Предикаты поиска / Хабр
По материалам статьи Craig Freedman
Перед тем, как SQL Server приступит к поиску по индексу, он должен определить, являются ли ключи индекса подходящими для оценки предиката запроса.
Индексы по одному столбцу
С индексами по одному столбцу всё довольно просто. SQL Server может их использовать для самых простых сравнений, например, равенства и неравенства (больше чем, меньше чем, и т.д.). Более сложные выражения, такие как функции по столбцу и предикаты «LIKE» с символами подстановки, будут в таких случаях создавать трудности для использования поиска по индексу.
Например, предположим, что мы имеем индекс по одному столбцу, созданный по полю «a». Этот индекс может использоваться для поиска при следующих предикатах:
a = 3.14 a > 100 a between 0 and 99 a like 'abc%' a in (2, 3, 5, 7)
Однако, поиск по индексу не будет задействован если использовать вот такие предикаты:
ABS(a) = 1 a + 1 = 9 a like '%abc'
Индексы по нескольким столбцам
С индексами по нескольким столбцам дело обстоит сложнее. Для таких индексов важен порядок ключей. Этим определяется порядок сортировки индекса, и от порядка ключей зависит набор предикатов поиска, которые SQL Server сможет использовать для этого индекса.
Для таких индексов важен порядок ключей. Этим определяется порядок сортировки индекса, и от порядка ключей зависит набор предикатов поиска, которые SQL Server сможет использовать для этого индекса.
Для того, чтобы проще понять важность порядка ключей, представьте себе телефонную книгу. Для телефонной книги походит индекс с ключами: «фамилия» и «имя». Содержание телефонной книги отсортировано по фамилии, что упрощает поиск кого-нибудь, если мы знаем его фамилию. Однако, если мы знаем только имя, очень трудно получить список людей с необходимым нам именем. В таком случае, нам бы лучше подошла другая телефонная книга, в которой абоненты отсортированы по имени.
Точно также обстоит дело, если мы имеем индекс по двум столбцам, т.е. мы сможем использовать индекс только для предиката по второму столбцу, если указан предикат равенства для первого столбца. Даже если мы не сможем использовать индекс для удовлетворения условия предиката второго столбца, мы сможем использовать его для первого столбца. В этом случае, вводится остаточный предикат для предиката второго столбца, который будет тем же самым предикатом, который используется для просмотра.
В этом случае, вводится остаточный предикат для предиката второго столбца, который будет тем же самым предикатом, который используется для просмотра.
Например, предположим, что у нас есть индекс по двум столбцам «a» и «b». Мы можем его использовать для поиска по любому из предикатов, которые применимы для индексов по одному столбцу. Кроме того, можно использовать это индекс и для поиска со следующими дополнительными предикатами:
a = 3.14 and b = 'pi' a = 'xyzzy' and b <= 0
Для следующих ниже примеров, мы можем использовать индекс для удовлетворения условий предиката для столбца «a», но не для столбца «b». В этих случаях потребуется остаточный предикат:
a > 100 and b > 100 a like 'abc%' and b = 2
И, наконец, невозможно использовать индекс для поиска со следующим ниже набором предикатов, поскольку поиск невозможен даже по столбцу «a». В таких случаях, оптимизатор вынужден использовать другой индекс (например, такой индекс, у которого столбец «b» указан первым), или он будет использовать просмотр с остаточным предикатом.
b = 0 a + 1 = 9 and b between 1 and 9 a like '%abc' and b in (1, 3, 5)
Добавим в пример немного конкретики.
Рассмотрим следующую схему:
create table person (id int, last_name varchar(30), first_name varchar(30)) create unique clustered index person_id on person (id) create index person_name on person (last_name, first_name)
Ниже представлены три запроса с соответствующими им текстовыми планами исполнения. Первый запрос осуществляет поиск по обоим столбцам индекса person_name. Второй запрос ищет только по первому столбцу и использует остаточный предикат, для оценки first_name. Третий запрос не может использовать поиск и использует просмотр с остаточным предикатом.
select id from person where last_name = 'Doe' and first_name = 'John' |--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name]='Doe' AND [person].[first_name]='John')) select id from person where last_name > 'Doe' and first_name = 'John' |--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name] > 'Doe'), WHERE:([person].[first_name]='John')) select id from person where last_name like '%oe' and first_name = 'John' |--Index Scan(OBJECT:([person].[person_name]), WHERE:([person].[first_name]='John' AND [person].[last_name] like '%oe'))
Внимание: Если Вы пробуете воспроизвести эти планы для этих и некоторых следующих примеров, учтите, что я использовал подсказки индексов (которые не указаны), позволяющие гарантировать получение необходимого плана запроса, поскольку я хотел проиллюстрировать эти примеры без необходимости вставки данных в таблицу.
Дополнение о ключах индекса
Очень часто ключи индекса являются набором столбцов, которые были указаны в инструкции по созданию этого индекса. Однако, когда создается некластеризованный уникальный индекс для таблицы с кластеризованным индексом, в ключ некластеризованного индекса добавляется ключ кластеризованного индекса, если он не является частью ключей некластеризованного индекса.
