Функции и типы данных даты и времени — SQL Server (Transact-SQL)
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 6 мин
Область применения: SQL Server (все поддерживаемые версии) Azure SQL Database Управляемый экземпляр SQL Azure Azure Synapse Analytics
В разделах этой статьи представлен обзор всех типов данных и функций даты и времени Transact-SQL.
- Типы данных даты и времени
- Функции даты и времени
- Функции, возвращающие значения системной даты и времени
- Функции, возвращающие компоненты даты и времени
- Функции, возвращающие значения даты и времени из их компонентов
- Функции, возвращающие значения разности даты и времени
- Функции, изменяющие значения даты и времени
- Функции, устанавливающие или возвращающие функции формата сеанса
- Функции, проверяющие значения даты и времени
- Дата и время — см. также
Типы данных даты и времени
Типы данных даты и времени Transact-SQL перечислены в следующей таблице:
| Тип данных | Формат | Диапазон | Точность | Объем памяти (в байтах) | Определяемая пользователем точность в долях секунды | Смещение часового пояса |
|---|---|---|---|---|---|---|
| time | чч:мм:сс[.ннннннн] | От 00:00:00.0000000 до 23:59:59.9999999 | 100 наносекунд | от 3 до 5 | Да | Нет |
| date | ГГГГ-ММ-ДД | От 0001-01-01 до 31. 12.99 12.99 | 1 день | 3 | Нет | Нет |
| smalldatetime | ГГГГ-ММ-ДД чч:мм:сс | От 01.01.1900 до 06.06.2079 | 1 минута | 4 | нет | Нет |
| datetime | ГГГГ-ММ-ДД чч:мм:сс[.ннн] | От 01.01.1753 до 31.12.9999 | 0,00333 секунды | 8 | Нет | Нет |
| datetime2 | ГГГГ-ММ-ДД чч:мм:сс[.ннннннн] | От 0001-01-01 00:00:00.0000000 до 9999-12-31 23:59:59.9999999 | 100 наносекунд | От 6 до 8 | Да | Нет |
| datetimeoffset | ГГГГ-ММ-ДД чч:мм:сс[.ннннннн] [+|-]чч:мм | От 0001-01-01 00:00:00.0000000 до 9999-12-31 23:59:59.9999999 (время в формате UTC) | 100 наносекунд | От 8 до 10 | Да | Да |
Примечание
Тип данных Transact-SQL rowversion не относится к типам данных даты и времени. Тип данных timestamp является устаревшим синонимом rowversion.
Функции даты и времени
В следующих таблицах приводятся функции даты и времени Transact-SQL. Дополнительные сведения о детерминизме см. в статье Детерминированные и недетерминированные функции.
Функции, возвращающие значения системной даты и времени
Transact-SQL наследует все значения системной даты и времени от операционной системы компьютера, на котором работает экземпляр SQL Server.
Высокоточные функции системной даты и времени
SQL Server 2019 (15.x) получает значения даты и времени с помощью функции GetSystemTimeAsFileTime() Windows API. Точность зависит от физического оборудования и версии Windows, в которой запущен экземпляр SQL Server. Точность возвращаемых значений этого API-интерфейса задана равной 100 нс. Точность может быть определена с помощью метода GetSystemTimeAdjustment() API-интерфейса Windows.
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| SYSDATETIME | SYSDATETIME ( ) | Возвращает значение типа datetime2(7), которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Возвращаемое значение не содержит смещение часового пояса. Возвращаемое значение не содержит смещение часового пояса. | datetime2(7) | Недетерминированная |
| SYSDATETIMEOFFSET | SYSDATETIMEOFFSET ( ) | Возвращает значение типа datetimeoffset(7), которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Возвращаемое значение содержит смещение часового пояса. | datetimeoffset(7) | Недетерминированная |
| SYSUTCDATETIME | SYSUTCDATETIME ( ) | Возвращает значение типа datetime2(7), которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Функция возвращает значения даты и времени в формате UTC. | datetime2(7) | Недетерминированная |
Функции системной даты и времени меньшей точности
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| CURRENT_TIMESTAMP | CURRENT_TIMESTAMP | Возвращает значение типа datetime, которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Возвращаемое значение не содержит смещение часового пояса. Возвращаемое значение не содержит смещение часового пояса. | datetime | Недетерминированная |
| GETDATE | GETDATE ( ) | Возвращает значение типа datetime, которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Возвращаемое значение не содержит смещение часового пояса. | datetime | Недетерминированная |
| GETUTCDATE | GETUTCDATE ( ) | Возвращает значение типа datetime, которое содержит дату и время компьютера, на котором запущен экземпляр SQL Server. Функция возвращает значения даты и времени в формате UTC. | datetime | Недетерминированная |
Функции, возвращающие компоненты даты и времени
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| DATE_BUCKET | DATE_BUCKET ( datepart, number | Возвращает значение даты и времени, соответствующее началу каждого контейнера даты и времени, из временной метки, определенной параметром origin или исходным значением по умолчанию 1900-01-01 00:00:00., если параметр orgin не указан. | Тип возвращаемого значения зависит от типа аргумента, переданного в параметре date. | Недетерминированная |
| DATENAME | DATENAME ( datepart, date ) | Возвращает строку символов, представляющую указанную часть datepart заданного типа date. | nvarchar | Недетерминированная |
| DATEPART | DATEPART ( datepart, date ) | Возвращает целое число, представляющее указанную часть datepart заданного типа date . | int | Недетерминированная |
| DATETRUNC | DATETRUNC ( datepart, date ) | Эта функция возвращает входную дату date, усеченную до указанной части datepart. | Тип возвращаемого значения зависит от типа аргумента, переданного в параметре date. | Недетерминированная |
| DAY | DAY ( date ) | Возвращает целое число, представляющее часть дня указанного типа date. | int | Детерминированный |
| MONTH | MONTH ( date ) | Возвращает целое число, представляющее часть месяца указанного типа date. | int | Детерминированный |
| YEAR | YEAR ( date ) | Возвращает целое число, представляющее часть года указанного типа | int | Детерминированный |
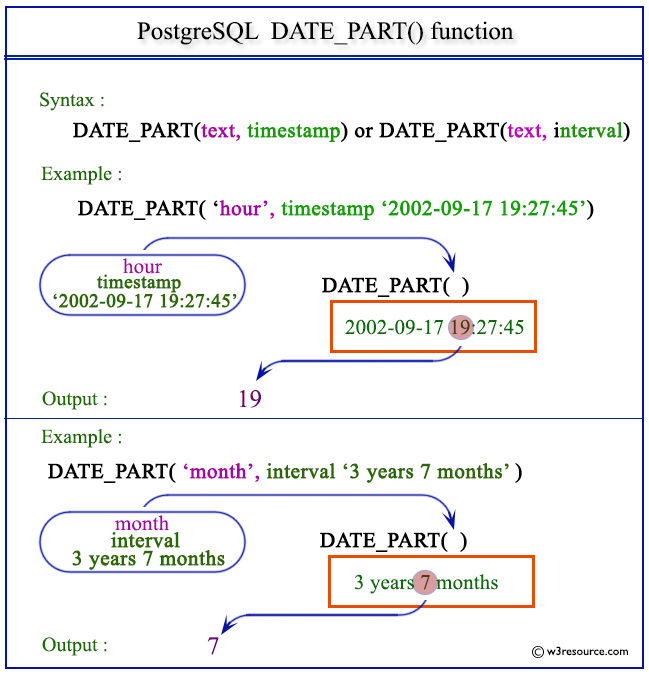 000
000Функции, возвращающие значения даты и времени из их компонентов
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| DATEFROMPARTS | DATEFROMPARTS ( year, month, day ) | Возвращает значение date, соответствующее указанному числу, месяцу и году. | date | Детерминированный |
| DATETIME2FROMPARTS | DATETIME2FROMPARTS ( year, month, day, hour, minute, seconds, fractions, precision) | Возвращает значение datetime2, соответствующее указанной дате и времени с заданной точностью. | datetime2(precision) | Детерминированный |
| DATETIMEFROMPARTS | DATETIMEFROMPARTS ( year, month, day, hour, minute, seconds, milliseconds) | Возвращает значение datetime, соответствующее указанной дате и времени. | datetime | Детерминированный |
| DATETIMEOFFSETFROMPARTS | DATETIMEOFFSETFROMPARTS ( year, month, day, hour, minute, seconds, fractions, hour_offset, minute_offset, precision) | Возвращает значение datetimeoffset для указанных даты и времени с указанными смещением и точностью. | datetimeoffset(precision) | Детерминированный |
| SMALLDATETIMEFROMPARTS | SMALLDATETIMEFROMPARTS ( year, month, day, hour, | Возвращает значение smalldatetime, соответствующее указанной дате и времени. | smalldatetime | Детерминированный |
| TIMEFROMPARTS | TIMEFROMPARTS ( hour, minute, seconds, fractions, precision ) | Возвращает значение time, соответствующее указанному времени с заданной точностью. | time(precision) | Детерминированный |
Функции, возвращающие значения разности даты и времени
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| DATEDIFF | DATEDIFF ( datepart, startdate, enddate ) | Возвращает количество границ даты или времени datepart, пересекающихся между двумя указанными датами. | int | Детерминированный |
| DATEDIFF_BIG | DATEDIFF_BIG ( datepart, startdate, enddate ) | Возвращает количество границ даты или времени datepart, пересекающихся между двумя указанными датами. | bigint | Детерминированный |
Функции, изменяющие значения даты и времени
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| DATEADD | DATEADD (datepart, number, date ) | Возвращает новое значение datetime, добавляя интервал к указанной части datepart заданной даты date. | Тип данных аргумента date | Детерминированный |
| EOMONTH | EOMONTH ( start_date [, month_to_add ] ) | Возвращает последний день месяца, содержащего указанную дату, с необязательным смещением. | Тип возвращаемого значения — это тип аргумента start_date или тип данных date. | Детерминированный |
| SWITCHOFFSET | SWITCHOFFSET (DATETIMEOFFSET, time_zone) | Функция SWITCHOFFSET изменяет смещение часового пояса для значения DATETIMEOFFSET и сохраняет значение UTC. | Значение datetimeoffset с точностью в долях секунд, заданной в аргументе DATETIMEOFFSET | Детерминированный |
| TODATETIMEOFFSET | TODATETIMEOFFSET (expression, time_zone) | TODATETIMEOFFSET преобразует значение типа datetime2 в значение типа datetimeoffset. Функция TODATETIMEOFFSET преобразует значение datetime2 в местное время для указанного time_zone. | Значение datetimeoffset с точностью в долях секунд, заданной в аргументе datetime | Детерминированный |
Функции, устанавливающие или возвращающие функции формата сеанса
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| @@DATEFIRST | @@DATEFIRST | Возвращает текущее значение параметра SET DATEFIRST для сеанса. | tinyint | Недетерминированная |
| SET DATEFIRST | SET DATEFIRST { number | @number_var } | Устанавливает первый день недели в виде числа от 1 до 7. | Неприменимо | Неприменимо |
| SET DATEFORMAT | SET DATEFORMAT { format | @format_var } | Задает порядок составляющих даты (месяц/день/год) для ввода данных типа datetime или smalldatetime. | Неприменимо | Неприменимо |
| @@LANGUAGE | @@LANGUAGE | Возвращает название использующегося в настоящий момент языка. @@LANGUAGE не является функцией даты или времени. Однако на данные, выводимые функциями даты, могут повлиять настройки языка. | Неприменимо | Неприменимо |
| SET LANGUAGE | SET LANGUAGE { [ N ] ‘language‘ | @language_var } | Устанавливает языковую среду сеанса и системных сообщений. SET LANGUAGE не является функцией даты или времени. Однако на данные, выводимые функциями даты, влияет параметр языка. | Неприменимо | Неприменимо |
| sp_helplanguage | sp_helplanguage [ [ = ] ‘language‘ ] | Возвращает сведения о формате даты всех поддерживаемых языков. sp_helplanguage не является хранимой процедурой даты или времени. Однако на данные, выводимые функциями даты, влияет параметр языка. sp_helplanguage не является хранимой процедурой даты или времени. Однако на данные, выводимые функциями даты, влияет параметр языка. | Неприменимо | Неприменимо |
Функции, проверяющие значения даты и времени
| Функция | Синтаксис | Возвращаемое значение | Тип возвращаемых данных | Детерминизм |
|---|---|---|---|---|
| ISDATE | ISDATE ( expression ) | Определяет, является ли входное выражение типа datetime или smalldatetime допустимым значением даты или времени. | int | Функция ISDATE детерминирована, только если используется совместно с функцией CONVERT и если заданный параметр стиля CONVERT не равен 0, 100, 9 или 109. |
| Статья | Описание |
|---|---|
| FORMAT | Возвращает значение в указанных формате и культуре (не обязательно). Для выполнения форматирования значения даты, времени и чисел с учетом локали в виде строк используется функция FORMAT. Для выполнения форматирования значения даты, времени и чисел с учетом локали в виде строк используется функция FORMAT. |
| Функции CAST и CONVERT (Transact-SQL) | Предоставляет сведения о преобразовании значений даты и времени в строковые литералы и обратно, а также в другие форматы даты и времени. |
| Написание инструкций Transact-SQL, адаптированных к международному использованию | Предоставляет рекомендации относительно переносимости баз данных и приложений баз данных, использующих инструкции Transact-SQL, с одного языка на другой или в многоязычную среду. |
| Скалярные функции ODBC (Transact-SQL) | Предоставляет сведения о скалярных функциях ODBC, которые могут использоваться в инструкциях Transact-SQL. К ним относятся функции даты и времени ODBC. |
| AT TIME ZONE (Transact-SQL) | Обеспечивает преобразование часовых поясов. |
См. также
- Функции
- Типы данных (Transact-SQL)
Индексы в PostgreSQL
Виталий Сушков
Full Stack Developer в DataArt
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Делаем то же самое для элементов правее 134.
 В середине у них число 158 — искомый элемент. Поиск закончен.
В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P.
В отсутствии индекса для колонки column_name, PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name, PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P, и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX:
CREATE INDEX index_name ON table_name (column_name_1, column_name_2,....)
Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE:
CREATE UNIQUE INDEX index_name ON table_name (column_name_1, column_name_2,....)
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
SELECT * FROM table_name WHERE lower(text_field) = 'some_string_in_lower_case'
Если мы создадим обычный индекс по полю text_field, он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower. Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields):
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING <тип_индекса>. Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
- Найти пользователя по его email:
SELECT * FROM users WHERE email='[email protected]'
- Найти товары одной из двух категорий:
SELECT * FROM goods WHERE category_id = 10 OR category_id = 20
- Найти количество пользователей, зарегистрировавшихся в конкретный месяц:
SELECT COUNT(id) FROM users WHERE reg_date >= 01.01.2021 AND reg_date <= 31.01.2021
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).
Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).

- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.
Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.
Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE 'start_substring%'
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
PostgreSQL поддерживает разные типы индексов для разных задач:
- B-дерево покрывает широчайший класс задач, т. к. применимо к любым данным, которые можно отсортировать.
- GiST и SP-GiST могут быть полезны при работе с геометрическими объектами и для создания совершенно новых типов индексов для новых типов данных.
