SQL запросы быстро. Часть 1 / Хабр
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')
Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM Customers
Выбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM Customers
WHERE
Фильтрация по одному условию и одному значению:
select * from Customers WHERE City = 'London'
Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15 select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers GROUP BY City
Группировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers GROUP BY Country, City
Группировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails GROUP BY ProductID
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers WHERE Country = 'Germany' GROUP BY City
Переименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers group by City
HAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers group by City HAVING count(CustomerID) >= 5
В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers group by City HAVING number_of_clients >= 5
Пример запроса, содержащего WHERE и HAVING.
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers ORDER BY City
Осуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers ORDER BY Country, City
По умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers order by CustomerID DESC
Обратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers order by Country DESC, City
JOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerID
Нередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders join Customers on Orders.CustomerID = Customers.CustomerID where Customers.CustomerID >10
Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
Книга по SQL от русского автора. SQL код – основы для начинающих программистов | Info-Comp.ru
Приветствую Вас, уважаемые посетители сайта Info-Comp.ru! Я с большим удовольствием, гордостью и радостью хочу представить Вам мою новую книгу по основам SQL, которая предназначена для начинающих программистов и ориентирована на изучение языка SQL как стандарта, чтобы после ее прочтения можно было работать с языком SQL в любой системе управления базами данных.
Книгу я назвал «SQL код» и в этом материале я подробно расскажу Вам об этой книге.
SQL (Structured Query Language) — язык структурированных запросов, с помощью него пишутся специальные запросы к базе данных с целью получения данных из базы данных и для манипулирования этими данными. SQL – это стандарт.
Содержание
- Описание книги
- Для кого предназначена эта книга
- Чему Вы научитесь
- Краткое содержание книги
Описание книги
Язык SQL, как было отмечено, — это стандарт, который должен быть реализован во всех СУБД, однако каждая СУБД отклоняется от этого стандарта и применяет свою реализацию SQL, свой диалект SQL, т.е. свой синтаксис.
Даже синтаксис казалось бы стандартных конструкций в разных СУБД может отличаться, и человеку, который прочитал книгу или прошёл курс по SQL на примере какой-то одной СУБД, придётся доучиваться и обновлять свои знания, в случае если у него возникнет необходимость работать с другой СУБД, отличной от той, которая использовалась в книге или на курсе.
Если говорить о книгах западных авторов, то они в основном направлены на людей, которые хоть немного, но владеют навыками программирования и языком SQL.
Поэтому совсем новичкам очень трудно читать такие книги, к тому же большинство книг по SQL уже просто устарело. Иными словами, все они для Вас будут
Именно поэтому у меня и возникла идея разработать универсальную книгу (а также полноценный курс) по SQL, которая не была бы привязана к какой-то конкретной СУБД, иными словами, после прочтения которой можно было бы работать с SQL в любой СУБД, т.е. чтобы SQL в ней рассматривался как стандарт. При этом чтобы эта книга была доступна и понятна всем, даже начинающим программистам, т.е. написана максимально простым языком, чтобы человек полностью с нуля смог без каких-либо проблем освоить язык SQL.
Как результат, у меня получилась книга – «SQL код»
После прочтения этой книги Вы научитесь писать универсальные SQL запросы, которые будут выполняться во всех популярных СУБД: и в MySQL, и в PosrgreSQL, и в Microsoft SQL Server, тем самым Вам не нужно будет задумываться о том, с какой системой Вам предстоит работать.
Именно это и нужно большинству программистов, которые разрабатывают сайты и небольшие клиентские приложения, т.е. им нужны базовые знания языка SQL, чтобы уметь взаимодействовать с базами данных.
Если в каких-то стандартных возможностях языка SQL есть отклонения в той или иной СУБД, то все это в книге подробно комментируется и показывается реализация для нескольких популярных СУБД.
Для кого предназначена эта книга
Книга в первую очередь предназначена для начинающих программистов, которые хотят освоить язык SQL как стандарт, чтобы с ним можно было работать во всех популярных системах управления базами данных.
Разработчикам, которым требуется работать с базами данных
IT специалистам, которые работают с несколькими СУБД
Web-программистам
Аналитикам, которым требуется язык SQL
Тем, кто работает с MySQL, PostgreSQL или Microsoft SQL Server
Всем, кто хочет изучить SQL как стандарт
Чему Вы научитесь
Создавать базы данных на SQL
Создавать, изменять и удалять таблицы на SQL
Добавлять, изменять и удалять данные в таблицах на SQL
Писать SQL запросы SELECT на выборку данных
Строить сложные составные условия на выборку данных
Писать многотабличные SQL запросы
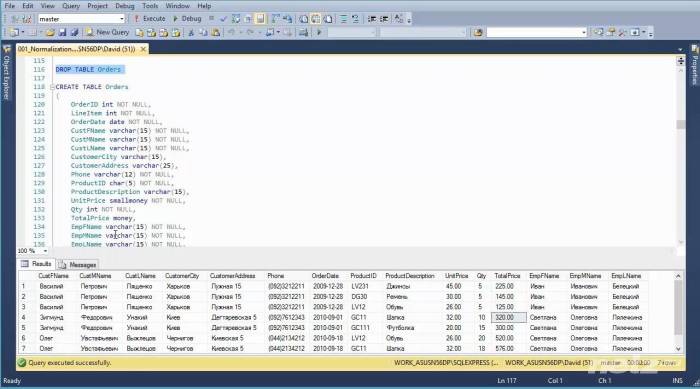
Группировать данные и осуществлять фильтрацию сгруппированных данных
Сортировать данные и использовать фильтры для ограничения строк
Создавать, изменять и удалять представления
Использовать встроенные функции
Создавать и удалять индексы
Создавать и удалять ограничения
Использовать CTE, вложенные запросы и конструктор табличных значений
Краткое содержание книги
Предисловие
Введение
Глава 1 – Введение в базы данных
Глава 2 – Системы управления базами данных
Глава 3 – Знакомство с SQL
Глава 4 – Таблицы
Глава 5 – Модификация данных
Глава 6 – Выборка данных
Глава 7 – Представления
Глава 8 – Функции
Глава 9 – Индексы
Глава 10 – Ограничения
Глава 11 – Транзакции
Заключение
Виталий Трунин
Основатель проектов Self-Learning. ru и Info-Comp.ru. Автор курсов по SQL и T-SQL, а также автор 5 книг и более чем 700 статей на тему компьютеров, программирования и баз данных.
ru и Info-Comp.ru. Автор курсов по SQL и T-SQL, а также автор 5 книг и более чем 700 статей на тему компьютеров, программирования и баз данных.
Стоимость книги 430 ₽
Перейти на страницу книги
Купить книгу
Надеюсь, данная книга Вам понравится и будет максимально полезна!
Желаю успехов в изучении языка SQL, искренне Ваш Виталий Трунин!
Подойдёт ли мне книга, если я даже не знаю, что такое SQL?
В каком формате книга?
Можно ли приобрести печатный вариант книги?
Подойдёт ли мне данная книга, если я буду работать с MySQL?
В каких СУБД тестировались SQL инструкции, рассматриваемые в книге?
Как я получу книгу?
Какие способы оплаты есть?
Источник – Официальный пресс-релиз на сайте Self-Learning.ru.
Иллюстрированный самоучитель по SQL для начинающих [страница — 1] | Самоучители по программированию
Добро пожаловать в область разработки баз данных, выполняемой с помощью стандартного языка запросов SQL.
 В системах управления базами данных (СУБД) имеется много инструментов, работающих на самых разных аппаратных платформах.
В системах управления базами данных (СУБД) имеется много инструментов, работающих на самых разных аппаратных платформах.В этой главе… | Организация информации | Что такое база данных | Что такое СУБД | Сравнение моделей баз данных | Что такое реляционная база данных
В этой главе… | Что такое SQL | Заблуждения, связанные с SQL | Взгляд на разные стандарты SQL | Знакомство со стандартными командами и зарезервированными словами SQL | Представление чисел, символов, дат, времени и других типов данных | Неопределенные значения и ограничения
В этой главе… | Создание баз данных | Обработка данных | Защита баз данных | SQL – это язык, специально разработанный, чтобы создавать и поддерживать данные в реляционных базах. И хотя компании, поставляющие системы для управления такими базами, предлагают свои реализации SQL, развитие самого языка определяется и контролируется стандартом ISO/ANSI.
В этой главе… | Создание, изменение и удаление таблицы из базы данных с помощью инструмента RAD.
 | Создание, изменение и удаление таблицы из базы данных с помощью SQL. | Перенос базы данных в другую СУБД.
| Создание, изменение и удаление таблицы из базы данных с помощью SQL. | Перенос базы данных в другую СУБД.В этой главе… | Что должно быть в базе данных | Определение отношений между элементами базы данных | Связывание таблиц с помощью ключей | Проектирование целостности данных | Нормализация базы данных | В этой главе будет представлен пример создания многотабличной базы данных.
В этой главе… | Работа с данными | Получение из таблицы нужных данных | Вывод информации, выбранной из одной или множества таблиц | Обновление информации, находящейся в таблицах и представлениях | Добавление новой строки в таблицу
В этой главе… | Использование переменных для уменьшения избыточного кодирования | Получение часто запрашиваемой информации, находящейся в поле таблицы базы данных | Комбинирование простых значений для создания составных выражений | В этой книге постоянно подчеркивается, насколько важной для поддержания целостности базы данных является структура этой базы.

В этой главе… | Использование условных выражений case | Преобразование элемента данных из одного типа данных в другой | Экономия времени ввода данных с помощью выражений со значением типа запись | В главе 2 SQL был назван подъязыком данных.
В этой главе… | Указание требуемых таблиц | Отделение нужных строк от всех остальных | Создание эффективных предложений where | Как работать со значениями null | Создание составных выражений с логическими связками | Группирование вывода результата запроса по столбцу
В этой главе… | Объединение таблиц, имеющих похожую структуру | Объединение таблиц, имеющих разную структуру | Получение нужных данных из множества таблиц | SQL – это язык запросов, используемый в реляционных базах данных.
