резервное копирование с помощью pg_dump и pg_restore
Задача резервного копирования — одна из основных при сопровождении и поддержке PostgreSQL. Для резервного копирования логической схемы и данных можно использовать как встроенные инструменты СУБД, так и внешние. В этой статье мы разберем оба варианта.
Для начала подготовим сервер. Для демо-стенда закажем виртуальный сервер в Облачной платформе. Для этого откроем панель управления my.selectel.ru, перейдем в меню Облачная платформа и нажмем на кнопку Создать сервер.
В статье будем использовать виртуальный сервер с конфигурацией 2 vCPU, 4 ГБ RAM и 10 ГБ HDD с операционной системой CentOS 8 64-bit.
Теперь прокрутим представление ниже, где находятся настройки сети. Важно, чтобы у сервера был внешний плавающий IP-адрес для доступа извне.
После выбора операционной системы, конфигурации сервера и выполнения сетевых настроек переходим к завершению заказа и нажимаем на кнопку Создать
 Через несколько минут сервер будет готов.
Через несколько минут сервер будет готов.Перед началом демонстрации возможностей резервного копирования, мы подготовили PostgreSQL. Для целей наполнения базы данных и создания непрерывного потока записи, развернули там Zabbix (некоторое время назад публиковали о нем статью).
Создание резервных копий и восстановление из командной строки
В этом разделе мы расскажем как сделать дамп базы данных PostgreSQL в консоли при подключении по SSH, разберем синтаксис и покажем примеры использования утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g.
Утилита pg_dump
В PostgreSQL есть встроенный инструмент для создания резервных копий — утилита pg_dump. Утилита имеет простой синтаксис:
# pg_dump <параметры> <имя базы> > <файл для сохранения копии> В простейшем случае достаточно указать имя базы данных, которую в дальнейшем нужно будет восстановить. Резервная копия создается следующей командой:
# pg_dump zabbix > /tmp/zabbix.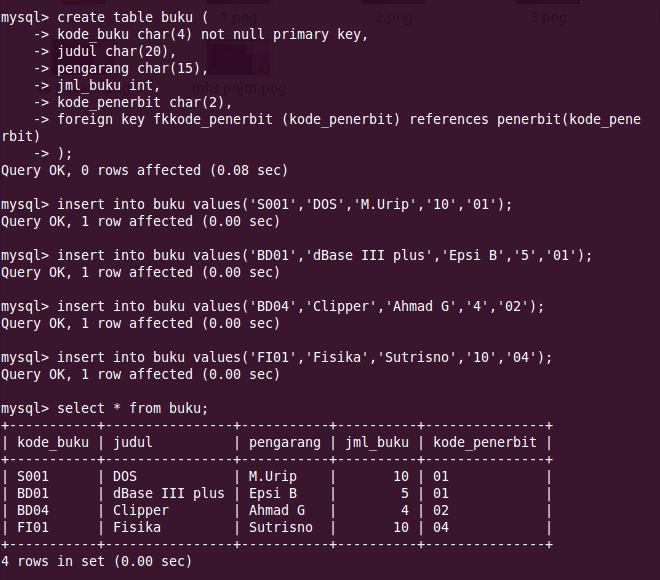 5].*" -o -name "*-[023]?.*" \) -ctime +61 -delete
pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date "+%Y-%m-%d").sql.gz
unset PGPASSWORD
5].*" -o -name "*-[023]?.*" \) -ctime +61 -delete
pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date "+%Y-%m-%d").sql.gz
unset PGPASSWORDЧтобы настроить регулярное выполнение, выполним следующую команду в планировщике crontab:
# crontab -e
3 0 * * * /etc/scripts/pgsql_dump.sh # postgres pg dumpЧтобы выполнить аналогичную команду на удаленном сервере, достаточно добавить ключ -h:
# pg_dump -h 192.168.56.101 zabbix > /tmp/zabbix.dumpКлюч -t задает таблицу, для которой нужно создать резервную копию:
# pg_dump -t history zabbix > /tmp/zabbix.dump # postgres dump tableПри помощи специальных ключей можно создавать резервные копии структуры данных или непосредственно данных:
# pg_dump --schema-only zabbix > /tmp/zabbix.dump
# pg_dump --data-only zabbix > /tmp/zabbix.dumpУ утилиты pg_dump также есть ключи для сохранения дампа в другие форматы. Чтобы сохранить копию в виде бинарного файла используются ключи -Fc:
Чтобы сохранить копию в виде бинарного файла используются ключи -Fc:
# pg_dump -Fc zabbix > /tmp/zabbix.bakЧтобы создать архив — -Ft:
# pg_dump -Ft zabbix > /tmp/zabbix.tarЧтобы сохранить в directory-формате — -Fd:
# pg_dump -Fd zabbix > /tmp/zabbix.dirРезервное копирование в виде каталогов позволяет выполнять процесс в многопоточном режиме.
Ниже мы перечислим возможные параметры утилиты pg_dump.
-d <имя_бд>, —dbname=имя_бд — база данных, к которой выполняется подключение.
-h <сервер>, —host=сервер — имя сервера.
-p <порт>, —port=порт — порт для подключения.
-U <пользователь>, —username=пользователь) — учетная запись, используемое для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой генерируется резервная копия.
-a, —data-only — вывод только данных, вместо схемы объектов (DDL).
-b, —blobs — параметр добавляет в выгрузку большие объекты.
-c, —clean — добавление команд DROP перед командами CREATE в файл резервной копии.
-C, —create
-E <кодировка>, —encoding=кодировка — определение кодировки резервной копии.
-f <файл>, —file=файл — задает имя файла, в который будет сохраняться вывод утилиты.
-F <формат>, —format=формат — параметр определяет формат резервной копии. Доступные форматы:
- p, plain) — формирует текстовый SQL-скрипт;
- c, custom) — формирует резервную копию в архивном формате;
- d, directory) — формирует копию в directory-формате;
- t, tar) — формирует копию в формате tar.

-j <число_заданий>, —jobs=число_заданий — параметр активирует параллельную выгрузку для одновременной обработки нескольких таблиц (равной числу заданий). Работает только при выгрузке копии в формате directory.
-n <схема>, —schema=схема — выгрузка в файл копии только определенной схемы.
-N <схема>, —exclude-schema=схема — исключение из выгрузки определенных схем.
-o, —oids — добавляет в выгрузку идентификаторы объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация создания команд, определяющих владельцев объектов в базе данных.
-s, —schema-only —добавление в выгрузку только схемы данных, без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, которая должна использоваться для отключения триггеров.
-t <таблица>, —table=таблица — активация выгрузки определенной таблицы.
-T <таблица>, —exclude-table=таблица —исключение из выгрузки определенной таблицы.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии pg_dump.
-Z 0..9, —compress=0..9 — установка уровня сжатия данных. 0 — сжатие выключено.
