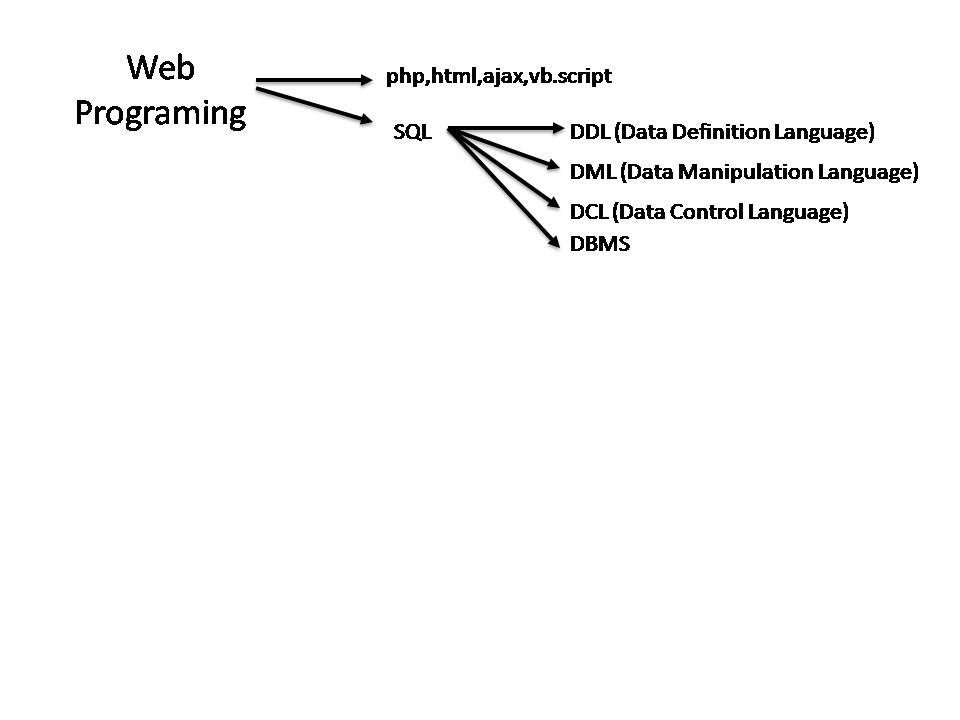
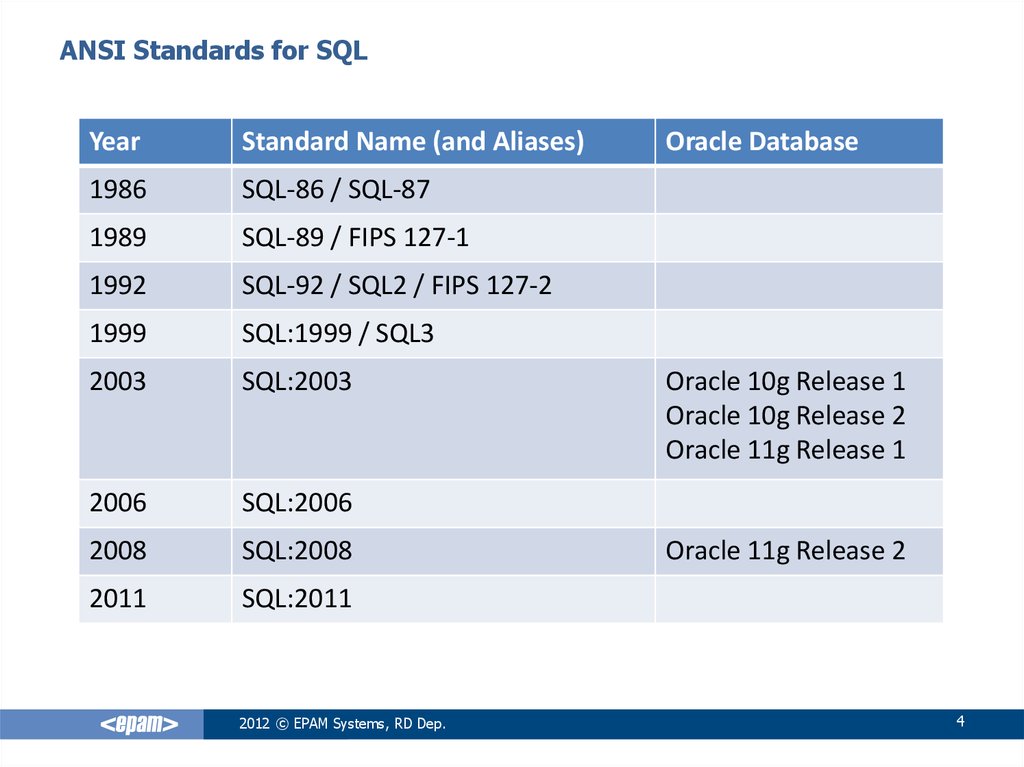
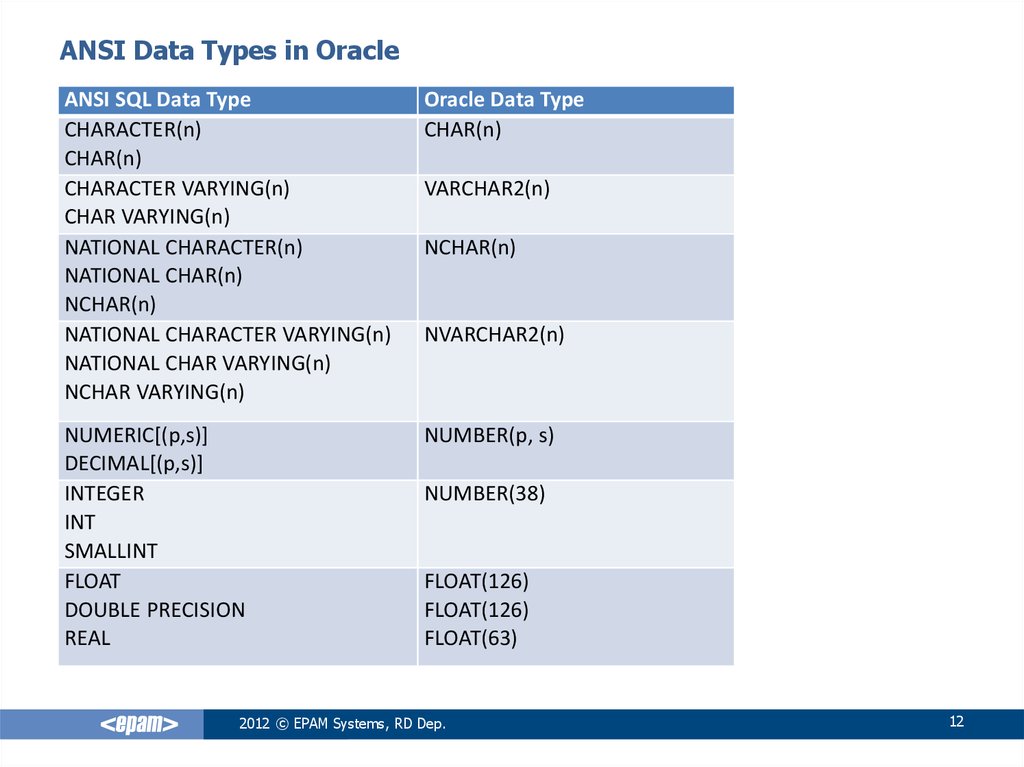
Эквивалентные типы данных ANSI SQL
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Область применения: Access 2013, Office 2013
В следующей таблице перечислены типы данных ANSI SQL, эквивалентные типы данных SQL ядра СУБД Microsoft Access и допустимые синонимы. В ней также перечислены эквивалентные типы данных Microsoft SQL Server™.
В ней также перечислены эквивалентные типы данных Microsoft SQL Server™.
BIT, BIT VARYING | BINARY (см. примечания) | VARBINARY, BINARY VARYING BIT VARYING | BINARY, VARBINARY |
Не поддерживается | BIT (см. примечания) | BOOLEAN, LOGICAL, LOGICAL1, YESNO | BIT |
Не поддерживается | TINYINT | INTEGER1, BYTE | TINYINT |
Не поддерживается | COUNTER (см. примечания) | AUTOINCREMENT | (См. примечания) |
Не поддерживается | MONEY | CURRENCY | MONEY |
DATE, TIME, TIMESTAMP | DATETIME | DATE, TIME (см. примечания) | DATETIME |
Не поддерживается | UNIQUEIDENTIFIER | GUID | UNIQUEIDENTIFIER |
DECIMAL | DECIMAL | NUMERIC, DEC | DECIMAL |
REAL | REAL | SINGLE, FLOAT4, IEEESINGLE | REAL |
DOUBLE PRECISION, FLOAT | FLOAT | DOUBLE, FLOAT8, IEEEDOUBLE, NUMBER (см. | FLOAT |
SMALLINT | SMALLINT | SHORT, INTEGER2 | SMALLINT |
INTEGER | INTEGER | LONG, INT, INTEGER4 | INTEGER |
INTERVAL | Не поддерживается | Не поддерживается | |
Не поддерживается | IMAGE | LONGBINARY, GENERAL, OLEOBJECT | IMAGE |
Не поддерживается | TEXT (см. примечания) | LONGTEXT, LONGCHAR, MEMO, NOTE, NTEXT (см. примечания) | TEXT |
CHARACTER, CHARACTER VARYING, NATIONAL CHARACTER, NATIONAL CHARACTER VARYING | CHAR (см. примечания) | TEXT(n), ALPHANUMERIC, CHARACTER, STRING, VARCHAR, CHARACTER VARYING, NCHAR, NATIONAL CHARACTER, NATIONAL CHAR, NATIONAL CHARACTER VARYING, NATIONAL CHAR VARYING (см. | CHAR, VARCHAR, NCHAR, NVARCHAR |
 примечания)
примечания) примечания)
примечания)Примечание
- Тип данных BIT ANSI SQL не соответствует типу данных BIT Microsoft Access SQL. Он соответствует типу данных BINARY. Для типа данных BIT Microsoft Access SQL отсутствует эквивалент ANSI SQL.
- TIMESTAMP больше не поддерживается в качестве синонима для DATETIME.
- NUMERIC больше не поддерживается в качестве синонима для FLOAT или DOUBLE. NUMERIC теперь используется в качестве синонима для DECIMAL.
- Поле LONGTEXT всегда хранится в формате представления Юникода.
- Если тип данных TEXT используется без указания необязательной длины, например TEXT(25), создается поле LONGTEXT. Это позволяет записывать операторы CREATE TABLE, возвращающие типы данных, которые соответствуют Microsoft SQL Server.
- Поле CHAR всегда хранится в формате представления Юникода, что соответствует типу данных NATIONAL CHAR ANSI SQL.
- Если тип данных TEXT используется с указанием необязательной длины, например TEXT(25), тип данных поля эквивалентен типу данных CHAR.
Критика уровней изолированности в стандарте ANSI SQL | Системы управления базами данных
- 2.1. Концепция сериализуемости
- 2.2. Уровни изолированности в ANSI SQL
- 2.3. Механизм блокировок
- 4.1. Устойчивость курсора
- 4.2. Изолированность Образа
- 4.3. Другие многоверсионные системы
В ANSI SQL-92 [MS, ANSI] Уровни Изолированности (Isolation Levels) определяются в терминах феноменов (phenomena): Грязное Чтение (Dirty Read), Неповторимое Чтение (Non-repeatable Read) и Фантом (Phantom). В статье показывается недостаточность феноменов и определений ANSI SQL для полного корректного описания некоторых популярных уровней изолированности, включая стандартные блокировочные реализации рассматриваемых уровней. Исследуется неоднозначность определений феноменов и дается более точное формальное определение феномена. Приводятся новые феномены, которые лучше характеризуют типы изолированности. Определяется новый тип многоверсионной изолированности называемый Изолированностью Образа (Snapshot Isolation).
В статье показывается недостаточность феноменов и определений ANSI SQL для полного корректного описания некоторых популярных уровней изолированности, включая стандартные блокировочные реализации рассматриваемых уровней. Исследуется неоднозначность определений феноменов и дается более точное формальное определение феномена. Приводятся новые феномены, которые лучше характеризуют типы изолированности. Определяется новый тип многоверсионной изолированности называемый Изолированностью Образа (Snapshot Isolation).
1. Введение
Возможность параллельного выполнения конкурирующих транзакций на различных уровнях изолированности позволяет разработчикам приложений повысить количество одновременно выполняющихся транзакций, сохраняя их корректность. Нижние уровни изолированности дают возможность увеличить количество одновременно выполняющихся транзакций за счет риска получения размытого или несогласованного состояния данных. Замечательно, что в то время, когда некоторые транзакции выполняются на высшем уровне изолированности (чистая сериализуемость), совместно выполняющиеся транзакции на нижних уровнях изолированности выполняются параллельно и могут работать с незафиксированными или устаревшими, прочитанными транзакцией ранее, данными [GLPT].
В стандарте ANSI SQL-92 [MS, ANSI] определяются четыре уровня изолированности.
1) Незафиксированное Чтение (READ UN-COMMITED).
2) Зафиксированное Чтение (READ COMMITED).
3) Повторимое Чтение (REPEATABLE READ).
4) Сериализуемость (SERIALIZABLE).
Они определяются с помощью классического определения сериализуемости и трех запрещенных последовательностей операций, названных феноменами: Грязное Чтение, Неповторимое Чтение и Фантом. В стандарте нет четкого определения феномена, предполагается что феномен — это последовательность операций, обладающая аномальным (возможно, не сериализуемым) поведением. В дальнейшем изложении мы говорим об аномалиях, когда делаем необходимые добавления ко множеству ANSI-феноменов. Показанное ниже техническое различие между аномалиями и феноменами несущественно для качественного понимания сути вопроса.
Показанное ниже техническое различие между аномалиями и феноменами несущественно для качественного понимания сути вопроса.
Уровни изолированности ANSI родственны по поведению планировщику блокировок. Некоторые планировщики блокировок позволяют транзакциям варьировать границы и продолжительность устанавливаемых ими запросов блокировок, таким образом отступая от чистой двухфазной блокировки. Эта идея была предложена в [GLPT], где степени согласованности определяются тремя способами: механизмом блокировок, графом потоков данных и аномалиями. В стандарте ANSI SQL определение уровней изолированности дается в терминах феноменов (аномалий) для того, чтобы такое определение уровней изолированности позволяло не только реализации стандарта SQL, основанные на механизме блокировок.
В этой статье показан ряд слабых мест ANSI в определении уровней изолированности с помощью аномалий. Определения трех ANSI-феноменов двусмысленны. Они даже в самой свободной своей интерпретации не исключают некоторые аномальные последовательности операций в историях выполнения транзакций.
Во втором разделе вводится основная терминология, связанная с уровнями изолированности. Определяются ANSI SQL и блокировочные уровни изолированности.
В третьем разделе исследуются недостатки уровней изолированности в ANSI SQL и предлагается к рассмотрению новый феномен. Также даны определения других популярных уровней изолированности. Проводятся сравнительные параллели между уровнями изолированности в ANSI SQL и степенями согласованности, определенными в [GLPT] в 1977 году.
В четвертом разделе описан механизм контроля многоверсионного параллельного выполнения транзакций. Он назван Изолированность Образа. Он позволяет избежать употребления феноменов ANSI SQL, но не является сериализуемым. Изолированность Образа интересна тем, что обеспечивает промежуточный уровень изолированности, лежащий между уровнями Зафиксированного Чтения и Повторимого Чтения. Новый формализм (описанный в более полной версии этой статьи [OOBBGM]) соединяет в себе промежуточный уровень изолированности для многоверсионных данных и классическую одноверсионную теорию блокировочной сериализуемости.
В пятом разделе исследуются несколько новых аномалий. Они позволяют выделить различия между уровнями изолированности, введенными в третьем и четвертом разделах. Дополнительные ANSI SQL-феномены, приводимые здесь, позволяют точно определить Изолированность Образа и Устойчивость Курсора. В шестом разделе представлено краткое Резюме и сделаны Выводы.
Дополнительные ANSI SQL-феномены, приводимые здесь, позволяют точно определить Изолированность Образа и Устойчивость Курсора. В шестом разделе представлено краткое Резюме и сделаны Выводы.
2. Определение изолированности
2.1. Концепция сериализуемости
Концепции транзакции и механизма блокировок хорошо документированы в литературе [BHG, PAP, PON, GR]. В следующих нескольких абзацах делается обзор терминологии, используемой в этой области.
Транзакцией называют упорядоченное множество операций, переводящих базу данных из одного непротиворечивого состояния в другое. История моделирует перекрывающееся выполнение множества транзакций в виде линейных последовательностей их операций Чтения и Записи (Вставки, Обновления, Удаления) определенных элементов данных. Говорят, что две операции в истории конфликтуют, если они осуществляются различными транзакциями над одним элементом данных и хотя бы одна из них выполняет операцию Записи. Согласно [EGLT], это определение можно широко интерпретировать в зависимости от того, что понимать под «элементом данных». Это может быть строка таблицы, конкретное поле на странице, целая таблица или коммуникационный объект, такой например как сообщение в очереди. Конфликтующие операции могут возникать не только на отдельных элементах данных, но и на множествах элементов данных, которые задаются с помощью предикатов.
Это может быть строка таблицы, конкретное поле на странице, целая таблица или коммуникационный объект, такой например как сообщение в очереди. Конфликтующие операции могут возникать не только на отдельных элементах данных, но и на множествах элементов данных, которые задаются с помощью предикатов.
Отдельные истории составляют граф зависимостей (dependency graph), определяющий потоки временных данных, передаваемых между транзакциями. Операции зафиксированных транзакций представляются вершинами графа. Если в истории операция op1 транзакции T1 конфликтует с предшествующей операцией op2 транзакции T2, то пара становится ребром графа зависимостей. Две истории считаются эквивалентными, если они имеют одинаковые зафиксированные транзакции и одинаковые графы зависимостей. История называется сериализуемой, если она эквивалентна последовательной истории. Другими словами, если она имеет такой же граф зависимостей (межтранзакционный поток временных данных), как если бы все транзакции в ней выполнялись последовательно (поочередно).
2.2. Уровни изолированности в ANSI SQL
Разработчики ANSI SQL дали такое определение изолированности, которое допускает широкий спектр механизмов реализации, не только механизм блокировки. Они определили изолированность с помощью следующих трех феноменов (phenomena):
P1 (Грязное Чтение) (Dirty Read)
Транзакция T1 модифицировала содержимое элемента данных. После этого другая транзакция T2 прочитала содержимое этого элемента данных, до того как транзакция T1 выполнила операцию COMMIT (зафиксировалась) или ROLLBACK (откатилась). Если T1 завершается операцией ROLLBACK, то получается, что транзакция T2 прочитала реально не существующие данные.
P2 (Неповторимое или Размытое Чтение) (Non-repeatable or Fuzzy Read)
Транзакция T1 прочитала содержимое элемента данных. После этого другая транзакция T2 модифицирует или удаляет этот элемент данных и фиксируется. Если T1 после этого попытается прочитать содержимое этого элемента данных снова, то она получит другое значение или обнаружит, что элемент данных больше не существует.
P3 (Фантом) (Phantom):
Транзакция T1 прочитала содержимое нескольких элементов данных, удовлетворяющих некоторому предикату . После этого транзакция T2 создает элемент данных, удовлетворяющий этому предикату, и фиксируется. Если транзакция T1 повторит чтение с тем же предикатом , то получит уже другой набор данных, отличный от полученного в первый раз.
Ни один из этих феноменов не может произойти в последовательной истории. Поэтому, по теореме о сериализуемости, они не могут произойти и в сериализуемой истории [EGLT, BHG Теорема 3.6, GR Раздел 7.5.8.2, PON Теорема 9.4.2].
Истории, состоящие из операций Чтения, Записи, Фиксации и Отката, могут быть записаны в сокращенной нотации: «w1[x]» обозначает операцию записи транзакции 1 в ячейку x (таким образом данные модифицируются)» «r2[x]» представляет операцию чтения из x транзакцией 2. Операции чтения и записи множества записей, удовлетворяющих предикату P, в транзакции 1 обозначаются соответственно r1[P] и w1[P]. Фиксация (COMMIT) и Откат (ROLLBACK) транзакции 1 соответственно обозначаются «c1» и «a1».
Фиксация (COMMIT) и Откат (ROLLBACK) транзакции 1 соответственно обозначаются «c1» и «a1».
Феномен P1 может быть представлен как запрещение на следующую последовательность операций:
(2.1) w1[x]...r2[x]... (a1 и c2 в любом порядке)
Словесное определение феномена P1 неоднозначно. Оно не настаивает на том, чтобы T1 заканчивалась откатом. Оно только утверждает, что если это произойдет, то может случиться что-то плохое. Некоторые люди интерпретируют P1 как:
(2.2) w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Запретив P1 в варианте (2.2), мы запретим любую историю следующего вида: T1 модифицирует содержимое элемента данных x. Затем T2 читает содержимое x, до того как T1 зафиксируется или откатится. Определение не настаивает на том, чтобы T1 откатилась или T2 зафиксировалась.
Определение (2.2) является более свободной интерпретацией P1, чем (2.1). Оно запрещает все четыре возможных варианта пар завершение-откат транзакций T1 и T2, когда в (2. 1) запрещаются только две пары из четырех. Интерпретация (2.2) феномена P1 запрещает все варианты последовательности выполнения, даже те, в которых что-то аномальное может произойти в будущем. Мы называем интерпретацию (2.2)- свободной интерпретацией P1, а (2.1)- строгой интерпретацией P1. Интерпретация (2.2) определяет феномен, который может быть аномальным, а (2.1) — который заведомо аномален. Обозначим их соответственно P1 и A1:
1) запрещаются только две пары из четырех. Интерпретация (2.2) феномена P1 запрещает все варианты последовательности выполнения, даже те, в которых что-то аномальное может произойти в будущем. Мы называем интерпретацию (2.2)- свободной интерпретацией P1, а (2.1)- строгой интерпретацией P1. Интерпретация (2.2) определяет феномен, который может быть аномальным, а (2.1) — который заведомо аномален. Обозначим их соответственно P1 и A1:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке)
Аналогично, словарные определения феноменов P2 и P3 тоже имеют свободную и строгую интерпретации. Обозначим свободные интерпретации через P2 и P3, а строгие через A2 и A3:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
A2: r1[x]...w2[x]...c2...r1[x]...c1
P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке)
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1
В третьем разделе все варианты интерпретаций феноменов рассматриваются более подробно. Аргументируется необходимость выбора свободных интерпретаций. Заметим, что в словесном ANSI SQL определении феномена P3 после чтения по предикату запрещается только вставлять данные, которые попадают в область действия предиката, а в определении P3, которое было приведено выше, запрещается производить любую операцию записи (вставка, обновление, удаление), влияющую на кортеж, удовлетворяющий предикату.
Аргументируется необходимость выбора свободных интерпретаций. Заметим, что в словесном ANSI SQL определении феномена P3 после чтения по предикату запрещается только вставлять данные, которые попадают в область действия предиката, а в определении P3, которое было приведено выше, запрещается производить любую операцию записи (вставка, обновление, удаление), влияющую на кортеж, удовлетворяющий предикату.
Далее в статье рассматривается концепция многозначной истории (multi-valued history) (сокращенно МВ-история, см. [BHG], Глава 5). Не вдаваясь в детали сейчас, многоверсионная система отличается тем, что может одновременно содержать несколько версий одного элемента данных. При выполнении операции чтения должно быть совершенно ясно, какую версию данных необходимо использовать. Здесь делаются попытки сопоставить определение условной изолированности ANSI с многоверсионными системами и более распространенными одноверсионными системами (single-version) (ОВ-истории) стандартного планировщика блокировок. Словесные определения феноменов P1, P2 и P3 подразумевают одноверсионные истории. В следующем разделе видно, как мы их интерпретируем.
Словесные определения феноменов P1, P2 и P3 подразумевают одноверсионные истории. В следующем разделе видно, как мы их интерпретируем.
