Уроки паскаль
Уроки паскальPascal — это высокоуровневый язык программирования, который в основном используется для разработки структурированных программ. Одной из важнейших составляющих программирования в Pascal являются типы данных, которые используются для хранения и обработки различных значений. В языке программирования…
2023-03-06 09:25:45
Далее
В компьютерном программировании типы данных очень важны для точности и эффективности компьютерных программ. Язык программирования Pascal — это строго типизированный язык, который имеет несколько различных типов данных, включая «настоящий» тип данных. Тип данных real используется для хранения чисел…
2023-03-06 08:19:16
Далее
Pascal — это язык программирования высокого уровня, который был создан в конце 1960-х годов швейцарским ученым-компьютерщиком по имени Никлаус Вирт. Он был разработан как простой язык, который было бы легко освоить новичкам, оставаясь при этом достаточно мощным для решения сложных задач.
2023-03-05 14:26:42
Далее
Продолжаем изучение языка программирования Паскаль. Сегодня мы познакомимся с файлами в Паскале, что это такое, как с ними работать, да и зачем они вообще…
2013-10-23 17:52:05
Далее
Продолжаем изучение и повторение основных алгоритмов Паскаль. Сегодня я расскажу про возведение числа в степень, а также поиск максимального и минимального элементов в массиве. Подробнее…
2013-10-08 17:46:39
Далее
При программировании на любом языке необходимо знать основные алгоритмы. Они являются как бы «азбукой» для программиста. Сегодня я хочу рассказать про основные алгоритмы в таком языке программирования, как…
2013-10-04 13:18:03
Далее
В прошлый раз мы разобрали стандартные процедуры в Pascal, применимые к строковому типу данных. Сегодня я расскажу про функции, которые применяются к этому типу. ..
..2013-02-19 16:25:05
Далее
Не так давно мы говорили про строковый тип данных в Паскаль — String. Сегодня пришло время поговорить о процедурах, существующих в Pascal для работы со строковым типом…
2013-02-10 19:32:51
Далее
Итак, продолжаем наши уроки Паскаль для начинающих. В прошлом уроке мы разобрали строковый тип данных, но там мы упомянули про символы, поэтому прежде чем глубоко изучать тип данных String, мы узнаем о типе Char. Символьный тип данных Char — тип данных, значениями которого являются одиночные…
2013-01-01 20:42:21
Далее
Строковый тип данных (STRING) в паскаль служит для проведения операций с текстом, состоящим из различных символов. В одну переменную типа String можно записать до 255 символов. По сути это массив, содержащий в себе элементы типа char (символьный тип данных). Подробнее…
2012-12-22 15:36:06
Далее
ЯМП Список литературы — It-Math.
 Ru
Ru
07.09.2013
Posted by Елена Борисовна
Список литературы
Паскаль
Основная литература
- Павловская Т.А. Паскаль. Программирование на языке высокого уровня: Учебник для вузов. – СПб.: Питер, 2007. – 293 с.
- Павловская Т.А. Паскаль. Программирование на языке высокого уровня: Практикум. – СПб.: Питер, 2007. – 317 с.
- Песни о Паскале
- Окулов С. Основы программирования
- Огнева М.В. TurboPascal Первые шаги
- Программирование на языке Паскаль: задачник.под редакцией О. Ф. Усковой, 2002
Дополнительная литература
- Фаронов В. В. Турбо Паскаль 7.0. Практика программирования: учебное пособие / Фаронов В. В. — М.: ОМД Групп, 2003. — 415с.
- Немнюгин С. А. Turbo Pascal. Программирование на языке высокого уровня: [учебник для вузов по направлению «Информатика и вычисл.
 техника»]/ Немнюгин С. А. — 2-е изд. — СПб.и др.: Питер, 2007. — 543с.
техника»]/ Немнюгин С. А. — 2-е изд. — СПб.и др.: Питер, 2007. — 543с. - Голицына О. Л. Основы алгоритмизации и программирования: [учебное пособие для сред.проф. образования по специальности «Информатика и вычисл. техника»]/ Голицына О. Л., Попов И. И. — М.: Форум, Инфра-М, 2004. — 430с.
- Архангельский А. Я. Язык Pascal и основы программирования в Delphi : [учебное пособие для вузов по направлению «Информатика и вычислительная техника»]/ Архангельский А. Я. — М.: БИНОМ, 2004. — 495с.
- Попов В. Б. Паскаль и Дельфи: самоучитель / Попов В. Б. — СПб.и др.: Питер, 2004. — 543с.
- Культин Н.Б. Программирование в TurboPascal 7.0 и Delphi: самоучитель [для начинающих программистов]/ Культин Н.Б. — 2-е изд. — СПб.: БХВ-Петербург, 2002. — 407с.
- Епанешников А. М. Программирование в среде TurboPascal 7.0: Диалог-МИФИ / Епанешников А. М., Епанешников В. А. — Изд. 4-е, испр. и доп. — М.: ДИАЛОГ-МИФИ, 2002. — 367с.
- Артемьев И. Т. Программирование на языке TurboPascal: [лаб.
 практикум:Для студентов 1 и 2 курсов физ. и мат. фак.]/ Артемьев И. Т., Новикова С. В., [отв. ред. Артемьев И. Т.]; Чуваш.гос. ун-т им. И. Н. Ульянова — Чебоксары: Изд-во Чуваш.ун-та, 2000. — 159 с.
практикум:Для студентов 1 и 2 курсов физ. и мат. фак.]/ Артемьев И. Т., Новикова С. В., [отв. ред. Артемьев И. Т.]; Чуваш.гос. ун-т им. И. Н. Ульянова — Чебоксары: Изд-во Чуваш.ун-та, 2000. — 159 с. - Крылов Е. В. Техника разработки программ: [учебник для вузов по направлениям «Информатика и вычислительная техника» и «Техника и технологии] : в 2 кн. / Крылов Е. В., Острейковский В. А., Типикин Н. Г. — М.: Высш. шк., 2008. — 469с.
- Истомин Е. П. Программирование на алгоритмических языках высокого уровня: учебник / Истомин Е. П., Неклюдов С. Ю., Балт. ин-т упр. — СПб.: Изд-во Михайлова В. А., 2003. — 718с.
- Робертсон Лесли Анна Программирование — это просто: пошаговый подход / [пер. с 4-го англ. изд. О. С. Журавлевой] ; под ред. С. М. Молявко, Робертсон Лесли Анна — М.: Бином. Лаб. знаний, 2008. — 383с.
- Ванюлин А.Н. Сборник задач по программированию. Чебоксары, 2003
- Пичугин В.Н., Фёдоров Р.В. Структуры и алгоритмы компьютерной обработки данных.
 Чебоксары, 2008
Чебоксары, 2008 - Павлов Л.А. Структуры и алгоритмы обработки данных, Чебоксары, 2008
- Златопольский Д.М. Сборник задач по программированию
- Шень А. Программирование: Теоремы и задачи
- Сухарев М. Турбо Паскаль 7.0. Теория и практика программирования
- Шелест В. Программирование
- Климова Л.М. Паскаль 7.0. Практическое программирование. Решение типовых задач.
- Милов А.В. Основы программирования в задачах и примерах
- Васюкова Н. Д., Тюляева В. В. — Практикум по основам программирования. Язык ПАСКАЛЬ
- Дональд Алкок — Паскаль в иллюстрациях (1991)
- Аляев, Козлов Алгоритмизация и языки программирования Pascal, C++, Visual Basic. Учебно-справочное пособие. 2002
- Васильев П.П. Турбо Паскаль в примерах и задачах
- Рапаков Г. Г., Ржеуцкая С. Ю. Программирование на языке Pascal, 2004
- М. С. Долинский Алгоритмизация и программирование на TurboPascal: от простых до олимпиадных задач, 2005
- Ю.
 А. Шпак TurboPascal 7.0 на примерах, 2003
А. Шпак TurboPascal 7.0 на примерах, 2003
Паскаль Указатель основ
ПаскальPascal Basics Index
Небольшая справка по языку программирования Object Pascal
, используемому в CodeTyphon Studio.
