НГТУ — СТАСЫШИНА Т.Л. — 6. Создание пользовательских функций в PostgreSql
CREATE [ OR REPLACE ] FUNCTIONимя_функции ([ [ метод_аргумента ][имя_аргумента ] тип_ аргумента [,…] ])
RETURNS тип_возвращаемого_значения
AS ‘определение‘
LANGUAGE ‘язык‘
[ WITH ( атрибут […])]
- CREATE FUNCTION имя_функции ([[ метод_аргумента ] [имя_аргумента ] тип_ аргумента [,…] ]) — после ключевых слов CREATE FUNCTION указывается имя создаваемой функции, после чего в круглых скобках перечисляются аргументы, разделенные запятыми. Для каждого аргумента достаточно указать только тип, но при желании можно задать метод (in, out, inout; по умолчанию in) и имя. Если список в круглых скобках пуст, функция вызывается без аргументов (хотя сами круглые скобки обязательно должны присутствовать как в определении функции, так и при ее использовании).

- RETURNS тип_возвращаемого_значения — тип данных, возвращаемый функцией.
- AS ‘определение‘ — программное определение функции. В процедурных языках (таких, как PL/pgSQL) оно состоит из кода функции. Для откомпилированных функций С указывается абсолютный системный путь к файлу, содержащему объектный код.
- LANGUAGE ‘язык‘. Название языка, на котором написана функция. В аргументе может передаваться имя любого процедурного языка (такого, как plpgsql или plperl, если соответствующая поддержка была установлена при компиляции), С или SQL.
[ - WITH ( атрибут [. …] ) ] — атрибут может принимать два значения: iscachable и isstrict.
iscachable. Оптимизатор может использовать предыдущие вызовы функций для ускоренной обработки будущих вызовов с тем же набором аргументов. Кэширование обычно применяется при работе с функциями, сопряженными с большими затратами ресурсов, но возвращающими один и тот же результат при одинаковых значениях аргументов.
Кэширование обычно применяется при работе с функциями, сопряженными с большими затратами ресурсов, но возвращающими один и тот же результат при одинаковых значениях аргументов.
isstrict. Функция всегда возвращает NULL в случае, если хотя бы один из ее аргументов равен NULL. При передаче атрибута isstrict результат возвращается сразу, без фактического выполнения функции.
Создание функций SQL
CREATE [ OR REPLACE ] FUNCTION
имя_функции ([ [ метод_аргумента ][имя_аргумента ] тип_ аргумента [,…] ])
RETURNS тип_возвращаемого_значения
AS ‘
оператор SQL;
[оператор SQL;
…]
‘
LANGUAGE sql
[ WITH ( атрибут […])];
- В теле функции обращение к параметрам осуществляется по имени или по номеру : $1 – первый параметр, $2- второй параметр и т.
 д.
д. - В теле функции sql могут стоять только операторы языка SQL, любые (Select, insert, delete,create,…) за исключением операторов управления транзакциями (commit, rollback…). Возвращаемым значением является результат выполнения оператора SELECT, его тип должен совпадать с типом, указанным после RETURNS. Если в теле функции несколько операторов SELECT, функция вернет результат выполнения последнего такого оператора. Если функция sql не содержит операторов SELECT, тип результата для нее следует указать void (фактически это процедура).
Примеры создания и использования функций sql
Пример 1. Создание функции, возвращающей столбец текстовых значений
— Функция возвращает имена поставщиков с рейтингом больше $1
select names from s where rg>$1;
‘ LANGUAGE sql;
Использование функции, возвращающей столбец текстовых значений
Результат
| sname |
| Блейк |
| Кларк |
| Адамс |
Пример 2. Создание функции, возвращающей столбец записей
Создание функции, возвращающей столбец записей
— — Функция возвращает сведения о поставщиках с рейтингом больше $1
select ns,names,rg,town from s where rg>$1 order by ns;
‘ LANGUAGE sql;
Примечание. Функция, возвращающая столбец записей, может быть использована в операторе SELECT , если она определена как функция SQL ( для функции plpgsql способ использования другой)
Использование функции, возвращающей столбец записей
Результат
| result |
| (“S3”, “Блейк ”, 30,”Париж ”) |
| (“S4”, “Кларк ”, 20,“Лондон ”) |
| (“S5”, “Адамс ”, 30,“Афины ”) |
Создание функций plpgSQL
CREATE [ OR REPLACE ] FUNCTION имя_функции ([ [ метод_аргумента ][имя_аргумента ] тип_ аргумента [,…] ])
RETURNS тип_возвращаемого_значения
AS ‘
[ DECLARE
объявления ]
BEGIN
оператор;
[оператор;…]
[EXCEPTION
WHEN условие [ OR условие .
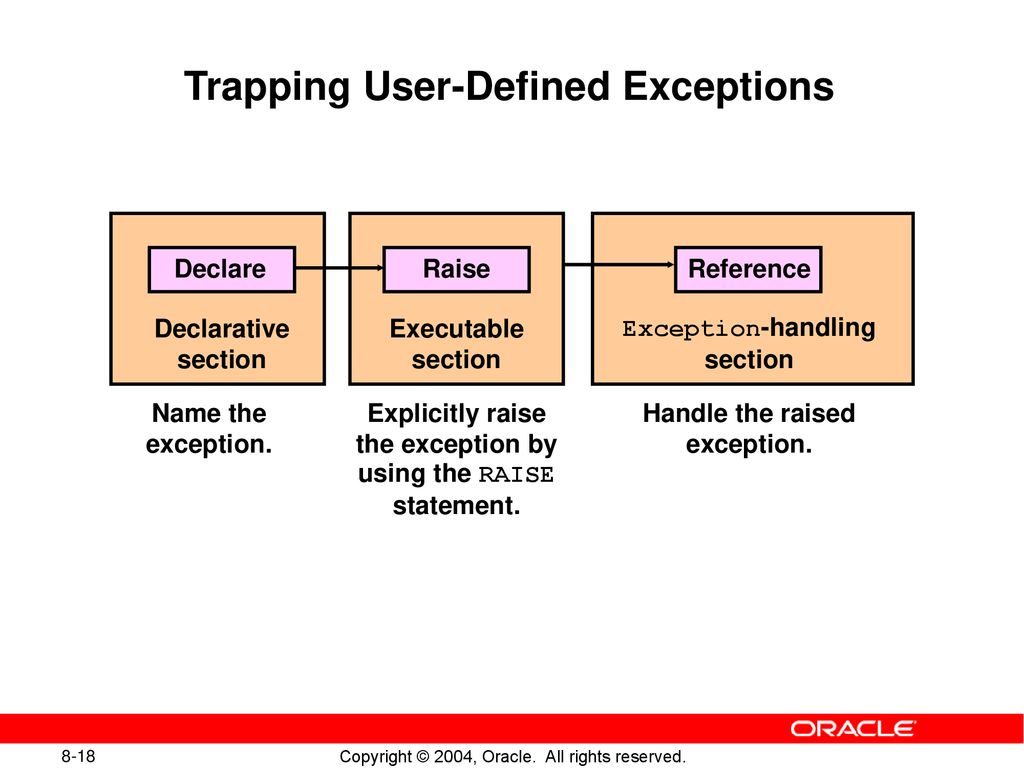 .. ] THEN
.. ] THENоператоры обработки исключения;
[ WHEN условие [ OR условие … ] THEN
операторы обработки исключения;
… ]
END;
‘
LANGUAGE plpgsql
[ WITH ( атрибут […])];
- В теле функции обращение к параметрам осуществляется по имени или по номеру : $1 – первый параметр, $2- второй параметр и т.д.
- В теле функции plpgsql кроме операторов SQL могут применяться конструкции языка PL/pgSQL, представляющего собой процедурное расширение SQL. Это могум быть операторы присваивания, условные операторы, циклы и т.п. Результат возвращается командой RETURN. В теле функции plpgsql обязательно должна быть хотя бы одна команда RETURN, кроме случая, когда тип результата void. Подробнее см. http://www.postgresql.org/docs/8.2/interactive/extend.
 html
html - Локальные переменные, используемые в теле функции, объявляются в блоке DECLARE
DECLARE
имя_переменной тип_переменной ;
[имя_переменной тип_переменной;…] - В блоке EXCEPTION обрабатываются ошибки. Условие – наименование ошибки (перечень см. http://www.sbin.org/doc/pg/doc/errcodes-appendix.html в колонке Constant). Если все ошибки обрабатываются по одной схеме (или вам просто лень подумать, какие здесь могут быть ошибки и найти, как они называются ), этот блок может выглядеть так
EXCEPTION
WHEN others THEN
RAISE exception ‘message of error’;Функция RAISE уровня exception генерирует исключение и выдает сообщение об ошибке (подробнее о функции RAISE см. http://www.sbin.org/doc/pg/doc/plpgsql-errors-and-messages.
 html ).
html ).
Примеры создания и использования функций plpgsql
Пример 3. Создание функции, возвращающей целое значение
DECLARE
i integer;
— Функция вычисляет количество поставок детали $1
BEGIN
select count(*) from spj into i where spj.np=$1;
— возвращение результата
return i;
END;
‘ LANGUAGE plpgsql;
Пример 4. Создание функции, возвращающей вещественное значение
DECLARE
aves real;
— Функция вычисляет средний вес поставок детали $1
BEGIN
select avg(spj.
 kol * p.ves ) from spj,p into aves where spj.np=$1 and spj.np=p.np ;
kol * p.ves ) from spj,p into aves where spj.np=$1 and spj.np=p.np ;— возвращение результата
return aves;
END;
‘ LANGUAGE plpgsql;
Пример 5. Использование функций в классическом SELECT
apf(p.np) AS kol , avgves(p.np) as sves,
apf(p.np)* avgves(p.np) as oves FROM p;
Результат
| Np | namep | kol | sves | oves |
| P1 | Гайка | 1 | 1200 | 1200 |
| P2 | Болт | 2 | 2550 | 5100 |
| P3 | Винт | 9 | 6611. 11 11 | 59500.001953125 |
| P4 | Винт | 2 | 9100 | 18200 |
| P5 | Кулачок | 4 | 3300 | 13200 |
| P6 | Блюм | 4 | 6175 | 24700 |
Пример 6. Использование функций, нестандартный вариант (только PostgreSql)
Результат
Основы мониторинга PostgreSQL. Алексей Лесовский
Предлагаю ознакомиться с расшифровкой доклада Алексей Лесовский из Data Egret «Основы мониторинга PostgreSQL»
В этом докладе Алексей Лесовский расскажет о ключевых моментах постгресовой статистики, что они означают, и почему они должны присутствовать в мониторинге; о том, какие графики должны быть в мониторинге, как их добавить и как интерпретировать. Доклад будет полезен администраторам баз данных, системным администраторам и разработчикам, которым интересен траблшутинг Postgres’а.
Меня зовут Алексей Лесовский, я представляю компанию Data Egret.
Немного слов о себе. Я начинал когда-то давным-давно системным администратором.
Администрировал всякие разные Linux, занимался разными вещами, связанными с Linux, т. е. виртуализацией, мониторингом, работал с прокси и т. д. Но в какой-то момент я стал заниматься больше базами данных, PostgreSQL. Он мне очень нравился. И в какой-то момент я стал заниматься PostgreSQL основную часть своего рабочего времени. И так постепенно я стал PostgreSQL DBA.
И на протяжении всей своей карьеры мне всегда были интересны темы статистики, мониторинга, снятия телеметрии. И когда я был системным администратором, я занимался очень плотно Zabbix. И написал небольшой набор скриптов как zabbix-extensions. Он был довольно популярным в свое время. И там можно было мониторить очень разные важные штуки, не только Linux, но еще разные компоненты.
Сейчас я занимаюсь уже PostgreSQL. Я пишу уже другую штуку, которая позволяет работать с PostgreSQL-статистикой. Она называется pgCenter (статья на хабре — Постгресовая стата без нервов и напрягов).
Небольшая вводная. Какие бывают ситуации у наших заказчиков, у наших клиентов? Происходит какая-то авария, связанная с базой данной. И когда уже восстановили базу данных, приходит начальник отдела или начальник разработки и говорит: «Друзья, надо бы нам замониторить базу данных, потому что случилось что-то плохое и надо, чтобы в будущем такого не происходило». И здесь начинается интересный процесс выбора системы мониторинга или адаптации существующей системы мониторинга для того, чтобы можно было мониторить свою базу данных – PostgreSQL, MySQL или какие-то другие. И коллеги начинают предлагать: «Я слышал, что есть такая-то база данных. Давайте использовать ее». Коллеги начинают друг с другом спорить. И в итоге получается, что мы выбираем какую-то базу данных, но мониторинг PostgreSQL в ней представлен довольно слабо и всегда приходится что-то допиливать.
Поэтому в этом докладе я постараюсь дать вам некие знания о том, как выбирать мониторинг не только для PostgreSQL, но и для базы данных. И дать те знания, которые позволят вам допилить ваш мониторинг, чтобы получить от него какую-то пользу, чтобы можно было мониторить свою базу данных с пользой, чтобы вовремя предупреждать какие-то предстоящие аварийные ситуации, которые могут возникнуть.
И те идеи, которые будут в этом докладе, их можно напрямую адаптировать к любой базе данных, будь это СУБД или noSQL. Поэтому тут не только PostgreSQL, но здесь будет много рецептов, как сделать это в PostgreSQL. Будут примеры запросов, примеры сущностей, которые есть в PostgreSQL для мониторинга. И если ваша СУБД имеет такие же вещи, которые позволяют засунуть их в мониторинг, вы тоже можете их адаптировать, добавить и будет хорошо.
В докладе я не буду
рассказывать про то, как доставлять и хранить метрики.
Но по ходу повествования я буду показывать разные скриншоты существующих мониторингов, как-то буду их критиковать. Но тем не менее я постараюсь не называть брендов, чтобы не создавать рекламу или антирекламу этим продуктам. Поэтому все совпадения случайны и остаются на вашей фантазии.
Для начала разберемся, что такое мониторинг. Мониторинг – это очень важная штука, которую нужно иметь. Это все понимают. Но в то же самое время мониторинг не относится к бизнес-продукту и на напрямую не влияет на прибыль компании, поэтому на мониторинг всегда уделяют время по остаточному принципу. Если у нас есть время, то мы занимаемся мониторингом, если времени нет, то ОК, поставим в бэклог и когда-нибудь вернемся к этим задачам.
Поэтому из нашей практики, когда мы приходим к клиентам, мониторинг часто недоработан и не имеет каких-то интересных вещей, которые помогали бы нам делать работу лучше с базой данных. И поэтому мониторинг всегда нужно допиливать.
И поэтому мониторинг всегда нужно допиливать.
Базы данных – это такие сложные штуки, которые тоже нужно мониторить, потому что базы данных – это хранилище информации. И информация очень важна для компании, ее нельзя никак терять. Но в то же время базы данных – это очень сложные куски программного обеспечения. Они состоят из большого количества компонентов. И многие из этих компонентов нужно мониторить.
Если мы говорим про конкретно про PostgreSQL, то его можно представить в виде такой схемы, которая состоит из большого количества компонентов. Эти компоненты взаимодействуют друг с другом. И в то же время в PostgreSQL есть, так называемая, подсистема Stats Collector, которая позволяет собирать статистику о работе этих подсистем и предоставлять некий интерфейс администратору или пользователю, чтобы он мог просматривать эту статистику.
