Ввод Товаров и остатков с помощью мастера «Ввод начальных остатков»
Ввод Товаров и остатков с помощью мастера «Ввод начальных остатков»
Эта статья является продолжением статьи Быстрый ввод Номенклатуры и начальных остатков через файл Excel. В статье узнаете как занести остатки товаров, денег, дебиторскую и кредиторскую задолженности и другие активы в информационную базу 1С: Управление Нашей Фирмой с помощью мастера «Ввод начальных остатков»
Данный вариант позволяет заполнить не только остатки товаров, но и денежные средства в кассе и на расчетном счете, дебиторскую и кредиторскую задолженность и другие остатки. Ввод остатков через обработку «Ввод начальных остатков» приходует остатки, но, в отличии от приходной накладной, не создает задолженность перед поставщиком.
Для ввода остатков в программу желательно заранее загрузить справочники по товарам, контрагентам и т. п.
Ссылка на мастер «Ввод начальных остатков» расположена в разделе Компания в блоке «Начальные остатки»
Рис 10. Путь к ссылке Ввод начальных остатков в 1С: Управление нашей фирмой
Путь к ссылке Ввод начальных остатков в 1С: Управление нашей фирмой
Клик по этой ссылке открывает журнал документов «Ввод начальных остатков»
Рис 11. Журнал документов Ввод начальных остатков в 1С: Управление нашей фирмой
На примере мы видим ранее созданный через загрузку Excel документ. Для создания нового документа нажимаем кнопку «Создать».
Откроется начальная страница «Помощник ввода начальных остатков»
Рис 12 Помощник Ввода начальных остатков в 1С: Управление нашей фирмой
На начальной странице вводим:
— Дату ввода остатков — можно ввести остатки ранним числом или более поздним, в зависимости от политики учета и текущей ситуации.
— Организацию — если организаций несколько, то по каждой организации создаем свой документ.
Ниже располагаются ссылки на материалы по автоматическим загрузкам из разных источников — Управление торговлей 10. 3, из Бухгалтерии 3.0 из сайта (UMI и 1С-Битрикс)
3, из Бухгалтерии 3.0 из сайта (UMI и 1С-Битрикс)
Для перехода к другим страницам или жмем кнопку «Далее» или кликаем на нужную ссылку справа от кнопки «Далее».
Следующая вкладка «Деньги»
Рис 13 Вкладка деньги в помощнике Ввода начальных остатков в 1С: Управление нашей фирмой
В этой вкладке заполняем остатки на счетах в банках и наличных в кассах, а также на руках у подотчетников.
Следующая вкладка «Товары» в которой мы заносим остатки по товарам на складах
Рис 14 Вкладка Товары в помощнике Ввода начальных остатков в 1С: Управление нашей фирмой
Основное отличие данной вкладки от Приходной накладной — она не создает долг перед контрагентом.
Ввод остатков можно сделать вручную:
— с помощью кнопки «Добавить»
— сканировать штрихкод с помощью Сканера штрихкода
— загрузить из Терминала сбора данных(ТСД) — можно загружать остатки проводя инвентаризацию с помощью ТСД
или загрузить из файла Excel — мастер ввода данных из Excel открывается нажатием на пиктограмму таблицы
Рис 15. Загрузка данных из Excel в помощнике Ввод начальных остатков в 1С: Управление нашей фирмой
Загрузка данных из Excel в помощнике Ввод начальных остатков в 1С: Управление нашей фирмой
Дальше действуем так как было описано выше — нажимаем «Далее», выбираем подготовленный файл
Рис 16. Выбор названия столбцов в табличной части Загрузки из стороннего файла в мастере Ввод начальных остатков в 1С: Управление нашей фирмой
В первой строке заполняем названия колонок — нажимаем на на ссылку «Не загружать». Обязательно должны быть указаны колонки выделенные красным цветом — Номенклатура, Количество и Цена.
Если Номенклатура, указанная в файле, ранее не вводилась — на завершающей странице необходимо поставить галочку «Создавать новые элементы, если полученные данные не сопоставлены.»
Рис 17. Завершающая страница Загрузки из стороннего файла в мастере Ввод начальных остатков в 1С: Управление нашей фирмой
На этом загрузку Начальных остатков товаров заканчиваем
Следующие вкладки мастера ввода начальных остатков заполняем по желанию
Вкладка «Расчеты» — позволяет внести в УНФ расчеты с:
Рис 18. Вкладка «Расчеты» Ввода начальных остатков в 1С: Управление нашей фирмой
Вкладка «Расчеты» Ввода начальных остатков в 1С: Управление нашей фирмой
— Поставщиками,
— Персоналом,
— Налогам,
— Эквайрингу.
Во вкладках Поставщики, Покупатели и Персонал есть возможность занесения данных из файла Excel.
Вкладка «Прочие» — позволяет внести в УНФ остатки, которые не вошли в предыдущие вкладки.
Рис 19. Вкладка «Прочие» Ввода начальных остатков в 1С: Управление нашей фирмой
Это может быть незавершенное производство, транспорт и другое
После заполнения нужных вкладок нажимаем ссылку «Финиш» — мастер создает документы ввода остатков.
Посмотрим журнал «Ввод начальных данных»
Рис 20. Журнал Ввод начальных остатков в 1С: Управление нашей фирмой.
Мы видим по сравнению с более ранней версией(см Рис 11) появились еще файлы и кнопка «Создать» превратилась в кнопку «Продолжить ввод остатков».
Если у нас несколько предприятий и должны внести остатки по другим предприятиям, то нажимаем «Продолжить ввод остатков» и заменяем данные первого предприятия новыми.
На этом рассмотрение завершаем. В следующей статье мы рассмотрим Ввод остатков с помощью документа «Приходная накладная»
Если у Вас появились вопросы по работе в программе 1С Управление Нашей Фирмой позвоните нам по телефонам +7(383)312-07-64 и +7-923-158-67-74 (он же WhatsApp) — наши консультанты помогут Вам.
Если Вы хотите попробовать 1С УНФ в работе мы предоставим Вам тестовый доступ к программе на 30 дней.
Вы можете купить у нас 1С УНФ для локального компьютера или арендовать ее в облачных сервисах 1СFresh и MacCloud
Ввод начальных остатков в 1С:ERP по убыткам от реализации основных средств в прошлом периоде
03 марта 2021 Главному бухгалтеру Информацию по этому вопросу найти непросто, поэтому мы решили поделиться своим опытом.
Информацию по этому вопросу найти непросто, поэтому мы решили поделиться своим опытом. В данной статье мы расскажем, как ввести начальные остатки в 1С:ERP по убыткам от реализации основных средств, которые мы понесли в прошлом периоде.
Разберем случай, когда мы продали основное средств в убыток.
В бухгалтерском учете затраты мы списываем сразу же, в налоговом – списание этих убытков мы растягиваем на оставшийся срок полезного использования. То есть, если у основного средства срок полезного использования еще 5-10 лет, неважно амортизировано оно или нет, то в налоговом учете мы эти убытки должны списывать равными долями в оставшийся срок.
Данные об убытках прошлых лет в налоговом учете нужно вводить только на субсчетах 97 счета. Убытки от реализации основных средств вводим на счете 97.21 «Прочие расходы будущих периодов».
Для ввода начальных остатков в 1С:ERP предусмотрены специальные документы.