В Таблице 1 приводятся четыре уровня изолированности определенные в ANSI SQL. Каждый уровень изолированности характеризуется возможностью происхождения феноменов (в строгой или свободной интерпретации). Однако сериализуемый уровень изолированности в ANSI SQL не определяется только в терминах феноменов. В работе [ANSI], подпункте 4.28 «SQL-транзакции», отмечается, что на уровне изолированности СЕРИАЛИЗУЕМОСТЬ должно обеспечиваться поведением, которое «хорошо известно как полностью сериализуемое выполнение». Анализируя верхнюю часть таблицы и принимая во внимание эту оговорку, обычно приходят к распространенному заблуждению, что запрещение всех трех феноменов приведет к сериализуемости. Истории, исключающие три указанных феномена, называют Аномально Сериализуемыми (ANOMALY SERIALIZABLE) (см. Таблицу 1).
Свободные интерпретации феноменов встречаются в большем количестве историй, чем строгие интерпретации. Так как уровни изолированности определяются запрещенными феноменами, то из того факта, что в третьем разделе мы агитируем за свободные интерпретации, следует, что мы агитируем за более ограниченные уровни изолированности (большее количество историй недопустимо). В третьем разделе показано, что даже если мы берем свободные интерпретации P1, P2 и P3 и запрещаем эти феномены, то мы все равно не получим истинной сериализуемости.
Так как уровни изолированности определяются запрещенными феноменами, то из того факта, что в третьем разделе мы агитируем за свободные интерпретации, следует, что мы агитируем за более ограниченные уровни изолированности (большее количество историй недопустимо). В третьем разделе показано, что даже если мы берем свободные интерпретации P1, P2 и P3 и запрещаем эти феномены, то мы все равно не получим истинной сериализуемости.
Было бы проще в [ANSI] оставить P3 и использовать подпункт 4.28 для определения ANSI СЕРИАЛИЗУЕМОСТЬ. В Таблице 1 представлен только промежуточный результат, окончательный результат будет представлен в Таблице 3.
2.3. Механизм блокировок
В большинстве SQL-продуктов изолированность реализована на основе механизма блокировок. Поэтому полезно описать уровни изолированности ANSI SQL в терминах блокировок.
Выполнение транзакций происходит под управлением планировщика блокировок. Перед выполнением операции Чтения или Записи с одним или несколькими элементами данных транзакция делает запрос планировщику блокировок на установление блокировки по Чтению (Share) или по Записи (Exclusive) на те элементы данных, к которым она обращается. Две блокировки, поставленные различными транзакциями на одни и те же элементы данных, конфликтуют, если хотя бы одна из них является блокировкой по Записи.
Две блокировки, поставленные различными транзакциями на одни и те же элементы данных, конфликтуют, если хотя бы одна из них является блокировкой по Записи.
Предикативная блокировка по Чтению (по Записи) множества элементов данных, определяющихся с помощью предиката , блокирует все элементы данных, удовлетворяющие этому предикату. Это множество элементов данных теоретически является бесконечным, потому что в него попадают все элементы, уже присутствующие в базе данных и удовлетворяющие предикату , и так же все фантомные элементы данных, которых еще нет в базе данных, но которые будут удовлетворять предикату , если попадут туда вследствие выполнения операции Вставки или Обновления. В терминах SQL предикативная блокировка закрывает все присутствующие в базе данных элементы, которые удовлетворяют предикату, и любые другие удовлетворяющие предикату блокировки элементы, которые могут быть внесены в базу данных с помощью операций Вставки, Обновления или Удаления. Две предикативных блокировки различных транзакций конфликтуют, если одна является блокировкой по Записи и если есть (возможно, фантомные) элементы данных, закрытые обеими блокировками. Блокировка элемента данных (блокировка записи) является предикативной блокировкой, у которой в предикате указано имя данной записи.
Блокировка элемента данных (блокировка записи) является предикативной блокировкой, у которой в предикате указано имя данной записи.
Транзакция имеет хорошо сформированные (well-formed writes) операции Записи (Чтения), если она запрашивает блокировку по Записи (по Чтению) на каждый элемент данных или предикат перед выполнением операции Записи (Чтения) над этим элементом данных или множеством элементов данных, определенных с помощью предиката. Транзакция называется хорошо сформированной (well-formed), если все ее операции Записи и Чтения хорошо сформированные. Транзакция имеет двухфазные (two-phase writes) операции Записи (Чтения), если она не устанавливает новую блокировку по Записи (Чтению) на элементы данных после снятия с них блокировки по Записи (Чтению). Транзакция осуществляет двухфазную блокировку (two-phase locking), если она не запрашивает новой блокировки (по Записи или по Чтению) после снятия какой-то блокировки.
Блокировка, запрашиваемая транзакцией, называется долговременной (long duration), если она не снимается до конца выполнения транзакции (когда она зафиксируется или откатится). В противном случае блокировка называется кратковременной (short duration). На практике кратковременные блокировки обычно снимаются сразу же после завершения операции.
В противном случае блокировка называется кратковременной (short duration). На практике кратковременные блокировки обычно снимаются сразу же после завершения операции.
Грязное чтение (Dirty Read) | Размытое чтение (Fuzzy Read) | Фантом (Phantom) | |
(ANSI READ UNCOMMITTED) | |||
(ANSI REPEATABLE READ) | |||
(ANOMALY SERIALIZABLE) |
Таблица 1.
Если одна транзакция установила блокировку, а другая транзакция запрашивает установление конфликтующей блокировки, то этот запрос будет выполнен только после того, как конфликтующая блокировка первой транзакции будет освобождена.
Фундаментальная теорема сериализуемости гласит, что хорошо сформированное двухфазное блокирование гарантирует сериализуемость, когда каждая история двухфазного блокирования эквивалентна некоторой последовательной истории. Наоборот, если транзакция или не является хорошо сформированной или не осуществляет двухфазное блокирование, то возможны несериализуемые истории выполнения [EGLT]. Исключения составляют только вырожденные случаи.
Для того чтобы показать эквивалентность механизма блокировок, зависимостей и механизмов, основанных на аномалиях, в статье [GLPT] определяются четыре степени согласованности (degrees of consistency). Определения аномалий (см. Определение 1) были даны очень расплывчато. Авторы продолжают критиковать определения в этом аспекте (см.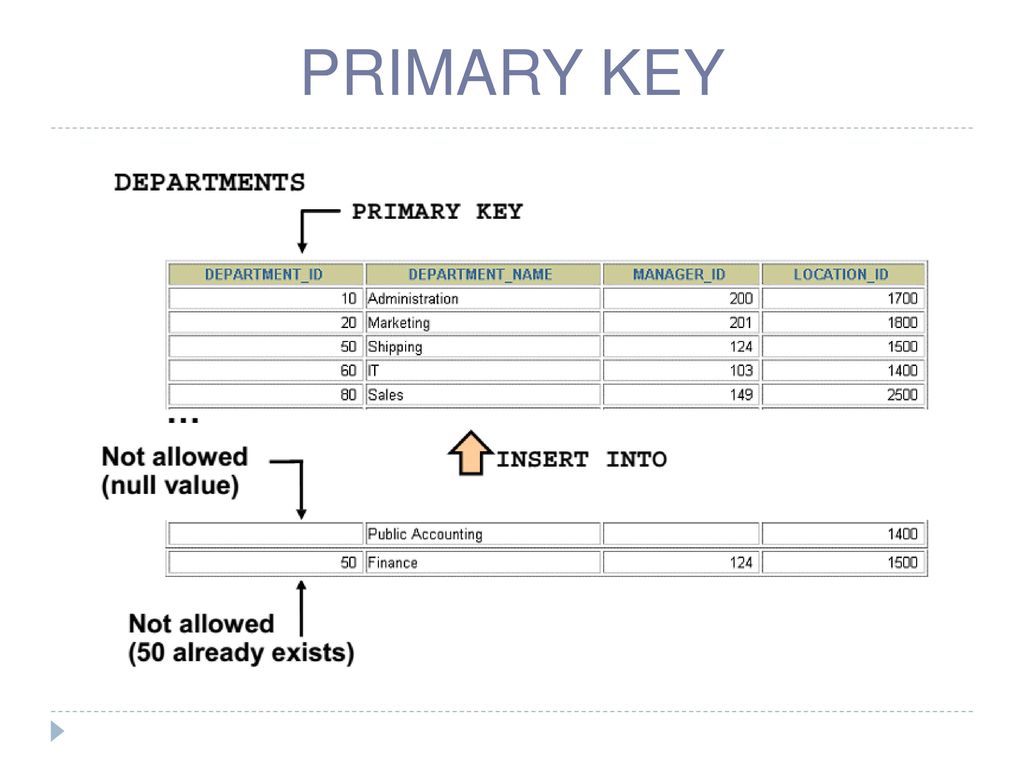 также [GR]). Со временем остались только математически точные определения в терминах историй и графов зависимостей или блокировок.
также [GR]). Со временем остались только математически точные определения в терминах историй и графов зависимостей или блокировок.
= Блокировочный уровень изолированности | Элементах Данных и Предикатах (одинаковы если нет замечаний) | Элементах Данных и Предикатах (везде одинаковы) |
Незафиксированное Чтение | Долговременные блокировки по Записи | |
Зафиксированное Чтение | Кратковременные блокировки по Чтению (обе) | Долговременные блокировки по Записи |
(см.  Раздел 4.1) Раздел 4.1) | Блокировка по Чтению устанавливается на текущем элементе курсора Кратковременные блокировки по Чтению на Предикатах | Долговременные блокировки по Записи |
Повторимое Чтение | Долговременные блокировки по Чтениюна элементах данных Кратковременные блокировки по Чтению на Предикатах | Долговременные блокировки по Записи |
СЕРИАЛИЗУЕМОСТЬ | Долговременные блокировки по Чтению(обе) | Долговременные блокировки по Записи |
Таблица 2.
Во второй Таблице определяется несколько типов изолированности в следующих терминах: количества блокируемых (элементов или предикатов), видов (по Чтению или по Записи) и по их продолжительности (кратковременные или долговременные). Уровни изолированности, названные как:
Уровни изолированности, названные как:
Блокировочное НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ UNCOMMITTED),
Блокировочное ЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ COMMITTED),
Блокировочное ПОВТОРИМОЕ ЧТЕНИЕ (Locking REPEATABLE READ),
Блокировочная СЕРИАЛИЗУЕМОСТЬ (Locking SERIALIZABLE),
являются блокировочными аналогами уровней изолированности ANSI SQL, но, как показывается дальше, они существенно отличаются друг от друга (см. Таблицы 1 и 2). Поэтому необходимо различать уровни изолированности, определенные в терминах блокировок, и уровни изолированности, определенные с помощью феноменов. Для достижения такого различия уровни изолированности, определенные во второй Таблице, имеют префикс «Блокировочные», а определенные в первой Таблице — «ANSI».
[GLPT] определяет согласованность Степени 0, на которой разрешаются операции Грязного Чтения и Записи (Dirty Reads and Writes). Требуется только атомарность операций. Степени 1, 2 и 3 относятся, соответственно, к блокировочным уровням изолированности: Блокировочное НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ UNCOMMITTED), Блокировочное ЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ COMMITTED), Блокировочная СЕРИАЛИЗУЕМОСТЬ (Locking SERIALIZABLE). Ни одна степень согласованности не соответствует уровню изолированности Блокировочное ПОВТОРИМОЕ ЧТЕНИЕ (Locking REPEATABLE READ).
Ни одна степень согласованности не соответствует уровню изолированности Блокировочное ПОВТОРИМОЕ ЧТЕНИЕ (Locking REPEATABLE READ).
Дэйт и IBM сначала использовали термин «Повторимое Чтение» [DAT, DB2] для обозначения сериализуемости или блокировочной сериализуемости. Этот термин кажется более понятным, чем термин [GLPT] «третья степень изолированности», хотя по значению они идентичны. Такая терминология неудачна, так как значение термина ANSI SQL ПОВТОРИМОЕ ЧТЕНИЕ отличается от оригинального определения, данного Дэйтом. Аномалия P3 специально не исключается на уровне изолированности ANSI SQL ПОВТОРИМОЕ ЧТЕНИЕ, но из определения P3 ясно, что чтение НЕ повторимое! Во второй Таблице мы продолжаем употреблять термин Блокировочное ПОВТОРИМОЕ ЧТЕНИЕ в параллель с ANSI-определением, хотя это и неправильно. Аналогично Дэйт ввел термин Устойчивость Курсора как более подходящее название для второй степени изолированности с добавленной защитой от потери при обновлении курсора, как объясняется в разделе 4. 1 ниже.
1 ниже.
Определение. Уровень изолированности L1 слабее (weaker), чем уровень изолированности L2 (или L2 сильнее (stronger), чем L1), обозначим как L1 >
Сравнивая уровни изолированности, мы различаем их только по несериализуемым историям, которые могут произойти на одном уровне и невозможны на другом. Два уровня изолированности могут также различаться по тем сериализуемым историям, которые они допускают, но мы подразумеваем, что Блокировочная СЕРИАЛИЗУЕМОСТЬ == СЕРИАЛИЗУЕМОСТИ, даже при том, что хорошо известно, — что планировщики блокировок не допускают всевозможные сериализуемые истории. Возможно, такие уровни изолированности будут немного непрактичны, ввиду того, что они не допускают слишком много сериализуемых историй, но мы здесь этот вопрос не рассматриваем.
Следующее замечание и определения, приведенные выше, показывают полезность введенного отношения
Замечание 1.
Блокировочное НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ UNCOMMITTED)
В следующем разделе мы сравним блокировочные системы с определениями ANSI.
3. Анализ Уровней Изолированности ANSI SQL
Сначала сделаем позитивное замечание с том, что блокировочные уровни изолированности удовлетворяют требованиям ANSI SQL.
Замечание 2. Блокировочные протоколы во второй Таблице определяют блокировочные уровни изолированности, которые, как минимум, сильны настолько же, как и соответствующие, основанные на феноменах, уровни изолированности в Таблице 1. Доказательство этого утверждения приводится в [OOBBGH].
Поэтому блокировочные уровни изолированности как минимум на столько же изолированные, как и одноименные ANSI-уровни. Могут ли они быть более изолированными? Ответ — да, даже на самом нижнем уровне. Для того чтобы устранить феномен, который мы называем «Грязная Запись» (Dirty Write), на уровне Блокировочное НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ (Locking READ UNCOMMITTED) по Записи производится долговременная блокировка, когда в определениях ANSI SQL, основанных на аномалиях, не исключается такое аномальное поведение. Например, на ANSI СЕРИАЛИЗУЕМОСТЬ (ANSI SERIALIZABLE).
P0 (Грязная Запись):
Транзакция T1 модифицирует элемент данных. После этого другая транзакция T2 тоже модифицирует этот элемент данных перед тем, как T1 выполнит COMMITT или ROLLBACK. Если T1 или T2 после этого выполнит ROLLBACK, то становится непонятным, каким должно быть корректное значение элемента. В свободной интерпретации это будет:
P0: w1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Одним из доводов, почему плох феномен Грязной Записи, является то, что он может нарушить согласованность базы данных. Предположим, что существует ограничение на значения x и y (например x=y). Обе транзакции, и T1, и T2, сохраняют ограничение если выполняются порознь. Однако ограничение легко нарушается, если транзакции одновременно производят операции Записи в x и y в различном порядке. Это может произойти, если не исключены Грязные Записи. Например, если история будет: w1[x]…w2[x]…w2[y]…c2…w1[y]…c1, то «выживают» изменения, сделанные T1 в x, и изменения, сделанные T2 в x. Если T1 записывает 1 в обе ячейки x и y, а T2 записывает 2, то результатом будет x=2, y=1. Что нарушает ограничение x=y.
Если T1 записывает 1 в обе ячейки x и y, а T2 записывает 2, то результатом будет x=2, y=1. Что нарушает ограничение x=y.
В работах [GLPT, BHG] и многих других рассматривается необходимость защиты от феномена P0 для возможности автоматического отката транзакций. Без защиты от P0 система не сможет аннулировать изменения, просто восстановив предыдущие значения. Рассмотрим историю: w1[x]…w2[x]…a1. Аннулирование w1[x] и восстановление предыдущего значения x вас не удовлетворит, потому что в результате такого восстановления уничтожится и модификация x, сделанная второй транзакцией w2[x]. В противном случае, если вы не восстанавливаете предыдущие значения x и вторая транзакция тоже выполняет откат, то вы также не можете аннулировать w2[x], просто восстановив значение x, которое было до выполнения этой операции Записи! Вот поэтому даже самые слабые системы блокировки по операции записи производят долговременную блокировку. В противном случае их механизмы восстановления не смогли бы работать.
Замечание 3. Уровни изолированности в ANSI SQL должны быть модифицированы так, чтобы исключить P0 на всех уровнях изолированности.
Теперь мы аргументируем, почему необходимы именно свободные интерпретации для всех трех ANSI-феноменов. Возвратимся и рассмотрим строгие интерпретации:
A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке) (Грязное Чтение)
A2: r1[x]...w2[x]...c2...r1[x]...c1 (Размытое или Неповторимое Чтение)
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (Фантом)
Согласно Таблице 1, на уровне изолированности ЗАФИКСИРОВАННОЕ ЧТЕНИЕ исключаются аномалии A1, на уровне ПОВТОРИМОЕ ЧТЕНИЕ исключены аномалии A1 и A2, и на уровне СЕРИАЛИЗУЕМОСТЬ исключаются аномалии A1, и A2, и A3. Рассмотрим историю h2, выполняющую перевод 40 долларов между строками x и y в банковском балансе:
h2: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
h2 не сериализуема, возникает классическая проблема анализа несогласованности (inconsistent analysis), когда транзакция T1 переводит 40 долларов с x на y, сохраняя размер общей суммы баланса, равный 100.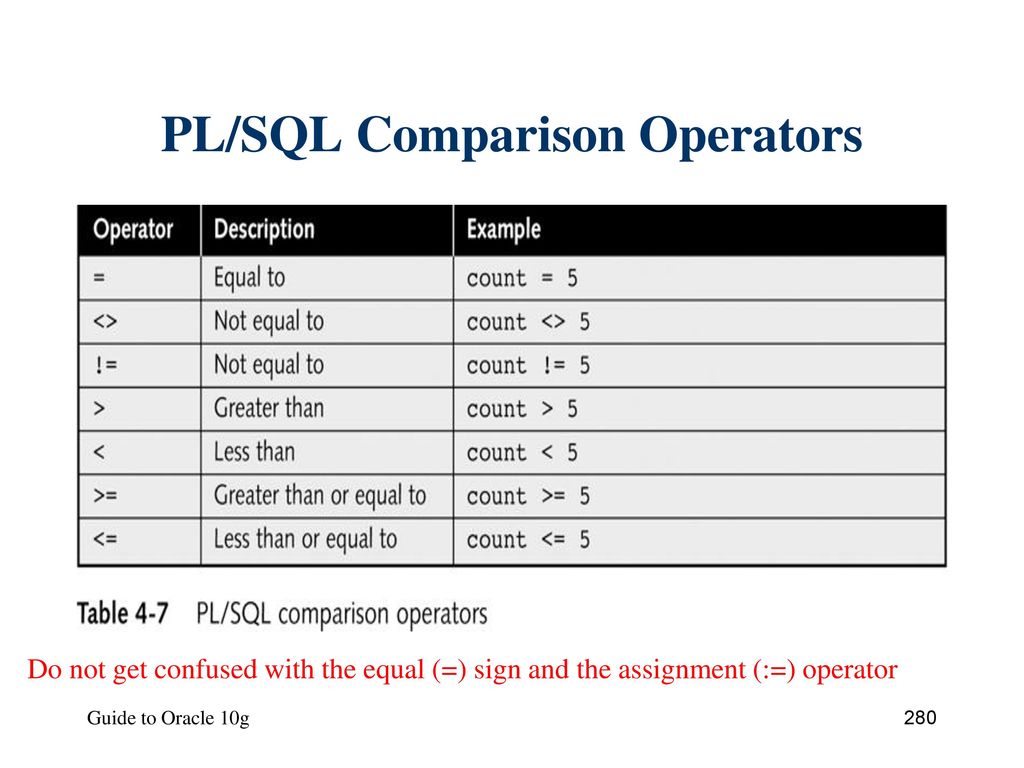 Но транзакция T2 производит операцию Чтения в тот момент, когда баланс находится в несогласованном состоянии при общей сумме равной 60. История h2 не подходит ни под одну из аномалий A1, A2 и A3. В случае A1 одна из транзакций должна выполнить откат. Для A2 элемент данных должен быть прочитан транзакцией повторно. В A3 требуется нарушение какого-нибудь соотношения. Ни что из этого не происходит в h2. Рассмотрим свободную интерпретацию A1, феномен P1:
Но транзакция T2 производит операцию Чтения в тот момент, когда баланс находится в несогласованном состоянии при общей сумме равной 60. История h2 не подходит ни под одну из аномалий A1, A2 и A3. В случае A1 одна из транзакций должна выполнить откат. Для A2 элемент данных должен быть прочитан транзакцией повторно. В A3 требуется нарушение какого-нибудь соотношения. Ни что из этого не происходит в h2. Рассмотрим свободную интерпретацию A1, феномен P1:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
h2 действительно нарушает P1. Поэтому мы должны брать интерпретацию P1, а не A1, как выражение идеи, заключенной в словесном определении ANSI первого феномена. Свободная интерпретация является единственной корректной интерпретацией.
Аналогично показывается, что для интерпретации второго ANSI-феномена необходимо брать интерпретацию P2, а не A2. Различия между A2 и P2 видны на примере следующей истории:
h3: r1[x=50] r2[x=50] w2[x=10] r2[y=50] w2[y=90] c2 r1[y=90] c1
h3 не сериализуема — еще одна проблема анализа несогласованности, где T1 видит общий баланс, равный 140. В этой истории ни одна транзакция не читает грязные (т.е. незафиксированные) данные. Таким образом, история не противоречит P1. Также ни один элемент данных не читается дважды и нет нарушающегося предикативного условия. Проблема с h3 состоит в том, что T1 читает значение y, когда значение x уже устарело. Если бы T1 прочитала значение x снова, то оно бы обновилось, но она этого не делает, и A2 к этому случаю не подходит. Заменяя A2 на P2, т.е. свободную интерпретацию, мы решаем эту проблему:
В этой истории ни одна транзакция не читает грязные (т.е. незафиксированные) данные. Таким образом, история не противоречит P1. Также ни один элемент данных не читается дважды и нет нарушающегося предикативного условия. Проблема с h3 состоит в том, что T1 читает значение y, когда значение x уже устарело. Если бы T1 прочитала значение x снова, то оно бы обновилось, но она этого не делает, и A2 к этому случаю не подходит. Заменяя A2 на P2, т.е. свободную интерпретацию, мы решаем эту проблему:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
h3 будет устранена при попытке второй транзакции w2[x=10] переписать значение переменной, прочитанной до этого первой транзакцией r1[x=50]. Теперь она подходит под определение (P2). И наконец, рассмотрим A3 и историю h4:
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (Фантом)
h4: r1[P] w2[insert y to P] r2[z] w2[z] c2 r1[z] c1
T1 осуществляет поиск по условию P= для получения списка служащих. Потом T2 производит вставку нового служащего и потом обновляет z, счетчик служащих в компании. Затем T1 читает значение счетчика служащих, проверяет и находит рассогласование. Ясно, что эта история несериализуема, но она допустима, т.к. не подходит под A3. Не происходит второе чтение по предикату. Снова только свободная интерпретация решает проблему:
Затем T1 читает значение счетчика служащих, проверяет и находит рассогласование. Ясно, что эта история несериализуема, но она допустима, т.к. не подходит под A3. Не происходит второе чтение по предикату. Снова только свободная интерпретация решает проблему:
P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке)
Если запретить P3, то история h4 тоже будет устранена. Ясно, что имели в виду в комитете ANSI, когда составляли спецификацию. Дальнейшая дискуссия направлена на то, чтобы продемонстрировать полученные результаты.
