Встраиваемые и неполные шрифты | ono
 Встраиваемый шрифт — это шрифт, который упакован в PDF-файл как ресурс. Внедрение гарантирует, что PDF-текст будет одинаково выглядеть везде, где бы он ни выводился или рассматривался, но это увеличивает размер файла документа. В этом методе взлома обсуждается внедрение и его альтернативы, положительные и отрицательные стороны, а также разбиение шрифта на подмножества, позволяющие внедрять только часть полного шрифта. Разбиение было разработано для уменьшения размера файла, но при неправильном использовании оно может значительно увеличить его.
Встраиваемый шрифт — это шрифт, который упакован в PDF-файл как ресурс. Внедрение гарантирует, что PDF-текст будет одинаково выглядеть везде, где бы он ни выводился или рассматривался, но это увеличивает размер файла документа. В этом методе взлома обсуждается внедрение и его альтернативы, положительные и отрицательные стороны, а также разбиение шрифта на подмножества, позволяющие внедрять только часть полного шрифта. Разбиение было разработано для уменьшения размера файла, но при неправильном использовании оно может значительно увеличить его.
Просмотрите, какие PD-шрифты или их подмножества внедрены в PDF-файл, открывая его в Acrobat или Reader и выбирая команду File\Document Properties\Fonts (Файл\Свойства документа\Шрифты). Внедренные шрифты обозначаются как Embedded (Встроенный).
Внедрение шрифтов в PDF-документ
В идеале, все шрифты должны быть внедрены. Если шрифт не внедрен в PDF-документ, программа Acrobat/Reader попробует найти его на компьютере. Если шрифт не установлен на компьютере, Acrobat/Reader попробует аппроксимировать его, используя свои собственные ресурсы (см. рисунок). Без внедренного шрифта PDF-документ может выглядеть по-разному на различных машинах.
Насколько хорошо Acrobat/Reader аппроксимирует шрифты? Отключите опцию Use Local Fonts in Reader or Acrobat (Использовать местные шрифты в Reader или Acrobat), чтобы увидеть, как будут выглядеть не внедренные шрифты. В Acrobat 6 выберите Advanced\Use Local Fonts (Дополнительно\Использовать местные шрифты), в Adode Reader 6 — Document\Use Local Fonts (Документ\Использовать местные шрифты), в Acrobat 5 — View\Use Local Fonts (Вид\Использовать местные шрифты) или просто используйте комбинацию клавиш Ctrl-Shift-Y.
Препятствием к внедрению шрифтов служит добавление каждым из них приблизительно 20 Кбайт к размеру PDF-файла. Для больших PDF-документов это незначительно. Для сетевых PDF-документов, состоящих из нескольких страниц, это может быть недопустимым.
Если размер PDF-файла критичен, выберите некоторые или все Base-шрифты документов из одной основной коллекции шрифтов, а затем сконфигурируйте программу Distiller, чтобы никогда не внедрять их. Шрифты Base 14 представляют ядро, которое можно использовать без внедрения. Шрифты Base 35 обеспечивают традиционные стили, которые также можно использовать без внедрения. Для внедрения отдавайте предпочтение шрифтам Туре 1, поскольку их размер значительно меньше, чем у TrueType.
Шрифты Base 14
Шрифты Base 14 можно использовать в любом PDF-документе без внедрения. Их названия: Times, Helvetica, Courier и Symbol. Times New Roman обычно используется вместо Times, a Arial — вместо Helvetica.
Если в документе используется шрифт Helvetica и требуется, чтобы PDF-документ отображался именно со шрифтом Helvetica (а не Arial), убедитесь, что он внедрен. Некоторые профили Distiller автоматически исключают все шрифты Base 14 из списка внедряемых.
На рисунке показаны образцы шрифтов Base 14 и Base 35.

Шрифты Base 35
Шрифты Base 35 — надмножество шрифтов Base 14. Они добавляют стиль, и большинство из них можно использовать без внедрения. Если ваша система не имеет одного из семейств шрифтов, показанных в таблице, попробуйте использовать вместо этого подобный шрифт.
Семейство шрифтов Base 35 и подобные шрифты, которые можно использовать без внедрения
Название семейства шрифтов | Подобные шрифты |
Times | Times New Roman |
Helvetica | Arial |
Helvetica Narrow | Arial Narrow |
Palatino | Book Antiqua |
Bookman | Bookman Old Style |
Avant Garde | Century Gothic |
New Century Schoolbook | Century Schoolbook |
Courier | Courier New |
Symbol |
Использование шрифтов Base 35, показанных в таблице, требует внедрения. Любой декоративный или стилизованный шрифт всегда должен быть внедрен.
Если шрифты Base 35, показанные на рисунке (или подобные им), отсутствуют в системе, установите бесплатные шрифты, поставляемые с Ghostscript.