Эта статистика представлена в виде некоторого набора функций и вьюх (view). Их можно еще назвать таблицами. Т. е. с помощью обычного psql клиента вы можете подключиться к базе данных, сделать select к этим функциям и вьюхам, и получить уже какие-то конкретные циферки о работе подсистем PostgreSQL.
Вы можете добавить эти циферки в вашу любимую систему мониторинга, нарисовать графики, добавить функции и получить аналитику в долгосрочной перспективе.
Но в этом докладе я не буду рассматривать поголовно все эти функции, потому что это может занять целый день. Я буду обращаться буквально к двум-трем-четырем штукам и буду рассказывать, как они помогают сделать мониторинг лучше.
И если говорить про мониторинг базы, то что нужно мониторить? В первую очередь нужно мониторить доступность, потому что база – это сервис, который предоставляет доступ к данным клиентам и нам нужно мониторить доступность, а предоставляет также ее некоторые качественные и количественные характеристики.
Также нужно мониторить клиентов, которые подключаются к нашей базе, потому что они могут быть как и нормальными клиентами, так и вредными клиентами, которые могут наносить вред базе данных. Их тоже нужно мониторить и отслеживать их деятельность.
Когда клиенты подключаются к базе данных, то очевидно, что они начинают работать с нашими данными, поэтому нам нужно мониторить и то, как клиенты работают с данными: с какими таблицами, в меньшей степени с какими индексами. Т. е. нам нужно оценить ворклоад (workload), который создается нашими клиентами.
Т. е. нам нужно оценить ворклоад (workload), который создается нашими клиентами.
Но и ворклоад состоит, конечно, из запросов. Приложения подключаются к базе, обращаются к данным с помощью запросов, поэтому важно оценивать, какие запросы у нас в базе данных, отслеживать их адекватность, что они не являются криво написанными, что какие-то опции нужно переписать и сделать так, чтобы они работали быстрее и с более лучшей производительностью.
И раз мы говорим про базу данных, то база данных – это всегда фоновые процессы. Фоновые процессы позволяют поддерживать производительность базы данных на хорошем уровне, поэтому для их работы они требуют некое количество ресурсов для себя. И в то же время они могут пересекаться с ресурсами клиентских запросов, поэтому жадная работа фоновых процессов может непосредственно влиять на производительность клиентских запросов. Поэтому их тоже нужно мониторить и отслеживать, что нет никаких перекосов в плане фоновых процессов.
И это все в плане мониторинга базы данных остается в системной метрике. Но учитывая, что у нас по большей части вся инфраструктура уезжает в облака, системные метрики отдельного хоста всегда отходят на второй план. Но в базах данных они все еще актуальны и мониторить системные метрики, конечно, тоже нужно.
Но учитывая, что у нас по большей части вся инфраструктура уезжает в облака, системные метрики отдельного хоста всегда отходят на второй план. Но в базах данных они все еще актуальны и мониторить системные метрики, конечно, тоже нужно.
С системными метриками более-менее все хорошо, все современные системы мониторинга уже поддерживают эти метрики, но в целом каких-то компонентов все-таки недостаточно и нужно некоторые вещи добавлять. Про них я тоже затрону, несколько слайдов будет про них.
Первый пункт плана – это доступность. Что такое доступность? Доступность в моем понимании – это способность базы обслуживать подключения, т. е. база поднята, она, как сервис, принимает подключения от клиентов. И эту доступность можно оценивать некоторыми характеристиками. Эти характеристики очень удобно выносить на дашборды.
Все знают, что такое дашборды. Это когда ты бросил один взгляд на экран, на котором сведена необходимая информация. И вы уже можете сразу определить – есть проблема в базе или нет.
Соответственно доступность базы данных и другие ключевые характеристики всегда необходимо выносить на дашборды, чтобы эта информация была под рукой, была у вас всегда рядом. Какие-то дополнительные детали, которые уже помогают при расследовании инцидентов, при расследовании каких-то аварийных ситуаций, их уже нужно выносить на вторичные дашборды, либо скрывать в drilldown-линках, которые ведут на сторонние системы мониторинга.
Пример одной известной системы мониторинга. Это очень крутая система мониторинга. Она собирает очень много данных, но с моей точки зрения, у нее странное понятие дашбордов. Там есть ссылка «создать дашборд». Но когда вы создаете дашборд, вы создаете некий список, состоящий из двух колонок, некий список графиков. И когда вам нужно что-то посмотреть, вы начинаете мышкой кликать, листать, искать нужный график. И на это уходит время, т. е. дашбордов, как таковых, нет. Есть лишь списки графиков.
Что нужно добавлять на эти дашборды? Можно начать с такой характеристики как время отклика. В PostgreSQL есть вьюха pg_stat_statements. По умолчанию она отключена, но это одна из важных системных вьюх, которую всегда необходимо включать и использовать. Она хранит в себе информацию о всех выполняющихся запросах, которые в базе данных выполнялись.
В PostgreSQL есть вьюха pg_stat_statements. По умолчанию она отключена, но это одна из важных системных вьюх, которую всегда необходимо включать и использовать. Она хранит в себе информацию о всех выполняющихся запросах, которые в базе данных выполнялись.
Соответственно, мы можем оттолкнуться от того, что можно взять суммарное время выполнения всех запросов и поделить на количество запросов с помощью вышеприведенных полей. Но это такая средняя температура по больнице. Мы можем оттолкнуться от других полей – минимальное время выполнения запросов, максимальное и медианное. И даже можем строить перцентили, в PostgreSQL есть соответствующие функции для этого. И мы можем получить какие-то цифры, которые характеризуют время отклика нашей базы по уже выполненным запросам, т. е. мы не выполняем фейковый запрос ‘select 1’ и смотрим время отклика, а мы анализируем время ответов по уже выполненным запросам и рисуем либо отдельной цифрой, либо строим по ней график.
Также важно отслеживать количество ошибок, которые генерируются системой в данный момент. И для этого можно использовать вьюху pg_stat_database. Мы ориентируемся на поле xact_rollback. Это поле показывает не только количество rollback, которые происходят в базе, но еще и учитывает количество ошибок. Условно говоря, мы можем выводить эту цифру в наш дашборд и смотреть сколько у нас ошибок в данный момент. Если ошибок много, то это уже хороший повод заглянуть в логи и посмотреть, что же это за ошибки и почему они происходят, а дальше уже инвестигировать и решать их.
И для этого можно использовать вьюху pg_stat_database. Мы ориентируемся на поле xact_rollback. Это поле показывает не только количество rollback, которые происходят в базе, но еще и учитывает количество ошибок. Условно говоря, мы можем выводить эту цифру в наш дашборд и смотреть сколько у нас ошибок в данный момент. Если ошибок много, то это уже хороший повод заглянуть в логи и посмотреть, что же это за ошибки и почему они происходят, а дальше уже инвестигировать и решать их.
Можно добавить такую штуку, как Тахометр. Это количество транзакций в секунду и количество запросов в секунду. Условно говоря, вы можете использовать эти цифры как текущую производительность вашей базы данных и наблюдать есть ли пики запросов, пики транзакций или, наоборот, база недогружена, потому что какой-то backend отвалился. Эту цифру важно всегда смотреть и помнить, что для нашего проекта вот такая производительность является нормальной, а значения выше и ниже уже какие-то проблемные и непонятные, а значит, нужно смотреть, почему такие цифры.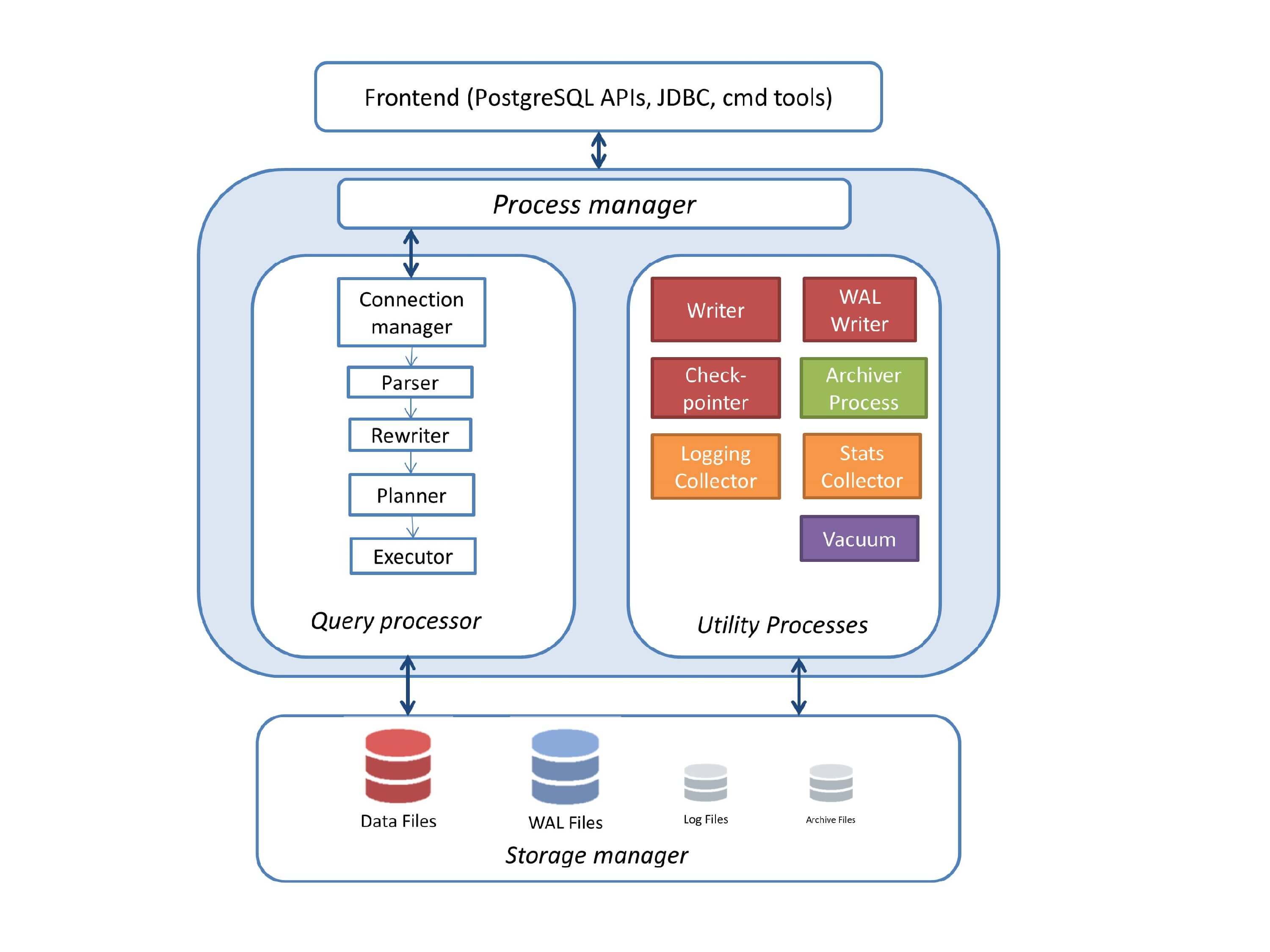
Для того чтобы оценивать количество транзакций, мы снова можем обратиться к вьюхе pg_stat_database. Мы можем сложить количество commit и количество rollback и получить количество транзакций в секунду.
Все понимают, что в одну транзакцию может уложиться несколько запросов? Поэтому TPS и QPS немного разные.
Количество запросов в секунду можно получить по pg_stat_statements и просто просчитать сумму всех выполненных запросов. Понятно, что мы сравниваем текущее значение с предыдущим, вычитаем, получаем дельту, получаем количество.
Можно добавить дополнительные метрики по желанию, которые также помогают оценивать доступность нашей базы и отслеживать – не было ли каких-то downtime.
Одна из этих метрик – это uptime. Но uptime в PostgreSQL – это немного хитрая штука. Расскажу, почему. Когда PostgreSQL запустился, начинается отчитываться uptime. Но если в какой-то момент, например, ночью выполнялась какая-то задача, пришел OOM-killer и завершил принудительно дочерний процесс PostgreSQL, то в этом случае PostgreSQL завершает соединение всех клиентов, сбрасывает область шардированной памяти и начинает восстановление с последней контрольной точки. И пока длится это восстановление с контрольной точки, база не принимает подключения, т. е. эту ситуацию можно оценивать, как downtime. Но при этом счетчик uptime не сбросится, потому что он учитывает время запуска postmaster с самого первого момента. Поэтому такие ситуации можно пропустить.
И пока длится это восстановление с контрольной точки, база не принимает подключения, т. е. эту ситуацию можно оценивать, как downtime. Но при этом счетчик uptime не сбросится, потому что он учитывает время запуска postmaster с самого первого момента. Поэтому такие ситуации можно пропустить.
Также следует мониторить количество воркеров вакуума. Все знают, что такое autovacuum в PostgreSQL? Это интересная подсистема в PostgreSQL. Про нее написано много статей, много сделано докладов. Много обсуждений про вакуум, о том, как он должен работать. Многие считают его неизбежным злом. Но так и есть. Это некий аналог сборщика мусора, который чистит устаревшие версии строк, которые не нужны ни одной из транзакции и освобождает место в таблицах, индексах для новых строк.
Почему нужно его мониторить? Потому что вакуум иногда делает очень больно. Он отжирает большое количество ресурсов и клиентские запросы от этого начинают страдать.
И мониторить следует его через вьюху pg_stat_activity, про которую я буду говорить в следующем разделе. Эта вьюха показывает текущую активность в базе данных. И через эту активность мы можем отследить количество вакуумов, которые работают прямо сейчас. Мы можем отслеживать вакуумы и видеть, что если у нас превышен лимит, то это повод заглянуть в настройки PostgreSQL и как-то оптимизировать работу вакуума.
Эта вьюха показывает текущую активность в базе данных. И через эту активность мы можем отследить количество вакуумов, которые работают прямо сейчас. Мы можем отслеживать вакуумы и видеть, что если у нас превышен лимит, то это повод заглянуть в настройки PostgreSQL и как-то оптимизировать работу вакуума.
Другой особенностью PostgreSQL является то, что PostgreSQL очень больно от долгих транзакций. Особенно, от транзакций, которые долго висят и ничего не делают. Это, так называемые, stat idle-in-transaction. Такая транзакция удерживает блокировки, она мешает работать вакууму. И как следствие – таблицы пухнут, они увеличиваются в размере. И запросы, которые работают с этими таблицами, они начинают работать медленнее, потому что нужно лопатить все старые версии строк из памяти на диск и обратно. Поэтому время, длительность самых долгих транзакций, самых долгих запросов вакуума тоже нужно мониторить. И если мы видим какие-то процессы, которые работают уже очень долго, уже больше 10-20-30 минут для OLTP-нагрузки, то на них нужно уже обращать внимание и завершать принудительно, либо оптимизировать приложение, чтобы они не вызывались и не висели так долго. Для аналитической нагрузки 10-20-30 минут – это нормально, там бывает еще и более долгие.
Для аналитической нагрузки 10-20-30 минут – это нормально, там бывает еще и более долгие.
Дальше у нас вариант с подключенными клиентами. Когда мы уже сформировали дашборд, вывесили на него ключевые метрики доступности, мы можем также добавить туда и дополнительную информацию о подключенных клиентах.
Информация о подключенных клиентах важна, потому что, с точки зрения PostgreSQL, клиенты бывают разными. Бывают хорошие клиенты, бывают плохие клиенты.
