Текстовый поиск по видео на YouTube / Хабр
linoleumВремя на прочтение 2 мин
Количество просмотров36K
JavaScript *Google Chrome Расширения для браузеров
Возникла необходимость текстового поиска по видео на ютубе, готового решения не нашел (может быть оно и есть), решил сам смастерить.
Технологии
Никаких. Ванила JS с самопальным шаблонизатором + webpack.
Делаем
Оформлено всё будет в виде расширения. Все действия выполняет скрипт, который внедряется в страницу обычным тегом script. Для этого скрипт нужно добавить в web_accessible_resources в манифесте, а потом просто добавить его в документ.
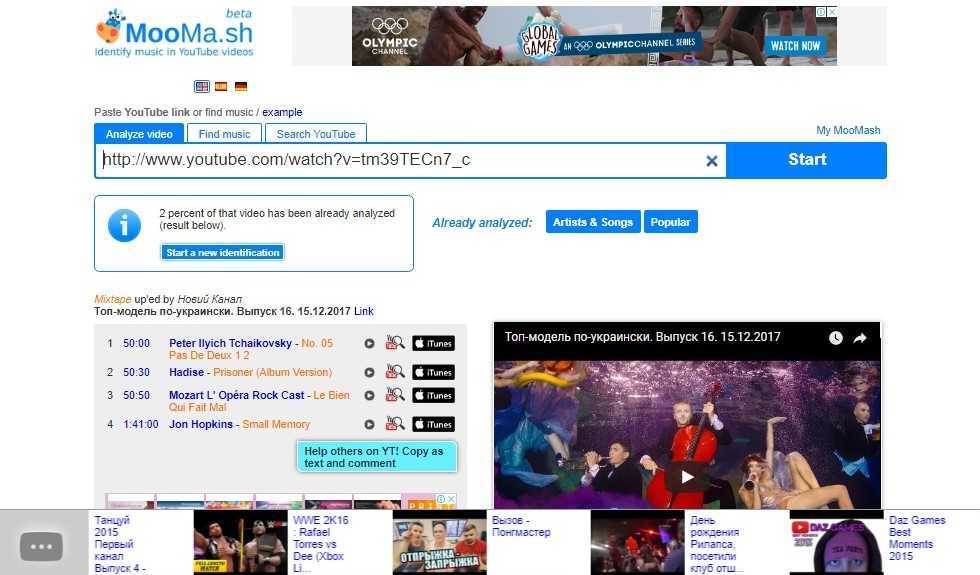
Для начала заполучим субтитры. Для это подсаживаем http-шпиона и когда уходит запрос на нужный эндпоинт — как-то его обрабатываем. Субтитры представляют собой xml:
Для это подсаживаем http-шпиона и когда уходит запрос на нужный эндпоинт — как-то его обрабатываем. Субтитры представляют собой xml:
примерно такого формата
<?xml version="1.0" encoding="utf-8" ?>
<timedtext format="3">
<head>
<pen fc="#E5E5E5"/>
<pen fc="#CCCCCC"/>
<ws mh="2" ju="0" sd="3"/>
<wp ap="6" ah="20" av="95" rc="2" cc="32"/>
</head>
<body>
<w t="0" wp="1" ws="1"/>
<p t="21119" d="2580" w="1"><s ac="254">some</s><s t="570" ac="255"> text</s></p>
<p t="21689" d="2010" w="1" a="1"></p>
</body>
</timedtext>
Но не всегда — формат может варьироваться (атрибут format=«3» намекает). В некоторых случаях внутри тегов p (видимо от predlozhenie) нет тегов s (видимо от slovo).
p содержится данный символ, что автоматически даст нам временну́ю отметку. Сам поиск выглядит немного странно. Это связано с тем, что вхождений может быть несколько, а также с тем, что один поисковый запрос может перекрывать несколько временны́х интервалов. Получили массив вхождений, круто.Рисуем
Просто вываливаем флажки примерно туда же, где находятся субтитры. При клике на флажок перематываем. Сама форма поиска появится если загрузить субтитры.
!@#%, !@#% и в продакшн
Красоту не наводил. Если штука окажется полезной — доведу до ума.
- Расширение для хрома (пока по ссылке)
- Github
- Баги/предложения желательно сюда
Только зарегистрированные пользователи могут участвовать в опросе.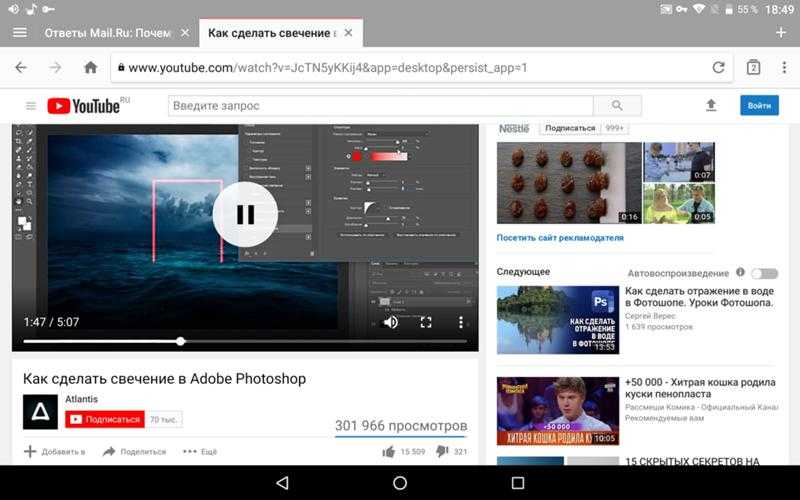
Будет ли такое расширение полезно?
