Агрегатные функции SQL — CodeTown.ru
Здравствуйте! Сегодня мы познакомимся с агрегатными функциями в SQL, подробно разберем их работу с данными из таблиц, которые создавали в прошлых уроках.
Общее понятие
В прошлом уроке по оператору SELECT мы познакомились с тем, как строятся запросы к данным. Агрегатные функции же существуют для того, чтобы была возможность каким либо образом обобщить полученные данные, то есть манипулировать ими так, как нам это захочется.
Эти функции выполняются с помощью ключевых слов, которые включаются в запрос SELECT, и о том, как они прописываются будет рассказано далее. Чтобы было понятно, вот некоторые возможности агрегатных функций в SQL:
- Суммировать выбранные значения
- Находить среднее арифметическое значений
- Находить минимальное и максимальное из значений
Примеры агрегатных функций SQL
Мы разберем самые часто используемые функции и приведем несколько примеров.
Функция SUM
Эта функция позволяет просуммировать значения какого либо поля при запросе SELECT. Достаточно полезная функция, синтаксис которой довольно прост, как и всех других агрегатных функций в SQL. Для понимания сразу начнем с примера:
Получить сумму всех заказов из таблицы Orders, которые были совершены в 2016 году.
Можно было бы просто вывести сумму заказов, но мне кажется, что это совсем просто. Напомним структуру нашей таблицы:
| onum | amt | odate | cnum | snum |
|---|---|---|---|---|
| 1001 | 128 | 2016-01-01 | 9 | 4 |
| 1002 | 1800 | 2016-04-10 | 10 | 7 |
| 1003 | 348 | 2017-04-08 | 2 | 1 |
| 1004 | 500 | 2016-06-07 | 3 | 3 |
| 1005 | 499 | 2017-12-04 | 5 | 4 |
| 1006 | 320 | 2016-03-03 | 5 | 4 |
| 1007 | 80 | 2017-09-02 | 7 | 1 |
| 1008 | 780 | 2016-03-07 | 1 | 3 |
| 1009 | 560 | 2017-10-07 | 3 | 7 |
| 1010 | 900 | 2016-01-08 | 6 | 8 |
Следующий код осуществит нужную выборку:
SELECT SUM(amt) FROM Orders WHERE odate BETWEEN '2016-01-01' and '2016-12-31';
В результате получим:
В данном запросе мы использовали функцию SUM, после которой в скобках нужно указать поле для суммирования. Затем мы указали условие в WHERE, которое отобрало строчки только с 2016 годом. На самом деле это условие можно записать по другому, но сейчас важнее агрегатная функция суммирования в SQL.
Функция AVG
Следующая функция осуществляет подсчет среднего арифметического поля данных, которое мы укажем в качестве параметра. Синтаксис такой функции идентичен функции суммирования. Поэтому сразу перейдем к простейшей задаче:
Вывести среднюю стоимость заказа из таблицы Orders.
И сразу запрос:
SELECT AVG(amt) FROM Orders;
В результате получим:
В целом, все похоже на предыдущую функцию. И синтаксис достаточно прост. В этом и состоит особенность языка SQL — быть понятным для человека.
Функции MIN и MAX
Еще 2 функции, которые близки по своему действию. Они находят минимальное или максимальное значение соответственно того параметра, который будет передан в скобках. Синтаксис повторяется и поэтому следующий пример:
Вывести максимальное и минимальное значения цены заказа, для тех заказов в которых цена менее 1000.
Получается такой запрос,
SELECT MAX(amt), MIN(amt) FROM Orders WHERE amt < 1000;
который выведет:
Также стоит сказать, что в отличие от предыдущих функций, эти 2 могут работать с символьными параметрами, то есть можно написать запрос типа MIN(odate) (в данном случае дата у нас символьная), и тогда нам вернется 2016-01-01.
Дело в том, что в этих функциях есть механизм преобразования символов в ASCII код, который потом они и сравнивают.
Еще одним важным моментом является то, что мы можем производить некоторые простые математические операции в запросе SELECT, например, такой запрос:
SELECT (MAX(amt) - MIN(amt)) AS 'Разница' FROM Orders;
Вернет такой ответ:
Функция COUNT
Эта функция необходима для того, чтобы подсчитать количество выбранных значений или строк. Существует два основных варианта ее использования:
Теперь разберем пример использования COUNT в SQL:
Подсчитать количество сделанных заказов и количество продавцов в таблице Orders.
SELECT COUNT(*), COUNT(DISTINCT snum) FROM Orders;
Получаем:
Очевидно, что количество заказов — 10, но если вдруг у вас имеется большая таблица, то такая функция будет очень удобной. Что касается уникальных продавцов, то здесь необходимо использовать DISTINCT, потому что один продавец может обслужить несколько заказов.
Оператор GROUP BY
Теперь рассмотрим 2 важных оператора, которые помогают расширить функционал наших запросов в SQL. Первым из них является оператор GROUP BY, который осуществляет группировку по какому либо полю, что иногда является необходимым. И уже для этой группы производит заданное действие. Например:
Вывести сумму всех заказов для каждого продавца по отдельности.