Замечание 4. Строгие интерпретации A1, A2 и A3 имеют существенные недостатки. Правильными являются свободные интерпретации. Определяя P1, P2 и P3, мы пытаемся следовать тому, что имели в виду в ANSI.
Замечание 5. Множество феноменов ANSI SQL неполно. Можно привести примеры нескольких аномалий, которые еще могут возникнуть. Для того чтобы сделать определение блокировки полным, необходимо ввести новые феномены. Определение P3 должно быть пересмотрено.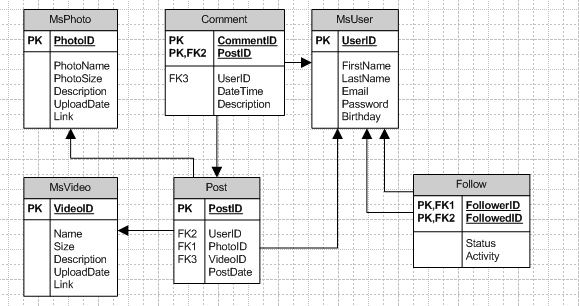 В следующих определениях мы опустили пары (c2 или a2), что не ограничивает возможных историй.
В следующих определениях мы опустили пары (c2 или a2), что не ограничивает возможных историй.
P0: w1[x]...w2[x]... (c1 или a1) (Dirty Write) (Грязная Запись)
P1: w1[x]...r2[x]... (c1 или a1) (Dirty Read) (Грязное Чтение)
P2: r1[x]...w2[x]... (c1 или a1) (Fuzzy or Non-Repeatable Read) (Размытое или Неповторимое Чтение)
P3: r1[P]...w2[y in P]... (c1 или a1) (Phantom) (Фантом)
Заметим, что определение P3, приведенное выше, отличается от определения P3 в ANSI SQL. Определение P3 в ANSI SQL запрещает только операции вставки (и модификации в соответствии с некоторыми интерпретациями), попадающие под область действия предиката, когда определение P3, приведенное выше, запрещает любую операцию записи (вставки, модификации, удаления), попадающую под предикат, по которому была произведена операция чтения.
Предполагаемые определения уровней изолированности ANSI в терминах этих феноменов даны в Таблице 3.
Грязная запись (Dirty Write) | Грязное чтение (Dirty Read) | Размытое чтение (Fuzzy Read) | Фантом (Phantom) | |
(READ COMMITTED) | ||||
(REPEATABLE READ) | ||||
(SERIALIZABLE) |
Таблица 3.
В одноверсионных историях оказывается, что P0-, P1-, P2- и P3-феномены являются замаскированными блокировочными версиями. Например, запрещая P0, мы устраняем возможность выполнения операции записи второй транзакцией над элементами, до этого записанными первой транзакцией. Это эквивалентно долговременной блокировке по Записи на элементах данных или предикате. Таким образом, Грязная Запись невозможна на всех уровнях. Подобно этому, запрещение P1 эквивалентно хорошо сформированным чтениям на элементах данных. Запрещение P2 означает долговременную блокировку по Чтению элементов данных. И наконец, запрещение P3 эквивалентно долговременной предикативной блокировке по Чтению. Таким образом, уровни изолированности, определенные в Таблице 3 с помощью феноменов, имеют такое же поведение, как и Блокировочные уровни изолированности, определенные во второй Таблице.
Замечание 6. Определения блокировочных уровней изолированности во второй Таблице эквивалентны феноменологическим определениям в третьей Таблице. Другими словами, P0, P1, P2 и P3 являются скрытыми определениями Блокировочного поведения.
Другими словами, P0, P1, P2 и P3 являются скрытыми определениями Блокировочного поведения.
В дальнейшем мы ссылаемся на уровни изолированности, перечисленные в третьей Таблице по их именам из этой таблицы, подразумевая их эквивалентность блокировочным уровням изолированности из второй Таблицы. Когда мы употребляем ANSI НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ, ANSI ЗАФИКСИРОВАННОЕ ЧТЕНИЕ, ANSI ПОВТОРИМОЕ ЧТЕНИЕ, АНОМАЛЬНАЯ СЕРИАЛИЗУЕМОСТЬ, то имеем в виду определения ANSI из первой Таблицы. (неадекватно, т.к. не включает P0)
В следующем разделе показывается, что большинство коммерческих реализаций изолированности имеют имеют уровни изолированности, которые по нашей классификации попадут между уровнями ЗАФИКСИРОВАННОЕ ЧТЕНИЕ и ПОВТОРИМОЕ ЧТЕНИЕ. Для того чтобы получить четкие уровни изолированности, на которых стали бы видны отличия в этих реализациях, мы предполагаем, что P0 и P1 являются базисом, и добавляем новые феномены по мере необходимости.
4. Другие типы изолированности
4.
 1. Устойчивость курсора
1. Устойчивость курсораУстойчивость курсора была разработана для того, чтобы предотвратить феномен потерянной модификации (Lost Update).
P4 (Потерянная Модификация) (Lost Update) Аномалия потерянной модификации происходит в случае, когда транзакция T1 прочитала элементы данных, после нее T2 их модифицировала (возможно, исходя из предыдущего чтения), после чего T1 (основываясь на ранее прочитанном ею значении) модифицирует содержимое элемента данных и фиксируется. В терминах историй это будет:
P4: r1[x]...w2[x]...w1[x]...c1 (Потерянная Модификация) (Lost Update)
Проблема, как показывается в истории h5, заключается в том, что, даже если T2 зафиксируется, сделанная ею модификация элементов данных будет потеряна.
h5: r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
Конечное значение переменной x равно 130. Его записала транзакция T1. P4 возможен на уровне изолированности ЗАФИКСИРОВАННОЕ ЧТЕНИЕ. Так, h5 допустима, когда запрещен P0 (операция фиксации транзакции, осуществляющей первую операцию записи, происходит до операции записи второй транзакции) или P1 (который требует чтения после записи). Конечно, запрещение P2 устранит P4, так как w2[x] происходит после r1[x] и перед фиксацией или откатом T1. Поэтому аномалия P4 полезна для различия промежуточных уровней изолированности между уровнями: ЗАФИКСИРОВАННОЕ ЧТЕНИЕ и ПОВТОРИМОЕ ЧТЕНИЕ.
Конечно, запрещение P2 устранит P4, так как w2[x] происходит после r1[x] и перед фиксацией или откатом T1. Поэтому аномалия P4 полезна для различия промежуточных уровней изолированности между уровнями: ЗАФИКСИРОВАННОЕ ЧТЕНИЕ и ПОВТОРИМОЕ ЧТЕНИЕ.
Уровень изолированности УСТОЙЧИВОСТЬ КУРСОРА расширяет блокировочное поведение уровня ЗАФИКСИРОВАННОЕ ЧТЕНИЕ для SQL-курсоров, добавляя новую операцию чтения для выборки (Fetch) из курсора rc (означает read cursor, т.е. курсор для чтения) и требуя, чтобы на текущий элемент в курсоре была поставлена блокировка. Блокировка удерживается, пока курсор не будет перемещен или закрыт, возможно операцией фиксации. Реально, выбирающая (Fetching) данные транзакция может модифицировать строку (wc), и в этом случае блокировка по записи на строке будет сохраняться до тех пор, пока транзакция не зафиксируется, даже после передвижения курсора с последующей выборкой (Fetch). Операция rc1[x] и последующая wc1[x] имеют промежуточную операцию w2[x]. Поэтому феномен P4, для этого случая несколько измененный и переименованный в P4C, представлен в следующем виде:
P4C: rc1[x]...w2[x]...wc1[x]...c1 (Lost Update) (Потерянная Модификация)
Замечание 7.
ЗАФИКСИРОВАННОЕ ЧТЕНИЕ
УСТОЙЧИВОСТЬ КУРСОРА ПОВТОРИМОЕ ЧТЕНИЕ.
УСТОЙЧИВОСТЬ КУРСОРА широко применяется в SQL-системах для предотвращения потери модификаций строк, читаемых через курсор. В некоторых системах ЗАФИКСИРОВАННОЕ ЧТЕНИЕ реально более сильный уровень, чем УСТОЙЧИВОСТЬ КУРСОРА. Стандарт ANSI это позволяет.
Техника установки курсора на элементы данных, для того чтобы сохранить их в неизменном виде, может быть использована для множества элементов за счет применения множества курсоров. Таким образом, программист может надеяться, что УСТОЙЧИВОСТЬ КУРСОРА даст такой же эффект изолированности, как и у Блокировочного ПОВТОРИМОГО ЧТЕНИЯ на любых транзакциях, оперирующих с небольшим, фиксированным числом элементов данных. Однако этот метод не является общеупотребительным и не всегда работает. Поэтому всегда существуют истории, удовлетворяющие феномену P4 (и, конечно, более общему P2) и не устранимые на уровне УСТОЙЧИВОСТЬ КУРСОРА.
4.2. Изолированность Образа
Транзакция, выполняющаяся на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА, всегда читает данные из образа (зафиксированных) данных, какими они были в момент начала транзакции, называемого Временной Меткой Старта. Он может быть сделан в любое время до первой операции чтения транзакции. Выполнение транзакции на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА никогда не блокируется при попытке выполнить операцию Чтения до тех пор, пока возможно использование данных из Временной Метки Старта. Все операции Записи (модификация, вставка и удаление), выполняемые транзакцией, будут отражаться в этой метке, если транзакция будет обращаться к данным (читать или модифицировать) вторично. После того как для транзакции T снята Временная Метка Старта, все модификации данных, производимые другими транзакциями, становятся для нее невидимыми.
Уровень ИЗОЛИРОВАННОСТЬ ОБРАЗА является разновидностью контроля многоверсионной конкурентности (multiversion concurrency control). Он расширяет Многоверсионный Смешанный Метод, описанный в [BHG], который допускает чтение данных из метка только для читающих транзакций.
Когда транзакция T1 готова к фиксации, она получает Временную Метку Фиксации. Она больше любой существующей Временной Метки Старта или Временной Метки Фиксации. Выполнение транзакции T1 успешно фиксируется только в том случае, если нет ни одной другой транзакции T2, которая имеет Временную Метку Фиксации, попадающий в интервал [Временная Метка Старта, Временная Метка Фиксации] транзакции T1, и пишет в те же элементы данных, что и T1. В противном случае T1 откатывается. Этот способ назван «Выигрывает Первый Зафиксированный» (First-committer-wins). Он устраняет феномен P4 потерянной модификации. Когда транзакция T1 зафиксировалась, то изменения данных, сделанные ею, становятся видны всем транзакциям, у которых Временная Метка Старта больше, чем Временная Метка Фиксации транзакции T1.
Метод Изолированности Образа является многоверсионным (многозначным) (МВ) методом. Он применим там, где одноверсионные (однозначные) (ОВ) истории не смогут однозначно отобразить временные последовательности операций. В любое время каждый элемент данных может иметь несколько своих версий, созданных активными или зафиксированными транзакциями. Операции чтения, выполняемые транзакциями, должны выбирать подходящую версию. Рассмотрим историю h2, приведенную в третьем разделе, которая показывает необходимость P1 при одноверсионном выполнении. При Изолированности Образа та же последовательность операций переносится на многозначную историю:
В любое время каждый элемент данных может иметь несколько своих версий, созданных активными или зафиксированными транзакциями. Операции чтения, выполняемые транзакциями, должны выбирать подходящую версию. Рассмотрим историю h2, приведенную в третьем разделе, которая показывает необходимость P1 при одноверсионном выполнении. При Изолированности Образа та же последовательность операций переносится на многозначную историю:
h2.SI: r1[x0=50] w1[x1=10] r2[x0=50] r2[y0=50] c2 r1[y0=50] w1[y1=90] c1
h2.SI имеет потоки данных сериализуемого выполнения. В [OOBBGM] мы показываем, что все истории с уровня ИЗОЛИРОВАННОСТЬ ОБРАЗА могут быть отображены о однозначные истории с сохранением зависимостей между потоками данных. Говорят, что МВ-истории Эквивалентны по Представлениям (View Equivalent) ОВ-историям. Этот подход описывается в [BHG], Глава 5. Например, МВ-история h2.SI может быть отображена в сериализуемую ОВ-историю.
h2.SI.SV: r1[x=50] r1[y=50] r2[x=50] r2[y=50] c2 w1[x=10] w1[y=90] c1
Отображение МВ-историй в ОВ-истории является единственным существенным основанием, благодаря которому мы должны разместить ИЗОЛИРОВАННОСТЬ ОБРАЗА в Иерархии Изолированности.
ИЗОЛИРОВАННОСТЬ ОБРАЗА не является сериализуемой, потому что операции чтения транзакции выполняются над одним экземпляром данных, а операции записи над другим. Для примера рассмотрим следующую однозначную историю:
H5: r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[y=-40] w2[x=-40] c1 c2
H5 не является сериализуемой и имеет такие же межтранзакционные потоки данных, которые могут произойти на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА (нет выбора версии, читаемой транзакциями). Предполагается, что обе транзакции, модифицирующие значения x и y, сохраняют ограничение, что сумма x+y всегда должна быть положительна. При полной изолированности обе транзакции сохраняют ограничение, а в примере H5 при одновременном выполнении нарушают его.
Нарушение ограничения (constrant violation) является характерным и основным типом аномалий, возникающих при конкурентном выполнении транзакций. Индивидуальные базы данных удовлетворяют ограничениям, заданным на множествах элементов данных (например уникальность ключей, целостность ссылок, репликация ссылок в двух таблицах и т. д.). Все вместе они формируют инвариантный ограничительный предикат базы данных C(DB). Предикат принимает значение Истина, если состояние базы данных DB не противоречит ограничениям, Ложь в противном случае. Для сохранения согласованности базы данных транзакции должны удовлетворять ограничительному предикату: если состояние базы данных непротиворечиво до начала транзакции, то оно должно остаться непротиворечивым и после ее фиксации. Если транзакция читает содержимое базы данных, находящейся в противоречивом состоянии, то в результате ее выполнения получится аномалия нарушения ограничения. Подобные нарушения ограничений называются противоречивый анализ (inconsistent analysis) [DAT].
д.). Все вместе они формируют инвариантный ограничительный предикат базы данных C(DB). Предикат принимает значение Истина, если состояние базы данных DB не противоречит ограничениям, Ложь в противном случае. Для сохранения согласованности базы данных транзакции должны удовлетворять ограничительному предикату: если состояние базы данных непротиворечиво до начала транзакции, то оно должно остаться непротиворечивым и после ее фиксации. Если транзакция читает содержимое базы данных, находящейся в противоречивом состоянии, то в результате ее выполнения получится аномалия нарушения ограничения. Подобные нарушения ограничений называются противоречивый анализ (inconsistent analysis) [DAT].
A5 (Нарушение ограничения на элементах данных) Предположим, что C() — ограничение между двумя элементами базы данных x и y. Ниже приводятся две аномалии, возникающие при нарушении ограничения.
A5A Искажение Чтения (Read Skew). Предположим, что транзакция T1 читает значение x. Затем другая транзакция T2 модифицирует значения x и y и фиксируется. Если теперь T1 прочитает значение y снова, она может обнаружить нарушение целостности, и поэтому результат ее работы тоже будет содержать нарушение. В терминах историй мы имеем аномалию:
Если теперь T1 прочитает значение y снова, она может обнаружить нарушение целостности, и поэтому результат ее работы тоже будет содержать нарушение. В терминах историй мы имеем аномалию:
A5A: r1[x]...w2[x]...w2[y]... c2...r1[y]...(c1 или a1) (Искажение Чтения) (Read Skew)
A5B Искажение Записи (Write Skew). Предположим, что транзакция T1 читает значения x и y, которые согласованы с предикатом C(). Затем другая транзакция T2 читает значения x и y, модифицирует x и фиксируется. После этого T1 модифицирует значение y. Если на x и y было какое-нибудь ограничение, то оно может нарушиться. В терминах историй:
A5B: r1[x]...r2[y]...w1[y]... w2[x]...(c1 или c2) (Искажение Записи) (Write Skew)
Феномен размытого чтения (P2) является частным случаем Искажения Чтения, где x=y. Обычно транзакция читает два различных, но взаимозависимых элемента (например целостность ссылок). Искажение Записи (Write Skew) (A5B) может возникнуть из ограничения целостности в банковском примере.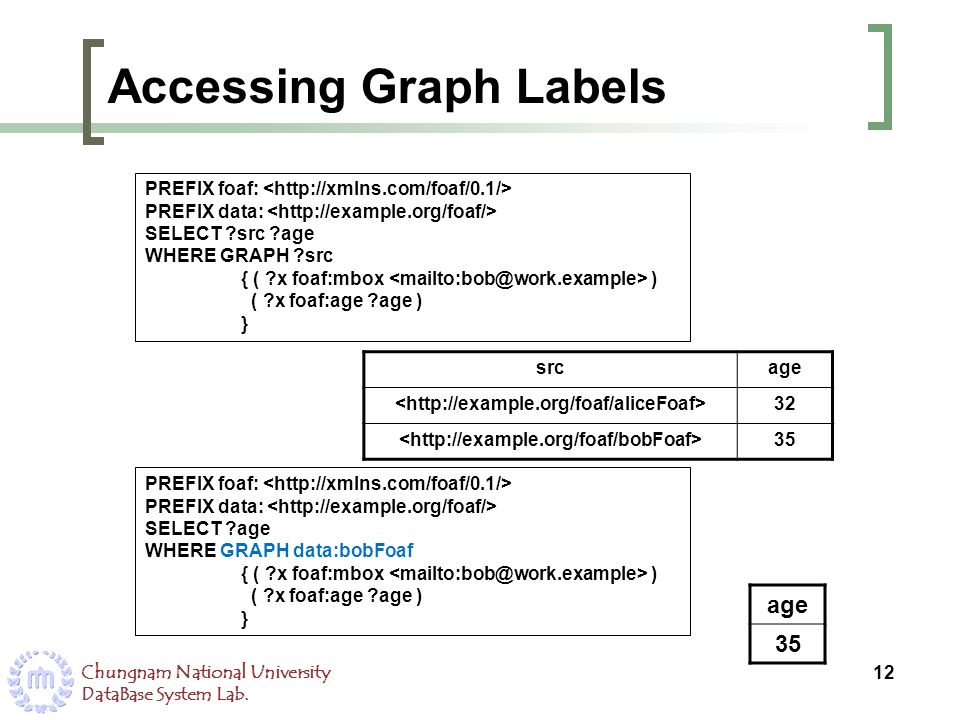 Предположим, что балансам счетов разрешается быть отрицательными, пока их общая сумма положительна. Здесь возникает аномалия, похожая на историю H5.
Предположим, что балансам счетов разрешается быть отрицательными, пока их общая сумма положительна. Здесь возникает аномалия, похожая на историю H5.
Если исключена аномалия P2, то становится невозможным появление в историях ситуаций, похожих на A5A и A5B, т.к. обе ситуации имеют операцию записи транзакции T2 в элемент данных, предварительно прочитанный незафиксированной транзакцией T1. Поэтому феномены A5A и A5B полезны только для классификации уровней изолированности, которые по уровню изолированности не сильнее уровня ПОВТОРИМОЕ ЧТЕНИЕ.
ANSI SQL определение уровня ПОВТОРИМОЕ ЧТЕНИЕ в строгой интерпретации осуществляет защиту от нарушения строковых ограничений только в частных примитивных случаях и не осуществляет таковой в общем виде. Конкретно, Блокировочное ПОВТОРИМОЕ ЧТЕНИЕ, определенное в Таблице 2, осуществляет защиту от нарушений строковых ограничений (row constraint violations), а ANSI SQL-определение из Таблицы 1, запрещая аномалии A1 и A2, — нет.
Возвращаясь к рассмотрению уровня ИЗОЛИРОВАННОСТЬ ОБРАЗА, можно заметить, что по изолированности он удивительно силен. Сильнее, даже чем ЗАФИКСИРОВАННОЕ ЧТЕНИЕ.
Сильнее, даже чем ЗАФИКСИРОВАННОЕ ЧТЕНИЕ.
Замечание 8.
ЗАФИКСИРОВАННОЕ ЧТЕНИЕ
Доказательство. На уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА механизм «Выигрывает-Первый-Зафиксированный» устраняет феномен P0 (Грязная Запись), а механизм снятия меток не допускает P1 (Грязное Чтение). Отсюда следует, что ИЗОЛИРОВАННОСТЬ ОБРАЗА не слабее, чем ЗАФИКСИРОВАННОЕ ЧТЕНИЕ. Так как феномен A5A возможен на уровне ЗАФИКСИРОВАННОЕ ЧТЕНИЕ, но невозможен на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА за счет работы механизма снятия отпечатков, то ЗАФИКСИРОВАННОЕ ЧТЕНИЕ
Заметим, что в однозначной интерпретации сложно показать, как на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА будут устраняться истории с феноменом P2. Аномалия A2 на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА произойти не может, так как транзакции на этом уровне даже в случае промежуточной модификации, сделанной другой транзакцией, будут читать одно и то же значение элемента данных. Очевидно, что на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА может произойти феномен Искажение Записи (A5B) (например в истории H5), а в простых однозначных реализациях историй запрещение феномена P2 устраняет A5B. Поэтому на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА допускаются истории с аномалиями, которые не допустимы на уровне ПОВТОРИМОЕ ЧТЕНИЕ.
Поэтому на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА допускаются истории с аномалиями, которые не допустимы на уровне ПОВТОРИМОЕ ЧТЕНИЕ.
Аномалия A3 не применима к случаю ИЗОЛИРОВАННОСТИ ОБРАЗА. Повторное чтение транзакции по предикату после модификации данных другой транзакцией будет всегда во всех случаях давать старый набор данных. Аномалии вида A3 применимы к уровню ПОВТОРИМОЕ ЧТЕНИЕ. ИЗОЛИРОВАННОСТЬ ОБРАЗА не допускает историй, содержащих феномен A3, но допускает с феноменом A5B, а у ПОВТОРИМОГО ЧТЕНИЯ все наоборот.
Замечание 9.
ПОВТОРИМОЕ ЧТЕНИЕ >>
Однако ИЗОЛИРОВАННОСТЬ ОБРАЗА не устраняет P3. Рассмотрим следующее ограничение: множество задач, определенное с помощью предиката, не могут иметь общую сумму часов, большую 8. T1 читает по предикату, определяет, что сумма равна 7 часам и добавляет новую задачу продолжительностью 1 час. Конкурирующая транзакция T2 делает то же самое. Это произошло потому, что транзакции манипулируют с различными экземплярами одних элементов данных (и так же с различными индексными полями). Такой сценарий может произойти на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА и не устраним с помощью механизма «Выигрывает-Первый-Зафиксированный». В любой эквивалентной последовательной истории такой сценарий приводит к возникновению феномена P3.
Такой сценарий может произойти на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА и не устраним с помощью механизма «Выигрывает-Первый-Зафиксированный». В любой эквивалентной последовательной истории такой сценарий приводит к возникновению феномена P3.
Возможно, наиболее впечатляюще то, что на уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА нет фантомов (в строгой интерпретации A3 определения ANSI). Каждая транзакция никогда не видит модификаций, производимых конкурирующими транзакциями. Таким образом, без дополнительных ограничений в подсекции 4.28 в [ANSI] можно сформулировать следующее: (напомним, что определенная в Таблице 1 АНОМАЛЬНАЯ СЕРИАЛИЗУЕМОСТЬ соответствует ANSI SQL определению СЕРИАЛИЗУЕМОСТЬ).
Замечание 10.
На уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА устраняются аномалии A1, A2 и A3. Поэтому для него выполняется следующее утверждение: АНОМАЛЬНАЯ СЕРИАЛИЗУЕМОСТЬ
На уровне ИЗОЛИРОВАННОСТЬ ОБРАЗА разрешается выполняться транзакциям с очень старыми метками. Это позволяет им иметь достаточно продолжительное время выполнения, благодаря чему имеется возможность наблюдать эволюцию базы данных. Конечно, если транзакция модифицирует данные и имеет очень старые метки, то при попытке модификации данных, уже модифицированных другими транзакциями, ее выполнение будет откачено назад.