Основы Pascal
- Индекс основ Pascal
Глава 1
- Паскаль — Общие
- Паскаль — Структура программы
- Паскаль — Основной синтаксис
- Паскаль — типы данных
- Паскаль — типы переменных
- Паскаль — Константы
- Паскаль — Операторы
Глава 2
- Паскаль — Принятие решений
- Паскаль — оператор if-then
- Паскаль — оператор if-then-else
- Паскаль — вложенные операторы if-then
- Паскаль — Заявление о деле
- Паскаль — оператор Case Else
- Паскаль — вложенные операторы case
- Паскаль — Петли
- Паскаль — циклы while-do
- Паскаль — цикл For-do
- Паскаль — повторение до цикла
- Паскаль — вложенные циклы
- Паскаль — Заявление об отказе
- Паскаль — Заявление о продолжении
- Паскаль — Инструкция перехода
Глава 3
- Паскаль — Функции
- Паскаль — Процедуры
- Паскаль — вызов подпрограммы по значению
- Паскаль — Вызов подпрограммы по ссылке
- Паскаль — переменная область видимости
- Паскаль — Струны
- Паскаль — логические значения
- Паскаль — Массивы
- Паскаль — многомерные массивы
- Паскаль — динамические массивы
- Паскаль — упакованные массивы
- Паскаль — Передача массивов в качестве аргументов подпрограммы
- Паскаль — Указатели
- Паскаль — арифметика указателя
- Паскаль — массив указателей
- Паскаль — указатель на указатель
- Паскаль — Передача указателей на подпрограммы
- Паскаль — указатель возврата из подпрограмм
Глава 4
- Паскаль — Записи
- Паскаль — Варианты
- Паскаль — Наборы
- Паскаль — Обработка файлов
- Паскаль — Управление памятью
- Паскаль — Единицы
- Паскаль — Дата и время
Глава 5
- Паскаль — Объекты
- Паскаль — Классы
Авторизоваться
Имя пользователя
Пароль
Запомнить меня
- Завести аккаунт
- Забыли свой логин?
- Забыли пароль?
Форум Последний
- Synapse Synaser, список последовательных портов в linux (2 сообщения)
- Спасибо
Мы протестируем и добавим ваш исходный код в.
 ..
.. - Матис А.
- 10 часов 2 минуты назад
- CT LAB вер 8.10 (14 сообщений)
- 1) Для часов Dlg а) Замените 2 файла в …
- Матис А.
- 3 дня 8 часов назад
- Установка компонентов FreePascal (5 сообщений)
- Всем спасибо, проблема решена
- Жоао Барбоса
- 3 дня 14 часов назад
- Доступ к файлам в локальной сети с других компьютеров (1 сообщение)
- Как я могу получить доступ к папке или файлам в локальной сети…
- Фернандо Сандовал
- 5 дней 21 час назад
- Сборка Win32 v8: GetTickCount64 в kernel32.dll (5 сообщений)
- Извините, но мы тестируем только CodeTyphon версии 8.xx на …
- Матис А.
- 1 неделя 3 дня назад
- Вопрос о перекрестной сборке (2 сообщения)
- Не могли бы вы опубликовать ошибку(и), пожалуйста
- Матис А.

- 2 недели 19 часов назад
- Эквивалент TRestClient для Delphi (2 сообщения)
- Я использую RESTDataware.
- от Рафала
- 3 недели 3 дня назад
- Толщина сетки сюжета при масштабировании [ORCA]… (2 сообщения)
- Мои предложения 1) pl_Graphics32 2) pl_Image32…
- Матис А.
- 1 месяц 6 часов назад
- Древовидная структура для переменных в отладке (6 сообщений)
- Привет, еще одна проблема с кириллицей…
- от teemu
- 1 месяц 1 день назад
- Ультра веб-сервер версии 5.1 (1 сообщения)
- Мы выпускаем Ultra Web Server (UWS) версии 5.1 …
- Стернас Стефанос
- 1 месяц 2 дня назад
Другие темы »
Кто онлайн
У нас 292 гостя и один участник онлайн
Руководство по настройке Pascal
Настройка приложений CUDA для Pascal
Руководство по настройке приложений CUDA для графических процессоров на основе архитектуры NVIDIA Pascal.
1.1. Вычислительная архитектура NVIDIA Pascal
Pascal сохраняет и расширяет ту же модель программирования CUDA, что и предыдущие архитектуры NVIDIA, такие как Maxwell, и приложения, которые следуют рекомендациям для этих архитектур, обычно должны получать ускорение в архитектуре Pascal без каких-либо изменений кода. В этом руководстве описаны способы точной настройки приложения для получения дополнительных ускорений за счет использования архитектурных возможностей Pascal.1
АрхитектураPascal состоит из двух основных вариантов: GP100 и GP104.2 Подробный обзор основных улучшений GP100 и GP104 по сравнению с более ранними архитектурами NVIDIA описан в двух официальных документах под названием NVIDIA Tesla P100: самый совершенный ускоритель центров обработки данных, когда-либо созданный для GP100. и NVIDIA GeForce GTX 1080: Gaming Perfected для GP104.
Дополнительные сведения о функциях программирования, обсуждаемых в этом руководстве, см. в Руководстве по программированию CUDA C++. Как уже отмечалось, некоторые функции Pascal, описанные в этом руководстве, относятся либо к GP100, либо к GP104; если не указано, функции применимы к обоим вариантам Pascal.
Как уже отмечалось, некоторые функции Pascal, описанные в этом руководстве, относятся либо к GP100, либо к GP104; если не указано, функции применимы к обоим вариантам Pascal.
1.2. Лучшие практики CUDA
Рекомендации по производительности и лучшие практики, описанные в Руководстве по программированию CUDA C++ и Руководстве по передовым практикам CUDA C++, применимы ко всем архитектурам графических процессоров с поддержкой CUDA. Программисты должны в первую очередь сосредоточиться на соблюдении этих рекомендаций для достижения наилучшей производительности.
Первоочередные рекомендации этих руководств следующие:
Поиск способов распараллеливания последовательного кода,
Свести к минимуму передачу данных между хостом и устройством,
Настройка конфигурации запуска ядра для максимального использования устройства,
Убедитесь, что доступ к глобальной памяти объединен,
По возможности минимизировать избыточный доступ к глобальной памяти,
Избегайте длинных последовательностей разнонаправленного выполнения потоков внутри одного варпа.

1.3. Совместимость приложений
Прежде чем приступать к конкретным вопросам настройки производительности, описанным в этом руководстве, обратитесь к Руководству по совместимости с Pascal для приложений CUDA, чтобы убедиться, что ваше приложение скомпилировано таким образом, чтобы оно было совместимо с Pascal.
1.4. Паскаль Тюнинг
1.4.1. Потоковый мультипроцессор
Потоковый мультипроцессор Pascal (SM) во многом подобен процессору Maxwell. Pascal дополнительно улучшает и без того превосходную энергоэффективность, обеспечиваемую архитектурой Maxwell, как за счет улучшенного 16-нм производственного процесса FinFET, так и за счет различных архитектурных модификаций.
1.4.1.1. Планирование инструкций
Как и Maxwell, Pascal использует число ядер CUDA, равное степени двойки, на раздел. Это упрощает планирование, поскольку каждый из планировщиков деформации SM выдает выделенный набор ядер CUDA, равный ширине деформации (32). Каждый планировщик деформации по-прежнему обладает гибкостью для двойного выпуска (например, выдачи математической операции для ядра CUDA в том же цикле, что и операция с памятью для модуля загрузки/сохранения), но одного выпуска теперь достаточно, чтобы полностью использовать все CUDA. Ядра.
Каждый планировщик деформации по-прежнему обладает гибкостью для двойного выпуска (например, выдачи математической операции для ядра CUDA в том же цикле, что и операция с памятью для модуля загрузки/сохранения), но одного выпуска теперь достаточно, чтобы полностью использовать все CUDA. Ядра.
GP100 и GP104 включают разное количество ядер CUDA на SM. Как и Maxwell, каждый GP104 SM предоставляет четыре планировщика деформации, управляющих в общей сложности 128 ядрами одинарной точности (FP32) и четырьмя ядрами двойной точности (FP64). Процессор GP104 обеспечивает до 20 SM, а аналогичная конструкция GP102 — до 30 SM.