Например, рассмотрим такую схему:
create table T_heap (a int, b int, c int, d int, e int, f int) create index T_heap_a on T_heap (a) create index T_heap_bc on T_heap (b, c) create index T_heap_d on T_heap (d) include (e) create unique index T_heap_f on T_heap (f) create table T_clu (a int, b int, c int, d int, e int, f int) create unique clustered index T_clu_a on T_clu (a) create index T_clu_b on T_clu (b) create index T_clu_ac on T_clu (a, c) create index T_clu_d on T_clu (d) include (e) create unique index T_clu_f on T_clu (f)
Столбцы ключей и покрываемые столбцы для каждого из индексов:
Индекс | Столбцы ключа | Покрываемые столбцы |
T_heap_a | a | a |
T_heap_bc | b, c | b, c |
T_heap_d | d | d, e |
T_heap_f | f | f |
T_clu_a | a | a, b, c, d, e |
b, a | a, b | |
T_clu_ac | a, c | a, c |
T_clu_d | d, a | a, d, e |
T_clu_f | f | a, f |
Обратите внимание, что каждый некластеризованный индекс таблицы T_clu включает ключевой столбец кластеризованного индекса, за исключением уникального индекса T_clu_f.
Описанное в этой статье поведение оптимизатора не изменилось и в SQL Server 2005. Уникальные некластеризованные индексы не включают ключи кластеризованного индекса в свой набор ключевых столбцов, но делают их покрываемыми столбцами. То есть Вы не можете искать по кластеризованному ключу, но Вы можете выбирать значения по индексу. Это происходит потому, что ключ кластеризованного индекса хранится только на страницах листового уровня сбалансированного дерева; он не хранится на страницах не листового уровня. Ключ кластеризованного индекса необходим для поиска закладок. Нет нужды искать по ключу кластеризованного индекса, поскольку поиск по ключу уникального индекса обычно возвращает одну строку. В SQL Server 2000, фактически может использоваться поиск по ключу кластеризованного индекса, но это относится к внутренней реализации в виде остаточного предиката, а не в виде поиска.
Указание предикатов на шаге выражения пути — SQL Server
- Статья
- Чтение занимает 4 мин
Применимо к: SQL Server (все поддерживаемые версии)
Как описано в разделе, выражения пути в XQuery, шаг оси в выражении пути включает следующие компоненты:
Необязательный предикат является третьим компонентом шага оси в выражении пути.
Предикаты
Предикат используется для фильтрации последовательности узлов при помощи заданного теста. Выражение предиката заключено в квадратные скобки и привязано к последнему узлу выражения пути.
Например, предположим, что значение параметра SQL (x) типа данных XML объявляется, как показано в следующем примере:
declare @x xml
set @x = '
<People>
<Person>
<Name>John</Name>
<Age>24</Age>
</Person>
<Person>
<Name>Goofy</Name>
<Age>54</Age>
</Person>
<Person>
<Name>Daffy</Name>
<Age>30</Age>
</Person>
</People>
'
В этом случае следующие выражения, использующие значение предиката, равное [1], на каждом из трех уровней узлов, будут допустимыми:
select @x.query('/People/Person/Name[1]')
select @x.query('/People/Person[1]/Name')
select @x.query('/People[1]/Person/Name')
Обратите внимание, что в каждом случае предикат привязан к узлу выражения пути, где он применяется. Например, первое выражение пути выбирает первый <
Например, первое выражение пути выбирает первый <Name> элемент в каждом узле /Люди/Person, а предоставленный экземпляр XML возвращает следующее:
<Name>John</Name><Name>Goofy</Name><Name>Daffy</Name>
Однако второе выражение пути выбирает все <
<Name>John</Name>
Порядок вычисления предикатов можно менять при помощи круглых скобок. Например, в следующем выражении круглые скобки используются для разделения пути (/People/Person/Name) от предиката [1]:
select @x.query('(/People/Person/Name)[1]')
В этом примере порядок применения предикатов изменяется. Сначала вычисляется путь, заключенный в круглые скобки (/People/Person/Name), а затем оператор предиката [1] применяется к набору, содержащему все узлы, которые соответствуют этому пути. Если убрать круглые скобки, порядок операций будет другим; предикат [1] будет применяться в качестве теста узла child::Name, так же, как и в первом примере.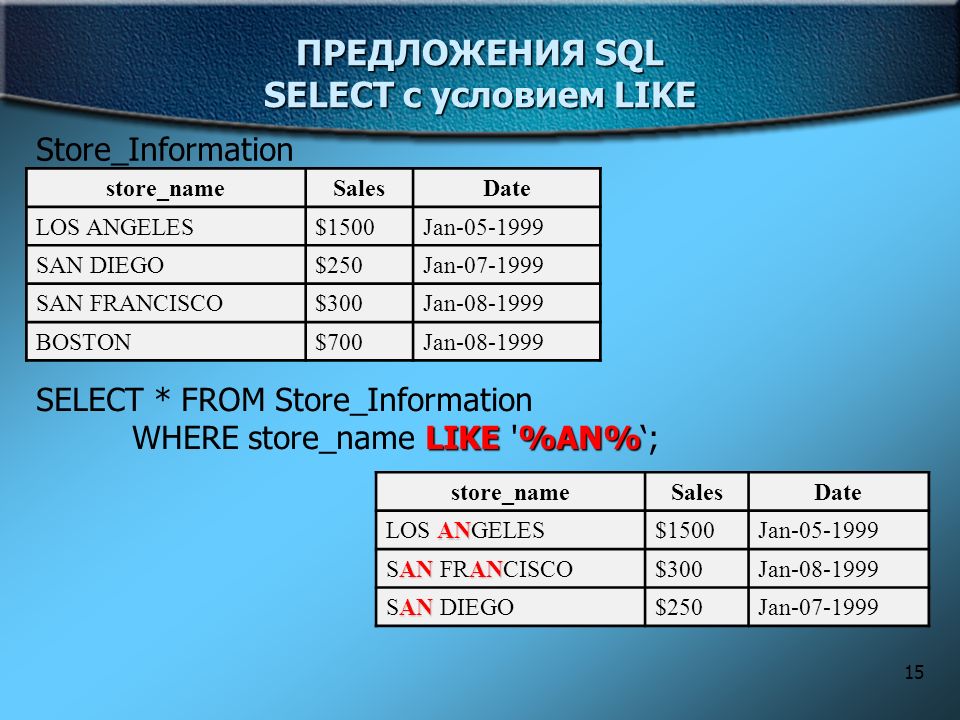
Квалификаторы и предикаты
Квалификаторы можно использовать более одного раза в фигурных скобках предиката. Например, в предыдущем примере можно использовать более одного квалификатора в сложном подвыражении предиката следующим образом.
