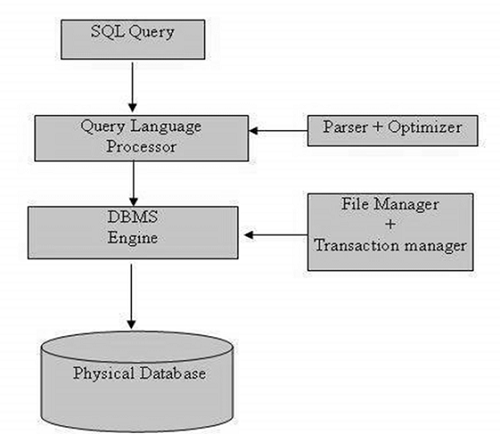
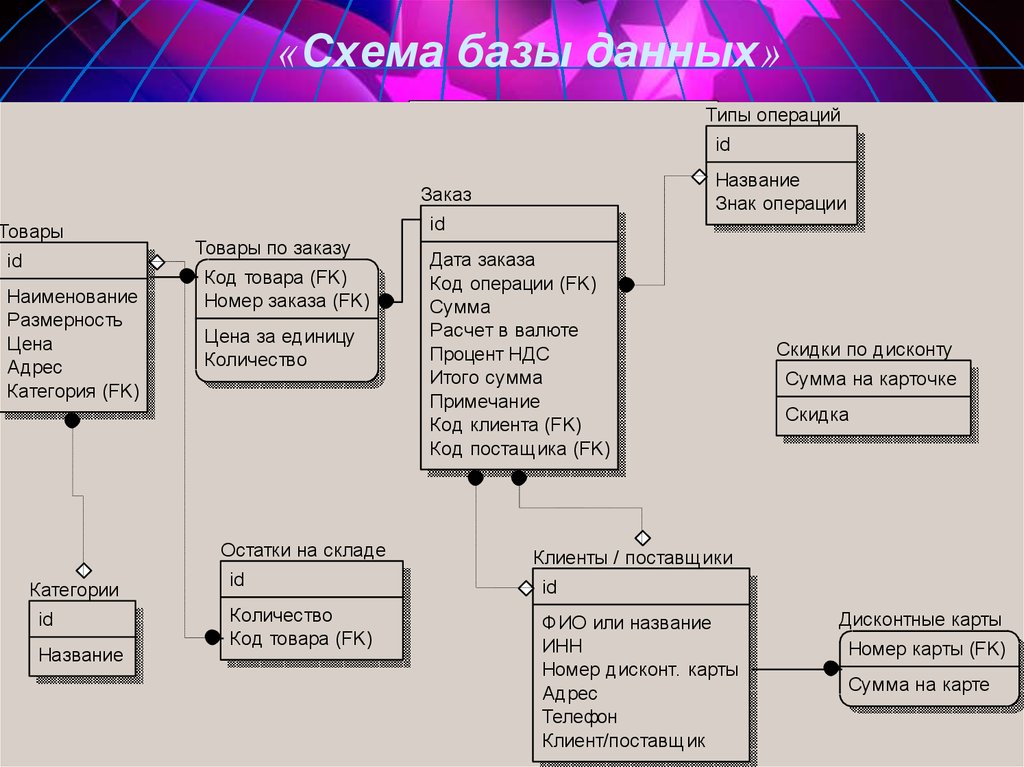
Настройка рекурсивных связей глубины с помощью sql:max-depth — SQL Server
- Статья
- Чтение занимает 7 мин
Применимо к:База данных SQL ServerAzure SQL
В реляционных базах данных участие таблицы в связи с самой собой называется рекурсивной связью. Например, таблица, в которой содержатся записи о сотрудниках и возможны связи «начальник-подчиненный», участвует в связи сама с собой. В этом случае таблица сотрудников выполняет роль начальника на одной стороне связи и та же таблица выполняет роль подчиненного на другой стороне.
Схемы сопоставления могут включать рекурсивные связи, в которых элемент и его предок относятся к одному типу.
Пример A
Рассмотрим следующую таблицу.
Emp (EmployeeID, FirstName, LastName, ReportsTo)
В этой таблице столбец ReportsTo содержит идентификатор служащего для менеджера.
Предположим, что нужно сформировать XML-иерархию служащих, на вершине которой находится менеджер, а служащие, подчиненные менеджеру, отображаются в соответствующей иерархии, как показано в следующем образце XML-фрагмента. В этом фрагменте показано рекурсивное дерево для сотрудника 1.
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
...
...
</root>
В этом фрагменте служащий 5 подчинен служащему 4, служащий 4 подчинен служащему 3, а служащие 3 и 2 подчинены служащему 1.
Чтобы получить этот результат, можно использовать следующую схему XSD и указать запрос XPath к ней. Схема описывает <элемент Emp> типа EmployeeType, состоящий из дочернего <элемента Emp> того же типа EmployeeType. Это рекурсивная связь (элемент и его предок относятся к одному типу). Кроме того, схема использует <sql:relationship> для описания отношений «родители-потомки» между руководителем и контролером. Обратите внимание, что в этом <sql:relationship> Emp является как родительской, так и дочерней таблицей.
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Поскольку связь рекурсивная, необходимо каким-то образом указать глубину рекурсии в схеме.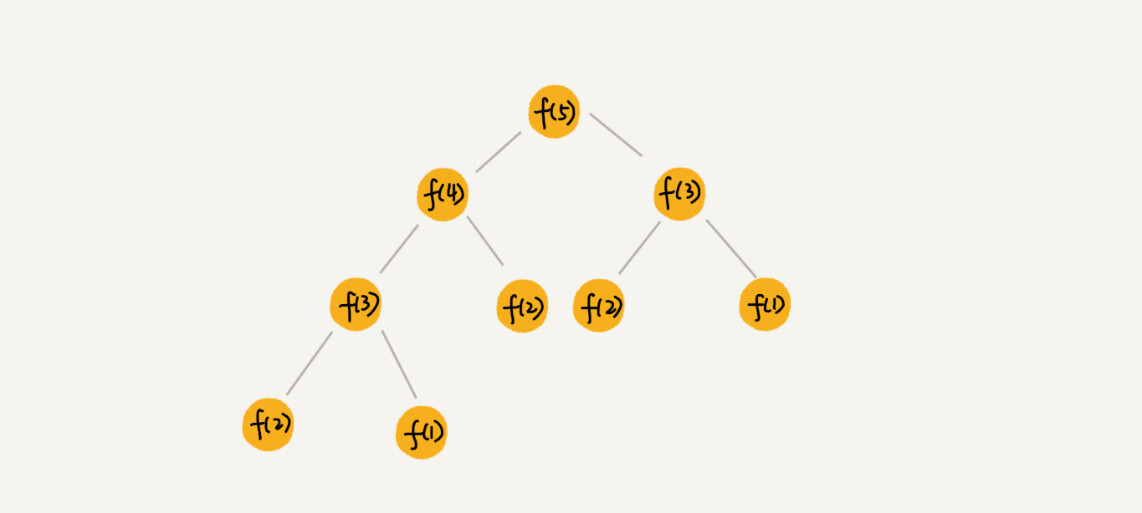 В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать, насколько глубоко будет проходить рекурсия. В этом примере, чтобы указать значение sql:max-depth, необходимо знать, насколько глубоко иерархия управления проходит в компании.