80.15% да 210
19.85% нет 52
Проголосовали 262 пользователя. Воздержались 116 пользователей.
Теги:
- javascript
- chrome
Хабы:
- JavaScript
- Google Chrome
- Расширения для браузеров
Как выполнить расширенный поиск на YouTube – GmodZ.ru
Поиск определенного видео на YouTube обычно не представляет сложности. Однако, если видео было загружено давным-давно или у него мало просмотров, найти его может быть непросто. К счастью, вы можете использовать параметры расширенного поиска YouTube, чтобы получить более качественные результаты поиска и гораздо быстрее находить малоизвестные видео.
В этой статье мы рассмотрим процесс выполнения расширенного поиска на YouTube. Мы также покажем вам, как улучшить результаты поиска в мобильном приложении YouTube.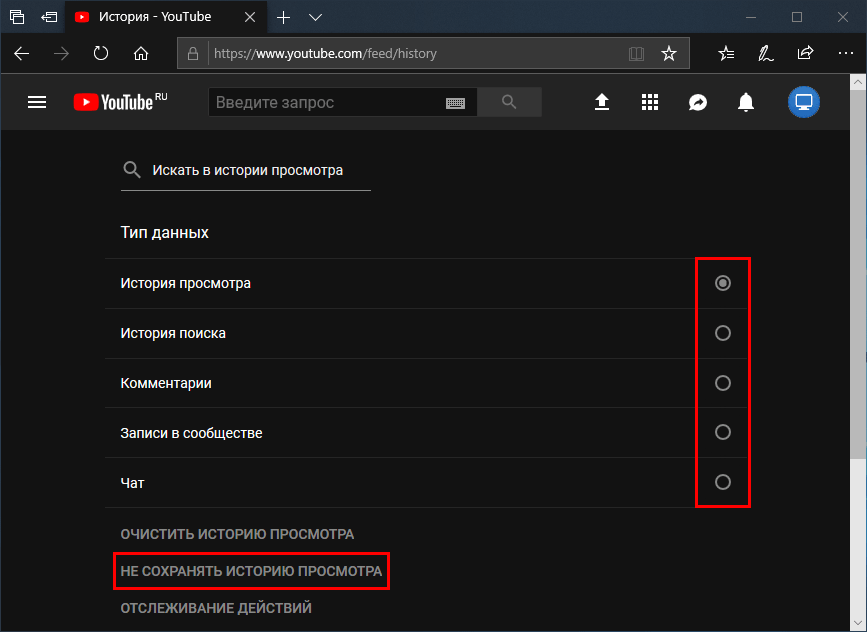
Как использовать фильтры для поиска на YouTube
Поиск видео на YouTube обычно занимает всего несколько секунд. Все, что вам нужно сделать, это ввести название видео, ключевое слово или человека, который его загрузил, нажать “Ввод” и он, вероятно, появится в верхней части страницы результатов поиска. Вы даже можете использовать новую функцию микрофона, чтобы найти видео. Если вашего видео там нет, вы можете прокручивать его вниз, пока YouTube не покажет нужный результат.
Однако этот простой поиск на YouTube может оказаться бесполезным. Независимо от того, ищете ли вы конкретное видео или у вас есть только общее представление о том, что вас интересует, найти контент на YouTube не всегда легко.
Именно здесь вступают в действие возможности расширенного поиска YouTube. Лучший способ выполнить расширенный поиск на YouTube — использовать поисковые фильтры. Однако эта функция скрыта и появляется только после того, как вы что-то ищете.
Вот как найти поисковые фильтры YouTube:
- Откройте свой любимый браузер и перейдите на YouTube.

- Перейдите к строке поиска в верхней части страницы.
- Введите название видео или что-либо, связанное с видео. Например, “джазовая музыка”
- Нажмите на значок увеличительного стекла в правой части панели или просто нажмите “Enter” на клавиатуре.
- Перейдите к разделу “Фильтры” вкладку в левом верхнем углу.
Вы увидите, что фильтры разделены на пять групп: “Дата загрузки” “Тип” “Продолжительность” “Функции” “и Сортировать по” Давайте посмотрим, как эти фильтры могут помочь вам сузить область поиска.
Дата загрузки
“Дата загрузки” Фильтр может быть очень полезен, если вы точно знаете, когда было загружено рассматриваемое видео. Он позволяет выбирать между пятью различными временными диапазонами: “Последний час” «Сегодня» «На этой неделе» “В этом месяце” и “В этом году” Если вы хотите просмотреть видео, опубликованные в один из этих периодов времени, просто нажмите на вкладку под “Дата загрузки” фильтр.
Эта функция полезна, если вы ищете последние новости или только что выпущенное видео. К сожалению, если видео, которое вы ищете, было загружено более года назад, этот фильтр вам не поможет.