Утилита pg_dumpall
Утилита pg_dumpall реализует резервное копирование всего экземпляра (кластера или инстанса) базы данных без указания конкретной базы данных на инстансе. По принципу схожа с pg_dump. Добавим, что только утилиты pg_dump и pg_dumpall предоставляют возможность создания логической копии данных, остальные утилиты, рассматриваемые в этой статье, позволяют создавать только бинарные копии.
# pg_dumpall > /tmp/instance.bakЧтобы сразу сжать резервную копию экземпляра базы данных, нужно передать вывод на архиватор gzip:
# pg_dumpall | gzip > /tmp/instance. tar.gz
tar.gzНиже приведены параметры, с которыми может вызываться утилита pg_dumpall.
-d <имя_бд>, —dbname=имя_бд — имя базы данных.
-h <сервер>, —host=сервер — имя сервера.
-p <порт>, —port=порт — TCP-порт, на который принимаются подключения.
-U <пользователь>, —username=пользователь — имя пользователя для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=<имя роли> — роль, от имени которой генерируется резервная копия.
-a, —data-only — создание резервной копии без схемы данных.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-f <имя_файла>, —file=имя_файла — активация направления вывода в указанный файл.
-g, —globals-only — выгрузка глобальных объектов без баз данных.
-o, —oids — выгрузка идентификаторов объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация генерации команд, устанавливающих принадлежность объектов, как в исходной базе данных.
-r, —roles-only — выгрузка только ролей без баз данных и табличных пространств.
-s, —schema-only — выгрузка только схемы без самих данных.
-S <имя_пользователя>, —superuser=имя_пользователя — привилегированный пользователь, используемый для отключения триггеров.
-t, —tablespaces-only — выгрузка табличных пространства без баз данных и ролей.
-v, —verbose — режим подробного логирования.
-V (—version — вывод версии утилиты pg_dumpall.
Утилита pg_restore
Утилита позволяет восстанавливать данные из резервных копий. Например, чтобы восстановить только определенную БД (в нашем примере zabbix), нужно запустить эту утилиту с параметром -d:
Например, чтобы восстановить только определенную БД (в нашем примере zabbix), нужно запустить эту утилиту с параметром -d:
# pg_restore -d zabbix /tmp/zabbix.bakЧтобы этой же утилитой восстановить определенную таблицу, нужно использовать ее с параметром -t:
# pg_restore -a -t history /tmp/zabbix.bakТакже утилитой pg_restore можно восстановить данные из бинарного или архивного файла. Соответственно:
# pg_restore -Fc zabbix.bak
# pg_restore -Ft zabbix.tarПри восстановлении можно одновременно создать новую базу:
# pg_restore -Ft -С zabbix.tarВосстановить данные из дампа также возможно при помощи psql:
# psql zabbix < /tmp/zabbix.dumpЕсли для подключения нужно авторизоваться, вводим следующую команду:
# psql -U zabbix -W zabbix < /tmp/zabbix.dumpНиже приведен синтаксис утилиты pg_restore.
-h <сервер>, —host=сервер — имя сервера, на котором работает база данных.
-p <порт>, —port=порт — TCP-порт, через база данных принимает подключения.
-U <пользователь>, —username=пользователь — имя пользователя для подключения..
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой выполняется восстановление резервная копия.
<имя_файла> — расположение восстанавливаемых данных.
-a, —data-only — восстановление данных без схемы.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-C, —create — создание базы данных перед запуском процесса восстановления.
-d <имя_бд>, —dbname=имя_бд — имя целевой базы данных.
-e, —exit-on-error — завершение работы в случае возникновения ошибки при выполнении SQL-команд.
-f <имя_файла>, —file=имя_файла — файл для вывода сгенерированного скрипта.
-F <формат>, —format=формат — формат резервной копии. Допустимые форматы:
- p, plain — формирует текстовый SQL-скрипт;
- c, custom — формирует резервную копию в архивном формате;
- d, directory — формирует копию в directory-формате;
- t, tar — формирует копию в формате tar.
-I <индекс>, —index=индекс — восстановление только заданного индекса.
-j <число-заданий>, —jobs=число-заданий — запуск самых длительных операций в нескольких параллельных потоках.
-l, —list) — активация вывода содержимого архива.
-L <файл-список>, —use-list=файл-список — восстановление из архива элементов, перечисленных в файле-списке в соответствующем порядке.
-n <пространство_имен>, —schema=схема — восстановление объектов в указанной схеме.
-O, —no-owner — деактивация генерации команд, устанавливающих владение объектами по образцу исходной базы данных.
-P <имя-функции(тип-аргумента[, …])>, —function=имя-функции(тип-аргумента[, …]) — восстановление только указанной функции.
-s, —schema-only — восстановление только схемы без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, используемая для отключения триггеров.
-t <таблица>, —table=таблица — восстановление определенной таблицы.
-T <триггер>, —trigger=триггер — восстановление конкретного триггера.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии утилиты pg_restore.
Утилита pg_basebackup
Утилитой pg_basebackup можно выполнять резервное копирования работающего кластера баз данных PostgreSQL. Результирующий бинарный файл можно использовать для репликации или восстановления на определенный момент в прошлом. Утилита создает резервную копию всего экземпляра базы данных и не дает возможности создавать слепки данных отдельных сущностей. Подключение pg_basebackup к PostgreSQL выполняется при помощи протокола репликации с полномочиями суперпользователя или с правом REPLICATION.
Для выполнения резервного копирования локальной базы данных достаточно передать утилите pg_basebackup параметр -D, обозначающий директорию, в которой будет сохранена резервная копия:
# pg_basebackup -D /tmpЧтобы создать сжатые файлы из табличных пространств, добавим параметры -Ft и -z:
# pg_basebackup -D /tmp -Ft -z То же самое, но со сжатием bzip2 и для экземпляра базы с общим табличным пространством:
# pg_basebackup -D /tmp -Ft | bzip2 > backup. tar.bz2
tar.bz2Ниже приведен синтаксис утилиты pg_basebackup.
-d <строка_подключения>, —dbname=строка_подключения — определение базы данных в виде строки для подключения.
-h <сервер>, —host=сервер — имя сервера с базой данных.
-p <порт>, —port=порт — TCP-порт, через база данных принимает подключения.
-s <интервал>, —status-interval=интервал — количество секунд между отправками статусных пакетов.
-U <пользователь>, —username=пользователь — установка имени пользователя для подключения.
-w, —no-password — отключение запроса на ввод пароля.
-W, —password — принудительный запрос пароля.
-V, —version — вывод версии утилиты pg_basebackup.
-?, —help — вывод справки по утилите pg_basebackup.
-D каталог, —pgdata=каталог — директория записи данных.
-F <формат>, —format=формат — формат вывода. Допустимые варианты:
- p, plain — значение для записи выводимых данных в текстовые файлы;
- t, tar — значение, указывающее на необходимость записи в целевую директорию в формате tar.
-r <скорость_передачи>, —max-rate=скорость_передачи — предельная скорость передачи данных в Кб/с.
