что это и как пользоваться
В этом уроке я расскажу о программе Microsoft Word (ворд). Что это за приложение, как его открыть на компьютере. Как пользоваться программой: печатать текст и работать с документами.
Содержание:
- Что такое Word
- Как открыть программу
- Основы работы в Ворде
Что такое Word
Microsoft Word – это программа для печати. В ней можно набрать текст любого типа: статью, документ, реферат, курсовую, диплом и даже книгу. Также в Ворде можно оформить текст: изменить шрифт, размер букв, добавить таблицу, фотографию и многое другое. И вывести на бумагу – распечатать на принтере.
Программа представляет собой белый лист бумаги, на котором, используя клавиатуру, печатают текст. Также на нем располагают другие элементы: таблицы, картинки и прочее.
Если нужно напечатать много текста и на один лист он не поместится, программа автоматически добавит еще страницы.
Набранный текст можно отредактировать: изменить размер букв, шрифт, начертание и многое другое. Для этого в Ворде есть специальная панель в верхней части. На ней находятся кнопки редактирования.
Для этого в Ворде есть специальная панель в верхней части. На ней находятся кнопки редактирования.
Но это не все кнопки. Остальные расположены на других вкладках.
Как открыть программу
Приложение Word запускается через вот такую иконку на Рабочем столе компьютера:
Если значка нет, ищите его среди всех программ в Пуске.
На заметку. Чтобы вынести иконку на экран, зажмите ее левой кнопкой мыши и перетяните на Рабочий стол. Или щелкните по ней правой кнопкой мыши, выберите «Отправить» – «Рабочий стол (создать ярлык)».
Вот как выглядит приложение Microsoft Word 2016-2019. Для начала работы нажмите на пункт «Новый документ».
Откроется пустой лист. Он как будто обрезан, но это из-за того, что страница не поместилась на экран. Чтобы ее увидеть целиком, покрутите колесико на мышке или подвиньте ползунок с правой стороны.
На сегодняшний день это последняя версия программы. Есть более ранняя 2010-2013 года — выглядит она примерно так же. Еще часто можно встретить версию 2007 года. Она выглядит немного иначе, но имеет все необходимые инструменты.
Еще часто можно встретить версию 2007 года. Она выглядит немного иначе, но имеет все необходимые инструменты.
На некоторых старых компьютерах можно встретить и версию 2003 года. У нее другой дизайн, меньше функций. Но с основными задачами программа справляется.
Основы работы в Ворде
Печать текста
Рабочая область приложения – белый лист, на котором мигает палочка. Этим мигающим курсором отмечено то место, где будет набираться текст.
По умолчанию он установлен в начале листа, в левом верхнем углу. Но не в самом верху страницы, так как у нее есть поля – пустые области с каждой стороны.
Без полей с документом работать неудобно, да и при распечатке часть слов обрежется. Поэтому пустое поле должно быть с каждой стороны: сверху, снизу, слева и справа.
Изменить масштаб страницы, то есть приблизить или отдалить ее, можно через ползунок в правом нижнем углу. Но учтите, что таким образом поменяется только отображение листа, но не него реальный размер.
Для печати текста установите нужную раскладку (язык) на панели задач – в правом нижнем углу экрана. Это можно сделать мышкой или через сочетание клавиш Shift и Alt.
- Для печати большой буквы нажмите Shift и, не отпуская, кнопку с буквой.
- Для печати знака в верхнем ряду клавиш (там, где цифры) также зажимайте Shift.
- Для удаления используйте клавишу Backspace. Обычно она находится после кнопки = в верхнем ряду и на ней нарисована стрелка влево.
- Для перехода на новую строку используйте клавишу Enter. А для удаления строки – Backspace.
- Промежутки между словами делайте пробелом – самой длинной кнопкой в нижней части. Между словами должен быть только один пробел (ни два, ни три).
- Точка в русской раскладке находится в нижнем ряду клавиш – после буквы Ю.
- Запятая в русской раскладке – это так же кнопка, что и точка, но нажимать ее нужно вместе с Shift.
О значении каждой клавиши на клавиатуре и их сочетаниях читайте в этом уроке.
Сохранение
Набранный текст не будет зафиксирован до тех пор, пока вы его не сохраните. Можно набрать хоть сто страниц, но они не останутся в компьютере.
Для сохранения используйте кнопку с изображением дискеты в верхнем левом углу программы. Или «Файл» — «Сохранить как…».
Если документ еще ни разу не записывался, то появится окно с выбором места, куда его отправить. Нажмите «Обзор».
Выскочит окошко сохранения. Перейдите через него в нужную папку, напечатайте название и нажмите «Сохранить». Документ запишется в файл. Найти его можно будет в указанном при сохранении месте.
А если документ уже был записан, то при нажатии на иконку дискеты окошко не появится. Новый документ автоматически перезапишется вместо старого файла (обновится).
Чтобы узнать, куда именно он был записан, нажмите «Файл» — «Сохранить как…». Появится окошко записи, где будет указана папка, в которой находится этот файл.
Редактирование текста
Для изменения внешнего вида текста используйте вкладку «Главная» на панели инструментов вверху. Здесь можно настроить шрифт, выравнивание, начертание и другие параметры.
Здесь можно настроить шрифт, выравнивание, начертание и другие параметры.
Если необходимо изменить уже напечатанный текст, то сначала его нужно выделить. Для этого поставить курсор в самое начало (перед первой буквой), зажать левую кнопку мыши и обвести текст. Он обозначится другим цветом.
Затем выбрать нужные параметры во вкладке «Главная» в верхней части. Все изменения затронут только выделенную часть.
Для отмены используйте кнопку со стрелкой в верхнем левом углу программы.
Основные инструменты редактирования текста:
- – шрифт: внешний вид букв.
