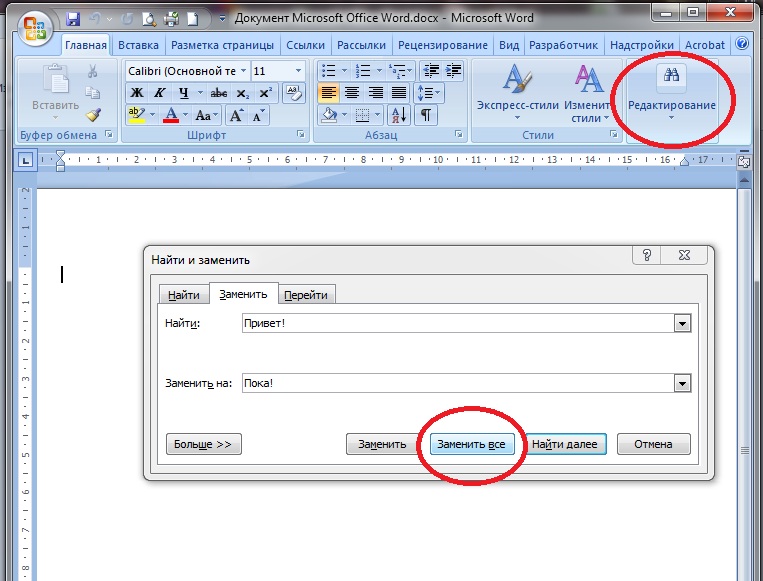
Выполнение поиска текста
На этой странице представлена информация о том, как выполнять пользователю JIRA поиск текста. Он применяется как к базовому поиску, так и к расширенному поиску (при использовании с оператором CONTAINS). Эта страница также применяется для быстрого поиска при выполнении текстового поиска в полях, поддерживаемых этой функцией.
Подтверждения (благодарности):
JIRA использует Apache Lucene для индексации текста, которая обеспечивает сложный язык задач. Большая часть информации на этой странице выводится на странице Синтаксис задач Parser документации Lucene.
Условия запроса (Query)
«Запрос (query)» разбивается на термины (terms) и операторы (operators). Существует два типа терминов: отдельные термины (Single Terms) и фразы (Phrases). Один термин — это одно слово, такое как «тест» или «привет».
Несколько терминов могут быть объединены вместе с булевыми операторами для формирования более сложного «запроса (query) » (см. ниже). Если вы объедините несколько терминов без указания каких-либо булевых операторов, они будут объединены с помощью операторов AND.
Модификаторы срока
JIRA поддерживает изменение условий задачи для предоставления широкого спектра вариантов поиска.
Wildcard searches: ? and * | Fuzzy searches: ~ | Proximity searches
В настоящее время JIRA НЕ поддерживает ведущие подстановочные знаки или Подстановочные знаки во фразах.
JIRA поддерживает одно- и многосимвольные групповые поиски.
Для выполнения поиска с одним символьным символом используйте символ? .Для выполнения поиска по шаблону с несколькими символами используйте символ «*».
Подстановочные знаки должны быть заключены в кавычки, поскольку они зарезервированы в расширенном поиске.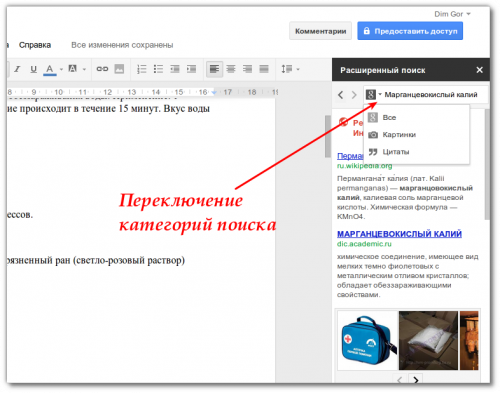 Использовать котировки, например summary ~ «cha?k and che*»
Использовать котировки, например summary ~ «cha?k and che*»
Односимвольный поиск по шаблону ищет термины, которые совпадают с заменой одного символа. Например, для поиска «текста» или «теста» вы можете использовать поиск:
te?t
Множественные символьные поиски подстановочного знака ищут 0 или больше символов. Например, для поиска Windows, Win95 или WindowsNT вы можете использовать поиск:
win*
Вы также можете использовать поиск подстановочных знаков в середине срока. Например, для поиска Win95 или Windows95 вы можете использовать поиск:
wi*95
Вы не можете использовать * или ? символ как первый символ поиска. Запрос функции для этого — JRA-6218
JIRA поддерживает нечеткие поиски. Чтобы сделать нечеткий поиск, используйте тильду «~», символ в конце одного слова. Например, для поиска термина, похожего на орфографию, на «бродят» используйте нечеткий поиск:
roam~
В этом поиске найдутся такие термины, как пена и бродяга. 4 querying
4 querying
По умолчанию коэффициент усиления релевантности равен 1. Коэффициент усиления релевантности должен быть положительным, и может быть меньше 1 (т. е. .2)
Булевы операторы
Булевы операторы позволяют комбинировать термины с помощью логических операторов. JIRA поддерживает AND, «+», OR, NOT и «-» в качестве булевых операторов.