- За рамками этой статьи оказался ещё один важный тип индексов — GIN. GIN индексы полезны для организации полнотекстового поиска и для индексации таких типов данных, как массивы или jsonb. Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
Ссылки на полезные материалы
- Создание индекса в PostgreSQL
- Алгоритмы работы с B-деревом
- Релизация B-дерева в PostgreSQL
- R-дерево
- Kd-дерево
- Индекс типа GiST в PostgreSQL
- Индекс типа SP-GiST в PostgreSQL
- Индекс типа GIN в PostgreSQL
- Индекс типа RUM в PostgreSQL
текущая дата и другие функции даты в времени
Функция текущей даты SQL CURDATE() и её аналоги CURRENT_DATE() и CURRENT_DATE среди других функций даты и времени
применяются наиболее часто из-за широких возможностей, обеспечиваемых ими для анализа данных.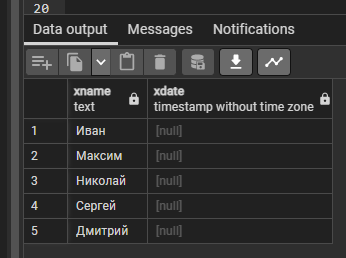 Знакомство с функциями даты и времени начнём с разбора практических примеров, демонстрирующих
возможности функции текущей даты. А затем перейдём к остальным функциям даты и времени, соблюдая для
удобства их классификацию по назначению.
Знакомство с функциями даты и времени начнём с разбора практических примеров, демонстрирующих
возможности функции текущей даты. А затем перейдём к остальным функциям даты и времени, соблюдая для
удобства их классификацию по назначению.
Функция текущей даты CURDATE() возвращает значение текущей даты в формате ‘YYYY-MM-DD’ и ‘YYYYDDMM’. Вычисляя несколькими способами (их как раз и разберём в этом параграфе) разницу значений дат, можно определить такие важные значения, как возраст человека, его трудовой стаж, продолжительность различных процессов и явлений и многое другое.
В примерах работаем с базой данных «Театр». Таблица Play содержит данные о постановках. Таблица Team — о ролях актёров. Таблица Actor — об актёрах. Таблица Director — о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).
Это уже база с большим объёмом данных по сравнению с примерами ко многим другим темам нашего курса. Поэтому не будем приводить строки данных таблиц и таблицы результатов запросов. Однако это будет
компенсировано подробным разбором логики построения запросов, которые, надо признать, имеют достаточно
высокую сложность.
Поэтому не будем приводить строки данных таблиц и таблицы результатов запросов. Однако это будет
компенсировано подробным разбором логики построения запросов, которые, надо признать, имеют достаточно
высокую сложность.
Пример 1. Сформировать список актеров старше 70 лет. Пишем следующий запрос:
SELECT FName, LName, BirthDate FROM ACTOR WHERE TIMESTAMPDIFF(YEAR, BirthDate, CURDATE()) > 70
В этом запросе вычисляется разница между текущей датой CURDATE() и датой рождения
актёра BirthDate, содержащейся в таблице ACTOR. Для вычисления разницы применена функция TIMESTAMPDIFF().
Ключевое слово YEAR — задаёт единицу измерения — в годах интервала между датами. Вычисленное значение и
результат его сравнения с числом 70 вполне
пригодны в качестве условия выборки в секции WHERE. Следует учесть, что функция TIMESTAMPDIFF()
существует лишь в MySQL. В других диалектах SQL для этого есть функция DATEDIFF, а для задания
единицы измерения применяются различные ключевые слова в различных вариантах написания.
Для вычисления разницы дат можно использовать и оператор «минус». Это сделано в следующем примере.
Пример 2. Вывести список актеров, которые не задействованы в новых постановках (в постановках последних 3 лет). Использовать CURDATE(), NOT IN. Запрос будет следующим:
SELECT fname, lname FROM actor WHERE actor_id NOT IN(SELECT actor_id FROM team WHERE play_id IN(SELECT play_id FROM play WHERE YEAR(premieredate) — YEAR(CURDATE())
В этом запросе задействована функция YEAR(). Аргументами её являются дата премьеры
постановки premieredate из таблицы play и текущая дата. Для вычисления разницы использован оператор
«минус». Он имеет больший приоритет по сравнению с оператором сравнения и поэтому выполняется первым.
Вычисленнное выражение сравнивается с числом 3 и подходящие значения служат условием выборки из таблицы
play, содержащей данные о постановках. Этот подзапрос — самый глубокий в «матрёшке» целого запроса.
Подзапрос более высокого уровня из таблицы team, содержащей данные о ролях, выбирает идентификаторы актёров,
с помощью предиката IN. Выбираются те актёры, которые участвовали в постановках трёх послежних лет. И,
наконец, самый внешний запрос к таблице actor выбирает значения с отрицанием (NOT IN) значения предыдущего
подзапроса.
Этот подзапрос — самый глубокий в «матрёшке» целого запроса.
Подзапрос более высокого уровня из таблицы team, содержащей данные о ролях, выбирает идентификаторы актёров,
с помощью предиката IN. Выбираются те актёры, которые участвовали в постановках трёх послежних лет. И,
наконец, самый внешний запрос к таблице actor выбирает значения с отрицанием (NOT IN) значения предыдущего
подзапроса.
- Страница 2 (Примеры с функцией DATEDIFF MS SQL Server)
- Страница 3 (Примеры с функцией DATEADD MS SQL Server)
Далее — пример использования соединения таблиц, среди которых из одной выбирается дата для вычисления разницы с текущей датой.
Пример 3. Сформировать список актеров с их стажем (в днях). Использовать CURDATE(), GROUP BY. Запрос будет следующим:
SELECT DISTINCT
a.Actor_ID, a.FName, a.LName,
CURDATE() — p1.PremiereDate AS ExpDays
FROM Play p1
JOIN
Team t1 ON p1.play_id = t1.play_id
JOIN
Actor a
ON t1. actor_id = a.Actor_id
WHERE t1.ACTOR_ID = a.Actor_ID
ORDER BY ExpDays, a.Actor_ID
DESC
actor_id = a.Actor_id
WHERE t1.ACTOR_ID = a.Actor_ID
ORDER BY ExpDays, a.Actor_ID
DESC
В этом запросе разница между текущей датой CURDATE() и датой премьеры постановки PremiereDate из таблицы Play вычисляется как имя столбца в результирующей таблице. Поскольку эти даты имеют один и тот же формат, для вычисления разницы достаточно использовать оператор «минус». Разница вычислена. Но из таблицы Play невозможно напрямую «достучаться» до таблицы Actor, содержащей данные об актёрах. Поэтому используем соединение (JOIN) этой таблицы с таблицей Team, которая уже связана с таблицей Actor при помощи ключа Actor_ID. Соединение таблиц Team и Actor — второе в этой цепочке из трёх таблиц.
Составить SQL запросы с текущей датой самостоятельно, а затем посмотреть решения
Пример 4. Определить самого востребованного актера за последние 5 лет. Оператор JOIN использовать 2 раза. Использовать CURDATE(), LIMIT 1.
Правильное решение и комментарий.
Пример 5. Определить спектакли, в которых средний возраст актеров от 20 до 30 (использовать BETWEEN, GROUP BY, AVG).
Правильное решение и комментарий.
В последующих параграфах приведено большинство функций даты и времени, используемых в СУБД MySQL. А примеры использования наиболее часто применимых в MS SQL Server функций DATEDIFF и DATEADD приведены соответственно на странице 2 и странице 3.
CURDATE(), CURRENT_DATE(), CURRENT_DATE — возвращают текущую дату в формате ‘YYYY-MM-DD’ или YYYYDDMM в зависимости от того, вызывается функция в текстовом или числовом контексте.
CURTIME(), CURRENT_TIME(), CURRENT_TIME — возвращают текущее время суток в формате ‘hh-mm-ss’ или hhmmss в зависимости от того, вызывается функция в текстовом или числовом контексте.
NOW() — возвращает текущие дату и время формате
‘YYYY-MM-DD hh:mm:ss’ или YYYYDDMMhhmmss в зависимости от того, вызывается функция в текстовом или числовом контексте.
TIMEDIFF(param1, param2) — возвращает разницу между значениями времени, заданными параметрами param1 и param2.
DATEDIFF(param1, param2) — возвращает разницу между датами param1 и param2. Значения param1 и param2 могут иметь типы DATE или DATETIME, а при вычислении разницы используется лишь часть DATE.
PERIOD_DIFF(param1, param2) — возвращает разницу в месяцах между датами param1 и param2. Значения param1 и param2 могут быть представлены в числовом формате YYYYMM или YYMM.
TIMESTAMPDIFF(interval, param1, param2) — возвращает разницу между
значениями датами param1 и param2. Значения param1 и param2 могут быть представлены в форматах
‘YYYY-MM-DD’ или ‘YYYY-MM-DD hh:mm:ss’. Единица измерения разницы задаётся параметром interval. Он может
принимать значения FRAC_SECOND (микросекунды), SECOND (секунды), MINUTE (минуты), HOUR (часы),
DAY (дни), WEEK (недели), MONTH (месяцы), QUARTER (кварталы), YEAR (годы).
- Страница 2 (Примеры с функцией DATEDIFF MS SQL Server)
- Страница 3 (Примеры с функцией DATEADD MS SQL Server)
ADDDATE(date, INTERVAL value) — возвращает дату, к которой прибавлено значение value. Ключевое слово INTERVAL обязательно следует в запросе, после него указывается значение value, а затем единицы измерения прибавляемого значения. Ими могут быть SECOND (секунды), MINUTE (минуты), HOUR (часы), MINUTE_SECOND (минуты и секунды), HOUR_MINUTE (часы и минуты), DAY_SECOND (дни, часы минуты и секунды), DAY_MINUTE (дни, часы и минуты), DAY_HOUR (дни и часы), YEAR_MONTH (годы и месяцы).
SUBDATE(date, INTERVAL value) — вычитает из величины даты date
произвольный временной интервал и возвращает результат. Ключевое слово INTERVAL обязательно следует в запросе, после него
указывается значение value, а затем единицы измерения вычитаемого значения. Возможные единицы измерения —
те же, что и для функции ADDDATE().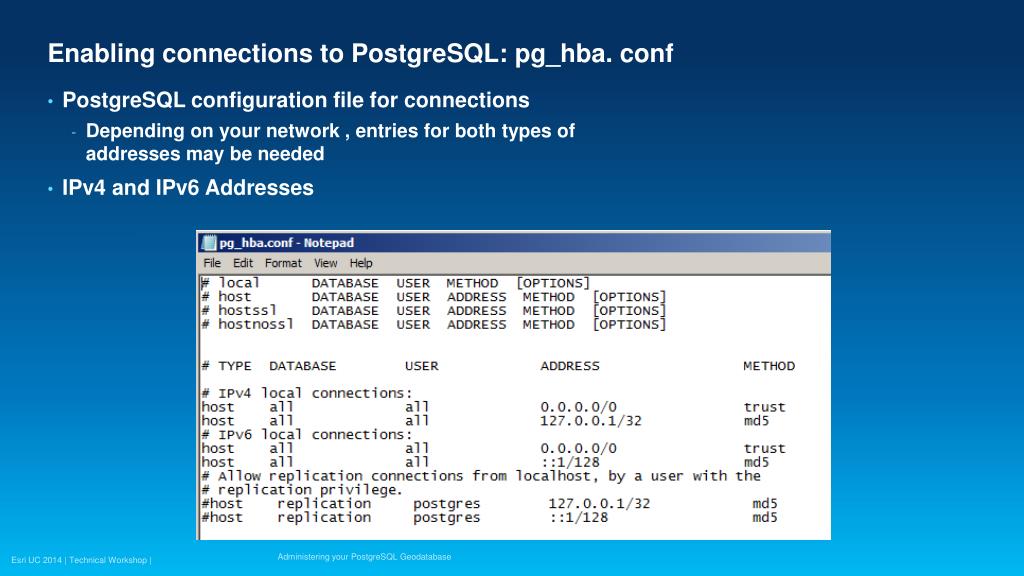
SUBTIME(datetime, time) — вычитает из величины времени datetime вида ‘YYYY-MM-DD hh:mm:ss’ произвольно заданное значение времени time и возвращает результат.
PERIOD_ADD(period, N) — добавляет N месяцев к значению даты period. Значение period должно быть представлено в числовом формате ‘YYYYMM’ или ‘YYMM’.
TIMESTAMPADD(interval, param1, param2) — прибавляет к дате и времени суток param2 в полном или кратком формате временной интервал param1, единицы измерения которого заданы параметром interval. Возможные единицы измерения — те же, что и для функции TIMESTAMPDIFF().
- Страница 2 (Примеры с функцией DATEDIFF MS SQL Server)
- Страница 3 (Примеры с функцией DATEADD MS SQL Server)
DATE(datetime) — извлекает из значения даты и времени суток
в формате DATETIME (‘YYYY-MM-DD hh:mm:ss’) только дату, отсекая часы, минуты и секунды.
TIME(datetime) — извлекает из значения даты и времени суток в формате DATETIME (‘YYYY-MM-DD hh:mm:ss’) только время суток, отсекая дату.
TIMESTAMP(param) — принимает в качестве аргумента дату и время суток в полном или кратком формате и возвращает полный вариант в формате DATETIME (‘YYYY-MM-DD hh:mm:ss’).
DAY(date), DAYOFMONTH(date) — принимают в качестве аргумента дату, и возвращают порядковый номер дня в месяце (от 1 до 31).
DAYNAME(date) — принимает в качестве аргумента дату, и возвращает день недели в виде полного слова на английском языке.
DAYOFWEEK(date) — принимает в качестве аргумента дату, и возвращает порядкоый номер дня недели от 1 (воскресенье) до 7 (суббота).
WEEKDAY(date) — принимает в качестве аргумента дату,
и возвращает порядкоый номер дня недели от 0 (понедельник) до 6 (воскресенье).
WEEK(date) — принимает в качестве аргумента дату, и возвращает номер недели в году для этой даты от 0 до 53.
WEEKOFYEAR(datetime) — возвращает порядковый номер недели в году для даты datetime от 1 до 53.
MONTH(datetime) — возвращает числовое значение месяца года от 1 до 12 для даты datetime.
MONTHNAME(datetime) — возвращает строку с названием месяца для даты datetime.
QUARTER(datetime) — возвращает значение квартала от 1 до 4 для даты datetime, которая может быть передана в формате ‘YYYY-MM-DD’ или ‘YYYY-MM-DD hh:mm:ss’.
YEAR(datetime) — возвращает год от 1000 до 9999 для даты datetime.
DAYOFYEAR(date) — возвращает порядковый номер дня в году от 1 до 366 для даты date.
HOUR(datetime) — возвращает значение часа от 0 до 23 для
времени datetime.
MINUTE(datetime) — возвращает значение минут от 0 до 59 для времени datetime.
SECOND(time) — возвращает количество секунд для времени суток time, которое задаётся либо в виде строки ‘hh:mm:ss’, либо числа hhmmss.
EXTRACT(type FROM datetime) — принимает дату и время суток datetime и возвращает часть, определяемую параметром type. Значениями параметра могут быть YEAR, MONTH, DAY, HOUR, MINUTE, SECOND.
- Страница 2 (Примеры с функцией DATEDIFF MS SQL Server)
- Страница 3 (Примеры с функцией DATEADD MS SQL Server)
TO_DAYS(date) — принимает дату date в кратком ‘YYYY-MM-DD’ или полном формате ‘YYYY-MM-DD hh:mm:ss’ и возвращает количество дней, прошедших с нулевого года.
FROM_DAYS(N) — принимает количество дней N, прошедших
с нулевого года, и возвращает дату в формате ‘YYYY-MM-DD’.
