Что такое группа доступности Always On? — SQL Server Always On
- Чтение занимает 14 мин
В этой статье
Применимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions) Применимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions)
В этом разделе рассматриваются основные понятия Группы доступности AlwaysOnAlways On availability groups , которые имеют большое значение для настройки групп доступности и управления группами доступности в среде SQL ServerSQL Server.This topic introduces the Группы доступности AlwaysOnAlways On availability groups concepts that are central for configuring and managing one or more availability groups in SQL ServerSQL Server. Сводное описание преимуществ групп доступности и общие сведения по терминологии Группы доступности AlwaysOnAlways On availability groups см. в разделе Группы доступности AlwaysOn (SQL Server).For a summary of the benefits offered by availability groups and an overview of Группы доступности AlwaysOnAlways On availability groups terminology, see Always On Availability Groups (SQL Server).
Группа доступности поддерживает реплицированную среду для дискретного набора пользовательских баз данных, известных как базы данных доступности.An availability group supports a replicated environment for a discrete set of user databases, known as availability databases. Можно создать группу доступности для обеспечения высокой доступности (HA) или для чтения и масштабирования.
Каждый набор баз данных доступности размещается с помощью реплики доступности.Each set of availability database is hosted by an availability replica. Существует два типа реплик доступности: одна первичная реплика,Two types of availability replicas exist: a single primary replica. которая размещает основные базы данных, и до восьми вторичных реплик, каждая из которых размещает набор вторичных баз данных и серверов как потенциальных объектов отказа для группы доступности.which hosts the primary databases, and one to eight secondary replicas, each of which hosts a set of secondary databases and serves as a potential failover targets for the availability group. Группа доступности выполняет переход на другой ресурс на уровне реплики доступности.An availability group fails over at the level of an availability replica. Реплика доступности обеспечивает избыточность только на уровне базы данных для набора баз данных из одной группы доступности.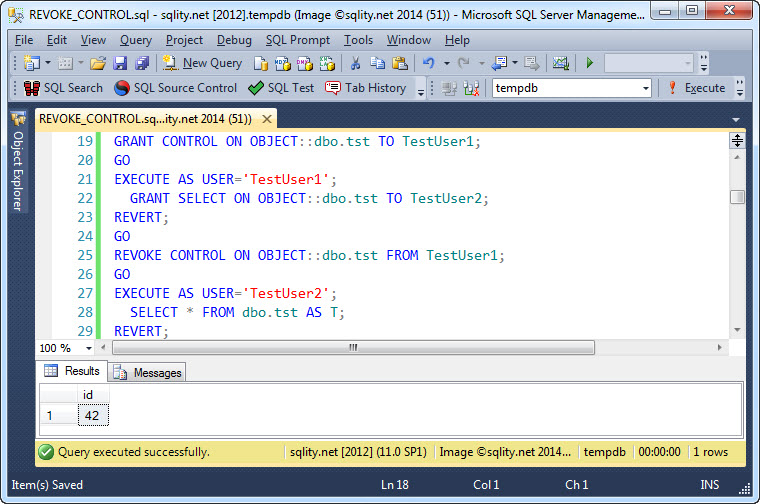
Первичная реплика делает базы данных-источники доступными для соединений с клиентами для чтения и записи.The primary replica makes the primary databases available for read-write connections from clients. первичная реплика отправляет записи журнала транзакций каждой базы данных-источника в каждую базу данных-получатель.The primary replica sends transaction log records of each primary database to every secondary database. Этот процесс, называемый 
Также можно настроить одну или несколько вторичных реплик для поддержки доступа только для чтения к базам данных-получателям и настроить какую-либо вторичную реплику для резервного копирования в базы данных-получатели.Optionally, you can configure one or more secondary replicas to support read-only access to secondary databases, and you can configure any secondary replica to permit backups on secondary databases.
В SQL Server 2017 представлены две различные архитектуры для групп доступности.SQL Server 2017 introduces two different architectures for availability groups.
Для развертывания Группы доступности AlwaysOnAlways On availability groups в целях обеспечения высокой доступности в Windows требуется кластер WSFC.Deploying Группы доступности AlwaysOnAlways On availability groups for HA on Windows requires a Windows Server Failover Cluster(WSFC). Все реплики доступности в заданной группе доступности должны располагаться на разных узлах одного кластера WSFC. Each availability replica of a given availability group must reside on a different node of the same WSFC. Единственное исключение состоит в том, что при переносе в другой кластер WSFC группа доступности может временно находится в двух кластерах.The only exception is that while being migrated to another WSFC cluster, an availability group can temporarily straddle two clusters.
Each availability replica of a given availability group must reside on a different node of the same WSFC. Единственное исключение состоит в том, что при переносе в другой кластер WSFC группа доступности может временно находится в двух кластерах.The only exception is that while being migrated to another WSFC cluster, an availability group can temporarily straddle two clusters.
В конфигурации с высоким уровнем доступности роль кластера создается для каждой создаваемой группы доступности.In an HA configuration, a cluster role is created for every availability group that you create. Кластер WSFC отслеживает эту роль для оценки работоспособности первичной реплики.The WSFC cluster monitors this role to evaluate the health of the primary replica. Кворум для Группы доступности AlwaysOnAlways On availability groups рассчитывается на всех узлах в кластере WSFC вне зависимости от того, хранится ли на данном узле кластера какая-либо реплика доступности.The quorum for Группы доступности AlwaysOnAlways On availability groups is based on all nodes in the WSFC cluster regardless of whether a given cluster node hosts any availability replicas. В отличие от процесса зеркального отображения базы данных, в Группы доступности AlwaysOnAlways On availability groups нет роли следящего объекта.In contrast to database mirroring, there is no witness role in Группы доступности AlwaysOnAlways On availability groups.
Ниже показана группа доступности, которая содержит одну первичную реплику и четыре вторичные реплики.The following illustration shows an availability group that contains one primary replica and four secondary replicas. Поддерживаются до 8 вторичных реплик, в том числе одна первичная реплика и две вторичные реплики с синхронной фиксацией.Up to eight secondary replicas are supported, including one primary replica and two synchronous-commit secondary replicas.
Базы данных доступностиAvailability databases
Чтобы можно было добавить базу данных в группу доступности, база данных должна быть в сети, быть доступной для чтения и записи и существовать на экземпляре сервера, на котором располагается первичная реплика. To add a database to an availability group, the database must be an online, read-write database that exists on the server instance that hosts the primary replica. При добавлении база данных присоединяется к группе доступности как база данных-источник, оставаясь доступной для клиентов.When you add a database, it joins the availability group as a primary database, while remaining available to clients. База данных-получатель не существует до тех пор, пока резервные копии новой базы данных-источника не будут восстановлены на экземпляр сервера, на котором размещается вторичная реплика (с помощью инструкции RESTORE WITH NORECOVERY).No corresponding secondary database exists until backups of the new primary database are restored to the server instance that hosts the secondary replica (using RESTORE WITH NORECOVERY). Новая база данных-получатель находится в состоянии RESTORING до тех пор, пока не войдет в состав группы доступности.The new secondary database is in the RESTORING state until it is joined to the availability group. Дополнительные сведения см. в статье Запуск перемещения данных для базы данных-получателя AlwaysOn (SQL Server).For more information, see Start Data Movement on an Always On Secondary Database (SQL Server).
To add a database to an availability group, the database must be an online, read-write database that exists on the server instance that hosts the primary replica. При добавлении база данных присоединяется к группе доступности как база данных-источник, оставаясь доступной для клиентов.When you add a database, it joins the availability group as a primary database, while remaining available to clients. База данных-получатель не существует до тех пор, пока резервные копии новой базы данных-источника не будут восстановлены на экземпляр сервера, на котором размещается вторичная реплика (с помощью инструкции RESTORE WITH NORECOVERY).No corresponding secondary database exists until backups of the new primary database are restored to the server instance that hosts the secondary replica (using RESTORE WITH NORECOVERY). Новая база данных-получатель находится в состоянии RESTORING до тех пор, пока не войдет в состав группы доступности.The new secondary database is in the RESTORING state until it is joined to the availability group. Дополнительные сведения см. в статье Запуск перемещения данных для базы данных-получателя AlwaysOn (SQL Server).For more information, see Start Data Movement on an Always On Secondary Database (SQL Server).
Присоединение переводит базу данных-получатель в режим ONLINE и инициирует синхронизацию данных с соответствующей базой данных-источником.Joining places the secondary database into the ONLINE state and initiates data synchronization with the corresponding primary database. Синхронизация данных — это процесс, в ходе которого изменения в базе данных-источнике воспроизводятся в базе данных-получателе.Data synchronization is the process by which changes to a primary database are reproduced on a secondary database. В процессе синхронизации данных база данных-источник отправляет записи журнала транзакций в базу данных-получатель.Data synchronization involves the primary database sending transaction log records to the secondary database.
Важно!
База данных доступности в , Powershell и управляющих объектах SQL Server (SMO) иногда называется репликой базы данных Transact-SQLTransact-SQL.An availability database is sometimes called a database replica in Transact-SQLTransact-SQL, PowerShell, and SQL Server Management Objects (SMO) names. Например, выражение «реплика базы данных» используется в именах динамических представлений управления AlwaysOn, возвращающих сведения о базах данных доступности: sys.dm_hadr_database_replica_states и sys.dm_hadr_database_replica_cluster_states.For example, the term «database replica» is used in the names of the Always On dynamic management views that return information about availability databases: sys.dm_hadr_database_replica_states and sys.dm_hadr_database_replica_cluster_states. Однако в электронной документации по SQL Server термин «реплика» обычно относится к репликам доступности.However, in SQL Server Books Online, the term «replica» typically refers to availability replicas. Например, фразы «первичная реплика» и «вторичная реплика» всегда относятся к репликам доступности.For example, «primary replica» and «secondary replica» always refer to availability replicas.
Реплики доступностиAvailability replicas
Каждая группа доступности определяет набор из двух или более партнеров по обеспечению отработки отказа, известных как реплики доступности.Each availability group defines a set of two or more failover partners known as availability replicas. Реплики доступности являются компонентами группы доступности.Availability replicas are components of the availability group. На каждой реплике доступности размещается копия баз данных доступности в группе доступности.Each availability replica hosts a copy of the availability databases in the availability group. Для данной группы доступности реплики доступности должны находиться на разных экземплярах SQL ServerSQL Server , работающих на разных узлах кластера WSFC. For a given availability group, the availability replicas must be hosted by separate instances of SQL ServerSQL Server residing on different nodes of a WSFC cluster. На каждом из этих экземпляров сервера необходимо включить AlwaysOn.Each of these server instances must be enabled for Always On.
For a given availability group, the availability replicas must be hosted by separate instances of SQL ServerSQL Server residing on different nodes of a WSFC cluster. На каждом из этих экземпляров сервера необходимо включить AlwaysOn.Each of these server instances must be enabled for Always On.
Данный экземпляр может размещать только одну реплику доступности для отдельной группы доступности.A given instance can host only one availability replica per availability group. Однако каждый экземпляр можно использовать на нескольких групп доступности.However, each instance can be used for many availability groups. Данный экземпляр сервера может быть изолированным экземпляром или экземпляром кластера отработки отказа SQL ServerSQL Server .A given instance can be either a stand-alone instance or a SQL ServerSQL Server failover cluster instance (FCI). Если требуется обеспечить избыточность на уровне сервера, используйте экземпляры кластера отработки отказа.If you require server-level redundancy, use Failover Cluster Instances.