Для этого необходимо зайти в НСИ «Администрирование» – «Начальное заполнение» – «Документы ввода начальных остатков».
Документы по убытку от реализации основных средств вводим в подразделе «Ввод остатков прочих расходов» (скрин.1).
Скриншот 1
Данные субконто 97 счета связаны со справочником «Статьи расходов с особым видом распределения». Для детализации данных по каждому проданному в убыток основному средству создаем свою статью расходов. Например, как на скриншоте 2.
Скриншот 2
Указываем тип расходов — «Прочие операционные и внереализационные расходы», вариант распределения расходов в регламентированном учете – «Отнести к расходам будущих периодов».
Особенностью введения данной статьи расходов будущих периодов (РБП) является то, что нужно указать вид РБП – «Убытки от реализации амортизируемого имущества» и счет учета – 97. 21 во вкладке «Регламентированный учет и МФУ» (скрин.3).
21 во вкладке «Регламентированный учет и МФУ» (скрин.3).
Скриншот 3
Как только мы выбрали вариант распределения расходов в регламентированном учете – «Отнести к расходам будущих периодов», становится активным поле по вводу правила распределения: по какому правилу эти расходы будут распределены (скрин.4).
Скриншот 4
Создаем новое правило распределения РБП.
В правиле указываем наименование правила, подразделение, и на какую статью расходов будем списывать убыток от реализации основного средства при распределении расходов будущих периодов (скрин.5).
Скриншот 5
Переходим к вводу данных (скрин.6).
Скриншот 6
Особенностью ввода данных по этой статье является то, что мы вводим данные только в налоговом учете. Соответственно, как только данные бухучета станут равны 0 и появятся данные в налоговом учете, система автоматически рассчитывает временную разницу. Она равна сумме остатка по этому убытку в налоговом учете, со знаком минус.
Соответственно, как только данные бухучета станут равны 0 и появятся данные в налоговом учете, система автоматически рассчитывает временную разницу. Она равна сумме остатка по этому убытку в налоговом учете, со знаком минус.
Таким образом получаем проводки следующего вида (скрин.7).
Скриншот 7
Счет Дт – 97.21. Субконто Дт – убыток от реализации основных средств.
В бухгалтерском учете никаких данных нет. В налоговом учете – сумма остатка по этому убытку. Во временных разницах – сумма остатка с минусом.
Для того чтобы далее отработать этот начальный остаток, необходимо зайти в рабочее место «Распределение РБП» в разделе «Финансовый учет и контроллинг».
После ввода начального остатка во вкладке «К распределению» появится строчка (статья РБП) по убытку. Нажимаем «Распределить расходы» (скрин.8).
Скриншот 8
Выбираем статью РБП во вкладке «Распределение расходов» (скрин.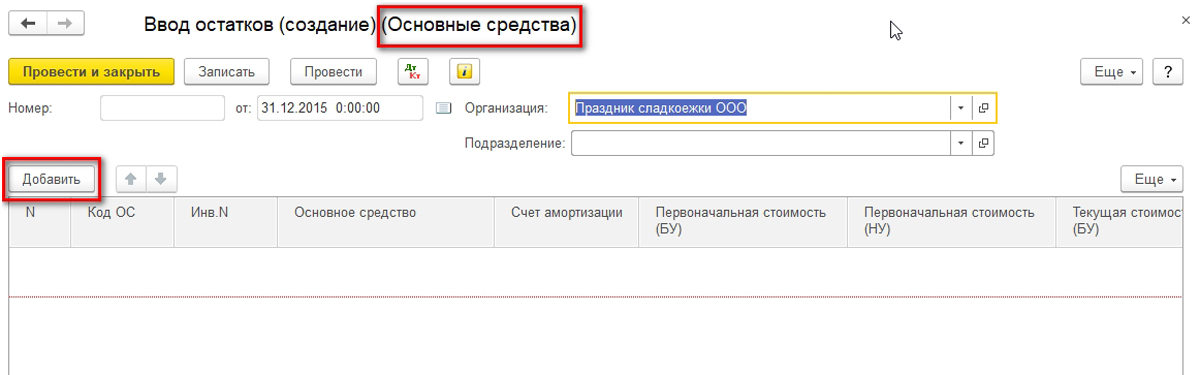 9).
9).
Скриншот 9
Система подтягивает данные по этой статье: подразделение, аналитику и сумму остатка в управленческий и налоговый учет.
Указываем, за какой период необходимо распределить этот остаток по убытку.
Затем заходим во вкладку «Распределение по месяцам» и нажимаем «Распределить расходы» (скрин.10).
Скриншот 10
Система рассчитает ежемесячные списания и создаст проводки до окончания периода распределения остатка.
Этот же документ содержит все данные по распределению убытка за весь период, указанный во вкладке «Основное» (скрин.11).
Скриншот 11
Мы рассмотрели, как ввести начальные остатки в 1С:ERP по убыткам от реализации основных средств, которые мы понесли в прошлом периоде. В следующей статье мы расскажем, как ввести начальные остатки в 1С:ERP по убыткам прошлых лет.
Если у вас есть вопросы и требуется консультация, звоните. Мы будем рады вам помочь.
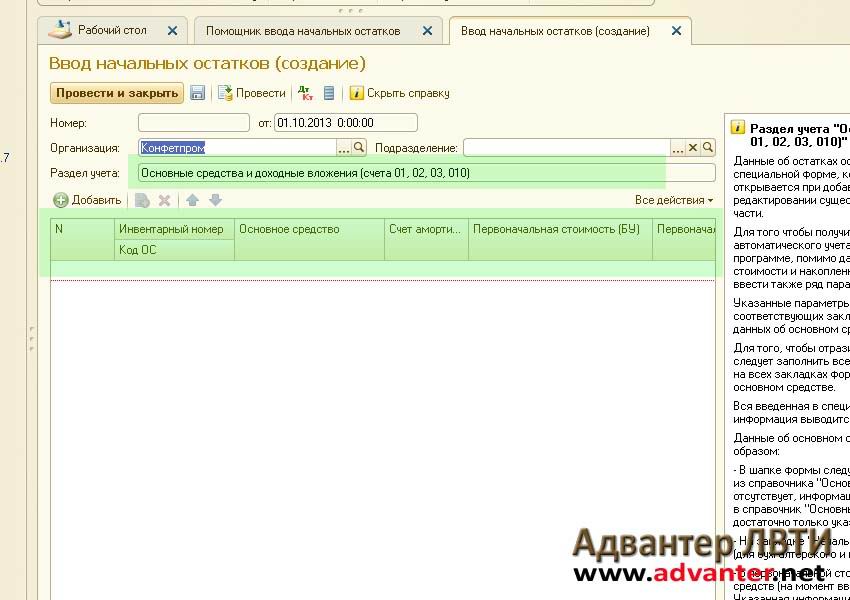
Ввод начальных остатков в 1С Бухгалтерия 8 редакция 3 с использованием помощника ввода
Начальные остатки по счетам учета обычно требуется ввести перед началом работы в программе, если ранее учет велся в другой программе. Учет в новой программе обычно начинают вести с начала года, в этом случае не возникнет проблем с формированием отчетов и отчетности. Если организация создана в том же году, в котором начала вести учет в программе, то вводить начальные остатки по ней не требуется.
Для ввода начальных остатков в программе «1С:Бухгалтерия 8» (ред. 3.0) предназначена специальная обработка «Помощник ввода начальных остатков».
Документы по вводу остатков по балансовым счетам (закладка «Основные счета плана счетов») создаются по разделам ведения учета. В одном документе обычно отражаются остатки по всем счетам соответствующего раздела.
|
Разделы учета, по которым вводятся остатки |
|||
|---|---|---|---|
|
|
|
|
Документы по вводу остатков по забалансовым счетам создаются на закладке «Забалансовые счета плана счетов» по разделу «Прочие счета бухгалтерского учета».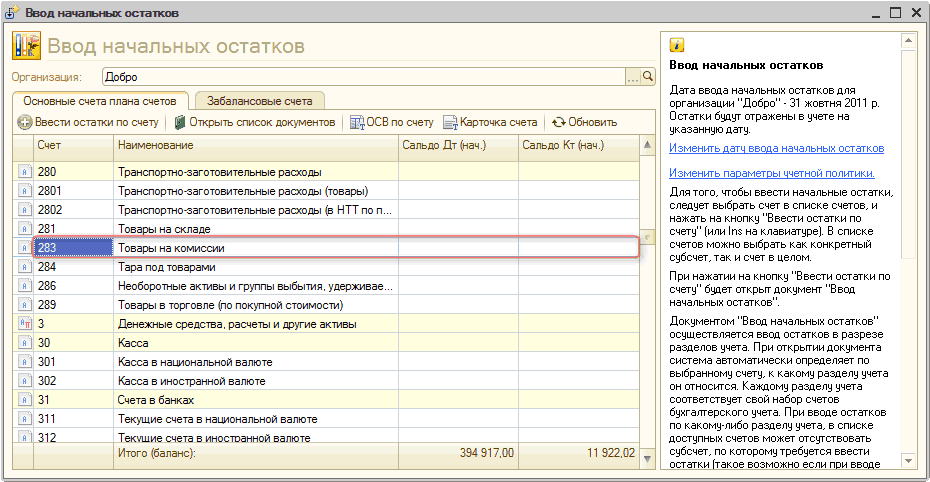 Суммы остатков по забалансовым счетам отображаются только на закладке «Забалансовые счета плана счетов».
Суммы остатков по забалансовым счетам отображаются только на закладке «Забалансовые счета плана счетов».
Предварительно перед вводом начальных остатков проверьте, что для организации на дату начала ведения учета в программе установлены параметры учета в формах «Учетная политика» и «Настройки налогов и отчетов».
1. Раздел: Главное – Помощник ввода остатков.
2. Перейдите по ссылке «Установить дату ввода остатков» и укажите дату ввода начальных остатков — 31 декабря года, предшествующего году начала ведения учета в программе. Установленная дата едина для всех документов «Ввод остатков» по организации. В самих документах изменить дату нельзя. При необходимости изменить дату ввода остатков перейдите по ссылке с указанной датой и укажите новую, при этом у всех проведенных документов «Ввод остатков» по организации дата изменится автоматически.
3. После установки даты, для создания документов «Ввод остатков» выберите в списке счет и нажмите кнопку «Ввести остатки по счету» (рис.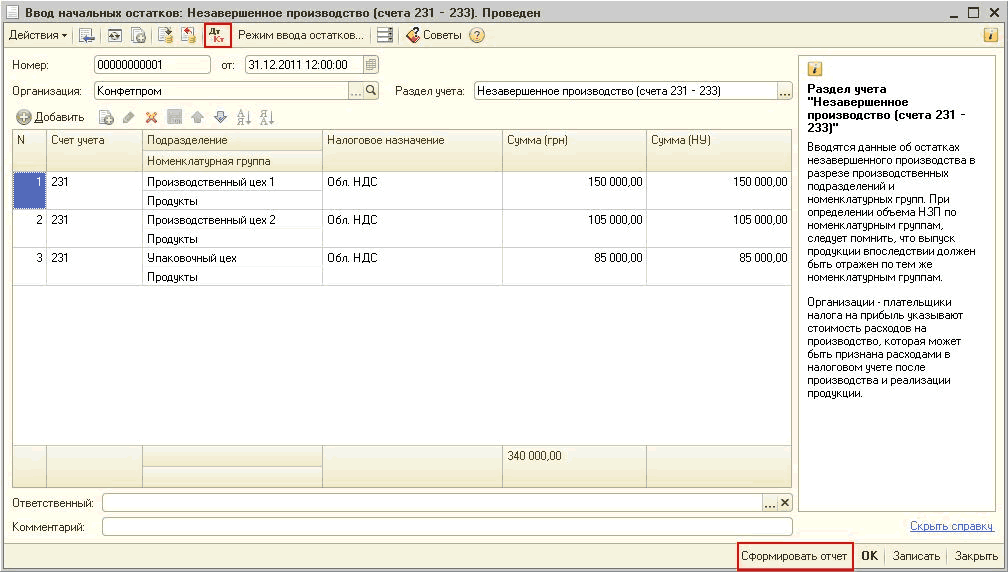 2). Автоматически будет создан документ «Ввод остатков» по соответствующему разделу учета (указывается в скобках в названии документа). Также можно создать документ по двойному щелчку левой клавишей мыши на выбранном счете и кнопке «Создать». В табличную часть документа вводятся остатки по всем счетам соответствующего раздела.
2). Автоматически будет создан документ «Ввод остатков» по соответствующему разделу учета (указывается в скобках в названии документа). Также можно создать документ по двойному щелчку левой клавишей мыши на выбранном счете и кнопке «Создать». В табличную часть документа вводятся остатки по всем счетам соответствующего раздела.
Если требуется открыть для просмотра и редактирования уже созданный документ, то в форме «Помощник ввода начальных остатков» дважды щелкните левой клавишей мыши на любом счете, чтобы открыть форму со списком документов, и снимите флажок «Раздел учета». Фильтр по разделам учета будет отключен и сформируется весь список документов «Ввод остатков».
Бухгалтерские проводки по вводу начальных остатков формируются в корреспонденции со счетом 000 «Вспомогательный счет». Сумма по данным налогового учета в документе по вводу остатков отражается в том случае, если на соответствующем счете ведется налоговый учет. В противном случае в налоговом учете операция не отражается, а реквизит для ввода суммы по данным налогового учета становится недоступным. В отдельных колонках указываются постоянные и временные разницы в оценке активов по данным бухгалтерского и налогового учета (ПБУ18/02 «Расчеты по налогу на прибыль»). Величину постоянных разниц необходимо указать, величина временных разниц рассчитывается автоматически как разница между оценкой стоимости по данным бухгалтерского учета и суммой оценки стоимости по данным налогового учета и величиной постоянных разниц. Постоянные и временные разницы в оценке стоимости редактируются и отражаются в учете в том случае, если на счете ведется налоговый учет, в противном случае разницы в учете не отражаются, а соответствующие реквизиты становятся недоступными.
В отдельных колонках указываются постоянные и временные разницы в оценке активов по данным бухгалтерского и налогового учета (ПБУ18/02 «Расчеты по налогу на прибыль»). Величину постоянных разниц необходимо указать, величина временных разниц рассчитывается автоматически как разница между оценкой стоимости по данным бухгалтерского учета и суммой оценки стоимости по данным налогового учета и величиной постоянных разниц. Постоянные и временные разницы в оценке стоимости редактируются и отражаются в учете в том случае, если на счете ведется налоговый учет, в противном случае разницы в учете не отражаются, а соответствующие реквизиты становятся недоступными.
Правильность ввода начальных остатков можно проверить, сопоставив сальдо по дебету и кредиту в форме «Помощник ввода начальных остатков».
Тот же результат должен получиться при формировании отчета «Оборотно-сальдовая ведомость» за год, указанный в документах ввода остатков. Показателем правильности ввода начальных остатков является нулевое сальдо по счету 000.
Ввод начальных остатков по денежным средствам в 1С предприятие
Ввод начальных остатков по денежным средствам в 1С предприятие — Ультрабизнес
3 октября 2013Перед вводом начальных остатков по денежным средствам необходимо заполнить справочники:
Статьи движения денежных средств. Меню Справочники/Денежные средства/Статьи движения денежных средств рекомендуется ввести статью «Ввод начальных остатков»
Ввести банки Меню Справочники/Классификаторы/Банки.
Ввести наши банковские счета. Меню Справочники/Организации/Осн. банковский счет
В общем случае, для ввода начальных остатков по денежным средствам необходимо использовать документы:
- Для безналичных счетов, «Платежное поручение входящее», с видом операции «прочий приход денежных средств»
- Для наличных денежных средств, «Приходный кассовый ордер», вид операции «прочий приход денежных средств».
Давайте рассмотрим их более детально.
Когда переносятся остатки по деньгам, они переносятся суммой на определенном расчетном счете или кассе. Нет необходимости, в таком случае переносить все выписки или кассовые ордера, существующие в старой учетной системе.Текущие счета в национальной валюте
Для ввода остатков по безналичным денежным средствам рекомендуется использовать документ «Платежное поручение входящее», с видом операции прочее поступление безналичных денежных средств, Меню Документы/Денежные средства/Банк/Платежное поручение входящее.
Счет корреспонденции выбираем 00 этот счет балансовый и специально предназначен для ввода начальных остатков.
Статья движения денежных средств это вторая аналитика по 311 счету в плане счетов.
Флаг оплачено именно от него зависит, сделает ли документ бухгалтерские проводки и какой датой.
В случае если этот флаг снят, платеж не акцептованный, например, в случае фактического захода денег на расчетный счет не сегодняшним днем. Это может быть вызвано какими-то задержками со стороны банка, функционал таких платежных документов используется в планировании движения денежных средств в управленческом учете, без флага оплачено документ не сделает проводок по бухгалтерскому учету.
После проведения, документ формирует проводки по бухгалтерскому учету:
Выписка банка в программе реализована 1С 8.2, но это не документ как в 1С 7.7, а обработка (Меню/Документы/Денежные средства/Банк/Выписка банка) по ней можно посмотреть все движения платежей за день, а также остаток на начало дня, сумму прихода, сумму расхода и конечный остаток, для нашего примера:
Текущие счета в иностранной валюте
Ввод начальных остатков по счетам в иностранной валюте также рекомендуется делать с помощью документа платежное поручение входящее, с видом операции «Прочее поступление денежных средств».
Особенность ввода начальных остатков по валютным счетам заключается в том, что на дату ввода необходимо предварительно заполнить курс валюты Меню Справочники/Валюта/курсы валют.
После нажатия мы попадаем в одноименный регистр, где выставляем курс валюты на момент ввода начальных остатков.
Курс валюты необходимо заполнить для того чтобы у нас сформировалась корректная стоимость валюты в бухгалтерском учете.
Рассмотрим особенности заполнения документа платёжное поручение входящее, с вводом остатков по валютам. Первая особенность счет учета здесь необходимо выбрать валютный счет, это может быть 312 или 314.
Второй особенностью есть то, что банковский счет, по которому вводим остатки по валюте, должен быть создан заранее и должен быть в той же валюте, в которой вводим начальные остатки.
Как видим с проводок бухгалтерского учета, документ формирует валютную сумму и сумму гривневого покрытия валюты, по курсу национального банка на дату ввода остатков.
Купить программу 1С можно здесь www.softmaster.com.ua
Посмотреть, а также ознакомится с нашими самостоятельными курсами по 1С, можно по ссылкам:
Ввод начальных остатков по запасам в 1С предприятие
Ввод начальных остатков по запасам в 1С предприятие — Ультрабизнес
20 ноября 2013Для ввода начальных остатков по запасам необходимо использовать документ «Оприходование товаров». «Меню Документы/Запасы (склад)/Оприходование товаров».
«Меню Документы/Запасы (склад)/Оприходование товаров».
Остатки также вводятся, последним днем квартала, что предшествует кварталу введения остатков.
Первоначально рекомендуется заполнить справочник склады, если в организации будет вестись учет запасов по складам: Меню Справочники/Предприятия/Склады (места хранения), если учет ТМЦ на предприятии не будет вестись в разрезе складов справочник заполнять не обязательно.
Рисунок 1
При заполнении важным моментом является вид склада (оптовый, розничный или неавтоматизированная торговая точка), в зависимости от вида склада нам будут доступны те, или иные механизмы учета запасов.
Также необходимо заполнить справочник виды номенклатуры: Меню/Справочники/Номенклатура/Виды номенклатуры.
Рисунок 2
Основным и важным показателем вида номенклатуры есть ее тип, он может быть услуга, товар, набор-пакет, набор комплект. Именно тип номенклатуры дает программе понять является ли введенная номенклатура материальной или не материальной сущностью.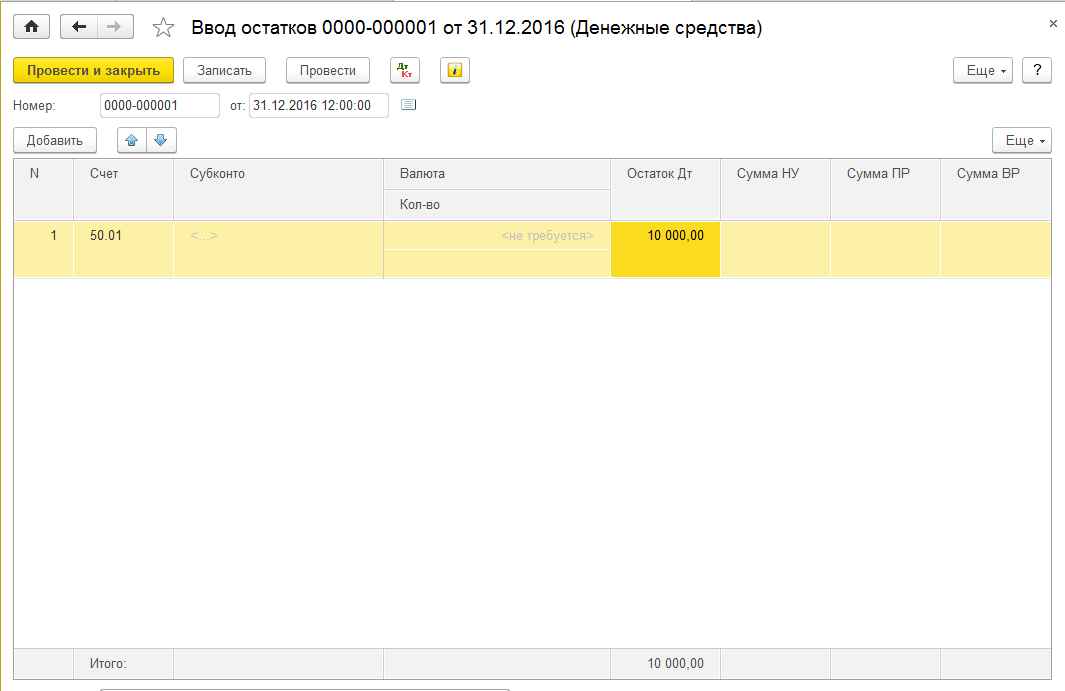
Набор пакет — это виртуальный тип номенклатуры при выборе этой номенклатуры при списании будут списаны все комплектующие входящие в набор, например: детский подарок — туда входит игрушка, шоколадка, конфеты, при выборе номенклатуры детский подарок в документе реализации или списания, табличная часть будет заполнена комплектующими и они будут списаны со склада.
Набор комплект это отдельная единица складского учета при списании или реализации у нас будет списан именно комплект.
Важным является первоначальное заполнение классификаторов единиц измерения: Меню Справочники/Классификаторы/Классификатор единиц измерения.
Рисунок 3
Теперь необходимо заполнить справочник номенклатура: Меню Справочники/Номенклатура.
Рисунок 4
В справочнике нужно создать папки для наших товаров, материалов, услуг. Создание папок даст нам в будущем быструю настройку счетов учета номенклатуры по умолчанию, для этих папок, а также повысит визуальное восприятие справочника.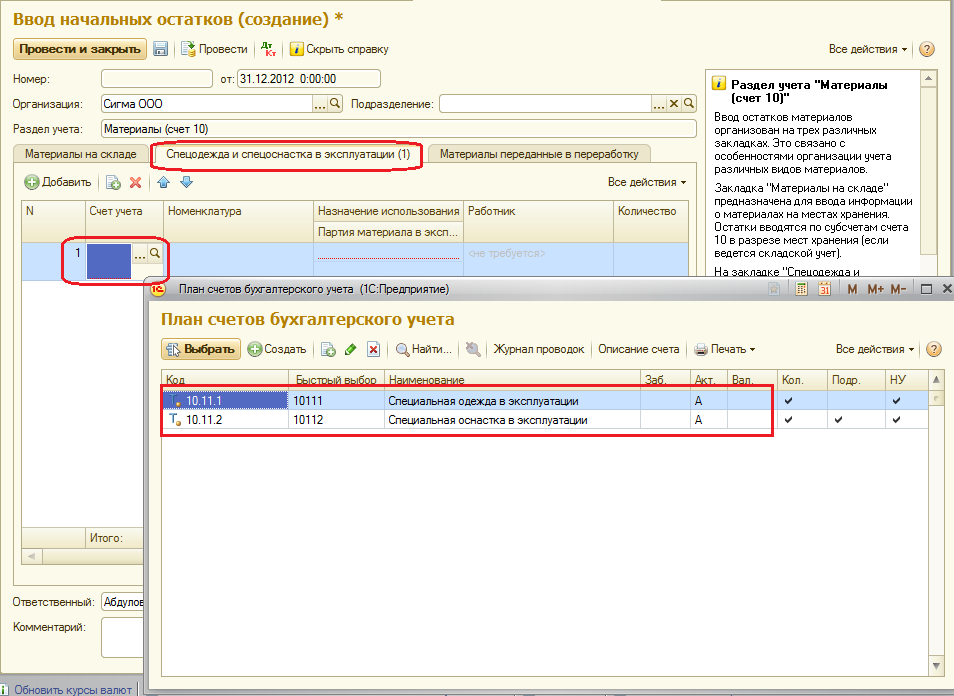
Теперь в папке товары можем создать несколько номенклатурных позиций.
Рисунок 5
Рисунок 6
Для того чтобы минимально заполнить информацию о вводимой номенклатурной позиции необходимо заполнить реквизиты наименование, вид номенклатуры и единицы измерения количества. После заполнения можно нажать на кнопку «Записать».
Для ввода начальных остатков по запасам воспользуемся документом «Оприходование товаров»: Меню Документы/Запасы склад/Оприходование товаров.
Рисунок 7
Рисунок 8
Цена — это цена в валюте управленческого учета, у нас валюта управленческого учета гривна, поэтому сюда вносится информация о себестоимости единицы товара.
Также в табличной части выставляем счета учета, на каких будет учитываться номенклатура после ввода начальных остатков и налоговое назначение НДС для данных запасов.
На закладке счета учета, указываем балансовый счет 00. После проведения документа он дает нам такие проводки по бухгалтерскому учету:
Рисунок 9
Данные по запасам в налоговом учете регистрируются в колонках Сумма (н/у) при проведении в проводках бухгалтерского учета.
Проконтролировать введенные начальные остатки по бухгалтерскому учету можно отчетом Оборотно-сальдовая ведомость по счету: «Меню Отчеты/Бухгалтерский и налоговый учет/Оборотно сальдовая ведомость по счету».
Рисунок 10
Проконтролировать введенные начальные остатки по налоговому учету можно этим же отчетом только с флагом НУ (данные налогового учета).
Рисунок 11
Проконтролировать введенные начальные остатки по управленческому учету можно отчетом Меню Отчеты/Запасы склад/Ведомость по товарам на складах, отчет показывает данные по остаткам только в количественном выражении.
Рисунок 12
Меню Отчеты/Запасы склад/Ведомость по партиям товаров на складах в количественном и стоимостном выражении.
Рисунок 13
Купить программу 1С можно здесь www.softmaster.com.ua
Посмотреть, а также ознакомится с нашими самостоятельными курсами по 1С, можно по ссылкам:
Поэтапный ввод системы в эксплуатацию.
 Учет себестоимости
Учет себестоимостиДля возможности поэтапного ввода программы в эксплуатацию в программе 1С:Комплексная автоматизация версии 2.4.9 создан механизм, позволяющий начать учет себестоимости в информационной базе с заданной даты.
Для настройки в информационной базе учета себестоимости с определенной даты создана функциональная опция Учет себестоимости товаров ведется с (меню НСИ и администрирование – Настройка НСИ и разделов – Финансовый результат и контроллинг – Учет товаров). Если указанная функциональная опция включена, но дата начала ее применения не задана, то учет себестоимости ведется без ограничения периода.
При выключенном в информационной базе учете себестоимости не поддерживается:
- учет по схемам неотфактурованных поставок и товаров в пути;
- распределение дополнительных расходов на партии товаров, поступивших/израсходованных до включения учета себестоимости.
При создании новых или при обновлении существующих информационных баз функциональная опция Учет себестоимости товаров ведется с включается без указания даты.
В связи с тем, что при поэтапном вводе системы в эксплуатацию ведение оперативного учета и учета себестоимости в информационной базе может быть начато в разные периоды (сначала оперативный учет, а учет себестоимости позднее), реализована возможность раздельного ввода остатков товарно-материальных ценностей для целей оперативного учета и учета себестоимости, а также ввода остатков незавершенного производства по партиям, выполнение работ по которым началось до даты начала учета себестоимости и продолжается после включения учета себестоимости в информационной базе.
Ввод остатков ТМЦ при включении в информационной базе учета себестоимости
В документах ввода остатков товарно-материальных ценностей:
- Ввод начальных остатков собственных товаров;
- Ввод начальных остатков переданных на комиссию товаров;
- Ввод начальных остатков полученных на комиссию товаров;
- Ввод начальных остатков принятой от поставщиков возвратной тары;
- Ввод начальных остатков переданных переработчику материалов;
- Ввод начальных остатков переданных в производство материалов
для поля Ввод остатков по добавлен вариант Себестоимость. При установленном флажке Себестоимость и снятом флажке ОУ табличная часть документа с указанием количественных остатков по данным оперативного учета может быть заполнена по кнопке Заполнить по остаткам ОУ. Суммовые остатки задаются пользователем.
При установленном флажке Себестоимость и снятом флажке ОУ табличная часть документа с указанием количественных остатков по данным оперативного учета может быть заполнена по кнопке Заполнить по остаткам ОУ. Суммовые остатки задаются пользователем.
При заполнении остатков для целей регламентированного учета при имеющихся данных оперативного учета товаров и учета себестоимости (при установленном флажке БУ и НУ и снятых флажках ОУ и Себестоимость) табличная часть документа с указанием количественных и суммовых остатков по данным учета себестоимости может быть заполнена по кнопке Заполнить по остаткам ОУ.
Перед началом ведения в информационной базе учета себестоимости и вводом остатков по себестоимости товаров рекомендуется провести сверку данных оперативного учета товаров в информационной базе с данными учета товаров во внешней системе. Для отражения результатов данной сверки и определения порядка учета выявленных отклонений в прикладное решение добавлен документ Сверка начальных остатков по складу (меню НСИ и администрирование – Начальное заполнение – Начальное заполнение – Сверки начальных остатков по складам). Указанный документ вводится в месяце, предшествующем месяцу начала учета себестоимости в информационной базе.
Указанный документ вводится в месяце, предшествующем месяцу начала учета себестоимости в информационной базе.
Документ Сверка начальных остатков по складу создается по организации и складу в валюте управленческого или регламентированного учета. При необходимости остатки могут быть детализированы по назначениям. Выбор значения переключателя Расхождения списать и оприходовать в документе устанавливает порядок устранения выявленных в результате сверки расхождений:
- во внешней системе, до переноса остатков – выявленные расхождения устраняются во внешней системе. В прикладном решении остатки вносятся в соответствии с данными оперативного учета товаров в информационной базе;
- в данной системе, после переноса остатков — выявленные расхождения устраняются в информационной базе документами списания недостач или оприходования излишков товаров. В прикладном решении остатки вносятся в соответствии с данными учета товаров во внешней системе.
Учетные данные по товарам из внешней системы и из оперативного учета в информационной базе заносятся в табличную часть закладки Данные внешней системы документа Сверка начальных остатков по складу. Данные из внешней системы указываются вручную или загружаются по кнопке Заполнить – Загрузить из файла. Данные оперативного учета товаров в информационной базе указываются вручную или заполняются по кнопке Заполнить – Сопоставить номенклатуру путем подбора номенклатуры по показателям Код, Артикул и Наименование.
В табличную часть закладки Результаты сверки документа Сверка начальных остатков по складу по кнопке Заполнить заполняются результаты сопоставления данных учета оперативного учета товаров в информационной базе с данными учета товаров во внешней системе:
- для каждой позиции в табличной части рассчитывается отклонение по количеству (количество по данным внешней системы минус количество по данным оперативного учета), а также стоимость этого отклонения;
- в табличную часть добавляются все позиции, по которым есть остатки по данным внешней системы либо по данным оперативного учета;
- для позиций, по которым нет данных во внешней системе, значения стоимостных остатков необходимо заполнить вручную.