К сожалению, если видео, которое вы ищете, было загружено более года назад, этот фильтр вам не поможет.
Введите
“Тип” фильтр не так полезен, как другие фильтры, поскольку он позволяет выбирать только между видео, каналами, плейлистами и фильмами. Другими словами, если вы ищете конкретное видео, этот фильтр ничем вам не поможет.
Продолжительность
Если вы знаете приблизительную продолжительность видео, этот фильтр может помочь сузить область поиска. Он предлагает три подфильтра: “Менее 4 минут” «4-20 минут» “Более 20 минут”
Возможности
“Функции” фильтр позволяет в значительной степени настроить результаты поиска. Например, вы можете выбирать между “Live,” «4K» «HD» “Субтитры/Копия” и аналогичные функции видео. Какими бы подробными ни были эти подфильтры, они полезны только в том случае, если вы точно знаете, какое видео ищете.
Сортировать по
Наконец, кнопка “Сортировать по” фильтр, пожалуй, самый полезный. Вы можете сортировать видео по “релевантности” “Дата загрузки” “Счетчик просмотров” и “Рейтинг” Выбор одного из этих фильтров, безусловно, поможет вам найти свое видео намного быстрее. YouTube по умолчанию выполняет поиск видео по релевантности, но вы можете изменить это.
YouTube по умолчанию выполняет поиск видео по релевантности, но вы можете изменить это.
Обратите внимание, что вы можете выбрать одну категорию из каждого фильтра одновременно. Например, вы можете выбрать “В этом году” с “Даты загрузки” группа «4-20 минут» из “Продолжительность” фильтр “HD” из раздела “Функции” категория и так далее. Это настоятельно рекомендуется, так как это может привести к значительным изменениям в результатах поиска. Если вы хотите отключить один из дополнительных файлов, просто нажмите “X” который отображается рядом с выбранным вложенным фильтром.
Имейте в виду, что некоторые комбинации фильтров не работают. Например, если вы выберете “Канал” подфильтр в разделе “Тип” группу, вы не сможете сортировать по “Дате загрузки”
Если вы ищете видео, которое уже смотрели на YouTube, посетите страницу “История” вкладку перед выполнением расширенного поиска. Он расположен на левой панели в разделе “Библиотека” вкладка У вас даже есть возможность выполнить поиск в истории просмотра и выбрать тип истории («История просмотра» или «Сообщество»).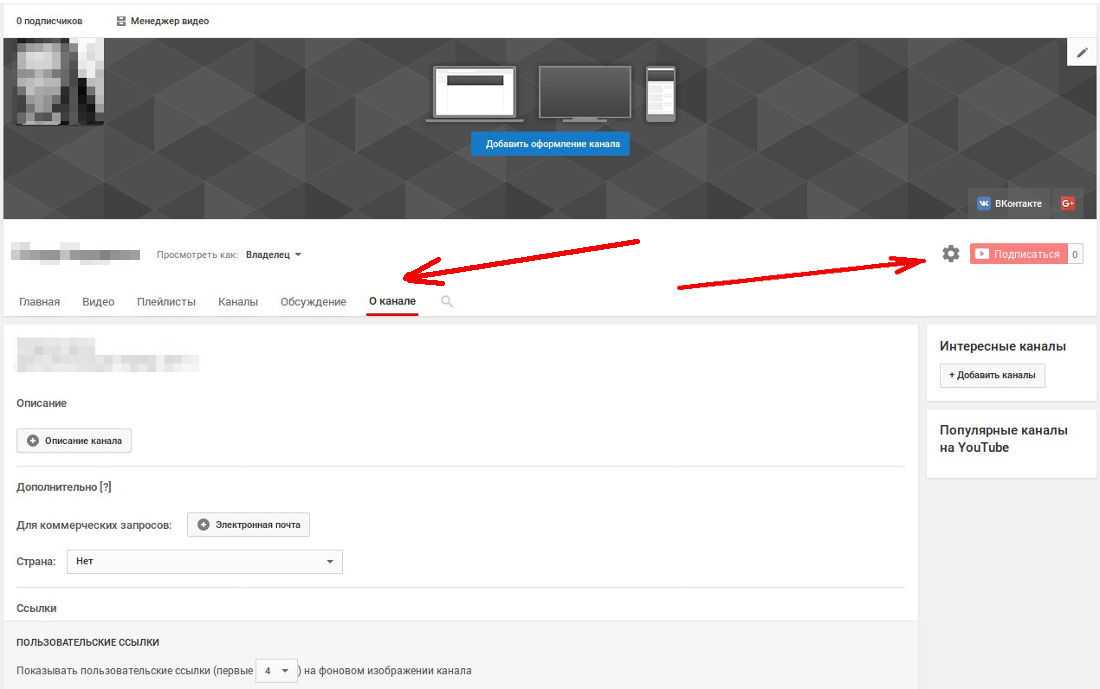
Найдя нужное видео, обязательно сохраните его. для облегчения доступа в будущем. Вы можете сделать это, открыв свое видео и нажав кнопку “+ СОХРАНИТЬ” кнопку в правом нижнем углу видео. В следующий раз, когда вы захотите посмотреть видео, просто перейдите на страницу “Посмотреть позже” вкладка на левой панели.
