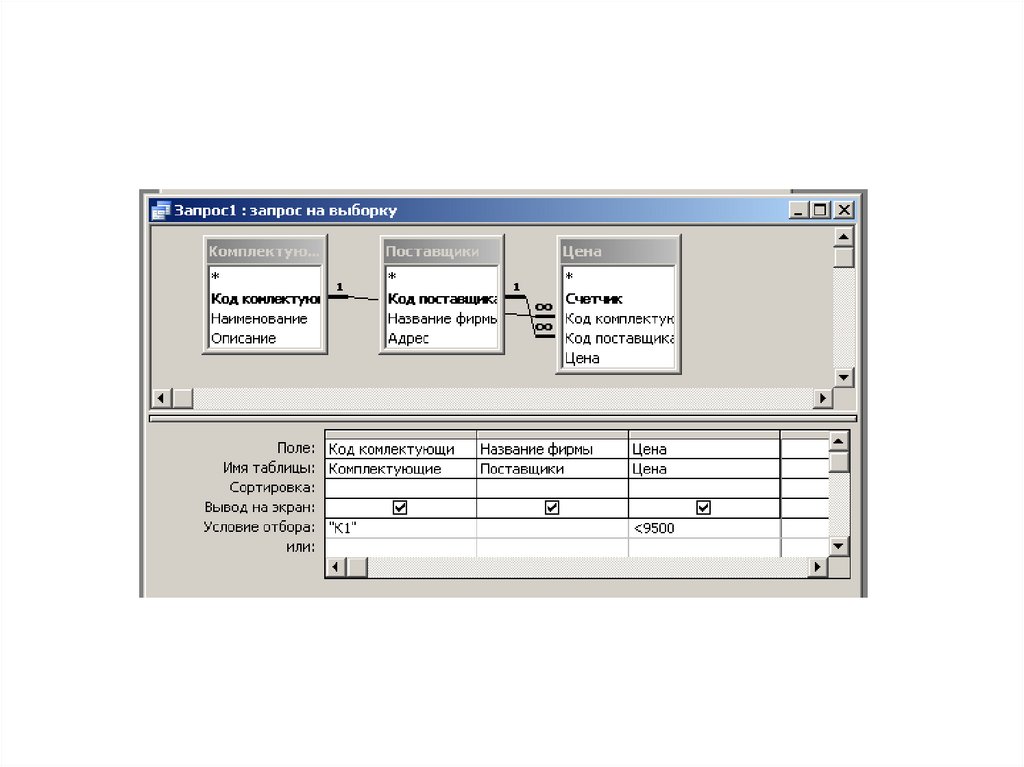
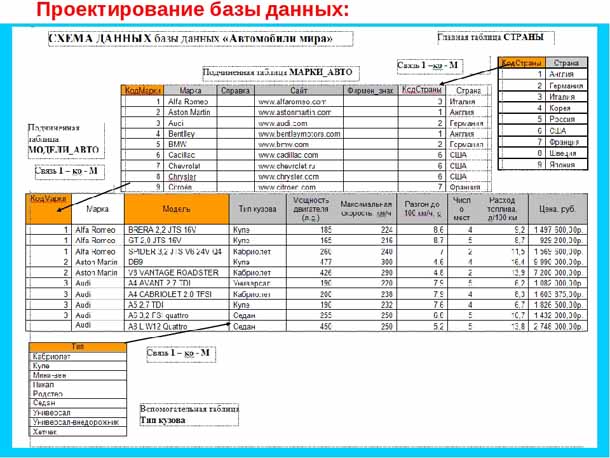
Проектирование многотабличной базы данных
Урок 8. Информатика 11 класс ФГОС
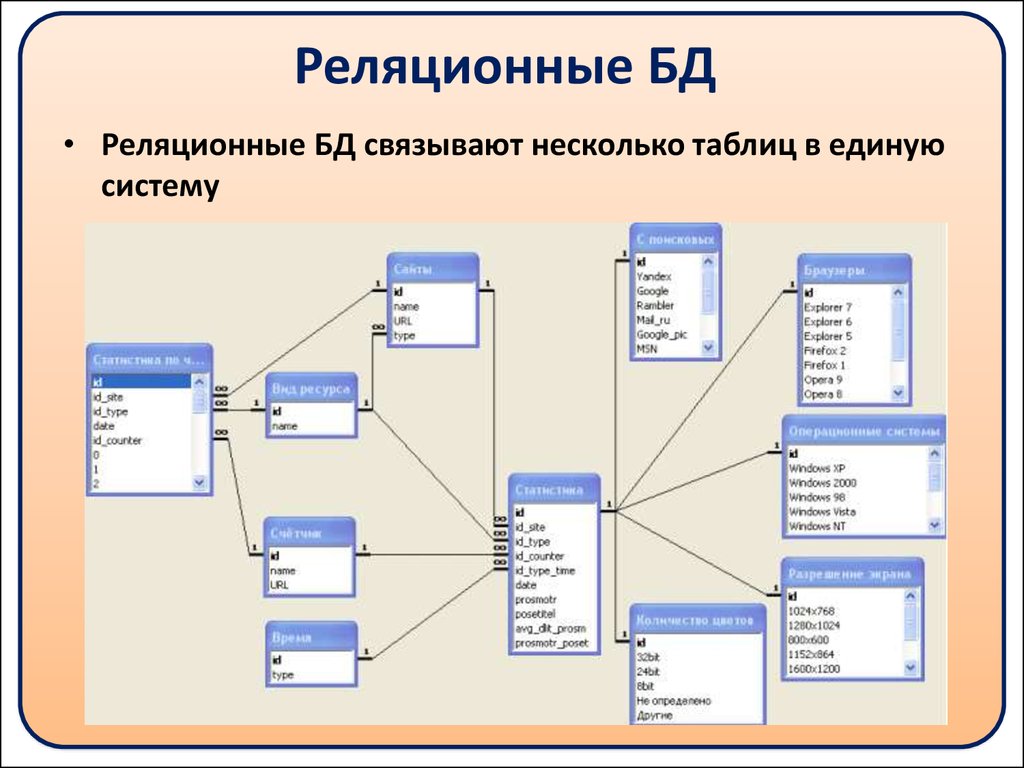
Этот урок включает в себя теоретическую часть, в которой рассказывается и показывается, как правильно проектировать многотабличную БД, чего нужно избегать и какие требования необходимо соблюдать.
Конспект урока «Проектирование многотабличной базы данных»
На данном уроке мы с вами научимся создавать структуру базы данных в виде таблиц, узнаем, какие отношения и связи бывают между таблицами, построим схему данных и многое другое.
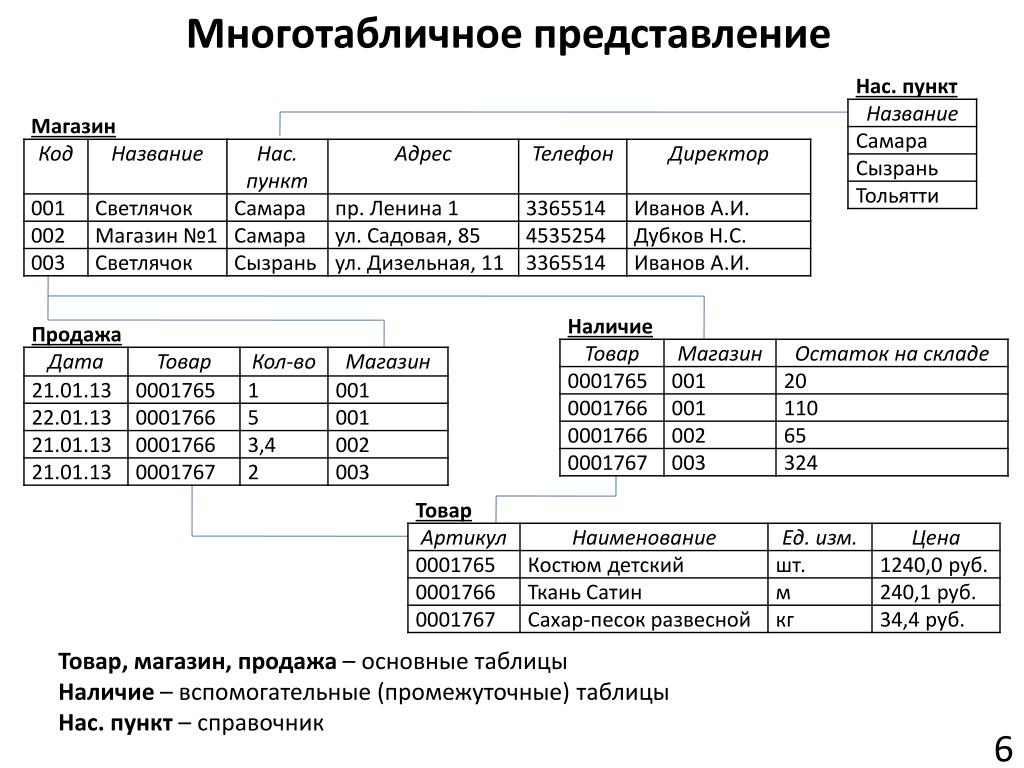
Чтобы узнать, как правильно проектировать многотабличную базу данных, мы рассмотрим этот процесс на примере. Для этого нам необходимо вернуться к примеру моделирования работы кредитного отдела банка.
Для
начала вспомним модель данных, которая состояла из трёх взаимосвязанных
таблиц. Она выглядит следующим образом.
Она выглядит следующим образом.
Данные таблицы представляют собой модель данных в реляционной СУБД. Но для удобной работы с базой данных, необходимо соблюдать некоторые
Одно и главное из них – это отсутствие избыточности данных. Это говорит о том, что нужно избегать лишних данных при построении базы данных, так как это приводит к лишнему расходу памяти. При выполнении этого требования можно сократить не только потребность в памяти компьютера, но и время поиска и обработки данных.
Видимый
недостаток наших таблиц в том, что многократно повторяются значения
полей в разных записях. Например, Вид кредита будет повторяться в 50
записях для 50 кредиторов, которые подали документы на кредит. Для удобства
можно в таблице «Кредитование населения с учётом плана» добавить поле «Код
кредита», а в таблице «Вид кредитования» поле «Вид кредита» заменить на поле
«Код кредита».
После изменения получим следующее.
Далее следует обратить внимание на таблицу «кредиторы». Она слишком большая и не удобная для работы. Можно разбить её на несколько таблиц поменьше. Получим следующее:
Такие таблицы более удобны.
В таблице «Анкета» содержатся данные о кредиторе. В таблице «Кредит» содержатся данные о виде кредита, сумме и отметке выдачи. А в таблице «Документы» содержится информация о поданных документах на кредит.
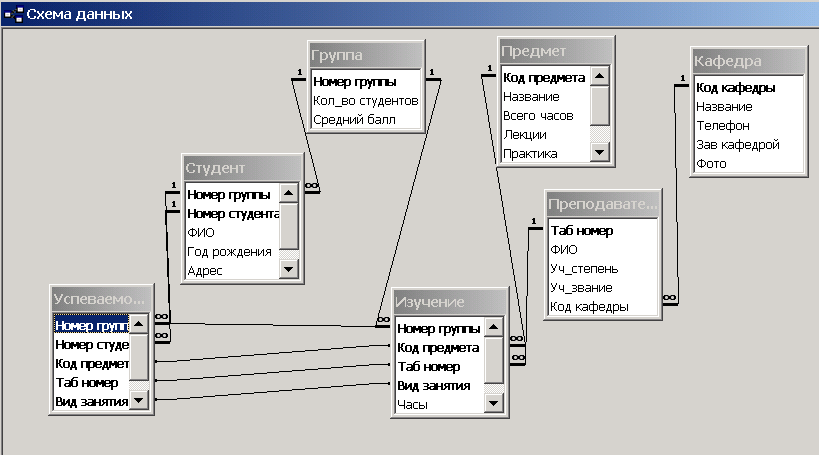
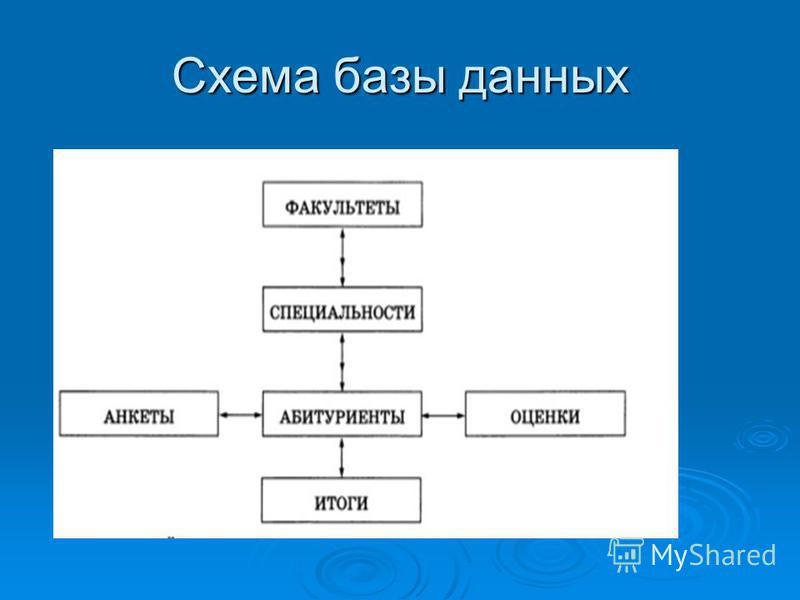
У нас получилось пять таблиц. Давайте представим их в строчном виде. Подчёркнутые поля будут обозначать ключевое поле.
Для
представления системы, все наши пять таблиц должны быть связаны между собой.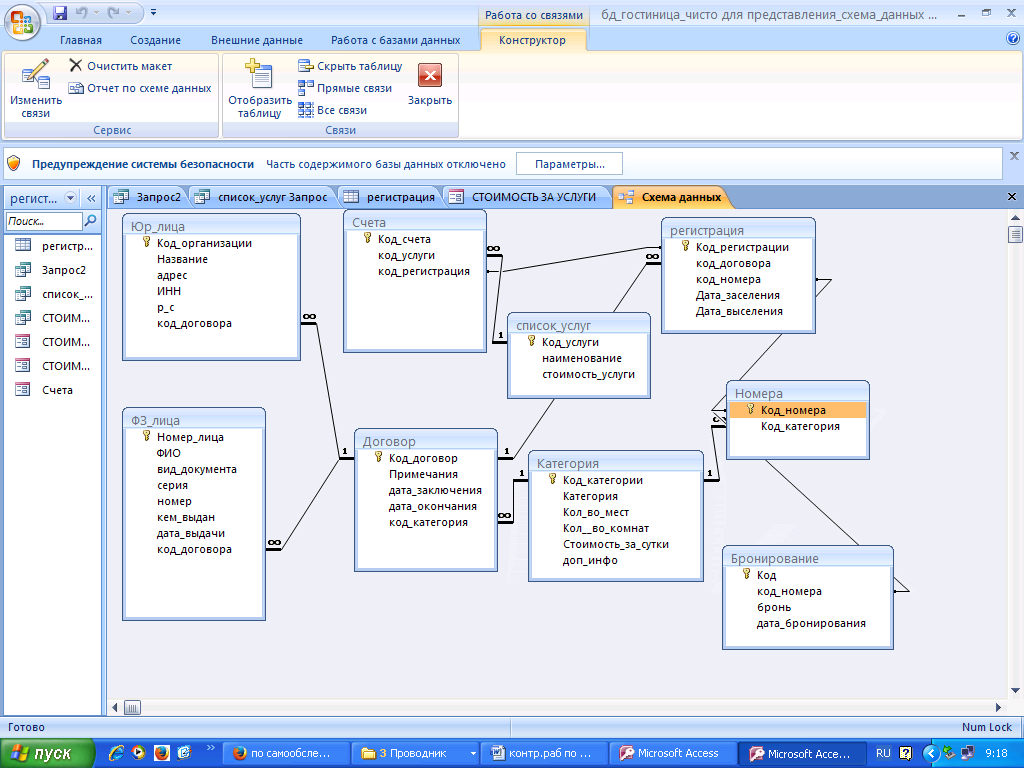
Если внимательно посмотреть на наши таблицы в строчном виде, то мы можем увидеть связи. Например, две первые таблицы имеют общее поле «Код кредита», а третья, четвёртая и пятая – регистрационный номер.