- – размер шрифта.
- – начертание: полужирный, курсив, подчеркнутый.
- – выравнивание: по левому краю, по центру, по правому краю, по ширине.
- – интервал: расстояние между строками и абзацами.
- – маркированный список.
При наведении курсора на любую из кнопок на панели инструментов, появится всплывающая подсказка с описанием.
Оформление
Если составляете документ исключительно для себя, то оформляйте его так, как вам удобнее. Но если нужно отправить файл другим людям, лучше следовать определенным правилам:
- В начале предложения первая буква печатается прописной (большой), остальные – строчными (маленькими).
- Заголовок набирается с большой буквы. После него точка не ставится.
- После знаков препинания ставится один пробел. Перед ними пробел не ставится. Например, цвет: белый, синий, красный.
- После кавычек и скобок пробел не ставится. Например, «Преступление и наказание».
- Тире отделяется пробелами с двух сторон. Дефис не отделяется ни одним пробелом.
- Текст должен быть структурированным: разбит на абзацы, иметь заголовки разных уровней. Желательно использовать маркированные и нумерованные списки.
Что касается требований к шрифту, они зависят от типа документа. Если речь идет о реферате, курсовой или дипломной работе, то обычно требования указываются отдельно. А официальные документы должны быть оформлены по ГОСТу.
А официальные документы должны быть оформлены по ГОСТу.
Универсальные правила оформления:
- Вид шрифта: Times New Roman или Arial.
- Размер шрифта: основной текст – 12 или 14, заголовки – 16, подзаголовки – 14, таблицы – 10 или 12.
- Выравнивание: основной текст – по ширине, заголовки – по центру.
- Междустрочный интервал – 1,5.
- Поля: левое — не менее 30 мм, правое — не менее 10 мм, верхнее и нижнее — не менее 20 мм.
Другие возможности программы Word
Добавить таблицу, изображение, фигуру. Делается это через вкладку «Вставка». Еще через нее можно вставить символ, диаграмму, титульный лист, сделать разрыв. А также добавить номера страниц.
Настроить поля, размер страниц, ориентацию. Эти инструменты находятся во вкладке «Макет». Также здесь можно настроить отступы и интервалы, выполнить автоматическую расстановку переносов.
Линейка и масштаб. Через вкладку «Вид» можно показать или скрыть линейку, настроить масштаб и визуальное представление страниц.
Вывод на печать. Для распечатки на принтере нажмите на «Файл» и выберите «Печать». Сделайте необходимые настройки и нажмите на кнопку «Печать».
В версии 2016-2021 для возврата к редактированию документа, щелкните по кнопке со стрелкой в верхнем левом углу.
Автор: Илья Кривошеев
Как напечатать текст на компьютере
В этом небольшом уроке я расскажу вам, как напечатать текст на компьютере. Где найти программу для печати и как в ней работать.
Откройте программу Word. Возможно, на Рабочем столе (на экране) Вашего компьютера есть специальный значок, который ее открывает.
Если же такой иконки нет, нажмите на кнопку «Пуск» в левом нижнем углу экрана.
Откроется список. Нажмите на пункт «Программы» (Все программы).
Появится новый список. Найдите пункт «Microsoft Office», нажмите на него и в появившемся небольшом списке нажмите на «Microsoft Word».
Если надписи «Microsoft Office» Вы не найдете, то, скорее всего, пакет офисных программ (в том числе программа Microsoft Word) не установлен на Вашем компьютере. В этом случае Вы можете воспользоваться стандартной программой WordPad (Пуск — Все программы — Стандартные). Или можно в качестве Ворда использовать Writer из пакета OpenOffice.
В этом случае Вы можете воспользоваться стандартной программой WordPad (Пуск — Все программы — Стандартные). Или можно в качестве Ворда использовать Writer из пакета OpenOffice.
Откроется следующее окно. Это и есть программа для печати текста Microsoft Word.
Нас интересует центральная белая часть. Это лист формата А4. Вот здесь мы и будем печатать.
Обратите внимание: лист как будто обрезан. На самом деле, он просто не поместился – ведь размер экрана компьютера меньше, чем размер листа формата А4. Та часть, которая не поместилась, «прячется» внизу. Чтобы ее увидеть, нужно покрутить колесико на мышке или перетянуть вниз ползунок с правой стороны программы.
Но печатать текст мы будем с начала листа, поэтому, если Вы опустились в его конец (вниз), поднимитесь в начало (наверх).
Для того, чтобы начать печатать текст, нужно щелкнуть левой кнопкой мышки по листу. Лучше щелкните где-нибудь в центре.
В верхнем левом углу программы должна мигать черная палочка. Тем самым, программа Word «подсказывает», что уже можно печатать текст.
Тем самым, программа Word «подсказывает», что уже можно печатать текст.
Кстати, он будет печататься там, где мигает палочка. Если хотите, чтобы он был в другом месте, нажмите по нужному месту два раза левой кнопкой мышки.
А теперь попробуйте напечатать что-нибудь, используя клавиатуру. Но для начала посмотрите, какой язык установлен. Внизу справа показан тот алфавит, который выбран на компьютере. Показан он двумя английскими буквами.
RU — это русский алфавит, EN — это английский алфавит.
Чтобы изменить язык ввода, нажмите на эти две буквы левой кнопкой мыши и из списка выберите нужный алфавит.
Попробуйте набрать небольшой текст. Если Вам сложно самостоятельно его придумать, откройте любую книгу и напечатайте небольшой кусок из нее.
Для перехода на другую строку (для набора текста ниже), нужно нажать кнопку Enter на клавиатуре. Мигающая палочка сместится на строчку вниз – там и будет печататься текст.