Каждая реплика доступности получает роль — первичную роль или вторичную роль, которая наследуется базами данных доступности этой реплики.Every availability replica is assigned an initial role-either the primary role or the secondary role, which is inherited by the availability databases of that replica. Роль данной реплики определяет, размещает ли она базы данных, доступные для чтения и записи, или базы данных только для чтения.The role of a given replica determines whether it hosts read-write databases or read-only databases. Одна реплика, известная как первичная реплика, получает первичную роль и размещает базы данных, доступные для чтения и записи, которые известны как базы данных-получатели.One replica, known as the primary replica, is assigned the primary role and hosts read-write databases, which are known as primary databases. По крайней мере одна из остальных реплик, называемая вторичной репликой, получает вторичную роль. At least one other replica, known as a secondary replica, is assigned the secondary role. Вторичная реплика размещает базы данных только для чтения, называемые базами данных-получателями.A secondary replica hosts read-only databases, known as secondary databases.
At least one other replica, known as a secondary replica, is assigned the secondary role. Вторичная реплика размещает базы данных только для чтения, называемые базами данных-получателями.A secondary replica hosts read-only databases, known as secondary databases.
Примечание
Если роль реплики доступности не определена, например, во время отработки отказа, ее базы данных временно пребывают в состоянии NOT SYNCHRONIZING.When the role of an availability replica is indeterminate, such as during a failover, its databases are temporarily in a NOT SYNCHRONIZING state. Их роль устанавливается в значение RESOLVING до тех пор, пока роль реплики доступности не будет разрешена.Their role is set to RESOLVING until the role of the availability replica has resolved. Если реплика доступности разрешается в основную роль, ее базы данных становятся базами данных-источниками.If an availability replica resolves to the primary role, its databases become the primary databases. Если реплика доступности разрешается во вторичную роль, ее базы данных становятся базами данных-получателями.If an availability replica resolves to the secondary role, its databases become secondary databases.
Режимы доступностиAvailability modes
Режим доступности — это свойство каждой реплики доступности.The availability mode is a property of each availability replica. Режим доступности определяет, ждет ли первичная реплика перед фиксацией транзакций для базы данных, чтобы данная вторичная реплика записала записи журнала транзакций на диск (записала журнал на диск).The availability mode determines whether the primary replica waits to commit transactions on a database until a given secondary replica has written the transaction log records to disk (hardened the log). Группы доступности AlwaysOnAlways On availability groups поддерживает два режима доступности — режим асинхронной фиксации и режим синхронной фиксации.supports two availability modes-asynchronous-commit mode and synchronous-commit mode.
Asynchronous-commit modeAsynchronous-commit mode
Реплика доступности, которая использует этот режим доступности, называется репликой асинхронной фиксации.An availability replica that uses this availability mode is known as an asynchronous-commit replica. В режиме асинхронной фиксации первичная реплика фиксирует транзакции, не ожидая подтверждения того, что вторичная реплика асинхронной фиксации записала журнал на диск.Under asynchronous-commit mode, the primary replica commits transactions without waiting for acknowledgment that an asynchronous-commit secondary replica has hardened the log. Режим асинхронной фиксации минимизирует задержку транзакций в базах данных-получателях, но позволяет им не успевать за базами данных-источниками, что создает риск возможной потери данных.Asynchronous-commit mode minimizes transaction latency on the secondary databases but allows them to lag behind the primary databases, making some data loss possible.
Synchronous-commit modeSynchronous-commit mode
Реплика доступности, которая использует этот режим доступности, называется репликой синхронной фиксации.An availability replica that uses this availability mode is known as a synchronous-commit replica. В режиме синхронной фиксации, прежде чем фиксировать транзакции, первичная реплика синхронной фиксации ждет, чтобы вторичная реплика синхронной фиксации подтвердила, что запись журнала на диск завершена.Under synchronous-commit mode, before committing transactions, a synchronous-commit primary replica waits for a synchronous-commit secondary replica to acknowledge that it has finished hardening the log. В режиме синхронной фиксации после синхронизации базы данных-получателя с базой данных-источником зафиксированные транзакции полностью защищены.Synchronous-commit mode ensures that once a given secondary database is synchronized with the primary database, committed transactions are fully protected.
 Эта защита достигается за счет повышения задержки транзакций.This protection comes at the cost of increased transaction latency.
Эта защита достигается за счет повышения задержки транзакций.This protection comes at the cost of increased transaction latency.
Дополнительные сведения см. в разделе Режимы доступности (группы доступности AlwaysOn).For more information, see Availability Modes (Always On Availability Groups).
Типы отработки отказаTypes of failover
В рамках контекста сеанса между первичной репликой и вторичной репликой, первичная и вторичная роли становятся потенциально взаимозаменяемыми в процессе, который называется отработка отказа.Within the context of a session between the primary replica and a secondary replica, the primary and secondary roles are potentially interchangeable in a process known as failover. Во время отработки отказа вторичная реплика принимает первичную роль и становится новой первичной репликой.During a failover the target secondary replica transitions to the primary role, becoming the new primary replica. Новая первичная реплика переводит свои базы данных в режим «в сети» в качестве баз данных-источников и выполняет откат всех незафиксированных транзакций.The new primary replica brings its databases online as the primary databases, and client applications can connect to them. Когда прежняя первичная реплика становится доступной, она принимает вторичную роль и становится вторичной репликой.When the former primary replica is available, it transitions to the secondary role, becoming a secondary replica. Прежние базы данных-источники становятся базами данных-получателями, и синхронизация данных возобновляется.The former primary databases become secondary databases and data synchronization resumes.
Существует три вида перехода на другой ресурс: автоматическая отработка отказа, отработка отказа вручную и принудительное обслуживание (с возможной потерей данных).Three forms of failover exist-automatic, manual, and forced (with possible data loss). Форма или формы отработки отказа, поддерживаемые определенной вторичной репликой, зависят от режима доступности и, для режима синхронной фиксации, от режима отработки отказа для первичной реплики и целевой вторичной реплики, как будет показано ниже. The form or forms of failover supported by a given secondary replica depends on its availability mode, and, for synchronous-commit mode, on the failover mode on the primary replica and target secondary replica, as follows.
The form or forms of failover supported by a given secondary replica depends on its availability mode, and, for synchronous-commit mode, on the failover mode on the primary replica and target secondary replica, as follows.
Режим синхронной фиксации поддерживает две формы перехода на другой ресурс — запланированный переход на другой ресурс вручную и автоматический переход на другой ресурс, если целевая вторичная реплика синхронизируется с первичной.Synchronous-commit mode supports two forms of failover-planned manual failover and automatic failover, if the target secondary replica is currently synchronized with the primary replica. Поддержка этих форм отработки отказа зависит от свойства режима отработки отказа партнеров по обеспечению отработки отказа.The support for these forms of failover depends on the setting of the failover mode property on the failover partners. Если режим перехода на другой ресурс имеет значение «вручную» для первичной или вторичной реплики, то для этой вторичной реплики поддерживается только режим перехода на другой ресурс «вручную».If failover mode is set to «manual» on either the primary or secondary replica, only manual failover is supported for that secondary replica. Если режим перехода на другой ресурс имеет значение «автоматический» как для первичной, так и для вторичной реплики, то эта вторичная реплика поддерживает как автоматический, так и переход на другой ресурс вручную.If failover mode is set to «automatic» on both the primary and secondary replicas, both automatic and manual failover are supported on that secondary replica.
Переход на другой ресурс вручную (без потери данных)Planned manual failover (without data loss)
Переход на другой ресурс вручную происходит вслед за тем, как администратор баз данных выполняет команду перехода на другой ресурс, после чего синхронизируемая вторичная реплика принимает первичную роль (с гарантированной защитой данных), а первичная реплика — вторичную роль.
 A manual failover occurs after a database administrator issues a failover command and causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection) and the primary replica to transition to the secondary role. Для перехода на другой ресурс вручную требуется, чтобы первичная реплика и целевая вторичная реплика работали в режиме синхронной фиксации, при этом вторичная реплика уже должна быть синхронизирована.A manual failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode, and the secondary replica must already be synchronized.
A manual failover occurs after a database administrator issues a failover command and causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection) and the primary replica to transition to the secondary role. Для перехода на другой ресурс вручную требуется, чтобы первичная реплика и целевая вторичная реплика работали в режиме синхронной фиксации, при этом вторичная реплика уже должна быть синхронизирована.A manual failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode, and the secondary replica must already be synchronized.Автоматический переход на другой ресурс (без потери данных)Automatic failover (without data loss)
Автоматический переход на другой ресурс возникает в ответ на сбой, в результате которого синхронизируемая вторичная реплика принимает первичную роль (с гарантированной защитой данных).An automatic failover occurs in response to a failure that causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection). Когда прежняя первичная реплика становится доступной, она принимает вторичную роль.When the former primary replica becomes available, it transitions to the secondary role. Для автоматического перехода на другой ресурс требуется, чтобы первичная реплика и целевая вторичная реплика работали в режиме синхронной фиксации, а режим отработки отказа имел значение «Автоматический».Automatic failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode with the failover mode set to «Automatic». Помимо этого, вторичная реплика уже должна быть синхронизирована, иметь WSFC-кворум и отвечать условиям, указанным в гибкой политике перехода на другой ресурсдля группы доступности.In addition, the secondary replica must already be synchronized, have WSFC quorum, and meet the conditions specified by the flexible failover policyof the availability group.

Важно!
Экземпляры отказоустойчивого кластера SQL Server не поддерживают автоматический переход на другой ресурс с учетом групп доступности, поэтому любая реплика доступности, размещенная в них, должна быть настроена для перехода на другой ресурс вручную.SQL Server Failover Cluster Instances (FCIs) do not support automatic failover by availability groups, so any availability replica that is hosted by an FCI can only be configured for manual failover.
Примечание
Заметьте, что если команда принудительной отработки отказа выполняется в синхронизированной вторичной реплике, то она работает так же, как в случае запланированного перехода на другой ресурс вручную.Note that if you issue a forced failover command on a synchronized secondary replica, the secondary replica behaves the same as for a planned manual failover.
В режиме асинхронной фиксации единственная возможная форма отработки отказа — это принудительный переход на другой ресурс вручную (с возможной потерей данных), который обычно называется принудительная отработка отказа.Under asynchronous-commit mode, the only form of failover is forced manual failover (with possible data loss), typically called forced failover. Принудительная отработка отказа считается формой перехода на другой ресурс вручную, поскольку она может быть инициирована только вручную.Forced failover is considered a form of manual failover because it can only be initiated manually. Принудительная отработка отказа является вариантом аварийного восстановления.Forced failover is a disaster recovery option. Это единственная форма отработки отказа, которая возможна в случае, если целевая вторичная реплика не синхронизирована с первичной репликой.It is the only form of failover that is possible when the target secondary replica is not synchronized with the primary replica.
Дополнительные сведения см. далее в подразделе Отработка отказа и режимы отработки отказа (группы доступности AlwaysOn). For more information, see Failover and Failover Modes (Always On Availability Groups).
For more information, see Failover and Failover Modes (Always On Availability Groups).
Клиентские соединенияClient connections
Можно обеспечить клиентское соединение с первичной репликой данной группы доступности, создав прослушиватель группы доступности.You can provide client connectivity to the primary replica of a given availability group by creating an availability group listener. Прослушиватель группы доступности предоставляет набор ресурсов, который закрепляется за определенной группой доступности и направляет клиентские соединения на соответствующую реплику доступности.An availability group listener provides a set of resources that is attached to a given availability group to direct client connections to the appropriate availability replica.