Как улучшить результаты поиска на YouTube
Если поисковые фильтры не принесли вам особой пользы, есть другие способы сделать результаты поиска более точными. Это делается с помощью операторов расширенного поиска. Вот несколько вариантов, которые вы можете попробовать.
Цитаты
Если вы хотите, чтобы YouTube искал именно те слова, которые вы ввели в поле поиска, заключите заголовок или ключевые слова в кавычки. Например, “5 лучших ноутбуков для студентов”
Запятые
Использование запятых в поиске позволяет интегрировать фильтры YouTube, фактически не включая их. Например, вы можете ввести “Как приготовить суши, в этом году, 4-20 минут, HD” и так далее. Хотя это может улучшить результаты поиска, обратите внимание, что иногда этот параметр расширенного поиска может не работать. Если ни одно видео не соответствует вашему описанию, YouTube предложит следующий лучший вариант.
Хотя это может улучшить результаты поиска, обратите внимание, что иногда этот параметр расширенного поиска может не работать. Если ни одно видео не соответствует вашему описанию, YouTube предложит следующий лучший вариант.
Плюс/минус
Оператор плюса (“+”) позволяет добавить ключевое слово, например “Лучшие туристические достопримечательности + Нью-Йорк” Оператор минус на самом деле представляет собой символ дефиса (“-“), который позволяет исключить определенные слова. Например, вместо того, чтобы набирать “Лучшие наушники для игр” вы можете просто выполнить поиск “Лучшие наушники для игр” Вы можете выбрать любой из этих операторов, поскольку результаты поиска будут практически идентичными.
Символ трубы
Оператор вертикальной черты (“|”) представляет собой вертикальную черту, которая должна быть помещена между двумя ключевыми словами, как в примере “суши |простые рецепты”
Хэштеги
Поскольку видео на YouTube часто содержат хэштеги, вы также можете использовать их для поиска своего видео. Например, просто введите “#glutenfreerecipes” в поле поиска.
Например, просто введите “#glutenfreerecipes” в поле поиска.
Как выполнить расширенный поиск в мобильном приложении YouTube
Если на вашем телефоне установлено приложение YouTube, вы также можете использовать расширенный поиск фильтры. Чтобы узнать, как это делается, выполните следующие действия:
- Запустите приложение YouTube на мобильном устройстве.
- Нажмите на значок увеличительного стекла в правом верхнем углу экрана.
- Введите название видео или ключевые слова.
- Перейдите к трем точкам в правом верхнем углу.
- Выберите “Фильтры поиска” во всплывающем меню.
- Выберите один или несколько фильтров из “Сортировать по” “Тип” “Дата загрузки” “Продолжительность” и “Функции” разделы.
Вот и все. Единственная разница между веб-приложением и мобильным приложением заключается в том, что вы можете выбрать вариант “Любой” поле “Длительность” «В любое время» для “Дата загрузки” и “Все” для “Тип”
Искать видео на YouTube профессионально
YouTube предлагает множество способов помочь вам найти видеоконтент. Независимо от того, прокручиваете ли вы страницу результатов поиска, используете поисковые фильтры или вводите операторы расширенного поиска, вы сможете найти свое видео в кратчайшие сроки. Просто не забудьте сохранить его в папке “Посмотреть позже” папку, чтобы не тратить время на поиски в следующий раз, когда вы захотите его посмотреть.
Независимо от того, прокручиваете ли вы страницу результатов поиска, используете поисковые фильтры или вводите операторы расширенного поиска, вы сможете найти свое видео в кратчайшие сроки. Просто не забудьте сохранить его в папке “Посмотреть позже” папку, чтобы не тратить время на поиски в следующий раз, когда вы захотите его посмотреть.
Вы когда-нибудь выполняли расширенный поиск на YouTube? Какой метод вы выбрали? Дайте нам знать в разделе комментариев ниже.
Улучшение поиска на YouTube с помощью НЛП
YouTube — культурный феномен. Первое видео «Я в зоопарке» было загружено в 2005 году. Это 19-секундный клип соучредителя YouTube Джаведа Карима в зоопарке. Это был исключительно обычный взгляд на жизнь другого человека, и в то время такого типа контента еще не видели.
Сегодняшний мир другой. 30 000 часов видео загружаются на YouTube каждый час , и более одного миллиарда 9Ежедневно просматривается 0004 часа видео[1][2].
Технологии и культура продвинулись вперед и стали еще более переплетенными. Некоторые из самых значительных технологических прорывов настолько тесно интегрированы в нашу культуру, что мы даже не замечаем их присутствия.
Некоторые из самых значительных технологических прорывов настолько тесно интегрированы в нашу культуру, что мы даже не замечаем их присутствия.
Одним из них является поиск с помощью искусственного интеллекта. Он поддерживает ваши результаты Google, рекомендации Netflix и рекламу, которую вы видите повсюду. Она быстро вплетается во все аспекты нашей жизни. Далее, это новая технология; его полный потенциал неизвестен.