На основании документа Сверка начальных остатков по складу создаются документы, корректирующие остатки оперативного учета и учета себестоимости:
- Ввод начальных остатков собственных товаров;
- Оприходование излишков товаров;
- Списание недостач товаров.
Для формирования/перезаполнения созданных документов по отражению результатов сверки необходимо перейти по соответствующей гиперссылке на вкладке Сформированные документы.
Для сверки данных оперативного учета и учета себестоимости товаров в программе 1С:Комплексная автоматизация версии 2.4.9 создан отчет Сверка остатков товаров организаций и себестоимости (меню Финансовый результат и контроллинг – Отчеты по финансовому результату).
В процедуре Закрытие месяца производится автоматическая сверка данных оперативного учета и учета себестоимости товаров.
Учет внеоборотных активов при отключенном учете себестоимости
При отключенном в информационной базе учете себестоимости ведение учета внеоборотных активов возможно только по Версия 2. 4 (функциональная опция НСИ и администрирование – Настройка НСИ и разделов – Внеоборотные активы – Учет внеоборотных активов).
4 (функциональная опция НСИ и администрирование – Настройка НСИ и разделов – Внеоборотные активы – Учет внеоборотных активов).
Если в информационной базе не ведется учет себестоимости, то при принятии к учету или модернизации внеоборотных активов их фактическая стоимость для целей бухгалтерского и налогового учета заполняется пользователем вручную. В процедуре Закрытие месяца регламентная операция Расчет стоимости ОС и НМА не производится. Реализовано заполнение в существующих в информационной базе документах фактической стоимости внеоборотных активов по данным оперативных регистров при отключении учета себестоимости после начала ведения учета. Заполнение стоимости производится в рамках добавленной в процедуру Закрытие месяца регламентной операции Заполнение фактической стоимости внеоборотных активов при отключенном учете себестоимости.
При отключенном в информационной базе учете себестоимости не создаются проводки при принятии к учету и модернизации внеоборотных активов. При необходимости проводки отражаются пользователем с помощью ручной корректировки проводок документа или документом Операция (регл. учет). Формирование проводок по начислению имущественных налогов производится пользователем документом Операция (регл. учет).
При необходимости проводки отражаются пользователем с помощью ручной корректировки проводок документа или документом Операция (регл. учет). Формирование проводок по начислению имущественных налогов производится пользователем документом Операция (регл. учет).
Учет ТМЦ в эксплуатации при отключенном учете себестоимости
При отключенном в информационной базе учете себестоимости не поддерживается стоимостной учет и формирование проводок по операциям с ТМЦ в эксплуатации. Ввод остатков по счету 10.11 «Специальная оснастка, специальная одежда и инвентарь в эксплуатации» производится документом Операция (регл. учет).
Оптимизация алгоритмов выполнения этапов закрытия месяца
Для сокращения времени выполнения регламентной операции Распределение затрат и расчет себестоимости процедуры Закрытие месяца внесены изменения в алгоритмы прикладного решения.
Ввод остатков по раздельному учету НДС
23 Октября 2019
Начиная с версии 3. 0.73 в «1С: Бухгалтерии 8» добавлена возможность автоматического ввода остатков по раздельному учету НДС.
0.73 в «1С: Бухгалтерии 8» добавлена возможность автоматического ввода остатков по раздельному учету НДС.
А значит у пользователей непременно появятся следующие вопросы:
-
Где устанавливается раздельный учет?
-
Как функционирует автоматический ввод остатком по раздельному учету НДС?
-
Почему решили перейти на автоматический ввод, и как вёлся учет раздельного НДС до этого релиза?
Ответы на все эти вопросы Вы найдете в данной статье.
Где устанавливается раздельный учет?
Для перехода на раздельный учет НДС по способам учета необходимо выставить флажок «Ведется раздельный учет входящего НДС по способам учета»: раздел Главное — Настройки — Налоги и отчеты — вкладка НДС.
После установки флажка начинает заполняться регистр накопления Раздельный учет НДС, который хранит остатки по приобретенным и реализованным ТМЦ.
Как функционирует автоматический ввод остатком по раздельному учету НДС?
Документы ввода остатком будут созданы автоматически при установки данного флажка, чтобы их посмотреть перейдите по указанной ссылки.В форме «Документы ввода остатков по раздельному учету НДС» нажмите кнопку Актуализировать остатки. В это время запускается автоматическое заполнение формы документами остатков по регистрам: Раздельный учет НДС (тип документа Ввод начальных остатков), Хозрасчетный (тип документа Операция).
После формирования остатков по раздельному учету проблем с отгрузкой при переходе на раздельный учет не будет. Остатки на момент перехода сформированы, программа прочитает их при списывании ТМЦ и проведет документ без ошибки.
Почему решили перейти на автоматический ввод, и как вёлся учет раздельного НДС до этого релиза?
До релиза 3. 0.73 при переходе на раздельный учет НДС с начала ведения учета в программе необходимо было вручную вносить данные в регистр накопления Раздельный учет НДС. Остатки в регистр вводились вручную документом Операция, введенная вручную: раздел Операции — Бухгалтерский учет — Операция, введенная вручную — кнопка Создать — Операция — кнопка ЕЩЕ — ссылка Выбор регистров — Регистры накопления — флажок Раздельный учет НДС.
0.73 при переходе на раздельный учет НДС с начала ведения учета в программе необходимо было вручную вносить данные в регистр накопления Раздельный учет НДС. Остатки в регистр вводились вручную документом Операция, введенная вручную: раздел Операции — Бухгалтерский учет — Операция, введенная вручную — кнопка Создать — Операция — кнопка ЕЩЕ — ссылка Выбор регистров — Регистры накопления — флажок Раздельный учет НДС.
Для записи аналитики учета НДС при ручном вводе данных требовалась помощь программиста. Начиная с релиза 3.0.73 программа автоматически создает остатки на момент перехода организации на раздельный учет входящего НДС по способам учета.
Статью подготовила Дарья, консультант «ИнфоСофт»
Wind-US — Мониторинг конвергенции Руководство пользователя
Wind-US — Мониторинг конвергенции (Домашняя страница документации Wind-US ) ( Wind-US Руководство пользователя ) ( Руководство пользователя GMAN ) ( Руководство пользователя MADCAP ) ( Руководство пользователя CFPOST ) ( Wind-US Utilities ) ( Руководство пользователя общих файлов ) ( Wind-US Руководство по установке ) ( Ссылка разработчика Wind-US ) ( Руководящие документы )( Введение ) ( Учебник ) ( Моделирование геометрии и физики потока ) ( Численное моделирование ) ( Граничные условия ) ( Мониторинг конвергенции ) ( Файлы ) ( скриптов ) ( Параллельная обработка ) ( Ссылка на ключевое слово ) ( Варианты испытаний )
Мониторинг конвергенции
Мониторинг и правильная оценка уровней конвергенции во время ветра-США
run имеют решающее значение для получения значимых и полезных результатов. Wind-US позволяет отслеживать сходимость по остаткам и / или
интегрированные силы, моменты и массовый расход.
Для инженерных приложений рекомендуется мониторинг сходимости
Метод — отслеживание интегральных количеств, представляющих интерес.
Например, если вы моделируете геометрию крыла / тела для определения сопротивления,
вы должны отслеживать интегрированное перетаскивание и устанавливать разумные границы для
колебания сопротивления в качестве критерия сходимости.
Wind-US позволяет отслеживать сходимость по остаткам и / или
интегрированные силы, моменты и массовый расход.
Для инженерных приложений рекомендуется мониторинг сходимости
Метод — отслеживание интегральных количеств, представляющих интерес.
Например, если вы моделируете геометрию крыла / тела для определения сопротивления,
вы должны отслеживать интегрированное перетаскивание и устанавливать разумные границы для
колебания сопротивления в качестве критерия сходимости.
Остатки
В установившихся (не точных по времени) решениях невязки — это величины, на которые вектор решения изменяется за одну итерацию.В идеале, при приближении к стационарному решению, невязки должны приближаются к нулю. Однако на практике сложные геометрические характеристики и особенности поля потока могут ограничивать уменьшение остатков примерно до двух порядков. Wind-US распечатывает остатки раствора в список выходной файл, чтобы получить общее представление о сходимости решения.
Для структурированных сеток Wind-US организует решаемые уравнения в виде
логические «группы», которые решаются вместе. Например, когда используется модель турбулентности с одним или двумя уравнениями,
Уравнения Навье-Стокса и уравнения модели турбулентности разделены на две части.
отдельные группы.
Например, когда используется модель турбулентности с одним или двумя уравнениями,
Уравнения Навье-Стокса и уравнения модели турбулентности разделены на две части.
отдельные группы.
Для каждой группы уравнений в каждой зоне Wind-US печатает номер зоны, номер цикла, положение максимальной невязки ( i , j , и k индексов), номер уравнения, для которого максимальная невязка произошло, значение максимальной невязки и L2-норма всех остатки для всех уравнений по всем точкам в этой зоне. L2-норма остатков даст вам представление об общем сходимость решения. Расположение максимального остатка может дать вам представление о проблемах. с конкретным решением.После «бомб» раствора или когда схождение недопустимо медленное, место максимальной невязки — это первое, на что следует обратить внимание возможные проблемы с решением.
По умолчанию остатки печатаются на каждой итерации.
Однако интервал вывода можно изменить, используя
ЦИКЛЫ и
Ключевые слова ITERATIONS. Остатки также могут быть нанесены на график сначала с помощью вспомогательной программы. респ. для создания файла GENPLOT, затем используя этот файл в качестве входных данных для
участок
команда в CFPOST
пакет постобработки.
Остатки также могут быть нанесены на график сначала с помощью вспомогательной программы. респ. для создания файла GENPLOT, затем используя этот файл в качестве входных данных для
участок
команда в CFPOST
пакет постобработки.
По умолчанию, если максимальная невязка для группы уравнений уменьшается на
четыре порядка величины в конкретной зоне, «конвергентное» сообщение
печатается в выходном файле списка, и итерации для этой группы в этом
зоны завершаются для текущего цикла.
Обратите внимание, что если остатки на ранних этапах расчета велики из-за
большие переходные процессы начального решения, Wind-US может решить, что зона
сходится, когда может потребоваться значительно больше итераций.
Во входном файле данных с
CONVERGE ключевое слово вы
можно указать различные критерии сходимости, задав количество
остаток должен уменьшиться, и, указав Wind-US использовать значение
остаточное, а не уменьшение на порядок.Вы также можете указать использование L2-нормы невязки вместо
максимальный остаток с использованием ТЕСТА
вариант 128.
Ключевые слова: CONVERGE, ЦИКЛЫ, ИТЕРАЦИИ, ТЕСТ 128
Интегрированные величины поля потока
Как отмечалось выше, оптимальный критерий проверки сходимости поскольку решение — это интегрированная величина, представляющая интерес для конкретного исследования. Например, для исследования лобового сопротивления для расчета сопротивления давления, интегрированное сопротивление, очевидно, является лучшим показателем для отслеживания мониторинг сходимости.Это может быть выполнено с использованием возможности интеграции полей потока Wind-US. Во входном файле данных вы можете указать количество вычислительных поверхности, для которых Wind-US интегрирует силы, моменты и / или массовые потоки. Если вы укажете справочную длину, площадь и центр момента, Wind-US выведет силы и моменты как коэффициенты; вы даже можете укажите вывод коэффициентов подъемной силы и сопротивления вместо x и y силовые коэффициенты.
Вы можете указать зоны и индексы вычислительной сетки подмножеств для
быть интегрированным, и вы можете запросить, чтобы были
интегрированы в каждое подмножество. Вы также можете контролировать частоту вывода и то,
выводит итоги подмножества и / или зональные и общие итоги.
Вспомогательная программа resplt создаст файлы графика GENPLOT
интегрируемых выходных величин в зависимости от числа циклов решения,
который затем может быть использован в качестве входных данных для
участок
команда в
Пакет пост-обработки CFPOST.
Вы также можете контролировать частоту вывода и то,
выводит итоги подмножества и / или зональные и общие итоги.
Вспомогательная программа resplt создаст файлы графика GENPLOT
интегрируемых выходных величин в зависимости от числа циклов решения,
который затем может быть использован в качестве входных данных для
участок
команда в
Пакет пост-обработки CFPOST.
Ключевые слова: НАГРУЗКИ
История отслеживания потоковых данных
В точных по времени расчетах, где фиксируется постоянный шаг по времени.
указан и одинаков во всем поле потока, вы можете
отслеживать конкретную переменную потока по мере того, как решение продвигается во времени.Например, вас может заинтересовать мониторинг статического давления.
на обратном шаге, когда вихри скатываются с обратной стороны ступеньки.
Вы можете запросить отслеживание истории во входном файле данных.
Спецификация должна включать номера зон и диапазоны точек сетки для отслеживания,
и частота выборки.
Когда вы запрашиваете отслеживание истории, Wind-US создает
файл истории времени, содержащий
выборочные данные.
Ключевые слова: ИСТОРИЯ
Последнее обновление 12 декабря 2005 г.
Объединение входной неопределенности и остаточной ошибки в прогнозах модели урожая: тематическое исследование виноградников
По мере того, как моделирование сельскохозяйственных культур созрело и было предложено в качестве инструмента для многих практических приложений, возрастает потребность в оценке неопределенности в прогнозах модели. Особый интерес, который не рассматривался ранее, — это когда учитывается как неопределенность в независимых переменных модели, так и остаточная ошибка модели (неопределенность в прогнозах модели, даже если объясняющие переменные полностью известны).Мы рассматриваем конкретный случай модели для прогнозирования водного стресса виноградника. Для многих объясняющих переменных модели виноградар (или советник фермера) имеет выбор между приблизительными значениями, которые легко получить, и более точными значениями, которые труднее (и дороже) получить. Мы специально обсуждаем объясняющую переменную «начальный водный стресс», которая напрямую зависит от начального содержания влаги в почве и может быть оценена или измерена (точно, но дорого).Виноградарь заинтересован в уменьшении неопределенности, которая может возникнуть в результате измерения начального водного стресса, но важно именно уменьшение общей неопределенности, включая остаточную ошибку модели.
Для многих объясняющих переменных модели виноградар (или советник фермера) имеет выбор между приблизительными значениями, которые легко получить, и более точными значениями, которые труднее (и дороже) получить. Мы специально обсуждаем объясняющую переменную «начальный водный стресс», которая напрямую зависит от начального содержания влаги в почве и может быть оценена или измерена (точно, но дорого).Виноградарь заинтересован в уменьшении неопределенности, которая может возникнуть в результате измерения начального водного стресса, но важно именно уменьшение общей неопределенности, включая остаточную ошибку модели.
Мы предлагаем использовать точные измерения водного стресса с течением времени на нескольких виноградниках, чтобы оценить остаточную ошибку модели. Неопределенность начального водного стресса можно оценить, имея приблизительные и точные значения начального водного стресса на нескольких виноградниках. Затем мы объединяем два источника ошибок с помощью моделирования благодаря гипотезе независимости; модель запускается несколько раз с распределением значений начального водного стресса, и каждый день к результату добавляется распределение остаточных ошибок модели.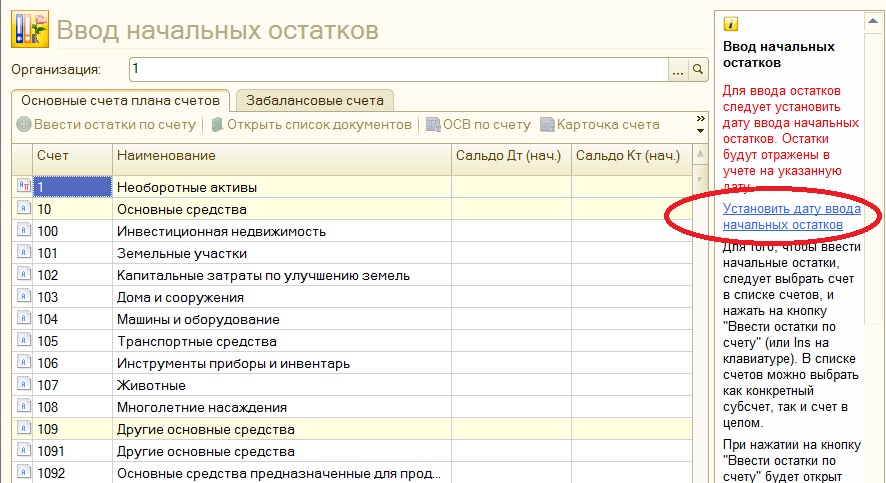
Результаты показывают, что результирующая неопределенность сильно различается в разных областях. В некоторых случаях неопределенность в начальном водном стрессе становится незначительной через короткое время после начала моделирования, в других случаях эта неопределенность остается важной по сравнению с остаточной ошибкой модели на протяжении всего вегетационного периода. Во всех случаях остаточная ошибка составляет значительный процент от общей ошибки и поэтому должна приниматься во внимание.
Как моделировать остаточные ошибки для исправления прогнозов временных рядов с помощью Python
Последнее обновление 24.04.2020 г.
Остаточные ошибки прогнозов временных рядов являются еще одним источником информации, которую мы можем моделировать.
Сами по себе остаточные ошибки образуют временной ряд, который может иметь временную структуру. Простая модель авторегрессии этой структуры может использоваться для прогнозирования ошибки прогноза, которая, в свою очередь, может использоваться для корректировки прогнозов. Этот тип модели называется моделью скользящего среднего, то же самое название, но сильно отличается от сглаживания скользящего среднего.
Этот тип модели называется моделью скользящего среднего, то же самое название, но сильно отличается от сглаживания скользящего среднего.
В этом руководстве вы узнаете, как смоделировать временной ряд с остаточной ошибкой и использовать его для исправления прогнозов с помощью Python.
После прохождения этого руководства вы будете знать:
- О том, как моделировать временные ряды остаточных ошибок с помощью авторегрессионной модели.
- Как разработать и оценить модель временного ряда остаточных ошибок.
- Как использовать модель остаточной ошибки для исправления прогнозов и улучшения навыков прогнозирования.
Начните свой проект с моей новой книги «Прогнозирование временных рядов с помощью Python», включающей пошаговых руководств и файлы исходного кода Python для всех примеров.
Приступим.
- Обновлено январь / 2017 г. : Улучшены некоторые примеры кода, чтобы сделать их более полными.