Связи помогают определить соответствия между любыми данными в этих таблицах, например, между фамилией кредитора и документами, которые он подал для кредитования. Благодаря этим связям можно получить ответы на запросы, которые требуют поиска информации в нескольких таблицах одновременно.
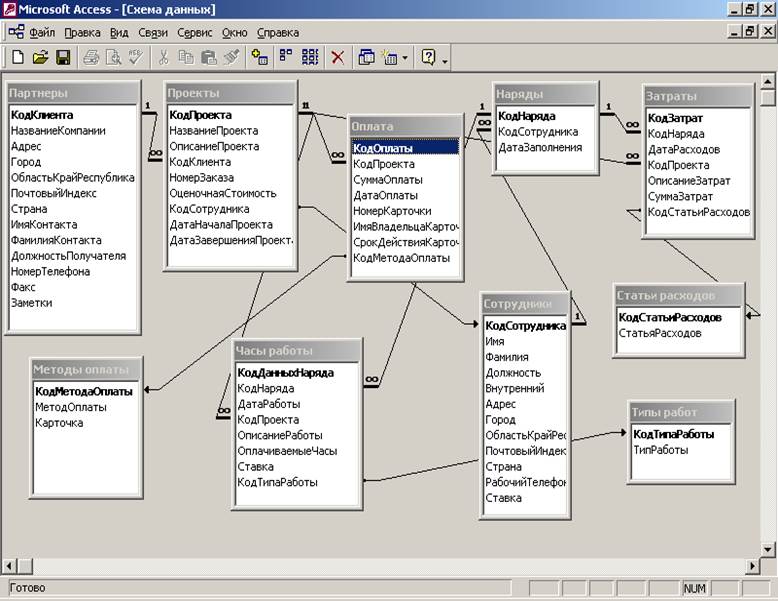
Следующее, с чем мы должны с вами познакомиться – это схема базы данных. Она создаётся для указания связей между таблицами. В схеме отображается наличие и типы связей между таблицами.
Если отобразить связи для нашей базы данных, то мы получим следующее:
Существует такие типы связей: «один к одному» и «один ко многим».
Чтобы
показать связь «один ко многим», добавим ещё одну таблицу «Перечень
документов», которая будет состоять из двух полей: «Номер документа» и
«Документ». В поле «Документ» будут перечислены все возможные документы для
всех видов кредита.
В поле «Документ» будут перечислены все возможные документы для
всех видов кредита.
Связь «один к одному» обозначается двунаправленной стрелкой, а связь «один ко многим» – одинарной стрелкой в одну сторону и двойной в другую. При связи «один к одному» с одной записью в таблице связана одна запись в другой таблице. Например, одна запись о кредиторе связана с одной записью о поданных им документах.
Связь «один ко многим» означает, что одна запись в одной таблице связана с несколькими записями в другой. Например, с одним видом кредита связано несколько видов документов.
Что же такое целостность данных?
Целостность данных – это свойство базы данных, которое обеспечивается поддерживанием организации связи между таблицами базы данных, которое осуществляет СУБД.
Система
не позволит, чтобы одноименные поля в разных связанных между собой таблицах
имели разные значения. Поэтому система автоматически контролирует ввод данных.
В связанных таблицах можно устанавливать режим каскадной замены. Это говорит о том, что при изменении значения поля в одной таблице, по которому установлена связь, будут автоматически изменены значения одноименных полей в других таблицах.
Если же установить режим каскадного удаления, то достаточно удалить запись из одной таблицы, чтобы связанные записи исчезли изо всех остальных таблиц.
На данном этапе проектирование базы данных подошло к концу.
Подведём итоги нашего урока.
Главное требование для удобной работы с базой данных – это отсутствие избыточности данных.
· Связи помогают определить соответствия между любыми данными в этих таблицах.
· Схема базы данных создаётся для указания связей между таблицами.
· Типы связей бывают следующих видов: «один к одному» и «один ко многим».
Предыдущий урок 7 Знакомство с СУБД LibreOffice Base
Следующий урок 9 Создание базы данных
Получите полный комплект видеоуроков, тестов и презентаций Информатика 11 класс ФГОС
Особенности проектирования многотабличных БД — Основные сведения о базах данных (Информатика и программирование)
Тема 6.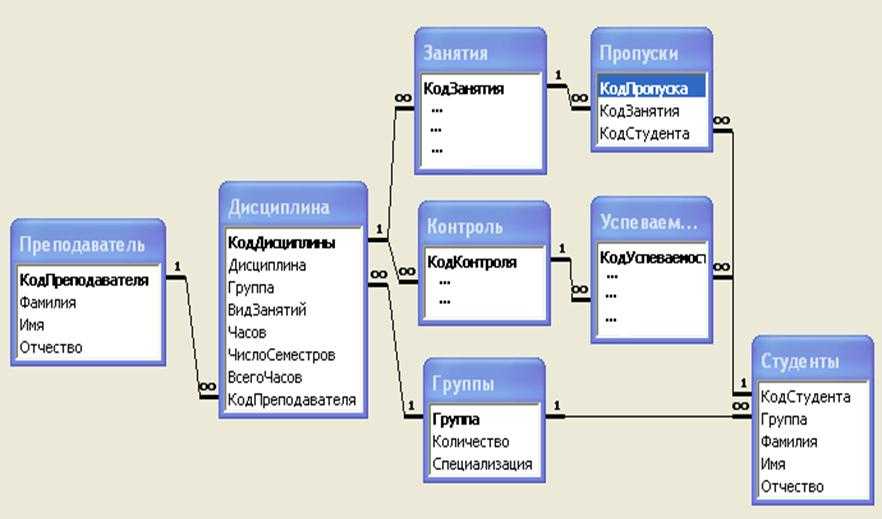 ОСОБЕННОСТИ ПРОЕКТИРОВАНИЯ МНОГОТАБЛИЧНЫХ БАЗ ДАННЫХ
ОСОБЕННОСТИ ПРОЕКТИРОВАНИЯ МНОГОТАБЛИЧНЫХ БАЗ ДАННЫХ
Как правило, базы данных Access являются многотабличными базами данных. Поэтому, немаловажным и достаточно трудоемким процессом является проектирование структуры баз данных, состоящее прежде всего в эффективно распределении данных между таблицами.
База данных, состоящая из множества таблиц, устанавливает связи между этими таблицами с помощью совпадающих полей. Например, таблицы:
Данные таблицы позволяют получить информацию о направлениях командировок,. имеющихся на фирме, и о командировках конкретных сотрудников.
В базе данных может хранится информация о сотрудниках.
Сотрудник Информация о ком. Ком
Каждая запись данных таблиц идентифицирует один объект. Сотрудника, Информация о его ком., Информация о предприятии-командире.
Отношения между таблицами определяется отношением между объектами (полями).
Существуют четыре типа отношений между таблицами:
— «один-к-одному »
— «один-ко-многим »
— «много-к-одному »
— «много-ко-многим »
Отношение «один-к-одному » означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице.
Например, таблицы Физические лица и
.
Обе таблицы содержат информацию о сотрудниках компании, но в таблице Физические лица содержатся данные о личности сотрудника, а в таблице Сотрудники профессиональные сведения. Между таблицами Физические лица и Сотрудники существуют отношения «один-к-одному » , поскольку для одного человека может существовать только одна запись, содержащая профессиональные сведения.
Связь между этими таблицами поддерживается при помощи совпадающих полей: Код сотрудника и Код физ. лица. Эти поля имеют разные наименования. Связь между таблицами устанавливается на основании значений совпадающих полей, а не их наименований.
Отношение «один-ко-многим » предполагает, что каждой записи в одной таблице может соответствовать несколько записей другой таблицы. Так, например, один и тот же сотрудник может несколько раз ездить в команд. Кроме того, в один и тот же город могут ездить несколько сотрудников. То есть, между таблицами Сотрудники и Информация о ком., а так же информация о ком. и Ком. Существует связь «один-ко-многим » .
То есть, между таблицами Сотрудники и Информация о ком., а так же информация о ком. и Ком. Существует связь «один-ко-многим » .
Отношение «много-к-одному » аналогично рассмотренному ранее типу «один-ко-многим » и зависит от точки зрения на отношение.
Отношение «много-ко-многим » возникает в том случае, если:
— одна запись из первой таблицы может быть связана с боле чем одной записью из другой таблицы;
— одна запись второй таблицы связана с более чем одной записью первой таблицы.
В качестве примера обратимся к магазину оптовой торговли. Рассмотрим две группы объектов:
— список товаров, производимых предприятиями ________
— список товаров, заказанных потребителями.
Поставки товаров Заказы потребителей
Между таблицами Поставки товаров и Заказы потребителей существует отношения «много-ко-многим » , так как на каждый поставляемый товар может быть более одного заказа.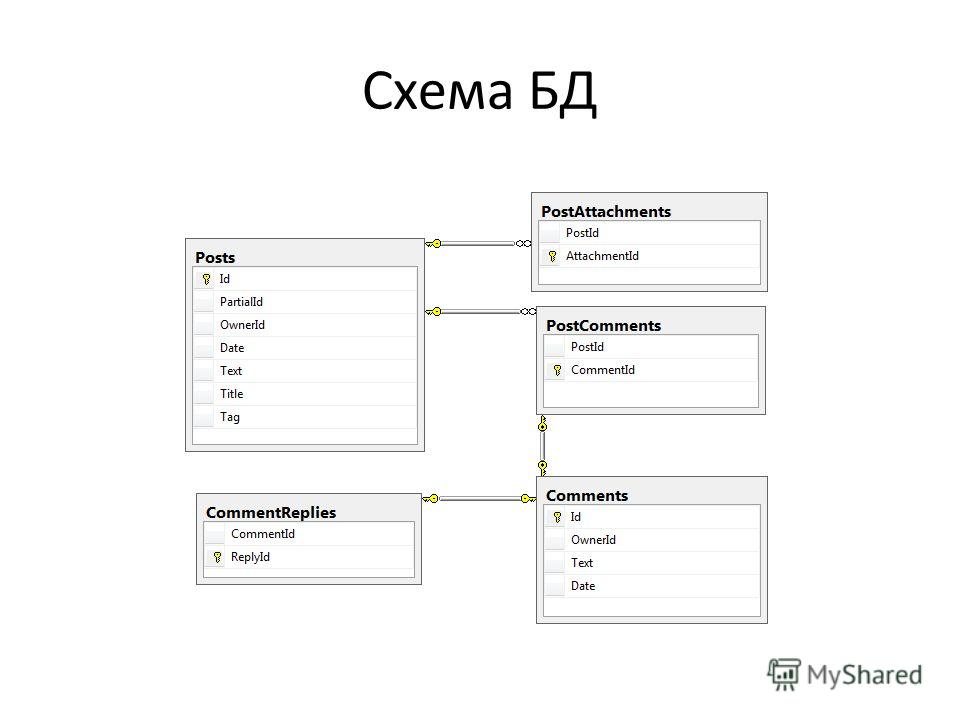 Аналогично, каждый заказанный товар может производится более чем одним предприятием. Связь между полями устанавливается на основании значения Код товара.
Аналогично, каждый заказанный товар может производится более чем одним предприятием. Связь между полями устанавливается на основании значения Код товара.
Проектирование нормализованной базы данных
При проектировании баз данных необходимо решить вопрос о наиболее эффективной структуре данных. Основные цели, которые при этом преследуются:
— обеспечить быстрый доступ к данным в таблицам
— исключить ненужное повторение данных
— обеспечить целостность данных так, чтобы при изменении значений одних полей выполнялось обновление всех связанных с ними полей таблиц.
Процесс уменьшения избыточности информации в базе данных называется нормализацией. В теории нормализации баз данных разработаны достаточно формализованные подходы по разбиению данных, обладающих сложной структурой, на несколько таблиц.
Теория нормализации оперирует понятиями нормальных форм таблиц (от 1 до 5), причем каждая последующая нормализованная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. (Мы рассмотрим 3 нормализованные формы).
(Мы рассмотрим 3 нормализованные формы).
В качестве примера рассмотрим информацию о продажах некоторых товаров.
Продажи
Данную таблицу можно рассматривать как однотабличную базу данных, но в ней есть множество недостатков:
— во всех заказах, сделанных одним и тем же предприятием, придется вводить информацию о покупке
— при изменении телефона или адреса покупателя эти координаты нужно выключить во всех заказах
— наличие новой информации снизит скорость выключения запросов и повысит вероятность ошибок
Поэтому, выполним нормализацию данных.
Первая нормальная форма таблицы
Таблица в первой нормальной форме должна удовлетворять следующим требованиям:
1. в таблице не должно быть повторение групп таблиц;
2. таблица не должна иметь повторных записей.
Поскольку покупатель может сделать несколько заказов, каждый из которых в свою очередь может содержать несколько товаров, нам необходимо две таблицы: Клиенты и Заказы.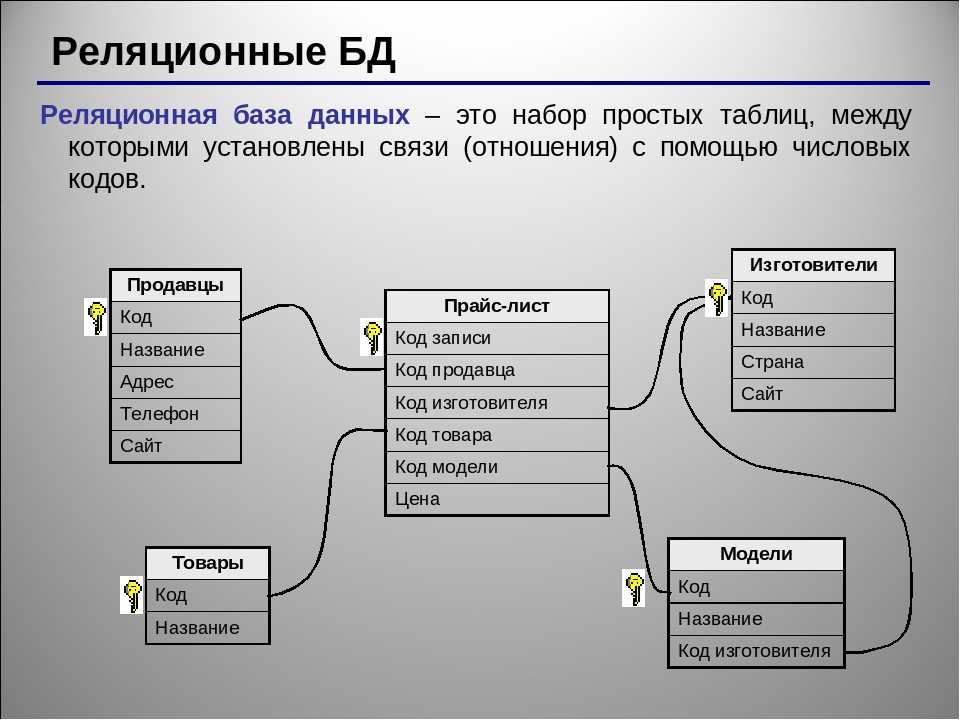 В качестве связывающего поля определим Код клиента, а отношение «один-ко-многим »
В качестве связывающего поля определим Код клиента, а отношение «один-ко-многим »
Клиенты Заказы
Данными действиями мы ликвидировали повторяющиеся группы полей.
Для исключения повторяющихся записей необходимо:
1. в таблице Клиенты определить первичный индекс с ключевым полем Код клиента.
2. Первичный ключ содержит информацию, которая однозначно идентифицирует запись (не допускает повторений значений поля).
Для этого нужно выделить название поля Код клиента в окне Конструктора таблицы Клиенты и нажать кнопку _____ Ключевое поле и команду контекстное меню Ключевое поле.