В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать, насколько глубоко будет проходить рекурсия. В этом примере, чтобы указать значение sql:max-depth, необходимо знать, насколько глубоко иерархия управления проходит в компании.
Примечание
Схема задает заметку sql:limit-field , но не указывает заметку
Примечание
В следующей процедуре используется база данных tempdb.
Проверка образца запроса XPath к схеме
Создайте образец таблицы с именем Emp в базе данных tempdb, на которую указывает виртуальный корневой каталог.
USE tempdb CREATE TABLE Emp ( EmployeeID int primary key, FirstName varchar(20), LastName varchar(20), ReportsTo int)Добавьте следующий образец данных:
INSERT INTO Emp values (1, 'Nancy', 'Devolio',NULL) INSERT INTO Emp values (2, 'Andrew', 'Fuller',1) INSERT INTO Emp values (3, 'Janet', 'Leverling',1) INSERT INTO Emp values (4, 'Margaret', 'Peacock',3) INSERT INTO Emp values (5, 'Steven', 'Devolio',4) INSERT INTO Emp values (6, 'Nancy', 'Buchanan',5) INSERT INTO Emp values (7, 'Michael', 'Suyama',6)
Скопируйте приведенный выше код схемы и вставьте его в текстовый файл. Сохраните файл под именем maxDepth.xml.
Скопируйте следующий шаблон и вставьте его в текстовый файл. Сохраните файл под именем maxDepthT.
 xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.
xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.<ROOT xmlns:sql="urn:schemas-microsoft-com:xml-sql"> <sql:xpath-query mapping-schema="maxDepth.xml"> /Emp </sql:xpath-query> </ROOT>Путь к каталогу схемы сопоставления (файл maxDepth.xml) задается относительно каталога, в котором сохранен шаблон. Можно также задать абсолютный путь, например:
mapping-schema="C:\MyDir\maxDepth.xml"
Создайте и запустите тестовый скрипт SQLXML 4.0 (Sqlxml4test.vbs), чтобы выполнить шаблон. Дополнительные сведения см. в статье Использование ADO для выполнения запросов SQLXML 4.0.
Результат:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
<Emp FirstName="Nancy" EmployeeID="6" LastName="Buchanan">
<Emp FirstName="Michael" EmployeeID="7" LastName="Suyama" />
</Emp>
</Emp>
</Emp>
</Emp>
</Emp>
</root>
Примечание
Чтобы получить иерархии разной глубины в результате, измените значение заметки sql:max-depth в схеме и выполняйте шаблон снова после каждого изменения.
В предыдущей схеме все <элементы Emp> имели точно одинаковый набор атрибутов (EmployeeID, FirstName и LastName). Следующая схема была немного изменена для возврата дополнительного атрибута ReportsTo
Например, этот XML-фрагмент показывает подчиненных служащего 1:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2"
ReportsTo="1" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3"
ReportsTo="1" LastName="Leverling">
...
...
Ниже приведена измененная схема:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:documentation>
Customer-Order-Order Details Schema
Copyright 2000 Microsoft. All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Заметка sql:max-depth
В схеме, состоящей из рекурсивных связей, глубина рекурсии должна быть явно указана в схеме. Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Используйте заметку sql:max-depth в схеме, чтобы указать глубину рекурсии в рекурсивной связи, описанной в схеме. Значение заметки sql:max-depth является положительным целым числом (от 1 до 50), которое указывает количество рекурсий: значение 1 останавливает рекурсию в элементе, для которого задана заметка sql:max-depth ; значение 2 останавливает рекурсию на следующем уровне от элемента, в котором указан параметр sql:max-depth ; и так далее.
Примечание
В базовой реализации запрос XPath, указанный в схеме сопоставления, преобразуется в select … ЗАПРОС FOR XML EXPLICIT. Для этого запроса необходимо указать конечную глубину рекурсии. Чем выше значение, указанное для параметра sql:max-depth, тем больше созданный запрос FOR XML EXPLICIT. Это может увеличить время выборки.
Примечание
Диаграммы обновления и массовая загрузка XML не учитывают заметку max-depth. Это означает, что рекурсивные обновления и вставки будут происходить независимо от значения, заданного для max-depth.
Задание sql:max-depth для сложных элементов
Заметку sql:max-depth можно указать в любом сложном элементе содержимого.
Рекурсивные элементы
Если параметр sql:max-depth указан как для родительского, так и для дочернего элемента в рекурсивной связи, то заметка sql:max-depth, указанная в родительском элементе, имеет приоритет. Например, в следующей схеме заметка sql:max-depth указывается для родительского и дочернего элементов employee. В этом случае приоритет имеет sql:max-depth=4, указанный в <родительском элементе Emp> (который играет роль супервизора). Значение sql:max-depth , указанное в дочернем <элементе Emp> (играющем роль контролируемого), игнорируется.
Пример Б
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo"
sql:max-depth="3" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="2" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для образца А ранее в этом разделе.
Нерекурсивные элементы
Если заметка sql:max-depth указана в элементе схемы, который не вызывает рекурсии, она игнорируется. В следующей схеме <элемент Emp> состоит из дочернего <элемента Constant> , который, в свою очередь, имеет дочерний <элемент Emp> .
В этой схеме заметка sql:max-depth, указанная для <элемента Constant> , игнорируется, так как рекурсия между <родительским элементом Emp> и дочерним <элементом Constant> отсутствует. Но есть рекурсия между <предком Эмп> и ребенком <Эмп> . Схема указывает заметку sql:max-depth для обоих. Поэтому заметка sql:max-depth , указанная в предке (<Emp> в роли супервизора), имеет приоритет.
Пример В
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
child="Emp"
parent-key="EmployeeID"
child-key="ReportsTo"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
sql:relation="Emp"
type="EmpType"
sql:limit-field="ReportsTo"
sql:max-depth="1" />
<xsd:complexType name="EmpType" >
<xsd:sequence>
<xsd:element name="Constant"
sql:is-constant="1"
sql:max-depth="20" >
<xsd:complexType >
<xsd:sequence>
<xsd:element name="Emp"
sql:relation="Emp" type="EmpType"
sql:relationship="SupervisorSupervisee"
sql:max-depth="3" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для примера А ранее в этом разделе.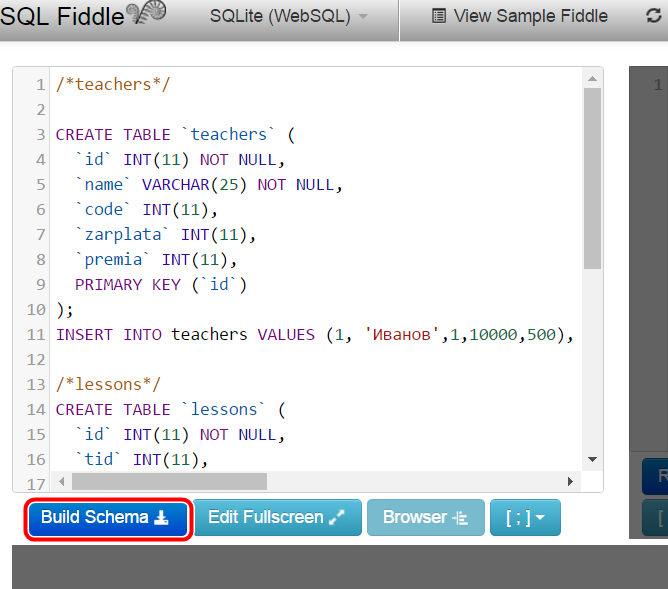
Сложные типы, наследуемые по ограничению
Если у вас есть наследование сложного типа по ограничению<>, элементы соответствующего базового сложного типа не могут указывать заметку sql:max-depth. В таких случаях заметку sql:max-depth можно добавить в элемент производного типа.
