Иллюстрированный самоучитель по SPSS
Программа SPSS
SPSS является самой распространённой программой для обработки статистической информации. В настоящем разделе описан путь этой программы к такому выдающемуся успеху. Затем приведен обзор отдельных модулей программы.
Основным достоинством программного комплекса SPSS, как одного из самых существенных достижений в области компьютеризированного анализа данных, является самый широкий охват существующих статистических методов, который удачно сочетается с большим количеством удобных средств визуализации результатов обработки. Программный комплекс SPSS развивается уже на протяжении 35 лет. 11-ая версия, выпущенная в мае 2002 года, предоставляет широкие возможности не только в сфере психологии, социологии, биологии и медицины, но и в области маркетинговых исследований и управлении качеством продукции, что значительно расширяет применимость комплекса.
Предлагаемый материал содержит минимально необходимый объем сведений по теории статистического анализа. Основное внимание сконцентрировано на особенностях использования отдельных методов, возможностях, которые эти методы предоставляют, а также интерпретации результатов применения данных методов. Ну и конечно, описаны презентационные возможности SPSS 10/11, которые значительно превосходят объем функций, обеспечиваемых стандартными бизнес-программами, типа Excel.
Изложенный материал достаточен для того, чтобы студент или молодой ученый сделали свои первые шаги в обобщении статистических данных и поиске скрытых закономерностей, а умудренные опытом профессионалы обрели еще один мощнейший инструмент, повышающий эффективность практической деятельности.
Материал предназначен для широкого круга читателей, специализирующихся на обработке данных в маркетинге, социологии, психологии, биологии и медицине.
Литература —
Бююль А., Цёфель П. SPSS: Искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей:
www.datuapstrade.lv
Как ввести данные в SPSS Как? Так!
Содержимое:
2 метода:
SPSS – программа для статического анализа, которая используется в различных сферах деятельности, начиная от маркетинговых исследований и заканчивая правительственными агентствами. Она позволяет проводить ряд различных функций с данными, но перед тем как начать сам анализ, вам сперва нужно ввести эти данные. Существует несколько способов ввода данных в SPSS, от ручного ввода до импорта из другого файла.
Шаги
Метод 1 Ручной ввод данных
- 1 Определите свои переменные. Для того чтобы ввести данные в SPSS вам понадобятся несколько переменных. Это столбцы таблицы, которые вы введете при помощи опции «Data View», каждый из которых будет содержать данные, находящиеся в одинаковом формате.
- Для того чтобы определить свои переменные, вы должны нажать двойным щелчком по заголовку столбца «Data View». После этого появится меню, в котором вы сможете определить переменные.
- Вводя название переменной, вы должны начинать писать с буквы, при этом написание с большой буквы будет игнорироваться.
- При выборе типа, вы можете выбрать между «String» (знаки) и рядом цифровых форматов.
- Прочитайте эту статью, чтобы узнать больше информации об определении переменных.
- 2 Создайте переменную с множественным выбором. При определении переменной, которая имеет два и более ряда возможностей, вы можете ввести метки для прочих значений. Например, если одна из ваших переменных активна, единственными двумя выборами для этой переменной будет «Active» и «Former».
- Откройте раздел «Labels» (Метки) в меню «Define Variable» (Определение переменных) и создайте числовое значение для каждой вероятности (например, 1, 2 и т.д.).
- Присвойте каждому значению соответствующую метку (например «Active» или «Former»).
- При вводе данных для этой переменной, вы должны лишь ввести «1» или «2», чтобы выбрать желаемую опцию.
- 3 Введите первый случай. Нажмите по пустой ячейке, которая находится сразу под крайним левым столбцом. Введите в ячейку значение, соответствующее типу переменной. Например, если столбец имеет название «Имя», вы можете ввести в ячейку имя сотрудника.
- Каждая строка имеет свой «случай». В других программах для работы с базами данных он называется записью.
- 4 Продолжайте вводить переменные. Перейдите к следующей пустой ячейке справа и введите соответствующее значение. За раз всегда вводите полную запись. Например, если вы вводите данные о сотрудниках, вы сначала должны ввести имя, домашний адрес, номер телефона и зарплату первого сотрудника, прежде чем переходить к другому сотруднику.
- Проверьте, чтобы вводимые вами значения соответствовали формату. Например, ввод долларового значения в столбец для дат приведет к ошибке.
- 5 Завершите вводить случаи. После того, как вы введете каждый случай, перейдите к следующему ряду и введите следующие данные. Убедитесь, что каждый случай имеет запись для каждой переменной.
- Если вы решите добавить новую переменную, нажмите двойным щелчком мыши по следующему заголовку столбца и создайте переменную.
- 6 Манипулирование данными. После того как вы завершите вводить все данные, вы сможете воспользоваться встроенным в SPSS инструментом, чтобы начать управлять своими данными. Вот несколько возможных примеров управления:
- Создайте частотную таблицу
- Проведите регрессионный анализ
- Проведите дисперсионный анализ
- Создайте точечный график
Метод 2 Импорт данных
- 1 Импорт файла Excel. При импортировании данных с файла Excel вы автоматически создадите переменные, которые будут основываться на первом ряду таблицы. Значения этого ряда станут названиями переменных. Вы также можете ввести переменные вручную.
- Нажмите Файл → Открыть → Данные…
- В качестве «Типа файла» выберите формат .xls.
- Найдите и откройте файл Excel.
- Установите галочку рядом с опцией «Считывать название переменных с первого ряда данных», если вы хотите, чтобы название переменных создались автоматически.
- 2 Импортируйте файл, значения которого разделены запятой. Это будет простой текстовый формат .csv, записи которого будут разделяться запятой. Вы можете сделать так, чтобы переменные создавались автоматически, основываясь на первой линии файла .csv.
- Нажмите Файл → Считать текстовые данные…
- В качестве типа файлов выберите «Все файлы (*.*)».
- Найдите и откройте файл .csv.
- Следуйте указаниям, чтобы импортировать файл. Когда программа вас спросит, не забудьте указать, что название переменных находятся вверху, а первый случай находится на линии 2.
Что вам понадобится
Прислал: Щербакова Анастасия . 2017-11-05 15:58:30
kak-otvet.imysite.ru
Учебник_SPSS
Введение в
SPSS для Windows
Краткая справка о программе.
SPSS для Windows– мощная система статистического анализа и управления данными. Многие возможности особенно полезны тем, кто занимается проведением опросов и маркетинговыми исследованиями.
