Java Core. Вопросы к собеседованию, ч. 1
Для тех, кто впервые слышит слово Java Core — это фундаментальные основы языка. С этими знаниями уже смело можно идти на стажировку/интернатуру. Приведенные вопросы помогут вам освежить знания перед собеседованием, или почерпнуть для себя что-то новое. Для получения практических навыков занимайтесь на JavaRush.
Приведенные вопросы помогут вам освежить знания перед собеседованием, или почерпнуть для себя что-то новое. Для получения практических навыков занимайтесь на JavaRush.Как создать неизменяемый объект в Java? Перечислите все преимущества
Неизменяемый класс – это класс, состояние которого не может быть изменено после создания. Здесь состоянием объекта по существу считаются значения, хранимые в экземпляре класса, будь то примитивные типы или ссылочные типы. Для того чтобы сделать класс неизменяемым, необходимо выполнить следующие условия:- Не предоставляйте сеттеры или методы, которые изменяют поля или объекты, ссылающиеся на поля. Сеттеры подразумевают изменение состояния объекта а это то, чего мы хотим тут избежать.
- Сделайте все поля
finalиprivate. Поля, обозначенныеprivatefinalгарантирует, что вы не измените их даже случайно. - Не разрешайте субклассам переопределять методы. Самый простой способ это сделать – объявить класс как
final. Финализированные классы в Java не могут быть переопределены. - Всегда помните, что ваши экземпляры переменных могут быть либо изменяемыми, либо неизменяемыми. Определите их и возвращайте новые объекты со скопированным содержимым для всех изменяемых объектов (ссылочные типы). Неизменяемые переменные (примитивные типы) могут быть безопасно возвращены без дополнительных усилий.
- легко конструировать, тестировать и использовать
- автоматически потокобезопасны и не имеют проблем синхронизации
- не требуют конструктора копирования
- позволяют выполнить «ленивую инициализацию» хэшкода и кэшировать возвращаемое значение
- не требуют защищенного копирования, когда используются как поле
- делают хорошие
Mapключи иSetэлементы (эти объекты не должны менять состояние, когда находятся в коллекции) - делают свой класс постоянным, единожды создав его, а он не нуждается в повторной проверке
- всегда имеют «атомарность по отношению к сбою» (failure atomicity, термин применил Джошуа Блох): если неизменяемый объект бросает исключение, он никогда не останется в нежелательном или неопределенном состоянии.
В Java передача по значению или по ссылке?
Java спецификация гласит, что все в Java передается по значению. Нет такого понятия, как «передача по ссылке» в Java. Эти условия связаны с вызовом методов и передачей переменных, как параметров метода. Хорошо, примитивные типы всегда передаются по значению без какой-либо путаницы. Но, концепция должна быть понятна в контексте параметра метода сложных типов. В Java, когда мы передает ссылку сложного типа как любой параметр метода, всегда адрес памяти копируется в новую ссылочную переменную шаг за шагом. Посмотрите на изображение: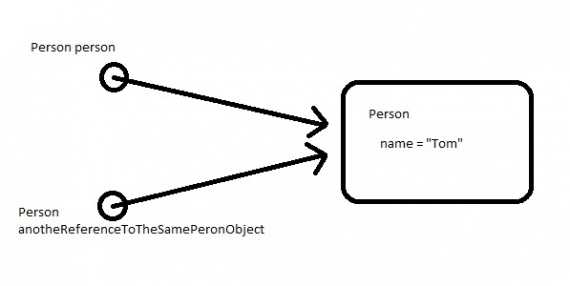
Какое применение блока finally? Гарантирует этот блок выполнение своего кода? Когда finally блок не вызывается?
Блокfinally всегда вызывается, если блок try существует. Это гарантирует, что блок finally вызывается даже, если случается неожиданное исключение. Но finally является более полезным, чем просто для обработки исключений – этот блок позволяет выполнить чистку кода, случайно обошедшего через return, continue или break. Размещение очищающего кода в блок finally всегда является хорошей практикой, даже когда не ожидается никаких исключений. Если виртуальная машина завершает работу во время выполнения блока try или catch, тогда блок finally не будет выполнен. Аналогично, если нить, выполняя блок try или catch, будет прервана или убита, блок finally не будет выполнен, даже не смотря на то, что приложение продолжает работать.Почему существует два класса Date, один в java.util package а другой в java.sql?
java.util.Date представляет дату и время, а java.sql.Date представляет только дату. Дополнением к java.sql.Date является класс java.sql.Time, который представляет только время. Класс java.sql.Date является субклассом (расширением) класса java.util.Date. Итак, что изменилось в java.sql.DatetoString()формирует другое представление строки: yyyy-mm-dd- статический метод
valueOf(String)создает дату из строки с вышеуказанным представлением - исключены геттеры и сеттеры для часов, минут и секунд
java.sql.Date используется в JDBC и предназначен, чтобы не иметь составляющую времени, то есть часы, минуты, секунды и миллисекунды должны быть нулю… но это не является обязательным для класса.Разъясните интерфейсы-маркеры.
Шаблон интерфейса-маркера – это шаблон проектирования в компьютерных науках, используемый языками программирования, которые предоставляют информацию об объектах во время выполнения. Это предоставляет способ ассоциации метаданных класса, где язык не имеет явной поддержки таких метаданных. В Java для этого используются интерфейсы без указания методов. Хорошим примером применения интерфейса-маркера в Java является интерфейсSerializable. Класс реализует этот интерфейс для указания, что его не transient данные могут быть записаны в поток байтов или на файловую систему. Главной проблемой интерфейса-маркера является то, что интерфейс определяет соглашение для реализующих его классов, и это соглашение наследуется всеми субклассами. Это значит, что вы не сможете «де-реализовать» маркер. В приведенном примере, если вы создадите субкласс, который вы бы не хотели сериализовать (возможно потому, что он находится в преходящем (transient) состоянии), вы должны прибегнуть к явному бросанию NotSerializableException.Почему метод main() объявлен как public static void?
Почему public? Методmain имеет модификатор доступа public, поэтому он может быть доступен везде и для любого объекта, который захочет использовать этот метод для запуска приложения. Тут я не говорю, что JDK/JRE имеют подобный повод, поскольку java.exe или javaw.exe (для windows) используют Java Native Interface (JNI) вызов для запуска метода, поэтому они могут вызвать его в любом случае, независимо от модификатора доступа. main не статический. Теперь, для вызова любого метода вам необходим экземпляр класса. Верно? Java разрешает иметь перегруженные конструкторы, это мы все знаем. Тогда который из них должен быть использован, и откуда возьмутся параметры для перегруженного конструктора? Почему void? Нет применения для возвращаемого значения в виртуальной машине, которая фактически вызывает этот метод. Единственное, что приложение захочет сообщить вызвавшему процессу – это нормальное или ненормальное завершение. Это уже возможно используя System.exit(int). Не нулевое значение подразумевает ненормальное завершение, иначе все в порядке.В чем разница между созданием строки как new() и литералом (при помощи двойных кавычек)?