С другой стороны, если у вас есть сложный тип, производный от <расширения>, элементы соответствующего базового сложного типа могут указывать заметку sql:max-depth .
Например, следующая схема XSD создает ошибку, так как заметка sql:max-depth указана в базовом типе. Эта заметка не поддерживается для типа, наследуемого ограничением<> от другого типа. Чтобы устранить эту проблему, необходимо изменить схему и указать заметку sql:max-depth для элемента в производном типе.
Пример Г
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:msdata="urn:schemas-microsoft-com:mapping-schema">
<xsd:complexType name="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID" msdata:field="CustomerID" />
<xsd:element name="CompanyName"/>
<xsd:element name="Customers" msdata:max-depth="3">
<xsd:annotation>
<xsd:appinfo>
<msdata:relationship
parent="Customers"
parent-key="CustomerID"
child-key="CustomerID"
child="Customers" />
</xsd:appinfo>
</xsd:annotation>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="Customers" type="CustomerType"/>
<xsd:complexType name="CustomerType">
<xsd:complexContent>
<xsd:restriction base="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID"
type="xsd:string"/>
<xsd:element name="CompanyName"
type="xsd:string"
msdata:field="CName" />
<xsd:element name="Customers"
type="CustomerType" />
</xsd:sequence>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
</xsd:schema>
В схеме sql:max-depth указывается в сложном типе CustomerBaseType . Схема также указывает <элемент Customer> типа CustomerType, который является производным от CustomerBaseType. Запрос XPath, указанный в такой схеме, вызовет ошибку, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схема также указывает <элемент Customer> типа CustomerType, который является производным от CustomerBaseType. Запрос XPath, указанный в такой схеме, вызовет ошибку, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схемы с глубокой иерархией
Схема может иметь глубокую иерархию, в которой элемент содержит дочерний элемент, который в свою очередь содержит другой дочерний элемент, и т. д. Если заметка sql:max-depth , указанная в такой схеме, создает XML-документ, включающий иерархию из более чем 500 уровней (с элементом верхнего уровня на уровне 1, его дочерним элементом на уровне 2 и т. д.), возвращается ошибка.
НОУ ИНТУИТ | Лекция | Средства формулировки аналитических и рекурсивных запросов
< Лекция 9 || Лекция 6: 123456
Аннотация: В этой лекции мы завершаем обсуждение средств выборки данных языка SQL коротким описанием сравнительно недавно появившихся в языке SQL средств формулировки аналитических и рекурсивных запросов.
Ключевые слова: SQL, стандарт SQL:1999, аналитический запрос к базе данных, рекурсивный запрос, заработная плата, агрегатные функции, СУБД, Внешняя сортировка, агрегирование, динамическая, базы данных, OLTP, оперативная аналитическая обработка баз данных, OLAP, стандарт языка, разделы, раздел GROUP BY ROLLUP, раздел GROUP BY CUBE, агрегатная функция GROUPING, неопределенное значение, операторы SQL, частное решение, логическое программирование, Prolog, реляционная база данных, рекурсивный запрос с разделом WITH, выражение, линейная рекурсия, взаимная рекурсия, рекурсивное определение, расходы, основные средства, таблица, EMP, ORDER, определение столбца, контекст, обход дерева в ширину, обход дерева в глубину, цикл в ориентированном графе, Ориентированный граф, прямая рекурсия, виртуальная таблица, подзапрос, монотонная прогрессия, отрицание, INTERSECT, distinction, начальный источник рекурсии, рекурсивные вычисления, стратификация, семантика фиксированной точки, конструкция SEARCH, cycle, CAR, атомарность, UNION, шасси, частичный результат, потомок, раздел CYRCLE, значение выражения, тип символьной строки, Типы данных столбцов, рекурсивное представление, recursive
Введение
 intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
 intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING , позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
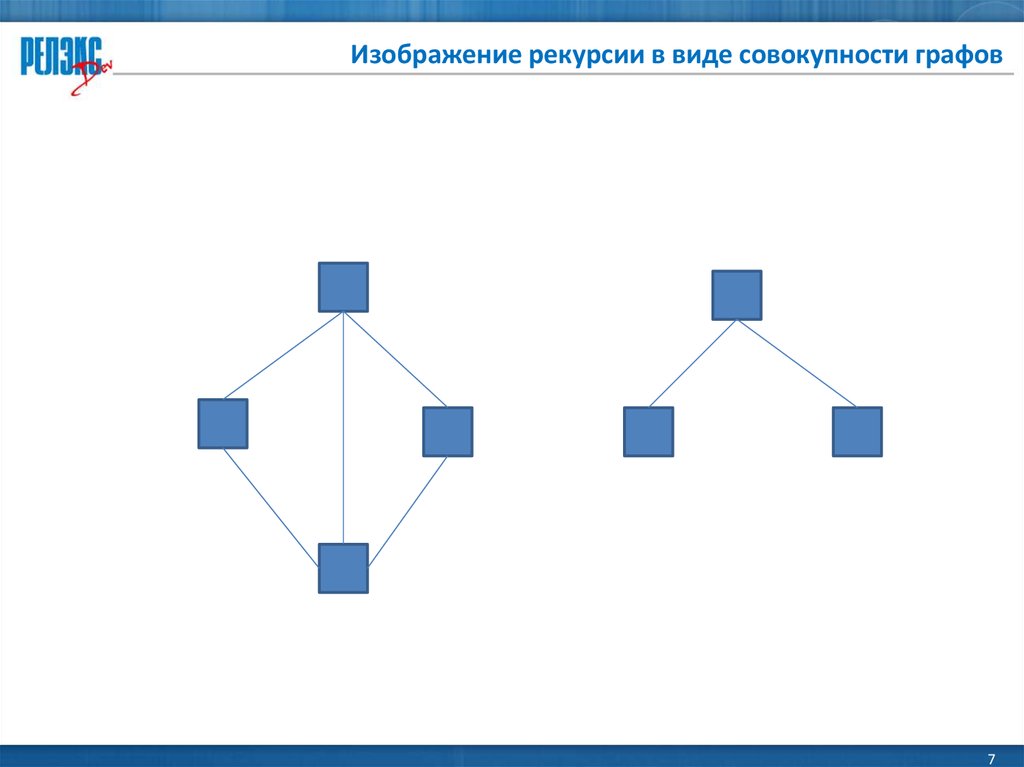
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций. Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Дальше >>
< Лекция 9 || Лекция 6: 123456
SQL-Recursion-Tool
Учебник — пользователь
- Введение
- Рекурсия в SQL и в инструменте
Учебник — сопровождающий
- Создание набора данных
Ссылка на SQL
- Дополнительные пояснения
Неподдерживаемый SQL
Внешние ресурсы
Журнал изменений
Учебное пособие — пользователь
Введение
Цель этого инструмента — предоставить платформу, помогающую практиковать рекурсию в SQL.