В этой главе… | Извлечение данных из множества таблиц с помощью одного оператора SQL | Поиск элементов данных путем сравнения значения из одной таблицы с набором значений из другой | Поиск элементов данных путем сравнения значения из одной таблицы с выбранным с помощью оператора select единственным значением из другой
В этой главе… | Управление рекурсией | Как определять рекурсивные запросы | Способы применения рекурсивных запросов | SQL-92 и более ранние версии часто критиковали за отсутствие реализации рекурсивной обработки.

В этой главе… | Управление доступом к таблицам базы данных | Принятие решения о предоставлении доступа | Предоставление полномочий доступа | Аннулирование полномочий доступа | Предотвращение попыток несанкционированного доступа
В этой главе… | Как избежать повреждения базы данных | Проблемы, вызванные одновременными операциями | Решение этих проблем с помощью механизмов SQL | Задание требуемого уровня защиты с помощью команды set transaction
В этой главе… | SQL в приложении | Совместное использование SQL с процедурными языками | Как избежать несовместимости | Код SQL, встроенный в процедурный код | Вызов модулей SQL из процедурного кода | Вызов SQL из RAD-инструмента | В предыдущих главах мы в основном рассматривали SQL-команды в отдельности, т.е. формулировалась задача обработки данных, и под нее создавался SQL-запрос.
В этой главе… | Определение ODBC | Описание частей ODBC | Использование ODBC в среде клиент/сервер | Использование ODBC в Internet | Использование ODBC в локальных сетях | Использование JDBC | С каждым годом компьютеры одной организации или нескольких различных организаций все чаще соединяются друг с другом.
 Поэтому возникает необходимость в налаживании совместного доступа к базам данных по сети.
Поэтому возникает необходимость в налаживании совместного доступа к базам данных по сети.В этой главе… | Использование SQL с XML | XML, базы данных и Internet | Одной из самых существенных новых функциональных возможностей языка SQL:2003 является поддержка файлов XML (extensible Markup Language – расширяемый язык разметки), которые все больше становятся универсальным стандартом обмена данными между разнородными платформами.
В этой главе… | Определение области действия курсора в операторе declare | Открытие курсора | Построчная выборка данных | Закрытие курсора | SQL отличается от большинства наиболее популярных языков программирования тем, что в нем операции производятся одновременно с данными всех строк таблицы, в то время как процедурные языки обрабатывают данные построчно.
В этой главе… | Сложные команды, атомарность, курсоры, переменные и состояния | Управляющие структуры | Создание циклов | Использование хранимых процедур и функций | Предоставление полномочий на выполнение
В этой главе… | Подача сигнала об ошибке | Переход к коду обработки ошибок | Ограничение, вызвавшее ошибку | Ошибка какой СУБД произошла | Правда, было бы замечательно, чтобы каждое написанное вами приложение все время работало прекрасно? Еще бы!
В этой главе… | Мнение, что клиенты знают, чего хотят | Игнорирование масштаба проекта | Учет только технических факторов | Отсутствие обратной связи с пользователями | Применение только своих любимых сред разработки | Использование только своих любимых системных архитектур
В этой главе… | Проверка структуры базы данных | Использование тестовых баз данных | Тщательная проверка любого запроса с оператором join | Проверка запросов с подвыборками | Использование предложения group by вместе с итоговыми функциями | Внимательное отношение к ограничениям из предложения group by
Зарезервированные слова SQL:2003.
 | ABS | COLLATE | DETERMINISTIC | ALL | COLUMN | DISCONNECT | ALLOCATE | COMMIT | DISTINCT | ALTER | CONDITION | DOUBLE | AND | CONNECT | DROP | ANY | CONSTRAINT | DYNAMIC | ARE | CONVERT | EACH | ARRAY | CORR | ELEMENT | AS | CORRESPONDING | ELSE
| ABS | COLLATE | DETERMINISTIC | ALL | COLUMN | DISCONNECT | ALLOCATE | COMMIT | DISTINCT | ALTER | CONDITION | DOUBLE | AND | CONNECT | DROP | ANY | CONSTRAINT | DYNAMIC | ARE | CONVERT | EACH | ARRAY | CORR | ELEMENT | AS | CORRESPONDING | ELSEA | API (Application Programmer’s Interface – интерфейс прикладного программиста). Стандартное средство взаимодействия приложения и базы данных или другого системного ресурса. | C | CODASYL DBTG. Сетевая модель базы данных.
Полное руководство по представлениям SQL для начинающих
Резюме : это руководство знакомит вас с концепцией представлений SQL и показывает, как управлять представлением в базе данных.
Знакомство с представлениями SQL
Реляционная база данных состоит из нескольких связанных таблиц, например, сотрудников, отделов, должностей и т. д. Если вы хотите просмотреть данные этих таблиц, используйте оператор SELECT с предложениями JOIN или UNION.
SQL предоставляет вам еще один способ просмотра данных с помощью представлений.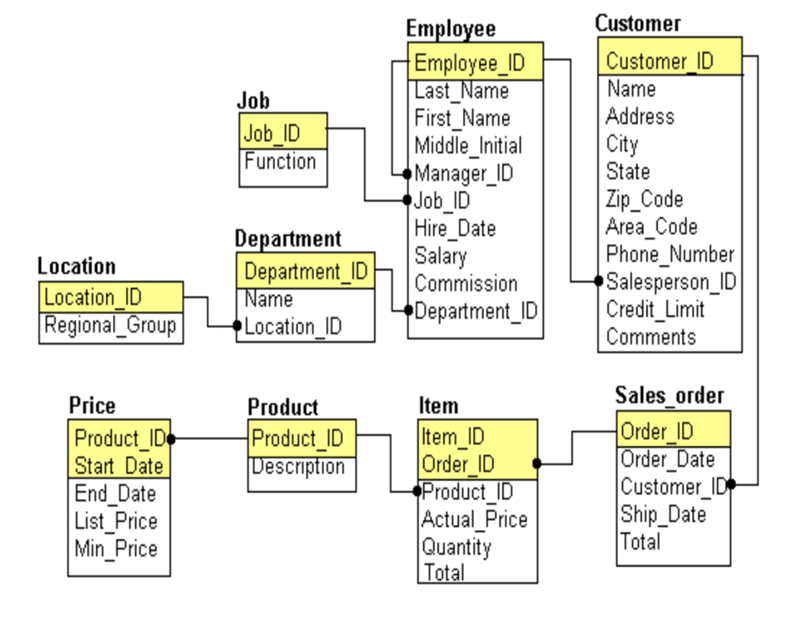 Представление похоже на виртуальную таблицу, созданную в результате выполнения запроса. Система управления реляционными базами данных (RDBMS) хранит представление в виде именованного
Представление похоже на виртуальную таблицу, созданную в результате выполнения запроса. Система управления реляционными базами данных (RDBMS) хранит представление в виде именованного SELECT в каталоге базы данных.
Всякий раз, когда вы вводите оператор SELECT , содержащий имя представления, СУРБД выполняет определяющий представление запрос для создания виртуальной таблицы. Затем эта виртуальная таблица используется в качестве исходной таблицы запроса.
Зачем нужно использовать представления
Представления позволяют хранить сложные запросы в базе данных. Например, вместо того, чтобы выполнять сложный SQL-запрос каждый раз, когда вы хотите просмотреть данные, вам просто нужно выполнить простой запрос следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ список_столбцов ОТ view_name;
Представления помогают упаковывать данные для определенной группы пользователей. Например, вы можете создать представление данных о зарплате для сотрудников финансового отдела.
Например, вы можете создать представление данных о зарплате для сотрудников финансового отдела.
Представления помогают поддерживать безопасность базы данных. Вместо предоставления пользователям доступа к таблицам базы данных вы создаете представление для отображения только необходимых данных и предоставляете пользователям доступ к представлению.
Создание представлений SQL
Чтобы создать представление, используйте оператор CREATE VIEW следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
CREATE VIEW имя_представления В КАЧЕСТВЕ Оператор SELECT
Сначала укажите имя представления после предложения CREATE VIEW .
Во-вторых, создайте оператор SELECT для запроса данных из нескольких таблиц.
Например, следующий оператор создает представление контактов сотрудников на основе данных сотрудников и отделов столов.
Язык кода: SQL (язык структурированных запросов) (sql)
СОЗДАТЬ ПРОСМОТР employee_contacts КАК ВЫБРАТЬ имя_имя, фамилия_имя, электронная почта, номер_телефона, название отдела ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.department_id = e.department_id ЗАКАЗАТЬ ПО first_name;
По умолчанию имена столбцов представления совпадают с именами столбцов, указанных в Оператор SELECT . Если вы хотите переименовать столбцы в представлении, вы включаете новые имена столбцов после предложения CREATE VIEW следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
CREATE VIEW view_name(new_column_list) В КАЧЕСТВЕ SELECT-оператор;
Например, следующая инструкция создает представление, имена столбцов которого не совпадают с именами столбцов базовых таблиц.
Язык кода: SQL (язык структурированных запросов) (sql)
СОЗДАТЬ ПРОСМОТР платежной ведомости (имя, фамилия, работа, компенсация) КАК ВЫБРАТЬ имя_имя, фамилия_имя, должность_название, зарплата ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ задания j ON j.job_id= e.job_id ЗАКАЗАТЬ ПО first_name;
Запрос данных из представлений
Запрос данных из представлений аналогичен запросу данных из таблиц. Следующий оператор выбирает данные из представления employee_contacts .
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ * ИЗ сотрудники_контакты;
Конечно, вы можете применить фильтрацию или группировку следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ работа, МИН(компенсация), МАКС(компенсация), СРЕДНЕЕ (компенсация) ИЗ начисление заработной платы КУДА работа КАК 'A%' СГРУППИРОВАТЬ ПО РАБОТЕ;
Изменение представлений SQL
Чтобы изменить представление, добавив новые столбцы в представление или удалив столбцы из представления, вы используете тот же CREATE OR REPLACE Заявление VIEW .
Язык кода: SQL (язык структурированных запросов) (sql)
СОЗДАТЬ ИЛИ ЗАМЕНИТЬ view_name КАК SELECT-оператор;
Оператор создает представление, если оно не существует, или изменяет текущее представление, если представление уже существует.
Например, следующая инструкция изменяет представление платежной ведомости, добавляя столбец отдела и переименовывая столбец компенсации в столбец зарплаты.