Семейство шрифтов Base 35, которые должны быть внедрены
Название семейства шрифтов | Подобные шрифты |
Zapf Dingbats | Monotype Sorts |
Zapf Chancery | Monotype Corsiva |
Конфигурирование внедрения шрифтов в Distiller
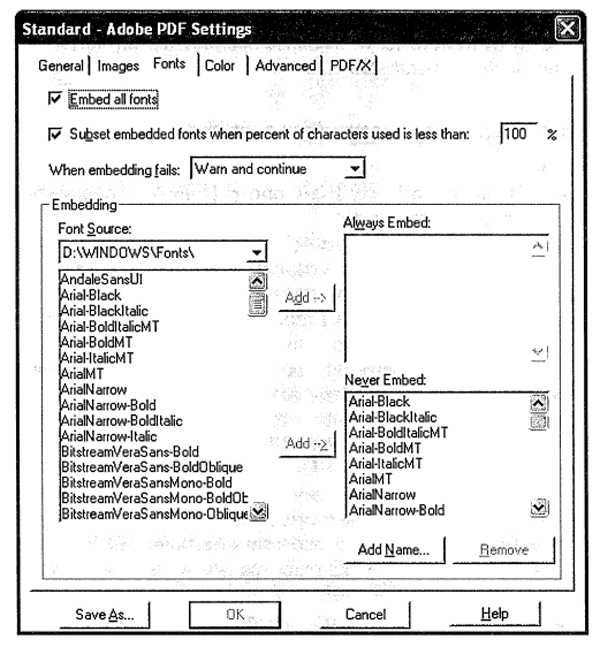 Настройка внедрения шрифтов производится на вкладке Fonts (Шрифты) диалогового окна Job Options (Рабочие параметры) программы Distiller (см. рисунок).
Настройка внедрения шрифтов производится на вкладке Fonts (Шрифты) диалогового окна Job Options (Рабочие параметры) программы Distiller (см. рисунок).
Переключатель Embed All Fonts (Внедрять все шрифты) устанавливает параметр по умолчанию. Отключение его означает Embed No Fonts (Не внедрять никаких шрифтов). Списки шрифтов Never Embed (Никогда не внедрять) и Always Embed (Всегда внедрять) используются для изменения установок по умолчанию. Так, если выбран режим Embed All Fonts, все шрифты исходного документа будут внедрены в PDF-документ, кроме перечисленных в списке Never Embed. Если режим Embed All Fonts не выбран, то только шрифты, перечисленные в списке Always Embed, внедряются в PDF-документ.
Сконфигурируйте программу Distiller, чтобы никогда не внедрять шрифты Base 14, поместив их (и им подобные) в список Never Embed (Никогда не внедрять). Если надо, поступите также со шрифтами Base 35 (и им подобными). При использовании Acrobat/Distiller 5.0 в шрифты Base 14 автоматически не включаются подобные им. В Windows измените в раскрывающемся списке Font Source (Источник шрифта) путь на C:\windows\fonts или C:\winnt\fonts , чтобы увидеть список системных шрифтов, в котором находятся подобные шрифты.
Acrobat 6 дает возможность удалить внедренные шрифты из PDF-документа, используя команду PDF Optimizer (PDF-оптимизатор). Выберите шрифты для удаления командой Advanced\PDF Optimizer\Fonts (Дополнительно\РОР-оптимизатор\Шрифты).
Конфигурирование внедрения шрифтов в программе Ghostscript
Программа Ghostscript внедряет все шрифты, кроме шрифтов Base 14, хотя, если необходимо, можно внедрить и их. Выясните опытным путем, отказ от внедрения каких шрифтов в Ghostscript может привести к созданию PDF-документа, работающего со сбоями в программах Acrobat и Reader. Возможно, следующая версия Ghostscript решит эту проблему.
Подмножество внедренных шрифтов
Нет смысла упаковывать в PDF-документ полный шрифт, если фактически из него используются несколько символов. Разбиение шрифта — методика внедрения только его части. Подмножество шрифта содержит те символы, которые используются в документе. Альтернативой является упаковка полного шрифта в PDF-документ. Distiller может полностью упаковать в PDF-документ только шрифт Туре 1. Шрифты любого другого формата, например TrueType, эта программа разбивает.
В большинстве случаев все внедренные шрифты должны быть разбиты на подмножества. Но это вызывает проблемы позже, при сборке нескольких частей PDF-документа в результирующий документ. Если каждая часть PDF-документа использует подмножества внедренных шрифтов, то итоговый документ будет содержать ненужные подмножества отдельного шрифта. Это может значительно увеличить размер файла документа.
Одно из решений состоит в том, чтобы использовать для сборки документа Acrobat 6. После сборки примените опцию Save As (Сохранить как) к новому PDF-документу. Acrobat 6 объединит индивидуальные подмножества шрифтов в единственное подмножество. Acrobat 5 этого не делает. Другое решение — повторная обработка PDF-документа после сборки.
Если вы планируете редактировать PDF-текст на уровне исходного документа, используя текстовый редактор, избегайте разбиения PDF-шрифтов. Если к PDF-документу добавляется текст, который использует символы, не содержащиеся в подмножестве шрифтов, то такой текст не будет отображаться.
Конфигурирование разбиения шрифтов в Distiller
Для управления разбиением внедренных шрифтов в программе Distiller используется вкладка Fonts (Шрифты). Чтобы избежать разбиения шрифта Туре 1, отключите переключатель Subset embedded fonts (Разбивать внедренные шрифты). Все другие шрифты (например, TrueType) всегда разбиваются.