То есть теперь нам нужно для каждого продавца в таблице Orders выделить поля с ценой заказа и просуммировать. Все это сделает оператор GROUP BY в SQL достаточно легко:
SELECT snum, SUM(amt) AS 'Сумма всех заказов' FROM Orders GROUP BY snum;
И в итоге получим:
| Сумма всех заказов | |
|---|---|
| 1 | 428 |
| 3 | 1280 |
| 4 | 947 |
| 7 | 2360 |
| 8 | 900 |
Как видно, SQL выделил группу для каждого продавца и посчитал сумму всех их заказов.
Оператор HAVING
Этот оператор используется как дополнение к предыдущему. Он необходим для того, чтобы ставить условия для выборки данных при группировке. Если условие выполняется то выделяется группа, если нет — то ничего не произойдет. Рассмотрим следующий код:
SELECT snum, SUM(amt) AS 'Сумма всех заказов' FROM Orders GROUP BY snum HAVING MAX(amt) > 1000;
Который создаст группу для продавца и посчитает сумму заказов этой группы, только в том случае, если максимальная сумма заказа больше 1000. Очевидно, что такой продавец только один, для него выделится группа и посчитается сумма всех заказов:
| snum | Сумма всех заказов |
|---|---|
| 7 | 2360 |
Казалось бы, почему тут не использовать условие WHERE, но SQL так построен, что в таком случае выдаст ошибку, и именно поэтому в SQL есть оператор HAVING.
Примеры на агрегатные функции в SQL
1. Напишите запрос, который сосчитал бы все суммы заказов, выполненных 1 января 2016 года.
SELECT SUM(amt) FROM Orders WHERE odate = '2016-01-01';
2. Напишите запрос, который сосчитал бы число различных, отличных от NULL значений поля city в таблице заказчиков.
SELECT COUNT(DISTINCT city) FROM customers;
3. Напишите запрос, который выбрал бы наименьшую сумму для каждого заказчика.
SELECT cnum, MIN(amt) FROM orders GROUP BY cnum;
4. Напишите запрос, который бы выбирал заказчиков чьи имена начинаются с буквы Г.
SELECT cname FROM customers WHERE cname LIKE 'Г%' ;
5. Напишите запрос, который выбрал бы высший рейтинг в каждом городе.
SELECT city, MAX(rating) FROM customers GROUP BY city;
Заключение
На этом мы будем заканчивать. В этой статье мы познакомились с агрегатными функциями в SQL. Разобрали основные понятия и базовые примеры, которые могут пригодиться далее.
Если у вас остались вопросы, то задавайте их в комментариях.
Поделиться ссылкой:
Похожее
codetown.ru
Агрегатные функции
Для подведения итогов по информации, содержащейся в БД, в SQL предусмотрены агрегатные функции. Агрегатная функция принимает в качестве аргумента какой-либо столбец данных целиком, а возвращает одно значение, которое определенным образом подытоживает этот столбец.
Например, агрегатная функция AVG() принимает в качестве аргумента столбец чисел и вычисляет их среднее значение.
Чтобы вычислить среднедушевой доход жителя Зеленограда, нужен такой запрос:
SELECT ‘СРЕДНЕДУШЕВОЙ ДОХОД=’, AVG(SUMD)
FROM PERSON
В SQL имеется шесть агрегатных функций, которые позволяют получать различные виды итоговой информации (рис. 1):
– SUM( ) вычисляет сумму всех значений, содержащихся в столбце;
– AVG( ) вычисляет среднее среди значений, содержащихся в столбце;
– MIN( ) находит наименьшее среди всех значений, содержащихся в столбце;
– MAX( ) находит наибольшее среди всех значений, содержащихся в столбце;
– COUNT( ) подсчитывает количество значений, содержащихся в столбце;
– COUNT(*) подсчитывает количество строк в таблице результатов запроса.
Аргументом агрегатной функции может быть простое имя столбца, как в предыдущем примере, или выражение, как в следующем запросе, задающем вычисление среднедушевого налога:
SELECT AVG(SUMD*0.13)
FROM PERSON
При выполнении этого запроса создается временный столбец, содержащий значения (SUMD*0.13) для каждой строки таблицы PERSON, а затем вычисляется среднее значение временного столбца.

Сумму доходов у всех жителей Зеленограда можно вычислить с помощью агрегатной функции SUM:
SELECT SUM(SUMD) FROM PERSON
Агрегатная функция может быть использована и для вычисления итогов по таблице результатов, полученной соединением нескольких исходных таблиц. Например, можно вычислить общую сумму дохода, которая получена жителями от источника с названием «Стипендия»:
SELECT SUM(MONEY)
FROM PROFIT, HAVE_D
WHERE PROFIT.ID=HAVE_D.ID
AND PROFIT.SOURCE=’Стипендия’
Агрегатные функции MIN( ) и MAX( ) позволяют найти соответственно наименьшее и наибольшее значения в таблице. При этом столбец может содержать числовые или строковые значения либо значения даты или времени.