В Таблице Заказы исключить повторяющиеся записи можно одним из следующих способов:
1. добавить в таблицу уникальное ключевое поле Код заказа
2. создать уникальный составной индекс, состоящий из полей Код клиента, Код товара и Дата заказа.
После этого данные таблицы находятся в первой нормальной форме.
Вторая нормальная форма
О таблице говорят, что она находится во второй нормальной форме, если:
1. она удовлетворяет условиям первой нормальной формы
2. любое неключевое поле однозначно идентифицируется полным набором ключевых полей.
Из приведенного выше определения следует, что понятие второй нормальной нормы применимо только к таблицам, имеющим составной индекс (Заказы). Данная таблица не является таблицей во второй нормальной форме, поскольку поля Категория, Наименование товара и Цена однозначно определяются только одним из ключевых полей – Код товара.
Поэтому, для приведения таблицы Заказы во вторую нормальную форму необходимо выделить из таблицы Заказы таблицу Товары, которую будет содержать информацию о товарах каждого типа. Для связывания таблиц Заказы и Товары используются поля Код товара.
Клиенты Заказы
Третья нормальная форма таблицы
О таблице говорят, что она находится в третьей нормальной форме если:
1. она удовлетворяет условиям второй нормальной формы
она удовлетворяет условиям второй нормальной формы
2. ни одно из неключевых полей таблицы не идентифицируется с помощью другого неключевого поля
Сведения таблицы к третьей нормальной форме предлагает разделения таблицы с целью помещения в отдельную таблицу столбцов, которые не зависят от значения индекса, а зависят от другого неключевого поля.
Так, в таблице Клиенты поле Руководитель однозначно определяется значением поля Предприятие. Поэтому, следует создать таблицу Предприятия:
а в таблице Клиенты хранить только название Предприятия.
Определение связей между таблицами
После определения структуры таблиц, необходимо определить связи между совпадающими полями другой таблицы.
Для этого:
— вызвать команду Сервис/Схема данных или кнопку Схема данных из панели инструментов.
— добавить в окно связей окно Добавить таблицу (п.м. Связь/Добавить таблицу или кнопка Добавить таблицу).
— в списке таблиц, последовательно выделяя таблицы, нажимать кнопку Добавить или выделить сразу все и Добавить.
— для связи полей выбрать поле первой таблицы (Код клиента) и переместить его мышье на соответствующее поле в первой таблице (Код клиента).
Ключевые поля в списке полей обычно отображается полужирным шрифтом. Связанные поля не обязательно должны иметь одно название, но обязательно должны иметь одинаковые имена данных (а для Числового поля – еще и одинаковое свойство Размер поля).
На экране откроется окно диалога «Связи » .
Тип создаваемой связи зависит от полей, которые были указаны при определении связи:
— отношение «один-ко-многим » — создается в том случае, когда только одно из полей является ключевым или имеет уникальный индекс
— отношение «один-к-одному » — создается в том случае, если оба связываемых поля является уникальными или ключевыми.
— связь «много-ко-многим » — фактически представляет две связи с отношением «один-ко-многим » через третью таблицу, ключ которой состоит, по крайней мере, из двух полей, которые являются полями внешнего ключа в двух других таблицах.
При переносе поля, на являющегося ключевым, на другое такое же поле, создаются неопределенные отношения.
В окне диалога «схема данных » можно не только устанавливать связи между таблицами, но и выполнять следующие действия:
— изменять структуру таблицы
— изменять существующую связь
— удалять связь
— удалять таблицу из окна диалога «Схема данных »
— вывести на экран все существующие связи или связи только для конкретной таблицы.
— определить связи для запросов, не задавая условия целостности данных.
Связывание двух полей одной таблицы
На практике может возникнуть необходимость в определении поля, связанного с полем той же таблицы. Например, в таблице Сотрудники может быть поле Подчиняется, которое связано с тем же полем Сотрудник.
Для связывания поля таблицы с другим полем той же таблицы нужно дважды добавить эту таблицу в окно диалога «Схема данных » и создать связь соединив ноля лишней связи.
Изменение структуры таблицы в окне Схема данных
Для изменения структуры таблицы нужно, находясь в окне Схема данных, выделить модифицируемую таблицу и щелкнув правой кнопкой мыши, вызвать команду Конструктор таблиц.
Для удаления связи нужно ее выделить и нажать клавишу Delete. Для удаления таблицы из схемы данных нужно ее выделить и нажать Delete (только из одного окна, а не из базы данных).
Определение условий целостности данных
Условием целостности данных называют набор правил, используемых в Access для поддержания связей меду записями в связанных таблицах. Эти правила делают невозможным случайные удаления или изменения связанных данных.
Условия целостности данных выполняются при следующих условиях:
— связанное поле главной таблицы является ключевым полем;
— связанные поля имеют один тип данных;
— обе таблицы принадлежат одной базе данных.
— для определения целостности данных нужно в окне диалога Схема данных установить флажок «Обеспечение целостности данных » .
Лекция «Команды ОС для компиляции» также может быть Вам полезна.
При этом, над под лишней соединяющей поля, появятся обозначения 1 ко ¥.
Данное условие делает доступным следующие два режима:
— каскадное обновление связанных полей
— каскадом удаление связанных полей.
Если данные режимы не установлены, то при удалении, например, записи из таблицы Клиенты будут появляться сообщения о невозможности выполнения данной операции в том случае, если в таблице Заказы есть заказы, относящиеся к данному покупателю.
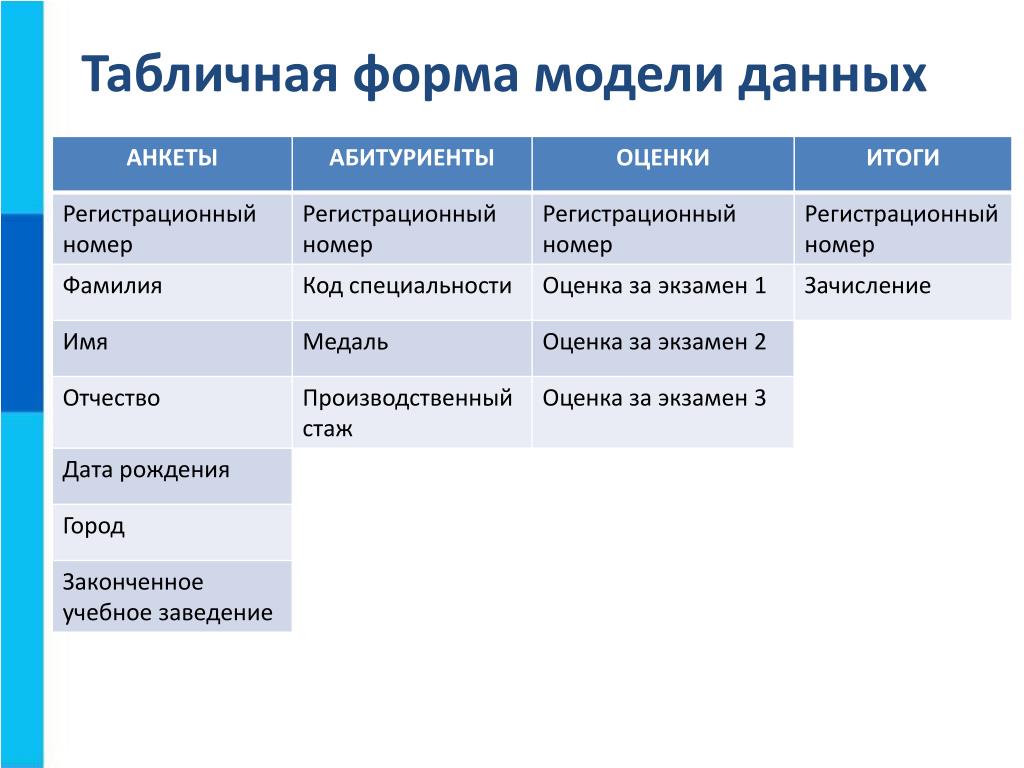
Проектирование многотабличной базы данных — презентация онлайн
Похожие презентации:
Проектирование многотабличной базы данных
Проектирование базы данных. Информационные системы и базы данных
Создание многотабличной базы данных. Практическая работа «Приемная комиссия»
Создание базы данных
Базы Данных (§12 — §23)
Базы данных. Многотабличные базы данных
Информационные системы. Базы данных
Базы данных
Проектирование и нормализация базы данных
Базы данных
Базы данных. Основы информационных систем
• Что такое информационная система (ИС)?
• Области применения ИС.
• Что такое база данных (БД)?
• Какие существуют варианты
классификаций БД.
• Какие БД называются реляционными?
– Что такое запись?
– Что такое поле, тип поля; какие бывают типы
– Что такое главный ключ записи? Приведите
примеры
• Определите главный ключ и типы
полей в следующих отношениях:
– АВТОБУСЫ (НОМЕР МАРШРУТА,
НАЧАЛЬНАЯ ОСТАНОВКА, КОНЕЧНАЯ
ОСТАНОВКА)
– КИНО (КИНОТЕАТР, СЕАНС, ФИЛЬМ,
РОССИЙСКИЙ, ДЛИТЕЛЬНОСТЬ)
– УРОКИ (ДЕНЬ НЕДЕЛИ, НОМЕР УРОКА,
КЛАСС, ПРЕДМЕТ, ПРЕПОДАВАТЕЛЬ)
3. Проектирование многотабличной базы данных
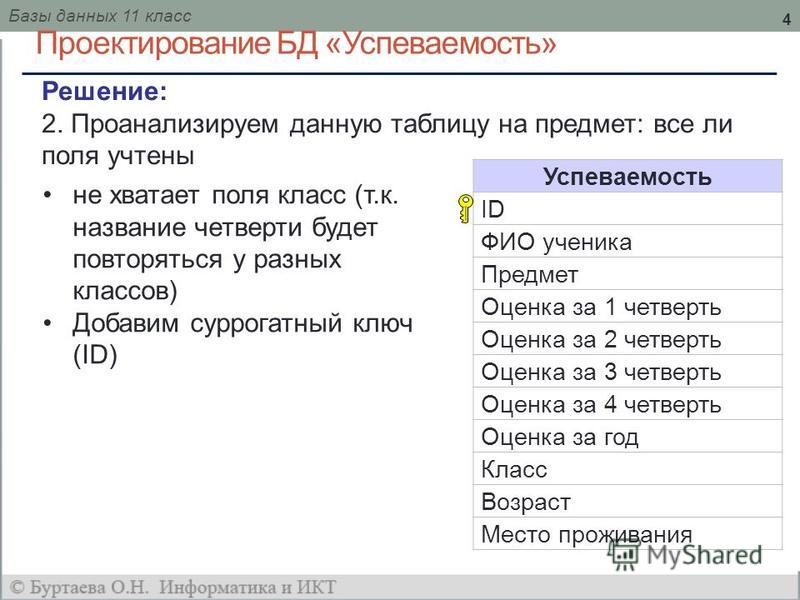
4. Пример структурной модели:
Объект моделирования: процесс приёмаабитуриентов в высшее учебное заведение
(университет)
1) Системный анализ предметной области
Предметная область:
Работа приемной
комиссии университета
1) определение предметной области
1
2
3
4
• Подготовительный этап:
• Предоставление информации о вузе.
 Его факультетах
Его факультетахдля принятия решения молодыми людьми…
• Приём документов от абитуриентов, оформление
документации
• Сдача абитуриентами приемных экзаменов, обработка
результатов экзаменов
• Процедура зачисления в университет по результатам
экзаменов
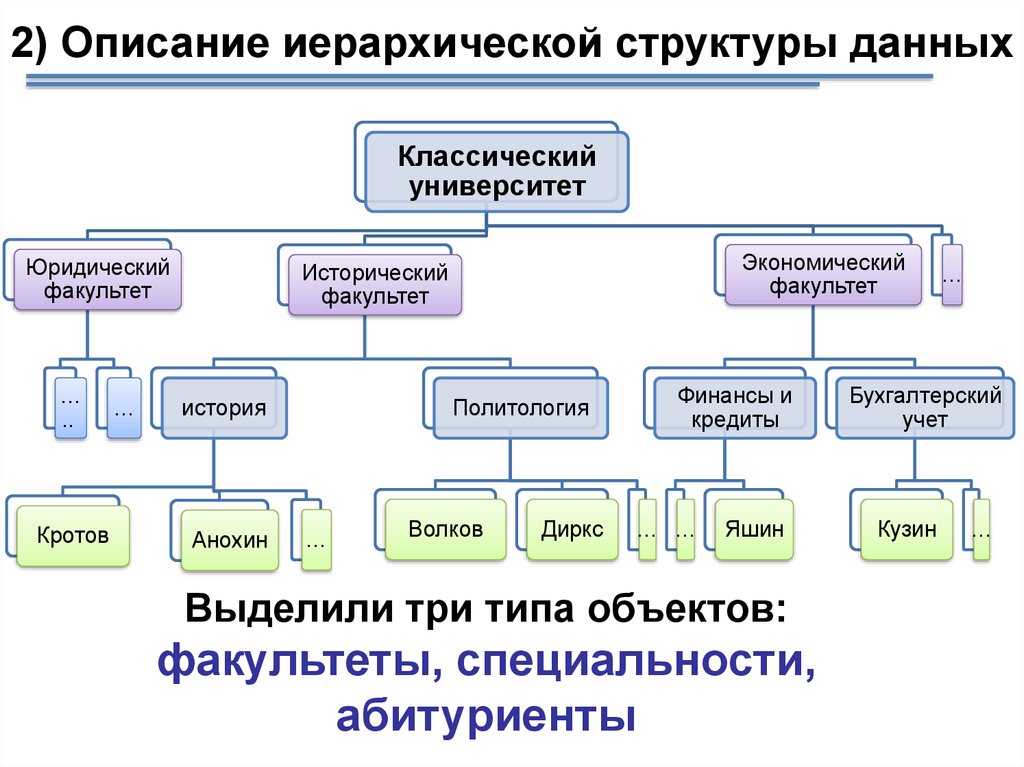
7. 2) Описание иерархической структуры данных
Классическийуниверситет
Юридический
факультет
…
..
Кротов
…
Экономический
факультет
Исторический
факультет
история
Анохин
Политология
…
Волков
Диркс
Финансы и
кредиты
… …
Яшин
Выделили три типа объектов:
факультеты, специальности,
абитуриенты
…
Бухгалтерский
учет
Кузин
…
8. 3) Определение необходимого набора параметров
(свойств, атрибутов) для каждого типа объектов)Название факультета
Экзамен 1
Экзамен 2
Регистрационный номер
Экзамен 3
Дата рождения
Фамилия
Имя
Отчество
Город
Законченное учебное заведение
Название специальности
Название
специальности
Название факультета
План приема
Производственный стаж
Медаль
Оценка за экзамен 1
Оценка за экзамен 2
Оценка за экзамен 3
Зачисление
9.
 Какой недостаток?Название факультета
Какой недостаток?Название факультетаЭкзамен 1
Экзамен 2
Регистрационный номер
Экзамен 3
Дата рождения
Фамилия
Имя
Отчество
Город
Законченное учебное заведение
Название специальности
Название
специальности
Название факультета
План приема
Производственный стаж
Медаль
Оценка за экзамен 1
Оценка за экзамен 2
Оценка за экзамен 3
Зачисление
10. Минимизируем избыточность
Код факультетаНазвание факультета
Экзамен 1
Экзамен 2
Экзамен 3
Код специальности
Название
специальности
Код факультета
План приема
Регистрационный
номер
Регистрационный
номер
Регистрацион
ный номер
Регистрацион
ный номер
Фамилия
Оценка за
экзамен 1
Зачисление
Имя
Код
специальности
Отчество
Медаль
Оценка за
экзамен 2
Дата рождения
Город
Законченное
учебное заведение
Оценка за
экзамен 3
12.
