Денормализованное хранение данных в PostgreSQL 9.2
Программный комитет еще не принял решения по этому докладу
Александр Коротков (ООО «Интаро Софт»)
денормализованное хранение данных в Postgre sql 9.2 александр коротков
View more presentations from Ontico.
Александр Коротков: Здравствуйте! Меня зовут Александр Коротков. Я представляю компанию «Интаро Софт». Мой доклад называется: «Денормализованное хранение данных в PostgreSQL 9.2». Из названия можно понять, что речь пойдет о различных новинках, о том, что нам предстоит увидеть в релизе 9.2 или в недавно появившихся расширениях (англ. extension).
Почему мы вообще используем денормализованное хранение данных? Почему мы в реляционных базах отходим от нормальных форм?
Краткий ответ на этот вопрос: потому же, почему развиваются различные новые MySQL-решения.
Хранение данных в массивах
Первое, о чем мы поговорим, будет хранение данных в массивах. Собственно, массивы в PostgreSQL есть давно, но в релизе 9.2 есть ряд новшеств, о которых я сегодня хочу рассказать.
Поговорим о преимуществах, которые дает хранение в массивах внутри базы.
Во-первых, исчезает лишний JOIN в SQL-запросе, поэтому можно извлечь необходимые данные быстрее.
Во-вторых, при использовании GIN и GiST индексов можно осуществлять быстрый поиск по значению массива.
В-третьих, SQL-запросы упрощаются.
Недостатки этого подхода
Как правило, если вы используете ORM, то готовой поддержки там нет.
Еще один недостаток – это мультиверсионность. Если вы используете массив и хотите обновить в нем одно значение, у вас создается новая версия для кортежа целиком. Если у вас большие массивы или частые апдейты, то количество служебной информации (англ. overhead) тоже будет большим.
Вот пример того, как нам могут помочь массивы. В данном случае используется выборка из таблицы по тэгу. В этом примере у нас некая аудиозапись: есть отдельная таблица тэгов и отдельная таблица, реализующая связь типа «много ко многому».
Если посмотреть, каким будет план запроса, то здесь созданы все необходимые индексы.
В данном тестовом примере извлечение всех записей, связанных с определенным тэгом, заняло 200 миллисекунд. Если мы будем хранить тэги непосредственно в таблице записей, запрос существенно упростится.
Если мы будем хранить тэги непосредственно в таблице записей, запрос существенно упростится.
Мы можем видеть, что время выполнения запроса тоже существенно сократилось, а его план упростился.
Коснусь новшества, которое, скорее всего, будет в PostgreSQL 9.2: будут реализованы массивы в качестве внешних ключей. Это востребованная возможность. На многих конференциях по PostgreSQL часто спрашивают: «Когда же, наконец, появится поддержка массивов в качестве внешних ключей, когда мы наконец перестанем писать для этой цели триггеры?»
Сейчас есть патч для PostgreSQL. Он уже в стадии «ready for commit». Это значит, что он успешно прошел стадию «review» и был одобрен. Есть определенная надежда на то, что эта возможность войдет в релиз 9.2.
Как этим пользоваться?
Немного о том, как этим пользоваться. Во внешних ключах добавилось ключевое слово EACH перед именем столбца. Оно как раз указывает, что это именно внешний ключ-массив, то есть каждый элемент массива ссылается на запись в другой таблице.
Добавились новые действия по обновлению или удалению той записи, на которую идет ссылка. Это EACH CASCADE. Это, соответственно, применение каскадного удаления или обновления к обновлениям массива.
EACH SET NULL – это установка значения массива в «null».
Небольшой пример
Предположим, у нас есть таблица film, которая представляет фильмы. Фильм связан с актером как «многое ко многому»: один актер может играть в нескольких фильмах, и наоборот. В данном случае представлено описание такого внешнего ключа, в котором перед полем actor_ids идет ключевое слово «EACH». Действия по «ON DELETE» и «ON UPDATE» стоят с пометкой «EACH CASCADE» (происходит каскадное обновление и удаление).
Отдельная тема – это массивы и планировщик. Это связано с моим вкладом в развитие PostgreSQL.
Дело в том, что в случае массивов обычные скалярные операции сравнения (меньше/больше/равно) нетипичны для поиска. Мало кто использует эти операции для поиска в массивах. Более типичные операторы (может быть, их названия не очень привычны тем, кто не работал с PostgreSQL): поиск массивов, которые пересекаются с заданным, включают в себя заданный массив, или, наоборот, включены в заданный массив.
Мало кто использует эти операции для поиска в массивах. Более типичные операторы (может быть, их названия не очень привычны тем, кто не работал с PostgreSQL): поиск массивов, которые пересекаются с заданным, включают в себя заданный массив, или, наоборот, включены в заданный массив.
В отношении них планировщик оказывается «слеп», потому что для этих операций применяются константные оценки селективности. Грубо говоря, для оператора пересечения планировщик всегда считает, что мы извлечем 20 % строк – неважно, с каким массивом было пересечение. Это в некоторых случая существенно ухудшает работу.
Дальше я приведу конкретный пример. В версии 9.2 реализован сбор специфичной статистики для массивов. Она как раз «заточена» под эти операции, что дает нам более адекватные планы запросов.
Вот еще один небольшой пример. Здесь выполняется операция «JOIN» для двух таблиц. К массиву в одной из них применяется оператор пересечения с другим массивом.
Можно видеть, что до PostgreSQL 9. 2 получался такой план. Он был основан на том, что мы извлечем много строк по нашей операции. Он планировал извлечь 2769 строк, а на самом деле извлек только 6. План был очень неоптимальным. Он был рассчитан на очень большое количество извлекаемых записей, а на самом деле их было мало. В итоге запрос работал порядка 50 секунд.
2 получался такой план. Он был основан на том, что мы извлечем много строк по нашей операции. Он планировал извлечь 2769 строк, а на самом деле извлек только 6. План был очень неоптимальным. Он был рассчитан на очень большое количество извлекаемых записей, а на самом деле их было мало. В итоге запрос работал порядка 50 секунд.
Посмотрим, что происходит в PostgreSQL 9.2 на том же запросе, на тех же данных – там уже другая оценка селективности. По оценке, будет извлечено 28 строк, а реально их 6. Это достаточно хорошо. Совершенно точные оценки селективности нам не нужны. Нужно было попасть в порядок, и мы попали.
Уже другой план, который состоит из Nested Index Scan. Время – всего 6 миллисекунд. От правильного плана может зависеть такая колоссальная разница. Это очень важно.
Как же это работает?
Собирается следующая статистика.