select @x.query('/People/Person[contains(Name[1], "J") and xs:integer(Age[1]) < 40]/Name/text()')
Результат выражения предиката преобразуется в значение типа Boolean и называется истинностью предиката. Набор результатов содержит только те узлы последовательности, для которых значение предиката равно True. Остальные узлы отбрасываются.
Например, предикат содержит второй шаг следующего выражения пути:
/child::root/child::Location[attribute::LocationID=10]
Условие, указанное этим предикатом, применяется ко всем дочерним <Location> элементам узла элемента. Возвращаются только те результаты, у которых значение атрибута LocationID равно 10.
Предыдущее выражение пути выполнялось в следующей инструкции SELECT:
SELECT Instructions.query(' declare namespace AWMI="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelManuInstructions"; /child::AWMI:root/child::AWMI:Location[attribute::LocationID=10] ') FROM Production.ProductModel WHERE ProductModelID=7
Проверка истинности предикатов
Чтобы определить истинность значения предиката согласно спецификации XQuery, применяются следующие правила:
Если значение выражения предиката представляет пустую последовательность, значение предиката равно False.
Пример:
SELECT Instructions.query(' declare namespace AWMI="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelManuInstructions"; /child::AWMI:root/child::AWMI:Location[attribute::LotSize] ') FROM Production.ProductModel WHERE ProductModelID=7Выражение пути в этом запросе возвращает только те <
Location> узлы элементов, которые имеют указанный атрибут LotSize. Если предикат возвращает пустую последовательность для определенного <Location>объекта, то расположение рабочего центра не возвращается в результате.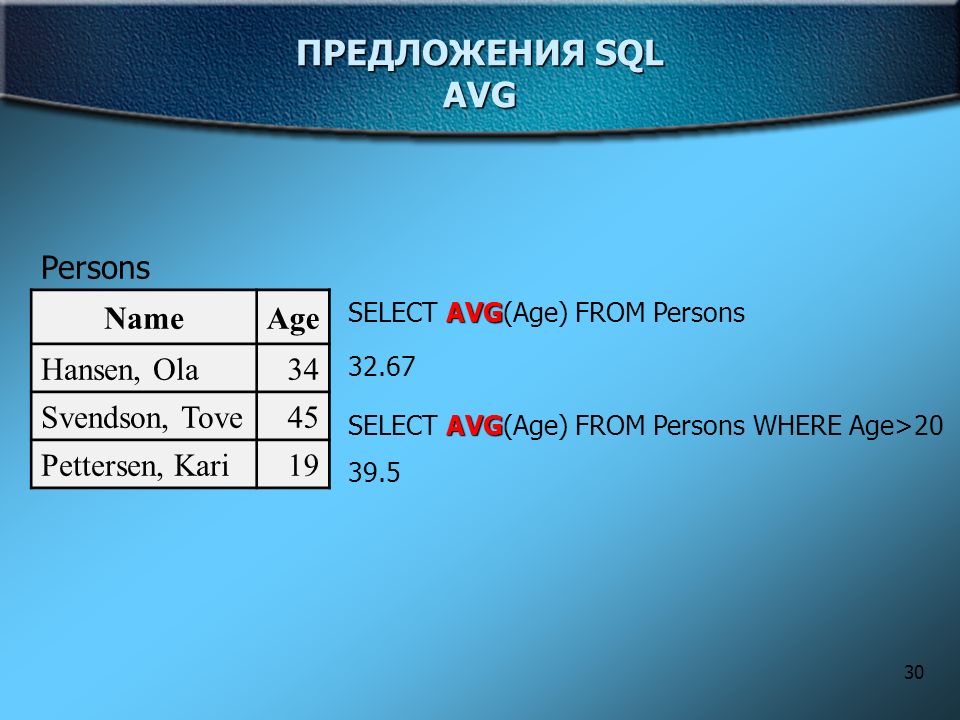
В качестве значений предикатов можно использовать только xs:integer, xs:Boolean или узел*. Если задан узел*, предикат принимает значение True, если такие узлы существуют, и False в противном случае. При использовании других числовых типов, например double или float, возникает ошибка статической типизации. Значение предиката выражения равно True тогда и только тогда, когда полученное значение типа integer равно значению позиции контекста. Кроме того, только целые литеральные значения и функция last() уменьшают кратность отфильтрованного выражения шага до 1.