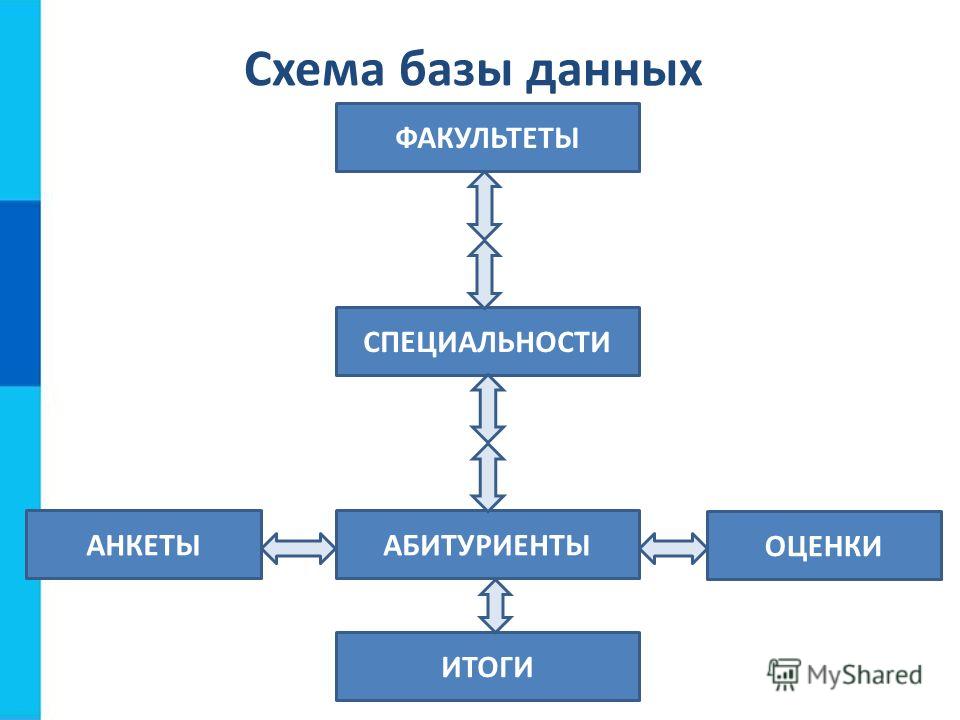
 БД «Приемная комиссия»• ФАКУЛЬТЕТЫ (КОД_ФАКТ, ФАКУЛЬТЕТ, ЭКЗАМЕН_1,
БД «Приемная комиссия»• ФАКУЛЬТЕТЫ (КОД_ФАКТ, ФАКУЛЬТЕТ, ЭКЗАМЕН_1,ЭКЗАМЕН_2, ЭКЗАМЕН_3)
• СПЕЦИАЛЬНОСТИ (КОД_СПЕЦ, СПЕЦИАЛЬНОСТЬ,
КОД_ФАКТ, ПЛАН)
• АБИТУРИЕНТЫ (РЕГ_НОМ, КОД_СПЕЦ, МЕДАЛЬ,
СТАЖ)
• АНКЕТЫ (РЕГ_НОМ, ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО,
ДАТА_РОЖД, ГОРОД, УЧ_ЗАВДЕНИЕ)
• ОЦЕНКИ (РЕГ_НОМ, ОЦЕНКА_1, ОЦЕНКА_2,
ОЦЕНКА_3)
• ИТОГИ (РЕГ_НОМ, ЗАЧИСЛЕНИЕ)
13. Отношения и связи (схема БД)
ФАКУЛЬТЕТЫСвязь один
ко многим
СПЕЦИАЛЬНОСТИ
АНКЕТЫ
АБИТУРИЕНТЫ
ОЦЕНКИ
ИТОГИ
Связь один к
одному
14. Целостность данных
!Свойство согласованности действий с
повторяющимися данными
Система не допускает, чтобы одноименные поля в
разных связанных между собой таблицах имели
разные значения
Режим каскадной замены: если в одной из таблиц
изменяется значение поля, по которому установлена связь,
то в других таблицах одноименные поля автоматически
изменяют свои значения
Режим каскадного удаления: достаточно удалить запись
из одной таблицы
15.
 Проектирование многотабличной БД • 1-ый этап: анализ предметной
Проектирование многотабличной БД • 1-ый этап: анализ предметнойобласти (результат: построение
структуры данных – информационной
модели предметной области)
• 2-ой этап: построение модели
данных для будущей БД
English Русский Правила
Access: Разработка многотабличного запроса
Урок 9: Разработка многотабличного запроса
/en/access/designing-a-simple-query/content/
Введение
На предыдущем уроке вы узнали, как создать простой запрос с одной таблицей. Большинство запросов, создаваемых в Access, скорее всего, будут использовать несколько таблиц , что позволит вам отвечать на более сложные вопросы. На этом уроке вы узнаете, как спроектировать и создать многотабличный запрос .
В этом руководстве мы будем использовать образец базы данных. Если вы хотите продолжить, вам необходимо загрузить нашу базу данных Access.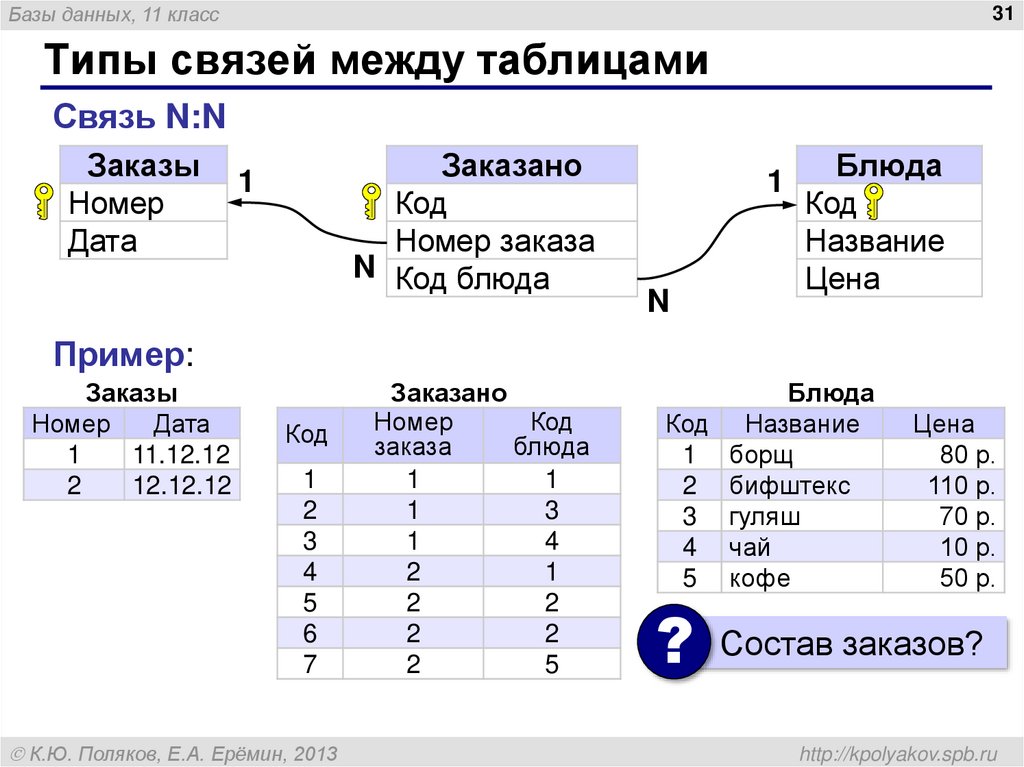 Чтобы открыть пример, на вашем компьютере должен быть установлен Access.
Чтобы открыть пример, на вашем компьютере должен быть установлен Access.
Посмотрите видео ниже, чтобы узнать, как создать запрос к нескольким таблицам (часть 1).
Посмотрите видео ниже, чтобы узнать больше о соединениях и критериях запросов (часть 2).
Разработка многотабличного запроса
Запросы могут быть трудными для понимания и построения, если у вас нет четкого представления о том, что вы пытаетесь найти и как это найти. Запрос с одной таблицей может быть достаточно простым, чтобы его можно было составить по мере продвижения, но для создания чего-то более мощного вам потребуется заранее спланировать запрос.
Планирование запроса
При планировании запроса, использующего более одной таблицы, выполните следующие четыре шага:
- Точно определите то, что вы хотите узнать.
 Если бы вы могли задать своей базе данных любой вопрос, что бы это было? Построение запроса сложнее, чем просто задать вопрос, но точно знать, на какой вопрос вы хотите ответить, необходимо для создания полезного запроса.
Если бы вы могли задать своей базе данных любой вопрос, что бы это было? Построение запроса сложнее, чем просто задать вопрос, но точно знать, на какой вопрос вы хотите ответить, необходимо для создания полезного запроса. - Определите все типы информации, которые вы хотите включить в результаты запроса. Какие поля содержат эту информацию?
- Найдите поля, которые вы хотите включить в свой запрос. В каких таблицах они содержатся?
- Определите критерии, которым должна соответствовать информация в каждом поле. Подумайте о вопросе, который вы задали на первом этапе. Какие поля вам нужны для поиска конкретной информации? Какую информацию вы ищете? Как вы будете его искать?
Поначалу этот процесс может показаться абстрактным, но по мере того, как мы будем проходить процесс планирования нашего собственного многотабличного запроса, вы должны начать понимать, как планирование ваших запросов может значительно упростить их построение.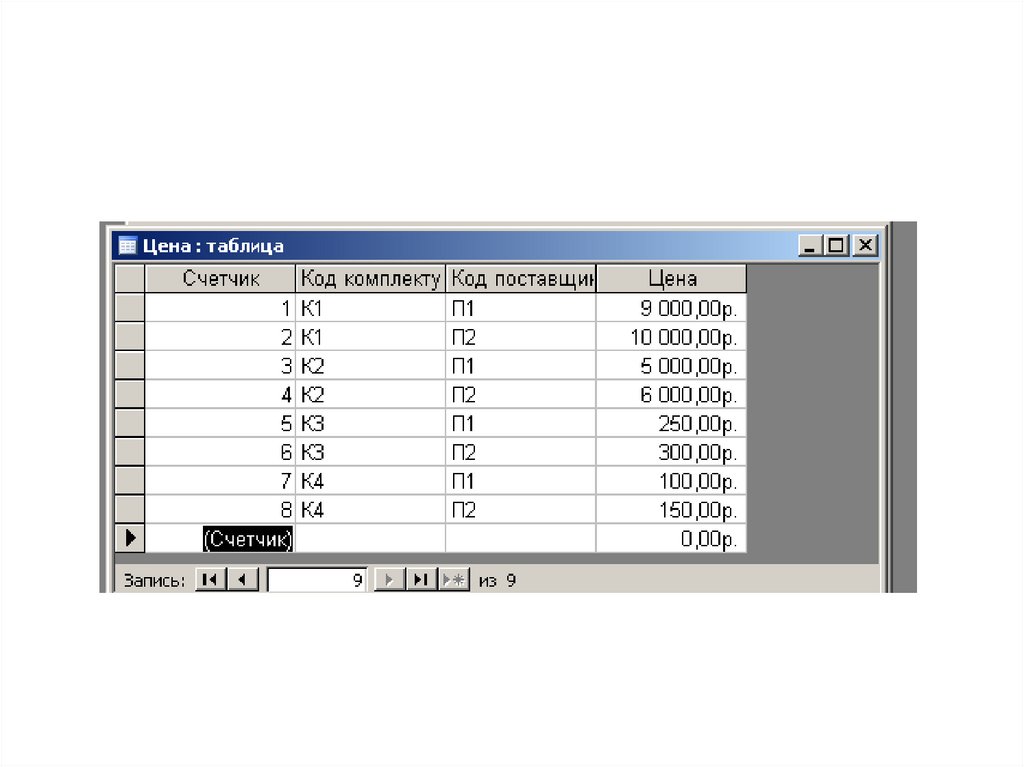
Планирование нашего запроса
Давайте пройдем этот процесс планирования с помощью запроса, который мы запустим в нашей базе данных пекарни. Читая процесс планирования шаг за шагом, подумайте о том, как каждая часть процесса планирования может применяться к другим запросам, которые вы можете выполнить.
Шаг 1: Определение вопроса, который мы хотим задать
Наша база данных пекарен содержит много клиентов, некоторые из которых никогда не размещали заказы, но которые находятся в нашей базе данных, потому что они подписались на нашу рассылку. Большинство из них живут в черте города, но другие живут за городом или даже за пределами штата. Мы хотим, чтобы наши иногородние клиенты, которые размещали заказы в прошлом, вернулись и дали нам еще одну попытку, поэтому мы собираемся отправить им несколько купонов по почте. На самом деле мы не хотим, чтобы наш список включал клиентов, которые живут слишком далеко; отправка купона тому, кто не живет в нашем районе, вероятно, не заставит этого человека прийти. Поэтому мы просто хотим найти людей, которые не живут в нашем городе, но все еще живут в нашем районе.
Поэтому мы просто хотим найти людей, которые не живут в нашем городе, но все еще живут в нашем районе.
Короче говоря, вопрос, на который мы хотим получить ответ, звучит так: Какие клиенты живут в нашем районе, находятся за чертой города и сделали заказ в нашей пекарне?
Шаг 2: Определение необходимой информации
Какую информацию мы хотели бы видеть в списке об этих клиентах? Очевидно, нам понадобятся имен клиентов и их контактная информация : их адресов , телефонных номеров и адреса электронной почты . Но как мы узнаем, разместили ли они заказы? Каждая запись заказа идентифицирует клиента, разместившего этот заказ. Если мы включим идентификаторов заказов , мы сможем сузить наш список только до клиентов, которые ранее размещали заказы.
Шаг 3: Поиск таблиц, содержащих нужную нам информацию
Чтобы написать запрос, вы должны быть знакомы с различными таблицами в вашей базе данных. Благодаря интенсивной работе с нашей собственной базой данных мы знаем, что необходимая нам информация о клиентах находится в полях Клиенты табл. Наши идентификаторы заказов находятся в поле в таблице Orders . Нам нужно только включить эти две таблицы, чтобы найти всю необходимую информацию.
Благодаря интенсивной работе с нашей собственной базой данных мы знаем, что необходимая нам информация о клиентах находится в полях Клиенты табл. Наши идентификаторы заказов находятся в поле в таблице Orders . Нам нужно только включить эти две таблицы, чтобы найти всю необходимую информацию.
Шаг 4: Определение критериев, которые должен искать наш запрос
Когда вы устанавливаете критерии для поля в запросе, вы фактически применяете к нему фильтр, который указывает запросу извлекать только информацию, соответствующую вашим критериям. Просмотрите список полей, которые мы включаем в этот запрос. Как и где мы можем установить критерии, которые лучше всего помогут нам ответить на наш вопрос?
Нам не нужны клиенты, которые живут в нашем городе, Роли, поэтому нам нужен критерий, который будет возвращать все записи , кроме с Роли в поле города. Нам также не нужны клиенты, которые живут слишком далеко. Все телефонные номера в области начинаются с кода города 919, поэтому мы также включим критерий, который будет возвращать только те записи, чьи записи из поля телефонного номера начинаются с 919. Это должно гарантировать, что мы отправляйте купоны только тем клиентам, которые живут достаточно близко, чтобы вернуться и использовать их.
Все телефонные номера в области начинаются с кода города 919, поэтому мы также включим критерий, который будет возвращать только те записи, чьи записи из поля телефонного номера начинаются с 919. Это должно гарантировать, что мы отправляйте купоны только тем клиентам, которые живут достаточно близко, чтобы вернуться и использовать их.
Мы не будем устанавливать критерии для поля идентификатора заказа или любых других полей, потому что мы хотим видеть все заказов, сделанных людьми, которые соответствуют двум критериям, которые мы только что установили.
Чтобы писать запросы, вы должны иметь возможность задавать критерии на языке, который Access понимает . Как вы можете видеть на изображении выше, наши критерии, требующие, чтобы номера телефонов начинались с 919, должны быть введены следующим образом: Like («919*») . Чтобы узнать, как писать дополнительные критерии, ознакомьтесь с нашим печатным справочным руководством по критериям запросов, которое включает несколько наиболее распространенных критериев, используемых в запросах Access.