Прослушиватель группы доступности связан с уникальным DNS-именем, которое является виртуальным сетевым именем (VNN), одним или несколькими виртуальными IP-адресами (VIP) и номером TCP-порта.An availability group listener is associated with a unique DNS name that serves as a virtual network name (VNN), one or more virtual IP addresses (VIPs), and a TCP port number. Дополнительные сведения см. в разделе Прослушиватели групп доступности, возможность подключения клиентов и отработка отказа приложений (SQL Server).For more information, see Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server).
Совет
Если в группе доступности имеется только две реплики доступности и в ней не разрешен доступ только для чтения к вторичной реплике доступности, клиенты смогут подключаться к первичной реплике доступности с помощью строк подключения к зеркальному отображению базы данных.If an availability group possesses only two availability replicas and is not configured to allow read-access to the secondary replica, clients can connect to the primary replica by using a database mirroring connection string. Этот подход может быть временно полезным после миграции базы данных с зеркального отображения базы данных на сервер Группы доступности AlwaysOnAlways On availability groups. This approach can be useful temporarily after you migrate a database from database mirroring to Группы доступности AlwaysOnAlways On availability groups. Прежде чем добавлять другие вторичные реплики, потребуется создать прослушиватель группы доступности, группу доступности и обновить приложения так, чтобы они использовали сетевое имя прослушивателя.Before you add additional secondary replicas, you will need to create an availability group listener the availability group and update your applications to use the network name of the listener.
This approach can be useful temporarily after you migrate a database from database mirroring to Группы доступности AlwaysOnAlways On availability groups. Прежде чем добавлять другие вторичные реплики, потребуется создать прослушиватель группы доступности, группу доступности и обновить приложения так, чтобы они использовали сетевое имя прослушивателя.Before you add additional secondary replicas, you will need to create an availability group listener the availability group and update your applications to use the network name of the listener.
Активные вторичные репликиActive secondary replicas
Группы доступности AlwaysOnAlways On availability groups поддерживает активные вторичные реплики.supports active secondary replicas. Активные вторичные функции поддерживают следующее.Active secondary capabilities include support for:
Проведение операций резервного копирования со вторичными репликами.Performing backup operations on secondary replicas
Вторичные реплики поддерживают создание резервных копий журнала и резервных копий только для копирования всей базы данных, файлов и файловых групп.The secondary replicas support performing log backups and copy-only backups of a full database, file, or filegroup. Можно настроить группу доступности, указав предпочтение, где следует выполнять резервное копирование.You can configure the availability group to specify a preference for where backups should be performed. Важно понимать, что приоритет не определяется в SQL Server, поэтому не влияет на выполнение нерегламентированного резервного копирования.It is important to understand that the preference is not enforced by SQL Server, so it has no impact on ad-hoc backups. Интерпретация данного приоритета зависит от логики, при ее наличии, которая внесена в задания резервного копирования для каждой из баз данных в указанной группе доступности.The interpretation of this preference depends on the logic, if any, that you script into your back jobs for each of the databases in a given availability group.
 Для отдельной реплики доступности можно указать приоритет выполнения резервного копирования на данной реплике по отношению к другим репликам из той же группы доступности.For an individual availability replica, you can specify your priority for performing backups on this replica relative to the other replicas in the same availability group. Дополнительные сведения см. в статье Активные вторичные реплики: резервное копирование во вторичных репликах (группы доступности Always On).For more information, see Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups).
Для отдельной реплики доступности можно указать приоритет выполнения резервного копирования на данной реплике по отношению к другим репликам из той же группы доступности.For an individual availability replica, you can specify your priority for performing backups on this replica relative to the other replicas in the same availability group. Дополнительные сведения см. в статье Активные вторичные реплики: резервное копирование во вторичных репликах (группы доступности Always On).For more information, see Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups).Доступ только для чтения к одной или нескольким вторичным репликам (доступные для чтения вторичные реплики)Read-only access to one or more secondary replicas (readable secondary replicas)
Любая вторичная реплика доступности может быть настроена на получение доступа только для чтения ко своим локальным базам данных, хотя некоторые операции поддерживаются не полностью.Any secondary availability replica can be configured to allow only read-only access to its local databases, though some operations are not fully supported. Это предотвратит попытки подключения для чтения и записи к вторичной реплике.This will prevent read-write connection attempts to the secondary replica. Кроме того, можно запретить рабочие нагрузки только для чтения на первичной реплике, разрешив доступ только для чтения и записи.It is also possible to prevent read-only workloads on the primary replica by only allowing read-write access. Это предотвратит подключение только для чтения к первичной реплике.This will prevent read-only connections from being made to the primary replica. Дополнительные сведения см. в статье Активные вторичные реплики: вторичные реплики для чтения (группы доступности Always On).For more information, see Active Secondaries: Readable Secondary Replicas (Always On Availability Groups).
Если в группе доступности имеется прослушиватель группы доступности и одна или несколько доступных для чтения вторичных реплик, то SQL ServerSQL Server может направлять запросы на установку соединения (с целью считывания данных) к одной из них (маршрутизация только для чтения).
 If an availability group currently possesses an availability group listener and one or more readable secondary replicas, SQL ServerSQL Server can route read-intent connection requests to one of them (read-only routing). Дополнительные сведения см. в разделе Прослушиватели групп доступности, возможность подключения клиентов и отработка отказа приложений (SQL Server).For more information, see Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server).
If an availability group currently possesses an availability group listener and one or more readable secondary replicas, SQL ServerSQL Server can route read-intent connection requests to one of them (read-only routing). Дополнительные сведения см. в разделе Прослушиватели групп доступности, возможность подключения клиентов и отработка отказа приложений (SQL Server).For more information, see Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server).
Период времени ожидания сеансаSession-timeout period
Период времени ожидания сеанса — это свойство реплики доступности, которое определяет, как долго соединение с другой репликой доступности может оставаться неактивным до закрытия соединения.The session-timeout period is an availability-replica property that determines how long connection with another availability replica can remain inactive before the connection is closed. Первичные и вторичные реплики проверяют связь друг с другом, чтобы подтвердить собственную активность.The primary and secondary replicas ping each other to signal that they are still active. Получение сообщения проверки связи от другой реплики до истечения периода времени ожидания указывает на то, что соединение все еще открыто и экземпляры сервера поддерживают связь.Receiving a ping from the other replica during the timeout period indicates that the connection is still open and that the server instances are communicating. После получения сообщения проверки связи реплика доступности сбрасывает счетчик времени ожидания сеанса для данного соединения.On receiving a ping, an availability replica resets its session-timeout counter on that connection.
Ограничение времени ожидания сеанса исключает неограниченное продолжение работы реплики, ожидающей сообщения проверки связи от другой реплики.The session-timeout period prevents either replica from waiting indefinitely to receive a ping from the other replica. Если в течение периода ожидания от другой реплики не приходит сообщение проверки связи, то реплика прекращает ожидание. Соединение закрывается, и реплика переходит в состояние DISCONNECTED.If no ping is received from the other replica within the session-timeout period, the replica times out. Its connection is closed, and the timed-out replica enters the DISCONNECTED state. Даже если для отключенной реплики настроен режим синхронной фиксации, транзакции не будут ожидать ее повторного подключения и повторной синхронизации.Even if a disconnected replica is configured for synchronous-commit mode, transactions will not wait for that replica to reconnect and resynchronize.
Соединение закрывается, и реплика переходит в состояние DISCONNECTED.If no ping is received from the other replica within the session-timeout period, the replica times out. Its connection is closed, and the timed-out replica enters the DISCONNECTED state. Даже если для отключенной реплики настроен режим синхронной фиксации, транзакции не будут ожидать ее повторного подключения и повторной синхронизации.Even if a disconnected replica is configured for synchronous-commit mode, transactions will not wait for that replica to reconnect and resynchronize.
По умолчанию период времени ожидания сеанса каждой реплики доступности составляет 10 секунд.The default session-timeout period for each availability replica is 10 seconds. Это значение задается пользователем и не может быть меньше 5 секунд.This value is user-configurable, with a minimum of 5 seconds. Обычно рекомендуется установить период времени ожидания 10 секунд и более.Generally, we recommend that you keep the time-out period at 10 seconds or greater. При установке значения меньше 10 секунд в сильно загруженной системе возникает вероятность ошибочного сообщения об ошибке.Setting the value to less than 10 seconds creates the possibility of a heavily loaded system declaring a false failure.
Примечание
В роли разрешения период времени ожидания сеанса не применяется, поскольку проверка связи не выполняется.In the resolving role, the session-timeout period does not apply because pinging does not occur.
Автоматическое восстановление страницAutomatic page repair
Каждая реплика доступности пытается автоматически восстановиться с учетом поврежденных страниц в локальной базе данных, разрешая определенные типы ошибок, которые предотвращают чтение страницы данных.Each availability replica tries to automatically recover from corrupted pages on a local database by resolving certain types of errors that prevent reading a data page. Если вторичная реплика не может прочитать страницу, реплика запрашивает свежую копию страницы с первичной реплики. If a secondary replica cannot read a page, the replica requests a fresh copy of the page from the primary replica. Если первичная реплика не может прочесть страницу, реплика направляет запрос получения свежей копии для всех вторичных реплик и получает страницу от первой ответившей реплики.If the primary replica cannot read a page, the replica broadcasts a request for a fresh copy to all the secondary replicas and gets the page from the first to respond. Если этот запрос завершился успешно, то нечитаемая страница заменяется копией, в результате чего ошибка обычно устраняется.If this request succeeds, the unreadable page is replaced by the copy, which usually resolves the error.
If a secondary replica cannot read a page, the replica requests a fresh copy of the page from the primary replica. Если первичная реплика не может прочесть страницу, реплика направляет запрос получения свежей копии для всех вторичных реплик и получает страницу от первой ответившей реплики.If the primary replica cannot read a page, the replica broadcasts a request for a fresh copy to all the secondary replicas and gets the page from the first to respond. Если этот запрос завершился успешно, то нечитаемая страница заменяется копией, в результате чего ошибка обычно устраняется.If this request succeeds, the unreadable page is replaced by the copy, which usually resolves the error.
Дополнительные сведения см. в статье Автоматическое восстановление страниц (группы доступности: зеркальное отображение баз данных).For more information, see Automatic Page Repair (Availability Groups: Database Mirroring).
Related contentRelated content
См. также:See Also
Режимы доступности (группы доступности AlwaysOn) Availability Modes (Always On Availability Groups)
Отработка отказа и режимы отработки отказа (группы доступности AlwaysOn) Failover and Failover Modes (Always On Availability Groups)
Общие сведения об инструкциях Transact-SQL для групп доступности AlwaysOn (SQL Server) Overview of Transact-SQL Statements for Always On Availability Groups (SQL Server)
Обзор командлетов PowerShell для групп доступности AlwaysOn (SQL Server) Overview of PowerShell Cmdlets for Always On Availability Groups (SQL Server)
Поддержка высокого уровня доступности в базах данных OLTP в памяти High Availability Support for In-Memory OLTP databases
Предварительные требования, ограничения и рекомендации для групп доступности AlwaysOn (SQL Server) Prerequisites, Restrictions, and Recommendations for Always On Availability Groups (SQL Server)
Создание и настройка групп доступности (SQL Server) Creation and Configuration of Availability Groups (SQL Server)
Активные вторичные реплики: вторичные реплики для чтения (группы доступности Always On) Active Secondaries: Readable Secondary Replicas (Always On Availability Groups)
Активные вторичные реплики: резервное копирование во вторичных репликах (группы доступности Always On) Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups)
Прослушиватели групп доступности, возможность подключения клиентов и отработка отказа приложений (SQL Server)Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server)
Оператор SQL INNER JOIN: синтаксис, примеры
Оператор SQL INNER JOIN формирует таблицу из записей двух или нескольких таблиц. Каждая строка из первой (левой) таблицы, сопоставляется с каждой строкой из второй (правой) таблицы, после чего происходит проверка условия. Если условие истинно, то строки попадают в результирующую таблицу. В результирующей таблице строки формируются конкатенацией строк первой и второй таблиц.