В отличие от этого, GP100 обеспечивает меньшие по размеру, но более многочисленные SM. Каждый GP100 обеспечивает до 60 SM.3 Каждый SM содержит два планировщика деформации, управляющих в общей сложности 64 ядрами FP32 и 32 ядрами FP64. Полученное в результате соотношение ядер FP32 и FP64 2:1 хорошо согласуется с новой конфигурацией канала передачи данных GP100, позволяя Pascal обрабатывать рабочие нагрузки FP64 более эффективно, чем Kepler GK210, предыдущая архитектура NVIDIA для повышения производительности FP64.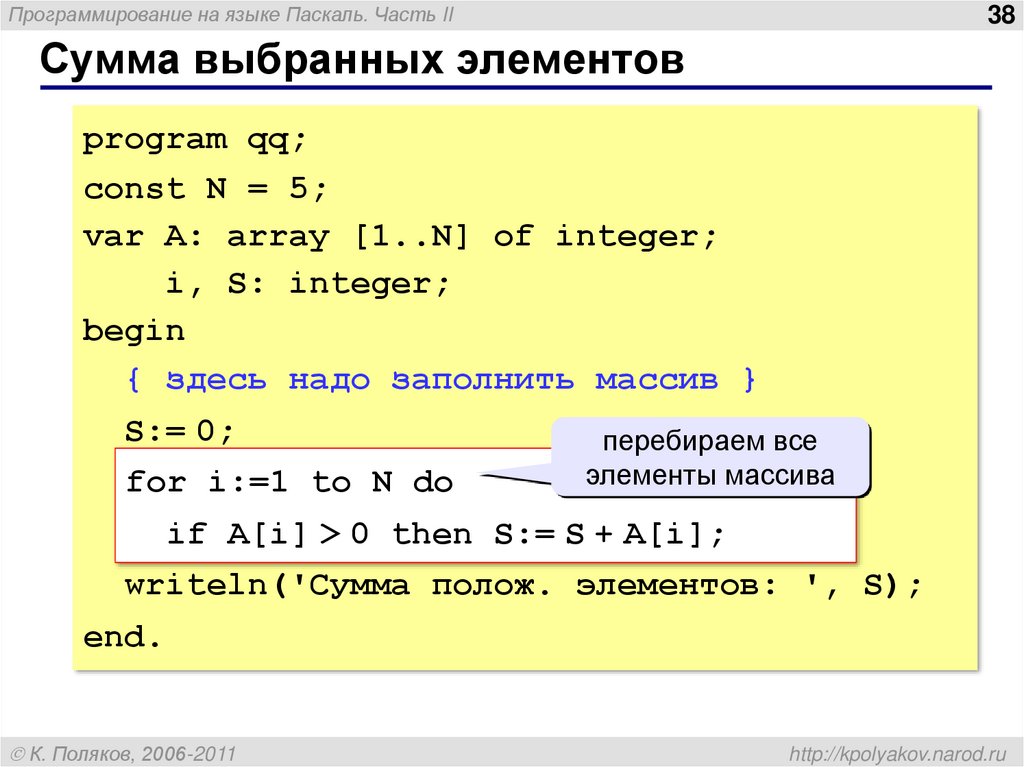
1.4.1.2. Вместимость
Максимальное количество одновременных варпов на SM остается таким же, как и в Maxwell (т.е. 64), и другие факторы, влияющие на занятость варпа, также остаются такими же:
Размер регистрового файла (64 КБ 32-битных регистров) такой же, как у Maxwell.
Максимальное количество регистров на поток, 255, соответствует значению Maxwell. Однако, как и в случае с предыдущими архитектурами, следует использовать эксперименты для определения оптимального баланса между переполнением регистров и заполненностью.
Максимальное количество блоков потоков на SM равно 32, как и в Maxwell.
Объем общей памяти на SM составляет 64 КБ для GP100 и 96 КБ для GP104. Для сравнения, Maxwell предоставил 96 КБ и до 112 КБ общей памяти соответственно. Но каждый GP100 SM содержит меньше ядер CUDA, поэтому общая память, доступная для каждого ядра, фактически увеличивается в GP100. Максимальная общая память на блок остается ограниченной на уровне 48 КБ, как и в предыдущих архитектурах (см.
 Емкость общей памяти).
Емкость общей памяти).
Таким образом, разработчики могут рассчитывать на такую же занятость, как и на Maxwell, без внесения изменений в свое приложение. В результате улучшений планирования по сравнению с Kepler требования к занятости варпа (т. Е. Доступный параллелизм), необходимые для максимального использования устройства, обычно снижаются.
1.4.2. Новые арифметические примитивы
1.4.2.1. Арифметическая поддержка FP16
Pascal обеспечивает улучшенную поддержку FP16 для приложений, таких как глубокое обучение, которые терпимы к низкой точности операций с плавающей запятой. 9Тип 0380 наполовину используется для представления значений FP16 на устройстве. Как и в случае с Maxwell, хранилище FP16 можно использовать для уменьшения необходимого объема памяти и пропускной способности по сравнению с хранилищем FP32 или FP64. Паскаль также добавляет поддержку собственных инструкций FP16. Пиковая пропускная способность FP16 достигается за счет использования парной операции для одновременного выполнения двух инструкций FP16 на ядро.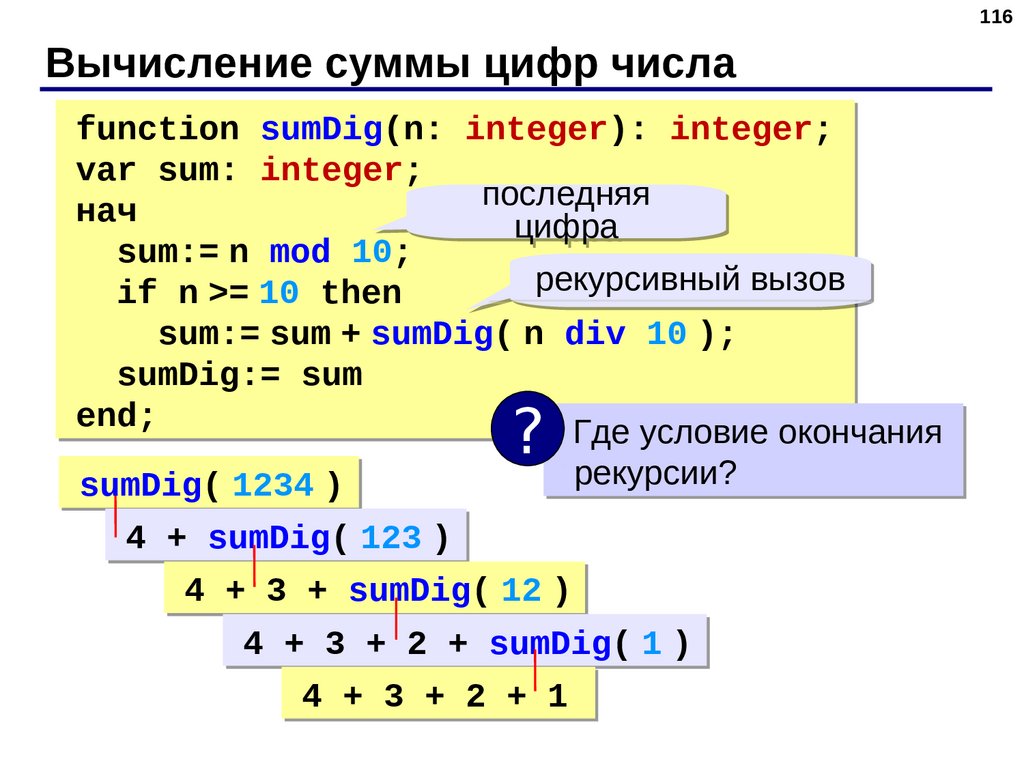 Чтобы иметь право на парную операцию, операнды должны храниться в векторном типе
Чтобы иметь право на парную операцию, операнды должны храниться в векторном типе half2 . GP100 и GP104 обеспечивают разную пропускную способность FP16. GP100, разработанный с учетом обучения глубоких нейронных сетей, обеспечивает пропускную способность FP16 до 2 раз по сравнению с арифметикой FP32. На GP104 пропускная способность FP16 ниже, 1/64 от пропускной способности FP32. Однако, компенсируя снижение пропускной способности FP16, GP104 обеспечивает дополнительную поддержку INT8 с высокой пропускной способностью, недоступную в GP100.
1.4.2.2. INT8 Скалярный продукт
GP104 содержит специальные инструкции для двусторонних и четырехмерных целочисленных скалярных произведений. Они хорошо подходят для ускорения рабочих нагрузок логического вывода глубокого обучения. Встроенная функция __dp4a вычисляет скалярное произведение четырех 8-битных целых чисел с накоплением в 32-битное целое число. Аналогично, __dp2a выполняет двухэлементное скалярное произведение между двумя 16-битными целыми числами в одном векторе и двумя 8-битными целыми числами в другом с суммированием в 32-битное целое число. Обе инструкции обеспечивают пропускную способность, равную арифметике FP32.