Это самые частые элементы, которые встречаются в массиве, и их частоты, а также гистограмма числа уникальных элементов.
Немного про JSON
В PostgreSQL 9.2 появилась, наконец, встроенная в ядро поддержка JSON. Вообще с JSON вышла грустная история, потому что соответствующий проект был на «Google Summer of Code». Студент написал очень много кода, и еще больше тестов к нему. Но в итоге это сообщество никому не понравилось. Практически все было выброшено.
В версии 9.2 была реализована только самая базовая поддержка JSON.
Она состоит из типа JSON и функций row_to_json и array_to_json. К сожалению, хранить данные в типе JSON бесполезно, потому что извлекать из него данные нечем. Можно только собрать JSON. Остается только собирать в JSON ответы.
Благодаря встроенной поддержке можно собрать JSON-объект на стороне СУБД. Это позволит нам упростить обработку результатов. Со стороны приложения мы можем из JSON сделать соответствующий объект того языка программирования, на котором вы разрабатываете.
Небольшой пример. У нас есть таблица фильмов и актеров. Они связаны как «многое ко многому». В этом примере запроса мы через вложенный запрос собираем в массив связанных с фильмами актеров, а потом оборачиваем все это в JSON.
Можно посмотреть, какой получится результат. У нас есть все данные по фильму и собран в JSON массив актеров, которые в нем играют.
Помимо этого, существует еще такой модуль-расширение к PostgreSQL, как Pl/v8 (он сравнительно недавно появился). Он позволяет реализовать Javascript как процедурный язык для PostgreSQL. Он сделан на основе движка v8 от Google. Там можно производить любые манипуляции с JSON-данными.
Еще можно организовать индексирование для JSON-данных. Как это делается?
Мы с помощью языка Pl/v8 пишем функцию, которая извлекает те данные, по которым мы потом будем осуществлять поиск. Это могут быть как скалярные значения, так и массивы, о которых мы раньше говорили.
Это могут быть как скалярные значения, так и массивы, о которых мы раньше говорили.
Потом строим индексное выражение для тех данных, которые извлекли (англ. expression index). Выполняем поиск с использованием этого выражения.
Вот небольшой пример.
Мы храним данные по фильмам. В данном случае это массив с именами участвующих в них актеров.
Пишем функцию. Функция тривиальная. Она просто по заданному ключу извлекает из структуры значения и в дальнейшем интерпретирует его как текстовый массив. Это важно: функция обязательно должна быть помечена как «IMMUTABLE», иначе мы не сможем построить по ней индекс. Свойство «IMMUTABLE» означает, что результат выполнения функции зависит только от входных параметров. Он не зависит от базы, и саму базу не меняет.
Аналогичная функция, которая извлекает значение из JSON в качестве вещественного числа.
Дальше мы можем построить соответствующие индексы для актеров, играющих в фильме, и для рентабельности фильма.
Можем потом сделать поисковый запрос, который использует эти выражения.
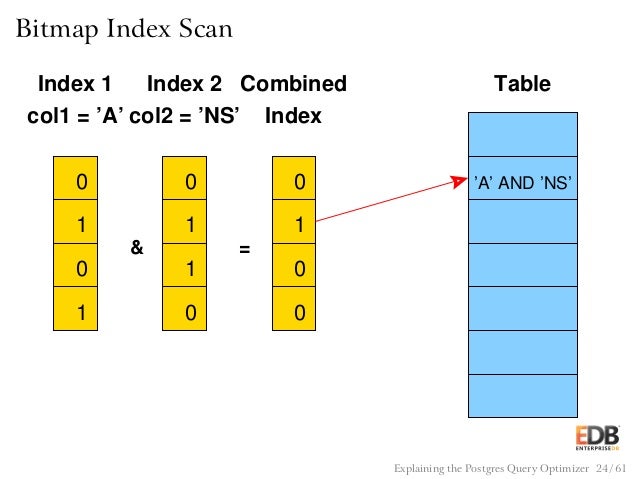
У этого запроса получится следующий план. Два Bitmap Index Scan по двум индексам. Затем выполняется объединение этих результатов.
Ограничения Pl/v8
JSON приходится хранить как текст. Нен никакой поддержки BSON и какой-то упрощенной сериализации/десериализации. Со встроенным в 9.2 типом JSON он тоже «не дружит», хотя можно надеяться, что это изменится до релиза. Каждый раз приходится заново парсить JSON в объект в хранимой функции.
Какого-то универсального индекса для JSON-документов нет. Например, для модуля расширения Hstore есть универсальный индекс. Но для JSON такого пока что нет.
Диапазонные типы
Еще одно новшество, о котором я хотел рассказать, это диапазонные типы.
Они представляют собой некий диапазон, заданный верхней и нижней границей. Поддерживаются различные виды такого рода интервалов: включающие в себя границы или не включающие, с бесконечностями и даже просто пустой интервал.
Поддерживаются различные виды такого рода интервалов: включающие в себя границы или не включающие, с бесконечностями и даже просто пустой интервал.
Где это можно применить?
Во-первых, это темпоральные данные. То есть данные, у которых есть некий период их актуальности. Во-вторых, это данные с точностью. Это актуально, например, в различных научных приложениях, где важно хранить не только измерение, но и его погрешность. Но чаще всего это именно темпоральные данные.
Отдельно стоит рассмотреть вопрос индексирования диапазонных типов. Здесь Btree поддерживает такие операции, как больше/меньше/равно. Для диапазонов они не очень полезны. Например, когда у нас есть диапазон, который хранит временную актуальность данных, мы, скорее всего, захотим выбрать какой-то временной срез.
С помощью операторов больше/меньше/равно мы этого сделать не сможем. Зато GiST индекс поддерживает те операторы, которые нужно: оператор пересечения с другим диапазоном и включение одного диапазона в другой.
Плюс к этому можно не хранить данные как диапазон, а просто строить индекс на соответствующем выражении. То есть в выражении собирать из двух значений диапазон и дальше уже строить на этом индекс.
Небольшой пример. Предположим, у нас есть некая таблица, которая хранит историю цен для определенных товаров. Как мы можем получить некий временной срез из этой таблицы?
Наиболее простой подход: использовать простые операции сравнения с временем актуальности. Время, с которого была актуальна данная запись, и время, по которое она была актуальна. Если мы не сделаем никаких индексов, у нас будет просто последовательное сканирование таблицы, которое работает довольно долго.