- Обновлено апр.2019 г. : обновлена ссылка на набор данных.
- Обновлено августу / 2019 : обновлена загрузка данных для использования нового API.
- Обновлено апр.2020 г. : AR изменен на AutoReg в связи с изменением API.
Модель остаточных ошибок
Разница между ожидаемым и предсказанным значением называется остаточной ошибкой.
Рассчитывается как:
остаточная ошибка = ожидаемая — прогнозируемая
остаточная ошибка = ожидаемая — прогнозируемая |
Как и сами входные наблюдения, остаточные ошибки временного ряда могут иметь временную структуру, такую как тенденции, смещение и сезонность.
Любая временная структура во временном ряду остаточных ошибок прогноза полезна в качестве диагностики, поскольку она предлагает информацию, которая может быть включена в прогностическую модель. В идеальной модели остаточная ошибка не оставляет структуры, а только случайные флуктуации, которые нельзя смоделировать.
В идеальной модели остаточная ошибка не оставляет структуры, а только случайные флуктуации, которые нельзя смоделировать.
Структура остаточной ошибки также может быть смоделирована напрямую. В остаточной ошибке могут быть сложные сигналы, которые трудно напрямую включить в модель. Вместо этого вы можете создать модель временного ряда остаточных ошибок и спрогнозировать ожидаемую ошибку для вашей модели.
Затем спрогнозированная ошибка может быть вычтена из прогноза модели и, в свою очередь, обеспечивает дополнительный рост производительности.
Простая и эффективная модель остаточной ошибки — авторегрессия. Здесь некоторое количество запаздывающих значений ошибок используется для прогнозирования ошибки на следующем временном шаге. Эти ошибки запаздывания объединены в модели линейной регрессии, очень похожей на модель авторегрессии прямых наблюдений за временными рядами.
Авторегрессия временного ряда остаточных ошибок называется моделью скользящего среднего (MA). Это сбивает с толку, потому что это не имеет ничего общего с процессом сглаживания скользящего среднего. Думайте об этом как о родственнике процесса авторегрессии (AR), за исключением запаздывающих остаточных ошибок, а не запаздывающих необработанных наблюдений.
Это сбивает с толку, потому что это не имеет ничего общего с процессом сглаживания скользящего среднего. Думайте об этом как о родственнике процесса авторегрессии (AR), за исключением запаздывающих остаточных ошибок, а не запаздывающих необработанных наблюдений.
В этом руководстве мы разработаем модель авторегрессии временного ряда остаточных ошибок.
Прежде чем мы углубимся, давайте рассмотрим одномерный набор данных, для которого мы разработаем модель.
Прекратить изучение временных рядов Прогнозирование медленного пути
!Пройдите бесплатный 7-дневный курс электронной почты и узнайте, как начать работу (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ мини-курс прямо сейчас!
Ежедневный набор данных о женских родах
Этот набор данных описывает количество ежедневных рождений женщин в Калифорнии в 1959 году.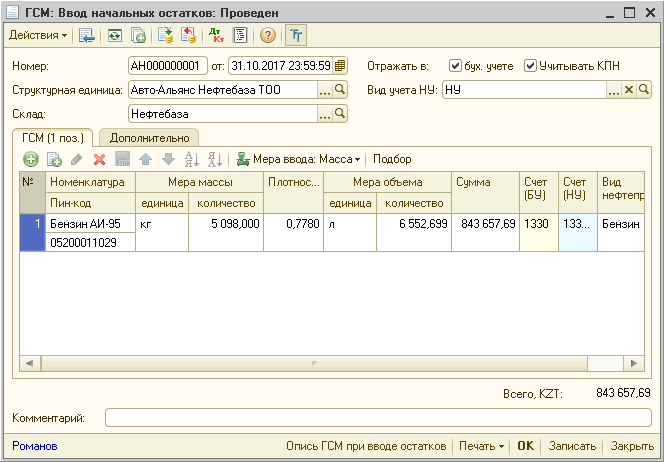
Единицы — это счет, и имеется 365 наблюдений. Источником набора данных является Ньютон (1988).
Загрузите набор данных и поместите его в текущую рабочую директорию с именем файла « ежедневных рождений среди женщин».csv “.
Ниже приведен пример загрузки набора данных о ежедневных женских рождениях из CSV.
из панд импортировать read_csv из matplotlib import pyplot series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0) печать (series.head ()) series.plot () pyplot.show ()
из pandas import read_csv из matplotlib import pyplot series = read_csv (‘daily-total-female-Births.csv ‘, header = 0, index_col = 0) print (series.head ()) series.plot () pyplot.show () |
При выполнении примера печатаются первые 5 строк загруженного файла.
Дата 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 Имя: Рождения, dtype: int64
Дата 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 Имя: Дата рождения, dtype : int64 |
Набор данных также показан в виде линейного графика наблюдений во времени.
График ежедневного общего числа рождений женщин
Мы видим, что нет явного тренда или сезонности. Набор данных выглядит стационарным, что является ожидаемым при использовании модели авторегрессии.
Модель прогноза послесвечения
Самый простой прогноз, который мы можем сделать, — это спрогнозировать, что то, что произошло на предыдущем временном шаге, будет таким же, как и то, что произойдет на следующем временном шаге.
Это называется «наивным прогнозом» или моделью прогноза устойчивости.Эта модель предоставит прогнозы, на основе которых мы сможем вычислить временные ряды остаточной ошибки. В качестве альтернативы мы могли бы разработать модель авторегрессии временных рядов и использовать ее в качестве нашей модели. Мы не будем разрабатывать модель авторегрессии в этом случае для краткости и сосредоточимся на модели остаточной ошибки.
Мы можем реализовать модель персистентности на Python.
После загрузки набора данных это формулируется как контролируемая задача обучения. Создается отсроченная версия набора данных, в которой предыдущий временной шаг (t-1) используется как входная переменная, а следующий временной шаг (t + 1) — как выходная переменная.
Создается отсроченная версия набора данных, в которой предыдущий временной шаг (t-1) используется как входная переменная, а следующий временной шаг (t + 1) — как выходная переменная.
# создать лагированный набор данных values = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1) dataframe.columns = [‘t-1’, ‘t + 1’]
# создать лагированный набор данных values = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1) dataframe.columns = [‘t-1’, ‘t + 1’] |
Затем набор данных разделяется на обучающий и тестовый наборы.В общей сложности 66% данных хранятся для обучения, а остальные 34% — для набора тестов. Для модели настойчивости обучение не требуется; это просто стандартный подход к тестовой оснастке.
После разделения комплекты поездов и тестов разделяются на их входные и выходные компоненты.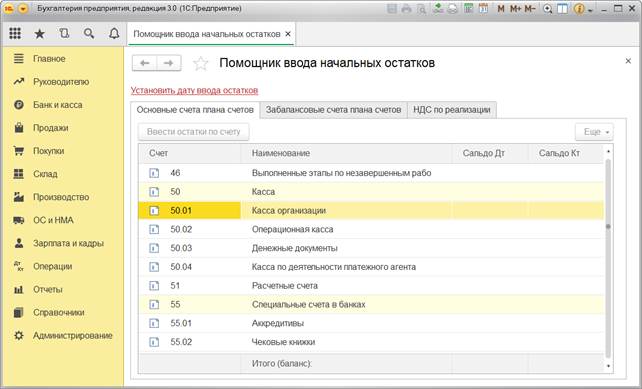
# разделить на обучающие и тестовые наборы X = dataframe.values train_size = интервал (длина (X) * 0,66) поезд, тест = X [1: train_size], X [train_size:] train_X, train_y = поезд [:, 0], поезд [:, 1] test_X, test_y = test [:, 0], test [:, 1]
# разделить на набор для обучения и тестирования X = фрейм данных.значения train_size = int (len (X) * 0.66) train, test = X [1: train_size], X [train_size:] train_X, train_y = train [:, 0], train [:, 1 ] test_X, test_y = test [:, 0], test [:, 1] |
Модель устойчивости применяется путем прогнозирования выходного значения ( y ) как копии входного значения ( x ).
# модель сохраняемости прогнозы = [x для x в test_X]
# модель персистентности прогнозы = [x для x в test_X] |
Остаточные ошибки затем вычисляются как разница между ожидаемым результатом ( test_y, ) и прогнозом ( прогноза, ).
# вычислить остатки остатки = [test_y [i] -predictions [i] для i в диапазоне (len (прогнозы))]
# вычислить остатки остатки = [test_y [i] -predictions [i] для i в диапазоне (len (прогнозы))] |
Пример объединяет все это и дает нам набор остаточных ошибок прогноза, которые мы можем изучить в этом руководстве.
# вычислить остаточные ошибки для модели прогноза устойчивости
из панд импортировать read_csv
из панд импортировать DataFrame
из pandas import concat
из склеарна.импорт показателей mean_squared_error
из математического импорта sqrt
# загрузить данные
series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True)
# создать лагированный набор данных
values = DataFrame (series.values)
dataframe = concat ([values.shift (1), values], axis = 1)
dataframe.columns = [‘t’, ‘t + 1’]
# разделить на обучающие и тестовые наборы
X = dataframe. values
train_size = интервал (длина (X) * 0,66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель сохраняемости
прогнозы = [x для x в test_X]
# навык модели настойчивости
rmse = sqrt (mean_squared_error (test_y, прогнозы))
print (‘Тест RMSE:%.3f ‘% ср.
# вычислить остатки
остатки = [test_y [i] -predictions [i] для i в диапазоне (len (прогнозы))]
остатки = DataFrame (остатки)
печать (остатки. голова ())
values
train_size = интервал (длина (X) * 0,66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель сохраняемости
прогнозы = [x для x в test_X]
# навык модели настойчивости
rmse = sqrt (mean_squared_error (test_y, прогнозы))
print (‘Тест RMSE:%.3f ‘% ср.
# вычислить остатки
остатки = [test_y [i] -predictions [i] для i в диапазоне (len (прогнозы))]
остатки = DataFrame (остатки)
печать (остатки. голова ())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # вычислить остаточные ошибки для модели прогноза устойчивости из pandas import read_csv из pandas import DataFrame из pandas import concat из sklearn. from math import sqrt # загрузить данные series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True) # создать лагированный набор данных values = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1) dataframe.columns = [‘t’, ‘t + 1 ‘] # разделить на наборы поездов и тестов X = dataframe.values train_size = int (len (X) * 0.66) поезд, test = X [1: train_size], X [train_size:] train_X, train_y = train [:, 0], train [:, 1] test_X, test_y = test [:, 0 ], test [:, 1] # модель настойчивости предсказания = [x для x в test_X] # навык модели настойчивости rmse = sqrt (mean_squared_error (test_y, predictions)) print (‘Test RMSE:% .3f ‘% rmse) # вычислить остатки остатки = [test_y [i] -predictions [i] для i в диапазоне (len (прогнозы))] остатки = DataFrame (остатки) print (остатки. |
 metrics import mean_squared_error
metrics import mean_squared_error голова ())
голова ())Затем в примере печатается RMSE и первые 5 строк с остаточными ошибками прогноза.
Среднеквадратичное значение теста: 9,151 0 0 9,0 1 -10,0 2 3,0 3 -6,0 4 30,0
Тест RMSE: 9,151 0 0 9,0 1-10,0 2 3,0 3-6,0 4 30,0 |
Теперь у нас есть временной ряд остаточных ошибок, который мы можем смоделировать.
Авторегрессия остаточной ошибки
Мы можем смоделировать временной ряд остаточных ошибок, используя модель авторегрессии.
Это модель линейной регрессии, которая создает взвешенную линейную сумму запаздывающих членов остаточной ошибки. Например:
ошибка (t + 1) = b0 + b1 * ошибка (t-1) + b2 * ошибка (t-2) … + bn * ошибка (t-n)
ошибка (t + 1) = b0 + b1 * ошибка (t-1) + b2 * ошибка (t-2) … + bn * ошибка (t-n) |
Мы можем использовать модель авторегрессии (AR), предоставленную библиотекой statsmodels.
Основываясь на модели персистентности из предыдущего раздела, мы можем сначала обучить модель остаточным ошибкам, вычисленным на обучающем наборе данных. Это требует, чтобы мы делали прогнозы устойчивости для каждого наблюдения в наборе обучающих данных, а затем создавали модель AR, как показано ниже.
# авторегрессионная модель остаточных ошибок
из панд импортировать read_csv
из панд импортировать DataFrame
из pandas import concat
из statsmodels.tsa.ar_model импорт AutoReg
series = read_csv (‘общее-ежедневное-рождений-женщин.csv ‘, header = 0, index_col = 0, parse_dates = True, squeeze = True)
# создать лагированный набор данных
values = DataFrame (series.values)
dataframe = concat ([values.shift (1), values], axis = 1)
dataframe.columns = [‘t’, ‘t + 1’]
# разделить на обучающие и тестовые наборы
X = dataframe.values
train_size = интервал (длина (X) * 0,66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель персистентности в обучающем наборе
train_pred = [x вместо x в train_X]
# вычислить остатки
train_resid = [train_y [i] -train_pred [i] для i в диапазоне (len (train_pred))]
# моделируем остатки обучающей выборки
model = AutoReg (train_resid, lags = 15)
model_fit = модель. соответствовать()
print (‘Coef =% s’% (model_fit.params))
соответствовать()
print (‘Coef =% s’% (model_fit.params))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # авторегрессионная модель остаточных ошибок из pandas import read_csv из pandas import DataFrame из pandas import concat из statsmodels.tsa.ar_model import AutoReg series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True) # создать лагированный набор данных values = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1) dataframe.columns = [‘t’, ‘t + 1’] # разделить на поезд и наборы тестов X = dataframe.values train_size = int (len (X) * 0. train, test = X [1: train_size], X [train_size:] train_X, train_y = train [:, 0], train [:, 1] test_X, test_y = test [:, 0], test [:, 1] # модель сохраняемости в обучающем наборе train_pred = [x for x in train_X] # вычислить остатки train_resid = [train_y [i] -train_pred [i] for i in range (len (train_pred))] # моделируем остатки обучающего набора model = AutoReg (train_resid, lags = 15) model_fit = модель.fit () print (‘Coef =% s’% (model_fit.params)) |
 66)
66)При выполнении этого фрагмента печатается выбранное запаздывание из 16 коэффициентов (пересечение и по одному для каждого запаздывания) обученной модели линейной регрессии.
Коэф = [0,10120699 -0,84940615 -0,77783609 -0,73345006 -0,68
1 -0,59270551 -0,5376728 -0,42553356 -0,24861246 -0,19972102 -0,15954013 -0,11045476 -0.14045572 -0.13299964 -0.12515801 -0.03615774] Coef = [0. -0,5376728 -0,42553356 -0,24861246 -0,19972102 -0,15954013 -0,11045476 -0,14025995701 -0,1402599570 -0,01 |
 10120699 -0,84940615 -0,77783609 -0,73345006 -0,68
10120699 -0,84940615 -0,77783609 -0,73345006 -0,68Затем мы можем пройти через набор тестовых данных, и для каждого временного шага мы должны:
- Вычислить прогноз сохраняемости (t + 1 = t-1).
- Предскажите остаточную ошибку, используя модель авторегрессии.
Модель авторегрессии требует остаточной ошибки 15 предыдущих временных шагов.Следовательно, мы должны держать эти значения под рукой.
По мере того, как мы шаг за шагом проходя через временной шаг набора тестовых данных, делая прогнозы и оценивая ошибку, мы можем затем вычислить фактическую остаточную ошибку и обновить значения запаздывания временного ряда остаточной ошибки (историю), чтобы мы могли вычислить ошибку на следующем временном шаге.
Это модель прогнозируемого прогноза или скользящего прогноза.
В итоге мы получаем временной ряд остаточной ошибки прогноза из набора данных поезда и прогнозируемой остаточной ошибки в наборе тестовых данных.
Мы можем построить их и получить быстрое представление о том, насколько умело модель предсказывает остаточную ошибку. Полный пример приведен ниже.
# прогноз остаточная ошибка прогноза
из панд импортировать read_csv
из панд импортировать DataFrame
из pandas import concat
из statsmodels.tsa.ar_model импорт AutoReg
из matplotlib import pyplot
series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True)
# создать лагированный набор данных
values = DataFrame (series.значения)
dataframe = concat ([values.shift (1), values], axis = 1)
dataframe.columns = [‘t’, ‘t + 1’]
# разделить на обучающие и тестовые наборы
X = dataframe.values
train_size = интервал (длина (X) * 0,66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель персистентности в обучающем наборе
train_pred = [x вместо x в train_X]
# вычислить остатки
train_resid = [train_y [i] -train_pred [i] для i в диапазоне (len (train_pred))]
# моделируем остатки обучающей выборки
окно = 15
model = AutoReg (train_resid, lags = window)
model_fit = модель. соответствовать()
coef = model_fit.params
# шаг вперед по времени в тесте
history = train_resid [len (train_resid) -window:]
history = [history [i] для i в диапазоне (len (history))]
прогнозы = список ()
ожидаемая_ошибка = список ()
для t в диапазоне (len (test_y)):
# упорство
yhat = test_X [t]
error = test_y [t] — yhat
ожидаемый_error.append (ошибка)
# предсказать ошибку
length = len (история)
lag = [история [i] для i в диапазоне (длина-окно, длина)]
pred_error = coef [0]
для d в диапазоне (окно):
pred_error + = coef [d + 1] * задержка [окно-d-1]
предсказания.добавить (пред_ошибка)
history.append (ошибка)
print (‘предсказанная ошибка =% f, ожидаемая ошибка =% f’% (pred_error, error))
# прогнозируемая ошибка графика
pyplot.plot (ожидаемая_ошибка)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
соответствовать()
coef = model_fit.params
# шаг вперед по времени в тесте
history = train_resid [len (train_resid) -window:]
history = [history [i] для i в диапазоне (len (history))]
прогнозы = список ()
ожидаемая_ошибка = список ()
для t в диапазоне (len (test_y)):
# упорство
yhat = test_X [t]
error = test_y [t] — yhat
ожидаемый_error.append (ошибка)
# предсказать ошибку
length = len (история)
lag = [история [i] для i в диапазоне (длина-окно, длина)]
pred_error = coef [0]
для d в диапазоне (окно):
pred_error + = coef [d + 1] * задержка [окно-d-1]
предсказания.добавить (пред_ошибка)
history.append (ошибка)
print (‘предсказанная ошибка =% f, ожидаемая ошибка =% f’% (pred_error, error))
# прогнозируемая ошибка графика
pyplot.plot (ожидаемая_ошибка)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | # прогноз остаточной ошибки прогноза из pandas import read_csv из pandas import DataFrame из pandas import concat из statsmodels. from matplotlib import pyplot series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True) # create lagged набор данных значения = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1) dataframe.columns = [‘t’, ‘t + 1’] # разделить на наборы для обучения и тестирования X = dataframe.values train_size = int (len (X) * 0.66) поезд, test = X [1: train_size], X [train_size:] train_X, train_y = train [:, 0], train [:, 1] test_X, test_y = test [:, 0 ], test [:, 1] # модель сохранения на обучающем наборе train_pred = [x для x в train_X] # вычисление остатков train_resid = [train_y [i] -train_pred [i] для i в диапазоне (len (train_pred))] # моделируем остатки обучающего набора window = 15 model = AutoReg (train_resid, lags = window) model_fit = model. coef = model_fit.params # переход вперед по временным шагам в тесте history = train_resid [len (train_resid) -window:] history = [history [i] for i in range (len ( history))] predictions = list () expected_error = list () для t в диапазоне (len (test_y)): # persistence yhat = test_X [t] error = test_y [t ] — yhat expected_error.append (error) # ошибка прогнозирования length = len (history) lag = [history [i] for i in range (length-window, length)] pred_error = coef [0] для d в диапазоне (окно): pred_error + = coef [d + 1] * lag [window-d-1] прогнозов.append (pred_error) history.append (error) print (‘предсказанная ошибка =% f, ожидаемая ошибка =% f’% (pred_error, error)) # построение предсказанной ошибки pyplot.plot (expected_error) pyplot.plot (прогнозы, цвет = ‘красный’) pyplot. |
 tsa.ar_model import AutoReg
tsa.ar_model import AutoReg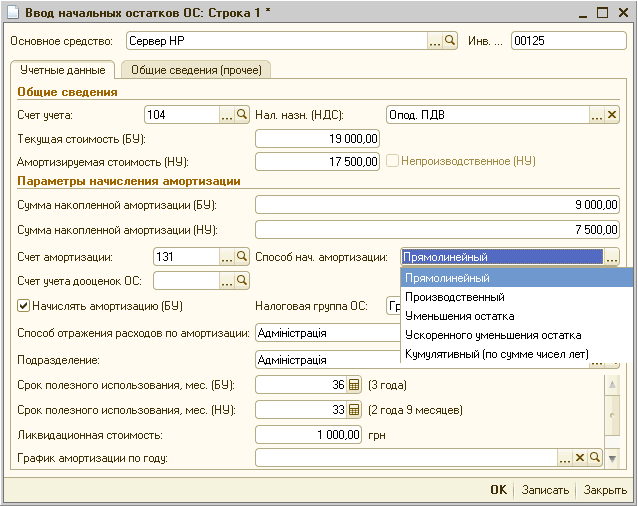 show ()
show ()При выполнении примера сначала печатается прогнозируемая и ожидаемая остаточная ошибка для каждого временного шага в тестовом наборе данных.
… прогнозируемая ошибка = -1.951332, ожидаемая ошибка = -10.000000 прогнозируемая ошибка = 6.675538, ожидаемая ошибка = 3.000000 прогнозируемая ошибка = 3,419129, ожидаемая ошибка = 15,000000 прогнозируемая ошибка = -7.160046, ожидаемая ошибка = -4.000000 прогнозируемая ошибка = -4,179003, ожидаемая ошибка = 7,000000 прогнозируемая ошибка = -10,425124, ожидаемая ошибка = -5,000000
… прогнозируемая ошибка = -1.951332, ожидаемая ошибка = -10.000000 прогнозируемая ошибка = 6.675538, ожидаемая ошибка = 3.000000 прогнозируемая ошибка = 3,419129, ожидаемая ошибка = 15,000000 прогнозируемая ошибка = -7,160046, ожидаемая ошибка = -4,000000 прогнозируемая ошибка = -4,179003, ожидаемая ошибка = 7,000000 прогнозируемая ошибка = -10,425124, ожидаемая ошибка = -5,000000 |
Затем фактическая остаточная ошибка для временного ряда наносится на график (синий) по сравнению с прогнозируемой остаточной ошибкой (красный).
Прогнозирование временного ряда остаточных ошибок
Теперь, когда мы знаем, как моделировать остаточную ошибку, теперь мы рассмотрим, как мы можем исправить прогнозы и улучшить навыки модели.
Правильные прогнозы с моделью остаточных ошибок
Модель остаточной ошибки прогноза интересна, но она также может быть полезна для улучшения прогнозов.
Имея хорошую оценку ошибки прогноза на временном шаге, мы можем делать более точные прогнозы.
Например, мы можем добавить ожидаемую ошибку прогноза к прогнозу, чтобы исправить его и, в свою очередь, улучшить навыки модели.
улучшенный прогноз = прогноз + расчетная ошибка
улучшенный прогноз = прогноз + расчетная ошибка |
Приведем конкретный пример.
Предположим, что ожидаемое значение для временного шага равно 10. Модель предсказывает 8 и оценивает ошибку как 3. Улучшенный прогноз будет:
улучшенный прогноз = прогноз + расчетная ошибка улучшенный прогноз = 8 + 3 улучшенный прогноз = 11
улучшенный прогноз = прогноз + оценочная ошибка улучшенный прогноз = 8 + 3 улучшенный прогноз = 11 |
Это принимает фактическую ошибку прогноза с 2 единиц до 1 единицы.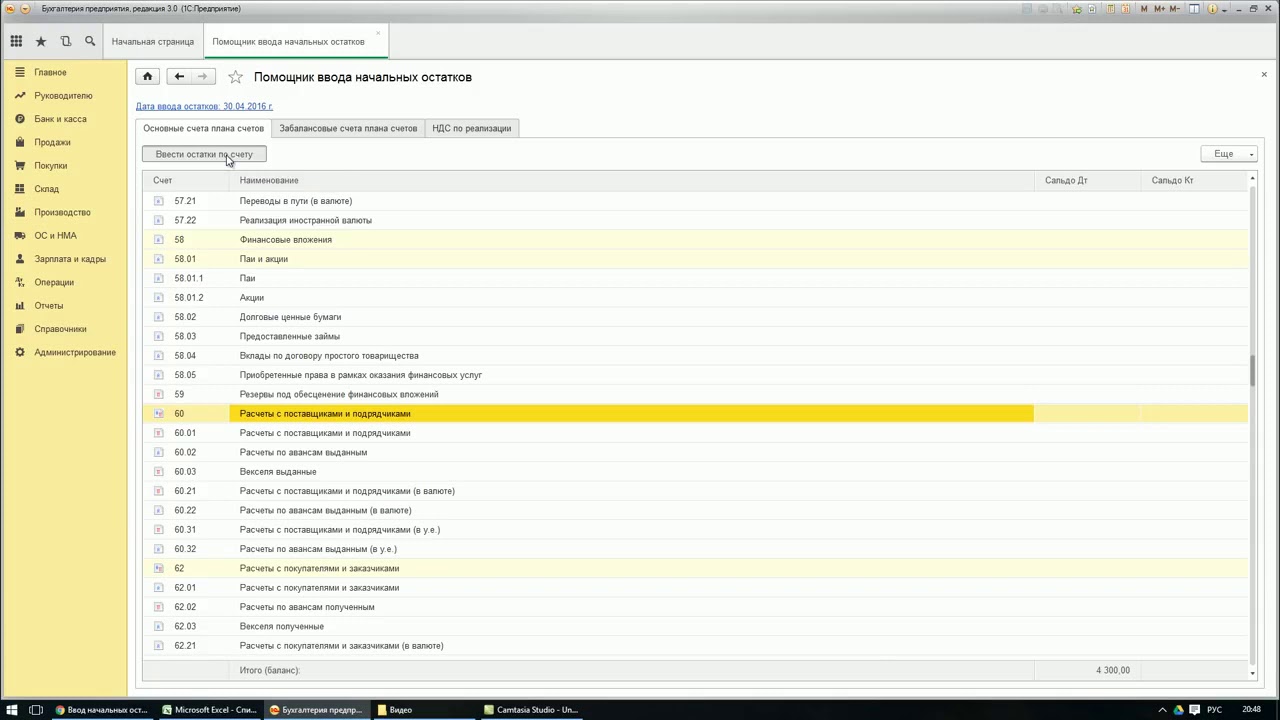
Мы можем обновить пример из предыдущего раздела, чтобы добавить предполагаемую ошибку прогноза к прогнозу устойчивости следующим образом:
# исправить прогноз yhat = yhat + pred_error
# исправить прогноз yhat = yhat + pred_error |
Полный пример приведен ниже.
# правильные прогнозы с моделью остаточных ошибок прогноза
из панд импортировать read_csv
из панд импортировать DataFrame
из pandas import concat
из statsmodels.tsa.ar_model импорт AutoReg
из matplotlib import pyplot
из sklearn.metrics import mean_squared_error
из математического импорта sqrt
# загрузить данные
series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True)
# создать лагированный набор данных
values = DataFrame (series.values)
dataframe = concat ([values.shift (1), values], axis = 1)
dataframe.columns = [‘t’, ‘t + 1’]
# разделить на обучающие и тестовые наборы
X = dataframe. values
train_size = int (len (X) * 0.66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель персистентности в обучающем наборе
train_pred = [x вместо x в train_X]
# вычислить остатки
train_resid = [train_y [i] -train_pred [i] для i в диапазоне (len (train_pred))]
# моделируем остатки обучающей выборки
окно = 15
model = AutoReg (train_resid, lags = 15)
model_fit = model.fit ()
coef = model_fit.params
# шаг вперед по времени в тесте
history = train_resid [len (train_resid) -window:]
history = [history [i] для i в диапазоне (len (history))]
прогнозы = список ()
для t в диапазоне (len (test_y)):
# упорство
yhat = test_X [t]
error = test_y [t] — yhat
# предсказать ошибку
length = len (история)
lag = [история [i] для i в диапазоне (длина-окно, длина)]
pred_error = coef [0]
для d в диапазоне (окно):
pred_error + = coef [d + 1] * задержка [окно-d-1]
# исправить прогноз
yhat = yhat + pred_error
предсказания.
values
train_size = int (len (X) * 0.66)
поезд, тест = X [1: train_size], X [train_size:]
train_X, train_y = поезд [:, 0], поезд [:, 1]
test_X, test_y = test [:, 0], test [:, 1]
# модель персистентности в обучающем наборе
train_pred = [x вместо x в train_X]
# вычислить остатки
train_resid = [train_y [i] -train_pred [i] для i в диапазоне (len (train_pred))]
# моделируем остатки обучающей выборки
окно = 15
model = AutoReg (train_resid, lags = 15)
model_fit = model.fit ()
coef = model_fit.params
# шаг вперед по времени в тесте
history = train_resid [len (train_resid) -window:]
history = [history [i] для i в диапазоне (len (history))]
прогнозы = список ()
для t в диапазоне (len (test_y)):
# упорство
yhat = test_X [t]
error = test_y [t] — yhat
# предсказать ошибку
length = len (история)
lag = [история [i] для i в диапазоне (длина-окно, длина)]
pred_error = coef [0]
для d в диапазоне (окно):
pred_error + = coef [d + 1] * задержка [окно-d-1]
# исправить прогноз
yhat = yhat + pred_error
предсказания. добавить (yhat)
history.append (ошибка)
print (‘предсказано =% f, ожидалось =% f’% (yhat, test_y [t]))
# ошибка
rmse = sqrt (mean_squared_error (test_y, прогнозы))
print (‘Test RMSE:% .3f’% rmse)
# прогнозируемая ошибка графика
pyplot.plot (test_y)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
добавить (yhat)
history.append (ошибка)
print (‘предсказано =% f, ожидалось =% f’% (yhat, test_y [t]))
# ошибка
rmse = sqrt (mean_squared_error (test_y, прогнозы))
print (‘Test RMSE:% .3f’% rmse)
# прогнозируемая ошибка графика
pyplot.plot (test_y)
pyplot.plot (прогнозы, цвет = ‘красный’)
pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | # правильные прогнозы с моделью остаточных ошибок прогноза из pandas import read_csv из pandas import DataFrame из pandas import concat из statsmodels. из matplotlib import pyplot from sklearn.metrics import mean_squared_error from math import sqrt # загрузить данные series = read_csv (‘daily-total-female-Births.csv’, header = 0, index_col = 0, parse_dates = True, squeeze = True) # создать лагированный набор данных values = DataFrame (series.values) dataframe = concat ([values.shift (1), values], axis = 1 ) dataframe.columns = [‘t’, ‘t + 1’] # разделить на наборы для обучения и тестирования X = dataframe.значения train_size = int (len (X) * 0.66) train, test = X [1: train_size], X [train_size:] train_X, train_y = train [:, 0], train [:, 1 ] test_X, test_y = test [:, 0], test [:, 1] # модель устойчивости в обучающем наборе train_pred = [x для x в train_X] # вычисление остатков train_resid = [train_y [i] -train_pred [i] for i in range (len (train_pred))] # моделировать остатки обучающего набора window = 15 model = AutoReg (train_resid, lags = 15) model_fit = model. coef = model_fit.params # шаг вперед по временным шагам в тесте history = train_resid [len (train_resid) -window:] history = [history [i] for i in range (len ( history))] predictions = list () for t in range (len (test_y)): # persistence yhat = test_X [t] error = test_y [t] — yhat # прогноз error length = len (history) lag = [history [i] for i in range (length-window, length)] pred_error = coef [0] для d в диапазоне (окно): pred_error + = coef [d + 1] * lag [window-d-1] # исправить предсказание yhat = yhat + pred_error предсказания.append (yhat) history.append (error) print (‘predicted =% f, expected =% f’% (yhat, test_y [t])) # error rmse = sqrt (mean_squared_error (test_y , прогнозы)) print (‘Test RMSE:% .3f’% rmse) # ошибка прогнозирования графика pyplot.plot (test_y) pyplot. pyplot .show () |
 tsa.ar_model import AutoReg
tsa.ar_model import AutoReg fit ()
fit () plot (прогнозы, color = ‘red’)
plot (прогнозы, color = ‘red’)При выполнении примера распечатываются прогнозы и ожидаемый результат для каждого временного шага в тестовом наборе данных.
RMSE скорректированных прогнозов по расчетам составляет 7,499, что намного лучше, чем оценка 9,151 для одной только модели устойчивости.
… прогнозируемый = 40,675538, ожидаемый = 37,000000 прогнозируемый = 40,419129, ожидаемый = 52,000000 прогнозируемый = 44,839954, ожидаемый = 48,000000 прогнозируемый = 43,820997, ожидаемый = 55,000000 прогнозируемый = 44,574876, ожидаемый = 50,000000 Тест RMSE: 7,499
… прогнозируемый = 40,675538, ожидаемый = 37,000000 прогнозируемый = 40,419129, ожидаемый = 52,000000 прогнозируемый = 44,839954, ожидаемый = 48,000000 прогнозируемый = 43,820997, ожидаемый = 55,000000 прогнозируемый = 44,574876, ожидаемый = 50,000000 Тестовый RMSE: 7,499 |
Наконец, ожидаемые значения для тестового набора данных нанесены на график (синий) по сравнению с скорректированным прогнозом (красный).
Мы видим, что модель персистентности была агрессивно скорректирована до временного ряда, который выглядит как скользящее среднее.
Скорректированный прогноз персистентности для суточных рождений женщин
Сводка
В этом руководстве вы узнали, как моделировать временные ряды остаточных ошибок и использовать их для исправления прогнозов с помощью Python.
В частности, вы узнали:
- О подходе скользящего среднего (MA) к разработке модели авторегрессии до остаточной ошибки.
- Как разработать и оценить модель остаточной ошибки для прогнозирования ошибки прогноза.
- Как использовать прогнозы ошибок прогнозов для исправления прогнозов и повышения навыков модели.
У вас есть вопросы о моделях скользящего среднего или об этом руководстве?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Хотите разрабатывать прогнозы временных рядов с помощью Python?
Создавайте собственные прогнозы за считанные минуты
. .. всего несколькими строками кода Python
.. всего несколькими строками кода Python Узнайте, как это сделать в моей новой электронной книге:
Введение в прогнозирование временных рядов с помощью Python
Он охватывает руководств для самообучения, и сквозных проектов, по таким темам, как: Загрузка данных, визуализация, моделирование, настройка алгоритмов, и многое другое…
Наконец, доведите прогнозирование временных рядов до
Ваши собственные проекты
Пропустить академики. Только результаты.
Посмотрите, что внутриscipy.optimize.least_squares — Справочное руководство SciPy v1.6.3
Решите нелинейную задачу наименьших квадратов с ограничениями на переменные.
Учитывая остатки f (x) (m-D вещественная функция n вещественных
переменных) и функции потерь rho (s) (скалярная функция), наименьших_квадратов находит локальный минимум функции стоимости F (x):
минимизировать F (x) = 0.5 * сумма (rho (f_i (x) ** 2), i = 0, ..., m - 1) при условии lb <= x <= ub
Назначение функции потерь rho (s) - уменьшить влияние выбросы в решении.
- Параметры
- fun callable
Функция, которая вычисляет вектор остатков с подписью
fun (x, * args, ** kwargs), т.е. минимизация продолжается с уважение к его первому аргументу. Аргументxпередан этому функция - это ndarray формы (n,) (никогда не скаляр, даже для n = 1).Он должен выделить и вернуть одномерный array_like формы (m,) или скаляр. Если аргументxсложный или функцияfunвозвращает комплексных остатков, он должен быть заключен в реальную функцию действительного аргументы, как показано в конце раздела Примеры.- x0 array_like с shape (n,) или float
Первоначальное предположение о независимых переменных. Если float, он будет обработан как одномерный массив с одним элементом.
- jac {«2-точечный», «3-точечный», «cs», вызываемый}, необязательно
Метод вычисления матрицы Якоби (матрица m на n, где element (i, j) - это частная производная от f [i] по х [j]).
 Ключевые слова выбирают конечно-разностную схему для численного
оценка. Схема «3 точки» более точна, но требует
в два раза больше операций, чем при «2 точках» (по умолчанию). Схема «cs»
использует сложные шаги, и хотя потенциально является наиболее точным, он
применимо только тогда, когда fun правильно обрабатывает сложные входные данные и
аналитически продолжается на комплексную плоскость. Метод «lm»
всегда использует «двухточечную» схему. Если вызываемый, он используется как
Ключевые слова выбирают конечно-разностную схему для численного
оценка. Схема «3 точки» более точна, но требует
в два раза больше операций, чем при «2 точках» (по умолчанию). Схема «cs»
использует сложные шаги, и хотя потенциально является наиболее точным, он
применимо только тогда, когда fun правильно обрабатывает сложные входные данные и
аналитически продолжается на комплексную плоскость. Метод «lm»
всегда использует «двухточечную» схему. Если вызываемый, он используется как jac (x, * args, ** kwargs)и должен возвращать хорошее приближение (или точное значение) для якобиана как array_like (np.atleast_2d применяется), разреженная матрица (для производительности предпочтительна csr_matrix) или ascipy.sparse.linalg.LinearOperator.- границы 2-кортеж array_like, необязательно
Нижняя и верхняя границы независимых переменных. По умолчанию без границ. Каждый массив должен соответствовать размеру x0 или быть скаляром, в последнем случае В этом случае граница будет одинаковой для всех переменных.
 Используйте
Используйте np.infс соответствующий знак для отключения границ для всех или некоторых переменных.- method {‘trf’, ‘dogbox’, ‘lm’}, необязательно
Алгоритм для выполнения минимизации.
‘trf’: алгоритм отражения доверительной области, особенно подходящий для больших разреженных задач с оценками. В целом надежный метод.
«dogbox»: алгоритм изогнутой формы с прямоугольными областями доверия, Типичный вариант использования - небольшие проблемы с границами. Не рекомендуется для задач с якобианом с дефицитом ранга.
‘lm’: алгоритм Левенберга-Марквардта, реализованный в MINPACK.Не обрабатывает границы и разреженные якобианы. Обычно самые эффективный метод для небольших неограниченных задач.
По умолчанию «trf». См. Примечания для получения дополнительной информации.
- ftol float или None, необязательно
Допуск для завершения путем изменения функции стоимости.
 По умолчанию
это 1e-8. Процесс оптимизации останавливается, когда
По умолчанию
это 1e-8. Процесс оптимизации останавливается, когда dF, и было адекватное согласие между локальной квадратичной моделью и истинная модель на последнем этапе. Если None и "method" не равно "lm", завершение по этому условию отключен. Если "method" равен "lm", этот допуск должен быть выше, чем машина эпсилон.
- xtol float или None, опционально
Допуск на прекращение при изменении независимых переменных. По умолчанию 1e-8. Точное состояние зависит от используемого метода :
Для «trf» и «dogbox»:
norm (dx). Для «лм»:
Дельта, где Дельта- радиус доверительной области иxs- это значениеxмасштабируется в соответствии с параметром x_scale (см. ниже).
Если None и "method" не равно "lm", завершение по этому условию отключен.
 Если "method" равен "lm", этот допуск должен быть выше, чем
машина эпсилон.
Если "method" равен "lm", этот допуск должен быть выше, чем
машина эпсилон.- gtol float или None, необязательно
Допуск на прекращение по норме уклона.По умолчанию 1e-8. Точное состояние зависит от используемого метода :
Для «trf»:
norm (g_scaled, ord = np.inf), где g_scaled- значение градиента, масштабируемое с учетом наличие границ [STIR].Для "dogbox":
norm (g_free, ord = np.inf), где g_free- градиент по переменным, которые находятся не в оптимальном состоянии на границе.Для «лм»: максимальное абсолютное значение косинуса углов. между столбцами якобиана и остаточного вектора меньше чем gtol , или остаточный вектор равен нулю.
Если None и "method" не равно "lm", завершение по этому условию отключен. Если "method" равен "lm", этот допуск должен быть выше, чем машина эпсилон.