Например, можно определить:
(а) наименьший общий доход, полученный жителями, и наибольший налог, подлежащий уплате:SELECT MIN(SUMD), MAX(SUMD*0.13)
FROM PERSON
(б) даты рождения самого старого и самого молодого жителя:
SELECT MIN(RDATE), MAX(RDATE)
FROM PERSON
(в) фамилии, имена и отчества самого первого и самого последнего жителей в списке, упорядоченном по алфавиту:
SELECT MIN(FIO), MAX(FIO)
FROM PERSON
Применяя эти агрегатные функции, нужно помнить, что числовые данные сравниваются по арифметическим правилам, сравнение дат происходит последовательно (более ранние значения дат считаются меньшими, чем более поздние), сравнение интервалов времени выполняется на основании их продолжительности.
При использовании функции MIN( ) и MAX( ) со строковыми данными результат сравнения двух строк зависит от используемой таблицы кодировки символов.
Агрегатная функция COUNT( ) подсчитывает количество значений в столбце любого типа:
(а) сколько квартир в 1-м микрорайоне?
SELECT COUNT(ADR) FROM FLAT WHERE ADR LIKE ‘%, 1_ _-%’
(б) сколько жителей имеют источники дохода?
SELECT COUNT(DISTINCT NOM) FROM HAVE_D
(в) сколько источников дохода используются жителями?
SELECT COUNT(DISTINCT ID) FROM HAVE_D (ключевой слово DISTINCT указывает, что подсчитываются неповторяющиеся значения в столбце).
Специальная агрегатная функция COUNT(*) подсчитывает строки в таблице результатов, а не значения данных:
(а) сколько квартир во 2-м микрорайоне?
SELECT COUNT(*) FROM FLAT WHERE ADR LIKE ‘%, 2__-%’
(б) сколько источников дохода у Иванова Ивана Ивановича?
SELECT COUNT(*) FROM PERSON, HAVE_D WHERE FIO=’Иванов Иван Иванович’ AND PERSON.NOM=HAVE_D.NOM
(в) сколько жителей проживает в квартире по определенному адресу?
SELECT COUNT(*) FROM PERSON WHERE ADR=’Зеленоград, 1001-45′
Один из способов понять, как выполняются итоговые запросы с агрегатными функциями, это представить выполнение запроса разбитым на две части. Сначала определяется, как бы запрос работал без агрегатных функций, возвращая несколько строк результатов. Затем применяются агрегатные функции к результатам запроса, возвращая одну итоговую строку.
Например, рассмотрим следующий сложный запрос: найти среднедушевой общий доход, сумму общих доходов жителей, а также среднюю доходность источника в процентах от общего дохода жителя. Ответ дает оператор
SELECT AVG(SUMD), SUM(SUMD), (100*AVG(MONEY/SUMD)) FROM PERSON, PROFIT, HAVE_D WHERE PERSON.NOM=HAVE_D.NOM AND HAVE_D.ID=PROFIT.ID
Без агрегатных функций запрос выглядел бы так:
SELECT SUMD, SUMD, MONEY/SUMD FROM PERSON, PROFIT, HAVE_D WHERE PERSON.NOM=HAVE_D.NOM AND HAVE_D.ID=PROFIT.ID
и возвращал бы одну строку результатов для каждого жителя и конкретного источника дохода. Агрегатные функции используют столбцы таблицы результатов этого запроса для получения однострочной таблицы с итоговыми результатами.
В строке возвращаемых столбцов вместо имени любого столбца можно указать агрегатную функцию. Например, она может входить в выражение, в котором суммируются или вычитаются значения двух агрегатных функций:
SELECT MAX(SUMD)-MIN(SUMD) FROM PERSON
Однако агрегатная функция не может быть аргументом для другой агрегатной функции, т.е. запрещены вложенные агрегатные функции.
Кроме того, в списке возвращаемых столбцов нельзя одновременно использовать агрегатные функции и обычные имена столбцов, поскольку в этом нет смысла, например:
SELECT FIO, SUM(SUMD) FROM PERSON
Здесь первый элемент списка указывает, чтобы СУБД создала таблицу, которая будет состоять из нескольких строк и содержать по одной строке для каждого жителя. Второй элемент списка просит СУБД получить одно результирующее значение, являющееся суммой значений столбца SUMD. Эти два указания противоречат друг другу, что приводит к ошибке.
По этой причине либо все ссылки на столбцы в списке возвращаемых столбцов должны являться аргументами агрегатных функций, либо в списке не должно быть ни одной агрегатной функции.
Сказанное не относится к случаям обработки подзапросов и запросов с группировкой.
studfiles.net
Агрегатные функции SQL — SUM, MIN, MAX, AVG, COUNT
Будем учиться подводить итоги. Нет, это ещё не итоги изучения SQL, а итоги значений столбцов таблиц базы данных. Агрегатные функции SQL действуют в отношении значений столбца с целью получения единого результирующего значения. Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX, AVG и COUNT. Следует различать два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных функций без группировки.