Кроме простого интерфейса для статистического анализа данных, рассчитанного на работу с мышью, в SPSS для Windowsесть:
Редактор данных. Гибкая система, внешне похожая на электронную таблицу, для определения, ввода, редактирования и просмотра данных.
Окно выходных результатов (Viewer). Окно выходных результатов упрощает просмотр результатов, позволяя показывать и скрывать отдельные элементы ввода, изменять порядок вывода результатов, перемещать готовые к презентации таблицы и графики изSPSSв другие приложения.
Редактор таблиц. Можно исследовать таблицы, перемещая строки, столбцы и слои для выявления важных моментов, которые могут потеряться в стандартных таблицах. Также можно сравнивать группы, расщеплять таблицы и др. возможности.
Редактор диаграмм. Высококачественная графика круговых и столбиковых диаграмм, гистограмм, гистограмм рассеяния, трехмерных диаграмм и множества других входят в базовый модульSPSS.
Редактор команд. Несмотря на то, что многие задачи могут быть выполнены с помощью мыши и диалоговых окон, вSPSSесть также мощный командный язык, позволяющий сохранять и автоматизировать многие повторяющиеся задачи.
Конструктор чтения баз данныхпозволяет загрузить данные из любого источника с помощью нескольких нажатий кнопки мыши.
Электронную почту, содержащую результаты анализа, можно создавать одним нажатием кнопки мыши. Также можно экспортировать таблицы и диаграммы в форматHTLMдля распространения через Интернет или Интранет.
Справочная системавключает Электронный Учебник, предлагающий детальный обзор; контексную Справку в диалоговых окнах, помогающую разобраться в конкретных задачах; всплывающие определения в мобильных таблицах, объясняющие статистические термины; Репетитор по статистике, помогающий в поиске необходимой процедуры; а Примеры анализа помогают в интерпретации результатов.
Новый дополнительный модуль SPSS Complex Samplesпозволяет собой специальный инструмент для планирования и анализа данных опросов и обследований, в которых использовалась как простая, так и сложная выборка.
РЕДАКТОР ДАННЫХ
Редактор данных– это окно, похожее по внешнему виду на окно электронной таблицы, предназначенное для создания и редактирования файлов данных. Окно Редактора данных открывается автоматически при запускеSPSS.
В окне редактора одновременно присутствуют два листа, два окна работы с данными. В левом нижнем углу редактора можно увидеть две вкладки: «Данные» и «Переменные».
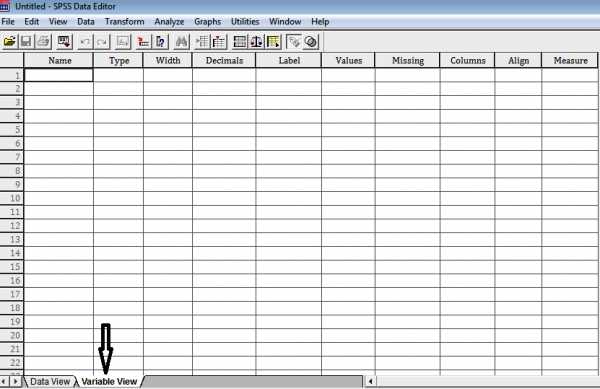
Данные.В этом режиме можно просматривать и редактировать фактические значения данных.
Переменные.В этом режиме можно просматривать и редактировать свойства переменных, включая метки переменных и значений, типы данных (например, текст, дата или число), типы шкал измерений (номинальная, порядковая или количественная) и определяемые пользователем пропущенные значения.
Например, представим себе, что речь идет о файле данных SPSSс результатами простейшего анкетрования работников.
В режиме «данные»мы увидим конкретные ответы на вопросы, полученные от каждого опрашиваемого. При этом каждая строка в электронной таблице – это наблюдение, то есть одна анкета (один респондент), а каждый столбец – переменная, то есть конкретный вопрос анкеты (или показатель). В каждой ячейке – ответ отдельного респондента на тот или иной вопрос анкеты.
В режиме «переменные»мы увидим описание упомянутых выше характеристик каждой переменной, то есть каждого вопроса обследования (программа наблюдения). Каждая строка – это отдельная переменная, или один вопрос. Каждый столбец – это конкретное свойство той или иной переменной.
Свойства переменных:
1. Имя переменной.
Имя должно начинаться с буквы и не должно заканчиваться точкой. В имени не должны использоваться пробелы и специальные символы (!, ?, * и др.), а также следует избегать в конце имени знака нижнего подчеркивания _. Длина имени не должны превышать 64 символа.
2. Тип переменной.
Указывается, о какой переменной идет речь: числовой, текстовой, формата даты или другие варианты.
3. Число цифр или символов в переменной. Задается максимальное число символов в значении переменной.
4. Число десятичных знаков. Задается число выводимых десятичных знаков.
5. и 6. Описательные метки переменных и значений.
Метки переменных поясняют содержательную часть переменной (по сути содержание самого вопроса или показателя), могут быть до 256 символов и содержать пробелы и символы, использование которых не допускается в именах переменных.
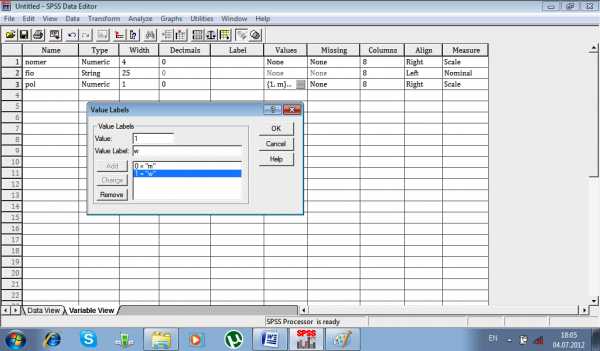
Метки значений поясняют содержательную часть каждого значения отдельной переменной (например, поясняют, что 1 означает мужской пол, 2 – женский пол) могут быть длиной до 60 символов и не применяются к длинным текстовым переменным.
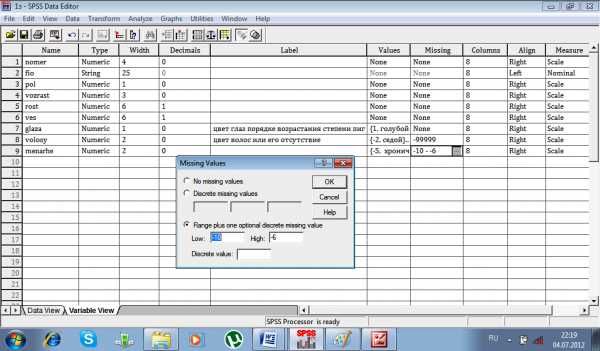
7. Пропущенные значения.