Простой пример. Под клиентом я пониманию приложение. Приложение подключилось к базе данных и начинает сразу слать туда свои запросы, база данных их обрабатывает и выполняет, результаты возвращает клиенту. Это хорошие и правильные клиенты.
Бывают ситуации, что клиент подключился, он удерживает коннект, но при этом ничего не делает. Он находится в состоянии idle.
Но бывают плохие клиенты. Например, тот же клиент подключился, открыл транзакцию, что-то поделал в базе и потом ушел в код, допустим, чтобы обратиться ко внешнему источнику или для того, чтобы сделать там обработку, полученных данных. Но при этом он не закрыл транзакцию. И транзакция висит в базе и удерживает в блокировку на строке. Это плохое состояние. И если вдруг приложение где-то внутри у себя упадет по эксепшену (Exception), то транзакция может остаться открытой на очень долгое время. И это влияет напрямую на производительность PostgreSQL. PostgreSQL будет работать медленнее. Поэтому таких клиентов важно вовремя отслеживать и завершать их работу принудительно. И нужно оптимизировать свое приложение, чтобы не было таких ситуаций.
Но при этом он не закрыл транзакцию. И транзакция висит в базе и удерживает в блокировку на строке. Это плохое состояние. И если вдруг приложение где-то внутри у себя упадет по эксепшену (Exception), то транзакция может остаться открытой на очень долгое время. И это влияет напрямую на производительность PostgreSQL. PostgreSQL будет работать медленнее. Поэтому таких клиентов важно вовремя отслеживать и завершать их работу принудительно. И нужно оптимизировать свое приложение, чтобы не было таких ситуаций.
Другими плохими клиентами являются ожидающие клиенты. Но они становятся плохими из-за обстоятельств. Например, простая простаивающая транзакция: может открыть транзакцию, взять блокировки на какие-то строки, потом где-то в коде она упадет, останется висящая транзакция. Придет другой клиент, запросит те же самые данные, но он столкнется с блокировкой, потому что та висящая транзакция уже удерживает блокировки на какие-то нужные строки. И вторая транзакция будет висеть в ожидании, когда первая транзакция завершится или ее администратор принудительно закроет. Таким образом, ждущие транзакции могут накапливаться и переполнять лимит подключений к базе данных. И когда лимит переполнен, то приложение уже не может работать с базой. Это уже аварийная ситуация для проекта. Поэтому плохих клиентов нужно отслеживать и своевременно на них реагировать.
Таким образом, ждущие транзакции могут накапливаться и переполнять лимит подключений к базе данных. И когда лимит переполнен, то приложение уже не может работать с базой. Это уже аварийная ситуация для проекта. Поэтому плохих клиентов нужно отслеживать и своевременно на них реагировать.
Другой пример мониторинга. И здесь уже приличный дашборд. Есть информация по коннектам сверху. DB connection – 8 штук. И это все. У нас нет информации о том, какие клиенты активные, какие клиенты просто idle, ничего не делают. Нет информации о висящих транзакциях и об ожидающих коннектах, т. е. это такая цифра, которая показывает количество коннектов и все. А дальше гадайте сами.
Соответственно, чтобы добавить эту информацию в мониторинг, нужно обратиться к системной вьюхе pg_stat_activity. Если вы много времени проводите в PostgreSQL, то это очень хорошая вьюха, которая должна стать вашим другом, потому что она показывает текущую активность в PostgreSQL, т. е. что происходит в нем. На каждый процесс есть отдельная строчка, которая показывает информацию по этому процессу: с какого хоста выполнено подключение, под каким пользователем, под каким именем, когда запущена транзакция, какой сейчас выполняется запрос, какой запрос выполнялся последним. И, соответственно, состояние клиента мы можем оценивать по полю stat. Условно говоря, мы можем сделать группировку по этому полю и получить те stats-ы, которые есть сейчас в базе данных и количество коннектов, которые с этим stat-ом в базе данных. И уже полученные цифры мы можем отправлять в наш мониторинг и рисовать по ним графики.
На каждый процесс есть отдельная строчка, которая показывает информацию по этому процессу: с какого хоста выполнено подключение, под каким пользователем, под каким именем, когда запущена транзакция, какой сейчас выполняется запрос, какой запрос выполнялся последним. И, соответственно, состояние клиента мы можем оценивать по полю stat. Условно говоря, мы можем сделать группировку по этому полю и получить те stats-ы, которые есть сейчас в базе данных и количество коннектов, которые с этим stat-ом в базе данных. И уже полученные цифры мы можем отправлять в наш мониторинг и рисовать по ним графики.
Также важно оценивать длительность транзакции. Я уже говорил, что важно оценивать длительность вакуумов, но и транзакции оцениваются точно так же. Есть поля xact_start и query_start. Они, условно говоря, показывают время старта транзакции и время старта запроса. Мы берем функцию now(), которая показывает текущую отметку времени и вычитаем timestamp транзакции и запроса. И получаем длительность транзакции, длительность запроса.
Если мы видим длинные транзакции, мы должны их уже завершать. Для OLTP-нагрузки длинные транзакции – это уже больше 1-2-3 минут. Для OLAP-нагрузки длинные транзакции являются нормальными, но если они выполняются больше двух часов, то это тоже признак того, что где-то у нас есть перекос.
Когда клиенты подключились к базе данных, они начинают работать с нашими данными. Они обращаются к таблицам, они обращаются к индексам, чтобы получить данные из таблицы. И важно оценивать то, как клиенты работают с этими данными.
Это нужно для того, чтобы оценивать наш ворклоад и примерно понимать, какие таблицы у нас самые «горячие». Например, это нужно в ситуациях, когда мы хотим «горячие» таблицы поместить на какое-то быстрое SSD хранилище. Например, какие-то архивные таблицы, которые мы уже давно не используем можно вынести на какой-то «холодный» архив, на SATA диски и пусть они там живут, к ним обращение будет идти по необходимости.
Также это полезно для обнаружения аномалий после всяких релизов и деплоев. Допустим, проект выкатил какую-то новую фичу. Например, добавили новую функциональность для работы с базой. И если мы построим графики использования таблиц, мы на этих графиках сможем легко обнаружить эти аномалии. Например, всплески update или всплески delete. Это очень хорошо будет видно.
Допустим, проект выкатил какую-то новую фичу. Например, добавили новую функциональность для работы с базой. И если мы построим графики использования таблиц, мы на этих графиках сможем легко обнаружить эти аномалии. Например, всплески update или всплески delete. Это очень хорошо будет видно.
Также можно обнаружить аномалии «поплывшей» статистики. Что это значит? В PostgreSQL очень сильный и очень хороший планировщик запросов. И разработчики много времени уделяют его развитию. Как он работает? Для того чтобы строить хорошие планы, PostgreSQL с некоторым интервалом времени, с некоторой периодичностью собирает статистику о распределении данных в таблицах. Это самые частые значения: количество уникальных значений, информация о NULL в таблице, очень много информации.
На основе этой статистики планировщик строит несколько запросов, выбирает наиболее оптимальный и использует этот план запроса для выполнения самого запроса и возвращения данных.
И бывает, что статистика «плывет». Данные качества, количества поменялись как-то в таблице, но статистика при этом не собралась. И сформированные планы могут оказаться не оптимальными. И если у нас планы окажутся неоптимальными по собираемому мониторингу, по таблицам, мы сможем увидеть эти аномалии. Например, где-то качественно изменились данные и вместе индекса стал использоваться последовательный проход по таблице, т.е. если запросу нужно вернуть всего лишь 100 строк (стоит ограничение limit 100), то для этого запроса будет выполнен полный перебор. И это всегда очень плохо сказывается на производительности.
Данные качества, количества поменялись как-то в таблице, но статистика при этом не собралась. И сформированные планы могут оказаться не оптимальными. И если у нас планы окажутся неоптимальными по собираемому мониторингу, по таблицам, мы сможем увидеть эти аномалии. Например, где-то качественно изменились данные и вместе индекса стал использоваться последовательный проход по таблице, т.е. если запросу нужно вернуть всего лишь 100 строк (стоит ограничение limit 100), то для этого запроса будет выполнен полный перебор. И это всегда очень плохо сказывается на производительности.
И мы сможем увидеть это в мониторинге. И уже посмотреть на этот запрос, выполнить для него explain, собрать статистику, построить новый дополнительный индекс. И уже отреагировать на эту проблему. Поэтому это важно.
Другой пример мониторинга. Я думаю, многие его узнали, потому что он очень популярный. Кто использует у себя в проектах Prometheus? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – postgres_exporter Prometheus. Но тут есть одна плохая деталь.
Но тут есть одна плохая деталь.
Есть несколько графиков. И в качестве unity указаны байты, т. е. там 5 графиков. Это Insert data, Update data, Delete data, Fetch data и Return data. В качестве unit измерения указаны байты. Но дело в том, что статистика в PostgreSQL возвращает данные в tuple (строках). И, соответственно, эти графики – это очень хороший способ занизить ваш ворклоад в несколько раз, в десятки раз, потому что tuple – это не байт, tuple – это строка, это много байтов и она всегда переменной длины. Т. е. вычислить ворклоад в байтах с помощью tuples – это нереальная задача или очень сложная. Поэтому, когда вы используете дашборд или встроенный мониторинг, всегда важно понимать, что он работает правильно и возвращает вам корректно оцененные данные.
Как получать статистику по этим таблицам? Для этого в PostgreSQL есть некоторое семейство вьюх. И основная вьюха – это pg_stat_user_tables. User_tables – это означает, что таблицы, созданные от лица пользователя. В противовес есть системные вьюхи, которые используются самим PostgreSQL. И есть сводная таблица Alltables, которая включает и системные, и пользовательские. Вы можете отталкиваться от любой из них, которая вам больше всего нравится.
В противовес есть системные вьюхи, которые используются самим PostgreSQL. И есть сводная таблица Alltables, которая включает и системные, и пользовательские. Вы можете отталкиваться от любой из них, которая вам больше всего нравится.
По вышеуказанным полям можно оценивать количество insert, update и delete. Тот пример дашборда, который я использовал, как раз использует эти поля для оценки характеристик ворклоада. Поэтому мы также можем отталкиваться от них. Но стоит помнить, что это tuples, а не байты, поэтому мы не можем взять и сделать это байтами.
На основе этих данных мы можем строить, так называемые, TopN-таблицы. Например, Top-5, Top-10. И можно отслеживать те горячие таблицы, которые утилизируются больше остальных. Например, 5 «горячих» таблиц по вставке. И по этим TopN-таблицам мы оцениваем наш ворклоад и можем оценивать всплески ворклоада после всяких релизов и апдейтов, и деплоев.
Также важно оценивать размеры таблицы, потому что иногда разработчики выкатывают новую фичу, и у нас таблицы начинают пухнуть в своих больших размерах, потому что решили дописать дополнительный объем данных, но при этом не спрогнозировали, как это скажется на размере базы данных. Такие случае тоже бывают для нас сюрпризами.
Такие случае тоже бывают для нас сюрпризами.
И сейчас небольшой вопрос для вас. Какой возникает вопрос, когда вы замечаете нагрузку на сервере с базой данных? Какой следующий вопрос у вас возникает?
Но на самом деле вопрос возникает следующий. Какие запросы вызывает нагрузка? Т. е. не интересно смотреть процессы, какие вызывает нагрузка. Понятно, что если host с базой данных, то там запущена база данных и понятно, что только базы данных там и будет утилизировать. Если мы откроем Top, то увидим там список процессов в PostgreSQL, которые что-то делают. Из Top будет не понятно, что они делают.
Соответственно, нужно обнаружить те запросы, которые вызывают наибольшую загрузку, потому что тюнинг запросов, как правило, дает больше профит, чем тюнинг конфигурации PostgreSQL или операционной системы, или даже тюнинг железа. По моей оценке – это примерно 80-85-90 %. И это делается гораздо быстрее. Быстрее поправить запрос, чем поправить конфигурацию, запланировать рестарт, особенно, если базу рестартовать нельзя, либо добавлять железо. Проще где-то переписать запрос или добавить индекс, чтобы получить уже более лучший результат от этого запроса.
Проще где-то переписать запрос или добавить индекс, чтобы получить уже более лучший результат от этого запроса.
Соответственно, нужно мониторить запросы и их адекватность. Возьмем другой пример мониторинга. И тут тоже вроде прекрасный мониторинг. Есть информация по репликации, есть информация по пропускной способности, блокировкам, утилизации ресурсов. Все прекрасно, но нет информации по запросам. Не понятно, какие запросы выполняются в нашей базе данных, как долго они выполняются, сколько этих запросов. Нам нужно в мониторинге всегда иметь эту информацию.
И для получения этой информации мы можем использовать модуль pg_stat_statements. На его основе можно строить самые разные графики. Например, можно получать информацию по самым частым запросам, т. е. по тем запросам, которые выполняются чаще всех. Да, после деплоев тоже очень полезно посмотреть на него и понимать, нет ли какого-то всплеска запросов.
Можно мониторить самые долгие запросы, т. е. те запросы, которые выполняются дольше всех. Они работают на процессоре, они потребляют ввод-вывод. Мы это тоже можем оценивать по полям total_time, mean_time, blk_write_time и blk_read_time.
Они работают на процессоре, они потребляют ввод-вывод. Мы это тоже можем оценивать по полям total_time, mean_time, blk_write_time и blk_read_time.
Мы можем оценивать и мониторить самые тяжелые запросы в плане использования ресурсов, те, которые читают с диска, которые работают с памятью или, наоборот, создают какую-то пишущую нагрузку.
Можем оценивать самые щедрые запросы. Это те запросы, которые возвращают большое количество строк. Например, это может быть какой-то запрос, где забыли поставить лимит. И он просто возвращает все содержимое таблицы или запроса по запрошенным таблицам.
И можно также мониторить запросы, которые используют временные файлы или временные таблицы.
И у нас остались фоновые процессы. Фоновые процессы – это в первую очередь чекпоинты или их еще называют контрольными точками, это autovacuum и репликация.
Другой пример мониторинга. Есть слева вкладка Maintenance, переходим на нее и надеемся увидеть, что-то полезное. Но здесь только время работы вакуума и сбора статистики, больше ничего. Это очень бедная информация, поэтому всегда нужно иметь информацию о том, как работают фоновые процессы у нас в базе данных и нет ли проблем от их работы.
Но здесь только время работы вакуума и сбора статистики, больше ничего. Это очень бедная информация, поэтому всегда нужно иметь информацию о том, как работают фоновые процессы у нас в базе данных и нет ли проблем от их работы.
Когда мы рассматриваем контрольные точки, то следует помнить, что контрольные точки у нас сбрасывают «грязные» страницы из области шардированной памяти на диск, затем создают контрольную точку. И эта контрольная точка уже дальше может использоваться как некое место при восстановлении, если вдруг PostgreSQL был завершен в аварийном порядке.
Соответственно, чтобы сбросить все «грязные» страницы на диск, нужно проделать некий объем записи. И, как правило, на системах с большим объемом памяти – это очень много. И если у нас чекпоинты делаются очень часто в какой-то короткий интервал, то дисковая производительность будет очень сильно проседать. И клиентские запросы будут страдать от нехватки ресурсов. Они будут бороться за ресурсы и им будет не хватать производительности.
Соответственно, через pg_stat_bgwriter по указанным полям мы можем мониторить количество случающихся чекпоинтов. И если у нас за какой-то промежуток времени (за 10-15-20 минут, за полчаса) очень много чекпоинтов, например, 3-4-5, то это уже может быть проблемой. И уже нужно посмотреть в базе данных, посмотреть в конфигурации, что вызывает такое обилие чекпоинтов. Может быть, какая-то большая запись идет. По ворклоаду можем уже оценить, потому что у нас графики ворклоада уже добавлены. Мы можем уже подтюнить параметры контрольных точек и сделать так, чтобы они не сильно влияли на производительность запросов.