Булевы операторы должны быть ВСЕМИ ЗАГЛАВНЫМИ БУКВАМИ.
OR | AND | Required term: + | NOT | Excluded term: —
Оператор OR является оператором соединения по умолчанию. Это означает, что если булевский оператор между двумя членами не используется, используется оператор OR. Оператор OR связывает два термина и находит соответствующий документ, если любое из условий существует в документе. Это эквивалентно объединению с использованием множеств. Символ || может использоваться вместо слова OR.
Для поиска документов, содержащих «atlassian jira» или просто «слияние», используйте задачу:
"atlassian jira" || confluence или "atlassian jira" OR confluence
Оператор AND соответствует документам, в которых оба термина существуют в любом месте текста одного документа. Это эквивалентно пересечению с использованием множеств. Символ && можно использовать вместо слова AND.
Это эквивалентно пересечению с использованием множеств. Символ && можно использовать вместо слова AND.
Для поиска документов, содержащих «atlassian jira» и «отслеживание проблем», используйте задачу:
"atlassian jira" AND "issue tracking"
Оператор «+» или требуемый оператор требует, чтобы термин «символ +» существовал где-то в поле одного документа.
Для поиска документов, которые должны содержать «jira» и могут содержать «atlassian», используйте задачу:
+jira atlassian
Оператор NOT исключает документы, содержащие термин после NOT. Это эквивалентно разнице с использованием множеств. Символ ! может использоваться вместо слова NOT.
Для поиска документов, содержащих «atlassian jira», но не «japan», используйте запрос:
"atlassian jira" NOT "japan"
Примечание. Оператор NOT не может использоваться только с одним условием. Например, следующий поиск не возвращает никаких результатов:
NOT "atlassian jira"
Использование оператора NOT по нескольким полям может возвращать результаты, которые включают указанное исключенное условие. Это связано с тем, что поисковый запрос (query) выполняется по каждому полю по очереди, и набор результатов для каждого поля объединяется для формирования окончательного набора результатов. Следовательно, в набор результатов поиска будет включена задача, которая соответствует поисковому запросу (query)на основе одного поля, но не выполняется на основе другого поля
Это связано с тем, что поисковый запрос (query) выполняется по каждому полю по очереди, и набор результатов для каждого поля объединяется для формирования окончательного набора результатов. Следовательно, в набор результатов поиска будет включена задача, которая соответствует поисковому запросу (query)на основе одного поля, но не выполняется на основе другого поля
Оператор «-» или запрет исключает документы, содержащие термин после символа «-».
Для поиска документов, содержащих «atlassian jira», но не «japan», используйте задачу:
"atlassian jira" -japan
Группирование
JIRA поддерживает использование круглых скобок для групповых предложений для формирования «подзапросов». Это может быть очень полезно, если вы хотите управлять логической логикой для «запроса».
Чтобы найти ошибки, либо atlassian, либо jira, используйте «запрос»:
bugs AND (atlassian OR jira)
Это устраняет любую путаницу и гарантирует, что ошибки должны существовать, и может существовать термин atlassian или jira.
Чтобы избежать этих символов, введите символ обратной косой черты «\» перед специальным символом (или, используя расширенный поиск, введите два обратных слэша «\\» перед специальным символом).
Например, для поиска (1 + 1) в простом или быстром поиске используйте задачу:
\ (1 \ + 1 \)
И для поиска (1 + 1) с использованием расширенного поиска (в JIRA Query Language или JQL) используйте запрос:
"\\ (1 + 1 \\ \\)"
Обратите внимание: если вы используете расширенный поиск — см. Зарезервированные символы для получения дополнительной информации о том, как эти символы и другие экраны скрываются на языке запросов JIRA.