UNIX_TIMESTAMP(), UNIX_TIMESTAMP(datetime) — если параметр не указан, то возвращает количество секунд, прошедших с 00:00 1 января 1970 года. Если параметр datetime указан (в кратком ‘YYYY-MM-DD’ или полном формате ‘YYYY-MM-DD hh:mm:ss’), то возвращает разницу в секундах между 00:00 1 января 1970 года и датой datetime.
FROM_UNIXTIME(unix_timestamp), FROM_UNIXTIME(unix_timestamp, format) — принимает количество секунд, прошедших с 00:00 1 января 1970 года и возвращает дату и время суток в виде строки ‘YYYY-MM-DD hh:mm:ss’ или в виде числа YYYYDDMMhhmmss в зависимости от того, вызвана функция в строковом или числовом контексте.
TIME_TO_SEC(time) — принимает время суток time в формате ‘hh:mm:ss’ и возвращает количество секунд, прошедших с начала суток.
SEC_TO_TIME(seconds) — принимает количество секунд seconds,
прошедших с начала суток и возвращает время в формате ‘hh:mm:ss’ или hhmmss в зависимости от того, вызвана
функция в строковом или числовом контексте.
MAKEDATE(year, dayofyear) — принимает год year, номер дня в году dayofyear и возвращает дату в формате ‘YYYY-MM-DD’.
MAKETIME(hour, minute, second) — принимает часы hour, минуты minute и секунды second и возвращает время суток в формате ‘hh:mm:ss’.
- Страница 2 (Примеры с функцией DATEDIFF MS SQL Server)
- Страница 3 (Примеры с функцией DATEADD MS SQL Server)
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Часовые пояса | Документация Django 4.0
Быстрый обзор
Когда поддержка часовых поясов включена, Django хранит информацию о времени в UTC в базе данных, использует внутренние объекты времени с учетом часовых поясов и переводит их в часовой пояс конечного пользователя в шаблонах и формах.
Это удобно, если ваши пользователи живут в нескольких часовых поясах и вы хотите отображать информацию о времени в соответствии с настенными часами каждого пользователя.
Даже если ваш сайт доступен только в одном часовом поясе, хранить данные в базе данных в формате UTC — хорошая практика. Основная причина — переход на летнее время (DST). Во многих странах существует система DST, при которой часы переводятся вперед весной и назад осенью. Если вы работаете по местному времени, вы, скорее всего, столкнетесь с ошибками два раза в год, когда происходит переход. Возможно, для вашего блога это не имеет значения, но это проблема, если вы каждый год дважды в год завышаете или занижаете счет своим клиентам на один час. Решение этой проблемы — использовать UTC в коде и использовать местное время только при взаимодействии с конечными пользователями.
По умолчанию поддержка часовых поясов отключена. Чтобы включить ее, установите значение USE_TZ = True в файле настроек.
Примечание
В Django 5.0 поддержка часовых поясов будет включена по умолчанию.
Поддержка часовых поясов использует zoneinfo, который является частью стандартной библиотеки Python, начиная с Python 3. 9. Пакет
9. Пакет backports.zoneinfo автоматически устанавливается вместе с Django, если вы используете Python 3.8.
Changed in Django 3.2:
Добавлена поддержка реализаций часовых поясов не«pytz«.
Changed in Django 4.0:
zoneinfo стал реализацией часового пояса по умолчанию. Вы можете продолжать использовать pytz в течение цикла выпуска 4.x с помощью настройки USE_DEPRECATED_PYTZ.
Примечание
Файл по умолчанию settings.py, созданный django-admin startproject, включает USE_TZ = True для удобства.
Если вы боретесь с конкретной проблемой, начните с time zone FAQ.
Концепции
Наивные и осознанные объекты времени суток
Объекты Python datetime.datetime имеют атрибут tzinfo, который может быть использован для хранения информации о часовом поясе, представленной в виде экземпляра подкласса datetime.. Когда этот атрибут установлен и описывает смещение, объект datetime является aware. В противном случае он является наивным. tzinfo
tzinfo
Вы можете использовать is_aware() и is_naive(), чтобы определить, являются ли времена данных осознанными или наивными.
Когда поддержка часовых поясов отключена, Django использует наивные объекты datetime в местном времени. Этого достаточно для многих случаев использования. В этом режиме, чтобы получить текущее время, вы напишите:
import datetime now = datetime.datetime.now()
Когда поддержка часовых поясов включена (USE_TZ=True), Django использует объекты datetime с учетом часовых поясов. Если ваш код создает объекты datetime, они также должны быть осведомлены об этом. В этом режиме приведенный выше пример становится:
from django.utils import timezone now = timezone.now()
Предупреждение
Работа с объектами datetime не всегда интуитивно понятна. Например, аргумент
Например, аргумент tzinfo стандартного конструктора datetime не работает надежно для часовых поясов с DST. Использование UTC обычно безопасно; если вы используете другие часовые пояса, вам следует внимательно изучить документацию zoneinfo.
Примечание
Объекты Python datetime.time также имеют атрибут tzinfo, а PostgreSQL имеет соответствующий тип time with time zone. Однако, как говорится в документации PostgreSQL, этот тип «проявляет свойства, которые приводят к сомнительной полезности».
Django поддерживает только наивные объекты времени, и если вы попытаетесь сохранить объект времени с информацией, то возникнет исключение, поскольку временная зона для времени без связанной даты не имеет смысла.
Интерпретация наивных объектов времени суток
Когда USE_TZ становится True, Django все еще принимает наивные объекты datetime, чтобы сохранить обратную совместимость. Когда уровень базы данных получает такой объект, он пытается дать о нем знать, интерпретируя его в default time zone, и выдает предупреждение.
К сожалению, во время перехода на летнее время некоторые объекты времени не существуют или являются неоднозначными. Поэтому всегда следует создавать объекты datetime, когда включена поддержка часовых поясов. (Примеры использования атрибута Using ZoneInfo section of the zoneinfo docs для указания смещения, которое должно применяться к дате во время перехода на летнее время, см. в fold).
На практике это редко является проблемой. Django предоставляет вам известные объекты datetime в моделях и формах, и чаще всего новые объекты datetime создаются из существующих с помощью арифметики timedelta. Единственное время, которое часто создается в коде приложения — это текущее время, и timezone.now() автоматически делает то, что нужно.
Часовой пояс по умолчанию и текущий часовой пояс
Часовой пояс по умолчанию — это часовой пояс, определяемый настройкой TIME_ZONE.
текущий часовой пояс — это часовой пояс, который используется для рендеринга.
Вы должны установить текущий часовой пояс на фактический часовой пояс конечного пользователя с помощью activate(). В противном случае будет использоваться часовой пояс по умолчанию.
Примечание
Как объясняется в документации к TIME_ZONE, Django устанавливает переменные окружения так, чтобы его процесс работал в часовом поясе по умолчанию. Это происходит независимо от значения USE_TZ и текущего часового пояса.
Когда USE_TZ равно True, это полезно для сохранения обратной совместимости с приложениями, которые все еще полагаются на местное время. Однако, as explained above, это не совсем надежно, и вы всегда должны работать с известным временем в UTC в своем собственном коде. Например, используйте fromtimestamp() и установите параметр tz в значение utc.
Выбор текущего часового пояса
Текущий часовой пояс эквивалентен текущему locale для переводов. Однако не существует эквивалента HTTP-заголовка Accept-Language, который Django мог бы использовать для автоматического определения часового пояса пользователя. Вместо этого Django предоставляет time zone selection functions. Используйте их для построения логики выбора часового пояса, которая имеет смысл для вас.
Вместо этого Django предоставляет time zone selection functions. Используйте их для построения логики выбора часового пояса, которая имеет смысл для вас.
Большинство сайтов, заботящихся о часовых поясах, спрашивают пользователей, в каком часовом поясе они живут, и хранят эту информацию в профиле пользователя. Для анонимных пользователей используется часовой пояс их основной аудитории или UTC. zoneinfo.available_timezones() предоставляет набор доступных часовых поясов, который можно использовать для построения карты от вероятных мест до часовых поясов.
Вот пример, который хранит текущий часовой пояс в сессии. (Для простоты в нем полностью пропущена обработка ошибок).
Добавьте следующее промежуточное программное обеспечение в MIDDLEWARE:
import zoneinfo
from django.utils import timezone
class TimezoneMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
tzname = request. session.get('django_timezone')
if tzname:
timezone.activate(zoneinfo.ZoneInfo(tzname))
else:
timezone.deactivate()
return self.get_response(request)
session.get('django_timezone')
if tzname:
timezone.activate(zoneinfo.ZoneInfo(tzname))
else:
timezone.deactivate()
return self.get_response(request)
Создайте представление, которое может устанавливать текущий часовой пояс:
from django.shortcuts import redirect, render
# Prepare a map of common locations to timezone choices you wish to offer.
common_timezones = {
'London': 'Europe/London',
'Paris': 'Europe/Paris',
'New York': 'America/New_York',
}
def set_timezone(request):
if request.method == 'POST':
request.session['django_timezone'] = request.POST['timezone']
return redirect('/')
else:
return render(request, 'template.html', {'timezones': common_timezones})
Включите форму в template.html, которая будет POST к этому представлению:
{% load tz %}
{% get_current_timezone as TIME_ZONE %}
<form action="{% url 'set_timezone' %}" method="POST">
{% csrf_token %}
<label for="timezone">Time zone:</label>
<select name="timezone">
{% for city, tz in timezones %}
<option value="{{ tz }}"{% if tz == TIME_ZONE %} selected{% endif %}>{{ city }}</option>
{% endfor %}
</select>
<input type="submit" value="Set">
</form>
Ввод данных о часовом поясе в формах
Когда вы включаете поддержку часовых поясов, Django интерпретирует даты, введенные в формах, в current time zone и возвращает осознанные объекты datetime в cleaned_data.
Преобразованные даты, которые не существуют или являются неоднозначными, поскольку попадают в переходный период DST, будут представлены как недопустимые значения.
Вывод в шаблонах с учетом часового пояса
Когда вы включаете поддержку часовых поясов, Django преобразует объекты datetime в current time zone, когда они отображаются в шаблонах. Это ведет себя очень похоже на format localization.
Предупреждение
Django не конвертирует наивные объекты datetime, потому что они могут быть неоднозначными, и потому что ваш код никогда не должен создавать наивные объекты datetime, если включена поддержка часовых поясов. Тем не менее, вы можете принудительно конвертировать их с помощью фильтров шаблонов, описанных ниже.
Конвертация в местное время не всегда уместна — возможно, вы генерируете вывод для компьютеров, а не для людей. Следующие фильтры и теги, предоставляемые библиотекой тегов шаблона tz, позволяют управлять преобразованиями часовых поясов.
Теги шаблона
localtimeВключает или выключает преобразование известных объектов datetime в текущий часовой пояс в содержащемся блоке.
Этот тег имеет точно такие же эффекты, как и параметр USE_TZ, в том, что касается шаблонизатора. Он позволяет более тонко управлять преобразованием.
Чтобы активировать или деактивировать преобразование для блока шаблона, используйте:
{% load tz %}
{% localtime on %}
{{ value }}
{% endlocaltime %}
{% localtime off %}
{{ value }}
{% endlocaltime %}
Примечание
Значение USE_TZ не соблюдается внутри блока {% localtime %}.
timezoneУстанавливает или отменяет текущий часовой пояс в содержащемся блоке. Если текущий часовой пояс не установлен, применяется часовой пояс по умолчанию.
{% load tz %}
{% timezone "Europe/Paris" %}
Paris time: {{ value }}
{% endtimezone %}
{% timezone None %}
Server time: {{ value }}
{% endtimezone %}
get_current_timezoneНазвание текущего часового пояса можно получить с помощью тега get_current_timezone:
{% get_current_timezone as TIME_ZONE %}
В качестве альтернативы можно активировать контекстный процессор tz() и использовать контекстную переменную TIME_ZONE.
Шаблонные фильтры
Эти фильтры принимают как известные, так и наивные даты. Для целей преобразования они предполагают, что наивные времена дат находятся в часовом поясе по умолчанию. Они всегда возвращают известные времена.
localtimeПринудительное преобразование одного значения в текущий часовой пояс.
Например:
{% load tz %}
{{ value|localtime }}
utcПринудительное преобразование одного значения в UTC.
Например:
{% load tz %}
{{ value|utc }}
timezoneПринудительное преобразование одного значения в произвольный часовой пояс.
Аргумент должен быть экземпляром подкласса tzinfo или именем часового пояса.
Например:
{% load tz %}
{{ value|timezone:"Europe/Paris" }}
Руководство по миграции
Вот как перенести проект, который был начат до того, как Django поддерживал часовые пояса.
База данных
PostgreSQL
Бэкенд PostgreSQL хранит время даты как timestamp with time zone. На практике это означает, что при хранении он преобразует время дат из часового пояса соединения в UTC, а при извлечении — из UTC в часовой пояс соединения.
Как следствие, если вы используете PostgreSQL, вы можете свободно переключаться между USE_TZ = False и USE_TZ = True. Часовой пояс соединения с базой данных будет установлен на TIME_ZONE или UTC соответственно, так что Django получит правильное время дат во всех случаях. Вам не нужно выполнять никаких преобразований данных.
Другие базы данных
Другие бэкенды хранят данные без информации о часовом поясе. Если вы переключаетесь с USE_TZ = False на USE_TZ = True, вы должны преобразовать ваши данные из местного времени в UTC — что не является детерминированным, если ваше местное время имеет DST.
Код
Первый шаг — добавить USE_TZ = True в файл настроек. На этом этапе все должно в основном работать. Если вы создаете наивные объекты datetime в своем коде, Django делает их известными, когда это необходимо.
Однако эти преобразования могут не сработать при переходе на летнее время, что означает, что вы еще не получили всех преимуществ поддержки часовых поясов. Кроме того, вы можете столкнуться с несколькими проблемами, потому что невозможно сравнить наивное время даты с известным временем даты. Поскольку Django теперь предоставляет вам знающие времена, вы будете получать исключения, когда будете сравнивать время, полученное из модели или формы, с наивным временем, которое вы создали в своем коде.
Поэтому вторым шагом будет рефакторинг вашего кода везде, где вы инстанцируете объекты datetime, чтобы сделать их осознанными. Это можно сделать постепенно. django.utils.timezone определяет несколько удобных помощников для кода совместимости: now(), is_aware(), is_naive(), make_aware() и make_naive().
Наконец, чтобы помочь вам найти код, который нуждается в обновлении, Django выдает предупреждение, когда вы пытаетесь сохранить наивное время даты в базе данных:
RuntimeWarning: DateTimeField ModelName.field_name received a naive datetime (2012-01-01 00:00:00) while time zone support is active.
Во время разработки вы можете превратить такие предупреждения в исключения и получить обратную трассировку, добавив в файл настроек следующее:
import warnings
warnings.filterwarnings(
'error', r"DateTimeField .* received a naive datetime",
RuntimeWarning, r'django\.db\.models\.fields',
)
Приспособления
При сериализации осознаваемого времени даты включается смещение UTC, например, так:
"2011-09-01T13:20:30+03:00"
В то время как для наивного времени даты это не так:
"2011-09-01T13:20:30"
Для моделей с DateTimeFieldс эта разница делает невозможным написание приспособления, которое работает как с поддержкой часовых поясов, так и без нее.
