Основные типы данных — books
Существует несколько основных типов данных, и важно знать, как можно работать с каждым из них, чтобы вы могли заниматься сбором данных в форме, которая лучше всего удовлетворяет ваши потребности. Существует много классификаций типов данных, но мы остановимся на таких уровнях измерения, как номинальный, порядковый, интервальный и нормативный.
Уровни измеренияПредставьте, что вы пришли за покупками в продовольственный магазин. Вы ходите от отдела к отделу и кладете в корзину то, что хотите купить, − овощи и зелень, молочные продукты, полуфабрикаты, консервы. Если бы вам нужно было составить список, в котором было бы указано, из какого отдела вы взяли каждый продукт, эти данные можно было бы отнести к номинальному типу. Термин «номинальный» имеет отношение к латинскому слову «nomen», которое означает «относящийся к именам». Мы называем этот вид данных номинальными, поскольку они содержат названия категорий, по которым распределяются данные. Номинальные данные по определению неупорядочены; овощи как общая категория математически не больше и не меньше, чем молочная продукция.
Номинальные данные по определению неупорядочены; овощи как общая категория математически не больше и не меньше, чем молочная продукция.
Номинальные данные можно посчитать, можно определить процент от целого, однако нельзя вычислить среднее значение. Можно говорить о том, сколько продуктов в вашей корзине было взято в молочном отделе, или сколько процентов от покупок занимают овощи, но посчитать среднее значение каждого продовольственного отдела в вашей корзине невозможно.
В случае, если доступны только две категории, данные относят к типу дихотомических. Ответы на вопросы, требующие ответа «да-нет», − это и есть дихотомические данные. Если, делая покупки, вы собрали данные о том, продавался товар со скидкой или нет, это и будут дихотомические данные.
Процент продукции из каждого отдела в корзинеПорядковые данныеВ конце концов, вы приходите на кассу и пытаетесь понять, какая очередь движется быстрее всего. Не считая людей в каждой очереди, вы мысленно разбиваете их на короткие, средние и длинные очереди. Поскольку такие данные естественным образом упорядочиваются по категориям, они называются порядковыми. Вопросы в анкетах, ответами на которые могут быть такие фразы, как «полностью не согласен», «не согласен», «нейтрально отношусь», «согласен», «полностью согласен», предназначены для сбора порядковых данных. Ни одна из категорий порядковой шкалы не имеет фактической математической величины. Числовые значения зачастую присваиваются категориям для того, чтобы облегчить запись или анализ данных (например: 1 = полностью не согласен, 5 = полностью согласен), но это распределение условно, и вы можете выбрать любую группу упорядоченных чисел для обозначения групп. Например, вы с такой же легкостью можете решить, что цифра 5 будет обозначать «полностью не согласен», а 1 − «полностью согласен».
Не считая людей в каждой очереди, вы мысленно разбиваете их на короткие, средние и длинные очереди. Поскольку такие данные естественным образом упорядочиваются по категориям, они называются порядковыми. Вопросы в анкетах, ответами на которые могут быть такие фразы, как «полностью не согласен», «не согласен», «нейтрально отношусь», «согласен», «полностью согласен», предназначены для сбора порядковых данных. Ни одна из категорий порядковой шкалы не имеет фактической математической величины. Числовые значения зачастую присваиваются категориям для того, чтобы облегчить запись или анализ данных (например: 1 = полностью не согласен, 5 = полностью согласен), но это распределение условно, и вы можете выбрать любую группу упорядоченных чисел для обозначения групп. Например, вы с такой же легкостью можете решить, что цифра 5 будет обозначать «полностью не согласен», а 1 − «полностью согласен».
Цифры, которые вы присваиваете порядковым категориям, влияют на толкование конечного анализа, но вы можете выбрать любой набор цифр, при условии соблюдения порядка нумерации.
В качестве точки отсчета наиболее принято использовать 0 или 1.
Так же как и номинальные данные, порядковые данные можно посчитать и определить процент от целого, однако нет единого мнения о том, можно ли для порядковых данных посчитать среднее значение. С одной стороны, невозможно определить среднее значение для категории «полностью согласен», например, и даже если вы определите их числовые значения, они не будут иметь фактической математической величины. Каждое числовое значение представляет определенную категорию, а не количество чего бы то ни было.
С другой стороны, если принять, что разница величин между последовательными категориями приблизительно одинаковая (например, разница между «полностью не согласен» и «не согласен» такая же, как и между «не согласен» и «отношусь нейтрально», и так далее), и для обозначения категорий используются последовательные числа, тогда среднее значение ответов тоже можно интерпретировать применительно к той же шкале.
В некоторых отраслях настоятельно не рекомендуется использовать порядковые данные для проведения подобных расчетов, в то время как в других − это постоянная практика. Ознакомьтесь с другими работами в вашей отрасли, чтобы понять, что принято.
Ознакомьтесь с другими работами в вашей отрасли, чтобы понять, что принято.
Оставим пока порядковые данные и вернемся в наш магазин. Вы стоите в очереди, как вам кажется, достаточно долго, и смотрите на часы, чтобы узнать, сколько именно. Вы стали в очередь в 11:15, а сейчас 11:30. Время суток – считается интервальными данными. Этот вид данных называется так, потому-что интервалы между точками измерения одинаковы. Поскольку в каждой минуте 60 секунд, разница между 11:15 и 11:30 такая же, как между 12:00 и 12:15.
Интервальные данные − числовые, поэтому вы можете производить с ними математические операции, однако такие данные не имеют «значимой» нулевой точки − то есть при значении ноль то, что вы измеряете, не отсутствует. 0:00 часов означает не отсутствие времени, а начало нового дня. Другие интервальные данные, с которыми вы сталкиваетесь в повседневной жизни, это календарный год и температура. Нулевое значение для годов не значит, что ранее времени не существовало, а нулевая температура (измеряемая в градусах Цельсия или Фаренгейта) отнюдь не показатель того, что тепла нет.
Увидев, что на часах 11:30, вы думаете: «Неужели я стою в очереди уже 15 минут?» Когда вы задумываетесь о времени в таком контексте, это уже нормативные данные. Нормативные данные − числовые, и имеют много общего с интервальными данными, кроме того, что нормативные, в отличие от интервальных, имеют значимую нулевую точку. В нормативных данных ноль означает отсутствие того, что вы измеряете, − ноль минут, ноль людей в очереди, ноль молочных продуктов в вашей корзине. Во всех этих случаях ноль означает, что у вас нет того, что вы измеряете, и это отличается от того, что мы обсуждали в разделе интервальных данных. Другие часто встречаемые переменные, которые можно отнести к нормативным данным, − рост, вес, возраст и деньги.
Интервальные и нормативные данные могут быть либо дискретными, либо непрерывными. Дискретные данные выражены ограниченным набором значений (обычно целыми числами), величины между этими значениями невозможны. В очереди должно быть целое число людей, в ней не может быть одной трети человека. У вас может получиться в среднем по 4,25 человека в каждой очереди, но фактическое количество людей должно быть целым числом. Непрерывные данные могут принимать любое значение на шкале. Вы можете купить 1,25 фунта сыра или стоять в очереди 7,75 минут. Это не значит, что данные могут принимать все возможные числовые значения − только все значения в рамках границ шкалы. Вы не можете стоять в очереди отрицательный промежуток времени и не можете купить отрицательное количество унций сыра, но тем не менее, эти данные − непрерывны.
У вас может получиться в среднем по 4,25 человека в каждой очереди, но фактическое количество людей должно быть целым числом. Непрерывные данные могут принимать любое значение на шкале. Вы можете купить 1,25 фунта сыра или стоять в очереди 7,75 минут. Это не значит, что данные могут принимать все возможные числовые значения − только все значения в рамках границ шкалы. Вы не можете стоять в очереди отрицательный промежуток времени и не можете купить отрицательное количество унций сыра, но тем не менее, эти данные − непрерывны.
Для простоты объяснения мы часто округляем непрерывные данные до определенного количества цифр. Но в таком случае эти данные остаются непрерывными, а не дискретными.
Чтобы повторить пройденное, давайте взглянем на чек из магазина. Можете ли вы определить, какого типа эти данные (номинальные, порядковые, интервальные или нормативные)?
| Дата: 06/01/2014 Время: 11:32 утра | ||||
| Продукт | Отдел | Ряд | Количество | Стоимость (US$) |
| Апельсины — фунты | Овощной | 4 | 2 | 2. 58 58 |
| Яблоки — фунты | Овощной | 4 | 1 | 1.29 |
| Моцарелла — фунты | Молочный | 7 | 1 | 3.49 |
| Молоко — обезжиренное — галлон | Молочный | 8 | 1 | 4.29 |
| Горох — упаковка | Полуфабрикаты | 15 | 1 | 0.99 |
| Зеленая фасоль — упаковка | Полуфабрикаты | 15 | 3 | 1.77 |
| Помидоры | Консервы | 2 | 4 | 3.92 |
| Картофель | Консервы | 3 | 2 | 2.38 |
| Грибы | Консервы | 2 | 5 | 2.95 |
Если вы поищете информацию о данных в учебниках и интернете, то увидите, что переменные часто описывают, как один из вышеперечисленных видов данных. Вы должны знать, что многие переменные не относятся к какому-либо определенному виду данных. Чаще всего вид данных определяется методом их сбора.
Чаще всего вид данных определяется методом их сбора.
Давайте рассмотрим переменную возраста. Данные о возрасте обычно собирают как нормативные, однако их также можно собрать и как порядковые. Это происходит, когда в анкетах спрашивают: “К какой возрастной группе вы относитесь?” В таком опросе у вас не будет данных о возрасте каждого отдельного респондента, вы только сможете узнать, скольким из них было между 18-24 годами, 25-34 и так далее. Вы можете собрать показатели холестерина респондентов для медицинского исследования, либо просто спросить участников опроса, повышен у них холестерин или нет. То есть, это одна переменная и два разных метода сбора данных − и два различных вида данных.
Общее правило состоит в том, что вы можете двигаться вниз по уровню измерения, но не вверх. Если можно собирать переменные как интервальные или рациональные данные, их также можно собирать как номинальные или порядковые данные, но если переменная номинальная по своей природе, как отдел в супермаркете, вы не можете собирать ее как интервальные, порядковые или нормативные данные. Переменные, имеющие порядковую природу, можно собирать как номинальные данные, но не как интервальные или нормативные. Однако, многие переменные, собираемые как порядковые данные, имеют схожую переменную, которую при желании можно собирать как интервальные или нормативные данные.
Переменные, имеющие порядковую природу, можно собирать как номинальные данные, но не как интервальные или нормативные. Однако, многие переменные, собираемые как порядковые данные, имеют схожую переменную, которую при желании можно собирать как интервальные или нормативные данные.
| Тип порядкового уровня | Соответствующий интервальный/нормативный уровень | Пример |
| Рейтинг | Единица измерения, на которой основан рейтинг | Фиксируйте время, за которое бегуны пробежали марафон вместо места в рейтинге, которое они заняли |
| Распределение по группам | Само измерение | Фиксируйте точный возраст вместо возрастной категории |
| Замещающая шкала | Исходная единица измерения, на которой была основана шкала | Фиксируйте точное количество баллов за тест вместо оценки, выраженной буквой |
Важно помнить, что общее правило “двигаться можно вниз, но не вверх”, применимо и во время анализа и визуализации данных. Если вы собираете переменную как нормативные данные, вы всегда можете позже сгруппировать данные для визуализации, если этого требует ваша работа. Если же вы собираете ее на более низком уровне измерения, позже вы не сможете перейти на более высокий уровень, не собрав больше данных. Например, если вы решили собирать данные о возрасте как порядковые данные, вы не сможете позже посчитать средний возраст, и ваша визуализация будет ограничена демонстрацией возрастных групп; вы не сможете показать возраст как непрерывные данные.
Если вы собираете переменную как нормативные данные, вы всегда можете позже сгруппировать данные для визуализации, если этого требует ваша работа. Если же вы собираете ее на более низком уровне измерения, позже вы не сможете перейти на более высокий уровень, не собрав больше данных. Например, если вы решили собирать данные о возрасте как порядковые данные, вы не сможете позже посчитать средний возраст, и ваша визуализация будет ограничена демонстрацией возрастных групп; вы не сможете показать возраст как непрерывные данные.
Если это не усложняет работу, собирать данные нужно на самом высоком уровне измерения, который вам может пригодиться позже. Мало что в работе с данными разочаровывает так, как понимание того, что вы собрали данные неправильным способом и не можете сделать то, что хотели.
Другие важные терминыСуществуют еще термины, часто используемые применимо к видам данных. Мы решили не использовать их из-за небольшого расхождения во мнениях относительно их значений, но вы должны знать их возможные значения на случай, если встретите их в других источниках.
Ранее мы говорили о номинальных и порядковых данных как о способе распределить данные по категориям. Некоторые источники считают, что оба типа принадлежат к категориальным данным, где номинальные данные − неупорядоченные категориальные данные, а порядковые − упорядоченные. Другие источники относят к категориальным данным только номинальные, и считают, что понятия “номинальные данные” и “категориальные данные” − взаимозаменяемы. Эти источники относят порядковые данные к отдельной группе.
Качественные и количественные данныеКачественные данные, грубо говоря, относятся к нечисловым данным, в то время как количественные данные − числовые и, соответственно, поддающиеся счету. По отношению к этим терминам существует некое общее мнение. Определенные данные всегда считаются качественными, поскольку требуют предобработки или других методов анализа, чем количественные данные. Примерами могут считаться записи прямого наблюдения либо транскрипты интервью. Подобным образом, интервальные и нормативные данные всегда считаются количественными, поскольку они всегда числовые. Однако есть некое расхождение во мнениях относительно номинальных и порядковых типов данных. Некоторые источники называют их качественными, так как их категории описательные, а не числовые. Однако, поскольку эти данные можно посчитать и использовать для подсчета процентов, другие источники считают их количественными, поскольку они в этом смысле поддаются счету.
Подобным образом, интервальные и нормативные данные всегда считаются количественными, поскольку они всегда числовые. Однако есть некое расхождение во мнениях относительно номинальных и порядковых типов данных. Некоторые источники называют их качественными, так как их категории описательные, а не числовые. Однако, поскольку эти данные можно посчитать и использовать для подсчета процентов, другие источники считают их количественными, поскольку они в этом смысле поддаются счету.
Чтобы избежать путаницы, мы будем придерживаться терминов, заданных в начале главы в течении всей книги, кроме главы о планировании и составлении опросов, где речь будет идти о полноформатных качественных данных. Если вам встретятся термины “категориальные данные”, “качественные данные”, или “количественные данные” в других источниках или в вашей работе, убедитесь, что понимаете, в каком значении они используются, и не полагайтесь на предположения!
Глава 1 Типы данных | Визуализация и анализ географических данных на языке R
Программный код главы
1.
 1 Типы данных
1 Типы данныхТип данных — это класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применены1. С помощью типов данных мы можем представлять привычные нам сущности, такие как числа, строки и т.д. В языке R существует 5 базовых типов данных:
complex | комплексные числа |
character | символьный (строки) |
integer | целые числа |
logical | логические (булевы) |
numeric | числа с плавающей точкой |
Помимо этого есть тип Date, который позволяет работать с датами. Рассмотрим использование каждого из перечисленных типов.
1.1.1 Числа
Числа — основной тип данных в R. К ним относятся числа c плавающей точкой и целые числа. В терминологии R такие данные называются интервальными, поскольку к ним применимо понятие интервала на числовой прямой. 3
## [1] 8
2 ** 3
## [1] 8
3
## [1] 8
2 ** 3
## [1] 8
Результат деления по умолчанию имеет тип с плавающей точкой:
5 / 3 ## [1] 1.666667 5 / 2.5 ## [1] 2
Если вы хотите чтобы деление производилось целочисленным образом (без дробной части) необходимо использовать оператор %/%:
5 %/% 3 ## [1] 1
Остаток от деления можно получить с помощью оператора %%:
5 %% 3 ## [1] 2
Вышеприведенные арифметические операции являются бинарными, то есть требуют наличия двух чисел. Числа называются “операндами”. Отделять операнды от оператора пробелом или нет — дело вкуса. Однако рекомендуется все же отделять, так как это повышает читаемость кода. Следующие два выражения эквивалентны. Однако сравните простоту их восприятия:
5%/%3 ## [1] 1
5 %/% 3 ## [1] 1
Как правило, в настоящих программах числа в явном виде встречаются лишь иногда. Вместо этого для их обозначения используют переменные. В вышеприведенных выражениях мы неоднократно использовали число 3. Теперь представьте, что вы хотите проверить, каковы будут результаты, если вместо 3 использовать 4. Вам придется заменить все тройки на четверки. Если их много, то это будет утомительная работа, и вы наверняка что-то пропустите. Конечно, можно использовать поиск с автозаменой, но что если тройки надо заменить не везде? Одно и то же число может выполнять разные функции в разных выражениях. Чтобы избежать подобных проблем, в программе вводят переменные и присваивают им значения. Оператор присваивания значения выглядит как
Теперь представьте, что вы хотите проверить, каковы будут результаты, если вместо 3 использовать 4. Вам придется заменить все тройки на четверки. Если их много, то это будет утомительная работа, и вы наверняка что-то пропустите. Конечно, можно использовать поиск с автозаменой, но что если тройки надо заменить не везде? Одно и то же число может выполнять разные функции в разных выражениях. Чтобы избежать подобных проблем, в программе вводят переменные и присваивают им значения. Оператор присваивания значения выглядит как
a = 5 b = 3
Чтобы вывести значение переменной на экран, достаточно просто ввести его:
a ## [1] 5 b ## [1] 3
Мы можем выполнить над переменными все те же операции что и над константами:
a + b ## [1] 8 a - b ## [1] 2 a / b ## [1] 1.666667 a %/% b ## [1] 1 a %% b ## [1] 2
Легко меняем значение второй переменной с 3 на 4 и выполняем код заново.
b = 4 a + b ## [1] 9 a - b ## [1] 1 a / b ## [1] 1.25 a %/% b ## [1] 1 a %% b ## [1] 1
Нам пришлось изменить значение переменной только один раз в момент ее создания, все последующие операции остались неизменны, но их результаты обновились!