Справа от этого переключателя можно установить порог разбиения шрифта. Если документ использует 95 % символов из шрифта, и вы не хотите разбивать его, введите в это поле число 94. Установка в этом поле числа 100 означает, что каждый шрифт будет разбит на подмножества.
Конфигурирование разбиения шрифтов в Ghostscript
Чтобы предотвратить разбиение шрифта Туре 1, укажите /SubsetFonts false в файле joboptions или добавьте -dSubsetFonts=false к командной строке. Если потребуется разбить шрифт на подмножества, замените в этих строках true на false.
Чтобы изменить порог разбиения шрифта на подмножества, определите /MaxSubsetPct 100 в файле joboptions или добавьте -dMaxSubsetPct=100 к командной строке. При необходимости замените число 100 нужным числом.
ono.org.ua
Некорректное отображение киррилических шрифтов в PDF формуляре
Некоторое время назад я столкнулся с интересной проблемой: у пользователя некорректно отображаются кириллические шрифты в PDF формуляре при просмотре расчетного листка. Расчетный листок формируется из портального сервиса самообслуживания сотрудников. В условиях данной задачи, также «дано», что в постоянных значениях основной записи пользователя, для параметра «Устройство вывода», установлено значение «PDF».
Посмотрим, что было сделано, для ее исправления этой ошибки.
Для начала необходимо определить наименование шрифта, который не отображается на портале. Для этого, в открывшемся сервисе «Просмотр расчетного листка», кликнуть кнопкой мыши и в контекстном меню выбрать пункт «Document Properties»:
 Рисунок 2. Свойства PDF
Рисунок 2. Свойства PDFЗатем перейти на вкладку Fonts:
 Рисунок 3. Свойства PDF — шрифты
Рисунок 3. Свойства PDF — шрифтыВ данном случае, используемый в PDF-формуляре шрифт, Courier. Скачиваем TrueType шрифт Courier и устанавливаем его в системе, с которой «связан» портал.
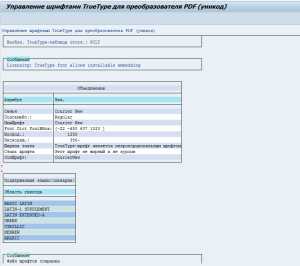
При этом необходимо обязательно убедиться, в том, что данный шрифт поддерживает кириллицу. Запускаем программу RSTXPDF2UC, выбираем на селекционном экране опцию «Перечислить атрибуты шрифта» и смотрим на раздел «Поддержанные языки/Сценарии»:
 Рисунок 4. Программа RSTXPDF2UC
Рисунок 4. Программа RSTXPDF2UCВ данном случае, раздел «Поддержанные языки/сценарии» пустой. Для решения проблемы с некорректно отображаемыми кириллическими шрифтами в PDF формуляре, необходимо найти шрифт, который будет поддерживать кириллическую область уникода. К таким шрифтам, к примеру, относится Courier New:
 Рисунок 5. Программа RSTXPDF2UC
Рисунок 5. Программа RSTXPDF2UCШрифт Courier New отлично подходит для решения вышеописанной проблемы.
После того, как необходимый шрифт был найден и сохранен на локальный компьютер (файл с расширение *.TTF) необходимо запустить программу RSTXPDF2UC в back-end системе, выбрать пункт «Инсталлировать шрифт True type»:
 Рисунок 6. Программа RSTXPDF2UC
Рисунок 6. Программа RSTXPDF2UCВ появившемся окне необходимо выбрать директорию, в которой сохранен TTF файл
Рисунок 6. Программа RSTXPDF2UC Рисунок 7. Выбор шрифта
Рисунок 7. Выбор шрифтаВ появившемся диалоговом окне консультанту будет предложено создание нового шрифта в системе. Необходимо выбрать «Да»:
В следующем диалоговом окне будет предложено использование данного шрифта в PDF-файлах. Необходимо выбрать «Да»
Затем система предложит внесенные изменения сохранить в транспортный запрос
После выполненной установки отобразится справочная информация о шрифте:
Далее нужно создать правило мэппинга для только что установленного в системе шрифта. Правило мэппинга определяет для каких символов будет использоваться тот или иной шрифт. Для этого необходимо выбрать пункт «Создать/изменить правило мэппинга» на селекционном экране программы RSTXPDF2UC:
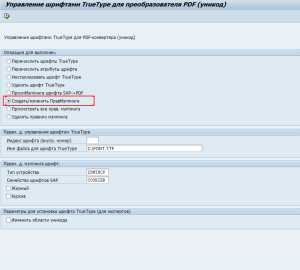 Рисунок 8. Программа RSTXPDF2UC
Рисунок 8. Программа RSTXPDF2UCВ появившемся диалоговом окне выбрать «Да»
Затем необходимо выбрать только что установленный шрифт (в данном примере, это Courier New)
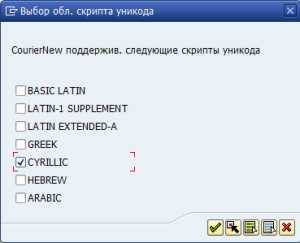
Определяем поддерживаемые области для нового шрифта (в нашем случае необходимо выбрать значение CYRYLLIC)
Затем внесем изменения в устройство вывода, использующееся в системе для работы с PDF формулярами. Для этого открываем транзакцию SPAD:
Рисунок 9. Транзакция SPADВыбираем устройство вывода «PDF», нажимаем на кнопку «Просмотр». В открывшемся экране меняем тип устройства с POST2 на PDUFC:
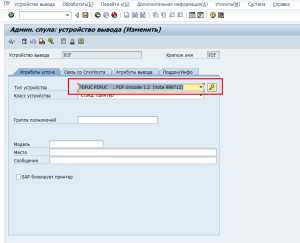 Рисунок 10. Изменение настроек устройства вывода PDF
Рисунок 10. Изменение настроек устройства вывода PDFСохраняем внесенные изменения и переходим к свойствам типов устройств:
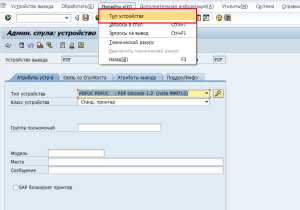 Рисунок 11. Переход к настройкам типов устройств
Рисунок 11. Переход к настройкам типов устройствЗаменяем значение кодировки на 1505 «Printer SAPWIN5 Russian MS-Windows codepage»
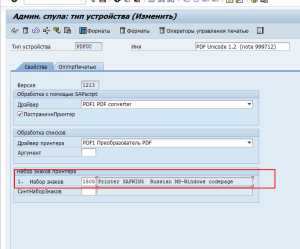
Сохраняем, и проверяем изменилось ли у пользователя отображение символов в формуляре сервиса «Просмотр расчетного листка».
Voilà:
Рисунок 12. Сервис самообслуживания сотрудников «Расчетный листок»
Поделиться ссылкой:
www.signatov.com
DTP — Настольные издательские системы
Все материалы, находящиеся в этом разделе, являются переводами документов с сайта http://www.prepressure.com.
Шрифты
В PDF могут использоваться шрифты PostScript (type 1 и type 3) и TrueType. Эти шрифты могут включаться в PDF-файл для того, чтобы он мог быть просмотрен и отпечатан таким же, каким и был создан. Если какой-либо шрифт пропущен в PDF-файле, то Acrobat автоматически попытается эмулировать его, используя один из шрифтов Multiple Master. Файл при этом не будет выглядеть точно так же, как был создан, но текст сохранится.
Шрифты Multiple Master, используемые в Acrobat, следующие:
- Adobe Serif MM
- Adobe Sans MM
Какие шрифты использовались в PDF?
В Acrobat есть опция ‘Font info’. Эта опция не показывает все шрифты, использованные в документе, а только те, которые использованы на текущей странице. Не полагайтесь на нее, если вы хотите получить список всех шрифтов в документе.
Чтобы получить список шрифтов, нужен плагин, типа Enfocus PitStop.
Включение шрифтов
В Acrobat Distiller есть опция автоматического включения шрифтов, отсутствующих в обрабатываемых PostScript-файлах. Пользователь может указать несколько папок, которые будут использованы для поиска таких шрифтов.
Шрифты, которые не включаются в PDF-файл
Есть фундаментальная разница в том, как Acrobat 3.x и Acrobat 4.x обрабатывают шрифты.
Есть 14 шрифтов, которые Distiller 3.x никогда не включает в PDF-файл. Это:
- Courier, Courier-Bold, Courier-Oblique, Courier-BoldOblique
- Times-Roman , Times-Bold , Times-Italic, Times-BoldItalic
- Helvetica, Helvetica-Bold, Helvetica-Oblique, Helvetica-BoldOblique
- Symbol
- ZapfDingbats.
Эти шрифты, за исключением ZapfDingbats, называются «Base 13 fonts».
Acrobat 4.x без проблем включает эти шрифты, но у него есть другое ограничение: если лицензия на TrueType шрифт запрещает его включение в файл, то Distiller 4 соблюдает это ограничение и не включает такой шрифт. Здесь эта проблема описана более подробно.
Подстановка шрифтов
Возможно включать в файл только те символы шрифта, которые используются в публикации. Эта технология называется подстановкой шрифтов (font subsetting). Параметр ‘Subset fonts below XX %’ в Distiller определяет сколько символов должно использоваться в публикации для использования подстановки.
Есть два преимущества у этой технологии:
- Уменьшается размер файла, что делает его более удобным при использовании, например, в Интернет.
- RIP всегда будет использовать этот шрифт, даже если его полная версия есть в RIP. Это дает гарантию, что шрифт будет использован именно тот, который нужен.
Есть и два недостатка у этой технологии:
- Если вы захотите редактировать текст, а нужного символа не будет в шрифте, то он не может быть введен.
- Слияние двух файлов, содержащих разные наборы символов одного шрифта приведет к потере некоторых символов.
mikeudin.net
Как узнать, какие шрифты используются в выбранной части документа PDF Bilee
Тем временем я нашел другой способ перечислить шрифты, используемые в PDF (и указать, что они встроены или нет), в котором используется только Ghostscript (нет необходимости в дополнительных сторонних утилит). К сожалению, это также НЕ удовлетворяет вашему требованию, чтобы узнать о шрифте, используемом для выделенного текста.
