Работа с переменными в SQL
—***************************************************************************
— Вещественные типы данных в T-SQL
—***************************************************************************
————————————- Float ———————————
— Вещественное со знаком, с плавающей точкой Float.
— Диапазон значений от -1.79Е+308 до 1.79Е+308.
— Числовой тип данных с плавающей запятой записывается как Float(n),
— где n — определяет точность(по умолчанию n = 53)
— Для типа Float имеется только два вида точности: 7 и 15 знаков после запятой.
— 7 знаков — при n, в диапазоне от 1 до 24; (выделение 4 байт)
— 15 знаков — при n, в диапазоне от 25 до 53; (выделение 8 байт)
PRINT ‘Float’
DECLARE @float float(24) = 1214782.123;
PRINT @float;
SET @float = 2147482435234412412. 38-1.
38-1.
— Числовой тип данных с фиксированной точкой Decimal записывается как Decimal(p, s),
— где p — определяет точность — максимальное количество знаков из которых состоит полное число
— (по умолчанию p = 18, максимальное значение p = 38, минимальное значение p = 1),
— a s — определяет масштаб — максимальное количество знаков после запятой.
PRINT ‘Decimal / Numeric’
DECLARE @decimal Decimal(5, 3); — p = 5, s = 3( не больше p-1)
SET @decimal = 1.42;
PRINT @decimal;
SET @decimal = 2.234654; — Произойдет округление дробной части.
PRINT @decimal;
SET @decimal = 41.12345; — Значение округлится, т.к после запятой больше 3-х знаков.
PRINT @decimal;
———————————- SmallMoney ——————————-
— Вещественное со знаком, с фиксированной точкой SmallMoney.
— Диапазон значений от -214 748.3648 до 214 748.3647
PRINT ‘SmallMoney’;
DECLARE @smoney SmallMoney = 214748. 63-1
63-1
PRINT ‘Money’;
DECLARE @money Money = 1.4234;
PRINT @money;
SET @money = 2.234954;
PRINT @money;
——————————————————————————
операторы JOIN,UNION, INTERSECT и EXCEPT
Соединение таблиц в запросе SELECT выполняется с помощью оператора JOIN.
Возможно также выполнить соединение и без оператора JOIN с помощью инструкции WHERE используя столбцы соединения, но этот синтаксис считается неявным и устаревшим.
Выделяют следующие виды соединения, каждому из которых соответствует своя форма оператора JOIN:
- CROSS JOIN — перекрестное или декартово соединение
- [INNER] JOIN — естественное или внутреннее соединение
- LEFT [OUTER] JOIN — левое внешнее соединение
- RIGHT [OUTER] JOIN — правое внешнее соединение
- FULL [OUTER] JOIN — полное внешнее соединение
Существует также тета-соединение, самосоединение и полусоединение.
Естественное соединение
Естественное соединение — внутреннее соединение или соединение по эквивалентности.
SELECT employee.*, department.* FROM employee INNER JOIN department ON employee.dept_no = department.dept_no;
SELECT employee.*, department.* FROM employee INNER JOIN department ON employee.dept_no = department.dept_no; |
Здесь предложение FROM определяет соединяемые таблицы и в нем явно указывается тип соединения — INNER JOIN. Предложение ON является частью предложения FROM и указывает соединяемые столбцы. Выражение employee.dept_no = department.dept_no определяет условие соединения.
Эквивалентный запрос с применением неявного синтаксиса:
SELECT employee.*, department.* FROM employee, department WHERE employee.dept_no = department.dept_no;
SELECT employee.*, department.* FROM employee, department WHERE employee. |

Соединяемые столбцы должны иметь идентичную семантику, т.е. оба столбца должны иметь одинаковое логическое значение. Соединяемые столбцы не обязательно должны иметь одинаковое имя (или даже одинаковый тип данных), хотя часто так и бывает.
Соединяются только строки имеющие одинаковое значение в соединяемых столбцах. Строки, не имеющие таких одинаковых значений в результирующий набор вообще не попадут.
