Лекция Кодирование текстовой информации
ТЕМА «Кодирование текстовой информации»
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации:
N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
В оперативную память символы попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части (смотреть приложение 2).
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер | Код | Символ |
0 — 31 | 00000000 — 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
32 — 127 | 00100000 — 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 — пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
128 — 255 | 10000000 — 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |


Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита так же в основном соблюдается принцип последовательного кодирования.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
Слово 1 | Память ПК | Слово 2 | Память ПК | |||
file | f | 01100110 | disk | d | 01100100 | |
i | 01101001 | i | 01101001 | |||
l | 01101100 | s | 01110011 | |||
e | 01100101 | k | 01101011 | |||
Коротко о главном
Каждый символ текста кодируется восьмиразрядным двоичным кодом. Для представления текстов в компьютере используется алфавит мощностью 256 символов.
Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код.
Все символы кодируются одинаковым числом бит (алфавитный подход)
Международным стандартом является код ASCII — американский стандартный код для информационного обмена.
Чаще всего используют кодировки, в которых на символ отводится 8 бит (8-битные ASCII) или 16 бит (16-битные Unicode)
После знака препинания внутри (не в конце!) текста ставится пробел
При измерении количества информации принимается, что в одном байте 8 бит, а в одном килобайте (1 Кбайт) – 1024 байта, в мегабайте (1 Мбайт) – 1024 Кбайта
Чтобы найти информационный объем текста I, нужно умножить количество символов N на число бит на символ K :
I=N*K
Примеры решения задач
Пример 1 Закодируйте кодом ASCII слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
M | O | S | C | O | W |
01001101 | 01001111 | 01010011 | 01000011 | 01001111 | 01110111 |
ОТВЕТ:
100110110011111010011100001110011111110111
Пример 2
Задача 1. Информационный объём сообщения составляет 8,5 Кбайт (I). Данное сообщение содержит 8704 символа (N). Какое минимально возможное количество символов содержится в использованном алфавите?
Решение задачи 1.
Информационный объём сообщения 8,5 Кбайт = 8,5 * 1024 = 8704 байта
I / N = K (число бит на символ)
8704 байта / 8704 символа = Одному символу сообщения соответствует 1 байт = 8 бит
С помощью 8 бит (1 байта) можно закодировать 28 = 256 символов, это меньше количества символов, содержащихся в сообщении.
Ответ:
В использованном алфавите содержится 256 символов, что соответствует полному алфавиту ASCII.
Пример 3
Задача 2.
Автоматическое устройство осуществило перекодировку информационного сообщения, первоначально записанного в 7-битном коде ASCII, в 16-битную кодировку Unicode. При этом информационное сообщение увеличилось на 108 бит.
Какова длина сообщения в символах?
1) 12
2) 27
3) 6
4) 62
Решение задачи 2.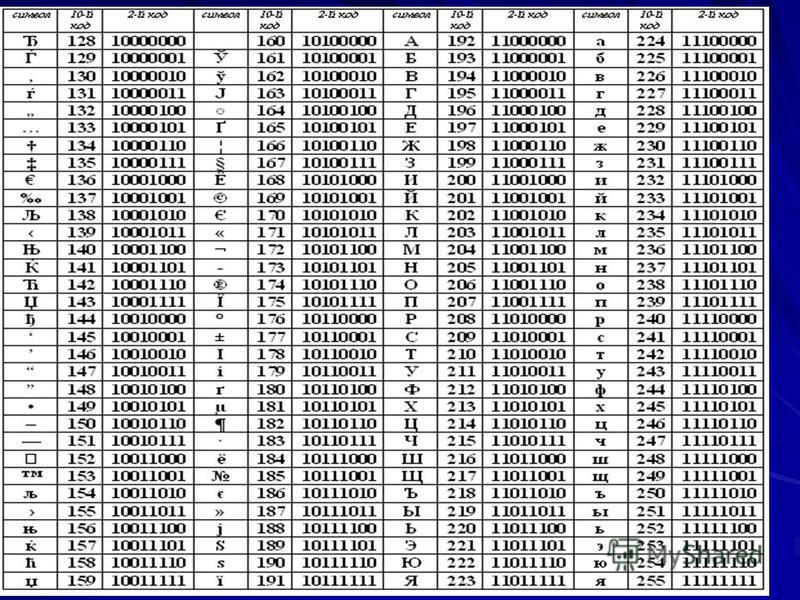
Изменение кодировки с 7 бит на 16 бит, равно 16 — 7 = 9 бит. Следовательно информационный объем каждого символа сообщения увеличился на 9 бит. По условиям задачи информационный объем сообщения после кодировки составил 108 бит, следовательно количество символов в сообщении = 108/9 = 12.
