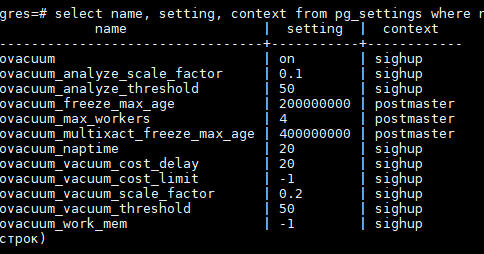
PostgreSQL — SELECT списки
Табличное выражение в SELECTкоманде строит промежуточную виртуальную таблицу, возможно комбинируя таблицы, представления, удаляя строки, группируя и т. д.
Эта таблица, наконец, передается для обработки списком выбора . Список выбора определяет, какие столбцы промежуточной таблицы фактически выводятся.
Элементы списка выбора
Самый простой вид списка выбора — это список, в *котором выводятся все столбцы, созданные табличным выражением. В противном случае список выбора представляет собой список выражений значений, разделенных запятыми. Например, это может быть список имен столбцов:
SELECT a, b, c FROM ...
Имена столбцов a, bи cявляются либо фактическими именами столбцов таблиц, на которые есть ссылки в FROMпредложении, либо присвоенными им псевдонимами. Пространство имен, доступное в списке выбора, такое же, как и в WHEREпредложении, если только не используется группировка, и в этом случае оно такое же, как в HAVINGпредложении.
Если более чем в одной таблице есть столбец с одинаковым именем, имя таблицы также должно быть указано, например:
SELECT tbl1.a, tbl2.a, tbl1.b FROM ...
При работе с несколькими таблицами также может быть полезно запросить все столбцы конкретной таблицы:
SELECT tbl1.*, tbl2.a FROM ...
Если в списке выбора используется выражение произвольного значения, оно концептуально добавляет новый виртуальный столбец в возвращаемую таблицу. Выражение значения оценивается один раз для каждой строки результата, при этом значения строки заменяются любыми ссылками на столбцы. Но выражения в списке выбора не должны ссылаться ни на какие столбцы в табличном выражении FROMпредложения; например, они могут быть постоянными арифметическими выражениями.
Метки столбцов
Записям в списке выбора можно присвоить имена для последующей обработки, например, для использования в ORDER BYпредложении или для отображения клиентским приложением. Например:
SELECT a AS value, b + c AS sum FROM ...
Если имя выходного столбца не указано с помощью AS, система назначает имя столбца по умолчанию. Для простых ссылок на столбцы это имя столбца, на который делается ссылка. Для вызовов функций это имя функции. Для сложных выражений система сгенерирует общее имя.
Ключевое ASслово обычно является необязательным, но в некоторых случаях, когда желаемое имя столбца совпадает с ключевым словом PostgreSQL , вы должны написать ASимя столбца или заключить его в двойные кавычки, чтобы избежать двусмысленности. Например, FROMэто одно из таких ключевых слов, так что это не работает:
SELECT a from, b + c AS sum FROM ...
но любой из них:
SELECT a AS from, b + c AS sum FROM ... SELECT a "from", b + c AS sum FROM ...
Для наибольшей безопасности от возможного добавления ключевых слов в будущем рекомендуется всегда либо писать ASимя выходного столбца, либо заключать его в двойные кавычки.
DISTINCTПосле обработки списка выбора из таблицы результатов можно дополнительно удалить повторяющиеся строки.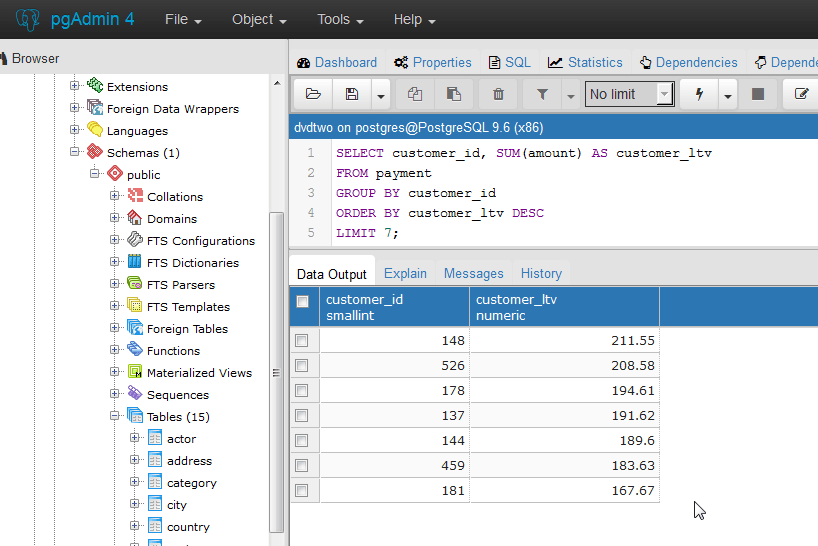 Ключевое
Ключевое DISTINCTслово пишется сразу после SELECT, чтобы указать это:
SELECT DISTINCT select_list ...