Например, следующий запрос извлекает третий дочерний <
Features> узел элемента элемента.SELECT CatalogDescription.query(' declare namespace PD="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription"; declare namespace wm="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelWarrAndMain"; /child::PD:ProductDescription/child::PD:Features/child::*[3] ') FROM Production. ProductModel
WHERE ProductModelID=19
ProductModel
WHERE ProductModelID=19
Обратите внимание на следующие данные из предыдущего запроса:
Третий шаг выражения задает выражение предиката со значением, равным 3. Таким образом, значение истинности предиката равно True только для тех узлов, у которых позиция контекста равна 3.
Третий шаг также содержит символ-шаблон (*), который указывает на все узлы в тесте узлов. Тем не менее предикат фильтрует узлы и возвращает только те из них, которые находятся на третьей позиции.
Запрос возвращает третий дочерний узел элемента дочерних <
Features> элементов дочерних <ProductDescription> элементов элемента корневого каталога документа.
Если значение выражения предиката представляет собой простое значение типа Boolean, значение истинности предиката совпадает с ним.
Например, следующий запрос указывается для переменной типа XML, содержащей экземпляр XML, экземпляр XML опроса клиента.
 Запрос получает только тех клиентов, у которых есть дети. В этом запросе это будет <HasChildren>1</HasChildren>.
Запрос получает только тех клиентов, у которых есть дети. В этом запросе это будет <HasChildren>1</HasChildren>.declare @x xml set @x=' <Survey> <Customer CustomerID="1" > <Age>27</Age> <Income>20000</Income> <HasChildren>1</HasChildren> </Customer> <Customer CustomerID="2" > <Age>27</Age> <Income>20000</Income> <HasChildren>0</HasChildren> </Customer> </Survey> ' declare @y xml set @y = @x.query(' for $c in /child::Survey/child::Customer[( child::HasChildren[1] cast as xs:boolean ? )] return <CustomerWithChildren> { $c/attribute::CustomerID } </CustomerWithChildren> ') select @yОбратите внимание на следующие данные из предыдущего запроса:
Выражение в цикле for состоит из двух шагов, а второй — предиката. Значение предиката имеет тип Boolean.
 Если это значение равно True, значение истинности предиката также равно True.
Если это значение равно True, значение истинности предиката также равно True.Запрос возвращает дочерние <
Customer> элементы, значение предиката которых равно True, дочерних <элементов элемента Survey> корневого каталога документа. Результат:<CustomerWithChildren CustomerID="1"/>
Если значение выражения предиката представляет последовательность как минимум из одного узла, значение истинности предиката равно True.
Например, следующий запрос извлекает ProductModelID для моделей продуктов, описание каталога XML которых содержит по крайней мере одну функцию, дочерний элемент <Features> элемента из пространства имен, связанного с префиксом WM .
SELECT ProductModelID
FROM Production.ProductModel
WHERE CatalogDescription.exist('
declare namespace PD="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
declare namespace wm="https://schemas. microsoft.com/sqlserver/2004/07/adventure-works/ProductModelWarrAndMain";
/child::PD:ProductDescription/child::PD:Features[wm:*]
') = 1
microsoft.com/sqlserver/2004/07/adventure-works/ProductModelWarrAndMain";
/child::PD:ProductDescription/child::PD:Features[wm:*]
') = 1
Обратите внимание на следующие данные из предыдущего запроса:
Предложение WHERE указывает метод exist() (тип данных XML).
Выражение пути внутри метода exist() указывает предикат во втором шаге. Если выражение предиката возвращает последовательность как минимум из одной функции, значение истинности выражения предиката равно True. В этом случае, так как метод exist() возвращает значение True, возвращается ProductModelID.
Предикаты также могут влиять на статически выведенный тип выражения. Целочисленные литеральные значения и функция last() уменьшают кратность отфильтрованного выражения шага до одного.
Предикаты ALL, DISTINCT, DISTINCTROW и TOP
Access
Запросы
Синтаксис SQL
Синтаксис SQL
Предикаты ALL, DISTINCT, DISTINCTROW и TOP
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Access 2007 Еще. ..Меньше
..Меньше
Эти предикаты задают записи, выбираемые с помощью запросов SQL.