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы начинаются так:
SELECT SUM(ИМЯ_СТОЛБЦА) …
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Пример 1. Есть база данных фирмы с данными о её подразделениях и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
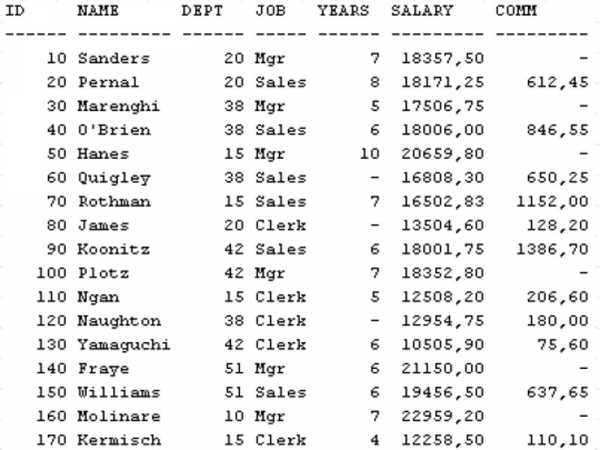
Для получения суммы размеров всех заработных плат используем следующий запрос:
SELECT SUM(Salary) FROM Staff
Этот запрос вернёт значение 287664,63.
А теперь упражнение для самостоятельного решения. В упражнениях уже начинаем усложнять задания, приближая их к тем, что встречаются на практике.
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3. База данных и таблица — те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос:
SELECT MIN(Salary) FROM Staff WHERE DEPT=42
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения. В этом и некоторых других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о подразделениях фирмы:
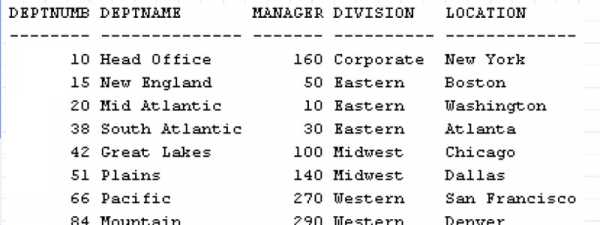
Пример 4. К таблице Staff добавляется таблица Org, содержащая данные о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе, расположенном в Бостоне.
Правильное решение и ответ.
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца.
Пример 5. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос:
SELECT MAX(Salary) FROM Staff WHERE DEPT=42
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения.
Пример 6. Вновь работаем с двумя таблицами — Staff и Org. Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе, относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц).
Правильное решение и ответ.
Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца.
Пример 7. База данных и таблица — те же, что и в предыдущих примерах.
Пусть требуется узнать средний трудовой стаж сотрудников отдела с номером 42. Для этого пишем следующий запрос:
SELECT AVG(Years) FROM Staff WHERE DEPT=42
Результатом будет значение 6,33
В следующем упражнении для самостоятельного решения помимо агрегатной функции требуется использовать также предикат BETWEEN.
Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) …, то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) …, то результатом будет количество всех записей (строк) таблицы.
Пример 9. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать число всех сотрудников, которые получают комиссионные. Число сотрудников, у которых значения столбца Comm — не NULL, вернёт следующий запрос:
SELECT COUNT(Comm) FROM Staff
Результатом будет значение 11.
Пример 10. База данных и таблица — те же, что и в предыдущих примерах.
Если требуется узнать общее количество записей в таблице, то применяем запрос со звёздочкой в качестве аргумента функции COUNT:
SELECT COUNT(*) FROM Staff
Результатом будет значение 17.
В следующем упражнении для самостоятельного решения потребуется использовать подзапрос.
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY служит для группировки результирующих значений по столбцам таблицы базы данных.
Пример 12. Есть база данных портала объявлений. В ней есть таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит данные о больших категориях объявлений (например, Недвижимость), а столбец Parts — о более мелких частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость). Столбец Units содержит данные о количестве поданных объявлений, а столбец Money — о денежных суммах, вырученных за подачу объявлений.
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Доски | 68 | 7140 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Книги | 96 | 6240 |
| Недвижимость | Дома | 47 | 9870 |
| Досуг | Музыка | 117 | 7605 |
| Досуг | Игры | 41 | 2665 |
Используя оператор SQL GROUP BY, найти суммы денег, вырученных за подачу объявлений в каждой категории. Пишем следующий запрос:
SELECT Category, SUM(Money) AS Money FROM Ads GROUP BY Category
Результатом будет следующая таблица:
| Category | Money |
| Досуг | 16510 |
| Недвижимость | 40530 |
| Стройматериалы | 18900 |
| Транспорт | 38560 |
| Электротехника | 17160 |
Пример 13. База данных и таблица — та же, что в предыдущем примере.