Новую переменную можно создать на основе значений существующих переменных:
c = b d = a+c
Посмотрим, что получилось:
c ## [1] 4 d ## [1] 9
Вы можете комбинировать переменные и заданные явным образом константы:
e = d + 2.5 e ## [1] 11.5
Противоположное по знаку число получается добавлением унарного оператора - перед константой или переменной:
f = -2 f ## [1] -2 f = -e f ## [1] -11.5
Операция взятия остатка от деления бывает полезной, например, когда мы хотим выяснить, является число четным или нет. Для этого достаточно взять остаток от деления на 2. Если число является четным, остаток будет равен нулю. В данном случае c равно 4, d равно 9:
c %% 2 ## [1] 0 d %% 2 ## [1] 1
1.1.1.1 Числовые функции
Прежде чем мы перейдем к рассмотрению прочих типов данных и структур данных нам необходимо познакомиться с функциями, поскольку они встречаются буквально на каждом шагу. Понятие функции идентично тому, к чему мы привыкли в математике. Например, функция может называться Z, и принимать 2 аргумента: x и y. В этом случае она записывается как x и y в скобках. Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Нас даже может не интересовать, как фактически устроена функция внутри, но важно понимать, что именно она должна вычислять. С созданием функций мы познакомимся позднее.
Важнейшие примеры функций — математические. Это функции взятия корня sqrt(x), модуля abs(x), округления round(x, digits), натурального логарифма abs(x), тригонометрические функции sin(x), cos(x), tan(x), обратные к ним asin(y), acos(y), atan(y) и многие другие. Основные математические функции содержатся в пакете base, который по умолчанию доступен в среде R и не требует подключения.
В качестве аргумента функции можно использовать переменную, константу, а также выражения:
sqrt(a) ## [1] 2.236068 sin(a) ## [1] -0.9589243 tan(1.5) ## [1] 14.10142 abs(a + b - 2.5) ## [1] 6.5
Вы также можете легко вкладывать функции одна в одну, если результат вычисления одной функции нужно подставить в другую:
sin(sqrt(a)) ## [1] 0.7867491 sqrt(sin(a) + 2) ## [1] 1.020331
Также как и с арифметическими выражениями, результат вычисления функции можно записать в переменную:
b = sin(sqrt(a)) b ## [1] 0.7867491
Если переменной b ранее было присвоено другое значение, оно перезапишется. Вы также можете записать в переменную результат операции, выполненной над ней же. Например, если вы не уверены, что a — неотрицательное число, а вам это необходимо в дальнейших расчетах, вы можете применить к нему операцию взятия модуля:
b = sin(a) b ## [1] -0.9589243 b = abs(b) b ## [1] 0.9589243
1.1.2 Строки
Строки — также еще один важнейший тип данных. Чтобы создать строковую переменную, необходимо заключить текст строки в кавычки:
s = "В историю трудно войти, но легко вляпаться (М.Жванецкий)" s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Строки состоят из символов, и, в отличие от некоторых других языков, в R нет отдельного типа данных для объекта, которых хранит один символ (в C++ для этого используется тип char). Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
Поэтому при создании строк вы можете пользоваться как одинарными, так и двойными кавычками:
s1 = "Это строка" s1 ## [1] "Это строка" s2 = 'Это также строка' s2 ## [1] "Это также строка"
Иногда бывает необходимо создать пустую строку (например, чтобы в нее далее что-то добавлять). В этом случае просто напишите два знака кавычек, идущих подряд без пробела между ними:
s1 = "" # это пустая строка s1 ## [1] "" s2 = '' # это также пустая строка s2 ## [1] "" s3 = ' ' # а это не пустая, тут есть пробел s3 ## [1] " "
Длину строки в символах можно узнать с помощью функции nchar()
nchar(s) ## [1] 56 nchar(s1) ## [1] 0 nchar(s3) ## [1] 1
Чтобы извлечь из строки подстроку (часть строки), можно использовать функцию substr(), указав ей номер первого и последнего символа:
substr(s, 3, 9) # извлекаем все символы с 3-го по 9-й ## [1] "историю"
В частности, зная длину строки, можно легко извлечь последние \(k\) символов:
n = nchar(s) k = 7 substr(s, n - k, n) ## [1] "анецкий)"
Строки можно складывать так же как и числа.
+, а специальной функцией paste(). Состыковываемые строки нужно перечислить через запятую, их число может быть произвольноs1 = "В историю трудно войти," s2 = "но легко вляпаться" s3 = "(М.Жванецкий)"
Посмотрим содержимое подстрок:
s1 ## [1] "В историю трудно войти," s2 ## [1] "но легко вляпаться" s3 ## [1] "(М.Жванецкий)"
А теперь объединим их в одну:
s = paste(s1, s2) s ## [1] "В историю трудно войти, но легко вляпаться" s = paste(s1, s2, s3) s ## [1] "В историю трудно войти, но легко вляпаться (М.Жванецкий)"
Настоящая сила конкатенации проявляется когда вам необходимо объединить в одной строке некоторое текстовое описание (заранее известное) и значения переменных, которые у вас вычисляются в программе (заранее неизвестные).
year, а население в переменную pop. Вы их значения пока что не знаете, они вычислены по табличным данным в программе. Как вывести эту информацию на экран “человеческим” образом? Для этого нужно использовать конкатенацию строк.Условно запишем значения переменных, как будто мы их знаем
year = 1950 pop = 1850
s1 = "Максимальная численность населения в Детройте пришлась на" s2 = "год и составила" s3 = "тыс. чел" s = paste(s1, year, s2, pop, s3) s ## [1] "Максимальная численность населения в Детройте пришлась на 1950 год и составила 1850 тыс. чел"
Обратите внимание на то что мы конкатенировали строки с числами. Конвертация типов осуществилась автоматически. Помимо этого, функция сама вставила пробелы между строками.
Функция
paste()содержит параметрsep, отвечающий за символ, который будет вставляться между конкатенируемыми строками.По умолчанию
sep = " ", то есть, между строками будет вставляться пробел. Подобное поведение желательно не всегда. Например, если после переменной у вас идет запятая, то между ними будет вставлен пробел. В таком случае при вызовеpaste()необходимо указатьsep = "", то есть пустую строку:paste(... sep = ""). Вы также можете воспользоваться функциейpaste0(), которая делает [почти] то же самое, что иpaste(..., sep = ""), но избавляет вас от задания параметраsep.
1.1.3 Даты и длительности
Для работы с временными данными в R существуют специальные типы. Чаще всего используются даты, указанные с точностью до дня. Такие данные имеют тип Date, а для их создания используется функция as.Date(). В данном случае точка — это лишь часть названия функции, а не какой-то особый оператор. В качестве аргумента функции необходимо задать дату, записанную в виде строки. Запишем дату рождения автора (можете заменить ее на свою):
Запишем дату рождения автора (можете заменить ее на свою):
birth = as.Date('1986/02/18')
birth
## [1] "1986-02-18"Сегодняшнюю дату вы можете узнать с помощью специальной функции Sys.Date():
current = Sys.Date() current ## [1] "2022-08-23"
Даты можно вычитать. Результатом выполнения. Например, узнать продолжительность жизни в днях можно так:
livedays = current - birth livedays ## Time difference of 13335 days
Вы также можете прибавить к текущей дате некоторое значение. Например, необходимо узнать, какая дата будет через 40 дней:
current + 40 ## [1] "2022-10-02"
Имея дату, вы можете легко извлечь из нее день, месяц и год. Существуют специальные функции для этих целей (описанные в главе 8), но прямо сейчас вы можете сделать это сначала преобразовав дату в строку, а затем выбрав из нее подстроку, соответствующую требуемой компоненте даты:
cdate = as.character(current) substr(cdate, 1, 4) # Год ## [1] "2022" substr(cdate, 6, 7) # Месяц ## [1] "08" substr(cdate, 9, 10) # День ## [1] "23"
Более подробно о преобразованиях типов, аналогичных функции as., используемой в данном примере, рассказано далее в настоящей главе. character()
character()
1.1.4 Время и периоды
1.1.5 Логические
Логические переменные возникают там, где нужно проверить условие. Переменная логического типа может принимать значение TRUE (истина) или FALSE (ложь). Для их обозначения также возможны более компактные константы T и F соответственно.
Следующие операторы приводят к возникновению логических переменных:
- РАВНО (
==) — проверка равенства операндов - НЕ РАВНО (
!=) — проверка неравенства операндов - МЕНЬШЕ (
<) — первый аргумент меньше второго - МЕНЬШЕ ИЛИ РАВНО (
<=) — первый аргумент меньше или равен второму - БОЛЬШЕ (
>) — первый аргумент больше второго - БОЛЬШЕ ИЛИ РАВНО (
>=) — первый аргумент больше или равен второму
Посмотрим, как они работают:
a = 1 b = 2 a == b ## [1] FALSE a != b ## [1] TRUE a > b ## [1] FALSE a < b ## [1] TRUE
Если необходимо проверить несколько условий одновременно, их можно комбинировать с помощью логических операторов. Наиболее популярные среди них:
Наиболее популярные среди них:
- И (
&&) — проверка истинности обоих условий - ИЛИ (
||) — проверка истинности хотя бы одного из условий - НЕ (
!) — отрицание операнда (истина меняется на ложь, ложь на истину)
c = 3 (b > a) && (c > b) ## [1] TRUE (a > b) && (c > b) ## [1] FALSE (a > b) || (c > b) ## [1] TRUE !(a > b) ## [1] TRUE
Более подробно работу с логическими переменными мы разберем далее при знакомстве с условным оператором if.
1.2 Манипуляции с типами
1.2.1 Определение типа данных
Определение типа данных осуществляется с помощью функции class() (см. раздел Диагностические функции во Введении)
class(1)
## [1] "numeric"
class(0.5)
## [1] "numeric"
class(1 + 2i)
## [1] "complex"
class("sample")
## [1] "character"
class(TRUE)
## [1] "logical"
class(as.Date('1986-02-18'))
## [1] "Date"В вышеприведенном примере видно, что R по умолчанию “повышает” ранг целочисленных данных до более общего типа чисел с плавающей точкой, тем самым закладываясь на возможность точного деления без остатка. Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
Если вы хотите, чтобы данные в явном виде интерпретировались как целочисленные, их нужно принудительно привести к этому типу. Операторы преобразования типов рассмотрены ниже.
1.2.2 Преобразование типов данных
Преобразование типов данных осуществляется с помощью функций семейства as(d, type), где d — это входная переменная, а type — название типа данных, к которому эти данные надо преобразовать (см. таблицу в начале главы). Несколько примеров:
k = 1 print(k) ## [1] 1 class(k) ## [1] "numeric" l = as(k, "integer") print(l) ## [1] 1 class(l) ## [1] "integer" m = as(l, "character") print(m) ## [1] "1" class(m) ## [1] "character" n = as(m, "numeric") print(n) ## [1] 1 class(n) ## [1] "numeric"
Для функции as() существуют обертки (wrappers), которые позволяют записывать такие преобразования более компактно и выглядят как as.<dataype>(d), где datatype — название типа данных:
k = 1 l = as.integer(k) print(l) ## [1] 1 class(l) ## [1] "integer" m = as.character(l) print(m) ## [1] "1" class(m) ## [1] "character" n = as.numeric(m) print(n) ## [1] 1 class(n) ## [1] "numeric" d = as.Date('1986-02-18') print(d) ## [1] "1986-02-18" class(d) ## [1] "Date"
Если преобразовать число c плавающей точкой до целого, то дробная часть будет отброшена:
as.integer(2.7) ## [1] 2
После преобразования типа данных, разумеется, к переменной будут применимы только те функции, которые определены для данного типа данных:
a = 2.5 b = as.character(a) b + 2 ## Error in b + 2: нечисловой аргумент для бинарного оператора nchar(b) ## [1] 3
1.2.3 Проверка типов данных и пустых значений
Для проверки типа данных можно использовать функции семейства is.<datatype>:
is.integer(2.7)
## [1] FALSE
is.numeric(2.7)
## [1] TRUE
is.character('Привет!')
## [1] TRUEОсобое значение имеют функции проверки пустых переменных (имеющих значение NA — not available), которые могут получаться в результате несовместимых преобразований или соответствовать пропускам в исходных данных:
as.integer('Привет!') ## [1] NA is.na(as.integer('Привет!')) ## [1] TRUE
1.3 Ввод и вывод данных в консоли
1.3.1 Ввод данных
Для ввода данных через консоль можно воспользоваться функцией readline(), которая будет ожидать пользовательский ввод и нажатие клавиши Enter, после чего вернет введенные данные в виде строки. Предположим, пользователь вызывает эту функцию и вводит с клавиатуры 1024:
a = readline()
Выведем результат на экран:
a ## [1] "1024"
Функция
readline()всегда возвращает строку, поэтому если вы ожидаете ввод числа, полученное значение необходимо явным образом преобразовать к числовому типу.
Весьма полезной особенностью readline() является возможность указания строки запроса (чтобы пользователь понимал, что от него хотят). Строку запроса можно указать при вызове функции:
lat = readline('Введите широту точки:')
## Введите широту точки:
## 54
lat
## [1] "54"1.
 3.2 Вывод данных
3.2 Вывод данныхДля вывода данных в консоль можно воспользоваться тремя способами:
- Просто напечатать название переменной с новой строки (не работает при запуске программы командой
Source) - Вызвать функцию
print() - Вызвать функцию
cat() - Заключить выражение в круглые скобки
()
Первый способ мы уже регулярно использовали ранее в настоящей главе. Следует обратить внимание на то, что он хорош для отладки программы, но выглядит некрасиво в рабочих программах, поскольку просто печатая название переменной с новой строки вы как бы явно не говорите о том, что хотите вывести ее значение в консоль, а лишь подразумеваете это. Более того, если скрипт запускается командой Source, данный метод вывода переменной просто не сработает, интерпретатор его проигнорирует.
Поэтому после отладки следует убрать из программы все лишние выводы в консоль, а оставшиеся (действительно нужные) оформить с помощью функций print() или cat(). 10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
10))
## [1] «2 в степени 10 равно 1024»
print(paste(«Сегодняшняя дата — «, Sys.Date()))
## [1] «Сегодняшняя дата — 2022-08-23»
Функция cat() отличается от print() следующими особенностями:
-
cat()выводит значение переменной, и не печатает ее измерения и внешние атрибуты типа двойных кавычек вокруг строки. Это означает, чтоcat()можно использовать и для записи данных в файл (на практике этим мало кто пользуется, но знать такую возможность надо). -
cat()принимает множество аргументов и может осуществлять конкатенацию строк аналогично функции paste() -
cat()не возвращает никакого значений, в то время какprint()возвращает значение, переданное ей в качестве аргумента. -
cat()можно использовать только для атомарных типов данных. Для классов (таких как Date) она будет выводит содержимое объекта, которое может не совпадать с тем, что пользователь ожидает вывести
Например:
cat(a)
## 1024
cat(b)
## Fourty winks in progress
cat("2 в степени 10 равно", 2^10)
## 2 в степени 10 равно 1024
cat("Сегодняшнаяя дата -", Sys. Date())
## Сегодняшнаяя дата - 19227
Date())
## Сегодняшнаяя дата - 19227Можно видеть, что в последнем случае cat() напечатала отнюдь не дату в ее привычном представлении, а некое число, которое является внутренним представлением даты в типе данных Date. Такие типы данных являются классами объектов в R, и у них есть своя функция print(), которая и выдает содержимое объекта в виде, который ожидается пользователем. Поэтому пользоваться функцией cat() надо с некоторой осторожностью.
Заключительная возможность — вывод с помощью заключения выражения в круглые скобки — очень удобна на стадии отладки программы. При этом переменная, которая создается в выражении, остается доступной в программе:
(a = rnorm(5)) # сгенерируем 5 случайных чисел, запишем их в переменную a и выведем на экран ## [1] -3.740944 2.263287 -1.012359 1.370046 -1.102049 (b = 2 * a) # переменная a доступна, ее можно использовать и далее для вычислений ## [1] -7.481888 4.526573 -2.024718 2.740092 -2.204099
1.4 Условный оператор
Проверка условий позволяет осуществлять так называемое ветвление в программе. Ветвление означает, что при определенных условиях (значениях переменных) будет выполнен один программный код, а при других условиях — другой. В R для проверки условий используется условный оператор if — else if — else следующего вида:
if (condition) {
statement1
} else if (condition) {
statement2
} else {
statement3
}Сначала проверяется условие в выражении if (condition), и если оно истинно, то выполнится вложенный в фигурные скобки программный код statement1, после чего оставшиеся условия не будут проверяться. Если первое условие ложно, программа перейдет к проверке следующего условия else if (condition). Далее, если оно истинно, то выполнится вложенный код statement2, если нет — проверка переключится на следующее условие и так далее. Заключительный код statement3, следующий за словом else, выполнится только если ложными окажутся все предыдущие условия.