Определенные значения переменной задаются как пользовательские пропущенные. Например, Вы хотите подводить итоги обследования по данному вопросу без учета тех анкет, а которых нет ответа на этот вопрос. Значения, помеченные как пользовательские пропущенные, помечаются для специальной обработки и исключаются из большинства вычислений.
Одновременно можно задать до трех отдельных пользовательских пропущенных значений для каждой переменной, диапазоны пропущенных значений могут быть заданы только для числовых переменных.
8. Ширина столбца.
9. Выравнивание значений в столбце. Возможно выравнивание по левому краю, правому краю, по центру.
10. Шкала измерений (имеет значение при построении таблиц).
Вы можете выбрать одну из трех шкал измерения:
Количественная.Значения данных представляют собой числовые значения (например, возраст, доход).
Порядковая.Значения данных представляют собой категории (градации) с некоторым естественным упорядочением (например: низкий, средний, высокий или: полностью не удовлетворен, скорее не удовлетворен, скорее удовлетворен, полностью удовлетворен). Порядковые переменные могут быть текстовыми или числовыми значениями, представляющими различные категории (например: 1-низкий, 2-средний, 3-высокий).
Номинальная.Значения данных представляют собой категории (градации) для которых не задано естественное упорядочение (примерами могут служить отделы компании, субъекты РФ).
Все свойства переменных могут быть изменены путем изменения значений в ячейках в закладке «переменные». Щелчок по конкретной ячейке вызывает окно, в котором можно изменить свойства переменной. Кроме того, значения ячеек могут быть скопированы и вставлены в другие ячейки. Это особенно полезно при задании меток значений и пропущенных значений для нескольких однотипных переменных.
ВВОД ДАННЫХ
Вводить данные можно прямо в Редактор данных в закладке Данные в любую ячейку. Для пременных всех типов, кроме простых числовых, прежде чем вводить данные, необходимо сначала задать тип переменной.
Если вводить значение в пустой столбец, Редактор данных автоматически создаст новую переменную и присвоит ей имя (VAR00001) и формат по умолчанию (числовой).
Кроме того, данные могут быть подготовлены заранее другими программными средствами. SPSSпозволяет открывать и работать с файлами данных любых форматов. Например, для открытия файла в формате *.xls, необходимо нажатьФайл…Открыть…Данные…
Если данных хранятся в базе данных, то для того, чтобы их открыть, нужно использовать Конструктор баз данных (Файл…Открыть базу данных…Новый запрос…).
ПРЕОБРАЗОВАНИЕ ДАННЫХ
Вычисление переменных.
Выберите в меню:
Преобразовать
Вычислить переменную…

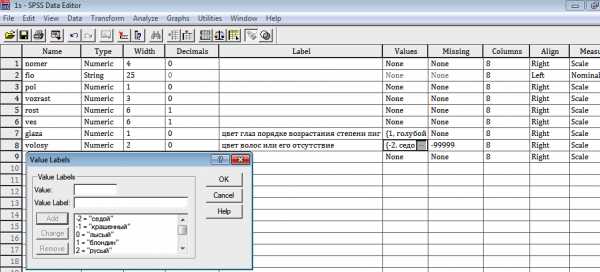
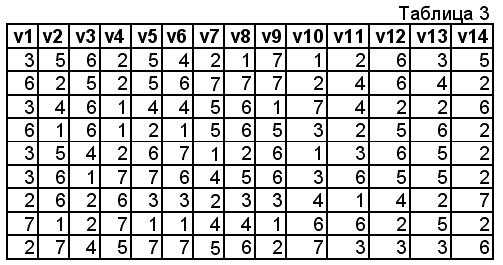
Введите имя вычисляемой переменной. Ей может быть существующая или новая переменная. Если Вы выбрали уже существующую, то следует иметь ввиду, что вычисленные новые значения заменят существующие значения и возврата к старым значениям не будет. Введем, например, имя«godrab», что будет означать «Количество лет работы на данном месте». Эту метку введем, щелкнув мышкой по «Тип и метка».
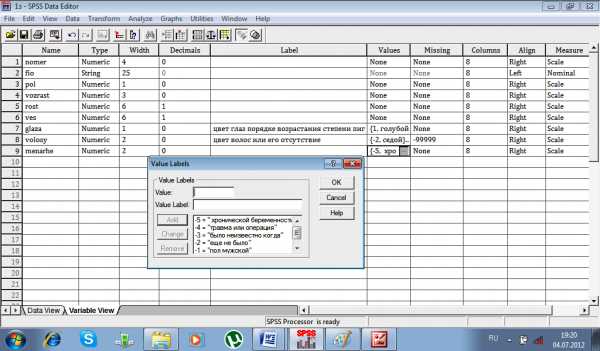
После нажатия клавиши «продолжить», можно закладывать формулу расчета. При этом можно воспользоваться более 70 встроенных функций, включая арифметические, статистические, текстовые и функции рапсределения. У нас в примере есть переменная «jobtime»– время работы с момента поступления (месяцы). Для того, чтобы месяцы перевести в годы, нам достаточно разделить эту переменную на 12. Эту формулу и закладываем в расчет:
После нажатия клавиши «ОК», в редакторе данных появляется дополнительный столбик с переменной «godrab», где стоит количество лет, отработанных на данном месте работы, а на вкладке переменные добавилась новая переменная.
Следует иметь ввиду, что в функциях и арифметических выражениях пропущенные значения обрабатываются по-разному. В выражении:
(var1 + var2 + var3) / 3
результатом будет пропущенное значение в случае, если значение хотя бы одной из трех переменных является пропущенным значением.
В выражении:
MEAN (var1, var2, var3)
результатом будет пропущенное значение только в том случае, если все три переменные являются пропущенными значениями.
Можно задать минимальное число значений, которые не должны иметь пропущенных значений, например, средняя величина из трех переменных может быть вычислена, если значения имеют минимум две из них:
MEAN.2 (var1, var2, var3)
Пользуясь кнопкой «Если» можно сделать вычисления не для всех значений исходной переменной, а только по тем, для которых выполняется то или иное условие.
Перекодировка переменных.
Первоначально собранные данные можно перекодировать с помощью средств SPSS. Это бывает необходимо, когда первоначальное разнообразие исходных данных не нужно для последующего анализа. Перекодирование в таком случае означает уменьшение объема обрабатываемой информации.