Эта технология напрямую связана с культурным феноменом YouTube. Представьте себе поисковую систему, такую как Google, которая позволяет вам быстро получить доступ к миллиардам часов контента YouTube. Ни с чем не сравнимый уровень видеоконтента в мире [3].
Все вспомогательные блокноты и скрипты можно найти здесь .
Данные для поиска
Для питания этой технологии нам потребуются данные. Мы будем использовать набор данных YTTTS Speech Collection от Kaggle. Набор данных организован в виде набора каталогов, содержащих папки, названные по идентификаторам видео.
Внутри каждого каталога идентификатора видео мы находим дополнительные каталоги, каждый из которых представляет временную метку начала и конца. Эти каталоги с отметками времени содержат файл subtitles.txt , содержащий текст из этого диапазона отметок времени.
Структура каталогов набора данных. Содержит идентификаторы видео > временные метки >
Мы можем извлечь транскрипции, их временные метки начала/окончания и даже URL-адрес видео (используя идентификатор).
Исходный набор данных превосходен, но нам нужно внести в него некоторые изменения, чтобы он лучше подходил для нашего варианта использования. Код для загрузки и обработки этого набора данных можно найти здесь.
При желании этот шаг можно пропустить, загрузив обработанный набор данных с помощью:
from datasets import load_dataset # pip install datasets
ytt = load_dataset(
"шишки/yt-транскрипции",
сплит = "поезд",
ревизия = "926a45"
)
Во-первых, нам нужно извлечь данные из файлов subtitles. txt . Мы делаем это, перебирая имена каталогов, структурированные по идентификаторам видео и временным меткам.
txt . Мы делаем это, перебирая имена каталогов, структурированные по идентификаторам видео и временным меткам.
В[5]:
документа = []
для video_id в tqdm(video_ids):
разбивается = отсортировано (os.listdir (f "data/{video_id}"))
# начинаем в 00:00:00
start_timestamp = "00:00:00"
проход = ""
для i, s в перечислении (разделениях):
с open(f"data/{video_id}/{s}/subtitles.txt") как f:
# добавить Tect к текущему чанку
выход = f.read()
проход += " " + выход
# средняя длина предложения 75-100 символов, поэтому мы обрезаем
# около 3-4 предложений
если длина (проход) > 360:
# теперь мы достигли нужной длины, создаем запись
# извлечь конечную временную метку из имени файла
end_timestamp = s.split("-")[1].split(",")[0]
# извлечение временных меток строки в фактические объекты даты и времени
start = time.strptime(start_timestamp,"%H:%M:%S")
конец = время.
strptime(end_timestamp,"%H:%M:%S")
# теперь мы извлекаем значения секунды/минуты/часа и конвертируем
# к общему количеству секунд
start_second = start.tm_sec + start.tm_min*60 + start.tm_hour*3600
end_second = end.tm_sec + end.tm_min*60 + end.tm_hour*3600
# сохранить это в список документов
документы.добавлять({
"идентификатор_видео": идентификатор_видео,
"текст": отрывок,
"старт_секунда": старт_секунда,
"конец_секунды": конец_секунды,
"url": f"https://www.youtube.com/watch?v={video_id}&t={start_second}s",
})
# теперь мы обновляем start_timestamp для следующего чанка
начальная_временная метка = конечная_временная метка
# обновить проход
проход = "" Исходящий[5]:
100%|██████████| 127/127 [00:19<00:00, 6,60 бит/с]
Входящие[6]:
документы[:3]
Исходящие[6]:
[{'video_id': 'ZPewmEu7644',
«текст»: «привет, это Джефф Дин.Добро пожаловать в приложения глубоких нейронных сетей Вашингтонского университета. В этом видео мы рассмотрим, как мы можем использовать ganz для создания дополнительных обучающих данных для последних на моем курсе I. и проекты, нажмите кнопку «Подписаться» в колокольчике рядом с ним, чтобы получать уведомления о каждом новом видео. У Дэна есть широкий спектр применений, помимо простого создания лица, которое вы»,
'старт_секунда': 0,
'конец_секунды': 20,
'URL': 'https://www.youtube.com/watch?v=ZPewmEu7644&t=0s'},
{'video_id': 'ZPewmEu7644',
'текст': 'часто вижу их использование, потому что они определенно могут генерировать другие типы изображений, но они также могут работать с табличными данными и действительно любыми данными, где вы пытаетесь иметь нейронную сеть, которая генерирует данные, которые должны быть настоящий или должен или может быть классифицирован как фальшивый, ключевой элемент наличия чего-то, опять же, - наличие этого дискриминатора, который определяет разницу »,
'старт_секунда': 20,
'конец_секунды': 41,
'url': 'https://www.youtube.com/watch?v=ZPewmEu7644&t=20s'},
{'video_id': 'ZPewmEu7644',
'текст': "в генераторе, который на самом деле генерирует данные, есть еще одна область, которую Ганц широко использует, — это полуконтролируемое обучение, поэтому давайте сначала поговорим о том, что такое полуконтролируемое обучение на самом деле, и посмотрим, как снова может быть использован для реализации этого, сначала давайте поговорим об обучении с учителем и обучении без учителя, которое вы, вероятно, видели в предыдущей машине»,
'старт_секунда': 41,
'конец_секунды': 64,
'url': 'https://www.youtube.com/watch?v=ZPewmEu7644&t=41s'}]
Теперь у нас есть основных данных для создания нашего инструмента поиска, но было бы неплохо включить названия видео и эскизы в результатах поиска.