Также стоит обратить Ваше внимание на одну очень важную кнопку в программе Word. Эта кнопка называется «Отменить» и выглядит следующим образом:
Эта кнопка называется «Отменить» и выглядит следующим образом:
Находится она в самом верху программы и позволяет отменить последнее, что Вы сделали в программе Word.
Например, Вы случайно удалили текст или как-то его испортили (сместили, закрасили и т.д.). Нажав на эту замечательную кнопку, программа Word вернет Ваш документ (текст) в то состояние, в котором он только что был. То есть эта кнопка возвращает на один шаг назад. Соответственно, если Вы нажмете на нее два раза, то вернетесь на два шага назад.
Автор: Илья Кривошеев
Изучениеслов | МАКЛаб | Psychological and Brain Sciences
В то время как большая часть нашей работы в MAClab касается слуховых и перцептивных аспектов слов, процесс преобразования звуков в значения предлагает некоторые концептуально схожие проблемы.
В период между рождением и взрослением дети должны выучить около 60 000 слов. Это означает 8-10 слов в день! Слова редко встречаются обособленно, многие из них не имеют наблюдаемых значений (что означает слово «the»?), и даже когда они имеют значение, не всегда понятно, о чем говорит говорящий.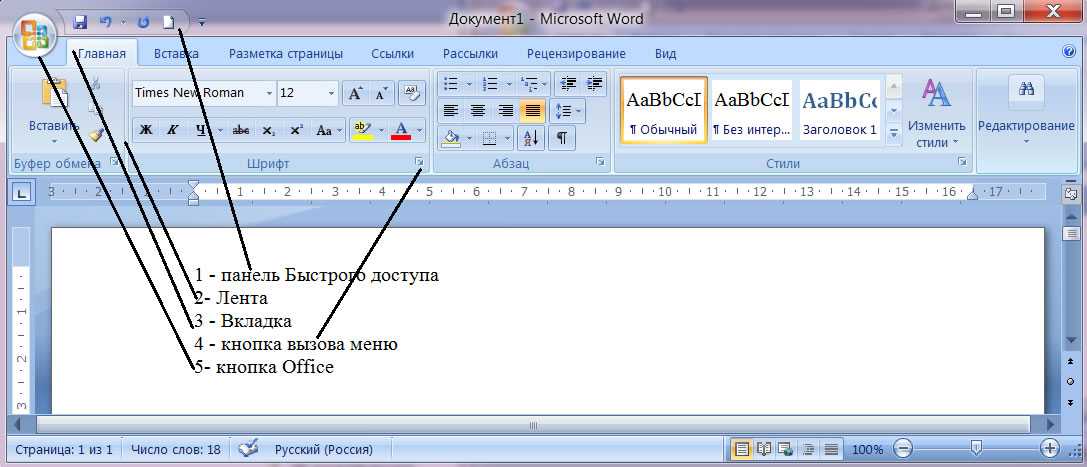 Таким образом, подобное восприятию речи мы наблюдаем проблема совладания с массовой неопределенностью.
Таким образом, подобное восприятию речи мы наблюдаем проблема совладания с массовой неопределенностью.
Из-за этой проблемы многие исследователи разработали специальные механизмы, которые помогают детям анализировать слуховые и визуальные входные данные и узнавать, что означают слова. Однако неясно, что это за механизмы и нужны ли они вообще. Наша работа в MAClab исследует это. В частности, мы исследуем две широкие точки зрения и их способность решать основные проблемы изучения слов.
Во-первых, развитие происходит в двух временных масштабах. Дети должны одновременно медленно, в течение недель и лет, изучать сопоставления слов и объектов, и они должны быть в состоянии использовать слова в тот момент, когда человек говорит о них. Предыдущая работа над такими идеями, как «быстрое картирование», часто объединяет эти идеи, предполагая, что то, что дети делают в данный момент, совпадает с обучением.
Во-вторых, простые ассоциативные механизмы (хотя это явно не вся история) могут иметь большую силу для решения проблем заучивания слов, если они встроены в более реалистичные системы (например, системы с двумя масштабами времени или процессами обработки).
Объединение этих двух простых идей привело к ряду интересных исследований. В сотрудничестве с Ларисой Самуэльсон и Джессикой Хорст, чтобы понять явление, известное как быстрое сопоставление, при котором дети используют слова, которые они знают, чтобы помочь выучить новые слова. Хотя это часто рассматривалось как специальный механизм изучения слов, наша работа предполагает, что дети не всегда сохраняют значения быстро отображаемых слов, и мы исследуем, как это связано с обучением.
Мы также исследовали так называемый всплеск словарного запаса или взрыв имен. Как правило, после изучения первых 50 слов или около того у детей процесс изучения буквально набирает обороты, поскольку они начинают учить 8-10 слов в неделю. Исследователи давно предполагали, что такие механизмы, как быстрое картирование, необходимы для объяснения этого скачка слов, но работая с математиком Коллин Митчелл, мы обнаружили, что математическое ускорение почти всегда гарантировано, когда дети изучают несколько вещей одновременно.
Наконец, ряд продолжающихся исследований изучает, как изучение слов влияет на восприятие речи. Наша работа над младенцами показывает, как это может помочь им разобраться в том, какие сигналы имеют отношение к делу, а текущая работа направлена на изучение того, как время заучивания слов может влиять на обработку звуков, а также на изучение того, что требуется для включения слов в лексическую обработку. система.
Рост, Г., и МакМюррей, Б. (2009) Изменчивость говорящих усиливает фонологическую обработку при раннем изучении слов. Наука развития, 12 (2), 339-349.
Рост, Г.К., и МакМюррей, Б. (2010) Обнаружение сигнала путем добавления шума: роль неконтрастной фонетической изменчивости в раннем изучении слов. Младенчество, 15 (6), 608-635.