SELECT [ALL | DISTINCT | DISTINCTROW | [TOP n [PERCENT]]]
FROM таблица
Инструкция SELECT, содержащая эти предикаты, состоит из следующих частей:
|
Элемент |
Описание |
|
ALL |
Используется по умолчанию, если вы не указываете ни один из предикатов. Ядро СУБД Microsoft Access выбирает все записи, которые удовлетворяют условиям в инструкции SQL. Следующие два примера эквивалентны и возвращает все записи из таблицы Employees: |
|
DISTINCT |
Исключает записи, содержащие повторяющиеся данные в выбранных полях. Если опустить DISTINCT, этот запрос возвратит обе записи с фамилией «Глазков». Если предложение SELECT содержит несколько полей, запись будет включена в результаты только в том случае, если сочетание значений всех таких полей уникально. Выходные данные запроса, использующего DISTINCT, не является обновляемыми и не отражают изменения, внесенные другими пользователями. |
|
DISTINCTROW |
Данные не просто повторяют поля, но и не повторяются. Если опустить DISTINCTROW, этот запрос создаст несколько строк для каждой компании, от которой поступало более одного заказа. DISTINCTROW действует только в том случае, если вы выбираете поля из некоторых (но не всех) таблиц, используемых в запросе. DISTINCTROW игнорируется, если запрос содержит только одну таблицу или вы включаете поля из всех таблиц. |
|
TOP n [PERCENT] |
Возвращает записи, относящиеся к верхней или нижней части диапазона, заданного предложением ORDER BY. Если не включить предложение ORDER BY, запрос вернет из таблицы Students произвольный набор, включающий 25 записей, которые удовлетворяют предложению WHERE. Предикат TOP не выбирает между равными значениями. Если в предыдущем примере двадцать пятый и двадцать шестой средний балл совпадают, запрос вернет 26 записей. Вы также можете использовать зарезервированное слово PERCENT для возвращения определенного процента записей из верхней или нижней части диапазона, заданного предложением ORDER BY. Предположим, что вместо 25 лучших студентов вы хотите получить 10 процентов худших студентов группы: Предикат ASC позволяет вернуть нижние значения. TOP не влияет на возможность обновления запроса. |
|
таблица |
Имя таблицы, из которой извлекаются записи. |
 Для включения в результаты запроса значения каждого из полей, перечисленных в инструкции SELECT, должны быть уникальными. Например, у нескольких сотрудников, перечисленных в таблице Employees, могут быть одинаковые фамилии. Если две записи содержат «Глазков» в поле LastName, следующая инструкция SQL возвращает только одну запись, содержащую значение «Глазков»:
Для включения в результаты запроса значения каждого из полей, перечисленных в инструкции SELECT, должны быть уникальными. Например, у нескольких сотрудников, перечисленных в таблице Employees, могут быть одинаковые фамилии. Если две записи содержат «Глазков» в поле LastName, следующая инструкция SQL возвращает только одну запись, содержащую значение «Глазков»: Например, можно создать запрос, который соединяет таблицы Customers и Orders по полю CustomerID. Таблица «Клиенты» не содержит повторяют поля CustomerID, но таблица Orders содержит, так как у каждого клиента может быть множество заказов. В следующей SQL показано, как использовать DISTINCTROW для создания списка компаний, у кого есть хотя бы один заказ, но нет сведений об этих заказах:
Например, можно создать запрос, который соединяет таблицы Customers и Orders по полю CustomerID. Таблица «Клиенты» не содержит повторяют поля CustomerID, но таблица Orders содержит, так как у каждого клиента может быть множество заказов. В следующей SQL показано, как использовать DISTINCTROW для создания списка компаний, у кого есть хотя бы один заказ, но нет сведений об этих заказах: Предположим, что вы хотите получить имена 25 лучших студентов из группы 1994 г.:
Предположим, что вы хотите получить имена 25 лучших студентов из группы 1994 г.: Значение после TOP должно быть целым числом без знака.
Значение после TOP должно быть целым числом без знака.Документация JDK 19 — Главная
- Главная
- Ява
- Java SE
- 19
Обзор
- Прочтите меня
- Примечания к выпуску
- Что нового
- Руководство по миграции
- Загрузить JDK
- Руководство по установке
- Формат строки версии
Инструменты
- Технические характеристики инструментов JDK
- Руководство пользователя JShell
- Руководство по JavaDoc
- Руководство пользователя средства упаковки
Язык и библиотеки
- Обновления языка
- Основные библиотеки
- HTTP-клиент JDK
- Учебники по Java
- Модульный JDK
- Руководство программиста API бортового регистратора
- Руководство по интернационализации
Технические характеристики
- Документация API
- Язык и ВМ
- Имена стандартных алгоритмов безопасности Java
- банок
- Собственный интерфейс Java (JNI)
- Инструментальный интерфейс JVM (JVM TI)
- Сериализация
- Проводной протокол отладки Java (JDWP)
- Спецификация комментариев к документации для стандартного доклета
- Прочие характеристики
Безопасность
- Руководство по безопасному кодированию
- Руководство по безопасности
Виртуальная машина HotSpot
- Руководство по виртуальной машине Java
- Настройка сборки мусора
Управление и устранение неполадок
- Руководство по устранению неполадок
- Руководство по мониторингу и управлению
- Руководство по JMX
Client Technologies
- Руководство по специальным возможностям Java
Предикаты | ENT
Полевые предикаты
- BOOL :
- = ,! =
- Числовой :
- = ,!,>,>, <, <=, <=,
- = ,!,>, <,>, <=,
- = ,!,>, <,>, <=,
- = ,!