- x_scale array_like или «jac», необязательно
Характерный масштаб каждой переменной.Установка x_scale эквивалентна переформулировать задачу в масштабированных переменных
xs = x / x_scale. Альтернативная точка зрения состоит в том, что размер доверительной области по jth размер пропорционаленx_scale [j]. Улучшение конвергенции может достигается установкой x_scale таким образом, чтобы шаг заданного размера по любой из масштабируемых переменных оказывает аналогичное влияние на стоимость функция. Если установлено значение «jac», шкала итеративно обновляется с использованием обратные нормы столбцов матрицы Якоби (как описано в [JJMore]).- loss str or callable, optional
Определяет функцию потерь. Разрешены следующие значения ключевых слов:
«линейный» (по умолчанию):
rho (z) = z. Дает стандарт проблема наименьших квадратов.
‘soft_l1’:
rho (z) = 2 * ((1 + z) ** 0,5 - 1). Гладкий аппроксимация потери l1 (абсолютного значения). Обычно хороший выбор для надежных наименьших квадратов.‘huber’:
rho (z) = z if z <= 1 else 2 * z ** 0.5 - 1. Работает аналогично soft_l1.«cauchy»:
rho (z) = ln (1 + z). Сильно ослабляет выбросы влияние, но может вызвать трудности в процессе оптимизации.‘arctan’:
rho (z) = arctan (z). Ограничивает максимальный убыток на единственный остаток имеет свойства, подобные «cauchy».
Если вызываемый, он должен взять 1-D ndarray
z = f ** 2и вернуть array_like с формой (3, m), где строка 0 содержит значения функции, строка 1 содержит первые производные, а строка 2 содержит вторую производные.Метод «lm» поддерживает только «линейные» потери.- f_scale float, необязательно
Значение мягкого запаса между остатками inlier и outlier, по умолчанию составляет 1.
 0. Функция потерь оценивается следующим образом
0. Функция потерь оценивается следующим образом rho_ (f ** 2) = C ** 2 * rho (f ** 2 / C ** 2), гдеC- f_scale , аrhoопределяется параметром потерь . Этот параметр имеет нет эффекта спотерями = 'linear', но для других потерь значений это решающее значение.- max_nfev Нет или int, необязательно
Максимальное количество оценок функции перед завершением. Если Нет (по умолчанию), значение выбирается автоматически:
Для «trf» и «dogbox»: 100 * n.
Для «lm»: 100 * n, если jac вызываемый и 100 * n * (n + 1) в противном случае (поскольку lm считает вызовы функций в якобиане оценка).
- diff_step None или array_like, необязательно
Определяет относительный размер шага для конечной разности приближение якобиана.Фактический шаг вычисляется как
х * diff_step. Если Нет (по умолчанию), то diff_step принимается за
условная «оптимальная» мощность машинного эпсилон для конечного
использованная разностная схема [NR].
Если Нет (по умолчанию), то diff_step принимается за
условная «оптимальная» мощность машинного эпсилон для конечного
использованная разностная схема [NR].- tr_solver {None, «точный», «lsmr»}, необязательный
Метод решения подзадач доверительной области, актуален только для «trf» и методы "собачьей будки".
«точный» подходит для не очень больших задач с плотным Матрицы Якоби.Вычислительная сложность на итерацию составляет сравнимо с сингулярным разложением якобиана матрица.
«lsmr» подходит для задач с разреженным и большим якобианом. матрицы. Он использует итеративную процедуру
scipy.sparse.linalg.lsmrдля нахождения решения линейного задача наименьших квадратов и требует только произведение матрицы на вектор оценки.
Если Нет (по умолчанию), решающая программа выбирается на основе типа якобиана. вернулся на первой итерации.
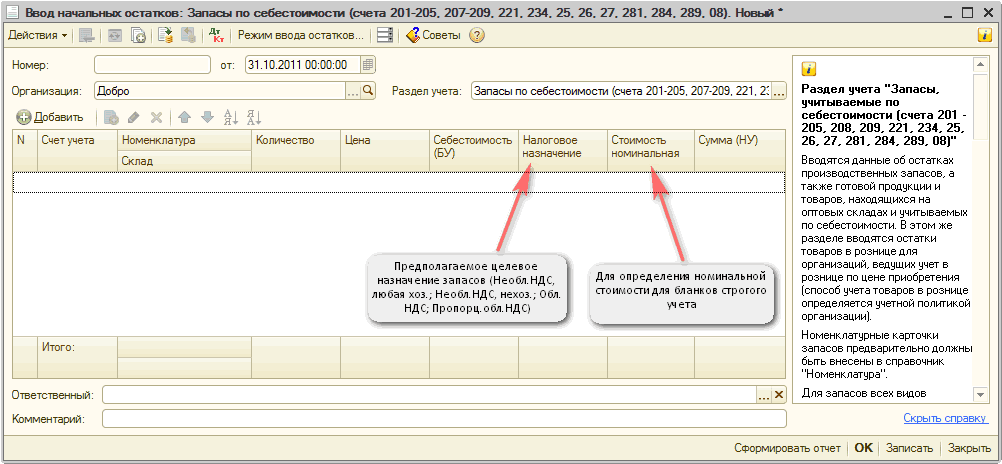
- tr_options dict, необязательно
Параметры ключевого слова, переданные в решатель доверительной области.
tr_solver = 'exact': tr_options игнорируются.tr_solver = 'lsmr': параметры дляscipy.sparse.linalg.lsmr. Кроме того,method = 'trf'поддерживает опцию «упорядочить». (bool, по умолчанию True), который добавляет термин регуляризации к нормальное уравнение, которое улучшает сходимость, если якобиан ранг-дефицитный [Берд] (ур.3.4).
- jac_sparsity {None, array_like, sparse matrix}, необязательно
Определяет разреженную структуру матрицы Якоби для конечных оценка разности, ее форма должна быть (m, n). Если якобиан имеет только несколько ненулевых элементов в каждой строке , обеспечивая разреженность структура значительно ускорит вычисления [Curtis].
 Ноль
запись означает, что соответствующий элемент в якобиане тождественно
нуль. Если предоставлено, принудительно использует решатель доверительной области lsmr.Если Нет (по умолчанию), будет использоваться плотное разложение. Не имеет эффекта
для метода «lm».
Ноль
запись означает, что соответствующий элемент в якобиане тождественно
нуль. Если предоставлено, принудительно использует решатель доверительной области lsmr.Если Нет (по умолчанию), будет использоваться плотное разложение. Не имеет эффекта
для метода «lm».- подробный {0, 1, 2}, необязательно
Уровень детализации алгоритма:
0 (по умолчанию): работать тихо.
1: отобразить отчет о завершении.
2: отображение прогресса во время итераций (не поддерживается lm метод).
- args, kwargs tuple и dict, необязательно
Дополнительные аргументы, переданные в fun и jac .Оба по умолчанию пустые. Вызывающая подпись -
fun (x, * args, ** kwargs)и то же самое для jac .
- Возвращает
- результат OptimizeResult
OptimizeResultсо следующими определенными полями:- xndarray, shape (n,)
Решение найдено.

- costfloat
Значение функции стоимости в решении.
- funndarray, shape (m,)
Вектор невязок в решении.Т Дж является приближением Гаусса-Ньютона гессиана функции стоимости. Тип такой же, как и используемый в алгоритме.
- gradndarray, shape (m,)
Градиент функции стоимости в решении.
- optimalityfloat
Мера оптимальности первого порядка. В неограниченных задачах это всегда единообразная норма градиента. В ограниченных задачах, это количество, которое сравнивалось с gtol во время итераций.
- active_maskndarray of int, shape (n,)
Каждый компонент показывает, активно ли соответствующее ограничение (то есть, находится ли переменная на границе):
0: ограничение неактивно.
-1: активна нижняя граница.
1: активна верхняя граница.
Может быть несколько произвольным для метода «trf», поскольку он генерирует последовательность строго допустимых итераций и active_mask определяется в пределах порога допуска.

- nfevint
Количество выполненных оценок функций. Методы trf и dogbox делают функция not count требует численного приближения якобиана, так как в отличие от метода «lm».
- njevint или нет
Количество выполненных оценок Якоби. Если числовой якобиан аппроксимация используется в методе «lm», для него установлено значение None.
- statusint
Причина завершения работы алгоритма:
-1: из MINPACK возвращен неправильный статус входных параметров.
0: превышено максимальное количество оценок функции.
1: gtol условие завершения выполнено.
2: футоль условие завершения выполнено.
3: xtol условие завершения выполнено.
4: Условия завершения ftol и xtol выполнены.
- messagestr
Устное описание причины прерывания.