В инструкции SELECT объединить можно до 64 таблиц (ограничение MS SQL), при этом один оператор JOIN соединяет только две таблицы:
SELECT emp_fname, emp_lname FROM works_on JOIN employee ON works_on.emp_no=employee.emp_no JOIN department ON employee.dept_no=department.dept_no
SELECT emp_fname, emp_lname FROM works_on JOIN employee ON works_on.emp_no=employee.emp_no JOIN department ON employee.dept_no=department.dept_no |
Декартово произведение (перекрестное соединение)
Декартово произведение (перекрестное соединение) соединяет каждую строку первой таблицы с каждой строкой второй.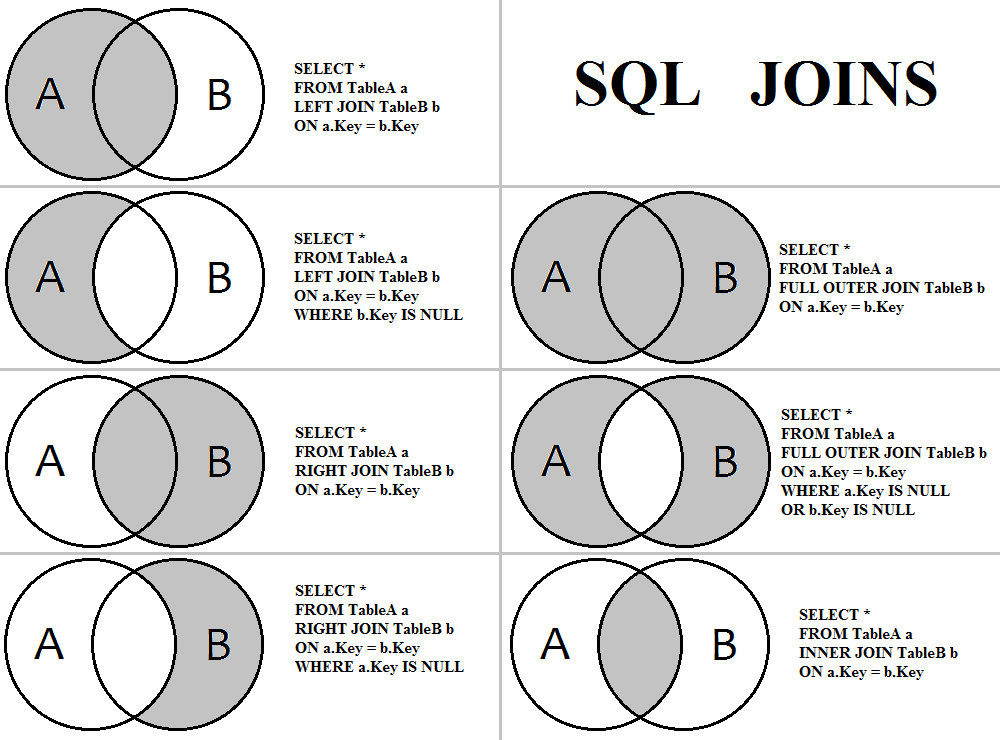 Результатом декартово произведения первой таблицы с n строками и второй таблицы с m строками будет таблица с n × m строками.
Результатом декартово произведения первой таблицы с n строками и второй таблицы с m строками будет таблица с n × m строками.
SELECT employee.*, department.* FROM employee CROSS JOIN department;
SELECT employee.*, department.* FROM employee CROSS JOIN department; |
Внешнее соединение
Внешнее соединение позволяет в отличие от внутреннего извлечь не только строки с одинаковыми значениями соединяемых столбцов, но и строки без совпадений из одной или обеих таблиц.
Выделяют три вида внешних соединений:
- левое внешнее соединение — в результирующий набор попадают все строки из таблицы с левой стороны оператора сравнения (независимо от того имеются ли совпадающие строки с правой стороны), а из таблицы с правой стороны — только строки с совпадающими значениями столбцов. При этом если для строки из левой таблицы нет соответствий в правой таблице, значениям строки в правой таблице будут присвоены NULL
SELECT employee_enh.
 *, department.location
FROM employee_enh LEFT OUTER JOIN department
ON domicile = location;
*, department.location
FROM employee_enh LEFT OUTER JOIN department
ON domicile = location;SELECT employee_enh.*, department.location
FROM employee_enh LEFT OUTER JOIN department
ON domicile = location;
- правое внешнее соединение — аналогично левому внешнему соединению, но таблицы меняются местами
SELECT employee_enh.domicile, department.* FROM employee_enh RIGHT OUTER JOIN department ON domicile =location;
SELECT employee_enh.domicile, department.*
FROM employee_enh RIGHT OUTER JOIN department
ON domicile =location;
- полное внешнее соединение — композиция левого и правого внешнего соединения: результирующий набор состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL.