Конструкций
else ifможет быть произвольное количество, конструкцииifиelseмогут встречаться в условном операторе только один раз, в начале и конце соответственно. При этом условный оператор может состоять только из конструкцииif, аelse ifиelseне являются обязательными.
Например, сгенерируем случайное число, округлим его до одного знака после запятой и проверим относительно нуля:
(a = round(rnorm(1), 1))
## [1] -0.1
if (a < 0) {
cat('Получилось отрицательное число!')
} else if (a > 0) {
cat('Получилось положительное число!')
} else {
cat('Получился нуль!')
}
## Получилось отрицательное число!Условия можно использовать, в частности, для того чтобы обрабатывать пользовательский ввод в программе. Например, охарактеризуем положение точки относительно Полярного круга:
phi = as.numeric(readline('Введите широту вашей точки:'))Пользователь вводит 68, а мы оцениваем результат:
if (!is.na(phi)) { # проверяем, является ли введенное значение числом if (abs(phi) >= 66.562 && abs(phi) <= 90) { # выполняем проверку на заполярность cat('Точка находится в Заполярье') } else { cat('Точка не находится в Заполярье') } } else { cat('Необходимо ввести число!') # оповещаем о некорректном вводе } ## Точка находится в Заполярье
1.5 Оператор переключения
Оператор переключения (switch) является удобной заменой условному оператору в тех случаях, когда надо вычислить значение переменной в зависимости от значения другой переменной, которая может принимать ограниченное (заранее известное) число значений. Например:
name = readline('Введите название федерального округа:')Пользователь вводит:
Приволжский
# Определим центр в зависимости от названия:
capital = switch(name,
'Центральный' = 'Москва',
'Северо-Западный' = 'Санкт-Петербург',
'Южный' = 'Ростов-на-Дону',
'Северо-Кавказский' = 'Пятигорск',
'Приволжский' = 'Нижний Новгород',
'Уральский' = 'Екатеринбург',
'Сибирский' = 'Новосибирск',
'Дальневосточный' = 'Хабаровск')
print(capital)
## [1] "Нижний Новгород"1.
 6 Прерывание программы
6 Прерывание программыВ процессе выполнения программы могут возникнуть ситуации, при которых дальнейшее выполнение программы невозможно или недопустимо. Например, пользователь вместо числа ввёл в консоли букву. Хорошим тоном разработчика в данном случае будет не пускать ситуацию на самотёк и ждать пока программа сама споткнется и выдаст системное сообщение об ошибке, а обработать некорректный ввод сразу, сообщить об этом пользователю и остановить программу явным образом.
Прервать выполнение программы можно разными способами. Рассмотрим две часто используемые для этого функции:
-
stop(...)выводит на экран объекты, перечисленные через запятую в...и завершает выполнение программы. При ручном вызове этой функции в...целесообразно передать текстовую строку с сообщением о причине остановки программы. Вызовstop()происходит обычно после проверки некоторого условия операторомif-else. -
stopifnot(.? 2) # возведем в квадрат и выведем на экран, если все ОК
2) # возведем в квадрат и выведем на экран, если все ОКВывод программы в случае ввода строки
abcбудет следующим:## Error in eval(expr, envir, enclos): Введенная строка не является числом
1.7 Технические детали
Когда вы присваиваете значение переменной другой переменной, копирования не происходит. Оба имени будут ссылаться на один и тот же объект, до тех пор, пока через одно из имен не будет предпринята попытка модифицировать объект. Это можно легко проверить с помощью функции
tracemem():a = 1 b = a cat('a:', tracemem(a), '\n') ## a: <0x7fca5b0295f0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0> a = 2 cat('a:', tracemem(a), '\n') # объект скопирован в другую область памяти ## a: <0x7fca5b0292e0> cat('b:', tracemem(b), '\n') ## b: <0x7fca5b0295f0>Подобное поведение называется copy-on-modify. Оно позволяет экономить на вычислениях в случае, когда копия и оригинал остаются неизменными.
 Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).
Аналогичное правило применяется когда вы копируете структуры данных, такие как векторы, списки и фреймы данных (см. Главу 2). Более подробно см. параграф 2.3 в (Wickham 2019).1.8 Краткий обзор
Для просмотра презентации щелкните на ней один раз левой кнопкой мыши и листайте, используя кнопки на клавиатуре:
Презентацию можно открыть в отдельном окне или вкладке браузере. Для этого щелкните по ней правой кнопкой мыши и выберите соответствующую команду.
1.9 Контрольные вопросы и упражнения
1.9.1 Вопросы
- Какие типы данных поддерживаются в R? Каковы их англоязычные наименования?
- Что такое переменная?
- Какой оператор используется для записи значения в переменную?
- С помощью какой функции можно узнать тип переменной?
- С помощью какого семейства функций можно преобразовывать типы переменных?
- Можно ли использовать ранее созданное имя переменной для хранения новых данных другого типа?
- Можно ли записать в переменную результат выполнения выражения, в котором она сама же и участвует?
- Какая функция позволяет прочитать пользовательский ввод с клавиатуры в консоли? Какой тип данных будет иметь возвращаемое значение?
- Какую функцию можно использовать для вывода значения переменной в консоль? Чем отличается использование этой функции от случая, когда вы просто пишете название переменной в строке программы?
- Какой символ является разделителем целой и дробной части при записи чисел с плавающей точкой?
- Что такое операторы и операнды? Приведите примеры бинарных и унарных операторов.
 , **
, **
- Как проверить, является ли число четным?
- Как определить количество символов в строке?
- Как называется операция состыковки нескольких строк и с помощью какой функции она выполняется? Как добиться того, чтобы при этом не добавлялись пробелы между строками?
- С помощью какой функции можно создать дату из строки?
- Как извлечь из даты год? Месяц? День?
- Какая функция позволяет получить дату сегодняшнего дня?
- Можно ли складывать даты и числа? Если да, то в каких единицах измерения будет выражен результат?
- Какова краткая форма записи логических значений
TRUEиFALSE? - Каким числам соответствуют логические значения
TRUEиFALSE? - Сколько операндов должно быть верно, чтобы оператор логического И (
&&) принял значениеTRUE? Что можно сказать в этом отношении об операторе ИЛИ (||)? - Можно ли применять арифметические операции к логическим переменным? Что произойдет, если прибавить или вычесть из числа
aзначениеTRUE? А если заменитьTRUEнаFALSE? - Что такое условный оператор и для каких сценариев обработки данных необходимы условные операторы?
- Перечислите ключевые слова, которые могут быть использованы для организации условных операторов
- При каких сценариях целесообразно использовать оператор переключения?
Запишите условие проверки неравенства чисел
aиbне менее чем тремя способами.Напишите программу, которая запрашивает в консоли целое число и определяет, является ли оно чётным или нечетным. Программа должна предварительно определить, является ли введенное число а) числом и б) целым числом.
Подсказка: результат конвертации строки в целое число и число с плавающей точкой отличается. Вы можете использовать это для проверки, является ли введенное число целым.
Напишите программу, которая считывает из консоли введенную пользователем строку и выводит в консоль количество символов в этой строке. Вывод оформите следующим образом:
"Длина введенной строки равняется ... символам", где вместо многоточия стоит вычисленная длина.В программе в виде переменных задайте координаты населенного пункта А (
x1, y1), а также дирекционный уголDи расстояниеLдо населенного пункта B. Напишите код, который определяет координаты населенного пункта B (
Напишите код, который определяет координаты населенного пункта B (x2, y2).Функция
atan2()позволяет найти математический азимут (полярный угол), если известны координаты вектора между двумя точками. Используя эту функцию, напишите программу, которая вычисляет географический азимут между точками А (x1, y1) и B (x2, y2). Координаты точек задайте в виде переменных непосредственно в коде.Математический азимут отсчитывается от направления на восток против часовой стрелки. Географический азимут отсчитывается от направления на север по часовой стрелке).
- Введение в типы данных
- Категориальные данные (Номинальные, Порядковые)
- Числовые данные (дискретные, непрерывные, интервальные, отношения)
- Почему типы данных важны?
- Статистические методы
- Резюме
- https://en.wikipedia.org/wiki/Statistical_data_type
- https://www.youtube.com/watch?v=hZxnzfnt5v8
- http://www.dummies.com/education/math/statistics/types-of-statistical-data-numerical-categorical-and-ordinal/
- https://www.isixsigma.com/dictionary/discrete-data/
- https://www.youtube.com/watch?v=zHcQPKP6NpM&t=247s
- http://www.mymarketresearchmethods.com/types-of-data-nominal-ordinal-interval-ratio/
- https://study.com/academy/lesson/what-is-discrete-data-in-math-definition-examples.html
- О ВУЗе
- Сведения об образовательной организации
- Кафедры
- Совет филиала
- Руководство
- История
- Библиотека
- Новости
- Объявления
- Контакты
- Видеогалерея
- Дополнительное образование
- Дистанционное обучение
- Противодействие коррупции
- Электронная информационно-образовательная среда (ЭИОС)
- Абитуриентам
- Приемная комиссия
- Документы и справки
- Специальности и направления
- Стоимость
- Правила и условия приема
- Общежитие
- Студенческая жизнь
- Фото-экскурсия
- Иностранным абитуриентам
- Сведения о поступлении
- Поступление 2022
- Приказы о зачислении
- Целевое обучение
- Студентам
- Учебные материалы
- Оплата обучения
- Документы и справки
- Студенческая жизнь
- Научная жизнь
- Спортивная жизнь
- Социальная сфера
- Иностранным студентам
- Независимая оценка качества условий осуществления образовательной деятельности
- Выпускникам
- Центр содействия занятости
- Совет молодых ученых
- Ассоциация выпускников
- Выдающиеся выпускники
- Форумы
- Отзывы выпускников
- Семинары и тренинги
- Обращения
- Отправить письмо
- Ответы на обращения
- Мои обращения
- Письменные обращения
- Личный прием
- Информация о рассмотрении обращений
- Дистанционные способы обратной связи и взаимодействия с получателями услуг
- Отзывы об образовательной организации
- Как нас найти
- Телефоны
- Вакцинация от COVID-19
- Профилактика COVID-19
- Противодействие коррупции
- Безопасность
- Относительные
- Интервальные
- Порядковые
- Номинальные
- Сравнение дискретных и непрерывных данных
- Более подробно о дискретных и непрерывных растровых данных
- На первом этапе необходимо проверить правильность составления анкет, полноту заполнения и качество интервьюирования, а также репрезентативность выборки.

- На этапе кодирования необходимо присвоить код каждому возможному варианту ответа по каждому вопросу. С этой целью используются следующие типы шкал измерения переменных:
- Номинальная
- Порядковая (ранговая)
- Интервальная
- Относительная
№ Тип шкалы Особенности построения 1 Номинальная Каждому свойству потребителя ставится в соответствие некоторый код, позволяющий отличить одно значение от другого. По данной шкале измеряются как правило качественные характеристики объекта исследования. Например, значению свойства пол «мужской» присваивается код «1», «женский» — код «2». 2 Порядковая Присваивает значения свойствам потребителя, находящимся на разных уровнях по отношению друг к другу.  Ответы респондентов можно упорядочить по уровню
изучаемого свойства переменной. Например, по степени предпочтений покупателей различных марок товара, «наиболее предпочитаемой» присваиваем код «1», коды 2, 3, 4 присваиваются маркам по
степени убывания предпочтений.
Ответы респондентов можно упорядочить по уровню
изучаемого свойства переменной. Например, по степени предпочтений покупателей различных марок товара, «наиболее предпочитаемой» присваиваем код «1», коды 2, 3, 4 присваиваются маркам по
степени убывания предпочтений.3 Интервальная Позволяет дать количественную оценку различиям между переменными, т.е. определить насколько одно значение схоже или отличается от другого. Например, шкала Цельсия, календарь. Данная шкала также используется при кодировании ответов респондентов, полученных в результате применения в процессе анкетирования семантического дифференциала. Например, когда от респондентов требуется оценить качество продукта по семибалльной шкале. 4 Относительная Предполагает существование естественного нуля. Поэтому в данной шкале можно сравнивать значения переменной по отношению друг к другу. Это могут быть физические характеристики (вес, длина, объем и пр.  ) и экономические характеристики (цена, объем продаж, прибыль и пр.).
) и экономические характеристики (цена, объем продаж, прибыль и пр.).Таблица 1.1 — Типы шкал
В программе SPSS интервальная и относительная шкалы объединяются в метрическую шкалу. - Выбор метода обработки данных основывается на итогах предыдущих этапов маркетинговых исследований, характеристиках информации, а также задачах, поставленных перед маркетинговым исследованием. Могут быть использованы следующие виды анализа: описательные статистики, корреляционный анализ, построение таблиц сопряженности, кросс—табуляция, проверка статистических гипотез о виде распределения, дисперсионный анализ, дискриминантный анализ, кластерный анализ, многомерное шкалирование, факторный анализ, анализ соответствий, регрессионный анализ, совместный анализ.
- В результате проведенного анализа исследователь получает массив данных, доступный осмыслению и содержательной интерпретации. На данном этапе необходимо представить, отредактировать и сохранить полученные данные,
так как исчерпывающий анализ обычно требует многократной обработки данных с применением разных методов.

- Интерпретация результата обработки данных — самостоятельная задача исследователя. Опираясь на полученные статистические данные важно выявить причинно—следственные отношения между изучаемыми признаками, факторы, оказывающие наибольшее влияние на исследуемую проблему, дать грамотную обоснованную оценку ситуации и выстроить прогноз.
шкала интервалов, которая не только показывает порядок и направление, но также показывает точную разницу в значении. Например, отметки на термометре или линейке равноудалены, проще говоря, измеряют одинаковое расстояние между двумя отметками.
- Разница интервалов: Расстояния между каждым значением в данных интервала равны. Например, разница между 10 см и 20 см такая же, как между 20 см и 30 см.
- Расчет: В интервальных данных можно складывать или вычитать значения, но нельзя делить или умножать. Почти весь статистический анализ применим при расчете интервальных данных, среднего значения, моды, медианы и т. д.
- Нулевая точка: Абсолютная нулевая точка является произвольной, что означает, что переменная может быть измерена, даже если она имеет отрицательное значение, например, температура может быть на -10 ниже нуля, но высота не может быть ниже нуля.

- Менее 40 000 долларов США
- 40 000–60 000 долл.
 США
США - 60 000–80 000 долл. США
- 80 000–100 000 долл. США
- Свыше 100 000 долларов США
- Следующий
- Предыдущий
- Автор темы Гость
- Дата начала
- #1
- #2
- Статья
- 21 минута на чтение
- Количество отслеживаемых таблиц с поддержкой CDC
- Частота изменений в отслеживаемых таблицах
- Пространство, доступное в исходной базе данных, поскольку артефакты CDC (например, таблицы CT, cdc_jobs и т. д.) хранятся в той же базе данных
- Является ли база данных одиночной или объединенной. Для баз данных в эластичных пулах помимо количества таблиц с включенным CDC обратите внимание на количество баз данных, которым принадлежат эти таблицы.
 Базы данных в пуле совместно используют ресурсы (например, дисковое пространство), поэтому при включении CDC для нескольких баз данных возникает риск достижения максимального размера размера диска эластичного пула. Мониторинг ресурсов, таких как ЦП, память и пропускная способность журналов.
Базы данных в пуле совместно используют ресурсы (например, дисковое пространство), поэтому при включении CDC для нескольких баз данных возникает риск достижения максимального размера размера диска эластичного пула. Мониторинг ресурсов, таких как ЦП, память и пропускная способность журналов. Рассмотрите возможность увеличения количества виртуальных ядер или перехода на более высокий уровень базы данных (например, гипермасштабирование), чтобы обеспечить тот же уровень производительности, который был до включения CDC в вашей базе данных SQL Azure.
Внимательно следите за использованием пространства и тщательно проверяйте рабочую нагрузку, прежде чем включать CDC для баз данных в рабочей среде.
Скорость генерации журнала монитора. Чтобы узнать больше здесь.
Сканирование/очистка являются частью рабочей нагрузки пользователя (используются ресурсы пользователя). Влияние на производительность может быть существенным, поскольку в таблицы изменений добавляются целые строки, а для операций обновления также включается предварительный образ.
Эластичные пулы — количество баз данных с поддержкой CDC не должно превышать количество виртуальных ядер пула, чтобы избежать увеличения задержки. Узнайте больше об управлении ресурсами в плотных эластичных пулах здесь.
Очистка — в зависимости от рабочей нагрузки клиента может быть рекомендовано оставить период хранения меньше трех дней по умолчанию, чтобы гарантировать, что очистка улавливает все изменения в таблице изменений. В общем, хорошо поддерживать низкий уровень удержания и отслеживать размер базы данных.