Используя оператор SQL GROUP BY, выяснить, в какой части каждой категории было подано наибольшее число объявлений. Пишем следующий запрос:
SELECT Category, Part, MAX(Units) AS Maximum FROM Ads GROUP BY Category
Результатом будет следующая таблица:
| Category | Part | Maximum |
| Досуг | Музыка | 117 |
| Недвижимость | Квартиры | 89 |
| Стройматериалы | Регипс | 112 |
| Транспорт | Мотоциклы | 131 |
| Электротехника | Холодильники | 137 |
Поделиться с друзьями
Другие темы в блоке «Реляционные базы данных»
function-x.ru
4.4. GROUP BY и агрегатные функции SQL
Ид_Сотр. | Фамилия | Имя | Отчество | Год_рожд. | Пол |
|
|
|
|
|
|
2 | Петров | Иван | Иванович | 1949 | М |
|
|
|
|
|
|
3 | Сидоров | Петр | Петрович | 1947 | М |
|
|
|
|
|
|
4 | Панов | Антон | Михайлович | 1975 | М |
|
|
|
|
|
|
5 | Петухов | Виктор | Борисович | 1940 | М |
|
|
|
|
|
|
7 | Петрова | Нина | Николаевна | 1970 | Ж |
|
|
|
|
|
|
8 | Сидорова | Екатерина | Ивановна | 1970 | Ж |
|
|
|
|
|
|
9 | Никитин | Валентин | Сергеевич | 1952 | М |
|
|
|
|
|
|
11 | Попов | Анатолий | Михайлович | 1947 | М |
|
|
|
|
|
|
| Рис. 4.20. Использование LIKE «^[Д-М]%» |
| |||
РЕЗЮМЕ
Теперь Вы можете создавать предикаты в терминах связей специально определенных SQL. Вы можете искать значения в определенном диапазоне (BETWEEN) или в числовом наборе (IN), или Вы можете искать символьные значения, которые соответствуют тексту внутри параметров (LIKE).
Результатом запроса может быть обобщенное групповое значение полей, точно так же, как и значение одного поля. Это делается с помощью стандартных агрегатных функций SQL, список которых приведен ниже:
COUNT | — число значений в столбце, |
SUM | — арифметическая сумма значений в столбце, |
AVG | — арифметическое среднее значение в столбце, |
MAX | — самое большое значение в столбце, |
MIN | — самое маленькое значение в столбце. |
Кроме специального случая COUNT(*), каждая из этих функций оперирует совокупностью значений столбца некоторой таблицы и выдает только одно значение.
Аргументу всех функций, кроме COUNT(*), может предшествовать ключевое слово DISTINCT (различный), указывающее, что дублирующие значения столбца
должны быть исключены перед тем, как будет применяться функция. Специальная же функция COUNT(*) служит для подсчета всех без исключения строк в таблице (включая дубликаты).
Агрегатные функции используются подобно именам полей в предложении запроса SELECT, но с одним исключением: они берут имена поля как аргументы. Только числовые поля могут использоваться с SUM и AVG.
С COUNT, MAX, и MIN могут использоваться и числовые или символьные поля. Когда они используются с символьными полями, MAX и MIN будут транслировать их в эквивалент ASCII кода, который должен сообщать, что MIN будет означать первое, а MAX — последнее значение в алфавитном порядке.
Чтобы найти SUM всех окладов в таблице ОТДЕЛ_СОТРУДНИК (рис. 2.3) надо ввести следующий запрос:
SELECT SUM ((Оклад)) | AS СУММА |
FROM Отдел_ Сотрудники;
И на экране увидим результат: 46800 (в таблице будет один столбец с именем СУММА).
Подсчет среднего значения по окладам также прост:
SELECT AVG ((Оклад))
FROM Отдел_ Сотрудники;
И на экране увидим результат: | 3342.85 |
Функция COUNT несколько отличается от всех. Она считает число значений в данном столбце или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT (различных) чтобы производить счет чисел уникальных значений в данном поле.
SELECT COUNT (DISTINCT | ОКЛАД) |
FROM Отдел_ Cотрудники; |
|
Результат: 8. |
|
В таблице восемь строк, в которых находятся различные значения окладов.
Отметим, что в последних трех примерах учитывается информация и об уволенных сотрудниках.
Следующее предложение позволяет определить число подразделений на
предприятии: |
|
SELECT COUNT (DISTINCT | Ид_Отд) |
FROM Отдел_Cотрудники; |
|
Результат: 3. |
|
DISTINCT, сопровождаемый именем поля, с которым он применяется, помещенный в круглые скобки, с COUNT применяется к индивидуальным столбцам.
Чтобы подсчитать общее число строк в таблице, используется COUNT со звездочкой вместо имени поля:
SELECT COUNT (*)
FROM Отдел_ Сотрудники;
Ответ будет: | 11. |
COUNT (*) подсчитывает все без исключения строки таблицы.
DISTINCT не применим c COUNT (*).
Предположим, что таблица ВЕДОМОСТЬ_ОПЛАТЫ (рис. 2.4) имеет еще один столбец, который хранит сумму произведенных вычетов (поле Вычет) для каждой строки ведомости. Тогда если Вас интересует вся сумма, то содержимое столбца Сумма иВычет надо сложить.