(Вместо DISTINCTключевого слова ALLможно использовать для указания поведения по умолчанию сохранения всех строк.)
Очевидно, что две строки считаются различными, если они отличаются хотя бы в одном значении столбца. Нулевые значения считаются равными в этом сравнении.
Кроме того, произвольное выражение может определить, какие строки следует считать различными:
SELECT DISTINCT ON (expression [, expression ...]) select_list ...
Вот expressionпроизвольное выражение значения, которое оценивается для всех строк. Набор строк, для которого все выражения равны, считается дубликатом, и в выходных данных сохраняется только первая строка набора. Обратите внимание, что « первая строка » набора непредсказуема, если только запрос не отсортирован по достаточному количеству столбцов, чтобы гарантировать уникальный порядок строк, попадающих в DISTINCTфильтр. (
( DISTINCT ONобработка происходит после ORDER BYсортировки.)
Предложение DISTINCT ONне является частью стандарта SQL и иногда считается дурным стилем из-за потенциально неопределенного характера его результатов. При разумном использовании GROUP BYи подзапросов в FROM, этой конструкции можно избежать, но часто это самая удобная альтернатива.
SELECT statement exercises: learn stage
SELECT statement exercises: learn stage | MSSQL, Oracle, PostgreSQL, MySQL| SQL exercises | Language Русский English | April 25, 23:35 MSK |
SQL Exercises is intended for acquiring good practical experience,
which is focused on data operation, namely on SQL DML. Certain exercises for beginners are provided on the site,
they are supplied with the necessary reference source on SQL syntax with a great number of examples.
Apart from them, 3 rating stages are suggested, they are aimed at testing of specialists and their certification.
The source is absolutely free of charge, and the certificate purchase has a voluntary basis. Certain exercises for beginners are provided on the site,
they are supplied with the necessary reference source on SQL syntax with a great number of examples.
Apart from them, 3 rating stages are suggested, they are aimed at testing of specialists and their certification.
The source is absolutely free of charge, and the certificate purchase has a voluntary basis.
NOTE: Your browser should support Cookies and Javascript to provide correct usage of this site. If you use content filter, it should allow opening child windows to explore help pages. |

On exercises’ page it is possible to carry out any SELECT statements which are addressing to the learning databases. To switch off checking the correctness of the solutions, click «without check» checkbox.
If you consider yourself as a professional and plan to compete with others or to get certificate, proceed to certification stages.
More about certification.
If you are recently on the site, we recommend you to read answers on FAQ.
- Login
- Password
Forgot password?
| Site news Week news |
Certification |
SQL exercises |
Forums |
Ratings |
HELP |
Performance |
Profile
|
Copyright SQL-EX © 2002-2023. All rights reserved. All rights reserved. contact |
WITH Queries (Common Table Expressions)
Эта документация предназначена для неподдерживаемой версии PostgreSQL.
Вы можете просмотреть ту же страницу для
текущий
версию или одну из других поддерживаемых версий, перечисленных выше.
WITH предоставляет способ записи подзапросы для использования в более крупном SELECT запрос. Подзапросы, которые часто называют общими Табличные выражения или CTE могут можно рассматривать как определение временных таблиц, которые существуют только для этот запрос. Одно из применений этой функции — разбить сложные запросы на более простые части. Пример:
С Regional_sales AS (
ВЫБЕРИТЕ регион, СУММА (сумма) КАК total_sales
ОТ заказов
СГРУППИРОВАТЬ ПО РЕГИОНАМ
), топ_регионы AS (
ВЫБЕРИТЕ регион
ОТ регионарных_продаж
ГДЕ total_sales > (ВЫБЕРИТЕ СУММУ(total_sales)/10 FROM Regional_sales)
)
ВЫБЕРИТЕ регион,
продукт,
SUM(количество) AS product_units,
СУММА(сумма) КАК product_sales
ОТ заказов
ГДЕ регион В (ВЫБЕРИТЕ регион ИЗ top_regions)
СГРУППИРОВАТЬ ПО региону, продукту;
, который отображает итоги продаж по каждому продукту только в самых популярных продажах. регионы. Этот пример можно было бы написать без WITH, но нам потребовались бы два уровня вложенности.