Фикстуры, созданные с помощью USE_TZ = False, или до Django 1.4, используют «наивный» формат. Если ваш проект содержит такие фикстуры, то после включения поддержки часовых поясов вы увидите RuntimeWarningпри их загрузке. Чтобы избавиться от предупреждений, вы должны преобразовать ваши фикстуры в формат «aware».
Вы можете регенерировать фикстуры с помощью loaddata, затем dumpdata. Или, если они достаточно малы, вы можете отредактировать их, чтобы добавить смещение UTC, соответствующее вашему TIME_ZONE, к каждому сериализованному времени даты.
FAQ
Настройка
Мне не нужно несколько часовых поясов. Должен ли я включить поддержку часовых поясов?
Да. Когда включена поддержка часовых поясов, Django использует более точную модель местного времени. Это защищает вас от тонких и невоспроизводимых ошибок, связанных с переходом на летнее время (DST).
Когда вы включите поддержку часовых поясов, вы столкнетесь с некоторыми ошибками, потому что вы используете наивные времена дат там, где Django ожидает знающие времена дат.
 Такие ошибки проявляются при выполнении тестов. Вы быстро узнаете, как избежать некорректных операций.
Такие ошибки проявляются при выполнении тестов. Вы быстро узнаете, как избежать некорректных операций.С другой стороны, ошибки, вызванные отсутствием поддержки часовых поясов, гораздо сложнее предотвратить, диагностировать и исправить. Все, что связано с запланированными задачами или арифметикой времени, является кандидатом на тонкие ошибки, которые будут кусать вас только один или два раза в год.
По этим причинам поддержка часовых поясов включена по умолчанию в новых проектах, и вы должны сохранить ее, если у вас нет очень веских причин не делать этого.
Я включил поддержку часовых поясов. Я в безопасности?
Возможно. Вы лучше защищены от ошибок, связанных с DST, но вы все еще можете прострелить себе ногу, неосторожно превращая наивные времена дат в осознанные времена дат, и наоборот.
Если ваше приложение подключается к другим системам — например, запрашивает веб-службу — убедитесь, что время даты указано правильно.
Для безопасной передачи временных данных их представление должно включать смещение UTC, или их значения должны быть в UTC (или и то, и другое!).Наконец, наша календарная система содержит интересные крайние случаи. Например, вы не всегда можете вычесть один год непосредственно из заданной даты:
>>> import datetime >>> def one_year_before(value): # Wrong example. ... return value.replace(year=value.year - 1) >>> one_year_before(datetime.datetime(2012, 3, 1, 10, 0)) datetime.datetime(2011, 3, 1, 10, 0) >>> one_year_before(datetime.datetime(2012, 2, 29, 10, 0)) Traceback (most recent call last): ... ValueError: day is out of range for month
Чтобы правильно реализовать такую функцию, вы должны решить, будет ли 2012-02-29 минус один год 2011-02-28 или 2011-03-01, что зависит от ваших бизнес-требований.
Как взаимодействовать с базой данных, в которой хранятся даты в местном времени?
Установите в параметре
TIME_ZONEсоответствующий часовой пояс для этой базы данных в параметреDATABASES.Это полезно для подключения к базе данных, которая не поддерживает часовые пояса и не управляется Django, когда
USE_TZстановитсяTrue.
Устранение неполадок
Мое приложение аварийно завершается с
TypeError: can't compare offset-naiveand offset-aware datetimes— что не так?Давайте воспроизведем эту ошибку, сравнив наивный и знающий datetime:
>>> from django.utils import timezone >>> aware = timezone.now() >>> naive = timezone.make_naive(aware) >>> naive == aware Traceback (most recent call last): ... TypeError: can't compare offset-naive and offset-aware datetimes
Если вы столкнулись с этой ошибкой, скорее всего, ваш код сравнивает эти две вещи:
- время даты, предоставленное Django — например, значение, считанное из формы или поля модели. Поскольку вы включили поддержку часовых поясов, это известно.
- дататайм, сгенерированный вашим кодом, что наивно (иначе вы бы не читали это).
Как правило, правильным решением будет изменить ваш код, чтобы вместо него использовать осознаваемое время даты.
Если вы пишете подключаемое приложение, которое должно работать независимо от значения
USE_TZ, вы можете найтиdjango.utils.timezone.now()полезным. Эта функция возвращает текущую дату и время в виде наивного времени, еслиUSE_TZ = False, и в виде осознанного времени, еслиUSE_TZ = True. Вы можете добавить или вычестьdatetime.timedeltaпо мере необходимости.- время даты, предоставленное Django — например, значение, считанное из формы или поля модели.
Я вижу много
RuntimeWarning: DateTimeField received a naive datetime(YYYY-MM-DD HH:MM:SS)while time zone support is active**- это плохо? **Когда включена поддержка часовых поясов, уровень базы данных ожидает, что ваш код будет получать от вас только известные значения времени.
Это предупреждение появляется, когда он получает наивное время даты. Это указывает на то, что вы не закончили перенос вашего кода для поддержки часовых поясов. Пожалуйста, обратитесь к migration guide за советами по этому процессу.В то же время, для обратной совместимости, время даты считается в часовом поясе по умолчанию, что обычно соответствует вашим ожиданиям.
<<< 0 >> ** это вчера! (или завтра)**
Если вы всегда пользовались наивными временами дат, вы, вероятно, считаете, что можно преобразовать время даты в дату, вызвав его метод
date(). Вы также считаете, чтоdateочень похож наdatetime, за исключением того, что он менее точен.Все это не верно в среде с учетом часовых поясов:
>>> import datetime >>> import zoneinfo >>> paris_tz = zoneinfo.ZoneInfo("Europe/Paris") >>> new_york_tz = zoneinfo.ZoneInfo("America/New_York") >>> paris = datetime. datetime(2012, 3, 3, 1, 30, tzinfo=paris_tz)
# This is the correct way to convert between time zones.
>>> new_york = paris.astimezone(new_york_tz)
>>> paris == new_york, paris.date() == new_york.date()
(True, False)
>>> paris - new_york, paris.date() - new_york.date()
(datetime.timedelta(0), datetime.timedelta(1))
>>> paris
datetime.datetime(2012, 3, 3, 1, 30, tzinfo=zoneinfo.ZoneInfo(key='Europe/Paris'))
>>> new_york
datetime.datetime(2012, 3, 2, 19, 30, tzinfo=zoneinfo.ZoneInfo(key='America/New_York'))
Как видно из этого примера, одно и то же время даты имеет разную дату в зависимости от часового пояса, в котором оно представлено. Но на самом деле проблема более фундаментальна.
Время даты представляет собой точку во времени. Она абсолютна: она ни от чего не зависит. Напротив, дата — это календарная концепция. Это период времени, границы которого зависят от часового пояса, в котором рассматривается дата.
Как видите, эти два понятия принципиально различны, и преобразование времени даты в дату не является детерминированной операцией.Что это означает на практике?
Как правило, следует избегать преобразования
datetimeвdate. Например, вы можете использовать фильтр шаблонаdateдля отображения только части даты. Этот фильтр преобразует дату в текущий часовой пояс перед форматированием, обеспечивая правильное отображение результатов.Если вам действительно необходимо выполнить преобразование самостоятельно, сначала необходимо убедиться, что время даты преобразовано в соответствующий часовой пояс. Обычно это текущий часовой пояс:
>>> from django.utils import timezone >>> timezone.activate(zoneinfo.ZoneInfo("Asia/Singapore")) # For this example, we set the time zone to Singapore, but here's how # you would obtain the current time zone in the general case. >>> current_tz = timezone. get_current_timezone()
>>> local = paris.astimezone(current_tz)
>>> local
datetime.datetime(2012, 3, 3, 8, 30, tzinfo=zoneinfo.ZoneInfo(key='Asia/Singapore'))
>>> local.date()
datetime.date(2012, 3, 3)
Я получаю ошибку «
Are time zone definitions for your database installed?»Если вы используете MySQL, смотрите раздел Определения часовых поясов в примечаниях к MySQL для инструкций по загрузке определений часовых поясов.
Применение
У меня есть строка
"2012-02-21 10:28:45"и я знаю, что она находится в"Europe/Helsinki"временной зоне. Как мне превратить это в известное время?Здесь нужно создать необходимый экземпляр
ZoneInfoи присоединить его к наивному datetime:>>> import zoneinfo >>> from django.
utils.dateparse import parse_datetime
>>> naive = parse_datetime("2012-02-21 10:28:45")
>>> naive.replace(tzinfo=zoneinfo.ZoneInfo("Europe/Helsinki"))
datetime.datetime(2012, 2, 21, 10, 28, 45, tzinfo=zoneinfo.ZoneInfo(key='Europe/Helsinki'))
Как я могу получить местное время в текущем часовом поясе?
Первый вопрос — действительно ли вам это нужно?
Вы должны использовать местное время только при взаимодействии с людьми, и слой шаблонов предоставляет filters and tags для преобразования времени даты в часовой пояс по вашему выбору.
Кроме того, Python умеет сравнивать известные времена дат, принимая во внимание смещения UTC, когда это необходимо. Гораздо проще (и, возможно, быстрее) писать весь код модели и представления в UTC. Таким образом, в большинстве случаев времени в UTC, возвращаемого командой
django.utils.timezone.now(), будет достаточно.Однако для полноты картины, если вам действительно нужно местное время в текущем часовом поясе, вот как вы можете его получить:
>>> from django.
utils import timezone
>>> timezone.localtime(timezone.now())
datetime.datetime(2012, 3, 3, 20, 10, 53, 873365, tzinfo=zoneinfo.ZoneInfo(key='Europe/Paris'))
В данном примере текущий часовой пояс —
"Europe/Paris".Как я могу увидеть все доступные часовые пояса?
zoneinfo.available_timezones()предоставляет набор всех допустимых ключей для временных зон IANA, доступных для вашей системы. Соображения по использованию см. в документации.
Golang time и Golang date: форматирование даты и времени в Go
В языке программирования Golang для выполнения операций над временем используется стандартный пакет time. Используя его, можно получить текущие параметры времени и даты, отформатировать дату в строку, создать таймер либо бегущую строку, cконвертировать временные зоны. В этой статье пойдёт рассказ о форматировании даты в строку, о парсинге даты в Golang, о популярных шаблонах для даты и времени и о том, какие существуют исключительные случаи во время работы с датой и временем (time) в Golang.
В качестве шаблона в языке программирования Go используют фиксированные значения времени либо даты, а не особые символы, такие как %d-%b-%Y. В целях форматирования задействуется метод Format:
func (t Time) Format(layout string) string
Для парсинга даты применяют функцию time.Parse:
func Parse(layout, value string) (Time, error)
Чтобы описать формат значения времени, нужен специальный параметр макета layout. Он д. б. референтной датой — Mon Jan 2 15:04:05 MST 2006, которая отформатирована так же, как и ожидаемое для форматирования значение.
Парсинг даты
Для парсинга «2017-08-31» применим шаблон строки «2006-01-02» (это эквивалентно yyyy-mm-dd референтной «магической» даты).
Может возникнуть справедливый вопрос: а что же такого магического есть в Mon Jan 2 15:04:05 MST 2006? Давайте посмотрим на шаблон в другом порядке:
Видно, что здесь нет двух одинаковых полей. А это означает, что для такой конкретной даты каждое поле будет точно идентифицированным вне зависимости от форматирования.
Форматируем даты в строку
Если нужно получить текстовое представление значения времени, то можно ожидать выполнения определенного форматирования. В пакете time есть тип Time, позволяющий создавать вывод string в указанном формате. Существует ряд правил относительно того, как правильно это выполнять. Наиболее важные моменты следует рассмотреть:
- Давайте создадим файл format.go с определённым содержанием:
- Теперь запустим код с помощью go run format.go.
- И увидим результат:
tTime is: 2017/3/5 The time is: 08:05 The time is: Sun, 05 Mar 2017 08:05:02 UTC tTime is: 2017/3/ 5 tTime is: 2017/03/05 tTime is: 08:05:02.00 tTime is: 08:05:02 The time is up: 08:05AM
Тип Time в пакете time предоставляет нам метод Format, необходимый для форматирования вывода в строку. Также пакет time содержит ряд предварительно установленных форматов (в качестве примера можно привести time.Kitchen). Чтобы ознакомиться с константами этого пакета, можно открыть их в официальной документации. Если же интересует более подробная информация как о предварительно определённых форматах, так и об опциях форматирования, получить её можно тоже в официальной документации, но уже для пакета time.
Чтобы определить макет вывода, в Go используется референтное значение времени Jan 2 15:04:05 2006 MST.
Популярные шаблоны
Ниже будут представлены таблицы с шаблонами для даты, времени, даты и времени.
Об исключительных случаях
Теперь следует перечислить особые случаи, с которыми, используя пакет time, справиться нельзя:
- Случай № 1. Нет возможности уточнить, что час должен быть представлен в 24-часовом временном формате без начального нуля.
- Случай № 2. Нет возможности указать полночь как 24:00 вместо 00:00. Типичное применение для этого — давать часы работы, которые заканчиваются в полночь, по типу 07:00-24:00.
- Случай № 3. Нет возможности указать время, которое содержит дополнительную високосную секунду: 23:59:60. На деле временной пакет предполагает использование григорианского календаря без високосных секунд.
Как получить timestamp в Golang?
Если интересует метка времени (timestamp), следует использовать time.Now, а также один из time.Unix либо time.UnixNano. Нижеследующий код можно проверить в любом онлайн-компиляторе Go:
package main
import (
"fmt"
"time"
)
func main() {
// местное время (текущее)
now := time.Now()
// число секунд с 1 января 1970 года по Гринвичу (UTC)
sec := now.Unix()
// число наносекунд с 1 января 1970 года
// по Гринвичу (UTC)
nsec := now.UnixNano()
fmt.Println(now) // time.Time
fmt.Println(sec) // int64
fmt.Println(nsec) // int64
}
Вывод в терминал на момент написания статьи был следующим:
2020-09-25 17:29:56.611382982 +0000 UTC m=+0.000159607 1601054996 1601054996611382982
Вот и всё, если хотите получить более продвинутые знания по программированию на Golang, записывайтесь на курсы в OTUS!
По материалам: • https://golangs. org/date-time-layout-2006-01-02;
• https://golang-blog.blogspot.com/2020/04/format-date-time-in-golang.html;
• https://golang-blog.blogspot.com/2020/04/timestamp-in-golang.html.
Sql разница между датами в днях
Содержание
- 0.1 SQL Server
- 0.2 MySQL
- 0.3 PostgreSQL
- 0.4 Oracle
- 1 10 ответов
Задача. Посчитать число минут в интервале между двумя датами – ‘2011-10-07 23:43:00’ и ‘2011-10-08 01:23:00’
SQL Server
Встроенная функция DATEDIFF решает проблему:
Результат – 100 минут.
В запросе используется стандартное представление даты (ISO) в виде текстовой строки ‘yyyy-mm-ddThh:mm:ss’, которое не зависит ни от локальных настроек сервера, ни и от самого сервера.
MySQL
Функция DATEDIFF есть и в MySQL, однако она имеет совсем другой смысл. DATEDIFF вычисляет число дней между двумя датами, являющихся аргументами этой функции. При этом если дата представлена в формате дата-время, используется только составляющая даты. Поэтому все три нижепредставленных запроса дадут один и тот же результат -1. Положительный результат будет получен, если первый аргумент больше второго.