Люди, которые не знают о существовании диапазонов, или не знали до этого о модуле pg_temporal, скорее всего, построили бы двухколоночный индекс. Там были бы две колонки «Actual from» и «Actual to», которые задавали бы нам период.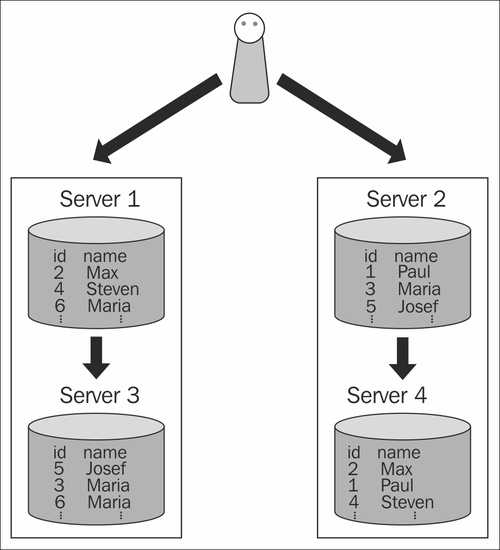
Этот план получше, но все равно очень большая часть индекса была просканирована. Это очень неоптимальный способ, но людям, которые об этом не знают, часто кажется, что лучше нельзя – индекс построили и все, что нужно, в него включили. Собственно, все. На самом деле, это не так.
В данном случае можно построить GiST-индекс на выражении. Конструировать диапазон из этого периода актуальности данных. Строить соответствующий запрос, который включает в себя диапазон, на котором мы построили индекс. В этом случае у нас все будет выполняться в Index Scan 1, который работает гораздо быстрее.
Перспективы развития
Теперь поговорим о некоторых перспективах развития, которые можно выделить для таких способов денормализованного хранения данных в PostgreSQL.
Было бы неплохо сделать некий универсальный индекс для JSON, именно для хранения JSON-документов. Подобно тому, как для Hstore есть универсальный индекс, было бы здорово сделать то же самое и для JSON. Но здесь такие же проблемы, как с универсальным индексированием xml. Мы можем получить либо индекс, который не будет поддерживать то, что нам надо, либо слишком громоздкий индекс, который будет занимать очень много места.
Подобно тому, как для Hstore есть универсальный индекс, было бы здорово сделать то же самое и для JSON. Но здесь такие же проблемы, как с универсальным индексированием xml. Мы можем получить либо индекс, который не будет поддерживать то, что нам надо, либо слишком громоздкий индекс, который будет занимать очень много места.
Нужно найти какую-то «золотую середину». Может быть, можно предложить несколько вариантов.
Еще одной перспективной вещью является сбор статистики для таких расширений, как Hstore, для хранения JSON-данных и прочего. Как было показано на примере для массивов, сбор статистики для составления правильных планов очень важен. Было бы здорово, если бы для этих типов тоже был реализован сбор статистики.
Еще одна вещь, которая до сих пор не реализована: GiST-индексы для разных массивов, а не только для целочисленных. Для всевозможных массивов в PostgreSQL есть встроенные gin-индексы.
Есть также специальный модуль, который реализует разные интересные вещи именно для массивов целых чисел.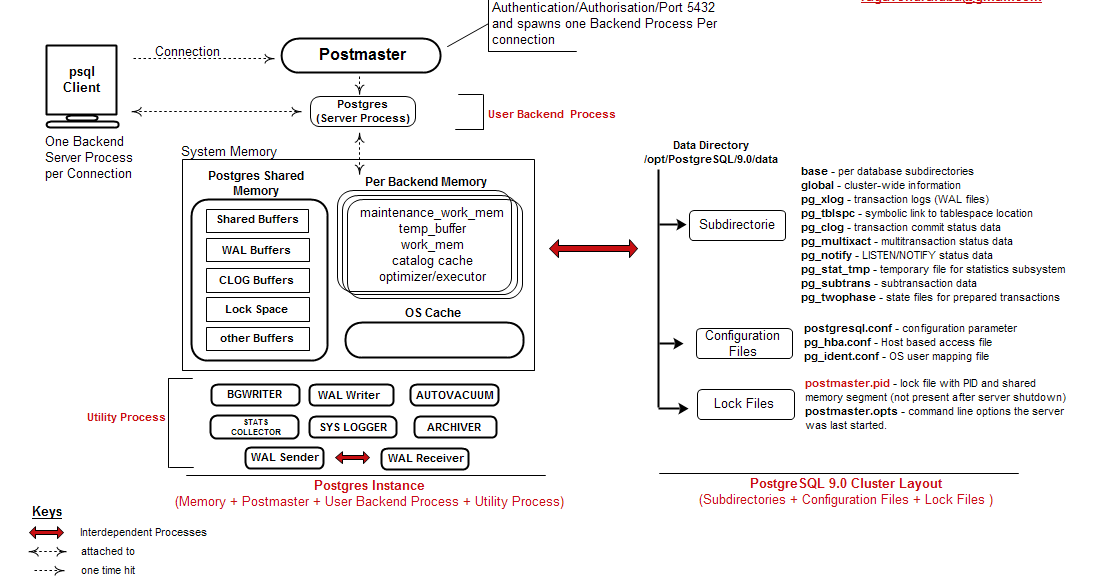 В нем, в частности, есть GiST-индексы, но для других типов поддержки таких индексов нет. В принципе, это несложно сделать. Рано или поздно, я думаю, это будет реализовано.
В нем, в частности, есть GiST-индексы, но для других типов поддержки таких индексов нет. В принципе, это несложно сделать. Рано или поздно, я думаю, это будет реализовано.
На этом у меня все. Спасибо за внимание. Слушаю вопросы.
Вопросы и ответы
Реплика из зала: Здравствуйте, меня зовут Михаил. Я не очень понял, для чего вам нужна встроенная поддержка JSON в SQL-базе данных. Если для этого есть MySQL-решения, зачем вам индексы и все остальное «тянуть» в базу, которая уже сформировалась как решение? Вы хотите какую-то универсальность добавить. На мой взгляд, бессмысленную. Зачем?
Александр Коротков: Универсальность в этой базе во многом уже реализована. Просто идет развитие ее потенциала, потому что в PostgreSQL уже очень давно есть возможность добавлять свои типы, свои операторы, свои индексы. Например, поддержка JSON не требует каких-то особых изменений с точки зрения ядра.
Тот же Pl/v8 разработан как модуль для PostgreSQL. Он не затрагивает ядра и может дальше совершенствоваться в этом качестве. Поскольку это малозатратно, почему бы этого не сделать? Почему бы не иметь возможность смешивать преимущества реляционных баз и MySQL-решений в рамках одной СУБД?