Выберите в меню:
Преобразовать
Перекодировать
В другие переменные…
Лучше всего выбирать перекодировку в другие переменные, нежели перекодировку в те же переменные. Представьте, что Вы делаете перекодировку возраста в числовых значениях в интервальные значения. Если же выбран режим перекодировки в те же переменные, то исходные данные возраста будут затерты интервалами и восстановить их уже не получится.
Далее выберите переменные для перекодировки (можно несколько, но они должны быть одного типа (числовые или текстовые).
Введите имя для каждой выходной (новой) переменной и щелкните Изменить.
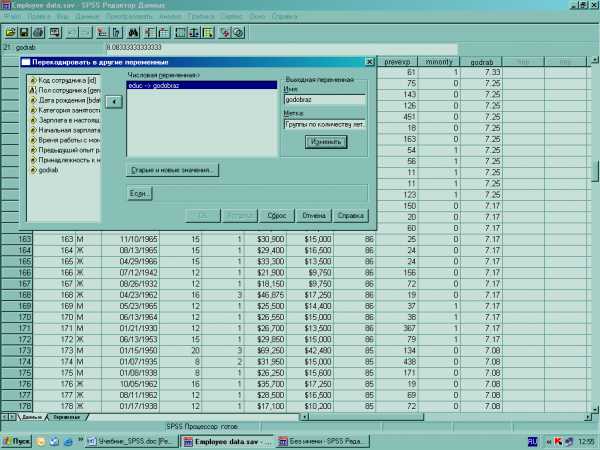
Щелкните по кнопке Старые и новые значенияи задайте перекодировку значений.
Старое значение– перекодируемое(ые) значение(я).Значение.Отдельное старое значение, которое нужно перекодировать в новое.Системное пропущенное (или пользовательское тоже).Такие значения (не заполненные числовые поля, неответы респондентов) иногда необходимо выделять в отдельную группу.Диапазон. Доступен только для числовых переменных и позволяет объединять в одно новое значение несколько старых в выбранном диапазоне (интервальная группировка).
Новое значение– значение, в которое будут перекодированы одно или несколько старых значений. Можно выбратьСкопировать старое значениедля тех, где перекодировка не нужна. Также старые значения числовой переменной можно перекодировать в новые текстовые, выбравНовые переменные – текстовые.
РАБОТА С ФАЙЛАМИ.
Сортировка наблюдений.
Выберите в меню:
Данные
Сортировать наблюдения…
Можно выбрать одну или несколько переменных. Если, например, выбраны полинациональность, то сначала наблюдения сортируются пополу, а затем внутри каждой полученной категории сортируются по значениям переменнойнациональность.
Транспонировать.
Выберите в меню:
Данные
Транспонировать…
В результате транспонирования создается новый файл, в котором строки и столбцы меняются местами.
Объединение файлов данных.
Файлы можно объединить двумя различными способами:
– Слить файлы, содержащие одни и те же переменные, но различные наблюдения
– Слить файлы, содержащие одни и те же наблюдения, но различный состав переменных.
В первом случае выберите в меню:
Данные
Слить файлы
Добавить наблюдения…
После этого выберите файл данных, который нужно добавить к открытому файлу данных. Удалите из списка Переменные в новом рабочем файле данныхвсе переменные, которых не должно быть в объединенном файле. Из спискаНепарные переменныедобавьте любые пары переменных, представляющие одну и ту же переменную, но записанную под различными именами в двух файлах.
Во втором случае выберите в меню:
Данные
Слить файлы
Добавить переменные…
Перед слиянием необходимо убедиться, что наблюдения в обоих файлах отсортированы в одинаковом порядке, особенно если используется слияние по ключу. Имена переменных во втором файле данных, совпадающие с именами переменных в рабочем файле данных по умолчанию исключаются, поскольку предполагается, что они содержат одну и ту же информацию.
Если в одном из файлов отсутствуют некоторые отдельные наблюдения, то для корректного слияния можно использовать переменные – ключи.
Преобразования временных рядов.
Преобразования временных рядов предполагают такую структуру файла данных, в которой каждая строка (наблюдение) представляет набор характеристик в определенный момент времени, а интервалы времени между наблюдениями равны.
Процедура Задать датыгенерирует переменные, которые могут быть использованы для выделения периодических компонент временного ряда.
Наблюдения – это. Здесь задаются единицы времени, которые будут использоваться для создания дат.
Первое наблюдение. Здесь задается значение начальной даты, которое будет присвоено первому наблюдению. Последующим наблюдениям будут присвоены последовательные значения, основанные на заданном интервале времени.
Выберите в меню:
Данные
Задать даты…
Выберите временной интервал из списка Наблюдения – это.
Введите значения даты в поля Первое наблюдение.
Переменные, созданные процедурой Задать датыотличаются от переменных, имеющих формат типаДанные, который определяется при задании свойств переменных. Значения переменных, созданных процедуройЗадать даты, — это целые положительные числа, каждое из которых представляет количество дней, недель, часов или других единиц времени, прошедших с заданного Вами начального момента времени.
Выберите в меню:
Преобразовать
Создать временной ряд…
Процедура создать временной ряд используется для создания новых переменных, которые являются функциями существующих переменных, образующих временной ряд.
Функции, предназначенные для создания временных рядов, включают разности, скользящие средние, скользящие медианы, функции задержки (лаги) и опережения.
Некоторые процедуры анализа временных рядов не работают при наличии пропущенных значений. В окне Заменить пропущенные значения задаются параметры новых переменных, содержащих временные ряды, в которых пропущенные значения заменены оценками, которые могут быть вычислены одним из нескольких способов.
Выберите в меню:
Преобразовать
Заменить пропущенные значения…
Выберите метод, который Вы хотите использовать для замены пропущенных значений.
ЧАСТОТЫ
Процедура Частоты дает возможность вычислять статистики и строить диаграммы, полезные для описания многих типов переменных.
Выберите в меню:
Анализ
Описательные статистики
Частоты…
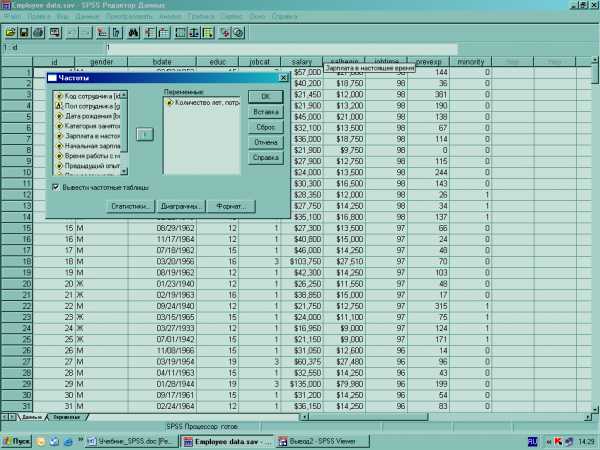
Выберите одну или несколько категориальных или количественных переменных.
