все запросы.
 В результате увеличивается время отклика, особенно при большом количестве запросов.
В результате увеличивается время отклика, особенно при большом количестве запросов.
Недостатки
- Дорогостоящее программное обеспечение . Обеспечение прозрачности данных и координации между несколькими сайтами часто требует использования дорогостоящего программного обеспечения в системе распределенной базы данных.
- Большой накладной . Многие операции на нескольких сайтах требуют многочисленных вычислений и постоянной синхронизации при использовании репликации базы данных, что приводит к большим затратам на обработку.
- Целостность данных . Возможной проблемой при использовании репликации базы данных является целостность данных, которая нарушается при обновлении данных на нескольких сайтах.
- Неправильное распределение данных . Реагирование на запросы пользователей во многом зависит от правильного распределения данных. Это означает, что скорость отклика может снизиться, если данные неправильно распределены по нескольким сайтам.