Обе инструкции обеспечивают пропускную способность, равную арифметике FP32.
1.4.3. Пропускная способность памяти
1.4.3.1. Память с высокой пропускной способностью 2 DRAM
GP100 использует память с высокой пропускной способностью 2 (HBM2) для своей DRAM. Память HBM2 размещена в одном кремниевом корпусе вместе с кристаллом графического процессора. Это позволяет использовать гораздо более широкие интерфейсы при одинаковой мощности по сравнению с традиционной технологией GDDR. GP100 связан с четырьмя стеками HBM2 и использует два 512-битных контроллера памяти для каждого стека. Тогда эффективная ширина шины памяти составляет 4096 бит, что значительно больше, чем 384 бита в GM200. Это позволяет значительно увеличить пиковую пропускную способность даже при уменьшенных тактовых частотах памяти. Таким образом, Tesla P100, оснащенная GP100, имеет пиковую пропускную способность 732 ГБ/с при скромной тактовой частоте памяти 715 МГц. Задержки доступа к DRAM остаются такими же, как и у Maxwell.
Чтобы скрыть задержки DRAM при полной пропускной способности HBM2, необходимо поддерживать больше обращений к памяти по сравнению с графическими процессорами, оснащенными традиционной GDDR5. Полезно то, что большое количество SM в GP100, как правило, увеличивает количество одновременных потоков (и, следовательно, операций чтения в процессе выполнения) по сравнению с предыдущими архитектурами. Ядра с ограниченными ресурсами, которые ограничены низкой занятостью, могут выиграть от увеличения количества одновременных обращений к памяти на поток.
Файлы регистров графического процессора GP100, общая память, кэши L1 и L2, а также DRAM защищены кодом ECC с исправлением одиночной ошибки и обнаружением двойной ошибки (SECDED). При включении поддержки ECC на Kepler GK210 доступная DRAM будет уменьшена на 6,25%, чтобы можно было хранить биты ECC. Извлечение битов ECC для каждой транзакции памяти также уменьшило эффективную пропускную способность примерно на 20% по сравнению с тем же графическим процессором с отключенным ECC. Память HBM2, с другой стороны, предоставляет выделенные ресурсы ECC, обеспечивая защиту ECC без накладных расходов.4
Память HBM2, с другой стороны, предоставляет выделенные ресурсы ECC, обеспечивая защиту ECC без накладных расходов.4
1.4.3.2. Унифицированный кэш L1/текстур
Как и Maxwell, Pascal объединяет функциональные возможности кэша L1 и текстур в унифицированный кэш L1/текстур, который действует как объединяющий буфер для доступа к памяти, собирая данные, запрошенные потоками варпа, перед доставкой этих данных в деформация.
По умолчанию GP100 кэширует глобальные загрузки в кэше L1/текстур. Напротив, GP104 следует за Maxwell в кэшировании глобальных загрузок только в L2, если только не используется LDG Механизм кэширования данных только для чтения. Как и в предыдущих архитектурах, GP104 позволяет разработчику включить кэширование всех глобальных загрузок в едином кэше L1/текстур путем передачи флага -Xptxas -dlcm=ca в nvcc во время компиляции.
Kepler обслуживал нагрузки со степенью детализации 128 байт, когда было включено кэширование L1 глобальных нагрузок, и 32 байт в противном случае. В Pascal единица доступа к данным составляет 32 байта независимо от того, кэшируются ли глобальные загрузки в L1. Таким образом, больше нет необходимости отключать кэширование L1, чтобы уменьшить потери транзакций глобальной памяти, связанных с несвязанным доступом.
В Pascal единица доступа к данным составляет 32 байта независимо от того, кэшируются ли глобальные загрузки в L1. Таким образом, больше нет необходимости отключать кэширование L1, чтобы уменьшить потери транзакций глобальной памяти, связанных с несвязанным доступом.
В отличие от Maxwell, Pascal кэширует локальную память потока в кэше L1. Это может снизить стоимость разлива регистров по сравнению с Maxwell. Следовательно, необходимо переоценить баланс занятости и разлива, чтобы обеспечить наилучшую производительность.
В CUDA Toolkit 6.0 добавлены два новых атрибута устройства: globalL1CacheSupported и localL1CacheSupported . Разработчики, которые хотят иметь отдельно настраиваемые пути для различных поколений архитектуры, могут использовать эти поля для упрощения процесса выбора пути.
Примечание
Включение кэширования глобальных переменных в GP104 может повлиять на занятость. Если использование ресурсов SM для каждого блока потока приведет к нулевой занятости при включенном кэшировании, драйвер CUDA переопределит выбор кэширования, чтобы обеспечить успешный запуск ядра. Об этой ситуации сообщает профайлер.
Об этой ситуации сообщает профайлер.
1.4.4. Операции с атомной памятью
Как и Максвелл, Паскаль предоставляет встроенные атомарные операции с общей памятью для 32-битной целочисленной арифметики, а также встроенные 32- или 64-битные операции сравнения и замены (CAS). Разработчики из Kepler, где атомарность разделяемой памяти была реализована в программном обеспечении с использованием последовательности блокировки/обновления/разблокировки, должны увидеть значительное улучшение производительности, особенно для атомарных операций с разделяемой памятью, подвергающихся сильной конкуренции.
Pascal также расширяет возможности атомарного сложения в глобальной памяти для работы с данными FP64. Таким образом, функция atomicAdd() в CUDA была обобщена для поддержки 32- и 64-битных целых чисел и типов с плавающей запятой. Режим округления для всех атомарных операций с плавающей запятой — округление до ближайшего даже в Паскале. Как и в предыдущих поколениях FP32 atomicAdd() сбрасывает денормализованные значения в ноль.
Для GP100 атомарные операции могут быть нацелены на память одноранговых графических процессоров, подключенных через NVLink. Одноранговые атомарные соединения через NVLink используют тот же API, что и атомарные соединения, нацеленные на глобальную память. Графические процессоры, подключенные через PCIE, не поддерживают эту функцию.
Графические процессоры Pascal обеспечивают поддержку общесистемных атомарных операций, нацеленных на переносимых распределений 5. Если требуется общесистемная атомарная видимость, операции, нацеленные на переносимую память, должны указывать системную область с помощью встроенных функций atomic[Op]_system() 6. Использование атомарности области устройства (например, atomicAdd() ) в переносимой памяти остается действительным, но обеспечивает атомарную видимость только в локальном графическом процессоре.
Примечание
Учитывая вероятность неправильного использования атомарных областей видимости, рекомендуется, чтобы приложения использовали вычислительные средства очистки для обнаружения и устранения ошибок.
Как реализовано для Pascal, общесистемные атомарности предназначены для того, чтобы позволить разработчикам экспериментировать с расширенными моделями памяти. Они реализованы в программном обеспечении, и для достижения хорошей производительности требуется определенная осторожность. Когда atomic нацеливается на переносимый адрес, поддерживаемый удаленным пространством памяти, локальный процессор выдает ошибку страницы, чтобы ядро могло перенести соответствующую страницу памяти в локальную память. Затем обычные аппаратные инструкции используются для выполнения atomic. Поскольку страница теперь находится локально, последующие атомарные запросы от того же процессора не приведут к дополнительным ошибкам страницы. Однако атомарные обновления с разных процессоров могут привести к частым ошибкам страницы.