-R, —write-recovery-conf — записать минимальный файл recovery.conf в директорию вывода.
-S <имя_слота>, —slot=имя_слота — задание слота репликации при использовании WAL в режиме потоковой передачи.
-T <каталог_1=каталог_2>, —tablespace-mapping=каталог_1=каталог_2 — активация миграции табличного пространства из одного каталога в другой каталог при копировании.
—xlogdir=каталог_xlog — директория хранения журналов транзакций.
-X <метод>, —xlog-method=метод — активация вывода файлов журналов транзакций WAL в резервную копию на основе следующих методов:
- f, fetch — включение режима сбора файлов журналов транзакций при окончании процесса копирования;
- s, stream — включение передачи журнала транзакций в процессе создания резервной копии.
-z, —gzip — активация gzip-сжатия результирующего tar-файла.
-Z <уровень>, —compress=уровень — определение уровня сжатия механизмом gzip.
-c , —checkpoint=fast|spread — активация режима реперных точек.
-l <метка>, —label=метка — установка метки резервной копии.
-P, —progress — активация в вывод отчета о прогрессе.
-v, —verbose — режим подробного логирования.
Утилита wal-g
Wal-g — утилита для резервного копирования и восстановления базы данных PostgreSQL. При помощи wal-g можно выполнять сохранение резервных копий на хранилищах S3 или просто на файловой системе. Ниже мы разберем установку, настройку и работу с утилитой. Покажем как выполнить резервное копирование в Облачное хранилище S3 от Selectel.
Создадим пользователя для облачного хранилища, учетные данные которого будем потом использовать для сохранения резервной копии. Перейдем в меню Пользователи и нажмем кнопку Создать пользователя:
Дополнительную информацию можно получить в нашей Базе знаний. Первую часть логина изменить нельзя — это идентификатор пользователя в панели управления. Вторая часть логина задается произвольно. Например, 123456_wal-g:
Теперь перейдем к установке wal-g. Скачаем готовый установочный пакет из репозитория на github.com, распакуем и скопируем папку содержающую исполняемые файлы:
# cd /tmp
# curl -L "https://github. com/wal-g/wal-g/releases/download/v0.2.19/wal-g.linux-amd64.tar.gz" -o "wal-g.linux-amd64.tar.gz
# tar -xzf wal-g.linux-amd64.tar.gz
# mv wal-g /usr/local/bin/
com/wal-g/wal-g/releases/download/v0.2.19/wal-g.linux-amd64.tar.gz" -o "wal-g.linux-amd64.tar.gz
# tar -xzf wal-g.linux-amd64.tar.gz
# mv wal-g /usr/local/bin/Заполним конфигурационный файл wal-g и изменим его владельца на учетную запись postgres:
# cat > /var/lib/pgsql/.walg.json << EOF
{
"WALG_S3_PREFIX": "s3://container",
"AWS_ENDPOINT": "https://s3.selcdn.ru"
"AWS_ACCESS_KEY_ID": "123456_wal-g",
"AWS_SECRET_ACCESS_KEY": "password",
"WALG_COMPRESSION_METHOD": "brotli",
"WALG_DELTA_MAX_STEPS": "5",
"PGDATA": "/var/lib/pgsql/data",
"PGHOST": "/var/run/postgresql/.s.PGSQL.5432"
}
EOF
# chown postgres: /var/lib/pgsql/.walg.jsonДалее настроим автоматизированное создание резервных копий в PostgreSQL и перезагрузим процессы базы данных:
# echo "wal_level=replica" >> /var/lib/pgsql/data/postgresql.conf
# echo "archive_mode=on" >> /var/lib/pgsql/data/postgresql. conf
# echo "archive_command='/usr/local/bin/wal-g wal-push \"%p\" >> /var/log/postgresql/archive_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# echo “archive_timeout=60” >> /var/lib/pgsql/data/postgresql.conf
# echo "restore_command='/usr/local/bin/wal-g wal-fetch \"%f\" \"%p\" >> /var/log/postgresql/restore_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# killall -s HUP postgres
conf
# echo "archive_command='/usr/local/bin/wal-g wal-push \"%p\" >> /var/log/postgresql/archive_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# echo “archive_timeout=60” >> /var/lib/pgsql/data/postgresql.conf
# echo "restore_command='/usr/local/bin/wal-g wal-fetch \"%f\" \"%p\" >> /var/log/postgresql/restore_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# killall -s HUP postgresТеперь проверим корректность проведения настроек и загрузим резервную копию в хранилище:
# su - postgres -c '/usr/local/bin/wal-g backup-push /var/lib/pgsql/data'После выполнения процесса резервного копирования, в созданном контейнере появится директория с резервными копиями баз данных:
Такой процесс в продакшене может выполняться при помощи планировщика заданий на регулярной основе.
Утилита pgAdmin
Управлять созданием резервных копий возможно также и в графическом интерфейсе. Для этого мы будем использовать утилиту pgAdmin. Актуальную версию для Windows или другой поддерживаемой ОС можно свободно скачать с официального сайта.
Для этого мы будем использовать утилиту pgAdmin. Актуальную версию для Windows или другой поддерживаемой ОС можно свободно скачать с официального сайта.
После скачивания утилиту нужно установить и запустить. Она работает в виде веб-приложения через браузер.
После добавления сервера с базой данных, в интерфейсе появляется возможность создания резервной копии. Аналогичным образом здесь же можно выполнить восстановление из резервной копии.
После выполнения команды Backup резервная копия сохраняется в заранее определенную директорию.
Работа с облачной базой данных в панели управления Selectel
В Облачной платформе Selectel есть возможность создавать управляемые базы данных (Managed Databases). Такие БД разворачиваются в несколько кликов мыши, однако, их основные преимущества — автоматическое резервное копирование, отказоустойчивость, быстрое масштабирование и управление различными характеристиками из графического интерфейса. Ниже мы создадим экземпляр управляемой базы данных, создадим резервную копию базы данных на виртуальном сервере и восстановим ее в управляемую базу данных.
Ниже мы создадим экземпляр управляемой базы данных, создадим резервную копию базы данных на виртуальном сервере и восстановим ее в управляемую базу данных.
Чтобы создать управляемую базу данных, перейдем в меню Базы данных и нажмем кнопку Создать кластер:
Появится форма создания кластера. Здесь можно выбрать версию PostgreSQL, конфигурацию кластера, настройки сети, режим пулинга и размер пула.
Обращаем внимание на блок Резервные копии, в котором указаны частота резервного копирования, время и срок хранения выгрузок. «Под капотом» используется механизм wal-g, о котором мы писали выше.
Автоматическое создание резервных копий отключить нельзя.
Следующий шаг — создание пользователя, от имени которого мы позже будем обращаться к базе данных. Для этого перейдем на вкладку Пользователи и нажмем на кнопку Создать пользователя.
После этого появится приглашение ввести имя пользователя и пароль. После ввода этих данных нажимаем Сохранить.
После ввода этих данных нажимаем Сохранить.
Пользователь создан и отображается в списке пользователей.