Каждая строка из первой (левой) таблицы, сопоставляется с каждой строкой из второй (правой) таблицы, после чего происходит проверка условия. Если условие истинно, то строки попадают в результирующую таблицу. В результирующей таблице строки формируются конкатенацией строк первой и второй таблиц.
Оператор SQL INNER JOIN имеет следующий синтаксис:
SELECT
column_names [,... n]
FROM
Table_1 INNER JOIN Table_2
ON condition
Условие для сравнения задается в операторе ON.
Примеры оператора SQL INNER JOIN. Имеются две таблицы:
Authors — содержит в себе информацию об авторах книг:
| AuthorID | AuthorName |
| 1 | Bruce Eckel |
| 2 | Robert Lafore |
| 3 | Andrew Tanenbaum |
Books — содержит в себе информацию о названии книг:
| BookID | BookName |
| 3 | Modern Operating System |
| 1 | Thinking in Java |
| 3 | Computer Architecture |
| 4 | Programming in Scala |
В таблице Books поле BookID являются внешним ключом и ссылаются на таблицу Authors.
Пример 1. Используя оператор SQL INNER JOIN вывести на экран, какими авторами были написаны какие из книг:
SELECT * FROM Authors INNER JOIN Books ON Authors.AuthorID = Books.BookID
В данном запросе оператора SQL INNER JOIN условие сравнения — это равенство полей AuthorID и BookID. В результирующую таблицу не попадет книга под названием Programming in Scala, так как значение ее BookID не найдет равенства ни с одной строкой AuthorID.
Результирующая таблица будет выглядеть следующим образом:
| Authors.AuthorID | Authors.AuthorName | Books.BookID | Books.BookName |
| 3 | Andrew Tanenbaum | 3 | Modern Operating System |
| 1 | Bruce Eckel | 1 | Thinking in Java |
| 3 | Andrew Tanenbaum | 3 | Computer Architecture |
Netwrix Data Classification for SQL Server
NEW
Автоматизируйте классификацию данныхНаходите и классифицируйте важную для бизнеса информацию. Избегайте ошибок и непостоянства мануальной классификации данных, исправление которых постоянно требовало бы нескольких часов рабочего времени.
NEW
Получайте точные результаты благодаря семантическому анализуСнизьте количество ложных положительных результатов, используя не только регулярные выражения и ключевые слова, но и статистический анализ.
NEW
Получите первые результаты сразу после установки ПО
Получайте пользу сразу после установки ПО — благодаря преднастроенным правилам классификации для данных, регулируемых GDPR, PCI DSS, HIPAA и другими стандартами вы быстро найдете и сможете защитить эти данные.
NEW
Упростите работу с таксономиямиВы и ваши сотрудники можете самостоятельно создавать и обновлять таксономии, и не придется оплачивать профессиональные услуги каждый раз, когда вам нужно что-то обновить.
NEW
Повышайте точность мета-тэговВаши коллеги смогут легко находить нужную информацию в разных системах, которые подгружают мета-тэги из баз данных. Тэги также помогут улучшить работу других инструментов для защиты данных в БД.
NEW
Получайте актуальные результаты сразу после обновленийПусть ваши коллеги полагаются только на достоверную информацию. При создании нового документа или изменении правил классификации обновленные результаты классификации будут доступны сразу.
NEW
Машинное обучение поможет создавать правила классификацииНаши алгоритмы машинного обучения проанализируют набор данных и определят ключевые слова, чтобы классифицировать похожие документы, и вам не придется дополнительно оплачивать профессиональные услуги по настройке правил классификации.
NEW
Точные результаты благодаря настройке весов каждого ключевика
Пусть правила классификации соответствуют особенностям вашего бизнеса и вашим требованиям. Назначайте веса для каждого ключевого слова, проверяйте результаты классификации и корректируйте значения весов, чтобы получать релевантные результаты.
Назначайте веса для каждого ключевого слова, проверяйте результаты классификации и корректируйте значения весов, чтобы получать релевантные результаты.
NEW
Быстрее находите нужные файлы с помощью функции поискаНаходите информацию, требуемую юридическим отделом, и быстро отвечайте на любые запросы. При этом вам не придется создавать новые правила, и поиск не вызовет сбоев в работе систем.
NEW
Работайте с 50 языкамиИспользуйте одну платформу для автоматизации поиска и классификации данных на вашем языке и языках ваших иностранных клиентов, партнеров, поставщиков, включая франзузский, греческий, корейский, китайский и японский.
NEW
Избегайте сбоев процессов благодаря безагентной работе ПОСнижайте риск сбоев систем и бизнес-процессов. Netwrix Data Classification for SQL Server не использует интрузивные агенты для сбора, анализа, хранения и обновления информации.
listagg in SQL для группировки строк в одну строку
у меня есть таблица 1, показанная ниже
Name role F1 status1 status 2
sam player yes null null
sam admin yes null null
sam guest no x x
я хочу, чтобы результат был
Name role status1 status 2
sam admin,player x x
я сделал запрос к list_agg роли в To one row. but статус null для Сэма, чтобы показать, когда F1=’yes’
but статус null для Сэма, чтобы показать, когда F1=’yes’
запрос, который я использовал
select name,list_agg(role,',') within group(order by name),max(status1),max(status2)
from table 1 where F1='yes'
group by name
но я получаю что-то вроде этого
name role status1 status2
sam admin,player null null
я хочу, чтобы столбец where работал только на role, а max (status1) был в status1 i.e.’x’.please help me .thank you
sql oracle11g listaggПоделиться Источник Eswar Vignesh 27 мая 2016 в 05:51
2 ответа
- Listagg + Count в некоторых дубликатов
Я пишу запрос и, похоже, не могу преодолеть это препятствие. Я использую в нем как LISTAGG, так и COUNT (side-by-side), и всякий раз, когда я это делаю, ListAgg будет дублироваться, когда count больше 1. Более того, он добавляет больше в count, когда ListAgg больше единицы. Каждый из них путается…
- Форматирование строк с использованием LISTAGG в Oracle. Экранирование одинарной кавычки ` ‘ `
Как я могу отформатировать вывод listagg в Oracle, чтобы получить вывод(каждое поле в одинарной кавычке) как ‘student1’, ‘student2’, ‘student3’ . Я просмотрел документацию и другие вопросы по listagg, но не могу найти много. SQL запрос для объединения значений столбцов из нескольких строк в Oracle…
2
Вы можете попробовать использовать LISTAGG() в запросе GROUP BY :
SELECT Name,
LISTAGG(Role, ',') WITHIN GROUP (ORDER BY Role) "Role"
MAX(CASE WHEN water_access = 'Y' THEN 'Y' ELSE NULL END) "water_access",
MAX(CASE WHEN food_access = 'Y' THEN 'Y' ELSE NULL END) "food_access",
MAX(CASE WHEN power_access = 'Y' THEN 'Y' ELSE NULL END) "power_access"
FROM yourTable
GROUP BY Name
ORDER BY Name DESC
Обратите внимание , что я решил упорядочить агрегацию каждой группы Name с помощью Role, потому что вы не предоставили нам ни одного столбца, который мог бы дать порядок, который вы показываете в своем ожидаемом выводе.
Второе примечание: MAX() в Oracle игнорирует значения NULL , поэтому его можно использовать в pivot для правильного определения значений Y , которые вы хотите отобразить.
Поделиться Tim Biegeleisen 27 мая 2016 в 06:00
1
попробуйте это…
select * from table_name pivot(sum(name) for role
Поделиться Dheerendra Yadav 27 мая 2016 в 06:00
Похожие вопросы:
Функция Listagg с коллекцией PLSQL
У меня есть коллекция PL/SQL следующего типа type p_typ_str_tab is table of varchar2(4000) index by pls_integer; Я хотел бы объединить значения в одну строку с помощью простой встроенной функции,…
Функция LISTAGG: «результат конкатенации строк слишком длинный»
Я использую Oracle SQL developer version 3.0.04. Я попытался использовать функцию LISTAGG для группировки данных.. CREATE TABLE FINAL_LOG AS SELECT SESSION_DT, C_IP, CS_USER_AGENT, listagg(WEB_LINK,…
Предел LISTAGG приводит к Oracle
Я пытаюсь ограничить один из моих столбцов в моем запросе SQL, который использует LISTAGG только для группировки первых 3 строк в один столбец. Например: Table —— Name Orders ————— Joe…
Listagg + Count в некоторых дубликатов
Я пишу запрос и, похоже, не могу преодолеть это препятствие. Я использую в нем как LISTAGG, так и COUNT (side-by-side), и всякий раз, когда я это делаю, ListAgg будет дублироваться, когда count…
Форматирование строк с использованием LISTAGG в Oracle. Экранирование одинарной кавычки ` ‘ `
Как я могу отформатировать вывод listagg в Oracle, чтобы получить вывод(каждое поле в одинарной кавычке) как ‘student1’, ‘student2’, ‘student3’ . Я просмотрел документацию и другие вопросы по…
Я просмотрел документацию и другие вопросы по…
Oracle sql использование подзапроса для группировки результатов нескольких строк в одну строку
Я использовал LISTAGG, который кто-то здесь помог, но после нескольких полей выбора я начал получать ошибку ORA. Я бы предпочел использовать подзапрос Oracle для группировки результатов нескольких…
oracle LISTAGG группировка результатов нескольких строк в одну строку не работает. ORA-00909
Я видел здесь сообщение, чтобы использовать LISTAGG для группировки нескольких строк в одну строку под 1 столбцом, я посмотрел на пример сообщения и веб-сайт oracle, но я не могу заставить запрос…
функция listagg без group by
У меня есть много столбцов в операторе select , многие из которых являются производными вычислениями. Я пытаюсь сгруппировать несколько строк в одну, используя listagg() в операторе select , но без…
Как объединить несколько строк в SQL (oracle), используя LISTAGG и несколько столбцов?
У меня есть оператор SQL, который возвращает данные, которые выглядят следующим образом: SOURCEDID ORGSOURCEDIDS ROLE USERNAME EMAIL GIVENNAME FAMILYNAME 123456 0 teacher test.teacher@ test.teacher@…
SQL запрос LISTAGG не создает объединенную строку
Я пытаюсь создать объединенную строку значений на основе строк с использованием Oracle LISTAGG. Вот упрощенный код, который все еще демонстрирует проблему, которую я пытаюсь решить. SELECT…
dbForge Index Manager for SQL Server — лицензия, русская версия, цена
dbForge Index Manager for SQL Server — представляет собой удобную SSMS надстройку для анализа состояния индексов SQL и устранения проблем с фрагментацией индекса. Инструмент позволяет быстро собирать статистику фрагментации индексов и обнаружения баз данных, которые требуют технического обслуживания. Вы можете моментально восстановить и реорганизовать индексы SQL в визуальном режиме или генерировать SQL скрипт для будущего использования.
