MS SQL Server и T-SQL
Циклы
Последнее обновление: 14.08.2017
Для выполнения повторяющихся операций в T-SQL применяются циклы. В частности, в T-SQL есть цикл WHILE. Этот цикл выполняет определенные действия, пока некоторое условие истинно.
WHILE условие
{инструкция|BEGIN...END}
Если в блоке WHILE необходимо разместить несколько инструкций, то все они помещаются в блок BEGIN…END.
Например, вычислим факториал числа:
DECLARE @number INT, @factorial INT SET @factorial = 1; SET @number = 5; WHILE @number > 0 BEGIN SET @factorial = @factorial * @number SET @number = @number - 1 END; PRINT @factorial
То есть в данном случае пока переменная @number не будет равна 0, будет продолжаться цикл WHILE. Так как @number равна 5, то цикл сделает пять
проходов. Каждый проход цикла называется итерацией. В каждой итерации будет переустанавливаться значение переменных @factorial и @number.
Другой пример — рассчитаем баланс счета через несколько лет с учетом процентной ставки:
USE productsdb; CREATE TABLE #Accounts ( CreatedAt DATE, Balance MONEY) DECLARE @rate FLOAT, @period INT, @sum MONEY, @date DATE SET @date = GETDATE() SET @rate = 0.065; SET @period = 5; SET @sum = 10000; WHILE @period > 0 BEGIN INSERT INTO #Accounts VALUES(@date, @sum) SET @period = @period - 1 SET @date = DATEADD(year, 1, @date) SET @sum = @sum + @sum * @rate END; SELECT * FROM #Accounts
Здесь создается временная таблица #Accounts, в которую добавляется в цикле пять строк с данными.
Операторы BREAK и CONTINUE
Оператор BREAK позволяет завершить цикл, а оператор CONTINUE — перейти к новой итерации.
DECLARE @number INT SET @number = 1 WHILE @number < 10 BEGIN PRINT CONVERT(NVARCHAR, @number) SET @number = @number + 1 IF @number = 7 BREAK; IF @number = 4 CONTINUE; PRINT 'Конец итерации' END;
Когда переменная @number станет равна 4, то с помощью оператора CONTINUE произойдет переход к новой итерации, поэтому последующая строка PRINT 'Конец итерации'
не будет выполняться, хотя цикл продолжится.
Когда переменная @number станет равна 7, то оператор BREAK произведет выход из цикла, и он завершится.
Урок 18. Хранимые процедуры. Циклы.
Сегодня узнаем, как работать с циклами, т.е. выполнять один и тот же запрос несколько раз. В MySQL для работы с циклами применяются операторы WHILE, REPEAT и LOOP.Оператор цикла WHILE
Сначала синтаксис:
WHILE условие DO
запрос
END WHILE
Запрос будет выполняться до тех пор, пока условие истинно. Давайте посмотрим на примере, как это работает. Предположим, мы хотим знать названия, авторов и количество книг, которые поступили в различные поставки. Интересующая нас информация хранится в двух таблицах — Журнал Поставок (magazine_incoming) и Товар (products). Давайте напишим интересующий нас запрос:
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products. id_product;
id_product;
А что, если нам необходимо, чтобы результат выводился не в одной таблице, а по каждой поставке отдельно? Конечно, можно написать 3 разных запроса, добавив в каждый еще одно условие:
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=1; SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=2; SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=3;
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT magazine_incoming. id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
Чтобы убедиться в работоспособности цикла создадим хранимую процедуру books и поместим в нее цикл:
DELIMITER //
CREATE PROCEDURE books ()
begin
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming. id_product=products.id_product
AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
end
//
id_product=products.id_product
AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
end
//
Теперь вызовем процедуру:
CALL books ()//
Теперь у нас 3 отдельные таблицы (по каждой поставке). Согласитесь, что код с циклом гораздо короче трех отдельных запросов. Но в нашей процедуре есть одно неудобство, мы объявили количество выводимых таблиц значением по умолчанию (DEFAULT 3), и нам придется с каждой новой поставкой менять это значение, а значит код процедуры. Гораздо удобнее сделать это число входным параметром. Давайте перепишем нашу процедуру, добавив входной параметр num, и, учитывая, что он не должен быть равен 0:
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
WHILE i
Убедитесь, что с другими параметрами, мы по-прежнему получаем таблицы по каждой поставке. У нашего цикла есть еще один недостаток — если случайно задать
слишком большое входное значение, то мы получим псевдобесконечный цикл, который загрузит сервер бесполезной работой.
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
wet : WHILE i 10) THEN LEAVE wet;
ENF IF;
SELECT magazine_incoming.id_incoming, products.name, products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND magazine_incoming.id_incoming=i;
SET i=i+1;
END WHILE wet;
ELSE
SELECT 'Задайте правильный параметр';
END IF;
end
//

Циклы в MySQL, так же как и операторы ветвления, на практике в web-приложениях почти не используются. Поэтому для двух других видов циклов приведем лишь синтаксис и отличия. Вряд ли вам доведется их использовать, но знать об их существовании все-таки надо.
Оператор цикла REPEAT
Условие цикла проверяется не в начале, как в цикле WHILE, а в конце, т.е. хотя бы один раз, но цикл выполняется. Сам же цикл выполняется, пока условие ложно. Синтаксис следующий:
REPEAT
запрос
UNTIL условие
END REPEAT
Оператор цикла LOOP
Этот цикл вообще не имеет условий, поэтому обязательно должен иметь оператор LEAVE. Синтаксис следующий:
LOOP
запрос
END LOOP
На этом мы заканчиваем уроки посвященные SQL. Конечно, мы рассмотрели не все возможности этого языка запросов, но в реальной жизни вам вряд ли придется столкнуться даже с тем, что вы уже знаете.
Напомню, на реальных сайтах, вы обычно вводите информацию в какие-нибудь html-формы, затем сценарий на каком-либо языке (php, java. ..) извлекает
эти данные из формы и заносит их в БД. При необходимости происходит обратный процесс, т.е. данные извлекаются из БД и выводятся на страницы
сайта. Оба процесса происходят посредством SQL-запросов. HTML вы знаете, с базами данных разобрались, SQL-запросы писать научились, осталось
изучить PHP, чтобы ваши сайты превратились в полноправные web-приложения. Это и есть ваш следующий шаг. До встречи в уроках PHP.
..) извлекает
эти данные из формы и заносит их в БД. При необходимости происходит обратный процесс, т.е. данные извлекаются из БД и выводятся на страницы
сайта. Оба процесса происходят посредством SQL-запросов. HTML вы знаете, с базами данных разобрались, SQL-запросы писать научились, осталось
изучить PHP, чтобы ваши сайты превратились в полноправные web-приложения. Это и есть ваш следующий шаг. До встречи в уроках PHP.
Предыдущий урок
Вернуться в раздел
Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.
План запросов, простой взгляд MSSQL Server
План запросов, простой взгляд:
План выполнения запроса — последовательность операций, необходимых для получения результата SQL-запроса в реляционной СУБД.
План в целом разделяется на две стадии:
- Выборка результатов;
- Сортировка и группировка, выполнение агрегаций.
Сортировка и группировка — это опциональная стадия, которая выполняется,
если не найдено путей доступа для получения результата в запрошенном порядке.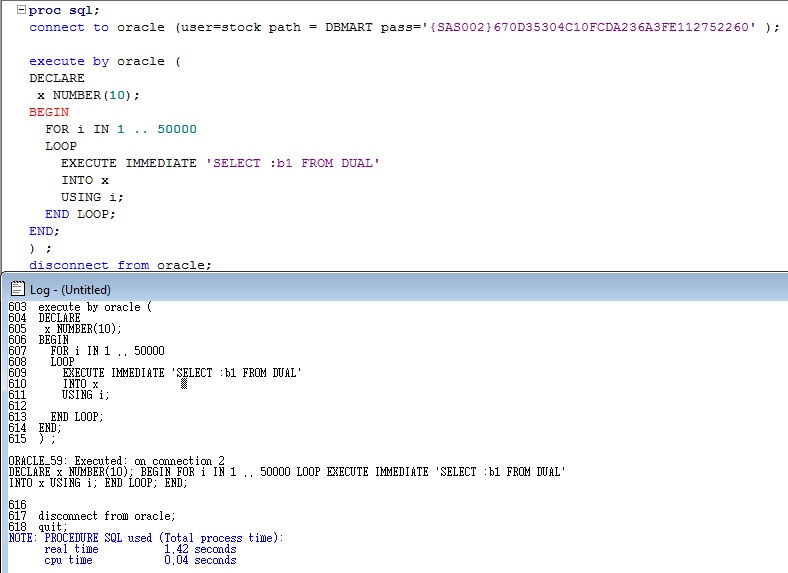
Выборка результатов выполняется следующими способами:
- Вложенные циклы;
- Слияние.
Вложенные циклы — это вложенные итеративные процессы поиска данных в каждой из соединяемых таблиц.
Внешний цикл извлекает все необходимые строки из внешней таблицы. Если часть или все ограничения для внешней таблицы могут быть использованы для поиска по индексу, то на каждой итерации цикла в индексе ищутся расположения всех необходимых строк и выполняется прямой доступ к таблице. В противном случае таблица сканируется целиком. Оставшиеся ограничения используются для фильтрации выбранных строк. Для каждой оставшейся строки вызывается внутренний цикл.
Внутренний цикл по условиям соединения и данным внешнего
цикла ищет строки во внутренней таблице. Если часть или все ограничения для
внутренней таблицы, а также ограничения, полученные от внешнего цикла, могут
быть использованы для поиска по индексу, то на каждой итерации цикла в индексе
ищутся расположения всех необходимых строк и выполняется прямой доступ к
таблице. В противном случае таблица сканируется целиком. Оставшиеся ограничения
используются для фильтрации выбранных строк.
В противном случае таблица сканируется целиком. Оставшиеся ограничения
используются для фильтрации выбранных строк.
Циклы могут вкладываться произвольное число раз. В этом случае внутренний цикл становится внешним для следующего цикла и т. д.
На каждой итерации самого глубокого цикла выбранные из таблиц строки конкатенируются, для получения одной строки итогового результата.
Если для некоторого цикла выполняется поиск по индексу, и всех колонок в индексе достаточно для получения итогового результата, то прямой доступ к таблице в этом цикле не выполняется.
Слияние
Если объединяемые таблицы имеют индексы по сравниваемым полям, то объединение
может быть выполнено с помощью слияния. Оба индекса
сканируются и в них ищутся одинаковые значения. Если колонок в индексах
достаточно для получения итогового результата, то чтение таблиц не выполняется.
В противном случае выполняется прямой доступ к сливаемым таблицам для получения
колонок, не входящих в индексы, но необходимых для получения результата.