МакМюррей, Б. (2007) Ослабление взрыва детского словарного запаса. Science, 317(5838), 631.
Митчелл, К., и МакМюррей, Б. (2009) Об обучении с использованием заемных средств в лексическом приобретении и его связи с ускорением.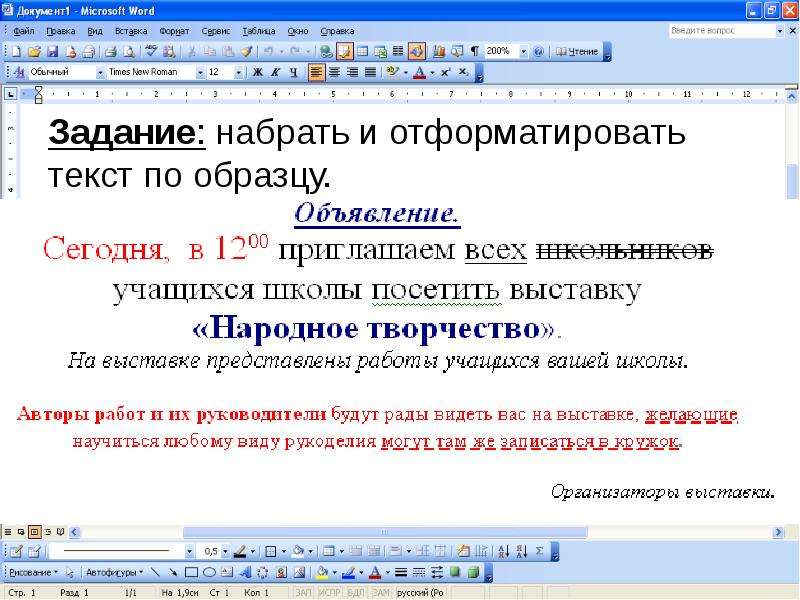 Когнитивная наука, 33(8), 1503-1523.
Когнитивная наука, 33(8), 1503-1523.
Хорст, Дж. С., Самуэльсон, Л. К., Кукер, С. и МакМюррей, Б. (2011) Что нового? Дети предпочитают новизну в выборе референтов. Познание, 118(2), 234-244.
Обучение встраиванию слов | Lil’Log
Человеческий словарный запас представлен в виде свободного текста. Чтобы модель машинного обучения понимала и обрабатывала естественный язык, нам нужно преобразовать слова произвольного текста в числовые значения. Один из простейших подходов к преобразованию состоит в том, чтобы выполнить горячее кодирование, в котором каждое отдельное слово обозначает одно измерение результирующего вектора, а двоичное значение указывает, представляет ли слово (1) или нет (0).
Однако однократное кодирование нецелесообразно с вычислительной точки зрения при работе со всем словарем, поскольку для представления требуются сотни тысяч измерений. Встраивание слов представляет слова и фразы в векторах (недвоичных) числовых значений с гораздо меньшими и, следовательно, более плотными размерностями.
Существует два основных подхода к обучению встраиванию слов, оба основаны на контекстуальном знании.
- На основе подсчета : Первый неконтролируемый, основанный на матричной факторизации глобальной матрицы совпадения слов. Необработанные подсчеты совпадений не работают, поэтому мы хотим делать умные вещи поверх них.
- На основе контекста : Второй подход контролируется. Учитывая локальный контекст, мы хотим разработать модель для прогнозирования целевых слов, а тем временем эта модель изучает эффективное представление встраивания слов.

Модели векторного пространства на основе подсчета в значительной степени полагаются на матрицу частотности и совпадения слов с предположением, что слова в одном и том же контексте имеют схожие или связанные семантические значения. Модели отображают статистику на основе подсчета, такую как совпадения между соседними словами, вплоть до небольших и плотных векторов слов. PCA, тематические модели и нейронные вероятностные языковые модели — все это хорошие примеры этой категории.
В отличие от подходов, основанных на подсчете, методы на основе контекста строят прогностические модели, которые непосредственно нацелены на предсказание слова с учетом его соседей. Плотные векторы слов являются частью параметров модели. Наилучшее векторное представление каждого слова изучается в процессе обучения модели.
Предположим, у вас есть скользящее окно фиксированного размера, перемещающееся по предложению: слово в середине — это «цель», а слова слева и справа в скользящем окне — контекстные слова.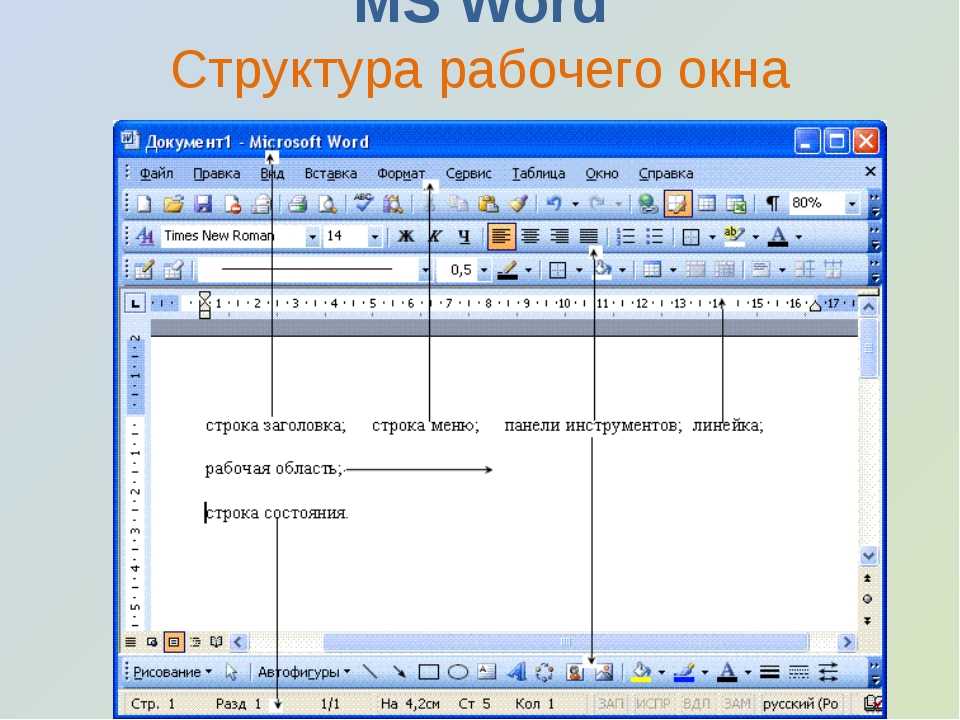 Модель скип-граммы (Миколов и др., 2013) обучена прогнозировать вероятность того, что слово будет контекстным словом для данной цели.