Конечно, если транзакция модифицирует данные и имеет очень старые метки, то при попытке модификации данных, уже модифицированных другими транзакциями, ее выполнение будет откачено назад.
Достаточно простая реализация уровня ИЗОЛИРОВАННОСТЬ ОБРАЗА была предложена Ридом (Reed) в [REE]. Существует несколько коммерческих реализаций такой много-версионной модели базы данных. InterBase 4 фирмы Borland [THA] и ядро, лежащее в основе Exchange System фирмы Microsoft, оба реализуют ИЗОЛИРОВАННОСТЬ ОБРАЗА с механизмом «Выигрывает-Первый-Зафиксированный». Этот механизм заставляет систему запоминать все модификации (блокировки по записи), принадлежащие каждой транзакции, которая фиксируется после снятия Временной Метки Старта для каждой активной транзакции. Он откатывает выполнение транзакции, если сделанные ею модификации конфликтуют с заполненными модификациями, сделанными другими транзакциями.
Совершенно ясно, что «оптимистический» подход ИЗОЛИРОВАННОСТИ ОБРАЗА контроля конкурентного выполнения транзакций имеет преимущество для только читающих транзакций, но его преимущества для модифицирующих транзакций до сих пор обсуждаются. Возможно, этот метод плох для долговременных модифицирующих данные транзакций, выполняющихся одновременно с кратковременными. Кратковременные транзакции будут фиксировать свои модификации быстрее, следовательно, поскольку «Выигрывает-Первый-Зафиксировавшийся», долговременные транзакции, вероятнее всего, будут постоянно откатываться. (Заметим, что такой сценарий также проблематичен и в блокировочных реализациях, и если принять решение не использовать долговременные модифицирующие транзакции, то ИЗОЛИРОВАННОСТЬ ОБРАЗА тоже будет применима.) Конечно, в случае, когда кратковременные транзакции конфликтуют минимально, а долговременные только читают данные, ИЗОЛИРОВАННОСТЬ ОБРАЗА должна дать хорошие результаты. В случае сильной конкуренции между транзакциями сопоставимой длины ИЗОЛИРОВАННОСТЬ ОБРАЗА предлагает классический оптимистический подход. Мнения относительно его эффективности расходятся.
Возможно, этот метод плох для долговременных модифицирующих данные транзакций, выполняющихся одновременно с кратковременными. Кратковременные транзакции будут фиксировать свои модификации быстрее, следовательно, поскольку «Выигрывает-Первый-Зафиксировавшийся», долговременные транзакции, вероятнее всего, будут постоянно откатываться. (Заметим, что такой сценарий также проблематичен и в блокировочных реализациях, и если принять решение не использовать долговременные модифицирующие транзакции, то ИЗОЛИРОВАННОСТЬ ОБРАЗА тоже будет применима.) Конечно, в случае, когда кратковременные транзакции конфликтуют минимально, а долговременные только читают данные, ИЗОЛИРОВАННОСТЬ ОБРАЗА должна дать хорошие результаты. В случае сильной конкуренции между транзакциями сопоставимой длины ИЗОЛИРОВАННОСТЬ ОБРАЗА предлагает классический оптимистический подход. Мнения относительно его эффективности расходятся.
4.3. Другие многоверсионные системы
Существуют другие модели многоверсионности. Некоторые коммерческие продукты поддерживают версии объектов, но ограничивают применение метода ИЗОЛИРОВАННОСТЬ ОБРАЗА только для читающих транзакций. (Например, SQL-92, Rdb, SET TRANSACTION READ ONLY в некоторых других базах данных [MS, HOB, DRA]; Postgress и Illustra [STO, ILL] поддерживают долговременный тип таких версий (long-term) и предоставляют мигрирующие во времени (time-travel) запросы.) Другие реализации допускают модифицирующие транзакции, но не поддерживают защиту «Выигрывает-Первый-Зафиксировавшийся». (Например, уровень изолированности НЕПРОТИВОРЕЧИВОСТЬ ЧТЕНИЯ (READ CONSISTENCY) в Oracle [ORA].)
(Например, SQL-92, Rdb, SET TRANSACTION READ ONLY в некоторых других базах данных [MS, HOB, DRA]; Postgress и Illustra [STO, ILL] поддерживают долговременный тип таких версий (long-term) и предоставляют мигрирующие во времени (time-travel) запросы.) Другие реализации допускают модифицирующие транзакции, но не поддерживают защиту «Выигрывает-Первый-Зафиксировавшийся». (Например, уровень изолированности НЕПРОТИВОРЕЧИВОСТЬ ЧТЕНИЯ (READ CONSISTENCY) в Oracle [ORA].)
На уровне НЕПРОТИВОРЕЧИВОСТЬ ЧТЕНИЯ в Oracle каждому SQL-оператору перед началом его выполнения дается самое свежее зафиксированное состояние базы данных. Это похоже на то, как если бы Временная Метка Старта транзакции снимался бы для каждого оператора. Элементы курсора имеют значения, которые они имели в момент открытия курсора. Описанный ниже механизм перевычисляет подходящие версии строк и операторных отпечатков. Операции Вставки, Модификации и Удаления строк защищаются блокировкой по Записи для того, чтобы работал механизм «Выигрывает-Первый-Записавший», отличающийся от механизма «Выигрывает-Первый-Зафиксировавшийся». НЕПРОТИВОРЕЧИВОСТЬ ЧТЕНИЯ сильнее, чем ЗАФИКСИРОВАННОЕ ЧТЕНИЕ (она исключает потерю модификации курсора (P4C)), но допускает неповторимое чтение (P3), потерю модификации в общем случае (P4) и искажение чтения (A5A). ИЗОЛИРОВАННОСТЬ ОБРАЗА не допускает P4 или A5A.
НЕПРОТИВОРЕЧИВОСТЬ ЧТЕНИЯ сильнее, чем ЗАФИКСИРОВАННОЕ ЧТЕНИЕ (она исключает потерю модификации курсора (P4C)), но допускает неповторимое чтение (P3), потерю модификации в общем случае (P4) и искажение чтения (A5A). ИЗОЛИРОВАННОСТЬ ОБРАЗА не допускает P4 или A5A.
Если пристально посмотреть на стандарт SQL, то можно сказать, что он трактует каждый оператор как атомарный. В начале каждого оператора имеется сериализуемая подтранзакция (или отпечаток). Можно представить иерархию уровней изолированности, определяемых различными вариантами комбинации оператора и присоединенного к нему оператора. (Например, в Oracle, операция выборки (fetch) из курсора имеет метку, снимаемый в момент открытия курсора.)
изолированности | Грязная Запись (Dirty Write) | Грязное Чтение (Dirty Read) | Потерянная Модификация Курсора (Cursor Lost Update) | Модификация (Lost Update) | Размытое Чтение (Fuzzy Read) | Фантом (Phantom) (Read Skew) | Искажение Чтения (Write Skew) | Искажение Записи |
РОВАННОЕ ЧТЕНИЕ UNCOMMITTED) ==Степень 1 | ||||||||
РОВАННОЕ ЧТЕНИЕ COMMITTED) ==Степень 2 | ||||||||
КУРСОРА (CURSOR STABILITY) | ||||||||
ЧТЕНИЕ (REPEATABLE READ) | ||||||||
ВАННОСТЬ ОБРАЗА (SNAPSHOT ISOLATION) | ||||||||
СЕРИАЛИЗУ- ЕМОСТЬ (SERIALIZABLE) ==Степень 3 ==Повторимое Чтение Дэйт, IBM, Tandem,.  .. .. |
Таблица 4.
Резюме и Выводы
Подводя итоги, можно сказать, что оригинальные ANSI SQL-определения уровней изолированности имеют серьезные недостатки (как показывается в третьем разделе). Словесные определения противоречивы и неполны. Не исключается феномен Грязной Записи (P0). В Замечании 5 мы даем рекомендации по тому, как модифицировать определения уровней изолированности ANSI SQL, чтобы сделать их эквивалентными Блокировочным уровням изолированности в [GLPT].
В ANSI SQL уровень изолированности ПОВТОРИМОЕ ЧТЕНИЕ мыслился как уровень, на котором исключаются все аномалии, кроме ФАНТОМА. Определение, данное в терминах аномалий в Таблице 1, не достигает этой
цели, в отличие от блокировочного определения из второй
Таблицы. Выбор ANSI-термина ПОВТОРИМОЕ ЧТЕНИЕ является крайне неудачным: (1) повторимые операции чтения не дают повторимых результатов» (2) в индустрии этот термин уже занят и обозначает следующее: в некоторых продуктах повторимое чтение означает сериализуемость. Мы рекомендуем найти для этого уровня новое название.
Выбор ANSI-термина ПОВТОРИМОЕ ЧТЕНИЕ является крайне неудачным: (1) повторимые операции чтения не дают повторимых результатов» (2) в индустрии этот термин уже занят и обозначает следующее: в некоторых продуктах повторимое чтение означает сериализуемость. Мы рекомендуем найти для этого уровня новое название.
Некоторые коммерчески популярные уровни изолированности, по степени изолированности попадающие в интервал между уровнями ПОВТОРИМОЕ ЧТЕНИЕ и СЕРИАЛИЗУЕМОСТЬ из Таблицы 3, справляются с некоторыми новыми феноменами и аномалиями в четвертом Разделе. Все уровни изолированности, о которых упоминается в этой статье, можно классифицировать, как показано на Рисунке 1 и в Таблице 4. Чем выше на Рисунке расположен уровень, тем выше на нем степень изолированности (см. Определение в начале Раздела 4.1). Уровни классифицируются с помощью линий между ними с надписанными феноменами или аномалиями.
Рисунок 1.
Заметим, что, несмотря на то, что уровни ограниченной изолированности для многоверсионных систем реализованы во многих продуктах, не существует работ по их классификации. Во многих приложениях борьба между блокировками устраняется введением уровней изолированности типа УСТОЙЧИВОСТИ КУРСОРА или НЕПРОТИВОРЕЧИВОСТИ ЧТЕНИЯ в Oracle. ИЗОЛИРОВАННОСТЬ ОБРАЗА имеет лучшие характеристики, чем любой из таких уровней: исключаются аномалия потерянной модификации, некоторые фантомные аномалии (например описанная в ANSI SQL), никогда не блокируются только читающие транзакции и читающие транзакции никогда не блокируют модифицирующих.
Во многих приложениях борьба между блокировками устраняется введением уровней изолированности типа УСТОЙЧИВОСТИ КУРСОРА или НЕПРОТИВОРЕЧИВОСТИ ЧТЕНИЯ в Oracle. ИЗОЛИРОВАННОСТЬ ОБРАЗА имеет лучшие характеристики, чем любой из таких уровней: исключаются аномалия потерянной модификации, некоторые фантомные аномалии (например описанная в ANSI SQL), никогда не блокируются только читающие транзакции и читающие транзакции никогда не блокируют модифицирующих.
Благодарности
Мы выражаем благодарность Крису Ларсону (Chris Larson) из Microsoft, Алану Рейтеру (Alan Reiter), которые нашли несколько новых аномалий в ИЗОЛИРОВАННОСТИ ОБРАЗА, Франко Путзолу (Franco Putzolu) и Анил Нори (Anil Nori) из Oracle, Майку Убеллу (Mike Ubell) из компании Illustra и всем анонимным рефери из SIGMOD за ценные предложения, которые улучшили эту статью. Сашил Джодиа (Sushil Jajodia), V.Atluri и E.Bertino, которые прислали нам черновой вариант своей работы [ABJ], касающейся уровней ограниченной изолированности для многозначных историй.
Литература
[ANSI] ANSI X3.135-1992, American National Standart for Information Systems — Database Language — SQL, November, 1992.
[ABJ] V.Atluri, E.Bertino, S.Jajodia, «A Theoretical Formuation for Degrees of Isolation in Databases», Technical Report, George Mason Iniversity, Fairfax, VA, 1995.
[BHG] P.A. Bernstein, V. Hadzilacos, N. Goodman, «Concurrency Control and Recovery in Database Systems», Addison-Wesley, 1987.
[DAT] C.J. Date, «An Introduction to Database Systems», Fifth Edition, Addison-Wesley, 1990.
[DB2] C.J. Date and C.J. White, «A Guide to DB2», Third Edition, Addison-Wesley, 1989.
[EGLT] K.P. Eswaran, J. Gray, R. Lorie, I. Traiger, «The Notions of Consistency and Predicate Locks in a Database System», CACM V 19.11, pp. 624-633, Nov. 1978.
[GLPT] J. Gray, R. Lorie, G. Putzolu and, I. Traiger, «Granularity of Locks and Degrees of Consistency in a Shared Data Base», in Readings in Database Systems, Second Edition, Chapter 3, Michael Stonebraker, Ed. , Morgan Kaufmann 1994 (ordinally published in 1997).
, Morgan Kaufmann 1994 (ordinally published in 1997).
[GR] J. Gray and A. Reuter, «Transaction Processing: Concepts and Techniques», Corrected Second Printing, Morgan Kaufmann 1993, Section 7.6 and following.
[HOB] L Hobbs and K. England, «Rdb/VMS, A Comprehensive Guide», Digital Press, 1991.
[ILL] Illustra Information Technologies, «Illustra User»s Guide», Illustra Information Technologies, Oakland, CA. 1994.
[MS] J. Meiton and A.R. Simon, «Understanding The New SQL: A Comlete Guide», Morgan Kaufmann, 1993.
[OOBBGM] P. O’Neil, E. O’Neil, H. Berenson, P. Bernstein, J. Gray, J. Melton, «An Investigation of Transactional Isolation Levels», UMass/Boston Dept. of Math &» C.S. Preprint.
[ORA] «PL/SQL User’s Guide and Reference, Version 1.0», Part. 800-V1.0, Oracle Corp., 1989.
[PAR] C. Papadimitriou, «The Theory of Database Concurrency Control», Computer Science Press, 1986.
[PON] P. O’Neil, «Database: Principles, Programming, Performance», Morgan Kaufmann, 1994, Section 9. 5.
5.
[REE] D. Reed, «Implementing Atomic Actions On Decentralized Data», ACM TOCS 1.1, 1981, pp. 3-23.
[STO] M.J. Stonebraker, «The Design of the POSTGRES Storage System», 13th VLDB, 1987, reprinted in Readings in Database Systems, Second Edition, M.J. Stonebraker, Ed., Morgan Kaufmann, 1994.
[THA] M. Thakur, «Transaction Models in InterBase 4», Proceedings of the Borland International Conference, June, 1994.
Hal Berenson, Microsoft Corp. [email protected]Phil Bernstein, Microsoft Corp. [email protected]Jim Gray, U.C. Berkeley [email protected]Jim Melton, Sybase Corp. [email protected]Elizabeth O’Neil, UMass/Boston [email protected]Patrick O’Neil, UMass/Boston [email protected]
*)Переведено из Proceeding of the ACM SIGMOO International Conference, May, 1995, с разрешения ACM 1996 (с) ACM, Inc
Подборка материалов для изучения баз данных и SQL
Подборка книг, видеокурсов и онлайн-ресурсов для изучения баз данных, основ реляционной теории и языка SQL.
Эта книга — прекрасный выбор для тех, кто стоит в начале тернистого пути изучения SQL. Она не только позволит приобрести необходимую базу начальных знаний, но и расскажет о наиболее популярных тонкостях и мощных средствах языка, которыми пользуются опытные программисты.
Многие пособия, посвященные базам данных, реляционной теории и языку SQL, переполнены скучным изложением теоретических основ. Эта книга является приятным исключением благодаря своему легкому, живому стилю. Автор мастерски преподносит читателю информацию об SQL-выражениях и блоках, типах условий, join-ах, подзапросах и многом другом.
Для закрепления полученных знаний на практике, автор создает учебную базу MySQL и приводит множество практических примеров запросов, охватывающих весь изложенный теоретический материал.
В книге идет речь о версии языка ANSI SQL-92 (SQL2). Подробно рассказывается о способах применения языка запросов для решения соответствующих классов задач по выборке и модификации данных и по работе с объектами структуры базы данных.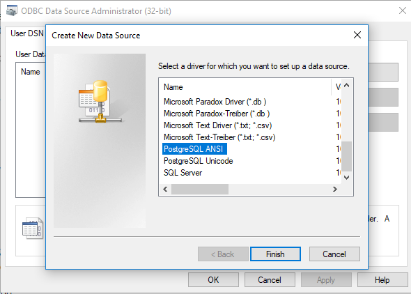 Все примеры подробно объясняются.
Все примеры подробно объясняются.
Особое внимание в этом издании уделено различиям диалектов SQL в реализации наиболее распространенных СУБД: MySQL, Oracle, MS SQL Server и PostgreSQL.
Книга предназначена всем, кто желает самостоятельно изучить язык SQL или усовершенствовать свои знания по этой теме.
Данное издание предназначено для тех, кто уже имеет некоторые знания SQL и хочет усовершенствовать свои навыки в этой области. Также оно будет весьма полезно и экспертам в сфере баз данных, так как автор предлагает примеры решения задач в разных СУБД: DB2, Oracle, PostgreSQL, MySQL и SQL Server.
Книга поможет научиться использовать SQL для решения более широкого круга задач: от операций внутри БД до извлечения данных и передачи их по сети в приложения.
Вы узнаете, как применять оконные функции и специальные операторы, а также расширенные методы работы с хранилищами данных: создание гистограмм, резюмирование данных в блоки, выполнение агрегации скользящего диапазона значений, формирование текущих сумм и подсумм. Вы сможете разворачивать строки в столбцы и наоборот, упрощать вычисления внутри строки и выполнять двойное разворачивание результирующего множества, выполнять обход строки, что позволяет использовать SQL для синтаксического разбора строки на символы, слова или элементы строки с разделителями. Приемы, предлагаемые автором, позволят оптимизировать код ваших приложений и откроют перед вами новые возможности языка SQL.
Вы сможете разворачивать строки в столбцы и наоборот, упрощать вычисления внутри строки и выполнять двойное разворачивание результирующего множества, выполнять обход строки, что позволяет использовать SQL для синтаксического разбора строки на символы, слова или элементы строки с разделителями. Приемы, предлагаемые автором, позволят оптимизировать код ваших приложений и откроют перед вами новые возможности языка SQL.
Книга уникальна тем, что в каждой главе приводится сравнение реализаций тех или иных запросов на диалектах трех ведущих СУБД. Благодаря этому она представляет собой исчерпывающий и практичный справочник по языку SQL для разработчиков от новичков до гуру, своего рода настольное пособие.
В издании охватываются темы от самых основ до транзакций и блокировок, функций и средств защиты баз данных.
В конце представлено несколько дополнительных тем: интеграция SQL в XML, бизнес-аналитика OLAP и многое другое.
В книге описаны большинство из современных баз данных с открытым исходным кодом: Redis, Neo4J, CouchDB, MongoDB, HBase, PostgreSQL и Riak. Для каждой базы приведены примеры работы с реальными данными, демонстрирующие основные идеи и сильные стороны.
Для каждой базы приведены примеры работы с реальными данными, демонстрирующие основные идеи и сильные стороны.
Эта книга прольет свет на сильные и слабые стороны каждой из семи баз данных и научит вас выбирать ту, которая лучше отвечает требованиям.
Справочное пособие по настройке и масштабированию PostgreSQL. В книге исследуются вопросы по настройке производительности PostgreSQL, репликации и кластеризации. Изобилие реальных примеров позволит как начинающим, так и опытным разработчикам быстро разобраться с особенностями масштабирования PostgreSQL для своих приложений.
Для начинающих:
- Основы SQL
- SQL для начинающих
- Серия коротких видео по основам SQL
- Администрирование PostgreSQL (часть 1, часть 2)
- Видеокурс по базам данных от Технопарка
Для продвинутых:
- SQL практикум
- SQL, how to…
- Погружение в СУБД (stepik.org)
Для мастеров:
- SQL Injection
- SQL Attack
Англоязычный ресурс для интерактивного изучения основ SQL. Курс разделен на 19 тематических уроков, содержащих теоретическую часть и набор упражнений, которые можно выполнять прямо на странице урока в специально предназначенной для этого интерактивной форме.
Курс разделен на 19 тематических уроков, содержащих теоретическую часть и набор упражнений, которые можно выполнять прямо на странице урока в специально предназначенной для этого интерактивной форме.
Еще один полезный ресурс для программистов с достаточным уровнем английского. Представляет собой охватывающий большое количество тем справочник с множеством примеров и упражнений.
Русскоязычный сайт с огромным количеством интерактивных упражнений для оттачивания навыков в написании операторов манипуляции данными языка SQL.
Упражнения начального уровня доступны без регистрации, для выполнения остальных нужно будет зарегистрироваться (регистрация абсолютно бесплатна).
По результатам тестирования на сайте можно заказать сертификат «SQL Data Manipulation Language Specialist», подтверждающий вашу квалификацию. Качество сертификата поддерживается периодической заменой задач и повышением сертификационных требований.
Курс введения в базы данных знакомит слушателей с историей создания систем обработки структурированных данных, подходами к обработке информации, развитием моделей данных и систем управления данными.
Важную часть курса составляет рассмотрение основных этапов проектирования реляционных баз данных, а также аномалий структурированных данных.
5 сайтов для оттачивания навыков написания SQL-запросов
Видеокурс по работе с MySQL
Почему ни одна база данных не поддерживает полностью стандарты ANSI или ISO SQL? [sql, database, database-design, standards, ansi-sql]
Если бы я проектировал нефтеперерабатывающий завод, я бы не ожидал, что материалы от разных поставщиков не будут соответствовать опубликованным стандартам тонкими, но важными способами. Трубопроводы, клапаны и другие компоненты от одного поставщика поставляются с фланцами и толщиной стенок в соответствии со стандартами ANSI, как и те же детали от любого другого поставщика. Таким образом обеспечивается совместимость и безопасность системы.
Почему же тогда обычные базы данных так разборчивы в том, каких частей стандартов они придерживаются, и почему на первый план не вышли системы, на 100% соответствующие стандартам? Являются ли стандарты «сломанными», недостаточными или слишком сложными для разработки?
Принимая это к выводу; в чем смысл определения стандартов ANSI (или ISO) для SQL?
Изменить: Список различий в реализации между распространенными базами данных
sql database database-design standards ansi-sql
person Lunatik
schedule 24. 04.2009
source источник
04.2009
source источник
Ответы (12)
arrow_upward
18
arrow_downward
В индустрии программного обеспечения у вас есть некоторые стандарты, которые на самом деле являются стандартами, то есть продукты, которые им не соответствуют, просто не работают. Спецификации файлов попадают в эту категорию. Но тогда у вас также есть «стандарты», которые больше похожи на рекомендации: они могут быть определены как стандарты с пошаговыми определениями, но обычно реализуются лишь частично или со значительными отличиями. Веб-разработка полна таких «стандартов», как HTML, CSS и «ECMAScript», где разные поставщики (например, веб-браузеры) реализуют стандарты по-разному.
Вариация вызывает головную боль, но стандартизация по-прежнему дает преимущества. Представьте, если бы не было стандарта HTML, и каждый браузер использовал бы свой собственный язык разметки. Точно так же представьте, что не было бы стандарта SQL, и каждый поставщик базы данных использовал бы свой собственный полностью проприетарный язык запросов. Будет гораздо больше привязки к поставщику, и разработчикам будет гораздо труднее работать с более чем одним продуктом.
Будет гораздо больше привязки к поставщику, и разработчикам будет гораздо труднее работать с более чем одним продуктом.
Итак, нет, ANSI SQL не служит той же цели, что и стандарты ANSI в других отраслях. Но, тем не менее, это служит полезной цели.
person John M Gant schedule 24.04.2009
arrow_upward
14
arrow_downward
Вероятно, потому, что соответствие стандартам не имеет большого значения для покупателей систем баз данных. Их больше интересует:
- совместимость с тем, что у них уже есть
- производительность
- цена
- Поддержка ОС
назвать лишь несколько факторов.