Ответ: 1) 12 символов.
Пример 4
Задача 3.
В одной из кодировок Unicode каждый символ кодируется 16 битами.
Определите размер следующего предложения в данной кодировке:
«Тише едешь – дальше будешь!»
216 бит
27 байт
54 байта
46 байт
Решение задачи 3:
Каждый символ кодируется 16 битами. Значит общее количество бит во всем предложении равно количеству символов умноженному на 16. Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Ответ: 3) 54 байта.
ЗАКРЕПЛЕНИЕ МАТЕРИАЛА.
Задание 1. Расшифруйте сообщение, используя таблицу ASCII.
1001001 | |
1101110 | |
1100110 | |
1101111 | |
1110010 | |
1101101 | |
1100001 | |
1110100 | |
1101001 | |
1101111 | |
1101110 |
Задание 2.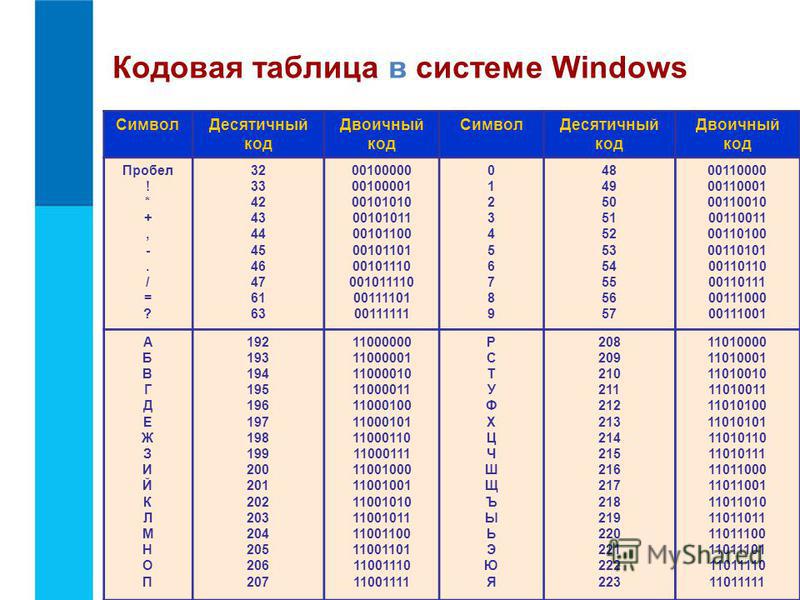
Задача. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения:
Один пуд – около 16,4 килограмм.
ПРИЛОЖЕНИЕ 1
Аналогичные (Базовой таблице кодировки ASCII) системы кодирования текстовых данных были разработаны и в других странах.
Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).
На практике данная кодировка используется редко (таблица 1.4).
На компьютерах, работающих в операционных системах MS—DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Первая половина таблицы кодов ASCII
Вторая половина таблицы кодов ASCII
8
Кодирование текста — таблицы кодировок ASCII и Unicode
Компьютер является универсальным устройством обработки информации и способен работать с различными ее типами. В том числе и с текстовой. Давайте рассмотрим эту возможность подробнее.
Проблема состоит в том, что компьютер в памяти может хранить только числа, причем числа двоичные (о системах счисления). Каким же образом в память можно поместить текст? Очень просто. Ведь символы можно пронумеровать, т. е. дать каждому символу цифровой код и уже его хранить в памяти. Собственно, все именно так устроено. Но тут возникает проблема — Вася пронумеровал буквы так, что прописная буква А имеет код 1, а у Пети прописная буква А имеет код 34. В итоге текст, закодированный на компьютере Васи будет некорректно отображаться на компьютере Пети и наоборот. Как поступить? Очень просто — закодировать символы и принять такое кодирование как стандартное. Таким образом появилась таблица кодировок ASCII (произносится аски).