Я снова возвращаюсь к autovacuum, потому что это такая штука, как я уже говорил, которая запросто может сложить производительность как дисков, так и запросов, поэтому всегда важно оценивать количество autovacuum.
Количество воркеров autovacuum в базе данных ограничено. По умолчанию их три, поэтому если у нас все время три воркера работают в базе, то это значит, что у нас autovacuum недонастроен, нужно поднимать лимиты, пересматривать настройки autovacuum и уже лезть в конфигурацию.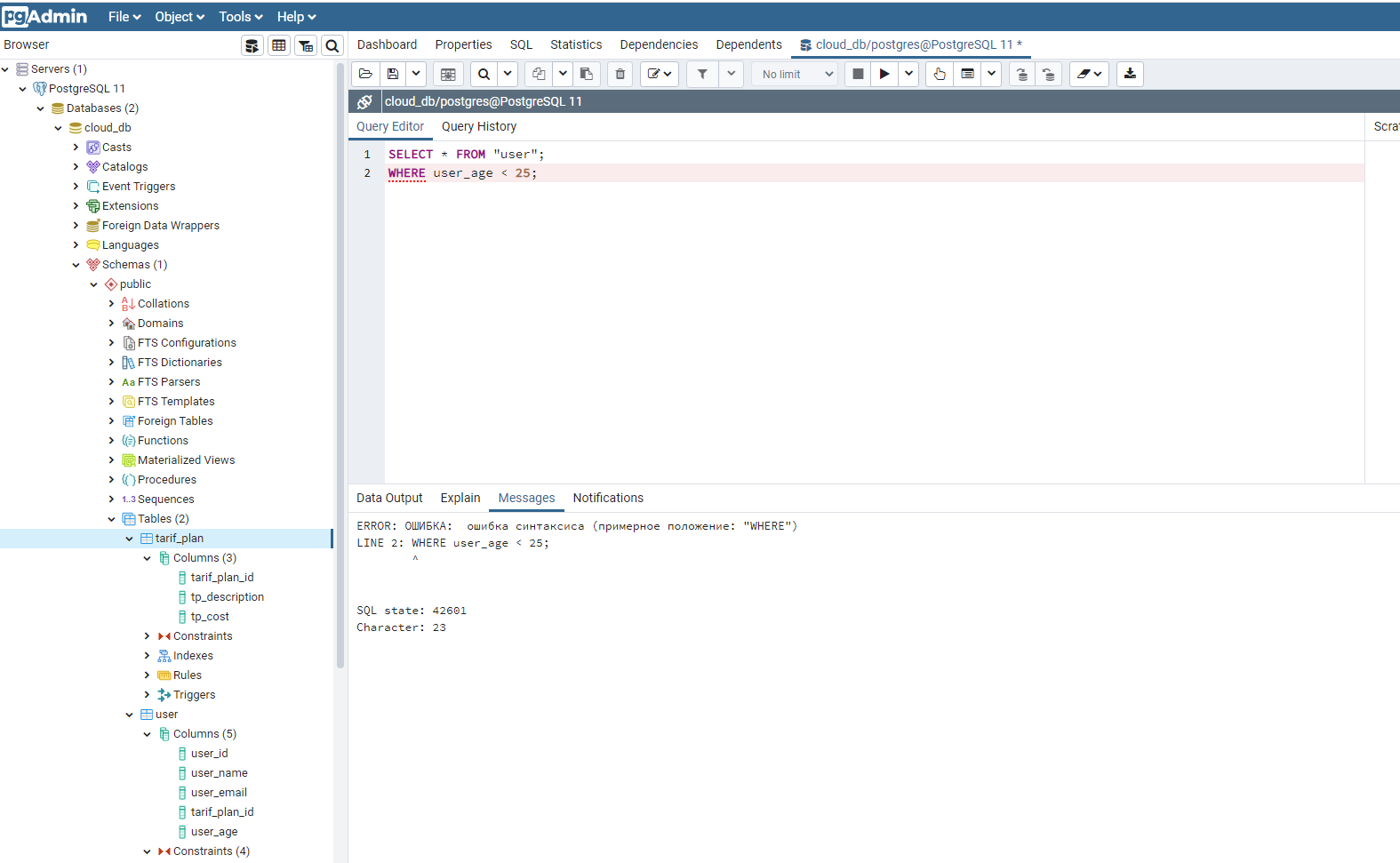
Важно оценивать какие у нас работают воркера вакуума. Либо это запущенный от пользователя, DBA пришел и руками запустил какой-то вакуум, и это создало нагрузку. У нас появилась какая-то проблема. Либо это количество вакуумов, которые откручивают счетчик транзакций. Для некоторых версий PostgreSQL – это очень тяжелые вакуумы. И они могут запросто сложить производительность, потому что они вычитывают всю таблицу целиком, сканируют все блоки в этой таблице.
И, конечно, длительность вакуумов. Если у нас долгие вакуумы, которые работают очень долгое время, то это значит, что нам снова стоит обратить внимание на конфигурацию вакуума и, возможно, пересмотреть его настройки. Потому что может появиться ситуация, когда вакуум работает над таблицей долгое время (3-4 часа), но за время работы вакуума в таблице успели накопиться снова большой объем мертвых строк. И как только вакуум завершится, ему снова нужно вакуумить эту таблицу. И мы приходим к ситуации – бесконечного вакуума. И в таком случае вакуум не справляется со своей работы, и таблицы начинают постепенно пухнуть в размерах, хотя объем полезных данных в ней остается прежним. Поэтому при долгих вакуумах мы всегда смотрим на конфигурацию и пытаемся оптимизировать ее, но при этом, чтобы не страдали производительность клиентских запросов.
Поэтому при долгих вакуумах мы всегда смотрим на конфигурацию и пытаемся оптимизировать ее, но при этом, чтобы не страдали производительность клиентских запросов.
Сейчас практически нет инсталляции PostgreSQL, где не было потоковой репликации. Репликация – это процесс переноса данных с мастера на реплику.
Репликация в PostgreSQL устроена через журнал транзакций. Мастер генерирует журнал транзакций. Журнал транзакции по сетевому соединению едет на реплику, дальше на реплике он воспроизводится. Все просто.
Соответственно, для мониторинга лага репликации используется вьюха pg_stat_replication. Но с ней не все просто. В версии 10 вьюха претерпела несколько изменений. Во-первых, часть полей была переименована. И часть полей была добавлена. В 10-ой версии появились поля, которые позволяют оценивать лаг репликации в секундах. Это очень удобно. До версии 10 была возможность оценивать лаг репликации в байтах. Такая возможность осталась и в 10-ой версии, т. е. вы можете выбирать, что вам удобнее – оценивать лаг в байтах или оценивать лаг в секундах. Многие делают и то и другое.
Многие делают и то и другое.
Но тем не менее, чтобы оценивать лаг репликации, нужно знать позицию журнала в транзакции. И эти позиции журнала транзакции как раз есть во вьюхе pg_stat_replication. Условно говоря, мы с помощью функции pg_xlog_location_diff() можем взять две точки в журнале транзакции. Посчитать между ними дельту и получить лаг репликации в байтах. Это очень удобно и просто.
В 10-ой версии эта функция бела переименована в pg_wal_lsn_diff(). Вообще, во всех функциях, вьюхах, утилитах, где встречалось слово «xlog», оно было заменено на значение «wal». Это и во вьюхах, и в функциях. Это вот такое нововведение.
Плюс в 10-ой версии добавились строчки, которые конкретно показывают лаг. Это write lag, flush lag, replay lag. Т. е. эти штуки важно мониторить. Если мы видим, что у нас лаг репликации, то нужно исследовать, почему он появился, откуда взялся и устранять проблему.
С системными метриками практически все в порядке. Когда зарождается любой мониторинг, он начинает с системных метрик. Это утилизация процессоров, памяти, swap, сети и диска. Но тем не менее многих параметров там по умолчанию нет.
Это утилизация процессоров, памяти, swap, сети и диска. Но тем не менее многих параметров там по умолчанию нет.
Если с утилизацией процесса все в порядке, то с утилизацией диска есть проблемы. Как правило, разработчики мониторингов добавляют информацию о пропускной способности. Она может быть в iops или байтах. Но они забывают про latency и утилизацию дисковых устройств. Это более важные параметры, которые позволяют оценивать, насколько у нас загружены диски и насколько они тормозят. Если у нас высокий latency, то это значит, что есть какие-то проблемы с дисками. Если у нас высокая утилизация, то это значит, что диски не справляются. Это более качественные характеристики, чем пропускная способность.
При том, что эту статистику можно также получить из файловой системы /proc, как это делается для утилизации процессоров. Почему эту информацию не добавляют в мониторинги, я не знаю. Но тем не менее важно иметь это в своем мониторинге.
Тоже самое относительно сетевых интерфейсов. Есть информация о пропускной способности сети в пакетах, в байтах, но тем не менее нет информации о latency и нет информации об утилизации, хотя это тоже полезная информация.
Есть информация о пропускной способности сети в пакетах, в байтах, но тем не менее нет информации о latency и нет информации об утилизации, хотя это тоже полезная информация.
Любые мониторинги имеют недостатки. И какой мониторинг вы бы не взяли, он всегда будет не соответствовать каким-то критериям. Но тем не менее они развиваются, добавляются новые фичи, новые вещи, поэтому выбирайте что-то и допиливайте.
И для того чтобы допиливать, нужно всегда иметь представление, что означает отдаваемая статистика и как с помощью ее можно решать проблемы.
И несколько ключевых моментов:
- Всегда нужно мониторить доступность, иметь дашборды, чтобы вы могли быстро оценить, что с базой все в порядке.
- Всегда нужно иметь представление о том, какие клиенты работают с вашей базой данной, чтобы отсеивать плохих клиентов и отстреливать их.
- Важно оценивать то, как эти клиенты работают с данными. Нужно иметь представление о вашем ворклоаде.

- Важно оценивать, как формируется этот ворклоад, с помощью каких запросов. Вы можете оценивать запросы, вы можете их оптимизировать, рефакторить, строить для них индексы. Это очень важно.
- Фоновые процессы могут негативно влиять на клиентские запросы, поэтому важно отслеживать, чтобы они не используют слишком много ресурсов.
- Системные метрики позволяют вам делать планы на масштабирование, на увеличение емкости ваших серверов, поэтому важно тоже их отслеживать и оценивать.
Если вас заинтересовала эта тема, то вы можете пройтись по этим ссылкам.
http://bit.do/stats_collector — это официальная документация с коллектора статистики. Там есть описание всех статистических вьюх и описание всех полей. Вы можете их прочитать, понять и проанализировать. И уже на основе них строить свои графики, добавлять в свои мониторинги.
Примеры запросов:
http://bit.do/dataegret_sql
http://bit.do/lesovsky_sql
Это корпоративный наш репозиторий и мой собственный. В них есть примеры запросов. Там нет запросов из серии select* from что-то там. Там уже готовые запросы с джойнами, с применением интересных функций, которые позволяют из сырых цифр сделать читаемые, удобные значения, т. е. это байты, время. Вы можете их ковырять, смотреть, анализировать, добавлять в свои мониторинги, строить на их основе свои мониторинги.
Вопросы
Вопрос: Вы сказали, что не будете рекламировать бренды, но мне все-таки интересно – в своих проектах вы какие дашборды используете?
Ответ: По-разному. Бывает, что мы приходим к заказчику и у него уже есть свой мониторинг. И мы консультируем заказчика о том, что нужно добавить в его мониторинг. Хуже всего обстоят дела с Zabbiх. Потому что у него нет возможности строить TopN-графики. Сами мы используем Okmeter, потому что мы консультировали этих парней по мониторингу. Они делали мониторинг PostgreSQL на основе нашего ТЗ. Я пишу свой pet-project, который данные собирает через Prometheus и отрисовывает их в Grafana. У меня задача сделать в Prometheus свой экспортер и дальше уже отрисовывать все в Grafana.
Вопрос: Есть ли какие-то аналоги AWR-отчетов или … агрегации? Известно вам о чем-то таком?
Ответ: Да, я знаю, что такое AWR, это крутая штука. На данный момент есть самые разные велосипеды, которые реализуют примерно следующую модель. С некоторым интервалом времени пишутся некоторые baselines в тот же самый PostgreSQL или в отдельное хранилище. Их можно погуглить в интернете, они есть. Один из разработчиков такой штуки сидит на форуме sql.ru в ветке PostgreSQL. Его можно там поймать. Да, такие штуки есть, их можно использовать. Плюс в своем pgCenter я тоже пишу штуку, которая позволяет делать то же самое.
P.S. Если вы иcпользуете postgres_exporter, то какой дашборд вы используете? Их там несколько. Они уже устаревшие. Может сообщество создатm обновленный шаблон?
Инструкция raise в Python, примеры кода.
Возбуждение исключений.
Инструкция raise позволяет программисту принудительно вызвать указанное исключение. Например:
>>> raise NameError('HiThere')
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# NameError: HiThere
В общем случае инструкция raise повторно вызывает последнее исключение, которое было активным в текущей области видимости. Если нужно определить, было ли вызвано исключение, но не обрабатывать его, более простая форма инструкции raise позволяет повторно вызвать исключение:
try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
# An exception flew by!
# Traceback (most recent call last):
# File "<stdin>", line 2, in <module>
# NameError: HiThere
Если в текущей области видимости не активировано ни одного исключения, то в месте, где указана инструкция raise, без указания выражения, возникает исключение RuntimeError, указывающее, что это ошибка.
В противном случае raise вычисляет первое выражение как объект исключения. Он должен быть подклассом BaseException или его экземпляром. Если это класс, то экземпляр исключения будет получен при необходимости путем создания экземпляра класса без аргументов.
Тип исключения — это класс экземпляра исключения, а значение — сам экземпляр.
Объект traceback обычно создается автоматически при возникновении исключения и присоединяется к нему в качестве атрибута __traceback__, который доступен для записи. Вы можете создать исключение и установить свой собственный traceback за один шаг, используя метод исключения with_traceback(), который возвращает тот же экземпляр исключения с его обратной трассировкой стека, установленным в его аргумент, например:
raise Exception("foo occurred").with_traceback(tracebackobj)
Предложение from используется для цепочки исключений. Если исключение задано, второе выражение должно быть другим классом или экземпляром исключения, который затем будет присоединен к брошенному исключению в качестве атрибута __cause__, который доступен для записи. Если возникшее исключение не обработано, то будут напечатаны оба исключения:
try:
print(1 / 0)
except Exception as exc:
raise RuntimeError("Something bad happened") from exc
# Traceback (most recent call last):
# File "<stdin>", line 2, in <module>
# ZeroDivisionError: division by zero
# The above exception was the direct cause of the following exception:
# Traceback (most recent call last):
# File "<stdin>", line 4, in <module>
# RuntimeError: Something bad happened
Подобный механизм работает неявно, если исключение вызывается внутри обработчика исключений или предложения finally, предыдущее исключение затем присоединяется в качестве атрибута __context__ нового исключения:
try:
print(1 / 0)
except Exception as exc:
raise RuntimeError("Something bad happened")
# Traceback (most recent call last):
# File "<stdin>", line 2, in <module>
# ZeroDivisionError: division by zero
# The above exception was the direct cause of the following exception:
# Traceback (most recent call last):
# File "<stdin>", line 4, in <module>
# RuntimeError: Something bad happened
Цепочка исключений может быть явно подавлена указанием None в предложении from:
try:
print(1 / 0)
except Exception as exc:
raise RuntimeError("Something bad happened") from None
# Traceback (most recent call last):
# File "<stdin>", line 4, in <module>
# RuntimeError: Something bad happened
Оптимизация запросов PostgreSQL с explain analyze
Один недавний занимательный разговор на тему SQL вообще и оптимизации запросов — в частности, натолкнул меня на исследование быстродействия выполнения некоторого типа запросов. Потому что я не была уверена в этом вопросе. И мне это не понравилось 🙂 Специально для такого дела создала БД с 3 таблицами. В этом посте буду использовать только 2 из них, возможно, 3-ю задействую в других тестах. Для работы воспользуемся командой explain analyze.