Ограничение
JRASERVER-40790 — Поиск проблем JIRA, содержащих специальные символы (в текстовых полях) Решено:
Комментарий разработчика:
При анализе текста мы удаляем все знаки препинания. Это не зависит от языка и других параметров. Первый процесс, который мы используем, — это токенизация текста. Для этого мы используем классический символизатор (токенизатор) Lucene, который:
Для этого мы используем классический символизатор (токенизатор) Lucene, который:
- Разделяет слова в пунктуационных символах, удаляя знаки препинания. Однако точка, за которой не следует пробел, считается частью символа.
- Разделяет слова в дефисах, если в символе нет номера, и в этом случае весь символ интерпретируется как номер продукта и не делится.
- Распознает адреса электронной почты и имена хостов Интернета как один токен.
В результате «[» и «]» символы не добавляются в индекс или не сохраняются в запросе фразы.
Чтобы сохранить размер индекса поиска и эффективность поиска в JIRA, следующие английские зарезервированные слова (также называемые «стоп-слова») игнорируются из индекса поиска и, следовательно, функции текстового поиска JIRA:
«a», «and», «are», «as», «at», «be», «but», «by», «for», «if», «in», «into», «is», «it», «no», «not», «of», «on», «or», «s», «such», «t», «that», «the», «their», «then», «there», «these», «they», «this», «to», «was», «will», «with»
Имейте в виду, что это иногда может привести к неожиданным результатам. Например, предположим, что одна задача содержит текстовую фразу «VSX сбой», а другая задача содержит фразу «VSX не сбой». Текстовый поиск «VSX сбой» вернет обе этих задачи. Это связано с тем, что слова будут и не будут частью зарезервированного списка слов.
Например, предположим, что одна задача содержит текстовую фразу «VSX сбой», а другая задача содержит фразу «VSX не сбой». Текстовый поиск «VSX сбой» вернет обе этих задачи. Это связано с тем, что слова будут и не будут частью зарезервированного списка слов.
Ваш администратор JIRA может сделать JIRA индексировать эти зарезервированные слова (чтобы JIRA обнаружила задачи на основе присутствия этих слов), изменив язык индексирования на другой (в разделе «Администрирование»> «Система»> «Общая настройка»).
Поскольку JIRA не может искать задачи, содержащие части слов (см. ниже), слово «stemming» позволяет вам извлекать задачи из поиска на основе «корневых» (или «стеблевых») форм слов вместо того, чтобы требовать точного соответствия с конкретными Формы этих слов. Количество задач, полученных из поиска на основе слова, имеющего исходное значение, обычно больше, поскольку любые другие проблемы, содержащие слова, которые возвращаются к одному и тому же корню, также будут извлекаться в результатах поиска.
Например, если вы ищете задачи, используя термин «настройка» в поле «Сводка», JIRA связывает это слово с его корневой формой «custom» и будет получать все задачи, поле Сводка которых также содержит любое слово, которое может быть восстановлено назад к ‘custom’. Следовательно, следующий
summary ~ "customize"
«Будет извлекать задачи, чье поле Summary содержит следующие слова:
customized
customizing
customs
customer
etc.
Пожалуйста, обратите внимание:
- Администратор JIRA может отключить словосочетание (так что JIRA найдет проблемы на основе точных совпадений со словами), изменив язык индексирования на другой (в разделе «Администрирование»> «Система»> «Общая настройка»).
- Словосочетание применяется ко всем полям JIRA (а также текстовым полям).
- Когда JIRA индексирует свои поля, любые слова, которые «стекаются», сохраняются в индексе поиска JIRA только в корневой форме.

Ограничения
Обратите внимание, что для поиска JIRA применяются следующие ограничения:
Только целые слова
JIRA не может искать задачи, содержащие части слов, но только для целых слов. Исключением являются слова, которые возникают.
Это ограничение также можно преодолеть с помощью нечетких поисков.
По материалам Atlassian JIRA User’s Guide: Performing Text Searches
Multi Text Finder — множественный поиск слов в файлах
Описание:
Данная программа осуществляет поиск по содержимому файла, ищет сразу несколько слов в документах. Бывают ситуации, когда нужно найти документы, но нет точного параметра для поиска, например, толи ООО «Сервис», толи ООО «Сервер» или «Север», или документы, в которых есть слово «зарплата», или слово «удержание», или «начисление». Данная программа найдет все документы, в которых есть заданные слова/словосочетания, укажет что нашла и покажет в каком контексте они используются.
Данная программа найдет все документы, в которых есть заданные слова/словосочетания, укажет что нашла и покажет в каком контексте они используются.
Инструкция:
- Укажите места поиска, можно сразу указать несколько папок
- Выберите в каких документах осуществлять поиск
- Укажите одно, или несколько слов поиска через запятую (регистр не важен)
Multi Text Finder найдет все документы, в которых есть данные слова. Вы можете посмотреть содержимое документов (найденые слова будут помечены), открыть, скопировать, или удалить их.