Дополнительно Вы можете:
Щелкнуть мышью по кнопке Статистики, чтобы задать вычисление описательных статистик для количественных переменных (среднее, мода, медиана и др.).
Щелкнуть мышью по кнопке Диаграммы, чтобы задать вывод столбиковых диаграмм, круговых диаграмм и гистограмм.
Щелкнуть мышью по кнопке Формат, чтобы задать порядок, в котором будут выводиться результаты.
Пример вывода:
Статистики
Количество лет, потраченных на образование
N | Валидные | 474 |
Пропущенные | 0 | |
Среднее | 13.49 | |
Медиана | 12.00 | |
Стд.отклонение | 2.885 | |
Количество лет, потраченных на образование
Частота | Процент | Валидный процент | Кумулятивный процент | ||
Валидные | 8 | 53 | 11.2 | 11.2 | 11.2 |
12 | 190 | 40.1 | 40.1 | 51.3 | |
14 | 6 | 1.3 | 1.3 | 52.5 | |
15 | 116 | 24.5 | 24.5 | 77.0 | |
16 | 59 | 12.4 | 12.4 | 89.5 | |
17 | 11 | 2.3 | 2.3 | 91.8 | |
18 | 9 | 1.9 | 1.9 | 93.7 | |
19 | 27 | 5.7 | 5.7 | 99.4 | |
20 | 2 | .4 | .4 | 99.8 | |
21 | 1 | .2 | .2 | 100.0 | |
Итого | 474 | 100.0 | 100.0 | ||
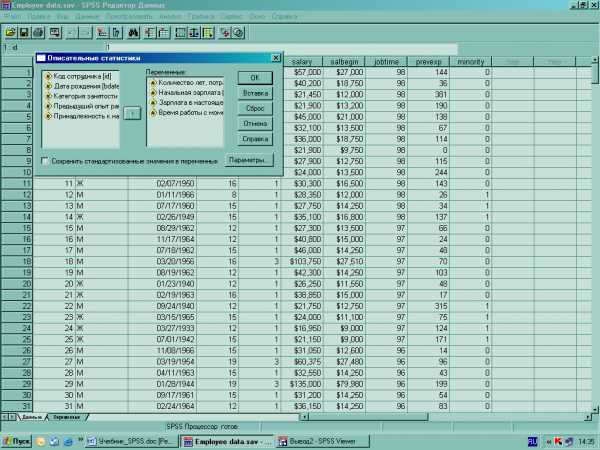
ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
Процедура Описательные статистики осуществляет вывод одномерных итожащих статистик для нескольких переменных в одной таблице.
Выберите в меню:
Анализ
Описательные статистики
Описательные…
Пример вывода:
Описательные статистики
N | Минимум | Максимум | Среднее | Стд. отклонение | |
Количество лет, потраченных на образование | 474 | 8 | 21 | 13.49 | 2.885 |
Начальная зарплата | 474 | $9,000 | $79,980 | $17,016.09 | $7,870.638 |
Зарплата в настоящее время | 474 | $15,750 | $135,000 | $34,419.57 | $17,075.661 |
Время работы с момента поступления (месяцы) | 474 | 63 | 98 | 81.11 | 10.061 |
N валидных (целиком) | 474 |
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
Процедура Таблицы сопряженности формирует двумерные и многомерные таблицы, а также вычисляет целый ряд критериев и мер силы связи для двумерных таблиц. Таким образом, таблицы сопряжённости применяются, когда нас интересует двумерный анализ, а также когда необходимо выяснить, существует ли взаимосвязь между двумя переменными.
Выберите в меню:
Анализ
Описательные статистики
Таблицы сопряженности…
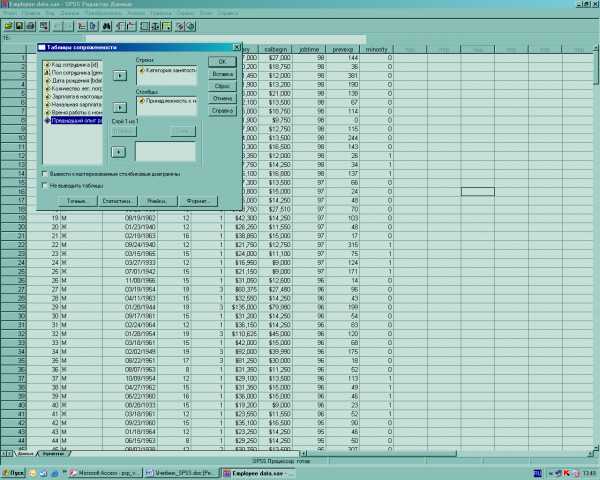
Выберите одну или несколько переменных для строк и одну или несколько переменных для столбцов.
Дополнительно Вы можете:
— выбрать одну или несколько переменных для слоев;
— щелкнуть мышью по кнопке Статистики и выбрать нужные критерии и меры силы связи для двумерных таблиц и подтаблиц;
— щелкнуть мышью по кнопке Ячейки, чтобы задать вывод наблюденных и ожидаемых значений, процентов, а также остатков;
— щелкнуть мышью по кнопке Формат для задания порядка, в котором следует располагать категории.
Пример вывода:
Таблица сопряженности Категория занятости * Принадлежность к национальному меньшинству
Частота
Принадлежность к национальному меньшинству | Итого | |||
Нет | Да | |||
Категория занятости | Сотрудник секретариата | 276 | 87 | 363 |
Сотрудник среднего звена | 14 | 13 | 27 | |
Менеджер | 80 | 4 | 84 | |
Итого | 370 | 104 | 474 | |
studfiles.net
Краткое руководство по SPSS: часть 2
16/03/14 16:33 Относится к категории: Анализ данных | SPSS Сегодняшняя статья посвещена перекодировке и вычислению переменных, а также построению фильтров в SPSS. Эти процедуры используются для подготовки данных перед их анализом, а именно для создания новых переменных на основании уже имеющихся (перекодировка и вычисление) и отбора определенной части респондентов для анализа (фильтры).Рассмотрим некоторые ситуации, когда это может пригодиться.
Случай первый.
Есть переменная с пятью категориями: 1 — совсем не доверяю, 2 — преимущественно не доверяю, 3 — сложно сказать, доверяю или нет, 4 — преимущественно доверяю, 5 — полностью доверяю. Для ее дальнейшего использования в построении таблицы сопряженности необходимо перекодировать ее в переменную с тремя категориями.