Если слияния недостаточно для получения итогового результата, то для каждой строки, полученной слиянием, может выполняться до двух серий вложенных циклов, соответственно, для каждой из сливаемых таблиц.
Оптимизатор запросов (компонент СУБД) использует хранящуюся в базе данных вместе с таблицами и индексами статистическую информацию, на основе которой он оценивает альтернативные способы формирования результатов запроса. Например, команду ORDER BY в инструкции SELECT можно выполнить с использованием имеющегося в базе индекса, либо же путём физической сортировки строк. Оптимизатор старается выбрать самый эффективный план выполнения запроса.
Изучение планов выполнения запросов, созданных оптимизатором, позволяет решить, как ускорить выполнение запроса — изменить сам запрос или создать в базе данных дополнительный индекс.
Планы выполнения отображаются следующими способами.
Среда SQL Server Management Studio
Отображает либо ориентировочный графический план выполнения (инструкции не выполнены), либо реальный графический план выполнения (при выполненных инструкциях), который можно просмотреть в Management Studio и сохранить.
Параметры инструкции SET Transact-SQL
При использовании параметров инструкции SET Transact-SQL можно вывести ожидаемый или реальный план выполнения в формате XML или в текстовом формате.
Классы событий Приложение SQL Server Profiler
Можно включить классы событий Приложение SQL Server Profiler в трассировки для получения ожидаемых или реальных планов выполнения в формате XML или в текстовом формате в результатах трассировки.
Ниже перечислены некоторые наиболее распространенные причины медленного выполнения запросов и обновлений.
Медленная передача данных в сети.
Недостаточно памяти на серверном компьютере или недостаточно памяти для SQL Server.
Не хватает полезной статистики.
Не хватает полезных индексов.
Не хватает полезных индексированных представлений.
Не хватает полезного расслоения данных.

Не хватает полезного секционирования.
Связана ли проблема производительности с другими компонентами, помимо запросов? Например, не является ли причиной проблемы низкая скорость передачи данных по сети? Существуют ли также другие компоненты, которые могут вызвать снижение производительности или способствовать низкой производительности?
Можно использовать системный монитор Windows для контроля производительности компонентов SQL Server и компонентов, не относящихся к SQL Server.
Если проблема производительности связана с запросами, то какой запрос или набор запросов вызывает проблему?
С помощью Приложение SQL Server Profiler определите медленный запрос или запросы.
Инструкции по анализу производительности медленного запроса.
После определения медленно выполняющихся запросов можно далее проанализировать производительность запросов, создав параметр showplan, который может быть текстом, XML или графическим представлением плана выполнения запросов, формируемого оптимизатором запросов.
 Параметр showplan можно создать при помощи
параметров SET языка Transact-SQL, среды Среда SQL Server Management Studio
или приложения Приложение SQL Server Profiler.
Параметр showplan можно создать при помощи
параметров SET языка Transact-SQL, среды Среда SQL Server Management Studio
или приложения Приложение SQL Server Profiler.Был ли оптимизирован запрос с помощью статистики?
Оптимизатор запросов использует статистику для создания планов запросов, которые повышают производительность запросов. Для большинства запросов оптимизатор уже создает достаточно статистики для формирования высококачественного плана запроса, но в некоторых случаях для достижения оптимальных результатов нужно создать дополнительную статистику или изменить структуру запроса.
Предлагаются следующие рекомендации.
Использование параметров статистики на уровне базы данных. Например, следует убедиться, что включены параметры автоматического создания статистики (AUTO_CREATE_STATISTICS) и автоматического обновления статистики (AUTO_UPDATE_STATISTICS), действующие на уровне базы данных. Если они отключены, то планы запросов могут быть неоптимальными и производительность запросов может понизиться.

Определение условий создания статистики. В некоторых случаях можно усовершенствовать планы запросов, создав дополнительную статистику с помощью инструкции CREATE STATISTICS (Transact-SQL). Эта дополнительная статистика может фиксировать статистическую корреляцию, которую не учитывает оптимизатор запросов при создании статистики для индексов или отдельных столбцов.
Определение условий обновления статистики. В некоторых случаях можно улучшить план запроса и тем самым повысить производительность запроса, обновляя статистику чаще, чем она обновляется при включенном параметре AUTO_UPDATE_STATISTICS. Статистику можно обновлять инструкцией UPDATE STATISTICS или хранимой процедурой sp_updatestats.
Создание запросов, эффективно использующих статистику. Некоторые особенности реализации запросов, например использование локальных переменных и сложных выражений в предикате запроса, могут привести к созданию неоптимальных планов запросов.
 Этого можно избежать, если следовать рекомендациям по
конструированию запросов.
Этого можно избежать, если следовать рекомендациям по
конструированию запросов.
Доступны ли подходящие индексы? Улучшит ли производительность запроса добавление одного или более индексов?
Имеются ли какие-нибудь данные или наиболее активные участки индексов? Возможно, будет полезно расслоение дисков. Расслоение дисков можно выполнить с использованием RAID (резервного массива независимых дисков) уровня 0, когда данные распределяются на несколько дисковых носителей.
Поддерживается ли в оптимизаторе запросов самая лучшая возможность оптимизации сложного запроса?
Если объем данных большой, необходимо ли секционирование данных? Управляемость данных является главным преимуществом секционирования, но секционирование может также повысить производительность запроса, если таблицы и индексы таблиц секционируются подобным образом.
Анализ плана запроса ;
Актуальный план выполнения вы можете посмотреть в Management Studio, нажав “Ctrl+M”
1. Оценка Estimated Subtree Cost –
суммарная стоимость всех операций внутри дерева (или поддерева).
Оценка Estimated Subtree Cost –
суммарная стоимость всех операций внутри дерева (или поддерева).
Если же стоимость больше 2.0, то, как правило, этот запрос нужно либо
оптимизировать, либо хорошо представлять то, как подобные запросы могут
отразиться на состоянии системы (особенно в моменты пиковой нагрузки).Показатель
в условных единицах, который говорит , насколько
тяжело исполнять этот запрос(стоимость всего запроса целиком). Чем меньше, тем
лучше.
Этот показатель всегда надо сравнивать. Например месяц назад.
Стоимость и скорость запроса- не одно и тоже. Например блокировки не сказываются
на стоимости.
Clustered Index Scan – сканирование кластерного индекса часто служит тревожным сигналом (гораздо больше радует глаз Index Seek)
2. Смотрим состав и последовательность операций.
3.Раскладка в стоимости по операциям и выделяем те
опрерации , которые имеют большую стоимость в % соотношении.
4. Смотрим подробности по дорогим операциям.
5. Толщина стрелок, которая отражает количество строк. и говрит , где идёт обработка большого количества данных.
6. Подрообнее исследуем план — xml-представление и свойства плана(F4)(настройки,уровень оптимизации,причина отказа от дальнейшей оптимизации)
7.Представить логику запроса;
-JOIN — логическая операция на плане (может выполнить 3 способами физическими nested loops,hash match,merge join), хинты — INNER LOOP JOIN(самый медленный),INNER HASH JOIN,INNER MERGE JOIN (самый быстрый), если в плане перед MERGE будет сортировка- то не хватет индексов по этому полю.
_WHERE
-GROUP BY
-HAVING
-оконные функции — partition by, order by
-distinct,select,top
Nested Loops Joins
Вложенные циклы это самый простой вариант соединения, который обычно
используется при соединении таблиц, когда с одной из сторон строк достаточно
много, а с другой – порядка десятка. В этом случае идет цикл по большому
количеству строк, и для каждой найденной строки выполняется маленький цикл.
Пример подобного плана выполнения можно получить, отфильтровав одну из таблиц по
нечасто встречающемуся значению. Например, такой запрос:
В этом случае идет цикл по большому
количеству строк, и для каждой найденной строки выполняется маленький цикл.
Пример подобного плана выполнения можно получить, отфильтровав одну из таблиц по
нечасто встречающемуся значению. Например, такой запрос:
select p.ProductID, p.Name, c.Name
from SalesLT.Product p join SalesLT.ProductCategory c
on c.ProductCategoryID = p.ProductCategoryID
where c.Name = ''Bike Stands''Приводит к такому плану выполнения:
Давайте посмотрим, что происходит по этому плану:
- Получаем набор записей для категорий по фильтру (в нашем случае одна категория). Поскольку категории индексированы по названию, происходит Index Seek, то есть быстрый поиск по индексу.
- Проходим
все записи таблицы товаров. При этом происходит сканирование всей таблицы,
потому что нет индекса по категории. В случае, когда мы редко добавляем
новые товары и редко меняем категорию товара, зато часто фильтруем по
категориям, скорее всего будет целесообразно проиндексировать товары по
категории (или даже сделать кластерный индекс, начинающийся с категории).
 Однако, учитывая небольшую стоимость запроса на данном этапе (я не стал ее
показывать на рисунке, но у меня она была меньше 0.1), такую оптимизацию
можно оставить “на потом”.
Однако, учитывая небольшую стоимость запроса на данном этапе (я не стал ее
показывать на рисунке, но у меня она была меньше 0.1), такую оптимизацию
можно оставить “на потом”. - Во время прохождения таблицы товаров проверяем, совпадает ли идентификатор категории с результатами шага (1). И, если совпадает, добавляем к результатам запроса. Это и отображено узлом “Nested Loops”.
Прежде чем перейти к обсуждению других вариантов, хочу рассказать историю,
которая может быть вам интересна. Несколько лет назад довелось общаться с
сотрудником Oracle (плотно занимающимся оптимизацией этой СУБД в американском
офисе). Из разговора я, в частности, узнал, что (по крайней мере на тот момент)
в Microsoft SQL Server именно Nested Loops были реализованы лучше, чем в других
топовых СУБД. А уж подобным заявлениям прямого конкурента обычно всегда имеет
смысл верить. Другой вопрос, что про остальные типы соединения я умолчу, чтобы
никого не обидеть, да и достоверной информации на сегодняшний момент у меня нет.
Hash joins
Данный вариант более сложен и используется для работы с несортированными данными средних и больших объемов.
В простом случае, когда одно из множеств прилично меньше доступной оперативной памяти, в памяти строится хэш-таблица, в которой затем ищется соответствие для каждой строки из второго множества. Когда же объемы данных становятся слишком большими, задача разбивается на более мелкие (данные предварительно секционируются на диске с помощью той же хэш-функции).
Пример запроса, который приводит к hash join такой:
select p.ProductID, p.Name, c.Name
from SalesLT.Product p join SalesLT.ProductCategory c
on c.ProductCategoryID = p.ProductCategoryID
where c.Name like ''%Bike%''А план выполнения выглядит следующим образом:
Давайте посмотрим, что происходит:
- Сначала
ищем категории по шаблону, который начинается с “%”, что автоматически не
дает использовать индекс, однако, мы хотя бы не сканируем всю таблицу, а
считываем только индекс (потому что фильтруем по названию, а значение
кластерного ключа содержит любой не-кластерный индекс).