- successbool
Истинно, если удовлетворен один из критериев сходимости (статус , > 0).
См. Также
-
leastsq Унаследованная оболочка для реализации MINPACK алгоритма Левенберга-Марквадта.
-
curve_fit Минимизация методом наименьших квадратов, примененная к задаче аппроксимации кривой.
Банкноты
Метод «lm» (Левенберг-Марквардт) вызывает оболочку по методу наименьших квадратов.
алгоритмы, реализованные в MINPACK (lmder, lmdif).Он управляет
Алгоритм Левенберга-Марквардта сформулирован как алгоритм типа доверительной области.
Реализация основана на бумаге [JJMore], она очень надежна и
эффективен с множеством хитрых приемов. Это должен быть ваш первый выбор
для неограниченных задач. Обратите внимание, что он не поддерживает границы. Также,
это не работает, когда m Метод «trf» (Trust Region Reflective) мотивирован процессом
решение системы уравнений, составляющих оптимальность первого порядка
условие для задачи минимизации с ограничениями, сформулированное в
[РАЗМЕШИВАТЬ]. Метод «dogbox» работает в рамках доверительного региона, но учитывает
прямоугольные доверительные области в отличие от обычных эллипсоидов [Фоглис].
Пересечение текущего доверительного региона и начальных границ снова
прямоугольной формы, поэтому на каждой итерации рассматривается задача квадратичной минимизации
к связанным ограничениям решается приблизительно методом изгиба Пауэлла
[NumOpt].Требуемый шаг Гаусса-Ньютона можно точно вычислить для
плотные якобианы или приблизительно на Реализованы надежные функции потерь, как описано в [BA]. Идея
заключается в изменении остаточного вектора и матрицы Якоби на каждой итерации.
такой, что вычисленный градиент и приближение Гаусса-Ньютона Гессе совпадают
истинный градиент и приближение Гессе функции стоимости.потом
алгоритм работает нормально, т.е. робастные функции потерь равны
реализован как простая оболочка над стандартными алгоритмами наименьших квадратов. Список литературы М. А. Бранч, Т. Ф. Коулман, Ю. Ли, «Подпространство, внутреннее,
и метод сопряженных градиентов для крупномасштабных связанных ограничений
Проблемы минимизации », SIAM Journal on Scientific Computing,
Vol. 21, Number 1, pp 1-23, 1999. Уильям Х.Press et. др., «Числовые рецепты. Искусство научного
Вычислительная техника. 3-е издание », п. 5.7. Р. Х. Берд, Р. Б. Шнабель и Г. А. Шульц, «Приблизительный
решение проблемы доверительного региона путем минимизации
двумерные подпространства ”, Матем. А. Кертис, М. Дж. Д. Пауэлл, Дж. Рид, «Об оценке
разреженные матрицы Якоби », Журнал Института
Математика и ее приложения, 13, стр.117-120, 1974. Дж. Дж. Мор, «Алгоритм Левенберга-Марквардта: реализация
и теория », Численный анализ, под ред. Г. А. Ватсон, Лекция
Примечания по математике 630, Springer Verlag, стр. 105-116, 1977. К. Фоглис, И. Э. Лагарис, «Прямоугольный подопечный»
Подход Dogleg для неограниченных и связанных ограничений
Нелинейная оптимизация », Международная конференция WSEAS по
Прикладная математика, Корфу, Греция, 2004. Дж. Нокедал и С. Дж. Райт, «Численная оптимизация,
Издание 2-е », глава 4. B. Triggs et. др., «Регулировка связки - современный синтез»,
Материалы международного семинара по алгоритмам зрения:
Теория и практика, стр. Примеры В этом примере мы находим минимум функции Розенброка без границ
по независимым переменным. Обратите внимание, что мы предоставляем только вектор остатков. Алгоритм
строит функцию стоимости как сумму квадратов остатков, которая
дает функцию Розенброка. Точный минимум составляет 6867e-30
>>> res_1.optimality
8.8928864934219529e-14
Теперь мы ограничиваем переменные таким образом, чтобы предыдущее решение
становится невозможным. В частности, мы требуем, чтобы Мы также предоставляем аналитический якобиан: Собирая все вместе, мы видим, что новое решение находится на грани: Теперь решаем систему уравнений (т.е. функция стоимости должна быть равна нулю.
как минимум) для трехдиагональной вектор-функции Бройдена 100000
переменные: Соответствующая матрица Якоби разреженная. Мы говорим алгоритм
оцените его конечными разностями и представьте разреженную структуру
Якобиан, чтобы значительно ускорить этот процесс. Давайте также решим проблему аппроксимации кривой, используя робастную функцию потерь для
позаботьтесь о выбросах в данных. Определите функцию модели как Сначала определите функцию, которая генерирует данные с шумом и
выбросы, определить параметры модели и сгенерировать данные: Определите функцию для вычисления остатков и начальной оценки
параметры. Вычислить стандартное решение методом наименьших квадратов: Теперь вычислите два решения с двумя разными надежными функциями потерь. В
параметр f_scale установлен на 0.1, что означает, что остатки инлиера должны
не превышает 0,1 (используемый уровень шума). И, наконец, постройте все кривые. Мы видим это, выбрав подходящий потери можно получить оценки, близкие к оптимальным даже при наличии
сильные выбросы.Но учтите, что обычно рекомендуется попробовать
"Soft_l1" или "huber" проигрывают первыми (если это вообще необходимо), так как два других
варианты могут вызвать трудности в процессе оптимизации. В следующем примере мы покажем, как комплексные функции невязки
Комплексные переменные можно оптимизировать с помощью Мы превращаем его в функцию вещественных переменных, которая возвращает реальные остатки.
просто обрабатывая действительную и мнимую части как независимые переменные: Таким образом, вместо исходной m-D комплексной функции n комплексной
переменных мы оптимизируем 2м-мерную действительную функцию 2n вещественных переменных: 3 + 0,49999999999 3j)
Остаточная стоимость, также известная как ликвидационная стоимость, представляет собой оценочную стоимость основных средств в конце срока аренды или срока полезного использования. В ситуациях аренды арендодатель использует остаточную стоимость в качестве одного из основных методов определения суммы, которую арендатор платит в виде периодических арендных платежей.Как правило, чем больше срок полезного использования или аренды актива, тем ниже его остаточная стоимость. Формулы остаточной стоимости различаются в зависимости от отрасли, но ее общий смысл - то, что остается - остается неизменным. В проектах составления бюджета остаточная стоимость отражает, за сколько вы можете продать актив после того, как фирма прекратила его использовать или когда денежные потоки, генерируемые активами, больше нельзя точно спрогнозировать.Для инвестиций остаточная стоимость рассчитывается как разница между прибылью и стоимостью капитала. В бухгалтерском учете собственный капитал - это остаточные чистые активы после вычета обязательств. В области математики, особенно в регрессионном анализе, остаточная стоимость находится путем вычитания предсказанного значения из наблюдаемого или измеренного значения. Если вы арендуете автомобиль на три года, его остаточная стоимость равна его стоимости через три года.Остаточная стоимость определяется банком, который выдает аренду, и основана на прошлых моделях и прогнозах на будущее. Наряду с процентной ставкой и налогом остаточная стоимость является важным фактором при определении ежемесячных арендных платежей за автомобиль. Кроме того, рассмотрим пример владельца бизнеса, у которого срок полезного использования рабочего стола составляет семь лет. Сколько стоит стол по истечении семи лет (его справедливая рыночная стоимость, определяемая соглашением или оценкой), является его остаточной стоимостью, также известной как ликвидационная стоимость.Для управления риском стоимости активов компании, которые имеют большое количество дорогостоящих основных средств, таких как станки, транспортные средства или медицинское оборудование, могут приобретать страховку остаточной стоимости, чтобы гарантировать стоимость активов, находящихся в надлежащем состоянии, в конце срока их полезного использования. Остаточная стоимость и стоимость при перепродаже - это два термина, которые часто используются при обсуждении условий покупки и лизинга автомобиля. В примере с лизингом автомобиля остаточная стоимость будет равна оценочной стоимости автомобиля в конце срока его аренды.Остаточная стоимость используется для определения суммы ежемесячного платежа за аренду и цены, которую лицо, владеющее арендой, должно будет заплатить за покупку автомобиля в конце срока аренды. Остаточная стоимость автомобилей часто выражается в процентах от рекомендованной производителем розничной цены (MSRP). Например, остаточная сумма может быть выражена следующим образом: рекомендованная производителем розничная цена 30 000 долларов * Остаточная стоимость 50% = стоимость 15 000 долларов через 3 года. Таким образом, автомобиль с рекомендованной розничной ценой 30 000 долларов США и остаточной стоимостью 50% через три года будет стоить 15 000 долларов США в конце срока аренды. Стоимость перепродажи - это аналогичное понятие, но оно относится к автомобилю, который был куплен, а не взят в аренду. Таким образом, стоимость при перепродаже относится к стоимости приобретенного автомобиля после амортизации, пробега и повреждений. Хотя остаточная стоимость заранее определена и основана на рекомендованной розничной цене, стоимость автомобиля при перепродаже может меняться в зависимости от рыночных условий. Если вы решите купить арендованный автомобиль, цена будет равна остаточной стоимости плюс все комиссии. Остаточная стоимость также учитывается при расчете износа или амортизации компании.Предположим, компания приобретает новую программу для внутреннего отслеживания заказов на продажу. Это программное обеспечение имеет начальную стоимость 10 000 долларов США и срок полезного использования пять лет. Чтобы рассчитать годовую амортизацию для целей бухгалтерского учета, владельцу требуется остаточная стоимость программного обеспечения или его стоимость по истечении пяти лет. Предположим, что это значение равно нулю, и компания использует линейный метод для амортизации программного обеспечения. Следовательно, компания должна вычесть нулевую остаточную стоимость из первоначальной стоимости в 10 000 долларов и разделить на срок полезного использования актива в пять лет, чтобы получить его годовую амортизацию, которая составляет 2000 долларов.Если бы остаточная стоимость составляла 2000 долларов, годовая амортизация составила бы 1600 долларов (10 000–2 000 долларов за 5 лет). Для материальных активов, таких как автомобили, компьютеры и оборудование, владелец бизнеса будет использовать тот же расчет, только вместо того, чтобы амортизировать актив в течение срока его полезного использования, он будет амортизировать его. Начальная стоимость за вычетом остаточной стоимости также называется «амортизируемой базой». В регрессионном анализе разница между наблюдаемым значением зависимой переменной и прогнозируемым значением называется остатком. Чтобы определить остаточную стоимость актива, вы должны учитывать предполагаемую сумму, которую владелец актива заработал бы, продав актив (за вычетом любых затрат, которые могут быть понесены во время выбытия). Остаточная стоимость часто используется, когда речь идет об арендованном автомобиле. Остаточная стоимость автомобиля - это оценочная стоимость автомобиля в конце срока аренды. Остаточная стоимость автомобиля рассчитывается банком или финансовым учреждением; Обычно он рассчитывается как процент от рекомендованной производителем розничной цены (MSRP). Остаточная стоимость автомобиля - это стоимость автомобиля в конце срока аренды. Остаточная стоимость и выкуп при аренде - это разные вещи. Выкуп по лизингу - это опция, которая содержится в некоторых договорах аренды, которые дают вам возможность купить арендованный автомобиль по окончании срока аренды. Остаточная стоимость часто используется в контексте аренды автомобилей. Остаточная стоимость - это стоимость автомобиля по окончании срока аренды. Хорошая остаточная стоимость составляет 55% -65% от рекомендованной производителем розничной цены (MSRP). Остаточная стоимость - один из важнейших аспектов расчета условий аренды. Он относится к будущей стоимости товара (обычно будущая дата наступает, когда заканчивается аренда).При использовании в контексте аренды автомобиля остаточная стоимость рассчитывается с использованием ряда различных факторов: В бухгалтерском учете под остаточной стоимостью понимается остаточная стоимость актива после его полной амортизации. Введение в LEAP ежедневно работают над поддержкой и консультированием различных производителей оборудования, технических консультантов и всех крупных университетов Австралии и Новой Зеландии.Наши инженеры службы поддержки CFD систематически работают с нашими клиентами, чтобы помочь в устранении неполадок моделирования, которое не ведет себя так, как ожидалось - и здесь мы сочли полезным задокументировать этот `` мысленный контрольный список '', который мы часто используем для решения сложных проблем (в надежде, что это Вам тоже поможет!). Вы можете узнать больше об опыте CFD-команды LEAP здесь. Этот контрольный список будет посвящен решателю ANSYS Fluent CFD, однако мы часто начинаем с обзора геометрии и сетки.Если вас также интересует контрольный список советов и приемов по «геометрии и построению сетки», сообщите нам об этом в комментариях. Естественно, когда вы начинаете процесс устранения неполадок, у вас уже может быть подозрение о причине вашей проблемы, поэтому вы можете обнаружить, что проверяете несколько параметров, вносите несколько изменений, а затем повторно запускаете / просматриваете результаты. Однако наш первый совет заключается в том, что для определения основной причины проблемы старайтесь вносить одно преднамеренное изменение за раз. Для простоты в этом блоге основное внимание уделяется статическому внешнему потоку, моделированию RANS, однако этот контрольный список для устранения неполадок также является полезным местом для начала и для других типов потоков. Мы остановимся на следующих разделах: Общие проблемы В этом разделе рассматриваются общие проблемы, когда моделирование не сходится (SNN) представляют собой значительный отход от стандартного способа работы искусственных нейронных сетей (Farabet et al., 2012). Большая часть успеха моделей глубокого обучения нейронных сетей в сложных задачах распознавания образов основана на нейронных единицах, которые получают, обрабатывают и передают аналоговую информацию. В целом, есть две основные категории для обучения SNN - контролируемые и неконтролируемые. Хотя механизмы неконтролируемого обучения, такие как Spike-Timing Dependent Plasticity (STDP), привлекательны для реализации локального обучения с низким энергопотреблением на кристалле, их производительность по-прежнему уступает управляемым сетям даже на простых платформах распознавания цифр, таких как набор данных MNIST (Diehl and Cook , 2015). Конкретные вклады нашей работы заключаются в следующем: (i) Как будет объяснено в последующих разделах, существуют различные архитектурные ограничения, связанные с обучением ИНС, которые могут быть преобразованы в SNN практически без потерь.Следовательно, неясно, будут ли предложенные методы масштабироваться для более крупных и глубоких архитектур для более сложных задач. Мы предоставляем доказательства концептуальных экспериментов, согласно которым глубокие SNN (от 16 до 34 уровней) могут обеспечить конкурентоспособную точность по сложным наборам данных, таким как CIFAR-10 и ImageNet. (ii) Мы предлагаем новую технику преобразования ИНС в СНС, которая статистически превосходит современные методы. Мы сообщаем об ошибке классификации в 8,45% в наборе данных CIFAR-10, что на сегодняшний день является наилучшим результатом для любой сети SNN.Впервые мы сообщаем о производительности SNN по всему набору валидации ImageNet 2012. Мы достигаем 30,04% частоты ошибок первой 1 и 10,99% первой пятерки для архитектур VGG-16. (iii) Мы исследуем архитектуры остаточной сети (ResNet) как потенциальный путь для создания более глубоких сетей SNN. Мы представляем идеи и конструктивные ограничения, необходимые для обеспечения преобразования ANN-SNN для ResNets. Мы сообщаем об ошибке классификации 12,54% в наборе данных CIFAR-10 и о 34,53% ошибок первой 1 и 13.67% ошибок в первой пятерке проверенных наборов ImageNet. Это первая работа, в которой делается попытка изучить SNN с остаточной сетевой архитектурой. (iv) Мы демонстрируем, что разреженность сети SNN значительно увеличивается по мере увеличения глубины сети. Это дополнительно мотивирует исследование преобразования ANN в SNN для операций, управляемых событиями, с целью сокращения накладных расходов на вычисления. Основное различие между работой ИНС и СНС - это понятие времени.В то время как входы ИНС статичны, SNN работают на основе входных динамических двоичных пиков как функции времени. Нейронные узлы также принимают и передают двоичные входные сигналы пиков в SNN, в отличие от ANN, где входы и выходы нейронных узлов являются аналоговыми значениями. В этой работе мы рассматриваем операцию сети с кодировкой скорости, при которой среднее количество пиков, передаваемых в качестве входных данных в сеть в течение достаточно большого временного окна, приблизительно пропорционально величине исходных входных данных ИНС (в данном случае интенсивности пикселей).Продолжительность временного окна определяется желаемой производительностью сети (например, точностью классификации) на выходном уровне сети. Процесс генерации событий Пуассона используется для создания входной последовательности всплесков в сети. Каждый временной шаг работы SNN связан с генерацией случайного числа, значение которого сравнивается с величиной соответствующего входа. Событие всплеска запускается, если сгенерированное случайное число меньше значения соответствующей интенсивности пикселя.Этот процесс гарантирует, что среднее количество входных всплесков в SNN пропорционально величине соответствующих входных данных ANN и обычно используется для моделирования SNN для задач распознавания на основе наборов данных для статических изображений (Diehl et al., 2015). На рисунке 1 показан конкретный моментальный снимок входных пиков, переданных в SNN для конкретного изображения из набора данных CIFAR-10. Обратите внимание, что, поскольку мы рассматриваем вычитаемые изображения на пиксель, входной слой получает пики, скорость которых пропорциональна входной величине со знаком, равным входному знаку.Однако для последующих слоев все всплески имеют положительный знак, поскольку они генерируются импульсами нейронов в сети. SNN-операции таких сетей являются «псевдо-одновременными», то есть конкретный уровень работает сразу с поступающими всплесками от предыдущего уровня и не должен ждать в течение нескольких временных шагов для накопления информации от нейронов предыдущего уровня. При подаче в сеть цепочки пиков, генерируемой Пуассоном, на выходах сети будут возникать пики.Вывод основан на кумулятивном количестве импульсов нейронов на выходном уровне сети за заданный временной интервал. Рисунок 1 . Крайняя левая панель отображает конкретное входное изображение из набора данных CIFAR-10 с вычтенным средним на пиксель (по обучающему набору), которое предоставляется в качестве входных данных для исходной ИНС. Средняя панель представляет собой конкретный пример последовательности пиков Пуассона, генерируемой из входного аналогового изображения. Накопленные события, предоставленные SNN за 1000 временных шагов, отображены на крайней правой панели.Это оправдывает тот факт, что входное изображение со временем кодируется со скоростью для работы SNN. ANN в SNN обычно рассматривают выпрямленный линейный блок (ReLU) как функцию активации ANN. Для нейрона, принимающего входы x i через синаптические веса w i , выход нейрона ReLU y определяется как, Хотя нейроны ReLU в настоящее время обычно используются в большом количестве задач машинного обучения, основная причина их использования в схемах преобразования ANN-SNN заключается в том, что они несут функциональную эквивалентность нейрону с импульсами Integrate-Fire (IF) без каких-либо утечек и рефрактерный период (Cao et al., 2015; Diehl et al., 2015). Обратите внимание, что это особый тип модели Spiking Neuron (Ижикевич, 2003). Давайте рассмотрим входы ИНС x i , закодированные во времени как последовательность пиков 𝕏 i ( t ), где среднее значение 𝕏 i ( t ), E [𝕏 i ( t )] ∝ x i (для сети кодирования скорости, рассматриваемой в данной работе).IF Spiking Neuron отслеживает свой мембранный потенциал v mem , который объединяет входящие импульсы и генерирует выброс на выходе всякий раз, когда мембранный потенциал пересекает определенный порог v th . Мембранный потенциал сбрасывается до нуля при генерации выброса на выходе. Все нейроны сбрасываются всякий раз, когда появляется последовательность спайков, соответствующая новому изображению / паттерну. Динамика импульсного нейрона ПЧ как функция временного шага, t , может быть описана следующим уравнением: Обратите внимание, что динамика нейрона не зависит от действительной величины временного шага. Давайте сначала рассмотрим простой случай, когда нейрон управляется одним входом ( t ) и положительным синаптическим весом w . Из-за отсутствия какого-либо члена утечки в нейронной динамике интуитивно понятно показать, что соответствующая скорость всплеска выходного сигнала нейрона задается как E [ Y ( t )] ∝ E [𝕏 ( t )], причем коэффициент пропорциональности зависит от соотношения w и v th .В случае, когда синаптический вес отрицательный, импульсная активность выходного сигнала IF-нейрона равна нулю, поскольку нейрон никогда не может пересечь пусковой потенциал v th , что отражает функциональность ReLU. Чем выше отношение порога к весу, тем больше времени требуется нейрону для всплеска, тем самым уменьшая скорость всплеска нейрона, E [ Y ( t )] или, что эквивалентно, увеличивает время -Задержка для нейрона, чтобы произвести спайк.Относительно высокий порог срабатывания может вызвать огромную задержку для нейронов генерировать всплески выходного сигнала. Для глубокой архитектуры такая задержка может быстро накапливаться и приводить к тому, что сеть не генерирует пики на выходе в течение относительно длительных периодов времени. С другой стороны, относительно низкий порог приводит к тому, что SNN теряет способность различать разные величины импульсных входов, накапливаемых в мембранном потенциале (термин ∑iwi.𝕏i (t) в уравнении 2) Spiking Neuron, заставляя его терять доказательства во время процесса интеграции мембранного потенциала.Это, в свою очередь, приводит к снижению точности преобразованной сети. Следовательно, соответствующий выбор отношения порога нейрона к синаптическому весу важен для обеспечения минимальной потери точности классификации во время процесса преобразования ИНС-СНС (Diehl et al., 2015). Следовательно, большая часть исследовательской работы в этой области была сосредоточена на изложении соответствующих алгоритмов для балансировки пороговых значений или, что эквивалентно, нормализации веса различных уровней сети для достижения преобразования ИНС-СНС практически без потерь. Обычно нейронные блоки, используемые для схем преобразования ИНС в СНС, обучаются без какого-либо смещения (Diehl et al., 2015). Это связано с тем, что оптимизация члена смещения в дополнение к пиковому порогу нейрона расширяет исследование пространства параметров, тем самым усложняя процесс преобразования ИНС-СНС. Требование нейронных единиц без смещения также влечет за собой то, что метод пакетной нормализации (Ioffe and Szegedy, 2015) не может использоваться в качестве регуляризатора во время процесса обучения, поскольку он смещает входные данные для каждого уровня сети, чтобы гарантировать, что каждый уровень снабжен входами, имеющими ноль. иметь в виду.Вместо этого мы используем выпадение (Srivastava et al., 2014) в качестве метода регуляризации. Этот метод просто маскирует части входных данных для каждого уровня, используя выборки из распределения Бернулли, где каждый вход в слой имеет заданную вероятность отбрасывания. Архитектура глубокой сверточной нейронной сети обычно состоит из промежуточных слоев пула, чтобы уменьшить размер выходных карт свертки. Хотя существуют различные варианты выполнения механизма объединения, два популярных варианта - это либо максимальное объединение (максимальный выход нейрона в окне объединения), либо пространственное усреднение (операция объединения двухмерных средних значений в окне объединения).Поскольку активации нейронов в SNN являются двоичными, а не аналоговыми значениями, выполнение max-pooling приведет к значительной потере информации для следующего уровня. Следовательно, мы рассматриваем пространственное усреднение как механизм объединения в этой работе (Diehl et al., 2015). Как упоминалось ранее, наша работа основана на предложении, изложенном авторами в работе Diehl et al. (2015), в котором порог нейрона конкретного слоя устанавливается равным максимальной активации всех ReLU в соответствующем слое (путем прохождения всего обучающего набора через обученную ИНС один раз после завершения обучения).Такой метод «нормализации на основе данных» был оценен для трехуровневых полностью связанных и сверточных архитектур на наборе данных MNIST (Diehl et al., 2015). Обратите внимание, что в этом тексте этот процесс называется «нормализация веса» и «балансировка порога» как синонимы. Как упоминалось ранее, цель этой работы - оптимизировать соотношение синаптических весов по отношению к порогу срабатывания нейрона, v th . Следовательно, либо все синаптические веса, предшествующие нейронному слою, масштабируются с помощью коэффициента нормализации w norm , равного максимальной нейронной активации, и порог устанавливается равным 1 («нормализация веса»), либо порог v th устанавливается равным максимальной активации нейрона для соответствующего слоя с неизменными синаптическими весами («балансировка порога»).Обе операции математически точно эквивалентны. Однако приведенный выше алгоритм приводит нас к вопросу: являются ли активации ИНС репрезентативными для активаций СНС? Рассмотрим частный пример для случая максимальной активации для одного ReLU. Нейрон получает два входа, а именно 0,5 и 1. Давайте рассмотрим единичные синаптические веса в этом сценарии. Поскольку максимальная активация ReLU составляет 1,5, порог нейрона будет установлен равным 1.5. Однако, когда эта сеть переведена в режим SNN, оба входа будут распространять двоичные пиковые сигналы. Вход ИНС, равный 1, будет преобразован в пики, передаваемые на каждом временном шаге, в то время как другой вход будет передавать пики 50% длительности достаточно большого временного окна. Следовательно, фактическое суммирование импульсных входных сигналов, полученных нейроном за временной шаг, будет равно 2 для большого количества выборок, что выше порога выброса (1.5). Ясно, что некоторая потеря информации будет иметь место из-за отсутствия интеграции этих доказательств. Исходя из этого наблюдения, мы предлагаем метод нормализации веса, который уравновешивает порог каждого уровня, учитывая фактическую работу SNN в цикле во время процесса преобразования ANN-SNN. Алгоритм последовательно нормализует веса сети для каждого уровня. Учитывая конкретную обученную ИНС, первым шагом является создание входной последовательности пиков Пуассона для сети по обучающему набору для достаточно большого временного окна. Последовательность импульсов Пуассона позволяет нам регистрировать максимальное суммирование взвешенных входных импульсов (термин ∑iwi.𝕏i (t) в уравнении 2 и далее в тексте означает максимальную активацию SNN), которая будет принята первым нейронным уровнем сети. Чтобы минимизировать временную задержку нейрона и одновременно гарантировать, что порог срабатывания нейрона не слишком низкий, мы нормализуем вес первого слоя в зависимости от максимального входного сигнала на основе пиков, полученного первым слоем. После того, как пороговое значение для первого уровня установлено, нам предоставляется типичная последовательность всплесков на выходе первого уровня, которая позволяет нам сгенерировать входной поток всплесков для следующего слоя.Процесс продолжается последовательно для всех уровней сети. Основное различие между нашим предложением и предыдущей работой (Diehl et al., 2015) заключается в том, что предлагаемая схема нормализации веса учитывает фактическую работу SNN в процессе преобразования. Как мы покажем в разделе «Результаты», эта схема имеет решающее значение для обеспечения преобразования ANN-SNN практически без потерь для значительно более глубоких архитектур и для сложных задач распознавания. Мы оцениваем наше предложение по сети VGG-16 (Симонян и Зиссерман, 2014), стандартной глубокой сверточной сетевой архитектуре, которая состоит из 16-слойной глубокой сети, состоящей из сверточных фильтров 3 × 3 (с промежуточными слоями пула для уменьшения размерности выходной карты с помощью увеличивающееся количество карт).Псевдокод алгоритма приведен ниже. Алгоритм 1 : S PIKE -N ORM была предложена как попытка масштабирования сверточных нейронных сетей до очень глубоких многоуровневых стеков (He et al., 2016a). Несмотря на то, что были изучены различные варианты базовой функциональной единицы, в этом тексте мы будем рассматривать только идентификационные ярлыки (ярлык типа A согласно статье; He et al., 2016а). Каждый блок состоит из двух параллельных дорожек. Неидентификационный путь состоит из двух пространственных слоев свертки с промежуточным слоем ReLU. В то время как исходная формулировка ResNet рассматривает ReLU на стыке параллельных неидентификационных и идентичных путей (He et al., 2016a), недавние формулировки не рассматривают соединения ReLU в сетевой архитектуре (He et al., 2016b). Отсутствие ReLU в точке пересечения неидентификационных и идентичных путей наблюдалось, что привело к небольшому повышению точности классификации в наборе данных CIFAR-10.Из-за наличия соединений быстрого доступа необходимо учитывать важные конструктивные особенности, чтобы гарантировать преобразование ANN-SNN практически без потерь. Мы начинаем с базового блока, как показано на рисунке 2A, и поэтапно налагаем различные архитектурные ограничения с обоснованиями. Обратите внимание, что обсуждение в этом разделе основано на балансировке пороговых значений (при этом синаптические веса остаются немасштабированными), то есть пороговые значения нейронов регулируются для минимизации потерь преобразования ANN-SNN. Рисунок 2.(A) Базовый функциональный блок ResNet. (B) В функциональный блок введены конструктивные ограничения, обеспечивающие преобразование ANN-SNN практически без потерь. (C) Типичное максимальное количество активаций SNN для ResNet, имеющей стыковочные уровни ReLU, но неидентификационные и идентификационные входные тракты, не имеющие одинаковых пороговых значений пиков. Хотя это не является репрезентативным для случая с равными порогами на двух путях, это действительно оправдывает утверждение о том, что после нескольких начальных уровней максимальное количество активаций SNN уменьшается до значений, близких к единице из-за сопоставления идентичности. Как мы покажем в разделе «Результаты», применение предложенного нами алгоритма S PIKE -N ORM на такой остаточной архитектуре привело к преобразованному SNN, точность которого снизилась по сравнению с исходной обученной ANN. Мы предполагаем, что это ухудшение связано в основном с отсутствием каких-либо ReLU в точках соединения. Каждый ReLU при преобразовании в нейрон импульса ПЧ накладывает определенную величину характерной временной задержки (временной интервал между входящим всплеском и исходящим всплеском из-за интеграции свидетельств).Благодаря быстрым соединениям информация о всплеске от начальных слоев мгновенно передается на более поздние уровни. Несбалансированная временная задержка в двух параллельных путях сети может привести к искажению информации о пиках, распространяемой по сети. Следовательно, как показано на рисунке 2B, мы включаем ReLU в каждую точку соединения, чтобы обеспечить эффект временного уравновешивания параллельных путей (при преобразовании в нейроны с импульсами ПЧ). Идеальным решением было бы включить ReLU в параллельный путь, но это уничтожило бы преимущество сопоставления идентичности. Как показано в следующем разделе, прямое применение предлагаемой нами схемы балансировки пороговых значений все же привело к некоторой потере точности по сравнению с базовой точностью ИНС. Однако обратите внимание, что слой нейрона соединения получает входные данные от слоя предыдущего нейрона соединения, а также путь неидентификационного нейрона. Поскольку выходная пиковая активность конкретного нейрона также зависит от порогового коэффициента балансировки, все слои входящего нейрона должны быть сбалансированы пороговым значением на одинаковую величину, чтобы гарантировать, что входная информация о пиках для следующего слоя кодируется соответствующим образом .Однако порог всплеска нейронного слоя на неидентификационном пути зависит от активности нейронного слоя в предыдущем соединении. Наблюдение за типичными пороговыми коэффициентами балансировки для сети без использования этого ограничения (показано на рисунке 2C) показывает, что коэффициенты балансировки порогов в большинстве случаев лежат около единицы после нескольких начальных уровней. Это происходит в основном из-за отображения идентичности. Максимальное суммирование импульсных входов, полученных нейронами в слоях соединений, определяется отображением идентичности (близким к единице).Исходя из этого наблюдения, мы эвристически выбираем пороги уровня неидентификационного ReLU и уровня идентичности-ReLU равными 1. Однако точность все еще не может приблизиться к базовой точности ИНС, что приводит нас к третьему ограничению проектирования. Наблюдение на рисунке 2C показывает, что пороговые коэффициенты балансировки начальных слоев нейронов соединения значительно выше единицы. Это может быть основной причиной ухудшения точности классификации преобразованного SNN.Отметим, что остаточные архитектуры, использованные авторами в He et al. (2016a) используют начальный сверточный слой с очень широким восприимчивым полем (7 × 7 с шагом 2) в наборе данных ImageNet. Основным мотивом такой архитектуры было показать влияние увеличения глубины их остаточных архитектур на точность классификации. Вдохновленные архитектурой VGG, мы заменяем первый сверточный слой 7 × 7 серией из трех сверток 3 × 3, где первые два слоя не имеют никаких быстрых соединений.Добавление таких начальных неостаточных уровней предварительной обработки позволяет нам применять предложенную схему балансировки порогов в начальных слоях, используя единичный коэффициент балансировки пороговых значений для более поздних остаточных слоев. Как показано в разделе «Результаты», эта схема значительно помогает в достижении точности классификации, близкой к базовой точности ИНС, поскольку после начальных слоев максимальные активации нейронов распадаются до значений, близких к единице из-за сопоставления идентичности. Мы оцениваем наши предложения по стандартным тестам распознавания визуальных объектов, а именно по наборам данных CIFAR-10 и ImageNet. Эксперименты, проводимые в сетях для набора данных CIFAR-10, обучаются на изображениях обучающего набора с вычитанием среднего попиксельного значения и оцениваются на тестовом наборе. Мы также представляем результаты по гораздо более сложному набору данных ImageNet 2012, который содержит 1,28 миллиона обучающих изображений и оценку отчетов (первые 1 и 5 основных ошибок) на 50 000 проверочных данных.Для этого эксперимента используются кадры 224 × 224 из входных изображений. Мы используем архитектуру VGG-16 (Симонян, Зиссерман, 2014) для обоих наборов данных. Конфигурация ResNet-20, описанная в He et al. (2016a) используется для набора данных CIFAR-10, а ResNet-34 используется для экспериментов с набором данных ImageNet. Как упоминалось ранее, мы не используем какие-либо уровни пакетной нормализации. Для сетей VGG слой исключения используется после каждого уровня ReLU, за исключением тех слоев, за которыми следует уровень объединения.Для остаточных сетей мы используем выпадение только для ReLU на неидентификационных параллельных путях, но не на уровнях соединения. Мы обнаружили, что это очень важно для достижения сходимости тренировок. Обратите внимание, что мы протестировали нашу структуру только для вышеупомянутых архитектур и наборов данных. В представленных результатах нет систематической ошибки отбора. Наша реализация является производным от кода реализации Facebook ResNet для наборов данных CIFAR и ImageNet, общедоступных . Мы используем те же шаги предварительной обработки изображения и методы увеличения масштаба и соотношения сторон, которые использовались в (например, преобразования случайного кадрирования, горизонтального отражения и нормализации цвета для набора данных CIFAR-10).Мы сообщаем о результатах тестирования одного урожая, в то время как количество ошибок можно дополнительно снизить с помощью тестирования 10 культур (Крижевский и др., 2012). Сети, используемые для набора данных CIFAR-10, обучаются на 2 графических процессорах с размером пакета 256 для 200 эпох, в то время как обучение ImageNet выполняется на 8 графических процессорах для 100 эпох с аналогичным размером пакета. Начальная скорость обучения 0,05. Скорость обучения делится на 10 дважды, на 81 и 122 эпохи для набора данных CIFAR-10 и на 30 и 60 эпохи для набора данных ImageNet. Снижение веса 0.0001 и импульс 0,9 используется для всех экспериментов. Правильная инициализация весов имеет решающее значение для достижения сходимости в таких глубоких сетях без пакетной нормализации. Для неостаточного сверточного слоя (для архитектур VGG и ResNet) с размером ядра k × k с n выходными каналами, веса инициализируются из нормального распределения и стандартного отклонения 2k2n. Однако для остаточных сверточных слоев стандартное отклонение, используемое для нормального распределения, составляло 2k2n.Мы заметили, что это важно для достижения сходимости обучения, и подобное наблюдение было также изложено в Hardt and Ma (2016), хотя их сети обучались без выпадения и пакетной нормализации. Наша модель архитектуры VGG-16 следует реализации, описанной в общих чертах, за исключением того, что мы не используем уровни пакетной нормализации. Мы использовали случайно выбранный мини-пакет размером 256 из обучающего набора для процесса нормализации веса в наборе данных CIFAR-10.Хотя для процесса нормализации веса можно использовать весь обучающий набор, использование репрезентативного подмножества не повлияло на результаты. Мы подтвердили это, выполнив несколько независимых прогонов для наборов данных CIFAR и ImageNet. Стандартное отклонение окончательной частоты ошибок классификации после 2500 временных шагов составило ~ 0,01%. Все результаты, представленные в этом разделе, представляют собой среднее значение 5 независимых прогонов сети пиков (поскольку вход в сеть является случайным процессом). Никакой заметной разницы в частоте ошибок классификации не наблюдалось в конце 2 500 временных шагов, и выходные данные сети сходились к детерминированным значениям, несмотря на то, что они управлялись стохастическими входными данными.Для схемы нормализации весов на основе модели SNN (алгоритм S PIKE -N ORM ) мы использовали 2500 временных шагов для каждого слоя последовательно для нормализации весов. Таблица 1 суммирует наши результаты для набора данных CIFAR-10. Базовая частота ошибок ИНС на тестовой выборке составила 8,3%. Поскольку основной вклад этой работы состоит в том, чтобы минимизировать потерю точности при преобразовании из ИНС в СНС для многоуровневых сетей, а не в продвижении современных результатов при обучении ИНС, мы не выполняли оптимизацию гиперпараметров. .Однако обратите внимание, что, несмотря на несколько архитектурных ограничений, присутствующих в нашей архитектуре ИНС, мы можем обучать глубокие сети, которые обеспечивают конкурентную точность классификации, используя механизмы обучения, описанные в предыдущем подразделе. Дальнейшее снижение базовой частоты ошибок ИНС возможно за счет соответствующей настройки параметров обучения. Для архитектуры VGG-16 наша реализация метода нормализации веса на основе ANN-модели, предложенная Diehl et al. (2015), средняя частота ошибок SNN составила 8.54%, что приводит к увеличению ошибки на 0,24%. Приращение ошибки было минимизировано до 0,15% при применении предложенного нами алгоритма S PIKE -N ORM . Обратите внимание, что мы рассматриваем строгую схему нормализации веса на основе модели, чтобы изолировать влияние рассмотрения влияния ИНС по сравнению с нашей моделью SNN для балансировки пороговых значений. Дальнейшая оптимизация с учетом максимального синаптического веса в процессе нормализации веса (Diehl et al., 2015) все еще возможна. Таблица 1 .Результаты для набора данных CIFAR-10. Предыдущие работы были в основном сосредоточены на гораздо менее глубоких архитектурах сверточных нейронных сетей. Хотя Hunsberger и Eliasmith (2016) сообщают о результатах с потерей точности 0,18%, их базовая ИНС страдает от некоторого снижения точности, поскольку их сети обучаются с использованием шума (в дополнение к архитектурным ограничениям, упомянутым ранее) для учета изменчивости ответа нейронов из-за к прибывающим поездам с шипами (Hunsberger and Eliasmith, 2016).Также неясно, будет ли механизм обучения с шумом масштабироваться до более глубоких многоуровневых сетей. Наша работа сообщает о лучшей производительности нейронной сети с пиками в наборе данных CIFAR-10 на сегодняшний день. Влияние предлагаемого нами алгоритма гораздо более очевидно на более сложном наборе данных ImageNet. Коэффициенты ошибок первой (первой пятерки) в наборе проверки ImageNet приведены в таблице 2. Обратите внимание, что это результаты для одного урожая. Потеря точности в процессе преобразования ANN-SNN минимизирована с запасом в 0.57% с учетом схемы нормализации веса на основе модели SNN. Поэтому ожидается, что предложенный нами алгоритм S PIKE -N ORM будет значительно работать лучше, чем схема преобразования на основе модели ANN, поскольку проблема распознавания образов становится более сложной, поскольку он учитывает фактическую работу SNN во время процесса преобразования. Обратите внимание, что Hunsberger и Eliasmith (2016) сообщают о производительности 48,2% (23,8%) в первом тестовом пакете 3072 изображений из набора данных ImageNet 2012. Таблица 2 . Результаты для набора данных ImageNet. В то время, когда мы разрабатывали эту работу, мы не знали о параллельных усилиях по увеличению производительности SNN для более глубоких сетей и крупномасштабных задач машинного обучения. Работа была недавно опубликована в Rueckauer et al. (2017). Однако их работа отличается от нашего подхода в следующих аспектах: (i) Их работа улучшает предыдущий подход, изложенный в Diehl et al. (2015), предложив методы преобразования для устранения ограничений, связанных с обучением ИНС (обсуждаются в разделе 4.3). Мы улучшаем уровень техники, расширяя методологию, изложенную в Diehl et al. (2015) для преобразования ИНС в СНС путем включения ограничений. (ii) Мы демонстрируем, что учет работы SNN в процессе преобразования помогает минимизировать потери при преобразовании. Rueckauer et al. (2017) использует схему нормализации на основе ИНС, используемую Diehl et al. (2015). Хотя устранение ограничений в обучении ИНС позволяет авторам в Rueckauer et al. (2017), чтобы обучить ИНС с большей точностью, они несут значительную потерю точности в процессе преобразования.Это происходит из-за неоптимального соотношения систематических ошибок / коэффициентов нормализации партии и весов Rueckauer et al. (2017). Это основная причина нашего исследования преобразования ИНС в СНС без смещения и пакетной нормализации. Например, их самая эффективная сеть на наборе данных CIFAR-10 приводит к потере конверсии 1,06% по сравнению с 0,15%, о которой сообщается в нашем предложении для более глубокой сети. Потеря точности намного больше для их сети VGG-16 в наборе данных ImageNet - 14,28% по сравнению с 0,56% для нашего предложения.Хотя Rueckauer et al. (2017) сообщает, что частота ошибок в топ-1 SNN составляет 25,40% для сети Inception-V3, их ANN обучается с частотой ошибок 23,88%. В результате потеря конверсии составляет 1,52% и намного превышает наши предложения. Преобразование сети Inception-V3 также было оптимизировано методом ограничения напряжения, который оказался специфичным для сети Inception и не применим к сети VGG Rueckauer et al. (2017). Обратите внимание, что результаты, опубликованные на ImageNet в Rueckauer et al. (2017) относятся к подмножеству из 1 382 образцов изображений для сети Inception-V3 и 2570 образцов для сети VGG-16.Следовательно, производительность для всего набора данных неясна. Наш вклад заключается в том, что мы демонстрируем, что ИНС могут быть обучены с указанными выше ограничениями с конкурентоспособной точностью для крупномасштабных задач и преобразованы в SNN практически без потерь. Это первая работа, в которой сообщается о конкурентоспособной производительности нейронной сети Spiking по всему набору валидации ImageNet 2012 из 50 000. Наши остаточные сети для наборов данных CIFAR-10 и ImageNet соответствуют реализации в He et al.(2016a). Сначала мы пытаемся объяснить наш выбор дизайна для ResNets, последовательно накладывая каждое ограничение на сеть и показывая их соответствующее влияние на производительность сети на рисунке 3. «Базовая архитектура» включает в себя остаточную сеть без каких-либо узлов ReLU. «Ограничение 1» включает соединения ReLU без одинаковых пороговых значений пиков для всех входящих нейронных слоев. «Ограничение 2» накладывает одинаковый порог единицы для всех уровней, в то время как «Ограничение 3» лучше всего работает с двумя простыми сверточными слоями предварительной обработки (3 × 3) в начале сети.Базовая ИНС ResNet-20 была обучена с ошибкой 10,9% на наборе данных CIFAR-10. Обратите внимание, что хотя мы используем терминологию, соответствующую He et al. (2016a) для сетевых архитектур наши ResNets содержат два дополнительных простых уровня предварительной обработки. Преобразованный SNN в соответствии с нашим предложением дал коэффициент ошибок классификации 12,54%. Нормализация веса первых двух слоев с использованием схемы нормализации веса на основе модели ИНС дала среднюю ошибку 12,87%, что еще раз подтвердило эффективность нашей методики нормализации веса. Рисунок 3 . Влияние архитектурных ограничений на остаточные сети. «Базовая архитектура» не включает в себя каких-либо узловых слоев ReLU. «Ограничение 1» включает ReLU соединения, в то время как «Ограничение 2» накладывает порог равной единицы для всех остаточных единиц. Точность сети значительно улучшена за счет включения «Ограничения 3», которое включает предварительную обработку нормализованных по весу простых сверточных слоев на этапе ввода сети. В наборе данных ImageNet мы используем более глубокую модель ResNet-34, описанную в He et al.(2016a). Начальный сверточный слой 7 × 7 заменяется тремя сверточными слоями 3 × 3, где два начальных слоя не являются остаточными простыми единицами. Базовая ИНС обучается с ошибкой 29,31%, в то время как преобразованная ошибка SNN составляет 34,53% в конце 2500 временных шагов. Результаты сведены в Таблицу 3, а графики сходимости для всех наших сетей представлены на Рисунке 4. Здесь стоит отметить, что основная мотивация исследования остаточных сетей состоит в том, чтобы углубиться в нейронные сети с пиковой нагрузкой.Мы исследуем относительно простые архитектуры ResNet, такие как те, которые использовались в He et al. (2016a), которые имеют на порядок меньше параметров, чем стандартные VGG-архитектуры. Возможны дальнейшие оптимизации гиперпараметров или более сложные архитектуры. Хотя потеря точности в процессе преобразования ANN-SNN больше для ResNets, чем для простых сверточных архитектур, все же можно изучить дальнейшие оптимизации, такие как включение большего количества начальных уровней предварительной обработки или лучшие схемы балансировки порогов для остаточных единиц.Эта работа является первой работой по изучению схем преобразования ИНС-СНС для остаточных сетей и пытается выделить важные конструктивные ограничения, необходимые для минимальных потерь в процессе преобразования. Таблица 3 . Результаты для остаточных сетей. Рисунок 4 . Графики сходимости для архитектур VGG и ResNet SNN для наборов данных CIFAR-10 и ImageNet показаны выше. Ошибка классификации уменьшается по мере того, как больше доказательств интегрируется в Spiking Neurons с увеличивающимися временными шагами.Обратите внимание, что хотя глубина сети аналогична для набора данных CIFAR-10, ResNet-20 сходится намного быстрее, чем архитектура VGG. Задержка логического вывода выше для ResNet-34 в наборе данных ImageNet из-за того, что количество слоев в два раза больше, чем в сети VGG. Операция ИНС для предсказания выходного класса конкретного входа требует одного прохода с прямой связью для каждого изображения. Для работы SNN сеть должна быть оценена за несколько временных шагов.Однако специализированное оборудование, которое учитывает управляемые событиями нейронные операции и «выполняет вычисления только при необходимости», потенциально может использовать такие альтернативные механизмы работы сети. Например, на рисунке 5 представлено среднее общее количество выходных пиков, создаваемых нейронами в архитектурах VGG и ResNet, как функция уровня для набора данных ImageNet. Для процесса усреднения использовалась случайно выбранная мини-партия. Мы использовали 500 временных шагов для накопления счетчиков всплесков для сетей VGG, в то время как 2000 временных шагов использовались для архитектур ResNet.Это согласуется с графиками сходимости, показанными на рисунке 4. Важным выводом, полученным из рисунка 5, является тот факт, что пиковая активность нейронов становится более редкой по мере увеличения глубины сети. Следовательно, ожидается, что преимущества от аппаратного обеспечения, управляемого событиями, возрастут по мере увеличения глубины сети. Хотя оценка фактического снижения энергопотребления для режима работы SNN выходит за рамки данной работы, мы обеспечиваем интуитивное понимание, предоставляя количество вычислений на одну синаптическую операцию, выполняемую в ANN vs.СНН. Рисунок 5 . Среднее кумулятивное количество всплесков, генерируемых нейронами в архитектурах VGG и ResNet в наборе данных ImageNet, как функция номера слоя. Пятьсот временных шагов использовались для накопления счетчиков всплесков для сетей VGG, в то время как 2000 временных шагов использовались для архитектур ResNet. Разреженность нейронных пиков значительно увеличивается с увеличением глубины сети. Количество синаптических операций на уровне сети для ИНС можно легко оценить на основе архитектуры сверточного и линейного уровней.Для ИНС вычисление умножения с накоплением (MAC) происходит за каждую синаптическую операцию. С другой стороны, специализированное оборудование SNN будет выполнять вычисление накопления (AC) для каждой синаптической операции только при получении входящего импульса. Следовательно, общее количество операций AC, происходящих в SNN, будет представлено скалярным произведением среднего кумулятивного числа нейронных всплесков для конкретного уровня и соответствующего количества синаптических операций. Расчет этого показателя показывает, что для сети VGG отношение операций AC SNN к операциям MAC сети ANN равно 1.975, в то время как для ResNet это соотношение составляет 2,4 (метрика включает только активации нейронов ReLU / IF в сети). Однако обратите внимание на тот факт, что операция MAC требует на порядок большего потребления энергии, чем операция переменного тока. Han et al. (2015b). Следовательно, ожидается, что снижение энергопотребления для нашей реализации SNN будет значительно ниже по сравнению с исходной реализацией ANN. Здесь стоит отметить, что реальная метрика, определяющая потребность в энергии SNN vs.ИНС - это количество импульсов на нейрон. Энергетические преимущества достигаются только тогда, когда среднее количество импульсов на нейрон за временное окно логического вывода <1 (поскольку в SNN синаптическая операция является условной на основе генерации импульсов нейронами на предыдущем уровне). Следовательно, чтобы получить выгоду от снижения энергии в SNN, нужно нацеливаться на более глубокие сети из-за разреженности пиков нейронов. В то время как операция SNN требует ряда временных шагов в отличие от одного прохода с прямой связью для ANN, фактическое время, необходимое для реализации одного временного шага SNN в нейроморфной архитектуре, может быть значительно меньше, чем прямая связь. пройти для реализации ИНС (из-за работы оборудования, управляемого событиями).Точная оценка сравнения задержки выходит за рамки этой статьи. Тем не менее, несмотря на накладные расходы, связанные с задержкой, как подчеркнуто выше, преимущества по мощности управляемых событиями SNN могут значительно повысить энергетическую эффективность (мощность x задержка) глубоких SNN по сравнению с ANN. Эта работа служит доказательством того факта, что SNN демонстрируют такую же вычислительную мощность, что и их аналоги в ANN. Это потенциально может проложить путь к использованию SNN в крупномасштабных задачах визуального распознавания, которые могут быть реализованы с помощью маломощного нейроморфного оборудования.Тем не менее, есть еще открытые области для улучшения характеристик SNN. Существенный вклад в нынешний успех глубоких нейронных сетей приписывается пакетной нормализации (Ioffe and Szegedy, 2015). Хотя использование нейронных единиц без смещения ограничивает нас обучением сетей без пакетной нормализации, следует изучить алгоритмические методы для реализации Spiking Neurons с термином смещения. Кроме того, желательно обучать ИНС и преобразовывать их в SNN без потери точности. Хотя предложенная методика преобразования пытается минимизировать потери преобразования в значительной степени, все же другие варианты нейронных функций, помимо ReLU-IF Spiking Neurons, могут быть потенциально исследованы для дальнейшего сокращения этого разрыва.Кроме того, следует изучить дальнейшие оптимизации для минимизации потери точности при преобразовании ANN-SNN для архитектур ResNet, чтобы масштабировать производительность SNN для еще более глубоких архитектур. AS разработала основные концепции, выполнила моделирование и написала статью. Все авторы помогали в написании статьи и разработке концепций. AS был принят на работу в Facebook во время летней стажировки.YY, RW и CL работали в компании Facebook. Оставшийся автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов. Акопян Ф., Савада Дж., Кэссиди А., Альварес-Иказа Р., Артур Дж., Меролла П. и др. (2015). TrueNorth: дизайн и набор инструментов программируемого нейросинаптического чипа мощностью 65 МВт и 1 миллион нейронов. IEEE Trans. Комп. Система автоматизированного проектирования Integr. Circ. Syst. 34, 1537–1557. DOI: 10.1109 / TCAD.2015.2474396 CrossRef Полный текст | Google Scholar Цао Ю., Чен Ю. и Хосла Д. (2015). Использование глубоких сверточных нейронных сетей для энергоэффективного распознавания объектов. Внутр. J. Comp. Видение 113, 54–66. DOI: 10.1007 / s11263-014-0788-3 CrossRef Полный текст | Google Scholar Chen, Z., Johnson, M., Wei, L., and Roy, W. (1998). «Оценка мощности утечки в режиме ожидания в схеме КМОП с учетом точного моделирования транзисторных блоков», в материалах Proceedings, International Symposium on Low Power Electronics and Design, 1998 (Monterey, CA: IEEE), 239–244. Google Scholar Диль П. У., Нил Д., Бинас Дж., Кук М., Лю С.-К. и Пфайффер М. (2015). «Быстрая классификация и высокая точность пиков глубоких сетей за счет балансировки веса и порога», в Международная объединенная конференция по нейронным сетям (IJCNN) 2015 г., (Килларни: IEEE), 1–8. Google Scholar Эссер, С. К., Меролла, П. А., Артур, Дж. В., Кэссиди, А. С., Аппусвами, Р., Андреопулос, А., и др. (2016). Сверточные сети для быстрых и энергоэффективных нейроморфных вычислений. Proc. Natl. Акад. Sci. США 113, 11441–11446. DOI: 10.1073 / pnas.1604850113 PubMed Аннотация | CrossRef Полный текст | Google Scholar Фарабет К., Пас Р., Перес-Карраско Дж., Замарреньо-Рамос К., Линарес-Барранко А., ЛеКун Ю. и др. (2012). Сравнение ConvNets с фиксированным значением фиксированного пикселя с ограничением кадра и ConvNets с динамическими всплесками без кадра для визуальной обработки. Фронт. Neurosci. 6:32. DOI: 10.3389 / fnins.2012.00032 PubMed Аннотация | CrossRef Полный текст | Google Scholar Хан, С., Мао, Х., и Далли, У. Дж. (2015a). Глубокое сжатие: сжатие глубоких нейронных сетей с сокращением, обученным квантованием и кодированием Хаффмана. arXiv препринт arXiv: 1510.00149 . Google Scholar Хан, С., Пул, Дж., Тран, Дж., И Далли, В. (2015b). «Изучение весов и связей для эффективной нейронной сети», в Advances in Neural Information Processing Systems (Montreal, QC), 1135–1143. Google Scholar Хардт, М., и Ма, Т. (2016). Идентичность имеет значение в глубоком обучении. arXiv препринт arXiv: 1611.04231 . Google Scholar Хе К., Чжан Х., Рен С. и Сун Дж. (2016a). «Глубокое остаточное обучение для распознавания изображений», в Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV), 770–778. Google Scholar Хе К., Чжан Х., Рен С. и Сун Дж. (2016b). «Отображения идентичности в глубоких остаточных сетях», European Conference on Computer Vision (Springer), 630–645. Google Scholar Hunsberger, E., and Eliasmith, C. (2016). Тренировка глубоких сетей для нейроморфного оборудования. arXiv препринт arXiv: 1611.05141 . Google Scholar Иоффе, С., Сегеди, К. (2015). «Пакетная нормализация: ускорение глубокого обучения сети за счет уменьшения внутреннего ковариантного сдвига», на Международной конференции по машинному обучению (Лилль), 448–456. Google Scholar Крижевский, А., Суцкевер И., Хинтон Г. Э. (2012). «Классификация ImageNet с глубокими сверточными нейронными сетями», в Advances in Neural Information Processing Systems (Lake Tahoe, NV), 1097–1105. Google Scholar ЛеКун, Ю., Ботту, Л., Бенжио, Ю., и Хаффнер, П. (1998). Применение градиентного обучения для распознавания документов. Продолжить. IEEE 86, 2278–2324. DOI: 10.1109 / 5.726791 CrossRef Полный текст | Google Scholar Меролла, П.А., Артур, Дж. В., Альварес-Икаса, Р., Кэссиди, А. С., Савада, Дж., Акопян, Ф. и др. (2014). Интегральная схема с миллионным импульсным нейроном с масштабируемой сетью связи и интерфейсом. Наука 345, 668–673. DOI: 10.1126 / science.1254642 PubMed Аннотация | CrossRef Полный текст | Google Scholar Перес-Карраско, Дж. А., Чжао, Б., Серрано, К., Ача, Б., Серрано-Готарредона, Т., Чен, С. и др. (2013). Преобразование от систем видения, управляемых кадрами, к системам машинного зрения, управляемых событиями без кадров, с помощью низкоскоростного кодирования и обработки совпадений - приложение к конвенциям с прямой связью. IEEE Trans. Pattern Anal. Мах. Интеллект 35, 2706–2719. DOI: 10.1109 / TPAMI.2013.71 PubMed Аннотация | CrossRef Полный текст | Google Scholar Пош, К., Матолин, Д., и Вольгенанн, Р. (2011). ШИМ-датчик изображения QVGA с динамическим диапазоном 143 дБ, без кадров, со сжатием видео на уровне пикселей без потерь и CDS во временной области. IEEE J. Solid-State Circ. 46, 259–275. DOI: 10.1109 / JSSC.2010.2085952 CrossRef Полный текст | Google Scholar Posch, C., Серрано-Готарредона, Т., Линарес-Барранко, Б., и Дельбрук, Т. (2014). Ретиноморфные датчики зрения, основанные на событиях: камеры с биоинспирированием и импульсным выходом. Proc. IEEE 102, 1470–1484. DOI: 10.1109 / JPROC.2014.2346153 CrossRef Полный текст | Google Scholar Rueckauer, B., Hu, Y., Lungu, I.-A., Pfeiffer, M., and Liu, S.-C. (2017). Преобразование глубоких сетей с непрерывной оценкой в эффективные сети, управляемые событиями, для классификации изображений. Фронт. Neurosci. 11: 682.DOI: 10.3389 / fnins.2017.00682 PubMed Аннотация | CrossRef Полный текст | Google Scholar Русаковский О., Дэн Дж., Су, Х., Краузе Дж., Сатиш, С., Ма, С. и др. (2015). ImageNet - задача крупномасштабного визуального распознавания. Внутр. J. Comp. Visi. 115, 211–252. DOI: 10.1007 / s11263-015-0816-y CrossRef Полный текст | Google Scholar Симонян К., Зиссерман А. (2014). Очень глубокие сверточные сети для распознавания крупномасштабных изображений. arXiv препринт arXiv: 1409.1556 . Google Scholar Шривастава Н., Хинтон Г. Э., Крижевский А., Суцкевер И. и Салахутдинов Р. (2014). Dropout: простой способ предотвратить переоснащение нейронных сетей. J. Mach. Учить. Res. 15, 1929–1958. Доступно в Интернете по адресу: http://dl.acm.org/citation.cfm?id=2627435.2670313 Чжао Б., Дин Р., Чен С., Линарес-Барранко Б. и Тан Х. (2015). Упреждающая категоризация событий движения AER с использованием функций коры головного мозга в нейронной сети с импульсами. Алгоритм итеративно решает подзадачи доверительной области.
дополнен специальным диагональным квадратичным членом и имеет форму доверительной области
определяется расстоянием от границ и направлением
градиент. Эти улучшения помогают избежать попадания шагов прямо в границы.
и эффективно исследовать все пространство переменных. Для дальнейшего улучшения
сходимости алгоритм учитывает направления поиска, отраженные от
границы. Чтобы соответствовать теоретическим требованиям, алгоритм сохраняет итерации
строго выполнимо.С плотными якобианами подзадачи доверительной области
решается точным методом, очень похожим на метод, описанный в [JJMore]
(и реализовано в MINPACK). Отличие от MINPACK
реализация состоит в том, что сингулярное разложение якобиана
матрица выполняется один раз за итерацию, вместо QR-разложения и ряда
исключения вращения Гивенса. Для больших разреженных якобианов двумерное подпространство
используется подход к решению подзадач trust-region [STIR], [Byrd].
Подпространство натянуто на масштабированный градиент и приблизительный
Решение Гаусса-Ньютона предоставлено
Алгоритм итеративно решает подзадачи доверительной области.
дополнен специальным диагональным квадратичным членом и имеет форму доверительной области
определяется расстоянием от границ и направлением
градиент. Эти улучшения помогают избежать попадания шагов прямо в границы.
и эффективно исследовать все пространство переменных. Для дальнейшего улучшения
сходимости алгоритм учитывает направления поиска, отраженные от
границы. Чтобы соответствовать теоретическим требованиям, алгоритм сохраняет итерации
строго выполнимо.С плотными якобианами подзадачи доверительной области
решается точным методом, очень похожим на метод, описанный в [JJMore]
(и реализовано в MINPACK). Отличие от MINPACK
реализация состоит в том, что сингулярное разложение якобиана
матрица выполняется один раз за итерацию, вместо QR-разложения и ряда
исключения вращения Гивенса. Для больших разреженных якобианов двумерное подпространство
используется подход к решению подзадач trust-region [STIR], [Byrd].
Подпространство натянуто на масштабированный градиент и приблизительный
Решение Гаусса-Ньютона предоставлено scipy.. Когда нет
накладываются ограничения, алгоритм очень похож на MINPACK и имеет
в целом сопоставимая производительность. Алгоритм работает довольно надежно в
неограниченные и ограниченные задачи, поэтому он выбран в качестве алгоритма по умолчанию. sparse.linalg.lsmr
sparse.linalg.lsmr scipy.sparse.linalg.lsmr для больших
редкие якобианцы. Алгоритм, вероятно, будет демонстрировать медленную сходимость, когда
ранг якобиана меньше числа переменных. Алгоритм
часто превосходит «trf» в ограниченных задачах с небольшим количеством
переменные.
 Программирование, 40, стр. 247-263,
1988.
Программирование, 40, стр. 247-263,
1988.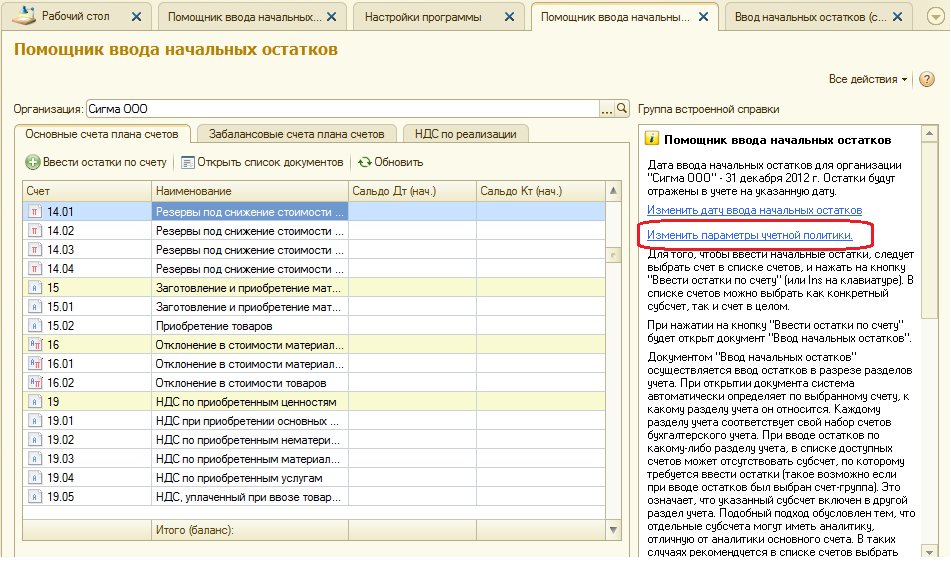 298-372, 1999.
298-372, 1999. >>> def fun_rosenbrock (x):
... return np.array ([10 * (x [1] - x [0] ** 2), (1 - x [0])])
x = [1.0, 1.0] . >>> из scipy.optimize import minimum_squares
>>> x0_rosenbrock = np.array ([2, 2])
>>> res_1 = минимум_квадратов (fun_rosenbrock, x0_rosenbrock)
>>> res_1.Икс
массив ([1., 1.])
>>> res_1.cost
9.8669242
x [1]> = 1,5 , и x [0] оставлено без ограничений. Для этого мы указываем параметр bounds . до
до наименьших_квадратов в виде границ = ([- np.inf, 1.5], np.inf) . >>> def jac_rosenbrock (x):
... return np.array ([
... [-20 * x [0], 10],
... [-1, 0]])
>>> res_2 = less_squares (fun_rosenbrock, x0_rosenbrock, jac_rosenbrock,
... bounds = ([- np.inf, 1.5], np.inf))
>>> res_2.x
массив ([1.22437075, 1.5])
>>> res_2.cost
0,025213093946805685
>>> res_2.optimality
1,5885401433157753e-07
>>> def fun_broyden (x):
... е = (3 - х) * х + 1
... f [1:] - = x [: - 1]
... f [: - 1] - = 2 * x [1:]
... вернуть f
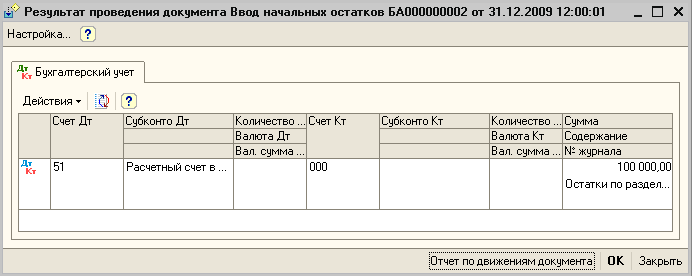
>>> из scipy.разреженный импорт lil_matrix
>>> def sparsity_broyden (n):
... разреженность = lil_matrix ((n, n), dtype = int)
... я = np.arange (n)
... разреженность [i, i] = 1
... я = np.arange (1, n)
... разреженность [i, i - 1] = 1
... я = np.arange (n - 1)
... разреженность [i, i + 1] = 1
... вернуть разреженность
...
>>> п = 100000
>>> x0_broyden = -np.ones (n)
...
>>> res_3 = less_squares (fun_broyden, x0_broyden,
... jac_sparsity = sparsity_broyden (n))
>>> res_3.Стоимость
4.5687069299604613e-23
>>> res_3.optimality
1.1650454296851518e-11
y = a + b * exp (c * t) , где t - предикторная переменная, y -
наблюдение, а a, b, c - параметры для оценки. >>> def gen_data (t, a, b, c, noise = 0, n_outliers = 0, random_state = 0):
.
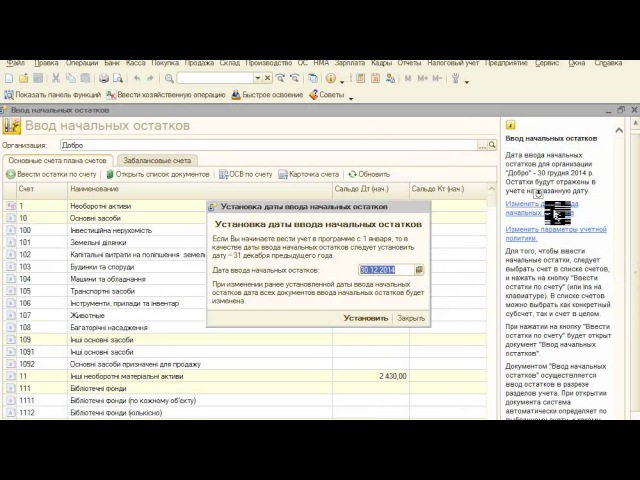 .. y = a + b * np.exp (t * c)
...
... rnd = np.random.RandomState (случайное_состояние)
... ошибка = шум * rnd.randn (t.size)
... выбросы = rnd.randint (0, t.size, n_outliers)
... ошибка [выбросы] * = 10
...
... вернуть ошибку y +
...
>>> а = 0,5
>>> b = 2,0
>>> c = -1
>>> t_min = 0
>>> t_max = 10
>>> n_points = 15
...
>>> t_train = np.linspace (t_min, t_max, n_points)
>>> y_train = gen_data (t_train, a, b, c, noise = 0.1, n_outliers = 3)
.. y = a + b * np.exp (t * c)
...
... rnd = np.random.RandomState (случайное_состояние)
... ошибка = шум * rnd.randn (t.size)
... выбросы = rnd.randint (0, t.size, n_outliers)
... ошибка [выбросы] * = 10
...
... вернуть ошибку y +
...
>>> а = 0,5
>>> b = 2,0
>>> c = -1
>>> t_min = 0
>>> t_max = 10
>>> n_points = 15
...
>>> t_train = np.linspace (t_min, t_max, n_points)
>>> y_train = gen_data (t_train, a, b, c, noise = 0.1, n_outliers = 3)
>>> def fun (x, t, y):
... вернуть x [0] + x [1] * np.exp (x [2] * t) - y
...
>>> x0 = np.array ([1.0, 1.0, 0.0])
>>> res_lsq = less_squares (веселье, x0, args = (t_train, y_train))