То же самое относится и к языкам программирования — очень немногие (если вообще есть) компиляторы поддерживают каждую отдельную функцию текущих стандартов ANSI C и C++.
Что касается того, зачем заморачиваться со стандартом, то большинство поставщиков в конечном итоге включают стандартную поддержку. Например, большинство поставщиков поддерживают более или менее весь SQL89. Это позволяет поставщику отметить (относительно неважный) флажок в своем листе спецификаций, а также позволяет таким людям, как я, которые заинтересованы в написании переносимого кода, делать это, хотя и отказываясь от множества наворотов.
Например, большинство поставщиков поддерживают более или менее весь SQL89. Это позволяет поставщику отметить (относительно неважный) флажок в своем листе спецификаций, а также позволяет таким людям, как я, которые заинтересованы в написании переносимого кода, делать это, хотя и отказываясь от множества наворотов.
person Community schedule 24.04.2009
arrow_upward
13
arrow_downward
См. статью «ЯВЛЯЕТСЯ ЛИ SQL БОЛЬШЕ РЕАЛЬНЫМ СТАНДАРТОМ?» для обсуждения текущего (2005 г.) вопросы стандарта SQL.
person oluies schedule 02.08.2010
arrow_upward
6
arrow_downward
Действительно, стандарт ANSI SQL не часто соблюдается. Просто прочитайте SO: большинство потоков SQL никогда не ссылаются на стандарт, в то время как, например, обсуждения сетевых протоколов часто включают реальную цитату, главу и стих соответствующего RFC.
Просто прочитайте SO: большинство потоков SQL никогда не ссылаются на стандарт, в то время как, например, обсуждения сетевых протоколов часто включают реальную цитату, главу и стих соответствующего RFC.
Я всегда подозревал, что одной из причин является тот факт, что стандарт SQL не распространяется свободно. Просто получить это не тривиально. Вокруг ходят различные неофициальные копии.)
Другая причина в том, что это очень сложный и плохо организованный текст. Он использует странный словарь (например, «authID» вместо «user»). Вам нужны книги только для того, чтобы понять стандарт («Руководство по стандарту SQL», C.J. Date, Hugh Darwen — Addison-Wesley).
person bortzmeyer schedule 27.04.2009
arrow_upward
5
arrow_downward
Я не знаю историю ANSI SQL конкретно. Но кажется, что много раз в разработке программного обеспечения стандарты писались после того, как основные игроки уже реализовали свои собственные проприетарные версии вещей. Как только компания инвестирует в свой собственный способ ведения дел, становится действительно трудно оправдать изменение или удаление функций, на которые люди привыкли полагаться только для того, чтобы придерживаться стандарта. Веб-стандарты являются основным примером этого явления.
Как только компания инвестирует в свой собственный способ ведения дел, становится действительно трудно оправдать изменение или удаление функций, на которые люди привыкли полагаться только для того, чтобы придерживаться стандарта. Веб-стандарты являются основным примером этого явления.
person Ryan Bolger schedule 24.04.2009
arrow_upward
5
arrow_downward
Mimer SQL имеет отличную поддержку стандартов, но малоизвестен. Он производится на нескольких крупных предприятиях, в основном в Швеции. Но я думаю, что многие сайты мигрируют на другие.
Подробная информация о поддержке:
- SQL-99
- SQL-2003
- ПСМ
- Триггеры и функции базы данных в соответствии с SQL:1999
- Поддержка больших двоичных и символьных объектов (BLOB/CLOB/NCLOB) в соответствии с SQL:1999.

- Транзакции с несколькими базами данных (двухэтапная фиксация), соответствующие стандарту XA Open Group.
- Поддержка профиля Java ME CDC Foundation и Java ME CLDC/MIDP
person oluies schedule 02.08.2010
arrow_upward
3
arrow_downward
Несколько лет назад одной из худших отраслей с точки зрения взаимной совместимости труб и соединителей было противопожарное оборудование. Были буквально десятки взаимно несовместимых соединений шланга с насосом. Когда взаимопомощь стала обычным явлением среди пожарных, им пришлось брать с собой десятки адаптеров, чтобы иметь возможность взаимодействовать со своим оборудованием.
11 сентября и у полиции, и у пожарных были частные беспроводные сети для связи между своими людьми. Но, знаете что? Эти две системы не были взаимно совместимы. Таким образом, были ненужные задержки в передаче информации от одного служащего общественной безопасности к другому.
Таким образом, были ненужные задержки в передаче информации от одного служащего общественной безопасности к другому.
Если вы вернетесь достаточно далеко в прошлое, вы можете найти время в Нью-Йорке, когда примерно половина электрической сети была на постоянном токе, которую предпочитал Эдисон, а другая половина была на переменном токе, которую предпочитал Вестингауз.
Стандарты иногда возникают сами по себе и называются стандартами де-факто. Чаще всего стандарты должны устанавливаться органом, специально уполномоченным для этого. Что касается стандартов SQL, то некоторые из крупнейших поставщиков появились раньше стандарта. Чтобы соответствовать стандарту, им пришлось бы нести инженерные расходы, которые не принесут пользы их существующей клиентской базе. Что еще хуже, они могут оказаться несовместимыми со своим предыдущим продуктом.
Полное соответствие стандарту SQL еще может произойти, но маловероятно. Даже если это так, между появлением нового стандарта SQL и его соответствием проходит время.
person Walter Mitty schedule 24.04.2009
arrow_upward
2
arrow_downward
ИМХО, поставщики БД продвигают стандарты ANSI SQL, чтобы включить новые функции и конструкции в свою область, гораздо больше, чем ANSI, говорящий поставщикам БД «единственный верный путь».
Рынок баз данных определяется функциями, масштабируемостью и стоимостью. Пренебрегать техническими преимуществами (т. е. разделением, поворотом, UPSERT, репликацией) и ждать, пока ANSI ратифицирует синтаксис, не является коммерческим приоритетом. К тому времени, когда это было сделано, уже была установлена значительная часть проприетарного синтаксиса.
При этом большинство поставщиков БД значительно улучшили свою базовую поддержку «ANSI SQL» за последние несколько лет. (SQL Server с SELECT FROM INFORMATION_SCHEMA и ANSI-соединениями Oracle действительно работают, а также нативные соединения в рамках CBO)
person Guy
schedule 24. 04.2009
04.2009
arrow_upward
2
arrow_downward
Согласно руководству HSQLDB, это самая совместимая со стандартами СУБД.
- Поддерживаются почти все синтаксические возможности SQL-92 вплоть до уровня Advanced.
- Ядро SQL:2008 и множество дополнительных функций этого стандарта
person Janus Troelsen schedule 25.03.2012
arrow_upward
1
arrow_downward
Настоящая причина: большинство «разработчиков» ориентированы на клиента и поэтому не понимают и не заботятся о 12 правилах доктора Кодда. По этой же причине MySql, которая не является реляционной базой данных в какой-либо значительной степени, часто используется при разработке WebKiddie. Таким разработчикам нужен только элементарный анализ SELECT, UPDATE, DELETE. Они избегают ограничений любого рода, предпочитая «делать это в приложении». Реакционные приложения 1960-х годов — вот что вы получаете.
Реакционные приложения 1960-х годов — вот что вы получаете.
person Community schedule 26.04.2009
arrow_upward
0
arrow_downward
Большинство из них вполне совместимы. Но вот плохие новости, ИМО — стандарты порождают посредственность. Поставщики хотят, чтобы вы были привязаны к их расширениям, и часто есть веские причины делать нестандартные вещи. На самом деле, насколько вероятно, что вы смените Oracle на SQL Server или наоборот? Если вы не создадите продукт, который ваши клиенты могут использовать против других баз данных, вы, как предприятие, вряд ли замените БД. Слишком болезненно.
person n8wrl schedule 24.04.2009
arrow_upward
0
arrow_downward
Компании обычно склонны использовать одного поставщика, чтобы избежать множества различных и, возможно, несовместимых систем для поддержки. Также намного дешевле обучить ваших разработчиков/системных инженеров использованию инструментов одного поставщика баз данных, чем трем различным наборам инструментов. Позже эта компания может стать достаточно крупной, чтобы купить некоторых своих конкурентов. Это будет означать совершенно другой набор инструментов, которыми вам придется управлять, интегрировать и т. д.
Также намного дешевле обучить ваших разработчиков/системных инженеров использованию инструментов одного поставщика баз данных, чем трем различным наборам инструментов. Позже эта компания может стать достаточно крупной, чтобы купить некоторых своих конкурентов. Это будет означать совершенно другой набор инструментов, которыми вам придется управлять, интегрировать и т. д.
Это много работы.
Представьте, что вместо этого у вас есть уровень переносимости, так что вам действительно все равно, что находится под ним. Это было бы намного лучше.
person Bill Catfish schedule 28.08.2010
Топ-65 вопросов по SQL с собеседований, к которым вы должны подготовиться в 2019 году. Часть I / Хабр
Перевод статьи подготовлен для студентов курса «MS SQL Server разработчик»
Реляционные базы данных являются одними из наиболее часто используемых баз данных по сей день, и поэтому навыки работы с SQL для большинства должностей являются обязательными.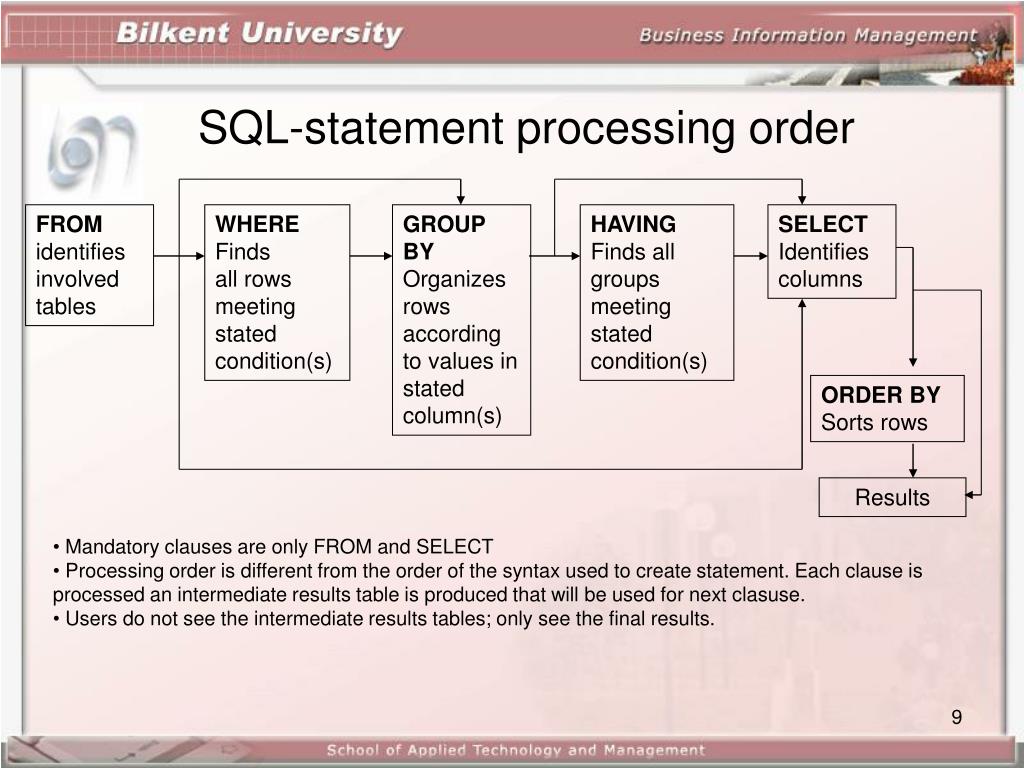 В этой статье с вопросами по SQL с собеседований я познакомлю вас с наиболее часто задаваемыми вопросами по SQL (Structured Query Language — язык структурированных запросов). Эта статья является идеальным руководством для изучения всех концепций, связанных с SQL, Oracle, MS SQL Server и базой данных MySQL.
В этой статье с вопросами по SQL с собеседований я познакомлю вас с наиболее часто задаваемыми вопросами по SQL (Structured Query Language — язык структурированных запросов). Эта статья является идеальным руководством для изучения всех концепций, связанных с SQL, Oracle, MS SQL Server и базой данных MySQL.
Наша статья с вопросами по SQL — универсальный ресурс, с помощью которого вы можете ускорить подготовку к собеседованию. Она состоит из набора из 65 самых распространенных вопросов, которые интервьюер может задать во время собеседования. Оно обычно начинается с базовых вопросов по SQL, а затем переходит к более сложным на основе обсуждения и ваших ответов. Эти вопросы по SQL с собеседований помогут вам извлечь максимальную выгоду на различных уровнях понимания.
Давайте начнем!
Вопрос 1. В чем разница между операторами DELETE и TRUNCATE?
| DELETE | TRUNCATE |
|---|---|
| Используется для удаления строки в таблице | Используется для удаления всех строк из таблицы |
| Вы можете восстановить данные после удаления | Вы не можете восстановить данные (прим. перевод.: операции логируются по разному, но в SQL Server есть возможность сделать откат) транзакции) перевод.: операции логируются по разному, но в SQL Server есть возможность сделать откат) транзакции) |
| DML-команда | DDL-команда |
| Медленнее, чем оператор TRUNCATE | Быстрее |
№ Вопрос 2. Из каких подмножеств состоит SQL?
- DDL (Data Definition Language, язык описания данных) — позволяет выполнять различные операции с базой данных, такие как CREATE (создание), ALTER (изменение) и DROP (удаление объектов).
- DML (Data Manipulation Language, язык управления данными) — позволяет получать доступ к данным и манипулировать ими, например, вставлять, обновлять, удалять и извлекать данные из базы данных.
- DCL (Data Control Language, язык контролирования данных) — позволяет контролировать доступ к базе данных. Пример — GRANT (предоставить права), REVOKE (отозвать права).
Вопрос 3. Что подразумевается под СУБД? Какие существуют типы СУБД?
База данных — структурированная коллекция данных. Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных. СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д.
Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных. СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д.
Существует два типа СУБД:
- Реляционная система управления базами данных: данные хранятся в отношениях (таблицах). Пример — MySQL.
- Нереляционная система управления базами данных: не существует понятия отношений, кортежей и атрибутов. Пример — Mongo.
Вопрос 4. Что подразумевается под таблицей и полем в SQL?
Таблица — организованный набор данных в виде строк и столбцов. Поле — это столбцы в таблице. Например:
Таблица: Student_Information
Поле: Stu_Id, Stu_Name, Stu_Marks
Вопрос 5.
 Что такое соединения в SQL?
Что такое соединения в SQL?Для соединения строк из двух или более таблиц на основе связанного между ними столбца используется оператор JOIN. Он используется для объединения двух таблиц или получения данных оттуда. В SQL есть 4 типа соединения, а именно:
- Inner Join (Внутреннее соединение)
- Right Join (Правое соединение)
- Left Join (Левое соединение)
- Full Join (Полное соединение)
Вопрос 6. В чем разница между типом данных CHAR и VARCHAR в SQL?
И Char, и Varchar служат символьными типами данных, но varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины. Например, char(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как varchar(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2.
Вопрос 7. Что такое первичный ключ (Primary key)?
- Первичный ключ — столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице.
- Однозначно идентифицирует одну строку в таблице
- Нулевые (Null) значения не допускаются
_Пример: в таблице Student StuID является первичным ключом.
Вопрос 8. Что такое ограничения (Constraints)?
Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений:
- NOT NULL
- CHECK
- DEFAULT
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
Вопрос 9. В чем разница между SQL и MySQL?
SQL — стандартный язык структурированных запросов (Structured Query Language) на основе английского языка, тогда как MySQL — система управления базами данных. SQL — язык реляционной базы данных, который используется для доступа и управления данными, MySQL — реляционная СУБД (система управления базами данных), также как и SQL Server, Informix и т. д.
д.
Вопрос 10. Что такое уникальный ключ (Unique key)?
- Однозначно идентифицирует одну строку в таблице.
- Допустимо множество уникальных ключей в одной таблице.
- Допустимы NULL-значения (прим. перевод.: зависит от СУБД, в SQL Server значение NULL может быть добавлено только один раз в поле с UNIQUE KEY).
Вопрос 11. Что такое внешний ключ (Foreign key)?
- Внешний ключ поддерживает ссылочную целостность, обеспечивая связь между данными в двух таблицах.
- Внешний ключ в дочерней таблице ссылается на первичный ключ в родительской таблице.
- Ограничение внешнего ключа предотвращает действия, которые разрушают связи между дочерней и родительской таблицами.
Вопрос 12. Что подразумевается под целостностью данных?
Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных.
Вопрос 13. В чем разница между кластеризованным и некластеризованным индексами в SQL?
- Различия между кластеризованным и некластеризованным индексами в SQL:
Кластерный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из некластеризованного индекса происходит относительно медленнее. - Кластеризованный индекс изменяет способ хранения записей в базе данных — он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в некластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске.
- Одна таблица может иметь только один кластеризованный индекс, тогда как некластеризованных у нее может быть много.
Вопрос 14. Напишите SQL-запрос для отображения текущей даты.
В SQL есть встроенная функция GetDate (), которая помогает возвращать текущий timestamp/дату.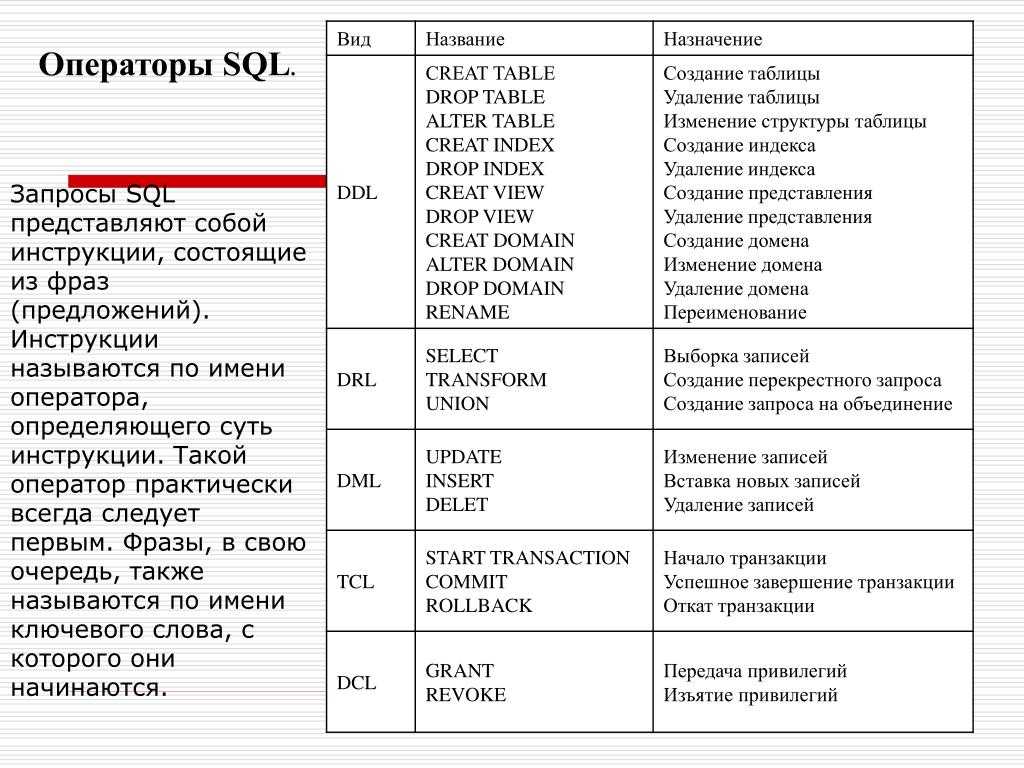
Вопрос 15. Перечислите типы соединений
Существуют различные типы соединений, которые используются для извлечения данных между таблицами. Принципиально они делятся на четыре типа, а именно:
Inner join (Внутреннее соединение): в MySQL является наиболее распространенным типом. Оно используется для возврата всех строк из нескольких таблиц, для которых выполняется условие соединения.
Left Join (Левое соединение): в MySQL используется для возврата всех строк из левой (первой) таблицы и только совпадающих строк из правой (второй) таблицы, для которых выполняется условие соединения.
Right Join (Правое соединение): в MySQL используется для возврата всех строк из правой (второй) таблицы и только совпадающих строк из левой (первой) таблицы, для которых выполняется условие соединения.
Full Join (Полное соединение): возвращает все записи, для которых есть совпадение в любой из таблиц. Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы.
Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы.
Вопрос 16. Что вы подразумеваете под денормализацией?
Денормализация — техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу.
Вопрос 17. Что такое сущности и отношения?
Сущности: человек, место или объект в реальном мире, данные о которых могут храниться в базе данных. В таблицах хранятся данные, которые представляют один тип сущности. Например — база данных банка имеет таблицу клиентов для хранения информации о клиентах. Таблица клиентов хранит эту информацию в виде набора атрибутов (столбцы в таблице) для каждого клиента.
Отношения: отношения или связи между сущностями, которые имеют какое-то отношение друг к другу. Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам).
Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам).
Вопрос 18. Что такое индекс?
Индексы относятся к методу настройки производительности, позволяющему быстрее извлекать записи из таблицы. Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные.
Вопрос 19. Опишите различные типы индексов.
Есть три типа индексов, а именно:
- Уникальный индекс (Unique Index): этот индекс не позволяет полю иметь повторяющиеся значения, если столбец индексируется уникально. Если первичный ключ определен, уникальный индекс может быть применен автоматически.
- Кластеризованный индекс (Clustered Index): этот индекс меняет физический порядок таблицы и выполняет поиск на основе значений ключа. Каждая таблица может иметь только один кластеризованный индекс.

- Некластеризованный индекс (Non-Clustered Index): не изменяет физический порядок таблицы и поддерживает логический порядок данных. Каждая таблица может иметь много некластеризованных индексов.
Вопрос 20. Что такое нормализация и каковы ее преимущества?
Нормализация — процесс организации данных, цель которого избежать дублирования и избыточности. Некоторые из преимуществ:
- Лучшая организация базы данных
- Больше таблиц с небольшими строками
- Эффективный доступ к данным
- Большая гибкость для запросов
- Быстрый поиск информации
- Проще реализовать безопасность данных
- Позволяет легко модифицировать
- Сокращение избыточных и дублирующихся данных
- Более компактная база данных
- Обеспечивает согласованность данных после внесения изменений
Вопрос 21. В чем разница между командами DROP и TRUNCATE?
Команда DROP удаляет саму таблицу, и нельзя сделать Rollback команды, тогда как команда TRUNCATE удаляет все строки из таблицы (прим. перевод.: в SQL Server Rollback нормально отработает и откатит DROP).
перевод.: в SQL Server Rollback нормально отработает и откатит DROP).
Вопрос 22. Объясните различные типы нормализации.
Существует много последовательных уровней нормализации. Это так называемые нормальные формы. Каждая последующая нормальная форма включает предыдущую. Первых трех нормальных форм обычно достаточно.
- Первая нормальная форма (1NF) — нет повторяющихся групп в строках
- Вторая нормальная форма (2NF) — каждое неключевое (поддерживающее) значение столбца зависит от всего первичного ключа
- Третья нормальная форма (3NF) — каждое неключевое значение зависит только от первичного ключа и не имеет зависимости от другого неключевого значения столбца
Вопрос 23. Что такое свойство ACID в базе данных?
ACID означает атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), долговечность (Durability). Он используется для обеспечения надежной обработки транзакций данных в системе базы данных.
Атомарность. Гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных. Это означает, что при сбое одной части любой транзакции происходит сбой всей транзакции и состояние базы данных остается неизменным.
Согласованность. Гарантирует, что данные должны соответствовать всем правилам валидации. Проще говоря, вы можете сказать, что ваша транзакция никогда не оставит вашу базу данных в недопустимом состоянии.
Изолированность. Основной целью изолированности является контроль механизма параллельного изменения данных.
Долговечность. Долговечность подразумевает, что если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода).