Случай второй.
Есть набор переменных, фиксирующих принадлежность респондента к общественным организациям различных типов (0 — не принадлежит, 1 — принадлежит). Необходимо вычислить по каждому респонденту, в каком количестве организаций он состоит.
Случай третий.
Из всей совокупности респондентов отобрать для дальнейшего анализа только тех, которые проживают в центральном и южном регионах Украины.
Рассмотрим решение каждой из этих задач с помощью SPSS.
Перекодировка
Для перекодировки необходимо выбрать: Преобразовать => Перекодировать в другие переменные…
После этого откроется окно, в левой части которого будет набор всех переменных. Из них необходимо выбрать ту, которая подлежит перекодировке. В нашем случае это переменная V68 о доверии церкви. Для того, чтобы продолжить работу сначала необходимо ввести новое имя в первом поле части окна «Выходная переменная» (я ввел имя «церковь_доверие») и нажать кнопку «Изменить». После того, как это сделано, станет активна кнопка «Старые и новые значения…».
После нажатия кнопки «Старые и новые значения…» откроется окно, в котором соотносятся старые (левая часть окна) и новые (правая часть окна) значения. Категории переменной про доверие можно перекодировать следующим образом: 1 и 2 в 1, 3 в 2, 4 и 5 в 3. Поэтому на первом этапе выбираем пункт меню «Диапазон» в левой части экрана и указваем этот диапазон — в верхнем поле единицу (начало диапазона), а в нижней — двойку (конец диапазона). В правой части экрана необходимо указать новое значение, в которое будут перекодированы все значения старого диапазона. По умолчанию пункт меню стоит напротив «Значение». В соответствующем поле указываем единицу, после чего нажимаем кнопку «Добавить».
На втором этапе перекодируется не диапазон, а еденичное значение. Поэтому необходимо выбрать пункт меню «Значение» в левой части окна, указать в соответствующем поле 3 и нажать кнопку «Добавить». На третем этапе необходимо опять перекодировать дипазон (поэтому мы его не рассматриваем — действия аналогичны первому этапу, кроме самих чисел). После того, как все условия перекодировки указаны, нажимается кнопка «Продолжить» и далее «ОК». В результате создается новая переменная (она появится в конце списка переменных в паспорте, а также в виде последнего столбца в окне с данными).
Вычисление
Для вычисления необходимо выбрать: Преобразовать => Вычислить переменную…
После этого откроется специальное окно, в левой части которого будет список имеющихся переменных и поле «Вычисляемая переменная», а в правой — собственно редактор для вычисления:
В поле «Вычисляемая переменная» необходимо задать имя новой переменной (в нашем случае — это «активность»). Вверху правой части экрана располагается поле «Числовое выражение», в котором задается выражение для вычисления новой переменной. Все необходимые математические операторы приведены ниже в форме калькулятора. Для того, чтобы вычислить новую переменную, я перенес все переменные про участие в общественных организация из списка имеющихся переменных в поле «Числовое выражение» и суммировал их (в конце необходимо нажать кнопку «ОК»; новая переменная появится в конце списка переменных в паспорте, а также в виде последнего столбца в окне с данными). Поскольку каждая из них может принимать только два значения — 0 и 1, постольку диапазон возможных значений для всех респондентов может варьироваться от 0 (если респондент не состоит ни в одной организации, то есть по всем 13-ти переменным имеет 0) до 13 (если респондент состоит во всех возможных организациях, то есть по всем 13-ти переменным имеет 1).
Фильтр
Для построения фильтра необходимо выбрать: Данные => Отобрать наблюдения…
В открывшемся окне необходимо выбрать пункт меню «Если выполнено условие» (по умолчанию стоит «Все наблюдения») и нажать кнопку «Если».
После этого опять откроется окно, в котором слева будет список имеющихся переменных, а справа — поле для задания логических условий и набор математических и логических операторов. При построении фильтров обычно используются логические операторы. Последние имеют следующий смысл:
а) меньше чем: б) меньше чем или равно: в) больше чем: >
г) больше чем или равно: >=
д) равно: ==
е) не равно: ~=
ж) или: | (вертикальный слеш, а не буква)
з) и: &
В нашем случае я выбрал переменную V329 и приравнял ее к 2 (двойкой закодирован центральный регион). После этого я поставил оператор | и ввел второе условие, в котором приравнял ту же переменную к 3 (тройкой закодирован южный регион). Таким образом, для дальнейшего анализа останутся наблюдения, которые имеют по переменной V329 двойку или тройку. Когда все условия определены необходимо нажать «Продолжить» и «ОК».
Успехов в работе с SPSS!
Тэги: Помощь студентам, Национальный авиационный университет
soc-research.info
Глава 1. Программа SPSS
1.3 Модули SPSS
Основу программы SPSS составляет SPSS Base (базовый модуль), предоставляющий разнообразные возможности доступа к данным и управления данными. Он содержит методы анализа, которые применяются чаще всего.
Традиционно вместе с SPSS Base (базовым модулем) поставляются ещё два модуля: Advanced Models (продвинутые модели) и Regression Models (регрессионные модели). Эти три модуля охватывают тот спектр методов анализа, который входил в раннюю версию программы для больших ЭВМ.
В приложении А Вы сможете найти информацию о том, какие методы анализа относятся к тому или иному модулю. Пользователь, который приобрёл все эти три модуля, может не обращать внимания на данное приложение.
Наряду с тремя упомянутыми, существует еще ряд специальных дополнительных модулей и самостоятельных программ, число которых постоянно растёт, так что пользователям следует постоянно знакомиться с информацией о нововведениях в SPSS.
В этой книге описываются базисный модуль, а также модули Regression Models, Advanced Models и Tables. Назначением последнего модуля является составление презентационных таблиц. В книге не рассматриваются логлинейные модели, анализ выживания и многомерное шкалирование, а также процедура составления презентаций.
SPSS Base (Базовый модуль)
SPSS Base входит в базовую поставку. Он включает все процедуры ввода, отбора и корректировки данных, а также большинство предлагаемых в SPSS статистических методов. Наряду с простыми методиками статистического анализа, такими как частотный анализ, расчет статистических характеристик, таблиц сопряженности, корреляций, построения графиков, этот модуль включает t-тесты и большое количество других непараметрических тестов, а также усложненные методы, такие как многомерный линейный регрессионный анализ, дискриминантный анализ, факторный анализ, кластерный анализ, дисперсионный анализ, анализ пригодности (анализ надежности) и многомерное шкалирование.