Тета-соединение
Условие сравнения столбцов соединения не обязательно должно быть равенством, но может быть любым другим сравнением. Соединение, в котором используется общее условие сравнения столбцов соединения, называется тета-соединением:
SELECT emp_fname, emp_lname, domicile, location FROM employee_enh JOIN department ON domicile < location;
SELECT emp_fname, emp_lname, domicile, location ON domicile < location; |
Самосоединение
Самосоединение — это естественное соединение таблицы с самой собой. При этом один столбец таблицы сравнивается сам с собой. Сравнивание столбца с самим собой означает, что в предложении FROM инструкции SELECT имя таблицы употребляется дважды. Поэтому необходимо иметь возможность ссылаться на имя одной и той же таблицы дважды. Это можно осуществить, используя, по крайней мере, один псевдоним. То же самое относится и к именам столбцов в условии соединения в инструкции SELECT. Для того чтобы различить столбцы с одинаковыми именами, необходимо использовать уточненные имена.
Для того чтобы различить столбцы с одинаковыми именами, необходимо использовать уточненные имена.
Полусоединение
Полусоединение похоже на естественное соединение, но возвращает только набор всех строк из одной таблицы, для которой в другой таблице есть одно или несколько совпадений.
Оператор UNION
Оператор UNION объединяет результаты двух или более запросов в один результирующий набор, в который входят все строки, принадлежащие всем запросам в объединении:
select_1 UNION [ALL] select_2 {[UNION [ALL] select_3]}…
select_1 UNION [ALL] select_2 {[UNION [ALL] select_3]}… |
Параметры select_1, select_2, … представляют собой инструкции SELECT, которые создают объединение. Если используется параметр ALL, отображаются все строки, включая дубликаты. По умолчанию дубликаты удаляются.
Объединять с помощью инструкции UNION можно только совместимые таблицы. Под совместимыми таблицами имеется в виду, что оба списка столбцов выборки должны содержать одинаковое число столбцов, а соответствующие столбцы должны иметь совместимые типы данных. Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Под совместимыми таблицами имеется в виду, что оба списка столбцов выборки должны содержать одинаковое число столбцов, а соответствующие столбцы должны иметь совместимые типы данных. Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Два других оператора для работы с наборами:
- INTERSECT — пересечение — набор строк, которые принадлежат к обеим таблицам
- EXCEPT — разность двух таблиц — все значения, которые принадлежат к первой таблице и не присутствуют во второй
Быстрый поиск объектов и данных в БД SQL Server
Очень часто разработчики и администраторы БД сталкиваются с задачей поиска в базе данных всех упоминаний какого-либо объекта, столбца, переменной или поиск всех таблиц, где встречается искомое значение. Если вам приходилось решать подобную проблему, то вы знаете, что это ни самая тривиальная задача и Ctrl+F здесь не поможет.
Готового решения нет ни в SQL Server Management Studio ни в Visual Studio, вот несколько сценариев, которые вы можете использовать:
Поиск данных в таблицах и представлениях
Есть много реализаций на T-SQL поиска данных по всем таблицам с просмотром всех столбцов и это не самая оптимальная реализация, так как везде используется перебор в курсоре системных представлений.
DECLARE
@SearchText varchar(200),
@Table varchar(100),
@TableID int,
@ColumnName varchar(100),
@String varchar(1000);
SET @SearchText = 'John';
DECLARE CursorSearch CURSOR
FOR SELECT name, object_id
FROM sys.objects
WHERE type = 'U';
OPEN CursorSearch;
FETCH NEXT FROM CursorSearch INTO @Table, @TableID;
WHILE
@@FETCH_STATUS
=
0
BEGIN
DECLARE CursorColumns CURSOR
FOR SELECT name
FROM sys. columns
WHERE
object_id
=
@TableID AND system_type_id IN(167, 175, 231, 239);
OPEN CursorColumns;
FETCH NEXT FROM CursorColumns INTO @ColumnName;
WHILE
@@FETCH_STATUS
=
0
BEGIN
SET @String = 'IF EXISTS (SELECT * FROM '
+ @Table
+ ' WHERE '
+ @ColumnName
+ ' LIKE ''%'
+ @SearchText
+ '%'') PRINT '''
+ @Table
+ ', '
+ @ColumnName
+ '''';
EXECUTE (@String);
FETCH NEXT FROM CursorColumns INTO @ColumnName;
END;