Один день мы получим даже в случае, если интервал между датами составляет все одну секунду:
Решение же нашей задачи можно получить при помощи другой встроенной функции – TIMESTAMPDIFF, которая аналогичная функции DATEDIFF в Язык структурированных запросов) — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL Server:
PostgreSQL
В PostgreSQL нет функции, подобной DATEDIFF (SQL Server) или TIMESTAMPDIFF (MySQL). Поэтому для решения задачи можно применить следующую последовательность действий:
- представить разность между двумя датами интервалом;
- посчитать число секунд в интервале;
- поделить полученное на шаге 2 значение на 60, чтобы выразить результат в минутах.
Для получения интервала можно взять разность двух значений темпорального типа, При этом требуется явное преобразование типа:
Результат — «01:40:00», который есть не что иное, как один час и сорок минут.
Можно также воспользоваться встроенной функцией AGE , которая выполняет заодно неявное преобразование типа своих аргументов:
Для получения числа секунд в интервале воспользуемся функцией
Значение интервала представим последним способом как наиболее коротким. Для получения окончательного решения задачи поделим полученный результат на 60:
В данном случае мы имеем результат, выраженный целым числом, поскольку оба значения времени в задаче не содержали секунд. В противном случае, будет получено десятичное число, например: 99.75:
Oracle
Oracle тоже не имеет в своем арсенале функции типа DATEDIFF. Кроме того, Oracle не поддерживает стандартное текстовое представление даты/времени.
Мы можем посчитать интервал в минутах, приняв во внимание, что разность дат (значений типа date ) в Oracle дает в результате число дней (суток). Тогда для вычисления интервала в минутах нужно просто разность дат умножить на 24 (число часов в сутках), а затем на 60 (число минут в часе):
Подобным образом можно получить и другие временные интервалы.
мне нужно получить разницу между двумя датами, скажем, если разница составляет 84 дня, я, вероятно, должен иметь вывод как 2 месяца и 14 дней, код, который у меня есть, просто дает итоги. Вот код
мне нужно, например, вывод для этого запроса должен быть либо 2 месяцев и 14 дней в худшем случае, иначе я не буду возражать, если я могу иметь точные дни после месяца, потому что эти дни на самом деле не 14, потому что все месяцы не в течение 30 дней.
обновлено для корректности. Первоначально ответил @jen.
SQLFiddle демо :
обратите внимание, как за последние две даты Oracle сообщает десятичную часть месяцев (которая дает дни) неправильно. 0.1290 соответствует 4 дней с Oracle учитывая 31 дней в месяц (для Марта и апреля).
Я думаю, что ваш вопрос недостаточно хорошо определен по следующей причине.
ответы, основанные на months_between, должны иметь дело со следующей проблемой: что функция сообщает ровно один месяц между 2013-02-28 и 2013-03-31, и между 2013-01-28 и 2013-02-28, и между 2013-01-31 и 2013-02-28 (я подозреваю, что некоторые ответчики не использовали эти функции на практике или теперь придется пересмотреть какой-то производственный код!)
Это документированное поведение, в котором даты, которые являются последними в соответствующих месяцах или которые приходятся на один и тот же день месяца, считаются целым числом месяцев.
таким образом, вы получаете тот же результат «1» при сравнении 2013-02-28 с 2013-01-28 или с 2013-01-31, но сравнение его с 2013-01-29 или 2013-01-30 дает 0.967741935484 и 0.935483870968 соответственно — так как одна дата приближается к другой, разница, сообщаемая этой функцией, может увеличение.
Если это неприемлемая ситуация, вам придется написать более сложную функцию или просто положиться на расчет, который предполагает 30 (например) дней в месяц. В последнем случае, как вы будете иметь дело с 2013-02-28 и 2013-03-31?
это то, что вы сделали ?
здесь я просто делаю разницу между сегодняшним днем и CREATED_DATE DATE поле в таблице, которое, очевидно, является датой в прошлом:
Я использую (365/12), или 30.416667, как мой коэффициент преобразования, потому что я использую общее количество дней и удаление лет и месяцев (Как дней), чтобы получить оставшееся количество дней. Во всяком случае, для моих целей этого было достаточно.
решение, которое я публикую, рассмотрит месяц с 30 днями
Недавно озадачился проблемой вычисления количества дней, прошедших с определенной даты до сегодняшнего дня. Данные хранятся в базе MySQL, соответственно нужно было сделать запрос, который возвращал бы количество дней.
После недолгих поисков ответ нашелся. В MySQL есть такая функция DATEDIFF (`[date1]`, `[date2]`), которая как раз возвращает нужное значение. Запрос выглядит следующим образом:
$sql=»select DATEDIFF(NOW(), `timestamp`) as `days` from `table` where `
Сравнение дат Postgresql — Руководства по SQL Server
В этом руководстве по PostgreSQL мы узнаем о « Сравнение дат Postgresql ». И мы также затронем следующие темы.
- Как мы можем сравнивать даты в Postgresql?
- Сравнить дату с помощью предложения WHERE
- Сравнить дату с помощью предложения BETWEEN
В PostgreSQL мы можем сравнить дату между двумя разными датами, которые мы будем использовать в качестве входных данных, и мы сравним дату с помощью ГДЕ и МЕЖДУ пунктами.
Мы также можем сравнить дату, используя функцию DATE_TRUNC в PostgreSQL. Мы также можем сравнить дату с TIMESTAMP , используя предложение where, условие WHERE необходимо при сравнении даты в PostgreSQL.
Также прочтите: Разница дат в PostgreSQL
Как мы можем сравнивать даты в PostgreSQL?
- В приведенном ниже примере показано, как мы можем сравнить даты.
- Предложение WHERE и BETWEEN очень полезно, когда нам нужно сравнить дату в PostgreSQL.
- Мы собираемся использовать таблицу путешествие , чтобы описать пример сравнения даты в PostgreSQL следующим образом.
- Ниже приведено описание данных таблицы путешествие .
Читать: Postgresql разница между двумя временными метками
Сравнить дату с помощью пункта WHERE
Теперь в этом разделе мы проиллюстрируем эту реализацию, используя SELECT, а также предложение UPDATE.
Используя предложение SELECT:
SELECT * FROM поездка, ГДЕ прибытие = '2017-05-06 07:30:00' и отправление = '2017-02-24 12:00:00';
В приведенном выше коде мы ищем имя человека, используя столбец прибытия и отправления таблицы с именем путешествие
После сравнения приведенного выше столбца прибытия, отправления с датой и временем мы получаем имя человека Дан .
Узнаем имя человека, чье время прибытия больше даты 07-14 20:40:30′; Сравните дату с помощью предложения WHERE
В приведенном выше выводе George, Jeff, John имеет время прибытия больше или равное 2019-07-14 20:40:30 .
Опять же, узнайте имя человека, время отправления которого меньше или равно дате 14.07.2019 16:15:00 .
SELECT * FROM поездка ГДЕ отправление <= '2019-07-14 16:15:00';Сравните дату с помощью предложения WHERE
В приведенном выше выводе у Дэна, Джеффа и Джони время отправления меньше или равно дате 2019-07-14 16:15:00 .
Используя предложение UPDATE:
Мы собираемся сравнить дату в операции UPDATE.
ОБНОВЛЕНИЕ путешествия SET имя = 'Джони' ГДЕ прибытие = '2020-01-08 14:00:00' и отправление = '2019-01-05 08:35:00'; SELECT * FROM trip WHERE name='Jhony'
В приведенном выше коде мы обновляем имя человека, чье время прибытия и отправления '2020-01-08 14:00:00' и '2019- 01-05 08:35:00' соответственно.
Вывод приведенного выше кода приведен ниже.
Сравните дату с помощью предложения WHERE.Чтение: добавление даты PostgreSQL + добавление дней к дате в PostgreSQL
Сравните дату с помощью предложения BETWEEN
Кроме того, в этом разделе мы проиллюстрируем эту реализацию с помощью SELECT и предложения UPDATE.
Использование предложения SELECT:
SELECT * FROM поездка, ГДЕ отправление МЕЖДУ '2017-02-24 12:00:00' И '2019-09-12 15:50:00';
В приведенном выше коде мы извлекаем записи, время отправления которых находится между ‘2017-02-24 12:00:00’ И ‘2019-09-12 15:50:00’ .
Вывод приведенного выше кода приведен ниже.
Сравните дату с помощью пункта BETWEEN. В приведенном выше выводе Дэн, Джефф, Джони имеет время отправления между ' 2017-02-24 12:00:00' И '2019-09-12 15:50: 00' .
Используя предложение UPDATE:
Мы будем обновлять идентификатор человека, используя предложение UPDATE, сравнивая две даты.
ОБНОВЛЕНИЕ путешествия SET имя = 'Lucifer' ГДЕ прибытие МЕЖДУ '2019-01-05 08:35:00' и 2020-01-08 14:00:00'; ВЫБЕРИТЕ * ИЗ путешествия;
В приведенном выше коде мы обновляем имя человека до Люцифер , время прибытия которого между ‘2019-01-05 08:35:00’ и ‘2020-01-08 14:00:00’ .
Вывод приведенного выше кода приведен ниже.
Сравните дату с помощью предложения BETWEENВ приведенном выше выводе имя человека изменено на Люцифер.
Также ознакомьтесь с некоторыми другими руководствами по PostgreSQL.
- PostgreSQL CREATE INDEX
- Postgresql, если еще
- Сумма Postgresql
- Диапазон дат Postgres
- Postgresql import SQL file
- Postgresql generate_series
- Postgresql date to string
- PostgreSQL Update
- Postgresql cast int
- PostgreSQL Subquery with Examples
охватила следующие темы.
- Как мы можем сравнивать даты в Postgresql?
- Сравнить дату с помощью пункта WHERE
- Сравнить дату с помощью пункта BETWEEN
Bijay Kumar Sahoo
Проработав более 15 лет в области программного обеспечения, особенно в технологиях Microsoft, я решил поделиться своими экспертными знаниями по SQL Server. Ознакомьтесь со всеми руководствами по SQL Server и связанным с ним базам данных, которыми я поделился здесь. Большинство читателей из таких стран, как Соединенные Штаты Америки, Великобритания, Новая Зеландия, Австралия, Канада и т. д. Я также являюсь Microsoft MVP. Узнайте больше здесь.
Сравнение дат в полях даты и времени в PostgreSQL
- Базовые операторы сравнения дат в PostgreSQL
- Использование операторов
<или>для сравнения дат в полях даты и времени в PostgreSQL - Модификации пользовательских запросов при использовании операторов сравнения для сравнения дат в полях даты и времени в PostgreSQL34 Тип RANGE для сравнения дат в полях даты и времени в PostgreSQL
- Используйте функции ФОРМАТИРОВАНИЯ ТИПА ДАННЫХ для сравнения дат в полях даты и времени в PostgreSQL
- Используйте оператор
BETWEENдля подстановки диапазона для сравнения дат в полях даты и времени в PostgreSQL
Даты в PostgreSQL могут быть реализованы с использованием отметки времени, даты или времени. Отметка времени представляет собой конкатенацию даты и времени, а дата представлена в формате; ГГГГ-ММ-ДД .
В нашей последней статье мы читали о том, как мы можем манипулировать отметкой времени и добавлять и вычитать из нее дни, часы, месяцы и годы в PostgreSQL. Сегодня мы рассмотрим операторы сравнения для типов DATE и посмотрим, как мы можем использовать их с пользой для себя.
Базовые операторы сравнения дат в PostgreSQL
PostgreSQL имеет определенный набор входных данных для своего формата DATETIME или отметки времени. Их можно просмотреть в приведенной ниже таблице:
Принимая во внимание, что TIME может иметь ввод во всех следующих синтаксисах:
А для метки времени вы можете использовать следующий синтаксис:
TIMESTAMP '2019-01- 01'
Помните, что дату можно сравнивать со всеми другими типами DATE , но только с похожими TYPES. Для сравнения могут быть реализованы разные способы.
Например, вы даже можете использовать функцию OVERLAP() , определенную в документации PostgreSQL, для проверки перекрывающихся дат и возврата ИСТИНА или ЛОЖЬ.
Теперь давайте продолжим и разберемся в различных операторах, которые мы можем использовать для сравнения двух дат.
Используйте операторы
< или > для сравнения дат в полях даты и времени в PostgreSQLПрямой запрос для сравнения может быть следующим:
Приведенное выше вернет значение TRUE.
ВЫБЕРИТЕ '2021-01-01' > '2022-01-01'
Вы также можете использовать другие операторы сравнения, такие как; <= , >= и = .
Если вы используете <> или != , что означает НЕ РАВНО, вышеуказанное вернет ИСТИНА, поскольку обе даты не похожи.
В документации PostgreSQL указано, что операторы сравнения доступны для всех типов данных. И вы не можете сравнивать более двух дат, так как результат первого сравнения вернет значение BOOL.
И значение BOOL нельзя сравнивать с типом DATETIME или любыми другими типами, представляющими DATE и TIME.
Приведенные выше операторы также учитывают аспект ВРЕМЕНИ. Если вы сделаете следующее:
выберите «2021-01-01 08:08:08» < «2021-01-01 10:01:01»
Он снова вернет ИСТИНА, что правильно, так как ВРЕМЯ первой ДАТЫ меньше второй.
Вы также можете использовать IS DISTINCT и IS NOT DISTINCT следующие операторы:
выражение ОТЛИЧНО ОТ выражения выражение НЕ ОТЛИЧНО ОТ выражения
Эквивалент оператора NOT EQUAL или EQUAL , но является альтернативой. Однако это вернет FALSE, если есть даты NULL, и TRUE, если только одна из них будет NULL.
Пользовательские модификации запроса при использовании операторов сравнения для сравнения дат в полях даты и времени в PostgreSQL
Предположим, у нас есть метка времени 2021-01-01 08:08:08 , и мы хотим сравнить это с 2021-01-01 .
С помощью следующего запроса:
выберите «2021-01-01 08:08:08» <= «2021-01-01»
Это должно вернуть ИСТИНА, но случается, что возвращается ЛОЖЬ.
Почему? Потому что при написании самого 2021-01-01 имеется в виду полночь 31 декабря 2021 года , что означает что-то вроде этого: 2020-31-31 23:59:59 .
Временная метка 2021-01-01 08:08:08 равна или меньше, потому что наша временная метка равна 9часов вперед от ДАТЫ, которую мы сравниваем.
Чтобы удалить это исключение, мы должны сообщить нашему серверу PostgreSQL, чтобы он не помещал TIME в нашу строку DATE автоматически. Мы можем использовать CAST для типа DATE , чтобы решить эту проблему.
Почему? Поскольку PostgreSQL перечисляет DATE следующим образом:
дата 4 байта дата (без времени суток)
Это означает, что он не будет включать ВРЕМЯ. Итак, теперь вы можете продолжить и использовать следующий запрос, который будет работать отлично.
выберите '2021-01-01 08:08:08' <= '2021-01-01'::дата
или следующее:
выберите '2021-01-01 08:08:08'::date <= '2021-01-01'
Используйте тип RANGE для сравнения дат в полях даты и времени в PostgreSQL
Так что же такое RANGES в PostgreSQL? ДИАПАЗОН, как вы могли догадаться по этому слову, представляет собой диапазон значений любого присутствующего типа данных.
ДИАПАЗОНЫ также включают следующие конфигурации:
tsrange — Диапазон меток времени без часового пояса tszrange - диапазон меток времени с часовым поясом daterange - Диапазон дат
Предположим, вы выполняете следующий запрос;
выберите '[2021-01-01,2021-01-01]'::tsrange
Это вернет что-то вроде этого:
Давайте сначала разберемся, как это работает, а затем изменим его для наших сравнений DATE.