Получить эти данные так же просто, как очистить заголовок и миниатюру для каждой записи, используя функцию url и пакет Python BeautifulSoup .
In[7]:
import lxml # если на Mac, pip/conda установите lxml
метаданные = {}
для _id в tqdm(video_ids):
r = request.get(f"https://www.youtube.com/watch?v={_id}")
суп = BeautifulSoup(r.content, 'lxml') # здесь используется пакет lxml
пытаться:
title = суп.найти("мета", свойство="og:title").получить("контент")
thumbnail = суп.найти("мета", свойство="ог:изображение").получить("контент")
metadata[_id] = {"title": заголовок, "миниатюра": миниатюра}
кроме Исключения как e:
печать (е)
печать (_идентификатор)
метаданные[_id] = {"название": "", "миниатюра": ""}
лен(метаданные) Исход[7]:
51%|█████ | 65/127 [02:56<02:01, 1,96 с/ит]
Объект 'NoneType' не имеет атрибута 'get'
fpDaQxG5w4o
52%|█████▏ | 66/127 [03:00<02:42, 2,67 с/ит]
Объект 'NoneType' не имеет атрибута 'get'
arbbhHyRP90
100%|██████████| 127/127 [05:21<00:00, 2,54 с/ит]
127
Входящие[8]:
документы[0]
Исходящие[8]:
{'video_id': 'ZPewmEu7644',
'текст': «привет, это Джефф Дин.Добро пожаловать в приложения глубоких нейронных сетей Вашингтонского университета. В этом видео мы рассмотрим, как мы можем использовать ganz для создания дополнительных обучающих данных для последних на моем курсе I. и проекты, нажмите «Подписаться» в колокольчике рядом с ним, чтобы получать уведомления о каждом новом видео. У Дэна есть широкий спектр применений, помимо простого создания лица, которое вы»,
'старт_секунда': 0,
'конец_секунды': 20,
'url': 'https://www.youtube.com/watch?v=ZPewmEu7644&t=0s'}
In[9]:
метаданные['ZPewmEu7644']
Out[9]:
{'title': 'GANS для частично контролируемого обучения в Keras (7.4)',
'миниатюра': 'https://i.ytimg.com/vi/ZPewmEu7644/maxresdefault.jpg'}
Нам нужно объединить данные, которые мы извлекли из набора данных YTTTS, и эти метаданные.
In[10]:
для i, doc in enumerate(documents):
_id = документ['идентификатор_видео']
мета = метаданные[_id]
# добавить метаданные в существующий документ
документы[i] = {**док, **мета} Входящие[11]:
документы[0]
Исходящие[11]:
{'video_id': 'ZPewmEu7644',
«текст»: «привет, это Джефф Дин.Добро пожаловать в приложения глубоких нейронных сетей Вашингтонского университета. В этом видео мы рассмотрим, как мы можем использовать ganz для создания дополнительных обучающих данных для последних на моем курсе I. и проекты, нажмите кнопку «Подписаться» в колокольчике рядом с ним, чтобы получать уведомления о каждом новом видео. У Дэна есть широкий спектр применений, помимо простого создания лица, которое вы»,
'старт_секунда': 0,
'конец_секунды': 20,
'URL': 'https://www.youtube.com/watch?v=ZPewmEu7644&t=0s',
'название': 'GANS для частично контролируемого обучения в Керасе (7.4)',
'миниатюра': 'https://i.ytimg.com/vi/ZPewmEu7644/maxresdefault.jpg'}
Это оставляет нам 11298 транскрипций видео длиной от предложения до абзаца. Используя это, мы теперь готовы перейти к разработке конвейера поиска видео.
Поисковый трубопровод
Наш поиск видео основан на подобласти НЛП, называемой семантическим поиском. Существует много подходов к семантическому поиску, на высоком уровне это поиск контекстов (предложений/абзацев), которые, кажется, отвечают на запросов .
Существует много подходов к семантическому поиску, на высоком уровне это поиск контекстов (предложений/абзацев), которые, кажется, отвечают на запросов .
Конвейер индексирования и запросов с компонентами извлечения и векторной базы данных.
Для извлечения контекстов требуются два компонента: база данных векторов и модель ретривера , оба из которых используются для индексации и извлечения данных.
База данных векторов
База данных векторов выступает в качестве нашего компонента для хранения и поиска данных. Он хранит векторные представления наших текстовых данных, которые можно получить с помощью другого вектора. Мы будем использовать векторную базу данных Pinecone.
Хотя здесь мы используем небольшую выборку, любое значимое освещение YouTube потребует масштабирования до миллиардов записей. База данных векторов Pinecone позволяет это делать через A ближайших N ближайших N соседей S поиск (ANNS). Используя ANNS, мы можем ограничить область поиска небольшим подмножеством индекса, избегая чрезмерной сложности сравнения (потенциально) миллиардов векторов.