Regression Models
Данный модуль включает в себя различные методы регрессионного анализа, такие как: бинарная и мультиномиальная логистическая регрессия, нелинейная регрессия и пробит-анализ.
Advanced Models
В этот модуль входят различные методы дисперсионного анализа (многомерный, с учетом повторных измерений), общая линейная модель, анализ выживания, включая метод Каплана-Майера и регрессию Кокса, логлинейные, а также логитлоглинсйные модели.
Tables
Модуль Tables служит для создания презентационных таблиц. Здесь предоставляются более широкие возможности по сравнению со упрощенными частотными таблицами и таблицами сопряженности, которые строятся в SPSS Base (базовом модуле).
Ниже в алфавитном порядке приведен список остальных модулей и программ предлагаемых для расширения SPSS.
Amos
Amos (Analysis of moment structures — анализ моментных структур) включает методы анализа с помощью линейных структурных уравнений. Целью программы является проверка сложных теоретических связей между различными признаками случайного процесса и их описание при помощи подходящих коэффициентов. Проверка проводится в форме причинного анализа и анализа траектории. При этом пользователь в графическом виде должен задать теоретическую модель, в которую вместе с данными непосредственных наблюдений могут быть включены и так называемые скрытые элементы. Программа Amos включена в состав модулей расширения SPSS, как преемник L1SREL (Linear Structural RELationships — линейные структурные взаимоотношения).
AnswerTree
AnswerTree (дерево решений) включает четыре различных метода автоматизированного деления данных на отдельные группы (сегменты). Деление проводится таким образом, что частотные распределения целевой (зависимой) переменной в различных сегментах значимо различаются. Типичным примером применения данною метода является создание характерных профилей покупателей при исследовании потребительского рынка. AnswerTree является преемницей программы СНАШ (Chi squared interaction Detector — детектор взаимодействий на основе хи-квадрата).
Categories
Модуль содержит различные методы для анализа категориальных данных, а именно: анализ соответствий и три различных метода оптимального шкалирования (анализ однородности, нелинейный анализ главных компонент, нелинейный канонический корреляционный анализ).
Clementine
Clementine — это программа для data mining (добычи знаний), в которой пользователю предлагаются многочисленные подходы к построению моделей, к примеру, нейронные сети, деревья решений, различные виды регрессионного анализа. Clementine представляет собой «верстак» аналитика, при помощи которого можно визуализировать процесс моделирования, перепроверять модели, сравнивать их между собой. Для удобства пользования программой имеется вспомогательная среда внедрения результатов.
Conjoint (совместный анализ)
Совместный анализ применяется при исследовании рынка для изучения потребительских свойств продуктов на предмет их привлекательности. При этом опрашиваемые респонденты по своему усмотрению должны расположить предлагаемые наборы потребительских свойств продуктов в порядке предпочтения, на основании которого можно затем вывести так называемые детализированные показатели полезности отдельных категорий каждого потребительских свойства.
Data Entry (ввод данных)
Программа Data Entry предназначена для быстрого составления вопросников, а также ввода и чистки данных. Заданные на этапе создания вопросника вопросы и категории ответов потом используются в качестве меток переменных и значений.
Exact Tests (Точные тесты)
Данный модуль служит для вычисления точного значения вероятности ошибки (величины р) в условиях ограниченности данных при проверке по критерию х2 (Chi-Quadrat-Test) и при непараметрических тестах. В случае необходимости для этого также может быть применён метод Монте-Карло (Monte-Carlo).
GOLDMineR
Программа содержит специальную регрессионную модель для регрессионного анализа упорядоченных зависимых и независимых переменных.
SamplePower
При помощи SamplePower может быть определён оптимальный размер выборки для большинства методов статистического анализа, реализованных в SPSS.
SPSS Missing Value Analysis
Данный модуль служит для анализа и восстановления закономерностей, которым подчиняются пропущенные значения. Он предоставляет различные варианты замены недостающих значений.
Trends
Модуль Trends содержит различные методы для анализа временных рядов, такие как: модели ARIMA, экспоненциальное сглаживание, сезонная декомпозиция и спектральный анализ.
Модули Amos, AnswerTree, Categories, Conjoint, LISREL и Trends описаны в книге этих же авторов: «SPSS. Методы исследования рынка и мнений».
lib.qrz.ru
Как работает SPSS (статистический пакет для социальных наук) — манекены 2019 — No-dummy.com
Разработчики Статистического пакета для социальных наук (SPSS) приложили все усилия, чтобы сделать программное обеспечение простым в использовании. Это мешает вам совершать ошибки или даже забывать что-то. Это не значит, что это невозможно сделать что-то неправильно, но программное обеспечение SPSS работает, чтобы держать вас от работы в канаву. Чтобы замалчивать себя, вы почти должны работать над тем, чтобы понять, как сделать что-то неправильно.
Вы всегда начинаете с определения набора переменных , , а затем вводите данные для переменных, чтобы создать несколько случаев . Например, если вы проводите анализ автомобилей, каждый автомобиль в вашем кабинете будет иметь дело. Переменными, которые определяют случаи, могут быть такие вещи, как год изготовления, лошадиная сила и кубические дюймы перемещения. Каждый автомобиль в исследовании определяется как один случай, и каждый случай определяется как набор значений, назначенных набору переменных. Каждый случай имеет значение для каждой переменной. (Ну, у вас может быть недостающее значение, но это особая ситуация, описанная ниже.)
Переменные имеют типы. То есть каждая переменная определяется как содержащая определенный тип номера. Например, переменная шкала представляет собой числовое измерение, такое как вес или мили на галлон. A категориальная переменная содержит значения, определяющие категорию; например, переменная с именем gender может быть категориальной переменной, определенной как содержащая только значения 1 для женщин и 2 для мужчин. Вещи, которые имеют смысл для одного типа переменных, не обязательно имеют смысл для другого. Например, имеет смысл рассчитать средние мили за галлон, но не средний пол.
После ввода ваших данных в SPSS — все ваши случаи определяются значениями, хранящимися в переменных — вы можете выполнить анализ. Вы уже закончили тяжелую работу. Выполнение анализа данных намного проще, чем ввод данных. Чтобы выполнить анализ, вы выбираете тот, который вы хотите запустить из меню, выберите соответствующие переменные и нажмите кнопку «ОК». SPSS читает все ваши дела, выполняет анализ и представляет вам результат.