Модель скип-граммы (Миколов и др., 2013) обучена прогнозировать вероятность того, что слово будет контекстным словом для данной цели.
Следующий пример демонстрирует несколько пар целевых и контекстных слов в качестве обучающих образцов, сгенерированных окном из 5 слов, скользящим по предложению.
«Человек, выносящий приговор, должен размахивать мечом». – Нед Старк
| Раздвижное окно (размер = 5) | Целевое слово | Контекст |
|---|---|---|
| [Человек, который] | человек, который | |
| [Проходящий мужчина] | человек | тот, кто проходит |
| [Человек, который проходит мимо] | кто | , человек, проходит, |
| [человек, выносящий приговор] | проходит | человек, который, приговор |
| … | … | … |
| [предложение должно размахивать мечом] | качели | предложение, должен, меч |
| [должен взмахнуть мечом] | должен, качели, меч | |
| [взмахнуть мечом] | меч | качели, |
{:. info} info} |
Каждая пара контекст-цель рассматривается как новое наблюдение в данных. Например, целевое слово «качели» в приведенном выше случае дает четыре обучающих образца: («качели», «предложение»), («качели», «следует»), («качели», «то») и ( «качели», «меч»).
Рис. 1. Модель скип-грамм. И входной вектор $\mathbf{x}$, и выходной $\mathbf{y}$ являются представлениями слов с горячим кодированием. Скрытый слой — это вложение слов размера $N$.Учитывая размер словаря $V$, мы собираемся выучить векторы вложения слов размера $N$. Модель учится предсказывать одно контекстное слово (выход), используя одно целевое слово (вход) за раз.
Согласно рис. 1,
- Как входное слово $w_i$, так и выходное слово $w_j$ закодированы горячим способом в двоичные векторы $\mathbf{x}$ и $\mathbf{y}$ размера $ В$.
- Во-первых, умножение двоичного вектора $\mathbf{x}$ на матрицу вложения слов $W$ размера $V \times N$ дает вектор вложения входного слова $w_i$: i-я строка матрицы $W$.

- Этот недавно обнаруженный вектор вложения размерности $N$ образует скрытый слой.
- Умножение скрытого слоя и матрицы контекста слова $W’$ размера $N \times V$ дает выходной горячий закодированный вектор $\mathbf{y}$.
- Матрица выходного контекста $W’$ кодирует значения слов как контекст, отличный от матрицы вложения $W$. ПРИМЕЧАНИЕ. Несмотря на название, $W’$ не зависит от $W$, не является транспонированием, инверсией или чем-либо еще.
Непрерывный набор слов (CBOW) — еще одна аналогичная модель для изучения векторов слов. Он предсказывает целевое слово (т. е. «качели») из слов исходного контекста (т. е. «предложение должно быть мечом»).
Рис. 2. Модель CBOW. Векторы слов из нескольких контекстных слов усредняются, чтобы получить вектор фиксированной длины, как в скрытом слое. Другие символы имеют те же значения, что и на рис. 1. Поскольку имеется несколько контекстных слов, мы усредняем их соответствующие векторы слов, построенные путем умножения входного вектора на матрицу $W$. Поскольку этап усреднения сглаживает большую часть информации о распределении, некоторые люди считают, что модель CBOW лучше подходит для небольшого набора данных.
Поскольку этап усреднения сглаживает большую часть информации о распределении, некоторые люди считают, что модель CBOW лучше подходит для небольшого набора данных.
Как модель скип-грамм, так и модель CBOW должны быть обучены для минимизации хорошо спроектированной функции потерь/целевой функции. Есть несколько функций потерь, которые мы можем использовать для обучения этих языковых моделей. В следующем обсуждении мы будем использовать модель пропуска граммов в качестве примера для описания того, как вычисляются потери.
Full Softmax
Модель скип-грамм определяет вектор вложения каждого слова с помощью матрицы $W$ и вектор контекста с помощью выходной матрицы $W’$. Для заданного входного слова $w_I$ пометим соответствующую строку $W$ как вектор $v_{w_I}$ (вектор вложения), а соответствующий столбец $W’$ как $v’_{w_I}$ (контекст вектор). Последний выходной слой применяет softmax для вычисления вероятности предсказания выходного слова $w_O$ при заданном $w_I$, и поэтому: 9{\ топ} v_ {w_I})} $$
Это точно, как показано на рис. 1. Однако, когда $V$ чрезвычайно велико, вычисление знаменателя путем перебора всех слов для каждой отдельной выборки нецелесообразно с вычислительной точки зрения. Потребность в более эффективной оценке условной вероятности приводит к появлению новых методов, таких как иерархический softmax .
1. Однако, когда $V$ чрезвычайно велико, вычисление знаменателя путем перебора всех слов для каждой отдельной выборки нецелесообразно с вычислительной точки зрения. Потребность в более эффективной оценке условной вероятности приводит к появлению новых методов, таких как иерархический softmax .