>>> res_soft_l1 = less_squares (fun, x0, loss = 'soft_l1', f_scale = 0.1,
... args = (t_train, y_train))
>>> res_log = less_squares (веселье, x0, потеря = 'cauchy', f_scale = 0.1,
... args = (t_train, y_train))
>>> t_test = np.linspace (t_min, t_max, n_points * 10)
>>> y_true = gen_data (t_test, a, b, c)
>>> y_lsq = gen_data (t_test, * res_lsq.x)
>>> y_soft_l1 = gen_data (t_test, * res_soft_l1.x)
>>> y_log = gen_data (t_test, * res_log.x)
...
>>> import matplotlib.pyplot как plt
>>> plt.plot (t_train, y_train, 'o')
>>> plt.plot (t_test, y_true, 'k', linewidth = 2, label = 'true')
>>> plt.plot (t_test, y_lsq, label = 'linear loss')
>>> plt.
 plot (t_test, y_soft_l1, label = 'soft_l1 loss')
>>> plt.plot (t_test, y_log, label = 'cauchy loss')
>>> plt.xlabel ("т")
>>> plt.ylabel ("y")
>>> plt.legend ()
>>> plt.show ()
plot (t_test, y_soft_l1, label = 'soft_l1 loss')
>>> plt.plot (t_test, y_log, label = 'cauchy loss')
>>> plt.xlabel ("т")
>>> plt.ylabel ("y")
>>> plt.legend ()
>>> plt.show ()
minimum_squares () .Рассмотрим
следующая функция: >>> def f (z):
... вернуть z - (0,5 + 0,5j)
>>> def f_wrap (x):
... fx = f (x [0] + 1j * x [1])
... вернуть np.array ([fx.real, fx.imag])
>>> из scipy.оптимизировать импорт less_squares
>>> res_wrapped = less_squares (f_wrap, (0.1, 0.1), bounds = ([0, 0], [1, 1]))
>>> z = res_wrapped.
 x [0] + res_wrapped.x [1] * 1j
>>> г
(0,49999999999
x [0] + res_wrapped.x [1] * 1j
>>> г
(0,49999999999 Определение остаточной стоимости
Что такое остаточная стоимость?
Ключевые выводы