- Время :
- =, !=, >, <, >=, <=
- IN, NOT IN
- Строка :
- =, !=, >, <, >=, <=
- IN, NOT IN
- SQL )
- JSON
- =, !=
- =, !=, >, <, >=, <= для вложенных значений (путь JSON).

- Содержит вложенные значения (путь JSON).
- HasKey, Len
-
нольпроверяет наличие вложенных значений (путь JSON).
- Необязательные поля:
- IsNil, NotNil
Edge Predicates
HasEdge. Например, для ребра с именем
ownerтипаPetиспользуйте:client.Pet.
Запрос().
Где(pet.HasOwner()).
Все(ctx)
HasEdgeWith . Добавьте список предикатов для предиката края.
клиент.Пэт.
Запрос().
Где(pet.HasOwnerWith(user.Name("a8m"))).
Все(ctx)
Отрицание (НЕ)
client.Pet.
Запрос().
Где(pet.Not(pet.NameHasPrefix("Ари"))).
All(ctx)
Disjunction (OR)
client.Pet.
Запрос().
Где(
pet.Or(
pet.HasOwner(),
pet.Not(pet.HasFriends()),
)
).
All(ctx)
Соединение (И)
client.Pet.
Запрос().
Где(
пет.И(
пет.ИмеетВладелец(),
пет.Не(пет.ИмеетДрузья()),
)
).
All(ctx)
Пользовательские предикаты
Пользовательские предикаты могут быть полезны, если вы хотите написать собственную логику для конкретного диалекта или контролировать выполняемые запросы.
Получить всех питомцев пользователей 1, 2 и 3
питомцев := client.Pet.
Запрос().
Where(func(s *sql.Selector) {
s.Where(sql.InInts(pet.FieldOwnerID, 1, 2, 3))
}).
AllX(ctx)
Приведенный выше код создаст следующий SQL-запрос:
SELECT DISTINCT `pets`.`id`, `pets`.`owner_id` FROM `pets` ГДЕ `owner_id` IN (1, 2, 3)
Подсчитайте количество пользователей, чье поле JSON с именем
URL-адрес содержит ключ схемы count := client.User.
Запрос().
Where(func(s *sql.Selector) {
s.Where(sqljson.HasKey(user.FieldURL, sqljson.Path("Scheme")))
}).
СчетX(ctx)
Приведенный выше код создаст следующий запрос SQL:
-- PostgreSQL
SELECT COUNT(DISTINCT "users"."id") FROM "users" WHERE "url"->'Scheme' IS NOT NULL-- SQLite и MySQL
SELECT COUNT(DISTINCT `users`.`id`) FROM `users` WHERE JSON_EXTRACT(`url`, "$.Scheme") НЕ NULL
Получить всех пользователей с автомобилем
"Tesla" Рассмотрим запрос типа ent:
пользователей := client.User.Query().
Где(пользователь.HasCarWith(car.Model("Tesla"))).
AllX(ctx)
Этот запрос можно перефразировать в 3 разных формах: IN , EXISTS и JOIN .
// Версия `IN`.
пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
s.Where(
sql.In(
s.C(user.FieldID),
sql.Select(t.C(user .FieldID)).From(t).Where(sql.EQ(t.C(car.FieldModel), "Tesla")),
),
)
}).
AllX(ctx)// версия `JOIN`.
пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
s.Join(t).On(s.C(user.FieldID), t.C(car.FieldOwnerID))
s .Where(sql.EQ(t.C(car.FieldModel), "Tesla"))
}).
AllX(ctx)// `СУЩЕСТВУЕТ` версия.
пользователей := client.User.Query().
Where(func(s *sql.Selector) {
t := sql.Table(car.Table)
p := sql.And(
sql.EQ(t.C(car.FieldModel), "Tesla"),
sql.ColumnsEQ(s.C(user.FieldID), t.C(car.FieldOwnerID)),
)
s.Where(sql.Exists(sql.Select().From(t).Where(p)))
}).
AllX(ctx)
Приведенный выше код создаст следующий SQL-запрос:
-- Версия `IN`.
SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` WHERE `users`.`id` IN (SELECT `cars`.`id` FROM ` cars` ГДЕ `cars`.`model` = 'Tesla')-- `JOIN` версия.

SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` ПРИСОЕДИНЯЙТЕСЬ к `cars` НА `users`.`id` = `cars`.`owner_id` ГДЕ `cars`.`model` = 'Tesla'-- `СУЩЕСТВУЕТ` версия.
SELECT DISTINCT `users`.`id`, `users`.`age`, `users`.`name` FROM `users` WHERE EXISTS (SELECT * FROM `cars` WHERE `cars`.`model` = 'Tesla ' AND `users`.`id` = `cars`.`owner_id`)
Получить всех домашних животных, имя которых содержит определенный шаблон
и СодержитFold предикаты для сопоставления с образцом.
Однако, чтобы использовать оператор LIKE с пользовательским шаблоном, используйте следующий пример.домашние животные := client.Pet.Query().
Where(func(s *sql.Selector){
s.Where(sql.Like(pet.Name,"_B%"))
}).