Иерархический Softmax
Морин и Бенжио (2005) предложили иерархический softmax для ускорения вычисления суммы с помощью двоичной древовидной структуры. Иерархический softmax кодирует выходной слой softmax языковой модели в древовидную иерархию, где каждый лист представляет собой одно слово, а каждый внутренний узел обозначает относительные вероятности дочерних узлов.
Рис. 3. Иллюстрация иерархического бинарного дерева softmax. Листовые узлы, выделенные белым цветом, — это слова из словаря. Серые внутренние узлы несут информацию о вероятности достижения дочерних узлов. Один путь от корня до листа $w\_i$. $n(w\_i, j)$ обозначает j-й узел на этом пути. (Источник изображения: объяснение изучения параметров word2vec) Каждое слово $w_i$ имеет уникальный путь от корня до соответствующего листа. Вероятность выбора этого слова эквивалентна вероятности выбора этого пути от корня вниз по ветвям дерева. Поскольку мы знаем вектор вложения $v_n$ внутреннего узла $n$, вероятность получения слова может быть вычислена произведением поворотов налево или направо на каждой остановке внутреннего узла. 9{\ топ} v_ {w_I})
$$
Вероятность выбора этого слова эквивалентна вероятности выбора этого пути от корня вниз по ветвям дерева. Поскольку мы знаем вектор вложения $v_n$ внутреннего узла $n$, вероятность получения слова может быть вычислена произведением поворотов налево или направо на каждой остановке внутреннего узла. 9{\ топ} v_ {w_I})
$$
, где $L(w_O)$ — глубина пути, ведущего к слову $w_O$, а $\mathbb{I}_{\text{turn}}$ — специальная индикаторная функция, возвращающая 1, если $ n(w_O, k+1)$ — левый дочерний элемент $n(w_O, k)$, иначе —1. Вложения внутренних узлов изучаются во время обучения модели. Древовидная структура помогает значительно снизить сложность оценки знаменателя от O(V) (размер словаря) до O(log V) (глубина дерева) во время обучения. Однако во время предсказания нам еще нужно вычислить вероятность каждого слова и выбрать лучшее, так как мы заранее не знаем, к какому листу тянуться.
Хорошая древовидная структура имеет решающее значение для производительности модели. Вот несколько удобных принципов: группируйте слова по частоте, как это реализовано в дереве Хаффмана для простого ускорения; группировать похожие слова в одинаковые или близкие ветви (т. {\top}{v_{w_I}}$ с выборочный набор шумовых слов, а не просмотр всего словарного запаса, является ключом к использованию подхода выборки на основе кросс-энтропии.
{\top}{v_{w_I}}$ с выборочный набор шумовых слов, а не просмотр всего словарного запаса, является ключом к использованию подхода выборки на основе кросс-энтропии.
Оценка контрастности шума (NCE)
Метрика оценки контрастности шума (NCE) предназначена для дифференциации целевого слова от образцов шума с использованием классификатора логистической регрессии (Gutmann and Hyvärinen, 2010).
Для данного входного слова $w_I$ правильное выходное слово известно как $w$. Тем временем мы выбираем $N$ других слов из распределения выборки шума $Q$, обозначаемых как $\tilde{w}_1, \tilde{w}_2, \dots, \tilde{w}_N \sim Q$ . Обозначим решение бинарного классификатора как $d$, а $d$$ может принимать только двоичное значение. 9N \log p(d=0|\tilde{w}_i, w_I)] $$
Когда $N$ достаточно велико, согласно Закону больших чисел
$$ \mathcal{L}_\theta = — [ \log p(d=1 \vert w, w_I) + N\mathbb{E}_{\tilde{w}_i \sim Q} \log p(d=0 |\тильда{w}_i, w_I)] $$
Чтобы вычислить вероятность $p(d=1 \vert w, w_I)$, мы можем начать с совместной вероятности $p(d, w \vert w_I)$. Среди $w, \tilde{w}_1, \tilde{w}_2, \dots, \tilde{w}_N$ у нас есть 1 из (N+1) шансов выбрать истинное слово $w$, которое выбирается из условной вероятности $p(w \vert w_I)$; тем временем у нас есть N из (N+1) шансов выбрать пропускаемое слово, каждое из которых взято из $q(\tilde{w}) \sim Q$. Таким образом,
Среди $w, \tilde{w}_1, \tilde{w}_2, \dots, \tilde{w}_N$ у нас есть 1 из (N+1) шансов выбрать истинное слово $w$, которое выбирается из условной вероятности $p(w \vert w_I)$; тем временем у нас есть N из (N+1) шансов выбрать пропускаемое слово, каждое из которых взято из $q(\tilde{w}) \sim Q$. Таким образом,
$$ p(d, w | w_I) = \begin{случаи} \frac{1}{N+1} p(w \vert w_I) & \text{if } d=1 \\ \frac{N}{N+1} q(\tilde{w}) & \text{if} d=0 \end{случаи} $$
Тогда мы можем вычислить $p(d=1 \vert w, w_I)$ и $p(d=0 \vert w, w_I)$:
$$ \начать{выравнивать} p (d = 1 \vert w, w_I) &= \frac{p(d=1, w \vert w_I)}{p(d=1, w \vert w_I) + p(d=0, w \vert w_I)} &= \frac{p(w \vert w_I)}{p(w \vert w_I) + Nq(\tilde{w})} \end{выравнивание} $$
$$ \начать{выравнивать} p (d = 0 \vert w, w_I) &= \frac{p(d=0, w \vert w_I)}{p(d=1, w \vert w_I) + p(d=0, w \vert w_I)} &= \frac{Nq(\tilde{w})}{p(w \vert w_I) + Nq(\tilde{w})} \end{выравнивание} $$ 9{\ top} {v_ {w_I}}) + Nq (\ тильда {w} _i)}] $$
Распределение шума $Q$ является настраиваемым параметром, и мы хотели бы разработать его таким образом, чтобы:
- интуитивно он был очень похож на реальное распределение данных; и
- должно быть легко взять образец.