Скобки внутри гаммы известны как границы EXCLUSIVE и INCLUSIVE . ЭКСКЛЮЗИВ граница означает такую скобку; (или) и ВКЛЮЧИТЕЛЬНО обозначают такие кронштейны; [или] .
Если вы пишете с использованием скобки EXCLUSIVE , это исключает следующее значение из ДИАПАЗОНА. Итак, если у нас есть что-то вроде (3,5) , он вернет диапазон как [4] .
Но если у нас есть; [3,5] , теперь он вернет [3,4] , а если (3,5] , он вернет [4,5] .
Итак, если мы хотим увидеть диапазон между двумя датами, мы можем использовать приведенный выше запрос. Но как он работает со сравнением дат?
Предположим, мы хотим проверить, меньше ли 2020-12-31 2021-01-01 . Итак, мы можем написать что-то вроде этого:
select '[2020-12-31,2021-01-01]'::tsrange
Он сообщит нам, были ли какие-либо даты в диапазоне обоих и упорядочены они или нет. Это означает, что 2021-12-30 был меньше, чем 2021-01-01 , или на более позднюю дату в ДИАПАЗОНЕ.
И если мы изменим это и запустим запрос следующим образом:
выберите '[2021-01-01,2020-12-31]'::tsrange
Вы заметите ошибку:
Вывод:
ОШИБКА: нижняя граница диапазона должна быть меньше или равна верхней границе диапазона LINE 1: выберите '[2021-01-01,2020-12-31]'::tsrange
Это говорит нам о том, что первая ДАТА не меньше второй. И поэтому мы можем использовать это для сравнения. Мы надеемся, что нам не нужно рассказывать вам о TSRANGE , потому что он был упомянут выше и другие типы.
Ошибка будет воспроизводиться снова, если вы попытаетесь запустить следующее:
выберите '[2021-01-01 09:09:10,2021-01-01 09:09:09]'::tsrange
Вместо TSRANGE можно использовать даже DATERANGE CAST.
Используйте функции ФОРМАТИРОВАНИЯ ТИПА ДАННЫХ для сравнения дат в полях даты и времени в PostgreSQL '2018-03-26','ГГГГ-ММ-ДД'::текст,'ГГГГ-ММ-ДД'::текст) = to_timestamp('2018-03-26', 'ГГГГ-ММ-ДД')
Что здесь происходит? Мы сравниваем тип DATE с меткой времени.
Это возможно, поскольку DATE можно сравнивать со всеми другими типами DATES. Таким образом, функция TO_DATE возвращает тип DATE , потому что она использует параметры как (текст, текст) .
Первый вызов TO_DATE преобразует несколько TEXTS в тип DATE , который затем снова преобразуется в TEXT для внешней функции TO_DATE .
PostgreSQL имеет тенденцию возвращать ошибку для второго параметра, так как он каким-то образом путает STRING и называет его UNKNOWN, а не TEXT. Поэтому мы также добавили к нему EXPLICIT TYPECAST.
Остальное довольно легко понять и хорошо послужит нашей цели.
Используйте оператор
BETWEEN для замены диапазона для сравнения дат в полях даты и времени в PostgreSQL -01' или ниже:
выберите «2021-01-01», а не между «2020-01-01» и «2022-01-01»
Оператор МЕЖДУ возвращает ИСТИНА, если он находится между ними, а оператор НЕ МЕЖДУ возвращает ЛОЖЬ, если он не находится в середине указанных диапазонов.
Итак, сегодня мы узнали о различных способах реализации использования операторов для сравнения различных типов DATE . Мы надеемся, что вы изучите их самостоятельно, хотя мы и постарались максимально полно охватить все решения.
Но технологии продолжают расти и расширяться, и рано или поздно на смену вышеперечисленным придут более новые и лучшие функции.
Функции даты PostgreSQL и 7 способов их использования в бизнес-анализе
Временные метки имеют решающее значение для бизнес-анализа по очень простой причине: они сообщают вам, когда что-то происходит. Представьте себе, что вы пытаетесь выяснить тенденции в ваших данных, таких как ежемесячный веб-трафик, квартальные доходы или ежедневный объем заказов , не зная, когда произошли события. Это был бы кошмар.
PostgreSQL предлагает различные функции работы с датами для управления временными метками. Чтобы отделить полезное от неясного, мы делимся практическими рекомендациями по наиболее часто используемым функциям даты Postgres и бизнес-сценариям, где они пригодятся.
Наиболее часто используемые функции даты Postgres и бизнес-сценарии, где они пригодятся:
Округление временных меток с помощью функции DATE_TRUNC
Поиск событий относительно текущего времени с помощью функций NOW() и CURRENT_DATE
Выделение часов и дней недели с помощью функции EXTRACT
Расчет прошедшего времени с помощью функции AGE
Мы сделали данные для каждого примера доступными в режиме Public Warehouse. Попробуйте каждую функцию даты в режиме, работая над этими примерами. Зарегистрируйте учетную запись в Mode Studio и откройте новый отчет, чтобы начать.
Округление меток времени с помощью функции DATE_TRUNC
DATE_TRUNC округляет значение метки времени до указанного интервала, что позволяет подсчитывать события. You can round off a timestamp to the following units of time:
microsecond
millisecond
second
minute
hour
day
week
месяц
квартал
год
Десятилетие
Century
Millenium
DATE_TRUNC Синтаксис выглядит так: DATE_TRUNC ('Interval', TIMESTAMP) 201010101010101010101010101010101010101010101010101
Например, SELECT DATE_TRUNC('day','2015-04-12 14:44:18') вернет результат 2015-04-12 00:00:00 .
Чтобы получить более подробное объяснение DATE_TRUNC (и распечатанный справочник, который вы можете держать на своем столе!), ознакомьтесь с этой публикацией.
Пример: Как изменился веб-трафик с течением времени?
Попробуйте DATE_TRUNC для себя, запросив таблицу modeanalytics.web_events, которая содержит образцы записей о посещениях веб-сайтов, включая столбец произошел_в . Вы можете изолировать месяц посещения с помощью DATE_TRUNC .
ВЫБЕРИТЕ DATE_TRUNC('месяц',происходит_в) КАК месяц
ИЗ demo.web_events
ГДЕ произошло_в МЕЖДУ '2015-01-01' И '2015-12-3123:59:59' Чтобы получить количество посещений веб-сайтов каждый месяц по каналу, добавьте канал столбец и COUNT в оператор SELECT , затем сгруппируйте по месяц и канал . (Поскольку месяц и канал являются первыми двумя значениями в операторе SELECT , вы можете GROUP BY 1,2 ), например:
SELECT DATE_TRUNC('month',occurred_at) AS month,
канал,
COUNT(id) AS посещений
ИЗ demo. web_events
ГДЕ произошло_в МЕЖДУ '2015-01-01' И'2015-12-31 23:59:59'
ГРУППА 1,2 Наконец, используйте ORDER BY 1,2 , чтобы упорядочить результаты в хронологическом (по месяцам) и алфавитном (по каналам) порядке.
SELECT DATE_TRUNC('month',occurred_at) AS месяц,
канал,
COUNT(id) AS посещений
ИЗ demo.web_events
ГДЕ произошло_в МЕЖДУ '2015-01-01' И'2015-12-31 23:59:59'
ГРУППА 1,2
ORDERBY1,2 В режиме можно построить линейную диаграмму для визуализации результатов запроса.
Поиск событий относительно текущего времени с помощью функций NOW() и CURRENT_DATE
Функция даты NOW() возвращает текущую отметку времени в формате UTC (если часовой пояс не указан). Вы можете вычесть интервалы из NOW() , чтобы получить события, произошедшие за последний час, последний день, последнюю неделю и т. д. результат 2016-10-11 09:00:00 .
Функция CURRENT_DATE возвращает только текущую дату, а не всю временную метку. Бег SELECT CURRENT_DATE в 9:00 UTC 11 октября 2016 г. будет возвращено 2016-10-11 .
Пример: Какие заказы были размещены за последние 7 лет?
Таблица demo.orders содержит примеры записей обо всех заказах, включая столбец метка времени в формате UTC.
Чтобы найти заказы, размещенные за последние 7 лет, используйте предложение WHERE , чтобы вернуть только те заказы, которые были размещены после или точно ( >= ) текущей метки времени ( СЕЙЧАС() ) минус интервал в 7 лет.
ВЫБЕРИТЕ * ОТ демо.заказов WHERE occurred_at >= NOW() - interval '7 year'
In addition to hour , you can use any of the following intervals:
microseconds
milliseconds
second
минута
час
день
неделя
месяц
год
десятилетие
век
тысячелетие
интервал '4 часа 3 минуты'
Пример: Какие заказы были размещены в этот день 7 лет назад?
Вы можете использовать ту же таблицу для поиска заказов, размещенных в этот день семь лет назад, путем объединения DATE_TRUNC и CURRENT_DATE функционирует.
Начните с использования функции DATE_TRUNC для округления значений prevent_at по дням (так как мы хотим знать, произошло ли что-то в этот день ). Затем используйте предложение WHERE , чтобы вернуть только те значения, в которых происшедшее_в день равно текущей дате (с помощью функции CURRENT_DATE ) минус интервал в 7 лет.
ВЫБЕРИТЕ *
ОТ демо.заказов
ГДЕ DATE_TRUNC('day',occurred_at) = CURRENT_DATE - интервал '7 лет' Изолирование часов дня и дня недели с помощью EXTRACT
Функция даты EXTRACT позволяет изолировать подполя, такие как год или час, от меток времени. По сути, это позволяет вам извлекать части даты из выражения даты и времени.
Вот синтаксис: EXTRACT(подполе ИЗ метки времени) . Выполнение EXTRACT(month FROM '2015-02-12') вернет результат 2 .
Имейте в виду, что хотя в приведенном ниже примере основное внимание уделяется подполю час (час дня), в вашем распоряжении множество других подполей в диапазоне от миллениум до микросекунд . Вы можете ознакомиться с полным списком доступных подполей здесь.
Пример: Сколько заказов размещается в каждый час дня?
Компания, управляющая центром выполнения заказов, может захотеть нанять больше сотрудников, когда поступает основная часть заказов. Чтобы выяснить, когда заказы размещаются в течение дня, вы можете использовать функцию EXTRACT и функцию 902:00 час подполе для выделения часа дня (от 0 до 23), в котором был выполнен заказ.
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ (час с момента возникновения_в) КАК час ОТ демо.заказов
Используйте функцию COUNT для подсчета заказов, а затем GROUP BY час. (Поскольку час является первым значением в вашем операторе SELECT , вы можете GROUP BY 1 ).
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ (час с момента возникновения_в) КАК час,
COUNT(*) КАК заказы
ОТ демо.заказов
ГРУППА 1 Наконец, чтобы упорядочить результаты последовательно, используйте ORDER BY 1 .
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ (час с момента возникновения_в) КАК час,
COUNT(*) КАК заказы
ОТ демо.заказов
ГРУППА 1
ORDERBY1 И вот результаты! Похоже, было бы полезно иметь несколько дополнительных рабочих на часах рано утром и в обеденное время.
Пример: Каков средний объем заказов в будние дни?
Чтобы определить средний объем заказов, выполненных по дням недели, используйте EXTRACT и подполе dow (день недели), чтобы выделить день недели (от 0 до 6, где 0 – воскресенье), в который был оформлен заказ.
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ (доу из произошло_в) КАК доу FROM demo.orders
Затем округлите временные метки заказов по дням с помощью DATE_TRUNC . Взяв COUNT ордеров, сгруппированных по dow и day , вы получите количество ордеров, размещенных каждый день, вместе с соответствующим днем недели.
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ(доу из произошло_в) КАК доу,
DATE_TRUNC('day',occurred_at) КАК день,
COUNT(id) AS заказов
ОТ демо. заказов
GROUPBY 1,2 Чтобы найти средний объем заказов в рабочие дни, используйте предыдущий запрос в качестве подзапроса (с псевдонимом a ). Возьмите среднее количество заказов (с помощью функции AVG() ), а затем используйте предложение WHERE , чтобы отфильтровать субботы и воскресенья.
ВЫБЕРИТЕ СРЕДНЕЕ (заказы) КАК avg_orders_weekday
ИЗ (
ВЫБЕРИТЕ ИЗВЛЕЧЕНИЕ (доу из произошло_в) КАК доу,
DATE_TRUNC('day',occurred_at) КАК день,
COUNT(id) AS заказов
ОТ демо.заказов
ГРУППА1,2) а
ГДЕ ДОУ НОТИН (0,6) Диаграммы с большими числами отлично подходят для отображения агрегированных показателей. Чтобы следить за объемом заказов, соберите такие показатели на одной панели.
Расчет времени, прошедшего с помощью AGE
Функция даты AGE вычисляет, как давно произошло событие. Он возвращает значение, представляющее количество лет, месяцев и дней, когда произошло событие, или разницу между двумя заданными аргументами.
Синтаксис довольно прост: примените AGE() к одной метке времени, и ваш запрос вернет количество времени, прошедшее с момента возникновения этого события. Бег SELECT AGE( '2010-01-01' ) 1 января 2011 года вернет результат 1 лет 0 месяцев 0 дней .
AGE() также может определить, сколько времени прошло между двумя событиями. Вместо того, чтобы помещать в круглые скобки одну временную метку, вставьте обе временные метки (начиная с самой последней временной метки) и разделите их запятой. Выполнение SELECT AGE('2012-12-01','2010-01-01') вернет 2 года 11 месяцев 0 дней .
Обратите внимание, что это приложение ВОЗРАСТ функция эквивалентна вычитанию временных меток: SELECT '2012-12-01' - '2010-01-01' .
Пример: Сколько лет учетной записи клиента?
Предположим, что ваш отдел продаж хочет персонализировать приветствия в зависимости от того, как долго клиент пользуется вашим продуктом. Узнать, сколько времени прошло с момента создания учетной записи, можно с помощью функции AGE .
Таблица modeanalytics.customer_accounts содержит записи образцов учетных записей клиентов. Выберите столбец имен учетных записей ( name ) и примените функцию AGE() к столбцу меток времени, показывающих время создания каждой учетной записи ( created ).
ВЫБЕРИТЕ имя,
ВОЗРАСТ (создано) AS account_age
FROM modeanalytics.customer_accounts Пример. Сколько времени в среднем требуется пользователям для заполнения своего профиля каждый месяц?
Таблица modeanalytics.profile создания событий содержит образцы данных о пользователях, создавших профиль, включая метки времени начала и окончания.
Чтобы найти среднее время для заполнения профиля каждый месяц, начните с определения времени, которое потребовалось каждому пользователю для заполнения профиля, а также месяца, в котором был начат процесс создания профиля. Во-первых, округлить отметку времени start_at по месяцам, используя функцию DATE_TRUNC . Затем найдите время, прошедшее с start_at до end_at для каждого профиля с помощью функции AGE .
ВЫБЕРИТЕ DATE_TRUNC('месяц',начало_в) КАК месяц,
ВОЗРАСТ(завершено_в,начало_в) время_до_завершения
ОТ modeanalytics.profile_creation_events Найдите среднее значение за каждый месяц, применив функцию AVG к значению прошедшего времени (ваш оператор AGE ) и сгруппировав данные по месяцам.