Соглашение об уровне обслуживания (SLA) не предусмотрено при внесении изменений в таблицы изменений.
Задержка меньше секунды также не поддерживается.
1.
 9.2 Упражнения
9.2 Упражнения| Самсонов Т.Е. Визуализация и анализ географических данных на языке R. М.: Географический факультет МГУ, 2022. DOI: 10.5281/zenodo.901911 |
Введение
2 Структуры данных
Типы данных в статистике
Дата публикации Mar 18, 2018
Типы данных являются важным понятием статистики, которое необходимо понимать, чтобы правильно применять статистические измерения к вашим данным и, следовательно, правильно сделать определенные предположения о них. В этом блоге вы познакомитесь с различными типами данных, которые вам необходимо знать, для проведения надлежащего аналитического анализа данных (EDA), который является одной из самых недооцененных частей проекта машинного обучения.
В этом блоге вы познакомитесь с различными типами данных, которые вам необходимо знать, для проведения надлежащего аналитического анализа данных (EDA), который является одной из самых недооцененных частей проекта машинного обучения.
Оглавление:
Хорошее понимание различных типов данных, также называемых шкалами измерений, является критически важным условием для проведения исследовательского анализа данных (EDA), поскольку вы можете использовать определенные статистические измерения только для определенных типов данных.
Вам также необходимо знать, с каким типом данных вы имеете дело, чтобы выбрать правильный метод визуализации. Думайте о типах данных как о способе классификации различных типов переменных. Мы обсудим основные типы переменных и рассмотрим пример для каждой. Иногда мы будем называть их шкалами измерения.
Мы обсудим основные типы переменных и рассмотрим пример для каждой. Иногда мы будем называть их шкалами измерения.
Категориальные данные представляют собой характеристики. Поэтому он может представлять такие вещи, как пол человека, язык и т. Д. Категориальные данные также могут принимать числовые значения (например: 1 для женщины и 0 для мужчины). Обратите внимание, что эти числа не имеют математического значения.
Номинальные значения представляют собой дискретные единицы и используются для обозначения переменных, которые не имеют количественного значения. Просто думайте о них как о ярлыках. Обратите внимание, что номинальные данные, которые не имеют порядка. Поэтому, если вы измените порядок его значений, значение не изменится. Вы можете увидеть два примера номинальных функций ниже:
Левая особенность, которая описывает пол человека, будет называться «дихотомической», что является типом номинальных шкал, который содержит только две категории.
Порядковые значения представляют собой дискретные и упорядоченные единицы. Поэтому он почти такой же, как и номинальные данные, за исключением того, что порядок имеет значение. Вы можете увидеть пример ниже:
Поэтому он почти такой же, как и номинальные данные, за исключением того, что порядок имеет значение. Вы можете увидеть пример ниже:
Обратите внимание, что разница между начальной и средней школой отличается от разницы между средней школой и колледжем. Это основное ограничение порядковых данных, различия между значениями на самом деле не известны. По этой причине порядковые шкалы обычно используются для измерения нечисловых характеристик, таких как счастье, удовлетворенность клиентов и так далее.
Мы говорим о дискретных данных, если их значения различны и разделены. Другими словами: мы говорим о дискретных данных, если данные могут принимать только определенные значения. Этот тип данныхне может быть измерено, но оно может быть подсчитано, Это в основном представляет информацию, которая может быть классифицирована в классификации. Примером является количество голов в 100 монетах.
Вы можете проверить, задав следующие два вопроса, имеете ли вы дело с дискретными данными или нет: можете ли вы считать их и можно ли разделить на меньшие и меньшие части?
Непрерывные данные представляют измерения и, следовательно, их значенияне могут быть подсчитаны, но они могут быть измерены, Примером может служить рост человека, который можно описать с помощью интервалов в строке действительных чисел.
Интервальные данные
Интервальные значения представляютупорядоченные единицы, которые имеют одинаковую разницу, Поэтому мы говорим об интервальных данных, когда у нас есть переменная, которая содержит числовые значения, которые упорядочены, и где мы знаем точные различия между значениями. Примером может служить функция, которая содержит температуру определенного места, как вы можете видеть ниже:
Проблема с данными интервальных значений заключается в том, что онине имеют «истинного нуля», Для нашего примера это означает, что нет такой вещи, как отсутствие температуры. С помощью интервальных данных мы можем складывать и вычитать, но мы не можем умножать, делить или вычислять отношения. Поскольку истинного нуля нет, множество описательной и логической статистики не может быть применено.
Соотношение данных
Значения отношения также являются упорядоченными единицами, которые имеют одинаковую разницу. Соотношение значенийтакие же как интервальные значения, с той разницей, что они имеют абсолютный ноль, Хорошие примеры: рост, вес, длина и т. Д.
Соотношение значенийтакие же как интервальные значения, с той разницей, что они имеют абсолютный ноль, Хорошие примеры: рост, вес, длина и т. Д.
Типы данных являются важной концепцией, потому что статистические методы могут использоваться только с определенными типами данных. Вы должны анализировать непрерывные данные иначе, чем категориальные данные, иначе это приведет к неправильному анализу. Поэтому, зная типы данных, с которыми вы имеете дело, вы сможете выбрать правильный метод анализа.
Теперь мы снова рассмотрим каждый тип данных, но на этот раз в отношении того, какие статистические методы можно применять Чтобы правильно понять, что мы сейчас будем обсуждать, вы должны понимать основы описательной статистики. Если вы их не знаете, вы можете прочитать мой пост в блоге (прочитано 9 минут):https://towardsdatascience.com/intro-to-descriptive-statistics-252e9c464ac9,
Когда вы имеете дело с номинальными данными, вы собираете информацию посредством:
частотыЧастота — это частота, с которой что-либо происходит в течение определенного периода времени или в наборе данных.
доля: Вы можете легко рассчитать пропорцию, разделив частоту на общее количество событий. (например, как часто что-то происходило, деленное на то, как часто это могло происходить)
Процент.
Методы визуализации: для визуализации номинальных данных вы можете использовать круговую диаграмму или гистограмму.
В Data Science вы можете использовать одно горячее кодирование для преобразования номинальных данных в числовую функцию.
Когда вы имеете дело с порядковыми данными, вы можете использовать те же методы, что и с номинальными данными, но у вас также есть доступ к некоторым дополнительным инструментам. Поэтому вы можете суммировать ваши порядковые данные с частотами, пропорциями, процентами. И вы можете визуализировать это с помощью круговой диаграммы и гистограммы. Кроме того, вы можете использовать процентили, медианы, моды и межквартильный диапазон, чтобы суммировать ваши данные.
В Data Science вы можете использовать одну метку кодирования, чтобы преобразовать порядковые данные в числовую функцию.
Когда вы имеете дело с непрерывными данными, вы можете использовать большинство методов для описания ваших данных. Вы можете суммировать свои данные, используя процентили, медиану, межквартильный диапазон, среднее значение, режим, стандартное отклонение и диапазон.
Методы визуализации:
Для визуализации непрерывных данных вы можете использовать гистограмму или блок-график. С помощью гистограммы вы можете проверить центральную тенденцию, изменчивость, модальность и эксцесс распределения. Обратите внимание, что гистограмма не может показать вам, если у вас есть какие-либо выбросы. Вот почему мы также используем боксы.
В этом посте вы обнаружили разные типы данных, которые используются в статистике. Вы узнали разницу между дискретными и непрерывными данными и узнали, каковы номинальные, порядковые, интервальные и относительные шкалы измерения. Кроме того, теперь вы знаете, какие статистические измерения вы можете использовать, для какого типа данных и какие методы визуализации являются правильными. Вы также узнали, какими методами категориальные переменные можно преобразовать в числовые переменные. Это позволяет вам создавать большую часть аналитического анализа для данного набора данных.
Вы также узнали, какими методами категориальные переменные можно преобразовать в числовые переменные. Это позволяет вам создавать большую часть аналитического анализа для данного набора данных.
Этот пост изначально был опубликован в моем блоге (https://machinelearning-blog.com).
Оригинальная статья
404 Cтраница не найдена
Системы измерений – значения и что они обозначают—ArcMap
Доступно с лицензией Spatial Analyst.
Тип используемой системы измерения может оказать значительное влияние на интерпретацию полученных значений. Расстояние в 20 километров вдвое превышает расстояние в 10 километров, а что-либо, весящее 100 фунтов является 1/3 от чего-либо, весящего 300 фунтов. Но победитель гонки необязательно прошел дистанцию в три раза быстрее, чем занявший третье место, почва, имеющая кислотность pH 6, не в два раза кислее, чем почва с pH 6. Продолжая сравнение, человек, которому 60 лет, вдвое старше человека, которому 30. Но, человек 60 лет может быть вдвое старше 30-летного только один раз в жизни.
Смысл этого обсуждения числовых значений – показать, что не все значения можно обрабатывать одинаково. Важно знать тип используемой в наборе растровых данных системы измерений, чтобы применить соответствующие операторы и функции и получить предсказуемый результат. Значения измерений можно разделить на четыре типа: относительные, интервальные, порядковые и номинальные.
Значения измерений можно разделить на четыре типа: относительные, интервальные, порядковые и номинальные.
Дополнительный модуль Spatial Analyst не делает различия между этими четырьмя различными типами измерений при обработке значений. Большинство математических операций хорошо работают с относительными значениями, но если интервальные, порядковые или номинальные значения умножаются, делятся или возводятся в степень, полученные результаты, как правило, не имеют смысла. С другой стороны, вычитание, сложение и Булевы вычисления могут использоваться с интервальными и порядковыми значениями. Обработка атрибутивных значений внутри и между наборами растровых данных наиболее эффективна при использовании номинальных измерений.
Относительные
Эти значения являются относительными к фиксированной нулевой точке на линейной шкале. С такими значениями можно использовать математические операторы, что позволяет получать предсказуемые и значащие результаты. Примерами таких измерений являются возраст, расстояние, вес и объем.
Интервальные
Время дня, даты, температурная шкала Фаренгейта и значения pH являются примерами интервальных измерений. Это значения калиброванной линейной шкалы, но они не являются относительными к истинной нулевой точке во времени или пространстве. Поскольку истинная нулевая точка отсутствует, между этими значениями можно проводить относительные сравнения, но определение отношений или пропорций не рекомендуется.
Пример интервальных измеренийПорядковые
Порядковые значения определяют положение. Эти измерения используются для отображения расположения, например, первое, второе или третье, но они не содержат величин или относительных пропорций. Порядковые значения не могут показать, насколько лучше, хуже, сильнее или слабее та или иная вещь или явление. Например, бегун, первый пришедший к финишу, вряд ли бежал вдвое быстрее, чем бегун, пришедший к финишу вторым. Зная победителей только по местам, которые они заняли, вы не сможете определить, насколько быстрее бежал первый по сравнению со вторым.
Номинальные
Значения этой системы измерений используются для отделения одних явлений от других. Также они могут определять группы, классы, членство или категории, с которыми ассоциирован данный объект. Эти значения являются качественными, не количественными, и не имеют привязки к фиксированной точке или к линейной шкале. Коды землепользования, типы почв и другие атрибуты рассматриваются как номинальные значения. Другие номинальные значения – это номер ИНН, почтовый индекс и телефонный номер.
Пример номинальных значенийСравнение дискретных и непрерывных данных
Значения ячеек могут также подразделяться на значения, отображающие дискретные или непрерывные данные.
Дискретные данные
Дискретные данные, иногда называющиеся данными категорий, чаще всего используются для отображения объектов. Эти объекты обычно относятся к классу (например, тип почв), категории (тип землепользования) или к группе (политической партии). Объект категории имеет четко определенные границы.
Как правило, в наборе дискретных растровых данных с каждой ячейкой связано целочисленное значение. Большинство целочисленных наборов растровых данных может иметь таблицу, содержащую дополнительную атрибутивную информацию. Значения с плавающей точкой могут использоваться для отображения дискретных данных, но в довольно редких случаях.
Дискретные данные лучше всего отображаются с использованием порядковых или номинальных значений.
Непрерывные данные
Непрерывный набор растровых данных или поверхность может отображаться в виде растра, использующего значения с плавающей точкой, а иногда – целочисленные значения. Значение каждой ячейки набора данных зависит от фиксированной точки (например, уровень моря), направления или расстояния до явления, и использует особую систему измерений (например, шум аэропорта измеряется в децибелах). Примерами непрерывных поверхностей являются высоты, экспозиции, уклоны, уровень радиации вокруг АЭС, концентрация соли вокруг солончака.
Наборы растровых данных с плавающей точкой не имеют связанной с ними таблицы, поскольку все или почти все значения ячеек являются уникальными, и сама природа непрерывных данных исключает использование связанных атрибутов.
Непрерывные данные лучше всего отображаются с использованием коэффициентов и интервальных значений.
Часто, при попытке комбинирования дискретных и непрерывных данных получаются бессмысленные результаты, например, при добавлении кодов землепользования (дискретные данные) к поверхности высот (непрерывные данные). В получившемся наборе растровых данных значение 104 является суммой кода землепользования 4 и высоты 100 метров.
Связанные разделы
Маркетинговые исследования с применением SPSS
1.1 Подготовка данных к анализу
Анализ маркетинговой информации с применением программы SPSS включает выполнение следующих необходимых шагов, представленных на рисунке 1.1:
Рисунок 1.1 — Анализ данных с применением программы SPSS
1.2 Структура редактора данных
Вверх
Файл исходной базы данных для проведения анализа в SPSS формируется в редакторе данных (Data Editor). Редактор данных имеет две вкладки: «Переменные» (Variable View) и «Данные» (Date View). Вкладки представляют собой таблицы, содержащие информацию о данных, собранных для проведения анализа.
Во вкладке «Переменные» представлена таблица с данными, котрые описывают свойства переменных. Каждая строка отображает переменную (вопрос анкеты), каждый столбец — ее свойства.
В столбце «Имя» (Name) записывают имя переменной — это может быть номер или часть вопроса в анкете.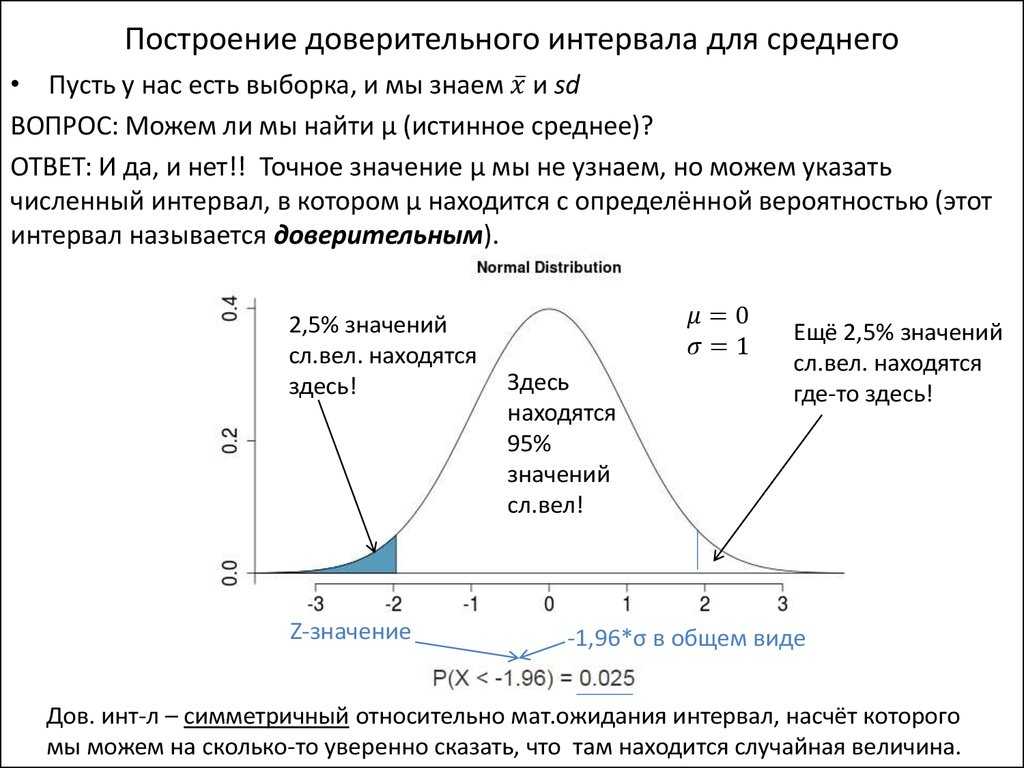 Например, переменная «пол», «занятость», «марка». Имя переменной не является произвольным, оно может содержать буквы
латинского алфавита и цифры, а также некоторые символы: $, #. Длина имени не более 64 знаков. Не допускаются пробелы и буквы других алфавитов. Имя переменной должно начинаться с буквы и не может заканчиваться знаком
подчеркивания «__» и точкой.
Например, переменная «пол», «занятость», «марка». Имя переменной не является произвольным, оно может содержать буквы
латинского алфавита и цифры, а также некоторые символы: $, #. Длина имени не более 64 знаков. Не допускаются пробелы и буквы других алфавитов. Имя переменной должно начинаться с буквы и не может заканчиваться знаком
подчеркивания «__» и точкой.