Теперь создадим базу данных. Для этого перейдем на вкладку Базы данных и нажмем на кнопку Создать базу данных.
Заполняем необходимые поля и нажимаем кнопку Сохранить.
База данных создана и отображается в списке баз данных.
Теперь проверим возможность подключения. Для этого откроем консоль и вводим реквизиты:
# psql "host=192.168.0.3 \
port=6432 \
user=rosella \
dbname=zabbix \
sslmode=disable"В консоли должно появиться приглашение к вводу SQL-запроса или других управляющих команд.
Выполним резервное копирование при помощи команды pg_dump:
# pg_dump zabbix > /tmp/zabbix.dumpИ следом резервное восстановление в созданную управляемую базу данных:
# psql -h 192. 168.0.3 -U rosella -d zabbix < /tmp/zabbix.dump
168.0.3 -U rosella -d zabbix < /tmp/zabbix.dumpВ результате выполнения команды выше мы восстановили резервную копию в управляемую базу данных.
Чтобы воспользоваться восстановлением из резервной копии, которая автоматически создается на платформе Selectel, необходимо нажать на символ с тремя точками. В открывшемся меню нужно нажать на опцию Восстановить. После этого появится модальное окно, в котором можно выбрать резервную копию, а также дату и время, на которое нужно восстановить базу данных. Это так называемый Point-in-Time Recovery из WAL-файлов.
Услуга «Управляемые базы данных в облаке» позволяет перенести существующий кластер PostgreSQL на сервис управляемых баз данных бесшовно и без простоя, обратившись в техническую поддержку. Инженеры Selectel готовы помочь с переносом, а также проконсультировать по всем связанным с этим процессом вопросам.
Заключение
Мы рассмотрели возможности выполнения резервного копирования и показали отличия утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g. Вы увидели как можно создать управляемую базу данных, чтобы переложить часть административных задач на облачного провайдера.
Вы увидели как можно создать управляемую базу данных, чтобы переложить часть административных задач на облачного провайдера.
Узнать подробнее об управляемых базах данных можно в документации Selectel.
Резервное копирование и восстановление PostgreSQL [АйТи бубен]
Резервное копирование и восстановление в PostgreSQL. Существуют три принципиально различных подхода к резервному копированию данных PostgreSQL:
Если работа сервера аварийно завершается, в логе сервера появляется сообщение с уровнем важности PANIC.
Восстановление после сбоя. Все изменения данных записываются на диск только после их гарантированного журналирования в WAL. Следует заметить, что изменения в базе данных не пишутся на диск в момент фиксации транзакции. Они записываются позже в фоновом процессе.
В логе WAL есть контрольный точки (checkpoints).
Ключи pg_dump:
Логическое резервирование заключается в создании текстового файла с командами SQL. Такой файл можно передать обратно на сервер и воссоздать базу данных в том же состоянии, в котором она была во время бэкапа. У PostgreSQL для этого есть специальная утилита — pg_dump. При выполнении pg_dump, таблицы блокируются минимально, только запрет на изменение структуры таблицы.
После восстановления бэкапа желательно запустить «ANALYZE», чтобы оптимизатор запросов обновил статистику.
Пример: Полное логическое (SQL) резервирование и восстановление БД mbillcz5054. Алгоритм:
- Копируем глобальный данные сервера, используя утилиту pg_dumpall (с ключем -g, –globals-only dump only global objects, no databases). Будут сохранены глобальные объекты roles и tablespaces, без баз данных:
sudo -u postgres pg_dumpall --globals-only > globals-only_`date +%Y-%m-%d.%H.%M`.sql
- Можно сохранить определение объектов базы данных: роли, табличные пространства, схемы, индексы, триггеры и т.д.
sudo -u postgres pg_dumpall --schema-only > schema-only_`date +%d.%m.%Y-%H.%M`.sql
- Копируем данные. Копируем каждую базу данных при помощи утилиты pg_dump
pg_dump -U postgres mbillcz5054 | gzip > mbillcz5054_backup_`date +%Y-%m-%d.%H.%M`.sql.gz
Если вы хотите исключить какие-либо таблицы из дампа, не забудьте сделать схему этой таблицы, чтобы в будущем Вы ее могли восстановить на новом сервере, например исключим таблицу cdr из дампа и создадим ее схему:
pg_dump -U postgres mbillcz5054 -T cdr | gzip > mbillcz5054_backup_`date +%d.%m.%Y-%H.%M`_NO_cdr.sql.gz sudo -u postgres pg_dump -s mbillcz5054 -t cdr > schema-only.cdr.sql
- Перед восстановлением нужно создать базу данных mbillcz5054
sudo -u postgres createdb mbillcz5054
- Восстановление пользовательских ролей, групп
psql -U postgres -f globals-only.sql
- Восстановление данных БД mbillcz5054 из сжатого бекапа. Создание исключенной таблицы.
gunzip -c mbillcz5054_backup.sql.gz | psql -U postgres mbillcz5054 psql -U postgres mb11 -f cdr_create.sql
- Желательно запустить ANALYZE для свеже восстановленной базы данных.
mbillcz5054=# ANALYZE VERBOSE;
#!/bin/bash # Backup PostgreSQL DIR="/var/log/BACKUP/db_backup_mbill" TIMENAME=`date +%Y-%m-%d.%H.%M` PG_DUMP="/usr/bin/pg_dump" SUDO="/usr/bin/sudo" GZIP="/bin/gzip" ExcludeTable="-T cdr" DBNAME=mbillcz5054 BACKUP=$DIR/psql-$DBNAME-backup-$TIMENAME-db.sql.gz echo "$SUDO -u postgres $PG_DUMP $DBNAME $ExcludeTable | $GZIP > $BACKUP"; $SUDO -u postgres $PG_DUMP $DBNAME $ExcludeTable | $GZIP > $BACKUP; echo `/usr/bin/du -hsx $BACKUP`;
Запускаем еженедельно при помощи Anacron (если установлено) или Использование планировщика cron в Linux, для этого создаем символическую ссылку в директорию /etc/cron.weekly
# ln -s /scripts/psql_backup_zabbix /etc/cron.weekly/
Обучение PostgreSQL. Полный курс по работе с базой данных PostgreSQL!
Курс включает в себя все инструменты: управление доступом, резервное копирование, репликация, журналирование, работа со статистикой, способы масштабирование, а также работа PostgreSQL в облаках AWS, GCP, Azure и в Kubernetes. Проверь свои знания — пройди тестирование
pg_dumpall без запроса пароля — CodeRoad
Мы пытаемся автоматизировать резервное копирование всех баз данных PostgreSQL кластера, и мы решили использовать утилиту ‘pg_dumpall’. Но мы не могли найти способ выполнить ‘pg_dumpall’ без запроса пароля. Мы используем PostgreSQL-10.