Первая таблица cities содержит минимальную информацию о некоторых городах. Таблица people — о некоторых людях. И таблица phonebook хранит данные телефонного справочника. PostgreSQL 10.
CREATE TABLE public.cities
(
id integer NOT NULL DEFAULT nextval('cities_id_seq'::regclass),
name text COLLATE pg_catalog."default",
CONSTRAINT cities_pkey PRIMARY KEY (id)
)
CREATE TABLE public.people
(
id integer NOT NULL DEFAULT nextval('people_id_seq'::regclass),
name text COLLATE pg_catalog."default",
city_id integer,
CONSTRAINT people_pkey PRIMARY KEY (id),
CONSTRAINT people_city_id_fkey FOREIGN KEY (city_id)
REFERENCES public.cities (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL
)
CREATE TABLE public.phonebook
(
id integer NOT NULL DEFAULT nextval('phonebook_id_seq'::regclass),
human_id integer,
CONSTRAINT phonebook_pkey PRIMARY KEY (id),
CONSTRAINT phonebook_human_id_fkey FOREIGN KEY (human_id)
REFERENCES public.people (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE CASCADE
)Для первого блока теста таблица people содержит 100 000 записей, phonebook — 50 000. Для второго блока таблица people содержит 1 000 000 записей, phonebook — 900 000. Таблица cities — 200 записей для всех тестов (ее пока использовать не будем). Поле human_id принимает случайное значение в диапазоне от 1 до количества записей таблицы people. То же относится и к значению city_id относительно записей в таблице cities.
Причем, прошу заметить, в таблице phonebook могут быть повторы значений human_id — для неидеальности 🙂
Необходимо написать запрос, который выявит, информации о каких людях нет в телефонном справочнике. Проанализировать скорость выполнения. Команда explain analyze построит план выполнения запроса и предоставит реальную информацию о ходе его выполнения (затраченное время на все узлы, количество обработанных записей и пр.).
Вот список того, что я испробовала, чтобы добиться результата:
- not in
- not in (distinct)
- with … as () select … not in ()
- left outer join
- except
- not exists
Тест 1
explain analyze select * from people where id not in (select human_id from phonebook)
Seq Scan on people (cost=1401.46..3579.81 rows=49734 width=45) (actual time=32.030..78.265 rows=44933 loops=1)
Filter: (NOT (hashed SubPlan 1))
Rows Removed by Filter: 55067
SubPlan 1
-> Seq Scan on phonebook (cost=0.00..1196.57 rows=81957 width=4) (actual time=0.055..8.931 rows=80000 loops=1)
Planning time: 0.092 ms
Execution time: 80.084 msnot in
explain analyze
select id from people where not exists(select human_id from phonebook where human_id = people.id)
Hash Anti Join (cost=2490.00..6776.52 rows=52178 width=4) (actual time=33.257..87.752 rows=44933 loops=1)
Hash Cond: (people.id = phonebook.human_id)
-> Seq Scan on people (cost=0.00..1935.00 rows=100000 width=4) (actual time=0.022..11.547 rows=100000 loops=1)
-> Hash (cost=1177.00..1177.00 rows=80000 width=4) (actual time=31.289..31.289 rows=80000 loops=1)
Buckets: 131072 Batches: 2 Memory Usage: 2425kB
-> Seq Scan on phonebook (cost=0.00..1177.00 rows=80000 width=4) (actual time=0.056..13.996 rows=80000 loops=1)
Planning time: 0.383 ms
Execution time: 88.953 msnot exists
Для выполнения этого запроса понадобилось также и дисковое пространство помимо памяти (часть хеш-таблицы, построенной по условию human_id = people.id), о чем нам говорит значение Batches — пакеты хеша (больше 1).
explain analyze
with humanids as (select human_id from phonebook)
select * from people where id not in (select human_id from humanids)
Seq Scan on people (cost=2977.00..5162.00 rows=50000 width=45) (actual time=56.068..88.467 rows=44933 loops=1)
Filter: (NOT (hashed SubPlan 2))
Rows Removed by Filter: 55067
CTE humanids
-> Seq Scan on phonebook (cost=0.00..1177.00 rows=80000 width=4) (actual time=0.045..8.966 rows=80000 loops=1)
SubPlan 2
-> CTE Scan on humanids (cost=0.00..1600.00 rows=80000 width=4) (actual time=0.049..29.229 rows=80000 loops=1)
Planning time: 0.112 ms
Execution time: 91.271 mswith … as () select … not in ()
Команда CTE запускает часть запроса (select human_id from phonebook) и сохраняет ее вывод, чтобы он мог быть использован другой частью (или частями) запроса.
explain analyze
select * from people where id not in (select distinct human_id from phonebook)
Seq Scan on people (cost=1974.78..4159.77 rows=50000 width=45) (actual time=61.699..94.220 rows=44933 loops=1)
Filter: (NOT (hashed SubPlan 1))
Rows Removed by Filter: 55067
SubPlan 1
-> HashAggregate (cost=1377.00..1855.22 rows=47822 width=4) (actual time=38.568..48.852 rows=55067 loops=1)
Group Key: phonebook.human_id
-> Seq Scan on phonebook (cost=0.00..1177.00 rows=80000 width=4) (actual time=0.062..5.701 rows=80000 loops=1)
Planning time: 0.201 ms
Execution time: 97.313 msnot in (distinct)
Здесь мы тратим дополнительное время на группировку подзапроса по полю human_id для получения только уникальных значений — команда HashAggregate.
explain analyze
select * from people a left outer join phonebook b on a.id = b.human_id where b.human_id is null
Hash Anti Join (cost=2490.00..7752.52 rows=52178 width=53) (actual time=31.286..102.744 rows=44933 loops=1)
Hash Cond: (a.id = b.human_id)
-> Seq Scan on people a (cost=0.00..1935.00 rows=100000 width=45) (actual time=0.020..8.954 rows=100000 loops=1)
-> Hash (cost=1177.00..1177.00 rows=80000 width=8) (actual time=29.745..29.745 rows=80000 loops=1)
Buckets: 131072 Batches: 2 Memory Usage: 2580kB
-> Seq Scan on phonebook b (cost=0.00..1177.00 rows=80000 width=8) (actual time=0.142..10.141 rows=80000 loops=1)
Planning time: 0.336 ms
Execution time: 104.143 msleft outer join
Здесь так же, как с запросом с использованием not exists(…), задействовалось дисковое пространство для построения хеш-таблицы, однако максимальное значение используемой памяти оказалось чуть большим.
explain analyze
select id from people
except
select human_id as id
from phonebook
HashSetOp Except (cost=0.00..5362.00 rows=100000 width=8) (actual time=93.970..101.420 rows=44933 loops=1)
-> Append (cost=0.00..4912.00 rows=180000 width=8) (actual time=0.104..38.616 rows=180000 loops=1)
-> Subquery Scan on *SELECT* 1 (cost=0.00..2935.00 rows=100000 width=8) (actual time=0.103..19.389 rows=100000 loops=1)
-> Seq Scan on people (cost=0.00..1935.00 rows=100000 width=4) (actual time=0.094..12.251 rows=100000 loops=1)
-> Subquery Scan on *SELECT* 2 (cost=0.00..1977.00 rows=80000 width=8) (actual time=0.035..13.465 rows=80000 loops=1)
-> Seq Scan on phonebook (cost=0.00..1177.00 rows=80000 width=4) (actual time=0.035..8.248 rows=80000 loops=1)
Planning time: 0.272 ms
Execution time: 110.812 msexcept
Здесь все понятно: выполнить запрос один, потом другой, потом из одного вычесть второй, что оказалось достаточно медленным процессом.
На сравнительно небольшом объеме данных лучше всего отработал простой not in, который по идее медленно работает на больших объемах, в чем следует убедиться во втором тесте. За ним по скорости оказался метод с not exists. И самым медленным методом оказался except — его 110 мс против 80 мс самого быстрого запроса.
Тест 2
Начнем с того, что запуск 3-х запросов с участием not in провалился: мне попросту надоело ждать, пока они выполнятся 🙂
explain analyze
select id from people where not exists(select human_id from phonebook where human_id = people.id)
Hash Anti Join (cost=27749.00..120029.24 rows=497004 width=4) (actual time=336.888..1068.268 rows=406246 loops=1)
Hash Cond: (people.id = phonebook.human_id)
-> Seq Scan on people (cost=0.00..19346.00 rows=1000000 width=4) (actual time=0.010..198.311 rows=1000000 loops=1)
-> Hash (cost=12983.00..12983.00 rows=900000 width=4) (actual time=334.733..334.733 rows=900000 loops=1)
Buckets: 131072 Batches: 16 Memory Usage: 3006kB
-> Seq Scan on phonebook (cost=0.00..12983.00 rows=900000 width=4) (actual time=0.027..165.294 rows=900000 loops=1)
Planning time: 7.914 ms
Execution time: 1076.457 msnot exists
explain analyze
select * from people a left outer join phonebook b on a.id = b.human_id where b.human_id is null
Gather (cost=28749.00..128472.53 rows=497004 width=53) (actual time=402.885..1604.822 rows=406246 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Hash Anti Join (cost=27749.00..77772.13 rows=207085 width=53) (actual time=404.052..1078.125 rows=135415 loops=3)
Hash Cond: (a.id = b.human_id)
-> Parallel Seq Scan on people a (cost=0.00..13512.67 rows=416667 width=45) (actual time=0.228..107.024 rows=333333 loops=3)
-> Hash (cost=12983.00..12983.00 rows=900000 width=8) (actual time=401.851..401.851 rows=900000 loops=3)
Buckets: 131072 Batches: 16 Memory Usage: 3227kB
-> Seq Scan on phonebook b (cost=0.00..12983.00 rows=900000 width=8) (actual time=0.289..132.538 rows=900000 loops=3)
Planning time: 4.037 ms
Execution time: 1617.159 msleft outer join
Видно, что здесь план изменился в отличие от первого теста: планировщик решил использовать параллелизацию чтения. Увеличим количество воркеров до максимального значения (по умолчанию — 8) и посмотрим, улучшится ли результат:
SET max_parallel_workers_per_gather TO 8;
explain analyze
select * from people a left outer join phonebook b on a.id = b.human_id where b.human_id is null
Gather (cost=28749.00..120081.57 rows=497004 width=53) (actual time=362.128..1539.175 rows=406246 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Hash Anti Join (cost=27749.00..69381.17 rows=160324 width=53) (actual time=451.500..953.874 rows=101562 loops=4)
Hash Cond: (a.id = b.human_id)
-> Parallel Seq Scan on people a (cost=0.00..12571.81 rows=322581 width=45) (actual time=0.024..39.357 rows=250000 loops=4)
-> Hash (cost=12983.00..12983.00 rows=900000 width=8) (actual time=448.565..448.565 rows=900000 loops=4)
Buckets: 131072 Batches: 16 Memory Usage: 3227kB
-> Seq Scan on phonebook b (cost=0.00..12983.00 rows=900000 width=8) (actual time=0.258..140.643 rows=900000 loops=4)
Planning time: 0.522 ms
Execution time: 1550.581 msНе смотря на то, что планировщику разрешили использование воркеров по полной, он задействовал только 3. Это значение зависит от размера таблицы и параметра min_parallel_table_scan_size (минимальный размер отношения, после которого планировщик начнет использовать дополнительных воркеров). Время объединения данных hash anti join немного уменьшилось. Уменьшим значение max_parallel_table_scan_size до 1 mb и повторим запрос:
set min_parallel_table_scan_size = 1;
explain analyze
select * from people a left outer join phonebook b on a.id = b.human_id where b.human_id is null
Gather (cost=28749.00..102459.88 rows=497004 width=53) (actual time=736.796..2742.606 rows=406246 loops=1)
Workers Planned: 8
Workers Launched: 7
-> Hash Anti Join (cost=27749.00..51759.48 rows=62126 width=53) (actual time=763.921..1519.470 rows=50781 loops=8)
Hash Cond: (a.id = b.human_id)
-> Parallel Seq Scan on people a (cost=0.00..10596.00 rows=125000 width=45) (actual time=0.015..33.532 rows=125000 loops=8)
-> Hash (cost=12983.00..12983.00 rows=900000 width=8) (actual time=754.606..754.606 rows=900000 loops=8)
Buckets: 131072 Batches: 16 Memory Usage: 3227kB
-> Seq Scan on phonebook b (cost=0.00..12983.00 rows=900000 width=8) (actual time=4.709..239.587 rows=900000 loops=8)
Planning time: 0.163 ms
Execution time: 2756.461 msА время-то увеличилось. Время получения объединенных данных двух таблиц заняло больше времени, чем в предыдущем запросе, равно как и чтение таблицы phonebook. Теперь принудительно выполним запрос без распараллеливания чтения:
SET max_parallel_workers_per_gather TO 1;
explain analyze
select * from people a left outer join phonebook b on a.id = b.human_id where b.human_id is null
Hash Anti Join (cost=27749.00..129795.24 rows=497004 width=53) (actual time=239.581..976.969 rows=406246 loops=1)
Hash Cond: (a.id = b.human_id)
-> Seq Scan on people a (cost=0.00..19346.00 rows=1000000 width=45) (actual time=0.013..70.748 rows=1000000 loops=1)
-> Hash (cost=12983.00..12983.00 rows=900000 width=8) (actual time=237.110..237.110 rows=900000 loops=1)
Buckets: 131072 Batches: 16 Memory Usage: 3227kB
-> Seq Scan on phonebook b (cost=0.00..12983.00 rows=900000 width=8) (actual time=0.019..71.010 rows=900000 loops=1)
Planning time: 0.392 ms
Execution time: 985.339 msВыходит, последовательное чтение все же выиграло в данном случае. И, кстати, во втором тесте в целом. Но планировщик решил иначе и — прогадал.
explain analyze
select id from people
except
select human_id as id
from phonebook
SetOp Except (cost=275452.90..284952.90 rows=1000000 width=8) (actual time=1586.086..2235.030 rows=406246 loops=1)
-> Sort (cost=275452.90..280202.90 rows=1900000 width=8) (actual time=1586.080..1945.365 rows=1900000 loops=1)
Sort Key: *SELECT* 1.id
Sort Method: external merge Disk: 33536kB
-> Append (cost=0.00..51329.00 rows=1900000 width=8) (actual time=0.069..434.805 rows=1900000 loops=1)
-> Subquery Scan on *SELECT* 1 (cost=0.00..29346.00 rows=1000000 width=8) (actual time=0.067..196.551 rows=1000000 loops=1)
-> Seq Scan on people (cost=0.00..19346.00 rows=1000000 width=4) (actual time=0.060..123.686 rows=1000000 loops=1)
-> Subquery Scan on *SELECT* 2 (cost=0.00..21983.00 rows=900000 width=8) (actual time=0.020..178.397 rows=900000 loops=1)
-> Seq Scan on phonebook (cost=0.00..12983.00 rows=900000 width=4) (actual time=0.019..110.814 rows=900000 loops=1)
Planning time: 0.853 ms
Execution time: 2257.742 msВ отличие от первого теста в ходе выполнения запроса с except во втором тесте были задействованы временные файлы (они хранятся в директории $PGDATA/base/pgsql_tmp/ и удаляются по ненужности) для сортировки данных. SetOp в купе с сортировкой (которая нужна для идентификации идентичных строк для включения или исключения из выходного набора) был замещен на HashSetOp еще в 8.4 версии постгреса. Почему его потянуло на винтаж сейчас? Значение enable_hashagg установлено в on… Возможно, планировщик посчитал, что такой метод будет более эффективным в данном случае.