 Все значения заносим
в хэш-таблицу (в данном случае, практически наверняка в оперативной памяти).
Все значения заносим
в хэш-таблицу (в данном случае, практически наверняка в оперативной памяти). - Затем сканируем таблицу товаров.
- При этом получаем соответствующую категорию из хэш-таблицы.
Хотя операции получаются более сложными да и количество данных больше, чем в примере с Nested Loops, стоимость запроса все равно невысока (у меня она была чуть больше 0.1). Это объясняется небольшим количеством исходных данных – тысяча строк для промышленной СУБД – это смешно (если, конечно, железо нормальное).
Merge joins
Этот вариант применяется, когда данных слишком много для применения Nested
Loops, и элементы обоих множеств
отсортированы по столбцу соединения. Когда сортировка отсутствует, иногда бывает
целесообразно предварительно отсортировать множество и свести ситуацию к
предыдущей. В последней же ситуации, оптимизатору приходится выбирать между
Merge и Hash joins (метод hash joins часто приводит к меньшей стоимости запроса,
потому что сортировка довольно затратная операция).
Данный метод основан на том, что в случае сортировки обоих множеств по столбцу соединения, для “inner join”, например, мы просто можем параллельно сканировать оба множества и отбрасывать “кусок”, значение в котором меньше, чем значение из другого множества (и не встретилось в другом множестве ранее).
Пример использования Merje joins можно получить, убрав фильтр из предыдущего запроса:
select p.ProductID, p.Name, c.Name
from SalesLT.Product p join SalesLT.ProductCategory c
on c.ProductCategoryID = p.ProductCategoryIDПри этом получаем такой план выполнения:
Последовательность действий здесь следующая:
- Сканируем все товары и получаем список товаров, отсортированный по категории (операции Scan и Sort).
- Сканируем таблицу категорий по кластерному индексу (здесь дополнительная сортировка не нужна, потому что строки уже хранятся в нужном порядке).
- Соединяем множества по алгоритму, описанному до примера.
8. Представить логику WHERE
— Можно ли ускорить этот фильтр индексом?
— Можно ли ствинуть фильтр перед JOIN
9. Оконные функции
—Инлекс по PARTITION BY и затем по ORDER BY
-Включить в инлекс (INCLUDE) поля для всех последующих операций в запросе
Например ранжирование с секционированием Select Name,listPrice,Size, Rank() OVER (PARTITION BY Size ORDER BY ListPrice) from Product
требуется создание индекса по полю Size и ListPrice , затем include индекс Name — CREATE INDEX ind2 on Product (Size,ListPrice) INCLUDE (Name)
10.Распаралеливанием
11 Обращать внимание на warning в плане запроса
циклов обработки в SQL Server
Введение
Нет ничего сложнее повторения. Если делать плохо — это неуклюже, глупо. Когда все сделано хорошо, это как небольшое эхо, как волны, как сама поэзия.

Лоуренс Коссе «Книжный магазин романов»
Содержание
Почему эта статья?
Любой, кто хоть раз участвует в форуме быстрых ответов здесь, в Code Project (а также в аналогичном форуме на «другом» сайте), снова и снова увидит, что некоторые общие темы возникают в вопросах.
В теме SQL особенно часто встречается одна тема, которая обычно формулируется как «Как я могу написать цикл в SQL, чтобы получить…», за которым следуют любые результаты, которых пытается достичь плакат.
Эта статья представляет собой попытку собрать воедино несколько потенциальных решений этого типа вопросов, основанных на принципе : петля вам не нужна!
Таким образом, я нацелен в первую очередь на «новичков» SQL, показывая, как многие функции SQL Server означают, что циклы необходимы очень редко.Однако есть некоторые уловки, которые могут оказаться полезными для опытных пользователей. Я использую отработанные примеры, чтобы объяснить каждую альтернативу.
Что такое петля?
Это может показаться очевидным, но формальное определение никогда не помешает:
В компьютерном программировании цикл — это последовательность инструкций, которая непрерывно повторяется до тех пор, пока не будет достигнуто определенное условие. Обычно выполняется определенный процесс, например получение элемента данных и его изменение, а затем проверяется какое-то условие, например, достиг ли счетчик заданного числа.]
Еще кое-что, о чем я время от времени упоминаю в «Попался!» разделов, представляет собой «бесконечный цикл». Вот определение:
Бесконечный цикл — это цикл, в котором отсутствует действующая процедура выхода. В результате цикл повторяется непрерывно, пока операционная система не обнаружит его и не завершит программу с ошибкой или пока не произойдет какое-либо другое событие (например, автоматическое завершение программы по истечении определенного времени).
]
Типичный код VB6 / VBA мог выглядеть как
Размеры как ADODB.Набор записей ‘. . . код, заполняющий набор записей С rs Если нет .BOF и не .EOF, то .MoveLast .MoveFirst Делай, пока нет (rs.EOF) rs.MoveNext Петля Конец, если .Закрыть Конец сExcel может способствовать аналогичному мышлению благодаря тому, что вычисления автоматически меняются для каждой строки, просто перетаскивая ячейку вниз …
Сценарий, который может укрепить это мышление, — это когда требования к проекту устанавливают несколько действий, которые необходимо выполнить с одним набором данных — что-то вроде:
Представьте отчет на основе таблицы myTable, которая содержит следующую информацию
- Показать каждую строку с ее рангом на основе значения
- Подсчитать количество строк
- Определить, какая строка имеет наибольшее значение
- Вычислить общее и среднее всех значений для каждого продукта
- Захватить даты первая и последняя записи
- Если строка имеет определенный атрибут по сравнению с другой таблицей, обновите поле статуса
Некоторые из этих инструкций должны быть повторены для каждой строки, поэтому мне нужен цикл, верно?
Пока я просматриваю эти строки в цикле, у меня будут переменные для сбора промежуточной суммы, счетчика, максимальной даты и минимальной даты .
.. это хорошая идея, верно?
Затем мне нужно перебрать мою таблицу и обновлять эту другую таблицу по ходу.]
Они предназначены для одновременного действия с группами из связанных вещей (данных). Реляционная база данных будет обрабатывать тот факт, что есть много строк, с которыми нужно выполнить действие. По сути, вы пишете что-то, что описывает то, что вы хотите, и позволяете системе управления реляционными базами данных (СУБД) позаботиться о , как это сделает.
Например: представьте себе требования: «Для любого продукта, если количество единиц на складе меньше 20 единиц и нет единиц в заказе, прекратите выпуск продукта, установив флаг« Прекращено »на 1».
Псевдокод для процедурного выполнения будет
.Старт в начале набора рекордов Пока есть записи для обработки Если единиц на складе <20 И единиц в заказе = 0, то Установить Снято с производства = 1 Конец, если Перейти к следующей записи Конец ПокаНо с логикой, основанной на наборах, инструкция становится очень простой
ОБНОВЛЕНИЕ НАБОР ПРОДУКТОВ Снято с производства = 1 ГДЕ UnitsInStock <20 И UnitsOnOrder = 0Попался!
Помните определение бесконечного цикла из введения? Один из эквивалентов бесконечного цикла в операторе обновления SQL - это забыть включить предложение WHERE.
]
Попался снова!
Если вы посмотрите на исходные данные в таблице «Продукты», то увидите, что некоторые продукты уже сняты с производства. Для многих СУБД наша текущая инструкция снова установит флаг «Прекращено» для этих записей. Мы без необходимости обновляем записи, которые нам не нужны. Это не сильно повлияет на нашу небольшую базу данных, но если бы тысячи записей уже были прекращены, мы могли бы тратить время и ресурсы. Итак, хотя это явно не упоминается в требованиях, которые нам дали, мы действительно должны добавить еще один фильтр…
UPDATE Products SET Discontinued = 1 WHERE UnitsInStock <20 AND UnitsOnOrder = 0 AND Discontinued = 0Измененный запрос повлияет на меньшее количество строк - наш новый набор содержит только те строки, которые действительно требуют обновления.
Альтернативы циклам - соединения и подзапросы
Для меня достаточно легко сказать: «Не используйте циклы в SQL», но было бы немного несправедливо не предлагать альтернативы с немного большей сложностью, чем я предлагал до сих пор.
В следующем разделе будут приведены некоторые отработанные примеры, чтобы дать вам некоторые идеи о других методах, которые можно использовать вместо этого. Я также буду ссылаться на некоторые другие статьи, в основном здесь, на CodeProject, где авторы полностью объяснили тему лучше, чем у меня есть место здесь.
Данные фильтрации
Представьте себе требование: «Получить список всех заказов для клиентов из Лондона».
Когда я смотрю на таблицу заказов, я вижу столбец [ShipCity], и когда я запрашиваю его с помощью
SELECT OrderID, CustomerID FROM orders WHERE ShipCity = 'London'Я получаю список из 33 заказов. Отлично, поэтому я передаю эту информацию пользователю, который возвращается с жалобой: «А как насчет заказов для моего клиента« Вокруг рога »?»
Возвращаясь к данным, я понимаю, что этот клиент Around the Horn находится в Лондоне, но его заказы отправлены в Колчестер.Мой первый запрос не соответствует требованиям.
Может возникнуть соблазн создать петлю по строкам:
Создайте таблицу для хранения результатов Создайте набор записей, содержащий только клиентов, у которых City = ’London’ Начать с начала набора записей Пока есть записи для обработки Скопируйте все заказы для этого клиента в выходные результаты Перейти к следующей записи клиента Конец покаНо я знаю, что SQL установлен на основе, поэтому я делаю это вместо этого - получаю все заказы, где идентификатор клиента находится в наборе клиентов, где город = «Лондон» или:
ВЫБРАТЬ * ИЗ заказов, ГДЕ ИД клиента В (ВЫБРАТЬ ИД клиента ИЗ клиентов, ГДЕ Город = 'Лондон')Так лучше.] .
Подзапросы - отличный способ ограничить элементы в наборе при использовании с предложением WHERE, но они также могут использоваться в операторе SELECT. Это простой способ включения сводной информации.
Представьте, что требования на самом деле гласят: «Получите список всех заказов для клиентов из Лондона и покажите сравнение фрахта каждой строки со средним фрахтом для всех заказов».