Он не затрагивает ядра и может дальше совершенствоваться в этом качестве. Поскольку это малозатратно, почему бы этого не сделать? Почему бы не иметь возможность смешивать преимущества реляционных баз и MySQL-решений в рамках одной СУБД?
Реплика из зала: Еще вопрос по поводу кастомных типов. Вы их тоже упомянули. Почему до сих пор (по крайней мере, в версии 9.1) нет простого решения для добавления и удаления значений кастомного типа?
Когда мы хотим сэмулировать ENUM, нет простого способа типа «remove from ENUM» (такое-то значение). Нужно что-то придумывать. Это нетривиальная задача, как в том же MySQL – встроенная поддержка ENUM. В PostgreSQL 9.1 нет этого.
Почему бы в эту сторону не двигаться, вместо того чтобы придумывать индексирование JSON?
Александр Коротков: В эту сторону тоже идет движение. Я, честно говоря, за проблемой ENUM не очень следил, но, насколько я знаю, в 9.2 есть улучшения, связанные с ENUM (именно с упрощением).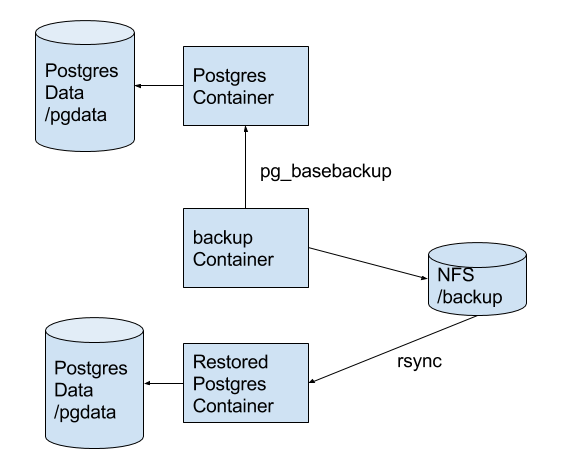
С композитными типами ситуация тоже меняется к лучшему. Насколько я знаю, кто-то работал над тем, чтобы можно было добавить или удалить поле из композитного типа, не пересобирая все значения композитного типа во всех таблицах. В этом направлении тоже работы ведутся.
Реплика из зала: Собственно, когда ждать релиза версии 9.2?
Александр Коротков: Ну, это точно неизвестно. Я думаю, в этом году он будет. Пока, к сожалению, это даже не beta. Последний коммитфест еще не завершен. Еще точно неизвестно, какие возможности войдут в релиз.
Реплика из зала: Сбор статистики по массивам реализован в момент вакуума или при старте?
Александр Коротков: В момент анализа, как и вся статистика.
Реплика из зала: Здравствуйте. Я заметил на планах запросов такую функцию – Index Only Scan.
Александр Коротков: Да.
Реплика из зала: Правильно я понимаю, что это новая функция 9. 2?
2?
Александр Коротков: Да.
Реплика из зала: Это тот самый «covering index»?
Александр Коротков: Да.
Реплика из зала: Войдет ли эта возможность в 9.2-релиз?
Александр Коротков: Однозначно войдет.
Реплика из зала: Вопрос такой. На слайде был показан поиск между from и till. Это будет именно индекс на поддержку «range tag», или это можно делать сейчас?
Александр Коротков: Не совсем понял вас.
Реплика из зала: Индекс ts_range связан с новым типом?
Александр Коротков: Да, это связанные вещи. Функция ts_range создает нам диапазон из верхней и нижней границы. Это как раз связано с диапазонами, которые в 9.2 появятся.
Но в прежних версиях это тоже можно делать с помощью модуля расширения pg_temporal. Роль диапазонов состояла в том, чтобы объединить все разные диапазоны, которые были реализованы в разных модулях к PostgreSQL.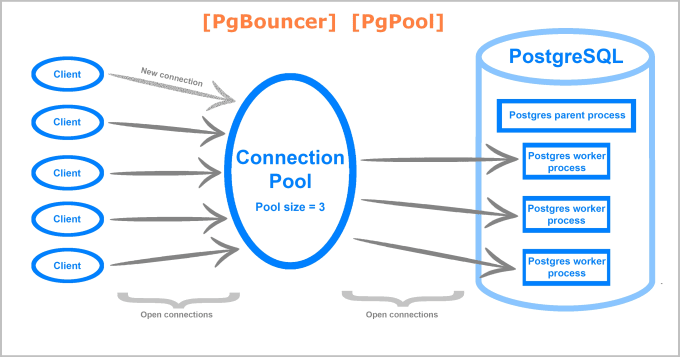 Есть модуль pg_temporal. Был еще ряд модулей, которые реализовывали, по сути, разные диапазоны. В 9.2 появилась универсальная поддержка для всех возможных диапазонов. Соответственно, и их индексирование.
Есть модуль pg_temporal. Был еще ряд модулей, которые реализовывали, по сути, разные диапазоны. В 9.2 появилась универсальная поддержка для всех возможных диапазонов. Соответственно, и их индексирование.
Реплика из зала: Вопрос по поводу JSON. Я правильно понимаю, что сейчас делается поддержка собирания в JSON, а дальше будет работа по тому, чтобы работать со значениями изнутри JSON? JSON-объект сохраняется более-менее как строка, или это именно вложенный объект типа «ключ-значение»?
Александр Коротков: Именно как строка – да, вы правильно поняли. После довольно неудачного проекта Google Summer of Code по поддержке JSON разработчики поняли, что надо двигаться в этом направлении. Сделали хотя бы базовую поддержку в виде типа и возможности собирать значения из базы.
В дальнейшем планируется расширение возможностей. Я, правда, не знаю, в какую сторону. Возможно, этот модуль как-нибудь будет реализован скриптом.
Реплика из зала: Тип JSON есть или результат будет как строка?
Александр Коротков: Тип JSON есть, но он, по сути, является строкой, которая еще дополнительно валидируется.
Реплика из зала: Понятно. Был вопрос по поводу ENUM. Насколько я понимаю, проблема в удалении из ENUM. В принципе, можно удалять руками из pg-каталог, из таблицы ENUM-значения. Но проблема в том…
Александр Коротков: …что есть такие значения в базе.
Реплика из зала: Да. Если значения в базе есть, вы просто с ней ничего дальше не сможете сделать. Ни «сдампить», ничего другого… Это ответ на предыдущий вопрос.
Александр Коротков: Все правильно. А в чем вопрос заключается?
Реплика из зала: Это не вопрос. Я, пользуясь случаем, поясняю, почему не сделали удаление.
Реплика из зала: Александр, может быть, у вас есть какая-то информация об улучшении поддержки XML?