Когда мы создаем строку используяnew(), она создается в хипе и также добавляется в пул строк, в то же время строка, созданная при помощи литерала, создается только в пуле строк. Вам необходимо ознакомиться с понятием пула строк глубже, чтобы ответить на этот или подобные вопросы. Мой совет – как следует выучите класс String и пул строк| У нас в переводах уже есть хорошая статья о строках и строковом пуле: Часть 1, Часть 2 |
Как работает метод substring() класса String?
Как и в других языках программирования, строки в Java являются последовательностью символов. Этот класс больше похож на служебный класс для работы с этой последовательностью. Последовательность символов обеспечивается следующей переменной:Каждый раз, когда мы создаем подстроку от существующего экземпляра строки, методprivate final char value[]; Для доступа к этому массиву в различных сценариях используются следующие переменныеprivate final int offset; private final int count;
substring() только устанавливает новые значения переменных offset и count. Внутренний массив символов не изменяется. Это возможный источник утечки памяти, если метод substring()value[] не изменяется. Поэтому если вы создадите строку длиной 10000 символов и создадите 100 подстрок с 5-10 символами в каждой, все 101 объекты будут содержать один и тот же символьный массив длиной 10000 символов. Это без сомнения расточительство памяти. Этого можно избежать, изменив код следующим образом: заменить original.substring(beginIndex) на new String(original.substring(beginIndex)),
где original – исходная строка.Примечание переводчика: я затрудняюсь сказать к какой версии Java это применимо, но на данный момент в Java 7 этот пункт статьи не актуален. Метод substring() вызывает конструктор класса new String(value, beginIndex, subLen), который в свою очередь обращается к методу Arrays.copyOfRange(value, offset, offset+count). Это значит, что у нас будет каждый раз новое значение переменной value[], содержащее наше новое количество символов. |
Объясните работу HashMap. Как решена проблема дубликатов?
Большинство из вас наверняка согласится, что HashMap наиболее любимая тема для дискуссий на интервью в настоящее время. Если кто-нибудь попросит меня рассказать «Как работает HashMap?», я просто отвечу: «По принципу хэширования». Так просто, как это есть. Итак, хеширование по сути является способом назначить уникальный код для любой переменной/объекта после применения любой формулы/алгоритма к своим свойствам. Определение карты (Map) таково: «Объект, который привязывает ключи к значениям». Очень просто, верно? Итак, HashMap содержит собственный внутренний класс Entry, который имеет вид:static class Entry implements Map.Entry
{
final K key;
V value;
Entry next;
final int hash;
…
}HashMap- В первую очередь, объект ключа проверяется на
null. Если ключnull, значение сохраняется в позициюtable[0]. Потому что хэшкод дляnullвсегда 0. - Затем, следующим шагом вычисляется хэш значение вызывая у переменной-ключа свой метод
hashCode(). Этот хэш используется для вычисления индекса в массиве для хранение объектаEntry. Разработчики JDK прекрасно понимали, что методhashCode()может быть плохо написан и может возвращать очень большое или очень маленькое значение. Для решения этой проблемы они ввели другойhash()метод, и передают хэшкод объекта этому методу для приведения этого значения к диапазону размера индекса массива. - Теперь вызывается метод
indexFor(hash, table.length)для вычисления точной позиции для хранения объектаEntry. - Теперь главная часть. Как мы знаем, два неодинаковых объекта могут иметь одинаковое значение хэшкода, как два разных объекта будет храниться в одинаковом расположении в архиве [называется корзиной]?
LinkedList. Если вы помните, класс Entry имеет свойство “next”. Это свойство всегда указывает на следующий объект в цепи. Такое поведение очень похоже на LinkedList. Итак, в случае совпадений хэшкодов, объекты Entry хранятся в форме LinkedList. Когда объект Entry необходимо разместить на конкретном индексе, HashMap проверяет, существует ли на этом месте другой объект Entry? Если там нет записи, наш объект сохранится в этом месте. Если на нашем индексе уже находится другой объект, проверяется его поле next. Если оно равно null, наш объект становится следующим узлом в LinkedList. Если next не равно null, эта процедура повторяется, пока не будет найдено поле next равное null. Что будет, если мы добавим другое значение ключа, равное добавленному ранее? Логично, что оно должно заменить старое значение. Как это происходит? После определения индекса позиции для объекта Entry, пробегая по LinkedList, расположенному на нашем индексе, HashMap вызывает метод equals() для значения ключа для каждого объекта Entry. Все эти объекты Entry в LinkedList имеют одинаковое значение хэшкода, но метод equals() будет проверять на настоящее равенство. Если ключ.equals(k) будет true, тогда оба будут восприниматься как одинаковый объект. Это вызовет замену только объекта-значение внутри объекта Entry. Таким образом HashMap обеспечивает уникальность ключей.Различия между интерфейсами и абстрактными классами?
Это очень распространенный вопрос, если вы проходите собеседование на программиста уровня junior. Наиболее значимые различия приведены ниже:- В интерфейсах Java переменные априори
final. Абстрактные классы могут содержать неfinalпеременные. - Интерфейс в Java безоговорочно не может иметь реализации. Абстрактный класс может иметь экземпляры методов, которые реализуют базовое поведение.
- Составляющие интерфейса должны быть
public. Абстрактный класс может иметь модификаторы доступа на любой вкус. - Интерфейс должен быть реализован ключевым словом
implements. Абстрактный класс должен быть расширен при помощи ключевого слова extends. - В Java класс может реализовывать множество интерфейсов, но может унаследоваться только от одного абстрактного класса.
- Интерфейс полностью абстрактный и не может иметь экземпляров. Абстрактный класс также не может иметь экземпляров класса, но может быть вызван, если существует метод
main(). - Абстрактный класс слегка быстрее интерфейса, потому что интерфейс предполагает поиск перед вызовом любого переопределенного метода в Java. В большинстве случаев это незначительное различие, но если вы пишите критичное по времени приложение, вам необходимо учесть и этот факт.
Когда вы переопределяете методы hashCode() и equals()?