Соединение таблиц в запросах
Последнее, что вам нужно учитывать при разработке запроса, — это способ связывания или соединения таблиц, с которыми вы работаете. Когда вы добавите две таблицы в запрос Access, это то, что вы увидите на панели Object Relationship :
Линия, соединяющая две таблицы, называется линией соединения . Видите, как линия соединения на самом деле является стрелкой? Это связано с тем, что он указывает порядок, в котором запрос просматривает данные из двух таблиц. На изображении выше стрелка указывает от left to right , что означает, что запрос сначала просматривает данные в таблице left , а затем просматривает только данные в таблице right , которая связывает с записями, которые он уже видел в левой таблице. .
Ваши таблицы не всегда будут соединяться таким образом. Иногда Access будет присоединять к ним справа до слева . В любом случае вам может потребоваться изменить направление соединения, чтобы убедиться, что ваш запрос содержит правильную информацию. Направление соединения может повлиять на какую информацию ваш запрос извлекает .
В любом случае вам может потребоваться изменить направление соединения, чтобы убедиться, что ваш запрос содержит правильную информацию. Направление соединения может повлиять на какую информацию ваш запрос извлекает .
Чтобы понять, что это значит, рассмотрим запрос, который мы разрабатываем. Для нашего запроса нам нужно увидеть клиентов, разместивших заказы, поэтому мы включили таблицу Customers и таблицу Orders . Давайте взглянем на некоторые данные, содержащиеся в этих таблицах.
Что вы замечаете, когда смотрите на эти списки? Прежде всего, каждый отдельный заказ в таблице Orders связан с кем-то из Таблица Customers — клиент, разместивший этот заказ. Однако, взглянув на таблицу «Клиенты», вы увидите, что клиенты, разместившие несколько заказов, связаны более чем с одним заказом, а те, кто никогда не размещал заказы, не связаны ни с одним заказом. Как видите, даже когда две таблицы связаны, в одной таблице могут быть записи, не имеющие отношения к какой-либо записи в другой таблице.
Как видите, даже когда две таблицы связаны, в одной таблице могут быть записи, не имеющие отношения к какой-либо записи в другой таблице.
Итак, что происходит, когда Access пытается выполнить наш запрос с текущим соединением, слева направо ? Он извлекает каждую запись из таблицы слева: нашей таблицы Customers.
Затем он извлекает каждую запись из правой таблицы , которая имеет связь с записью, уже взятой Access из левой таблицы.
Поскольку наше соединение началось с таблицы Customers , наш запрос будет включать записи для всех наших клиентов, включая тех, кто никогда не размещал заказы. Это больше информации, чем нам нужно. У нас всего хотите просмотреть записи для клиентов, разместивших заказы .
К счастью, мы можем решить эту проблему, изменив направление линии соединения. Если вместо этого мы соединим таблицы справа налево , Access сначала извлечет заказы из таблицы right , наша таблица Orders :
Затем Access просмотрит левую таблицу и извлечет только записи клиенты, которые связаны с заказом справа.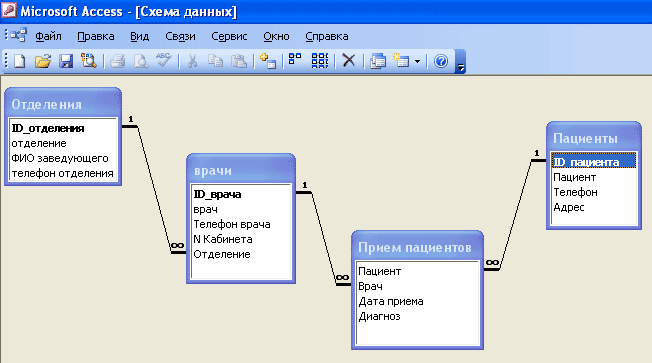
Теперь у нас есть именно та информация, которую мы хотели: все клиентов, разместивших заказ, и только этих клиентов. Как видите, нам пришлось соединить наши таблицы в правильном направлении , чтобы получить нужную нам информацию.
Теперь, когда мы понимаем, какое направление соединения нам нужно использовать, мы готовы построить наш запрос!
В нашем запросе нам нужно было использовать соединение вправо — влево , но правильное направление соединения для таблиц в ваших запросах будет зависеть от какую информацию вы хотите видеть и где хранится эта информация. Когда вы добавляете таблицы в запрос, Access автоматически соединяет таблицы вместо вас, но часто не в правильном направлении. Вот почему так важно всегда проверять соединения между вашими таблицами перед построением запроса.
Создание многотабличного запроса
Теперь, когда мы спланировали наш запрос, мы готовы разработать и запустить его. Если вы создали письменные планы для своего запроса, не забывайте часто ссылаться на них в процессе разработки запроса.
Если вы создали письменные планы для своего запроса, не забывайте часто ссылаться на них в процессе разработки запроса.
Чтобы создать запрос с несколькими таблицами:
- Выберите команду Query Design на вкладке Create на ленте.
- В появившемся диалоговом окне выберите каждую таблицу, которую вы хотите включить в свой запрос, и нажмите Добавить . Вы можете нажать и удерживать клавишу Ctrl на клавиатуре, чтобы выбрать более одной таблицы. Когда мы планировали наш запрос, мы решили, что нам нужна информация из таблиц Customers и Orders , поэтому мы добавим их.
- После добавления всех нужных таблиц нажмите Закрыть .
- Таблицы появятся на панели Object Relationship , связанные линией соединения . Дважды щелкните тонкий участок линии соединения между двумя таблицами, чтобы изменить направление соединения .
- Появится диалоговое окно Свойства соединения . Выберите параметр, чтобы выбрать направление вашего соединения. В нашем примере мы выберем вариант 3, потому что нам нужно соединение справа налево.
- В окнах таблиц дважды щелкните имен полей , которые вы хотите включить в свой запрос. Они будут добавлены в сетку дизайна в нижней части экрана. В нашем примере мы включим большинство полей из таблицы Customers : Имя , Фамилия , Улица Адрес , Город , Код Штата , Zip 1 Номер телефона . Мы также включим Идентификационный номер из таблицы Orders .
- Установите критерии для поля , введя нужные критерии в строку критериев каждого поля. Мы хотим установить два критерия: Не в («Роли») в поле Город и Нравится («919*») в поле Номер телефона .
 Это позволит найти клиентов, которые не живут в Роли, но живут в районе с кодом 919.
Это позволит найти клиентов, которые не живут в Роли, но живут в районе с кодом 919. - После того, как вы установили критерии, запустите запрос, нажав кнопку Запустите команду на вкладке Design .
- Результаты запроса будут отображаться в представлении таблицы запроса, которое выглядит как таблица. Если хотите, сохраните свой запрос, нажав команду Сохранить на панели быстрого доступа. Когда будет предложено назвать его, введите желаемое имя, затем нажмите OK .
Теперь вы знаете, как создать многотабличный запрос . В следующем уроке мы рассмотрим дополнительные варианты дизайна запросов, которые могут сделать ваш запрос еще более мощным.
Вызов!
- Откройте нашу базу данных практики.
- C повторите новый запрос.
- Выберите таблицы Customers и Orders для включения в запрос.

- Измените направление соединения на справа на l слева .
- Добавьте в свой запрос поля Имя , Фамилия и Почтовый индекс из таблицы Клиенты .
- Добавьте поле Оплачено из таблицы Заказы в свой запрос.
- Задайте следующие критерии : В поле Почтовый индекс введите 27609 для возврата только записей с почтовым индексом 27609 . В поле Оплачено введите Да , чтобы вернуть только клиентов, которые заплатили.
- Запустите запрос. Если вы ввели запрос правильно, ваши результаты будут включать 20 записей о клиентах, проживающих в почтовом индексе 27609.и оплатили заказ. Если нет, щелкните стрелку раскрывающегося списка View на ленте, чтобы вернуться в представление «Дизайн» и проверить свою работу.
- Сохранить запрос с именем Paying Customers в 27609 .
Предыдущая: Разработка простого запроса
Далее:Дополнительные параметры дизайна запроса
/en/access/more-query-design-options/content/
Создание запроса на основе нескольких таблиц
Иногда процесс построения и использования запросов в Access сводится к простому выбору полей из таблицы, возможному применению некоторых критериев и последующему просмотру результатов. Но что, если, как это часто бывает, нужные вам данные разбросаны по нескольким таблицам? К счастью, вы можете создать запрос, объединяющий информацию из нескольких источников. В этом разделе рассматриваются некоторые сценарии, в которых вы извлекаете данные из более чем одной таблицы, и демонстрируется, как вы это делаете.
Что ты хочешь сделать?
Используйте данные из связанной таблицы, чтобы улучшить информацию в запросе.
Соедините данные в двух таблицах, используя их связи с третьей таблицей.
Просмотрите все записи из двух похожих таблиц
Использование данных из связанной таблицы для уточнения информации в запросе
У вас могут быть случаи, когда запрос, основанный на одной таблице, дает вам необходимую информацию, но извлечение данных из другой таблицы поможет сделать результаты запроса еще более четкими и полезными. Например, предположим, что у вас есть список идентификаторов сотрудников, которые появляются в результатах вашего запроса. Вы понимаете, что было бы полезнее просмотреть имя сотрудника в результатах, но имена сотрудников находятся в другой таблице.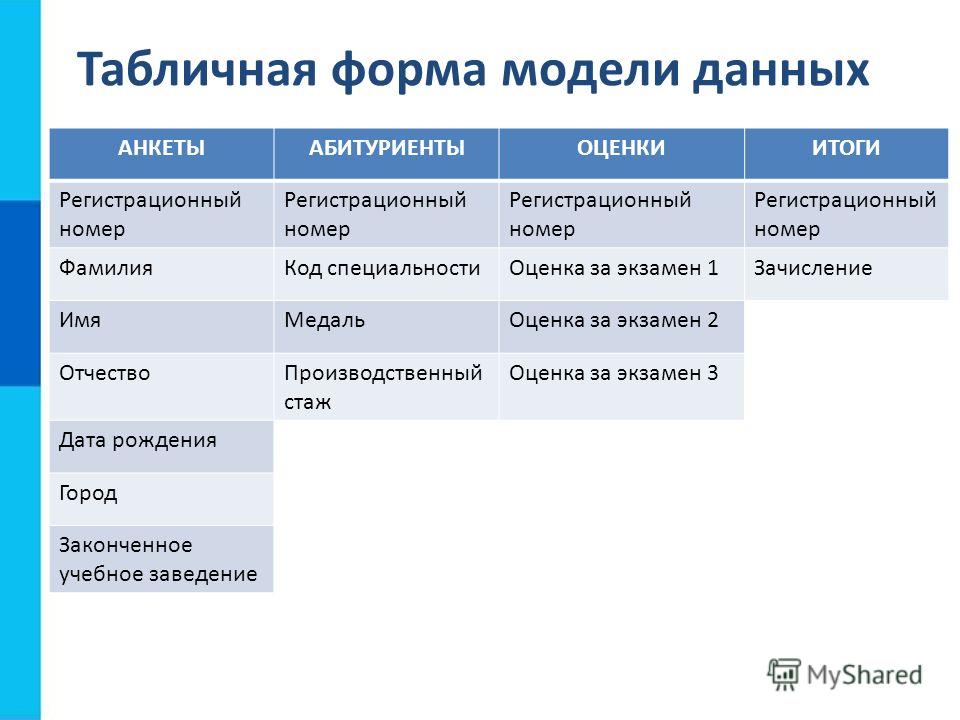 Чтобы имена сотрудников отображались в результатах запроса, необходимо включить в запрос обе таблицы.
Чтобы имена сотрудников отображались в результатах запроса, необходимо включить в запрос обе таблицы.
Используйте мастер запросов для создания запроса из основной таблицы и связанной таблицы
Убедитесь, что таблицы имеют определенную связь в окне «Связи».
Как?
Об инструментах базы данных , в группе Показать/скрыть щелкните Отношения .
 org/ListItem»>
org/ListItem»>На вкладке Проект в группе Взаимосвязи щелкните Все взаимосвязи .
Определите таблицы, которые должны иметь определенную связь.
Если таблицы видны в окне «Связи», убедитесь, что связь уже определена.
Отношение отображается как линия, соединяющая две таблицы в общем поле. Вы можете дважды щелкнуть линию связи, чтобы увидеть, какие поля в таблицах связаны связью.
Если таблицы не отображаются в окне «Связи», их необходимо добавить.
На вкладке Design в группе Показать/скрыть щелкните Имена таблиц .
Дважды щелкните каждую из таблиц, которые вы хотите отобразить, а затем щелкните Закрыть .
Если вы не найдете связи между двумя таблицами, создайте ее, перетащив поле из одной таблицы в поле другой таблицы. Поля, в которых вы создаете связь между таблицами, должны иметь одинаковые типы данных.
Примечание. Можно создать связь между полем типа данных «Счетчик» и полем типа «Число», если это поле имеет размер длинного целочисленного поля. Это часто будет иметь место, когда вы создаете отношения «один ко многим».
Появится диалоговое окно Редактировать отношения .

Нажмите Создайте , чтобы создать связь.
Дополнительные сведения о параметрах, доступных при создании отношения, см. в статье Создание, изменение или удаление отношения.
Закрыть окно Отношения .
На Создать , в группе Запросы щелкните Мастер запросов .
В диалоговом окне Новый запрос щелкните Мастер простых запросов , а затем щелкните OK .

В поле со списком Таблицы/запросы щелкните таблицу, содержащую основную информацию, которую вы хотите включить в свой запрос.
В списке Доступные поля щелкните первое поле, которое вы хотите включить в свой запрос, а затем нажмите кнопку со стрелкой вправо, чтобы переместить это поле в список Выбранные поля . Сделайте то же самое с каждым дополнительным полем из этой таблицы, которое вы хотите включить в свой запрос. Это могут быть поля, которые вы хотите вернуть в выходных данных запроса, или поля, которые вы хотите использовать для ограничения строк в выходных данных путем применения критериев.
 org/ListItem»>
org/ListItem»>В поле со списком Таблицы/запросы щелкните таблицу, содержащую связанные данные, которые вы хотите использовать для улучшения результатов запроса.
Добавьте поля, которые вы хотите использовать для улучшения результатов запроса, в список Выбранные поля и нажмите Далее .
Под номером Вам нужен подробный или общий запрос? , щелкните либо Деталь , либо Сводка .
Если вы не хотите, чтобы ваш запрос выполнял какие-либо агрегатные функции ( Sum , Avg , Min , Max , Count , StDev или Var 9043 ), выберите деталь запроса. Если вы хотите, чтобы ваш запрос выполнял агрегатную функцию, выберите сводный запрос.
 После того, как вы сделаете свой выбор, нажмите Следующий .
После того, как вы сделаете свой выбор, нажмите Следующий .Щелкните Готово , чтобы просмотреть результаты.
Пример, в котором используется образец базы данных «Борей»
В следующем примере вы используете мастер запросов для создания запроса, который отображает список заказов, стоимость доставки для каждого заказа и имя сотрудника, который обрабатывал каждый заказ.
Примечание. В этом примере необходимо изменить учебную базу данных «Борей». Вы можете сделать резервную копию образца базы данных Northwind, а затем следовать этому примеру, используя эту резервную копию.
Используйте мастер запросов для создания запроса
Откройте образец базы данных «Борей». Закройте форму входа.
На вкладке Создать в группе Запросы щелкните Мастер запросов .
В диалоговом окне Новый запрос щелкните Мастер простых запросов , а затем щелкните OK .
В таблицах/запросах 9В поле со списком 0437 щелкните Таблица: Заказы .
 org/ListItem»>
org/ListItem»>В списке Доступные поля дважды щелкните OrderID , чтобы переместить это поле в список Выбранные поля . Дважды щелкните Плата за доставку , чтобы переместить это поле в список Выбранные поля .
В таблицах/запросах 9В поле со списком 0437 щелкните Таблица: Сотрудники .
В списке Доступные поля дважды щелкните Имя , чтобы переместить это поле в список Выбранные поля . Дважды щелкните Фамилия , чтобы переместить это поле в список Выбранные поля . Нажмите Далее .
 org/ListItem»>
org/ListItem»>Поскольку вы создаете список всех заказов, вы хотите использовать подробный запрос. Если вы суммируете стоимость доставки по сотруднику или выполняете какую-либо другую агрегатную функцию, вы используете сводный запрос. Щелкните Детали (показывает каждое поле каждой записи) , а затем щелкните Далее .