Вопрос 24. Что вы подразумеваете под «триггером» в SQL?
Триггер в SQL — особый тип хранимых процедур, которые предназначены для автоматического выполнения в момент или после изменения данных. Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице.
Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице.
Вопрос 25. Какие операторы доступны в SQL?
В SQL доступно три типа оператора, а именно:
- Арифметические Операторы
- Логические Операторы
- Операторы сравнения
Вопрос 26. Совпадают ли значения NULL со значениями нуля или пробела?
Значение NULL вовсе не равно нулю или пробелу. Значение NULL представляет значение, которое недоступно, неизвестно, присвоено или неприменимо, тогда как ноль — это число, а пробел — символ.
Вопрос 27. В чем разница между перекрестным (cross join) и естественным (natural join) соединением?
Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах.
Вопрос 28. Что такое подзапрос в SQL?
Подзапрос — это запрос внутри другого запроса, в котором определен запрос для извлечения данных или информации из базы данных.![]() В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос. Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =.
В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос. Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =.
Вопрос 29. Какие бывают типы подзапросов?
Существует два типа подзапросов, а именно: коррелированные и некоррелированные.
- Коррелированный подзапрос: это запрос, который выбирает данные из таблицы со ссылкой на внешний запрос. Он не считается независимым запросом, поскольку ссылается на другую таблицу или столбец в таблице.
- Некоррелированный подзапрос: этот запрос является независимым запросом, в котором выходные данные подзапроса подставляются в основной запрос.
Вопрос 30. Перечислите способы получить количество записей в таблице?
Для подсчета количества записей в таблице вы можете использовать следующие команды:SELECT * FROM table1SELECT COUNT(*) FROM table1SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Ещё 35 вопросов с ответами опубликуем в следующей части… Следите за новостями!
Стандарт SQL — ISO/IEC 9075:2016 (ANSI X3.
 135)
135)SQL (расшифровывается как язык структурированных запросов) — это стандартный язык для систем управления реляционными базами данных. Когда он возник еще в 1970-х годах, предметно-ориентированный язык предназначался для выполнения запроса к базе данных, который мог бы перемещаться по сети указателей, чтобы найти желаемое местоположение. Его применение для обработки структурированных данных получило широкое распространение в эпоху цифровых технологий. Фактически, мощные возможности SQL для работы с базами данных и определения, а также его интуитивно понятное табличное представление стали доступны в той или иной форме практически на каждой важной компьютерной платформе в мире.
Некоторые примечательные функции SQL включают возможность обработки наборов данных как групп, а не отдельных единиц, автоматический переход к данным и использование операторов, которые являются сложными и мощными по отдельности. Используемый для различных задач, таких как запрос данных, управление доступом к базе данных и ее объектам, обеспечение согласованности базы данных, обновление строк в таблице, а также создание, замена, изменение и удаление объектов, SQL позволяет пользователям работать с данными на логическом уровне. уровень.
уровень.
Не существует такого понятия, как «Стандарты ANSI», поскольку ANSI не разрабатывает стандарты. Вместо этого есть американские национальные стандарты и другие документы, написанные одобренными ANSI комитетами организаций по разработке стандартов. Тем не менее, мы получаем много запросов на «стандарт ANSI» для SQL. Стоит отметить, что хотя эта фраза вводит в заблуждение и является неточной по многим причинам, она относится к существующим стандартным документам. SQL, как и многие великие вещи, которые пережили 70-е годы, имеет богатую историю, удачно переплетенную со стандартами. В концепции спецификаций SQL был ANSI (еще один великий подвиг за всю нашу 100-летнюю историю).
Текущая редакция ISO/IEC 9075 для SQL Если вы не хотите читать всю историю SQL, которую мы подробно описали ниже, для краткости, SQL был стандартизирован в ANSI X3.135 в 1986 г., и через несколько месяцев он был принят ISO как ISO 9075-1987. Хотя большинство поставщиков модифицируют SQL в соответствии со своими потребностями, они обычно основывают свои программы на текущей версии этого стандарта. С тех пор международный стандарт (теперь ISO/IEC 9075) периодически пересматривался, последний раз в 2016 году. Он существует в 9части:
Хотя большинство поставщиков модифицируют SQL в соответствии со своими потребностями, они обычно основывают свои программы на текущей версии этого стандарта. С тех пор международный стандарт (теперь ISO/IEC 9075) периодически пересматривался, последний раз в 2016 году. Он существует в 9части:
ISO/IEC 9075-1:2016 – Информационные технологии – Языки баз данных – SQL – Часть 1: Framework (SQL/Framework)
ISO/IEC 9075-2:2016 – Информационные технологии – Языки баз данных – SQL – Часть 2: Foundation (SQL/Foundation)
ISO/IEC 9075-3:2016 — Информационные технологии — Языки баз данных — SQL — Часть 3: Интерфейс уровня вызовов (SQL/CLI)
ISO/IEC 9075-4:2016 — Информационные технологии – Языки баз данных – SQL – Часть 4. Постоянные хранимые модули (SQL/PSM)
ISO/IEC 9075-9:2016 – Информационные технологии – Языки баз данных – SQL – Часть 9: Управление внешними данными (SQL/MED)
ISO/IEC 9075-10:2016 – Информационные технологии – Языки баз данных – SQL – Часть 10: Привязки объектного языка (SQL/OLB)
ISO/IEC 9075-11:2016 – Информационные технологии – Языки баз данных – SQL – Часть 11: Схемы информации и определений (SQL/Schemata)
ISO/IEC 9075-13 :2016 – Информационные технологии – Языки баз данных – SQL – Часть 13: Подпрограммы и типы SQL с использованием языка программирования Java TM (SQL/JRT)
ISO/IEC 9075-14:2016 – Информационные технологии – Языки баз данных – SQL – Часть 14: Спецификации, связанные с XML (SQL/XML)
Обратите внимание, что разработчик исходного стандарта ANSI X3. 135-1986, был Аккредитованный комитет по стандартам (ASC) X3, который теперь является аккредитованной ANSI организацией по разработке стандартов INCITS. Сегодня, когда Объединенный технический комитет ISO/IEC (JTC) 1 по информационным технологиям разрабатывает международный стандарт, INCITS принимает серию ISO/IEC 9075 в качестве американских национальных стандартов.
135-1986, был Аккредитованный комитет по стандартам (ASC) X3, который теперь является аккредитованной ANSI организацией по разработке стандартов INCITS. Сегодня, когда Объединенный технический комитет ISO/IEC (JTC) 1 по информационным технологиям разрабатывает международный стандарт, INCITS принимает серию ISO/IEC 9075 в качестве американских национальных стандартов.
Читайте дальше, если вам интересно, как появился SQL.
SQL: стандартизированная историяКогда SQL был создан в начале 70-х, он назывался SEQUEL (Structured English Query Language). Однако из-за проблем с авторскими правами он был изменен на SQL. На самом деле сегодня SQL обычно произносится как «sequel», но некоторые предпочитают неаббревиатурное произношение «ess-cue-el» (если вы не знали, аббревиатура — это аббревиатура, которую вы можете произносить как слово, например SQL или ANSI).
Создатели SQL, Дональд Чемберлин и Рэй Бойс, опираясь на модель, установленную Э. Ф.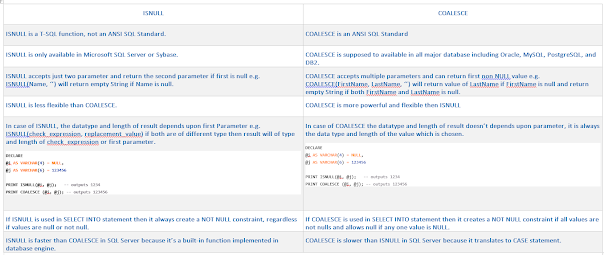 Коддом в его статье «Реляционная модель данных для больших общих банков данных», разработали язык программирования в своей собственной статье «ПРОДОЛЖЕНИЕ: A Структурированный английский язык запросов». Они взяли языки Кодда с целью разработки реляционного языка, который был бы более доступным для пользователей без формального обучения математике или информатике. Эта исходная версия SQL, которую они разработали, использовалась для манипулирования и извлечения данных, хранящихся в исходных системах реляционных баз данных IBM, известных как «System R».
Коддом в его статье «Реляционная модель данных для больших общих банков данных», разработали язык программирования в своей собственной статье «ПРОДОЛЖЕНИЕ: A Структурированный английский язык запросов». Они взяли языки Кодда с целью разработки реляционного языка, который был бы более доступным для пользователей без формального обучения математике или информатике. Эта исходная версия SQL, которую они разработали, использовалась для манипулирования и извлечения данных, хранящихся в исходных системах реляционных баз данных IBM, известных как «System R».
В последующие годы SQL не был общедоступен. Однако в 1979 году Oracle, тогда известная как Relational Software, выпустила собственную версию SQL под названием Oracle V2, которая была выпущена на коммерческой основе. Важно отметить, что SQL не был первым языком программирования для навигации по базам данных, но он добился безупречного присутствия благодаря своей интуитивности, мощности и надежности. Есть причина, по которой мы все еще говорим об этом сегодня.
Однако продолжительный успех SQL нельзя объяснить только его качествами. Помощь стандартов не только помогла SQL приблизиться к универсальности, но и добавила ключевые атрибуты тому, что расцвело в его современных спецификациях. Все началось, когда в дело вмешался ANSI.
В 1986 году язык SQL был официально принят, и Технический комитет по базам данных ANSI (ANSI X3h3) Аккредитованного комитета по стандартам (ASC) X3 разработал первый стандарт SQL, ANSI X3.135-1986. Это было началом того, что люди ошибочно называют стандартом ANSI для SQL. На самом деле стандартов ANSI не существует, есть только стандарты, разработанные одобренными ANSI комитетами, многие из которых действуют в соответствии с основными требованиями ANSI (американскими национальными стандартами). Через несколько месяцев ISO опубликовала технически идентичный стандарт ISO 9.075-1987, выведя SQL, который когда-то был ограничен базами данных IBM в зачаточном состоянии, на международную арену.
Во время первоначальной публикации этого стандарта, безусловно, требовались более подробные спецификации относительно SQL, но ANSI X3. 135-1986 действительно помог заложить основу для некоторых важных возможностей языка программирования. Этот стандарт дал возможность вызывать возможности SQL из четырех языков программирования: COBOL, FORTRAN, Pascal и PL/I.
135-1986 действительно помог заложить основу для некоторых важных возможностей языка программирования. Этот стандарт дал возможность вызывать возможности SQL из четырех языков программирования: COBOL, FORTRAN, Pascal и PL/I.
Эти стандарты были пересмотрены совместно, впервые в 1989 (ANSI X3.135-1989 и ISO/IEC 9075:1989) и снова в 1992 году (ANSI X3.135-1992 и ISO/IEC 9075:1992). В выпуске 1989 г. добавлена поддержка двух дополнительных языков программирования, Ada и C. Эти выпуски в просторечии стали известны как SQL-86, SQL-89 и SQL-92. Итак, если вы слышите эти имена в отношении формата SQL, обратите внимание, что они относятся к различным редакциям этого стандарта.
Перед следующей редакцией Аккредитованный комитет по стандартам X3, информационные технологии, изменился. с 19С 61 по 1996 год этот комитет по разработке стандартов, аккредитованный ANSI, работал во многих аспектах отрасли при поддержке ITI, торговой ассоциации, тогда известной как Ассоциация компьютеров и бизнес-оборудования (CBEMA). Однако в конце этого периода. ASC X3 стала INCITS (Международный комитет по стандартам информационных технологий), аккредитованной ANSI организацией по разработке стандартов.
Однако в конце этого периода. ASC X3 стала INCITS (Международный комитет по стандартам информационных технологий), аккредитованной ANSI организацией по разработке стандартов.
Стандарт снова пересматривался в 1993 (SQL3), 2003, 2008, 2011 и 2016 годах, и эта редакция остается текущей. С начала века стандарт SQL состоит из нескольких частей, но начиная с издания 2003 года он подразделяется на 9 частей.частей, каждая из которых охватывает отдельный аспект общего стандарта и подпадает под общее название «Информационные технологии — Языки баз данных — SQL».
Международный стандарт ISO/IEC 9075 для SQL разработан Объединенным техническим комитетом ISO/IEC (JTC) 1 по информационным технологиям. В текущем издании ISO/IEC 9075:2016 каждая из 9 частей была принята INCITS в качестве американских национальных стандартов.
Этот полувековой процесс разработки принес нам более жизнеспособную форму языка SQL, которую мы знаем и на которую опираемся сегодня. SQL используется многими поставщиками, и, хотя большинство крупных поставщиков модифицируют язык в соответствии со своими потребностями, большинство из них основывают свои программы SQL на стандартной версии. ИСО/МЭК 9075:2016, как и многие другие существующие добровольные согласованные стандарты, призван способствовать инновациям и конкурентоспособности, а не препятствовать им.
ИСО/МЭК 9075:2016, как и многие другие существующие добровольные согласованные стандарты, призван способствовать инновациям и конкурентоспособности, а не препятствовать им.
Эквивалентные типы данных ANSI SQL
Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Применяется к : Access 2013, Office 2013
В следующей таблице перечислены типы данных ANSI SQL, их эквивалентные типы данных SQL ядра базы данных Microsoft Access и их допустимые синонимы. В нем также перечислены эквивалентные типы данных Microsoft SQL Server™.
БИТ, БИТ ИЗМЕНЯЕТСЯ | ДВОИЧНЫЙ (см. | VARBINARY, BARY ИЗМЕНЯЕТСЯ БИТ ИЗМЕНЯЕТСЯ | ДВОИЧНЫЕ, ВАРБИНАРНЫЕ |
Не поддерживается | БИТ (см. примечания) | BOOLEAN, LOGICAL, LOGICAL1, YESNO | БИТ |
Не поддерживается | МАЛЕНЬКИЙ | ЦЕЛОЕ 1, БАЙТ | МАЛЕНЬКИЙ |
Не поддерживается | СЧЕТЧИК (см. примечания) | АВТОМАТИЧЕСКОЕ УВЕЛИЧЕНИЕ | (см. примечания) |
Не поддерживается | ДЕНЬГИ | ВАЛЮТА | ДЕНЬГИ |
ДАТА, ВРЕМЯ, ОТМЕТКА ВРЕМЕНИ | ДАТАВРЕМЯ | ДАТА, ВРЕМЯ (см. примечания) | ДАТАВРЕМЯ |
Не поддерживается | УНИКАЛЬНЫЙ ИДЕНТИФИКАТОР | GUID | УНИКАЛЬНЫЙ ИДЕНТИФИКАТОР |
ДЕСЯТИЧНЫЙ | ДЕСЯТИЧНЫЙ | ЦИФРОВОЙ, ДЕК | ДЕСЯТИЧНЫЙ |
ДЕЙСТВИТЕЛЬНОЕ | НАСТОЯЩИЙ | ОДИНАРНЫЙ, FLOAT4, IEEEESINGLE | НАСТОЯЩИЙ |
DOUBLE PRECISION, FLOAT | ПОПЛАВОК | DOUBLE, FLOAT8, IEEEDOUBLE, NUMBER (см. | ПОПЛАВОК |
МАЛЕНЬКИЙ | МАЛЕНЬКИЙ | КОРОТКИЙ, ЦЕЛОЕ 2 | МАЛЕНЬКИЙ |
ЦЕЛОЕ ЧИСЛО | ЦЕЛОЕ ЧИСЛО | ДЛИННОЕ, ЦЕЛОЕ, ЦЕЛОЕ4 | ЦЕЛОЕ ЧИСЛО |
ИНТЕРВАЛ | Не поддерживается | Не поддерживается | |
Не поддерживается | ИЗОБРАЖЕНИЕ | LONGBINARY, GENERAL, OLEOBJECT | ИЗОБРАЖЕНИЕ |
Не поддерживается | ТЕКСТ (см. примечания) | LONGTEXT, LONGCHAR, MEMO, NOTE, NTEXT (см. примечания) | ТЕКСТ |
ХАРАКТЕР, РАЗЛИЧНЫЙ ХАРАКТЕР, НАЦИОНАЛЬНЫЙ ХАРАКТЕР, РАЗНЫЙ НАЦИОНАЛЬНЫЙ ХАРАКТЕР | СИМВОЛ (см. примечания) | ТЕКСТ(n), БУКВЕННО-ЦИФРОВОЙ, ЗНАК, СТРОКА, VARCHAR, ПЕРЕМЕННЫЙ ЗНАК, NCHAR, НАЦИОНАЛЬНЫЙ ЗНАК, НАЦИОНАЛЬНЫЙ ЗНАК, НАЦИОНАЛЬНЫЙ ЗНАК, ИЗМЕНЯЮЩИЙСЯ, НАЦИОНАЛЬНЫЙ ЗНАК, ИЗМЕНЯЮЩИЙСЯ (см. | ЧАР, ВАРЧАР, НЧАР, НВАРЧАР |
 примечания)
примечания) примечания)
примечания) примечания)
примечания)Примечание
- Тип данных ANSI SQL BIT не соответствует типу данных Microsoft Access SQL BIT. Вместо этого он соответствует типу данных BINARY. Для типа данных Microsoft Access SQL BIT не существует эквивалента ANSI SQL.
- TIMESTAMP больше не поддерживается в качестве синонима для DATETIME.
- NUMERIC больше не поддерживается в качестве синонима для FLOAT или DOUBLE. NUMERIC теперь используется как синоним для DECIMAL.
- Поле LONGTEXT всегда сохраняется в формате представления Unicode.
- Если имя типа данных TEXT используется без указания дополнительной длины, например TEXT(25), создается поле LONGTEXT. Это позволяет писать операторы CREATE TABLE, которые будут давать типы данных, совместимые с Microsoft SQL Server.
- Поле CHAR всегда сохраняется в формате представления Unicode, который эквивалентен типу данных ANSI SQL NATIONAL CHAR.

- Если используется имя типа данных TEXT и указана необязательная длина, например TEXT(25), тип данных поля эквивалентен типу данных CHAR. Это сохраняет обратную совместимость для большинства приложений Microsoft Jet, позволяя согласовать тип данных TEXT (без указания длины) с Microsoft SQL Server.
Урок 2. Выполнение запросов с помощью ANSI SQL
Цель
В этом уроке показано, как выполнить стандартный анализ SQL в Apache Drill: для Например, суммирование данных с помощью простых агрегатных функций и подключение источников данных с помощью объединений. Обратите внимание, что Apache Drill обеспечивает поддержку ANSI SQL, не «SQL-подобный» интерфейс.
Запросы в этом уроке
Теперь, когда вы знаете, как выглядят источники данных в необработанном виде, используя
выберите * запросы, попробуйте выполнить несколько простых, но более полезных запросов для каждого из данных
источник. Эти запросы демонстрируют, как Drill поддерживает конструкции ANSI SQL и
также как вы можете комбинировать данные из разных источников данных в одном SELECT
утверждение.
- Показать совокупный запрос к одному файлу или таблице. Используйте предложения GROUP BY, WHERE, HAVING и ORDER BY.
- Выполнение соединений между Hive, MapR-DB и источниками данных файловой системы.
- Использовать псевдонимы таблиц и столбцов.
- Создайте представление детализации.
Агрегация
Установить схему для куста:
0: jdbc:drill:> use hive.`default`; |---------------------|------------------------------------------------------- --| | хорошо | резюме | |---------------------|------------------------------------------------------- --| | правда | Схема по умолчанию изменена на [hive.default] | |---------------------|------------------------------------------------------- --| Выбрана 1 строка
Сумма возвратных продаж по месяцам:
0: jdbc:drill:> select `month`, sum(order_total) из группы заказов по порядку «месяц» по 2 уб.; |------------|---------| | месяц | EXPR$1 | |------------|---------| | июнь | 950481 | | Май | 947796 | | март | 836809 | | апрель | 807291 | | июль | 757395 | | Октябрь | 676236 | | август | 572269 | | февраль | 532901 | | Сентябрь | 373100 | | январь | 346536 | |------------|---------| Выбрано 10 строк
Drill поддерживает агрегатные функции SQL, такие как SUM, MAX, AVG и MIN. Стандартные предложения SQL работают в запросах Drill так же, как и в реляционных запросах.
запросы к базе данных.
Стандартные предложения SQL работают в запросах Drill так же, как и в реляционных запросах.
запросы к базе данных.
Обратите внимание, что обратные галочки необходимы для столбца «месяц» только потому, что «месяц» является зарезервированным словом в SQL.
Вернуть первые 20 итогов продаж по месяцам и состояниям:
0: jdbc:drill:> выберите «месяц», состояние, сумма (заказ_общая) как продажи из групп заказов по «месяцу», состояние заказ по 3 десн лимит 20; |-----------|--------|---------| | месяц | состояние | продажи | |-----------|--------|---------| | Май | ca | 119586 | | июнь | ca | 116322 | | апрель | ca | 101363 | | март | ca | 99540 | | июль | ca || | Октябрь | ca | 80090 | | июнь | Тех | 78363 | | Май | Тех | 77247 | | март | Тех | 73815 | | август | ca | 71255 | | апрель | Тех | 68385 | | июль | Тех | 63858 | | февраль | ca | 63527 | | июнь | фл | 62199 | | июнь | Нью-Йорк | 62052 | | Май | эт | 61651 | | Май | Нью-Йорк | 59369 | | Октябрь | Тех | 55076 | | март | эт | 54867 | | март | Нью-Йорк | 52101 | |-----------|--------|---------| выбрано 20 строк Обратите внимание на псевдоним результата функции СУММ.
Сверло поддерживает колонну псевдонимы и псевдонимы таблиц.
Предложение HAVING
Этот запрос использует предложение HAVING для ограничения совокупного результата.
Установить рабочее пространство на dfs.clicks
0: jdbc:drill:> use dfs.clicks; |---------------------|------------------------------------------------------- | | хорошо | резюме | |---------------------|------------------------------------------------------- | | правда | Схема по умолчанию изменена на [dfs.clicks] | |---------------------|------------------------------------------------------- | Выбрана 1 строкаВозвращает общее количество кликов для устройств, которые указывают на высокие клики:
0: jdbc:drill:> select t.user_info.device, count(*) from `clicks/clicks.json` t группа по t.user_info.device количество (*) > 1000; |---------|---------| | EXPR$0 | EXPR$1 | |---------|---------| | IOS5 | 11814 | | АОС4.2 | 5986 | | iOS6 | 4464 | | iOS7 | 3135 | | АОС4.4 | 1562 | | АОС4.3 | 3039 | |---------|---------| выбрано 6 рядов
Агрегат представляет собой количество записей для каждого отдельного мобильного устройства в данные о посещениях. Только активность для устройств, которые зарегистрировали больше более 1000 транзакций соответствуют набору результатов.
Оператор UNION
Используйте то же рабочее пространство, что и раньше (dfs.clicks).