Александр Коротков: Почему именно XML?
Реплика из зала: Он хранится, как и JSON, в виде строки. Улучшение в плане какого-то специального хранилища для него и индексации не ожидается?
Александр Коротков: Я могу ответить про индексацию. Был проект на Google Summer of Code 2011, связанный с индексацией. Я особо глубоко в него не вникал, но он заключается в том, что XML раскладывается по отдельным таблицам. По ним потом строятся индексы и какая-то функция, которая преобразует запрос к XML в запрос к этим таблицам.
Это сделано, по-моему, в виде модуля, который тоже от 9.2 зависит. Но более детально не могу сказать.
Реплика из зала: Понятно. Спасибо.
Реплика из зала: Александр, то, о чем вы рассказали, уже можно попробовать?
Александр Коротков: Да, можно. Из GIT делается клон от версии 9.2. Собираете ее. Чтобы попробовать внешние ключи на массивах, нужно еще «накатить» патч. Модуль v8 просто скачиваете – собираете к PostgreSQL и более «младшим» версиям PostgreSQL. По-моему, начиная с 9.1, он тоже собирается и работает. Все можно пробовать. Все открыто.
PG Day’21 Russia
Доклады
Я расскажу о различных паттернах использования массивов в постгресе, в т.
 ч. для оптимизации по сравнению с классической реляционной моделью, об организации ссылочной целостности на базе массивов, и об использовании наследования таблиц.
ч. для оптимизации по сравнению с классической реляционной моделью, об организации ссылочной целостности на базе массивов, и об использовании наследования таблиц.Инты, массивы, внешние ключи, наследование Как масштабировать процессы разработки и тестирования с частыми изменениями схемы БД и кода в быстрорастущих проектах.

Сдвигаем тестирование БД влево EXPLAIN is a deep topic, and to do a good introduction talk, you have to skip over a lot of the tricky bits. As such, this talk will not be a good introduction, but instead a deeper dive into some of the things most don’t cover.
EXPLAIN: beyond the basics Patroni is a solid and reliable HA tool.
 Pgbackrest is the perfect choice to have a proper DR solution in place. The talk will walk the audience through the configuration of patroni coupled with pgbackrest.
Pgbackrest is the perfect choice to have a proper DR solution in place. The talk will walk the audience through the configuration of patroni coupled with pgbackrest.Protecting your data with Patroni and pgbackrest Have you already installed pgBackRest but are now wondering if you discovered all of its possibilities? This talk will start from a base installation of the tool and then deep dive into its richer features for more expert use.
Unleash the Power within pgBackRest This talk explores the new features coming in the next PostgreSQL release. This talk changes for every release.
Upcoming PostgreSQL 14 Features Join this talk to learn more about DynamoDB’s architecture, similarities and differences with Postgres, and understand how Postgres may scale in a similar way.

Can Postgres scale like DynamoDB? Облако предоставляет множество технологий, включая PostgreSQL as a Service.
Не всегда и не во всех компаниях можно просто взять и начать использовать облако, а тем более СУБД в облаке.
Поговорим о том, какие могут быть возражения у службы безопасности и какие именно технологии обеспечивают безопасное использование облака.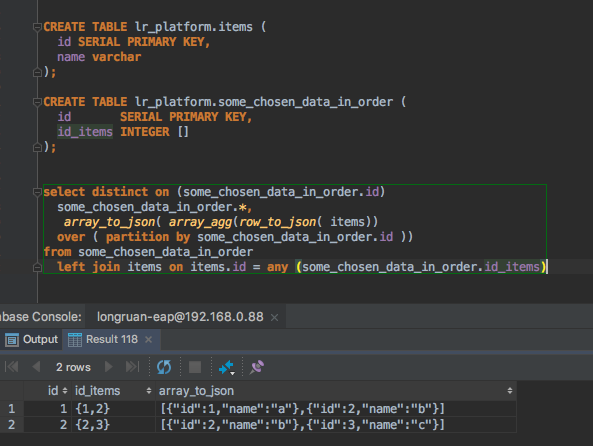 Обсудим то, как можно организовать сетевую связность с облаком. Ну и немного о том, как облегчить переезд баз, если всех убедили.
Обсудим то, как можно организовать сетевую связность с облаком. Ну и немного о том, как облегчить переезд баз, если всех убедили.Миграция в облако: технологии, люди и процессы Доклад о том, как PostgreSQL может взаимодействовать с ClickHouse – зачем это нужно и какие возможности для этого есть.
 Будет рассказано о разных вариантах интеграции: реализация специализированных PostgreSQL движков разных видов для разных целей, у каждого свои преимущества.
Будет рассказано о разных вариантах интеграции: реализация специализированных PostgreSQL движков разных видов для разных целей, у каждого свои преимущества.Большая часть рассказа будет посвящена репликации из PostgreSQL в ClickHouse – когда ClickHouse притворяется репликой PostgreSQL базы, причем реплицироваться может как вся база, так и любое подмножество таблиц. Расскажу о том, как реализована репликация – о протоколе логической репликации, подробно про его устройство и о том как он реализован в ClickHouse для репликации из PostgreSQL.
Возможности интеграции PostgreSQL с ClickHouse Что нормальному человеку нужно для счастья? Динамический и ассоциативный массив, немного очередей и графов, да горстку битовых операций.
 Но в погоне за масштабируемостью и миллионами транзакций в секунду сон разума рождает велосипеды. Так например, стандартный способ создать мапу у нас называется «Andres’s steampunk macro-based robinhood template».
Но в погоне за масштабируемостью и миллионами транзакций в секунду сон разума рождает велосипеды. Так например, стандартный способ создать мапу у нас называется «Andres’s steampunk macro-based robinhood template».В докладе я расскажу о суровом, но зато нескучном быте разработчика PostgreSQL. Полезно для кругозора, но, возможно, вы захотите развидеть что-то из этого.
Алгоритмы и структуры данных: PostgreSQL Edition Logical replication in postgres: What is logical replication? When to use logical replication? Architecture of logical replication:
— Publications
— Subscriptions
— System tables/views
— Logical replication statistics
— Restrictions
— Current work
— Future workLogical Replication in Postgres Пройдёмся по инструментам из https://github.
 com/dataegret/pg-utils, опишем, что делает тот или иной инструмент, покажем примеры использования и в каких случаях их применять.
com/dataegret/pg-utils, опишем, что делает тот или иной инструмент, покажем примеры использования и в каких случаях их применять.Инструменты от Data Egret для облегчения администрирования баз данных Датацентричная архитектура Luxms BI.