Этот метод использует небольшую служебную программу, написанную на PostScript, отправляющую исходный код Ghostscript. Посмотрите в subdir toolbin для файла pdf_info.ps .
Включенные комментарии говорят, что вы должны запускать его так, чтобы отображать шрифты, используемые размеры носителей
gs -dNODISPLAY ^ -q ^ -sFile=____.pdf ^ [-dDumpMediaSizes] ^ [-dDumpFontsUsed [-dShowEmbeddedFonts]] ^ toolbin/pdf_info.ps Я запустил его в файле локального примера. Вот результат:
C:\> gswin32c ^ -dNODISPLAY ^ -q ^ -sFile=SHARE.pdf ^ -dDumpMediaSizes ^ -dDumpFontsUsed ^ -dShowEmbeddedFonts ^ C:\\pa\\gs\\gs8.64\\lib\\pdf_info.ps SHARE.pdf has 12 pages. Title: SHARE_Information_070808.indd Creator: Adobe InDesign CS2 (4.0) Producer: Adobe PDF Library 7.0 CreationDate: D:20080808103516+02'00' ModDate: D:20080808103534+02'00' Trapped: False Page 1 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 2 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 3 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 4 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 5 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 6 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 7 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 8 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 9 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 10 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 11 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Page 12 MediaBox: [ 595.276 841.89 ] CropBox: [ 595.276 841.89 ] Font or CIDFont resources used: DKCTOS+FrutigerLT-BlackCn DKCTOS+FrutigerLT-BoldItalic DKCTOS+Wingdings3 TIELEM+FrutigerLT-Black TIELEM+FrutigerLT-Bold TIELEM+FrutigerLT-BoldCn TIELEM+FrutigerLT-Cn TIELEM+FrutigerLT-Italic TIELEM+FrutigerLT-UltraBlack TIELEM+TimesNewRomanPS-BoldItalicMT www.bilee.com
fonts — Встроенные шрифты в формате PDF: копирование и вставка
Сначала вы должны проверить шрифты PDF-документа с помощью утилиты pdffonts. Это часть пакета XPDF для Windows и может использоваться без установки, только из окна DOS.
Чтобы успешно извлечь текст (или скопировать его) из PDF, шрифт должен либо использовать стандартную кодировку (а не Custom), и она должна иметь таблицу /ToUnicode связанную с ней внутри PDF.
pdffonts возвращает несколько основных информационных элементов о шрифтах, используемых вашим PDF- pdffonts.
Пример вывода:
$ pdffonts -f 3 -l 5 sample.pdf
name type encoding emb sub uni object ID
------------------------- ------------- ------------ --- --- --- ---------
IADKRB+Arial-BoldMT CID TrueType Identity-H yes yes yes 10 0
SSKFGJ+ArialMT CID TrueType Custom yes yes no 11 0
В приведенной выше команде были запрошены шрифты, используемые в диапазоне страниц 3 (сначала для проверки) до 5 (последняя страница для проверки).
В приведенном выше случае, оба используемые шрифты встраиваются как подмножества (обозначается XYZABC+ -prefixes, чтобы их имена, а также по yes в emb и sub столбцов).
Шрифт SSKFGJ+ArialMT использует настраиваемую кодировку, но PDF не имеет /ToUnicode для этого шрифта, о чем свидетельствует запись no для столбца, возглавляемого uni.
Следовательно, нелегко извлечь текст, который отображается с помощью этого шрифта (для извлечения потребуется ручная обратная инженерия), но тогда вы также можете просто «прочитать» страницы PDF).
Сначала вы должны проверить, если copy’n’pasting текста работает, если вы используете простой текстовый файл в качестве цели (а не документ MS Word). Если это не так, вы уже можете забыть о MS Word…
- Будет ли установка таких шрифтов в Microsoft Word работать?
- Очень вероятно: нет. (Я не могу дать однозначный ответ, не имея доступа к рассматриваемому PDF файлу).
- Если да, где я могу получить или даже создать те подмножества шрифтов, которые мне нужны?
- Вы можете извлечь подмножество шрифтов из самого PDF. (Как ни странно, qaru.site/questions/49299/… касается именно этого вопроса — я не знаю, почему люди кажутся настолько сумасшедшими в том, чтобы извлекать шрифты из файлов PDF, кроме как для целей отладки…)
- Если нет, как я могу решить эту проблему?
- Нет другого решения, кроме как сделать это вручную.
Обновить
Вы, к сожалению, не можете получить точно такую же информацию о шрифтах, используемых PDF через Acrobat или Adobe Reader. Что вы можете получить через меню → Файл → Свойства…
- имена шрифтов,
- информацию подмножества (но не префиксы, используемые для подмножеств шрифтов),
- кодирование и
- тип шрифта.
Но вы не получаете информацию о наличии таблицы /ToUnicode.
qaru.site
fonts — Как извлечь встроенные шрифты из PDF в качестве допустимых файлов шрифтов?
У вас есть несколько вариантов. Все эти методы работают как с Linux, так и с Windows или Mac OS X. Однако имейте в виду, что большинство PDF файлов не включают полный, полный шрифт, когда у них есть встроенный шрифт. В основном они включают только подмножество глифов, используемых в документе.