ВЫБЕРИТЕ DATE_TRUNC('месяц',начало_в) КАК месяц,
AVG(ВОЗРАСТ(завершено_в,начало_в)) AS avg_time_to_complete
ОТ modeanalytics.profile_creation_events
ГРУППА 1
ORDERBY 1 Чтобы вернуть значения в согласованных единицах для диаграммы, примените функцию EXTRACT и подполе epoch к своим значениям, чтобы вернуть результаты в виде количества секунд.
ВЫБЕРИТЕ DATE_TRUNC('месяц',начало_в) КАК месяц,
EXTRACT(EPOCHFROM AVG(ВОЗРАСТ(завершено_в,начало_в))) AS avg_seconds
ОТ modeanalytics.profile_creation_events
ГРУППА 1
ORDERBY 1 Заключение
Как видите, функции даты ProstgreSQL одновременно мощные и полезные. Они дают вам возможность манипулировать метками времени и отвечать на вопрос, когда что-то происходит. Благодаря их функциональным возможностям предприятия могут лучше анализировать тенденции в своих данных и получать полезную информацию.
Хотите еще потренироваться? Изучайте SQL и Python, используя реальные данные, с помощью нашего бесплатного руководства по SQL и Python.
Руководство для групп данных по маркетинговым показателям
Используйте это руководство, чтобы настроить свою маркетинговую команду в Mode. Лучше понять показатели, которые они ищут, и вдохновиться примерами диаграмм, которые они могут использовать для ускорения своих целей.
3 способа работы со временем в Postgres (и ActiveRecord)
Допустим, вы разрабатываете приложение для управления проектами с пользователями и проектами, и менеджер по продукту спрашивает вас:
- Сколько времени требуется данному пользователю для создания своего первого проекта?
- Дайте мне список пользователей, которым потребовалось больше месяца, чтобы создать свой первый проект.
- Сколько времени в среднем требуется пользователю для создания своего первого проекта?
- Каково среднее время между созданием проекта на одного пользователя?
Вы можете подойти к решению вышеуказанных проблем исключительно на Ruby и ActiveRecord . Однако данные, с которыми мы хотим работать, находятся в базе данных. База данных умная, мощная и быстрая; с помощью SQL мы можем заставить базу данных извлекать произвольные строки и выполнять сложные вычисления. Поэтому само собой разумеющимся является то, что если база данных «выполнит работу» в максимально возможной степени перед отправкой информации в Ruby-land, это принесет нам прирост производительности.
В этой статье мы собираемся изучить, как мы можем решить вышеупомянутые проблемы в Rails, используя SQL и немного АктивРекорд . SQL, использованный в этой статье, применим только к Postgres (версия 9.4.1), хотя идеи в целом можно перенести на другие системы управления базами данных.
Сначала краткое введение в
SELECT Оператор SELECT извлекает ноль или более строк из одной или нескольких таблиц базы данных или представлений базы данных.
Что-то вроде:
ВЫБРАТЬ * ОТ пользователей
извлечет все доступные строки из пользователей таблица.
Вы также можете передать в SELECT функции «агрегатора», такие как MIN(), COUNT(), MEAN() и т. д. Когда эти функции передаются в SELECT, возвращаемое значение представляет собой один фрагмент данных (целое число, строка, отметка времени и т. д.).
Так например это:
ВЫБЕРИТЕ MIN(created_at) ОТ пользователей
вернет самый ранний created_at (который является отметкой времени) в таблице пользователей.
SELECT Функции также могут быть вложены друг в друга, как мы скоро увидим.
В ActiveRecord для достижения того же результата можно использовать метод select . Кроме того, вызовы таких методов, как .all , .where , .find и т. д., преобразуются в функции SELECT .
Я подготовил удобную 3-страничную шпаргалку в формате PDF, содержащую основные моменты этой статьи. Если вы предпочитаете скачать и распечатать его, нажмите здесь, чтобы получить его!
Для целей этой статьи предположим, что наши модели выглядят так:
класс Пользователь < ActiveRecord::Base has_many: проекты конец класс Project < ActiveRecord::Base принадлежит_кому: пользователь конец
Арифметические операторы (
-, +, * и /) Первая проблема, которую мы должны решить, — это выяснить, сколько времени требуется пользователю для создания своего первого проекта. Это время равняется разнице между самым ранним проектом пользователя Project#created_at и User#created_at .
В Postgres мы можем использовать оператор арифметической разности - для вычисления разницы между двумя метками времени или датами. Тип данных имеет значение — если мы вычисляем разницу между двумя временными метками, возвращаемое значение представляет собой «интервал», а если мы вычисляем разницу между двумя датами, возвращаемое значение представляет собой целое число, представляющее количество дней между двумя датами.
Чтобы упростить отображение данных, мы планируем использовать метод select с чем-то вроде:
пользователей = User.select('users.email, (projects.created_at - users.created_at) as time_to_first_project')
Это вернет ActiveRecord::Relation , который мы затем можем перебрать и вызвать #time_to_first_project on:
<% users.each делать |пользователь| %> <%= user.email %> <%= user.time_to_first_project %> <% конец%>
Однако указанный выше select нам не подойдет по двум причинам. Во-первых, ActiveRecord будет жаловаться, что нет 9Пункт 0200 FROM для таблицы проектов . Мы можем решить эту проблему вызовом joins :
User.joins(:projects).select('users.email, (projects.created_at - users.created_at)....')
Во-вторых, приведенный выше оператор сравнивает время создания всех проектов заданных пользователей с User#created_at . Нас интересует только самый ранний проект, поэтому мы можем сузить его до , где :
User.joins(:проекты)
.where('projects.created_at = (ВЫБЕРИТЕ МИН(projects.created_at) ИЗ проектов, ГДЕ проекты.user_id = users.id)')
.select("users.email, (projects.created_at - users.created_at) as time_to_first_project")
Поскольку самый ранний проект пользователя created_at зависит от пользователя, мы получаем эту метку времени, передавая функцию агрегатора MIN() во вложенную функцию SELECT (в данном случае вложенную в первый select ). Эта вложенная функция SELECT также известна как «подзапрос».
Будет возвращена коллекция из объектов ActiveRecord с атрибутами электронная почта и time_to_first_project . Поскольку мы вычитаем две метки времени, time_to_first_project будет «интервалом».
Интервалы в Postgres являются самым большим типом данных, доступным для хранения времени, и, следовательно, содержат много деталей. Если вы проверите time_to_first_project для нескольких записей, вы заметите, что они выглядят примерно так: "00:18:43.082321" или "9 days 12:48:48.220725" , что означает, что вам, возможно, придется сделать немного синтаксического анализа и/или оформления перед тем, как предоставить информацию пользователю.
Postgres также предоставляет функцию AGE(..) , в которую вы можете передать 2 метки времени и получить интервал. Если вы передадите одну метку времени в AGE() , вы получите разницу между текущей датой (в полночь) и переданной меткой времени.
Если у вас есть две метки времени и вы хотите найти количество дней между ними, вы можете использовать функцию CAST , чтобы воспользоваться тем фактом, что при вычитании двух дат вы получаете количество дней между ними. Мы вернемся к CAST немного.
Сравнение и фильтрация
Далее нам нужен список пользователей, которым потребовалось больше 1 месяца для создания проекта. В идеале мы хотели бы иметь возможность получить список пользователей, которым потребовалось больше времени, чем любой произвольный период времени, чтобы создать проект. Эта операция сводится к сравнению «больше чем» между time_to_first_project и периодом времени, через который мы проходим (например, 1 месяц). Postgres поддерживает сравнение дат и времени друг с другом. В этом случае с time_to_first_project — это интервал, мы должны убедиться, что мы сравниваем его с интервалом в нашем вызове , где . Это означает, что если мы сделаем:
пользователей.где("(projects.created_at - users.created_at) > 30")
Postgres будет жаловаться, что оператор для сравнения интервала и целого числа не существует. Чтобы обойти это, мы должны убедиться, что правая часть сравнения является интервалом. Мы делаем это с помощью ключевого слова типа INTERVAL . Мы бы использовали его так:
User.joins(:проекты)
.where('projects.created_at = (ВЫБЕРИТЕ МИН(projects.created_at) ИЗ проектов, ГДЕ проекты.user_id = users.id)')
.where("(projects.created_at - users.created_at) > ИНТЕРВАЛ '1 месяц'")
.Выбрать(...)
Как видите, мы можем передать удобочитаемую строку, такую как «1 месяц», в INTERVAL , что приятно.
Агрегаты
Далее в списке мы хотим рассчитать среднее время, необходимое для создания проекта. Учитывая то, что известно на данный момент, это не потребует особых объяснений. Наш запрос будет выглядеть так:
User.joins(:проекты)
.where('projects.created_at = (ВЫБЕРИТЕ МИН(projects.created_at) ИЗ проектов, ГДЕ проекты.user_id = users.id)')
.select("AVG(projects.created_at - users.created_at) как среднее_время_до_первого_проекта")
Мы используем функцию AVG() , и наш запрос вернет один объект User , для которого мы можем вызвать Average_time_to_first_project .
ActiveRecord также доступен средний , которую мы можем вызвать так:
Пользователь. присоединяется (...)
.куда(...)
.average('projects.created_at - users.created_at)
Возвращаемое значение этого запроса будет BigDecimal , и из-за этого мы можем потерять некоторую информацию. Например, если истинное среднее равно INTERVAL "1 day 23:00:01.2234" , значение BigDecimal будет 1 .
Наконец, что, если мы хотим рассчитать среднее время между созданием проекта для каждого пользователя?
Среднее время между проектами для пользователя — это среднее значение разницы между последовательными значениями Project#created_at . Так, например, если есть три проекта, среднее время между проектами:
"((project3#created_at - project2#created_at) + (project2#created_at - project1#created_at))/2"
Это равно (project3#created_at - project1#created_at) / 2 . Для проектов N среднее время между проектами составляет:
"(проектN#создан_в - проект1#создан_в) / (N - 1)"
В нашем примере «projectN» соответствует последнему проекту пользователя, поэтому дата его создания равна MAX(projects.created_at) . Точно так же более ранняя дата создания проекта пользователя соответствует MIN(projects.created_at) . Количество проектов рассчитывается как COUNT(проекты) .
Допустим, для нашего вывода мы хотим, чтобы среднее время между проектами отображалось в днях. Поскольку вычитание двух дат в Postgres возвращает целое число дней, мы можем получить среднее время между проектами в днях путем первого приведения MAX(projects.created_at) и MIN(projects.created_at) в даты, вычитая их и затем деля на COUNT(projects) - 1 . В Postgres мы можем создавать временные метки с помощью функции CAST . Например:
CAST(MIN(projects.
преобразует метку времени created_at в дату.
Наконец, мы хотим, чтобы это вычисление выполнялось один раз для каждого пользователя. Для этого мы должны использовать метод group , который соответствует GROUP BY пункт. Этот пункт нужен нам потому, что если бы его не было, то расчет будет производиться только один раз для всего набора проектов, а не для каждого пользователя.
Наш запрос будет выглядеть так:
User.joins(:проекты)
.группа('пользователи.электронная почта')
.having('COUNT(проектов) > 1')
.select("(CAST(MAX(projects.created_at) как дата) - CAST(MIN(projects.created_at) как дата))/(COUNT(проекты) - 1) как avg_time_between_projects, users.email как электронная почта")
Вы также заметите, что я включил вызов .having('COUNT(projects) > 1') . Это гарантирует, что учитываются только пользователи, у которых есть более одного проекта.
Куда мы должны поместить этот материал в нашей кодовой базе?
В базе
Может быть полезно, чтобы этот SQL находился в базе данных, а не на уровне приложения. Вы можете сделать это с помощью представлений. «Представление» — это сохраненный запрос, который мы можем запрашивать так же, как и таблицу. Что касается ActiveRecord, то нет никакой разницы между представлением и таблицей.
Идея состоит в том, что, создав представление с электронной почтой пользователя и интересующими нас полями, такими как среднее время между проектами и время, затраченное на создание первого проекта, код нашего приложения станет чище, потому что теперь мы можем сказать что-то вроде UserReport.where('average_time_between_projects > ?', 30 дней) вместо «все SQL».
Чтобы создать представление, сначала создайте миграцию следующим образом:
изменение определения
sql = <<-SQL
СОЗДАТЬ ПРОСМОТР user_reports КАК
SELECT (CAST(MAX(packages.created_at) как дата) - CAST(MIN(packages.created_at) как дата))/(COUNT(packages)-1) как time_between_projects, COUNT(packages) как количество, users.email как электронная почта ОТ \"пользователей\" ВНУТРЕННЕЕ СОЕДИНЕНИЕ \"пакетов\" НА \"пакеты\". \"user_id\" = \"пользователи\".\"id\" ГДЕ \"пользователи\".\"роль\" = 'client' GROUP BY users.email HAVING COUNT(packages) > 1
SQL
выполнить (sql)
конец
SQL, который я использовал, был создан путем вызова метода to_sql для запроса, который мы выполнили ранее. Запустите миграцию, а затем создайте класс модели UserReport , который наследуется от ActiveRecord::Base . Теперь вы можете делать такие вещи, как UserReport.average('time_between_projects') . Вы также можете заметить, что результаты возвращаются быстрее.
В этом подходе есть одна проблема: ваш файл схемы не будет отображать это представление. Поэтому, если вы хотите, чтобы ваш CI строился правильно, вам, возможно, придется изменить параметр схемы, чтобы вместо этого генерировать sql. Это довольно просто сделать с помощью Rails. Другое предостережение заключается в том, что это приводит к затратам на переключение на другую серверную часть базы данных, потому что SQL, который у нас теперь есть в нашей миграции, специфичен для Postgres.
Вот несколько хороших ресурсов по просмотрам:
- https://blog.pivotal.io/labs/labs/database-views-performance-rails
- http://blog.roberteshleman.com/2014/09/17/using-postgres-views-with-rails/
- Жемчужина Scenic для представлений, позволяющая обойти проблему схемы
В приложении
Если вы не хотите идти по пути представлений, вы можете организовать свои запросы с помощью объектов запросов и областей. Взгляните на это для краткого введения в объекты запроса.
Заключение
С информацией, изложенной в этой статье, мы теперь можем приступить к разработке ответа для нашего гипотетического менеджера по продукту, возложив на сервер базы данных основную тяжесть работы.
Я подготовил удобную 3-страничную шпаргалку в формате PDF, содержащую основные моменты этой статьи. Если вы предпочитаете скачать и распечатать его, нажмите здесь, чтобы получить его!
Управление датой и временем с помощью PostgreSQL и TypeORM
При работе с данными нам часто приходится обрабатывать дату и время. При этом нужно учитывать довольно много вещей. В этой статье мы подходим к различным вопросам как с точки зрения PostgreSQL, так и с точки зрения TypeORM.
Способы хранения и отображения даты и времени в PostgreSQL
По умолчанию Postgres представляет даты в соответствии со стандартом ISO 8601. Мы можем убедиться в этом, выполнив следующий запрос:
Переменная DateStyle состоит из двух компонентов:
- вывод даты/времени по умолчанию
- интерпретация ввода
Поскольку ISO является выводом даты и времени по умолчанию, формат отображения - ГГГГ-ММ-ДД. Чтобы увидеть это в действии, воспользуемся функцией NOW(), которая возвращает текущую дату и время.
Чтобы испытать интерпретацию ввода, давайте вставим новый пост со столбцом запланированной даты.