Например, реализация выборки (log_uniform_candidate_sampler) потери NCE в тензорном потоке предполагает, что такие выборки шума следуют логарифмически равномерному распределению, также известному как закон Ципфиана. Ожидается, что вероятность данного слова в логарифме будет обратно пропорциональна его рангу, в то время как высокочастотным словам присваиваются более низкие ранги. В этом случае $q(\tilde{w}) = \frac{1}{\log V}(\log (r_{\tilde{w}} + 1) — \log r_{\tilde{w}} )$, где $r_{\tilde{w}} \in [1, V]$ — ранг слова по частоте в порядке убывания.
Отрицательная выборка (NEG)
Отрицательная выборка (NEG), предложенная Mikolov et al. (2013) представляет собой упрощенный вариант потери NCE. Он особенно известен обучением проекта Google word2vec. В отличие от NCE Loss, который пытается приблизительно максимизировать логарифмическую вероятность вывода softmax, отрицательная выборка еще больше упрощает, поскольку она фокусируется на изучении высококачественного встраивания слов, а не на моделировании распределения слов на естественном языке.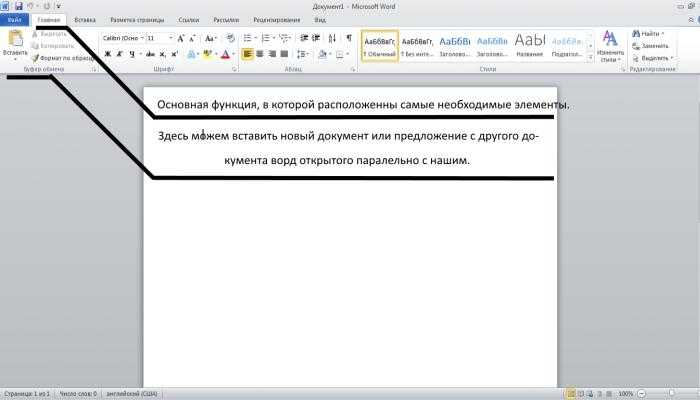
NEG аппроксимирует выходные данные бинарного классификатора сигмовидными функциями следующим образом: 9\top v_{w_I})] $$
Миколов и др. (2013) предложили несколько полезных практик, которые могут привести к внедрению хороших слов в результаты обучения.
Мягкое раздвижное окно . При объединении слов в скользящем окне мы могли бы присвоить меньший вес более удаленным словам. Одна эвристика такова: при заданном параметре максимального размера окна $s_{\text{max}}$ фактический размер окна выбирается случайным образом в диапазоне от 1 до $s_{\text{max}}$ для каждой обучающей выборки. Таким образом, каждое контекстное слово имеет вероятность наблюдения 1/(его расстояние до целевого слова), в то время как соседние слова всегда наблюдаются.
Подвыборка частых слов . Чрезвычайно частые слова могут быть слишком общими, чтобы различать контекст (например, подумайте о стоп-словах). С другой стороны, редкие слова с большей вероятностью несут отчетливую информацию.
 Чтобы сбалансировать частые и редкие слова, Миколов и др. предложено отбрасывать слова $w$ с вероятностью $1-\sqrt{t/f(w)}$ при выборке. Здесь $f(w)$ — частота слов, а $t$ — регулируемый порог.
Чтобы сбалансировать частые и редкие слова, Миколов и др. предложено отбрасывать слова $w$ с вероятностью $1-\sqrt{t/f(w)}$ при выборке. Здесь $f(w)$ — частота слов, а $t$ — регулируемый порог.Изучение фраз сначала . Фраза часто выступает как концептуальная единица, а не как простая композиция из отдельных слов. Например, мы не можем сказать, что «Нью-Йорк» — это название города, даже зная значения слов «нью» и «йорк». Сначала изучение таких фраз и обработка их как словесных единиц перед обучением модели встраивания слов улучшает качество результата. Простой подход, основанный на данных, основан на подсчете униграмм и биграмм: $s_{\text{фраза}} = \frac{C(w_i w_j) — \delta}{C(w_i)C(w_j)}$, где $ C(.)$ – это просто подсчет униграммы $w_i$ или биграммы $w_i w_j$, а $\delta$ – порог дисконтирования для предотвращения очень редких слов и фраз. Более высокие баллы указывают на более высокие шансы быть фразами. Чтобы сформировать фразы длиннее двух слов, мы можем просмотреть словарь несколько раз, уменьшая пороговые значения.

Модель Global Vector (GloVe), предложенная Pennington et al. (2014) стремится объединить матричную факторизацию на основе подсчета и модель пропуска грамм на основе контекста.
Все мы знаем, что подсчеты и совпадения могут раскрывать значения слов. Чтобы отличить от $p(w_O \vert w_I)$ в контексте слова, включающего слово, мы хотели бы определить вероятность совпадения как:
$$ p _ {\ text {co}} (w_k \ vert w_i) = \ frac {C (w_i, w_k)} {C (w_i)} $$
$C(w_i, w_k)$ подсчитывает совпадение слов $w_i$ и $w_k$.