Собственно, все именно так устроено. Но тут возникает проблема — Вася пронумеровал буквы так, что прописная буква А имеет код 1, а у Пети прописная буква А имеет код 34. В итоге текст, закодированный на компьютере Васи будет некорректно отображаться на компьютере Пети и наоборот. Как поступить? Очень просто — закодировать символы и принять такое кодирование как стандартное. Таким образом появилась таблица кодировок ASCII (произносится аски).
Разработчики первых компьютеров использовали английский язык, поэтому им необходимо было закодировать 26 прописных букв, 26 строчных букв (строчная буква А и прописная буква а для компьютера совершенно разные символы и имеют разные коды), 10 цифр, знаки препинания, знаки арифметических операций, пробел (да, пробел — тоже символ и имеет свой код), различные спецзнаки. В итоге получается немногим более 100 символов. Сколько памяти необходимо, чтобы сохранить код одного символа? Давайте посчитаем. Воспользуемся формулой
2i=N
где N — количество символов, а i — количество памяти в битах, необходимое для хранения одного символа. Значение N примем равным 100. Чему же равно i? Если i = 6, то 26=64. Этого мало, ведь у нас 100 символов. Если i=7, то 27=128 — то, что нам нужно. Если необходимо закодировать 128 символов, на каждый необходимо 7 бит памяти.
Значение N примем равным 100. Чему же равно i? Если i = 6, то 26=64. Этого мало, ведь у нас 100 символов. Если i=7, то 27=128 — то, что нам нужно. Если необходимо закодировать 128 символов, на каждый необходимо 7 бит памяти.
А что же делать тем, кто использует кириллические буквы? Ведь места в получившейся таблице не хватает. А почему бы не расширить ее? Если на каждый символ отвести 8 бит памяти, то можно будет закодировать уже 28=256 символов. Таким образом, появилась расширенная таблица кодировок ASCII, в которой первая часть (символы с десятичными кодами от 0 до 127) содержит латинский алфавит, цифры, знаки препинания, знаки арифметических операций, спецсимволы, а вторая часть (символы с кодами от 128 до 255) — национальные символы разных стран. В России это русские буквы. К сожалению, было несколько вариантов второй части таблицы кодировок ASCII для кириллического алфавита, что часто приводило к некорректному отображению текста. К примеру, прописная буква А в различных таблицах кодировок имеет такие коды:
| Кодировка | Windows (CP1251) | MS-DOS (CP866) | Macintosh | ISO-8859 | |
| Десятичный код символа | 192 | 128 | 225 | 128 | 176 |
Логотип Unicode
Получается, что русский текст, закодированный в кодировке Windows, будет нечитаем в кодировке КОИ-8. Аналогично и с другими кодировками. Как же решить эту проблему? Может сделать действительно единую международную кодовую таблицу, в которой можно будет поместить гораздо больше, чем 256 символов? Так и поступили в 1991 году, когда консорциум UNICODE представил стандарт кодирования Unicode (читается как юникод), который позволил закодировать символы практически всех языков Мира. Если в ASCII для хранения одного символа требуется 8 бит или 1 байт памяти, то в Unicode — 2 байта или 16 бит. Соответственно, используя 16бит мы можем закодировать 216 = 65536 различных символов! Кроме того, стандарт Unicode развивается и на данный момент позволяет закодировать гораздо больше, чем 65536 символов.
Аналогично и с другими кодировками. Как же решить эту проблему? Может сделать действительно единую международную кодовую таблицу, в которой можно будет поместить гораздо больше, чем 256 символов? Так и поступили в 1991 году, когда консорциум UNICODE представил стандарт кодирования Unicode (читается как юникод), который позволил закодировать символы практически всех языков Мира. Если в ASCII для хранения одного символа требуется 8 бит или 1 байт памяти, то в Unicode — 2 байта или 16 бит. Соответственно, используя 16бит мы можем закодировать 216 = 65536 различных символов! Кроме того, стандарт Unicode развивается и на данный момент позволяет закодировать гораздо больше, чем 65536 символов.