CLOSE CursorColumns;
DEALLOCATE CursorColumns;
FETCH NEXT FROM CursorSearch INTO @Table, @TableID;
END;
CLOSE CursorSearch;
DEALLOCATE CursorSearch;
columns
WHERE
object_id
=
@TableID AND system_type_id IN(167, 175, 231, 239);
OPEN CursorColumns;
FETCH NEXT FROM CursorColumns INTO @ColumnName;
WHILE
@@FETCH_STATUS
=
0
BEGIN
SET @String = 'IF EXISTS (SELECT * FROM '
+ @Table
+ ' WHERE '
+ @ColumnName
+ ' LIKE ''%'
+ @SearchText
+ '%'') PRINT '''
+ @Table
+ ', '
+ @ColumnName
+ '''';
EXECUTE (@String);
FETCH NEXT FROM CursorColumns INTO @ColumnName;
END;
CLOSE CursorColumns;
DEALLOCATE CursorColumns;
FETCH NEXT FROM CursorSearch INTO @Table, @TableID;
END;
CLOSE CursorSearch;
DEALLOCATE CursorSearch;
У этого решения есть много недостатков:
- Использование курсоров, а это, как правило неэффективный код
- Сложный запрос, который медленно работает даже на небольших базах данных
- Поиск работает только по текстовым данным, поэтому для поиска, например, даты потребуется доработка
Поиск объектов
Поиск объектов в БД по имени или их упоминание в других объектах немного проще, чем поиск определённого текста. Есть так же несколько разных сценариев поиска, но все их объединяет одно: обращение к системным объектам.
Во всех следующих сценариях осуществляется поиск переменной @StartProductID в хранимых процедурах. Но скрипты можно использовать и для поиска в других объектах – в триггерах, функциях, столбцах и т.д.
INFORMATION_SCHEMA.ROUTINES
Системное представление INFORMATION_SCHEMA.ROUTINES позволяет найти любой параметр, встречающийся в процедурах или функциях. Колонка ROUTINE_DEFINITION содержит полный текст объекта, который был указан при его создании.
SELECT ROUTINE_NAME, ROUTINE_DEFINITION
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_DEFINITION LIKE '%@StartproductID%'
AND ROUTINE_TYPE='PROCEDURE'
Результат работы запроса:
Не используйте представления INFORMATION_SCHEMA, чтобы определить схему объекта. Единственный надежный способ найти схему объекта — выполнить запрос к представлению каталога sys.objects.
Представление sys.syscomments
Содержит записи для всех представлений, правил, значений по умолчанию, триггеров, ограничений CHECK и DEFAULT, а также для всех хранимых процедур в базе данных. Столбец text содержит инструкции исходных определений SQL.
SELECT OBJECT_NAME( id ) FROM SYSCOMMENTS WHERE text LIKE '%@StartProductID%' AND OBJECTPROPERTY(id , 'IsProcedure') = 1 GROUP BY OBJECT_NAME( id );
Результат:
Этот метод не желательно использовать, так как в будущих версиях SQL Server представление sys.syscomments будет удалено.
Представление sys.sql_modules
Содержит по одной строке для каждого объекта, являющегося модулем, определенным на языке SQL в SQL Server.
SELECT OBJECT_NAME( object_id )
FROM sys.sql_modules
WHERE
OBJECTPROPERTY(object_id , 'IsProcedure')
=
1 AND definition LIKE '%@StartProductID%';
Результат такой же, как в предыдущем способе:
Другие представления информационной схемы
Запрос к представлениям sys.syscomments, sys.schemas и sys.objects. Представление sys.schemas содержит информацию обо всех схемах внутри базы данных. В представление sys.objects содержится информация обо всех объектах базы данных. Обратите внимание, что для поиска информации о триггерах необходимо просматривать отдельное представление sys.triggers.
DECLARE
@searchString nvarchar( 50 );
SET@searchString = '@StartProductID';
SELECT DISTINCT
s.name AS Schema_Name , O.name AS Object_Name , C.text AS Object_Definition
FROM
syscomments C INNER JOIN sys.objects O
ON
C.id
=
O.object_id
INNER JOIN sys.schemas S
ON
O.schema_id
=
S.schema_id
WHERE
C.text LIKE
'%'
+ @searchString
+ '%'
OR O.name LIKE
'%'
+ @searchString
+ '%'
ORDER BY
Schema_name , Object_name;Полученный результат:
Основным недостатком данных методов поиска является то, что для поиска каждого нового типа объектов необходимо вносить в скрипты изменения. Чтобы сделать это вы должны хорошо понимать внутреннюю организацию и структуру системных объектов SQL Server. Кроме того, нужно позаботиться об обработке различных ошибок и исключений, например, связанных с поиском строк, содержащих экранирующие символы.