МетодыhashCode() и equals() определены у класса Object, который является родительским классом для всех объектов Java. По этой причине, все объекты Java наследуют базовую реализацию этих методов. Метод hashCode() используется для получения уникального значения integer для данного объекта. Это значение используется для определения расположения корзины, когда объект необходимо хранить в структуре данных наподобие HashTable. По умолчанию метод hashCode() возвращает целочисленное представление адреса памяти, где хранится объект. Метод equals(), как предполагает название, используется для простой эквивалентности объектов. Базовая реализация метода заключается в проверке ссылок двух объектов для проверки их эквивалентности. Обратите внимание, что обычно необходимо переопределять метод hashCode() всякий раз, когда переопределен метод equals(). Это необходимо для поддержки общего соглашения метода hashCode, в котором говорится что равные объекты должны иметь равные хэшкоды. Метод equals() должен определять равенство отношений (он должен быть возвратным, симметричным и транзитивным). В дополнение, он должен быть устойчивым (если объект не изменялся, метод должен возвращать то же самое значение). Кроме того, o.equals(null) всегда должно возвращать false. hashCode() должен быть также устойчивым (если объект не изменялся по условиям метода equals(), он должен продолжать возвращать то же самое значение. Отношение между двумя методами такое: всегда, если a.equals(b), тогда a.hashCode() должно быть таким же, как и b.hashCode(). Удачи в обучении!! Автор статьи Lokesh Gupta Оригинал статьи Ссылки на остальные части:
Java Core. Вопросы к собеседованию, ч. 2
Java Core. Вопросы к собеседованию, ч. 3javarush.ru
Java Core. Вопросы к собеседованию, ч. 2
Для тех, кто впервые слышит слово Java Core – это фундаментальные основы языка. С этими знаниями уже смело можно идти на стажировку/интернатуру. Приведенные вопросы помогут вам освежить знания перед собеседованием, или почерпнуть для себя что-то новое. Для получения практических навыков занимайтесь на JavaRush. Оригинал статьи
Ссылки на остальные части:
Java Core. Вопросы к собеседованию, ч. 1
Java Core. Вопросы к собеседованию, ч. 3
Приведенные вопросы помогут вам освежить знания перед собеседованием, или почерпнуть для себя что-то новое. Для получения практических навыков занимайтесь на JavaRush. Оригинал статьи
Ссылки на остальные части:
Java Core. Вопросы к собеседованию, ч. 1
Java Core. Вопросы к собеседованию, ч. 3Почему необходимо избегать метода finalize()?
Все мы знаем утверждение, что методfinalize() вызывается сборщиком мусора перед освобождением памяти, занимаемой объектом. Вот пример программы, которая доказывает, что вызов метода finalize() не гарантирован:public class TryCatchFinallyTest implements Runnable {
private void testMethod() throws InterruptedException
{
try
{
System.out.println("In try block");
throw new NullPointerException();
}
catch(NullPointerException npe)
{
System.out.println("In catch block");
}
finally
{
System.out.println("In finally block");
}
}
@Override
protected void finalize() throws Throwable {
System.out.println("In finalize block");
super.finalize();
}
@Override
public void run() {
try {
testMethod();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}public class TestMain
{
@SuppressWarnings("deprecation")
public static void main(String[] args) {
for(int i=1;i< =3;i++)
{
new Thread(new TryCatchFinallyTest()).start();
}
}
}finalize не был выполнен ни для одной нити. Это доказывает мои слова. Я думаю, причина в том, что финализаторы выполняются отдельной нитью сборщика мусора. Если виртуальная машина Java завершается слишком рано, тогда сборщик мусора не имеет достаточно времени для создания и выполнения финализаторов. Другими причинами не использовать метод finalize() могут быть:- Метод
finalize()не работает с цепочками, как конструкторы. Имеется ввиду, что когда вы вызываете конструктор класса, то конструкторы суперклассов будут вызваны безоговорочно. Но в случае с методомfinalize(), этого не последует. Методfinalize()суперкласса должен быть вызван явно. - Любое исключение, брошенное методом
finalizeигнорируется нитью сборщика мусора, и не будет распространяться далее, что означает, что событие, не будет занесено в ваши логи. Это очень плохо, не правда ли? Также вы получаете значительное ухудшение производительности, если метод
finalize()присутствует в вашем классе. В «Эффективном программировании» (2-е изд.) Джошуа Блох сказал:
«Да, и еще одно: есть большая потеря производительности при использовании финализаторов. На моей машине время создания и уничтожения простых объектов составляет примерно 5,6 наносекунд.
Добавление финализатора увеличивает время до 2 400 наносекунд. Другими словами, примерно в 430 раз медленнее происходит создание и удаление объекта с финализатором.»
Почему HashMap не должна использоваться в многопоточном окружении? Может ли это вызвать бесконечный цикл?
Мы знаем, чтоHashMap — это не синхронизированная коллекция, синхронизированным аналогом которой является HashTable. Таким образом, когда вы обращаетесь к коллекции и многопоточном окружении, где все нити имеют доступ к одному экземпляру коллекции, тогда безопасней использовать HashTable по очевидным причинам, например во избежание грязного чтения и обеспечения согласованности данных. В худшем случае это многопоточное окружение вызовет бесконечный цикл. Да, это правда. HashMap.get() может вызвать бесконечный цикл. Давайте посмотрим как? Если вы посмотрите на исходный код метода HashMap.get(Object key), он выглядит так:public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
while (true) {
if (e == null)
return e;
if (e.hash == hash && eq(k, e.key))
return e.value;
e = e.next;
}
}while(true) всегда может стать жертвой бесконечного цикла в многопоточном окружении времени исполнения, если по какой-то причине e.next сможет указать на себя. Это станет причиной бесконечного цикла, но как e.next укажет на себя(то есть на e)? Это может произойти в методе void transfer(Entry[] newTable), который вызывается, в то время как HashMap изменяет размер.do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);HashMap). Единственный способ избежать описанного сценария – использовать синхронизацию в коде, или еще лучше, использовать синхронизированную коллекцию.Объясните абстракцию и инкапсуляцию. Как они связаны?