Язык кода: SQL (язык структурированных запросов) (sql)
СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОСМОТР платежной ведомости (имя, фамилия, должность, отдел, зарплата) КАК ВЫБРАТЬ имя_имя, фамилия_имя, должность_название, название отдела, зарплата ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ задания j ON j.job_id = e.job_id ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.department_id = e.department_id ЗАКАЗАТЬ ПО first_name;
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT * ИЗ начисление заработной платы;
Удаление представлений SQL
Чтобы удалить представление из базы данных, используйте оператор DROP VIEW :
Язык кода: SQL (язык структурированных запросов) (sql)
имя представления DROP;
The DROP VIEW 9Оператор 0012 удаляет только представление, а не базовые таблицы.
Например, чтобы удалить представление платежной ведомости, используйте следующую инструкцию:
Язык кода: SQL (язык структурированных запросов) (sql)
DROP VIEW payroll;
В этом руководстве вы узнали о представлениях SQL и их практическом использовании. Теперь вы должны знать, что такое представления и как создавать, изменять и удалять представления в базе данных.
Учебное пособие по SQL для начинающих — изучите основы SQL
Чему вы научитесь в этом уроке? Это учебное пособие по SQL для начинающих представляет собой полный набор для изучения SQL в Интернете. Из этого руководства вы получите четкое представление об основах SQL, о том, что такое язык структурированных запросов и как развертывать SQL для работы с реляционной базой данных.
Итак, язык структурированных запросов — это язык, который используется для работы с реляционными базами данных. Некоторые из основных способов использования SQL в сочетании с реляционной базой данных предназначены для хранения, извлечения и управления данными, хранящимися в реляционной базе данных.
Посетите блог Intellipaat, чтобы получить полное представление о методах оптимизации SQL !
Вот список тем, если вы хотите сразу перейти к конкретной:
- Что такое SQL?
- Зачем нужен SQL?
- Почему так широко используется программирование на SQL?
- Особенности SQL
- Приложения SQL
- Процесс SQL
- Синтаксис SQL
- Что можно делать с SQL?
- Фильтрация данных SQL
- Почему вам следует изучать SQL онлайн?
- Агрегированные функции
- Рекомендуемая аудитория
- Предпосылки
Учебное пособие по SQL для начинающих Учебное пособие по SQL для начинающих
Что такое SQL?
Язык структурированных запросов, или SQL, — это язык, который помогает управлять базами данных. Он помогает создавать данные, работать с ними и извлекать их. Это также стандартный язык, используемый в системах реляционных баз данных. Различные системы реляционных баз данных, такие как MySQL, Sybase, Oracle, MS Access, Postgres, Infomix, SQL Server и т. д., используют SQL в качестве базового языка.
Он помогает создавать данные, работать с ними и извлекать их. Это также стандартный язык, используемый в системах реляционных баз данных. Различные системы реляционных баз данных, такие как MySQL, Sybase, Oracle, MS Access, Postgres, Infomix, SQL Server и т. д., используют SQL в качестве базового языка.
Чтобы узнать, что такое SQL, сначала давайте сравним SQL с NoSQL в таблице ниже:
| Критерии сравнения | SQL | NoSQL |
| Тип базы данных | Родственный | Нереляционный |
| Как хранятся данные? | Структурированные данные в таблицах | Неструктурированные данные в файлах JSON |
| Пригодность для систем OLTP | Отлично | Средний |
| Соответствие базе данных | свойства КИСЛОТЫ | Теорема CAP |
Языком для связи с реляционной базой данных является SQL или язык структурированных запросов. Программирование на языке SQL помогает управлять реляционной базой данных и извлекать из нее информацию.
Программирование на языке SQL помогает управлять реляционной базой данных и извлекать из нее информацию.
Некоторые из операций, которые включает SQL, — это создание базы данных, выборка, изменение, обновление и удаление строк, а также сохранение, обработка и извлечение данных в реляционной базе данных. Программирование SQL — это стандартный язык ANSI, но также используется множество версий SQL.
Зачем нужен SQL?
SQL требуется, потому что он предлагает следующие преимущества для пользователей:
- SQL помогает в создании новых баз данных, представлений и таблиц.
- Используется для вставки, обновления, удаления и извлечения записей данных в базе данных.
- Позволяет пользователям взаимодействовать с данными, хранящимися в системах управления реляционными базами данных.
- SQL требуется для создания представлений, хранимых процедур, функций в базе данных.
Почему так широко используется программирование на SQL?
Программирование на языке структурированных запросов так широко используется по следующим причинам.
- SQL позволяет получить доступ к любым данным в реляционной базе данных
- Вы можете описать данные в базе данных с помощью SQL
- Используя SQL, вы можете манипулировать данными с реляционной базой данных
- SQL может быть встроен в другие языки с помощью модулей и библиотек SQL
- SQL позволяет легко создавать и удалять базы данных и таблицы
- SQL позволяет создавать представления, функции и хранимые процедуры в базах данных
- Используя SQL, вы можете устанавливать разрешения для процедур, таблиц и представлений.
Хотите пройти собеседование по SQL? Лучшие вопросы Intellipaat для интервью по SQL предназначены только для вас!
Возможности SQL
Здесь, в этом разделе руководства по MS SQL для начинающих, мы перечисляем некоторые основные возможности SQL, которые делают его настолько универсальным, когда речь идет об управлении реляционными базами данных.
- SQL — очень простой и легкий для изучения язык.
- SQL универсален, поскольку работает с системами баз данных Oracle, IBM, Microsoft и т. д.
- SQL — это стандартный язык ANSI и ISO для создания баз данных и управления ими.
- SQL имеет четко определенную структуру, поскольку использует давно установленные стандарты .
- SQL очень быстро и эффективно извлекает большие объемы данных.
- SQL позволяет вам управлять базами данных, не зная большого количества кода.
Приложения SQL
В этом разделе учебника Advanced SQL мы узнаем о приложениях SQL, которые делают его столь важным в мире, управляемом данными, где управление огромными базами данных является нормой дня.
- SQL используется в качестве языка определения данных (DDL), что означает, что вы можете самостоятельно создать базу данных, определить ее структуру, использовать ее, а затем отказаться от нее, когда вы закончите с ней
- Он также используется в качестве языка манипулирования данными (DML), что означает, что вы можете использовать его для обслуживания уже существующей базы данных.
 SQL — это мощный язык для ввода данных, изменения данных и извлечения данных из базы данных 9.0210
SQL — это мощный язык для ввода данных, изменения данных и извлечения данных из базы данных 9.0210 - Он также развернут как язык управления данными (DCL), который указывает, как вы можете защитить свою базу данных от повреждения и неправильного использования.
- Он широко используется в качестве языка клиент/сервер для соединения внешнего интерфейса с внутренним, таким образом поддерживая архитектуру клиент/сервер
- Его также можно использовать в трехуровневой архитектуре клиента, сервера приложений и базы данных, которая определяет архитектуру Интернета.
Процесс SQL
Когда вы запускаете команду SQL для любой СУБД, система определяет лучший способ выполнить ваш запрос, а механизм SQL определяет, как его интерпретировать.
Эта процедура состоит из нескольких компонентов. Диспетчер запросов, механизмы оптимизации, классический механизм запросов и механизм запросов SQL — вот некоторые из этих элементов. Запросы, отличные от SQL, обрабатываются классическим механизмом запросов, но логические файлы не обрабатываются механизмом запросов SQL.
Запросы, отличные от SQL, обрабатываются классическим механизмом запросов, но логические файлы не обрабатываются механизмом запросов SQL.
Синтаксис SQL
Синтаксис представляет собой набор правил и указаний, которых придерживается SQL. Поскольку SQL нечувствителен к регистру, термины SELECT и select в операторах SQL имеют тот же смысл. MySQL, с другой стороны, различает имена таблиц. Если вы используете MySQL, вам нужно указать имена таблиц точно так, как они появляются в базе данных.
Различные ключевые слова SQL:
- INSERT
- ОБНОВЛЕНИЕ
- УДАЛИТЬ
- ИЗМЕНИТЬ
- КАПЛЯ
- СОЗДАТЬ
- ЕГЭ и т. д.
Что можно делать с SQL?
С помощью SQL мы можем создавать, обновлять, реорганизовывать и изменять данные. Мы можем решать проблемы с электронными таблицами, например, в Microsoft Excel мы можем компилировать много данных, потому что SQL предназначен для компиляции и обработки данных в гораздо больших количествах. С помощью SQL Server мы можем преобразовывать необработанные данные в осмысленные идеи, а также выполнять операции бизнес-аналитики. Интеграция данных и операции ETL легко выполняются с помощью SQL.
С помощью SQL Server мы можем преобразовывать необработанные данные в осмысленные идеи, а также выполнять операции бизнес-аналитики. Интеграция данных и операции ETL легко выполняются с помощью SQL.
Фильтрация данных SQL
SQL имеет возможность фильтровать данные в базе данных, то есть мы можем выбирать только необходимые записи из набора данных. Фильтр представляет собой предложение SQL WHERE, которое указывает набор сравнений, которые должны быть истинными, чтобы элемент данных возвращался для базы данных SQL и внутренних типов данных. Обычно эти различия делаются между именами полей и их значениями.
Остались вопросы? Приходите в Intellipaat's SQL Community развейте все свои сомнения и преуспейте в своей карьере!
Получите 100% повышение!
Осваивайте самые востребованные навыки прямо сейчас!
Зачем изучать SQL онлайн?
Сегодня, вне зависимости от систем реляционных баз данных крупных корпораций, таких как Oracle, IBM, Microsoft и других, их объединяет только язык структурированных запросов или SQL.
Итак, если вы освоите SQL в Интернете, вы сможете сделать очень широкую карьеру, охватывающую множество ролей и обязанностей. Кроме того, если вы изучаете SQL, то это также важно для карьеры в области науки о данных, поскольку специалисту по данным также придется иметь дело с реляционными базами данных и запрашивать их, используя стандартный язык SQL.
Агрегирующие функции
Агрегирующая функция в управлении базами данных — это функция, которая группирует значения нескольких строк в качестве входных данных для определенных параметров, чтобы создать одно значение, имеющее более важное значение.
Различные агрегатные функции
COUNT – подсчитывается количество элементов в данной группе
SUM – вычисляется общее количество данного атрибута/выражения в указанной категории
AVG – вычисляется среднее значение данного атрибута/выражения в фиксированной категории
MIN — находит наименьшее значение в наборе чисел.