В столбце «Тип» (Туре) задается тип переменной; текущим типом является числовой (Numeric). В подавляющем большинстве случаев лучше иметь дело с числовыми переменными. Если требуется изменить тип переменной, нужно нажать на кнопку «Тип переменной» (Van ible Type).
В столбце «Ширина» (Width) задается максимальное количество знаков, которые может иметь переменная, включая дробную часть.
В столбце «Десятичные» (Decimal) выбирается количество десятичных знаков после запятой, в случае если тип переменной допускает использование дробных чисел.
В столбце «Метка» (Label) можно задать метку переменной. Метка используется для того, чтобы боле подробно отразить смысл переменной. Это своего рода комментарий к имени переменной. При задании меток переменных часто используются формулировки вопросов, содержащихся в анкете.
Метка используется для того, чтобы боле подробно отразить смысл переменной. Это своего рода комментарий к имени переменной. При задании меток переменных часто используются формулировки вопросов, содержащихся в анкете.
В столбце «Значения» (Values) отображаются значения меток переменных. В поле «Значения» указываются коды возможных вариантов ответа на этот вопрос. Для заполнения данного столбца необходимо произвести кодировку вариантов ответа. В диалоговом окне «Значение меток переменных» в поле «Значение» указываются числовые коды вариантов ответа, а в поле «Метка» — их формулировки.
В столбце «Пропущенные значения» (Missing) следует указать, какие коды вариантов ответов следует исключить из анализа. Например, отсутствие определенного ответа: «98» — не знаю, «99» — нет ответа.
В столбце «Столбцы» (Columns) таблицы «Переменные» указывается ширина столбца, содержащего значения соответствующей переменной в таблице другой вкладки редактора
данных: «Данные» (Date View). По умолчанию ширина столбца задается «8».
По умолчанию ширина столбца задается «8».
В столбце «Выравнивание» (Alignment задается положение кодов ответов в таблице «Значения переменных» во вкладке редактора данных «Данные». Они могут быть выровнены по правому краю (Right), по левому краю (Left) или по центру (Center). По умолчанию задается выравнивание по правому краю.
В столбце «Шкала измерения» (Measure) указывается тип шкалы, по которой измеряется переменная. По умолчанию задается метрическая шкала (Scale). В случае необходимости тип шкалы можно изменить
Основное правило создания файла данных в SPSS: переменные должны быть одновариантными, каждая переменная может иметь только одну метку. Таким образом, если вопрос может иметь несколько вариантов ответа каждого респондента, необходимо создать несколько одновариантных переменных (дихотомическая кодировка данных).
Например, на вопрос «Какую марку одежды Вы предпочитаете?» может быть закодирован следующим образом: «1» —предпочитаю, «0» — не предпочитаю. Следовательно,
ответы респондентов так, как показано в таблице 1.2.
Следовательно,
ответы респондентов так, как показано в таблице 1.2.
| Респонденты | Марка A | Марка B | Марка C |
|---|---|---|---|
| Респондент 1 | 1 | 0 | 1 |
| Респондент 2 | 0 | 1 | 1 |
| Респондент 3 | 0 | 1 | 1 |
| Респондент 4 | 1 | 0 | 1 |
Таблица 1.2 — Дихотомическая кодировка данных. Вопрос анкеты «Какую марку одежды Вы предпочитаете?»
Интервальные данные: определение, характеристики и примеры
Интервальные данные: определение?Интервальные данные, также называемые целыми числами, определяются как тип данных, которые измеряются по шкале, в которой все точки расположены на равном расстоянии друг от друга. Интервальные данные всегда отображаются в виде чисел или числовых значений, где расстояние между двумя точками стандартизировано и равно.
Интервальные данные нельзя умножать или делить, однако их можно складывать или вычитать.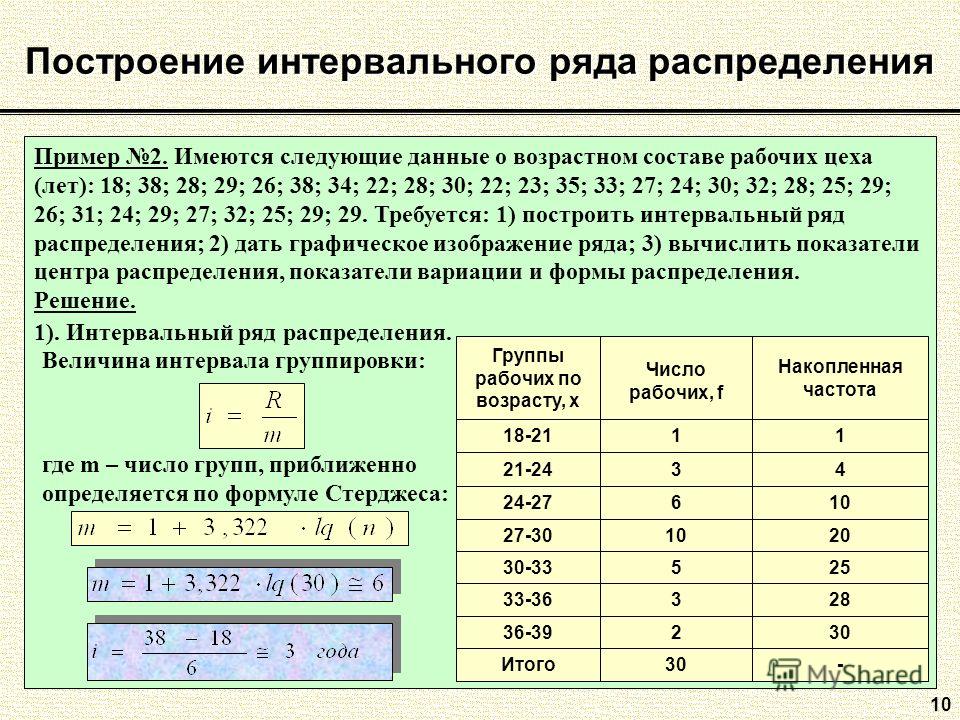 Интервальные данные измеряются по шкале интервалов. Простой пример интервальных данных: разница между 100 градусами по Фаренгейту и 90 градусов по Фаренгейту это то же самое, что 60 градусов по Фаренгейту и 70 градусов по Фаренгейту.
Интервальные данные измеряются по шкале интервалов. Простой пример интервальных данных: разница между 100 градусами по Фаренгейту и 90 градусов по Фаренгейту это то же самое, что 60 градусов по Фаренгейту и 70 градусов по Фаренгейту.
В исследованиях рынка или любых других формах социальных, экономических или бизнес-исследований интервальные данные играют ключевую роль. Что делает интервальные данные такими популярными и востребованными, так это то, что интервальные данные поддерживают почти все статистические тесты и преобразования при получении количественных данных.
Интервальные данные имеют очень отличительные признаки, которые отличают их от номинальных данных, порядковых данных или даже данных отношений. Интервальные данные не имеют определенной абсолютной нулевой точки, которая присутствует в данных соотношения. Отсутствие абсолютной нулевой точки делает невозможным сравнение прямых величин. Например, объект A в два раза больше, чем объект B, что невозможно в интервальных данных.
Подробнее: Шкалы переменных измерений — номинальная, порядковая, интервальная и относительная.
Интервальный анализ данныхПоскольку интервальные данные относятся к типу количественных данных, можно использовать почти все методы, используемые для количественного анализа. Вот несколько примеров:
1. Анализ трендов
Анализ трендов — это популярный метод интервального анализа данных, используемый для выявления трендов и выводов путем сбора данных опроса за определенный период времени. Другими словами, анализ тенденций в интервальных данных проводится путем сбора данных с использованием опроса по интервальной шкале в нескольких итерациях с использованием одного и того же вопроса.
2. SWOT-анализ
Анализ, проводимый для оценки сильных и слабых сторон организации, возможностей и угроз, называется SWOT-анализом и широко используется для оценки интервальных данных. Сильные и слабые стороны являются внутренними аспектами организации, тогда как возможности и угрозы являются внешними по отношению к организации. Организация может измерять интервальные данные для оценки рыночной конкуренции, а также планировать будущие маркетинговые мероприятия, используя результаты SWOT-анализа.
Организация может измерять интервальные данные для оценки рыночной конкуренции, а также планировать будущие маркетинговые мероприятия, используя результаты SWOT-анализа.
3. Совместный анализ
Совместный анализ — это метод исследования рынка продвинутого уровня, обычно применяемый для анализа того, как люди принимают сложные решения в интервальной шкале. Какие факторы важны для клиентов, прежде чем они примут решение, когда в их распоряжении есть несколько вариантов.
4. Анализ TURF
Анализ TURF расшифровывается как Totally Unduplicated Reach and Frequency analysis — это метод, который позволяет маркетологу анализировать потенциал исследования рынка для комбинации продуктов и услуг. Он оценивает интервальные данные о клиентах, достигших определенного источника связи, и его частоту. Этот метод анализа используется исследователями, чтобы понять, будет ли новый продукт или услуга хорошо воспринята на целевом рынке или нет. Этот метод анализа в основном использовался для разработки кампаний в СМИ, но его расширили до использования в распределении продуктов и анализе ассортимента.
Сбор и анализ интервальных данных с помощью опросов
Получите бесплатную учетную запись сейчас
Основные характеристики интервальных данныхВот несколько характеристик интервальных данных:
1. Можно измерять время в течение дня, используя 12-часовые часы, это хороший пример интервальных данных. Время в 12-часовом формате представляет собой вращательную меру, которая постоянно перезапускается с нуля с заданной периодичностью. Эти числа находятся на шкале интервалов, поскольку расстояние между ними измеримо и сравнимо. Например, разница между 5 минутами и 10 минутами такая же, как 15 минут и 20 минут в 12-часовом формате.
2. Температура измеряется в градусах Фаренгейта и Цельсия, но не в градусах Кельвина. Если вы измеряете температуру в градусах Фаренгейта и Цельсия, то она будет считаться интервальной, так как 0 является произвольным. Но в Кельвине 0 является абсолютным. Не может быть температуры ниже нуля градусов по Кельвину.
3. При подсчете баллов интеллекта в тесте IQ. Нет нулевой точки для IQ. Согласно психологическим исследованиям, у человека не может быть нулевого интеллекта, поэтому в данном примере ноль условен. IQ — это числовые данные, выраженные в интервалах с использованием фиксированной шкалы измерения.
IQ — это числовые данные, выраженные в интервалах с использованием фиксированной шкалы измерения.
4. Результаты таких экзаменов, как SAT. Баллы в тесте SAT находятся в диапазоне 200-800. Числа от 0 до 200 не используются, когда они сопоставляют необработанную оценку (количество вопросов, на которые даны правильные ответы) с оценкой раздела. Контрольная точка не является абсолютным нулем, поэтому она может стать интервальной.
5. Возраст также является переменной, которую можно измерить по интервальной шкале. Например, если А 15 лет, а В 20 лет, то не только ясно, что В старше А, но и В старше А на 5 лет.
Интервальные данные — один из наиболее часто используемых типов данных. Инструменты опроса предлагают несколько способов получения интервальных данных. Когда опрос развернут к респонденту с определенным демографическим вопросом, который просит респондентов указать свой доход, эти цифры могут варьироваться от нуля до бесконечности!
Например:
Укажите свой годовой доход
Числовые данные, собранные таким образом, можно разделить на группы, в приведенных выше примерах группы могут основываться на годовом доходе респондентов. Люди, подпадающие под категорию с одинаковым доходом.
Существует несколько типов вопросов опроса, которые можно использовать для создания интервальных данных. Полученные данные богаты идеями, но исследователь должен тщательно все обдумать, прежде чем использовать их в опросе.
Сбор и анализ интервальных данных с помощью опросов
Получите бесплатную учетную запись сейчас
Данные + Дизайн
Данные + Дизайн ОткрытымЗакрыть
Простое введение в подготовку и визуализацию информации
Глава 1
Майкл Кастелло
Существует несколько различных основных типов данных, и важно знать, что вы можете делать с каждым из них, чтобы собирать данные в форме, наиболее подходящей для ваших нужд. Люди описывают типы данных по-разному, но в первую очередь мы будем использовать уровни измерения, известные как номинальный, порядковый, интервальный и относительный.
Люди описывают типы данных по-разному, но в первую очередь мы будем использовать уровни измерения, известные как номинальный, порядковый, интервальный и относительный.
Уровни измерения
Допустим, вы отправились в продуктовый магазин. Вы перемещаетесь между разделами магазина, помещая товары в свою корзину. Вы берете свежие продукты, молочные продукты, замороженные продукты и консервы. Если бы вы составили список, указывающий, из какого отдела магазина поступил каждый товар, эти данные относились бы к номинальному типу. Термин «номинальный» связан с латинским словом «nomen», что означает «относящийся к именам». мы называем эти данные номинальными данными, потому что они состоят из именованных категорий, в которые попадают данные. Номинальные данные по своей природе неупорядочены; продукты как общая категория математически не больше и не меньше, чем молочные продукты.
Номинал
Номинальные данные можно подсчитывать и использовать для расчета процентов, но нельзя брать среднее значение номинальных данных. Имеет смысл говорить о том, сколько продуктов в вашей корзине из молочного отдела или какой процент составляют продукты, но вы не можете подсчитать средний продуктовый отдел вашей корзины.
Имеет смысл говорить о том, сколько продуктов в вашей корзине из молочного отдела или какой процент составляют продукты, но вы не можете подсчитать средний продуктовый отдел вашей корзины.
Когда доступны только две категории, данные называются дихотомическими. Ответы на вопросы «да/нет» представляют собой дихотомические данные. Если во время совершения покупок вы собирали данные о том, продается товар или нет, это будет дихотомия.
Порядковый номер
Наконец, вы подходите к кассе и пытаетесь решить, какая очередь быстрее выведет вас из магазина. На самом деле, не считая, сколько людей стоит в каждой очереди, вы грубо разбиваете их в уме на короткие, средние и длинные очереди. Поскольку такие данные имеют естественный порядок категорий, они называются порядковыми данными. Вопросы опроса, которые имеют такие шкалы ответов, как «полностью не согласен», «не согласен», «нейтрально», «согласен», «полностью согласен», собирают порядковые данные. Ни одна категория в порядковой шкале не имеет истинного математического значения. Номера часто присваиваются категориям, чтобы облегчить ввод или анализ данных (например, 1 = категорически не согласен, 5 = полностью согласен), но эти присвоения произвольны, и вы можете выбрать любой набор упорядоченных чисел для представления групп. Например, вы можете так же легко решить, что 5 означает «полностью не согласен», а 1 — «полностью согласен».
Номера часто присваиваются категориям, чтобы облегчить ввод или анализ данных (например, 1 = категорически не согласен, 5 = полностью согласен), но эти присвоения произвольны, и вы можете выбрать любой набор упорядоченных чисел для представления групп. Например, вы можете так же легко решить, что 5 означает «полностью не согласен», а 1 — «полностью согласен».
Числа, которые вы выбираете для представления порядковых категорий, изменяют способ интерпретации вашего конечного анализа, но вы можете выбрать любой набор, какой пожелаете, если вы соблюдаете порядок чисел.
Чаще всего в качестве начальной точки используется 0 или 1.
Как и номинальные данные, вы можете подсчитывать порядковые данные и использовать их для расчета процентов, но есть некоторые разногласия по поводу того, можно ли усреднять порядковые данные. С одной стороны, вы не можете усреднять именованные категории, такие как «полностью согласен», и даже если вы присваиваете числовые значения, они не имеют истинного математического смысла. Каждое числовое значение представляет определенную категорию, а не количество чего-либо.
Каждое числовое значение представляет определенную категорию, а не количество чего-либо.
С другой стороны, если предполагается, что разница в степени между последовательными категориями на шкале примерно равна (например, разница между категорически не согласен и не согласен такая же, как между несогласием и нейтральным и т. д.) и используются последовательные числа для представления категорий, то среднее значение ответов также можно интерпретировать по той же шкале.
В некоторых полях настоятельно не рекомендуется использовать порядковые данные для подобных расчетов, в то время как другие считают это обычной практикой. Вы должны посмотреть на другие работы в вашей области, чтобы увидеть, каковы обычные процедуры.Интервал
На данный момент достаточно порядковых данных… назад в магазин! Вы стоите в очереди, кажется, некоторое время, и вы смотрите на часы, чтобы узнать время. Вы встали в очередь в 11:15, а сейчас 11:30. Время суток относится к классу данных, называемых интервальными данными, названными так потому, что интервал между каждой последовательной точкой измерения равен всем другим. Поскольку каждая минута равна шестидесяти секундам, разница между 11:15 и 11:30 имеет такое же значение, как разница между 12:00 и 12:15.
Поскольку каждая минута равна шестидесяти секундам, разница между 11:15 и 11:30 имеет такое же значение, как разница между 12:00 и 12:15.
Интервальные данные являются числовыми, и вы можете выполнять с ними математические операции, но они не имеют «значащей» нулевой точки, то есть значение нуля не указывает на отсутствие того, что вы измеряете. 0:00 утра — это не отсутствие времени, это просто означает начало нового дня. Другими интервальными данными, с которыми вы сталкиваетесь в повседневной жизни, являются календарные годы и температура. Нулевое значение года не означает, что до этого времени не существовало, а нулевая температура (при измерении в градусах Цельсия или Фаренгейта) не означает отсутствия тепла.