Использование pdftops
Один из наиболее часто используемых методов для этого в системах * nix состоит из следующих шагов:
- Преобразование PDF в PostScript, например, с помощью XPDF
pdftops(в Windows:pdftops.exeвспомогательная программа. - Теперь шрифты будут внедрены в формат
.pfa(PostScript) +, вы можете извлечь их с помощью текстового редактора . - Вам может потребоваться преобразовать
.pfa(ASCII) в.pfb(двоичный) файл с помощьюt1utilsиpfa2pfb. - В файлах PDF нет встроенных файлов
.pfmили.afm(шрифтовых метрических файлов) (поскольку просмотрщик PDF имеет внутренние знания об этом). Без них файлы шрифтов вряд ли пригодны для использования визуально приятным способом.
Использование fontforge
Другой метод — использовать редактор бесплатных шрифтов FontForge:
- Используйте диалоговое окно «Открыть шрифт», используемое при открытии файлов.
- Затем выберите «Извлечь из PDF» в разделе фильтра диалога.
- Выберите PDF файл с подлежащим извлечению шрифтом.
- Откроется диалоговое окно «Выбрать шрифт» — выберите здесь, какой шрифт открыть.
Проверьте руководство FontForge. Вам может потребоваться выполнить несколько конкретных шагов, которые не обязательно являются простыми, чтобы сохранить извлеченные данные шрифта в качестве файла, который можно повторно использовать.
Использование mupdf
Далее, MuPDF. Это приложение поставляется с утилитой под названием pdfextract (в Windows: pdfextract.exe), которая может извлекать шрифты и изображения из PDF файлов. (Если вы не знаете о MuPDF, который по-прежнему остается относительно неизвестным и новым: «MuPDF — это бесплатный легкий просмотрщик PDF и инструментарий, написанный на портативном компьютере C.», написанный разработчиками программного обеспечения Artifex, той же компанией, которая дала нам Ghostscript. )
(Обновление:). Новые версии MuPDF перенесли прежнюю функциональность «pdfextract» в команду «Извлечение mutool». Загрузите ее здесь: mupdf.com/downloads)суб >
Примечание. pdfextract.exe — это программа командной строки. Чтобы использовать его, сделайте следующее:
c:\> pdfextract.exe c:\path\to\filename.pdf # (on Windows)
$> pdfextract /path/tofilename.pdf # (on Linux, Unix, Mac OS X)
Эта команда будет выгружать все извлекаемые файлы из файла pdf, указанного в текущем каталоге. Как правило, вы увидите множество файлов: изображения, а также шрифты. К ним относятся PNG, TTF, CFF, CID и т.д. Имена изображений будут похожи на img-0412.png, если номер объекта PDF для изображения был 412. Шрифты будут похожи на FGETYK + LinLibertineI-0966.ttf, если шрифт Номер объекта PDF был 966.
Файлы CFF (Compact Font Format) являются признанным форматом, который может быть преобразован в другие форматы с помощью различных преобразователей для использования в разных операционных системах.
Опять же: имейте в виду, что большинство этих файлов шрифтов могут иметь только подмножество символов и не могут представлять полный шрифт.
Обновление: (июль 2013 г.) Последние версии mupdf видели внутреннюю перестановку и переименование их двоичных файлов не один раз, а несколько раз. Основная утилита, которая использовалась как «швейцарский нож», называлась mubusy (название, вдохновленное busybox?), Которое в последнее время было переименовано в mutool. Они поддерживают подкоманды info, clean, extract, poster и show. К сожалению, официальная документация по этим инструментам не является актуальной (пока). Если вы используете Mac с помощью «MacPorts»: тогда утилита была переименована во избежание конфликтов имен с другими утилитами с использованием одинаковых имен, и вам может понадобиться использовать mupdfextract.
Чтобы достичь (примерно) эквивалентных результатов с помощью mutool, как было показано в предыдущем инструменте pdfextract, просто запустите mubusy extract .... *
Чтобы извлечь шрифты и изображения, вам может потребоваться выполнить одну из следующих команд:
c:\> mutool.exe extract filename.pdf # (on Windows)
$> mutool extract filename.pdf # (on Linux, Unix, Mac OS X)
Загрузки находятся здесь: mupdf.com/downloads
Использование gs (Ghostscript)
Затем Ghostscript также может извлекать шрифты непосредственно из PDF файлов. Однако он нуждается в помощи специальной утилиты с именем extractFonts.ps, написанный на языке PostScript, который доступен из репозитория исходного кода Ghostscript.
Теперь используйте его, вам нужно запустить оба, этот файл extractFonts.ps и ваш файл PDF. Ghostscript затем будет использовать инструкции из программы PostScript для извлечения шрифтов из PDF. Это похоже на Windows (да, Ghostscript понимает «прямую косую черту», /, как разделитель путей и в Windows!):
gswin32c.exe ^
-q -dNODISPLAY ^
c:/path/to/extractFonts.ps ^
-c "(c:/path/to/your/PDFFile.pdf) extractFonts quit"
или в Linux, Unix или Mac OS X:
gs \
-q -dNODISPLAY \
/path/to/extractFonts.ps \
-c "(/path/to/your/PDFFile.pdf) extractFonts quit"
Я испытал метод Ghostscript несколько лет назад. В то время он действительно извлекал *.ttf(TrueType) просто отлично. Я не знаю, будут ли вообще удалены другие типы шрифтов, и если это так, то можно использовать повторно. Я не знаю, действительно ли утилита блокирует извлечение шрифтов, отмеченных как защищенные.