MAX — возвращает наибольшее значение в определенной группе. Разработчики программного обеспечения, администраторы баз данных, архитекторы и менеджеры могут воспользоваться этим бесплатным учебным пособием в качестве первого шага к изучению SQL и преуспеть в своей карьере.
Предварительные условияНет предварительных условий для изучения SQL с помощью этого SQL для начинающих. Если у вас есть базовые знания компьютерных языков и баз данных, это будет полезно.
Часто задаваемые вопросы
Как быстро выучить SQL?
Ответ на этот вопрос полностью зависит от знаний учащегося в области программирования. Если учащийся знаком с базовыми навыками программирования, он может освоить основы SQL за несколько дней. Однако, чтобы овладеть продвинутыми навыками SQL, учащиеся должны пройти онлайн-обучение SQL под руководством инструктора. Это обучение длится до 4 недель.
Как бесплатно попрактиковаться в SQL?
Этот учебник по базе данных SQL поможет вам всесторонне понять концепции SQL. Вы также можете обратиться к нашему бесплатному видеоруководству по SQL на YouTube.
Вы также можете обратиться к нашему бесплатному видеоруководству по SQL на YouTube.
Легко ли новичкам выучить SQL?
Да, с помощью этого руководства легко выучить SQL, поскольку сам по себе он не является языком программирования; скорее это язык запросов. Большинство синтаксисов SQL похожи на английский язык, и поэтому почти каждый, кто понимает английский, может с легкостью писать запросы SQL.
Как я могу изучать SQL дома?
Вы можете изучить основы SQL, обратившись к этому учебному пособию по основам SQL или бесплатным видеоруководствам по SQL на YouTube или записавшись к нам на онлайн-обучение SQL.
Почему SQL такой мощный?
SQL является мощным, поскольку это основной язык, который используется для управления большими базами данных в организациях. Соединения в SQL позволяют пользователям получать данные из нескольких источников и сравнивать их для внесения необходимых изменений. SQL позволяет персоналу баз данных управлять базами данных с минимальными усилиями.
Почему используется SQL?
Основные приложения SQL включают в себя написание сценариев интеграции данных, настройку и выполнение аналитических запросов, извлечение подмножеств информации в базе данных для приложений аналитики и обработки транзакций, а также добавление, обновление и удаление строк и столбцов данных в базе данных.
Стоит ли изучать SQL?
SQL — самый популярный язык баз данных в мире информационных технологий, поэтому его стоит изучить. С обширными приложениями в различных вертикалях SQL может помочь вам построить прибыльную карьеру в области управления базами данных.
Сколько существует типов SQL?
Существует несколько типов операторов SQL. Это:
- Язык определения данных (DDL)
- Язык обработки данных (DML)
- Язык управления данными (DCL)
- Заявления об управлении транзакциями (TCS)
- Операторы управления сеансом (SCS)
Расписание курсов
Основы SQL — Практическое руководство по SQL для начинающих Анализ совместного использования велосипедов
1 февраля 2021 г.
В этом руководстве мы будем работать с набором данных службы велопроката Hubway, который включает данные о более чем 1,5 миллионах поездок, совершенных с помощью этой службы.
Мы начнем с того, что немного рассмотрим базы данных, что они из себя представляют и почему мы их используем, а затем начнем писать собственные запросы на SQL.
Если вы хотите продолжить, вы можете загрузить файл hubway.db здесь (130 МБ).
Основы SQL: реляционные базы данных
Реляционная база данных — это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию более чем в одной таблице одновременно.
Легче понять, как это работает, на примере. Представьте, что вы представляете компанию и хотите отслеживать информацию о продажах. Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер отслеживания доставки, имя клиента, адрес клиента и номер телефона клиента.
Эта настройка отлично подойдет для отслеживания информации, с которой вам нужно начать, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона сохраняются в нескольких строках вашей электронной таблицы.
По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снижать эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами целостности данных. Например, нет гарантии, что каждое поле будет заполнено данными правильного типа или что имя и адрес будут каждый раз вводиться одинаково.
При использовании реляционной базы данных, подобной показанной на приведенной выше диаграмме, вы избегаете всех этих проблем. Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживали. Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер для отслеживания, и вместо отдельного поля для каждого элемента данных клиента в ней будет столбец для идентификатора клиента.
Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер для отслеживания, и вместо отдельного поля для каждого элемента данных клиента в ней будет столбец для идентификатора клиента.
Это позволяет нам получать всю информацию о клиенте для любого данного заказа, но нам нужно сохранить ее только один раз в нашей базе данных, а не выводить ее снова для каждого отдельного заказа.
Наш набор данных
Начнем с нашей базы данных. В базе данных есть две таблицы: поездок и станций . Для начала мы просто посмотрим на таблицу trips . Он содержит следующие столбцы:
-
id— Уникальное целое число, которое служит ссылкой для каждой поездки -
duration— Продолжительность поездки, измеренная в секундах -
start_date— Дата и время начала поездки -
start_station— Целое число, соответствующее столбцуidв таблицеstationдля станции, с которой началось путешествие . -
end_date— Дата и время окончания поездки -
end_station— Идентификатор станции, на которой закончилась поездка -
bike_number— Уникальный идентификатор Hubway для велосипеда, использованного в поездке -
sub_type— Тип подписки пользователя.«Зарегистрированный»для пользователей с членством,«Обычный»для пользователей без членства -
zip_code— Почтовый индекс пользователя (доступно только для зарегистрированных пользователей) -
birth_date— Год рождения пользователя (доступно только для зарегистрированных пользователей) -
пол— Пол пользователя (доступно только для зарегистрированных пользователей)
Наш анализ
С этой информацией и командами SQL, которые мы вскоре изучим, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста:
- Какова была продолжительность самой длинной поездки?
- Сколько поездок совершили «зарегистрированные» пользователи?
- Какова средняя продолжительность поездки?
- Зарегистрированные или случайные пользователи совершают длительные поездки?
- На каком велосипеде совершалось больше всего поездок?
- Какова средняя продолжительность поездок пользователей старше 30 лет?
Команды SQL, которые мы будем использовать для ответа на эти вопросы:
-
ВЫБЕРИТЕ -
ГДЕ -
ПРЕДЕЛ -
ЗАКАЗАТЬ -
ГРУППА ПО -
И -
ИЛИ -
МИН -
МАКС -
АВГ -
СУММА -
СЧЕТ
Установка и настройка
Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3. SQLite входит в состав Python, начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет и SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
SQLite входит в состав Python, начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет и SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фрейм данных Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки этого руководства.
В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код, чтобы открыть базу данных:
~$ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15:17:14Введите «.help» для использования подсказок.sqlite>
Отсюда мы можем просто ввести запрос, который хотим запустить, и мы увидим данные, возвращенные в нашем окне терминала.
Альтернативой использованию терминала является подключение к базе данных SQLite через Python. Это позволило бы нам использовать блокнот Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице.
Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде форматированного фрейма данных:
импорт sqlite3
span>импортировать панд как pd
б = sqlite3.connect('hub.db')
span>def run_query (запрос):
вернуть pd.read_sql_query (запрос, БД) Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» станет отличным стартом.
ВЫБЕРИТЕ
Первая команда, с которой мы будем работать, это SELECT . SELECT будет основой почти каждого написанного нами запроса — он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (разделенные запятыми) или использовать подстановочный знак
Мы можем указать столбцы по имени (разделенные запятыми) или использовать подстановочный знак * для возврата каждого столбца в таблице.
В дополнение к столбцам, которые мы хотим получить, мы также должны сообщить базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово FROM , за которым следует имя таблицы. Например, если мы хотим увидеть start_date и bike_number для каждой поездки в таблице trips , мы можем использовать следующий запрос:
ВЫБЕРИТЕ start_date, bike_number ИЗ поездок;
В этом примере мы начали с команды SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла для нас некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number . Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .
Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой ( ; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку.
ПРЕДЕЛ
Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы к нашей базе данных Hubway, — это LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть.
Запрос SELECT , который мы рассмотрели в предыдущем разделе, возвращает запрошенную информацию для каждой строки в таблице trips , но иногда это может означать большой объем данных. Мы можем не хотеть всего этого. Если бы вместо этого мы хотели увидеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБЕРИТЕ start_date, bike_number ИЗ поездок LIMIT 5;
Мы просто добавили команду LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть. В этом примере мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
В этом примере мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
Мы будем часто использовать LIMIT в наших запросах к базе данных Hubway в этом руководстве — таблица trips содержит более 1,5 миллиона строк данных, и нам, конечно же, не нужно отображать их все!
Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных. Взгляните на следующий пример:
запрос = 'ВЫБЕРИТЕ * ИЗ ОГРАНИЧЕНИЯ 5 поездок;' un_query(запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9 | 28-07-2011 10:12:00 | 23 | 28-07-2011 10:12:00 | 23 | B00468 | Зарегистрировано | ‘97217 | 1976. 0 0 | Мужчина |
| 1 | 2 | 220 | 28-07-2011 10:21:00 | 23 | 28-07-2011 10:25:00 | 23 | В00554 | Зарегистрировано | ‘02215 | 1966.0 | Мужчина |
| 2 | 3 | 56 | 28-07-2011 10:33:00 | 23 | 2011-07-28 10:34:00 | 23 | B00456 | Зарегистрировано | ‘02108 | 1943.0 | Мужчина |
| 3 | 4 | 64 | 28-07-2011 10:35:00 | 23 | 2011-07-28 10:36:00 | 23 | В00554 | Зарегистрировано | ‘02116 | 1981.0 | Женщина |
| 4 | 5 | 12 | 28-07-2011 10:37:00 | 23 | 28-07-2011 10:37:00 | 23 | В00554 | Зарегистрировано | ‘97214 | 1983,0 | Женщина |
Этот запрос использует * в качестве подстановочного знака вместо указания возвращаемых столбцов. Это означает, что команда
Это означает, что команда SELECT предоставила нам каждый столбец в таблице trips . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы.
Вы часто будете видеть, что люди пишут ключевые слова команд в своих запросах с большой буквы (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений. Такое использование заглавных букв облегчает чтение кода, но фактически никак не влияет на функцию кода. Если вы предпочитаете писать свои запросы с помощью команд нижнего регистра, запросы все равно будут выполняться правильно.