Допустим, у нас есть два слова: $w_i$=«лед» и $w_j$=«пар». Третье слово $\tilde{w}_k$=»твердый» относится к слову «лед», но не к «пару», поэтому мы ожидаем, что $p_{\text{co}}(\tilde{w}_k \vert w_i )$ намного больше, чем $p_{\text{co}}(\tilde{w}_k \vert w_j)$ и, следовательно, $\frac{p_{\text{co}}(\tilde{w}_k \ vert w_i)}{p_{\text{co}}(\tilde{w}_k \vert w_j)}$ будет очень большим. Если третье слово $\tilde{w}_k$ = «вода» связано с обоими или $\tilde{w}_k$ = «мода» не связано ни с одним из них, $\frac{p_{\text{co }}(\tilde{w}_k \vert w_i)}{p_{\text{co}}(\tilde{w}_k \vert w_j)}$ должно быть близко к единице.
Интуиция здесь такова, что значения слов определяются отношениями вероятностей совпадений, а не самими вероятностями. Глобальный вектор моделирует отношения между двумя словами относительно третьего контекстного слова как:
$$ F(w_i, w_j, \tilde{w}_k) = \frac{p_{\text{co}}(\tilde{w}_k \vert w_i)}{p_{\text{co}}(\tilde{ w}_k \vert w_j)} $$
Кроме того, поскольку цель состоит в том, чтобы изучить осмысленные векторы слов, $F$ разработан как функция линейной разницы между двумя словами $w_i — w_j$: 9\alpha & \text{если} c
Изучив все вышеизложенные теоретические знания, давайте попробуем провести небольшой эксперимент по встраиванию слов, извлеченных из «корпуса Игр престолов». Процесс очень прост с использованием gensim.
Шаг 1: Извлечение слов
import sys
из nltk.corpus импортировать стоп-слова
из nltk.tokenize импортировать sent_tokenize
STOP_WORDS = установить(стоп-слова.слова('английский'))
определение get_words (txt):
обратный фильтр(
лямбда x: x не в STOP_WORDS,
re. findall(r'\b(\w+)\b', txt)
)
def parse_sentence_words (входные_файлы_имена):
"""Возвращает список слов. Каждый подсписок является предложением."""
предложения_слова = []
для имени_файла в input_file_names:
для строки в open(file_name):
строка = строка.полоса().нижний()
строка = строка.decode('unicode_escape').encode('ascii','игнорировать')
sent_words = карта (get_words, sent_tokenize (строка))
send_words = filter(лямбда sw: len(sw) > 1, send_words)
если len(sent_words) > 1:
предложения_слова += отправленные_слова
вернуть предложение_слов
# Вы увидите пять файлов .txt после распаковки 'a_song_of_ice_and_fire.zip'
input_file_names = ["001ssb.txt", "002ssb.txt", "003ssb.txt",
"004ssb.txt", "005ssb.txt"]
GOT_SENTENCE_WORDS= parse_sentence_words(входные_имена_файлов)
findall(r'\b(\w+)\b', txt)
)
def parse_sentence_words (входные_файлы_имена):
"""Возвращает список слов. Каждый подсписок является предложением."""
предложения_слова = []
для имени_файла в input_file_names:
для строки в open(file_name):
строка = строка.полоса().нижний()
строка = строка.decode('unicode_escape').encode('ascii','игнорировать')
sent_words = карта (get_words, sent_tokenize (строка))
send_words = filter(лямбда sw: len(sw) > 1, send_words)
если len(sent_words) > 1:
предложения_слова += отправленные_слова
вернуть предложение_слов
# Вы увидите пять файлов .txt после распаковки 'a_song_of_ice_and_fire.zip'
input_file_names = ["001ssb.txt", "002ssb.txt", "003ssb.txt",
"004ssb.txt", "005ssb.txt"]
GOT_SENTENCE_WORDS= parse_sentence_words(входные_имена_файлов)
Шаг 2. Загрузка модели word2vec
из gensim.models import Word2Vec # размер: размерность векторов встраивания.# окно: максимальное расстояние между текущим и прогнозируемым словом в предложении. модель = Word2Vec (GOT_SENTENCE_WORDS, размер = 128, окно = 3, min_count = 5, рабочие = 4) model.wv.save_word2vec_format ("got_word2vec.txt", двоичный файл = ложь)
Шаг 3: Проверьте результаты
В пространстве для встраивания слов GoT слова, наиболее похожие на «король» и «королева», следующие:
model.most_similar('король', topn=10) (слово, сходство с ‘царем’) | model.most_similar('королева', topn=10) (слово, схожее с королевой) |
|---|---|
| («короли», 0,897245) | («серсея», 0,942618) |
| («баратеон», 0,809675) | («Джоффри», 0,933756) |
| («сын», 0,763614) | («маргери», 0,931099) |
| («Роберт», 0,708522) | («сестра», 0,928902) |
| («лорды», 0,698684) | («принц», 0,927364) |
| («Джоффри», 0,696455) | («дядя», 0. 922507) 922507) |
| («принц», 0,695699) | («варис», 0,918421) |
| («брат», 0,685239) | («нед», 0,917492) |
| («аерис», 0,684527) | («мелисандра», 0.915403) |
| («станнис», 0,682932) | («грабить», 0,915272) |
Цитируется как:
@article{weng2017wordembedding,
title = "Изучаем встраивание слов",
автор = "Венг, Лилиан",
журнал = "lilianweng.github.io",
год = "2017",
url = "https://lilianweng.github.io/posts/2017-10-15-word-embedding/"
}
[1] Tensorflow Tutorial Векторные представления слов.
[2] «Учебное пособие по Word2Vec — модель Skip-Gram» Криса Маккормика.
[3] «О встраивании слов — Часть 2: приближение к Softmax» Себастьяна Рудера.
[4] Синь Ронг. Объяснение обучения параметрам word2vec
[5] Миколов, Томас, Кай Чен, Грег Коррадо и Джеффри Дин. «Эффективная оценка представлений слов в векторном пространстве».