Высокопроизводительные стыковки из PostgreSQL: ClickHouse, Redis, Greenplum.
Кластеры PostgreSQL на Partoni.
Как подружить PostgreSQL и микросервисы.
PostgreSQL как интеграционное ядро корпоративного ландшафта.
Бизнес-логика на PostgreSQL по опыту внедрений в РЖД, ГПН и Ростелеком.Внедрение HighLoad BI на PostgreSQL в крупнейших корпорациях: опыт ГК Luxms Известно, что в Postgres очень много самой разной статистики, при помощи которой можно наблюдать за работой постгреса.
 Практически все инструменты и плагины для мониторинга PostgreSQL берут данные из этой статистики. Статистики действительно очень много, но, даже несмотря на это, с каждым релизом появляется что-то новое.
Практически все инструменты и плагины для мониторинга PostgreSQL берут данные из этой статистики. Статистики действительно очень много, но, даже несмотря на это, с каждым релизом появляется что-то новое.В этом докладе я расскажу про нововведения в средствах для мониторинга, которые появились в последних двух релизах: текущем и предстоящем, который выйдет осенью, но уже доступен для бета-тестирования. Я расскажу о том, какие конкретно добавлены улучшения, в каких случаях они могут быть полезны и как их применять, приведу практические примеры их использования. Доклад будет полезен системным администраторам и ДБА, которые интересуются мониторингом.
Что нового в плане мониторинга в PostgreSQL Microservices are a useful concept.
 But there are a few things to consider when microservices need to interact with a “traditional” database, RDBMS or data-store.
But there are a few things to consider when microservices need to interact with a “traditional” database, RDBMS or data-store.In some cases, you can even have your RDBMS (Oracle, PostgreSQL or mySQL) take up the role of a microservice, and achieve remarkable efficiency.
Microservices and Databases, a Smart combination
Использование массивов в PostgreSQL. Научитесь создавать списки и управлять ими… | by Merlin Schäfer
Научитесь создавать списки и вложенные структуры в SQL и манипулировать ими
Фото Caspar Camille Rubin на Unsplash Когда вы думаете об SQL-образах таблиц, SELECT-запросах и концепции одной строки на точку данных без вложенности структура, вероятно, приходит на ум.
Но что, если вы хотите хранить список чисел, продуктов и т. д. в строке?
Конечно, вы можете разбить список на множество строк, но это может привести к джунглям строк, которые может быть трудно отслеживать. К счастью, PostgreSQL предлагает тип данных Array, который можно использовать для хранения списков и управления ими.
Вот как:
Тип массива
С помощью массива PostgreSQL позволяет определять столбцы таблицы как многомерные массивы переменной длины. Могут быть созданы массивы любого встроенного или определяемого пользователем базового типа, типа перечисления, составного типа, типа диапазона или домена.
Создание массивов
Массивы могут принимать различные формы, и существует множество способов их объявления.
Вы можете использовать ключевое слово ARRAY после объявления типа данных для столбца, чтобы указать, что вы хотите создать массив ранее объявленного типа данных, как показано ниже.
Вы также можете использовать квадратные скобки после объявления типа данных (например, text[]), но я нахожу это менее явным и не соответствует стандарту SQL, который соответствует ключевому слову version.
В следующем примере я создаю небольшую таблицу, чтобы имитировать карточку покупок и заполняю ее некоторыми перестановками нескольких продуктов. Если вы запустите полный запрос, вы также увидите, как массивы представлены в виде вывода.
Создание и заполнение столбца массиваРезультирующая таблицаОдним из альтернативных способов добавления массива в таблицу является использование синтаксиса {} вместо ключевого слова МАССИВ со скобками. Оба способа работают, вам просто нужно обратить пристальное внимание на цитаты с фигурными скобками . Опять же, я нахожу синтаксис ключевого слова более явным, а скобки ближе к представлениям массива в других языках программирования, но оба работают нормально.
Распаковка массива
Но подождите! Что, если бы вам действительно нужно было развернуть или разложить массив для определенных строк, чтобы объединить их в какой-либо таблице информации о продукте или выполнить другие операции на основе элемента списка?
Нет проблем, массивы в PostgreSQL могут быть легко удалены из вложенности с помощью ключевого слова UNNEST:
Отмена вложения столбца массиваКак и ожидалось, UNNEST создает одну строку для каждого элемента в соответствующем массиве в исходной строке:
Результат отмены вложения массиваДоступ к элементам массива
Вы можете задаться вопросом, нужно ли удалять вложенность массива каждый раз, когда вы хотите получить доступ к одному элементу для дальнейших операций. Если бы это было так, структура массива, возможно, не была бы хорошей идеей. К счастью, массивы в PostgreSQL позволяют осуществлять доступ через индексирование с использованием квадратных скобок и срезов, как показано ниже. Это позволяет легко выбирать, например, первый элемент в каждом списке или определенный диапазон элементов в списке.
Если бы это было так, структура массива, возможно, не была бы хорошей идеей. К счастью, массивы в PostgreSQL позволяют осуществлять доступ через индексирование с использованием квадратных скобок и срезов, как показано ниже. Это позволяет легко выбирать, например, первый элемент в каждом списке или определенный диапазон элементов в списке.
Примечание. Индексация в массивах PostgreSQL начинается с 1, а не с 0, что может отличаться от того, к чему вы привыкли в других языках программирования.
Доступ к элементам массива посредством индексацииСрезы работают с синтаксисом [начало:конец].
Доступ к элементу массива посредством среза для всех строк, содержащих более двух элементов массива.Если вы не уверены, сколько элементов в вашем массиве, или если вы хотите отфильтровать по размеру массива, как я сделал выше, вы можете использовать ключевое слово CARDINALITY. Это вернет количество элементов в массиве в виде целого числа.
Фильтр по элементу массива
Что делать, если вы хотите выбрать все корзины, в массиве которых есть определенный продукт? Или любую другую операцию фильтрации, основанную на элементе массива? Нет проблем, PostgreSQL позволяет использовать значение элемента в предложении WHERE в сочетании с ключевым словом ANY. Ниже я фильтрую строки, содержащие «product_c» в столбце массива продуктов. Этот способ фильтрации наиболее удобен для отдельных значений фильтра.
Ниже я фильтрую строки, содержащие «product_c» в столбце массива продуктов. Этот способ фильтрации наиболее удобен для отдельных значений фильтра.