1.4.5. Общая память
1.4.5.1. Емкость общей памяти
Для Kepler общая память и кэш L1 совместно использовали одно и то же хранилище на кристалле.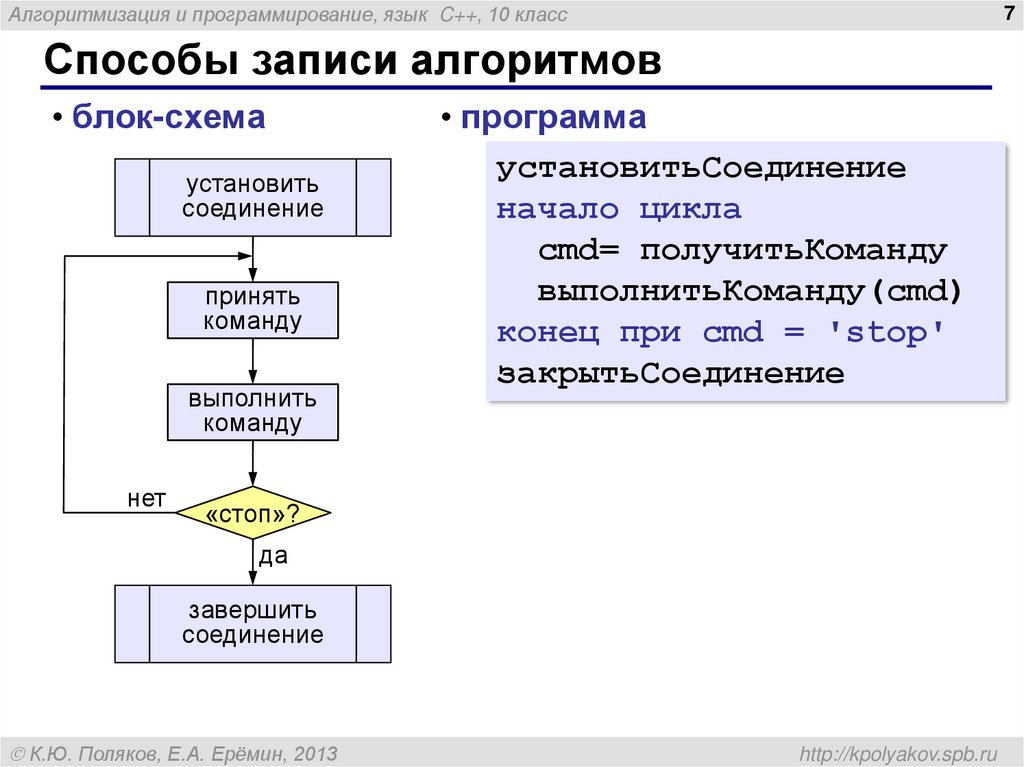 Maxwell и Pascal, напротив, выделяют выделенное пространство для общей памяти каждого SM, поскольку функциональные возможности кэша L1 и текстур объединены. Это увеличивает пространство общей памяти, доступное для каждого SM, по сравнению с Kepler: GP100 предлагает 64 КБ общей памяти на SM, а GP104 — 96 КБ на SM.
Maxwell и Pascal, напротив, выделяют выделенное пространство для общей памяти каждого SM, поскольку функциональные возможности кэша L1 и текстур объединены. Это увеличивает пространство общей памяти, доступное для каждого SM, по сравнению с Kepler: GP100 предлагает 64 КБ общей памяти на SM, а GP104 — 96 КБ на SM.
Это дает разработчикам приложений несколько преимуществ:
Алгоритмы со значительными требованиями к емкости разделяемой памяти (например, сортировка по основанию) обеспечивают автоматическое увеличение емкости от 33% до 100% на SM в дополнение к совокупному увеличению за счет увеличения количества SM.
Приложениям больше не нужно выбирать предпочтение разделения L1/общий для оптимальной производительности.
Примечание
Блоки потоков по-прежнему ограничены 48 КБ общей памяти. Для максимальной гибкости NVIDIA рекомендует, чтобы приложения использовали не более 32 КБ общей памяти в любом блоке потока.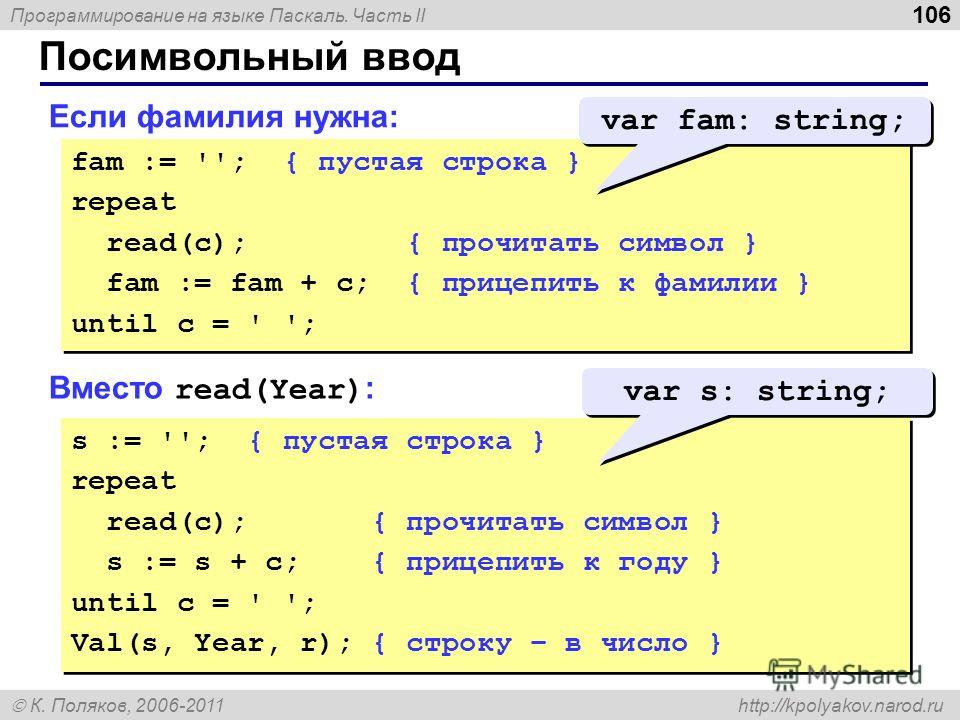 Это, например, позволит установить по крайней мере два блока резьбы на GP100 SM или 3 блока резьбы на GP104 SM.
Это, например, позволит установить по крайней мере два блока резьбы на GP100 SM или 3 блока резьбы на GP104 SM.
1.4.5.2. Общая пропускная способность памяти
Kepler предоставил дополнительный 8-байтовый режим банка общей памяти, который потенциально мог увеличить пропускную способность общей памяти на SM для доступа к общей памяти 8 или 16 байт. Однако приложения могли извлечь из этого выгоду только при хранении этих более крупных элементов в общей памяти (т. е. целые числа и значения fp32 не получили никакой выгоды) и только тогда, когда разработчик явно выбрал режим 8-байтового банка через API.
Чтобы упростить это, Паскаль вслед за Максвеллом возвращается к фиксированным банкам по четыре байта. Это позволяет всем приложениям, использующим общую память, использовать более высокую пропускную способность без указания каких-либо конкретных предпочтений через API.
1.4.6. Связь между графическими процессорами
1.4.6.1. Межсоединение NVLink
NVLink — это новое высокоскоростное соединение для передачи данных от NVIDIA.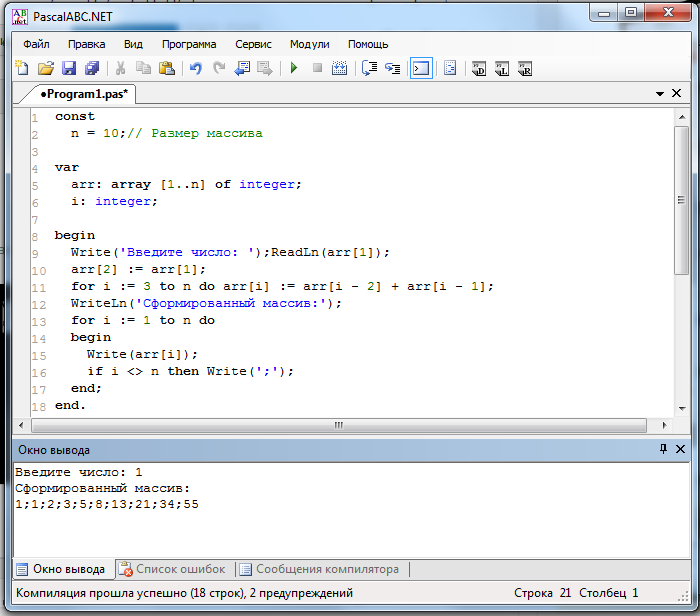 NVLink можно использовать для значительного повышения производительности как при обмене данными между графическими процессорами, так и при доступе графического процессора к системной памяти. GP100 поддерживает до четырех подключений NVLink, каждое из которых обеспечивает двунаправленную пропускную способность до 40 ГБ/с.
NVLink можно использовать для значительного повышения производительности как при обмене данными между графическими процессорами, так и при доступе графического процессора к системной памяти. GP100 поддерживает до четырех подключений NVLink, каждое из которых обеспечивает двунаправленную пропускную способность до 40 ГБ/с.