Щелкните Готово , чтобы просмотреть результаты.
 org/ItemList»>
org/ItemList»>Запрос возвращает список заказов, каждый из которых имеет свою стоимость доставки, а также имя и фамилию сотрудника, который его обрабатывал.
Верх страницы
Соедините данные в двух таблицах, используя их отношения с третьей таблицей
Часто данные в двух таблицах связаны друг с другом через третью таблицу.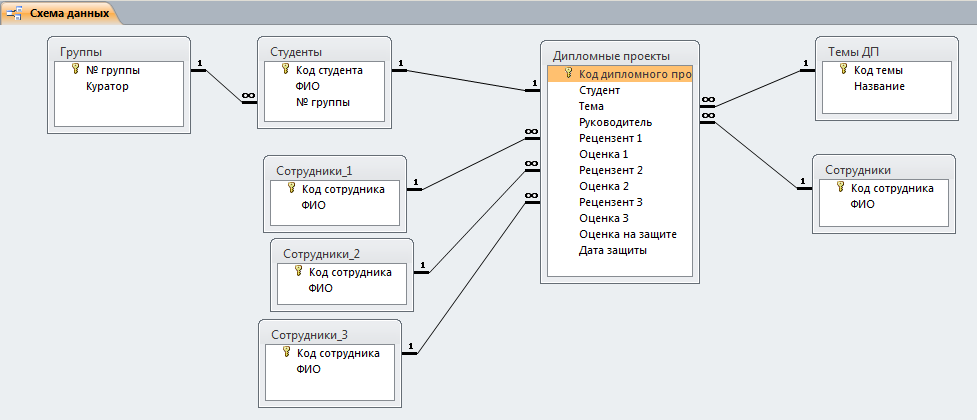 Обычно это так, потому что данные между первыми двумя таблицами связаны отношением «многие ко многим». Часто хорошей практикой проектирования баз данных является разделение отношения «многие ко многим» между двумя таблицами на два отношения «один ко многим», включающих три таблицы. Вы делаете это, создавая третью таблицу, называемую соединительной таблицей или таблицей отношений, которая имеет первичный ключ и внешний ключ для каждой из других таблиц. Затем создается отношение «один ко многим» между каждым внешним ключом в соединительной таблице и соответствующим первичным ключом одной из других таблиц. В таких случаях вам необходимо включить в свой запрос все три таблицы, даже если вы хотите получить данные только из двух из них.
Обычно это так, потому что данные между первыми двумя таблицами связаны отношением «многие ко многим». Часто хорошей практикой проектирования баз данных является разделение отношения «многие ко многим» между двумя таблицами на два отношения «один ко многим», включающих три таблицы. Вы делаете это, создавая третью таблицу, называемую соединительной таблицей или таблицей отношений, которая имеет первичный ключ и внешний ключ для каждой из других таблиц. Затем создается отношение «один ко многим» между каждым внешним ключом в соединительной таблице и соответствующим первичным ключом одной из других таблиц. В таких случаях вам необходимо включить в свой запрос все три таблицы, даже если вы хотите получить данные только из двух из них.
Создайте запрос на выборку, используя таблицы с отношением «многие ко многим»
 org/ListItem»>
org/ListItem»>На вкладке Создать в группе Запросы щелкните Дизайн запроса .
Дважды щелкните две таблицы, содержащие данные, которые вы хотите включить в запрос, а также соединительную таблицу, которая их связывает, а затем щелкните Закрыть .
Все три таблицы отображаются в рабочей области разработки запросов, объединенные соответствующими полями.
Дважды щелкните каждое из полей, которые вы хотите использовать в результатах запроса. Затем каждое поле появляется в сетке дизайна запроса.
В сетке дизайна запроса используйте строку Criteria для ввода критериев поля.
 Чтобы использовать критерий поля без отображения поля в результатах запроса, снимите флажок в поле Показать строку для этого поля.
Чтобы использовать критерий поля без отображения поля в результатах запроса, снимите флажок в поле Показать строку для этого поля.Чтобы отсортировать результаты на основе значений в поле, в сетке дизайна запроса щелкните По возрастанию или По убыванию (в зависимости от того, каким образом вы хотите отсортировать записи) в строке Сортировать для этого поля.
На вкладке Design в группе Results нажмите Прогон .
Access отображает выходные данные запроса в режиме таблицы.
Пример, в котором используется образец базы данных «Борей»
Примечание.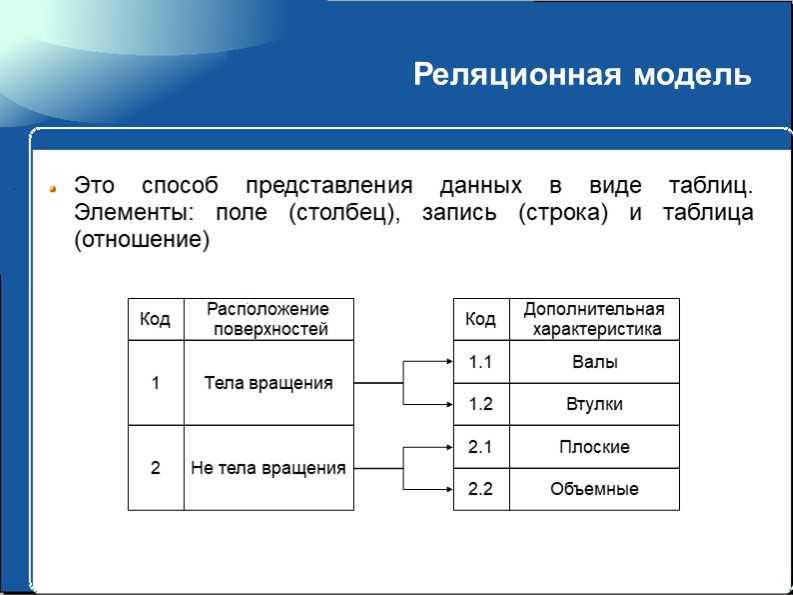 В этом примере необходимо изменить образец базы данных «Борей». Вы можете сделать резервную копию образца базы данных Northwind, а затем следовать этому примеру, используя резервную копию.
В этом примере необходимо изменить образец базы данных «Борей». Вы можете сделать резервную копию образца базы данных Northwind, а затем следовать этому примеру, используя резервную копию.
Предположим, у вас есть новая возможность: поставщик в Рио-де-Жанейро нашел ваш веб-сайт и может захотеть иметь с вами дело. Однако они работают только в Рио и близлежащем Сан-Паулу. Они поставляют все категории продуктов питания, которые вы брокер. Это довольно крупный бизнес, и они хотят, чтобы вы заверили их в том, что вы можете предоставить им доступ к достаточному количеству потенциальных продаж, чтобы они окупились: объем продаж не менее 20 000 реалов в год (около 9 долларов США).,300.00). Можете ли вы предоставить им рынок, в котором они нуждаются?
Данные, необходимые для ответа на этот вопрос, находятся в двух местах: в таблице «Клиенты» и в таблице «Сведения о заказе». Эти таблицы связаны друг с другом таблицей Orders. Отношения между таблицами уже определены. В таблице «Заказы» у каждого заказа может быть только один клиент, связанный с таблицей «Клиенты» в поле «Идентификатор клиента». Каждая запись в таблице «Сведения о заказе» связана только с одним заказом в таблице «Заказы» в поле «Идентификатор заказа». Таким образом, у данного клиента может быть много заказов, каждый из которых имеет много деталей заказа.
В таблице «Заказы» у каждого заказа может быть только один клиент, связанный с таблицей «Клиенты» в поле «Идентификатор клиента». Каждая запись в таблице «Сведения о заказе» связана только с одним заказом в таблице «Заказы» в поле «Идентификатор заказа». Таким образом, у данного клиента может быть много заказов, каждый из которых имеет много деталей заказа.
В этом примере вы создадите перекрестный запрос, отображающий общий объем продаж за год в городах Рио-де-Жанейро и Сан-Паулу.
Создайте запрос в режиме конструктора
Откройте базу данных «Борей». Закройте форму входа.
На вкладке Создать в 9Группа 0436 Запросы , нажмите Дизайн запроса .
Дважды щелкните Клиенты , Заказы , а затем Детали заказа .
Все три таблицы отображаются в рабочей области разработки запросов.
В таблице «Клиенты» дважды щелкните поле «Город», чтобы добавить его в сетку дизайна запроса.
В таблице макета запроса в столбце City в строке Criteria введите In («Рио-де-Жанейро», «Сан-Паулу») . В результате в запрос включаются только те записи, в которых клиент находится в одном из этих двух городов.
 org/ListItem»>
org/ListItem»>В таблице «Сведения о заказе» дважды щелкните поля «Дата доставки» и «Цена за единицу».
Поля добавлены в сетку дизайна запроса.
В столбце ShippedDate в сетке дизайна запроса выберите строку Поле . Замените [ShippedDate] на Year: Format([ShippedDate],»yyyy») . Это создает псевдоним поля Year , который позволяет использовать только часть значения года в поле ShippedDate.
В столбце UnitPrice в сетке дизайна запроса выберите строку Поле . Замените [Цена за единицу] на Продажи: [Сведения о заказе].[Цена за единицу]*[Количество]-[Сведения о заказе].[Цена за единицу]*[Количество]*[Скидка] .
 Это создает псевдоним поля Sales , который вычисляет продажи для каждой записи.
Это создает псевдоним поля Sales , который вычисляет продажи для каждой записи.На модели , в группе Тип запроса щелкните Crosstab .
Две новые строки, Total и Crosstab , появляются в сетке дизайна запроса.
В столбце Город в сетке дизайна запроса щелкните строку Crosstab , а затем щелкните Заголовок строки .
Это приводит к тому, что значения городов отображаются в виде заголовков строк (то есть запрос возвращает одну строку для каждого города).
В столбце Год щелкните строку Crosstab , а затем щелкните Заголовок столбца .

Это приводит к тому, что значения года отображаются в виде заголовков столбцов (то есть запрос возвращает один столбец для каждого года).
В столбце Sales щелкните строку Crosstab , а затем щелкните Значение .
Это приводит к тому, что значения продаж отображаются на пересечении строк и столбцов (то есть запрос возвращает одно значение продаж для каждой комбинации города и года).
В столбце Продажи щелкните строку Итоги , а затем щелкните Сумма .
Это приводит к тому, что запрос суммирует значения в этом столбце.
Вы можете оставить строку Totals для двух других столбцов со значением по умолчанию Group By , потому что вы хотите видеть каждое значение для этих столбцов, а не агрегированные значения.

На вкладке Design в группе Results щелкните Run .
Теперь у вас есть запрос, возвращающий общий объем продаж по годам в Рио-де-Жанейро и Сан-Паулу.
Верх страницы
Просмотр всех записей из двух похожих таблиц
Иногда вам может понадобиться объединить данные из двух таблиц, идентичных по структуре, но одна из них находится в другой базе данных. Рассмотрим следующий сценарий.
Предположим, вы аналитик, работающий с данными учащихся. Вы начинаете инициативу по обмену данными между вашей школой и другой школой, чтобы обе школы могли улучшить свои учебные программы. Для некоторых вопросов, которые вы хотите изучить, было бы лучше просмотреть все записи из обеих школ вместе, а не записи каждой школы по отдельности.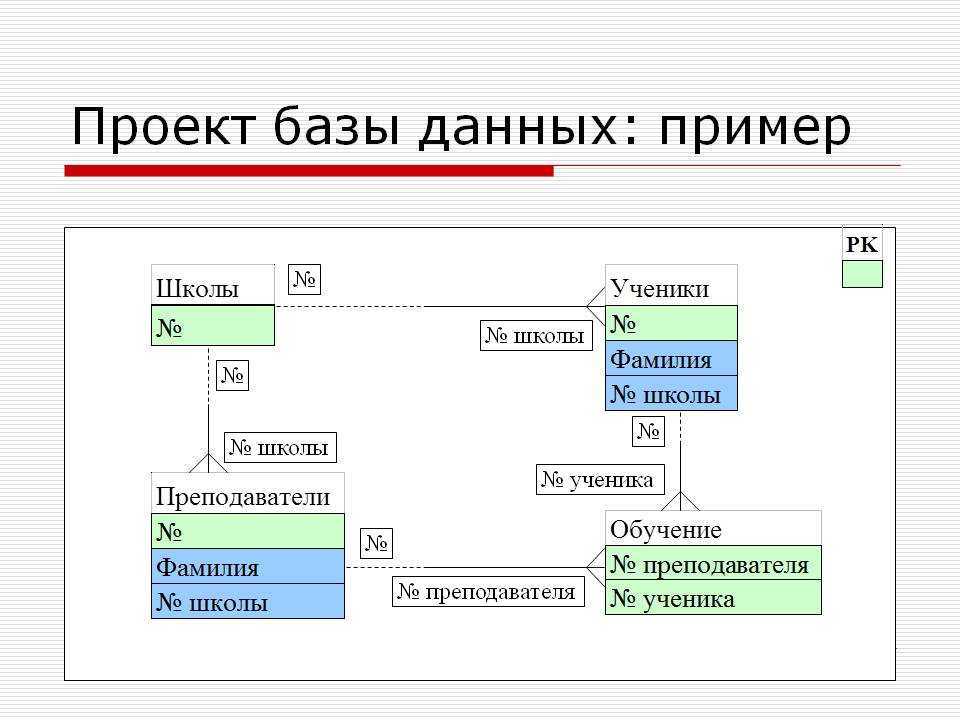
Вы можете импортировать данные другой школы в новые таблицы вашей базы данных, но тогда любые изменения в данных другой школы не будут отражаться в вашей базе данных. Лучшим решением было бы создать ссылку на таблицы другой школы, а затем создать запросы, объединяющие данные при их выполнении. Вы сможете анализировать данные как единый набор, а не выполнять два анализа и пытаться интерпретировать их так, как если бы они были одним набором.
Чтобы просмотреть все записи из двух таблиц с одинаковой структурой, используйте запрос на объединение.
Запросы на объединение не могут отображаться в представлении «Дизайн». Вы создаете их с помощью команд SQL, которые вы вводите на вкладке объекта представления SQL.
Создайте запрос на объединение, используя две таблицы
 org/ListItem»>
org/ListItem»>На вкладке Создать в группе Запросы щелкните Дизайн запроса .
На вкладке Design в группе Query Type щелкните Union .
Запрос переключается с представления «Дизайн» на представление SQL. На данный момент вкладка объекта представления SQL пуста.
В представлении SQL введите SELECT , а затем список полей из первой таблицы, которую вы хотите включить в запрос. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите ENTER. Курсор перемещается вниз на одну строку в представлении SQL.
 org/ListItem»>
org/ListItem»>Введите FROM , а затем имя первой таблицы, которую вы хотите включить в запрос. Нажмите Ввод.
Если вы хотите указать критерий для поля из первой таблицы, введите ГДЕ , затем имя поля, оператор сравнения (обычно знак равенства ( = )) и критерий. Вы можете добавить дополнительные критерии в конец предложения WHERE, используя ключевое слово AND и тот же синтаксис, что и для первого критерия; например, ГДЕ [ClassLevel]=»100″ AND [CreditHours]>2. Когда вы закончите указывать критерии, нажмите ENTER.
Введите UNION и нажмите клавишу ВВОД.
 org/ListItem»>
org/ListItem»>Введите SELECT , а затем список полей из второй таблицы, которую вы хотите включить в запрос. Вы должны включить те же поля из этой таблицы, что и из первой таблицы, и в том же порядке. Имена полей должны быть заключены в квадратные скобки и разделены запятыми. Когда вы закончите вводить имена полей, нажмите ENTER.
Введите FROM , а затем имя второй таблицы, которую вы хотите включить в запрос. Нажмите Ввод.
Если хотите, добавьте предложение WHERE, как описано в шаге 6 этой процедуры.
Введите точку с запятой ( ; ), чтобы обозначить конец запроса.
На вкладке Design в группе Results щелкните Run .