Простыми словами «Абстракция отображает только те свойства объекта, которые значимы для текущего ракурса». В теории объектно-ориентированного программирования, абстракция включает возможность определения объектов, представляющих абстрактных «действующих лиц», которые могут выполнять работу, изменять и сообщать об изменении своего состояния, и «взаимодействовать» с другими объектами в системе. Абстракция в любом языке программирования работает во многих отношениях. Это видно начиная от создания подпрограмм для определения интерфейсов низкоуровневых языковых команд. Некоторые абстракции стараются ограничить ширину общего представления потребностей программиста, полностью скрывая абстракции, на которых они построены, например шаблоны проектирования. Как правило, абстракцию можно увидеть в двух отношениях: Абстракция данных – это способ создания сложных типов данных и выставляя только значимые операции для взаимодействия с моделью данных, в то же время, скрывая все детали реализации от внешнего мира. Абстракция исполнения – это процесс выявления всех значимых операторов и выставляя их как рабочую единицу. Мы обычно используем эту особенность, когда мы создаем метод для выполнения какой-либо работы. Заключение данных и методов внутри классов в комбинации с осуществлением сокрытия (используя контроль доступа) часто называется инкапсуляцией. Результатом является тип данных с характеристиками и поведением. Инкапсуляция, в сущности, содержит также сокрытие данных и сокрытие реализации. «Инкапсулируйте все, что может измениться». Эта цитата является известным принципом проектирования. Если на то пошло, в любом классе, изменения данных могут произойти во время исполнения и изменения в реализации может произойти в следующих версиях. Таким образом, инкапсуляция применима как к данным, так и к реализации. Итак, они могут быть связаны таким образом:- Абстракция по большей части является Что класс может делать [Идея]
- Инкапсуляция более является Как достигнуть данной функциональности [Реализация]
Различия между интерфейсом и абстрактным классом?
Основные различия могут быть перечислены следующим:- Интерфейс не может реализовать никаких методов, зато абстрактный класс может.
- Класс может реализовать множество интерфейсов, но может иметь только один суперкласс (абстрактный или не абстрактный)
- Интерфейс не является частью иерархии классов. Несвязанные классы могут реализовывать один и тот же интерфейс.
Cat и Dog могут наследоваться от абстрактного класса Animal, и этот абстрактный базовый класс будет реализовывать метод void Breathe() – дышать, который все животные будут таким образом выполнять одинаковым способом. Какие глаголы могут быть применены к моему классу и могут применяться к другим? Создайте интерфейс к каждому из этих глаголов. Например, все животные могут питаться, поэтому я создам интерфейс IFeedable и сделаю Animal реализующим этот интерфейс. Только Dog и Horse достаточно хороши для реализации интерфейса ILikeable (способны мне нравиться), но не все. Кто-то сказал: главное отличие в том, где вы хотите вашу реализацию. Создавая интерфейс, вы можете переместить реализацию в любой класс, который реализует ваш интерфейс. Создавая абстрактный класс, вы можете разделить реализацию всех производных классов в одном месте и избежать много плохих вещей, таких как дублирование кода.Как StringBuffer экономит память?
КлассString реализован как неизменный (immutable) объект, то есть, когда вы изначально решили положить что-то в объект String, виртуальная машина выделяет массив фиксированной длины, точно такого размера, как и ваше первоначальное значение. В дальнейшем это будет обрабатываться как константа внутри виртуальной машины, что предоставляет значительное улучшение производительности в случае, если значение строки не изменяется. Однако если вы решите изменить содержимое строки любым способом, на самом деле виртуальная машина копирует содержимое исходной строки во временное пространство, делает ваши изменения, затем сохраняет эти изменения в новый массив памяти. Таким образом, внесение изменений в значение строки после инициализации является дорогостоящей операцией. StringBuffer, с другой стороны выполнен в виде динамически расширяемого массива внутри виртуальной машины, что означает, что любая операция изменения может происходить на существующей ячейке памяти, и новая память будет выделяться по мере необходимости. Однако нет никакой возможности виртуальной машине сделать оптимизацию StringBuffer, поскольку его содержимое считается непостоянным в каждом экземпляре.Почему методы wait и notify объявлены у класса Object взамен Thread?
Методыwait, notify, notifyAll необходимы только тогда, когда вы хотите, чтобы ваши нити имели доступ к общим ресурсам и общий ресурс мог быть любым java объектом в хипе(heap). Таким образом эти методы определены на базовом классе Object, так что каждый объект имеет контроль, позволяющий нитям ожидать на своем мониторе. Java не имеет какого-либо специального объекта, который используется для разделения общего ресурса. Никакая такая структура данных не определена. Поэтому на класс Object возложена ответственность иметь возможность становиться общим ресурсом, и предоставлять вспомогательные методы, такие как wait(), notify(), notifyAll(). Java основывается на идее мониторов Чарльза Хоара (Hoare). В Java все объекты имеют монитор. Нити ожидают на мониторах, поэтому для выполнения ожидания нам необходимо два параметра:- нить
- монитор (любой объект).
wait). Это хороший замысел, поскольку если мы можем заставить любую другую нить ожидать на определенном мониторе, это приведет к «вторжению», оказывая трудности проектирования/программирования параллельных программ. Помните, что в Java все операции, которые вторгаются в другие нити являются устаревшими(например, stop()).Напишите программу для создания deadlock в Java и исправьте его
В Javadeadlock – это ситуация, когда минимум две нити удерживают блок на разных ресурсах, и обе ожидают освобождения другого ресурса для завершения своей задачи. И ни одна не в состоянии оставить блокировку удерживаемого ресурса. Пример программы:package thread;
public class ResolveDeadLockTest {
public static void main(String[] args) {
ResolveDeadLockTest test = new ResolveDeadLockTest();
final A a = test.new A();
final B b = test.new B();
Runnable block1 = new Runnable() {
public void run() {
synchronized (a) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
System.out.println("In block 1");
}
}
}
};
Runnable block2 = new Runnable() {
public void run() {
synchronized (b) {
synchronized (a) {
System.out.println("In block 2");
}
}
}
};
new Thread(block1).start();
new Thread(block2).start();
}
private class A {
private int i = 10;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
}
private class B {
private int i = 20;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
}
}
Runnable block1 = new Runnable() {
public void run() {
synchronized (b) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (a) {
System.out.println("In block 1");
}
}
}
};
Runnable block2 = new Runnable() {
public void run() {
synchronized (b) {
synchronized (a) {
System.out.println("In block 2");
}
}
}
};Что случится, если ваш класс, реализующий Serializable интерфейс содержит несериализуемый компонент? Как исправить это?
В таком случае будет выброшеноNotSerializableException в процессе выполнения. Для исправления этой проблемы, есть очень простое решение – отметить эти поля transient. Это означает, что отмеченные поля не будут сериализованы. Если вы также хотите сохранить состояние этих полей, тогда вам необходимо рассмотреть ссылочные переменные, которые уде реализуют интерфейс Serializable. Также вам может понадобиться использовать методы readResolve() и writeResolve(). Подведем итоги:- Во-первых, сделайте ваше несериализуемое поле
transient. - В
writeObjectпервым делом вызовитеdefaultWriteObjectна потоке, для сохранения всех неtransientполей, затем вызовите остальные методы для сериализации индивидуальных свойств вашего несериализуемого объекта. - В
readObject, сперва вызовитеdefaultReadObjectна потоке для чтения всех неtransientполей, затем вызовите другие методы (соответствующие тем, которые вы добавили вwriteObject) для десериализации вашего неtransientобъекта.