NVLink работает прозрачно в рамках существующей модели CUDA. Передачи между конечными точками, подключенными через NVLink, автоматически маршрутизируются через NVLink, а не через PCIe. cudaDeviceEnablePeerAccess() Вызов API по-прежнему необходим для включения прямой передачи (через PCIe или NVLink) между графическими процессорами. cudaDeviceCanAccessPeer() можно использовать для определения возможности однорангового доступа между любой парой графических процессоров.
1.4.6.2. Пропускная способность GPUDirect RDMA
GPUDirect RDMA позволяет сторонним устройствам, таким как сетевые карты (NIC), напрямую обращаться к памяти GPU. Это устраняет ненужные буферы копирования, снижает нагрузку на ЦП и значительно уменьшает задержку при отправке/получении сообщений MPI из/в память графического процессора. Pascal удваивает предоставляемую пропускную способность RDMA при чтении данных из исходной памяти графического процессора и записи в память целевой сетевой карты через PCIe.
Это устраняет ненужные буферы копирования, снижает нагрузку на ЦП и значительно уменьшает задержку при отправке/получении сообщений MPI из/в память графического процессора. Pascal удваивает предоставляемую пропускную способность RDMA при чтении данных из исходной памяти графического процессора и записи в память целевой сетевой карты через PCIe.
1.4.7. Вычислить вытеснение
Compute Preemption — это новая функция, характерная для GP100. Compute Preemption позволяет прерывать вычислительные задачи, выполняемые на графическом процессоре, на уровне инструкций. Контекст выполнения (регистры, разделяемая память и т. д.) заменяется на DRAM графического процессора, так что другое приложение может быть загружено и запущено. Упреждающее прерывание вычислений предлагает разработчикам два ключевых преимущества:
Долго работающие ядра больше не нужно разбивать на небольшие временные интервалы, чтобы избежать зависания графического пользовательского интерфейса или тайм-аутов ядра, когда графический процессор используется одновременно для вычислений и графики.
Теперь возможна интерактивная отладка ядра в системе с одним GPU.
1.4.8. Улучшения единой памяти
Pascal предлагает новые аппаратные возможности для расширения поддержки единой памяти (UM). Расширенное 49-битное виртуальное адресное пространство позволяет графическим процессорам Pascal обращаться ко всему 48-битному виртуальному адресному пространству современных ЦП, а также к памяти всех графических процессоров в системе через единое виртуальное адресное пространство, не ограниченное размерами физической памяти любой процессор. Графические процессоры Pascal также поддерживают отказы страниц памяти. Сбой страниц позволяет приложениям получать доступ к одним и тем же управляемым выделениям памяти как с хоста, так и с устройства без явной синхронизации. Это также устраняет необходимость предварительной синхронизации среды выполнения CUDA 9.0408 все управляемых выделений памяти перед каждым запуском ядра. Вместо этого, когда ядро обращается к нерезидентной странице памяти, происходит сбой, и страница может быть перенесена в память графического процессора по запросу или отображена в адресное пространство графического процессора для доступа через интерфейсы PCIe/NVLink.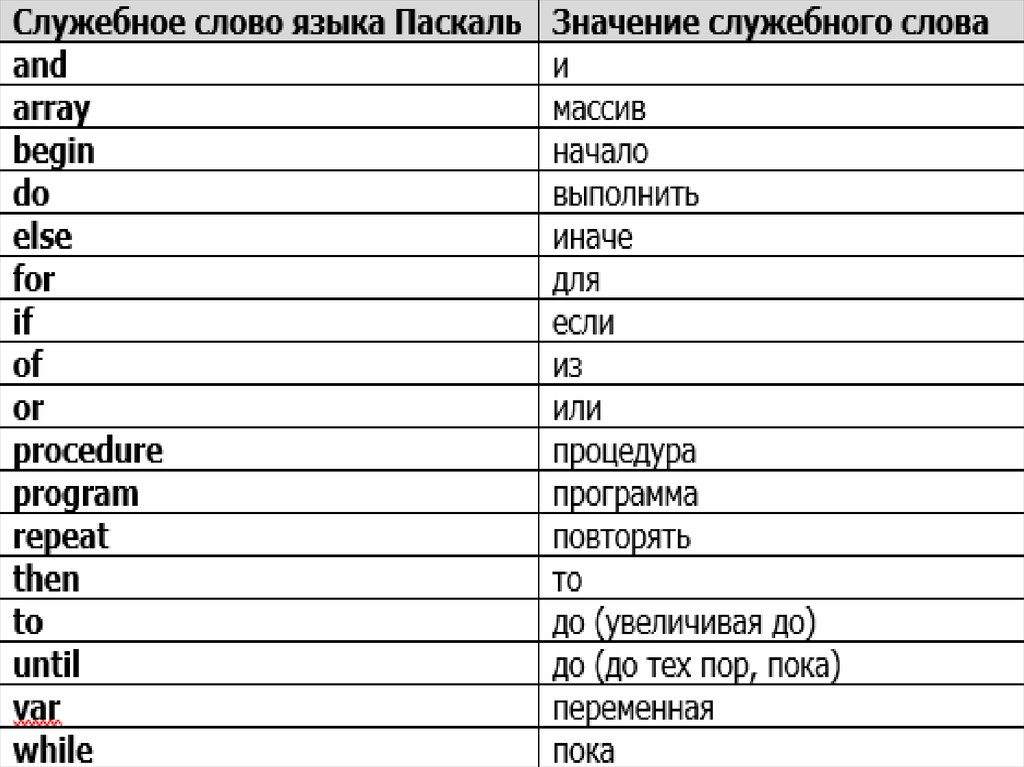
Эти функции повышают производительность Pascal для многих типичных рабочих нагрузок единой системы обмена сообщениями. В тех случаях, когда эвристики единой системы обмена сообщениями оказываются неоптимальными, возможна дальнейшая настройка с помощью набора указаний по миграции, которые можно добавить в исходный код.
На поддерживаемых платформах операционных систем к любой памяти, выделенной с помощью распределителя ОС по умолчанию (например, malloc или new), можно получить доступ как из кода графического процессора, так и из кода ЦП с использованием одного и того же указателя. Фактически вся виртуальная память системы может быть доступна из GPU. В таких системах нет необходимости явно выделять управляемую память с помощью cudaMallocManaged() .
Версия 1.0
Версия 1.1
3.1. Уведомление
Этот документ предоставляется только в информационных целях и не должен рассматриваться как гарантия определенной функциональности, состояния или качества продукта. Корпорация NVIDIA («NVIDIA») не делает никаких заявлений или гарантий, явных или подразумеваемых, в отношении точности или полноты информации, содержащейся в этом документе, и не несет ответственности за любые содержащиеся в нем ошибки. NVIDIA не несет ответственности за последствия или использование такой информации или за любые нарушения патентов или других прав третьих лиц, которые могут возникнуть в результате ее использования. Этот документ не является обязательством по разработке, выпуску или поставке какого-либо Материала (определение приведено ниже), кода или функций.
Корпорация NVIDIA («NVIDIA») не делает никаких заявлений или гарантий, явных или подразумеваемых, в отношении точности или полноты информации, содержащейся в этом документе, и не несет ответственности за любые содержащиеся в нем ошибки. NVIDIA не несет ответственности за последствия или использование такой информации или за любые нарушения патентов или других прав третьих лиц, которые могут возникнуть в результате ее использования. Этот документ не является обязательством по разработке, выпуску или поставке какого-либо Материала (определение приведено ниже), кода или функций.
NVIDIA оставляет за собой право вносить исправления, модификации, дополнения, улучшения и любые другие изменения в этот документ в любое время без предварительного уведомления.
Клиент должен получить самую последнюю соответствующую информацию перед размещением заказов и должен убедиться, что такая информация актуальна и полна.
Продукты NVIDIA продаются в соответствии со стандартными положениями и условиями продажи NVIDIA, предоставляемыми во время подтверждения заказа, если иное не оговорено в отдельном договоре купли-продажи, подписанном уполномоченными представителями NVIDIA и покупателем («Условия продажи»). Настоящим NVIDIA прямо возражает против применения каких-либо общих положений и условий для клиентов в отношении покупки продукта NVIDIA, упомянутого в этом документе. Никакие договорные обязательства прямо или косвенно этим документом не образуются.