Оператор «Содержит»
Вы также можете расширить описанную выше логику фильтра и запросить любую карточку покупок, содержащую определенный подмассив. Здесь я использую оператор «@>», который означает «содержит». Его можно прочитать следующим образом:
«массив продуктов содержит массив [‘product_a’, ‘product_b’]»
Обновление массива
Массивы и значения массивов могут быть обновлены аналогично другим типам данных с помощью UPDATE … SET … предложение, как показано ниже. Вы можете либо обновить один элемент массива с помощью индексации, либо весь массив.
Prepend and Append
Если вы хотите специально изменить массивы путем добавления или добавления (вставки перед текущими значениями) к ним, вы можете использовать функции ARRAY_APPEND и ARRAY_PREPEND соответственно. Обязательно обратите внимание на разницу в порядке аргументов , который отличается для каждой функции, но следует интуитивному порядку.
Обязательно обратите внимание на разницу в порядке аргументов , который отличается для каждой функции, но следует интуитивному порядку.
Удаление элементов массива
Если вы хотите избавиться от определенного элемента массива, вы можете использовать UPDATE…SET… вместе с функцией ARRAY_REMOVE. Это позволяет вам либо удалить элемент из массивов для всех строк, либо только один конкретный элемент при использовании с предложением WHERE.
Удаление элемента массиваОбъединение массивов
Наконец, вы можете объединить массивы PostgreSQL в один больший массив с помощью ARRAY_CAT следующим образом:
Могут ли массивы PostgreSQL делать еще больше? Конечно, обратитесь к документации PostgreSQL, чтобы найти множество дополнительных возможностей.
Теперь у вас есть все инструменты для использования списков и вложенных структур в ваших таблицах SQL. Хотя эти мощные инструменты позволяют вам отказаться от парадигмы «одна строка — одна запись», вам следует использовать их только в том случае, если они представляют реальную ценность и не могут быть заменены более традиционным подходом. Существуют веские причины для существующих лучших практик SQL, поэтому ваши причины для их обхода должны быть еще лучше.
Хотя эти мощные инструменты позволяют вам отказаться от парадигмы «одна строка — одна запись», вам следует использовать их только в том случае, если они представляют реальную ценность и не могут быть заменены более традиционным подходом. Существуют веские причины для существующих лучших практик SQL, поэтому ваши причины для их обхода должны быть еще лучше.
Надеюсь, вы что-то узнали, спасибо за чтение.
Присоединяйтесь к Medium по моей реферальной ссылке — Merlin Schäfer
Прочитайте все истории от Мерлина Шефера (и тысяч других авторов на Medium). Ваш членский взнос напрямую поддерживает…
ms101196.medium.com
MTM на массивах в PostgreSQL. С тех пор, как я обнаружил массивы в… | от AlekseyL
С тех пор, как я обнаружил массивы в PostgreSQL как тип данных, я не перестаю задаваться вопросом, что произойдет, если отношение многие ко многим будет осуществляться через массивы, а не через промежуточную таблицу mtm. Конечно в масштабе 100К выглядит вроде ничего интересного, но это неверное предположение, даже в масштабе 100К*100К с интенсивной связью между объектами мы можем увидеть некоторые интересных тенденций .
Многие ко многим
В системном анализе связь многие ко многим — это тип кардинальности, относящийся к связи между двумя сущностями[1] A и B, в которой A может содержать родительский экземпляр, для которого в B много детей и наоборот.
Например, представьте, что A — это Авторы, а B — Книги. Автор может написать несколько Книг, а Книгу могут написать несколько Авторов.
В системе управления реляционными базами данных такие отношения обычно реализуются с помощью ассоциативной таблицы (также известной как таблица перекрестных ссылок ), скажем, AB с двумя отношениями «один ко многим» A -> AB и B — > АБ. В этом случае логический первичный ключ для AB формируется из двух внешних ключей (то есть копий первичных ключей A и B).
Простая модель данных
Предположим, у нас есть частные документов и пользователей . Каждый документ может быть доступен многим пользователям, и каждый пользователь может иметь доступ ко многим общим документам. Давайте соединим их через таблицу предоставил доступ . Предположим, что каждый документ доступен для 1 000 пользователей.
Давайте соединим их через таблицу предоставил доступ . Предположим, что каждый документ доступен для 1 000 пользователей.
Если у нас есть 100 тысяч документов и 100 тысяч пользователей, то общее количество разрешенных доступов будет равно 100 миллионам записей.
Размер таблицы grant_accesses в байтах будет равен b: 100M * 3 * sizeof(bigint) bytes ~ 2,4 Гб, , где 3 — это не магическое число, а количество столбцов: user_id, doc_id и первичный ключ. (В этом расчете отсутствует информация о внутренних строках, см. разделы «UPD» ниже)
Если нам нужен двунаправленный поиск, нам понадобятся как минимум два индекса [doc_id, user_id] и [user_id, doc_id], каждый из которых принесет +2,4 ГБ сам по себе (потому что он будет содержать такое же количество данных, как и чистые данные строки) + a индекс первичного ключа, как обычно, ~ +0,8 Гб (на самом деле я вижу 2 Гб в своей тестовой таблице, но я воссоздавал его пару раз, поэтому давайте предположим самое низкое предсказуемое значение).
UPD: на самом деле каждый индекс также содержит дополнительную системную информацию для каждой записи, так что это будет даже больше, чем указано выше.
Общий размер кросс-таблицы + индексы будет около 8Гб!
UPD: Спасибо Мацею Бонку за комментарий ниже! На самом деле этот расчет не включает заголовки кортежей, что дает +23 байта на строку! Это означает, что размер таблицы будет больше 10 Гб!
Добавление двух столбцов массива с 1 КБ bigints в строке к таблицам пользователей и документов может принести по 0,8 Гб каждый, но поскольку pg_toast сжимает такие данные, это может быть менее 0,8 Гб (я вижу прирост ~400 Мб+ на моем наборе , но это может не быть проблемой в ваших случаях).
Таким образом, общий размер необходимых данных будет ~ 1,6 Гб или меньше.
Связанные записи без JOIN
--с массивами
SELECT "users".*
FROM "users"
WHERE "users"."id" IN (
SELECT unnest(user_ids)
FROM "docs"
ГДЕ «документы». «id» = ID
) -- с таблицей mtm
ВЫБЕРИТЕ «пользователей». *
ИЗ «пользователей»
ГДЕ «пользователи». «id» В (
ВЫБЕРИТЕ «granted_accesses». «user_id»
ОТ "granted_accesses"
ГДЕ "granted_accesses"."doc_id" = ID
)
1,25 — 1,5 раза быстрее при использовании массива.