Соотношение
Увидев, что время 11:30, думаешь про себя: «Я уже пятнадцать минут в очереди…???» Когда вы начинаете думать о времени таким образом, это считается относительными данными. Данные отношения являются числовыми и очень похожи на данные интервала, за исключением того, что имеет значащую нулевую точку. В данных соотношения значение нуля указывает на отсутствие того, что вы измеряете, — ноль минут, ноль людей в очереди, ноль молочных продуктов в вашей корзине. Во всех этих случаях ноль на самом деле означает, что у вас нет ничего из этого, что отличается от данных, которые мы обсуждали в разделе об интервалах. Некоторые другие часто встречающиеся переменные, которые часто записываются как данные соотношения, — это рост, вес, возраст и деньги.
В данных соотношения значение нуля указывает на отсутствие того, что вы измеряете, — ноль минут, ноль людей в очереди, ноль молочных продуктов в вашей корзине. Во всех этих случаях ноль на самом деле означает, что у вас нет ничего из этого, что отличается от данных, которые мы обсуждали в разделе об интервалах. Некоторые другие часто встречающиеся переменные, которые часто записываются как данные соотношения, — это рост, вес, возраст и деньги.
Интервальные и относительные данные могут быть дискретными или непрерывными. Дискретность означает, что вы можете иметь только определенные количества измеряемой вами вещи (обычно целые числа) и никаких значений между этими количествами. В очереди должно быть целое количество людей; не может быть трети лица. У вас может быть 90 167 в среднем 90 168, скажем, 4,25 человека на строку, но фактическое количество людей должно быть целым числом. Непрерывный означает, что данные могут иметь любое значение по шкале. Вы можете купить 1,25 фунта сыра или стоять в очереди 7,75 минут. Это не означает, что данные должны принимать все возможные числовые значения — только все значения в пределах шкалы. Вы не можете стоять в очереди отрицательное количество времени и не можете покупать отрицательное количество фунтов сыра, но они все еще непрерывны.
Это не означает, что данные должны принимать все возможные числовые значения — только все значения в пределах шкалы. Вы не можете стоять в очереди отрицательное количество времени и не можете покупать отрицательное количество фунтов сыра, но они все еще непрерывны.
Для ознакомления давайте взглянем на чек из магазина. Можете ли вы определить, какие элементы информации измеряются на каждом уровне (номинальный, порядковый, интервальный и относительный)?
| Дата: 01.06.2014 Время: 11:32 | ||||
|---|---|---|---|---|
| Товар | Раздел | Проход | Количество | Стоимость (долл. США) |
| Апельсины — фунты | Продукт | 4 | 2 | 2,58 |
| Яблоки — фунты | Продукт | 4 | 1 | 1,29 |
| Моцарелла — фунты | Молочная | 7 | 1 | 3,49 |
| Молоко — обезжиренное — галлон | Молочная | 8 | 1 | 4,29 |
| Горох — пакет | Замороженный | 15 | 1 | 0,99 |
| Зеленая фасоль — пакет | Замороженный | 15 | 3 | 1,77 |
| Помидоры | Консервы | 2 | 4 | 3,92 |
| Картофель | Консервы | 3 | 2 | 2,38 |
| Грибы | Консервы | 2 | 5 | 2,95 |
Тип переменной vs.
 Тип данных
Тип данныхЕсли вы посмотрите в Интернете или в учебниках информацию о данных, вы часто найдете переменные, описанные как один из перечисленных выше типов данных. Имейте в виду, что многие переменные не являются исключительно тем или иным типом данных. Что часто определяет тип данных, так это способ сбора данных.
Рассмотрим переменную age. Возраст часто собирается в виде данных об отношении, но также может собираться в виде порядковых данных. Это происходит в опросах, когда спрашивают: «К какой возрастной группе вы относитесь?» Там у вас не будет данных об индивидуальном возрасте вашего респондента — вы будете знать только, сколько из них находится в диапазоне 18–24, 25–34 и т. д. спросите, повышен ли у них уровень холестерина. Опять же, это одна переменная с двумя разными методами сбора данных и двумя разными типами данных.
Общее правило состоит в том, что вы можете опуститься на уровень измерения, но не подняться. Если есть возможность собрать переменную как интервальные или относительные данные, вы также можете собрать ее как номинальные или порядковые данные, но если переменная по своей природе является только номинальной, например, раздел продуктового магазина, вы не можете зафиксировать ее как порядковую, интервальную. или данные соотношения. Переменные, которые являются естественными порядковыми, не могут быть захвачены как данные интервала или отношения, но могут быть захвачены как номинальные. Однако многие переменные, которые записываются как порядковые, имеют аналогичную переменную, которая может быть захвачена как данные интервала или отношения, если вы того пожелаете.
или данные соотношения. Переменные, которые являются естественными порядковыми, не могут быть захвачены как данные интервала или отношения, но могут быть захвачены как номинальные. Однако многие переменные, которые записываются как порядковые, имеют аналогичную переменную, которая может быть захвачена как данные интервала или отношения, если вы того пожелаете.
| Тип порядкового уровня | Соответствующее измерение уровня интервала/отношения | Пример |
|---|---|---|
| Рейтинг | Измерение, на котором основывается ранжирование | Записывайте время бегунов на марафоне вместо того, на каком месте они финишируют |
| Сгруппированные весы | Само измерение | Укажите точный возраст вместо возрастной категории |
| Сменные весы | Исходное измерение шкалы было создано из | Запишите точный результат теста вместо буквенной оценки |
Важно помнить, что общее правило «вниз можно, но не вверх» действует и при анализе и визуализации ваших данных. Если вы собираете переменную как данные отношения, вы всегда можете позже решить сгруппировать данные для отображения, если это имеет смысл для вашей работы. Если вы соберете его как более низкий уровень измерения, вы не сможете вернуться позже, не собрав больше данных. Например, если вы решите собирать возраст как порядковые данные, вы не сможете вычислить средний возраст позже, и ваша визуализация будет ограничена отображением возраста по группам; у вас не будет возможности отображать его как непрерывные данные.
Если это не увеличивает нагрузку на сбор данных, вам следует собирать данные на самом высоком уровне измерения, который, по вашему мнению, может понадобиться позже. В работе с данными мало что разочаровывает так, как если вы собираетесь построить график или вычислить только для того, чтобы понять, что вы не собрали данные таким образом, чтобы вы могли сгенерировать то, что вам нужно!
Другие важные термины
Есть и другие термины, которые часто используются для обозначения типов данных. Мы решили не использовать их здесь, потому что есть некоторые разногласия по поводу их значений, но вы должны знать о них и о том, каковы их возможные определения на случай, если вы встретите их в других ресурсах.
Категориальные данные
Выше мы говорили как о номинальных, так и о порядковых данных как о разделении данных на категории. В некоторых текстах оба рассматриваются как типы категориальных данных, причем номинальные являются неупорядоченными категориальными данными, а порядковые — упорядоченными категориальными данными. Другие называют только номинальные данные категориальными и используют термины «номинальные данные» и «категориальные данные» как синонимы. Эти тексты просто называют порядковые данные «порядковыми данными» и вообще считают их отдельной группой.
Качественные и количественные данные
Качественные данные, грубо говоря, относятся к нечисловым данным, в то время как количественные данные обычно являются числовыми данными и, следовательно, поддаются количественному определению. В отношении этих терминов существует некоторый консенсус. Определенные данные всегда считаются качественными, поскольку для их анализа требуется предварительная обработка или другие методы, чем количественные данные. Примерами являются записи непосредственного наблюдения или стенограммы интервью. Точно так же данные об интервалах и отношениях всегда считаются количественными, поскольку они всегда являются числовыми. Разногласия возникают с номинальным и порядковым типами данных. Некоторые считают их качественными, поскольку их категории являются описательными, а не числовыми. Однако, поскольку эти данные могут быть подсчитаны и использованы для расчета процентов, некоторые считают их количественными, поскольку таким образом они поддаются количественному определению.
Во избежание путаницы в оставшейся части этой книги мы будем придерживаться вышеуказанного уровня терминов измерения, за исключением обсуждения полных качественных данных в главе, посвященной плану обследования. Если вы встретите термины «категориальные», «качественные данные» или «количественные данные» в других ресурсах или в своей работе, убедитесь, что вы знаете, какое определение используется, а не просто предполагаете!
Ввод данных с интервалом времени | Обзор ПК
JavaScript отключен. Для лучшего опыта, пожалуйста, включите JavaScript в вашем браузере, прежде чем продолжить.
Привет
У меня проблемы с макросом, который мне нужен. Мне нужен рабочий лист, который позволяет пользователям
вводить значение (от 1 до 5) с помощью клавиатуры, но только на определенных
временных интервалов. Например, каждые 2 минуты пользователь получает напоминание (мигающее текстовое поле
?) для ввода значения. затем значение вводится с клавиатуры
, и «мигающее напоминание» исчезает. Через 2 минуты то же самое, и
и так далее в течение заданного периода времени, пока у вас не будет списка номеров. Мои основные проблемы с
заключаются в том, что, хотя я могу «обойти» в VBA, я не могу понять, как:
а) получить повторяющееся мигающее сообщение-напоминание
б) заблокировать ввод данных между периодами ввода
c) позволить пользователю вводить данные во время работы макроса.
Базовый дизайн:
<интервал = 120 секунд>
start_time
интервал ожидания
выполнение задач active_time
интервал ожидания
выполнение задач active_time
и т.д…
до end_time
active_time tasks {
всплывающее окно сообщения (или поле ввода?)
разрешить пользователю вводить номер с клавиатуры
сохранить номер в списке
остановить быстрое окно сообщения
увеличить позицию ячейки, чтобы следующий ввод был в новой ячейке
}
Возможно ли это?
Я целую вечность бился над этим, но мои навыки программирования не дотягивают до
этого.
Спасибо
Конор
Реклама
Том Огилви
Посмотрите страницу Чипа Пирсона об использовании Application.Ontime. Макрос не
работает все время, так что это часть решения.
http://www.cpearson.com/excel/ontime.htm
Вы можете использовать код для защиты и снятия защиты листа (возможно).
Хотите ответить в этой теме или задать свой вопрос?
Вам нужно будет выбрать имя пользователя для сайта, что займет всего пару минут. После этого вы можете опубликовать свой вопрос, и наши участники помогут вам.
| ПОМОГИТЕ!! Макрос удаляет последний интервал | 4 | |
| странное поведение msgbox | 5 | |
| данные заполняются несколько раз через форму Excel | 5 | |
| Обновление значения в текстовом поле | 4 | |
| Дата Ввод через подсказку ввода | 9 | |
| Умножить выбранную ячейку на форму ввода | 1 | |
| 2 приятные просьбы | 3 | |
| Проверка данных для % ввода в userfom | 8 |
Делиться:
Фейсбук Твиттер Реддит Пинтерест Тамблер WhatsApp Эл. адрес Делиться Ссылка на сайт
Типы данных Weibull++
В Weibull++ существует два типа данных о сроке службы: данные о времени наработки на отказ и данные в произвольной форме. Кроме того, данные о времени наработки на отказ могут содержать три формы цензуры: приостановка, интервальная цензура или данные левой цензуры.
В фолио с данными о жизни Weibull++ тип данных, который вы выбираете, определяет столбцы ввода данных, которые появляются в листе данных. В следующих разделах описывается каждый тип данных и демонстрируется, как вводить данные в лист данных Weibull++ life data folio.
Совет. Вы можете изменить столбцы ввода данных для существующей таблицы данных Weibull++ в любое время, выбрав Life Data > Format and View > Alter Data Type.
Данные о времени до отказа
Наборы данных о времени до отказа, также известные как полные данные, получаются путем регистрации точного времени, когда блоки отказали. Например, если мы протестировали пять единиц, и все они отказали, и мы записали время, когда произошел каждый отказ, у нас была бы полная информация о времени каждого отказа в выборке.
Чтобы использовать этот тип данных, установите флажок Данные о времени до отказа в окне настройки. В вашем листе данных будет столбец «Время сбоя» для записи времени до отказа. В приведенном ниже примере показан лист данных фолио с данными о жизни, в котором все единицы в образце вышли из строя. Фиксируется точное время каждого отказа.
Примечание. В этом и остальных примерах столбец идентификатора подмножества используется в пояснительных целях и не предназначен для демонстрации того, как обычно используется этот столбец.
Если несколько устройств вышли из строя одновременно, вы можете ввести данные группами. Для этого установите флажок Я хочу вводить данные группами в окне настройки. Это добавит третий столбец в лист данных, как показано далее. В этом примере блоки, отказавшие одновременно, сгруппированы вместе. В столбце «Число в состоянии» указано количество неисправных устройств в этой группе (программа автоматически введет 1, если вы оставите эту ячейку пустой), а в столбце «Время окончания состояния» указано точное время отказа устройств в каждой группе.
Время до отказа с подвесками (правильные цензурированные данные)
Термин «подвеска» описывает блоки, которые не вышли из строя в течение периода наблюдения. Такие единицы также известны как данные с цензурой справа. Например, если мы протестировали пять устройств и только три из них вышли из строя к концу теста, наблюдаемое время работы двух устройств, которые не вышли из строя, будет называться цензурированными данными. Термин «цензура справа» означает, что интересующее событие (т. е. время до отказа) находится справа от нашей точки данных на шкале времени.
Чтобы использовать этот тип данных, установите флажок Данные о времени до отказа и флажок Мои данные содержат приостановки (данные с цензурой справа) в окне настройки. В вашем листе данных будет столбец «Состояние F» или «S» для записи того, является ли точка данных отказом (F) или приостановкой (S). В приведенном ниже примере было проведено испытание, и первые пять единиц в образце вышли из строя, но шестая установка все еще работала, когда испытание закончилось через 190 часов.
Совет. Если вы введете время как отрицательное число (например, -190), Weibull++ автоматически назначит его как приостановку. Эта экономящая время функция применяется только к таблицам данных, настроенным для поддержки цензурированных данных.
При вводе данных этого типа в группы блоки, находящиеся в одном и том же состоянии (т. е. неисправные или приостановленные) и имеющие одинаковое значение в столбце «Время окончания состояния», могут быть сгруппированы вместе, как показано ниже.
Время наработки на отказ с интервалом и цензурированными данными слева
Термин «данные с цензурой интервала» описывает неопределенность в отношении точного времени отказа блока в течение интервала. Этот тип данных часто поступает из тестов или ситуаций, когда устройства не контролируются постоянно. Например, если мы тестируем пять блоков и проверяем их каждые 100 часов, мы знаем только, что блок вышел из строя или не вышел из строя между проверками. В частности, если мы проверим определенный блок через 100 часов и обнаружим, что он работает, а затем проведем еще один осмотр через 200 часов и обнаружим, что блок больше не работает, то единственная информация, которую мы имеем, это то, что блок вышел из строя в какой-то момент времени. интервал от 100 до 200 часов.
Данные, подвергнутые цензуре слева, являются частным случаем данных, подвергнутых цензуре интервалов. В данных с левой цензурой интервал находится между временем = 0 и некоторым временем проверки.
Чтобы использовать этот тип данных, установите флажок Данные о времени до отказа и флажок Мой набор данных содержит интервальные и/или левые цензурированные данные в окне настройки. В приведенном ниже примере первый блок был проверен через 150 часов и оказался неисправным. Второй блок все еще работал в 150 часов, но в какой-то момент вышел из строя до следующего наблюдения в 300 часов и так далее.
Примечание. Хотя в этом примере показан сценарий, в котором проверки происходят через регулярные запланированные интервалы, Weibull++ не требует, чтобы время начала интервала было равно времени окончания предыдущего интервала.
При групповом вводе данных этого типа все блоки, отказавшие в течение одного интервала, считаются частью одной группы.
Наработка до отказа со всеми типами цензурированных данных
Данные о наработке на отказ с различными типами цензуры можно добавить в один лист данных. Данные можно вводить группами или разгруппировать. Ниже приведен пример сгруппированного набора данных с полными, приостановленными, интервальными и оставленными цензурированными данными.
На следующем рисунке показаны различия между полными данными и различными типами подвергнутых цензуре данных.
Данные в произвольной форме (пробит)
Тип данных в произвольной форме используется для анализа взаимосвязи между независимой переменной (данные по оси X) и процентом отказов (данные по оси Y) в ответ на переменная. Данные по оси Y обрабатываются как единицы вероятности или пробиты, и они показывают, как процент отказов увеличивается в ответ на переменную (например, время, расстояние, уровень стресса и т. д.). Например, вы можете использовать тип данных произвольной формы для записи Y процентов автомобилей, которые потребуют ремонта через X миль, или Y процентов отказов продуктов при X градусах температуры.
Чтобы использовать этот тип данных, установите флажок Данные произвольной формы (пробит) в окне настройки. В таблице данных введите значения для независимой переменной в столбце значений по оси X и введите совокупный процент сбоев в столбце значений по оси Y. Ниже приведен пример набора данных, который показывает влияние времени (данные по оси X) на вероятность отказа (данные по оси Y) продукта.
Что такое сбор измененных данных (CDC)? — SQL-сервер
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL
В этой статье вы узнаете об изменении системы сбора данных (CDC), которая записывает действия в базе данных при изменении таблиц и строк. Сбор измененных данных обычно доступен в базе данных SQL Azure, SQL Server и Управляемом экземпляре SQL Azure.