AllX(ctx)
Приведенный выше код выдаст следующий запрос SQL:
SELECT DISTINCT `pets`.`id`, `pets`.`owner_id`, `pets`.`name`, `pets`. `age`, `pets`.`species` FROM `pets` WHERE `name` LIKE '_B%'
Пользовательские функции SQL
используйте один из следующих вариантов:
1. Передайте функцию предиката с учетом диалекта, используя параметр
Передайте функцию предиката с учетом диалекта, используя параметр sql.P :
пользователей := client.User.Query().
Выберите(user.FieldID).
Where(sql.P(func(b *sql.Builder) {
b.WriteString("DATE(").Ident("last_login_at").WriteByte(')').WriteOp(OpGTE).Arg(значение)
})).
AllX(ctx)
Приведенный выше код выдаст следующий SQL-запрос:
SELECT `id` FROM `users` WHERE DATE(`last_login_at`) >= ?
2. Встроить выражение предиката, используя ExprP() опция:
пользователей := client.User.Query().
Выберите(user.FieldID).
Where(func(s *sql.Selector) {
s.Where(sql.ExprP("DATE(last_login_at) >=?", value))
}).
AllX(ctx)
Приведенный выше код выдаст тот же SQL-запрос:
SELECT `id` FROM `users` WHERE DATE(`last_login_at`) >= ?
Предикаты JSON
Предикаты JSON не генерируются по умолчанию как часть генерации кода. Тем не менее, ent предоставляет официальный пакет
по имени
Тем не менее, ent предоставляет официальный пакет
по имени sqljson для применения предикатов к столбцам JSON с использованием
опция пользовательских предикатов.
Сравните значение JSON , контент, sqljson.DotPath(«атрибуты[1].body.content»))
sqljson.ValueGTE(user.FieldData, status.StatusBadRequest, sqljson.Path(«ответ», «статус»))
Проверить наличие ключа JSON
sqljson.HasKey(user.FieldData, sqljson.Path("атрибуты", "[1]", "тело")) sqljson.HasKey(user.FieldData, sqljson.DotPath("атрибуты[1].body" ))
Обратите внимание, что ключ с литералом null в качестве значения также соответствует этой операции.
Проверить JSON
null литералы («атрибуты[1].тело»)) Обратите внимание, что ValueIsNull возвращает true, если значение равно JSON null ,
но не база данных NULL .
Сравните длину массива JSON .
 LenLT(user.FieldData, 20, sqljson.Path(«attributes»)),
LenLT(user.FieldData, 20, sqljson.Path(«attributes»)), )
Проверить, содержит ли значение JSON другое значение
sqljson.ValueContains(user.FieldData, data)sqljson.ValueContains(user.FieldData, attrs, sqljson.Path("атрибуты"))
sqljson.ValueContains(user.FieldData, code, sqljson.DotPath("attributes[0].status_code"))
Проверить, содержит ли строковое значение JSON заданную подстроку или указанный суффикс или префикс
sqljson.StringContains(user.FieldURL, "github", sqljson.Path("host")) ".com", sqljson.Path("host"))
sqljson.StringHasPrefix(user.FieldData, "20", sqljson.DotPath("attributes[0].status_code"))
Проверить, равно ли значение JSON любому из значений в списке
sqljson.ValueIn(user.FieldURL, []any{"https", "ftp"}, sqljson.Path("Scheme" )) sqljson.ValueNotIn(user.FieldURL, []any{"github", "gitlab"}, sqljson.Path("Host"))
Начало работы с SQL
Начало работы с SQL Предикаты позволяют создавать условия таким образом, чтобы
строки, удовлетворяющие этим условиям, обрабатываются. Обсуждаются базовые предикаты
в разделе «Выбор строк». В этом разделе обсуждаются IN, BETWEEN, LIKE, EXISTS и количественные предикаты.
раздел.
Обсуждаются базовые предикаты
в разделе «Выбор строк». В этом разделе обсуждаются IN, BETWEEN, LIKE, EXISTS и количественные предикаты.
раздел.
Использование предиката IN
Используйте предикат IN для сравнения значения с несколькими другими значениями. За пример:
ВЫБЕРИТЕ ИМЯ
ОТ ПЕРСОНАЛА
ГДЕ ОТДЕЛ В (20, 15)
Этот пример эквивалентен:
ВЫБЕРИТЕ ИМЯ
ОТ ПЕРСОНАЛА
ГДЕ ОТДЕЛ = 20 ИЛИ ОТДЕЛ = 15
Вы можете использовать операторы IN и NOT IN, когда подзапрос возвращает набор ценности. Например, следующий запрос выводит фамилии сотрудников ответственный за проекты MA2100 и OP2012:
ВЫБЕРИТЕ ФАМИЛИЯ
ОТ СОТРУДНИКОВ
ГДЕ ЭМПНО В
( ВЫБОР ОТВЕТ
ИЗ ПРОЕКТА
ГДЕ PROJNO = 'MA2100'
ИЛИ PROJNO = 'OP2012')
Подзапрос выполняется один раз, и результирующий список заменяется
непосредственно в запрос внешнего уровня. Например, приведенный выше подзапрос выбирает
номера сотрудников 10 и 330, запрос внешнего уровня оценивается так, как будто его
Предложение WHERE было:
Например, приведенный выше подзапрос выбирает
номера сотрудников 10 и 330, запрос внешнего уровня оценивается так, как будто его
Предложение WHERE было:
ГДЕ ЭМПНО В (10, 330)
Список значений, возвращаемых подзапросом, может содержать ноль, одно или несколько значений. ценности.