Полученные знания с успехом позволят решить вам задачи А1 части 1 ГИА по информатике
Автор: Александр Чернышов
Что такое таблица в вычислительной технике? – Определение из TechTarget
К
- Пол Кирван
Таблица в компьютерном программировании — это структура данных, используемая для организации информации, как на бумаге. Существует множество различных типов связанных с компьютером таблиц, которые работают по-разному. Какой тип таблицы используется, зависит от типа собираемых данных и от того, какой тип анализа необходим.
Существует множество различных типов связанных с компьютером таблиц, которые работают по-разному. Какой тип таблицы используется, зависит от типа собираемых данных и от того, какой тип анализа необходим.
К различным типам таблиц данных относятся следующие:
Обработка данных. В обработке данных компьютерная таблица также называется массивом и представляет собой организованную группу полей. Таблицы могут хранить постоянные данные или часто обновляться. Например, таблица, содержащаяся в дисковом томе, обновляется при записи секторов. Расположение информации является ключевой функцией таблицы.
Реляционная база данных. В реляционной базе данных таблица иногда называется файлом. Он организует информацию по одной теме в строки и столбцы. Например, предприятия обычно поддерживают реляционные базы данных с информацией о клиентах в виде ряда столбцов с именами столбцов, такими как номера счетов, адреса и номера телефонов. Каждая часть данных представляет собой поле в таблице. Столбец состоит из всех записей для одного поля, например телефонных номеров всех клиентов. Различные поля организованы в виде записей, которые представляют собой полные наборы информации, например всю информацию о конкретном клиенте, каждая из которых содержит строку. Процесс нормализации определяет наиболее эффективный способ организации данных в таблицы.
Каждая часть данных представляет собой поле в таблице. Столбец состоит из всех записей для одного поля, например телефонных номеров всех клиентов. Различные поля организованы в виде записей, которые представляют собой полные наборы информации, например всю информацию о конкретном клиенте, каждая из которых содержит строку. Процесс нормализации определяет наиболее эффективный способ организации данных в таблицы.
Решение. Таблицу решений часто называют таблицей истинности, которая может быть сгенерирована компьютером или нарисована на бумаге. Таблицы решений содержат список решений и критерии, на которых они основаны. Перечислены все возможные ситуации для принятия решений и указаны действия, предпринимаемые в каждой ситуации. Например, на перекрестке решение продолжить движение может быть выражено как да или нет , и критериями могут быть зеленый свет или красный свет соответственно.
Язык гипертекстовой разметки (HTML). Таблица HTML используется для пространственной организации элементов веб-страницы или для создания структуры данных, которые лучше всего отображать в виде таблиц, таких как списки или спецификации.
Пример столовНекоторые таблицы являются текстовыми, например следующая:
| Фамилия | Имя | Отдел |
| Смит | Давид | Бухгалтерский учет |
| Миллер | Сьюзен | ИТ |
| Эндрюс | Ричард | Операции |
| Митчелл | Роберт | Юридический |