Объясните ключевые слова transient и volatile в Java
«Ключевое словоtransient используется для обозначения полей, которые не будут сериализованы». Согласно спецификации языка Java: Переменные могут быть маркированы индикатором transient для обозначения, что они не являются частью устойчивого состояния объекта. Например, вы можете содержать поля, полученные из других полей, и их предпочтительнее получать программно, чем восстанавливать их состояние через сериализацию. К примеру, в классе BankPayment.java такие поля, как principal (директор) и rate (ставка) могут быть сериализованы, а interest (начисленные проценты) могут быть вычислены в любое время, даже после десериализации. Если мы вспомним, каждая нить в Java имеет собственную локальную память и производит операции чтения/записи в эту локальную память. Когда все операции сделаны, она записывает модифицированное состояние переменной в общую память, откуда все нити получают доступ к переменной. Как правило, это обычный поток внутри виртуальной машины. Но модификатор volatile говорит виртуальной машине, что обращение нити к этой переменной всегда должно согласовывать свою собственную копию этой переменной с основной копией переменной в памяти. Это означает, что каждый раз, когда нить хочет прочитать состояние переменной, она должна очистить состояние внутренней памяти и обновить переменную из основной памяти. Volatile наиболее полезно в свободных от блокировок алгоритмах. Вы отмечаете переменную, хранящую общие данные как volatile, тогда вы не используете блокировки для доступа к этой переменной, и все изменения, сделанные одной нитью, будут видимы для других. Или если вы хотите создать отношение «случилось-после» для обеспечения того, чтобы не повторялись вычисления, опять же для обеспечения видимости изменений в реальном времени. Volatile должно использоваться для безопасной публикации неизменяемых объектов в многопоточном окружении. Объявление поля public volatile ImmutableObject обеспечивает, что все нити всегда видят текущую доступную ссылку на экземпляр.Разница между Iterator и ListIterator?
Мы можем использоватьIterator для перебора элементов Set, List или Map. Но ListIterator может быть применим только для перебора элементов List. Другие отличия описаны ниже. Вы можете:- итерировать в обратном порядке.
- получить индекс в любом месте.
- добавить любое значение в любом месте.
- установить любое значение в текущей позиции.
javarush.ru
Java Core. Вопросы к собеседованию, ч. 3
В предыдущих двух статьях мы обсудили некоторые важные вопросы, которые Вам чаще всего задают на собеседованиях. Настало время продолжить и рассмотреть остальную часть вопросов.
Глубокое копирование и поверхностное копирование
Точной копией оригинала является его клон. В Java это означает возможность создавать объект с аналогичной структурой, как и у исходного объекта. Методclone() обеспечивает эту функциональность. Поверхностное копирование копирует настолько малую часть информации, насколько это возможно. По умолчанию, клонирование в Java является поверхностным, т.е. Object class не знает о структуре класса, которого он копирует. При клонировании, JVM делает такие вещи:- Если класс имеет только члены примитивных типов, то будет создана совершенно новая копия объекта и возвращена ссылка на этот объект.
- Если класс содержит не только члены примитивных типов, а и любого другого типа класса, тогда копируются ссылки на объекты этих классов. Следовательно, оба объекта будут иметь одинаковые ссылки.
- Нет необходимости копировать отдельно примитивные данные;
- Все классы-члены в оригинальном классе должны поддерживать клонирование. Для каждого члена класса должен вызываться
super.clone()при переопределении методаclone(); - Если какой-либо член класса не поддерживает клонирование, то в методе клонирования необходимо создать новый экземпляр этого класса и скопировать каждый его член со всеми атрибутами в новый объект класса, по одному.
Что такое синхронизация? Блокировка на уровне объекта и блокировка на уровне класса?
Синхронизация относится к многопоточности. Синхронизированный блок кода может исполняться одновременно только одним потоком. Java позволяет обрабатывать одновременно несколько потоков. Это может привести к тому, что два или более потока хотят получить доступ к одному и тому же полю. Синхронизация позволяет избежать ошибок памяти, возникающих при неправильном использовании ресурсов памяти. Когда метод объявлен как синхронизированный, нить удерживает его монитор. Если другая нить пытается в это время получить доступ к синхронизированному методу, то поток блокируется, и ждет освобождения монитора. Синхронизация в Java осуществляется специальным ключевым словом synchronized. Вы можете помечать таким образом отдельные блоки или методы в вашем классе. Ключевое слово synchronized не может быть использовано вместе с переменными или атрибутами класса. Блокировка на уровне объекта – механизм, когда вы хотите синхронизировать non-static метод или non-static блок кода таким образом, что только один поток сможет выполнить блок кода в данном экземпляре класса. Это нужно всегда делать, чтобы сделать экземпляр класса потокобезопасным. Блокировка на уровне класса предотвращает вход нескольких потоков в синхронизированный блок для всех доступных экземпляров класса. Например, если есть 100 экземпляров класса DemoClass, то только 1 поток сможет выполнить demoMethod () используя одну из переменных в определенный момент времени. Это должно быть всегда сделано, что бы обеспечить безопасность статического потока. Узнайте больше о синхронизации здесь.Какая разница между sleep() и wait()?
Sleep() — это метод, который используется, чтобы задержать процесс на несколько секунд. В случае сwait(), нить находится в состоянии ожидания, пока мы не вызовем метод notify() или notifyAll().
Основное различие заключается в том, что wait() снимает блокировку монитора, в то время как sleep() не освобождает блокировку. Wait() используется для многопотоковых приложений, sleep() используют просто для паузы выполнения нити. Thread.sleep() ставит текущий поток в «Not Runnable» состояние на определенное количество времени. Нить сохраняет состояние монитора, которое было до вызова данного метода. Если же другая нить вызывает t.interrupt(), нить которая «заснула» — проснется. Обратите внимание, что sleep() является статическим методом, что означает, что он всегда влияет на текущий поток (тот, который выполняет метод sleep()). Распространенной ошибкой является вызов t.sleep(), где t является другим потоком; даже тогда, когда текущая нить, которая вызвала метод sleep(), не является t нитью. Object.wait() посылает текущий поток в «Not Runnable» состояние на некоторое время, так же как и sleep(), но все же с некоторым нюансом. Wait() вызывается для объекта, а не для нити; мы называем этот объект “lock object”. Перед вызовом lock.wait(), текущая нить должна быть синхронизирована с “lock object”; wait() после этого снимает эту блокировку, и добавляет нить в ”wait list” связанный с этой блокировкой. Позже, другая нить может быть синхронизирована с тем же самым lock object и вызвать метод lock.notify(). Этот метод «разбудит» оригинальную нить, которая все еще ждет. В принципе, wait()/notify() можно сравнить с sleep()/interrupt(), только активной нити не нужен прямой указатель на спящую нить, нужно только знать общий lock object. Читайте детальную разницу здесь.Можно ли присвоить null к this ссылочной переменной?