Настоящим NVIDIA прямо возражает против применения каких-либо общих положений и условий для клиентов в отношении покупки продукта NVIDIA, упомянутого в этом документе. Никакие договорные обязательства прямо или косвенно этим документом не образуются.
Продукты NVIDIA не предназначены, не одобрены и не имеют гарантий для использования в медицинском, военном, авиационном, космическом оборудовании или оборудовании жизнеобеспечения, а также в приложениях, в которых сбой или неисправность продукта NVIDIA может привести к травме. , смерти или ущерба имуществу или окружающей среде. NVIDIA не несет ответственности за включение и/или использование продуктов NVIDIA в таком оборудовании или приложениях, поэтому такое включение и/или использование осуществляется на собственный риск клиента.
NVIDIA не делает заявлений и не гарантирует, что продукты, основанные на этом документе, будут пригодны для любого указанного использования. Тестирование всех параметров каждого продукта не обязательно выполняется NVIDIA.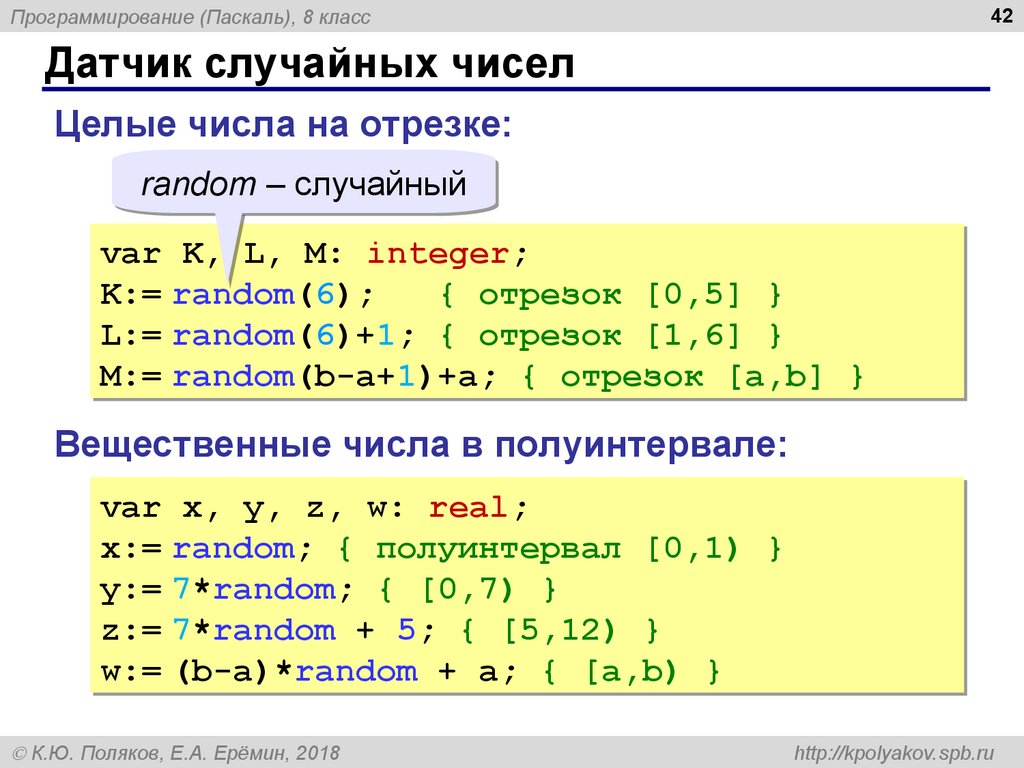 Заказчик несет единоличную ответственность за оценку и определение применимости любой информации, содержащейся в этом документе, за обеспечение того, что продукт подходит и подходит для применения, запланированного заказчиком, и за выполнение необходимого тестирования для приложения, чтобы избежать отказа приложения. или продукт. Слабые стороны конструкции продукта клиента могут повлиять на качество и надежность продукта NVIDIA и привести к дополнительным или отличным условиям и/или требованиям, помимо тех, которые содержатся в этом документе. NVIDIA не несет никакой ответственности, связанной с любым невыполнением обязательств, ущербом, расходами или проблемами, которые могут быть основаны или связаны с: (i) использованием продукта NVIDIA каким-либо образом, противоречащим данному документу, или (ii) конструкцией продукта клиента.
Заказчик несет единоличную ответственность за оценку и определение применимости любой информации, содержащейся в этом документе, за обеспечение того, что продукт подходит и подходит для применения, запланированного заказчиком, и за выполнение необходимого тестирования для приложения, чтобы избежать отказа приложения. или продукт. Слабые стороны конструкции продукта клиента могут повлиять на качество и надежность продукта NVIDIA и привести к дополнительным или отличным условиям и/или требованиям, помимо тех, которые содержатся в этом документе. NVIDIA не несет никакой ответственности, связанной с любым невыполнением обязательств, ущербом, расходами или проблемами, которые могут быть основаны или связаны с: (i) использованием продукта NVIDIA каким-либо образом, противоречащим данному документу, или (ii) конструкцией продукта клиента.
Никакие лицензии, явные или подразумеваемые, не предоставляются в соответствии с какими-либо патентными правами NVIDIA, авторскими правами или другими правами интеллектуальной собственности NVIDIA в соответствии с этим документом. Информация, опубликованная NVIDIA относительно сторонних продуктов или услуг, не является лицензией NVIDIA на использование таких продуктов или услуг, а также гарантией или их подтверждением. Для использования такой информации может потребоваться лицензия от третьей стороны в соответствии с патентами или другими правами на интеллектуальную собственность третьей стороны или лицензия от NVIDIA в соответствии с патентами или другими правами на интеллектуальную собственность NVIDIA.
Информация, опубликованная NVIDIA относительно сторонних продуктов или услуг, не является лицензией NVIDIA на использование таких продуктов или услуг, а также гарантией или их подтверждением. Для использования такой информации может потребоваться лицензия от третьей стороны в соответствии с патентами или другими правами на интеллектуальную собственность третьей стороны или лицензия от NVIDIA в соответствии с патентами или другими правами на интеллектуальную собственность NVIDIA.
Воспроизведение информации в этом документе разрешено только в том случае, если оно предварительно одобрено NVIDIA в письменной форме, воспроизведено без изменений и в полном соответствии со всеми применимыми экспортными законами и правилами, а также со всеми соответствующими условиями, ограничениями и уведомлениями.