Процедурный подход, вероятно, будет выглядеть так
ОБЪЯВИТЬ @O TotalAvg NUMERIC (15,2) SET @O TotalAvg = (ВЫБРАТЬ СРЕДНЕЕ (Фрахт) ИЗ заказов) SELECT *, Freight - @O GeneralAvg как AvgFreight FROM заказов ГДЕ CustomerID IN (ВЫБЕРИТЕ CustomerID из списка клиентов, ГДЕ City = 'London')Но, используя другой подзапрос, мы можем сделать все, что нам нужно, в одном операторе
SELECT *, Freight - (SELECT AVG (Freight) FROM Orders) как AvgFreight ИЗ заказов ГДЕ CustomerID IN (ВЫБЕРИТЕ CustomerID из списка клиентов, ГДЕ City = 'London')Теперь, когда моя таблица заказов растет и растет, мой администратор базы данных обеспокоен производительностью и просит меня еще раз взглянуть на мой запрос, чтобы увидеть, могу ли я его улучшить.
Вернемся к тому факту, что SQL основан на наборах. Я могу определить набор данных, с которыми я хочу работать, обратившись к более чем одной таблице с помощью объединений.
]]
Вот первый пример выше, на этот раз с использованием внутреннего соединения вместо подзапроса
ВЫБРАТЬ O.*, Фрахт - (ВЫБЕРИТЕ СРЕДНЕЕ (Фрахт) ИЗ заказов) как Ср. Фрахт ИЗ заказов O ВНУТРЕННИЕ ПРИСОЕДИНЯЙТЕСЬ к клиентам C ON O.CustomerID = C. ГДЕ Город = 'Лондон'Или даже
SELECT O. *, Freight - (SELECT AVG (Freight) FROM Orders) как AvgFreight ИЗ заказов O ВНУТРЕННИЕ ПРИСОЕДИНЯЙТЕСЬ к клиентам C ON O.CustomerID = C.CustomerID AND City = 'London'Оба этих запроса возвращают все данные, которые я ожидал, но гораздо более эффективно (в данном случае), чем при использовании предложения IN. А как насчет этого подзапроса в SELECT?
Ну, мы также можем использовать подзапросы в JOIN, например
ВЫБРАТЬ O.*, Грузовые перевозки - SQ.O TotalAvg как AvgFreight ИЗ заказов O ВНУТРЕННИЕ ПРИСОЕДИНЯЙТЕСЬ к клиентам C ON O.CustomerID = C.CustomerID AND City = 'London' ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБЕРИТЕ СРЕДНЕЕ (Фрахт) КАК ОбщееСредн. ИЗ заказов) SQ ON 1 = 1
Поскольку из нашей временной таблицы, созданной из SQ, возвращается только одно значение, я использовал трюк с использованием предложения ON, которое всегда истинно ...
ON 1 = 1.К сожалению, это не обязательно лучший способ с точки зрения производительности, но я думаю, что он позволяет немного упорядочить предложение SELECT.
[Примечание. Я сказал, что JOIN работает лучше, чем подзапросы для подобных запросов, однако обсуждение производительности выходит за рамки этой статьи. Я включил некоторые рекомендуемые материалы для дальнейшего чтения в ссылки в конце статьи]
Фильтрация данных с НЕ ВХОДИТ и НЕ СУЩЕСТВУЕТ
Теперь мы знаем, что можем использовать внутренние соединения как способ включения фильтра в наш набор данных. Что произойдет, если требования изменятся?
Представьте, что нашим пользователям теперь нужно, чтобы я вел список телефонных номеров, по которым Заказчик заявил, что , а не , хотят, чтобы с ними связывались по телефону.
Я решаю сохранить список этих клиентов в очень простой новой таблице…
СОЗДАТЬ ТАБЛИЦУ DoNotTelephone ( [CustomerID] [nchar] (5) НЕ NULL ) НА [ПЕРВИЧНОМ]И я заполняю эту таблицу идентификаторами клиентов, с которыми не следует связываться по телефону.
ВСТАВИТЬ ЗНАЧЕНИЯ DoNotTelephone ('LAZYK'), ('LETSS'), ('NORTS') и т.д…Теперь пользователи спрашивают у меня список телефонных номеров для кампании продаж, им нужен список всех клиентов из США. Они не упоминают об этом, но, конечно, мне не следует включать какие-либо числа в список DoNotTelephone.
Хорошо, теперь мы знаем, что нам определенно не нужно использовать процедурный цикл. Вы можете подумать, что присоединение, вероятно, хороший вариант, но как присоединиться к чему-то, чего там нет?
Для этого я могу использовать функцию
LEFT OUTERJoins. ОбъединениеINNERвернет только записи, которые находятся в обеих таблицах.Соединение
LEFT OUTERбудет возвращать записи для каждой строки в «левой» таблице, и, если строка не существует в «правой» таблице, SQL предоставитNULLзначений для столбцов из этой таблицы. .]Итак, если я отфильтрую результаты до , только получу записи с
NULLзначениями из таблицы DoNotTelephone, это эквивалентно высказыванию «не в таблице DoNotTelephone»…ВЫБЕРИТЕ ContactName, ContactTitle, CompanyName, C.Phone ОТ клиентов C ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ DoNotTelephone DNT НА C.CustomerID = DNT.CustomerID ГДЕ Страна = 'США' И dnt.CustomerID НУЛЯНо по мере того, как в список DoNotTelephone добавляется все больше и больше записей, выполнение этого запроса будет все больше и больше, поскольку мы запрашиваем значения, которые на самом деле нам не нужны.
К счастью, предложение
NOT INкажется именно тем, что мне нужно:ВЫБРАТЬ * ИЗ КЛИЕНТОВ ГДЕ CustomerID НЕ В (ВЫБЕРИТЕ CustomerID из DoNotTelephone) И Страна = "США"Но я все еще запрашиваю данные, которые мне не нужны - любой из клиентов, которые не в США, но и в списке DoNotTelephone, все еще опрашиваются, несмотря на то, что они нам не нужны.
(вероятно) лучшее решение - использовать
NOT EXISTS.Почему? Что ж, подзапрос не вернет никаких фактических данных - он возвращает только эквивалентTrueилиFalse. В измененном запросе ниже я использовалSELECT 1, а неSELECT Phone, чтобы подчеркнуть этот факт.ВЫБРАТЬ * ИЗ клиентов C ГДЕ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ DoNotTelephone, ГДЕ CustomerID = C.CustomerID) И Country = 'USA'Я кратко коснулся потенциальных проблем, связанных с запросом данных, которые нам на самом деле не нужны.Если вы хотите узнать больше о том, как подзапросы могут повлиять на производительность, в нижней части этой статьи есть несколько дополнительных материалов для чтения.
Обновление таблиц с помощью объединений
Очень распространенный сценарий включает обновление одной таблицы на основе содержимого другой.
Примите во внимание следующие требования: «Для любого продукта из категорий« Морепродукты »или« Мясо / птица »установите флаг« Прекращено »на 1».
Посмотрите на таблицу «Товары», и вы заметите, что Категория для каждого продукта представлена
CategoryID, который является числом, а не текстом.«Морепродукты» относятся к категории 8, а «Мясо / птица» - к категории 6.Нам нужно определить, какие записи в наборе данных необходимо обновить. Я мог бы запросить таблицу категорий, чтобы найти строку для «Морепродукты», принять к сведению
CategoryIDи затем использовать этот номер для обновления таблицы «Продукты»… но вам придется повторить этот процесс для «Мясо / птица». категория.- Попытка №1 ОБЪЯВИТЬ @id INT = (ВЫБРАТЬ ИДЕНТИФИКАТОР категории ИЗ категорий ГДЕ CategoryName = 'Морепродукты') ОБНОВЛЕНИЕ НАБОР ПРОДУКТОВ Discontinued = 1 WHERE CategoryID = @id AND Discontinued = 0 SET @id = (ВЫБРАТЬ ИДЕНТИФИКАЦИЮ КАТЕГИИ ИЗ категорий ГДЕ CategoryName = 'Мясо / Птица') ОБНОВЛЕНИЕ НАБОР ПРОДУКТОВ Discontinued = 1 WHERE CategoryID = @id AND Discontinued = 0Это просто ужасно! Я повторяю весь этот код.
Это опасная точка, когда наш процедурный мозг решает, «хорошо, что цикл там будет хорошо работать». Возникает искушение перебрать Категории - псевдокод выглядит так:
Создать набор записей, содержащий только категории, соответствующие требованиям Начать с начала этого набора записей Пока есть записи для обработки Обновите таблицу продуктов для этого CategoryID Перейти к следующей категории Конец ПокаНо сейчас мы начинаем понимать, что так делать не будем!
I может использовать предложение
IN- с жестко заданными значениями 6 и 8, которые я искал вручную.- Попытка №2 ОБНОВЛЕНИЕ Набор продуктов прекращен = 1 ГДЕ CategoryID IN (6,8) И снято с производства = 0Но через пару месяцев я могу забыть, откуда взялись эти «магические числа», или, что еще хуже, коллега должен забрать мою работу и просто не знает, откуда эти числа вообще взялись!
Использование безымянных магических чисел в коде скрывает намерение разработчиков при выборе этого числа, увеличивает возможности для скрытых ошибок .
.. и затрудняет адаптацию и расширение программы в будущем.]
К счастью, я могу выполнить обновление за один раз и при этом сделать очевидным, чего я пытаюсь достичь, используя объединение…
- Попытка №3 ОБНОВЛЕНИЕ Набор продуктов прекращен = 1 ИЗ продуктов P ВНУТРЕННЕЕ СОЕДИНЕНИЕ Категории C НА P.CategoryID = C.CategoryID ГДЕ CategoryName IN («Морепродукты», «Мясо / птица») И снято с производства = 0Стоит уделить время тому, чтобы взглянуть на различия между этими двумя последними операторами SQL. («Попытка №2» и «Попытка №3»)
- Бит, выполняющий ОБНОВЛЕНИЕ, одинаков в обоих - это логично, что - это , чего мы пытаемся достичь.
- Предложение WHERE очень похоже… в первой версии есть «магические числа», тогда как во второй версии явно используются слова из требований, «Морепродукты» и «Мясо / птица», но предложения по сути остаются теми же.
- Строка INNER JOIN в # 3 выглядит нормально - ничего особенного, хотя, возможно, мы не ожидали этого в операторе UPDATE.
- Этот лишний FROM в Попытке №3 выглядит странно. Похоже, что мы определяем SELECT, а не обновляем таблицу.В каком-то смысле это именно то, что мы делаем…
Мы определяем набор данных, для которых мы хотим выполнить обновление. Думайте об этом как о «обновлении строк, полученных ОТ этого запроса». Теперь это внутреннее объединение имеет смысл, поскольку мы уже видели, как объединения могут помочь фильтровать набор данных.
В приведенном выше примере мы устанавливали значение столбца на одно значение для всех строк в наборе. Что, если мы хотим установить значения на основе фактических значений в другой таблице?