Выше, поскольку для ввода установлено значение MDY (месяц-день-год), 04 считается месяцем, а 05 — днем. Использование даты, не соответствующей этому формату, вызывает ошибку.
Использование ГГГГ-ММ-ДД выше также будет работать нормально, если для параметра DateStyle установлено значение MDY.
Хотя по умолчанию DateStyle установлен на ISO, MDY, есть несколько других возможностей. Если вы хотите поэкспериментировать с ними, ознакомьтесь с официальной документацией.
Столбцы, встроенные в Postgres для управления датой и временем
Существуют различные столбцы, которые мы могли бы использовать для описания даты и времени. В предыдущем абзаце этой статьи мы видели вывод запроса SELECT NOW()::DATE. Мы используем двойное двоеточие, чтобы привести возвращаемое значение функции NOW к дата тип.
Помимо столбца даты, есть несколько примечательных типов, о которых следует упомянуть. Одним из них является тип столбца time .
Выше мы видим, что время представлено в 24-часовом формате. У нас есть часы, минуты и секунды, которые включают дробное значение.
Важным столбцом, который мы также должны упомянуть, является тип данных timestamp . Он хранит и дату, и время.
Под капотом Postgres хранит метки времени в виде чисел, представляющих определенный момент времени. То, как они отображаются, основано на нашем DateStyle. Поскольку значение по умолчанию для DateStyle — ISO, MDY, Postgres отображает дату в формате ISO.
Часовые пояса
Работа с часовыми поясами может быть весьма проблематичной. Они зависят как от географии, так и от политики и даже могут меняться из-за перехода на летнее время. Есть много разных случаев, которые нужно рассмотреть, и это видео дает их отличное резюме.
Оба типа time и timestamp имеют версии, включающие метку времени. Хотя SQL позволяет использовать часовые пояса с типом time , использовать его может быть сложно. Без информации о дате мы не можем работать с летним временем. Документация PostgreSQL не рекомендует его использовать.
При использовании типа с отметкой времени в запросах выше в этой статье Postgres отобразил его как без часового пояса . В этом варианте PostgreSQL сохраняет локальную дату и время и обрабатывает их так, как если бы мы не указывали часовой пояс. Когда мы используем метку времени без часового пояса, PostgreSQL не выполняет преобразования, связанного с часовым поясом. Когда мы вводим 2021-03-15 15:00:00 в нашу базу данных, оно всегда будет оставаться неизменным, независимо от того, в каком часовом поясе мы его отобразим позже.
Всемирное координированное время ( UTC ) является основным стандартом времени, используемым во всем мире. Часовые пояса обычно определяются разницей часов со временем UTC. Примером является восточное стандартное время (EST), которое можно описать как UTC-5. Если в настоящее время время UTC будет 15:00, часы в Нью-Йорке покажут 10:00.
Временная метка с часовым поясом хранит данные внутри, как если бы дата была в формате UTC. Кроме того, он также сохраняет точку на временной шкале UTC. Благодаря объединению этих двух частей информации Postgres преобразует время в соответствии с нашим часовым поясом.
Мы можем увидеть текущую конфигурацию часового пояса, выполнив следующий запрос:
Поскольку наш часовой пояс настроен на UTC, сохранение метки времени, помеченной как Восточное стандартное время, добавляет 5 часов при отображении результата.
Использование столбцов даты с TypeORM
Сначала давайте рассмотрим типы столбцов даты и времени .
@Column({ type: 'time' }) timeOnly: string;
@Column({ type: 'date' }) dateOnly: string; |
Объект Date в JavaScript включает дату и время. Ни столбцы , время , ни столбцы , дата сами по себе не содержат полной информации, необходимой для создания объекта Date. Из-за этого TypeoORM сериализует их в строки, хотя это и вызывает путаницу.
TypeORM работает по-разному с отметкой времени и отметкой времени с часовым поясом столбцы.
@Column({ type: 'timestamp', nullable: true }) timestamp: Date;
@Column({ type: 'timestamptz', nullable: true }) timestampWithTimezone: Date; |
В отличие от столбцов time и date , timestamp data time содержит все необходимое для создания объекта Date.
К сожалению, похоже, что у TypeORM есть некоторые проблемы с обработкой метка времени столбец. Мы можем либо применить предложенные обходные пути, либо вместо этого использовать часовой пояс с отметкой времени .
Специальные столбцы дат
TypeORM имеет набор декораторов, которые позволяют нам получить доступ к различным датам, связанным с конкретным объектом.
1 2 3 4 5 6 7 8 | @createDateColumn () Создан. Дата; даида
@UpdateDateColumn() updatedDate: Date;
@DeleteDateColumn() deleteDate: Дата; |
Нам не нужно явно записывать значения в вышеуказанные столбцы. Это происходит под капотом автоматически.
Резюме.
В этой статье мы рассмотрели, какие типы данных в PostgreSQL могут описывать дату и время. Он также включал краткое обсуждение часовых поясов и того, как они влияют на то, как мы храним даты. Мы также рассмотрели, как управлять различными столбцами времени и даты с помощью TypeORM.
Функции ДАТА/ВРЕМЯ в SQL. Учебное пособие по использованию CAST, EXTRACT… | Джейсон Ли
Учебник по использованию CAST, EXTRACT и DATE_TRUNC
Фото Лукаса Блазека на Unsplash Работа с датами и временем является обычной практикой при работе с SQL. Используя даты, мы можем рассчитать изменения во времени, тенденции в данных, выполнить интервальную арифметику. Чтобы лучше понять последствия основной бизнес-проблемы.
«данные временного ряда» как последовательность точек данных, измеряющих одно и то же во времени, хранящихся во временном порядке.
Некоторые распространенные способы использования данных временного ряда иметь средний уровень владения SQL. Мы рассмотрим три функции и поработаем с синтаксисом PostgreSQL.
- CAST
- EXTRACT
- DATE_TRUNC
Каждая из этих функций может быть полезна при разбивке наборов данных с большим количеством данных. Мы увидим преимущества каждого из них, когда рассмотрим код с некоторыми примерами.
Функция CAST преобразует выбранный тип данных в другой. Довольно прямолинейно. Он изменяет один тип на ваш предпочтительный тип. Синтаксис ниже.
CAST(выражение AS тип данных )
Ниже приведен пример того, как его можно применить к дате и времени.
SELECT
NOW(),
CAST(NOW() AS TIMESTAMP),
CAST(NOW() AS DATE),
CAST(NOW() AS TIME),
CURRENT_DATE,
CURRENT_TIME
В этом запросе мы ожидаем иметь 6 выходов. Если вы не знакомы с NOW() , CURRENT_DATE , CURRENT_TIME это функции SQL, которые извлекают текущее время или дату. Ниже приведены все результаты запроса по порядку. (примечание — вы получите разные числа, так как функции вызывают точное время или дату)
- 2020–03–28 23:18:20.261879+00:00
- 2020–03–28 23:18:20.261879
- 2020 –03–28
- 23:18:20,261879
- 2020–03–28
- 23:18:20,261879+00:00
Глядя на первый результат из NOW() используется отдельно, мы получаем полное значение метки времени, включая часовой пояс. Теперь, когда мы переходим ко второму выводу, мы использовали CAST только для получения TIMESTAMP, который не включает часовой пояс из NOW() . Теперь мы можем увидеть, как работает приведение. Мы передаем значение, которое хотим преобразовать, а затем указываем нужный тип.
Затем мы используем CAST() на NOW() , но передаем DATE в качестве желаемого типа. Теперь мы получаем метку времени, разделенную только на формат год/месяц/день. Точно так же посмотрите на CAST() функция с NOW() и только TIME , и мы получаем только значение времени без даты.
Мы можем видеть, как функция CAST работает со временем, а последние два вывода с использованием CURRENT_DATE и CURRENT_TIME приведены для сравнения результатов.
Другие примеры — без временных меток
SQL также позволяет использовать функции CAST() с типами без временных меток.
SELECT
CAST(1.34 AS INT),
CAST(1 AS BOOLEAN),
CAST(2.65 AS DEC(3,0))
Результаты этого запроса:
- 1 → Поскольку целое число не t имеют десятичные дроби, оно будет округлено до ближайшего целого числа
- true → 1, поскольку логическое значение истинно, а 0 равно false
- 3 → используя
DEC(), мы также можем сделать обратное нашему первому целочисленному CAST.
Интервалы
В SQL вы также можете использовать ИНТЕРВАЛ , чтобы добавить больше времени к любой имеющейся у вас метке времени. Для приведенных ниже примеров вам не нужно использовать CAST() , но я решил сделать это только для того, чтобы иметь дату.
ВЫБЕРИТЕOutput
ПЕРЕДАЧА(СЕЙЧАС() КАК ДАТА) КАК СЕГОДНЯ_ДАТА,
ПЕРЕДАЧА(( ИНТЕРВАЛ '3 ДНЯ' + СЕЙЧАС()) КАК ДАТА) КАК three_days,
ПЕРЕДАЧА(( ИНТЕРВАЛ '3 НЕДЕЛИ' + СЕЙЧАС ()) AS DATE) AS three_weeks,
CAST(( INTERVAL '3 MONTHS' + NOW()) AS DATE) AS three_months,
CAST(( INTERVAL '3 YEARS' + NOW()) AS DATE) AS three_years
Мы можем видеть, что используя INTERVAL в дополнение к длине интервала в днях, неделях, месяцах или годах добавляет время к любой имеющейся у вас дате — в этом примере текущая дата получается из NOW() .
Далее мы можем посмотреть на извлечение определенного формата из метки времени. Цель состоит в том, чтобы извлечь часть из метки времени. Например, если нам нужен только месяц с даты 10.12.2018, мы получим декабрь (12).
Рассмотрим синтаксис EXTRACT
EXTRACT(part FROM date)
Мы указываем желаемый тип извлечения как часть , а затем источник, который нужно извлечь date . EXTRACT — это инструмент импорта для анализа данных временных рядов. Это помогает вам изолировать группы в ваших временных метках для агрегирования данных на основе точного времени. Например, если магазин проката автомобилей хочет найти самый загруженный прокат ЧАСОВ по ПОНЕДЕЛЬНИКАМ каждые МАЯ , вы можете сделать это с помощью EXTRACT . Вы можете детализировать детали и увидеть более ценную информацию.
Предположим, мы запускаем NOW() и наша отметка времени 2020–03–29 00:27:51. 677318+00:00 , мы можем использовать EXTRACT , чтобы получить следующее.
ВЫБЕРИТЕВыход
ИЗВЛЕЧЕНИЕ(МИНУТА ОТ СЕЙЧАС()) КАК МИНУТА,
ИЗВЛЕЧЕНИЕ(ЧАС ОТ СЕГОДНЯ()) КАК ЧАС,
ИЗВЛЕЧЕНИЕ(ДЕНЬ ОТ СЕГОДНЯ()) КАК ДЕНЬ,
ИЗВЛЕЧЕНИЕ(НЕДЕЛЯ ОТ СЕЙЧАС()) КАК НЕДЕЛЯ ,
ВЫДЕРЖКА(МЕСЯЦ С СЕГОДНЯ()) КАК МЕСЯЦ,
ВЫДЕРЖКА(ГОД С СЕГОДНЯ()) КАК ГОД,
ВЫДЕРЖКА(ДАЧА С СЕГОДНЯ()) КАК ДЕНЬ_НЕДЕЛИ,
ВЫДЕРЖКА(ДАТА ОТ СЕГОДНЯ()) КАК ДЕНЬ_ГОД,
ВЫДЕРЖКА(КВАРТАЛ С СЕЙЧАС()) КАК КВАРТАЛ,
ВЫДЕРЖКА(ЧАСОВОЙ ПОЯС ОТ СЕГОДНЯ()) КАК ЧАСОВОЙ ПОЯС
Мы видим, что можем вдаваться в мельчайшие детали в как мы хотим извлечь информацию из наших меток времени. Примечание — DOW — день недели с воскресенья (0) по субботу (6).
Мы можем использовать приведенный выше пример с арендованным автомобилем и посмотреть, как это будет работать.
ВЫБЕРИТЕ900 по
ВЫДЕРЖКА (ЧАС ОТ RENTAL_DATE) КАК ЧАС,
COUNT(*) as RENTALS
FROM RENTAL
WHERE
EXTRACT(DOW FROM RENTAL_DATE) = 1 AND
EXTRACT(MONTH FROM RENTAL_DATE) = 5
GROUP BY 1
ORDER BY RENTALS DESC
ПОНЕДЕЛЬНИКАМ каждые МАЯ . Во-первых, мы используем EXTRCT в SELECT , чтобы указать, что нам нужны только HOUR и общее количество COUNT . Затем мы передаем две функции EXTRACT для Условие WHERE для фильтрации только ПОНЕДЕЛЬНИКОВ и МАЯ . Глядя на таблицу ниже, 11:00 — самое популярное время аренды каждый понедельник в мае, всего 11 аренд. Выходные данные Усечение — сокращение или как бы отсечение
Целью усечения даты в SQL является получение интервала с абсолютной точностью. Значения точности представляют собой подмножество идентификаторов полей, которые можно использовать с EXTRACT . DATE_TRUNC вернет интервал или метку времени, а не число.
Синтаксис для DATE_TRUNC , time_column — это столбец базы данных, который содержит метку времени, которую вы хотите округлить, а ‘[интервал]’ диктует желаемый уровень точности.
DATE_TRUNC('[interval]', time_column) Предположим, что наш NOW() возвращает то же самое 2020–03–29 00:27:51.677318+00:00 , мы можем использовать date1part для получения date1part следующее.
ВЫБРАТЬOutput
CAST(DATE_TRUNC('DAY', NOW()) AS DATE) AS DAY,
CAST(DATE_TRUNC('WEEK', NOW()) AS DATE) AS WEEK,
CAST(DATE_TRUNC('MONTH', NOW()) AS DATE) AS MONTH,
CAST(DATE_TRUNC('YEAR', NOW()) AS DATE) AS YEAR
Думайте об использовании DATE_TRUNC как о получении интервала текущего положения, и каждый уровень интервала - это то, как обрезается дата. Примечание — в этом примере нам не нужно было использовать CAST . Я использовал его, чтобы убедиться, что формат чист для анализа.
Мы можем использовать DATE_TRUNC в предыдущем сценарии аренды автомобиля и попытаться определить, какой день в году, независимо от времени, более популярен для аренды.
SELECT. как использовать
CAST (DATE_TRUNC ('Day', Rental_Date) как дата) как rent_day,
Count (*) в качестве аренды
от аренды
Группа по
Rental_day
Порядок Rentals Desc
CAST , EXTRACT и DATE_TRUNC мы можем объединить некоторые из изученных нами методов в один практический пример. В этом примере мы добавим новую функцию времени с именем AGE , которая принимает 2 даты в качестве аргумента и выводит «AGE» или время в годах и месяцах между датами.
Давайте завершим это руководство, извлекая список клиентов, у которых была самая большая продолжительность аренды ( AGE ) из 2019–05–01 + 30 дней .
ВЫБЕРИТЕВывод
CUSTOMER_ID,
ВЫДЕРЖКА (ДОУ ОТ RENTAL_DATE) AS DAY_OF_WEEK,
Возраст (return_date, rent_date) в качестве аренды_ дней
от
Rental
, где
Rental_date
между брошен («2019-05-01 + INTERVAL '30 DAY'
ORDER BY 3 DESC
Надеюсь, вам удобно работать с отметками времени в SQL.