Понимание остаточной стоимости

Примеры остаточной стоимости

Остаточная стоимость и стоимость при перепродаже

Расчет износа / амортизации с использованием остаточной стоимости

Часто задаваемые вопросы об остаточной стоимости
Что такое остаточная стоимость в статистике?
 Каждая точка данных имеет один остаток.
Каждая точка данных имеет один остаток. Как рассчитывается остаточная стоимость?
Какова остаточная стоимость автомобиля?
Остаточная стоимость совпадает с выкупом?

Что считается хорошей остаточной стоимостью?
Итог
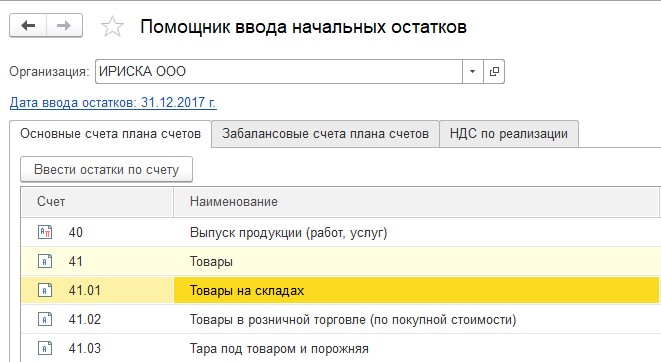
Ваше моделирование CFD работает неправильно? Контрольный список для устранения серьезных проблем

 Это поможет вам настроить соответствующие входные данные и проверить ваши результаты, когда ваша интуиция скажет вам, что что-то не так.
Это поможет вам настроить соответствующие входные данные и проверить ваши результаты, когда ваша интуиция скажет вам, что что-то не так. Е. Применении мм / с вместо м / с или применении неправильных векторов направления на вращающихся стенах.
Е. Применении мм / с вместо м / с или применении неправильных векторов направления на вращающихся стенах. границ | Углубляясь в рост нейронных сетей: VGG и остаточные архитектуры
1. Введение
Нейронные сети с пиковыми импульсами Однако такие аналоговые нейронные сети (ИНС) игнорируют тот факт, что биологические нейроны в головном мозге (вычислительная структура, после которой они создаются) обрабатывают двоичную информацию, основанную на шипах. Благодаря этому наблюдению за последние несколько лет мы стали свидетелями значительного прогресса в моделировании и формулировании схем обучения для SNN как новой вычислительной парадигмы, которая потенциально может заменить ANN в качестве нейронных сетей следующего поколения.В дополнение к тому факту, что SNN по своей природе более правдоподобны с биологической точки зрения, они предлагают перспективу управляемой событиями работы оборудования. Пиковые нейроны обрабатывают входную информацию только при получении входящих двоичных пиковых сигналов. Учитывая редко распределенную последовательность входных пиков, накладные расходы на оборудование (энергопотребление) для таких пиков или оборудования, основанного на событиях, будут значительно сокращены, поскольку большие участки сети, которые не управляются входящими пиками, могут быть заблокированы по мощности (Chen et al.
Однако такие аналоговые нейронные сети (ИНС) игнорируют тот факт, что биологические нейроны в головном мозге (вычислительная структура, после которой они создаются) обрабатывают двоичную информацию, основанную на шипах. Благодаря этому наблюдению за последние несколько лет мы стали свидетелями значительного прогресса в моделировании и формулировании схем обучения для SNN как новой вычислительной парадигмы, которая потенциально может заменить ANN в качестве нейронных сетей следующего поколения.В дополнение к тому факту, что SNN по своей природе более правдоподобны с биологической точки зрения, они предлагают перспективу управляемой событиями работы оборудования. Пиковые нейроны обрабатывают входную информацию только при получении входящих двоичных пиковых сигналов. Учитывая редко распределенную последовательность входных пиков, накладные расходы на оборудование (энергопотребление) для таких пиков или оборудования, основанного на событиях, будут значительно сокращены, поскольку большие участки сети, которые не управляются входящими пиками, могут быть заблокированы по мощности (Chen et al. al., 1998). Однако подавляющее большинство исследований SNN было ограничено очень простыми и неглубокими сетевыми архитектурами на относительно простых наборах данных распознавания цифр, таких как MNIST (LeCun et al., 1998), в то время как лишь немногие работы сообщают об их эффективности на более сложных стандартных наборах данных технического зрения, таких как CIFAR. -10 (Крижевский, Хинтон, 2009) и ImageNet (Русаковский и др., 2015). Основная причина их ограниченной производительности связана с тем фактом, что SNN значительно отличаются от работы ANN из-за их способности обрабатывать временную информацию.Это потребовало переосмысления механизмов обучения для сетей SNN.
2. Сопутствующие работы
 Руководствуясь этим фактом, определенная категория контролируемых алгоритмов обучения SNN пытается обучить ИНС, используя стандартные схемы обучения, такие как обратное распространение (чтобы использовать превосходные характеристики стандартных методов обучения для ИНС), а затем преобразовать их в управляемые событиями SNN для работы сети (Перес- Carrasco et al., 2013; Cao et al., 2015; Diehl et al., 2015; Zhao et al., 2015). Это может быть особенно привлекательно для реализаций NN в маломощном нейроморфном оборудовании, специализированном для SNN (Merolla et al., 2014; Akopyan et al., 2015) или взаимодействие с кремниевыми улитками или сенсорами, управляемыми событиями (Posch et al., 2011, 2014). Наша работа попадает в эту категорию и основана на схеме преобразования ИНС-СНС, предложенной авторами в работе Diehl et al. (2015). Однако, хотя в предыдущих работах работа ИНС рассматривается только во время процесса преобразования, мы показываем, что учет фактической работы СНС на этапе преобразования имеет решающее значение для достижения минимальной потери точности классификации. С этой целью мы предлагаем новую технику нормализации веса, которая гарантирует, что фактическая операция SNN находится в цикле во время фазы преобразования.Обратите внимание, что в этой работе делается попытка использовать разреженность нейронной активации путем преобразования сетей в область пиков для энергоэффективной аппаратной реализации и дополняет усилия, направленные на изучение разреженности синаптических соединений (Han et al., 2015a).
Руководствуясь этим фактом, определенная категория контролируемых алгоритмов обучения SNN пытается обучить ИНС, используя стандартные схемы обучения, такие как обратное распространение (чтобы использовать превосходные характеристики стандартных методов обучения для ИНС), а затем преобразовать их в управляемые событиями SNN для работы сети (Перес- Carrasco et al., 2013; Cao et al., 2015; Diehl et al., 2015; Zhao et al., 2015). Это может быть особенно привлекательно для реализаций NN в маломощном нейроморфном оборудовании, специализированном для SNN (Merolla et al., 2014; Akopyan et al., 2015) или взаимодействие с кремниевыми улитками или сенсорами, управляемыми событиями (Posch et al., 2011, 2014). Наша работа попадает в эту категорию и основана на схеме преобразования ИНС-СНС, предложенной авторами в работе Diehl et al. (2015). Однако, хотя в предыдущих работах работа ИНС рассматривается только во время процесса преобразования, мы показываем, что учет фактической работы СНС на этапе преобразования имеет решающее значение для достижения минимальной потери точности классификации. С этой целью мы предлагаем новую технику нормализации веса, которая гарантирует, что фактическая операция SNN находится в цикле во время фазы преобразования.Обратите внимание, что в этой работе делается попытка использовать разреженность нейронной активации путем преобразования сетей в область пиков для энергоэффективной аппаратной реализации и дополняет усилия, направленные на изучение разреженности синаптических соединений (Han et al., 2015a). 3. Основные взносы
4. Предварительные мероприятия
4.1. Представление ввода и вывода
4.2. Нейронные операции ANN и SNN
Схемы преобразования 4.3. Архитектурные ограничения
4.3.1. Смещение в нейронных единицах
4.3.2. Операция объединения
5. Глубокие сверточные архитектуры SNN: VGG
5.1. Предлагаемый алгоритм: Spike-Norm
6. Расширение остаточной архитектуры
Архитектура остаточной сети 6.1. ReLU в каждой точке соединения
6.2. Одинаковый порог для всех слоев Fan-In
6.3. Начальные неостаточные слои предварительной обработки
7.Эксперименты
7.1. Наборы данных и реализация
7.2. Эксперименты для VGG Architectures
7.3. Эксперименты для остаточных архитектур
7,4. Сокращение вычислений из-за редких нейронных событий
8. Выводы и дальнейшая работа
Авторские взносы
Компания Заявление о конфликте интересов
Сноски
Список литературы