Нет, нельзя. В Java левая часть оператора присваивания должен быть переменной. «This» — это специальное ключевое слово, которое всегда дает текущий экземпляр класса. Это не любая переменная. Точно также, null нельзя присвоить переменной, используя ключевое слово “super” или любое другое подобное.Какая разница между && и &?
& — побитово а && — логически.&оценивает обе стороны операции;&&оценивает левую сторону операции. Если она true, он продолжает оценить правую сторону.
Как переопределить equals() и hachCode() методы?
hashCode() и equals() методы определены в классе Object, который является родительским классом для Java объектов. По этой причине, все объекты Java наследуют реализацию по умолчанию для методов. Метод hashCode() используется для получения уникального целого числа для данного объекта. Это целое число используется для определения местоположения объекта, когда этот объект необходимо сохранить, например к HashTable. По умолчанию, hashCode() возвращает integer представление адреса ячейки памяти, где хранится объект. Метод equls(), как и следует из его имени, используется, чтобы просто проверить равенство двух объектов. Реализация по умолчанию проверяет ссылки на объекты на предмет их равенства. Ниже приведены важные рекомендации для перезагрузки данных методов:- Всегда используйте одинаковые атрибуты объектов при генерации
hashCode()иequals(); - Симметричность. Т.е. если для каких-либо объектов
xиyx.equals(y)возвращает true, то иy.equals(x)должен возвращать true; - Рефлексивность. Для любого объекта
xx.equals(x)должен возвращать true; - Постоянство. Для любых объектов
xиyx.equals(y)возвращает одно и то же, если информация, используемая в сравнениях, не меняется; - Транзитивность. Для любых объектов
x,yиz, еслиx.equals(y)вернет true иy.equals(z)вернет true, то иx.equals(z)должен вернуть true; - Всякий раз, когда метод вызывается у одного и того же объекта во время выполнения приложения, он должен возвращать одно и то же число, если используемая информация не изменяется.
hashCodeможет возвращать разные значения для идентичных объектов в различных экземплярах приложения; - Если два объекта равны, согласно
equals, то ихhashCodeдолжны возвращать одинаковые значения; - Обратное требование необязательно. Два неравных объекта могут возвращать одинаковый hashCode. Однако для повышения производительности, лучше, чтобы разные объекты возвращали разные коды.
Расскажите про модификаторы доступа
Классы Java, поля, конструкторы и методы могут иметь один из четырех различных модификаторов доступа: private Если метод или переменная помечены как private, то только код внутри одного класса может получить доступ к переменной, или вызвать метод. Код внутри подклассов не может получить доступ к переменной или методу, также как и не может получить доступ из любого другого класса. Модификатор доступа private чаще всего используется для конструкторов, методов и переменных. default Модификатор доступа default объявляется в том случае, если модификатор не указан вообще. Данный модификатор означает, что доступ к полям, конструкторам и методам данного класса может получить код внутри самого класса, код внутри классов в том же пакете. Подклассы не могут получить доступ к методам и переменным – членам суперкласса, если они объявлены как default, если подкласс не находится в том же пакете, что и суперкласс. protected Модификатор protected работает так же, как и default, за исключением того, что подклассы так же могут получить доступ к защищенным методам и переменным суперкласса. Данное утверждение является верным, даже если подкласс не находится в том же пакете, что и суперкласс. public Модификатор доступа public означает, что весь код может получить доступ к классу, его переменным, конструкторам или методам, независимо от того, где расположен этот код.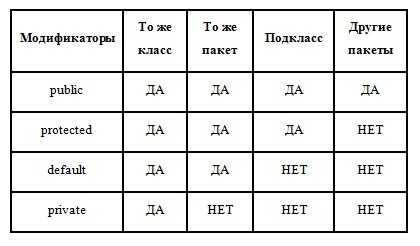
Что такое сборщик мусора? Можем ли мы вызвать его?
Сбор мусора является функцией автоматического управления памятью во многих современных языках программирования, таких как Java и языков в NET.Framework. Языки, которые используют сбор мусора, часто интерпретируют сбор мусора в виртуальной машине, такой как JVM. Сбор мусора имеет две цели: любая неиспользованная памяти должна быть освобождены, и память не должна быть освобождены, если программа еще будет ее использовать. Можете ли вы запустить сбор мусора вручную? Нет,System.gc() предоставляет вам настолько большой доступ, насколько можно. Лучшим вариантом является вызов метода System.gc(), который намекнет сборщику мусора про необходимость запуска. Нет никакого способа запустить его немедленно, так как сборщик мусора является недетерминированным. Кроме того, согласно документации, OutOfMemoryError не будет проброшена, если виртуальной машине не удалось освободить память после полной сборки мусора. Узнайте больше о сборщике мусора здесь.Что означает ключевое слово native? Объясните в деталях
Ключевое слово native применяется, чтобы указать, что метод реализован не в файле Java, а на другом языке программирования. Native методы использовались в прошлом. В текущих версиях Java это нужно реже. В настоящее время, native методы необходимы, когда:- Вы должны вызвать библиотеку из Java, которая написана на другом языке.
- Вам нужен доступ к системным или аппаратным ресурсам, к которым можно получить доступ только используя другой язык (как правило, С). На самом деле, многие системные функции, которые взаимодействуют с реальным компьютером (например диски или сетевые данные) могут быть вызваны только native методом.
- JNI/JNA могут дестабилизировать JVM, особенно если вы попытаетесь сделать что-то сложное. Если ваш native метод делает что-то неправильно, есть вероятность аварийного завершения JVM. Также, неприятные вещи могут произойти, если ваш native метод вызывается из нескольких нитей. И так далее.
- Программу с native кодом сложнее дэбажить.
- Native код требует отдельного построения фрэймворков, что может создать проблемы с переносом на другие платформы.
Что такое сериализация?