Наш предыдущий пример возвратил каждый столбец в таблице trips . Если бы нас интересовали только продолжительность и столбцы start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
запрос = 'ВЫБЕРИТЕ продолжительность, start_date FROM trips LIMIT 5' un_query (запрос)
| продолжительность | start_date | |
|---|---|---|
| 0 | 9 | 28-07-2011 10:12:00 |
| 1 | 220 | 28-07-2011 10:21:00 |
| 2 | 56 | 28-07-2011 10:33:00 |
| 3 | 64 | 28-07-2011 10:35:00 |
| 4 | 12 | 28-07-2011 10:37:00 |
ЗАКАЗАТЬ
Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, это ORDER BY . Эта команда позволяет нам сортировать базу данных по заданному столбцу.
Эта команда позволяет нам сортировать базу данных по заданному столбцу.
Чтобы использовать его, мы просто указываем имя столбца, по которому мы хотим выполнить сортировку. По умолчанию ORDER BY сортирует по возрастанию. Если мы хотим указать порядок сортировки базы данных, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания.
Например, если мы хотим отсортировать таблицу поездок от самой короткой продолжительности до самой длинной, мы можем добавить следующую строку в наш запрос:
ПОРЯДОК ПО длительности ASC
С SELECT , LIMIT и ORDER BY команд в нашем репертуаре, теперь мы можем попытаться ответить на наш первый вопрос: Какова была продолжительность самого длинного путешествия?
Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам потребуются для решения каждой части.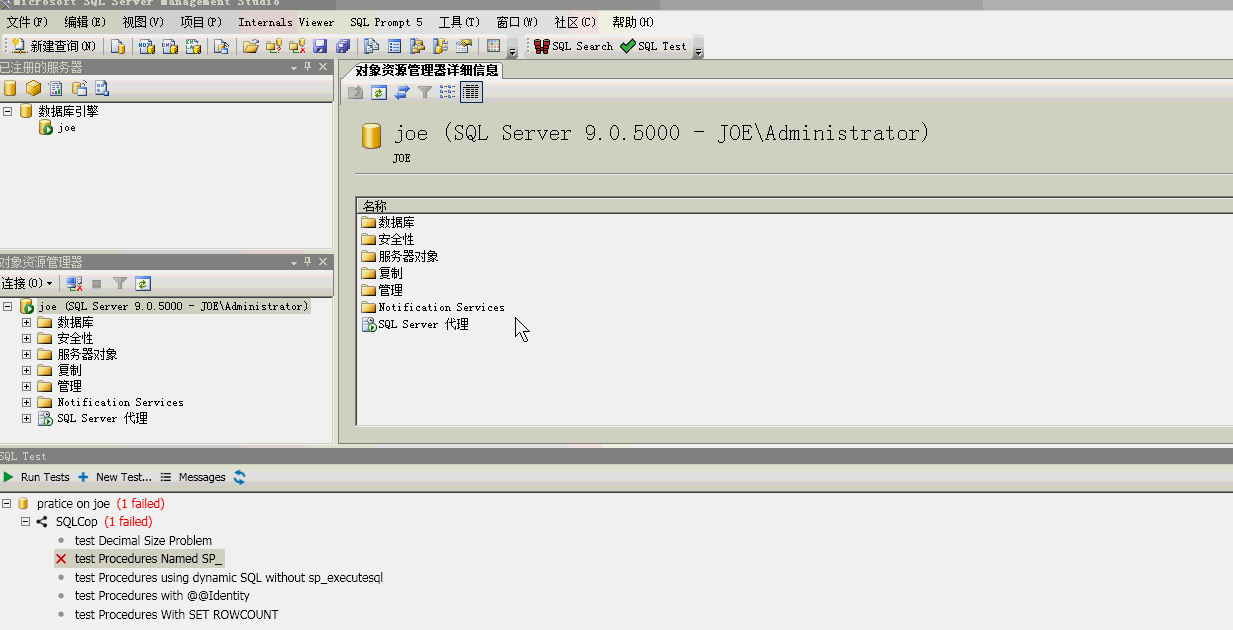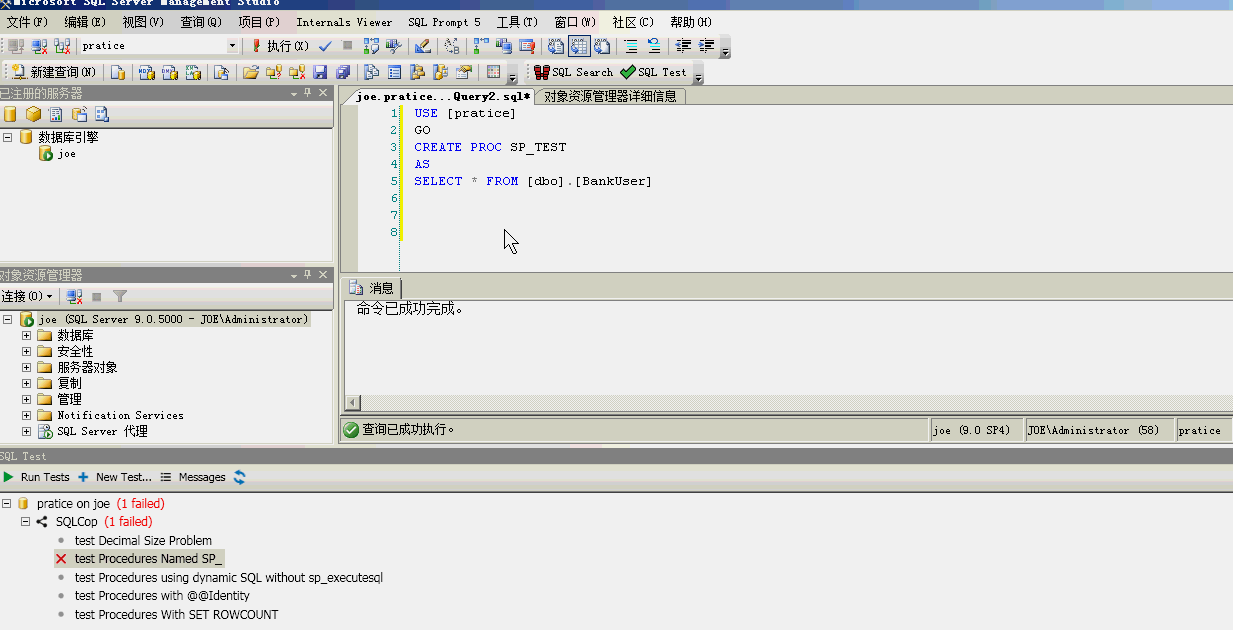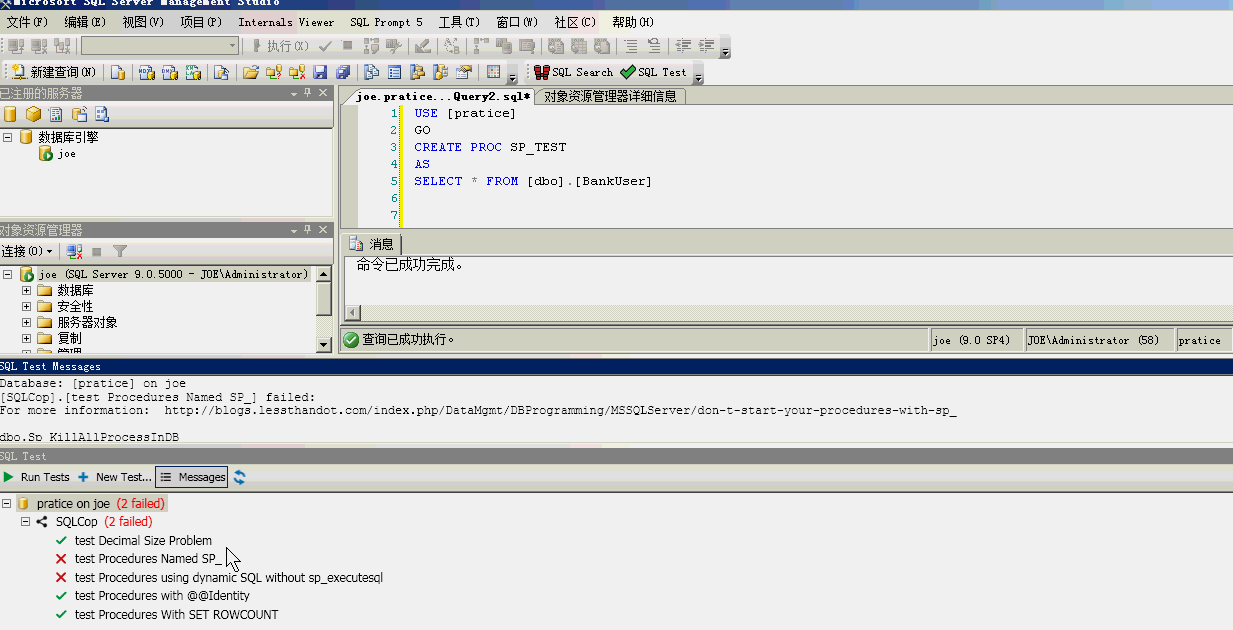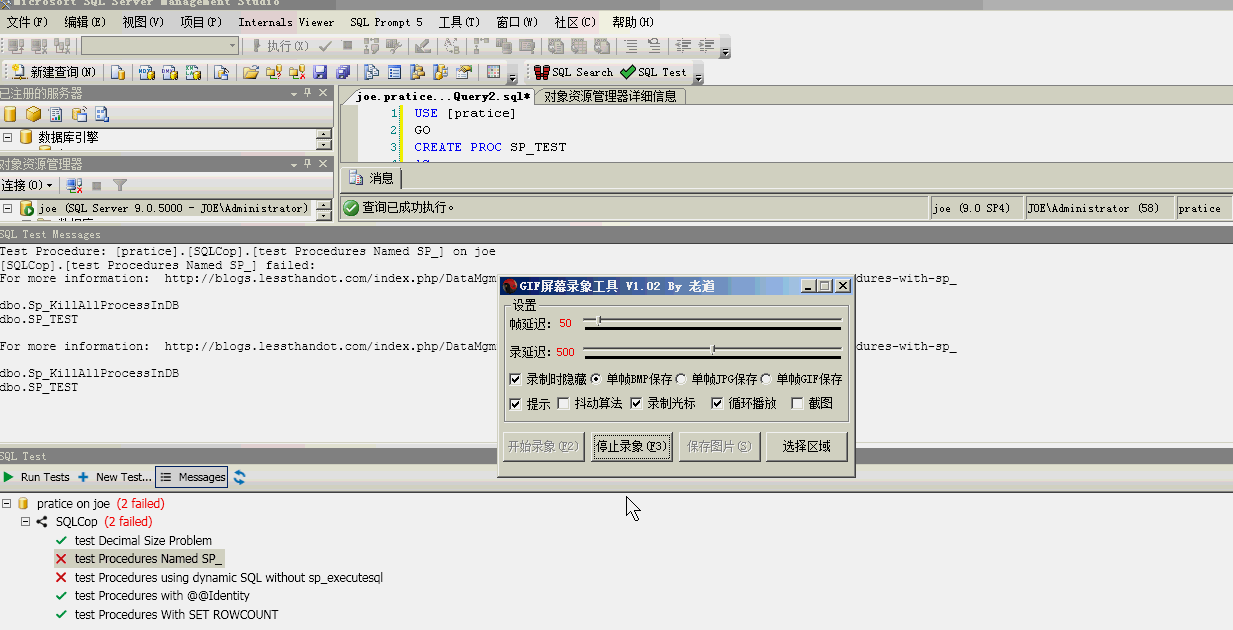
Сначала нам нужно извлечь информацию из столбца продолжительность таблицы trips . Затем, чтобы найти самую длинную поездку, мы можем отсортировать столбец продолжительности в порядке убывания. Вот как мы могли бы проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем:
- Используйте
SELECT, чтобы получитьпродолжительностьстолбецИЗпоездкитаблица - Используйте
ORDER BYдля сортировки столбцапродолжительностьи используйте ключевое словоDESC, чтобы указать, что вы хотите отсортировать в порядке убывания - Используйте
LIMIT, чтобы ограничить вывод одной строкой
Использование этих команд таким образом вернет одну строку с наибольшей продолжительностью, что даст нам ответ на наш вопрос.