Представьте, что наш отдел поддержки переместил несколько серверов и переместил все фотографии наших сотрудников.Они любезно предоставили нам список идентификаторов сотрудников и новое расположение их фотографий. Таблица довольно простая:
СОЗДАТЬ ТАБЛИЦУ [dbo]. [NewPhotos] ( [EmployeeID] [int] IDENTITY (1,1) NOT NULL, [PhotoPath] [nvarchar] (255) NULL ) НА [ПЕРВИЧНОМ]Мы используем ту же технику, что и для категории, то есть соединение, но на этот раз объединение не просто предоставляет фильтр (набор сотрудников, фотографии которых переместились), оно также предоставляет новое значение, которое нам нужно использовать.
на каждого Сотрудника:
ОБНОВЛЕНИЕ сотрудников SET PhotoPath = New.PhotoPath ОТ сотрудников E INNER JOIN newPhotos New ON E.EmployeeID = New.EmployeeIDКлючевой особенностью здесь является то, что вам нужно упомянуть обновляемую таблицу дважды ...
ОБНОВЛЕНИЕдолжно знать, какую таблицу обновлять, но нам также необходимо использовать таблицу так, как мы определяем набор данные для использования в обновлении.Для экономии ввода можно использовать псевдоним таблицы вместо полного имени
ОБНОВЛЕНИЕ E НАБОР PhotoPath = New.PhotoPath ОТ сотрудников E INNER JOIN newФотографии Новинки ON E.EmployeeID = New.EmployeeIDПромежуточные итоги с использованием самостоятельных соединений
Чтобы получить «текущие» итоги или счетчики из набора данных, вы можете использовать таблицу с «самосоединением», то есть соединением с самим собой.
Самосоединение - это запрос, в котором таблица соединяется (сравнивается) сама с собой.
Самосоединения используются для сравнения значений в столбце с другими значениями в том же столбце в той же таблице. Одно из практических применений самосоединений: получение текущих счетчиков и текущих итогов в запросе SQL.]
Представьте, что мы хотим получить промежуточную сумму и текущее количество всех заказов по продуктам. Мы можем использовать:
ВЫБЕРИТЕ P.ProductName, t1.OrderID, t1.Quantity, RunningTotal = SUM (t2.Quantity), RunningCount = COUNT (t2.Quantity) FROM [Детали заказа] AS t1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ [Детали заказа] КАК t2 НА t1.ProductID = t2.ProductID И t1.OrderID> = t2.OrderID INNER JOIN Products P ON t1.ProductID = P.ProductID ГРУППА ПО P.ProductName, t1.OrderID, t1.Quantity ЗАКАЗ П.ProductName, t1.OrderIDОбратите внимание на
AND t.OrderID> t2.OrderID…- это та часть предложенияON, которая обеспечивает механизм для «бегущей» суммы, когда мы выполняемSUMиCOUNT.]
Попался! - Присоединяйтесь к подсказкам
Я собираюсь упомянуть здесь подсказки Join очень кратко и только потому, что есть такая вещь, как подсказка LOOP JOIN.] . Однако я крайне опасаюсь предполагать, что смогу определить, какими должны быть эти улучшения!
Что еще более важно, существует явная опасность того, что подсказки останутся в рабочем коде и никогда не будут пересмотрены после обновления системы. Это увеличивает риск того, что со временем они станут контрпродуктивными.
Для целей этой статьи, которая в основном предназначена для начинающих, я сообщил вам, что они существуют, и предоставил некоторые дополнительные материалы для чтения по ссылке в тексте, если вы решите продолжить изучение этой темы.
Решает множество проблем с помощью общих табличных выражений
Общее табличное выражение (CTE) можно рассматривать как временный набор результатов, который определяется в пределах области выполнения одного оператора SELECT, INSERT, UPDATE, DELETE или CREATE VIEW.
CTE похож на производную таблицу в том, что он не хранится как объект и действует только на время запроса. В отличие от производной таблицы, CTE может ссылаться на себя и на него можно ссылаться несколько раз в одном запросе.] - отличный способ избежать использования процедурных циклов. Вот несколько примеров…
CTE, пример 1 - обход иерархии
База данных Northwind содержит таблицу «Сотрудники», в которой перечислены все сотрудники компании, а также указаны сотрудники, которым подчиняются (кто их руководитель).
Если запросить таблицу
ВЫБЕРИТЕ EmployeeID, ReportsTo, LastName, FirstName, Title ОТ сотрудников ORDER BY ReportsTo, EmployeeIDПолучаем
Это нормально, но не очень помогает, когда мы пытаемся изобразить сотрудников на организационной диаграмме.Вот наглядное изображение того, какими мы хотели бы видеть эти результаты.
Из диаграммы легко увидеть, что Энн Додсворт, Роберт Кинг и Майкл Суяма находятся на «низшем» уровне, Эндрю Фуллер - «начальник», а все остальные находятся на том же уровне отчетности на среднем уровне (уровень 2).
Не так просто увидеть эту структуру в результатах запроса, поскольку нам приходится возвращаться к результатам, чтобы увидеть, кто кому подчиняется.
Мы можем обойти эту проблему, используя рекурсивное общее табличное выражение (rCTE) для обхода этой иерархии и получения дополнительной информации по каждой строке, т.е.е. «Уровень» на диаграмме для каждого сотрудника и путь отчетности. Вот полный запрос
; С Emp_CTE AS ( ВЫБЕРИТЕ EmployeeID, ReportsTo, LastName, FirstName, Title , 1 как RLevel , MtoE = CAST (isnull (ReportsTo, 0) AS VARCHAR (MAX)) + '/' + CAST (EmployeeID КАК VARCHAR (MAX)) ОТ сотрудников ГДЕ ReportsTo IS NULL СОЮЗ ВСЕ ВЫБЕРИТЕ e.EmployeeID, e.ReportsTo, e.LastName, e.FirstName, e.Title , RLevel + 1 , MtoE = MtoE + '/' + CAST (например,EmployeeID КАК VARCHAR (MAX)) ОТ сотрудников e ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ Emp_CTE ecte ON ecte.EmployeeID = e.ReportsTo ) ВЫБЕРИТЕ EmployeeID, EC.ReportsTo, LastName, FirstName, Title, RLevel, MtoE ОТ Emp_CTE EC
Что на самом деле происходит в этом запросе?
Первая часть запроса
ВЫБЕРИТЕ EmployeeID, ReportsTo, LastName, FirstName, Title, 1 как RLevel , MtoE = CAST (isnull (ReportsTo, 0) AS VARCHAR (MAX)) + '/' + CAST (EmployeeID AS VARCHAR (MAX)) ОТ сотрудников ГДЕ ReportsTo IS NULLявляется «якорным элементом» для CTE, также называемым «вызов» - i.е. наша отправная точка. В этом случае я ищу любого Сотрудника, который никому не подчиняется - «босса».
Следующая часть запроса - это «рекурсивный элемент», который вызывается многократно, пока не будут обработаны все записи.
ВЫБЕРИТЕ e.EmployeeID, e.ReportsTo, e.LastName, e.FirstName, e.Title, RLevel + 1 , MtoE = MtoE + '/' + CAST (e.EmployeeID AS VARCHAR (MAX)) ОТ сотрудников e ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ Emp_CTE ecte ON ecte.EmployeeID = e.ReportsTo
UNION ALLобъединяет все наборы результатов вместе во временный набор результатов, называемыйEmp_CTE.Наконец, я запрашиваю этот временный набор результатов, как если бы это была просто еще одна таблица в базе данных.Итак, наш элемент привязки возвращает этот набор данных
2 NULL Фуллер Эндрю Вице-президент по продажам 1 0/2Первая итерация рекурсивного элемента возвращает список сотрудников, которые отчитываются перед Эндрю, то есть первая итерация использует набор результатов из элемента Anchor в качестве входных данных.
1 2 Davolio Nancy Торговый представитель 2 0/2/1 3 2 Leverling Джанет, торговый представитель 2 0/2/3 4 2 Павлин Маргарет Торговый представитель 2 0/2/4 5 2 Бьюкенен Стивен Менеджер по продажам 2 0/2/5 8 2 Каллахан Лаура Координатор внутренних продаж 2 0/2/8Следующая итерация возвращает следующие результаты - список всех людей, которые подчиняются Нэнси, Джанет, Маргарет, Стивену или Лоре.
Итерация рекурсивного элемента использует выходные данные предыдущей итерации (рекурсивного элемента) в качестве входных данных и перемещается на один уровень вниз по иерархии.
6 5 Суяма Майкл Торговый представитель 3 0/2/5/6 7 5 Торговый представитель King Robert 3 0/2/5/7 9 5 Додсворт Энн, торговый представитель 3 0/2/5/9Следующая итерация возвращает пустой набор данных, поскольку у Майкла, Роберта и Анны нет никого, кто отчитывается перед ними, и поэтому рекурсия заканчивается.Все результаты объединяются в виде выходных данных rCTE в качестве выходных данных и могут быть запрошены, как если бы вы запрашивали любую другую таблицу.
Все rCTE дает эти результаты
Давайте более подробно рассмотрим эти производные столбцы RLevel и MtoE
.RLevel прост - мы устанавливаем его в 1 в элементе Anchor, а затем увеличиваем его на 1 каждый раз, когда вызывается рекурсивный элемент. Таким образом, он показывает «уровень» в иерархии для каждого сотрудника.
MtoE (от менеджера к сотруднику) отслеживает «путь» вниз по дереву иерархии к каждому сотруднику, используя EmployeeID на каждом уровне отчетности - «Уровень 0» / «Уровень 1» / «Уровень 2» / «Уровень 3» /… и т. Д. .
Например. Для сотрудника Энн Додсворт столбец MtoE выглядит как «0/2/5/9»…
- Начиная с правой стороны этой строки найдите идентификатор сотрудника 9 на самом нижнем уровне (например, Энн Додсворт)
- На следующем уровне вверх (Уровень 2) найдите идентификатор сотрудника 5 (Стивен Бьюкенен)
- На следующем уровне вверх (уровень 1) найдите идентификатор сотрудника 2 (Эндрю Фуллер)
- На следующем уровне выше (уровень 0) найдите идентификатор сотрудника 0 (никто)
Итак, Энн Додсворт отчитывается Стивену Бьюкенену, который отчитывается перед Эндрю Фуллером, который не отчитывается перед один.
Возможность отслеживать такие записи может быть полезна для вашего уровня представления - например, так что вы можете сразу перечислить каждого менеджера, за которым следуют их непосредственные подчиненные.
Попался! - MAXRECURSION
При использовании рекурсии довольно легко попасть в ситуацию бесконечного цикла с плохо сформированным CTE.
Давайте посмотрим на CTE для структуры отчетности менеджеров с небольшими поправками - я использовал псевдоним CTE в SELECT рекурсивного элемента вместо таблицы Employees i.е. Я использовал псевдоним «ecte» вместо «e». В приведенном ниже коде он выделен жирным шрифтом.