Используя ANNS, мы можем ограничить область поиска небольшим подмножеством индекса, избегая чрезмерной сложности сравнения (потенциально) миллиардов векторов.
Для инициализации базы данных подписываемся на бесплатный ключ API Pinecone и pip устанавливаем pinecone-client . Когда все будет готово, мы инициализируем наш индекс:
import pinecone # pip install pinecone-client
# подключиться к pinecone (получить ключ API и env на app.pinecone.io)
pinecone.init(api_key="ВАШ_API_KEY", среда="ВАШ_ENV")
# создать индекс
сосновая шишка.create_index(
'youtube-поиск',
измерение = 768, метрика = 'косинус'
)
# подключиться к новому индексу
index = pinecone.Index('youtube-поиск')
При создании индекса мы передаем:
- Имя индекса, здесь мы используем
'youtube-search'но это может быть что угодно. - Измерение вектора

- Retrieval
метрика, описывающая метод вычисления близости векторов, здесь мы используем'косинус'сходство, которое выравнивается с выводом ретривера (опять же, подробнее позже).
У нас есть индекс, но нам не хватает ключевой детали. Как нам перейти от текста транскрипции, который у нас есть сейчас, к векторным представлениям для нашей векторной базы данных? Нам нужна модель ретривера.
Модель ретривера
Ретривер представляет собой модель-трансформер, специально обученную для встраивания предложений/абзацев в осмысленное векторное пространство. Под осмысленностью мы ожидаем, что предложения с похожим семантическим значением (например, пары вопрос-ответ) будут помещены в модель и встроены в аналогичное векторное пространство.
Модель ретривера кодирует семантически связанные фразы в аналогичное векторное пространство.
Отсюда мы можем поместить эти векторы в нашу базу данных векторов. Когда у нас есть запрос, мы используем ту же модель ретривера для создания вектора запроса. Этот вектор запроса используется для извлечения наиболее похожих (уже проиндексированных) векторов контекста.
При наличии вектора запроса база данных векторов выполняет поиск и извлечение похожих векторов контекста.
Мы можем загрузить уже существующую модель ретривера из библиотеки преобразователей предложений ( pip установить преобразователи предложений ).
В [3]:
из предложения_преобразователей импорта SentenceTransformer
ретривер = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_mpnet-base')
ретривер Out[3]:
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) с моделью Transformer: MPNetModel
(1): Объединение ({'word_embedding_dimension': 768, 'pooling_mode_cls_token': Ложь, 'pooling_mode_mean_tokens': Истина, 'pooling_mode_max_tokens': Ложь, 'pooling_mode_mean_sqrt_len_tokens': Ложь})
(2): нормализовать ()
)
Теперь мы можем увидеть детали модели, в том числе то, что она выводит векторы размерности 768 . Сюда не входит метрика подобия, для использования которой оптимизирована модель. Эту информацию часто можно найти через [карточку модели] (ссылка на ТЗ) (если есть сомнения, чаще всего используется косинус).
Индексирование
Мы можем начать внедрение и вставку наших векторов в базу данных векторов с инициализированными базой данных векторов и ретривером. Мы будем делать это партиями по 32 .
В [6]:
из tqdm.auto импортировать tqdm
docs = [] # здесь будут храниться идентификаторы, встраивания и метаданные
размер партии = 32
для i в tqdm (диапазон (0, len (ytt), размер партии)):
i_end = мин (i+batch_size, длина (ytt))
# извлечь пакет из данных транзакций YT
партия = ytt[i:i_end]
# закодировать пакет текста
вставки = извлекатель.кодировать(пакет['текст']).tolist()
# каждому фрагменту нужен уникальный идентификатор
# для этого мы объединим ID видео и start_seconds
ids = [f"{x[0]}-{x[1]}" для x в zip(пакет['video_id'], пакет['start_second'])]
# создать записи метаданных
мета = [{
'идентификатор_видео': х[0],
'название': х[1],
'текст': х[2],
'начало_секунды': х[3],
'конец_секунды': х[4],
'адрес': х[5],
'миниатюра': х[6]
} для x в zip(
пакет['идентификатор_видео'],
партия ['название'],
пакет['текст'],
партия ['start_second'],
пакет['конец_секунды'],
партия ['URL-адрес'],
пакет['миниатюра']
)]
# создать список (идентификаторы, векторы, метаданные) для upsert
to_upsert = список (zip (идентификаторы, встраивания, мета))
# добавить в сосновую шишку
index. upsert(vectors=to_upsert)
upsert(vectors=to_upsert) Выход[6]:
0%| | 0/177 [00:00In[13]:
index.describe_index_stats()Out[13]:
{'dimension': 768,'index_fullness': 0,01,'namespaces': {'': {'vector_count': 11298}}}Когда мы закончим индексацию наших данных, мы можем проверить, что все записи были добавлены, используя
index.describe_index_stats()или через Приборная панель из сосновой шишки.Мы можем увидеть детали индекса на приборной панели Pinecone.