Объединение кликов до и после маркетинговой кампании
0: jdbc:drill:> выберите транзакцию t.trans_id, t.user_info.cust_id клиента из `clicks/clicks.campaign.json` t союз всех выберите u.trans_id, u.user_info.cust_id из `clicks/clicks.json` u limit 5; |-------------|-------------| | транзакция | клиент | |-------------|-------------| | 35232 | 18520 | | 31995 | 17182 | | 35760 | 18228 | | 37090 | 17015 | | 37838 | 18737 | |-------------|-------------|Этот запрос UNION ALL возвращает строки, существующие в двух файлах (и включает любые повторяющиеся строки из этих файлов):
clicks.иcampaign.json
clicks.json.Подзапросы
Установить рабочее пространство в куст:
0: jdbc:drill:> use hive.`default`; |---------------------|------------------------------------------------------- --| | хорошо | резюме | |---------------------|------------------------------------------------------- --| | правда | Схема по умолчанию изменена на [hive.default] | |---------------------|------------------------------------------------------- --| Выбрана 1 строкаСравните итоговые суммы заказов по штатам:
0: jdbc:drill:> выберите ny_sales.cust_id, ny_sales.total_orders, ca_sales.total_orders из (выберите o.cust_id, sum(o.order_total) как total_orders из hive.orders o, где state = группа 'ny' по o.cust_id) ny_sales левое внешнее соединение (выберите o.cust_id, sum(o.order_total) как total_orders из hive.orders o, где state = группа 'ca' по o.cust_id) ca_sales на ny_sales.cust_id = ca_sales.cust_id заказать по ny_sales.cust_id предел 20; |------------|-------------|-------------| | cust_id | ny_sales | ca_sales | |------------|-------------|-------------| | 1001 | 72 | 47 | | 1002 | 108 | 198 | | 1003 | 83 | ноль | | 1004 | 86 | 210 | | 1005 | 168 | 153 | | 1006 | 29 | 326 | | 1008 | 105 | 168 | | 1009 | 443 | 127 | | 1010 | 75 | 18 | | 1012 | 110 | ноль | | 1013 | 19 | ноль | | 1014 | 106 | 162 | | 1015 | 220 | 153 | | 1016 | 85 | 159 | | 1017 | 82 | 56 | | 1019| 37 | 196 | | 1020 | 193 | 165 | | 1022 | 124 | ноль | | 1023 | 166 | 149 | | 1024 | 233 | ноль | |------------|-------------|-------------|
В этом примере демонстрируется поддержка детализации для подзапросов.
Функция CAST
Использовать рабочее пространство maprdb:
0: jdbc:drill:> use maprdb; |---------------------|-------------------------------------| | хорошо | резюме | |---------------------|-------------------------------------| | правда | Схема по умолчанию изменена на [maprdb] | |---------------------|-------------------------------------| Выбрана 1 строка (0,088 секунды)Вернуть данные клиента с соответствующими типами данных
0: jdbc:drill:> выберите cast(row_key as int) как cust_id, cast(t.personal.name as varchar(20)) как name, cast(t.personal.gender as varchar(10)) как пол, cast(t.personal.age as varchar(10)) как возраст, cast(t.address.state as varchar(4)) as state, cast(t.loyalty.agg_rev as dec(7,2)) as agg_rev, cast(t.loyalty.membership as varchar(20)) как членство от клиентов t лимит 5; |----------|----------------------|------------|--- --------|--------|----------|-------------| | cust_id | имя | пол | возраст | состояние | agg_rev | членство | |----------|----------------------|------------|--- --------|--------|----------|-------------| | 10001 | "Коррин Мечам" | "ЖЕНСКИЙ" | «15-20» | "ва" | 197.00 | "серебро" | | 10005 | "Бретани Парк" | "МАЛЕ" | "26-35" | "в" | 230,00 | "серебро" | | 10006 | "Роза Локей" | "МАЛЕ" | "26-35" | "ок" | 250,00 | "серебро" | | 10007 | "Джеймс Фаулер" | "ЖЕНСКИЙ" | «51-100» | "я" | 263,00 | "серебро" | | 10010 | "Гильермо Келер" | "ДРУГОЕ" | «51-100» | "мин" | 202.00 | "серебро" | |----------|----------------------|------------|--- --------|--------|----------|-------------|
Обратите внимание на следующие особенности этого запроса:
- Функция CAST требуется для каждого столбца в таблице.
Эта функция возвращает двоичные данные MapR-DB/HBase в виде удобочитаемых целых чисел и строк. Кроме того, вы можете использовать функции CONVERT_TO/CONVERT_FROM для декодирования строковых столбцов. CONVERT_TO/CONVERT_FROM в большинстве случаев более эффективны, чем CAST. Используйте только CONVERT_TO для преобразования двоичных типов в любой тип, кроме VARCHAR.
- Столбец row_key функционирует как первичный ключ таблицы (в данном случае идентификатор клиента).
- Требуется псевдоним таблицы t; в противном случае имена семейств столбцов будут проанализированы как имена таблиц, и запрос вернет ошибку.
Удалить кавычки из строк:
Вы можете использовать функцию regexp_replace для удаления кавычек вокруг строки в результатах запроса. Например, чтобы вместо этого вернуть имя состояния va из «va»:
0: jdbc:drill:> select cast(row_key as int), regexp_replace(cast(t.address.state as varchar(10)),'"','') от клиентов t лимит 1; |------------|-------------| | EXPR$0 | EXPR$1 | |------------|-------------| | 10001 | ва | |------------|-------------| Выбрана 1 строкаКоманда CREATE VIEW
0: jdbc:drill:> use dfs.views; |---------------------|-------------------------------------------------------| | хорошо | резюме | |---------------------|-------------------------------------------------------| | правда | Схема по умолчанию изменена на [dfs.views] | |---------------------|-------------------------------------------------------| Выбрана 1 строка
Использовать изменяемое рабочее пространство:
Изменяемое (или доступное для записи) рабочее пространство — это рабочее пространство, в котором разрешена запись. операции. Этот атрибут является частью конфигурации подключаемого модуля хранилища. Ты может создавать представления и таблицы детализации в изменяемых рабочих пространствах.
Создать представление в таблице MapR-DB
0: jdbc:drill:> создать или заменить представление custview as select cast(row_key as int) as cust_id, cast(t.personal.name as varchar(20)) как имя, cast(t.personal.gender as varchar(10)) как пол, cast(t.personal.age as varchar(10)) как возраст, cast(t.address.state as varchar(4)) как состояние, cast(t.loyalty.agg_rev как dec(7,2)) как agg_rev, cast(t.loyalty.membership as varchar(20)) как членство от maprdb.customers t; |---------------------|------------------------------------------------------- --------------------| | хорошо | резюме | |---------------------|------------------------------------------------------- --------------------| | правда | Представление «custview» успешно создано в схеме «dfs.views» | |---------------------|------------------------------------------------------- --------------------| Выбрана 1 строка
Drill предоставляет синтаксис CREATE OR REPLACE VIEW, аналогичный реляционным базам данных. для создания представлений. Используйте параметр ИЛИ ЗАМЕНИТЬ, чтобы упростить обновление просмотреть позже, не удаляя его сначала. Обратите внимание, что предложение FROM в этот пример должен ссылаться на maprdb.customers. Таблицы MapR-DB не непосредственно виден рабочей области dfs.views.
В отличие от традиционной базы данных, где представления обычно управляются администраторами баз данных или разработчиками операций представления на основе файловой системы в Drill очень легковесны.
Представление просто специальный файл с определенным расширением (.drill). Вы можете хранить просмотры даже в вашей локальной файловой системе или указать на определенную рабочую область. Вы можете укажите любой запрос к любому источнику данных Drill в теле CREATE VIEW утверждение.
Drill предоставляет децентрализованную модель метаданных. Drill может запрашивать метаданные определенные в источниках данных, таких как Hive, HBase и файловая система. Сверлить также поддерживает создание метаданных в файловой системе.
Данные запроса из представления:
0: jdbc:drill:> select * from custview limit 1; |----------|-------------------|------------------- ----|--------|----------|-------------| | cust_id | имя | пол | возраст | состояние | agg_rev | членство | |----------|-------------------|------------------- ----|--------|----------|-------------| | 10001 | "Коррин Мечам" | "ЖЕНСКИЙ" | «15-20» | "ва" | 197.00 | "серебро" | |----------|-------------------|------------------- ----|--------|----------|-------------| Выбрана 1 строкаКогда пользователи узнают, какие данные доступны, изучая их непосредственно из файловой системы, представления можно использовать как способ считывания данных в нижестоящие инструменты, такие как Tableau и MicroStrategy, для анализа и визуализации.
Для этих инструментов представление отображается просто как «таблица» с выбираемыми «столбцами» в ней.
Запрос между источниками данных
Продолжайте использовать
dfs.viewsдля этого запроса.Присоединитесь к представлению клиентов и таблице заказов:
0: jdbc:drill:> выберите членство, сумму (order_total) как продажи из hive.orders, custview где заказы.cust_id=custview.cust_id сгруппировать по порядку членства на 2; |------------|-------------| | членство | продажи | |------------|-------------| | "базовый" | 380665 | | "серебро" | 708438 | | "золото" | 2787682 | |------------|-------------| выбрано 3 строкиВ этом запросе мы считываем данные из таблицы MapR-DB (представленной custview) и объединяя его с информацией о заказе в Hive. При выполнении перекрестные запросы к источникам данных, такие как этот, вам необходимо использовать полностью квалифицированные имена таблиц/представлений. Например, таблица заказов имеет префикс «улей», который — это имя подключаемого модуля хранилища, зарегистрированное в Drill.
Мы не используем префикс для «custview», потому что мы явно переключили рабочую область dfs.views, где пользовательский вид сохраняется.
Примечание. Если результаты любого из ваших запросов кажутся усеченными из-за строки широкие, установите максимальную ширину дисплея на 10000:
Не используйте точку с запятой для этой команды SET.
Объедините данные о клиентах, заказах и посещениях:
0: jdbc:drill:> выберите custview.membership, sum(orders.order_total) как продажи из hive.orders, custview, dfs.`/mapr/demo.mapr.com/data/nested/clicks/clicks.json` c где orders.cust_id=custview.cust_id и orders.cust_id=c.user_info.cust_id сгруппировать по порядку custview.membership на 2; |------------|-------------| | членство | продажи | |------------|-------------| | "базовый" | 372866 | | "серебро" | 728424 | | "золото" | 7050198 | |------------|-------------| выбрано 3 строкиЭто трехстороннее соединение выбирает из трех разных источников данных в одном запросе:
- таблица hive.
orders
- custview (представление таблицы клиентов HBase)
- файл clicks.json
Столбцом соединения для обоих наборов условий соединения является столбец cust_id. рабочая область views используется для этого запроса, чтобы можно было получить доступ к custview. Таблица hive.orders также видна для запроса.
Однако обратите внимание, что файл JSON не виден напрямую из представлений. workspace, поэтому в запросе указывается полный путь к файлу:
dfs.`/mapr/demo.mapr.com/data/nested/clicks/clicks.json`Что дальше
Перейдите к уроку 3. Выполнение запросов к сложным типам данных.
← Урок 1. Знакомство с набором данныхУрок 3. Выполнение запросов к сложным типам данных →
ANSI SQL — Simple Talk
если вы не можете победить их, присоединяйтесь к ним. Грегори Ю. Тительман Начиная с Oracle 9i, Oracle SQL поддерживает синтаксис ANSI SQL. К этому нужно немного привыкнуть, особенно если вы знакомы с синтаксисом Oracle, но он гораздо более подробный и самодокументируемый, если хотите.
Синтаксис Частью синтаксиса Select является объединение таблиц. Чтобы присоединиться
, если вы не можете победить их, присоединяйтесь к ним.
Грегори Ю. ТительманНачиная с Oracle 9i, Oracle SQL поддерживает синтаксис ANSI SQL. К этому нужно немного привыкнуть, особенно если вы знакомы с синтаксисом Oracle, но он гораздо более подробный и самодокументируемый, если хотите.
Синтаксис
Частью синтаксиса Select является объединение таблиц. Есть два варианта объединения двух таблиц (или представлений). Внутреннее объединение (обе таблицы должны содержать записи) или внешнее объединение (записи в одной или обеих таблицах необязательны).
1
2
3
4
5
6
7
8
10
110003
12
13
14 0003 9000
15
16
17
18
19
20
21
22
inner_cross_join_clause
table_reference
{ [ INNER ] JOIN table_reference
{ ON condition
| USING (столбец [ столбец].
..)
}
| { КРЕСТ
| ЕСТЕСТВЕННЫЙ [ ВНУТРЕННИЙ ]
}
JOIN table_reference
}
outer_join_clause
table_reference
[ query_partition_clause ]
{ external_join_type JOIN
| ЕСТЕСТВЕННЫЙ [ external_join_type ] JOIN
}
table_reference [ query_partition_clause ]
[ ON условие
| ИСПОЛЬЗОВАНИЕ (столбец [ столбец]…)
]
Для этой статьи нам понадобятся две таблицы, чтобы показать различные методы соединения.
Таблица A
Ключ Значение Тип 1 Яблоко 1 2 Груша 1 3 Оранжевый 1 4 Салат 2 5 Шпинат 2 6 Гамбургер 3 7 Стейк 3 Стол B
Ключ Значение 1 Фрукты 2 Овощи 3 Мясо 4 Рыба
Перекрестное соединение
Перекрестное соединение, также называемое декартовым соединением, выполняется в Oracle SQL путем пропуска предиката соединения.
ВЫБЕРИТЕ *
ИЗ a
,b
Если вы столкнулись с чем-то подобным, вы, скорее всего, думаете, что отсутствует предикат соединения. Если вы используете ANSI SQL, вы записываете это следующим образом:
ВЫБЕРИТЕ *
ИЗ a
ПОПЕРЕЧНОЕ СОЕДИНЕНИЕ b
Неявно указывает, что предполагается декартово соединение. Оба подхода дают одинаковый результат, но версия ANSI более самодокументируема. В первой версии вы должны добавить комментарий, указывающий на это.
Естественное соединение
При использовании естественного соединения вы указываете СУРБД выполнять соединение для всех столбцов с одинаковыми именами. Столбцы в обеих таблицах должны иметь одинаковое значение, чтобы удовлетворить условию соединения. В приведенном примере запрос:
ВЫБРАТЬ *
ИЗ НАТУРАЛЬНОГО
СОЕДИНИТЬ b
не возвращает никаких результатов, поскольку в обеих таблицах нет одинаковых значений.
Присоединение
На самом деле здесь есть два варианта:
ПРИСОЕДИНИТЬСЯ…ИСПОЛЬЗОВАНИЕМ
и
ПРИСОЕДИНИТЬСЯ…ВКЛ.
При использовании первой версии вы указываете имена столбцов, которые следует использовать в условии соединения. Если вы хотите использовать столбцы в обеих таблицах с одинаковыми именами, но не со всеми (например, при естественном соединении), вы можете выполнить такой запрос:
SELECT *
FROM a
JOIN b
USING (ключ)
Таким образом, таблицы соединяются только с использованием ключевого столбца для выполнения условия, тогда как при естественном соединении также учитывается столбец значений.
Если имена столбцов, которые будут использоваться в условии соединения, различны в обеих таблицах (что, как мне кажется, наиболее распространено), вам следует использовать синтаксис JOIN…ON.
SELECT *
FROM a
JOIN b ON (a.
type = b.key)
Таким образом вы сообщаете механизму SQL, какие именно условия использовать для соединения. Имена могут быть разными в обеих таблицах.
Левое/правое внешнее соединение
Больше всего привыкаешь к внешнему соединению. В Oracle SQL вы, вероятно, привыкли писать что-то вроде этого:
. SELECT *
FROM a
,b
ГДЕ a.type(+) = b.key
, где (+) указывает, что значения не обязательно должны существовать в таблице, чтобы получить строку в результирующем наборе. Если поставить знак (+) с другой стороны уравнения, это означает, что строки в другой таблице являются необязательными.
SELECT *
FROM a
,b
ГДЕ a.type = b.key(+)
В ANSI SQL используется синтаксис LEFT или RIGHT OUTER JOIN.
SELECT *
FROM a
ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ b ON (a.
type = b.key)
и
SELECT *
FROM a
LEFT OUTER JOIN b ON (a.type = b.key)
Поначалу больше всего сбивает с толку то, что когда (+) находится слева от уравнения, вы должны использовать ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ и наоборот. Этот синтаксис говорит на простом английском языке: FROM a LEFT OUTER JOIN b т. е. взять таблицу слева от этой команды и соединить ее строки со строками в таблице справа, если они существуют. Если они этого не делают, то просто возвращают значения из таблицы слева, добавляя значения NULL для столбцов, которые должны поступать из таблицы справа.
Полное внешнее соединение
С помощью ANSI SQL можно «легко» выполнить ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, означающее, что вы хотите, чтобы результирующий набор содержал все записи из обеих таблиц, и если соответствующая запись не существует в в другой таблице просто добавьте значения NULL для отсутствующих столбцов.
SELECT *
FROM a
,b
ГДЕ a.type(+) = b.key(+)
К сожалению, этот синтаксис не поддерживается Oracle SQL. Вы можете имитировать это поведение, используя левое внешнее соединение, объединенное правым внешним соединением:
. 1
2
3
4
5
6
7
8
9
SELECT *
FROM a
,b
WHERE a.type(+) = b.key
UNION
SELECT *
9 FROM a.0003
,b
ГДЕ a.type = b.key(+)
При использовании ANSI SQL это можно сделать в одном операторе
SELECT *
FROM a
FULL OUTER JOIN b ON (a.type = b.key)
В двух простых таблицах можно легко использовать объединение, но представьте, что ваш реальный запрос состоит из десятков таблиц, из которых только пара должна быть внешне соединена в обоих направлениях.
Здесь пригодится Copy-Paste, но подумайте об изменении спецификации. Скорее всего, вы забудете внести изменение в один из запросов.
Заключение
Если вы еще не используете ANSI SQL, я думаю, вам следует как можно скорее ознакомиться с ним. Ваш SQL будет независимым от поставщика (как если бы вы когда-нибудь захотели отказаться от Oracle), а ваши операторы стали более самодокументируемыми, освобождая вас от обязанности документировать свои операторы. Другое дело, что легче объяснить своим коллегам по Java или PHP (или…) разработчикам, когда вы используете ANSI SQL. Скорее всего, они лучше знакомы с синтаксисом ANSI SQL, так как его также можно использовать, например, в MySQL.
ref:
www.oracle-base.com
docs.oracle.com
ANSI SQL Compatibility of ClickHouse SQL Dialect
E011 Numeric data types Partial E011 -01 INTEGER and SMALLINT data types Yes E011-02 REAL, DOUBLE PRECISION and FLOAT data types data types Yes E011-03 DECIMAL and NUMERIC data types Yes E011-04 Arithmetic operators Yes E011-05 Numeric comparison Yes E011-06 Неявное приведение числовых типов данных Нет ANSI SQL допускает произвольное неявное приведение числовых типов, в то время как ClickHouse полагается на функции с несколькими перегрузками вместо неявного приведения E021 Character string types Partial E021-01 CHARACTER data type Yes E021-02 CHARACTER VARYING data type Yes E021-03 Символьные литералы Да E021-04 CHARACTER_109 Функция 909 CHARACTER_10 No USINGclauseE021-05 OCTET_LENGTH function No LENGTHbehaves similarlyE021-06 SUBSTRING Partial No support for SIMILARandESCAPEпредложения, нетSUBSTRING_REGEXвариантE021-07 Объединение символов Частичное Нет COLLATE0474 ПунктE021-08 Верхний и нижний и типы символьных строк переменной длины Частичное ANSI SQL допускает произвольное неявное приведение типов строк, в то время как ClickHouse полагается на функции с несколькими перегрузками вместо неявного приведения E021-11 POSITION function Partial No support for INandUSINGclauses, noPOSITION_REGEXvariantE021-12 Character comparison Yes E031 Идентификаторы Частичные E031-01 Частичные идентификаторы 09 Unicode literal support is limited E031-02 Lower case identifiers Yes E031-03 Trailing underscore Yes E051 Basic query спецификация Частично E051-01 SELECT DISTINCT Да Пункт GRO 901-0 9Yes E051-04 GROUP BY can contain columns not in Yes E051-05 Select items can be renamed Yes E051-06 Имея пункт Да E051-07 Квалифицированный * в избранном списке Да . 0109
Yes E051-09 Rename columns in the FROM clause No E061 Basic predicates and search conditions Partial E061-01 Предикат сравнения Да E061-02 МЕЖДУ предикатом Частичное Нет 73 SYMRIC 730474 ПунктE061-03 в предикате со списком значений Да E061-04 , как предикат y061-04 . No E061-06 NULL predicate Yes E061-07 Quantified comparison predicate No E061-08 EXISTS predicate No E061-09 Subqueries in comparison predicate Yes E061-11 Subqueries in IN predicate Yes E061-12 Подзапросы в предикате количественного сравнения Нет E061-13 Коррелированные подзапросы 6 Нет60122E061-14 Search condition Yes E071 Basic query expressions Partial E071-01 UNION DISTINCT table operator Yes E071-02 Табличный оператор UNION ALL Да E071-03 EXCEPT DISTINCT табличный оператор Нет0109 E071-05 Columns combined via table operators need not have exactly the same data type Yes E071-06 Table operators in subqueries Yes E081 Основные привилегии Да E081-01 Привилегия SELECT на уровне таблицы 15 29 Да106 E081-02
DELETE privilege E081-03 INSERT privilege at the table level Yes E081-04 UPDATE privilege at the table level Yes E081-05 UPDATE privilege at the column level E081-06 REFERENCES privilege at the table level E081-07 REFERENCES privilege at the column level E081-08 WITH GRANT OPTION Yes E081-09 USAGE privilege E081-10 EXECUTE privilege E091 Установите функции Да E091-01 AVG ДА 999999Да Да Да Да Да Да Да Да . 0330
E091-02 COUNT Yes E091-03 MAX Yes E091-04 MIN Yes E091-05 SUM Yes E091-06 ALL quantifier Yes E091-07 DISTINCT quantifier Yes Not all aggregate functions supported E101 Basic data manipulation Partial E101-01 INSERT statement Yes Note: primary key in ClickHouse does not imply the UNIQUEconstraintE101-03 Поиск оператора UPDATE Частичный Имеется оператор ALTER UPDATEдля модификации пакетных данныхE101-04 Searched DELETE statement Partial There’s an ALTER DELETEstatement for batch data removalE111 Single row SELECT statement No E121 Базовая поддержка курсора Нет E121-01 DECLARE CURSOR 9 E121-02 Заказ по столбцам Не нужно быть в списке избранных Да 22222222222222222222222222222222222222222222222222222222222222222222222222222222н. E121-03 Выражения значений в порядке по пункту Да NO E121-06 ОТВЕТСТВЕННОЕ ОБНОВЛЕНИЕ NO E121-07 Положений DEDETE 99999999999999999999999999999999999999309 99999999999999999999999.0122 E121-08 CLOSE statement No E121-10 FETCH statement: implicit NEXT No E121-17 WITH HOLD cursors No E131 Поддержка нулевых значений (пустые значения вместо значений) Да Применяются некоторые ограничения 90 9106 E140009 Основные ограничения целостности
Частичный E141-01 Не нулевые ограничения Да Примечание: Не нулевой. не нулевые столбцыno E141-03 Ограничения первичной ключ Частичная E141-04 Base Base Constrain действие No E141-06 CHECK constraint Yes E141-07 Column defaults Yes E141-08 NOT NULL inferred on PRIMARY KEY Да E141-10 Имена в иностранном ключе можно указать в любом порядке NO E151 9. 0010
No E151-01 COMMIT statement No E151-02 ROLLBACK statement No E152 Basic SET TRANSACTION statement № E152-01 Оператор SET TRANSACTION: УРОВЕНЬ ИЗОЛЯЦИИ SERIALIZABLE пункт № 502-106 E1 SET TRANSACTION statement: READ ONLY and READ WRITE clauses No E153 Updatable queries with subqueries Yes E161 SQL comments using leading double минус Да E171 Поддержка SQLSTATE Нет 2 E182 Host language binding No F031 Basic schema manipulation Partial F031-01 CREATE TABLE statement to create persistent base tables Частичная Нет ВЕРСИЯ СИСТЕМЫ,ЗАПИСАТЬСЯ,ГЛОБАЛЬНАЯ,ЛОКАЛЬНАЯ,СОХРАНИТЬ,УДАЛИТЬ ,,40473 REF IS
WITH OPTIONS,UNDER,LIKE,PERIOD FORclauses and no support for user resolved data typesF031-02 CREATE VIEW statement Partial No RECURSIVE,CHECK,UNDER,WITH OPTIONSпредложения и без поддержки разрешенных пользователем типов данныхF031-03 Оператор GRANT 9 Да F031-04 ALTER TABLE statement: ADD COLUMN clause Yes No support for GENERATEDclause and system time periodF031-13 DROP TABLE statement: RESTRICT clause № F031-16 Оператор DROP VIEW: Пункт RESTRICT № F031-19 Оператор REVOKE0 No F041 Basic joined table Partial F041-01 Inner join (but not necessarily the INNER keyword) Yes F041- 02 Внутреннее ключевое слово Да F041-03 Внешнее соединение левого. ДА F041-05 Внешние соединения могут быть вложены Да F041-07 . Да, F041-08 Все операторы сравнения поддерживаются (а не только =) NO F051 999999 9 базовый0106 Частичный F051-01 Тип данных даты (включая поддержку даты) Да F051-02 не менее 0 Нет F051-03 Тип данных TIMESTAMP (включая поддержку литерала TIMESTAMP) с точностью до долей секунды не менее 0 и 6 Да F051-04 Сравнение Предикат на дату, время и типы данных TimeStamp Да F051-05 COPLICIT CASTICIT MIVERE DATETIME TIMESTIME и характерные названия. F051-06 Current_Date NO Сегодня ()аналогичнаF051-07 Localtime NO 9069 3333 ()3333 ()9069 ().0109
F051-08 LOCALTIMESTAMP No F081 UNION and EXCEPT in views Partial F131 Grouped operations Partial F131-01 Предложения WHERE, GROUP BY и HAVING поддерживаются в запросах со сгруппированными представлениями Да F131-02 Multiple tables supported in queries with grouped views Yes F131-03 Set functions supported in queries with grouped views Yes F131-04 Subqueries with Предложения GROUP BY и HAVING и сгруппированные представления Да F131-05 Однострочный SELECT с предложениями GROUP BY и HAVING и сгруппированными представлениями Нет F181 Multiple module support No F201 CAST function Yes F221 Explicit defaults № F261 Выражение CASE Да F261-09106 Simple CASE Yes F261-02 Searched CASE Yes F261-03 NULLIF Yes F261-04 COALESCE Yes F311 Определение схемы Частичный F311-01 Create Schema Partiator . See CREATE DATABASE F311-02 CREATE TABLE for persistent base tables Yes F311-03 CREATE VIEW Yes F311-04 CREATE VIEW: С опцией проверки no F311-05 Гранта Да F471 SBALAR.0010 Yes F481 Expanded NULL predicate Yes F812 Basic flagging No S011 Отдельные типы данных T321 Базовые подпрограммы, вызываемые SQL Нет T321-01 User-defined functions with no overloading No T321-02 User-defined stored procedures with no overloading No T321-03 Function invocation No T321-04 CALL statement No T321-05 RETURN statement No T631 Предикат IN с одним элементом списка Да Язык базы данных SQL
Язык базы данных SQL SQL — популярный язык реляционных баз данных, впервые стандартизированный в 1986 году.Американским национальным институтом стандартов (ANSI). С тех пор он был официально принят в качестве международного стандарта Международной Организация по стандартизации (ISO) и Международная электротехническая комиссия (МЭК). Он также был принят в качестве федерального закона об обработке информации. Стандарт (FIPS) для федерального правительства США.