подвыборки. Это немного легче следовать этому пути.
регионы. Этот пример можно было бы написать без WITH, но нам потребовались бы два уровня вложенности.
подвыборки. Это немного легче следовать этому пути.
Необязательный модификатор RECURSIVE меняется на WITH с простого синтаксического удобство в функцию, которая выполняет вещи иначе возможно в стандартном SQL. Использование RECURSIVE, запроса WITH может ссылаться на собственный вывод. Очень простой пример — этот запрос суммировать целые числа от 1 до 100:
С РЕКУРСИВНЫМ t(n) КАК (
ЦЕННОСТИ (1)
СОЮЗ ВСЕХ
ВЫБЕРИТЕ n+1 ИЗ t, ГДЕ n < 100
)
ВЫБЕРИТЕ сумму (n) ОТ t;
Общая форма рекурсивного оператора WITH запрос всегда нерекурсивный терм , затем СОЮЗ (или СОЮЗ ВСЕ), затем рекурсивных терминов , где только рекурсивный терм может содержать ссылку на запрос собственный выход. Такой запрос выполняется следующим образом:
Рекурсивная оценка запроса
Оценить нерекурсивный терм.
 Для UNION (но не UNION
ВСЕ), отбросить повторяющиеся строки. Включить все оставшиеся
строк в результате рекурсивного запроса, а также разместить
их во временном рабочий
таблица .
Для UNION (но не UNION
ВСЕ), отбросить повторяющиеся строки. Включить все оставшиеся
строк в результате рекурсивного запроса, а также разместить
их во временном рабочий
таблица .Пока рабочий стол не пуст, повторяйте эти шагов:
Вычислите рекурсивный термин, заменив текущее содержимое рабочей таблицы для рекурсивного ссылка на самого себя. Для UNION (но не UNION ALL), отбросить повторяющиеся строки и строки, которые дублируют любые предыдущие строка результата. Включить все оставшиеся строки в результат рекурсивный запрос, а также поместить их во временную промежуточная таблица .
Заменить содержимое рабочей таблицы на содержимое промежуточной таблицы, затем очистите промежуточный стол.

Примечание: Строго говоря, этот процесс является итерацией не рекурсия, а RECURSIVE - это терминология, выбранная комитетом по стандартам SQL.
В приведенном выше примере рабочая таблица имеет только одну строку. на каждом шаге и принимает значения от 1 до 100 в последовательные шаги. На 100-м шаге нет вывода, потому что предложения WHERE, поэтому запрос заканчивается.
Рекурсивные запросы обычно используются для работы с иерархическими или древовидные данные. Полезным примером является этот запрос, чтобы найти все прямые и косвенные части продукта, учитывая только таблица, показывающая немедленные включения:
С РЕКУРСОВЫМ включенным_частям (под_часть, часть, количество) КАК (
ВЫБЕРИТЕ под_часть, часть, количество ИЗ частей, ГДЕ часть = 'наш_продукт'
СОЮЗ ВСЕХ
ВЫБЕРИТЕ p.sub_part, p.part, p.quantity
ИЗ включенных_деталей пр, частей п
ГДЕ p. part = pr.sub_part
)
SELECT sub_part, SUM(количество) как total_quantity
ИЗ включенных_деталей
СГРУППИРОВАТЬ ПО sub_part
part = pr.sub_part
)
SELECT sub_part, SUM(количество) как total_quantity
ИЗ включенных_деталей
СГРУППИРОВАТЬ ПО sub_part
При работе с рекурсивными запросами важно быть уверенным что рекурсивная часть запроса в конечном итоге не вернет кортежи, иначе запрос будет бесконечно повторяться. Иногда, использование UNION вместо UNION ALL может выполнить это, отбрасывая строки которые дублируют предыдущие выходные строки. Однако часто цикл не включать в себя выходные строки, которые полностью повторяются: это может быть необходимо проверить только одно или несколько полей, чтобы увидеть, совпадают ли точка была достигнута раньше. Стандартный способ обработки таких ситуациях заключается в вычислении массива уже посещенных ценности. Например, рассмотрим следующий запрос, который ищет табличный график с использованием поля ссылки:
С РЕКУРСИВНЫМ search_graph(идентификатор, ссылка, данные, глубина) КАК (
ВЫБРАТЬ g.id, g.link, g.data, 1
С графа г
СОЮЗ ВСЕХ
ВЫБЕРИТЕ g.