Если же Вас интересует максимальная сумма с учетом вычетов, содержащаяся в ведомости, то это можно сделать с помощью следующего предложения:
SELECT MAX (Сумма + Вычет)
FROM Ведомость_ оплаты;
Для каждой строки таблицы этот запрос будет складывать значение поля Сумма со значением поляВычет и выбирать самое большое значение, которое он найдет.
ПРЕДЛОЖЕНИЕ GROUP BY (перекомпоновка, порядок)
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT.
Например, предположим, что Вы хотите определить, сколько сотрудников находятся в каждом отделе (ответ приведен на рис. 4.21):
SELECT Ид_Отд, COUNT (DISTINCT Ид_Отд) AS Кол-во_сотрудников
FROM | Отдел_ Сотрудники |
| |
WHERE | Дата_ увольнения | NOT NULL | |
GROUP BY |
| Ид_Отд; |
|
|
|
|
|
|
| Ид_Отд | Кол-во_сотрудников |
|
|
|
|
|
| 1 | 5 |
|
|
|
|
|
| 2 | 4 |
|
|
|
|
|
| 3 | 1 |
|
|
|
|
Рис. 4.21. Запрос с группировкой
В результате выполнения предложения GROUP BY остаются только уникальные значения столбцов, по умолчанию отсортированныепо возрастанию. В этом аспекте предложение GROUP BY отличается от предложения ORDER BY тем, что последнее хотя и сортирует записи по возрастанию, но не удаляет повторяющиеся значения. В приведенном примере запрос группирует строки таблицы по значениям столбцаИд_Отд (по номерам отделов). Строки с одинаковыми номерами отделов сначала объединяются в группы, но при этом для каждой группы отображается только одна строка. Во втором столбце выводится количество строк в каждой группе, т.е. число сотрудников в каждом отделе.
Значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода так же, как это делает агрегатная функция. Результатом является совместимость, которая позволяет агрегатам и полям объединяться таким образом.
Пусть, например, таблица ВЕДОМОСТЬ_ОПЛАТЫ имеет вид рис. 4.22 и мы хотим определить максимальную сумму, выплаченную по ведомости каждому сотруднику.
Ид_сотр | Ид_Отд | Дата | Сумма | Вид_оплаты |
|
|
|
|
|
1 | 1 | 02.03.03 | 1200 |
|
|
|
|
|
|
2 | 1 | 01.03.03 | 1200 |
|
|
|
|
|
|
3 | 1 | 01.03.03 | 1000 |
|
|
|
|
|
|
1 | 1 | 01.04.03 | 1200 |
|
|
|
|
|
|
1 | 1 | 01.03.03 | 800 |
|
|
|
|
|
|
2 | 1 | 02.04.03 | 2000 |
|
|
|
|
|
|
| Рис. 4.22. Состояние таблицы Ведомость1 |
SELECT | ИД_Сотр, MAX (Сумма) AS «Сумма максимальная» |
FROM | Ведомость1 |
GROUP | BY ИД_Сотр; |
В результате получим.
Ид_сотр | Сумма_максимальная |
|
|
3 | 1000 |
|
|
1 | 1200 |
|
|
2 | 2000 |
|
|
Рис. 4.23. Агрегатная функция с AS
Группировка может быть осуществлена и по нескольким атрибутам: SELECT Ид_сотр, Дата, MAX ((Сумма))
FROM Ведомость1
GROUP BY Ид_сотр, Дата;
Результат:
Ид_сотр | Дата |
|
|
|
|
1 | 01.03.03 | 800 |
|
|
|
1 | 02.03.03 | 1200 |
|
|
|
1 | 01.04.03 | 1200 |
|
|
|
2 | 01.03.03 | 1200 |
|
|
|
2 | 02.04.03 | 2000 |
|
|
|
2 | 01.03.03 | 1000 |
|
|
|
Рис. 4.24. Группировка по нескольким атрибутам
Если же возникает необходимость ограничить число групп, полученных после GROUP BY, то, используя предложение HAVING, можно это реализовать.
4.5. Использование фразы HAVING
Фраза HAVING играет такую же роль для групп, что и фраза WHERE для строк: она используется для исключения групп, точно так же, как WHERE используется для исключения строк. Эта фраза включается в предложение
лишь при наличии фразы GROUP BY, а выражение в HAVING должно принимать единственное значение для группы.
Например, пусть надо выдать количественный состав всех отделов (рис. 2.3), исключая отдел с номером 3.
SELECT Ид_Отд, COUNT (DISTINCT Ид_Отд) AS Кол-во_сотрудников
FROM | Отдел_ Сотрудники | |||
WHERE | Дата_ увольнения |
| NOT NULL | |
GROUP BY |
| Ид_Отд | HAVING Ид_Отд < > 3; | |
|
|
|
|
|
|
| Ид_Отд |
| Кол_во_сотрудников |
|
|
|
|
|
|
| 1 |
| 5 |
|
|
|
|
|
|
| 2 |
| 4 |
|
|
|
|
|
Рис. 4.25. Запрос с группировкой и ограничением
Последним элементом при вычислении табличного выражения используется раздел HAVING (если он присутствует). Синтаксис этого раздела следующий:
<having clause> ::=
HAVING <search condition>
Условие поиска этого раздела задает условие на группу строк сгруппированной таблицы. Формально раздел HAVING может присутствовать и в табличном выражении, не содержащем GROUP BY. В этом случае полагается, что результат вычисления предыдущих разделов представляет собой сгруппированную таблицу, состоящую из одной группы без выделенных столбцов группирования.