Сколько стоит купить лицензию, варианты поставки
- Артикул: 300696595
- НДС: 20 % (включен в стоимость)
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Включает техническую поддержку на 1 год
- Платформа: Windows/Linux/Mac OS
- Тип лицензии: Постоянная
- Тип покупателя: Коммерческая
- Доступна оплата картой
- Артикул: 300696605
- НДС: 20 % (включен в стоимость)
- Тип поставки: Электронная (e-mail)
- Язык (версия): Русский/Английский
- Срок поставки лицензионной программы или ключа активации: 3-14 рабочих дней
- Примечания: Продление технической поддержки на 1 год
- Платформа: Windows/Linux/Mac OS
- Тип лицензии: Продление
- Срок действия лицензии:
12 мес.
- Тип покупателя: Коммерческая
- Оплата картой недоступна
- Только для юр. лиц и ИП
SQL присоединяется к
SQL ПРИСОЕДИНЯТЬСЯ
Предложение JOIN используется для объединения строк из двух или более таблиц на основе
связанный столбец между ними.
Рассмотрим выборку из таблицы «Заказы»:
| Код заказа | Идентификатор клиента | Дата заказа |
|---|---|---|
| 10308 | 2 | 1996-09-18 |
| 10309 | 37 | 1996-09-19 |
| 10310 | 77 | 1996-09-20 |
Затем посмотрите на выбор из таблицы «Клиенты»:
| Идентификатор клиента | Имя клиента | ContactName | Страна |
|---|---|---|---|
| 1 | Альфредс Футтеркисте | Мария Андерс | Германия |
| 2 | Ana Trujillo Emparedados y helados | Ана Трухильо | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Мексика |
Обратите внимание, что столбец «CustomerID» в таблице «Заказы» относится к
«CustomerID» в таблице «Клиенты». Связь между двумя таблицами выше
столбец «CustomerID».
Связь между двумя таблицами выше
столбец «CustomerID».
Затем мы можем создать следующий оператор SQL (который содержит ВНУТРЕННЕЕ СОЕДИНЕНИЕ ),
который выбирает записи, которые имеют совпадающие значения в обеих таблицах:
Пример
ВЫБЕРИТЕ Orders.OrderID, Customers.CustomerName, Orders.OrderDate
ИЗ Orders
ВНУТРЕННИЕ СОЕДИНЯЙТЕСЬ с клиентами НА Orders.CustomerID = Customers.CustomerID;
, и он выдаст что-то вроде этого:
| Код заказа | Имя клиента | Дата заказа |
|---|---|---|
| 10308 | Ana Trujillo Emparedados y helados | 18.09.1996 |
| 10365 | Антонио Морено Такерия | 27.11.1996 |
| 10383 | Вокруг Рога | 16.12.1996 |
| 10355 | Вокруг Рога | 15.11.1996 |
| 10278 | Berglunds snabbköp | 12.08.1996 |
Различные типы SQL JOIN
Вот различные типы JOIN в SQL:
-
(INNER) JOIN: возвращает записи, которые имеют совпадающие значения в обеих таблицах -
LEFT (OUTER) JOIN: возвращает все записи из левой таблицы и соответствующие записи из правой таблицы -
RIGHT (OUTER) JOIN: возвращает все записи из правой таблицы и сопоставленных записи из левой таблицы -
ПОЛНОЕ (ВНЕШНЕЕ) СОЕДИНЕНИЕ: возвращает все записи, если есть совпадение в любом из левых или правый стол
Разница между WHERE и ON в данных SQL для JOIN
Последнее изменение: 5 апреля 2021 г.
Есть ли разница между предложением WHERE и ON?
Да.ON следует использовать для определения условия соединения, а WHERE следует использовать для фильтрации данных. Я использовал слово «должен», потому что это не жесткое правило. Разделение этих целей с соответствующими предложениями делает запрос наиболее читаемым, а также предотвращает получение неверных данных при использовании типов JOIN, отличных от INNER JOIN.
Я использовал слово «должен», потому что это не жесткое правило. Разделение этих целей с соответствующими предложениями делает запрос наиболее читаемым, а также предотвращает получение неверных данных при использовании типов JOIN, отличных от INNER JOIN.
Чтобы углубиться в подробности, мы рассмотрим два варианта использования, которые могут поддерживаться WHERE или ON:
- Объединение данных
- Данные фильтрации
Объединение данных
Оба этих предложения могут использоваться для объединения данных путем определения условия, при котором две таблицы объединяются.Чтобы продемонстрировать это, давайте воспользуемся примером набора данных друзей facebook и подключений linkedin.
Мы хотим видеть людей, которые являются нашими друзьями и связующим звеном. Так что в данном случае это будет только Мэтт. Теперь давайте сделаем запрос, используя различные определения условия JOIN.
Все три запроса дают одинаковый правильный результат:
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
ГДЕ facebook.name = linkedin.name
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name
Первые два — это типы явного соединения, а последний — неявное соединение. Явное JOIN явно сообщает вам, как присоединиться к данным, указав тип JOIN и условие соединения в предложении ON. Неявное JOIN не указывает тип JOIN и не использует предложение WHERE для определения условия соединения.
Читаемость
Основное различие между этими запросами заключается в том, насколько легко понять, что происходит.В первом запросе мы можем легко увидеть, как таблицы соединяются в предложениях FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем дважды взглянуть на предложение WHERE, поскольку оно обычно используется для фильтрации данных, а не для присоединения к ним. В последнем запросе мы должны внимательно посмотреть, как установить, к какой таблице присоединяются, и как они присоединяются.
В последнем запросе мы должны внимательно посмотреть, как установить, к какой таблице присоединяются, и как они присоединяются.
Последний запрос использует так называемое неявное СОЕДИНЕНИЕ (СОЕДИНЕНИЕ, которое явно не указано в запросе.В большинстве случаев неявные СОЕДИНЕНИЯ будут действовать как ВНУТРЕННИЕ СОЕДИНЕНИЯ. Если вы хотите использовать JOIN, отличное от INNER JOIN, заявив, что это явно проясняет, что происходит.
ПРИСОЕДИНЕНИЕ к предложению WHERE может вызвать путаницу, поскольку это не типичная цель. Чаще всего используется для фильтрации данных. Поэтому, когда к предложению WHERE добавляются дополнительные условия фильтрации в дополнение к его использованию для определения того, как ПРИСОЕДИНЯТЬСЯ к данным, становится труднее понять.
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name И (facebook.name = Matt OR linkedin.city = "SF")
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.name = Мэтт ИЛИ linkedin.city = "SF"
Хотя в первом запросе меньше символов, чем во втором, его не так легко понять.
Оптимизация
Иногда написание запроса другим способом может улучшить скорость. Однако в этом случае не должно быть преимуществ в скорости из-за того, что называется планом запроса.План запроса — это код, который SQL предлагает для выполнения запроса. Он принимает запрос, а затем создает оптимизированный способ поиска данных. Использование WHERE или ON для JOIN данных должно привести к тому же плану запроса.
Однако способ создания планов запросов может различаться в зависимости от языка и версии SQL, опять же, в этом случае все должно быть одинаковым, но вы можете протестировать его в своей базе данных, чтобы увидеть, повысится ли производительность. Будьте осторожны, чтобы кеширование не повлияло на результаты ваших запросов.
Фильтрация данных
И предложение ON, и предложение WHERE можно использовать для фильтрации данных в запросе. Есть проблемы с удобочитаемостью и точностью, которые нужно решить с помощью фильтрации в предложении ON. Давайте воспользуемся немного большим набором данных, чтобы продемонстрировать это.
Есть проблемы с удобочитаемостью и точностью, которые нужно решить с помощью фильтрации в предложении ON. Давайте воспользуемся немного большим набором данных, чтобы продемонстрировать это.
На этот раз мы ищем людей, которые являются нашими друзьями и связями, но мы хотим видеть только тех, кто также живет в Сан-Франциско.
Читаемость
Давайте оценим, насколько удобочитаема каждая опция, эти два запроса дадут одинаковый результат:
ВЫБРАТЬ *
ПРИСОЕДИНЯЙТЕСЬ linkedin
На Фейсбуке.name = linkedin.name
ГДЕ facebook.city = 'SF'
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
Первый запрос понятен, каждое предложение имеет свое назначение. Второй запрос труднее понять, потому что предложение ON используется как для СОЕДИНЕНИЯ данных, так и для их фильтрации.
Точность
Фильтрация в предложении ON может привести к неожиданным результатам при использовании LEFT, RIGHT или OUTER JOIN.Эти два запроса не дадут одинаковый результат:
ВЫБРАТЬ *
С Фейсбука
LEFT JOIN linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.city = 'SF'
В LEFT JOIN он вводит каждую строку из первой таблицы «facebook» и присоединяется везде, где истинно условие соединения (facebook.name = linkedin.name), это будет верно как для Мэтта, так и для Дэйва. Так и была бы промежуточная таблица.
Затем предложение WHERE фильтрует эти результаты в строки, где facebook.city = ‘SF’, оставив одну строку.
ВЫБРАТЬ *
С Фейсбука
LEFT JOIN linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
В этом запросе другое условие соединения. LEFT JOIN вводит каждую строку, а данные, которые присоединяются из linkedin, происходят только тогда, когда facebook.name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых не было facebook. city = ‘SF’
city = ‘SF’
Оптимизация
Здесь возможны вариации в том, как строится план запроса, поэтому может быть полезно попробовать фильтрацию в ON.Некоторые языки SQL могут фильтровать при объединении, а другие могут ждать, пока будет построена полная таблица, перед фильтрацией. Первый план будет быстрее.
Сводка
Разделяйте контекст между , соединяющим таблицы, и , фильтрующим объединенную таблицу. Он наиболее читаемый, с наименьшей вероятностью может быть неточным и не должен быть менее производительным.
- Данные JOIN в ON
- Данные фильтра в ГДЕ
- Напишите явные JOIN, чтобы сделать ваш запрос более читаемым
- Отфильтруйте данные в предложении WHERE вместо JOIN, чтобы убедиться, что они правильные и читаемые
- У разных языков SQL могут быть разные планы запросов на основе фильтрации в предложении ON и в предложении WHERE, поэтому проверьте производительность в своей базе данных.
Написано:
Мэтт Дэвид
Проверено:
В чем разница между «ON» и «WHERE» в операторе соединения в SQL / MySQL?