Все расчеты производятся прямо в браузере, поэтому инструмент не требует подключения к базе данных.
Он поддерживает большинство часто используемых функций и команд SQL, включая рекурсию. Список всех поддерживаемых функций и объяснение того, как их использовать, см. в приведенном ниже справочнике по SQL.
Список всех поддерживаемых функций и объяснение того, как их использовать, см. в приведенном ниже справочнике по SQL.
Рекурсия в SQL и в инструменте
В SQL:1999 введены общие табличные выражения (CTE). CTE — это временный набор, содержащий результат запроса. Вы можете обратиться к этому набору с запросом или он может обратиться к самому себе соответственно. Ссылаясь на себя, можно делать рекурсивные запросы. Для более подробного ознакомления с рекурсивными запросами в SQL обратитесь к официальной документации Microsoft.
В этом инструменте рекурсивный запрос может выполняться шаг за шагом. При этом текущий шаг, соответствующий код, а также задействованные таблицы будут выделены. Это должно помочь пользователю лучше понять, как работает такой запрос. Следует также подчеркнуть тот факт, что рекурсию следует рассматривать не как непонятную конструкцию, а как совокупность ее отдельных компонентов, которыми обычно являются простые запросы.
Запрос должен соответствовать определенным критериям, чтобы средство распознало его как рекурсивный запрос. Если какой-либо из следующих пунктов не выполнен, инструмент не распознает запрос как рекурсивный, и поэтому пошаговое решение будет недоступно.
Если какой-либо из следующих пунктов не выполнен, инструмент не распознает запрос как рекурсивный, и поэтому пошаговое решение будет недоступно.
- With-Clause
CTE необходимо, поскольку это единственный способ выполнения рекурсивных запросов в SQL. - Union All
В SQL рекурсия вернет желаемый результат только в том случае, если инициализация и регистр шага объединены с помощью оператора Union All. - Рекурсивная ссылка и соединение в случае шага
Оператор Select-Statement секунд в CTE должен каким-то образом ссылаться на себя (фактическая рекурсия). Кроме того, этот оператор также должен содержать соединение, чтобы гарантировать, что результат действительно может увеличиваться с каждым шагом . - Выбор пункта With
Внешний запрос должен выбрать хотя бы один столбец только что вычисленной рекурсии. На самом деле этот пункт не нужен — он скорее для того, чтобы пользователь знал, что окончательный результат рекурсии может быть отображен только с этим запросом.
Учебник — сопровождающий
Любой может создавать и совместно использовать наборы данных, которые можно использовать в инструменте. Это можно сделать с помощью GitHub Gists, бесплатной платформы для обмена фрагментами кода. После создания такой набор данных можно импортировать в инструмент, используя его уникальный идентификатор. Его можно найти в конце URL-адреса или вверху страницы как gist:xxxxxxxxxxxxx .
Создание набора данных
Набор данных указывается в виде простого текстового файла, который создается как Github Gist (имя сути не имеет значения). RelaX — калькулятор реляционной алгебры использует один и тот же синтаксис для своих данных, поэтому суть можно использовать в обоих инструментах.
Уже включенная база данных полетов будет использоваться в качестве примера того, как создать совместимый файл gist для этого инструмента. Полный файл также можно найти здесь.
Во-первых, необходимо определить атрибут группы . Он служит заголовком базы данных и отображается в меню «Выбрать базу данных».
Он служит заголовком базы данных и отображается в меню «Выбрать базу данных».
Этот атрибут может состоять из любого символа и читается до первого разрыва строки.
группа: Рейсы простые
Следующий атрибут описание . Это опционально и его не нужно включать.
Он отображается под редактором и должен использоваться для дальнейшего описания набора данных и предоставления дополнительных ссылок на источники.
Это может быть либо однострочное описание с синтаксисом, аналогичным атрибуту in group, либо многострочное описание, в котором скобки должны использоваться для обозначения начала и конца описания.
Кроме того, поддерживается синтаксис Markdown для простого преобразования описания в код HTML
description[[
Пример 1 представляет собой простую рекурсию для вычисления всех аэропортов, до которых можно добраться из Вены.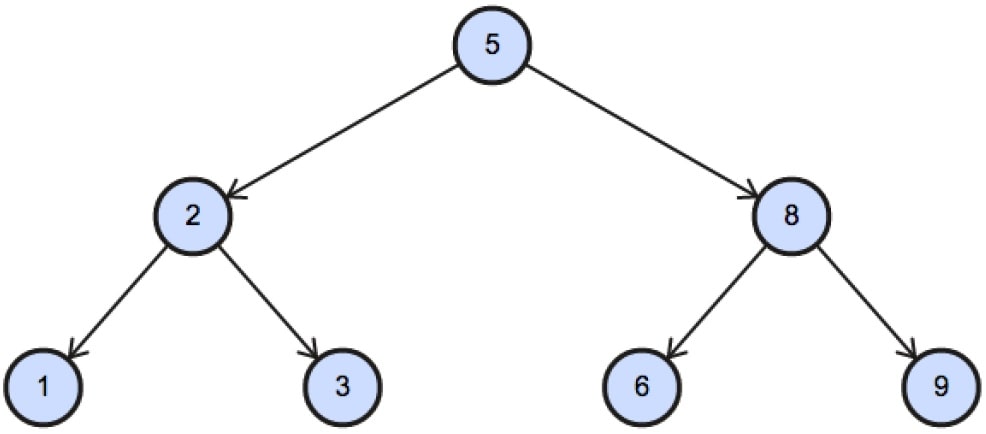
Пример 2 — это в основном тот же запрос, который дополнительно подсчитывает шаги и вычисляет пройденный путь.