Использование pdf-parser.py
Наконец, Didier Stevens pdf-parser.py: этот, вероятно, не так прост в использовании, потому что вам нужно иметь некоторые ноу-хау о внутренних структурах PDF. pdf-parser.py — это Python script, который может делать много других вещей. Он также может распаковывать и извлекать произвольные потоки из объектов, и поэтому он также может извлекать встроенные файлы шрифтов.
Но вам нужно знать, что искать. Посмотрим на это с примером. У меня есть файл с именем big.pdf. В качестве первого шага я использую параметр -s для поиска PDF файла для любого вхождения ключевого слова FontFile (pdf-parser.py не требует поиска с учетом регистра):
pdf-parser.py -s fontfile big.pdf
В моем случае, для моего big1.pdf, я получаю этот результат:
obj 9 0
Type: /FontDescriptor
Referencing: 15 0 R
<<
/Ascent 728
/CapHeight 716
/Descent -210
/Flags 32
/FontBBox [ -665 -325 2000 1006 ]
/FontFile2 15 0 R
/FontName /ArialMT
/ItalicAngle 0
/StemV 87
/Type /FontDescriptor
/XHeight 519
>>
obj 11 0
Type: /FontDescriptor
Referencing: 16 0 R
<<
/Ascent 728
/CapHeight 716
/Descent -210
/Flags 262176
/FontBBox [ -628 -376 2000 1018 ]
/FontFile2 16 0 R
/FontName /Arial-BoldMT
/ItalicAngle 0
/StemV 165
/Type /FontDescriptor
/XHeight 519
>>
Он говорит мне, что внутри PDF есть два экземпляра FontFile2, и они находятся в объектах PDF no. 15 и №. 16, соответственно. Номер объекта. 15 содержит /FontFile2 для шрифта /ArialMT, номер объекта. 16 содержит /FontFile2 для шрифта /Arial -BoldMT.
Чтобы показать это более четко:
pdf-parser.py -s fontfile big1.pdf | grep -i fontfile
/FontFile2 15 0 R
/FontFile2 16 0 R
Быстрый просмотр в спецификации PDF показывает, что ключевое слово /FontFile2 относится к «потоку, содержащему программу шрифтов TrueType» (/FontFile будет относиться к «потоку, содержащему программу шрифтов типа 1» и /FontFile3 относятся к «потоку, содержащему программу шрифтов, формат которой указан в записи подтипа в словаре потока» (следовательно, является либо типом Type1C, либо подтипом CIDFontType0C).
Чтобы посмотреть на объект PDF нет. 15 (который содержит шрифт /ArialMT ), можно использовать параметр -o 15:
pdf-parser.py -o 15 big1.pdf
obj 15 0
Type:
Referencing:
Contains stream
<<
/Length2 778552
/Length 1581435
/Filter /ASCIIHexDecode
>>
Этот вывод pdf-parser.py сообщает нам, что этот объект содержит поток (который он не будет отображать непосредственно), длина которого составляет 1.581.435 байт и кодируется (== «сжата» ) с помощью ASCIIHexEncode и должна быть расшифрована (== «де-сжатый» или «отфильтрованный» ) с помощью стандартного фильтра /ASCIIHexDecode.
Чтобы выгрузить любой поток из объекта, pdf-parser.py можно вызвать с параметром -d dumpname. Позвольте сделать это:
pdf-parser.py -o 15 -d dumped-data.ext big1.pdf
Наш извлеченный дамп данных будет находиться в файле с именем dumped-data.ext. Посмотрим, насколько это велико:
ls -l dumped-data.ext
-rw-r--r-- 1 kurtpfeifle staff 1581435 Apr 11 00:29 dumped-data.ext
Посмотрите, это 1.581.435 байт. Мы увидели эту цифру в предыдущем выпуске команды. Открытие этого файла текстовым редактором подтверждает, что его содержимое является шестнадцатеричным кодированным ASCII-данным.
Открытие файла с помощью инструмента для чтения шрифтов, такого как otfinfo (это часть пакета lcdf-typetools) приведет к некоторому разочарованию:
otfinfo -i dumped-data.ext
otfinfo: dumped-data.ext: not an OpenType font (bad magic number)
ОК, это потому, что мы еще не допустили pdf-parser.py использовать его полную магию: чтобы сбросить отфильтрованный, декодированный поток. Для этого мы должны добавить параметр -f:
pdf-parser.py -o 15 -f -d dumped-data-decoded.ext big1.pdf
Каков размер этого нового файла?
ls -l dumped-data-decoded.ext
-rw-r--r-- 1 kurtpfeifle staff 778552 Apr 11 00:39 dumped-data-decoded.ext
О, посмотрите, что точное число также было сохранено в объекте PDF no. 15 в качестве значения для клавиши /Length2…
Что думает file?
file dumped-data-decoded.ext
dumped-data-decoded.ext: TrueType font data
Что сообщает otfinfo об этом?
otfinfo -i dumped-data-decoded.ext
Family: Arial
Subfamily: Regular
Full name: Arial
PostScript name: ArialMT
Version: Version 5.10
Unique ID: Monotype:Arial Regular:Version 5.10 (Microsoft)
Designer: Monotype Type Drawing Office - Robin Nicholas, Patricia Saunders 1982
Manufacturer: The Monotype Corporation
Trademark: Arial is a trademark of The Monotype Corporation.