Еще одно замечание: по мере того, как ваши запросы добавляют больше команд и становятся более сложными, вы можете обнаружить, что их легче читать, если вы разделите их на несколько строк. Это, как и заглавные буквы, зависит от личных предпочтений. Это не влияет на то, как работает код (система просто читает код с самого начала, пока не дойдет до точки с запятой), но может сделать ваши запросы более четкими и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Это, как и заглавные буквы, зависит от личных предпочтений. Это не влияет на то, как работает код (система просто читает код с самого начала, пока не дойдет до точки с запятой), но может сделать ваши запросы более четкими и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Давайте запустим этот запрос и узнаем, как долго длилась самая длинная поездка.
запрос = ''' ВЫБЕРИТЕ продолжительность ИЗ поездок RDER BY продолжительность DESC ИМИТ 1; '' un_query (запрос)
| продолжительность | |
|---|---|
| 0 | 9999 |
Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или немногим более 166 минут. Однако с максимальным значением 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только на четырехзначное число.
Если правда, что особенно длительные поездки обрезаются базой данных, то мы можем ожидать много поездок за 9999 секунд, когда они достигают предела. Давайте попробуем запустить тот же запрос, что и раньше, но скорректируем
Давайте попробуем запустить тот же запрос, что и раньше, но скорректируем LIMIT , чтобы он возвращал 10 самых высоких значений длительности, чтобы проверить, так ли это:
запрос = ''' ВЫБЕРИТЕ продолжительность ОТ поездок RDER BY продолжительность DESC ИМИТ 10 '' un_query (запрос)
| продолжительность | |
|---|---|
| 0 | 9999 |
| 1 | 9998 |
| 2 | 9998 |
| 3 | 9997 |
| 4 | 9996 |
| 5 | 9996 |
| 6 | 9995 |
| 7 | 9995 |
| 8 | 9994 |
| 9 | 9994 |
Здесь мы видим, что на 9999 нет целой группы поездок, поэтому не похоже, что мы отрезаем верхнюю часть нашей продолжительности, но все же трудно сказать, является ли это реальной продолжительностью. поездки или просто максимально допустимое значение.
поездки или просто максимально допустимое значение.
Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что 4 цифры будут достаточными для отслеживания большинства поездок.
ГДЕ
Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот тут-то и появляется WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены. Например, вы можете использовать следующую команду для возврата каждой поездки на велосипеде B00400 :
ГДЕ bike_number = "B00400"
Вы также заметите, что в этом запросе мы используем кавычки. Это потому, что bike_number хранится в виде строки. Если бы столбец содержал числовые типы данных, кавычки не были бы необходимы.
Если бы столбец содержал числовые типы данных, кавычки не были бы необходимы.
Давайте напишем запрос, который использует ГДЕ для возврата каждого столбца в таблице trips для каждой строки с длительностью более 9990 секунд:
запрос = ''' ВЫБРАТЬ * ИЗ поездок ЗДЕСЬ продолжительность > 9990; '' un_query(запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4768 | 9994 | 03.08.2011 17:16:00 | 22 | 03.08.2011 20:03:00 | 24 | B00002 | Повседневная | |||
| 1 | 8448 | 9991 | 06.08. 2011 13:02:00 2011 13:02:00 | 52 | 06.08.2011 15:48:00 | 24 | B00174 | Повседневная | |||
| 2 | 11341 | 9998 | 09.08.2011 10:42:00 | 40 | 09.08.2011 13:29:00 | 42 | В00513 | Повседневная | |||
| 3 | 24455 | 9995 | 20.08.2011 12:20:00 | 52 | 20.08.2011 15:07:00 | 17 | В00552 | Повседневная | |||
| 4 | 55771 | 9994 | 14-09-2011 15:44:00 | 40 | 14-09-2011 18:30:00 | 40 | B00139 | Повседневная | |||
| 5 | 81191 | 9993 | 03.10.2011 11:30:00 | 22 | 03.10.2011 14:16:00 | 36 | B00474 | Повседневная | |||
| 6 | 89335 | 9997 | 09. 10.2011 02:30:00 10.2011 02:30:00 | 60 | 09.10.2011 05:17:00 | 45 | B00047 | Повседневная | |||
| 7 | 124500 | 9992 | 09.11.2011 09:08:00 | 22 | 09.11.2011 11:55:00 | 40 | B00387 | Повседневная | |||
| 8 | 133967 | 9996 | 19-11-2011 13:48:00 | 4 | 19-11-2011 16:35:00 | 58 | B00238 | Повседневная | |||
| 9 | 147451 | 9996 | 23-03-2012 14:48:00 | 35 | 23-03-2012 17:35:00 | 33 | В00550 | Повседневная | |||
| 10 | 315737 | 9995 | 03-07-2012 18:28:00 | 12 | 03-07-2012 21:15:00 | 12 | В00250 | Зарегистрировано | ‘02120 | 1964 | Мужчина |
| 11 | 319597 | 9994 | 05. 07.2012 11:49:00 07.2012 11:49:00 | 52 | 05.07.2012 14:35:00 | 55 | B00237 | Повседневная | |||
| 12 | 416523 | 9998 | 15-08-2012 12:11:00 | 54 | 15-08-2012 14:58:00 | 80 | B00188 | Повседневная | |||
| 13 | 541247 | 9999 | 2012-09-26 18:34:00 | 54 | 2012-09-26 21:21:00 | 54 | Т01078 | Повседневная |
Как мы видим, этот запрос вернул 14 различных поездок, каждая продолжительностью 9990 секунд или более. В этом запросе выделяется то, что все результаты, кроме одного, имеют sub_type из "Casual" . Возможно, это показатель того, что "зарегистрированных" пользователей больше осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway могла бы лучше донести свою структуру ценообразования до случайных пользователей, чтобы помочь им избежать переплат.
Мы уже видим, как даже начальный уровень владения SQL может помочь нам ответить на вопросы бизнеса и найти ценную информацию в наших данных.
Возвращаясь к WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя И или ИЛИ . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с продолжительностью в течение 9990 секунд, которые также имели подтип Зарегистрировано, мы могли бы использовать И для указания обоих условий.
Вот еще одна рекомендация по личным предпочтениям: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже. Это не обязательно для функционирования кода, но круглые скобки облегчают понимание ваших запросов по мере увеличения сложности.
Давайте запустим этот запрос сейчас. Мы уже знаем, что он должен возвращать только один результат, поэтому должно быть легко проверить правильность ответа:
.
запрос = ''' ВЫБРАТЬ * ИЗ поездок ЗДЕСЬ (продолжительность >= 9990) И (sub_type = "Зарегистрировано") RDER BY продолжительность DESC; '' un_query (запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 315737 | 9995 | 03-07-2012 18:28:00 | 12 | 03-07-2012 21:15:00 | 12 | В00250 | Зарегистрировано | ‘02120 | 1964.0 | Мужчина |
Следующий вопрос, который мы поставили в начале поста, — «Сколько поездок совершили «зарегистрированные» пользователи?» Чтобы ответить на него, мы могли бы запустить тот же запрос, что и выше, и изменить выражение WHERE , чтобы оно возвращало все строки, где sub_type равен 9. 0011 «Зарегистрировано» , а затем подсчитайте их.
0011 «Зарегистрировано» , а затем подсчитайте их.
Однако на самом деле в SQL есть встроенная команда для подсчета за нас, COUNT .