Мы пытаемся выполнить следующую команду
pg_dumpall -U "username" -h "hostname" > "location"
Как мы можем автоматизировать pg_dumpall без запроса пароля? Пожалуйста, помогите нам в этом. Спасибо
postgresql postgresql-10 pg-dumpallПоделиться Источник jithin giri 18 мая 2018 в 04:58
1 ответ
- Что мне нужно, чтобы pg_dumpall работал без пароля?
Итак, я работаю над настройкой pg_dumpall , но не могу заставить его работать без ввода пароля. Я пытался: Как передать пароль в pg_dump? и последовал за этим сюда: http:/ / www.postgresql.org / docs/8.4 / static/libpq-pgpass.html и все равно не повезло. Моя струна и реакция: pg_dumpall -U user…
- Могу ли я выполнить `git pull` без запроса пароля, но `git push` с запросом пароля?
Я знаю, что могу использовать протокол SSH для выполнения git pull & git push без запроса пароля. Но я хочу более удобный способ. Могу ли я сделать git pull без запроса пароля, но git push с запросом пароля? Причина, по которой я хочу этого предпочтения: Я хочу самый простой способ git pull…
3
Я отвечаю на свой собственный вопрос
мы можем использовать файл «.pgpass», чтобы избежать запроса пароля
«СОЗДАНИЕ И ИСПОЛЬЗОВАНИЕ .PGPASS FILE
=====================================
Файл .pgpass позволит вам использовать инструменты postgres CLI, такие как psql и pg_dump, без необходимости вручную вводить пароль — вы можете использовать программы из скриптов без необходимости запускать их как незащищенный паролем пользователь.
Сначала создайте файл .pgpass
#nano /root/.pgpass
Согласно официальной документации формат файла выглядит следующим образом:
hostname:port:database:username:password
Файл поддерживает использование тегов # для комментариев и * для сопоставления с подстановочными знаками. Вот мой пример:
*:*:*:postgres:jerry_pass
Введите информацию о своей базе данных и сохраните ее.
Затем установите разрешения. Если их нет, то Postgres проигнорирует этот файл.
#chmod 600 /root/.pgpass
Теперь, как мы заставим postgres использовать его? Быстрое сканирование через справочную страницу psql показывает:
-w, --no-password
Никогда не выдавайте запрос пароля. Если сервер требует аутентификации по паролю, а пароль недоступен другими средствами, такими как файл .pgpass, попытка подключения завершится неудачей. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет пользователя для ввода пароля.
Вот несколько примеров использования:
#psql -d postgres -U postgres -w
#pg_dump -U postgres -w -Fc "
Поделиться jithin giri 18 мая 2018 в 05:12
Похожие вопросы:
PostgreSQL без запроса пароля : .pgpass игнорируется
Я пытаюсь включить root (Ubuntu 8.04) для использования команды psql без запроса пароля (для сценариев). Все работало нормально с PostgreSQL 8.3, но я мигрирую на PostgreSQL 8.4, и логин без пароля…
Запустите PostgreSQL CLI (psql) в скрипте bash без запроса пароля?
Запуск PostgreSQL CLI (psql) через скрипт bash в качестве пользователя postgres вызывает отправку запроса пароля, хотя я могу запустить его вручную без пароля. Когда я пытаюсь вставить -w в скрипт,…
Как выполнить mysqldump без запроса пароля?
Я хотел бы знать команду для выполнения mysqldump базы данных без запроса пароля. REASON: Я хотел бы запустить задание cron, которое принимает mysqldump базы данных один раз в день. Поэтому я не…
Что мне нужно, чтобы pg_dumpall работал без пароля?
Итак, я работаю над настройкой pg_dumpall , но не могу заставить его работать без ввода пароля. Я пытался: Как передать пароль в pg_dump? и последовал за этим сюда: http:/ / www.postgresql.org /…
Могу ли я выполнить `git pull` без запроса пароля, но `git push` с запросом пароля?
Я знаю, что могу использовать протокол SSH для выполнения git pull & git push без запроса пароля. Но я хочу более удобный способ. Могу ли я сделать git pull без запроса пароля, но git push с…
Как обновить pg_dumpall
Я пытаюсь мигрировать с Postgres 9.3 на 9.4, и я хотел бы запустить: pg_dumpall > outfile.sql Но я продолжаю получать эту ошибку: server version: 9.3.10; pg_dumpall version: 9.2.13 aborting…
PostgreSQL pg_dumpall теряет схемы
У меня есть база данных postgres, и я пытаюсь использовать pg_dumpall для создания полного сценария воспроизведения моей базы данных (также используя github для отслеживания версий файла дампа). Мой…
postgresql ошибка пароля pg_dumpall
postgresql 9.4 следуя этой шпаргалке http:/ / www.postgresonline.com/special_feature. php? sf_name=postgresql90_pg_dumprestore_cheatsheet&outputformat=html попытка резервного копирования вот моя…
pg_dumpall сохранить результаты на другой сервер?
Я использовал большую часть пространства на своем сервере Postgres и не могу сохранить результаты pg_dumpall на своей машине. Есть ли в любом случае возможность получить результаты pg_dumpall на…
pg_dumpall исключая некоторые таблицы
Я хочу получить полную резервную копию postgres 9.6. Включая пользователей и разрешения. Однако я хочу исключить некоторые таблицы. В pg_dump есть опция исключения некоторых таблиц ( -T )., однако в…
Резервное копирование через дамп и восстановление — база данных Azure для PostgreSQL на одиночном сервере
- Чтение занимает 4 мин
В этой статье
ОБЛАСТЬ ПРИМЕНЕНИЯ: База данных Azure для PostgreSQL — отдельный сервер База данных Azure для PostgreSQL — гибкий сервер
Базу данных PostgreSQL можно извлечь в файл дампа с помощью pg_dump. Затем необходимо использовать pg_restore для восстановления базы данных PostgreSQL из файла архива, созданного pg_dump.
Предварительные требования
Прежде чем приступить к выполнению этого руководства, необходимы следующие компоненты:
Создание файла дампа, содержащего необходимые для загрузки данные
Чтобы создать резервную копию базы данных PostgreSQL локально или на виртуальной машине, выполните следующую команду:
pg_dump -Fc -v --host=<host> --username=<name> --dbname=<database name> -f <database>.dump
Например, если имеется локальный сервер с базой данных testdb, запустите на нем следующее:
pg_dump -Fc -v --host=localhost --username=masterlogin --dbname=testdb -f testdb.dump
Восстановление данных в целевую базу данных
После создания целевой базы данных можно воспользоваться командой pg_restore с параметром --dbname, чтобы восстановить данные в целевую базу данных из файла дампа.
pg_restore -v --no-owner --host=<server name> --port=<port> --username=<user-name> --dbname=<target database name> <database>.dump
При включении параметра --no-owner все объекты, созданные во время восстановления, будут присвоены пользователю, отмеченному --username. Дополнительные сведения см. в документации по PostgreSQL.