Запрос
Все инициализировано и проиндексировано. Все, что осталось сделать, это запрос. Для этого мы создаем запрос типа
«что такое глубокое обучение?», вставьте его с помощью нашего ретривера и запросите черезindex.query.In[10]:
query = "Что такое глубокое обучение?" xq = retriever.encode([query]).tolist()In[15]:
xc = index.query(xq, top_k=3, include_metadata=Истина) для контекста в xc['results'][0]['matches']: print(context['метаданные']['текст'], end="\n---\n")
Out[15]:
условия оптимизации, но каков алгоритм обновления параметров или обновления любого состояния сети, а затем последняя часть — это набор данных, например, как вы на самом деле представляете мир таким, какой он есть. входит в вашу систему машинного обучения, поэтому я думаю о глубоком обучении как о том, что говорит нам что-то о том, как выглядит модель, и, по сути, как о глубоком обучении.---любые теоретические компоненты любые теоретические вещи, которые вам нужно понять о глубоком обучении, могут быть больны позже для этой ссылки еще раз, просто снова просмотрели файл документа слова, в котором я упомянул ссылку, также второй канал - мой канал, потому что глубокое обучение может быть завершено Плейлист глубокого обучения, который я создал, полностью подходит для других---под камнем за последние несколько лет вы слышали о глубоких сетях и о том, как они произвели революцию в компьютерном зрении, и стандартный классический способ сделать это - это в основном классическая задача обучения с учителем, которую вы даете сети, которую вы можете подумайте о большом черном ящике с парами входных изображений и выходных меток XY пары, хорошо, и этот большой черный ящик, по сути, вы---В методе
index.мы передаем наш вектор запросаquery
xq, top_k количество похожих векторов контекста для возврата, и что мы хотели бы вернуть метаданные.Внутри этих метаданных у нас есть несколько важных функций:
title,url,thumbnailиstart_second. Мы можем создать удобный интерфейс, используя эти функции и структуру, такую как Streamlit, с простым кодом.Streamlit создал демонстрационную версию поиска YouTube, попробуйте сами здесь.
Области НЛП и векторного поиска переживают возрождение, так как растущий интерес и применение вызывают больше исследований, что подпитывает еще больший интерес и применение технологии.
В этом пошаговом руководстве мы продемонстрировали один вариант использования, который, несмотря на его простоту, может быть невероятно полезным и интересным. По мере того, как внедрение NLP и векторного поиска продолжает расти, будет появляться больше вариантов использования, которые внедрятся в нашу повседневную жизнь, как это делали в прошлом поиск Google и рекомендации Netflix, оказывая все большее влияние в мире.
Ресурсы
Блокноты статей и сценарии
[1] Л. Сеси, Количество часов видео, загружаемых на YouTube каждую минуту (2022 г.), Statistica
[2] К. Гудроу, Знаешь, что круто? Миллиард часов (2017 г.), блог YouTube
[3] А. Хейс, Отчет о состоянии видеомаркетинга (2022 г.), Wyzowl
Как найти слова или фразы в видео на YouTube?
- Дом
- YouTube
- Как найти слова или фразы в видео на YouTube?
Вики | Последнее обновление
Как искать слова в видео на YouTube? Как найти фразы в видео на YouTube? Эти два вопроса беспокоили многих пользователей YouTube. К счастью, этот пост от MiniTool uTube Downloader предлагает руководство по поиску транскриптов YouTube .
Поиск определенного момента в видео на YouTube занимает много времени. К счастью, в этом посте есть хитрость, с помощью которой вы сможете быстро найти нужный момент. Хитрость заключается в поиске транскриптов на YouTube.
Хитрость заключается в поиске транскриптов на YouTube.
Поиск стенограмм YouTube
Для поиска стенограмм YouTube применимы два способа. Один из них — использовать сочетания клавиш, а другой — использовать инструмент под названием YouGlish. Теперь проверьте их один за другим.
Используйте короткие клавиатуры
Шаг 1: Откройте веб-сайт YouTube и воспроизведите видео, которое вы хотите найти.
Шаг 2: Под экраном воспроизведения щелкните три точки , а затем щелкните Открыть стенограмму 9вариант 0206.
Теперь вы должны увидеть список субтитров с отметками времени сбоку от видео.
Шаг 3: Откройте функцию поиска в браузере, используя Ctrl + F , если вы используете Windows; Cmd + F (вы используете macOS).
Шаг 4: Введите слова или фразы, которые вы хотите найти, и они будут выделены, если будут найдены.
Шаг 5: Щелкните строку заголовка, чтобы перейти к определенному моменту видео.
Используйте YouGlish
Для поиска расшифровок на YouTube вы также можете использовать YouGlish. YouGlish подходит для тех случаев, когда вы хотите найти определенные слова или фразы во многих видео на YouTube.
Ну как пользоваться YouGlish? Следуйте инструкциям ниже.
Шаг 1: Перейдите на веб-сайт YouGlish.
Шаг 2: На веб-странице введите слова или фразы, которые вы хотите найти, в строку поиска и нажмите кнопку Скажи это .
Шаг 3: Когда YouGlish найдет соответствующее видео, вы можете использовать элементы управления Play и Next под видео, чтобы перейти к точным моментам, где появляются эти слова или фразы.
Бонус: как скачать стенограммы YouTube?
Вы нашли стенограммы YouTube? Я считаю, что вам удалось сделать это двумя вышеуказанными способами.