; С Emp_CTE AS ( ВЫБЕРИТЕ EmployeeID, ReportsTo, LastName, FirstName, Title ОТ сотрудников ГДЕ ReportsTo IS NULL СОЮЗ ВСЕ ВЫБЕРИТЕ ecte.EmployeeID, ecte.ReportsTo, ecte.LastName, ecte.FirstName, ecte.Title ОТ сотрудников e ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ Emp_CTE ecte ON ecte.EmployeeID = e.ReportsTo ) ВЫБЕРИТЕ EC.EmployeeID КАК ID, ISNULL (E.LastName + ',' + E.FirstName, 'No-one!') Как Manager, EC.Фамилия, EC.FirstName, EC.Title ОТ Emp_CTE EC LEFT JOIN Employees E ON EC.ReportsTo = E.EmployeeID ЗАКАЗ ОТ MtoE, EC.ReportsTo, EC.EmployeeIDКогда я запускаю этот запрос, я получаю сообщение об ошибке
Msg 530, уровень 16, состояние 1, строка 1 Оператор завершен. Максимальное количество рекурсии 100 было исчерпано до завершения оператора.
Странно! В таблице «Сотрудники» всего 9 записей, поэтому я ожидаю, что в результате получится только 9 строк - ну, конечно, не более 100! Такие ошибки бывает сложно остановить, но в данном случае я сделал это намеренно.Что происходит с использованием псевдонима ecte вместо e? Я , а не , пытаюсь передать результат предыдущей итерации на следующий проход, я на самом деле неоднократно ссылаюсь на предыдущий набор результатов (ecte), который всегда будет содержать данные (в этом примере) - т.е. бесконечный цикл.
К счастью, SQL Server имеет значение по умолчанию для количества рекурсий (как ни странно, 100), поэтому мне не нужно сидеть и ждать, пока этот запрос (никогда) не завершится.Но это отличный способ убедиться, что мой код не вызывает бесконечного цикла, и если есть один SQL Server, он убьет его за меня!
Итак, я получил сообщение об ошибке, посмотрел на свой код, обнаружил ошибку в рекурсивном элементе и исправил эти псевдонимы с ecte на e. Теперь, когда я повторно запускаю запрос, я получаю ожидаемые результаты, которые мы обсуждали выше. Работа сделана? Не совсем.
Что, если бы на столе было более 100 сотрудников? Собирается ли количество рекурсий по умолчанию остановить наш запрос, прежде чем мы доберемся до того места, где нам нужно быть? Короче говоря, да, но мы можем что-то с этим поделать.] по запросу.
Допустим, мы ожидали возврата около 150 строк, мы могли бы добавить
ОПЦИЯ(MAXRECURSION 150)до конца запроса (после предложения ORDER BY)
Фантастика! Тестирую. Оно работает. Я могу подписать его на продакшн и отправиться отмечать успешное внедрение.
Переместите время вперед, и теперь в нашей компании работает 151 сотрудник. Взрыв! Запрос снова начинает терпеть неудачу. Я мог бы изменить подсказку на произвольно большое число, но нет ничего, что говорило бы о том, что наша компания не собирается выходить на мировой рынок и нарушать любое число, которое я выберу.Придется снова изменить код. Не забывайте, что мы говорили о магических числах ранее.
Я могу избежать этой ситуации, сказав SQL Server, что мы не хотим никаких ограничений на количество рекурсий, и я делаю это с помощью
ОПЦИЯ (МАКСИМАЛЬНАЯ ЗАЩИТА 0)Параметр 0 (ноль) не означает «без рекурсий»; это означает « без ограничений на рекурсии».
Попался снова!
Никогда использовать
OPTION (MAXRECURSION 0)в запросе до тех пор, пока запрос не будет тщательно протестирован… или вы можете вернуться к сценарию бесконечного цикла.CTE, пример 2 - сравнение предыдущих и последующих значений
Поскольку CTE создают временные наборы данных, подобные временным таблицам, у вас есть большая гибкость в том, что вы можете с ними делать. Например, у вас может быть несколько CTE, к которым вы можете присоединиться, или вы также можете выполнить «самостоятельное присоединение». Вот пример, демонстрирующий, как это может быть полезно…
Представьте, что меня попросили узнать информацию о частоте заказов, размещаемых клиентским кодом ERNSH. Наши пользователи хотят знать, сколько дней проходит между каждым заказом для этого клиента.
Достаточно просто получить OrderDates для этого клиента
ВЫБЕРИТЕ CustomerID, OrderDate ОТ Заказы ГДЕ CustomerID = 'ERNSH'И получаем 30 строк данных…
Теперь, чтобы увидеть разницу между датами, похоже, мне нужно пройтись по этим результатам, зафиксировать дату заказа в переменной, сравнить текущее значение переменной со следующим в цикле ... Давайте остановимся на этом - вы получите идея, и вы знаете, что я все равно не буду использовать процедурный цикл.
Взгляните на этот CTE:
; С КТР КАК ( ВЫБЕРИТЕ CustomerID, OrderDate , ROW_NUMBER () OVER (ORDER BY OrderID) AS rn ОТ Заказы ГДЕ CustomerID = 'ERNSH' ) ВЫБЕРИТЕ CTE.CustomerID, CTE.OrderDate, ISNULL (DATEDIFF (dd, prev.OrderDate, CTE.OrderDate), 0) AS DIFF ОТ CTE LEFT OUTER JOIN CTE prev ON prev.rn = CTE.rn - 1К нашему исходному запросу для получения дат заказа мы добавили вызов функции SQL ROW_NUMBER (), которая присвоит всем заказам последовательный номер строки от 1 до 30 (этот «последовательный» важен… ) на основе идентификатора заказа.Идентификатор заказа был определен как
[OrderID] [int] IDENTITY (1,1) NOT NULL, поэтому заказ в этом столбце означает, что я получу заказы, возвращенные в том порядке, в котором они были введены.
Я поместил этот запрос в простое выражение общей таблицы («простое» в данном случае означает «нерекурсивный»), затем я запускаю запрос к этому CTE. Этот запрос включает LEFT OUTER JOIN обратно к тому же CTE - он имеет ALIAS
prevвыше. Это соединение дает нам запись, имеющую номер предыдущей строки для строки, которую мы в данный момент просматриваем.LEFT OUTER JOIN CTE prev.rn = CTE.rn - 1Итак, теперь мы можем сравнить OrderDate из CTE с OrderDate в объединении
до, чтобы получить разницу в днях между заказами.РАЗНДАТ (дд, предыдущая дата заказа, CTE.Дата заказа) КАК РАЗННаш новый запрос дает результаты:
Обратите внимание, что мы также можем заглянуть в следующую запись, используя
LEFT OUTER JOIN CTE nxt ON nxt.rn = CTE.rn + 1И вы можете делать с CTE практически все, что вы делали бы со столом - e.г. Группировать по, средним и т. Д.
; С КТР КАК ( ВЫБЕРИТЕ CustomerID, OrderDate , ROW_NUMBER () OVER (ORDER BY OrderID) AS rn ОТ Заказы ГДЕ CustomerID = 'ERNSH' ) ВЫБЕРИТЕ CTE.CustomerID, AVG (ISNULL (DATEDIFF (dd, prev.OrderDate, CTE.OrderDate))) AS DIFF ОТ CTE LEFT OUTER JOIN CTE prev ON prev.rn = CTE.rn - 1 ГРУППА ПО CTE.CustomerIDЧтобы получить
ЭРНШ 21CTE Пример 3 - Использование нескольких CTE
Я собираюсь продемонстрировать другой метод получения этого среднего значения, используя второй CTE, связанный с первым.]
; С КТР КАК ( ВЫБЕРИТЕ CustomerID, OrderDate , ROW_NUMBER () OVER (ORDER BY OrderID) AS rn ОТ Заказы ГДЕ CustomerID = 'ERNSH' ), CTE2 AS ( ВЫБЕРИТЕ CTE.CustomerID, ISNULL (DATEDIFF (дд, предыдущийOrderDate, CTE.OrderDate), 0) AS DIFF ОТ CTE LEFT OUTER JOIN CTE prev ON prev.rn = CTE.rn - 1 ) ВЫБЕРИТЕ CustomerID, «Среднее», AVG (DIFF) ОТ CTE2 ГРУППА ПО CustomerIDОбратите внимание, что второй CTE (гениально названный
CTE2) использует первый CTE для получения некоторых данных, а окончательный запрос относится только к CTE2.Это все хорошо, но в нашей базе данных много клиентов. На самом деле мы не хотим, чтобы этот запрос выполнялся отдельно для каждого клиента. К счастью, есть версия функции ROW_NUMBER, которая РАЗБИРАЕТ данные для нас. Мы можем указать запросу перезапускать нумерацию строк с 1 каждый раз, когда мы сталкиваемся с новым CustomerId. Вот измененный запрос для получения номеров строк для каждого клиента
ВЫБЕРИТЕ CustomerID, OrderDate, OrderID , ROW_NUMBER () НАД (РАЗДЕЛЕНИЕ ПО CustomerID ORDER BY OrderId) AS rn ОТ ЗаказыМы изменили предложение OVER, чтобы упорядочить данные только по OrderId, и передали его PARTITION или проанализировать данные по каждому CustomerId.Этот запрос дает следующие результаты
Обратите внимание, как значение rn перезапускается с 1 для каждого нового набора данных клиента.
Попался! Номер строки больше не уникален
Если я помещу этот запрос в наш CTE и выполню его, я получу… 45844 строки в нашем наборе результатов! Ого! Всего заказов 830, что происходит?
Запомните мое присоединение к «предыдущей» строке из запроса…
LEFT OUTER JOIN CTE prev.rn = CTE.rn - 1Предполагалось, что каждый номер строки уникален - потому что мы запрашивали только один CusomerId.Теперь у нас столько строк с номером 1, сколько CustomerIds. Нам необходимо внести поправки в этот пункт ON…
; С КТР КАК ( ВЫБЕРИТЕ CustomerID, OrderDate, OrderID , ROW_NUMBER () OVER (РАЗДЕЛЕНИЕ ПО идентификатору клиента ORDER BY OrderId) КАК rn ОТ Заказы ) ВЫБЕРИТЕ CTE.CustomerID, CTE.OrderDate, ISNULL (DATEDIFF (dd, prev.OrderDate, CTE.OrderDate), 0) AS DIFF ОТ CTE LEFT OUTER JOIN CTE prev ON prev.rn = CTE.rn - 1 И CTE.CustomerID = предыдущийCustomerIDТеперь мы получаем разумные результаты - 830 строк, начинающихся с
.Вам понадобится нечто подобное с нашим примером с несколькими CTE, если вы хотите получить среднее количество дней между заказами для всех клиентов (помня, что это был надуманный пример для демонстрации нескольких CTE, а не хороший способ получить эти данные. ).