Обзор
Система отслеживания измененных данных (CDC) использует агент SQL Server для записи операций вставки, обновления и удаления, которые применяются к таблице. Это делает сведения об изменениях доступными в удобном для использования реляционном формате. Информация о столбцах и метаданные, необходимые для применения изменений к целевой среде, фиксируются для измененных строк и сохраняются в таблицах изменений, которые отражают структуру столбцов отслеживаемых исходных таблиц. Табличные функции обеспечивают систематический доступ потребителей к данным об изменениях.
Хорошим примером потребителя данных, на которого нацелена эта технология, является приложение извлечения, преобразования и загрузки (ETL). Приложение ETL постепенно загружает данные об изменениях из исходных таблиц SQL Server в хранилище или киоск данных. Хотя представление исходных таблиц в хранилище данных должно отражать изменения в исходных таблицах, сквозная технология, которая обновляет реплику источника, не подходит. Вместо этого вам нужен надежный поток данных об изменениях, структурированный таким образом, чтобы потребители могли применять его к различным целевым представлениям данных. Эта технология реализована в системе сбора измененных данных SQL Server.
CDC и база данных SQL Azure
В базе данных SQL Azure планировщик сбора данных об изменениях заменяет агент SQL Server, который вызывает хранимые процедуры для запуска периодического сбора и очистки таблиц сбора данных об изменениях. Планировщик автоматически запускает захват и очистку в базе данных SQL, без какой-либо внешней зависимости для обеспечения надежности или производительности. Пользователи по-прежнему могут запускать захват и очистку вручную по требованию.
Чтобы узнать больше об отслеживании измененных данных, вы также можете обратиться к этому выпуску Data Exposed:
Вопросы производительности
Влияние на производительность включения отслеживания измененных данных в базе данных SQL Azure аналогично влиянию на производительность включения CDC для SQL Server или Управляемого экземпляра Azure SQL. Ниже приведены некоторые аспекты, влияющие на производительность включения CDC:
Чтобы предоставить клиентам более конкретные рекомендации по оптимизации производительности, необходимы дополнительные сведения о рабочей нагрузке каждого клиента. Однако ниже приведены некоторые дополнительные общие рекомендации, основанные на тестах производительности, проведенных при рабочей нагрузке TPCC:
Поток данных
На следующем рисунке показан основной поток данных для отслеживания измененных данных.
Источником данных об изменениях для сбора данных об изменениях является журнал транзакций SQL Server. Когда к отслеживаемым исходным таблицам применяются вставки, обновления и удаления, в журнал добавляются записи, описывающие эти изменения. Журнал служит входными данными для процесса захвата. Это считывает журнал и добавляет информацию об изменениях в связанную таблицу изменений отслеживаемой таблицы. Предоставляются функции для перечисления изменений, которые появляются в таблицах изменений в указанном диапазоне, возвращая информацию в виде отфильтрованного набора результатов. Отфильтрованный набор результатов обычно используется процессом приложения для обновления представления источника в некоторой внешней среде.
Экземпляр захвата
Прежде чем можно будет отслеживать изменения в каких-либо отдельных таблицах в базе данных, для базы данных необходимо явно включить отслеживание измененных данных. Это делается с помощью хранимой процедуры sys.sp_cdc_enable_db. Когда база данных включена, исходные таблицы можно идентифицировать как отслеживаемые с помощью хранимой процедуры sys.sp_cdc_enable_table. Когда таблица включена для сбора данных об изменениях, создается связанный экземпляр отслеживания для поддержки распространения данных об изменениях в исходной таблице. Экземпляр захвата состоит из таблицы изменений и до двух функций запроса. Метаданные, описывающие сведения о конфигурации экземпляра системы отслеживания, сохраняются в таблицах метаданных системы отслеживания измененных данных cdc.change_tables , cdc.index_columns и cdc.captured_columns . Эту информацию можно получить с помощью хранимой процедуры sys.sp_cdc_help_change_data_capture.
Все объекты, связанные с экземпляром отслеживания, создаются в схеме отслеживания измененных данных включенной базы данных. Требование к имени экземпляра отслеживания состоит в том, что оно должно быть допустимым именем объекта и уникальным для всех экземпляров отслеживания базы данных. По умолчанию имя < имя схемы _ имя таблицы > исходной таблицы. Связанная с ней таблица изменений называется путем добавления _CT к имени экземпляра захвата. Функция, которая используется для запроса всех изменений, называется путем добавления fn_cdc_get_all_changes_ к имени экземпляра отслеживания. Если экземпляр Capture настроен на поддержку net change , функция запроса net_changes также создается и именуется путем добавления fn_cdc_get_net_changes_ к имени экземпляра захвата.
Таблица изменений
Первые пять столбцов таблицы изменений сбора данных об изменениях являются столбцами метаданных. Они предоставляют дополнительную информацию, относящуюся к записанному изменению. Остальные столбцы отражают идентифицированные захваченные столбцы из исходной таблицы по имени и, как правило, по типу. Эти столбцы содержат захваченные данные столбца, собранные из исходной таблицы.
Каждая операция вставки или удаления, применяемая к исходной таблице, отображается в виде одной строки в таблице изменений. Столбцы данных строки, полученной в результате операции вставки, содержат значения столбца после вставки. Столбцы данных строки, полученной в результате операции удаления, содержат значения столбцов до удаления. Для операции обновления требуется запись в одной строке, чтобы идентифицировать значения столбца до обновления, и запись второй строки, чтобы идентифицировать значения столбца после обновления.
Каждая строка в таблице изменений также содержит дополнительные метаданные, позволяющие интерпретировать действия по изменению. Столбец __$start_lsn определяет порядковый номер журнала фиксации (LSN), присвоенный изменению. Номер LSN фиксации идентифицирует изменения, которые были зафиксированы в рамках одной и той же транзакции, и упорядочивает эти транзакции. Столбец __$seqval можно использовать для упорядочения дополнительных изменений, происходящих в одной и той же транзакции. В столбце __$operation записана операция, связанная с изменением: 1 = удалить, 2 = вставить, 3 = обновить (до изображения) и 4 = обновить (после изображения). Столбец __$update_mask представляет собой переменную битовую маску с одним определенным битом для каждого захваченного столбца. Для записей вставки и удаления в маске обновления всегда будут установлены все биты. Однако в строках обновления будут установлены только те биты, которые соответствуют измененным столбцам.
Интервал действия
Интервал действия системы отслеживания измененных данных для базы данных — это время, в течение которого данные об изменениях доступны для экземпляров системы отслеживания. Интервал действия начинается с момента создания первого экземпляра отслеживания для таблицы базы данных и продолжается до настоящего времени.
База данных
Данные, хранящиеся в таблицах изменений, будут неуправляемо расти, если вы не будете периодически и систематически удалять данные. Процесс очистки системы сбора измененных данных отвечает за применение политики очистки на основе хранения. Во-первых, он перемещает нижнюю конечную точку интервала достоверности, чтобы удовлетворить ограничение по времени. Затем он удаляет просроченные записи таблицы изменений. По умолчанию сохраняются данные за три дня.
На верхнем уровне, когда процесс захвата фиксирует каждый новый пакет данных об изменениях, новые записи добавляются в cdc.lsn_time_mapping для каждой транзакции, имеющей записи в таблице изменений. В таблице сопоставления сохраняются как порядковый номер журнала фиксации (LSN), так и время фиксации транзакции (столбцы start_lsn и tran_end_time соответственно). Максимальное значение LSN, найденное в cdc.lsn_time_mapping , представляет собой верхнюю границу окна достоверности базы данных. Соответствующее время фиксации используется в качестве базы, на основе которой очистка на основе удержания вычисляет новую нижнюю отметку.
Поскольку процесс захвата извлекает данные об изменениях из журнала транзакций, существует встроенная задержка между моментом фиксации изменения в исходной таблице и моментом появления изменения в связанной с ним таблице изменений. Хотя эта задержка обычно невелика, тем не менее важно помнить, что данные об изменениях недоступны до тех пор, пока процесс захвата не обработает соответствующие записи журнала.
Экземпляр Capture
Хотя период действия базы данных и интервал действия отдельного экземпляра Capture часто совпадают, это не всегда так. Интервал действия экземпляра отслеживания начинается, когда процесс захвата распознает экземпляр отслеживания и начинает регистрировать связанные изменения в его таблице изменений. В результате, если экземпляры захвата создаются в разное время, у каждого из них изначально будет своя нижняя конечная точка. Столбец start_lsn результирующего набора, возвращаемого sys.sp_cdc_help_change_data_capture, показывает текущую нижнюю конечную точку для каждого определенного экземпляра отслеживания. Когда процесс очистки очищает записи таблицы изменений, он корректирует значения start_lsn для всех экземпляров отслеживания, чтобы отразить новую нижнюю отметку для доступных данных об изменениях. Корректируются только те экземпляры захвата, значения start_lsn которых в настоящее время меньше новой нижней отметки. Со временем, если новые экземпляры захвата не создаются, интервалы действия для всех отдельных экземпляров будут иметь тенденцию совпадать с интервалом действия базы данных.
Интервал действия важен для потребителей данных об изменениях, поскольку интервал извлечения для запроса должен полностью покрываться текущим интервалом действия системы отслеживания измененных данных для экземпляра системы отслеживания. Если нижняя конечная точка интервала извлечения находится слева от нижней конечной точки интервала достоверности, данные об изменениях могут отсутствовать из-за агрессивной очистки. Если верхняя конечная точка интервала извлечения находится справа от верхней конечной точки интервала достоверности, процесс захвата еще не обрабатывался в течение периода времени, представленного интервалом извлечения, и данные об изменениях также могут отсутствовать.
Функция sys. fn_cdc_get_min_lsn используется для получения текущего минимального номера LSN для экземпляра отслеживания, а функция sys.fn_cdc_get_max_lsn используется для получения текущего максимального значения LSN. При запросе данных об изменениях, если указанный диапазон LSN не находится в пределах этих двух значений LSN, функции запроса отслеживания данных об изменениях завершатся ошибкой.
Обработка изменений в исходной таблице
Приспособление к изменениям столбцов в отслеживаемых исходных таблицах является сложной задачей для нижестоящих потребителей. Хотя включение отслеживания измененных данных в исходной таблице не предотвращает такие изменения DDL, сбор измененных данных помогает смягчить их влияние на потребителей, позволяя доставляемым наборам результатов, которые возвращаются через API, оставаться неизменными даже при изменении структуры столбцов таблицы. основные изменения исходной таблицы. Эта фиксированная структура столбца также отражается в базовой таблице изменений, к которой обращаются определенные функции запросов.
Чтобы приспособить фиксированную таблицу изменений структуры столбцов, процесс отслеживания, ответственный за заполнение таблицы изменений, будет игнорировать любые новые столбцы, которые не определены для сбора, когда исходная таблица была включена для отслеживания измененных данных. Если отслеживаемый столбец удален, для него в последующих записях изменений будут предоставлены нулевые значения. Однако если в существующем столбце изменяется тип данных, это изменение распространяется на таблицу изменений, чтобы гарантировать, что механизм захвата не приведет к потере данных в отслеживаемых столбцах. Процесс захвата также отправляет любые обнаруженные изменения в структуре столбцов отслеживаемых таблиц в таблицу cdc.ddl_history. Потребители, желающие получать уведомления о корректировках, которые могут потребоваться для последующих приложений, используют хранимую процедуру sys.sp_cdc_get_ddl_history.
Как правило, текущий экземпляр системы отслеживания продолжает сохранять свою форму, когда изменения DDL применяются к связанной с ним исходной таблице. Однако для таблицы можно создать второй экземпляр отслеживания, отражающий новую структуру столбцов. Это позволяет процессу захвата вносить изменения в одну и ту же исходную таблицу в две отдельные таблицы изменений, имеющие две разные структуры столбцов. Таким образом, в то время как одна таблица изменений может продолжать питать текущие рабочие программы, вторая может управлять средой разработки, которая пытается включить данные нового столбца. Разрешение механизму захвата одновременно заполнять обе таблицы изменений означает, что переход от одной к другой может быть выполнен без потери данных об изменениях. Это может произойти в любое время, когда две временные шкалы сбора измененных данных перекрываются. Когда переход затрагивается, устаревший экземпляр захвата может быть удален.
Примечание
Максимальное количество экземпляров системы отслеживания, которые могут быть одновременно связаны с одной исходной таблицей, равно двум.
Связь с агентом чтения журнала
Логика процесса сбора измененных данных встроена в хранимую процедуру sp_replcmds, внутреннюю функцию сервера, созданную как часть sqlservr. exe и также используемую репликацией транзакций для сбора изменений из журнала транзакций. В SQL Server и Управляемом экземпляре SQL Azure, когда для базы данных включена только система отслеживания измененных данных, вы создаете задание сбора измененных данных агента SQL Server в качестве средства для вызова процедуры sp_replcmds. Когда репликация также присутствует, только средство чтения журнала транзакций используется для удовлетворения потребностей в данных об изменениях для обоих этих потребителей. Эта стратегия значительно снижает количество конфликтов в журналах, когда для одной и той же базы данных включены и репликация, и система отслеживания измененных данных.
Переключение между этими двумя рабочими режимами для сбора данных об изменениях происходит автоматически всякий раз, когда происходит изменение состояния репликации базы данных с включенным отслеживанием измененных данных.
Примечание
В SQL Server и Управляемом экземпляре Azure SQL оба экземпляра логики захвата требуют, чтобы агент SQL Server работал для выполнения процесса.
Основной задачей процесса сбора данных является сканирование журнала и запись данных столбцов и информации, связанной с транзакциями, в таблицы изменений сбора данных об изменениях. Чтобы обеспечить согласованную с транзакциями границу для всех заполняемых им таблиц изменений системы отслеживания данных об изменениях, процесс регистрации открывает и фиксирует собственную транзакцию в каждом цикле сканирования. Он определяет, когда в таблицах вновь включается сбор данных об изменениях, и автоматически включает их в набор таблиц, которые активно отслеживаются на наличие записей об изменениях в журнале. Точно так же будет обнаружено отключение отслеживания измененных данных, в результате чего исходная таблица будет удалена из набора таблиц, активно отслеживаемых на наличие измененных данных. Когда обработка раздела журнала завершена, процесс захвата сигнализирует логике усечения журнала сервера, которая использует эту информацию для определения записей журнала, подходящих для усечения.
Примечание
Если для базы данных включена система отслеживания измененных данных, даже если для режима восстановления задано простое восстановление, точка усечения журнала не будет продвигаться вперед, пока все изменения, помеченные для сбора, не будут собраны процессом отслеживания. Если процесс захвата не запущен и есть изменения, которые нужно собрать, выполнение CHECKPOINT не приведет к усечению журнала.
Процесс захвата также используется для хранения истории изменений DDL в отслеживаемых таблицах. Операторы DDL, связанные с отслеживанием измененных данных, вносят записи в журнал транзакций базы данных всякий раз, когда база данных или таблица, поддерживающая отслеживание измененных данных, удаляется или столбцы таблицы, поддерживающей отслеживание измененных данных, добавляются, изменяются или удаляются. Эти записи журнала обрабатываются процессом захвата, который затем отправляет связанные события DDL в таблицу cdc.ddl_history. Вы можете получить информацию о событиях DDL, влияющих на отслеживаемые таблицы, с помощью хранимой процедуры sys. sp_cdc_get_ddl_history.
Задания агента
Два задания агента SQL Server обычно связаны с базой данных, поддерживающей сбор данных об изменениях: одно используется для заполнения таблиц изменений базы данных, а другое отвечает за очистку таблицы изменений. Оба задания состоят из одного шага, на котором выполняется команда Transact-SQL. Вызываемая команда Transact-SQL — это определенная хранимая процедура отслеживания измененных данных, которая реализует логику задания. Задания создаются, когда первая таблица базы данных включена для отслеживания измененных данных. Задание очистки создается всегда. Задание захвата будет создано только в том случае, если для базы данных не определены публикации транзакций. Задание захвата также создается, когда для базы данных включены и сбор измененных данных, и репликация транзакций, а задание чтения журнала транзакций удаляется, поскольку в базе данных больше нет определенных публикаций.
Задания захвата и очистки создаются с использованием параметров по умолчанию. Задание захвата запускается немедленно. Он работает непрерывно, обрабатывая максимум 1000 транзакций за цикл сканирования с 5-секундным ожиданием между циклами. Задание по очистке выполняется ежедневно в 2 часа ночи. Он сохраняет записи таблицы изменений в течение 4320 минут или 3 дней, удаляя максимум 5000 записей с помощью одного оператора удаления.
Задания агента отслеживания измененных данных удаляются, если для базы данных отключен сбор измененных данных. Задание сбора также можно удалить, когда первая публикация добавляется в базу данных, и включены как сбор измененных данных, так и репликация транзакций.
Внутренне задания агента сбора измененных данных создаются и удаляются с помощью хранимых процедур sys.sp_cdc_add_job и sys.sp_cdc_drop_job соответственно. Эти хранимые процедуры также доступны, чтобы администраторы могли управлять созданием и удалением этих заданий.