- ON применяется к набору, используемому для создания перестановок каждой записи как часть операции JOIN
- WHERE указывает фильтр, примененный после операции JOIN
Фактически, ON заменяет каждое поле, которое не удовлетворяет своему условию, на NULL.Учитывая пример @Quassnoi
подарков
1 плюшевый мишка
2 цветы
подарки
1 Алиса
1 Боб
---
ВЫБРАТЬ *
ОТ подарков г
ВЛЕВО ПРИСОЕДИНИТЬСЯ
Sengifts SG
НА g.giftID = sg.giftID
---
Перестановки LEFT JOIN были бы вычислены для следующих коллекций, если бы не было условия ON:
{'Плюшевый мишка': {'ALICE', 'Bob'}, 'Flowers': {'ALICE', 'Bob'}}
с условием g.giftID = sg.giftID ON, это коллекции, которые будут использоваться для создания перестановок:
{'Плюшевый мишка': {'ALICE', 'Боб'}, 'Цветы': {NULL, NULL}}
, который на самом деле:
{'Плюшевый мишка': {'ALICE', 'Боб'}, 'Цветы': {NULL}}
, и в результате получается ЛЕВОЕ СОЕДИНЕНИЕ:
Мишка Тедди Алиса
Плюшевый мишка Боб
Цветы NULL
, а для ПОЛНОГО ВНЕШНЕГО СОЕДИНЕНИЯ у вас будет:
{'Teddy bear': {'ALICE', 'Bob'}, 'Flowers': {NULL}} для LEFT JOIN и {'ALICE': {'Teddy bear', NULL}, 'Flowers': {'Teddy bear', NULL}} для RIGHT JOIN:
Мишка Тедди Алиса
Плюшевый мишка Боб
Цветы NULL
Если у вас также было условие, такое как ON g. это будет giftID = 1
giftID = 1
{NULL: {'ALICE', 'Bob'}, 'Flowers': {NULL}}
, что для LEFT JOIN приведет к
Цветы NULL
и для ПОЛНОГО ВНЕШНЕГО СОЕДИНЕНИЯ приведет к {NULL: {'ALICE', 'Bob'}, 'Flowers': {NULL}} для LEFT JOIN и {'ALICE': {NULL, NULL}, 'Flowers': {NULL, NULL}} для RIGHT JOIN
NULL Алиса
NULL Боб
Цветы NULL
Примечание MySQL не имеет ПОЛНОГО ВНЕШНЕГО СОЕДИНЕНИЯ, и вам необходимо применить UNION к LEFT JOIN и RIGHT JOIN
join — Что означает ON в SQL?
join — Что означает ON в SQL? — Переполнение стекаПрисоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено 437 раз
Закрыт .Этот вопрос должен быть более конкретным. В настоящее время он не принимает ответы.Хотите улучшить этот вопрос? Обновите вопрос, чтобы он фокусировался только на одной проблеме, отредактировав это сообщение.
Закрыт в прошлом году.
Я только начинаю изучать SQL .Может кто-нибудь объяснить, что означает ON в примере?
ВЫБРАТЬ заголовок, imdb_score
ИЗ фильмов
ПРИСОЕДИНЯЙТЕСЬ к отзывам
НА movies.id = reviews.film_id
ГДЕ title = 'Убить пересмешника';
Создан 30 янв.
2НА пленки.id = reviews.film_id
Чтобы указать JOIN condition. С предложением ON вы точно указываете, в каком столбце вы хотите сопоставить обе записи таблицы. Вы также можете указать дополнительные условия, например
НА movies.id = reviews.film_id
И <дополнительное условие>
Создан 30 янв.
РахулРахул71.1k1313 золотых знаков5656 серебряных знаков104104 бронзовых знака
«ВКЛ» показывает связь между таблицами. Для вашего примера основная таблица — это «фильмы», и вы хотите вывести данные из таблицы «обзоры». Если вы не укажете компьютеру, как подключать данные, он не сможет узнать, у какого фильма есть обзоры. Вы говорите, что идентификаторы одинаковы для обеих этих таблиц, когда вы используете ‘ON’
Создан 30 янв.
Это условие соединения.В вашем примере вы получите title и imdb_score из этих строк из фильмов и обзоров , которые имеют одинаковые id и film_id .
https://www.geeksforgeeks.org/sql-on-clause/
Создан 30 янв.
Я бы добавил для лучшей читаемости ON рядом с названием таблицы, к которой вы хотите присоединиться
ВЫБРАТЬ заголовок, imdb_score
ИЗ фильмов
ПРИСОЕДИНЯЙТЕСЬ к обзорам фильмов.id = reviews.film_id
ГДЕ title = 'Убить пересмешника';
Создан 30 янв.
Wevaya1111 бронзовый знак
Не тот ответ, который вы ищете? Посмотрите другие вопросы с метками sql join или задайте свой вопрос.
lang-sql
Stack Overflow лучше всего работает с включенным JavaScriptВаша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie Настроить параметры
Пошаговое руководство по SQL Inner Join
Организации генерируют и анализируют непревзойденные объемы данных каждую минуту.В этой статье мы продемонстрируем, как мы можем использовать SQL Inner Join для запроса и доступа к данным из нескольких таблиц, которые хранят эти непрерывно растущие данные в базах данных SQL.
SQL присоединяется к
Прежде чем мы начнем с SQL Inner Join, я хотел бы вызвать здесь SQL Join. Присоединение — это широко используемое предложение в SQL Server, по сути, для объединения и извлечения данных из двух или более таблиц. В реальной реляционной базе данных данные структурированы в виде большого количества таблиц, поэтому существует постоянная потребность в объединении этих нескольких таблиц на основе логических отношений между ними.В SQL Server существует четыре основных типа объединений — внутреннее, внешнее (левое, правое, полное), самостоятельное и перекрестное соединение. Чтобы получить краткий обзор всех этих объединений, я бы порекомендовал пройти по этой ссылке, обзору типов соединений SQL и руководству.
Эта статья посвящена внутреннему соединению в SQL Server, так что давайте перейдем к ней.
Определение внутреннего соединения SQL
Предложение Inner Join в SQL Server создает новую таблицу (не физическую) путем объединения строк, имеющих совпадающие значения в двух или более таблицах.Это соединение основано на логической связи (или общем поле) между таблицами и используется для извлечения данных, которые появляются в обеих таблицах.
Предположим, у нас есть две таблицы, Таблица A и Таблица B, которые мы хотели бы объединить с помощью SQL Inner Join. Результатом этого соединения будет новый набор результатов, который возвращает совпадающие строки в обеих этих таблицах. В части пересечения, выделенной черным цветом ниже, показаны данные, полученные с помощью внутреннего соединения в SQL Server.
Результатом этого соединения будет новый набор результатов, который возвращает совпадающие строки в обеих этих таблицах. В части пересечения, выделенной черным цветом ниже, показаны данные, полученные с помощью внутреннего соединения в SQL Server.
Синтаксис внутреннего соединения SQL Server
Ниже приведен базовый синтаксис Inner Join.
SELECT Column_list
FROM TABLE1
INNER JOIN TABLE2
ON Table1.ColName = Table2.ColName
Синтаксис внутреннего соединения в основном сравнивает строки таблицы 1 с таблицей 2, чтобы проверить, совпадает ли что-либо, на основе условия, указанного в предложении ON. Когда условие соединения выполнено, оно возвращает совпадающие строки в обеих таблицах с выбранными столбцами в предложении SELECT.
Предложение SQL Inner Join аналогично предложению Join и работает таким же образом, если мы не указываем тип (INNER) при использовании предложения Join.Короче говоря, Inner Join — это ключевое слово по умолчанию для Join, и оба могут использоваться взаимозаменяемо.
Примечание. В этой статье мы будем использовать ключевое слово «внутреннее» присоединение для большей ясности. Вы можете опустить его при написании запросов, а также можете использовать только «Присоединиться».
Внутреннее соединение SQL в действии
Давайте попробуем понять концепцию внутреннего соединения с помощью интересной выборки данных, касающейся пиццерии и ее распределения.Сначала я собираюсь создать две таблицы — таблицу PizzaCompany, которая управляет различными филиалами пиццерий в нескольких городах, и таблицу Foods, в которой хранятся данные о распределении продуктов питания в этих компаниях. Вы можете выполнить приведенный ниже код, чтобы создать и заполнить данные в этих двух таблицах. Все эти данные являются гипотетическими, и их можно создать в любой из существующих баз данных.
СОЗДАТЬ ТАБЛИЦУ [dbo]. [PizzaCompany] ( [CompanyId] [int] IDENTITY (1,1) PRIMARY KEY CLUSTERED, [CompanyName] [varchar] (50), [CompanyCity] [ varchar] (30) ) УСТАНОВИТЬ IDENTITY_INSERT [dbo].[PizzaCompany] ВКЛ; ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (1, ‘Dominos’, ‘Los Angeles’); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (2, «Pizza Hut», «Сан-Франциско»); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (3, ‘Papa johns’, ‘San Diego’); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (4, ‘Ah Pizz’, ‘Fremont’); ВСТАВИТЬ В [dbo].[PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) ЗНАЧЕНИЯ (5, «Нино Пицца», «Лас-Вегас»); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (6, ‘Пиццерия’, ‘Бостон’); ВСТАВИТЬ В [dbo]. [PizzaCompany] ([CompanyId], [CompanyName], [CompanyCity]) VALUES (7, ‘chuck e cheese’, ‘Chicago’); ВЫБРАТЬ * ОТ PizzaКомпания: |
Вот так выглядят данные в таблице PizzaCompany:
Давайте сейчас создадим и заполним таблицу Foods.CompanyID в этой таблице — это внешний ключ, который ссылается на первичный ключ таблицы PizzaCompany, созданной выше.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 | СОЗДАТЬ ТАБЛИЦУ [dbo].[Foods] ( [ItemId] INT PRIMARY KEY CLUSTERED, [ItemName] Varchar (50), [UnitsSold] int, CompanyID int, FOREIGN KEY (CompanyID) REFERENCES Pizza ) ВСТАВИТЬ [dbo]. INSERT INTO [dbo ]. [Продукты] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES (2, ‘Garlic Knots’, 6,3) ВСТАВИТЬ В [dbo].[Еда] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (3, ‘Большая пицца’, 3,3) ВСТАВИТЬ В [dbo]. [Foods] ([ItemId], [ ItemName], [UnitsSold], [CompanyId]) VALUES (4, ‘Средняя пицца’, 8,4) INSERT INTO [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId ]) VALUES (5, ‘Breadsticks’, 7,1) INSERT INTO [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId] »VALUES (6, ‘Medium Pizza’) , 11,1) INSERT INTO [dbo]. [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) VALUES (7, ‘Маленькая пицца’, 9,6) INSERT INTO [dbo].[Еда] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (8, ‘Маленькая пицца’, 6,7) ВЫБРАТЬ * ИЗ Foods |
 [Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (1, ‘Large Pizza’, 5,2)
[Foods] ([ItemId], [ItemName], [UnitsSold], [CompanyId]) ЗНАЧЕНИЯ (1, ‘Large Pizza’, 5,2)В следующей таблице показаны данные из таблицы «Продукты питания». В этой таблице хранится такая информация, как количество проданных единиц продукта питания, а также точка доставки пиццы (CompanyId), которая ее доставляет.
Теперь, если мы хотим увидеть предметы, а также единицы, проданные каждой пиццерией, мы можем объединить эти две таблицы с помощью предложения внутреннего соединения, используемого в поле CompanyId (в нашем случае это имеет отношение внешнего ключа ).
SELECT pz.CompanyCity, pz.CompanyName, pz.CompanyId AS PizzaCompanyId, f.CompanyID AS FoodsCompanyId, f.ItemName, f.UnitsSold FROM PizzaCompany pz INNER JOIN Foods f CompanyId |
Ниже приведен набор результатов указанного выше запроса SQL Inner Join. Для каждой строки в таблице PizzaCompany функция Inner Join сравнивает и находит совпадающие строки в таблице Foods и возвращает все совпадающие строки, как показано ниже. И если вы заметили, CompanyId = 5 исключается из результата запроса, так как он не соответствует в таблице Foods.
С помощью приведенного выше набора результатов мы можем различить товары, а также количество товаров, доставленных пиццериями в разных городах. Например, Dominos доставил в Лос-Анджелес 7 хлебных палочек и 11 средних пицц.