id, g.link, g.data, sg.depth + 1
FROM граф г, search_graph sg
ГДЕ g.id = sg.link
)
SELECT * FROM search_graph;
Этот запрос зациклится, если ссылка отношения содержат циклы. Поскольку нам требуется вывод «глубины», простое изменение UNION ALL на UNION приведет к не устранить зацикливание. Вместо этого мы должны признать, что мы снова достигли той же строки, следуя определенному путь ссылок. Мы добавляем два столбца пути и цикла к склонный к петле запрос:
WITH RECURSIVE search_graph(id, ссылка, данные, глубина, путь, цикл) КАК (
ВЫБРАТЬ g.id, g.link, g.data, 1,
МАССИВ[g.id],
ЛОЖЬ
С графа г
СОЮЗ ВСЕХ
ВЫБЕРИТЕ g.id, g.link, g.data, sg.depth + 1,
путь || г.ид,
g.id = ЛЮБОЙ (путь)
FROM граф г, search_graph sg
ГДЕ g.id = sg.link И НЕ цикл
)
SELECT * FROM search_graph;
Помимо предотвращения циклов, значение массива часто полезно
сам по себе как представляющий «путь», по которому можно добраться до любой конкретной строки.
В общем случае, когда необходимо указать более одного поля. проверено, чтобы распознать цикл, используйте массив строк. Например, если бы нам нужно было сравнить поля f1 и f2:
WITH RECURSIVE search_graph(id, ссылка, данные, глубина, путь, цикл) КАК (
ВЫБРАТЬ g.id, g.link, g.data, 1,
МАССИВ[СТРОКА(g.f1, g.f2)],
ЛОЖЬ
С графа г
СОЮЗ ВСЕХ
ВЫБЕРИТЕ g.id, g.link, g.data, sg.depth + 1,
путь || РЯД(g.f1, g.f2),
РЯД(g.f1, g.f2) = ЛЮБОЙ(путь)
FROM граф г, search_graph sg
ГДЕ g.id = sg.link И НЕ цикл
)
SELECT * FROM search_graph;
Совет: Не используйте синтаксис ROW() в общем случае, когда нужно проверить только одно поле распознать цикл. Это позволяет использовать простой массив, а не массив составного типа, который будет использоваться, повышая эффективность.
Совет: Алгоритм оценки рекурсивного запроса производит вывод в порядке поиска в ширину.
Ты можешь отображать результаты в порядке поиска в глубину, сделав внешний запрос ORDER BY для столбца "путь", построенного таким образом.
Полезный прием для тестирования запросов, когда вы не уверены если они могут зациклиться, это установить LIMIT в родительском запросе. Например, этот запрос будет зацикливаться вечно. без ОГРАНИЧЕНИЯ:
С РЕКУРСИВНЫМ t(n) КАК (
ВЫБЕРИТЕ 1
СОЮЗ ВСЕХ
ВЫБРАТЬ n+1 ИЗ t
)
ВЫБЕРИТЕ n ОТ ПРЕДЕЛА 100;
Это работает, потому что реализация PostgreSQL оценивает только столько строк запроса WITH, сколько есть фактически извлекается родительским запросом. Используя этот прием в производство не рекомендуется, потому что другие системы могут работать иначе. Кроме того, обычно это не сработает, если вы сделаете внешний запрос сортирует результаты рекурсивного запроса или объединяет их с некоторыми другой стол.
Полезным свойством запросов WITH является
что они оцениваются только один раз за выполнение родителя
запрос, даже если родитель ссылается на них более одного раза
запрос или одноуровневые запросы WITH. Таким образом,
дорогие вычисления, которые необходимы в нескольких местах, могут быть
помещается в запрос WITH, чтобы избежать
избыточная работа. Другим возможным применением является предотвращение
нежелательные множественные оценки функций с побочными эффектами.
Однако другая сторона этой медали заключается в том, что оптимизатор
меньше возможностей переносить ограничения из родительского запроса в
WITH запрос, чем обычный подзапрос.
Запрос WITH обычно будет
оценивается, как указано, без подавления строк, которые родительский
впоследствии запрос может быть отброшен. (Но, как было сказано выше,
оценка может быть остановлена раньше, если ссылка(и) на запрос
требуют только ограниченное количество строк.)
Таким образом,
дорогие вычисления, которые необходимы в нескольких местах, могут быть
помещается в запрос WITH, чтобы избежать
избыточная работа. Другим возможным применением является предотвращение
нежелательные множественные оценки функций с побочными эффектами.
Однако другая сторона этой медали заключается в том, что оптимизатор
меньше возможностей переносить ограничения из родительского запроса в
WITH запрос, чем обычный подзапрос.
Запрос WITH обычно будет
оценивается, как указано, без подавления строк, которые родительский
впоследствии запрос может быть отброшен. (Но, как было сказано выше,
оценка может быть остановлена раньше, если ссылка(и) на запрос
требуют только ограниченное количество строк.)