Ваши результаты отображаются в режиме таблицы.
Верх страницы
См. также
Объединение таблиц и запросов
Сравнение многотабличных и однотабличных подходов к проектированию модели данных DynamoDB
DynamoDB — это преобладающая база данных общего назначения в бессерверной экосистеме AWS. Низкие операционные издержки, простота подготовки и настройки, возможность потоковой передачи, оплата по мере использования и обещание почти бесконечного масштабирования делают его популярным выбором среди разработчиков, создающих приложения с использованием Lambda и API Gateway, в отличие от более традиционного маршрута СУБД.
Когда дело доходит до проектирования модели данных в DynamoDB, вы можете использовать два различных подхода к проектированию: многотабличный или одностоловый . В этой статье я рассмотрю, как оба подхода к проектированию могут повлиять на общую стоимость владения вашим приложением в течение жизненного цикла его поставки. и, надеюсь, поможет вам решить, какой подход подходит для ваших нужд.
Каковы основные различия между каждым подходом?
Давайте начнем с обзора того, что каждый включает в себя:
- Несколько таблиц — Одна таблица для каждого типа объектов. Каждый элемент (строка) сопоставляется с одним экземпляром этой сущности, а атрибуты (столбцы) одинаковы для каждого элемента. Это то, как большинство людей привыкли думать о моделях данных, и, по моему неподтвержденному опыту, это наиболее распространенный подход.
- Одна таблица — Одна таблица обслуживает все приложение или службу и содержит несколько типов сущностей.
 Каждый элемент имеет различные атрибуты, установленные для него в зависимости от его типа сущности. Я считаю, что этот подход менее распространен (по крайней мере, с точки зрения статей и примеров кода в Интернете), и его определенно сложнее понять большинству новичков в DynamoDB. Но что особенно важно, именно этот подход поддерживает команда AWS DynamoDB (несколько безоговорочно) в своих официальных документах:
Каждый элемент имеет различные атрибуты, установленные для него в зависимости от его типа сущности. Я считаю, что этот подход менее распространен (по крайней мере, с точки зрения статей и примеров кода в Интернете), и его определенно сложнее понять большинству новичков в DynamoDB. Но что особенно важно, именно этот подход поддерживает команда AWS DynamoDB (несколько безоговорочно) в своих официальных документах:
В приложении DynamoDB следует поддерживать как можно меньше таблиц. Для большинства хорошо разработанных приложений требуется только одна таблица .
Основными преимуществами дизайна с одной таблицей являются более высокая производительность чтения и записи в масштабе и более низкие расходы на оплату счетов за облако. В основе его шаблона проектирования лежит концепция «перегрузки индекса». Это означает, что один индекс (как глобальный вторичный, так и локальный вторичный) в вашей одной таблице может использоваться для поддержки нескольких различных шаблонов запросов. Это позволяет выполнять SQL-подобные запросы JOIN, в результате чего несколько связанных сущностей извлекаются за одно обращение к базе данных. Этот шаблон невозможен в одной сущности на табличную модель.
Во-вторых, поскольку индексы многоцелевые, в целом требуется меньше индексов. Это означает, что при выполнении записи требуется обновлять меньше индексов, что приводит как к более быстрой записи, так и к снижению затрат на выставление счетов.
Это позволяет выполнять SQL-подобные запросы JOIN, в результате чего несколько связанных сущностей извлекаются за одно обращение к базе данных. Этот шаблон невозможен в одной сущности на табличную модель.
Во-вторых, поскольку индексы многоцелевые, в целом требуется меньше индексов. Это означает, что при выполнении записи требуется обновлять меньше индексов, что приводит как к более быстрой записи, так и к снижению затрат на выставление счетов.
Я ценю, что это было очень краткое введение в дизайн с одной таблицей, поэтому, если вы совершенно не знакомы с этим и все еще задаетесь вопросом: «Как вы можете втиснуть разные сущности в одну и ту же таблицу базы данных?», Пожалуйста, ознакомьтесь с ссылками. в разделе ресурсов ниже.
Мой опыт работы с обоими подходами
До середины 2019 года я когда-либо использовал многотабличный подход к моделированию данных только в DynamoDB и вообще в базах данных NoSQL в целом (ранее я регулярно использовал MongoDB). С тех пор я работал над несколькими новыми проектами, в которых используется модель данных с одной таблицей для поддержки приложений, ориентированных на транзакции.
В оставшихся разделах я рассмотрю каждую фазу типичной реализации проекта, связанную с базой данных вашего приложения.
Прежде чем будут подготовлены какие-либо таблицы базы данных или написана хотя бы одна строка кода, в первую очередь необходимо спроектировать модель данных. В официальной документации DynamoDB указано следующее общее руководство для любого типа дизайна NoSQL:
.… вам не следует начинать разработку схемы, пока вы не знаете, на какие вопросы она должна будет ответить. Понимание бизнес-проблем и вариантов использования приложений очень важно.
Это второе предложение поразило меня, когда я впервые прочитал его. Я работаю почти исключительно над гибкими проектами, где изменения, связанные с отзывами клиентов, являются нормой. Значит ли это, что DynamoDB (и NoSQL в целом) полностью исключены для меня в этих проектах?
Короткий ответ на этот вопрос — «нет», и существуют стратегии управления изменениями (о которых я расскажу позже), но никуда не деться от того факта, что с DynamoDB больше возможностей для создания больших планов, чем с использованием базы данных SQL.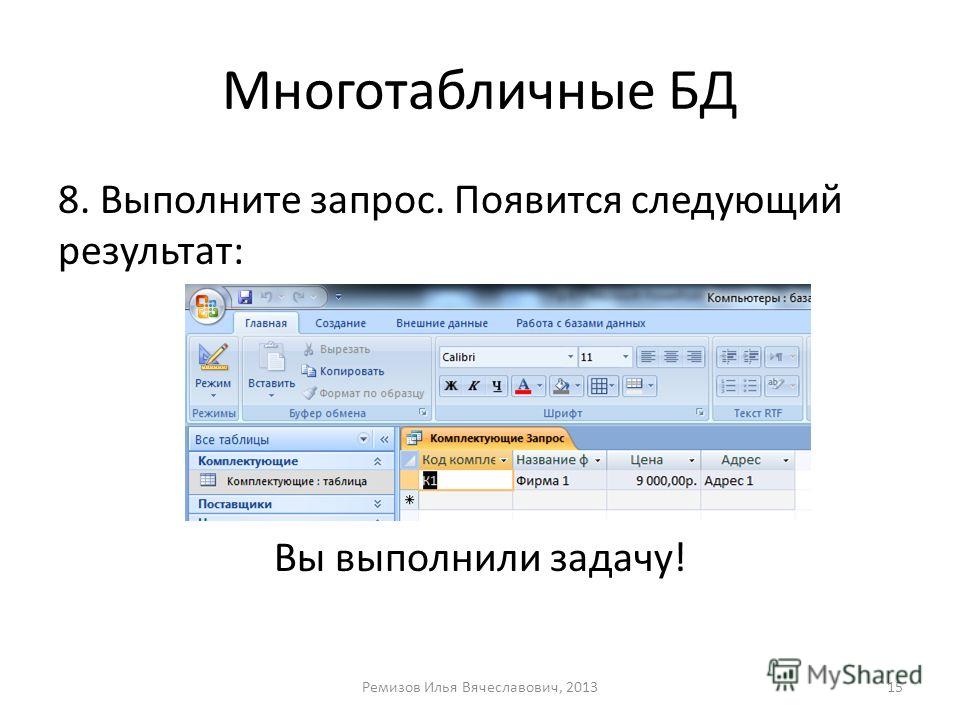 Но преимущества «безсерверности» DynamoDB по сравнению с РСУБД, которые я описал во вступительном абзаце выше, перевешивают влияние этих предварительных усилий по проектированию, ИМХО.
Но преимущества «безсерверности» DynamoDB по сравнению с РСУБД, которые я описал во вступительном абзаце выше, перевешивают влияние этих предварительных усилий по проектированию, ИМХО.
Что касается инструментов, я использую электронную таблицу для определения своего проекта, и многие эксперты DynamoDB делают то же самое. AWS недавно выпустила новый инструмент DynamoDB NoSQL Workbench, который на момент написания этой статьи находится в предварительной предварительной версии, но мы надеемся, что он обеспечит немного больше структуры для процесса проектирования моделирования данных.
Итак, каков процесс создания вашей модели данных? У Джереми Дейли есть отличный список из 20 шагов для проектирования модели DynamoDB с использованием подхода с одной таблицей, который я рекомендую вам проверить, так как он быстро читается. В частности, шаги 11–14 должны дать вам представление о требуемом уровне строгости:
Принятие решения о составе ваших индексных полей является ключевым для всего процесса проектирования и потребует многих итераций. Вам необходимо рассмотреть все ваши шаблоны доступа для всех сущностей, чтобы придумать окончательный дизайн.
Вам необходимо рассмотреть все ваши шаблоны доступа для всех сущностей, чтобы придумать окончательный дизайн.
Основное различие схем между моделями с одной и несколькими таблицами заключается в том, что у одной таблицы будут атрибуты с общими именами, которые используются для формирования раздела таблицы и ключа сортировки. Это необходимо, поскольку разные типы сущностей, скорее всего, будут иметь разные имена полей первичного ключа. Общепринятым соглашением является использование атрибутов с именем 9.1096 pk и sk , которые соответствуют разделу таблицы и ключам сортировки соответственно. Подобные атрибуты с общими именами могут использоваться для составных ключей, составляющих GSI или LSI.
Управление инициализацией и конфигурацией
Итак, теперь у нас есть разработанные модели данных, теперь пришло время подготовить наши таблицы. Это, вероятно, самый простой шаг всего процесса разработки.
DynamoDB имеет хорошую поддержку CloudFormation, что упрощает использование инфраструктуры как кода.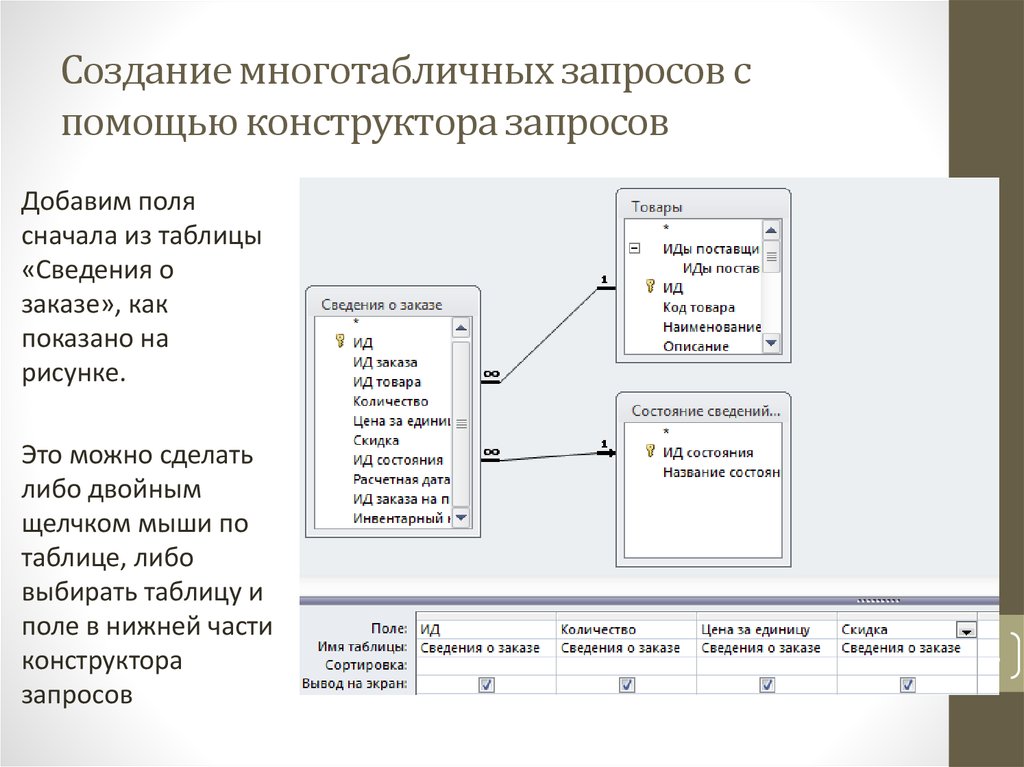 С помощью нескольких строк YAML и команды развертывания CLI вы можете быстро подготовить свои таблицы и индексы DynamoDB вместе с соответствующими привилегиями управления доступом IAM менее чем за минуту. Я использую Serverless Framework, который позволяет встраивать сырой CloudFormation в
С помощью нескольких строк YAML и команды развертывания CLI вы можете быстро подготовить свои таблицы и индексы DynamoDB вместе с соответствующими привилегиями управления доступом IAM менее чем за минуту. Я использую Serverless Framework, который позволяет встраивать сырой CloudFormation в ресурсов разделов.
В этой области подход с одной таблицей выигрывает с точки зрения меньшего количества конфигурации для управления и более быстрой подготовки — мне нужно только определить одну таблицу и передать ее имя в мои функции Lambda в качестве переменной среды. В многотабличном подходе у меня есть переменные конфигурации и среды для каждой отдельной таблицы. Незначительное преимущество во всей схеме вещей, но все же приятное.
Реализация доступа к данным в кодовой базе
Теперь ваша база данных развернута, и пришло время начать общение с ней из вашего приложения.
Скорее всего, у вас будут объекты сущностей домена, которые вы передаете в своем коде (например, в полезной нагрузке запроса/ответа API или сообщениях SNS/SQS).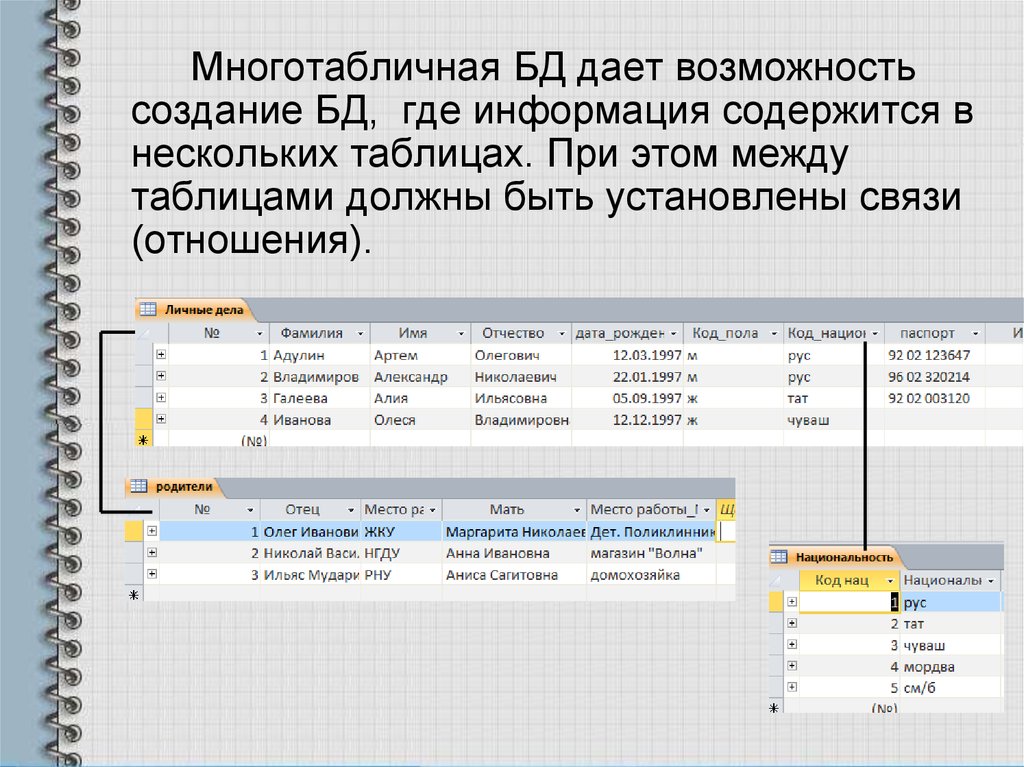 Если вам нужно сохранить эти объекты в своей базе данных, вы можете использовать для этого один из SDK AWS DynamoDB более высокого уровня (например, DocumentClient для Node.js). Но здесь есть несколько ключевых различий между многостоловыми и одностоловыми конструкциями…
Если вам нужно сохранить эти объекты в своей базе данных, вы можете использовать для этого один из SDK AWS DynamoDB более высокого уровня (например, DocumentClient для Node.js). Но здесь есть несколько ключевых различий между многостоловыми и одностоловыми конструкциями…
Запись объектов в базу данных
В дизайне с несколькими таблицами часто можно просто записать объект домена в памяти непосредственно в базу данных без какого-либо сопоставления. Поля вашего объекта станут атрибутами вашего элемента DynamoDB. Иногда вам может понадобиться создать объединенное составное поле, которое используется в индексе, чтобы обеспечить поддержку определенного требования фильтрации или сортировки.