Примечание
На серверах базы данных Azure для PostgreSQL соединения TLS и SSL включены по умолчанию. Если сервер PostgreSQL требует соединения TLS или SSL, но не содержит их, задайте переменную среды PGSSLMODE=require чтобы утилита pg_restore могла подключаться с помощью TLS. Без протокола TLS может появиться ошибка «FATAL: SSL connection is required. Please specify SSL options and retry.» (Критическая ошибка: необходимо соединение SSL. Настройте SSL и повторите попытку) В командной строке Windows выполните команду SET PGSSLMODE=require перед выполнением команды pg_restore. В Linux или Bash выполните команду export PGSSLMODE=require перед выполнением команды pg_restore.
В этом примере необходимо восстановить данные из файла дампа testdb.dump в базу данных mypgsqldb на целевом сервере mydemoserver.postgres.database.azure.com.
Ниже приведен пример использования этого pg_restore для одиночного сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin@mydemoserver --dbname=mypgsqldb testdb.dump
Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin --dbname=mypgsqldb testdb.dump
Оптимизация процесса миграции
Один из способов миграции существующей базы данных PostgreSQL в службу баз данных Azure для PostgreSQL — это резервное копирование базы данных в источнике и ее восстановление в Azure. Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
Примечание
Подробные сведения о синтаксисе см. в статьях о pg_dump и pg_restore.
Для резервного копирования
Создайте резервную копию с использованием параметра -Fc, чтобы можно было выполнять восстановление параллельно. Это позволит ускорить процесс. Пример:
pg_dump -h my-source-server-name -U source-server-username -Fc -d source-databasename -f Z:\Data\Backups\my-database-backup.dump
Для восстановления
Переместите файл резервной копии на виртуальную машину Azure в том же регионе, в котором находится сервер базы данных Azure для PostgreSQL, на который выполняется миграция. Выполните
pg_restoreиз этой виртуальной машины, чтобы снизить задержку в сети. Создание виртуальной машины с ускоренной сетью.Откройте файл дампа, чтобы убедиться в том, что инструкции создания индекса находятся после вставки данных. Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.
Для параллелизации восстановления необходимо выполнить восстановление с параметрами
-Fcи-j(с номером). Указанное вами число — это количество ядер на целевом сервере. Вы также можете попробовать установить вдвое большее количество ядер целевого сервера, чтобы оценить нагрузку.Ниже приведен пример использования этого
pg_restoreдля одиночного сервера:pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dumpНиже приведен пример использования этого
pg_restoreдля гибкого сервера:pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dumpФайл дампа также можно отредактировать, добавив в его начале команду
set synchronous_commit = off;, а в конце — командуset synchronous_commit = on;. Если не включить ее в конце, это может привести к последующей потере данных прежде, чем приложения изменят данные.Перед восстановлением рассмотрите возможность выполнения следующих действий на целевом сервере Базы данных Azure для PostgreSQL.
Отключите отслеживание производительности запросов. Эти статистические данные не требуются во время миграции. Это можно сделать, установив для параметров
pg_stat_statements.track,pg_qs.query_capture_modeиpgms_wait_sampling.query_capture_modeзначениеNONE.Используйте SKU с высоким объемом ресурсов вычисления и памяти, например модель 32 vCore Memory Optimized (32 виртуальных ядра с оптимизацией для операций в памяти), чтобы ускорить миграцию. Вы можете легко вернуться к предпочитаемому SKU после завершения восстановления. Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра
-jв командеpg_restore.Увеличьте число операций ввода-вывода в секунду на целевом сервере — это может улучшить производительность восстановления. Вы можете подготовить больше операций ввода-вывода в секунду, увеличив объем хранилища на сервере. Этот параметр необратим, но стоит принять во внимание, будет ли большее количество операций ввода-вывода в секунду полезным для вашей рабочей нагрузки в будущем.
Не забудьте проверить и протестировать эти команды в тестовой среде, прежде чем использовать их в рабочей среде.
Дальнейшие действия
Как легко обновить основную версию базы данных AWS RDS postgres?
Этим утром я занимался обновлением базы данных PostgreSQL на AWS RDS. Мы хотели перейти с версии 9.3.3 на версию 9.4.4. Мы «протестировали» обновление для промежуточной базы данных, но промежуточная база данных намного меньше и не использует Multi-AZ. Оказалось, что этот тест был довольно неадекватным.
Наша производственная база данных использует Multi-AZ. В прошлом мы выполняли незначительные обновления версий, и в этих случаях RDS сначала обновит резервный режим, а затем повысит его до мастерского. Таким образом, единственное время простоя составляет ~ 60 с во время аварийного переключения.
Мы предполагали, что то же самое произойдет и при обновлении основной версии, но как же мы ошиблись.
Некоторые подробности о нашей настройке:
- db.m3.large
- Обеспеченный IOPS (SSD)
- 300 ГБ памяти, из которых 139 ГБ используется
- У нас были обновления ОС RDS, мы хотели сделать пакетное обновление, чтобы минимизировать время простоя
Вот события RDS, зарегистрированные во время нашего обновления:
ЦП базы данных был максимально загружен между 08:44 и 10:27. Казалось, что большую часть этого времени RDS делала снимок перед обновлением и после обновления.
Документы AWS не предупреждают о таких последствиях, хотя из их прочтения становится ясно, что очевидным недостатком нашего подхода является то, что мы не создали копию производственной базы данных в настройке Multi-AZ и пытаемся обновить ее как пробный запуск
В целом это было очень неприятно, потому что RDS предоставил нам очень мало информации о том, что он делал и как долго это могло занять. (Опять же, пробный запуск помог бы …)
Кроме того, мы хотим извлечь уроки из этого инцидента, поэтому вот наши вопросы:
- Это нормально при обновлении основной версии на RDS?
- Если бы мы хотели сделать обновление основной версии в будущем с минимальным временем простоя, как бы мы поступили? Есть ли какой-нибудь умный способ использовать репликацию, чтобы сделать ее более прозрачной?
azure-docs.ru-ru/howto-migrate-using-dump-and-restore.md at master · MicrosoftDocs/azure-docs.ru-ru · GitHub
| title | description | author | ms.author | ms.service | ms.subservice | ms.topic | ms.date | ms.openlocfilehash | ms.sourcegitcommit | ms.translationtype | ms.contentlocale | ms.lasthandoff | ms.locfileid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Дамп и восстановление — база данных Azure для PostgreSQL — один сервер | Описывает, как извлечь базу данных PostgreSQL в файл дампа и выполнить восстановление из файла, созданного pg_dump в базе данных Azure для PostgreSQL-Single Server. | sr-msft | srranga | postgresql | migration-guide | how-to | 09/22/2020 | 16166183b56b371fe8338894f83dbacf2e659c53 | 772eb9c6684dd4864e0ba507945a83e48b8c16f0 | MT | ru-RU | 03/20/2021 | 103563561 |
[!INCLUDEapplies-to-postgres-single-flexible-server]
Можно извлечь базу данных PostgreSQL в файл дампа с помощью pg_dump и с помощью pg_restore восстановить базу данных PostgreSQL из файла архива, созданного pg_dump.