Оператор SELECT для PostgreSQL
Postgres поддерживает оператор SELECT для извлечения записей из нуля или более таблиц или представлений в базе данных.
ВЫБЕРИТЕ [ * | столбец1, столбец2,... | выражение ]
[ FROM [таблица1 [ таблица2,. .] [представление1, представление2..]
[ ГДЕ состояние ]
[ СГРУППИРОВАТЬ ПО [столбец1 [столбец2,..]]]
[ ЕСТЬ состояние ]
[ WINDOW имя_окна КАК ( определение_окна )]
[ ORDER BY выражение [ ASC | DESC | ИСПОЛЬЗОВАНИЕ оператора ] ]
[ ПРЕДЕЛ { количество | ВСЕ } ]
[ СМЕЩЕНИЕ начало [ РЯД | РЯДЫ ] ]
[ ВЫБЕРИТЕ { ПЕРВЫЙ | СЛЕДУЮЩИЙ } [ количество ] { СТРОКА | РЯДЫ } { ТОЛЬКО | С СВЯЗЯМИ } ]
[ДЛЯ {ОБНОВЛЕНИЯ | НЕТ ОБНОВЛЕНИЯ КЛЮЧА | ПОДЕЛИТЬСЯ | KEY SHARE } [ OF table_name] [ NOWAIT | ПРОПУСТИТЬ ЗАБЛОКИРОВАНО ]]
.] [представление1, представление2..]
[ ГДЕ состояние ]
[ СГРУППИРОВАТЬ ПО [столбец1 [столбец2,..]]]
[ ЕСТЬ состояние ]
[ WINDOW имя_окна КАК ( определение_окна )]
[ ORDER BY выражение [ ASC | DESC | ИСПОЛЬЗОВАНИЕ оператора ] ]
[ ПРЕДЕЛ { количество | ВСЕ } ]
[ СМЕЩЕНИЕ начало [ РЯД | РЯДЫ ] ]
[ ВЫБЕРИТЕ { ПЕРВЫЙ | СЛЕДУЮЩИЙ } [ количество ] { СТРОКА | РЯДЫ } { ТОЛЬКО | С СВЯЗЯМИ } ]
[ДЛЯ {ОБНОВЛЕНИЯ | НЕТ ОБНОВЛЕНИЯ КЛЮЧА | ПОДЕЛИТЬСЯ | KEY SHARE } [ OF table_name] [ NOWAIT | ПРОПУСТИТЬ ЗАБЛОКИРОВАНО ]]
С оператором SELECT,
- Укажите одно или несколько имен столбцов после предложения SELECT, для которых вы хотите получить данные. Имена нескольких столбцов должны быть разделены запятой.
- При желании укажите выражение также с предложением SELECT.
- Укажите звездочку (*) после SELECT, чтобы выбрать все столбцы. Список выбора также может содержать выражения или литеральные значения.
- Укажите одно или несколько имен таблиц, из которых вы хотите выбрать данные, после предложения FROM.
- При необходимости используйте предложение WHERE, GROUP BY, HAVING, ORDER BY, WINDOW, LIMIT, OFFSET, FETCH, FOR.
Ключевые слова SQL нечувствительны к регистру, поэтому вы можете писать SELECT, Select или select. В целях форматирования мы сохраним все ключевые слова SQL заглавными буквами.
Давайте посмотрим, как использовать оператор SELECT для получения данных из следующих сотрудник стол.
Следующая инструкция SELECT извлекает данные из одного столбца таблицы сотрудников .
ВЫБЕРИТЕ first_name ОТ сотрудника;
Ниже показан результат в pgAdmin.
Следующая инструкция SELECT извлекает данные из нескольких столбцов таблицы employee .
ВЫБЕРИТЕ emp_id, имя, фамилию ОТ сотрудника;
Ниже показан результат в pgAdmin.
Следующая инструкция SELECT использует * для извлечения данных из всех столбцов таблицы employee .
ВЫБЕРИТЕ * ОТ сотрудника;
Ниже показан результат в pgAdmin.
Выражение с пунктом SELECT
Вы можете использовать выражение в операторе SELECT. Следующее объединяет столбцы first_name и last_name с помощью || оператор.
ВЫБЕРИТЕ имя_имя || ' ' || фамилия ОТ сотрудника;
Ниже показан результат в pgAdmin.
Он также может возвращать результат основной математической операции.
ВЫБЕРИТЕ 6 * 4;
Псевдоним столбца
Псевдоним позволяет присвоить временное имя столбцу или выражению в операторе SELECT.