Внутреннее соединение SQL для трех таблиц
Давайте подробнее рассмотрим это объединение и предположим, что в штате открываются три аквапарка (похоже, летом), и эти аквапарки передают еду на аутсорсинг в пиццерии, упомянутые в таблице PizzaCompany.
Я собираюсь быстро создать таблицу WaterPark и загрузить в нее произвольные данные, как показано ниже.
СОЗДАТЬ ТАБЛИЦУ [dbo]. [WaterPark] ( [WaterParkLocation] VARCHAR (50), [CompanyId] int, FOREIGN KEY (CompanyID) ССЫЛКИ PizzaSCompany (CompanyID) IN [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Улица 14’, 1)ВСТАВИТЬ В [dbo].[WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Бульвар 2’, 2) ВСТАВИТЬ [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Rogers 54’, 4) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Street 14’, 3) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Rogers 54’, 5) ВСТАВИТЬ В [dbo]. [WaterPark] ([WaterParkLocation], [CompanyId]) ЗНАЧЕНИЯ (‘Boulevard 2’, 5) ВЫБРАТЬ * ИЗ WaterPark |
И ниже вывод этой таблицы.
Как говорится, картина стоит тысячи слов. Давайте быстро посмотрим на схему базы данных этих трех таблиц с их взаимосвязями, чтобы лучше понять их.
Теперь мы собираемся включить эту третью таблицу в предложение SQL Inner Join, чтобы увидеть, как это повлияет на набор результатов. Согласно данным в таблице «Аквапарк», три аквапарка передают еду на аутсорсинг всем пиццериям, кроме пиццерии (Id = 6) и Chuck e Cheese (Id = 7).Выполните приведенный ниже код, чтобы увидеть, как распределяется еда в аквапарках у точек Pizza.
Согласно данным в таблице «Аквапарк», три аквапарка передают еду на аутсорсинг всем пиццериям, кроме пиццерии (Id = 6) и Chuck e Cheese (Id = 7).Выполните приведенный ниже код, чтобы увидеть, как распределяется еда в аквапарках у точек Pizza.
SELECT pz.CompanyId, pz.CompanyCity, pz.CompanyName, f.ItemName, f.UnitsSold, w.WaterParkLocation ОТ PizzaCompany pz INNER JOIN Foodpanys f ON pz.CompanyId = ПРИСОЕДИНЯЙТЕСЬ к аквапарку w.CompanyId = pz.CompanyId ЗАКАЗАТЬ pz.CompanyId |
На основе CompanyId SQL Inner Join сопоставляет строки в обеих таблицах, PizzaCompany (Таблица 1) и Foods (Таблица 2), а затем ищет совпадение в WaterPark (Таблица 3), чтобы вернуть строки.Как показано ниже, с добавлением внутреннего соединения в WaterPark, CompanyId (6,7 (кроме 5)) также исключается из окончательного набора результатов, поскольку условие w.CompanyId = pz.CompanyId не выполняется для идентификаторов (6, 7). Вот как внутреннее соединение SQL помогает возвращать определенные строки данных из нескольких таблиц.
Давайте углубимся в SQL Inner Join, добавив еще несколько предложений T-SQL.
Использование WHERE с внутренним соединением
Мы можем фильтровать записи на основе указанного условия, когда внутреннее соединение SQL используется с предложением WHERE.Предположим, мы хотели бы получить строки, в которых проданных единиц было больше 6.
В следующем запросе предложение WHERE добавляется для извлечения результатов со значением более 6 для проданных единиц.
SELECT pz.CompanyId, pz.CompanyCity, pz.CompanyName, f.ItemName, f.UnitsSold FROM PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId WHERE f.U ЗАКАЗАТЬ pz.КомпанияCity |
Выполните приведенный выше код в SSMS, чтобы увидеть результат ниже. Этот запрос возвращает четыре таких записи.
Этот запрос возвращает четыре таких записи.
Использование Group By с внутренним соединением
SQL Inner Join позволяет нам использовать предложение Group by вместе с агрегатными функциями для группировки набора результатов по одному или нескольким столбцам. Группировать по обычно работает с внутренним объединением по окончательному результату, возвращаемому после объединения двух или более таблиц. Если вы не знакомы с предложением Group by в SQL, я бы посоветовал пройти через это, чтобы быстро понять эту концепцию.Ниже приведен код, в котором используется предложение Group By с внутренним соединением.
SELECT pz.CompanyCity, pz.CompanyName, SUM (f.UnitsSold) AS TotalQuantitySold FROM PizzaCompany pz INNER JOIN Foods f ON pz.CompanyId = f.CompanyId GROUP BY pz.CompanyCity ЗАКАЗАТЬ pz.CompanyCity |
Здесь мы собираемся получить общее количество товаров, проданных каждой пиццерией, присутствующей в городе.Как видно ниже, агрегированный результат в столбце «totalquantitysold» равен 18 (7 + 11) и 9 (6 + 3) для Лос-Анджелеса и Сан-Диего соответственно.
Краткое описание Equi и Theta Join
Прежде чем мы закончим эту статью, давайте быстро рассмотрим термины, которые разработчик SQL может время от времени слышать — Equi и Theta Join.
Equi Присоединиться
Как следует из названия, equi join содержит оператор равенства ‘=’ либо в предложении Join, либо в условии WHERE.SQL Inner, Left, Right — все равнозначные соединения, когда оператор «=» используется в качестве оператора сравнения. Обычно, когда упоминается внутреннее соединение SQL, оно рассматривается как внутреннее равное соединение, только в необычной ситуации оператор равенства не используется.
Чтобы упростить задачу, я собираюсь обратиться к образцу базы данных AdventureWorksDW2017 и запустить запрос к существующим таблицам, чтобы продемонстрировать, как выглядит равное соединение.
ВЫБРАТЬ e.EmployeeKey, e.FirstName, e.Title, e.HireDate, fs.SalesAmountQuota ОТ DimEmployee e INNER JOIN FactSalesQuota fs ON e.EmployeeKey = fs.Employee22Key |
Theta Join (Неравномерное соединение)
Неравномерное соединение в основном противоположно равнозначному соединению и используется, когда мы соединяемся с условием, отличным от оператора «=». На практике этот тип используется редко. Ниже приведен пример, в котором используется тета-соединение с оператором неравенства (<) для оценки прибыли путем оценки себестоимости и продажных цен в двух таблицах.
ВЫБРАТЬ * ИЗ Таблица1 T1, Таблица2 T2 ГДЕ T1.ProductCost |
Заключение
Я надеюсь, что эта статья о «Внутреннем соединении SQL» обеспечивает понятный подход к одному из важных и часто используемых предложений — «Внутреннее соединение» в SQL Server для объединения нескольких таблиц. Если у вас есть какие-либо вопросы, не стесняйтесь задавать их в разделе комментариев ниже.
Чтобы продолжить изучение SQL-соединений, вы можете обратиться к сообщениям ниже:
Гаури является специалистом по SQL Server и имеет более 6 лет опыта работы с международными международными консалтинговыми и технологическими организациями. Она очень увлечена работой над темами SQL Server, такими как База данных SQL Azure, Службы отчетов SQL Server, R, Python, Power BI, ядро базы данных и т. Д. Она имеет многолетний опыт работы с технической документацией и увлекается разработкой технологий. Она имеет большой опыт в разработке решений для данных и аналитики, а также в обеспечении их стабильности, надежности и производительности. Она также сертифицирована по SQL Server и прошла такие сертификаты, как 70-463: Внедрение хранилищ данных с Microsoft SQL Server.
Посмотреть все сообщения от Gauri Mahajan
Последние сообщения от Gauri Mahajan (посмотреть все)Разница между предложением JOIN .. ON в SQL и предложением Where — Java, SQL и jOOQ.
Среди участников моего тренинга по SQL часто возникает вопрос:
В чем разница между помещением предиката в
JOIN.. Пункт ONи пунктWHERE?
Я определенно вижу, как это сбивает с толку некоторых людей, так как кажется, что на первый взгляд не имеет разницы при выполнении таких запросов, например в Oracle. Я, как всегда, использую базу данных Sakila:
- Первый запрос ВЫБЕРИТЕ a.actor_id, a.first_name, a.last_name, count (fa.film_id) ОТ АКТЕРА ПРИСОЕДИНЯЙТЕСЬ film_actor fa ON a.actor_id = fa.actor_id ГДЕ fa.film_id <10 ГРУППА ПО a.идентификатор_актера, a.first_name, a.last_name ORDER BY count (fa.film_id) DESC;
Это даст что-то вроде:
ACTOR_ID FIRST_NAME LAST_NAME COUNT -------------------------------------- 108 УОРРЕН НОЛТ 3 162 ОПРА КИЛМЕР 3 19 БОБ ФАВСЕТ 2 10 ХРИСТИАНСКИЙ ДВИГАТЕЛЬ 2 53 ХРАМ МЕНА 2 137 МОРГАН УИЛЬЯМС 1 2 НИК ВАЛЬБЕРГ 1
Конечно, мы могли бы написать это вместо этого и получить тот же результат:
- Второй запрос Выберите.идентификатор_актера, a.first_name, a.last_name, count (fa.film_id) ОТ АКТЕРА ПРИСОЕДИНЯЙТЕСЬ film_actor fa ON a.actor_id = fa.actor_id И fa.film_id <10 ГРУППА ПО a.actor_id, a.first_name, a.last_name ORDER BY count (fa.film_id) DESC;
Теперь я переместил фильтр FILM_ID <10 из предложения WHERE в предложение ON . Но план выполнения одинаков для обоих запросов:
-------------------------------------------------- -------
| Id | Операция | Имя | Ряды |
-------------------------------------------------- -------
| 0 | ВЫБРАТЬ ЗАЯВЛЕНИЕ | | 49 |
| 1 | СОРТИРОВАТЬ ЗАКАЗ ПО | | 49 |
| 2 | ХЭШ ГРУППА ПО | | 49 |
| * 3 | HASH JOIN | | 49 |
| * 4 | ИНДЕКС БЫСТРО ПОЛНОЕ СКАНИРОВАНИЕ | PK_FILM_ACTOR | 49 |
| 5 | ПРОСМОТР | VW_GBF_7 | 200 |
| 6 | ДОСТУП К ТАБЛИЦЕ ПОЛНЫЙ | АКТЕР | 200 |
-------------------------------------------------- -------
Информация о предикате (определяется идентификатором операции):
-------------------------------------------------- -
3 - доступ ("ITEM_1" = "FA".«ACTOR_ID»)
4 - фильтр («FA». «FILM_ID» <10)
Это вообще не имеет значения. Оба запроса дают один и тот же результат, а также один и тот же план. Итак…
Действительно ли ВКЛ и ГДЕ одно и то же?
Они - это при выполнении внутреннего соединения. Но это не так, когда вы запускаете внешнее соединение.