Из выполнившихся за адекватное количество времени запросов последний — except — оказался самым медленным. Наиболее приемлемым вариантом для выполнения подобного типа запросов на подобном наборе данных является использование запросов с использованием not exists или left outer join.
Хочу поделиться некоторыми ссылками, по которым можно найти использованную мной информацию:
Counting missing rows: PostgreSQL
https://habr.com/ru/post/203320/
https://habr.com/ru/post/281036/
https://habr.com/ru/post/275851/
https://habr.com/ru/post/276973/
https://postgrespro.ru/docs/postgresql/10/using-explain
https://docs.aws.amazon.com/redshift/latest/dg/r_EXPLAIN.html
https://books.google.by/books?id=iPBZDwAAQBAJ&printsec=frontcover&hl=ru&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
Поделиться ссылкой:
Понравилось это:
Нравится Загрузка…
Похожие записи
Ошибка СУБД 1С при работе с PostgreSQL
При нарушении целостности файловой системы сервера баз данных PostgreSQL, последний выдает “Ошибка СУБД” 1С, и часто сопровождается текстом, типа “ERROR: invalid page header in block ХХХХХ of relation base/ХХХХХ/ХХХХХ”.
Причиной подобных исключений может служить разрушенная файловая система и нарушение логической целостности всей базы данных, произошедшие в результате некорректного завершения работы ОС.
Выводимую 1С “Ошибка СУБД” на самом деле надо начинать исправлять не в 1С, а с проверки файловой системы. Полный алгоритм восстановления будет приблизительно следующий:
- Исправление ошибок файловой системы;
- Выявление неисправных таблиц СУБД и их ремонт;
- Проверка и исправление ошибок на уровне 1С в конфигураторе.
Если “Ошибка СУБД” в 1С произошла после некорректного завершения работы ОС, начинаем с команд Chkdsk в Windows и fsck в Linux. Это позволит устранить ошибки на уровне файловой системы.
Затем надо выяснить в каких таблицах БД PostgreSQL возникает ошибка “ERROR: invalid page header in block…”. Для этого обращаемся к логам или пытаемся снять дамп базы данных, например подключившись к СУБД утилитой pgAdmin. Если возникает ошибка “Ошибка СУБД” в 1С, наверняка найдется хотя бы 1 испорченная таблица. В моем случае ошибка возникла при дампе public._enum332.
Для того, чтобы восстановить сломанную таблицу, выполним 3 запроса:
SET zero_damaged_pages = on;
VACUUM FULL public._enum332;
REINDEX TABLE public._enum332;Далее снова пытаемся снять дамп базы данных, пока база не выгрузится без ошибок.
Следующим этапом исправления ошибки СУБД в 1С будет Тестирование и исправление базы в конфигураторе 1С. Для этого запускаем испорченную БД в конфигураторе. Через пункт Администрирование – Тестирование и исправление ИБ пробуем восстановить логическую целостность нашей базы. Обратите внимание, на галочки, выбранные на изображении.
При большом количестве ошибок СУБД, 1С потребуется помощь программиста или грамотного пользователя 1С помимо системного администратора, поэтому будьте готовы к привлечению подобных специалистов.
На этом процедуру исправления ошибки PostgreSQL “ERROR: invalid page header in block…” при работе с 1С можно считать законченной, однако стоит отметить несколько пунктов, которые позволят не допустить возникновение ошибки СУБД в 1С:
- Регулярное резервное копирование БД автоматическими средствами без участия человека;
- Использование источника бесперебойного питания с контроллером управления, корректно выключающего сервер при низком заряде батарей;
- Регулярное обслуживание серверов.
Обсудим в социальных сетях
Hibernate и PostgreSQL: примеры настройки
Перед тем, как соединяться из Hibernate с PostgreSQL, не забудьте создать пользователя, базу данных и предоставить пользователю права на неё:
CREATE ROLE test WITH PASSWORD ‘test’; ALTER ROLE test WITH LOGIN; CREATE DATABASE test OWNER test;
CREATE ROLE test WITH PASSWORD ‘test’; ALTER ROLE test WITH LOGIN;
CREATE DATABASE test OWNER test; |
Команды выше создают пользователя test с паролем test, создают базу данных test и назначают пользователя владельцем базы. В условиях реального приложения разумеется следует выбрать пароль посложнее.
Перед тем, как использовать PostgreSQL, необходимо добавить его JDBC драйвер в зависимости maven:
<properties> <postgresql.version>9.4.1212.jre7</postgresql.version> </properties> <dependencies> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>${postgresql.version}</version> </dependency> </dependencies>
<properties> <postgresql.version>9.4.1212.jre7</postgresql.version> </properties>
<dependencies> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>${postgresql.version}</version> </dependency> </dependencies> |
С драйвером PostgreSQL в classpath можно настраивать Hibernate:
<hibernate-configuration> <session-factory> <property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.connection.username»>test</property> <property name=»hibernate.connection.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property> <!— Other configuration —> </session-factory> </hibernate-configuration>
<hibernate-configuration> <session-factory>
<property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.connection.username»>test</property> <property name=»hibernate.connection.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property>
<!— Other configuration —> </session-factory>
</hibernate-configuration> |
JDBC url у PostgresSQL имеет следующий формат: jdbc:postgresql://хост:порт/имябазы, например jdbc:postgresql://127.0.0.1:5432/test. Имя пользователя и пароль передаются отдельными параметрами. Наконец, надо не забыть переключить диалект Hibernate на PostgresqlSQL, что делается в последней строке.
Однако, одно соединение не очень удобно использовать в реальном приложении. Поэтому настроим пул c3p0 для совместного использования с Hibernate и PostgreSQL.
<properties> <hibernate.version>5.2.1.Final</hibernate.version> <c3p0.version>0.9.5.2</c3p0.version> </properties> <dependencies> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>${c3p0.version}</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-c3p0</artifactId> <version>${hibernate.version}</version> </dependency> </dependencies>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | <properties> <hibernate.version>5.2.1.Final</hibernate.version> <c3p0.version>0.9.5.2</c3p0.version> </properties>
<dependencies> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>${c3p0.version}</version> </dependency>
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-c3p0</artifactId> <version>${hibernate.version}</version> </dependency> </dependencies> |
Для включения c3p0 достаточно передать по меньшей мере один параметр c3p0 в настройки Hibernate:
<hibernate-configuration> <session-factory> <property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.connection.username»>test</property> <property name=»hibernate.connection.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property> <property name=»hibernate.c3p0.min_size»>5</property> <!— Other configuration —> </session-factory> </hibernate-configuration>
<hibernate-configuration> <session-factory>
<property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.connection.username»>test</property> <property name=»hibernate.connection.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property> <property name=»hibernate.c3p0.min_size»>5</property>
<!— Other configuration —> </session-factory> </hibernate-configuration> |
Остальные параметры остаются такими же, как и для PostgreSQL без c3p0.
К сожалению, в Hibernate нет настолько высококачественной поддержки HikariCP, аналогичной c3p0. Поэтому настройка HikariCP требует чуть чуть больше работы.
В первую очередь, конечно же, надо добавить ещё и артефакт HikariCP в зависимости (не забываем про PostgreSQL JDBC драйвер):
<properties> <hikaricp.version>2.4.3</hikaricp.version> </properties> <dependencies> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>${hikaricp.version}</version> </dependency> </dependencies>
<properties> <hikaricp.version>2.4.3</hikaricp.version> </properties>
<dependencies> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>${hikaricp.version}</version> </dependency> </dependencies> |
Потом необходимо изменить конфигурацию Hibernate для работы с HikariCP:
<hibernate-configuration> <session-factory> <property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.provider_class»>com.zaxxer.hikari.hibernate.HikariConnectionProvider</property> <property name=»hibernate.hikari.dataSourceClassName»>org.postgresql.ds.PGSimpleDataSource</property> <property name=»hibernate.hikari.dataSource.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.hikari.username»>test</property> <property name=»hibernate.hikari.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property> <!— Other settings —> </session-factory> </hibernate-configuration>
<hibernate-configuration> <session-factory>
<property name=»hibernate.hbm2ddl.auto»>update</property> <property name=»hibernate.connection.provider_class»>com.zaxxer.hikari.hibernate.HikariConnectionProvider</property> <property name=»hibernate.hikari.dataSourceClassName»>org.postgresql.ds.PGSimpleDataSource</property> <property name=»hibernate.hikari.dataSource.url»>jdbc:postgresql://127.0.0.1:5432/test</property> <property name=»hibernate.hikari.username»>test</property> <property name=»hibernate.hikari.password»>test</property> <property name=»hibernate.dialect»>org.hibernate.dialect.PostgreSQL94Dialect</property>
<!— Other settings —> </session-factory> </hibernate-configuration> |
Все настройки соединения с PostgreSQL переименовываются и к ним добавляется два дополнительных параметра. Вначале в Hibernate настраивается использование HikariCP, затем указывается какой класс использовать для соединения с PostgreSQL.
Исключение PostgreSQL
Резюме : в этом руководстве вы узнаете, как перехватывать исключения PostgreSQL в PL / pgSQL.
Введение в пункт об исключениях PL / pgSQL
При возникновении ошибки в блоке PostgreSQL прерывает выполнение блока, а также окружающую транзакцию.
Для восстановления после ошибки можно использовать предложение исключения в блоке начало ... конец .
Ниже показан синтаксис предложения исключения :
<
Как это работает.
- Во-первых, когда возникает ошибка между
beginи исключением - Во-вторых, PL / pgSQL ищет первое
условие, которое соответствует возникшей ошибке. - В-третьих, если есть совпадение, будут выполнены соответствующие операторы
handle_exception.PL / pgSQL передает управление оператору после ключевого словаend. - Наконец, если совпадение не найдено, ошибка распространяется и может быть обнаружена предложением
исключенияохватывающего блока. В случае отсутствия включающего блока с предложениемисключенияPL / pgSQL прервет обработку.
Именами условий могут быть no_data_found в случае, если оператор select не возвращает строк или too_many_rows , если оператор select возвращает более одной строки.Полный список названий условий на сайте PostgreSQL.
Также можно указать условие ошибки с помощью кода SQLSTATE . Например, P0002 для no_data_found и P0003 для too_many_rows .
Обычно вы перехватываете определенное исключение и обрабатываете его соответствующим образом. Чтобы обрабатывать другие исключения, а не то, которое вы указали в списке, вы можете использовать предложение , когда другие, а затем предложение .
Примеры обработки исключений
Мы будем использовать таблицу film из базы данных примеров для демонстрации.
1) Обработка исключения no_data_found, пример
В следующем примере возникает ошибка, поскольку фильм с идентификатором 2000 не существует.
до $$ объявить запись записи; v_film_id int = 2000; начать - выбрать фильм выберите film_id, title в строгие правила из фильма где film_id = v_film_id; конец; $$ язык plpgsql;
Вывод:
ОШИБКА: запрос не вернул строк КОНТЕКСТ: PL / pgSQL функция inline_code_block строка 6 в операторе SQL Состояние SQL: P0002
В следующем примере используется условие исключения для перехвата исключения no_data_found и вывода более значимого сообщения:
do $$ объявить запись записи; v_film_id int = 2000; начать - выбрать фильм выберите film_id, title в строгие правила из фильма где film_id = v_film_id; - поймать исключение исключение когда no_data_found тогда возбудить исключение «film% not found», v_film_id; конец; $$ язык plpgsql;
Вывод:
ОШИБКА: пленка 2000 не найдена КОНТЕКСТ: функция inline_code_block в PL / pgSQL, строка 14 в RAISE Состояние SQL: P0001
2) Пример обработки исключения too_many_rows
В следующем примере показано, как обрабатывать исключение too_many_rows :
do $$ объявить запись записи; начать - выбрать фильм выберите film_id, title в строгие правила из фильма где название LIKE 'A%'; исключение когда too_many_rows тогда вызвать исключение «Поисковый запрос возвращает слишком много строк»; конец; $$ язык plpgsql;
Выход:
ОШИБКА: поисковый запрос возвращает слишком много строк КОНТЕКСТ: PL / pgSQL функция inline_code_block строка 15 в RAISE Состояние SQL: P0001
В этом примере возникает исключение too_many_rows , потому что оператор select into возвращает более одной строки, в то время как он должен возвращать одну строку.
3) Обработка нескольких исключений
В следующем примере показано, как перехватить несколько исключений:
do $$ объявить запись записи; v_length int = 90; начать - выбрать фильм выберите film_id, title в строгие правила из фильма где длина = v_length; - поймать исключение исключение когда sqlstate 'P0002', тогда вызвать исключение «фильм с длиной% не найден», v_length; когда sqlstate 'P0003' тогда возбудить исключение "Длина% не уникальна", v_length; конец; $$ язык plpgsql;
Выход:
ОШИБКА: длина 90 не уникальна КОНТЕКСТ: функция inline_code_block в PL / pgSQL, строка 17 в RAISE Состояние SQL: P0001
4) Обработка исключений как кодов SQLSTATE
Следующий пример аналогичен приведенному выше, за исключением того, что в нем используются коды SQLSTATE вместо имен условий:
do $$ объявить запись записи; v_length int = 30; начать - выбрать фильм выберите film_id, title в строгие правила из фильма где длина = v_length; - поймать исключение исключение когда sqlstate 'P0002', тогда вызвать исключение «фильм с длиной% не найден», v_length; когда sqlstate 'P0003', тогда возбудить исключение «Длина% не уникальна», v_length; конец; $$ язык plpgsql;
Вывод:
ОШИБКА: пленка длиной 30 не найдена КОНТЕКСТ: PL / pgSQL функция inline_code_block строка 15 в RAISE Состояние SQL: P0001
Сводка
- Используйте предложение
исключенияв начале...endблок для перехвата и обработки исключений.
- Было ли это руководство полезным?
- Да Нет
Ссылка — документация py-postgresql 1.3.0
py-postgresql — это пакет Python для использования PostgreSQL. Это включает в себя низкоуровневую инструменты протокола, драйвер (PG-API и DB-API 2.0) и инструменты управления кластером.
См.
-
postgresql.версия= ‘1.3.0’ Строка версии py-postgresql.
-
postgresql.информация_версии= (1, 3, 0) Тройная версия py-postgresql: (major, minor, patch).
-
postgresql.открытый( iri = None , prompt_title = None , ** кВт ) [источник] Создайте файл postgresql.api.Connection к серверу, на который ссылается данный iri :
>>> импортировать postgresql # Общий формат: >>> db = postgresql.open ('pq: // пользователь: пароль @ хост: порт / база данных') # Подключиться к postgres на локальном хосте. >>> db = postgresql.open ('локальный / постгрес')Ключевые слова подключения также могут использоваться с открытым . См. Рассказы о больше информации.