COUNT позволяет нам перенести вычисления в базу данных и избавляет нас от необходимости писать дополнительные сценарии для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT(column_name) вместо (или в дополнение) столбцов, которые вы хотите SELECT , например:
ВЫБЕРИТЕ СЧЕТЧИК (id) span>ИЗ поездок
В данном случае не имеет значения, какой столбец мы выбираем для подсчета, потому что в каждом столбце должны быть данные для каждой строки в нашем запросе. Но иногда запрос может иметь отсутствующие (или «нулевые») значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш COUNT для столбца id — столбец id никогда не бывает нулевым, поэтому мы можем быть уверены, что наш подсчет ничего не пропустит.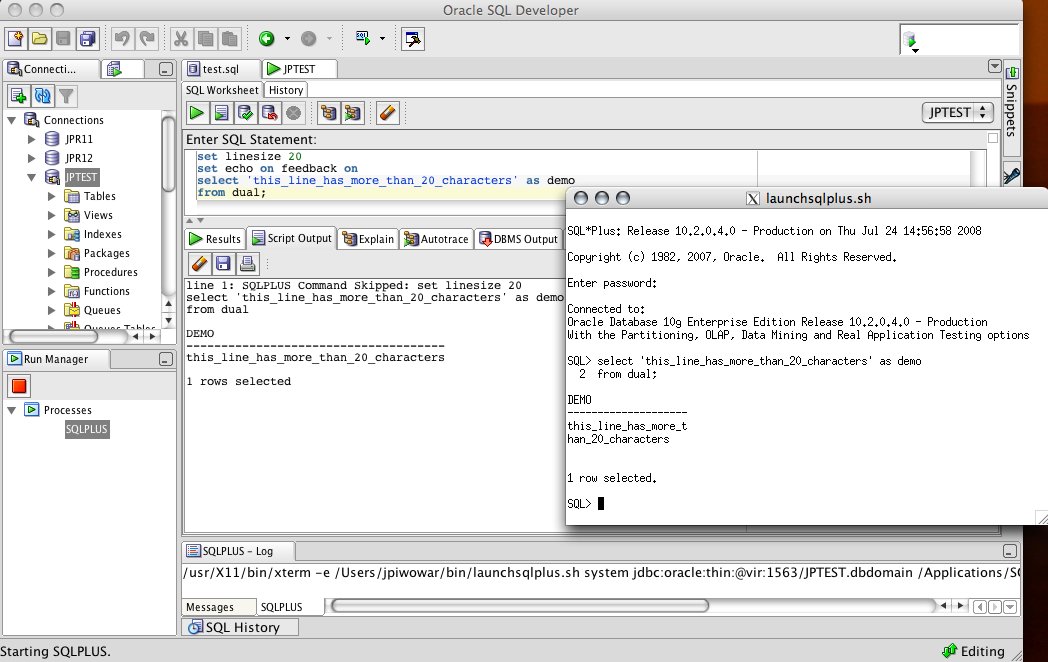
Мы также можем использовать COUNT(1) или COUNT(*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам действительно может понадобиться запустить COUNT для столбца с нулевыми значениями. Например, мы можем захотеть узнать, сколько строк в нашей базе данных имеют пропущенные значения для столбца.
Давайте посмотрим на запрос, чтобы ответить на наш вопрос. Мы можем использовать SELECT COUNT(*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = ''' ВЫБРАТЬ COUNT(*)FROM поездок ЗДЕСЬ sub_type = "Зарегистрировано"; '' un_query (запрос)
| СЧЕТ(*) | |
|---|---|
| 0 | 1105192 |
Этот запрос сработал и вернул ответ на наш вопрос.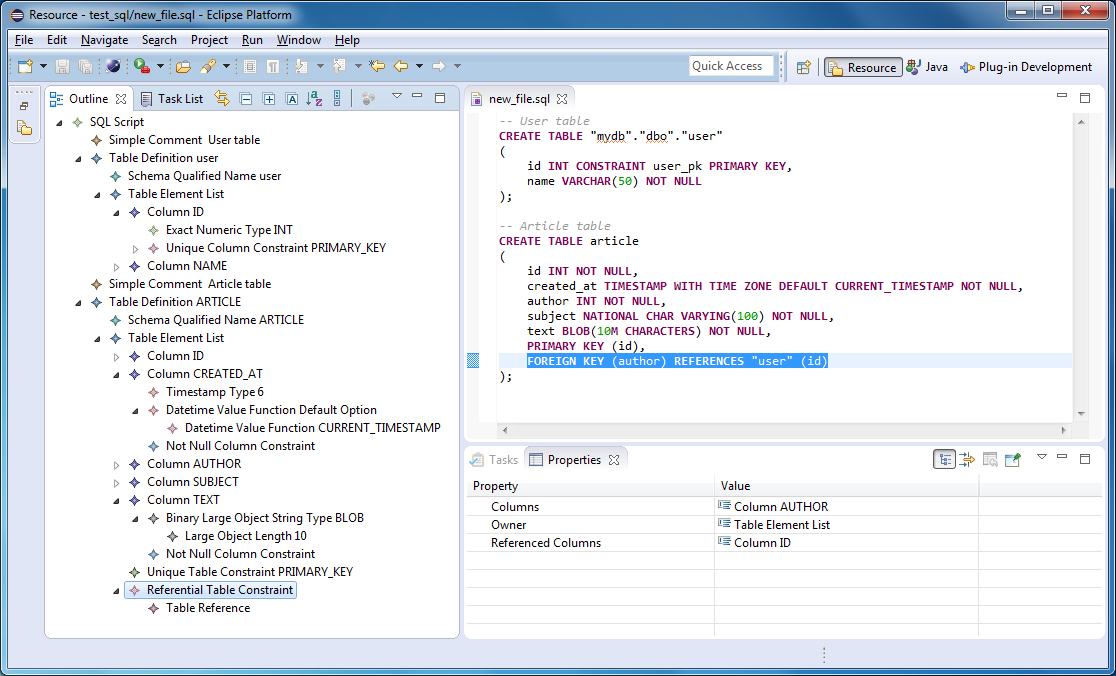 Но заголовок столбца не особенно описателен. Если бы кто-то другой посмотрел на эту таблицу, он бы не смог понять, что она означает.
Но заголовок столбца не особенно описателен. Если бы кто-то другой посмотрел на эту таблицу, он бы не смог понять, что она означает.
Если мы хотим сделать наши результаты более читабельными, мы можем использовать AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно запустим предыдущий запрос, но дадим заголовку нашего столбца псевдоним Total Trips by Registered Users :
запрос = ''' ВЫБРАТЬ COUNT(*) AS "Общее количество поездок зарегистрированных пользователей" ROM поездки ЗДЕСЬ sub_type = "Зарегистрировано"; '' un_query (запрос)
| Всего поездок зарегистрированных пользователей | |
|---|---|
| 0 | 1105192 |
Агрегированные функции
COUNT — не единственная математическая уловка, которая есть в SQL. Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимума и максимума столбца соответственно. Они, наряду с
Они, наряду с COUNT , известны как агрегатные функции.
Итак, чтобы ответить на наш третий вопрос, «Какова была средняя продолжительность поездки?» , мы можем использовать AVG в столбце продолжительность (и снова используйте AS , чтобы дать нашему выходному столбцу более описательное имя):
запрос = ''' ВЫБЕРИТЕ AVG(длительность) КАК "Средняя продолжительность" ПЗУ поездки; '' un_query (запрос)
| Средняя продолжительность | |
|---|---|
| 0 | 912.409682 |
Получается, что средняя продолжительность поездки составляет 912 секунд, что составляет около 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для пассажиров, совершающих короткие поездки в один конец.
Как насчет нашего следующего вопроса, зарегистрированные или случайные пользователи совершают более длительные поездки? Мы уже знаем один способ ответить на этот вопрос — мы можем выполнить два запроса SELECT AVG(duration) FROM trips с предложениями WHERE , которые ограничивают один до "Зарегистрированных" и один до "Обычных" пользователей.
Но давайте по-другому. SQL также позволяет ответить на этот вопрос в одном запросе с помощью команды GROUP BY .
ГРУППА ПО
GROUP BY разделяет строки на группы на основе содержимого определенного столбца и позволяет нам выполнять агрегатные функции для каждой группы.
Чтобы лучше понять, как это работает, давайте взглянем на столбец пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных пол для случайных пользователей).
Когда мы используем GROUP BY , база данных разделит каждую из строк на разные группы на основе значения в столбце пол , почти так же, как мы могли бы разделить колоду карт на разные масти. Мы можем представить себе две стопки, одну из всех самцов, другую из всех самок.
Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе на каждой из них по очереди. Например, если бы мы использовали
Например, если бы мы использовали COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно.
Давайте рассмотрим, как именно написать запрос, чтобы ответить на наш вопрос о том, совершают ли зарегистрированные или случайные пользователи более длительные поездки.
- Как и в каждом из наших запросов, мы начнем с
SELECT, чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам понадобитсяsub_typeиAVG(duration). - Мы также включим
GROUP BY sub_type, чтобы разделить наши данные по типу подписки и рассчитать средние значения для зарегистрированных и случайных пользователей отдельно.
Вот как выглядит код, когда мы сложим его вместе:
запрос = ''' ВЫБЕРИТЕ подтип, AVG (продолжительность) AS «Средняя продолжительность» ROM поездки ГРУППИРОВАТЬ ПО подтипу; '' un_query (запрос)
| подтип | Средняя продолжительность | |
|---|---|---|
| 0 | Повседневная | 1519. 643897 643897 |
| 1 | Зарегистрировано | 657.026067 |
Какая разница! В среднем зарегистрированные пользователи совершают поездки, которые длятся около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку. Зарегистрированные пользователи, вероятно, совершают более короткие и частые поездки, возможно, в рамках поездки на работу. С другой стороны, обычные пользователи тратят примерно в два раза больше времени на поездку.
Вполне возможно, что случайные пользователи, как правило, относятся к демографическим группам (например, туристы), которые более склонны к длительным поездкам, чтобы убедиться, что они перемещаются и осматривают все достопримечательности. Как только мы обнаружим эту разницу в данных, у компании появится множество способов исследовать ее, чтобы лучше понять, что ее вызывает.
Однако для целей этого руководства давайте двигаться дальше. Наш следующий вопрос был , какой велосипед использовался для большинства поездок? . Мы можем ответить на это, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы понять, что делает каждая строка — после этого мы пройдемся по ним шаг за шагом, чтобы вы могли убедиться, что все правильно:
Мы можем ответить на это, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы понять, что делает каждая строка — после этого мы пройдемся по ним шаг за шагом, чтобы вы могли убедиться, что все правильно:
запрос = ''' ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT(*) как "Количество поездок" ROM поездки ГРУППИРОВАТЬ ПО номеру велосипеда ЗАКАЗАТЬ ПО СЧЕТУ(*) DESC ИМИТ 1; '' un_query(запрос)
| Номер велосипеда | Количество поездок | |
|---|---|---|
| 0 | B00490 | 2120 |
Как видно из вывода, велосипед B00490 совершал больше всего поездок. Давайте пробежимся по тому, как мы туда попали:
- Первая строка — это предложение
SELECT, сообщающее базе данных, что мы хотим видеть столбецbike_numberи количество каждой строки. Он также используетAS, чтобы указать базе данных отображать каждый столбец с более удобным именем.