; С КТР КАК ( ВЫБЕРИТЕ CustomerID, OrderDate, OrderID , ROW_NUMBER () НАД (РАЗДЕЛЕНИЕ ПО CustomerID ORDER BY OrderId) AS rn ОТ Заказы ), CTE2 AS ( ВЫБЕРИТЕ CTE.CustomerID, ISNULL (DATEDIFF (дд, предыдущийOrderDate, CTE.OrderDate), 0) AS DIFF ОТ CTE LEFT OUTER JOIN CTE prev ON prev.rn = CTE.rn - 1 И CTE.CustomerID = prev.CustomerID ) ВЫБЕРИТЕ CustomerID, «Среднее», AVG (DIFF) ОТ CTE2 ГРУППА ПО CustomerIDCTE Пример 4 - Последовательности - Создание списков
ЗапросыCTE могут быть легко использованы для генерации последовательностей.]
Представьте, что мы хотим составить список сотрудников на следующие две недели.
Мы можем использовать rCTE для генерации последовательности дат, начиная с сегодняшнего дня в течение 14 дней. Если мы затем ПЕРЕСЕЧЕМ эту небольшую последовательность с таблицей сотрудников, мы получим каждую строку из rCTE для каждого сотрудника. Как это:
; С КТР КАК ( ВЫБЕРИТЕ GETDATE () КАК данные СОЮЗ ВСЕ ВЫБРАТЬ ДАТУ ДОБАВИТЬ (ДД; 1, данные) ОТ CTE ГДЕ DATEADD (DD; 1; данные)Что дает следующие результаты:
CTE, пример 5 - Последовательности - поиск недостающих элементов
Один из приемов с последовательностями дат - определить, какие даты отсутствуют в наборе данных. Как и в примере выше, мы будем использовать rCTE для генерации последовательности всех дат между датой начала и датой окончания. Второй запрос к нему будет LEFT OUTER JOIN к таблице Orders.Результатом будут все даты, когда не было размещено ни одного заказа.
ОБЪЯВИТЬ @minDate DATE ОБЪЯВИТЬ @maxDate ДАТУ ВЫБЕРИТЕ @minDate = MIN (OrderDate), @maxDate = MAX (OrderDate) ИЗ заказов ; С CTE AS ( ВЫБРАТЬ @minDate как данные СОЮЗ ВСЕ ВЫБРАТЬ ДАТУ ДОБАВИТЬ (ДД; 1, данные) ОТ CTE ГДЕ ДОБАВИТЬ ДАТУ (ДД; 1; данные) <= @maxDate ), DateSeq AS ( ВЫБРАТЬ данные ОТ CTE ) ВЫБРАТЬ D. ОТ DateSeq D LEFT OUTER JOIN Заказы O ON O.OrderDate = D.datum ГДЕ О.OrderID IS NULL ВАРИАНТ (MAXRECURSION 0)Совет - эта точка с запятой
При создании CTE у вас могут быть другие операторы SQL перед ним или после его тестирования вы можете захотеть вставить код CTE в гораздо более крупную процедуру. Затем вы можете встретить это сообщение об ошибке:
Неправильный синтаксис рядом с ключевым словом «с». Если этот оператор является общим табличным выражением, предложением xmlnamespaces или предложением контекста отслеживания изменений, предыдущий оператор должен заканчиваться точкой с запятой.
Это довольно очевидное сообщение об ошибке, и решение довольно простое ... просто поставьте точку с запятой в конце строки над объявлением CTE. Но если вы вставите еще код перед CTE, вам придется не забыть сделать это снова. Среди разработчиков MSSQL распространена привычка ставить точку с запятой перед WITH, как в приведенных выше примерах.
Решение проблем с функциями окна SQL
Методы, которые мы использовали в предыдущем разделе, будут работать с большинством версий SQL Server, но одна из областей, которые постоянно улучшаются по сравнению с выпусками, - это «Оконные функции».]
Это отличный способ получить подробную информацию об отдельных строках, а также получить агрегированную информацию.
В приведенном выше примере я использовал оконную функцию ROW_NUMBER (). Включив предложение PARTITION, я смог применить нумерацию строк к каждому набору данных для каждого клиента (без использования процедурного цикла). «Дескриптор окна» был CustomerID. Мы заметили, что если мы опускаем PARTITION BY, тогда все строки в таблице получают номер строки - i.]







Этот запрос работал хорошо и получил данные, которые мы хотели, но было бы неплохо, если бы существовал более лаконичный способ сделать это - вместо того, чтобы генерировать дополнительные данные (ROW_NUMBER ()), создавать CTE и затем выполнять самостоятельное присоединение. Что ж, для SQL Server 2012 (не в версии Express) и более поздних версий (включая 2014 Express) для этого доступны дополнительные функции окна SQL.
Этот запрос дает точно такие же результаты, как и до
ВЫБЕРИТЕ CustomerID, OrderDate,
ISNULL (DATEDIFF (dd, LAG (OrderDate, 1) OVER (РАЗДЕЛ ПО CustomerID
ORDER BY CustomerID, OrderId), OrderDate), 0) AS DIFF
ОТ Заказы
Если раньше мы использовали пред.OrderDate в функции DATEDIFF, теперь мы используем
LAG (OrderDate, 1) OVER (РАЗДЕЛЕНИЕ ПО CustomerID ORDER BY OrderId)
Обратите внимание на то, что предложение OVER точно такое же, что я использовал ранее для ROW_NUMBER ()? Это имеет смысл, потому что нас по-прежнему интересуют данные для каждого идентификатора клиента, и нам по-прежнему нужны заказы в порядке OrderDate. Номер строки пропал, и мы не используем никаких самосоединений, поэтому псевдоним таблицы prev также исчез.
Функция LAG делает все за меня. В этой части запроса теперь указано
| Получить значение OrderDate из предыдущей строки | LAG (OrderDate, |
| Возвращение на одну строку из текущей строки в коллекции | , 1) |
| Коллекция должна быть разделенным на CustomerID I.e. не выбирайте предыдущий OrderDate, если он не был для того же CustomerID, что и текущая строка.] предоставляется в более поздних версиях SQL Server. Другой пример - помните одно из «требований» с самого начала, которое может побудить вас подумать об использовании цикла? «Вычислить общее и среднее всех значений для каждого продукта» Давайте попробуем получить подробную информацию обо всех продуктах, включая общее количество проданных продуктов, среднее количество заказов на один продукт и количество заказов каждого продукта. Это выглядит довольно сложно, но на самом деле довольно просто; Я могу использовать некоторые функции агрегирования SQL и GROUP BY… ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ P.ProductID, p.ProductName,
COUNT (OD.OrderID) AS CountOfOrders,
AVG (количество) AS AvgPerOrder,
СУММА (количество) КАК ВсегоПродано
ИЗ [Продукты] P
LEFT JOIN [Детали заказа] OD на OD.ProductID = P.ProductID
ГРУППА ПО P.ProductID, p.ProductName
ЗАКАЗАТЬ ПО P.ProductName
Но скажем, что я также должен показать количество на единицу, единицы на складе, единицы в заказе и уровень повторного заказа в наших результатах. Когда мы добавляем эти поля в наш список SELECT, мы получаем ошибки
Одно из решений - расширить наше предложение GROUP BY, включив в него ВСЕ другие поля, которые мы хотим показать… ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ P.ProductID, p.ProductName, QuantityPerUnit, UnitsInStock, UnitsOnOrder, ReorderLevel,
СЧЕТ (OD.OrderID) КАК CountOfOrders,
AVG (количество) AS AvgPerOrder,
СУММА (количество) КАК ВсегоПродано
ИЗ [Продукты] P
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [Детали заказа] OD на OD.ProductID = P.ProductID
ГРУППА ПО P.ProductID, p.ProductName, QuantityPerUnit, UnitsInStock, UnitsOnOrder, ReorderLevel
ЗАКАЗАТЬ ПО P.ProductName
ИЛИ нам нужно выполнить какой-то подзапрос, а затем выполнить соединение… ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЕ SummaryData.ProductID, SummaryData.ProductName,
Prod.QuantityPerUnit, Prod.UnitsInStock, Prod.UnitsOnOrder, Prod.ReorderLevel,
SummaryData.CountOfOrders, SummaryData.AvgPerOrder, SummaryData.TotalSold
ОТ (ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ P.ProductID, p.ProductName,
COUNT (OD.OrderID) AS CountOfOrders,
AVG (количество) AS AvgPerOrder,
СУММА (количество) КАК ВсегоПродано
ИЗ [Продукты] P
LEFT JOIN [Детали заказа] OD на OD.ProductID = P.ProductID
ГРУППА ПО P.ProductID, p.ProductName) SummaryData
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [Продукты] Prod ON SummaryData.ProductID = Prod.ProductID
ЗАКАЗАТЬ ПО SummaryData.ProductName
Это начинает выглядеть ужасно беспорядочно! Однако вместо этого мы можем использовать предложения OVER с этими агрегатными функциями (начиная с SQL2008) и РАЗБИРАТЬ данные в нужные нам окна, полностью избавившись от предложения GROUP BY… ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ P.ProductID, p.ProductName, QuantityPerUnit, UnitsInStock, UnitsOnOrder, ReorderLevel,
COUNT (OD.OrderID) OVER (РАЗДЕЛ ПО P.ProductID) AS CountOfOrders,
СРЕДНЕЕ (количество) БОЛЕЕ (РАЗДЕЛЕНИЕ ПО ИДЕНТИФИКАТОРУ ПРОДУКТА) КАК СРЕДН.