Вы можете поручить SPSS рисовать графики и диаграммы так же, как вы инструктируете его выполнять анализ. Вы выбираете нужный граф из меню, назначаете ему переменные и нажимаете OK.
При подготовке SPSS для выполнения анализа или рисования графика кнопка «ОК» недоступна, пока вы не сделаете все, что необходимо для создания вывода.SPSS не только требует, чтобы вы выбрали достаточное количество переменных для вывода вывода, но также потребовали, чтобы вы выбрали правильные типы переменных. Если для определенного слота требуется категориальная переменная, SPSS не позволит вам выбрать какой-либо другой вид. Независимо от того, какой результат имеет смысл, зависит от вас и ваших данных, но SPSS уверен, что сделанные вами варианты могут использоваться для получения какого-то результата.
Все выходные данные SPSS переходят в одно и то же место — диалоговое окно с именем SPSS Viewer. Он открывается, чтобы отобразить результаты того, что вы сделали. После того, как вы выполните вывод, если вы выполняете какое-то действие, которое производит больше выходных данных, новый вывод отображается в том же диалоговом окне. И почти все, что вы делаете, дает результат.
ru.no-dummy.com
Исходные данные для SPSS
Вначале инструкции будут очень подробными. Для кого-то может быть даже чрезмерно. Найдите в меню Пуск программу SPSS for Windows > SPSS 13.0. for Windows. Запустите ее, и Вы увидите пустую таблицу. В нее надо ввести данные, показанные в табл.1.1. Участники, как всегда, различаются по скорости решения задачи. Но не торопитесь. Ввести эти данные сразу же в таком виде у вас не получится. А если и получится, то в дальнейшем может привести к затруднениям.
Давайте введем данные правильно. Переключитесь на закладку Variable view (редактор переменных)в нижней левой части окна. Вы видите таблицу, в которой первый столбец называется Name, второй столбец – Type и т.д. Введите в первую строку столбца Name название нашей первой переменной – Имя. Во вторую строку столбца Name введите название второй переменной – Область. Имена переменных должны быть короткими и не могут содержать пробелов. В третью и четвертую строки введите имена двух оставшихся переменных (назовем их Время и Ранг). Т.е. каждой переменной здесь соответствует отдельная строка. Переключитесь на закладку Data view (редактор данных) в нижней левой части окна. Вы видите, что имена переменных теперь являются заголовками столбцов, что соответствует табл.1.1.
Сохранение файла. Создайте в указанной преподавателем папке свою папку и сохраните в нее файл (File > Save as…). Присвойте файлу имя d1. (d – сокращение от data (данные)).
Числовые и текстовые данные. Попытайтесь ввести в первую (левую верхнюю) ячейку имя Иван. Давайте разберемся, почему не получилось. Переключитесь снова в редактор переменных. Вы видите, что все 4 переменные имеют числовой (Numeric) тип (Type). Конечно же, бесполезно пытаться вводить данные текстового типа в переменную числового типа. Но и менять тип переменной на String (строка, текст) тоже, как правило, не стоит … Тип String позволил бы ввести в переменную текстовые данные. Но делать этого не рекомендуется. Как с точки зрения рациональности при вводе данных, так и с точки зрения доступности многих статистических процедур. Значения переменной и надписи этих значений. Сейчас мы поступим более профессионально. Вы видите, что две переменные в табл.1.1. (Имя и Область) являются текстовыми. Переменная Имя содержит 4 категории (4 имени), а переменная Область содержит 3 категории (3 области деятельности). Правильный подход такой: надо каждой категории присвоить числовой код. И в таблицу вводить именно числовые коды. Давайте сделаем это для переменной Область. Пусть категория Программирование имеет код 1, категория Бизнес – код 2 и категория Филология – код 3. Значениями переменной будут числовые коды. Найдите столбец Value (значение) и откройте в нем диалоговое окно для переменной Область. В поле Value введите 1, в поле Value label (надпись значения) введите Программирование и нажмите Add (добавить). Точно также добавьте и пары 2=«Бизнес» и 3=«Филология». Обратите внимание, что такие числа, как 1,00 в данном случае неуместны. Коды должны быть целыми. Это легко исправить с помощью Decimals (количество знаков после запятой). Точно также добавьте все значения и их надписи для переменной Имя. Пронумеровать можете в любом порядке. Теперь желательно бы увидеть все значения и надписи одновременно. Воспользуйтесь меню File > Display data file information > Working file (вывести информацию о файле). Найдите таблицу Variable values (значения переменной). Сейчас у вас будет возможность оценить удобство этой таблички.Ввод данных. Переключитесь снова на ваш файл d1 и откройте редактор данных (Data view). Размер этой таблицы сейчас будет соответствовать табл.1.1. Четыре столбца (4 переменные) и 4 случая. Первый случай – это Иван, занимающийся программированием и решивший задачу за 4 минуты, благодаря чему получил в этой группе ранг 2,5. Вместо слова Случай можно с равным успехом использовать слово Наблюдение. Программист Иван – первое наблюдение. Вы понимаете, что вместо текста сейчас надо вводить числа. Поэтому, например, вместо программирования, надо ввести 1. Введите информацию о первом случае. Если Ивану Вы присвоили код 1, то тогда Вы введете буквально следующее: . Не забывайте, что если вас не устраивают такие числа, как 4,00, Вы можете исправить это в редакторе переменных.
Точно также введите информацию и об остальных 3-х случаях. Слева Вы видите их номера. Нет желания запоминать числовые коды и сопоставлять разные таблицы? Конечно, в больших базах данных эти операции можно автоматизировать. Но сейчас пока автоматизировать не надо.
Информация о случаях. Как же нам увидеть таблицу в том же виде как в табл.1.1? Несложно. Воспользуйтесь меню Analyze > Reports > Case summaries … Выделите 4 переменные в левой части окна и перенесите их в правую часть окна, чтобы все они оказались в списке Variables. Нажмите Ок и найдите таблицу Case summaries. Она отличается от предыдущей таблицы тем, что предназначена не для компьютера, а для человека. Научитесь редактировать ее: выполните двойной щелчок, увеличьте ширину столбцов, измените шрифт и выравнивание …
Исходные данные и результаты. Sav и Spo.
Сейчас уже пора сказать о главном, что есть в пользовательском интерфейсе SPSS. Обратите внимание, что сейчас у вас открыто 2 файла SPSS. В первом файле (d1) находятся исходные данные, а во второй файл выводятся результаты. Откройте в обоих файлах меню File > Save as … и посмотрите: исходные данные имеют тип файла Sav, а результаты – Spo.
Сохраните файл Spo в свою папку.
expect.ru