]]
Далее можно определить один или несколько примеров . Этот атрибут также является необязательным и может быть опущен
Если набор данных содержит примеры, их можно вставить в редактор с помощью соответствующей кнопки в правом нижнем углу редактора
Снова используется синтаксис со скобками для многострочных описаний. Для разделения нескольких примеров используется точка с запятой
Примеры вставляются в редактор в том же формате, что и в gist-файле, включая разрывы строк и табуляторы
/* Вычисляет все аэропорты, до которых можно добраться из Вены, считает шаги и вычисляет пройденный путь. */ example[[
/* Этот запрос вычисляет все аэропорты, до которых можно добраться из Вены. */
WITH RecRel(отправление,пункт назначения) AS
(
ВЫБЕРИТЕ пункт отправления, пункт назначения ОТ рейса, ГДЕ отправление = "VIE"
ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ шаг.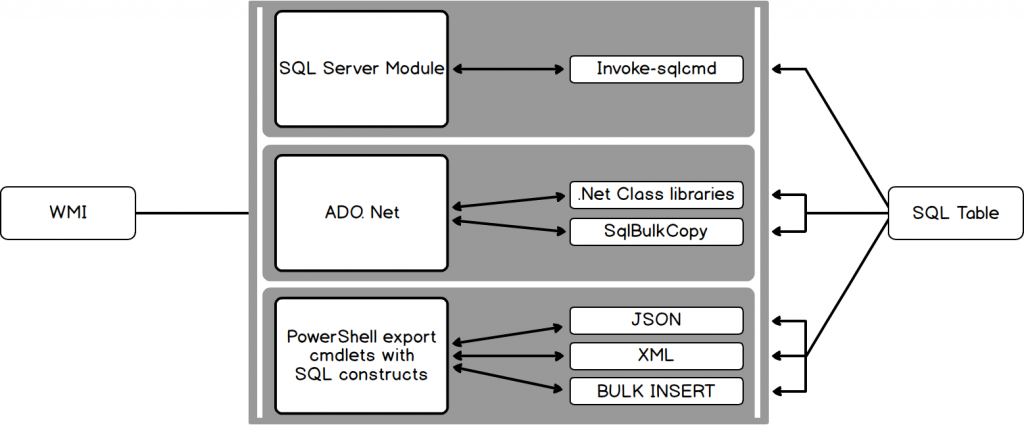 отправления, шаг.пункт назначения
отправления, шаг.пункт назначения
ИЗ RecRel AS rec ПРИСОЕДИНЯЙТЕСЬ к рейсу КАК шаг ON (rec.destination = step.departure)
)
SELECT * FROM RecRel;
WITH RecRel(шаг,путь,отправление,пункт назначения) AS
(
SELECT 1, concat(отправление," - ",пункт назначения),отправление, пункт назначения ОТ рейса, ГДЕ отправление = "VIE"
ОБЪЕДИНЕНИЕ ВСЕХ
SELECT rec. step+1, concat(rec.path," - ",step.destination),step.departure, step.destination
FROM RecRel AS rec JOIN Flight AS step ON (rec.destination = step.departure)
)
SELECT * FROM RecRel
]]
Наконец, должны быть определены фактические данные. Это похоже на определение переменных в нескольких языках программирования.
Имя переменной в данном случае является именем таблицы, а внутри определены столбцы.
Первая строка определяет имя и тип данных столбца. Тип данных является необязательным, поэтому каждый столбец определяется как имя или имя:тип данных .
Тип данных является необязательным, поэтому каждый столбец определяется как имя или имя:тип данных .
Обратите внимание, что поддерживаются только типы данных «строка» и «число», все остальное рассматривается как строка.
В следующих строках могут быть определены записи таблицы, где одинарные кавычки должны использоваться для строк
аэропорт = рейс =
{
отправление: строка, пункт назначения: строка, идентификатор: номер
'VIE', 'FRA', 0
'FRA', 'LHR', 1
...
}
{
местоположение: строка, страна: строка, иата: строка, идентификатор: число
«Вена», «Австрия», «VIE», 0
«Франкфурт», «Германия», «FRA», 1
...
}
Справочник по SQL
Этот инструмент вычисляет запросы самостоятельно, поэтому не все функции из SQL могут быть использованы в инструменте. Далее будут перечислены все возможные функции и команды и, при необходимости, объяснены.
- Выбрать (Отдельно) — Откуда — Где
- И и Или
- Заказ по номеру
- Нравится
- Подстановочные знаки
- Между
- Не
- Псевдонимы с As
- Присоединяется с помощью/на
- Левое/Правое/Полное/Перекрёстное/Естественное соединение
- Группа по и наличие
- Ограничение
- Объединение/За исключением/Пересечение (Все)
- Агрегированные функции (AVG, COUNT, MIN, MAX, SUM)
- Конкатенация строк с помощью concat() в Select
- Основные расчеты и модуль в Select
- Рекурсивные запросы
- Комментарии
Дальнейшее объяснение
Во избежание неясности некоторые функции и характеристики инструмента будут объяснены дополнительно:
- Ссылки
Нет необходимости всегда указывать таблицу в запросах. Если таблицу можно четко определить, достаточно имени столбца. Однако, если столбец не имеет уникального имени, он не может быть однозначно назначен таблице автоматически, и его необходимо указать как 9.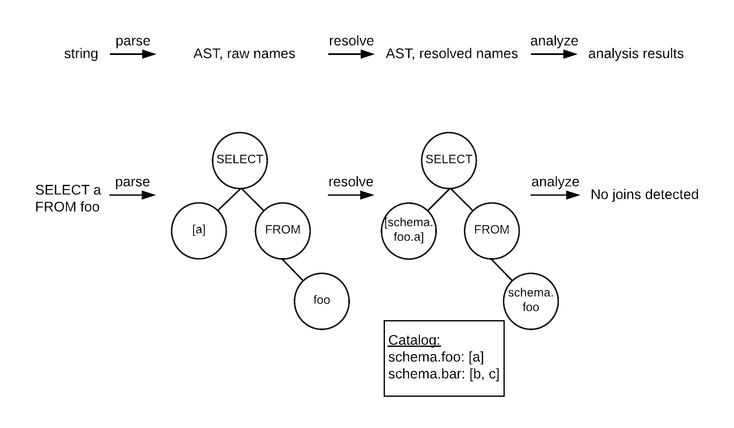 0067 таблица.столбец .
0067 таблица.столбец . - Соединения
Соединения любой формы будут выполняться слева направо. Это важно при выполнении запросов с несколькими соединениями, поскольку другой тип соединения может возвращать разные имена столбцов и, кроме того, приводить к неправильному результату. Например, соединение с использованием возвращает только один столбец, а соединение с включением возвращает два столбца с соответствующим префиксом своей таблицы. При выполнении запросов рекомендуется смешивать различные типы соединений, если это возможно. - Group By и Have
Have может использоваться только в сочетании с Group By и только в том случае, если оно следует непосредственно за оператором Group By. - Объединение строк с помощью concat()
Любая комбинация столбцов и строк может быть объединена в части запроса Select. Это делается с помощью функции concat().
SELECT concat("Это рейс ",id," до ",пункт назначения) ОТ рейса - Основные вычисления и модуль
Вычисления с десятичными числами можно напрямую объявлять как столбец. В качестве альтернативы можно использовать функцию calc(), похожую на concat().
В качестве альтернативы можно использовать функцию calc(), похожую на concat().