Однако в дизайне с одной таблицей всегда будет какое-то сопоставление, которое вам нужно выполнить во время записи. В частности, вам нужно будет добавить 2 новых поля pk и sk в объект домена, прежде чем сохранять его в DynamoDB. Если вы используете другие общие поля составного индекса, вам также нужно будет сделать то же самое для каждого из них. Значения этих полей должны соответствовать форматам, определенным в вашей электронной таблице модели данных. Я обнаружил, что обычно мне нужно объединить статический префикс (который однозначно идентифицирует тип объекта и предотвращает конфликты) с одним или несколькими полями из моего доменного объекта, которые мне нужно отфильтровать или отсортировать.
Значения этих полей должны соответствовать форматам, определенным в вашей электронной таблице модели данных. Я обнаружил, что обычно мне нужно объединить статический префикс (который однозначно идентифицирует тип объекта и предотвращает конфликты) с одним или несколькими полями из моего доменного объекта, которые мне нужно отфильтровать или отсортировать.
Частичные обновления предметов снова стали более сложными. Учитывая, что в дизайне с одной таблицей существует дублирование данных в каждом элементе , если вы используете API DynamoDB UpdateItem для обновления одного поля, вам необходимо проверить, используется ли это поле также в составном индексированном поле, и если да , также обновите значение составного поля. Я несколько раз забывал об этом, и это может быть довольно сложно исправить.
Чтение объектов из базы данных
Когда вы возвращаете элементы из DynamoDB (через вызовы GetItem или Query API), вы почти всегда захотите удалить составные индексированные поля, прежде чем, скажем, вернуть сущность вызывающему клиенту ваш API. К сожалению, вызовы API DynamoDB не позволяют заносить в черный список атрибуты, которые вы не хотите возвращать. Поэтому вместо этого вам нужно либо внести в список разрешенных все остальные поля, которые вы хотите вернуть (используя
К сожалению, вызовы API DynamoDB не позволяют заносить в черный список атрибуты, которые вы не хотите возвращать. Поэтому вместо этого вам нужно либо внести в список разрешенных все остальные поля, которые вы хотите вернуть (используя ProjectionExpression ) или вы делаете черный список в своем коде приложения после возврата запроса. Я обычно выбираю последний вариант, так как он требует меньше кода, несмотря на то, что он немного менее производительный (поскольку данных возвращается больше, чем мне нужно).
Стратегии управления сложностью кода в однотабличном дизайне
Как при чтении, так и при записи вам придется выполнять множество конкатенаций строк, используя одни и те же префиксы и символы-разделители. Это может быть довольно подвержено ошибкам. По этой причине я рекомендую вам хранить весь код доступа к данным для каждого типа сущности в одном модуле/файле, чтобы вы могли быстро ссылаться на то, как была создана сущность, когда вы пишете функцию для запроса или обновления.
В бессерверных приложениях я обычно структурирую свой код таким образом, чтобы обработчик Lambda передавался модулю модели/службы, который затем отвечал бы за доступ к данным, а также за взаимодействие с любыми другими нижестоящими службами (SNS и т. д.). Если ваш код доступа к данным становится достаточно сложным (что легко может произойти после введения составных полей), есть смысл использовать шаблон репозитория, при котором вы создаете модули, единственной обязанностью которых является выполнение операций DynamoDB для определенного типа объекта.
Еще одна рекомендация по повышению ремонтопригодности вашего кода доступа к данным заключается в том, чтобы поддерживать электронную таблицу проектирования модели данных в актуальном состоянии и проверять ее вместе с кодом в рамках процесса запроса на вытягивание. Я обнаружил, что полезно иметь столбец флага «Статус реализации» или цветовой код в моей электронной таблице дизайна как часть каждого шаблона запроса, показывающего, был ли он уже реализован.
Миграция схемы
Это сценарий, о котором вас предупреждали официальные документы AWS. Те варианты использования в бизнесе, которые вы полностью понимали в начале проекта, изменились! Вам нужно внести изменения в существующие шаблоны доступа — возможно, изменить порядок сортировки или фильтр по другому полю. В целом, решение этой проблемы будет включать одно или оба из следующего:
- Создание нового индекса GSI/LSI, указывающего на новые поля (при желании также удаление существующего индекса, который больше не нужен)
- Написание сценария миграции, который сканирует таблицу и выполняет обновления для каждого элемента, например изменение значения составного индексированного поля.
После того, как новые индексы/составные индексированные поля будут установлены, можно будет развернуть обновления кода приложения. Затем вы можете запустить сценарий очистки, чтобы удалить старые составные поля/индексы.
Такой сценарий миграции может быть сложным в управлении, особенно в однотабличном проекте, который сильно зависит от составных индексированных полей.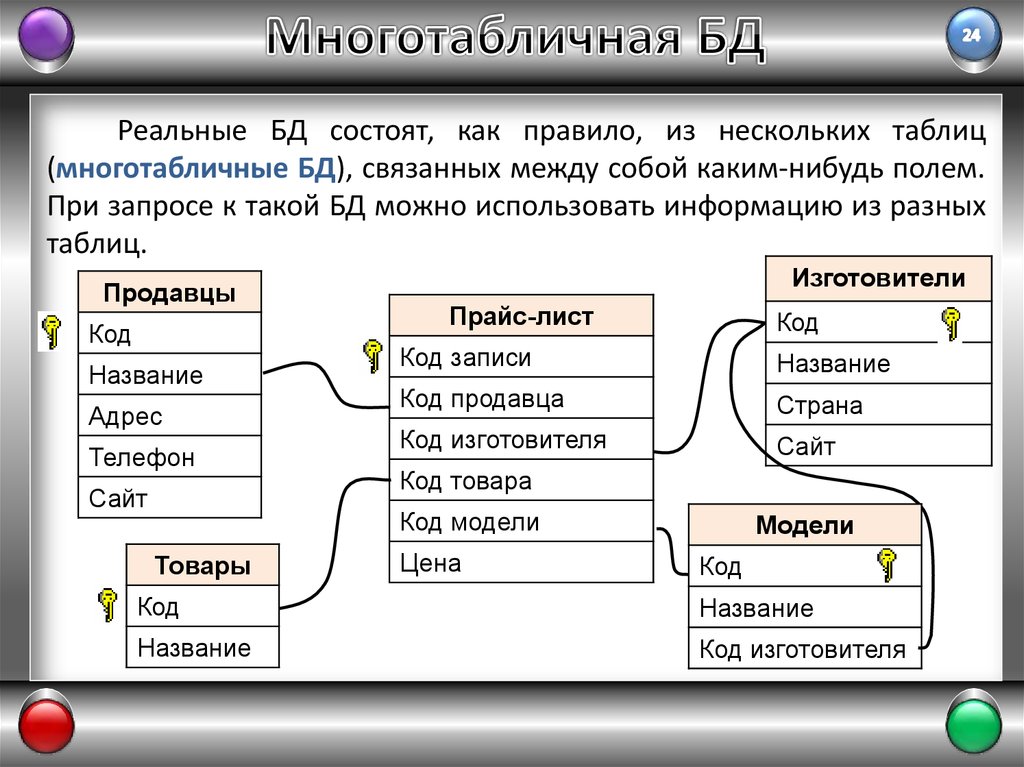 Операции полного сканирования таблицы могут занять много времени. Таким образом, во время работы ваша база данных будет находиться в несогласованном состоянии: некоторые элементы будут исправлены, а некоторые — нет. Возможно, вам придется написать свой сценарий таким образом, чтобы он мог работать с меньшими пакетами/разделами и убедиться, что он идемпотентный (например, путем сохранения состояния где-то, чтобы показать, какие миграции были применены или какие элементы уже были исправлены). Кроме того, я не смог найти каких-либо известных инструментов, которые в настоящее время помогают в этом так же, как Rails ActiveRecord Migrations работает с базами данных SQL.
Операции полного сканирования таблицы могут занять много времени. Таким образом, во время работы ваша база данных будет находиться в несогласованном состоянии: некоторые элементы будут исправлены, а некоторые — нет. Возможно, вам придется написать свой сценарий таким образом, чтобы он мог работать с меньшими пакетами/разделами и убедиться, что он идемпотентный (например, путем сохранения состояния где-то, чтобы показать, какие миграции были применены или какие элементы уже были исправлены). Кроме того, я не смог найти каких-либо известных инструментов, которые в настоящее время помогают в этом так же, как Rails ActiveRecord Migrations работает с базами данных SQL.
Я еще не сталкивался с этой проблемой в рабочей среде после запуска, поэтому я не изучал подробно, какие решения в настоящее время доступны для этого. Если у вас есть хорошая стратегия управления миграцией схемы, сообщите мне об этом в комментариях.
Интеграция с другими хранилищами данных
Еще одна проблема, влияющая на схемы с одной таблицей, заключается в том, что некоторые управляемые службы со встроенной интеграцией для экспорта данных из DynamoDB (для аналитики) ожидают, что каждая таблица будет сопоставлена с одной сущностью домена. Экспорт одной таблицы, содержащей объекты различной формы, просто не будет работать без специального промежуточного шага для выполнения преобразования. Примером этого является интеграция DynamoDB с Redshift. Это может быть то, что вам нужно учитывать при выборе подхода к дизайну.
Экспорт одной таблицы, содержащей объекты различной формы, просто не будет работать без специального промежуточного шага для выполнения преобразования. Примером этого является интеграция DynamoDB с Redshift. Это может быть то, что вам нужно учитывать при выборе подхода к дизайну.
Когда следует использовать любой из подходов?
Мы рассмотрели влияние многотабличного и однотабличного подхода к проектированию на каждом этапе жизненного цикла доставки, от проектирования до управления изменениями после ввода в эксплуатацию. Большой вопрос, который теперь остается, заключается в том, когда вы должны предпочесть один подход другому?
Чрезмерно упрощенная официальная фраза AWS «Большинству хорошо разработанных приложений требуется только одна таблица» не передает нюансы этого решения, ИМХО.
Это означает, что если вы не используете подход с одной таблицей, ваше приложение плохо спроектировано. Но их определение «хорошо спроектированного» учитывает только производительность, масштабирование и затраты на выставление счетов, игнорируя другие факторы, влияющие на общую стоимость владения приложением.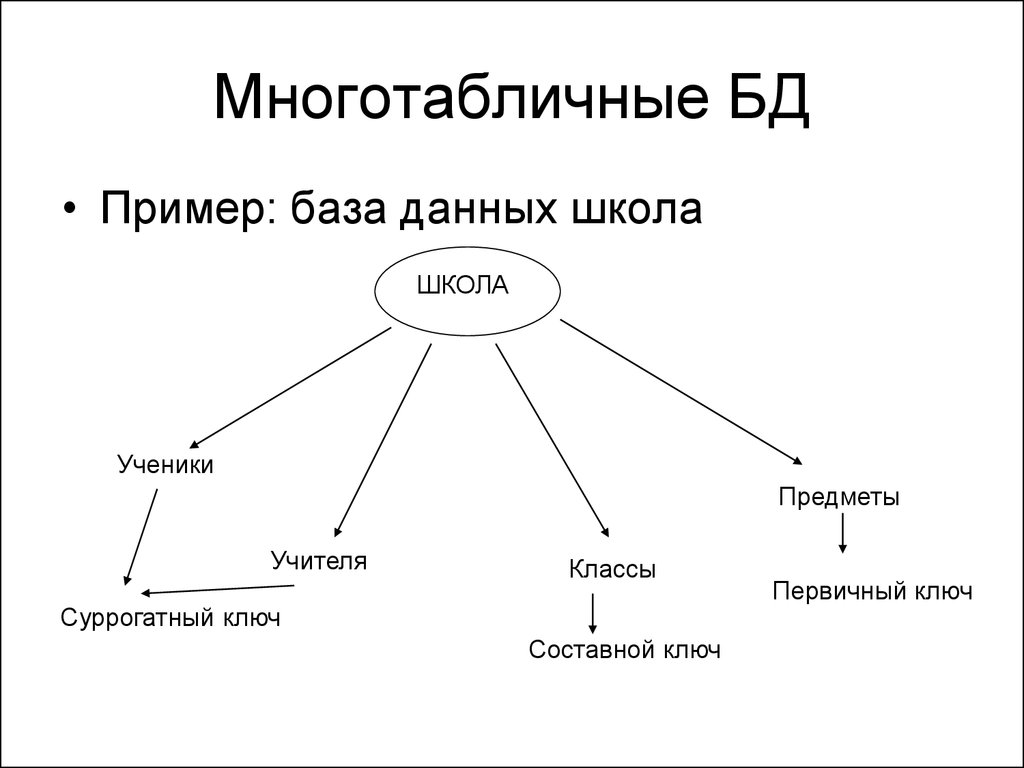
Итак, для меня все сводится к ответу на вопрос — что вы хотите оптимизировать:
- время выхода на рынок и гибкость требований; или:
- производительность, масштабируемость и эффективная стоимость выставления счетов?
Один из основных принципов бессерверного движения заключается в том, что оно позволяет разработчикам больше сосредоточиться на текущей бизнес-задаче и гораздо меньше на технических и операционных проблемах, на которые им приходилось тратить время в прошлом, работая в серверной части. основанные архитектуры. Другой основной принцип — почти неограниченная масштабируемость. Часто оба они находятся в тандеме, но в этом споре они противостоят друг другу.
Подход с несколькими таблицами является более удобным для разработчиков, имеющих опыт работы с РСУБД (а это большинство разработчиков). Добавление подхода к проектированию с одной таблицей увеличивает крутизну кривой обучения. Добавьте к этому жесткость, вызванную созданием перегруженных индексов, и накладные расходы, если необходимо выполнить какие-либо миграции, и я думаю, будет справедливо сказать, что для большинства команд они быстрее выпускали бы приложение, используя подход с несколькими таблицами
С многотабличным подходом. табличной модели, я бы сказал, что ваша команда будет меньше зависеть от присутствия постоянного «эксперта по моделированию DynamoDB» для внедрения или утверждения любых изменений в доступе к данным приложения.
Я уверен, что большинство из вас сталкивались с частью архитектуры приложения или кодовой базы, к которой вы боитесь прикасаться, потому что вы на самом деле не понимаете ее и она кажется чем-то вроде волшебства.
табличной модели, я бы сказал, что ваша команда будет меньше зависеть от присутствия постоянного «эксперта по моделированию DynamoDB» для внедрения или утверждения любых изменений в доступе к данным приложения.
Я уверен, что большинство из вас сталкивались с частью архитектуры приложения или кодовой базы, к которой вы боитесь прикасаться, потому что вы на самом деле не понимаете ее и она кажется чем-то вроде волшебства.
Все это говорит о том, что как только вы освоите подход с одной таблицей и изучите новые стратегии создания составных индексов для поддержки новых шаблонов запросов, он, несомненно, станет очень мощным.
Вашему коду нужно совершить только одно быстрое обращение к базе данных, чтобы получить пакет связанных сущностей. И вы получаете это теплое нечеткое чувство уверенности в том, что производительность вашего приложения и затраты на выставление счетов оптимизированы настолько, насколько это возможно. (Но помните, что стоимость времени вашего инженера обычно превышает стоимость вашего счета за облачные услуги).