ЭТОТ ДОКУМЕНТ И ВСЕ СПЕЦИФИКАЦИИ ПО ПРОЕКТИРОВАНИЮ NVIDIA, СПРАВОЧНЫЕ ПЛАТЫ, ФАЙЛЫ, ЧЕРТЕЖИ, ДИАГНОСТИКА, СПИСКИ И ДРУГИЕ ДОКУМЕНТЫ (ВМЕСТЕ И ОТДЕЛЬНО, «МАТЕРИАЛЫ») ПРЕДОСТАВЛЯЮТСЯ «КАК ЕСТЬ».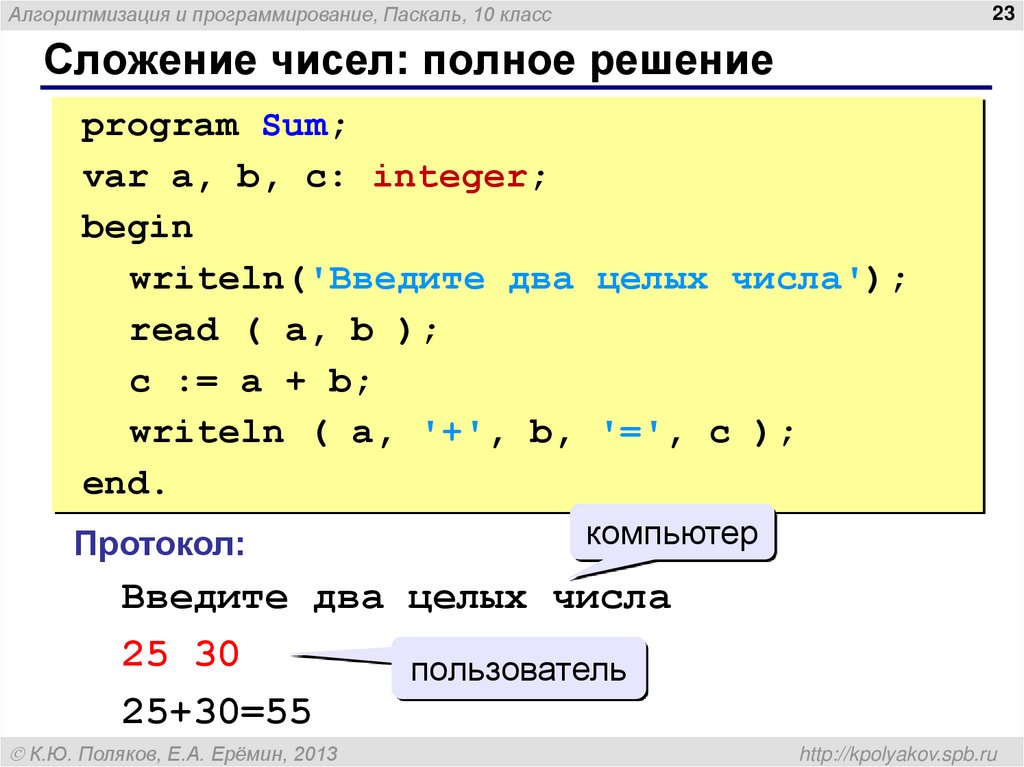 NVIDIA НЕ ПРЕДОСТАВЛЯЕТ НИКАКИХ ЯВНЫХ, ПОДРАЗУМЕВАЕМЫХ, ПРЕДУСМОТРЕННЫХ ЗАКОНОМ ИЛИ ИНЫМ ОБРАЗОМ ГАРАНТИЙ В ОТНОШЕНИИ МАТЕРИАЛОВ И ЯВНО ОТКАЗЫВАЕТСЯ ОТ ВСЕХ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ НЕНАРУШЕНИЯ ПРАВ, КОММЕРЧЕСКОЙ ПРИГОДНОСТИ И ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ. В СТЕПЕНИ, НЕ ЗАПРЕЩЕННОЙ ЗАКОНОМ, NVIDIA НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ ЗА ЛЮБОЙ УЩЕРБ, ВКЛЮЧАЯ, ПОМИМО ПРОЧЕГО, ЛЮБОЙ ПРЯМОЙ, КОСВЕННЫЙ, ОСОБЫЙ, СЛУЧАЙНЫЙ, ШТРАФНЫЕ ИЛИ ПОСЛЕДУЮЩИЕ УБЫТКИ, КАКИМ ОБРАЗОМ ПРИЧИНЕН И НЕЗАВИСИМО ОТ ТЕОРИИ ОТВЕТСТВЕННОСТИ, ВОЗНИКШИЙ ЛЮБОЕ ИСПОЛЬЗОВАНИЕ ЭТОГО ДОКУМЕНТА, ДАЖЕ ЕСЛИ NVIDIA БЫЛА УВЕДОМЛЕНА О ВОЗМОЖНОСТИ ТАКИХ УЩЕРБОВ. Невзирая на любые убытки, которые покупатель может понести по любой причине, совокупная и совокупная ответственность NVIDIA по отношению к покупателю за описанные здесь продукты ограничивается в соответствии с Условиями продажи продукта.
NVIDIA НЕ ПРЕДОСТАВЛЯЕТ НИКАКИХ ЯВНЫХ, ПОДРАЗУМЕВАЕМЫХ, ПРЕДУСМОТРЕННЫХ ЗАКОНОМ ИЛИ ИНЫМ ОБРАЗОМ ГАРАНТИЙ В ОТНОШЕНИИ МАТЕРИАЛОВ И ЯВНО ОТКАЗЫВАЕТСЯ ОТ ВСЕХ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ НЕНАРУШЕНИЯ ПРАВ, КОММЕРЧЕСКОЙ ПРИГОДНОСТИ И ПРИГОДНОСТИ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ. В СТЕПЕНИ, НЕ ЗАПРЕЩЕННОЙ ЗАКОНОМ, NVIDIA НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ ЗА ЛЮБОЙ УЩЕРБ, ВКЛЮЧАЯ, ПОМИМО ПРОЧЕГО, ЛЮБОЙ ПРЯМОЙ, КОСВЕННЫЙ, ОСОБЫЙ, СЛУЧАЙНЫЙ, ШТРАФНЫЕ ИЛИ ПОСЛЕДУЮЩИЕ УБЫТКИ, КАКИМ ОБРАЗОМ ПРИЧИНЕН И НЕЗАВИСИМО ОТ ТЕОРИИ ОТВЕТСТВЕННОСТИ, ВОЗНИКШИЙ ЛЮБОЕ ИСПОЛЬЗОВАНИЕ ЭТОГО ДОКУМЕНТА, ДАЖЕ ЕСЛИ NVIDIA БЫЛА УВЕДОМЛЕНА О ВОЗМОЖНОСТИ ТАКИХ УЩЕРБОВ. Невзирая на любые убытки, которые покупатель может понести по любой причине, совокупная и совокупная ответственность NVIDIA по отношению к покупателю за описанные здесь продукты ограничивается в соответствии с Условиями продажи продукта.
3.2. OpenCL
OpenCL — товарный знак Apple Inc., используемый по лицензии Khronos Group Inc.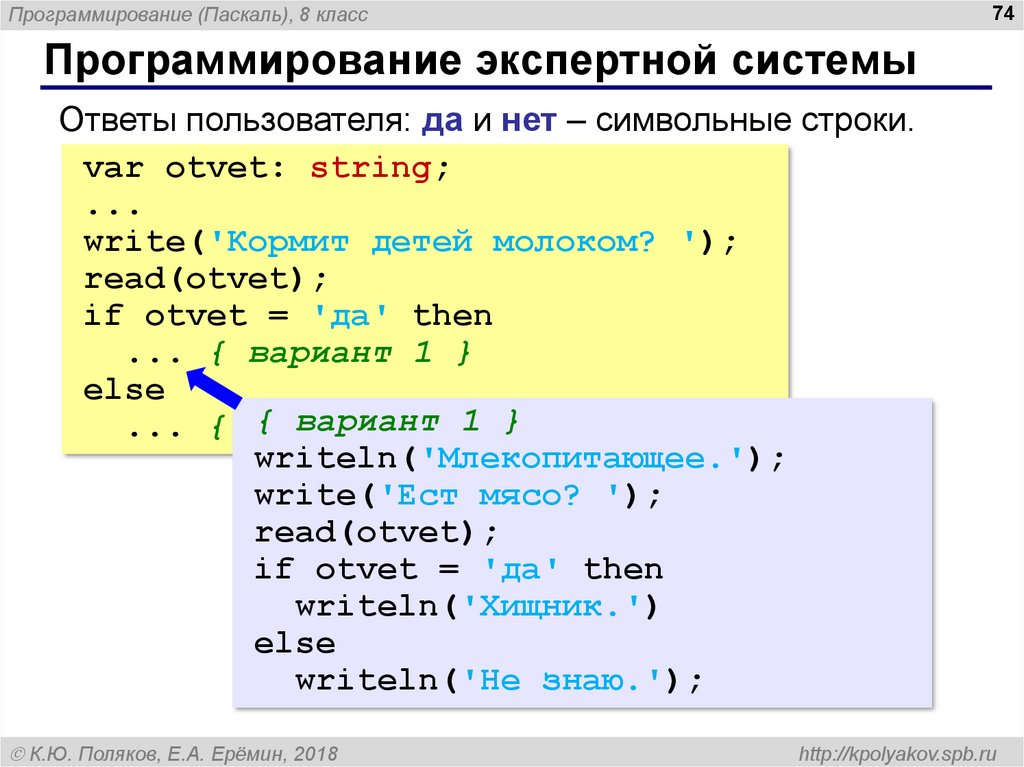
3.3. Товарные знаки
NVIDIA и логотип NVIDIA являются товарными знаками или зарегистрированными товарными знаками NVIDIA Corporation в США и других странах. Другие названия компаний и продуктов могут быть товарными знаками соответствующих компаний, с которыми они связаны.
- 1
В данном руководстве Kepler относится к устройствам с вычислительными возможностями 3.x, Maxwell относится к устройствам с вычислительными возможностями 5.x, а Pascal относится к устройствам с вычислительными возможностями 6.x.
- 2
Конкретные вычислительные возможности GP100 и GP104 — 6.0 и 6.1 соответственно. Архитектура GP102 аналогична GP104.
- 3
В Tesla P100 включено 56 SM.
- 4
В качестве исключения при разрозненных операциях записи в HBM2 возникают некоторые издержки из-за ECC, но они намного меньше, чем при аналогичных шаблонах доступа к памяти GDDR5 с ECC-защитой.