ПРИСОЕДИНЯЙТЕСЬ
--mtm-table
ВЫБЕРИТЕ * ИЗ карточек
ПРИСОЕДИНЯЙТЕСЬ предоставленным_доступам НА doc_id = docs.id
ПРИСОЕДИНЯЙТЕСЬ к пользователям НА users.id = user_id
ГДЕ SELECT docds.id = ID *0;-0ar id = ID *0;-0ar С карты
ПРИСОЕДИНЯЙТЕСЬ к пользователям ПО users.id = ANY(docs.user_ids)
ГДЕ docs.id = ID;
1,4–1,7 раза в пользу представления массива
Это простые случаи, и все же массивы показывают лучшие результаты, хотя они оба сделали это за пару миллисекунд.
Не забудьте запустить ANALYZE после заполнения промежуточной таблицы, иначе postgres может пропустить сканирование только индекса! И да, эти цифры для сканирования IndexOnly, неплохо для массива!
Сложные поиски
В некоторых случаях промежуточная таблица может дать лучший результат, например в этом запросе:
--mtm
SELECT * FROM docs (?) И user_id IN(?) --arr
SELECT * FROM docs
ГДЕ id IN (?) AND user_ids && ARRAY[?]::bigint[];
С массивами планировщик pg не может принести ничего, кроме сканирования индекса docs. id с фильтром по user_id. Наоборот, поиск mtm может оптимизировать этот случай и выиграть 1,7-кратный прирост на средних наборах (100–1000 элементов) , но все же mtm медленнее на малых и больших наборах данных: ≤ 10, ≥ 2000.
id с фильтром по user_id. Наоборот, поиск mtm может оптимизировать этот случай и выиграть 1,7-кратный прирост на средних наборах (100–1000 элементов) , но все же mtm медленнее на малых и больших наборах данных: ≤ 10, ≥ 2000.
Хотя единственный способ Запросы overperfom на основе массива для соединения должны оставаться только в условиях doc_id + user_id, добавление еще одного ограничения индексированного столбца может легко восстановить превосходство массивов во всем диапазоне случаев. Такой запрос может выглядеть примерно так:
--mtm
ВЫБЕРИТЕ * ИЗ документов
ПРИСОЕДИНЯЙТЕСЬ предоставленным_доступам НА doc_id =cards.id
ГДЕ doc_id В (?) И user_id В(?) И indexed_rare_key = ? --arr
SELECT * FROM docs
ГДЕ id IN (?) AND user_ids && ARRAY[?]::bigint[] AND indexed_rare_key = ? ;
Еще один случай, когда массив выигрывает не раздельным решением, а нокаутом: это непропорциональное или асимметричное отношение.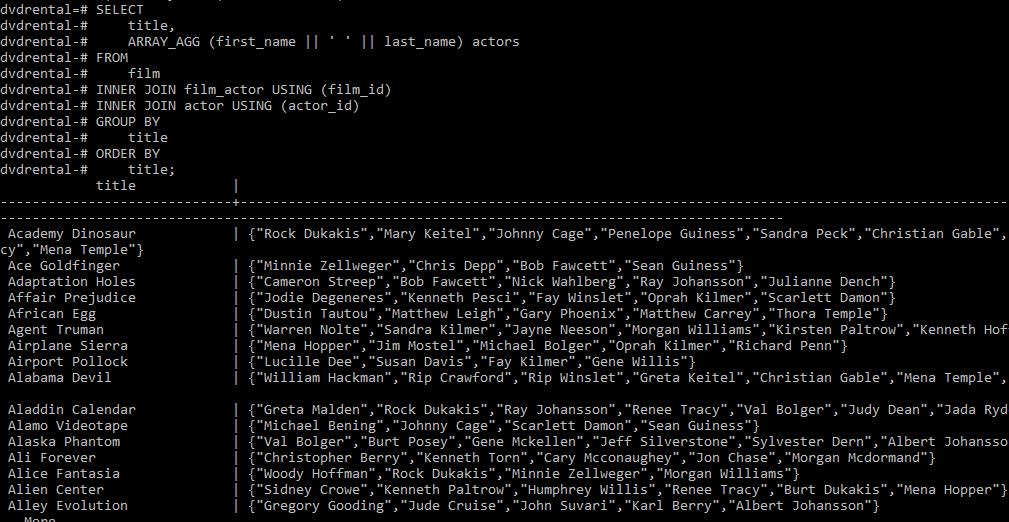 В одном из моих тестовых наборов данных было 1К элементов с одной стороны отношения и 3–5 элементов с другой, и мне нужен был полнотекстовый поиск в сочетании с ограничениями на это отношение «многие ко многим». я получаю Увеличение производительности в 20–30 раз в пользу массива по сравнению с таблицей mtm, , конечно, с соответствующим индексом GIN.
В одном из моих тестовых наборов данных было 1К элементов с одной стороны отношения и 3–5 элементов с другой, и мне нужен был полнотекстовый поиск в сочетании с ограничениями на это отношение «многие ко многим». я получаю Увеличение производительности в 20–30 раз в пользу массива по сравнению с таблицей mtm, , конечно, с соответствующим индексом GIN.
Небольшое замечание : GIN плохо выглядит в масштабе тысяч (т.е. не используйте его, когда массивы в столбце содержат тысячи элементов) и бесполезен для первого примера, но отлично работает на десятках.
Ограничения/проблемы
Есть два основных ограничения, о которых я могу думать: ссылочная целостность и поддержка ORM.
Если вы хотите быть уверенным и сохранить ссылочную целостность — вы должны сделать это самостоятельно, создав триггеры в своей БД. Менее безопасно, но обычно дешевле: обратные вызовы на моделях ORM.
--Не забывайте использовать функции массива, например:
ОБНОВЛЕНИЕ карт
SET user_ids = array_remove(user_ids, ?::bigint)
WHERE ... #or
user.docs.update_all('user_ids = array_remove (user_ids,?)', user.id)
Другая проблема в том, что ваш ORM скорее всего не будет поддерживать отношение mtm на основе массива из коробки, поэтому вам нужно будет создать собственные обходные пути для всех необходимых вам функций.
Еще одно замечание — у вас должны быть массивы с обеих сторон отношения mtm , вы не можете просто хранить user_id в документе, не сохраняя doc_id на пользователе, это сделает неприемлемо медленными любые обратные операции.
Сводка
Clear JOIN работает быстро, а компромисс производительности на простых запросах относительно невелик (1,25–1,7 раза в пользу массива), это ничего не стоит в миллисекундном масштабе. Но на более сложных поисковых запросах может стать заметным прирост производительности массивного решения даже в 1,5 раза, не говоря уже о частных случаях, когда массив просто нокаутирует mtm-таблицу с приростом в 20–30 раз.