Другие таблицы представляют собой смесь текста и чисел, например, эта, где все данные числовые:
| Выручка за 1 квартал | Выручка за 2 квартал | Выручка за 3 квартал | Выручка за четвертый квартал | Итого на конец года | |
| Продукт А | 255 750 | 265 500 | 278 500 | 285 600 | 1 085 350 |
| Продукт В | 126 600 | 177 000 | 165 650 | 169 500 | 638 750 |
| Служба А | 95 600 | 98 500 | 87 550 | 88 600 | 370 250 |
| Итого по кварталам | 477 950 | 541 000 | 531 700 | 543 700 | 2 094 350 |
Таблицы используются всеми, кому необходимо структурировать или анализировать данные.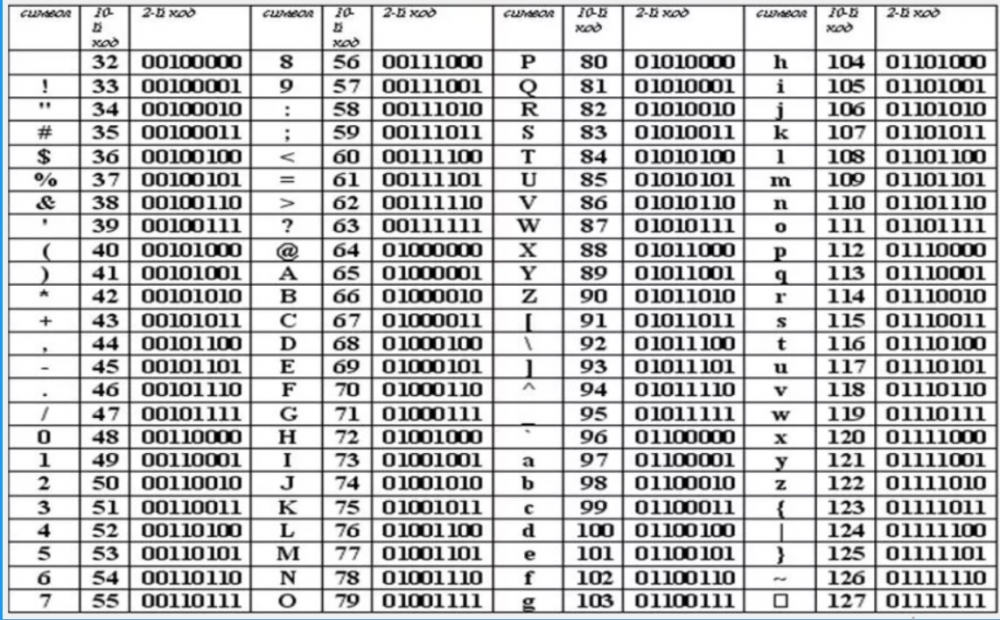 В бизнес-среде различные специалисты используют таблицы, в том числе следующие:
В бизнес-среде различные специалисты используют таблицы, в том числе следующие:
- финансовые аналитики
- руководителей проектов
- аналитики по информатике
- консультанты
- исследователи рынка
- специалисты по кадрам
- инженеры
- риск-менеджеры
- аналитики данных
- ученых
- медицинские работники
- актуариев
Таблицы помогают организовывать и представлять данные в формате, более понятном людям и компьютерам, чем маркированные списки, описательный текст или другие способы передачи информации. Ценность таблицы часто коррелирует с количеством содержащихся в ней данных. Другими словами, по мере роста объема данных возможность их использования в структурированном, управляемом формате становится все более полезной.
Таблицы полезны для аналитической деятельности, когда необходимо проанализировать значительный объем информации по заданным параметрам. Приложения для работы с электронными таблицами, такие как Microsoft Excel, могут выполнять эти действия быстро, точно и большими партиями, экономя время и уменьшая количество ошибок.
Приложения для работы с электронными таблицами, такие как Microsoft Excel, могут выполнять эти действия быстро, точно и большими партиями, экономя время и уменьшая количество ошибок.
Таблицы можно использовать для реорганизации данных в соответствии с различными параметрами, такими как дата создания и значения в порядке возрастания или убывания. Этот тип анализа данных можно использовать для выявления тенденций, исторических факторов и уровней важности.
Ниже приведены примеры использования таблиц:
- Сложный темп роста. Таблицу можно использовать для расчета совокупного годового темпа роста доходов от продаж предприятия за определенный период времени.
- Алфавитные списки. Таблицы полезны, когда большое количество текстовых данных, таких как списки имен, необходимо отсортировать в алфавитном порядке.
Excel является наиболее популярным приложением для работы с электронными таблицами для личного и делового использования. Однако есть альтернативы, включая Google Sheets и LibreOffice.
Однако есть альтернативы, включая Google Sheets и LibreOffice.
Сводная таблица — это инструмент в программах для работы с электронными таблицами, упрощающий процесс анализа сотен или даже тысяч данных в строках таблицы.
Всего несколькими щелчками мыши различные поля данных могут быть переупорядочены, а затем проанализированы для выявления новых тенденций и закономерностей без изменения самой исходной таблицы. Инструменты сводных таблиц могут создавать отчеты, которые можно легко изменить, просто перетащив поля в другое место, чтобы выделить различные типы данных для анализа.