, SUM (количество) OVER (РАЗДЕЛЕНИЕ ПО P.ProductID) AS TotalSold
ИЗ [Продукты] P
LEFT JOIN [Детали заказа] OD на OD.ProductID = P.ProductID
ЗАКАЗАТЬ ПО P.ProductName
Лично я думаю, что это выглядит намного аккуратнее - и легче понять, что происходит.]. Табличные результаты (от строк к столбцам) - Игра с PivotЕще одна концепция, с которой сталкиваются новички, - это когда есть требование свести в таблицу набор результатов. Представьте, что нас попросили узнать общее количество заказов, размещенных по странам, по годам. Достаточно легко получить информацию ВЫБЕРИТЕ DATEPART (Год, Дата заказа) КАК Год заказа,
ShipCountry, COUNT (идентификатор заказа)
ОТ Заказы
ГРУППА ПО DATEPART (год, дата заказа), страна доставки
Но результаты выводятся в виде одной строки за год для каждой страны…, / p> Это не совсем то, что нам нужно, было бы уместно что-то более похожее. Я мог бы просмотреть наши результаты, создав новую таблицу в правильном формате ... но вы знаете, что мне не нужно этого делать.] вместо… ВЫБРАТЬ *
ИЗ
(
ВЫБЕРИТЕ DATEPART (год, дата заказа) как год заказа, страна доставки, идентификатор заказа
ОТ Заказы
) Как источник
PIVOT
(
COUNT (идентификатор заказа)
FOR OrderYear IN ([1996], [1997], [1998])
) AS pvt
ЗАКАЗАТЬ ПО стране доставки
Обратите внимание на этот запрос, который я называю Раздел PIVOT будет подсчитывать заказы для меня на основе каждого года FOR OrderYear IN ([1996], [1997], [1998])
и.е. список «столбцов» в предложении IN. Обратите внимание, что эти годы не являются строками, они представляют собой столбцы окончательного набора результатов). PIVOT вращает данные на основе этого списка. Другими словами, SQL ищет значения в OrderYear, которые соответствуют именам в списке столбцов, а затем подсчитывает количество совпадающих OrderID (вместо COUNT можно использовать другие агрегатные функции). В результате получается секционированных на основе других элементов в операторе SELECT источника Отлично - Теперь мы можем легко создавать таблицы из наших данных. Подводя итог, для сводных данных вам нужен исходный запрос ... он должен содержать поле, в котором вы хотите повернуть данные, и любые поля, по которым вы хотите разделить данные. Затем вам понадобится ключевое слово PIVOT, за которым следуют инструкции о том, как повернуть данные.Этот раздел должен использовать агрегатную функцию, такую как COUNT, MAX, MIN и т. Д. Предложение FOR будет определять столбцы в таблице результатов ... будут отображаться только эти столбцы, вам не нужно включать все возможные значения, если вас не интересует эта информация, но, что важно, если вы не включите все возможные значения, вы можете случайно исключить информацию, которую действительно хотели. Попался! - Имена столбцов не могут быть числамиПоскольку имя столбца не может быть полностью числовым, нам пришлось заключить имена «столбцов» в квадратные скобки - [], чтобы сделать его допустимым именем столбца.Следовательно, FOR OrderYear IN ([1996], [1997], [1998])
А не ДЛЯ ГОД ЗАКАЗА (1996,1997,1998)
То же самое верно, если значения, которые вы пытаетесь развернуть, являются зарезервированными словами в SQL, например FOR SomeData IN ([Имя], [Дата], [Сумма], значение)
Также верно, если значения, которые вы пытаетесь развернуть, содержат пробелы, например FOR Title IN ([Торговый представитель], [Менеджер по продажам])
Это становится очень важным, когда вы генерируете SQL из динамического запроса… Динамические запросы SQL и списки, разделенные запятымиПроблема с Pivot заключается в том, что со временем в последующие годы появятся Даты заказов.Эти данные не будут включены в наш запрос, потому что мы жестко запрограммировали столбцы, которые хотим видеть… 1996, 1997 и 1998 годы. Мы действительно не хотим обновлять запрос каждый год. Было бы неплохо, если бы мы могли сгенерировать этот список из самих данных. Получить информацию достаточно просто SELECT DISTINCT DATEPART (Year, OrderDate) AS OrderYear из заказов
Мне нужно записать этот список лет в список, разделенный запятыми, и заключить числа в квадратные скобки.] в довольно простом запросе, как показано ниже DECLARE @listStr VARCHAR (MAX) = null
; С лет КАК
(
ВЫБЕРИТЕ DISTINCT DATEPART (Year, OrderDate) AS OrderYear из заказов
)
ВЫБРАТЬ @listStr = COALESCE (@listStr + '], [', '') + CAST (OrderYear AS Varchar)
С года
ПЕЧАТЬ '[' + @listStr + ']'
Что дает нам список таких столбцов. [1998], [1996], [1997]
Примечание.] Я могу поместить свой SQL-запрос в строковую переменную, используя переменную @listStr, полученную мной выше, для перечисления столбцов, которые мне нужны.Я немного разбил это здесь, чтобы было немного понятнее. ОБЪЯВИТЬ @sql NVARCHAR (МАКС) =
N'SELECT * FROM (выберите DATEPART (Year, OrderDate) AS OrderYear '
УСТАНОВИТЕ @sql = @sql + N ', ShipCountry, OrderID из заказов) как s'
НАБОР @sql = @sql +
N'PIVOT (COUNT (OrderID) FOR OrderYear IN (['+ @listStr + N'])) '
SET @sql = N 'AS pvt order by ShipCountry'
Если вы распечатаете содержимое @sql, вы увидите, что мы получаем тот же запрос, что и раньше (добавлены пробелы, чтобы сделать его более читаемым) ВЫБРАТЬ *
ИЗ
(
SELECT DATEPART (Year, OrderDate) Циклы записи в SQLВ программировании цикл позволяет вам написать набор кода, который будет запускать повторно в одной и той же программе.Многие языки программирования имеют несколько разных типов цикла на выбор, но в SQL Server есть только один: WHILE loop. Если вы часто (более одного раза!) Пишете циклы в SQL, вы, вероятно, неправильно подходите к делу. Наш онлайн-курс продвинутого уровня SQL можно взять с собой в любую точку мира, и он объяснит, как программировать эффективно в SQL (вы можете увидеть подробности всего нашего обучения SQL здесь). Базовый синтаксис цикла WHILEПрежде чем мы сделаем что-нибудь полезное с циклом, давайте посмотрим на основной синтаксис. В приведенном ниже коде показаны основные элементы, которые вам понадобятся для работы цикла: ЗАЯВИТЬ @Counter INT НАБОР @Counter = 0 ПОКА @Counter <= 10 НАЧАТЬ НАБОР @Counter + = 1 КОНЕЦ Комментарии в приведенном выше коде объясняют, что происходит на каждом этапе процедура.В нашем примере мы использовали счетчик, чтобы отслеживать, сколько раз цикл выполнен. В этом случае цикл будет продолжать выполняться, пока значение счетчика 10 или меньше. Вы можете с радостью выполнить приведенный выше код, и процедура запустится, она просто не дает никакого результата! Чтобы доказать, что цикл работает указанное количество раз мы можем добавить простой оператор для печати значения переменной счетчика: ЗАЯВИТЬ @Counter INT НАБОР @Counter = 0 ПОКА @Counter <= 10 НАЧАТЬ ПЕЧАТЬ @ Счетчик НАБОР @Counter + = 1 КОНЕЦ Впечатляющий результат процедуры показан ниже: Хорошо, это по-прежнему бесполезно, но показывает, что цикл работает. Теперь, когда у нас есть основной цикл, следующая часть этого В серии показано, как выполнить запрос внутри цикла. T-SQL Programming Part 2 - Building a T-SQL Loop - DatabaseJournal.comГрегори А. Ларсен Это вторая статья в моей серии программ T-SQL. В этой статье будет обсуждаться построение программы цикл с использованием T-SQL. Помимо построения петли, я также обсудить способы управления обработкой цикла и различные методы прерывания вне петли. Цикл программирования - это кусок кода, который выполняется снова и снова. В цикле есть логика выполняется многократно итеративно, пока не будет выполнено какое-либо условие, позволяет коду выйти из цикла. Один из примеров того, где вы можете использовать цикл будет обрабатывать набор записей по одной записи за раз. Другой пример может быть, когда вам нужно сгенерировать некоторые тестовые данные и цикл позволит вам вставить запись в таблицу тестовых данных с небольшим разные значения столбца при каждом выполнении цикла.В этой статье я обсудят операторы WHILE, BREAK, CONTINUE и GOTO. ПРИ ЗаявленииВ T-SQL оператор WHILE это наиболее часто используемый способ выполнения цикла. Вот основной синтаксис для цикл WHILE: WHILE <логическое выражение> <блок кода> Где В этом примере я увеличу счетчик от 1 до 10 и каждый раз отображать счетчик через ПОКА петля. объявить @counter int установить @counter = 0 а @counter <10 начать установить @counter = @counter + 1 print 'Счетчик' + cast (@counter as char) конец Здесь код выполняет WHILE, если целочисленная переменная @counter меньше 10, этот это логическое выражение цикла WHILE.Переменная @counter начинается равен нулю, и каждый раз в цикле WHILE он увеличивается на 1. Оператор PRINT отображает значение переменной @counter каждый раз через цикл WHILE. Результат этого примера выглядит так: Счетчик 1 Счетчик 2 Счетчик 3 Счетчик 4 Счетчик 5 Счетчик 6 Счетчик 7 Счетчик 8 Счетчик 9 Счетчик 10 Как видите, когда-то переменная @counter достигает 10 логического выражения, которое управляет WHILE loop больше не является истинным, поэтому код внутри цикла while больше не выполняется. У вас не только одиночный цикл while, но вы можете иметь циклы WHILE внутри циклов WHILE. Или же обычно называется вложением циклов WHILE. Есть много разных применений где гнездование ценно. Я обычно использую вложение циклов WHILE для создания тестовые данные. В моем следующем примере цикл WHILE будет использоваться для создания тестовых записей. для таблицы PART. Данная запись PART однозначно идентифицируется с помощью Part_Id, и Category_Id. Для каждого Part_Id есть три разных Category_Id.Вот это мой пример, который генерирует 6 уникальных записей для моей таблицы PART с использованием вложенного WHILE цикл. объявить @Part_Id int объявить @Category_Id int объявить @Desc varchar (50) создать таблицу PART (Part_Id int, Category_Id int, Description varchar (50)) установить @Part_Id = 0 установить @Category_Id = 0 а @Part_Id <2 начать установить @Part_Id = @Part_Id + 1 а @Category_Id <3 начать установить @Category_Id = @Category_Id + 1 установить @Desc = 'Part_Id is' + cast (@Part_Id as char (1)) + 'Category_Id' + cast (@Category_Id как char (1)) вставить в значения ЧАСТЬ (@Part_Id, @Category_Id, @Desc) конец установить @Category_Id = 0 конец выберите * из ЧАСТИ drop table PART Вот вывод Оператор SELECT в нижней части этого примера вложенного цикла WHILE. Part_Id Category_Id Описание ----------- ----------- ---------------------------- ------------- 1 1 Part_Id равно 1 Category_Id 1 1 2 Part_Id равно 1 Category_Id 2 1 3 Part_Id равно 1 Category_Id 3 2 1 Part_Id равно 2 Category_Id 1 2 2 Part_Id равно 2 Category_Id 2 2 3 Part_Id равно 2 Category_Id 3 Как видите, используя вложенный цикл WHILE, каждая комбинация Part_Id и Category_Id уникальна.В код в первом цикле WHILE управлял увеличением Part_Id, где второй цикл WHILE устанавливает для Category_Id разные значения для каждого время через петлю. Код в первом цикле while был выполнен только дважды, но код внутри второго цикла WHILE был выполнен 6 раз. Таким образом давая мне 6 образцов записей PART. . |