Если вы не являетесь опытным разработчиком, не знакомы с внутренним устройством хранения DDL информации объектов БД или предпочитаете использовать проверенное и безошибочное решение, то начните использовать ApexSQL Search.
ApexSQL Search – это надстройка (ADD-IN) для SSMS и Visual Studio, которая позволяет искать любой текст в объектах базы данных (в том числе имена объектов), данные, хранящиеся в таблицах и представлениях (даже если они зашифрованы), осуществлять повторные поиски по истории в один клик.
Для поиска данных в таблицах и представлениях:
- В меню SQL Server Management Studio или Visual Studio найдите ApexSQL Search
Выберите вариант Database text search…:
- В текстовом поле поиска Search text укажите искомый текст.
- В раскрывающемся меню Database выберите базу данных для поиска
- В дереве поиска Select objects to search укажите таблицы и представления для поиска или оставьте их все выделенными
- С помощью флажков укажите в каких типах данных необходимо осуществить поиск (numeric, text type, uniqueidentifier, date columns), искать ли в представлениях, необходимо ли строгое совпадение и, при поиске даты, укажите её формат.
После нажатия кнопки Find now, вы получите сводную таблицу со списком таблиц и представлений, которые содержат искомое значение:
- Нажмите кнопку с многоточием в колонке Column value, чтобы получить детали:
Для поиска объектов:
- В меню SQL Server Management Studio или Visual Studio найдите ApexSQL Search
Выберите вариант Database object search…:
- В поле поиска Search text укажите искомый объект, например, имя переменной.
- В раскрывающемся меню Database выберите базу данных для поиска
- В дереве поиска Objects укажите типы объектов для поиска или оставьте их все выделенными
- Флажками укажите детали поиска: искать ли в именах объектов, колонок, индексов или только в самих описания объектов. Просматривать ли системные объекты, нужно ли точное совпадение, а также можно указать экранирующий символ.
- После этого начинаем поиск Find now:
В таблице будет полный список объектов, которые содержат искомое значение.
- При двойном щелчке по объекту в таблице Database object search, можно увидеть его ссылку в Object Explorer
SQL Server Management Studio и Visual Studio не имеют встроенной возможности поиска объектов и данных в БД. Запросы, которые решают эту задачу неэффективны, медленные в работе и требуют глубоких знаний системных объектов SQL Server. Но зато с этой задачей прекрасно справляется ApexSQL Search
Переводчик: Алексей Князев
November 20, 2015SQL WHERE IN, SELECT WHERE IN Список или подзапрос — с примерами
Что возвращает SQL IN?
WHERE IN возвращает значения, соответствующие значениям в списке или подзапросе.
Предложение WHERE IN — это сокращение для нескольких условий OR.
Синтаксис SQL WHERE IN
Общий синтаксис
ВЫБЕРИТЕ имена столбцов ОТ имя-таблицы ГДЕ имя-столбца IN (значения)
| ПОСТАВЩИК |
|---|
| Идентификатор |
| Название компании |
| Контактное имя |
| Город |
| Страна |
| Телефон |
| Факс |
SQL WHERE IN Примеры
Проблема : перечислить всех поставщиков из США, Великобритании или Японии
ВЫБЕРИТЕ Id, CompanyName, City, Country
ОТ поставщика
ГДЕ Страна В ("США", "Великобритания", "Япония")
Результат: 8 записей.
| Id | Название компании | Город | Страна |
|---|---|---|---|
| 1 | Экзотические жидкости | Лондон | Великобритания |
| 2 | Новый Орлеан Cajun Delights | Новый Орлеан | США |
| 3 | Усадьба бабушки Келли | Анн-Арбор | США |
| 4 | Tokyo Traders | Токио | Япония |
| 6 | Маюми | Осака | Япония |
| 8 | Specialty Biscuits, Ltd. | Манчестер | Великобритания |
SQL IN — Учебное пособие по SQL
Предложение SQL IN позволяет указывать дискретные значения в критериях поиска SQL WHERE.