Узнайте, как использовать интерфейс прикладной программы без кода или API, чтобы упростить анализ электронных таблиц в любом масштабе.
Последнее обновление: сентябрь 2022 г.
Продолжить чтение о таблице- Excel — это молоток для слишком многих гвоздей бизнеса
- Следует ли запускать базу данных локально или в облаке?
- Графовая база данных и реляционная база данных: ключевые отличия
- Установите приоритеты ИТ-поддержки и отчетности с помощью сводной таблицы Excel
- 8 видов предвзятости при анализе данных и как их избежать
распознавание голоса
Распознавание голоса или говорящего — это способность машины или программы принимать и интерпретировать диктовку или понимать и выполнять голосовые команды.
Сеть
- система управления сетью
Система управления сетью, или NMS, представляет собой приложение или набор приложений, которые позволяют сетевым инженерам управлять сетевыми .
 ..
.. - хост (в вычислениях)
Хост — это компьютер или другое устройство, которое взаимодействует с другими хостами в сети.
- Сеть как услуга (NaaS)
Сеть как услуга, или NaaS, представляет собой бизнес-модель предоставления корпоративных услуг глобальной сети практически на основе подписки.
Безопасность
- API веб-аутентификации
API веб-аутентификации (WebAuthn API) — это программный интерфейс приложения (API) для управления учетными данными, который позволяет …
- Общая система оценки уязвимостей (CVSS)
Общая система оценки уязвимостей (CVSS) — это общедоступная система оценки серьезности уязвимостей безопасности в …
- Вредоносное ПО Dridex
Dridex — это форма вредоносного ПО, нацеленное на банковскую информацию жертв с основной целью кражи учетных данных онлайн-аккаунта .
 ..
..
ИТ-директор
- программа аудита (план аудита)
Программа аудита, также называемая планом аудита, представляет собой план действий, в котором документируются процедуры, которым аудитор будет следовать для проверки …
- децентрализация блокчейна
Децентрализация — это распределение функций, контроля и информации вместо того, чтобы быть централизованным в едином учреждении.
- аутсорсинг
Аутсорсинг — это деловая практика, при которой компания нанимает третью сторону для выполнения задач, выполнения операций или предоставления услуг…
HRSoftware
- командное сотрудничество
Совместная работа в команде — это подход к коммуникации и управлению проектами, который делает упор на командную работу, новаторское мышление и равенство .
 ..
.. - самообслуживание сотрудников (ESS)
Самообслуживание сотрудников (ESS) — это широко используемая технология управления персоналом, которая позволяет сотрудникам выполнять множество связанных с работой …
- платформа обучения (LXP)
Платформа обучения (LXP) — это управляемая искусственным интеллектом платформа взаимного обучения, предоставляемая с использованием программного обеспечения как услуги (…
Служба поддержки клиентов
- сегментация рынка
Сегментация рынка — это маркетинговая стратегия, в которой используются четко определенные критерии для разделения общей адресной доли рынка бренда …
- воронка продаж
Воронка продаж — это визуальное представление потенциальных клиентов и того, где они находятся в процессе покупки.
- анализ потребительской корзины
Анализ потребительской корзины — это метод интеллектуального анализа данных, используемый розничными торговцами для увеличения продаж за счет лучшего понимания покупательских покупок.
 ..
..
Элементы компьютерного кода HTML
❮ Назад Далее ❯
HTML содержит несколько элементов для определения пользовательского ввода и компьютерный код.
Пример
<код>
х = 5;
у = 6;
г = х + у;
Попробуйте сами »
HTML
Для ввода с клавиатуры Используется элемент HTML для определения ввода с клавиатуры. Содержимое внутри отображается в браузере
моноширинный шрифт по умолчанию.
Пример
Определить ввод текста с клавиатуры в документе:
Сохраните документ, нажав Ctrl + S
Результат:
Сохраните документ, нажав Ctrl + S
Попробуйте сами »
HTML
Для вывода программы определить образец вывода из компьютерной программы. Содержимое внутри отображается в
моноширинный шрифт браузера по умолчанию.
Пример
Определить некоторый текст как образец вывода компьютерной программы в документе:
Сообщение с моего компьютера:
Файл не найден.