А теперь сравним эти два запроса:
- Первый запрос ВЫБЕРИТЕ a.actor_id, a.first_name, a.last_name, count (fa.film_id) ОТ АКТЕРА LEFT JOIN film_actor fa ON a.act_id = fa.actor_id ГДЕ fa.film_id <10 ГРУППА ПО a.actor_id, a.first_name, a.last_name ORDER BY count (fa.film_id) ASC;
Урожайность
ACTOR_ID FIRST_NAME LAST_NAME COUNT -------------------------------------- 194 МЕРИЛ АЛЛЕН 1 198 МЭРИ КЕЙТЕЛЬ 1 30 САНДРА ПЕК 1 85 МИННИ ЗЕЛЛВЕГЕР 1 123 ДЖУЛИАННА ДЕНЧ 1
Обратите внимание, что с этим синтаксисом мы не получаем актеров, у которых нет фильмов с FILM_ID <10 .Мы должны получить десятки! Как насчет этого:
- Второй запрос ВЫБЕРИТЕ a.actor_id, a.first_name, a.last_name, count (fa.film_id) ОТ АКТЕРА LEFT JOIN film_actor fa ON a.actor_id = fa.actor_id И fa.film_id <10 ГРУППА ПО a.actor_id, a.first_name, a.last_name ORDER BY count (fa.film_id) ASC;
Это использовалось для получения того же результата для ( INNER ) JOIN , но, учитывая LEFT JOIN , мы теперь не получаем Susan Davis в результате:
ACTOR_ID FIRST_NAME LAST_NAME COUNT ----------------------------------------- 3 ED CHASE 0 4 ДЖЕННИФЕР ДЭВИС 0 5 ДЖОННИ ЛОЛЛОБРИГИДА 0 6 БЕТТ НИКОЛСОН 0 ... 1 пенелопа гинесс 1 200 ХРАМ ТОРА 1 2 НИК ВАЛЬБЕРГ 1 198 МЭРИ КЕЙТЕЛЬ 1
Тарифы тоже разные:
-------------------------------------------------- -------
| Id | Операция | Имя | Ряды |
-------------------------------------------------- -------
| 0 | ВЫБРАТЬ ЗАЯВЛЕНИЕ | | 49 |
| 1 | СОРТИРОВАТЬ ЗАКАЗ ПО | | 49 |
| 2 | ХЭШ ГРУППА ПО | | 49 |
| * 3 | HASH JOIN | | 49 |
| * 4 | ИНДЕКС БЫСТРО ПОЛНОЕ СКАНИРОВАНИЕ | PK_FILM_ACTOR | 49 |
| 5 | ПРОСМОТР | VW_GBF_7 | 200 |
| 6 | ДОСТУП К ТАБЛИЦЕ ПОЛНЫЙ | АКТЕР | 200 |
-------------------------------------------------- -------
Информация о предикате (определяется идентификатором операции):
-------------------------------------------------- -
3 - доступ ("ITEM_1" = "FA".«ACTOR_ID»)
4 - фильтр («FA». «FILM_ID» <10)
Здесь нет внешнего соединения! По сравнению с
-------------------------------------------------- -------------
| Id | Операция | Имя | Ряды |
-------------------------------------------------- -------------
| 0 | ВЫБРАТЬ ЗАЯВЛЕНИЕ | | 200 |
| 1 | СОРТИРОВАТЬ ЗАКАЗ ПО | | 200 |
| 2 | MERGE JOIN OUTER | | 200 |
| 3 | ДОСТУП К ТАБЛИЦЕ ПО ИНДЕКСУ ROWID | АКТЕР | 200 |
| 4 | ИНДЕКС ПОЛНОЕ СКАНИРОВАНИЕ | PK_ACTOR | 200 |
| * 5 | СОРТИРОВАТЬ ПРИСОЕДИНИТЬСЯ | | 44 |
| 6 | ПРОСМОТР | VW_GBC_5 | 44 |
| 7 | ХЭШ ГРУППА ПО | | 44 |
| * 8 | ИНДЕКС БЫСТРО ПОЛНОЕ СКАНИРОВАНИЕ | PK_FILM_ACTOR | 49 |
-------------------------------------------------- -------------
Информация о предикате (определяется идентификатором операции):
-------------------------------------------------- -
5 - доступ («А»."ACTOR_ID" = "ЭЛЕМЕНТ_1" (+))
filter ("A". "ACTOR_ID" = "ITEM_1" (+))
8 - фильтр ("FILM_ID" (+) <10)
Первый запрос не произвел операцию внешнего соединения, второй - сделал!
В чем разница?
Разница:
-
INNER JOINпроизводит всех актеров, которые играли хотя бы в одном фильме, отфильтровывая актеров, которые не играли в фильме. Это само определение внутреннего соединения. Если мы отфильтруем фильмы сFILM_ID <10, это просто означает, что нам не нужны актеры без таких фильмов. -
LEFT JOINсоздаст все строки с левой стороны соединения, независимо от того, есть ли соответствующая строка на правой стороне соединения.
В обоих случаях совпадающие строки определяются предложением ON . Если две строки не совпадают, то:
-
INNER JOINудаляет их обоих из результата -
LEFT JOINсохраняет левую строку в результате
Но независимо от того, что дает JOIN , предложение WHERE снова удалит строки, не удовлетворяющие фильтру.Итак,
- В случае
INNER JOINне имеет значения, не имеет значения, если мы удаляем актеров без фильмов, , а затем актеров без фильмов сFILM_ID <10, OR , если мы удаляем актеров без фильмов сFILM_ID <10напрямую. Они все равно будут удалены. - В случае
LEFT JOIN, имеет значение , если мы сохраняем актеров без фильмов, , а затем удаляем актеров без фильмов сFILM_ID <10(в случае которых актеры без фильмов будут снова удалены), OR , если мы сохраняем актеров без фильмов сFILM_ID <10, а затем не применяем никаких дополнительных фильтров.
Заключение
Для INNER JOIN , WHERE предикатов и ON имеют тот же эффект .
Для OUTER JOIN , WHERE предикатов и ON предикатов имеют различных эффекта .
В общем, всегда лучше помещать предикат там, где он принадлежит, , логически . Если предикат связан с операцией JOIN , он принадлежит к предложению ON .Если предикат связан с фильтром, применяемым ко всему предложению FROM , он принадлежит к предложению WHERE .
SQL: FROM пункт
В этом руководстве по SQL объясняется, как использовать предложение SQL FROM с синтаксисом и примерами.
Описание
Предложение SQL FROM используется для перечисления таблиц и любых объединений, необходимых для оператора SQL.
Синтаксис
Синтаксис предложения FROM в SQL:
ИЗ table1
[ { ВНУТРЕННЕЕ СОЕДИНЕНИЕ
| LEFT [OUTER] JOIN
| ПРАВО [ВНЕШНИЙ] ПРИСОЕДИНИТЬСЯ
| FULL [OUTER] JOIN} table2
НА table1.column1 = table2.column1] Параметры или аргументы
- таблица1 и таблица2
- Это таблицы, используемые в операторе SQL. Две таблицы объединяются на основе table1.column1 = table2.column1.
Примечание
- При использовании предложения FROM в операторе SQL должна быть по крайней мере одна таблица, указанная в предложении FROM.
- Если в предложении SQL FROM перечислено две или более таблиц, эти таблицы обычно объединяются с помощью соединений INNER или OUTER.
DDL / DML для примеров
Если вы хотите следовать этому руководству, получите DDL для создания таблиц и DML для заполнения данных. Тогда попробуйте примеры в своей базе данных!
Получить DDL / DML
Пример - одна таблица, указанная в пункте FROM
Мы начнем с рассмотрения того, как использовать предложение FROM, которое перечисляет только одну таблицу в операторе SQL.
В этом примере у нас есть таблица с названием поставщиков со следующими данными:
| ID поставщика | имя_поставщика | город | состояние |
|---|---|---|---|
| 100 | Microsoft | Редмонд | Вашингтон |
| 200 | Маунтин-Вью | Калифорния | |
| 300 | Оракул | Редвуд-Сити | Калифорния |
| 400 | Кимберли-Кларк | Ирвинг | Техас |
| 500 | Тайсон Фудс | Спрингдейл | Арканзас |
| 600 | СК Джонсон | Расин | Висконсин |
| 700 | Dole Food Company | Вестлейк Виллидж | Калифорния |
| 800 | Цветы Еда | Thomasville | Грузия |
| 900 | Электронное искусство | Редвуд-Сити | Калифорния |
Введите следующий оператор SQL:
ПопытайсяВЫБРАТЬ * ОТ поставщиков ГДЕ provider_id <400 ЗАКАЗАТЬ ПО городу DESC;
Будет выбрано 3 записи.Вот результаты, которые вы должны увидеть:
| ID поставщика | имя_поставщика | город | состояние |
|---|---|---|---|
| 300 | Оракул | Редвуд-Сити | Калифорния |
| 100 | Microsoft | Редмонд | Вашингтон |
| 200 | Маунтин-Вью | Калифорния |
В этом примере мы использовали предложение FROM, чтобы перечислить таблицу с именем поставщиков .В этом запросе не выполняется никаких соединений, поскольку мы указали только одну таблицу.
Пример - две таблицы в предложении FROM (INNER JOIN)
Давайте посмотрим, как использовать предложение FROM для INNER JOIN двух таблиц вместе.
В этом примере у нас есть таблица с названием продуктов со следующими данными:
| product_id | название_продукта | category_id |
|---|---|---|
| 1 | Груша | 50 |
| 2 | банан | 50 |
| 3 | оранжевый | 50 |
| 4 | Яблоко | 50 |
| 5 | Хлеб | 75 |
| 6 | Ветчина нарезанная | 25 |
| 7 | Клинекс | НУЛЬ |
И таблица с названием категории со следующими данными:
| category_id | имя_категории |
|---|---|
| 25 | Гастроном |
| 50 | Продукция |
| 75 | Пекарня |
| 100 | Товары общего назначения |
| 125 | Технологии |
Введите следующий оператор SQL:
ПопытайсяВЫБРАТЬ продукты.product_name, category.category_name ИЗ продуктов Категории INNER JOIN НА products.category_id = category.category_id ГДЕ product_name <> 'Груша';
Будет выбрано 5 записей. Вот результаты, которые вы должны увидеть:
| название_продукта | имя_категории |
|---|---|
| Банан | Продукция |
| Оранжевый | Продукция |
| Яблоко | Продукция |
| Хлеб | Пекарня |
| Ветчина нарезанная | Гастроном |
В этом примере предложение FROM используется для объединения двух таблиц - продуктов и категорий .В этом случае мы используем предложение FROM, чтобы указать ВНУТРЕННЕЕ СОЕДИНЕНИЕ между таблицами продуктов и категорий на основе столбца category_id в обеих таблицах.
Пример - две таблицы в предложении FROM (OUTER JOIN)
Давайте посмотрим, как использовать предложение FROM, когда мы объединяем две таблицы вместе с помощью OUTER JOIN. В этом случае мы посмотрим на LEFT OUTER JOIN.
Давайте использовать те же таблицы продуктов и категорий из приведенного выше примера INNER JOIN, но на этот раз мы объединим таблицы с помощью LEFT OUTER JOIN.Введите следующий оператор SQL:
ПопытайсяВЫБЕРИТЕ продукты.имя_продукта, категории.название_категории ИЗ продуктов Категории LEFT OUTER JOIN НА products.category_id = category.category_id ГДЕ product_name <> 'Груша';
Будет выбрано 6 записей. Вот результаты, которые вы должны увидеть:
| название_продукта | имя_категории |
|---|---|
| Банан | Продукция |
| Оранжевый | Продукция |
| Яблоко | Продукция |
| Хлеб | Пекарня |
| Ветчина нарезанная | Гастроном |
| Клинекс | НУЛЬ |
В этом примере используется предложение FROM для LEFT OUTER JOIN таблиц продуктов и категорий на основе category_id в обеих таблицах.