Синтаксис SQL IN выглядит так:
| ВЫБРАТЬ Column1, Column2, Column3, FROM Table1 WHERE Column1 IN (Valu1, Value2,) |
Давайте используем таблицу EmployeeHours, чтобы проиллюстрировать, как работает SQL IN :
| Сотрудник | Дата | Часы |
| Джон Смит | 06.05.2004 | 8 |
| Аллан Бабель | 06.05.2004 | 8 |
| Тина Корона | 06.05.2004 | 8 |
| Джон Смит | 07.05.2004 | 9 |
| Аллан Бабель | 07.05.2004 | 8 |
| Тина Корона | 07.05.2004 | 10 |
| Джон Смит | 08.05.2004 | 8 |
| Аллан Бабель | 08.05.2004 | 8 |
| Тина Корона | 08.05.2004 | 9 |
Рассмотрим следующий SQL-запрос с использованием предложения SQL IN :
| ВЫБЕРИТЕ * ИЗ EmployeeHours ГДЕ ДАТА ВХОДА (‘5/6/2004’, ‘07.05.2004’) |
Это выражение SQL выберет только те записи, в которых столбец Date имеет значение «5/6/2004» или «5/7/2004», и вы можете увидеть результат ниже:
| Сотрудник | Дата | Часы |
| Джон Смит | 06.05.2004 | 8 |
| Аллан Бабель | 06.05.2004 | 8 |
| Тина Корона | 06.05.2004 | 8 |
| Джон Смит | 07.05.2004 | 9 |
| Аллан Бабель | 07.05.2004 | 8 |
| Тина Корона | 07.05.2004 | 10 |
Мы можем использовать оператор SQL IN с другим столбцом в нашей таблице EmployeeHours:
| ВЫБЕРИТЕ * ОТ EmployeeHours ГДЕ ЧАСЫ В (9, 10) |
Результатом приведенного выше SQL-запроса будет:
| Сотрудник | Дата | Часы |
| Джон Смит | 07.05.2004 | 9 |
| Тина Корона | 07.05.2004 | 10 |
| Тина Корона | 08.05.2004 | 9 |
SQL SELECT — SQL
L’utilisation la plus courante de SQL consiste à lire des données issues de la base de données.Cela s’effectue grâce à la command SELECT, qui retourne des enregistrements dans un tableau de résultat. Cette commande peut sélectionner une ou plusieurs colnes d’une table.
Commande basique
L’utilisation basique de cette commande s’effectue de la manière suivante:
ВЫБРАТЬ nom_du_champ FROM nom_du_tableau
Cette Requête SQL va sélectionner FR_champant (SELECT) du tableau appelé «nom_du_tableau».
Exemple
Imaginons une base de données appelée «client», который содержит информацию о клиентах на предприятии.
Стол «клиент»:
| идентификатор | prenom | nom | ville | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Pierre | Dupond | Paris | ||||||||||||||||||||||||||||||||||||||||||
| 2 | Sabrina Дюран | Нант | |||||||||||||||||||||||||||||||||||||||||||
| 3 | Жюльен | Мартин | Лион | ||||||||||||||||||||||||||||||||||||||||||
| 4 | Дэвид | Бернар | Марсель | ||||||||||||||||||||||||||||||||||||||||||
| 5 | Мари | Лерой | Гренобль |
| ville |
|---|
| Париж |
| Нант |
| Marseille |
| Grenoble |
Получить больше колонок
Avec la même table client il est possible de lire plus columns à la fois.Il достаточно tout simplement de séparer les noms des champs souhaités par une virgule. Залейте заявок и заявок клиентов il faut alors faire la Requête suivante:
SELECT prenom, nom FROM client
Ce qui retourne ce résultat:
| Пьер | Дюпон |
| Сабрина | Дюран |
| Жюльен | Мартин |
| Дэвид | Бернар |
| Мари | Леруа Колонтис |
Леруа Колонтис ‘un tableau
Il est possible de retourner automatiquement toutes lescolnes d’un tableau sans neverir à connaître le nom de toutes lescolnes.Au lieu de lister toutes lescolnes, il faut simplement utiliser le caractère «*» (étoile). C’est un joker qui permet de sélectionner toutes lescolnes. Использовать suivante:
SELECT * FROM client
Cette Requête SQL Retourne Exactement les mêmes columns qu’il y a dans la base de données. Dans notre cas, le résultat sera donc:
| идентификатор | prenom | nom | ville |
|---|---|---|---|
| 1 | Pierre | Dupond | Paris |
| 2 | Sabrina Дюран | Нант | |
| 3 | Жюльен | Мартин | Лион |
| 4 | Дэвид | Бернар | Марсель |
| 5 | Мари | Лерой | Гренобль |