Предварительные требования
Прежде чем приступить к выполнению этого руководства, необходимы следующие компоненты:
Выполните указанные ниже действия, чтобы создать дамп базы данных PostgreSQL и восстановить ее.
Создание файла дампа, содержащего загружаемые данные, с помощью pg_dump
Чтобы создать резервную копию базы данных PostgreSQL локально или на виртуальной машине, выполните следующую команду:
pg_dump -Fc -v --host=<host> --username=<name> --dbname=<database name> -f <database>.dump
Например, если имеется локальный сервер с базой данных testdb.
pg_dump -Fc -v --host=localhost --username=masterlogin --dbname=testdb -f testdb.dump
Восстановите данные в целевую базу данных Azure для PostgreSQL с помощью pg_restore
После создания целевой базы данных можно воспользоваться командой pg_restore с параметром -d, —dbname, чтобы восстановить данные в целевую базу данных из файла дампа.
pg_restore -v --no-owner --host=<server name> --port=<port> --username=<user-name> --dbname=<target database name> <database>.dump
Если включить параметр —no-owner, все объекты, созданные во время восстановления, будут присвоены пользователю —username. Дополнительные сведения см. в официальной документации PostgreSQL по pg_restore.
[!NOTE] Если серверу PostgreSQL требуются подключения TLS/SSL (по умолчанию в базе данных Azure для серверов PostgreSQL), задайте переменную среды,
PGSSLMODE=requireчтобы pg_restore средство подключается к TLS. Без TLS ошибка может быть прочитанаFATAL: SSL connection is required. Please specify SSL options and retry.В командной строке Windows выполните команду
SET PGSSLMODE=requireперед выполнением команды pg_restore. В Linux или Bash выполните командуexport PGSSLMODE=requireперед выполнением команды pg_restore.
В этом примере восстановите данные из файла дампа testdb.dump в базу данных mypgsqldb на целевом сервере mydemoserver.postgres.database.azure.com.
Ниже приведен пример использования этого pg_restore для одного сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin@mydemoserver --dbname=mypgsqldb testdb.dump
Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin --dbname=mypgsqldb testdb.dump
Оптимизация процесса миграции
Один из способов миграции существующей базы данных PostgreSQL в службу «База данных Azure для PostgreSQL» — это резервное копирование базы данных в источнике и ее восстановление в Azure. Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
[!NOTE] Подробные сведения о синтаксисе см. в статьях о pg_dump и pg_restore.
Для резервного копирования
Создайте резервную копию с использованием параметра -Fc, чтобы вы могли выполнять восстановление параллельно, что позволит ускорить его. Пример:
pg_dump -h my-source-server-name -U source-server-username -Fc -d source-databasename -f Z:\Data\Backups\my-database-backup.dump
Для восстановления
Мы предлагаем переместить файл резервной копии на виртуальную машину Azure в том же регионе, где находится сервер Базы данных Azure для PostgreSQL, на который перемещается база данных, и выполнить команду pg_restore с этой виртуальной машины, чтобы уменьшить задержку сети. Мы также рекомендуем, чтобы виртуальная машина была создана с функцией ускорения работы в сети.
Это должно происходить по умолчанию, но откройте файл дампа, чтобы проверить, что инструкции создания индекса находятся после вставленных данных. Если это не так, переместите инструкции создания индекса после вставленных данных.
Для параллелизации восстановления необходимо выполнить восстановление с помощью коммутаторов-FC и-j # . # число ядер на целевом сервере. Также можно попробовать # установить в два раза больше, чем количество ядер целевого сервера, чтобы увидеть влияние. Пример:
Ниже приведен пример использования этого pg_restore для одного сервера:
pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dump
Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dump
Можно также изменить файл дампа, добавив команду set synchronous_commit = off; в начале и команду set synchronous_commit = on; в конце. Если не включить ее в конце, прежде чем приложения изменят данные, это может привести к последующей потере данных.
Перед восстановлением рассмотрите возможность выполнения следующих действий на целевом сервере Базы данных Azure для PostgreSQL.
Отключите отслеживание производительности запросов, так как эти статистические данные не нужны во время миграции. Вы можете сделать это, задав для pg_stat_statements.track, pg_qs.query_capture_mode и pgms_wait_sampling.query_capture_mode значение NONE.
Используйте номер SKU с высоким объемом ресурсов вычисления и памяти, например номер с оптимизацией для операций в памяти с 32 виртуальными ядрами, чтобы ускорить миграцию. Вы можете легко вернуться к предпочитаемому номеру SKU после завершения восстановления. Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра
-jв команде pg_restore.Увеличьте число операций ввода-вывода в секунду на целевом сервере. Это может улучшить производительность восстановления. Вы можете подготовить больше операций ввода-вывода в секунду, увеличив объем хранилища на сервере. Этот параметр необратим, но стоит принять во внимание, будет ли большее количество операций ввода-вывода в секунду полезным для вашей рабочей нагрузки в будущем.
Не забудьте проверить и протестировать эти команды в тестовой среде, прежде чем использовать их в рабочей среде.
Следующие шаги
Создание бэкапа базы PostgreSQL для Windows
В PostgreSQL есть утилита, которая создает дамп базы данных и называется она pg_dump. Для того чтобы автоматизировать процесс создания бэкапов баз PostgreSQL нужно будет создать bat-файл, который будет вызывать утилиту pg_dump и вызывать его с помощью планировщика заданий. Результатом выполнения такого сценария будет ежедневное копирование базы данных PostgreSQL, ведение журнала с информацией о датах и результатах выполнения, сохранение подробных сведений о ходе выполнения каждой резервной копии в отдельный текстовый файл и в случае неудачи отображение диалогового окна с сообщением.Содержимое bat-файла следующее:
REM ПРИМЕР СОЗДАНИЯ РЕЗЕРВНОЙ КОПИИ БАЗЫ ДАННЫХ POSTGRESQL CLS ECHO OFF CHCP 1251 REM Установка переменных окружения SET PGBIN=c:\Program Files\PostgreSQL\9.2.4-1.1C\bin SET PGDATABASE=ut SET PGHOST=localhost SET PGPORT=5432 SET PGUSER=postgres SET PGPASSWORD=123456 REM Смена диска и переход в папку из которой запущен bat-файл %~d0 CD %~dp0 REM Формирование имени файла резервной копии и файла-отчета SET DATETIME=%DATE:~6,4%-%DATE:~3,2%-%DATE:~0,2% %TIME:~0,2%-%TIME:~3,2%-%TIME:~6,2% SET DUMPFILE=%PGDATABASE% %DATETIME%.backup SET LOGFILE=%PGDATABASE% %DATETIME%.log SET DUMPPATH="Backup\%DUMPFILE%" SET LOGPATH="Backup\%LOGFILE%" REM Создание резервной копии IF NOT EXIST Backup MD Backup CALL "%PGBIN%\pg_dump.exe" --format=custom --verbose --file=%DUMPPATH% 2>%LOGPATH% REM Анализ кода завершения IF NOT %ERRORLEVEL%==0 GOTO Error GOTO Successfull REM В случае ошибки удаляется поврежденная резервная копия и делается соответствующая запись в журнале :Error DEL %DUMPPATH% MSG * "Ошибка при создании резервной копии базы данных. Смотрите backup.log." ECHO %DATETIME% Ошибки при создании резервной копии базы данных %DUMPFILE%. Смотрите отчет %LOGFILE%. >> backup.log GOTO End REM В случае удачного резервного копирования просто делается запись в журнал :Successfull ECHO %DATETIME% Успешное создание резервной копии %DUMPFILE% >> backup.log GOTO End :End
Справочную информацию о командах, испульзуемых в этом файле можно получить из командной строки набрав следующую команду: «[Имя команды] /?»