Язык базы данных SQL находится в стадии постоянной разработки вышеупомянутым органы по стандартизации. Самая последняя опубликованная версия была в 1992 году, спецификация на 580 страниц, опубликованная ANSI как американский национальный стандарт X3.135-1992 и ISO/IEC в качестве международного стандарта 9075:1992. Два характеристики дословно идентичны. Обе версии доступны в печатном виде только от ANSI (телефон отдела продаж: +1-212-642-4900). Дальше расширения и усовершенствования находятся в стадии разработки (см. УЛУЧШЕНИЯ SQL ниже).
Спецификация FIPS SQL опубликована как FIPS. ПАБ 127-2 ; он указывает на спецификацию ANSI по ссылке, представляет четыре уровня соответствия FIPS SQL и определяет дополнительные требования FIPS SQL для пометки расширений, для документации поддерживаемых функций и для поддержка набора символов.
Стандарт SQL очень популярен среди большого и растущего числа соответствующих реализаций. Он является или скоро станет основой определения для большинства федеральных баз данных и приложений баз данных, включающих структурированные данные.
ОБЛАСТЬ ПРИМЕНЕНИЯ FIPS SQL
Стандарт языка базы данных определяет семантику различных компонентов. системы управления базами данных (СУБД). В частности, он определяет структуры и операции модели данных, реализуемой СУБД, а также другие компоненты, которые поддерживают определение данных, доступ к данным, безопасность, программирование языковой интерфейс и управление данными. Стандарт SQL определяет определение данных, манипулирование данными и другие связанные с ними средства СУБД, поддерживающая реляционную модель данных.Стандарт языка базы данных подходит для всех приложений баз данных. где данные будут использоваться совместно с другими приложениями, где жизнь применение дольше, чем срок службы существующего оборудования, или где приложение должно быть понято и поддерживаться программистами, отличными от оригинальные.
ОПИСАНИЕ SQL
Базовая структура реляционной модели представляет собой таблицу, состоящую из строк и столбцы. Определение данных включает в себя объявление имени каждой таблицы для включения в базу данных, имена и типы данных всех столбцов каждой таблице, ограничения на значения в столбцах и среди столбцов, а также предоставление привилегий на манипулирование таблицами для потенциальных пользователей. Доступ к таблицам возможен вставляя новые строки, удаляя или обновляя существующие строки или выбирая строки, которые удовлетворяют заданному условию поиска для вывода. Таблицы можно манипулировать создавать новые таблицы декартовыми произведениями, объединениями, пересечениями, соединениями на соответствующие столбцы или проекции на заданные столбцы.Операции манипулирования данными SQL могут быть вызваны с помощью курсора или через общую спецификацию запроса. Язык включает в себя всю арифметику операции, предикаты для сравнения и сопоставления строк, универсальные и экзистенциальные квантификаторы, суммарные операции для максимума/минимума или количества/суммы и Предложение GROUP BY и HAVING для разделения таблиц по группам.
Управление транзакциями достигается с помощью операторов COMMIT и ROLLBACK.
Стандарт предоставляет языковые средства для определения конкретных приложений. представления данных. Каждое представление является спецификацией операций с базой данных. это создаст желаемую таблицу. Затем просматриваемая таблица материализуется. во время выполнения приложения.
Стандарт SQL предоставляет язык модулей для интерфейса с другими языками. Каждый оператор SQL может быть упакован как процедура, которую можно вызвать и иметь параметры, переданные ему из внешнего языка. Механизм курсора обеспечивает построчный доступ из языков, которые могут обрабатывать только одну строку стола за один раз.
Управление доступом обеспечивается операторами GRANT и REVOKE. Каждый потенциальный пользователю должны быть явно предоставлены права доступа к определенной таблице или просмотреть с помощью определенного оператора.
Средство улучшения целостности SQL предлагает дополнительные инструменты для целостность, предложения ограничения CHECK и предложения DEFAULT.
Ссылочная целостность позволяет указывать первичные и внешние ключи с требованием, чтобы никакая строка внешнего ключа не может быть вставлена или обновлена, если не указан соответствующий первичный ключ. ключевая строка существует. Пункты Check позволяют указывать ограничения между столбцами. поддерживаться системой баз данных. Предложения по умолчанию предоставляют необязательные значения по умолчанию для отсутствующих данных.
Спецификация Embedded SQL обеспечивает интерфейс SQL для программирования языки, в частности Ada, C, COBOL, FORTRAN, MUMPS, Pascal и PL/I. Таким образом, приложения могут интегрировать структуры управления программой с SQL. возможности манипулирования данными. Синтаксис Embedded SQL — это просто сокращение для явного модуля SQL, доступ к которому осуществляется из стандартного соответствующего программирования язык.
SQL-92 значительно увеличивает размер исходного стандарта 1986 года. включить язык манипулирования схемами для модификации или изменения схем, информационные таблицы схемы, чтобы сделать определения схемы доступными для пользователей, новые средства для динамического создания операторов SQL и новые типы данных и домены.
Другой новый SQL-92 функции включают внешнее соединение, каскадное обновление и удалить ссылочные действия, задать алгебру для таблиц, согласованность транзакций уровни, прокручиваемые курсоры, отложенная проверка ограничений и значительно расширенный отчет об исключении. SQL-92 также снимает ряд ограничений, чтобы сделать язык более гибким и ортогональным.
Следующие учебники определяют и объясняют все функции в спецификация SQL-92:
Джим Мелтон и Алан Р. Саймон Понимание нового SQL: полное руководство Издательство Morgan-Kauffman, Сан-Матео, Калифорния 94403 США октябрь 1992 г. CJ Свидание с Хью Дарвеном Руководство по стандарту SQL, 3-е издание Издательство Addison-Wesley Publishing Company, Рединг, Массачусетс, 01867, США октябрь 1992 г. Стивен Кэннан и Джерард Оттен SQL — стандартный справочник McGraw-Hill Book Company Europe, Беркшир, SL6 2QL, Англия ноябрь 1992 г.ОБЩЕЕ ИСПОЛЬЗОВАНИЕ FIPS SQL
Цель стандарта языка баз данных — обеспечить переносимость определения базы данных и прикладные программы базы данных среди соответствующих реализации.Использование стандарта языка базы данных уместно в все случаи, когда должен происходить некоторый обмен информацией из базы данных между системами. Язык определения схемы может использоваться для обмена определения базы данных и представления для конкретных приложений. Манипуляции с данными язык обеспечивает операции с данными, которые позволяют обмениваться готовые прикладные программы.
Реляционная модель данных и, следовательно, стандарт SQL подходят для приложений баз данных, требующих гибкости в структурах данных и пути доступа к базе данных. Желательно как для приложений под производственным контролем и когда есть существенная потребность в специальном манипулирование данными конечными пользователями, не являющимися компьютерными профессионалами.
Язык определения схемы SQL особенно подходит для описания таблицы информации, которые могут быть переданы между различными системами управления данными Приложения. Используется с Стандарт удаленного доступа к базе данных (RDA) , возможен обмен вхождения данных стандартным образом и для обеспечения взаимодействия соответствующих систем.
УЛУЧШЕНИЯ SQL
В настоящее время ведутся разработки по превращению SQL в вычислительную полный язык для определения и управления постоянными, сложными объекты. Сюда входят: иерархии обобщения и специализации, множественное наследование, определяемые пользователем типы данных, триггеры и утверждения, поддержка систем, основанных на знаниях, рекурсивных выражений запросов и дополнительных инструменты администрирования данных. Он также включает в себя спецификацию абстрактных типы данных (ADT), идентификаторы объектов, методы, наследование, полиморфизм, инкапсуляция и все другие средства, обычно связанные с управление данными объекта. SQL3 Каталог FTP содержит статьи отдельных авторов с описаниями. и состояние различных предлагаемых улучшений SQL.В 1993 году комитеты по развитию ANSI и ISO решили разделить будущее Разработка SQL в составной стандарт. Части, по состоянию на декабрь 1995 г., находятся:
Часть 1: Каркас. Нетехническое описание того, как документ структурированный.
Часть 2: Основание. Основная спецификация, включая все новые функции ADT и Object SQL; в настоящее время более 800 страниц.
Часть 3: SQL/CLI. Интерфейс уровня вызова. зависит только от версии по SQL-92 был опубликован в 1995 году как ISO/IEC 9075-3:1995. Продолжение, обеспечивающее поддержка новых функций в других частях SQL находится в стадии разработки.
Часть 4: SQL/PSM. Спецификация хранимых процедур, включая вычислительные полнота. В настоящее время обрабатывается бюллетень DIS.
Часть 5: SQL/привязки. Используемые привязки Dynamic SQL и Embedded SQL из SQL-92. В настоящее время нет активной новой работы, хотя интерфейсы C++ и Java находятся на стадии обсуждения.
Часть 6: SQL/XA. Разработана SQL-специализация популярного интерфейса XA. через X/Open (см. ниже).
Часть 7: SQL/временная. Недавно утвержденный подпроект SQL для разработки расширенных средства для управления временными данными с использованием SQL.
SQL, часть 2: SQL Foundation
SQL Foundation включает все новые абстрактные типы данных SQL (ADT). удобства. Некоторые функции в предлагаемой новой Части 2 очень стабильны, и готовы к немедленной стандартизации, в то время как другие функции проходят активная эволюция и поэтому несколько нестабильны. Эта часть скоро будет разделена в произведение, которое можно прогрессировать «раньше» по сравнению с произведением, которое может подождать пока "позже".Ранняя часть может быть записана на компакт-диск в 1996 году с окончательным принятием. в 1998 году. Все определяемые пользователем ADT VALUE, семейства подтипов, утверждения, Расширения Triggers, Savepoints и Cursor легко попали в «ранние» кусок, как все согласны, они являются стабильными спецификациями. ОБЪЕКТ ADT объект находится на грани между "ранним" и "позже" и С ВИДИМЫМ OID альтернатива в настоящее время находится в «более поздней» части. Все типа коллекции вещи (то есть списки, наборы, массивы, мультимножества) также находятся на грани, потому что их спецификация еще не завершена.
SQL, часть 3: интерфейс уровня вызовов (SQL/CLI)
Интерфейс уровня вызова SQL является обязательным требованием для стороннего программного обеспечения. разработчики, производящие «упакованное» программное обеспечение для использования на персональных компьютерах. и рабочие станции. Они не хотят использовать модульный процессор или встроенный Стиль привязки препроцессора SQL, потому что они не хотят распространять какие-либо исходный код с продуктами, которые они продают отдельным пользователям. Вместо этого они нужен интерфейс вызова служб для репозиториев данных SQL, который можно вызывать из среды вызова, предоставляемой операционной системой хоста. обращения к репозиторию данных SQL затем могут быть встроены в объектный код точно так же, как вызовы любой другой системной службы.Интерфейс уровня вызовов — это альтернативный механизм выполнения SQL. заявления. SQL/CLI состоит из ряда подпрограмм, которые:
-- Выделение и освобождение ресурсов.
-- Управление подключениями к SQL-серверам.
-- Выполнять операторы SQL, используя механизмы, аналогичные динамическому SQL.
-- Получить диагностическую информацию.
-- Завершение управляющей транзакции.
Процедура CLI ExecDirect и процедура подготовки CLI поддерживают каждую параметр строки входных символов, идентифицированный как StatementText. Если P значение StatementText, то P должен удовлетворять следующим ограничениям:
1. P должен соответствовать Формату, правилам синтаксиса и правилам доступа для «подготовленное заявление», как указано в Подпункте 17.6, «подготовить заявление», стандарта SQL'92.
2. P не должен быть "оператором фиксации" или "оператором отката".
3. P должен соблюдать Правила выравнивания заявленного уровня поддержки SQL сервером SQL/ERI.
Спецификация SQL/CLI предназначена для поддержки подпрограмм CLI, встроенных как в языки программирования, основанные на указателях, так и в языки программирования, не основанные на указателях.
языки.
В частности, подпрограммы CLI могут быть встроены в любой из следующих стандартные языки программирования: Ada, C, COBOL, Fortran, MUMPS, Pascal, и ПЛ/I.
Сервер SQL/ERI укажет, какой из этих языков он поддерживает.
SQL/CLI содержит ряд функций, делающих его полностью совместимым с SQL-92 (например, обработка международных наборов символов, прокручиваемый курсор поддержку и поддержку динамического SQL), а также "краткие" подпрограммы. добавлен, чтобы сделать его обратно совместимым с ODBC от MicroSoft и ранним Спецификация SQL Access и X/Open Snapshot.
Редактор подготовит текст DIS к середине октября 1994, с надеждой что голосование DIS может быть завершено к маю 1995 года. Если все пойдет хорошо, должен стать опубликованным стандартом ISO/IEC SQL/CLI в конце 1995 года.
SQL3, часть 4: постоянные хранимые модули (SQL/PSM)
Эта часть включает в себя все новые «потоки управления языком программирования».функции в SQL, например. присваивание, переменные, цикл, ветвление, процедура блочная структура, вызовы процедур и функций, обработка исключений и т. д. Он предоставляет очень мощное средство для "хранимых процедур", то есть Процедуры SQL, хранящиеся и оптимизированные на сервере, которые можно вызывать из клиента одним звонком.
Это очень важное требование в средах клиент/сервер.
Преимуществом спецификации PSM является то, что репозитории данных, отличные от SQL, теперь смогут представить себя в среде SQL как соответствующие к минимальному уровню манипулирования данными SQL, в то же время предлагая их «дополнительные» возможности в виде функций и процедур, вызываемых SQL. Это должно стать важным стимулом для получения устаревших систем и других не-SQL систем. репозитории данных, такие как системы управления документами и географическая информация Системы, чтобы заявить о соответствии одному из профилей SQL/ERI, определенных в FIPS PUB для сред SQL (см. ОКРУЖЕНИЯ SQL ниже).
Спецификация SQL/PSM пройдет первое голосование CD этой осенью, с вероятным переходом в DIS не позднее июля 1995 года. принят в качестве стандарта ISO/IEC в 1996 календарном году.
SQL3, часть 6: специализация интерфейса SQL XA (SQL/XA)
Эта спецификация стандартизирует интерфейс прикладных программ (API). между глобальным диспетчером транзакций и диспетчером ресурсов SQL. Это было бы стандартизировать вызовы функций на основе семантики ISO/IEC 10026, «Распределенная обработка транзакций», которую диспетчер ресурсов SQL должны поддерживать двухэтапную фиксацию. Базовый документ является производным от публикация X/Open с разрешением X/Open, которая указывает явное входные и выходные параметры и семантика с точки зрения типов данных SQL, для следующих функций: xa_close, xa_commit, xa_complete, xa_end, xa_forget, xa_open, xa_prepare, xa_recover, xa_rollback и xa_start.Текущее расписание для SQL/XA требует регистрации CD в 1996 г., с официальное принятие в качестве стандарта ISO/IEC в 1998 году.
МУЛЬТИМЕДИА SQL (SQL/MM)
Новый проект международной стандартизации ISO/IEC для разработки библиотека классов SQL для мультимедийных приложений была одобрена в начале 1993. Эта новая деятельность по стандартизации, названная SQL Multimedia (SQL/MM), будет указывать пакеты определений абстрактного типа данных SQL (ADT), используя средства для спецификации и вызова ADT, предоставляемые в появляющемся Спецификация SQL3. SQL/MM намерен стандартизировать библиотеки классов для науки инженерно-техническую, полнотекстовую и документальную обработку, а также методы управление мультимедийными объектами, такими как изображение, звук, анимация, музыка, и видео. Скорее всего, он обеспечит привязку к языку SQL для мультимедиа. объекты, определенные другими органами стандартизации JTC1 (например, SC18 для документов, SC24 для изображений и SC29для фотографий и кинофильмов).В плане проекта для SQL/MM указано, что он будет состоять из нескольких частей. стандарт, состоящий из изменяющегося количества частей.
Часть 1 будет фреймворком который указывает, как должны быть построены другие части. Каждый из других части будут посвящены конкретному пакету приложений SQL. Следующее Структура части SQL/MM существует по состоянию на декабрь 1995 г.:
Часть 1: Каркас. Нетехническое описание того, как документ структурированный.
Часть 2: Полный текст. Методы и АТД для обработки текстовых данных. Только минимальный содержание в настоящее время.
Часть 3: Пространственная. Методы и АТД для управления пространственными данными. О Более 125 страниц с активным вкладом экспертов по пространственным данным из 3 национальных тела.
Часть 4: Объекты общего назначения. Методы и АТД для комплексных чисел, триггерные и экспоненциальные функции, векторы, множества и т. д. В настоящее время около 85 страницы.
СРЕДА SQL
Среда SQL — это интегрированная среда обработки данных, в которой разнородные продукты, поддерживающие некоторые аспекты стандарта FIPS SQL, ПАБ ФИПС 127-2 , могут общаться друг с другом и предоставлять общие доступ к данным и операциям с данными и методам с соблюдением надлежащей безопасности, целостность и механизмы контроля доступа.Некоторые компоненты в среде SQL будут полнофункциональными реализациями SQL, соответствующими всему уровню FIPS SQL и поддерживать все его необходимые пункты для определения схемы, манипулирование данными, управление транзакциями, ограничения целостности, доступ управление и информация о схеме. Другие компоненты в среде SQL могут быть специализированные хранилища данных или графические пользовательские интерфейсы и составители отчетов, которые поддерживают отдельные части стандарта SQL и тем самым обеспечивают определенную степень интеграции между собой и другими продуктами в той же среде SQL. Цель состоит в том, чтобы обеспечить высокий уровень контроля над разнообразным набором устаревших или специализированных ресурсов данных. SQL среда позволяет организации получить многие преимущества SQL без больших, сложных и подверженных ошибкам усилий по преобразованию; вместо этого организация может контролируемым образом эволюционировать в новую Окружающая среда.
ПАБ ФИПС 193 , FIPS PUB для сред SQL, является началом продолжающегося усилия по определению соответствующих профилей соответствия, которые могут использоваться как поставщиков и пользователей, чтобы указать точные требования к тому, как различные продукты вписаться в среду SQL.
Акцент делается на указание общей цели, Профили интерфейса внешнего репозитория SQL (SQL/ERI) для репозиториев данных, отличных от SQL. Эти профили определяют, как можно использовать подмножество стандарта SQL для предоставлять ограниченный доступ SQL к устаревшим базам данных или поддерживать шлюзы SQL специализированным менеджерам данных, таким как географические информационные системы (ГИС), системы управления полнотекстовыми документами или системы управления объектными базами данных. Все указанные здесь профили предназначены для серверных продуктов, т.е. продукты, которые контролируют постоянные данные и предоставляют интерфейс для доступ пользователя к этим данным. Последующие версии FIPS PUB для сред SQL могут указывать профили SQL для клиентских продуктов, т. е. продуктов, которые получить доступ к данным, а затем представить эти данные в графическом или отчетном стиле конечному пользователю или обрабатывать данные иным образом от имени конечный пользователь.
Для многих приложений требуется логически интегрированная база данных различных данные (например, документы, графика, пространственные данные, буквенно-цифровые записи, сложные объекты, изображения, голос, видео), хранящиеся в географически разделенных данных банки под управлением и контролем гетерогенного управления данными системы.
Главное требование состоит в том, чтобы эти различные менеджеры данных иметь возможность общаться друг с другом и предоставлять общий доступ к данным и операции с данными и методы при надлежащей безопасности, целостности, и механизмы контроля доступа. Большая часть этих исходных данных может храниться в простые файловые системы, устаревшие системы управления данными или очень специализированные репозитории данных, которые удовлетворяют лишь небольшой процент этих требований по управлению данными требования. Цель среды SQL состоит в логической интеграции эти разнообразные хранилища данных "как если бы" они находились под контролем единый менеджер данных SQL. Инструменты представления пользователя, такие как графические интерфейсы или составители отчетов, могут затем использовать этот интерфейс SQL для сбора данные из различных источников, объединять их вместе в условиях ad hoc соединения, и представить его пользователю в приятном графическом формате.
Правильно функционирующая среда SQL будет использовать язык SQL для описывать эти данные с помощью стандартизированных средств, интегрировать их в единый федеративная коллекция, обеспечивать соблюдение любых ограничений целостности или контроля доступа, и сделать его доступным как логическое целое для искушенных пользователей или средства презентации.
Затем эти клиентские инструменты могут использовать всю мощь и гибкость SQL для поиска и обработки данных. лежащий в основе менеджеры данных могут реализовывать нереляционные модели данных и, таким образом, иметь трудности с поддержкой требований SQL для вложенных подзапросов, многотабличных соединения, производные столбцы в списке выбора, ссылочная целостность или другие особенности реляционной модели. С другой стороны, они могут предлагать расширенные функции. других моделей данных, которые редко поддерживаются реляционными реализациями. Благодаря новым функциям языка SQL для определяемых пользователем абстрактных данных типов (ADT), хранимых процедур, инкапсуляции, полиморфизма и других средства управления объектами, эти разнообразные хранилища данных могут быть описаны в виде специализированных репозиториев SQL и доступ к ним осуществляется с использованием уже стандартизированных Варианты привязки SQL.
При таком подходе SQL может оказаться столь же успешным, как интегратор разнородных хранилищ данных, как это было в качестве языкового интерфейса к реляционной модели данных.