Нажмите F1, чтобы
продолжить
Результат:
Сообщение с моего компьютера:
Файл не найден.
Нажмите F1, чтобы продолжить
Попробуйте сами »
HTML
Для компьютерного кода Используется элемент HTML
для определения фрагмента компьютерного кода. Содержимое внутри отображается в
моноширинный шрифт браузера по умолчанию.
Пример
Определить некоторый текст как компьютерный код в документе:
x = 5;
у = 6;
г = х + у;
Результат:
х = 5;
у = 6;
г = х + у;
Попробуйте сами »
Обратите внимание, что элемент не сохраняет лишние пробелы и разрывы строк.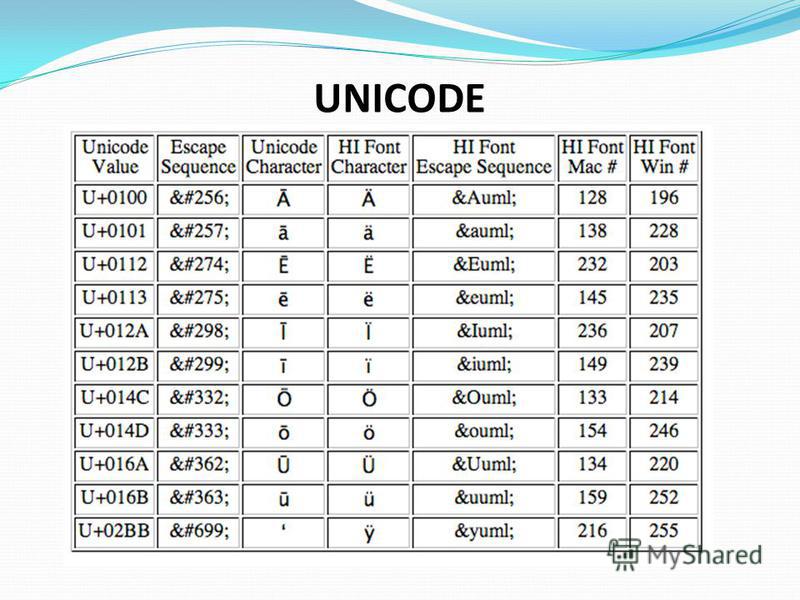
Чтобы исправить это, вы можете поместить элемент внутрь 9Элемент 0410:
Пример
x = 5;
у = 6;
г = х + у;
Результат:
х = 5;
у = 6;
г = х + у;
Попробуйте сами »
HTML
Для переменных Используется элемент HTML
для определения переменной в программировании или в математическом выражении.
содержимое внутри обычно отображается курсивом.
Пример
Определите некоторый текст как переменные в документе:
Площадь треугольника: 1/2 x b x h, где < вар>б — основание, а h — высота по вертикали.
Результат:
Площадь треугольника: 1/2 x b x h , где b — это основание, а h — высота по вертикали.
Попробуйте сами »
Резюме главы
- Элемент
определяет
ввод с клавиатуры - Элемент
определяет
образец вывода из компьютерной программы - Элемент
определяет часть компьютерного кода - Элемент
определяет переменную в программировании или в математическом выражении - Элемент
определяет
предварительно отформатированный текст
HTML-упражнения
Проверьте себя с помощью упражнений
Упражнение:
Определите текст "var person;" как программный код.
Пример кода: var person;
Запустить упражнение
Элементы компьютерного кода HTML
Тег Описание <код> Определяет программный код Определяет ввод с клавиатуры <образец> Определяет вывод компьютера <вар> Определяет переменную <пред> Определяет предварительно отформатированный текст
Полный список всех доступных тегов HTML см. в нашем справочнике по тегам HTML.
в нашем справочнике по тегам HTML.
❮ Предыдущий
Следующий ❯
ВЫБОР ЦВЕТА
Лучшие учебники
Учебное пособие по HTML
Учебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебное пособие по SQL
Учебное пособие по Python
Учебное пособие по W3.CSS
Учебное пособие по Bootstrap
Учебное пособие по PHP
Учебное пособие по Java
Учебное пособие по C++
Учебное пособие по jQuery
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.