Достоинства программы:
- Одновременный поиск нескольких слов
- Поддержка основных форматов документов
- Интеграция с проводником Windows
- Предпросмотр найденого
- Высокая скорость поиска
- Простота и удобство
Текущая версия 2.
 1
1- Возможность вставки любого количества скопированных слов для поиска (через запятую)
- Выбор нескольких папок для поиска
- Авто сохранение всех необходимых параметров и истории поиска
- Информация о количестве вхождений слова в тексте документа и сумма вхождений во всех документах
- Удобная навигация по найденному тексту
- Ограничения по дате и размеру файлов
- Поиск в любых файлах по маскам (например *.php, *.css, *.sql и тд)
- Сортировка списка и необходимые манипуляции с найденными файлами (Открыть расположение, копировать, удалить и тд)
- Современный и удобный интерфейс
- Поддержка всех версий Windows, начиная с XP(SP3)
- Переработанные алгоритмы и увеличенная скорость поиска
- Специальная редакция для разработчиков 1С, которая дополнительно позволяет вести поиск в файлах внешних обработок и конфигурациях (epf, erf и cf).
 Найти нужный кусок кода теперь просто и удобно. — Скачать Multi Text Finder для разработчиков 1С
Найти нужный кусок кода теперь просто и удобно. — Скачать Multi Text Finder для разработчиков 1С
Получить PRO версию
Скачать FREE версию
Скачать PORTABLE версию
Регистратор рабочего времени
Отмечайте приход/уход сотрудников, оперативно смотрите кто на месте, а кто отсутствует, или сверяйте посетителей по фотографиям для контроля доступа.
Бесплатная FREE версия
Выполнение текстового поиска (предыдущая версия) — Руководство по MongoDB Atlas Search для данных, размещенных на MongoDB Атлас.
 Пользователям доступна устаревшая возможность текстового поиска.
самоуправляемые развертывания MongoDB.
Пользователям доступна устаревшая возможность текстового поиска.
самоуправляемые развертывания MongoDB. Для выполнения устаревших запросов текстового поиска необходимо иметь текстовый индекс на
ваша коллекция. MongoDB предоставляет текстовые индексы для поддержки запросов текстового поиска по строковому содержимому. текст 9Индексы 0008 могут включать любое поле, значение которого является строкой или
массив строковых элементов. В коллекции может быть только один текст
индекс поиска, но этот индекс может охватывать несколько полей.
Полный текстовый справочник см. в разделе «Текстовые индексы». индексы, включая поведение, токенизацию и свойства.
В этом примере показано, как создать текстовый индекс и использовать его для поиска кафе, учитывая только текстовые поля.
Создать коллекцию
Создать коллекцию хранит со следующими документами:
db. stores.insertMany( stores.insertMany( |
| [ |
| { _id: }, name: "Coffee, 1, name:"Coffee, |
| { _id: 2, название: "Булочки для бургеров", описание: "Гамбургеры для гурманов" }, |
| { _id: 3, название: "Кофейня", описание: "Просто кофе" }, |
| { _id: 4, name: "Одежда Одежда Одежда", description: "Одежда со скидкой" }, |
| {_ID: 5, имя: «Java Shopping», «Описание:« Индонезийские товары »} |
| ] |
| ) |
Создайте текстовый INDEX
77777777777777777777777777777777 гг. , чтобы разрешить текстовый поиск имя и описание поля: | db.stores.createIndex( { name: «text», description: «text» } ) |
Поиск фазы 9 Exactr0019
Вы также можете искать точные фразы, заключив их в двойные кавычки.
Если строка $search включает фразу и отдельные термины, текст
поиск будет соответствовать только документам, которые включают фразу.
Например, ниже будут найдены все документы, содержащие «кофейня»:
| db.stores.find( { $text: { $search: «\»кофейня\»» } } ) |
Дополнительные сведения см. в разделе Фразы.
Исключить термин
Чтобы исключить слово, вы можете добавить перед ним символ « - «. Например, чтобы
найти все магазины, содержащие «java» или «магазин», но не «кофе», используйте
следующее:
| db.stores.find( { $text: { $search: «java shop -coffee» } } ) |
Сортировка результатов
MongoDB вернет результаты в неупорядоченном виде По умолчанию. Однако, запросы текстового поиска будут вычислять оценку релевантности для каждого документа который указывает, насколько хорошо документ соответствует запросу.