- Во второй строке используется
FROM, чтобы указать, что данные, которые мы ищем, находятся в таблицеtrips. - В третьей строке все становится немного сложнее. Мы используем
GROUP BY, чтобы указать функцииCOUNTв строке 1 подсчитывать каждое значение дляbike_numberотдельно. - В четвертой строке у нас есть предложение
ORDER BYдля сортировки таблицы в порядке убывания и обеспечения того, чтобы наш наиболее часто используемый велосипед находился вверху. - Наконец, мы используем
LIMIT, чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, использованным в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке.
Арифметические операторы
Наш последний вопрос немного сложнее остальных. Мы хотим знать среднюю продолжительность поездок зарегистрированных пользователей старше 30 лет .
Мы могли бы просто вычислить год, в котором родились 30-летние в нашей голове, а затем подставить его, но более элегантное решение — использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать +, - , * и / для выполнения арифметической операции над всем столбцом сразу.
запрос = ''' ВЫБРАТЬ AVG(длительность) из поездок ЗДЕСЬ (2017 - дата_рождения) > 30; '' un_query (запрос)
| СРЕДНЕЕ (длительность) | |
|---|---|
| 0 | 923.014685 |
ПРИСОЕДИНЯЙТЕСЬ
До сих пор мы рассматривали запросы, которые извлекают данные только из поездок табл. Однако одна из причин, по которой SQL настолько эффективен, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе.
Наша база данных велопроката содержит вторую таблицу, станций . Таблица
Таблица station содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица trips .
Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов, которую мы использовали ранее. В этой базе данных у нас было две таблицы, заказы и клиенты , и они были связаны столбцом customer_id .
Допустим, мы хотели написать запрос, который возвращал order_number и name для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБЕРИТЕ номер_заказа, имя диапазон>ОТ заказов;
К сожалению, столбец order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте уделим немного времени тому, чтобы подумать о дополнительных вещах, которые база данных должна знать, прежде чем она сможет вернуть нужную нам информацию:
- В какой таблице находится столбец
order_number? - В какой таблице находится столбец
name? - Каким образом информация в таблице
заказовсвязана с информацией в таблицеклиентов?
Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду SELECT . Мы делаем это просто, записывая имя таблицы и имя столбца, разделяя их цифрой 9.0011 . . Например, вместо
Мы делаем это просто, записывая имя таблицы и имя столбца, разделяя их цифрой 9.0011 . . Например, вместо SELECT order_number, name мы напишем SELECT Orders.order_number, customers.name . Добавление здесь имен таблиц помогает базе данных находить искомые столбцы, сообщая ей, в какой таблице искать каждый из них.
Чтобы сообщить базе данных, как связаны таблицы заказов и клиентов , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть соединены и ON указывает, какие столбцы в каждой таблице связаны.
Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращены только в том случае, если есть совпадение в столбцах, указанных в ON . В этом примере мы хотим использовать JOIN для любой таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать либо ОТ заказов ВНУТРЕННЕГО СОЕДИНЕНИЯ клиентов , либо ОТ клиентов ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ заказов .
Как мы обсуждали ранее, эти таблицы связаны на столбец customer_id в каждой таблице. Поэтому мы будем использовать ON , чтобы сообщить базе данных, что эти два столбца ссылаются на одно и то же, например:
ON orders.customer_ID = customers.customer_id
Мы снова используем . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Итак, когда мы сложим все это вместе, мы получим запрос, который выглядит следующим образом:
ВЫБЕРИТЕ orders.order_number, customers.name диапазон>ОТ заказов span>ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов span>ON orders.customer_id = customers.customer_id
Этот запрос вернет номер каждого заказа в базе данных вместе с именем клиента, связанным с каждым.
Вернемся к нашей базе данных Hubway. Теперь мы можем написать несколько запросов, чтобы увидеть JOIN в действии.
Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице станций . Вот запрос, чтобы показать нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица
Вот запрос, чтобы показать нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица станций :
запрос = ''' ВЫБРАТЬ * ОТ станций ИМИТ 5; '' un_query(запрос)
| идентификатор | станция | муниципалитет | широта | длинный | |
|---|---|---|---|---|---|
| 0 | 3 | Колледжи Фенуэя | Бостон | 42.340021 | -71.100812 |
| 1 | 4 | Тремонт-стрит на Беркли-стрит | Бостон | 42.345392 | -71.069616 |
| 2 | 5 | Северо-Восточный U / Северная парковка | Бостон | 42.341814 | -71.0 |
| 3 | 6 | Кембридж-стрит на Джой-стрит | Бостон | 42.361284999999995 | -71.06514 |
| 4 | 7 | Вентиляторный пирс | Бостон | 42. 353412 353412 | -71.044624 |
-
id— Уникальный идентификатор для каждой станции (соответствуетстолбцы start_stationиend_stationв таблицеtrips) -
станция— Название станции -
муниципалитет— Муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилл) -
lat— Широта станции -
lng— Долгота станции - Какие станции чаще всего используются для поездок туда и обратно?
- Сколько поездок начинается и заканчивается в разных муниципалитетах?
Как и раньше, мы попытаемся ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте рассмотрим это шаг за шагом:
- Сначала мы хотим использовать
SELECTдля возврата столбцаstationиз таблицыstationиCOUNTколичества строк.
- Затем мы указываем таблицы, к которым мы хотим
ПРИСОЕДИНИТЬСЯ, и говорим базе данных соединить ихONстолбецstart_stationв таблицеtripsи столбецidв таблицеstation. - Затем мы переходим к сути нашего запроса – мы
ГРУППИРУЕМ ПОстолбецстанцияв таблицестанций, чтобы нашCOUNTподсчитывал количество поездок для каждой станции отдельно - Наконец, мы можем
ORDER BYнашиCOUNTиLIMITвывод до управляемого количества результатов
запрос = ''' ВЫБЕРИТЕ station.station КАК "Станция", COUNT(*) КАК "Количество" ROM отключает станции INNER JOIN N trips.start_station = station.idGROUP BY station.stationORDER BY COUNT(*) DESC ИМИТ 5; '' un_query (запрос)
| Станция | Считать | |
|---|---|---|
| 0 | Южный вокзал – 700 Атлантик-авеню | 56123 |
| 1 | Бостонская публичная библиотека – 700 Boylston St. | 41994 |
| 2 | Чарльз Серкл — Чарльз-стрит на Кембридж-стрит | 35984 |
| 3 | Бикон-стрит / Масс-авеню | 35275 |
| 4 | Массачусетский технологический институт на Масс-авеню / Амхерст-стрит | 33644 |
Если вы знакомы с Бостоном, то поймете, почему это самые популярные станции. Южный вокзал — одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с некоторыми красивыми живописными маршрутами, а улицы Бойлстон и Бикон проходят прямо в центре города рядом с несколькими офисными зданиями.
Следующий вопрос, который мы рассмотрим, это , какие станции чаще всего используются для поездок туда и обратно? Мы можем использовать тот же запрос, что и раньше. Мы будем SELECT те же выходные столбцы и JOIN таблицы таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная_станция .
запрос = '''ВЫБЕРИТЕ station.station AS "Станция", COUNT(*) AS "Count" ROM отключает станции INNER JOIN N trips.start_station = station.id ЗДЕСЬ trips.start_station = trips.end_station ГРУППИРОВАТЬ ПО станциям.станция ЗАКАЗАТЬ ПО СЧЕТУ(*) DESC ИМИТ 5; '' un_query(запрос)
| Станция | Считать | |
|---|---|---|
| 0 | Эспланада — Бикон-стрит на Арлингтон-стрит | 3064 |
| 1 | Чарльз Серкл — Чарльз-стрит на Кембридж-стрит | 2739 |
| 2 | Бостонская публичная библиотека – 700 Boylston St. | 2548 |
| 3 | Бойлстон-стрит на Арлингтон-стрит | 2163 |
| 4 | Бикон-стрит / Масс-авеню | 2144 |
Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными станциями, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки А в точку Б, а не ездят на велосипеде некоторое время, прежде чем вернуться туда, где они начали.
Здесь есть одно существенное отличие — Эспланда, которая не была одной из самых загруженных станций по нашему первому запросу, оказывается самой загруженной для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно похоже на хорошее место для велосипедной прогулки:
К следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос делает шаг вперед. Мы хотим знать, сколько поездок начинается и заканчивается в другом муниципалитете . Для этого нам нужно ПРИСОЕДИНИТЬСЯ к таблице trips к таблице станций дважды. Один раз ON столбец start_station , а затем ON столбец end_station .
Чтобы сделать это, мы должны создать псевдоним для таблицы station , чтобы мы могли различать данные, относящиеся к start_station , и данные, относящиеся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя
Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS .
Например, мы можем использовать следующий код для ПРИСОЕДИНЯЙСЯ к станциям в таблицу trips , используя псевдоним start. Затем мы можем объединить «начало» с именами наших столбцов, используя . для ссылки на данные, поступающие из этого конкретного JOIN (вместо второго JOIN мы будем делать ON в столбце end_station ):
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ станций КАК начать ВКЛ trips.start_station = start.id
Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали <> для обозначения «не равно», но != тоже подойдет.
запрос = размах>''' ВЫБРАТЬ COUNT(trips.id) КАК "Count" ROM отключает станции INNER JOIN AS start N trips.start_station = start.id NNER JOIN станции AS конец N trips.end_station = end.id ЗДЕСЬ start.municipality <> end.municipality; '' un_query (запрос)
| Считать | |
|---|---|
| 0 | 309748 |
Это показывает, что около 300 000 из 1,5 миллиона поездок (или 20%) заканчивались в другом муниципалитете, чем они начинались, — еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами.
Если вы дошли до этого места, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд: SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции. Это даст вам прочную основу для продолжения вашего пути к SQL.
Вы освоили основы SQL. Что теперь?
После изучения этого руководства по SQL для начинающих вы сможете выбрать интересующую вас базу данных и написать запросы для извлечения информации.