В компьютерных науках, в контексте хранения и передачи данных, сериализация – это процесс перевода структуры данных или состояния объекта в формат, который может быть сохранен и восстановлен потом в другой компьютерной среде. После приема серии битов, они пересчитываются в соответствии с форматом сериализации, и могут быть использованы для создания семантически идентичного клона исходного объекта. Java предоставляет автоматическую сериализацию, которая требует, чтобы объект реализовал интерфейсjava.io.Serializable. Реализация интерфейса помечает класс как «сериализуемый». В интерфейсе java.io.Serializable нет методов сериализации, но сериализуемый класс может дополнительно определить методы, которые будут вызваны как часть процесса сериализации/дисериализации. При внесении изменений в классы, необходимо учитывать, какие из них будут совместимы и не совместимы с сериализацией. Вы можете прочитать полную инструкцию здесь. Самые главные пункты я приведу: Несовместимые изменения:- Удаление поля;
- Перемещение класса вверх или вниз по иерархии;
- Изменение non-static поля на static или non-transient на transient;
- Изменение объявленного типа примитивный данных;
- Изменение метода
WriteObjectилиReadObjectтак, что они больше не пишут или не читают поля по умолчанию; - Изменение класса
SerializableнаExternalizableили наоборот; - Изменение класса enum на non-enum или наоборот;
- Удаление
SerializableилиExternalizable; - Добавление
writeReplaceилиreadResolveметода к классу.
- Добавление полей;
- Добавление/удаление классов;
- Добавление методов
WriteObject/ReadObject[методыdefaultReadObjectилиdefaultWriteObjectдолжны быть вызваны в начале]; - Удаление методов
WriteObject/ReadObject; - Добавление
java.io.Serializable; - Изменение доступа к полю;
- Изменение static поля на non-static или transient на non-transient.
javarush.ru
Руководство по Java Core. Введение. – PROSELYTE
Язык программирования Java был разработан компанией и был представлен как ключевой компонент Sun Microsystems Java platform в 1995 году. Этот и год и считается годом выпуска Java 1.0.
На данный момент (Февраль 2015 года) крайней версией является Java SE 8.
С развитием Java были созданы её различные типы:
- J2SE – ключевой функционал языка Java.
- J2EE – для разработки корпоративных приложений
- J2ME – для разработки мобильных приложений
Девизом Java является: “Write Once, Rune Anywhere”. Другими словами, речь идёт о кроссплатформенности. Они достигается за счёт использования вирутальной машины Java (Java Virtual Machine – JVM).
Какие сильные стороны самого популярного языка программирования в мире (на Февраль 2016 года)?
Мы можем назвать такие:
- Платформо-независимость
Наш класс, написанный на Java компилируется в платформо-независимый байт-код, который интерпретируется и исполняется JVM. - Простота
Синтаксис языка крайне прост в изучении. От нас требуется лишь понимание основ ООП, потому что Java является полностью объекто-ориентированной. - Переносимость
Тот факт, что Java не реализовывает специфичных аспектов для каждого типа машин, делает программы, написанные с её использованием переносимыми. - Объекто-ориентированность
Всё сущности в Java являются объектами, что позволяет нам использовать всю мощь ООП. - Безопасность
Безопасность Java позволяет разрабатывать ситсемы, защищённые от вирусов и взломов. Авторизация в Java основана на шифровании открытого ключа. - Устойчивость
Защита от ошибок обеспечивается за счёт проверок во время компиляции и во время непосредственного выполнения программ. - Интерпретируемость
Байт-код Java транслируется в машинные команды “на лету” и нигде не хранится. - Распределённость
Java разработана для распредёленного окружения Internet. - Многопоточность
Язык поддерживает многопоточность (одновременное выполнение нескольких задач), что позволяет нам создавать хорошо отлаженные приложения - Производительность
Использование JIT (Just-In-Time) компилятора, позволяет достигать высоких показателей.
Что нам понадобится для того, чтобы использовать Java:
- ОС Linux или Windows (для наших уроков предпочтительнее Ubuntu )
- Java JDK 8
- IDE (для наших уроков предпочтительнее Intellij IDEA 14)
В ходе этого цикла уроков Вы увидите, как создавать простые, графические и веб приложения используя язык программирования Java.
В дальнейших уроках мы рассмотрим как установить JDK и создадим нашу первую программу на Java.
proselyte.net
Курс Java Core — Лекция: Адаптеры
— Привет, Амиго! Сегодня я расскажу тебе, что же такое «адаптер». Надеюсь, что после его изучения ты начнешь понимать потоки ввода-вывода гораздо лучше.

Представь, что в твоей программе ты используешь два фреймворка, написанные другими программистами/компаниями. Оба фреймворка очень хорошие и используют принципы ООП: абстракцию, полиморфизм, инкапсуляцию. Они вместе практически полностью покрывают задачи твоей программы. За тобой осталось простая задача — объекты, которые создает один фреймворк нужно передать во второй. Но оба фреймворка совершенно разные и «не знают друг о друге» — т.е. не имеют общих классов. Тебе нужно как-то преобразовывать объекты одного фреймворка в объекты другого.
Эту задачу можно красиво решить, применив подход (паттерн проектирования) «адаптер»:
| Код на Java | Описание |
|---|---|
| Это схематическое описание «паттерна проектирования адаптер». Суть его в том, что класс MyClass является преобразователем (адаптером) одного интерфейса к другому. |
— А можно более конкретный пример?
— Ок. Допустим, что у каждого фреймворка есть свой уникальный интерфейс «список», вот как это может выглядеть:
| Код на Java | Описание |
|---|---|
| Код из первого(Alpha) фреймворка. AlphaList – это один из интерфейсов, для взаимодействия кода фреймворка и кода, который будет использовать этот фреймворк. |
| AlphaListManager – класс фреймворка, метод которого createList создает объект типа AlphaList |
| Код из второго(Beta) фреймворка. BetaList – это один из интерфейсов, для взаимодействия кода фреймворка и кода, который будет использовать этот фреймворк. BetaSaveManager – класс фреймворка, метод которого saveList сохраняет на диск объект типа BetaList |
| Класс «адаптер» (т.е. переходник) от интерфейса AlphaList к интерфейсу BetaList Класс ListAdapter реализует интерфейс BetaList из второго фреймворка. Когда кто-то вызывает эти методы, код класса перевызывает методы переменной list, которая имеет тип AlphaList из первого фреймворка. Объект типа AlphaList передается в конструктор ListAdapter в момент создания Метод setSize работает по принципу: если нужно увеличить размер списка – добавим туда пустых (null) элементов. Если нужно уменьшить – удалим несколько последних. |
| Пример использования |
— Больше всего понравился пример использования. Очень компактно и понятно.
javarush.ru
Курс Java Core — Лекция: Интерфейсы — это больше чем интерфейсы — это поведение
Интерфейсы сильно упрощают жизнь программиста. Очень часто в программе тысячи объектов, сотни классов и всего пара десятков интерфейсов – ролей. Ролей мало, а их комбинаций – классов – очень много.