Администратор не имеет явного контроля над конфигурацией по умолчанию заданий агента сбора измененных данных. Хранимая процедура sys.sp_cdc_change_job позволяет изменять параметры конфигурации по умолчанию. Кроме того, хранимая процедура sys.sp_cdc_help_jobs позволяет просматривать текущие параметры конфигурации. Как задание захвата, так и задание очистки извлекают параметры конфигурации из таблицы msdb.dbo.cdc_jobs при запуске. Любые изменения, внесенные в эти значения с помощью sys.sp_cdc_change_job, не вступят в силу, пока задание не будет остановлено и перезапущено.
Предусмотрены две дополнительные хранимые процедуры, позволяющие запускать и останавливать задания агента сбора измененных данных: sys.sp_cdc_start_job и sys.sp_cdc_stop_job.
Примечание
Запуск и остановка задания захвата не приводит к потере данных об изменениях. Это только предотвращает процесс захвата от активного сканирования журнала на наличие записей об изменениях для внесения в таблицы изменений. Разумной стратегией предотвращения увеличения нагрузки при сканировании журналов в периоды пиковой нагрузки является остановка задания захвата и перезапуск его при снижении нагрузки.
Оба задания агента SQL Server были спроектированы так, чтобы быть достаточно гибкими и достаточно настраиваемыми для удовлетворения основных потребностей сред сбора измененных данных. Однако в обоих случаях базовые хранимые процедуры, обеспечивающие базовую функциональность, были раскрыты, так что возможна дальнейшая настройка.
Сбор измененных данных не может работать должным образом, если служба компонента Database Engine или служба агента SQL Server запущены под учетной записью NETWORK SERVICE. Это может привести к ошибке 22832.
Примечание
В базе данных SQL Azure задания агента заменены планировщиком, который автоматически запускает захват и очистку.
Захват и очистка CDC в базе данных SQL Azure
В базе данных SQL Azure планировщик сбора данных об изменениях заменяет агент SQL Server, который вызывает хранимые процедуры для запуска периодического сбора и очистки таблиц отслеживания измененных данных. Планировщик автоматически запускает захват и очистку в базе данных SQL, без какой-либо внешней зависимости для обеспечения надежности или производительности. Пользователи по-прежнему могут запускать захват и очистку вручную по требованию с помощью процедур sp_cdc_scan и sp_cdc_cleanup_change_tables.
База данных SQL Azure включает два динамических представления управления, помогающих отслеживать сбор измененных данных: sys.dm_cdc_log_scan_sessions и sys.dm_cdc_errors.
Различия в параметрах сортировки
Важно помнить о ситуации, когда между базой данных и столбцами таблицы, сконфигурированной для отслеживания измененных данных, имеются разные параметры сортировки. CDC использует временное хранилище для заполнения боковых таблиц. Если в таблице есть столбцы CHAR или VARCHAR с параметрами сортировки, отличными от параметров сортировки базы данных, и если в этих столбцах хранятся символы, отличные от ASCII (например, двухбайтовые символы DBCS), CDC может быть не в состоянии сохранить измененные данные в соответствии с данными в базовые таблицы. Это связано с тем, что переменные промежуточного хранения не могут иметь связанных с ними параметров сортировки.
Рассмотрите один из следующих подходов, чтобы обеспечить соответствие данных об изменениях базовым таблицам:
Например, если у вас есть одна база данных, в которой используется сопоставление SQL_Latin1_General_CP1_CI_AS, рассмотрите следующую таблицу:
CREATE TABLE T1(
C1 ВНУТРЕННИЙ ПЕРВИЧНЫЙ КЛЮЧ,
C2 VARCHAR(10) сопоставить китайский_PRC_CI_AI)
CDC может не захватить двоичные данные для столбца C2 из-за другого сопоставления (Chinese_PRC_CI_AI). Используйте NVARCHAR, чтобы избежать этой проблемы:
СОЗДАТЬ ТАБЛИЦУ T1(
C1 ВНУТРЕННИЙ ПЕРВИЧНЫЙ КЛЮЧ,
C2 NVARCHAR(10) collate Chinese_PRC_CI_AI --Тип данных Unicode, CDC хорошо работает с этим типом данных
)
Требуются разрешения
Для включения отслеживания измененных данных для SQL Server или Управляемого экземпляра Azure SQL требуются разрешения системного администратора. Роль db_owner требуется для включения отслеживания измененных данных для базы данных SQL Azure.
Общие рекомендации
Для правильной работы системы сбора данных изменений (CDC) не следует вручную изменять какие-либо метаданные CDC, такие как схема CDC, таблицы изменений, системные хранимые процедуры CDC, по умолчанию cdc разрешения пользователя ( sys.database_principals ) или переименуйте cdc пользователя.
Любые объекты в sys.objects со свойством is_ms_shipped , для которого установлено значение 1 , не должны изменяться.
ВЫБЕРИТЕ имя КАК имя_объекта ,SCHEMA_NAME(schema_id) AS схема_имя ,type_desc ,is_ms_shipped ИЗ sys.objects ГДЕ is_ms_shipped= 1 И SCHEMA_NAME(schema_id) = 'cdc'
Ограничения
Сбор измененных данных имеет следующие ограничения:
Linux
CDC теперь поддерживается для SQL Server 2017 в Linux, начиная с CU18, и SQL Server 2019 в Linux.
Индексы columnstore
Сбор измененных данных нельзя включить для таблиц с кластеризованным индексом columnstore. Начиная с SQL Server 2016, его можно включить для таблиц с некластеризованным индексом columnstore.
Переключение разделов с переменными
Использование переменных с переключением разделов в базах данных или таблицах с системой отслеживания измененных данных (CDC) не поддерживается для ALTER TABLE... SWITCH TO... PARTITION... оператор. См. ограничения на переключение разделов, чтобы узнать больше.
Доступность CDC в базах данных SQL Azure
CDC можно включить только в базах данных уровня S3 и выше. Базы данных Sub-core (Basic, S0, S1, S2) Azure SQL не поддерживаются для CDC.
Dbcopy из уровней базы данных выше S3 с включенным CDC в SLO подъядра в настоящее время сохраняет артефакты CDC, но артефакты CDC могут быть удалены в будущем.
Настройка захвата и очистки в базах данных SQL Azure
Настройка частоты процессов захвата и очистки для CDC в базах данных SQL Azure невозможна. Захват и очистка запускаются планировщиком автоматически.
Вычисляемые столбцы
CDC не поддерживает значения для вычисляемых столбцов, даже если вычисляемый столбец определен как сохраняемый. Вычисляемые столбцы, включенные в экземпляр отслеживания, всегда имеют значение NULL 9.0878 . Такое поведение задумано, а не является ошибкой.
Восстановление на момент времени (PITR)
Если вы включите CDC в своей базе данных в качестве пользователя Microsoft Azure Active Directory (Azure AD), восстановление на момент времени (PITR) в подчиненную -основной СРБ. Рекомендуется восстановить базу данных до исходной или более высокой SLO, а затем при необходимости отключить CDC.
Microsoft Azure Active Directory (Azure AD)
Если вы создаете базу данных в базе данных SQL Azure от имени пользователя Microsoft Azure Active Directory (Azure AD) и включаете для нее сбор измененных данных (CDC), пользователь SQL (например, , даже роль системного администратора) не сможет отключить/внести изменения в артефакты CDC. Однако другой пользователь Azure AD сможет включать и отключать CDC в той же базе данных.
Аналогичным образом, если вы создаете базу данных SQL Azure в качестве пользователя SQL, включение или отключение сбора измененных данных в качестве пользователя Azure AD не будет работать.
Агрессивное усечение журнала
При включении сбора измененных данных (CDC) в базе данных SQL Azure помните, что агрессивное усечение журнала отключено (сканирование CDC использует журнал транзакций базы данных).
Включение отслеживания измененных данных (CDC) в базе данных отключает агрессивное усечение журнала. Активные транзакции будут продолжать удерживать усечение журнала транзакций до тех пор, пока транзакция не будет зафиксирована и сканирование CDC не догонит ее, или пока транзакция не будет прервана. Это может привести к заполнению журнала транзакций и переходу базы данных в режим только для чтения.
Ошибка CDC после ALTER COLUMN to VARCHAR и VARBINARY
Когда тип данных столбца в таблице с поддержкой CDC изменяется с TEXT на VARCHAR или IMAGE на VA, существующая строка обновляется на 8RBIN879 VA до значения вне строки. После обновления сканирование CDC приведет к ошибкам.
Включение CDC завершается сбоем в восстановленной базе данных SQL Azure, созданной с помощью Microsoft Azure Active Directory (Azure AD). • включите CDC, затем восстановите базу данных и включите CDC в восстановленной базе данных.
Чтобы решить эту проблему, выполните следующие действия:
- Войдите в систему как администратор Azure AD сервера
- Запустите команду ALTER AUTHORIZATION в базе данных:
ИЗМЕНЕНИЕ АВТОРИЗАЦИИ В БАЗЕ ДАННЫХ::[] TO [ ]; EXEC sys.sp_cdc_enable_db
См. также
Отслеживание изменений данных (SQL Server)
Включение и отключение сбора данных об изменениях (SQL Server)
Работа с данными об изменениях (SQL Server)
Администрирование и мониторинг сбора данных об изменениях (SQL Server)
Временные таблицы
Ввод данных в SPSS Statistics
Ввод данных в SPSS Statistics | Статистика ЛаэрдПравило «один человек, одна строка»
SPSS Statistics представляет свои данные в виде электронных таблиц. Принцип ввода данных почти во всех случаях в SPSS Statistics заключается в том, чтобы вводить каждый уникальный случай в новую строку. Случай — это «объект», который вы каким-то образом измеряете. Обычно кейс — это индивид, но это может быть и коммерческий продукт или биологическая клетка (или что-то совсем другое). Для целей этого объяснения мы будем предполагать, что случай является индивидуумом. Поэтому при вводе данных в SPSS Statistics вы должны поместить данные одного человека только в одну строку. Если вы обнаружите, что у вас есть данные об отдельном человеке более чем в одной строке, вы допустили ошибку. Точно так же, если строка содержит данные более чем об одном человеке, вы также допустили ошибку.
Теперь мы рассмотрим три наиболее распространенные задачи, с которыми вы сталкиваетесь при вводе данных в SPSS Statistics, а также три дополнительные настройки:
- Ввод переменных (например, рост, вес).
- Определение отдельных групп (межсубъектных факторов) (например, пол, уровень образования).
- Ввод повторных измерений (внутрисубъектные факторы) (например, динамика во времени).
- Несколько отдельных групп (например, пол и уровень образования).
- Отдельные группы и повторные измерения (например, пол и динамика во времени).
- Создание фиктивных переменных (например, в множественном регрессионном анализе с категориальными независимыми переменными).
SPSS Statistics
Ввод переменных
Если у вас нет повторных измерений, SPSS Statistics обрабатывает каждый столбец как отдельную переменную. Таким образом, каждая переменная идет в отдельном столбце. Например, если бы мы измерили рост и вес группы людей, данные в SPSS Statistics выглядели бы следующим образом:
Опубликовано с письменного разрешения SPSS Statistics, IBM Corporation.
Столбец Субъект был добавлен, чтобы было ясно, что каждый человек помещен в отдельную строку. Тем не менее, SPSS Statistics не требует ввода этого столбца, и в основном это нужно для того, чтобы вы могли лучше визуализировать свои данные. Итак, даже если мы проигнорировали столбец Субъект , мы можем увидеть, что один человек был ростом 1,55 м и весил 56 кг, глядя на Рост 9.0050 и Вес столбцов соответственно. Как пометить столбцы переменных, описано в нашем руководстве по работе с переменными. Чтобы добавить больше переменных, просто добавьте больше столбцов — по одному столбцу на переменную. Единственный вариант этого обсуждается позже в этом руководстве, когда нам нужно вводить повторные измерения.
SPSS Statistics
Определение отдельных групп
Отдельные группы чаще называют межсубъектными факторами или независимыми группами. Это группы, в которых люди в каждой группе уникальны (т. Е. Ни один человек не входит более чем в одну группу). В этом смысле вы можете назвать группы «взаимоисключающими». Типичным примером является дифференциация между полами. Вы хотите пометить некоторых из ваших людей как женщин, а других как мужчин. Чтобы определить, какие испытуемые были мужчинами, а какие женщинами, вам необходимо создать «группирующую переменную» в SPSS Statistics. Это отдельная колонка, включающая информацию о том, к какой группе относится предмет. Мы делаем это, нумеруя наши группы. Например, мы обозначаем «мужчин» как « 1 ", а "женщины" как " 2 ". С помощью атрибута value мы можем пометить эти числа как представляющие мужчин и женщин соответственно. Пример показан ниже:
Опубликовано с письменного разрешения SPSS Statistics, IBM Корпорация
Глядя на столбцы слева, мы видим, что мы создали «группирующую переменную» под названием «Пол», которая имеет две категории: « 1 » и « 2 ». атрибут значения, мы можем использовать кнопку метки значения, чтобы переключиться на текстовую версию категорий «группирующая переменная». В этом примере мы видим, что «1» и «2» заменены на « Male " и " Female " соответственно. Как это сделать, описано в нашем руководстве по работе с переменными. Вам не нужно добавлять текстовые метки SPSS Statistics будет работать без них но это может внести дополнительную ясность при анализе ваших данных (особенно потому, что в выводе вместо чисел часто используются текстовые метки это очень помогает). В этом примере мы видим, что первые три испытуемых были мужчинами, а последние четыре субъекта были женщинами. Что, если у вас есть более двух категорий вашей "переменной группировки"? Просто добавьте больше чисел, мы рекомендуем, с соответствующими текстовыми метками.
Присоединяйтесь к 10 000 студентов, ученых и профессионалов, которые полагаются на Laerd Statistics. ПОЛУЧИТЕ ПЛАНЫ ТУРОВ И ЦЕНЫ
SPSS Statistics
Ввод повторных измерений
Повторные измерения, также называемые внутрипредметными факторами или связанными группами, представляют собой переменные, которые измеряются более чем один раз. Это может произойти, если вы измеряли один и тот же объект для одной и той же переменной более чем в один момент времени или при более чем одном условии. Например, вы измеряли массу тела в начале и в конце программы по снижению веса. Чтобы ввести это в SPSS Statistics, вы должны игнорировать правило «одна переменная — один столбец» и помещать каждый момент времени или условие в новый столбец следующим образом:
Опубликовано с письменного разрешения SPSS Statistics, IBM Corporation.
Здесь мы обозначили их вес в начале программы снижения веса как " Weight_Pre ", а их вес после программы снижения веса как " Weight_Post ". Неважно, как вы назовете эти «связанные» столбцы (например, вы могли бы назвать их «вес1» и «вес2»), если эти столбцы имеют для вас смысл. Если у вас много моментов времени и/или условий, логическая маркировка переменных важна, поскольку в противном случае может возникнуть путаница при определении того, какая переменная является какой. Это важно, так как SPSS Statistics не может определить разницу между столбцами, содержащими разные переменные, и столбцами, содержащими повторяющиеся переменные. Поэтому он не может вам помочь.
SPSS Statistics
Множественное разделение групп
Иногда, например, при выполнении двустороннего дисперсионного анализа или при вводе данных всего исследования, вам необходимо дважды разделить испытуемых (т. е. по двум отдельным переменным). Например, вам нужно разделить субъектов по их полу (мужской/женский) и уровню их физической активности (сидячий/активный). Для этого потребуются два столбца, которые действуют как «группирующие переменные», как показано ниже:
Опубликовано с письменного разрешения SPSS Statistics, IBM Corporation.
Здесь мы видим, что, например, Субъект 1 был мужчиной и вел малоподвижный образ жизни, а Субъект 7 был женщиной и был активен. Обратите внимание, что мы используем текстовые метки, как описано ранее в этом руководстве, для большей ясности.
Присоединяйтесь к 10 000 студентов, ученых и профессионалов, которые полагаются на Laerd Statistics. ПОЛУЧИТЕ ПЛАНЫ ТУРОВ И ЦЕНЫ
SPSS Statistics
Смешивание отдельных групп и повторные измерения
Иногда мы разделяем предметы на группы, а затем повторно измеряем их той же зависимой переменной. Такие данные могут быть проанализированы с использованием смешанного дисперсионного анализа. Если бы мы попросили мужчин и женщин пройти программу по снижению веса и взвесили их до и после вмешательства, у нас была бы следующая установка в SPSS Statistics:
Опубликовано с письменного разрешения SPSS Statistics, IBM Corporation.
Чтобы создать этот тип настройки, просто используйте правила, которые вы изучили в этом руководстве в разделах «Определение отдельных групп» и «Ввод повторных измерений».
SPSS Statistics
Создание фиктивных переменных
Если вы анализируете свои данные с помощью множественной регрессии и любая из ваших независимых переменных была измерена по номинальной или порядковой шкале, вам нужно знать, как создать фиктивных переменных и интерпретировать их результаты. Это связано с тем, что номинальные и порядковые независимые переменные, более широко известные как категориальные независимые переменные , не могут быть непосредственно введены в анализ множественной регрессии. Вместо этого их нужно преобразовать в фиктивные переменные. Исключением являются порядковые независимые переменные, которые вводятся в множественную регрессию как непрерывные независимые переменные, для которых , а не , необходимо преобразовать в фиктивные переменные.