Чтобы отсортировать результаты в порядке оценки релевантности, вы должны явно
спроецируйте поле $meta textScore и отсортируйте по нему:
db. stores.find( stores.find( | ||
| { $text: { $search: «907 0, 9027 | } 2 } } | {score: { $meta: «textScore» } } |
| ).sort( {score: { $meta: «textScore» } } ) |
Текстовый поиск также доступен в конвейере агрегации.
← Текстовый поиск Операторы текстового поиска (предыдущие версии) →
База данных полнотекстового поиска (индекс FTS)
Что такое полнотекстовый поиск?
Полнотекстовый поиск упрощает поиск содержимого базы данных. Пользователи задают текстовые критерии поиска, такие как ключевые слова, и система сканирует один или несколько индексов на наличие совпадений. Полнотекстовые индексы — это простые архивы информации, предварительно организованные для ускорения поиска и решения запросов быстрее, чем если бы база данных сканировала каждое поле по отдельности.
Проблемы с текстовым поиском сдерживают ваш бизнес?
Архитектурная сложность
Синхронизация данных и индексов по отдельности в разрозненных системах поиска и баз данных является трудоемкой и снижает производительность.
Высокая стоимость владения
Использование нескольких поставщиков приводит к дублированию затрат на лицензирование систем поиска и баз данных, обучение и поддержку, что значительно увеличивает общую стоимость вашего стека технологий.
Кошмар безопасности
Многосистемная архитектура требует нескольких точек управления, что снижает общую безопасность.
Расширьте возможности своих приложений с помощью интегрированной платформы полнотекстовой поисковой системы
Распределенный быстрый поиск в формате JSON
Простота разработки современных приложений
Поиск является основным требованием для современных приложений. Благодаря полнотекстовому поиску вы можете легко добавить мощные и гибкие возможности поиска в свои приложения Couchbase. Никакой дополнительной загрузки или установки Couchbase не требуется. Просто включите эту функцию, создайте индекс и сразу приступайте к поиску текста.
Просто включите эту функцию, создайте индекс и сразу приступайте к поиску текста.
Упрощает код благодаря встроенным запросам и поискам
Вы можете использовать запросы полнотекстового поиска непосредственно в запросе SQL++, избавляя от необходимости писать сложный код для обработки и объединения результатов отдельных запросов SQL и поиска.
Встроенная высокая доступность и возможность любого масштаба
Инструменты текстового поиска интегрированы в Couchbase со встроенными секционированием, репликацией и автоматическим аварийным переключением для обеспечения высокой доступности. Вы можете легко масштабировать полнотекстовый поиск с помощью распределенной и масштабируемой архитектуры платформы Couchbase.
Связанные функции и возможности
Индексирование данных JSON
Индексирование данных JSON с помощью мощных анализаторов текста на нескольких языках. Гибкий индекс для нескольких полей, вложенных объектов и массивов.
Подробнее
Гибкий поиск
Единый индекс для поддержки запросов по нескольким полям на основе точных или нечетких совпадений, а также любых комбинаций И и ИЛИ.
Подробнее
Интеграция запросов
Уменьшите сложность кода с помощью запросов полнотекстового поиска непосредственно в запросе N1QL.
Узнать больше
Bleve с открытым исходным кодом
Механизм полнотекстового поиска Couchbase основан на проекте Bleve — мощной библиотеке поиска и индексирования с открытым исходным кодом, написанной на Go.
Узнать больше
Варианты использования и решения
Клиент 360
Объединяйте данные, собранные из разных источников, на одной платформе, чтобы создать единое представление о вашем клиенте или бизнесе.
Подробнее
Каталог и инвентарь
Публикуйте информацию о новых продуктах и инвентаре в режиме реального времени и масштабируйте до миллионов продуктов и запросов в секунду, чтобы предоставлять нужные данные в нужное время.
Подробнее
Выездное обслуживание
Предоставьте выездным сотрудникам с одной платформой возможность управлять данными из разных источников, переносить эти данные на периферию и обеспечивать их доступность в сети и в автономном режиме.
Подробнее
Управление данными IoT
Управляйте, поддерживайте и анализируйте данные в режиме реального времени на периферии с помощью встроенных и облачных баз данных, синхронизации и гарантированной доступности данных.
Узнать больше
Связанные ресурсы
Обучение и видео
- Онлайн-обучение: введение в полнотекстовый поиск Couchbase
- Полнотекстовый поиск: как это работает и что он может делать
- Seenit: применение N1QL и полнотекстового поиска вместо машинного обучения
- Веб-семинар по запросу: Полнотекстовый поиск: ключ к улучшению запросов на естественном языке для NoSQL в Node.