Условие поиска раздела HAVING строится по тем же синтаксическим правилам, что и условие поиска раздела WHERE, и может включать те же самые предикаты.
Однако имеются специальные синтаксические ограничения по части использования в условии поиска спецификаций столбцов таблиц из раздела FROM данного табличного выражения. Эти ограничения следуют из того, что условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки.
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Пусть запрос вида (в качестве базовой таблицы см. рис. 4.22):
SELECT Ид_сотр, Дата, MAX ((Сумма))
FROM Ведомость1
GROUP BY Ид_сотр, Дата;
необходимо уточнить тем, чтобы были показаны только выплаты, превышающие 1000.
Однако по стандарту агрегатную функцию в предложении WHERE использовать запрещено (если вы не используете подзапрос, описанный позже), потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции оцениваются в терминах группы строк.
Следующее предложение будет неправильным:
SELECT Ид_сотр, Дата, MAX (Сумма)
FROM Ведомость1
WHERE MAX ((Сумма)) > 1000 GROUP BY Ид_сотр, Дата;
Правильным предложением будет:
SELECT Ид_сотр, Дата, MAX ((Сумма))
studfiles.net
Cybern.ru » SQL Урок 3. Агрегатные функции
В данной статье мы рассмотрим работу с функциями, которые вычисляют какое — то значение на основе выборки по столбцу. Примерами таких функций могут служить нахождения минимального или максимального значения в столбце. Перечислим агрегатные функции:
- MAX — нахождение максиума
- MIN — нахождение минимума
- COUNT — количество записей
- SUM — сумма всех значений
- AVG — среднее
Функцию COUNT можно применять не только для подсчета количества элементов в столбце, но и для подсчета количество записей в подмножестве:
SELECT COUNT(*) FROM Student
Для того, чтобы найти количество уникальных записей будем использовать DISTINCT. Пусть нам надо вывести количество различных возрастов в таблице Student.
SELECT COUNT(DISTINCT Age) FROM Student
Теперь попробуем вывести тех студентов, которые имеют максимальный возраст:
SELECT * FROM Student WHERE Age=MAX(Age)
Соответственно для того, чтобы вывести самых младших студентов:
SELECT * FROM Student WHERE Age=MIN(Age)
Теперь хотим вернуть средний возраст студентов:
SELECT AVG(Age) FROM Student
Для того, чтобы переименовать столбец, который вернется, необходимо использовать AS:
SELECT SUM(Age) AS SUM_Age FROM Student
Получим в результате таблицу с единственным столбцом с именем SUM_Age и с единственной записью в которой будет содержаться сумма всех возрастов. Приведем пример переименования столбцов для таблицы Student, который показывает что ключевое слово AS применяется по умолчанию, т.е вам не обязательно его писать.
SELECT ID AS Student_Number,Name FirstName, Age AS StudentAge FROM Student
Таким образом у вам выведется таблица в которой будут три столбца: Student_Number, FirstName и StudentAge.
При использовании агрегатных функций может потребоваться посчитать их для различных групп для этого используется GROUP BY. Выведем максимальный возраст для каждого имени студента:
SELECT Name, MAX(Age) AS Max_Age FROM Student
GROUP BY Name
Таким образом агрегатные функции исполняются над всеми данными, если не использован модификатор GROUP BY, который выполнит функции отдельно для каждой группы.
Для того, чтобы использовать проверку условий после GROUP BY необходимо использовать HAVING вместо WHERE
SELECT Name, MAX(Age) AS Max_Age FROM Student
GROUP BY Name
HAVING Age > 18
Порядок обработки операторов:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
cybern.ru
Агрегатные функции SQL

Использование агрегатных функций
В SQL определено множество встроенных функций различных категорий, среди которых особое место занимают агрегатные функции, оперирующие значениями столбцов множества строк и возвращающие одно значение. Аргументами агрегатных функций могут быть как столбцы таблиц, так и результаты выражений над ними. Агрегатные функции и сами могут включаться в другие арифметические выражения. В следующей таблице приведены наиболее часто используемые стандартные унарные агрегатные функции.
Общий формат унарной агрегатной функции следующий:
имя_функции([АLL | DISTINCT] выражение)
где DISTINCT указывает, что функция должна рассматривать только различные значения аргумента, а ALL — все значения, включая повторяющиеся (этот вариант используется по умолчанию). Например, функция AVG с ключевым словом DISTINCT для строк столбца со значениями 1, 1, 1 и 3 вернет 2, а при наличии ключевого слова ALL вернет 1,5.