Ключевое слово prompt_title игнорируется. открыть никогда не будет запрашивать пароль, если это не указано явно.
(Примечание: «pq» — это имя протокола, используемого для связи с PostgreSQL)
Интерфейсы прикладного программиста для PostgreSQL.
postgresql.api — это набор API-интерфейсов Python для СУБД PostgreSQL. Это
разработан, чтобы в полной мере использовать возможности PostgreSQL для обеспечения
Программист на Python с большим удобством.
Этот модуль используется для определения «PG-API». Создает набор азбуки который составляет основные интерфейсы, используемые для работы с сервером PostgreSQL.
- класс
postgresql.api.Сообщение[источник] Базы:
postgresql.python.element.ElementСообщение, отправленное PostgreSQL. Сообщение, представляющее собой УВЕДОМЛЕНИЕ, ПРЕДУПРЕЖДЕНИЕ, ИНФОРМАЦИЮ и т. Д.
-
код Код состояния SQL сообщения.
-
детали Дополнительная информация, указанная в сообщении. Общие ключи должны быть следующее:
- «серьезность»
- «контекст»
- «деталь»
- «подсказка»
- «файл»
- «строка»
- «функция»
- «позиция»
- «внутренняя_позиция»
- «внутренний_запрос»
-
согласован( другой ) → bool [источник] Согласованы ли поля объекта other Message с поля сам .
Этот должен возвращать результат сравнения кода, источника, сообщения, и подробности.
Этот метод предоставляется как альтернатива отмене равенства; часто равенство указателей является желательным средством для сравнения, но равенство полей также необходимо.
-
сообщение Основная строка сообщения.
-
источник Откуда пришло сообщение.Обычно «СЕРВЕР», но иногда «КЛИЕНТ».
-
- класс
postgresql.api.Заявление[источник] Базы:
postgresql.python.element.ElementЭкземпляры инструкции возвращаются методом подготовки База данных экземпляра.
Оператор может быть как итерируемым, так и вызываемым.
Iterable interfac
PostgreSQL — общие — Почему RAISE EXCEPTION не предоставляет контекст ошибки?
Добавление «сырого» контента, присутствующего в Nabble, который фильтруется списком рассылки. В среду, 1 апреля 2015 года, Тайтай <[скрытый адрес электронной почты]> написал:
Мы активно используем `GET STACKED DIAGNOSTICS`, чтобы определить, где возникают ошибки
получилось.
Однако я пытаюсь использовать RAISE EXCEPTION для сообщения об ошибках, и у меня
обнаружил, что RAISE специально предотвращает добавление к ошибке
контекст:
—-
static void
plpgsql_exec_error_callback (void * arg)
{
PLpgSQL_execstate * estate = (PLpgSQL_execstate *) arg;
/ * если мы делаем RAISE, не сообщать его местоположение * /
if (estate-> err_text == raise_skip_msg)
return;
—-
Значит, это не работает:
RAISE EXCEPTION ‘Это исключение не получит трассировку стека’;
ИСКЛЮЧЕНИЕ КОГДА ДРУГИЕ ТОГДА
— Если исключение, которое мы улавливаем, — это исключение, которое выбросил Постгрес,
— как ошибка деления на ноль, тогда будет получена полная
— трассировка стека места, где было выброшено исключение.
— Однако, поскольку мы перехватываем исключение, которое мы подняли вручную
— при использовании RAISE EXCEPTION, трассировки контекста / стека нет!
ПОЛУЧИТЬ ДИАГНОСТИКУ УПАКОВКИ v_error_stack = PG_EXCEPTION_CONTEXT;
Я разместил более подробную информацию здесь:
http://dba.stackexchange.com/questions/96743/postgres-how-to-get-stack-trace-for-a-manually-raised-exceptionЭтот контекст был бы ужасным полезно для нас, даже для сгенерированных вручную
исключения.
Может ли кто-нибудь пролить свет на А) почему это так и Б) если это еще желательно,
и C) Если да, то есть ли обходные пути? Есть ли исключение, я могу обмануть
Postgres в бросок, который будет включать мою пользовательскую строку?Большое спасибо за любую помощь, которую вы можете предложить.
проблем при переходе с Oracle на PostgreSQL — и способы их преодоления
Дэвид Рейдер — вице-президент по разработке в OpenSCG.
OpenSCG — партнер-консультант AWS и ведущий эксперт по PostgreSQL, помогающий клиентам переходить на PostgreSQL и другие платформы данных и оптимизировать их локально и в облаке.
В предыдущих сообщениях мы рассмотрели общий подход к успешной миграции базы данных и то, как выбрать первую базу данных для миграции. В этом посте давайте рассмотрим несколько проблем, связанных с миграцией, и советы по их решению.
Когда организации стремятся перейти с Oracle на базу данных PostgreSQL с открытым исходным кодом, они обычно сосредотачиваются на расширенных функциях, высокой производительности, надежной целостности данных, гибком лицензировании с открытым исходным кодом и легкой доступности от поставщиков общедоступного облака, включая AWS.Но путь к миграции не всегда гладкий, и знание того, как избежать выбоин, может помочь обеспечить успешный переход.
Проблемы, о которых я пишу в этом посте, имеют разные последствия: от удобства и простоты разработки в будущем до снижения производительности перенесенной базы данных и того, что она может сделать миграцию невозможной. Поскольку это самая страшная проблема, давайте начнем с задачи, которая может просто сделать миграцию существующего приложения невозможной.
Пакетные приложения
PostgreSQL поддерживает большинство языков разработки, включая Java, C #, Python, PHP, C / C ++, JavaScript / Node.js, Go и другие. PostgreSQL полностью соответствует требованиям ACID и полностью соответствует стандарту ANSI SQL: 2008. Но если вы используете пакетное программное приложение, поставщик которого не сертифицирован для PostgreSQL, миграция, вероятно, не начнется.
Если вы хотите перенести свое коммерческое приложение ERP / CRM / бухгалтерский учет с Oracle на PostgreSQL, вам, возможно, придется попросить поставщика добавить PostgreSQL в список поддерживаемых баз данных или перейти на новое бизнес-приложение.Но это не проблема для приложений, которые вы контролируете и для которых у вас есть исходный код.
Типы данных и преобразование схемы
Теперь, когда мы рассмотрели самую большую проблему, давайте вернемся к одной из самых простых. PostgreSQL имеет полный набор встроенных типов данных и поддержку настраиваемых типов расширений. Основные типы данных Oracle можно легко сопоставить с типами PostgreSQL. Большинство операций по сопоставлению и преобразованию таблиц можно автоматизировать с помощью AWS Schema Conversion Tool (AWS SCT) или другого инструмента миграции.
С некоторыми типами данных PostgreSQL гораздо проще работать, чем с соответствующими типами Oracle. Например, тип Text может хранить до 1 ГБ текста и может обрабатываться в SQL так же, как поля char и varchar . Для них не требуются специальные функции для больших объектов, такие как большие символьные объекты (CLOB).
Однако следует отметить некоторые важные отличия. Поле Numeric в PostgreSQL можно использовать для сопоставления любых типов данных Number .Но когда он используется для соединений (например, для внешнего ключа), он менее эффективен, чем использование int или bigint .
Отметка времени PostgreSQL с полем часового пояса немного отличается от отметки времени Oracle с полем часового пояса — на самом деле она эквивалентна отметке времени Oracle с местным часовым поясом . Эти небольшие различия могут вызвать проблемы с производительностью или незначительные ошибки приложения, требующие тщательного тестирования.
Перенос данных
После преобразования схемы и настройки таблиц для наилучшего соответствия конкретному приложению пора переместить данные. Для баз данных меньшего размера (100 ГБ или меньше) этот процесс довольно прост. Используя AWS Data Migration Service (AWS DMS) или такой инструмент, как HVR, вы можете создавать задания миграции данных, которые выполняются на инстансах Amazon EC2, подключаться к вашей локальной базе данных Oracle и передавать данные в Amazon RDS для инстанса PostgreSQL. Вам нужно будет проверить данные в целевой базе данных.Затем запустите миграцию пару раз в среде разработки, тестирования и, наконец, в производственной среде и устраните все возникающие проблемы.
Когда вы освоитесь с процессом миграции, снова выполните его в рабочей среде. Перенесите большую часть существующих данных и отслеживайте текущие изменения транзакций с помощью экземпляра репликации AWS DMS. Затем оставьте службу миграции работающей, чтобы целевая база данных оставалась синхронизированной с изменениями в действующей системе.
Большие объемы данных
Для больших объемов данных — например, более 1 ТБ — чисто оперативная миграция данных может занять слишком много времени или занять слишком большую часть доступной полосы пропускания. В этой ситуации вам следует использовать подходы экспорта, перезагрузки и синхронизации. При таком подходе вы экспортируете самые большие таблицы. Затем вы либо сжимаете и отправляете их в Amazon S3, либо используете AWS Snowball, чтобы переместить их в регион AWS и загрузить в Amazon S3. После того, как данные будут помещены в Amazon S3, вы можете массово загрузить файлы данных в PostgreSQL.
Использование разделов на основе даты упрощает выбор и изоляцию данных, перемещаемых в автономном режиме. Неизменяемые исторические данные, содержащие записи на основе меток времени, можно экспортировать до известного момента времени, а любые данные после этого момента можно перенести с помощью AWS DMS. Или вы можете использовать порядковый номер журнала Oracle (LSN) или последовательный идентификатор приложения в качестве точки отсечки для задания экспорта и миграции.
Очистка архитектуры
Миграция — отличное время для очистки определенных частей вашей архитектуры и приложения.Например, если вы храните файлы (PDF-файлы, изображения и т. Д.) В своей базе данных, сейчас самое время поместить их в надежную корзину хранилища Amazon S3. Уменьшите размер базы данных и время, необходимое для операций резервного копирования и восстановления, а также повысьте гибкость вашего приложения за счет большей гибкости в работе с файлами.
Если у вас есть статические исторические данные, вы можете либо полностью очистить их, если они никогда не использовались вашим приложением, либо переместить их в отдельное хранилище архивных данных.Это хранилище данных может быть либо в базе данных PostgreSQL с более низкой производительностью (и менее дорогой), либо, возможно, в системе Amazon Athena или Apache Spark с поддержкой Amazon S3, которая подходит для нечастых запросов к холодным данным.
И, если вы смешали онлайн-обработку транзакций (OLTP) и доступ к данным в стиле аналитики, переход от единого инструмента для всех настроек Oracle к использованию отдельного хранилища для отчетов и аналитики может улучшить как скорость отклика вашего приложения, так и вашу возможности аналитики.Есть варианты создания выделенного хранилища на базе Postgres-XL или использования Amazon Redshift в качестве мощного управляемого хранилища.
В целом, перенос данных требует планирования и практики, но это очень решаемая задача.
Перенос кода
Наиболее интенсивными усилиями при миграции с Oracle на PostgreSQL обычно является перенос кода для работы с PostgreSQL. Это относится к хранимым процедурам, пакетам и функциям в базе данных, а также к коду приложения, которое считывает и записывает в базу данных.
Код базы данных
PostgreSQL во многом похож на Oracle. Основной процедурный язык программирования, PL / pgSQL, достаточно похож на PL / SQL, поэтому большинство администраторов баз данных (DBA) и разработчиков могут легко изучить его синтаксис. Автоматизированные инструменты, такие как AWS Schema Conversion Tool (AWS SCT) или Ora2Pg с открытым исходным кодом, обычно могут автоматически преобразовать более 70 процентов кода базы данных для правильной работы.
Автоматическое преобразование включает преобразование специфичных для Oracle функций в стандартные функции ANSI (например, переход от nvl () к coalesce () ), изменение устаревшего синтаксиса, такого как знак плюс (+), используемого для внешних соединений, на стандартные синтаксис внешнего соединения и добавление псевдонимов для подзапросов, которые Oracle считает необязательными, но требует PostgreSQL.В этих случаях преобразованный код совместим как с Oracle, так и с PostgreSQL. Его можно фактически объединить с текущей базой кода приложения и развернуть в существующей базе данных до того, как вы полностью выполните миграцию.
Автоматизированные инструменты также могут преобразовывать код, использующий синтаксис, специфичный для базы данных, такой как обработка последовательности с помощью Oracle sequence.nextval по сравнению с PostgreSQL nextval (sequence) или немного другой синтаксис для выполнения динамического SQL внутри хранимой процедуры.Эти изменения несовместимы с Oracle и поэтому используются только в вашей целевой системе PostgreSQL.
Оставшийся код необходимо преобразовать вручную, либо потому, что SQL и PL / SQL были слишком сложными для того, чтобы инструмент мог идеально проанализировать и преобразовать, либо потому, что не существует точного однозначного преобразования, которое можно было бы применить автоматически. Многие такие случаи тривиальны для преобразования опытных разработчиков и администраторов баз данных, если они понимают как подход PostgreSQL, так и используемую логику приложения.
Нишевые функции: автономные транзакции, сбор всего и BFILE
Есть некоторые функции Oracle, которые либо не поддерживаются PostgreSQL, либо обрабатываются с помощью расширения или обходного пути. Например, PostgreSQL не поддерживает напрямую автономные транзакции, которые позволяют фиксировать изменения одной хранимой процедуры внутри более крупной транзакции, которая откатывается. Обычный обходной путь — использовать «удаленное» соединение DBLink с той же базой данных. Вы выполняете функцию, которую хотите зафиксировать, как «удаленный» вызов, который рассматривается как отдельное соединение — и отдельная транзакция.
Точно так же ядро PostgreSQL не поддерживает таблицы с внешней организацией или прямой доступ к файлам в файловой системе базы данных. Однако и то, и другое возможно с использованием оболочки внешних данных (FDW).
Некоторые распространенные пакеты Oracle, такие как DBMS_OUTPUT, поддерживаются расширениями orafce с открытым исходным кодом и расширениями совместимости с AWS, которые снижают стоимость преобразования. Другие, такие как UTL_FILE, UTL_HTTP и пакет SMTP, могут поддерживаться через расширения. Но вам следует проверить, является ли это правильным архитектурным решением или архитектура вашего приложения должна быть обновлена в рамках преобразования.Вам необходимо проверить, поддерживается ли рассматриваемое расширение в среде, управляемой Amazon RDS, в противном случае вы не сможете использовать Amazon RDS.
Код приложения
Как отмечалось ранее, PostgreSQL имеет широкую поддержку языков программирования, и есть драйверы, доступные для всех основных языков разработки, а также для многих других. В зависимости от архитектуры вашего приложения и уровня соединения с базой данных вам может потребоваться лишь небольшое количество изменений или у вас могут быть значительные изменения при переносе.
Например, довольно легко преобразовать приложение на основе Java, которое использует общие классы JDBC (а не классы, специфичные для Oracle) и всегда вызывает хранимые процедуры без SQL в коде, будь то динамически построенные или жестко запрограммированные. Если вы используете объектно-реляционное сопоставление (ORM), такое как Hibernate или JCA, переключить диалект с Oracle на PostgreSQL может быть тривиально просто. Есть еще небольшие отличия. Например, если вы используете секционирование, требуемые триггеры PostgreSQL изменяют количество записей, возвращаемых при вставке, и обманывают Hibernate.Таким образом, вам нужно добавить аннотации к запросам Hibernate, которые обновляют секционированные таблицы.