Использование предиката BETWEEN
Используйте предикат BETWEEN для сравнения значения с диапазоном значений. диапазон включен, и он рассматривает два выражения в МЕЖДУ предикат для сравнения.
В следующем примере выполняется поиск имен сотрудников, которые зарабатывают между 10 000 и 20 000 долл. США:
ВЫБЕРИТЕ ФАМИЛИЯ
ОТ СОТРУДНИКОВ
ГДЕ ЗАРПЛАТА МЕЖДУ 10000 И 20000
Это эквивалентно:
ВЫБЕРИТЕ ФАМИЛИЯ
ОТ СОТРУДНИКОВ
ГДЕ ЗАРПЛАТА >= 10000 И ЗАРПЛАТА <= 20000
Следующий пример находит имена сотрудников, которые зарабатывают менее 10 000 долларов США или более 20 000 долларов США:
ВЫБЕРИТЕ ФАМИЛИЯ
ОТ СОТРУДНИКОВ
ГДЕ ЗАРПЛАТА НЕ МЕЖДУ 10000 И 20000
Использование предиката LIKE
Используйте предикат LIKE для поиска строк с определенными шаблонами. Шаблон задается с помощью знаков процента и подчеркивания.
Шаблон задается с помощью знаков процента и подчеркивания.
- Символ подчеркивания (_) представляет любой отдельный символ.
- Знак процента (%) представляет строку из нуля или более персонажи.
- Любой другой символ представляет себя.
В следующем примере выбираются имена сотрудников длиной семь букв. на букву «С»:
ВЫБЕРИТЕ ИМЯ
ОТ ПЕРСОНАЛА
ГДЕ ИМЯ НРАВИТСЯ 'S_ _ _ _ _ _'
В следующем примере выбираются имена сотрудников, которые не начинаются с буквы':
ВЫБЕРИТЕ ИМЯ
ОТ ПЕРСОНАЛА
ГДЕ ИМЯ НЕ КАК 'S%'
Использование предиката EXISTS
Вы можете использовать подзапрос для проверки существования строки, которая удовлетворяет некоторому условию. В этом случае подзапрос связан с запрос внешнего уровня с помощью предиката EXISTS или NOT EXISTS.
При связывании подзапроса с внешним запросом с помощью предиката EXISTS
подзапрос не возвращает значение. Скорее, предикат EXISTS истинен, если
набор ответов подзапроса содержит одну или несколько строк и false, если он содержит
нет рядов.
Скорее, предикат EXISTS истинен, если
набор ответов подзапроса содержит одну или несколько строк и false, если он содержит
нет рядов.
Предикат EXISTS часто используется со связанными подзапросами. Пример ниже перечислены отделы, которые в настоящее время не имеют записей в ПРОЕКТЕ стол:
ВЫБЕРИТЕ НОМЕР ОТДЕЛА, ИМЯ ОТДЕЛА
ОТ ОТДЕЛ X
ГДЕ НЕ СУЩЕСТВУЕТ
( ВЫБЕРИТЕ *
ИЗ ПРОЕКТА
ГДЕ DEPTNO = X.DEPTNO)
ЗАКАЗАТЬ ПО ТЕЛЕФОНУ DEPTNO
Вы можете соединить предикаты EXISTS и NOT EXISTS с другими предикатами с помощью используя AND и OR в предложении WHERE запроса внешнего уровня.
Количественные предикаты
Количественный предикат сравнивает значение с набором значений. Если
fullselect возвращает более одного значения, вы должны изменить сравнение
операторы в вашем предикате, присоединив суффикс ALL, ANY или SOME. Эти
суффиксы определяют, как набор возвращаемых значений должен обрабатываться в
предикат внешнего уровня. В качестве примера используется оператор сравнения > (оператор сравнения
примечания ниже относятся и к другим операторам):
Эти
суффиксы определяют, как набор возвращаемых значений должен обрабатываться в
предикат внешнего уровня. В качестве примера используется оператор сравнения > (оператор сравнения
примечания ниже относятся и к другим операторам):
- выражение > ВСЕ (полный выбор)
- Предикат истинен, если выражение больше каждого отдельного
значение, возвращаемое полной выборкой. Если полная выборка не возвращает никаких значений,
предикат истинен. Результат ложный, если указанное отношение ложно
по крайней мере для одного значения. Обратите внимание, что количественный предикат <>ALL
эквивалентно предикату NOT IN.
В следующем примере используется подзапрос и сравнение > ALL, чтобы найти имя и профессия всех сотрудников, которые зарабатывают больше, чем все руководители:
ВЫБЕРИТЕ ФАМИЛИЯ, РАБОТА ОТ СОТРУДНИКОВ ГДЕ ЗАРПЛАТА > ВСЕ ( ВЫБЕРИТЕ ЗАРПЛАТА ОТ СОТРУДНИКОВ ГДЕ РАБОТА='МЕНЕДЖЕР') - выражение > ЛЮБОЙ (полный выбор)
- Предикат истинен, если выражение больше хотя бы одного из
значения, возвращаемые полной выборкой.