Агрегатные функции применяются во фразах SELECT и HAVING. Здесь мы рассмотрим их использование во фразе SELECT. В этом случае выражение в аргументе функции применяется ко всем строкам входной таблицы фразы SELECT. Кроме того, во фразе SELECT нельзя использовать и агрегатные функции, и столбцы таблицы (или выражения с ними) при отсутствии фразы GROUP BY, которую мы рассмотрим в следующем разделе.
Функция COUNT имеет два формата. В первом случае возвращается количество строк входной таблицы, во втором случае — количество значений аргумента во входной таблице:
- COUNT(*)
- COUNT([DISTINCT | ALL] выражение)
Простейший способ использования этой функции — подсчет количества строк в таблице (всех или удовлетворяющих указанному условию). Для этого используется первый вариант синтаксиса.
Запрос: Количество видов продукции, информация о которых имеется в базе данных.
SELECT COUNT(*) AS ‘Количество видов продукции’
FROM Product
Во втором варианте синтаксиса функции COUNT в качестве аргумента может быть использовано имя отдельного столбца. В этом случае подсчитывается количество либо всех значений в этом столбце входной таблицы, либо только неповторяющихся (при использовании ключевого слова DISTINCT).
Запрос: Количество различных имен, содержащихся в таблице Customer.
SELECT COUNT(DISTINCT FNAME)
FROM Customer
Использование остальных унарных агрегатных функции аналогично COUNT за тем исключением, что для функций MIN и MAX использование ключевых слов DISTINCT и ALL не имеет смысла. С функциями COUNT, MAX и MIN кроме числовых могут использоваться и символьные поля. Если аргумент агрегатной функции не содержит значений, функция COUNT возвращает 0, а все остальные — значение NULL.
Запрос: Дата последнего заказа до 1 сентября 2010 года.
SELECT MAX(OrdDate)
FROM [Order]
WHERE OrdDate’1.09.2010′
Задание для самостоятельной работы: Сформулируйте на языке SQL запросы на выборку следующих данных:
- Суммарная стоимость всех заказов;
- Количество различных городов, содержащихся в таблице Customer.
Еще записи по теме
www.ikasteko.ru
предложения GROUP BY, HAVING и агрегатные функции
Предложение GROUP BY (инструкции SELECT) позволяет группировать данные (строки) по значению какого-либо столбца или нескольких столбцов или выражений. Результатом будет набор сводных строк.
Каждый столбец в списке выборки должен присутствовать в предложении GROUP BY, исключение составляют только константы и столбцы — операнды агрегатных функций.
Таблицу можно сгруппировать по любой комбинации ее столбцов.
Агрегатные функции используются для получения из группы строк одного единственного суммарного значения. Все агрегатные функции выполняют вычисления над одним аргументом, который может быть или столбцом, или выражением. Результатом вычислений любой агрегатной функции является константное значение, отображаемое в отдельном столбце результата.
Агрегатные функции указываются в списке столбцов инструкции SELECT, которая также может содержать предложение GROUP BY. Если в инструкции SELECT отсутствует предложение GROUP BY, а список столбцов выборки содержит, по крайней мере, одну агрегатную функцию, тогда он не должен содержать простых столбцов. С другой стороны, список выборки столбцов может содержать имена столбцов, которые не являются аргументами агрегатной функции, если эти столбцы служат аргументами предложения GROUP BY.
Если запрос содержит предложение WHERE, то агрегатные функции вычисляют значение для результатов выборки.
Агрегатные функции MIN и MAX вычисляют наименьшее и наибольшее значение столбца соответственно. Аргументами могут быть числа, строки и даты. Все значения NULL удаляются перед вычислением (т.е. в расчет не берутся).
Агрегатная функция SUM вычисляет общую сумму значений столбца. Аргументами могут быть только числа. Использование параметра DISTINCT устраняет все повторяющиеся значения в столбце перед применением функции SUM. Аналогично удаляются все значения NULL перед применением этой агрегатной функции.
Агрегатная функция AVG возвращает среднее значение для всех значений столбца. Аргументами также могут быть только числа, а все значения NULL удаляются перед вычислением.
Агрегатная функция COUNT имеет две разные формы:
- COUNT([DISTINCT] col_name) — подсчитывает количество значений в столбце col_name, значения NULL не учитываются
- COUNT(*) — подсчитывает количество строк в таблице, значения NULL также учитываются
Если в запросе используется ключевое слово DISTINCT, перед применением функции COUNT удаляются все повторяющиеся значения столбца.
Функция COUNT_BIG аналогична функции COUNT. Единственное различие между ними заключается в типе возвращаемого ими результата: функция COUNT_BIG всегда возвращает значения типа BIGINT, тогда как функция COUNT возвращает значения данных типа INTEGER.
В предложении HAVING определяется условие, которое применяется к группе строк. Оно имеет такой же смысл для групп строк, что и предложение WHERE для содержимого соответствующей таблицы (WHERE применяется до группировки, HAVING после):
Параметр condition содержит агрегатные функции или константы.
blog.rc21net.ru