Для таких простых случаев вы даже можете использовать AWS SCT для сканирования кода Java или .NET, чтобы найти операторы SQL и преобразовать SQL в PostgreSQL-совместимый SQL — аналогично преобразованию, сделанному для PL / SQL.
Однако преобразование кода приложения намного сложнее, если вы используете встроенный SQL, такой как Oracle Pro * C, связываетесь с библиотеками, специфичными для Oracle, такими как OCI или классы Oracle JDBC, или динамически создаете SQL на основе условий приложения.PostgreSQL поддерживает C / C ++ либо со встроенным SQL (ECPG), либо с библиотекой libpq. Но они не совместимы с аналогами Oracle.
Аналогичным образом, изменение кода приложения, которое динамически создает SQL, требует глубокого понимания логики приложения и надежного тестирования, чтобы гарантировать, что функциональность работает должным образом. Мы работали с клиентами над автоматизацией некоторых аспектов этих миграций, но это по-прежнему требует внимания со стороны группы обслуживания приложений.
Управление транзакциями и обработка исключений
Каждое приложение должно обеспечивать надлежащее управление транзакциями и обработку ошибок — именно так мы предотвращаем критические случаи, сбои времени выполнения и неожиданный ввод пользователя от создания неверных данных. PostgreSQL обеспечивает надежную обработку транзакций, поддерживает полную семантику ACID и различные уровни изоляции. PostgreSQL также аккуратно обрабатывает ошибки времени выполнения и выдает надежные коды ошибок и сообщения вызывающему коду — PL / pgSQL или приложениям.Но есть несколько отличий в том, как PostgreSQL решает эти проблемы изнутри, и в том, как Oracle ведет себя, что требует изменений в коде или дизайне приложения.
Во-первых, PostgreSQL не позволяет управлять транзакциями внутри PL / pgSQL — вы не можете зафиксировать или откатить транзакцию внутри хранимой процедуры. Приложение, вызывающее хранимую процедуру, должно выполнять управление транзакциями — запуск и фиксацию или откат. Хранимая процедура выполняется в контексте вызывающей транзакции.Очевидно, что если в вашем существующем коде базы данных есть процедуры управления транзакциями, его необходимо изменить.
Во-вторых, когда в транзакции возникло исключение времени выполнения, вы должны откатить эту транзакцию, прежде чем вы сможете выполнить любой оператор в соединении. Вы часто видите это, когда обнаруживаете в журнале приложения следующее сообщение об ошибке:
ОШИБКА: текущая транзакция прервана, команды игнорируются до конца блока транзакции.
Это сообщение указывает на то, что произошла ошибка, ошибка была проигнорирована и был выполнен другой оператор ( SELECT , INSERT , EXECUTE , что угодно…). Затем второй оператор завершился неудачно, потому что транзакция уже находится в состоянии ошибки. (прервано).Увидев это сообщение, внимательно просмотрите вызовы базы данных и обработку исключений. Убедитесь, что везде, где может произойти ошибка (любой вызов базы данных), вы проверяете ошибки или настраиваете обработчик исключений и ROLLBACK (или ROLLBACK до точки сохранения или закрываете соединение) перед попыткой другой операции с базой данных.
В-третьих, для логики приложения и устранения указанной выше ошибки у вас должна быть обработка исключений. В PL / pgSQL использование блока BEGIN… EXCEPTION… END позволяет вашему коду уловить возникающую ошибку.Этот блок автоматически создает точку сохранения перед блоком и откатывается к этой новой точке сохранения при возникновении исключения. Затем вы можете определить, какую логику выполнять, в зависимости от того, произошла ли ошибка. Однако блоки исключений, поскольку они создают точку сохранения, дороги. Если вам не нужно перехватывать ошибку или если вы планируете просто передать сообщение об ошибке вызывающему приложению, не создавайте блок исключения вообще. Позвольте исходной ошибке перетечь в приложение.
Точно так же Java, встроенный SQL и другие языки имеют механизмы для перехвата исключений.Проверьте приложение, чтобы убедиться в правильной обработке ошибок при вызовах базы данных. Если приложение в настоящее время перехватывает и игнорирует исключение, вы должны изменить его, чтобы откатить транзакцию, прежде чем может быть выполнен новый вызов базы данных. Если приложение ожидает сохранить частичные изменения транзакции до исключения, вам, возможно, придется добавить точки сохранения в код приложения и откатиться к точке сохранения, чтобы продолжить после исключения.
Обратите внимание, что, как и блок исключений в PL / pgSQL, добавление точек сохранения влияет на производительность.Поэтому используйте их там, где это необходимо, но не при каждом обращении к базе данных. Например, предположим, что вы сохраняете запись заголовка вместе с дочерними записями, и вы откатите всю транзакцию, если получите исключение. В этом случае вам не нужно создавать точку сохранения после вставки записи заголовка, потому что в случае сбоя дочерних записей вы откатываете вставку.
Наконец, вы должны отобразить коды ошибок и типы исключений, которые ваше приложение ожидает от Oracle, в PostgreSQL. Некоторые коды ошибок (например, 100, код не найдено) одинаковы для обоих, но другие различаются.В зависимости от вашего языка программирования, если вы перехватываете специфичные для Oracle исключения JDBC, вы должны заменить эти специфические исключения либо общими исключениями между базами данных, либо переключиться на специфичные для PostgreSQL исключения.
Обеспечение правильности обработки транзакций и ошибок в ваших приложениях является важной частью миграции и обычно требует изменений в базе данных и коде приложения.
Навыки
За годы работы ваши администраторы баз данных и разработчики накопили большой опыт в ваших текущих технологиях.Этот опыт включает в себя использование различных расширенных функций, настройку производительности и поддержание стабильности и работоспособности системы. Переход на новую технологию требует изучения новых навыков, разработки новых способов решения проблем и отказа от старых способов ведения дел. Не стоит недооценивать количество времени, которое требуется высококвалифицированному администратору баз данных, чтобы привыкнуть к поддержке критически важной системы на новой платформе.
Вы также должны понимать, что, хотя Oracle и PostgreSQL являются реляционными базами данных и поддерживают большую часть одного и того же синтаксиса SQL для создания таблиц и запросов данных, внутреннее устройство отличается.Поэтому в некоторых ситуациях они ведут себя по-разному.
Например, Multiversion Concurrency Control (MVCC) PostgreSQL сильно отличается от сегментов отката Oracle, хотя они оба обеспечивают основу для транзакций ACID. Разработчики, которые привыкли разрабатывать приложения для одного, или администраторы баз данных, которые привыкли оптимизировать производительность для одного, могут столкнуться с неприятными «лежачими полицейскими», если будут использовать те же методы для другого.
Обучение вашей команды работе с PostgreSQL на ранних этапах процесса миграции окупается.Им будет удобнее выполнять миграцию и они смогут быстрее доставить рабочее приложение и базу данных. Кроме того, они могут избежать некоторых из этих неприятных «лежачих полицейских», если они поймут различия до того, как начнут преобразовывать свой код.
Минимизация времени простоя
Ключевым требованием для успешной миграции является стремление не нарушить работу вашего бизнеса. Это означает, что вы должны убедиться, что ваши данные переносятся правильно, приложение работает правильно, а производительность обеспечивает хорошее взаимодействие с пользователем.Это также означает сокращение времени простоя, когда ваше приложение недоступно для пользователей или клиентов.
Эти шаги помогают сократить время, необходимое для переключения в производственную среду, от архивации старых данных до использования AWS DMS для миграции и поддержания репликации текущих транзакций, чтобы гарантировать тщательное тестирование вашего кода. Написав сценарии шагов развертывания и несколько раз репетируя их в тестовой и промежуточной средах, вы можете быть уверены, что ваша команда хорошо подготовлена к производственному переходу.А использование ресурсов AWS означает, что вы можете запускать и останавливать эти тестовые среды, не неся полную стоимость установки большого сервера базы данных.
Синхронизация целевой БД
Если вы переносите все данные, используя комбинацию автономных подходов и подходов репликации (например, AWS DMS), у вас может быть полностью заполненная, готовая к использованию копия перенесенной базы данных, прежде чем вы начнете переключение процесс. Вам не нужно будет выполнять страшное упражнение по подсчету, насколько быстро вы можете преобразовать базу данных размером 1 ТБ, или предоставлять текущие обновления руководству о количестве таблиц, перенесенных в течение субботнего окна обслуживания.
Советы по ускорению миграции
В этом посте я обсудил некоторые проблемы, с которыми вы можете столкнуться при миграции с Oracle на PostgreSQL, а также несколько советов по их преодолению.
Следующие стратегии могут помочь сократить общее время, необходимое для завершения миграции:
Обучение: Ваши ведущие архитекторы, администраторы баз данных и разработчики должны понимать различия между Oracle и PostgreSQL и понимать, как правильно переносить приложения.Недельный учебный курс помогает избежать длительных задержек, поскольку они изо всех сил пытаются обойти неожиданные сюрпризы в конце вашего проекта.
Тестирование: Тестирование приложений — огромная часть общих усилий по миграции. Наличие автоматизированных тестов, которые могут выполняться на уровне приложения или доступа к данным, может помочь значительно сократить время цикла тестирования и повторения.
Двухэтапный: Если у вас есть приложение, которое требует значительных модификаций SQL или изменений кода для совместимости, сократите продолжительность обслуживания двух ветвей кода, максимально переместившись на стандартный код ANSI, который работает как в Oracle, так и в PostgreSQL.Затем разверните эти изменения в существующей производственной системе. Это также уменьшает количество изменений, которые необходимо протестировать при окончательном преобразовании.
Скрипт: Используйте автоматизированные инструменты, такие как AWS SCT. Работайте с партнером, который может создать сценарии автоматического преобразования для очистки вашего основного кода, вместо того, чтобы полагаться на грубую силу для изменения тысяч файлов кода.
Ссылка— документация py-postgresql 1.1.0
py-postgresql — это пакет Python для использования PostgreSQL.Это включает в себя низкоуровневую инструменты протокола, драйвер (PG-API и DB-API) и инструменты управления кластером.
Если это не указано в описании, postgresql.documentation.index , тогда стабильности API следует доверять , а не .
См.
- postgresql.version = ‘1.1.0’
Строка версии py-postgresql.
- postgresql.version_info = (1, 1, 0)
Тройная версия py-postgresql: (major, minor, patch).
- postgresql.open ( iri = None , prompt_title = None , ** kw ) [источник]
Создайте postgresql.api.Connection к серверу, на который ссылается данный iri :
>>> импортировать postgresql # Общий формат: >>> db = postgresql.open ('pq: // пользователь: пароль @ хост: порт / база данных') # Подключиться к postgres на локальном хосте.>>> db = postgresql.open ('локальный / постгрес')Ключевые слова подключения также могут использоваться с открытым . См. Рассказы о больше информации.
Ключевое слово prompt_title игнорируется. открыть никогда не будет запрашивать пароль, если это не указано явно.
(Примечание: «pq» — это имя протокола, используемого для связи с PostgreSQL)
Интерфейсы прикладного программиста для PostgreSQL.
postgresql.api — это набор API-интерфейсов Python для СУБД PostgreSQL. Это разработан, чтобы в полной мере использовать возможности PostgreSQL для обеспечения Программист на Python с большим удобством.
Этот модуль используется для определения «PG-API». Создает набор азбуки который составляет основные интерфейсы, используемые для работы с сервером PostgreSQL.
- класс postgresql.api.Message [источник]
Базы: postgresql.python.element.Element
Сообщение, отправленное PostgreSQL.Сообщение, представляющее собой УВЕДОМЛЕНИЕ, ПРЕДУПРЕЖДЕНИЕ, ИНФОРМАЦИЮ и т. Д.
- код [источник]
Код состояния SQL сообщения.
- подробнее [источник]
Дополнительная информация, указанная в сообщении. Общие ключи должны быть следующее:
- «серьезность»
- «контекст»
- «деталь»
- «подсказка»
- «файл»
- «строка»
- «функция»
- «позиция»
- «внутренняя_позиция»
- «внутренний_запрос»
- isconsistent ( self , other ) [источник]
Согласованы ли поля объекта other Message с поля сам .
Этот должен возвращать результат сравнения кода, источника, сообщения, и подробности.
Этот метод предоставляется как альтернатива отмене равенства; часто равенство указателей является желательным средством для сравнения, но равенство полей также необходимо.
- сообщение [источник]
Основная строка сообщения.
- источник [источник]
Откуда пришло сообщение.Обычно «СЕРВЕР», но иногда «КЛИЕНТ».
- class postgresql.api.Statement [источник]
Базы: postgresql.python.element.Element, collections.abc.Callable, collections.abc.Iterable
Экземпляры инструкции возвращаются методом подготовки База данных экземпляра.
Оператор может быть как итерируемым, так и вызываемым.
Интерфейс Iterable поддерживается для запросов, которые не принимают аргументов в все.Это позволяет синтаксис:
>>> для x в db.prepare ('select * FROM table'): ... проходить- clone ( self ) [источник]
Создайте новый объект выписки, используя те же факторы, что и self .
При использовании для обновления планов новый клон должен заменять ссылки на оригинал.
- закрыть ( self ) [источник]
Закройте подготовленный оператор, освободив связанные с ним ресурсы.
- column_names [источник]
Имена атрибутов столбцов, созданных оператором.
Последовательность объектов str с указанием имени столбца:
['столбец1', 'столбец2', 'emp_name']
- column_types [источник]
Типы Python столбцов, создаваемых оператором.
Последовательность типов объектов:
[<класс 'int'>, <класс 'str'>]
- parameter_types [источник]
Типы Python, ожидаемые от параметров, данных оператору.
Последовательность типов объектов:
[<класс 'int'>, <класс 'str'>]
- pg_column_types [источник]
Тип Oid столбцов, созданных оператором.
Последовательность объектов int , указывающая имя типа SQL:
- pg_parameter_types [источник]
Тип Oid параметров, требуемых оператором.
Последовательность объектов int , указывающих Oid типа PostgreSQL:
- sql_column_types [источник]
Тип столбцов, создаваемых оператором.
Последовательность объектов str , указывающих имя типа SQL:
[INTEGER, VARCHAR, INTERVAL]
- sql_parameter_types [источник]
Тип параметров, требуемых оператором.
Последовательность объектов str , указывающих имя типа SQL:
[INTEGER, VARCHAR, INTERVAL]
- statement_id [источник]
Статус
Массив PostgreSQL: функции, тип, пример
- Домашняя страница
Тестирование
- Назад
- Agile Testing
- BugZilla
- Тестирование базы данных Cucumber
Тестирование ET- Jmeter
- JIRA
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества (ALM)
- RPA
- SAP Testing
- Selenium
- SoapUI
- Управление тестированием
- TestLink
SAP 900 05
- Назад
- ABAP
- APO
- Начинающий
- Основа
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- FICO
- HANA HR
- MM
- QM
- Заработная плата
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
Web
- Назад
- Apache
- AngularJS
- ASP.Net
- C
- C #
- C ++
- CodeIgniter
- СУБД
- JavaScript
- Назад
- Java
- JSP
- Kotlin
- Linux
- MariaDB
- MS Access
- MYSQL
- Node. js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL
- SQLite
- Назад
- SQL Server
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно изучите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Дизайн компилятора
- Назад
- Встроенные системы
- Этический взлом
- Учебники по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сеть
- Операционная система
- Назад
- Подготовка
- PMP
- Photoshop
- Управление проектами
- Обзоры
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps
- HBase
- Back
- Hive
- Informatica
- MongoDB
- NiFi