ВЫБЕРИТЕ 2*id ИЗ рейса
ВЫБЕРИТЕ calc(2+id%2) ИЗ рейса - Комментарии
Комментарии можно использовать так же, как и в SQL.
-- однострочный комментарий
/*
многострочный комментарий
*/
Неподдерживаемый SQL
Для полноты приведем список функций, которые не поддерживаются этим инструментом. В основном потому, что они не нужны или по техническим причинам
- Подзапросы
- В
- Является (Не) Нулевым
- Сложные типы данных (например, DATE)
- Язык определения данных (например, CREATE TABLE)
- Язык обработки данных (например, INSERT INTO или UPDATE)
Внешние ресурсы
- AngularJS
- Начальная загрузка
- Просмотр
- Код Зеркало
- jQuery
- Showdown — Конвертер Markdown в HTML
- SQLike
- sql.
 pegjs
pegjs
Список изменений
10-06-16
- Добавлен лимит рекурсивных шагов (100) и сообщение при достижении лимита
07-06-16
- Вычисления для десятичных чисел теперь работают и без использования функции calc()
24-05-16
- Добавлена панель навигации для обратной связи и помощи
- Обновленное пошаговое решение
- Количество строк теперь отображается для каждой таблицы (и автоматически увеличивается в пошаговом решении)
- Текущее состояние рекурсии теперь отображается под кнопками
- Незначительные изменения в кнопках, например кнопка «инициализация» в начале
21-05-16
- Обновлено «показать полные столы»: кнопка меньше, макс. 10 строк в таблице, количество отображаемых строк
- Кнопки-примеры теперь отображаются для каждого набора данных отдельно
- Обновлен gist-parser, теперь он также включает примеры запросов
- Gist-парсер: группа, описание (необязательно), пример (необязательно), таблицы
- Та же схема, что и в многострочном описании с двойными скобками для открытия и закрытия
- Несколько примеров разделены точкой с запятой
- Пример примеров:
пример[[выбрать * из рейса; выберите * из рейса, где id > 2]] - Пошаговое решение больше не исчезает при изменении запроса (перед нажатием кнопки «Отправить»)
19-05-16
- Несколько объединений теперь должны работать должным образом
- Переведены примеры наборов данных и примеры запросов с немецкого на английский
- Запросы с лимитом >= 10 теперь работают корректно
- Многострочное описание для gist-файлов теперь наконец работает (также с синтаксисом уценки)
28-04-16
- Таблицы больше не нужно указывать в запросах
- Инструмент теперь просматривает соответствующую часть запроса «от» и пытается добавить отсутствующие таблицы, если это возможно
- Работает для запроса любого размера -> одиночный выбор, объединение (2 выбора), рекурсия (3 выбора) и т.
 д.
д. - Добавлены сообщения об ошибках для несуществующих столбцов в выбранных таблицах и для неуникальных столбцов в выбранных таблицах
20-04-16
- Оповещения о правильном нерекурсивном вводе теперь отображаются желтым цветом, чтобы лучше различать рекурсивный и нерекурсивный ввод
15-04-16
- Добавлен еще один шаг, прежде чем пошаговое решение покажет окончательный результат
- Пошаговое решение теперь сохраняет разрывы строк запроса
13-04-16
- Нравится и Лимит теперь снова работают правильно
- Исправлена ошибка, приводившая к тому, что некоторые условия Where не работали
- Добавлены оповещения об успехе/ошибке при импорте gist-файлов
- Обновлен gist-parser для анализа каждого типа данных (если он неизвестен, он обрабатывается как строка)
- Добавлено предупреждение при импорте набора данных неизвестного типа (пример: 2923a30a474fdcb46bee)
12-04-16
- Обновлен gist-parser для использования описания с уценкой
- Обновлено описание базы данных под редактором, чтобы оно снова работало корректно
07-04-16
- Расширенное пошаговое решение с выделением соответствующей части кода
- Порядок вычислений в select больше не ограничен, т.
 е. 1+id и id+1 должны работать одинаково
е. 1+id и id+1 должны работать одинаково
06-04-16
- Агрегатные функции больше не чувствительны к регистру
- Пошаговое решение теперь заканчивается корректно
- Добавлена SQL-часть к результату
05-04-16
- Выбор номера теперь корректно работает с ‘as’
- Добавлена возможность выбора чисел со знаком (+/-)
- SQL-комментарии теперь можно использовать в редакторе
- Однострочный: — мой комментарий
- Примечание: редактор выделяет однострочные комментарии, только если после — есть пробел, но он работает и без .
- /* мой комментарий */ для многострочного
04-04-16
- Добавлен тип данных (если есть) в столбцы
- Мелкие исправления в SQL-анализаторе и синтаксическом анализаторе
29-03-16
- Множественные условия теперь снова работают, как предполагалось
28-03-16
- Теперь возможна загрузка списков (такой же/похожий шаблон, что и списки для инструмента релаксации)
- Гисты также временно сохраняются после загрузки
- Протестировано с идентификатором gist 7d1871f79a8bcb4788de
- Отображает db-информацию (если доступна) под редактором
23-03-16
- Изменение наборов данных больше не должно вызывать проблем с результатами
22-03-16
- Добавлен синтаксический анализатор основных/локальных наборов данных
- Можно выбрать из разных наборов данных
21-03-16
- Улучшенная семантическая проверка запроса (теперь корректно охватывает alias и with-clauses)
- Добавлена информация о том, почему пошаговое решение недоступно
20-03-16
- Реализован более сложный пошаговый функционал
18-03-16
- Добавлена возможность производить расчеты с +-*/% в select
- Расчет с использованием чисел или столбцов
- Начать вычисление с числа или использовать функцию calc() (calc() должна работать всегда) Пример
- : calc(1+flug.
 id) или calc(flug.id+2*flug.id)
id) или calc(flug.id+2*flug.id) - Сообщения об ошибках теперь с позицией ошибки
- Кнопки для простого пошагового решения (только для рекурсии)
17-03-16
- Добавлена функция concat() для выбора, комбинация строки (двойные кавычки) и table.column в качестве возможных параметров
- Добавлен еще один пример, показывающий, как работает concat()
16-03-16
- Обновление парсера:
- Действительный запрос больше не требует точки с запятой в конце
- Выбор строкового литерала теперь действителен — необходимы двойные кавычки
- выбор числового литерала теперь действителен — десятичные числа в сочетании с +,-,*,/
10-03-16
- Рекурсивные запросы теперь должны работать
03-09-16
- Исправлена ошибка, из-за которой операторы соединения по-прежнему чувствительны к регистру
- Результат запроса теперь отображается прямо на странице
08-03-16
- Исправлена ошибка, из-за которой ‘as’ не работал должным образом при использовании в ‘from’
- Теперь должны работать нерекурсивные предложения with
- Парсер теперь различает рекурсивные и нерекурсивные запросы
22-02-16
- Расширенные синтаксические и семантические проверки, включающие также особые случаи для предложений with
20-02-16
- Добавлен базовый синтаксис with в синтаксический анализатор
18-02-16
- Парсер: агрегатные функции теперь также для groupby/имеющих
- Исправлена ошибка в SQLike, из-за которой group by не работал над table.