Весь смысл в том, что тебе не нужно писать код для взаимодействия со всеми классами. Тебе достаточно взаимодействовать с их ролями (интерфейсами).
Представь, что ты – робот-строитель и у тебя в подчинении есть десятки роботов, каждый из которых может иметь несколько профессий. Тебе нужно срочно достроить стену. Ты просто берешь всех роботов, у которых есть способность «строитель» и говоришь им строить стену. Тебе все равно, что это за роботы. Хоть робот-поливалка. Если он умеет строить – пусть идет строить.
Вот как это выглядело бы в коде:
| Код на Java | Описание |
|---|---|
| — способность «строитель стен». Понимает команду «(по)строить стену» — имеет соответствующий метод. |
| — роботы у которых есть эта профессия/особенность. — для удобства я сделал классам имена на русском. Такое допускается в java, но крайне нежелательно. — поливалка не обладает способностью строить стены (не реализует интерфейс WallBuilder). |
| — как дать им команду – построить стену? |
— Чертовски интересно. Даже и не думал, что интерфейсы – такая интересная тема.
— А то! В совокупности с полиморфизмом – это вообще бомба.
javarush.ru
Руководство по Java Core. Коллекции. – PROSELYTE
Для хранения групп обхектов одинакового типа в языке программирования Java был разработан Collections Framework.
К нему были предъявлены следующие требования:
- Должен позволять работать с разными типами данных одинаково и с высокой степенью совместимости.
- Должен иметь выскоую производительность и эфективно реализовывать фундаментальные структуры данных такие, как связный список, деревья, хэш-таблицы и динамичесике массивы.
- Должен позволять легко создавать собственные коллекции для специфических задач.
Для реализации этих целей, был разработан набор интерфейсов, на базе которых были созданы готовые коллекции и которые позволяют разрабатывать собственные.
Collections Framework состоит из:
- Интерфейсов
Эти интерфейсы представляют коллекции и позволяют манипулировать данными таким образом, чтобы создавать собственные коллекции для специфичных задач. - Классов, которые реализуют интерфейсы
Конкретные имплементации интерфейсов, которые представляют собой структуры данных. - Алгоритмов
Набор методов, которые позволяют эффективно выполнять такие операции, как поиск и сортировка в структурах данных Collections Framework.
Интерфейсы
Давайте рассмотрим различные интерфейсы Collections Framework:
- Collection
Этот интерфейс позволяет нам работать с группами объектов. - List
Наследует класс Collection и является упорядоченным списком элементов. - Set
Наследует класс Collection и содержит множество уникальных элементов. - SortedSet
Наследует Set и является упорядоченныи множеством уникальных элементов. - Map
Хранит уникальные элементы типа “ключ – значение”. - Map.Entry
Описывает элемент в Map. Внутренний класс Map. - SortedMap
Расширяет класс Map и сортирует элементы по возрастанию. - Enumeration
Интерфейс, который определяет методы для “перебора” элементов в коллекции. Заменён интерфейсом Iterator.
Классы
В языке программирования Java разработан набор стандартных классов, которые представляют базовые структуры данных. Некоторые из них являются полной реализацией и готовы к использованию, а некоторые являются лишь карскасами для будущих коллекций.
Рассмотрим их:
- AbstractCollection
Этот класс реализовывает большинство методов класса Collection. - AbstractList
Наследует класс AbstractCollection и реализовывает большинство методов интерфейса List. - AbstractSequentialList
Наследует класс AbstractList для использования коллекции с последовательным, а не со свободным доступом к элементам. - AbstractSet
Наследует AbstractCollection и реализовывает большинство методов интерфейса Set. - AbstractMap
Реализовывает большинство методов интерфейса Map. - ArrayList (ссылка на пример)
Наследует абстрактный класс AbstractList и является реализацией динамического массива. - LinkedList (ссылка на пример)
Наследует AbstractSequentialList и является реализацией связного списка. - HashSet (ссылка на пример)
Наследует AbstractSet и является реализацией хэш-таблицы. - LinkedHashSet (ссылка на пример)
Наследует HashSet и является запоминает порядок добавления элементов. - TreeSet (ссылка на пример)
Наследует AbstractSet и является реализацией красно-чёрного дерева (множества уникальных элементов в виде дерева). - HashMap (ссылка на пример)
Наследует AbstractMap и является реализацией хэш-таблицы. - TreeMap (ссылка на пример)
Наследует AbstractMap для создания дерева. - WeekHashMap (ссылка на пример)
Наследует AbstractMap для использования хэш-таблицы со “слабыми” ключами. - LinkedHashMap (ссылка на пример)
Наследует HashMap для запоминания порядка добавления элементов. - IdentityHashMap (ссылка на пример)
Наследует AbstractMap и использует равенство ссылок при сравнении документов.
Алгоритмы
Collections Framework имет несколько алгоритмов, которые могут быть применены к коллекциям и структурам, хранящим элементы типа “ключ-значение” (Maps).
Эти алгоритмы определены в виде статических методов внутри классов коллекций.
Рассмотрим сами алгоритмы и пример простого приложения с их спользованием.
Перейдите по ЭТОЙ ССЫЛКЕ.
Компаратор
Такие стурктуры данных, как TreeMap и TreeSet сортируют элементы, которые хранят. Для сравнения этих элементов разработана такая сущность, как компаратор (Comaprator).
Более подробно компаратор описан на странице, перейти на которую можно по ЭТОЙ ССЫЛКЕ.
Итератор
Часто мы сталкиваемся с ситуацией, когда нам необходимо отобразить все элементы нашей коллекции. Для того в языке программирования Java разработана такая сущность, как Iterator.
Iterator позволяет нам “пробежаться” по коллекции, получать и удалять элементы.
Listerator наследует Iterator и позволяет нам пробегать коллекцию в обоих направлениях, а самое главное – позволяет модифицировать элементы коллекции.
Более подробно Iterator описан на странице, перейти на которую можно по ЭТОЙ ССЫЛКЕ.
В этом уроке мы изучили основы Collections Framework. Мы рассмотрели интерфейсы, конкретные классы и аогритмы этого модуля. Мы также разобрали примеры простых приложений с их использованием.
В следующем уроке мы изучим сериализацию объектов в языке программирования Java.
proselyte.net