Copyright: © 2011 The Monotype Corporation. All Rights Reserved.
License Description: You may use this font to display and print content as permitted by
the license terms for the product in which this font is included.
You may only (i) embed this font in content as permitted by the
embedding restrictions included in this font; and (ii) temporarily
download this font to a printer or other output device to help
print content.
Vendor ID: TMC
Итак, Bingo!, у нас есть победитель: pdf-parser.py действительно извлек правильный файл шрифта для нас. Учитывая размер этого файла (778,552 байта), похоже, что этот шрифт был встроен даже полностью в PDF…
Мы могли бы переименовать его в arial-regular.ttf и установить его как таковой и с радостью использовать его.
Предостережение:
В любом случае вам необходимо выполнить лицензию, применимую к шрифту. Некоторые лицензии на шрифты не разрешают бесплатное использование и/или распространение. Пиратские шрифты похожи на пиратство любого программного обеспечения или другого материала, защищенного авторскими правами.
Большинство PDF файлов, которые находятся в дикой природе, в любом случае не вставляют полный шрифт, а только подмножества. Извлечение подмножества шрифта полезно только в очень ограниченной области, если вообще.
Прочитайте также о преимуществах и (более) недостатках в отношении усилий по извлечению шрифтов:
qaru.site
pdf — Как извлечь встроенные шрифты из PDF в качестве допустимых файлов шрифтов?
У вас есть несколько вариантов. Все эти методы работают как с Linux, так и с Windows или Mac OS X. Однако имейте в виду, что большинство PDF-файлов не включают полный, полный шрифт, когда у них есть встроенный шрифт. В основном они включают только подмножество глифов, используемых в документе.
Использование pdftops
Один из наиболее часто используемых методов для этого в системах * nix состоит из следующих шагов:
- Преобразуйте PDF в PostScript, например, используя pdftops
pdftops(в Windows:pdftops.exeвспомогательная программа. - Теперь шрифты будут встроены в
.pfa(PostScript) +, вы можете извлечь их с помощью текстового редактора . - Вам может потребоваться преобразовать
.pfa(ASCII) в.pfb(двоичный) файл, используяt1utilsиpfa2pfb. - В PDF-файлах нет
.afmфайлов.pfmили.afm(шрифтовых метрических файлов) (потому что просмотрщик PDF имеет внутренние знания об этом). Без них файлы шрифтов вряд ли пригодны для использования визуально.
Использование fontforge
Другой метод — использовать редактор шрифтов Free FontForge :
- Используйте диалоговое окно «Открыть шрифт», используемое при открытии файлов.
- Затем выберите «Извлечь из PDF» в разделе фильтра диалога.
- Выберите файл PDF с выбранным шрифтом.
- Откроется диалоговое окно « Выбрать шрифт» — выберите здесь, какой шрифт открыть.
Проверьте руководство FontForge. Вам может потребоваться выполнить несколько конкретных шагов, которые не обязательно являются простыми, чтобы сохранить извлеченные данные шрифта в качестве файла, который можно повторно использовать.
Использование mupdf
Далее, MuPDF . Это приложение поставляется с утилитой pdfextract (в Windows: pdfextract.exe ), которая может извлекать шрифты и изображения из PDF-файлов. (Если вы не знаете о MuPDF, который по-прежнему остается относительно неизвестным и новым: «MuPDF — это бесплатный легкий просмотрщик PDF и инструментарий, написанный на портативном компьютере C.» , написанный разработчиками программного обеспечения Artifex, той же компанией, которая дала нам Ghostscript. )
( Обновление: Новые версии MuPDF перенесли прежнюю функциональность «pdfextract» в команду «Извлечение mutool» . Загрузите ее здесь: mupdf.com/downloads )
Примечание. pdfextract.exe — это программа командной строки. Чтобы использовать его, выполните следующие действия:
c:\> pdfextract.exe c:\path\to\filename.pdf # (on Windows)
$> pdfextract /path/tofilename.pdf # (on Linux, Unix, Mac OS X)
Эта команда сбрасывает все извлекаемые файлы из файла pdf, указанного в текущем каталоге. Как правило, вы увидите множество файлов: изображения, а также шрифты. К ним относятся PNG, TTF, CFF, CID и т. Д. Имена изображений будут похожи на img-0412.png, если номер объекта PDF для изображения был 412. Шрифты будут похожи на FGETYK + LinLibertineI-0966.ttf , если шрифт Номер документа PDF был 966.
CFF ( Compact Font Format ) — это признанный формат, который может быть преобразован в другие форматы с помощью различных преобразователей для использования в разных операционных системах.
Опять же: имейте в виду, что большинство этих файлов шрифтов могут иметь только подмножество символов и не мог
code-examples.net