 column
column - groupby/having теперь можно использовать в запросах (имея работает, только если следует непосредственно после group by)
16-02-16
- Исправления парсера для groupby/имеющих
- Добавлены агрегатные функции (avg, sum, count, min, max) в синтаксический анализатор
- Агрегатная функция теперь может использоваться при выборе
04-02-16
- Исправления парсера для подобных/между
- ‘(не) между/как’ теперь можно использовать в запросах
Узнайте, как написать SQL рекурсивное CTE за 5 шагов
Вам не нужна база данных Graph, чтобы следовать иерархии узлов. SQL может итеративно выполнять соединения, самосоединения и даже соединения с предыдущим результатом. это 9Предложение 0083 WITH RECURSIVE часто называют «рекурсивным CTE». Это может потребовать некоторой абстракции от разработчиков, привыкших к процедурным языкам. Вот как я это объясняю, соединяя «вручную» два первых уровня без рекурсии, а затем переключаясь на «рекурсивно», чтобы идти дальше. Начиная с первых двух уровней, можно легко проверить логику.
Начиная с первых двух уровней, можно легко проверить логику.
(0) Пример: создать таблицу EMP
Создам самую старую примерную таблицу: EMP для сотрудников с самоотнесением к руководителю:
СОЗДАТЬ ТАБЛИЦУ emp (empno, ename, job, MGR, Hiredate, Sal, comm, deptno, email, other_info) как значения
(7369, 'СМИТ', 'КЛЕРК', 7902, '1980-12-17', 800, NULL, 20, 'СМИТ@acme.com', '{"навыки":["бухгалтерский учет"]}'),
(7499, 'ALLEN', 'ПРОДАВЕЦ', 7698, '1981-02-20', 1600, 300, 30, '[email protected]', ноль),
(7521, 'WARD', 'ПРОДАВЕЦ', 7698, '1981-02-22', 1250, 500, 30, '[email protected]', ноль),
(7566, 'ДЖОНС', 'МЕНЕДЖЕР', 7839, '1981-04-02', 2975, NULL, 20, '[email protected]', ноль),
(7654, 'МАРТИН', 'ПРОДАВЕЦ', 7698, '1981-09-28', 1250, 1400, 30, '[email protected]', ноль),
(7698, «ЧЕРНЫЙ», «МЕНЕДЖЕР», 7839, «1981-05-01», 2850, NULL, 30, «[email protected]», нуль),
(7782, 'КЛАРК', 'МЕНЕДЖЕР', 7839, '1981-06-09', 2450, NULL, 10, '[email protected]', '{"skills":["C","C++", "SQL"]}'),
(7788, 'СКОТТ', 'АНАЛИТИК', 7566, '1982-12-09', 3000, NULL, 20, 'СКОТТ@acme. com', '{"кот":"тигр"}'),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 10, '[email protected]', null),
(7844, 'ТЕРНЕР', 'ПРОДАВЕЦ', 7698, '1981-09-08', 1500, 0, 30, '[email protected]', ноль),
(7876, «АДАМС», «КЛЕРК», 7788, «1983-01-12», 1100, NULL, 20, «[email protected]», нуль),
(7900, 'ДЖЕЙМС', 'КЛЕРК', 7698, '1981-12-03', 950, NULL, 30, '[email protected]', null),
(7902, 'FORD', 'АНАЛИТИК', 7566, '1981-12-03', 3000, NULL, 20, '[email protected]', '{"навыки":["SQL","CQL"] }'),
(7934, 'МИЛЛЕР', 'КЛЕРК', 7782, '1982-01-23', 1300, NULL, 10, '[email protected]', нуль)
;
com', '{"кот":"тигр"}'),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 10, '[email protected]', null),
(7844, 'ТЕРНЕР', 'ПРОДАВЕЦ', 7698, '1981-09-08', 1500, 0, 30, '[email protected]', ноль),
(7876, «АДАМС», «КЛЕРК», 7788, «1983-01-12», 1100, NULL, 20, «[email protected]», нуль),
(7900, 'ДЖЕЙМС', 'КЛЕРК', 7698, '1981-12-03', 950, NULL, 30, '[email protected]', null),
(7902, 'FORD', 'АНАЛИТИК', 7566, '1981-12-03', 3000, NULL, 20, '[email protected]', '{"навыки":["SQL","CQL"] }'),
(7934, 'МИЛЛЕР', 'КЛЕРК', 7782, '1982-01-23', 1300, NULL, 10, '[email protected]', нуль)
;
Войти в полноэкранный режимВыйти из полноэкранного режима Самоссылка от mgr к empno может быть объявлена как:
ALTER TABLE emp ADD PRIMARY KEY (empno) ; ИЗМЕНИТЬ ТАБЛИЦУ emp ДОБАВИТЬ ВНЕШНИЙ КЛЮЧ (mgr) ССЫЛКИ emp (empno) ;Войти в полноэкранный режимВыйти из полноэкранного режима
Это не требуется, но гарантирует правильность того, что вы запрашиваете, чтобы вы могли сосредоточиться на своей бизнес-логике, а не на проверке согласованности.
(1) найти корень (уровень 0)
Первым шагом является определение корня графа. Вы хотите начать с сотрудников и показать их менеджера или начать с менеджера и показать его сотрудников? Я сделаю последнее. Корнем иерархии является тот, у которого нет менеджера ( , где mgr равно null )
-- (1) запрос на поиск корня выберите emp.empno,emp.ename,emp.mgr из emp, где mgr равен нулю -- (1) это уровень 0 ;Войти в полноэкранный режимВыйти из полноэкранного режима
Результат прост:
югабайт-> ; эмпно | эмаль | магистр -------+-------+----- 7839 | КОРОЛЬ | (1 ряд) югабайт =>Войти в полноэкранный режимВыйти из полноэкранного режима
(2) определить этот уровень 0 в предложении WITH
Я помещу его в CTE (Common Table Expression), помеченный как levelN , но пока не добавим рекурсию это уровень 0, и я выбираю из него:
с -- (2) определить корень как levelN (это уровень 0, пока мы не добавим рекурсию) уровень N как ( -- (1) запрос на поиск корня выберите emp.Войти в полноэкранный режимВыйти из полноэкранного режимаempno,emp.ename,emp.mgr из emp, где mgr равен нулю -- (1) это уровень 0 ) -- (2) запросить этот уровень выберите * из уровня N ;
Результат тот же. Топ-менеджер — КИНГ. Мы просто назвали его и поместили в предложение WITH, чтобы подготовиться к будущей рекурсии.
югабайт-> ; эмпно | эмаль | магистр -------+-------+----- 7839 | КОРОЛЬ | (1 ряд) югабайт =>Войти в полноэкранный режимВыйти из полноэкранного режима
Я просто строю блоки один за другим. И я оставил комментарии, чтобы было понятно, что взято из предыдущего шага, а что добавлено.
(3) определить присоединение к следующему уровню
Теперь, когда мой уровень 0 определен, я снова запрашиваю таблицу emp , чтобы получить следующий уровень, с соединением с уровнем 0, чтобы получить имя менеджера:
с -- (2) определить корень как levelN, который является уровнем 0, пока мы не добавим рекурсию уровень N как ( -- (1) запрос на поиск корня выберите emp.Войти в полноэкранный режимВыйти из полноэкранного режимаempno,emp.ename,emp.mgr из emp, где mgr равен нулю -- (1) это уровень 0 ) -- (3) присоединиться к сотрудникам с уровнем N, чтобы получить уровень N+1 (здесь это уровень 1) выберите emp.empno,emp.ename,emp.mgr,mgr.ename mgr_name из эмп присоединяйтесь к mgr levelN на mgr.empno=emp.mgr ;
Я назвал уровень 0 псевдонимом mgr , потому что это будет менеджер этого нового уровня сотрудника, для которого я сохраняю имя таблицы emp . Затем объединение на mgr.empno=emp.mgr связывает два уровня.
В результате соединения я добавил mgr.ename как mgr_name , чтобы увидеть имя менеджера в той же строке.
Вот сотрудники, ссылающиеся на KING:
yugabyte-> ; эмпно | эмаль | менеджер | имя_менеджера -------+-------+------+---------- 7698 | БЛЕЙК | 7839 | КОРОЛЬ 7566 | ДЖОНС | 7839 | КОРОЛЬ 7782 | Кларк | 7839 | КОРОЛЬ (3 ряда) югабайт =>Войти в полноэкранный режимВыйти из полноэкранного режима
(4) соединить два уровня с помощью UNION
Теперь, когда у меня есть два уровня, я могу начать строить иерархию, объединяя их с помощью UNION ALL. Вы видите
Вы видите levelN , который является уровнем 0, в первой ветви UNION, чтобы показать уровень 0 и во второй ветви, чтобы соединить два уровня.
Поскольку я добавил имя менеджера на уровень 1, я добавляю его и на нулевой уровень, как пустую строку здесь, чтобы иметь такую же структуру в UNION.
с -- (2) определить корень как levelN, который равен level0, пока мы не добавим рекурсию уровень N как ( -- (1) запрос для поиска корня --(4) добавить все столбцы выберите emp.empno,emp.ename,emp.mgr,'' как управляющий из emp, где mgr равен нулю -- (1) это уровень 0 ) -- (4) объединить уровень 0 поверх уровня l выберите * из уровня N союз всех -- (3) объединить сотрудников с уровнем n, чтобы получить уровень n+1 (здесь это уровень 1) выберите emp.empno,emp.ename,emp.mgr,mgr.ename mgr_name из эмп присоединяйтесь к mgr levelN на mgr.empno=emp.mgr ;Войти в полноэкранный режимВыйти из полноэкранного режима
Это начинает выглядеть хорошо, вот два уровня вместе:
югабайт-> ; эмпно | эмаль | менеджер | имя_менеджера -------+-------+------+---------- 7839 | КОРОЛЬ | | 7698 | БЛЕЙК | 7839 | КОРОЛЬ 7566 | ДЖОНС | 7839 | КОРОЛЬ 7782 | Кларк | 7839 | КОРОЛЬ (4 ряда) югабайт =>Войти в полноэкранный режимВыйти из полноэкранного режима
Здесь вы можете проверить правильность вашего соединения.
Следующий шаг просто добавит рекурсию, чтобы вам не нужно было делать то же самое, чтобы добавить уровень 3. То же самое определение (ОБЪЕДИНЕНИЕ ВСЕХ и СОЕДИНЕНИЕ с предыдущего уровня) может попасть на следующие уровни.
(5) получить его в одном рекурсивном предложении WITH
Теперь, когда я проверил результат для двух первых уровней, пришло время сделать его рекурсивным, добавив ключевое слово RECURSIVE и переместив UNION ALL в Common Table Expression. Первая часть UNION ALL выполняется только один раз в первой итерации, а вторая часть объединяет следующий уровень.
-- (5) изменить на рекурсивный с рекурсивным -- (2) определить корень как levelN, который равен level0, пока мы не добавим рекурсию уровень N как ( -- (1) запрос для поиска корня --(4) добавить все столбцы выберите emp.empno,emp.ename,emp.mgr,'' как управляющий из emp, где mgr равен нулю -- (1) это уровень 0 -- (5) переместите вторую ветвь в CTE, которая будет повторяться.Войти в полноэкранный режимВыйти из полноэкранного режимаОн ссылается на levelN из предыдущей итерации. союз всех -- (3) объединить сотрудников с уровнем n, чтобы получить уровень n+1 (здесь это уровень 1) выберите emp.empno,emp.ename,emp.mgr,mgr.ename mgr_name из эмп присоединяйтесь к mgr levelN на mgr.empno=emp.mgr ) -- (4) объединить уровень 0 поверх уровня l выберите * из уровня N -- (5) здесь мы запрашиваем только с уровня N, который включает в себя предыдущие уровни благодаря рекурсии
Если вы подтвердили соединение с первыми двумя уровнями, это последнее преобразование выполняется автоматически. Во время выполнения первая итерация получит первый уровень, а вторая часть UNION ALL не будет иметь строк из-за объединения с предыдущим результатом, который пуст (предыдущего уровня нет). Следующая итерация добавит результат соединения. И снова до тех пор, пока соединение не вернет ни одной строки, потому что мы находимся на листе с предыдущим результатом, взятым как список менеджеров, в котором нет сотрудников.
югабайт-> ; эмпно | эмаль | менеджер | имя_менеджера -------+--------+------+---------- 7839 | КОРОЛЬ | | 7698 | БЛЕЙК | 7839 | КОРОЛЬ 7566 | ДЖОНС | 7839 | КОРОЛЬ 7782 | Кларк | 7839 | КОРОЛЬ 7788 | СКОТТ | 7566 | ДЖОНС 7902 | ФОРД | 7566 | ДЖОНС 7844 | ТЕРНЕР | 7698 | БЛЕЙК 7499 | АЛЛЕН | 7698 | БЛЕЙК 7521 | Уорд | 7698 | БЛЕЙК 7654 | МАРТИН | 7698 | БЛЕЙК 7900 | ДЖЕЙМС | 7698 | БЛЕЙК 7934 | МИЛЛЕР | 7782 | Кларк 7876 | АДАМС | 7788 | СКОТТ 7369| СМИТ | 7902 | ФОРД (14 рядов) югабайт =>Войти в полноэкранный режимВыйти из полноэкранного режима
Вот где волшебство. Если вы тщательно протестируете свои первые два уровня, все остальные будут получены путем преобразования запроса в рекурсивный, повторяющийся путем объединения предыдущего результата.
В плане выполнения вы видите это как Рекурсивное объединение
ПЛАН ЗАПРОСА -------------------------------------------------- -------------------------------------------------- ---------------------------------- CTE Scan on leveln (стоимость=20,23.