Многие использованные здесь команды достаточно распространены и известны, поэтому хочется акцентировать внимание на нескольких менее известных.
Строки 15, 16 выполняют переход в папку в которой находится файл «backup.bat». «%0» возвращает имя bat-файла; «%~d0» и «%~dp0» возвращают соответственно диск и путь к bat-файлу. Подробные сведения о работе с параметрами файла можно посмотреть по этой ссылке.
В строке 19 формируется строковое представление даты и времени в нужном формате. При формировании происходит обращение к переменным окружения DATE и TIME, которые хранят текстовое представление даты и времени соответственно. После имени переменной указывается строка вида «:~m,n», где m — позиция в строке, n — количество символов.
В строке 27 вызывается утилита резервного копирования pg_dump.exe. Вызов выполняется с применением команды CALL, это позволяет дождаться завершения утилиты и проанализировать результат выполнения. Вызов утилиты завершается строкой «2>%LOGPATH%». Эта строка означает что поток ошибок STDERR, номер которого 2, приложения pg_dump.exe перенаправляется в файл, имя которого сохранено в переменной окружения LOGPATH. Так как приложение pg_dump.exe выводит все сообщения в стандартный поток ошибок, то в файле LOGPATH будет сохранен подробный отчет о выполнении резервного копирования.
В строках 37 и 42 выполняется перенаправление вывода в файл backup.log. Перенаправление осуществляется оператором «>>». Различие между операторами «>» и «>>» в том, что первый каждый раз создает новый файл, затирая ранее записанные данные, а второй — дописывает данные в существующий файл. Таким образом можно вести журнал с подробными сведениями о результатах резервного копирования.
Проверяем как работает bat-файл. Если дампы базы создаются, то можно приступать к созданию задачи для планировщика заданий Windows.
Создаем задание, которое будет запускать bat-файл каждый день в ночное время.
Ежедневные бэкапы со временям породят проблему свободного пространства на жестком диске. Можно чистить ручками, но лучше уж автоматизацию сделать полной. Решается этот вопрос также созданием bat-файла и задачи в планировщике заданий Windows.
Содержимое bat-файла такое:
forfiles /p "E:\BACKUP\Backup" /S /D -5 /C "cmd /c del /f /a /q @file"
Здесь указана команда при выполнении которой будут удаляться файлы старше 5 дней.
В планировщике заданий можно создать задачу на исполнения этого bat-файла раз в неделю.
с использованием инструментов резервного копирования PostgreSQL: pg_dump & pg_dumpall
Резюме : в этом руководстве вы узнаете, как создавать резервные копии баз данных PostgreSQL с помощью инструментов pg_dump и pg_dumpall .
Резервное копирование баз данных — одна из важнейших задач администрирования баз данных. Перед резервным копированием баз данных вы должны рассмотреть следующие типы резервных копий:
- Полные / частичные базы данных
- И данные, и структуры, или только структуры
- Восстановление на определенный момент времени
- Восстановление производительности
PostgreSQL поставляется с pg_dump и pg_dumpall инструменты, которые помогут вам легко и эффективно создавать резервные копии баз данных.
Для тех, кто хочет увидеть команду для быстрого резервного копирования баз данных, вот она:
Язык кода: SQL (структурированный запрос Язык) (sql)
pg_dump -U username -W -F t database_name> c: \ backup_file.tar
В следующем разделе вы шаг за шагом научитесь создавать резервную копию одной базы данных, всех баз данных и только объектов базы данных.
Как сделать резервную копию одной базы данных
Для резервного копирования одной базы данных вы можете использовать инструмент pg_dump . pg_dump выгружает содержимое всех объектов базы данных в один файл.
Сначала перейдите в папку bin PostgreSQL:
Язык кода: SQL (язык структурированных запросов) (sql)
C: \> cd C: \ Program Files \ PostgreSQL \ 12 \ bin
Во-вторых, запустите программу pg_dump и используйте следующие параметры для резервного копирования базы данных dvdrental в файл dvdrental.tar в папке c: \ pgbackup \ .
Язык кода: SQL (язык структурированных запросов) (sql)
pg_dump -U postgres -W -F t dvdrental> c: \ pgbackup \ dvdrental.tar
Давайте рассмотрим параметры более подробно.
-U postgres : указывает пользователя для подключения к серверу базы данных PostgreSQL. В этом примере мы использовали postgres .
-W : заставляет pg_dump запрашивать пароль перед подключением к серверу базы данных PostgreSQL.После того, как вы нажмете Enter, pg_dump запросит пароль пользователя postgres .
-F : задает формат выходного файла, который может быть одним из следующих:
-
c: формат файла архива нестандартного формата -
d: архив в формате каталога -
t: tar -
p: текстовый файл сценария SQL).
В этом примере мы используем -F t , чтобы указать выходной файл как файл tar.
dvdrental : имя базы данных, резервную копию которой вы хотите создать.
> c: \ pgbackup \ dvdrental.tar — путь к выходному файлу резервной копии.
Как сделать резервную копию всех баз данных
Чтобы создать резервную копию всех баз данных, вы можете запустить отдельную команду pg_dump , указанную выше, последовательно или параллельно, если вы хотите ускорить процесс резервного копирования.
- Во-первых, из psql используйте команду
\ list, чтобы вывести список всех доступных баз данных в вашем кластере. - Во-вторых, создайте резервную копию каждой отдельной базы данных с помощью программы
pg_dump, как описано в предыдущем разделе.
Помимо программы pg_dump , PostgreSQL также предоставляет вам инструмент pg_dumpall , который позволяет создавать резервные копии всех баз данных одновременно. Однако не рекомендуется использовать этот инструмент по следующим причинам:
- Программа
pg_dumpallэкспортирует все базы данных, одну за другой, в один файл сценария, что не позволяет выполнить параллельное восстановление. Если вы создадите резервную копию всех баз данных таким образом, процесс восстановления займет больше времени. - Обработка дампа всех баз данных занимает больше времени, чем обработка каждой отдельной базы данных, поэтому вы не знаете, какой дамп каждой базы данных относится к определенному моменту времени.
Если у вас есть веская причина использовать pg_dumpall для резервного копирования всех баз данных, следующая команда:
Язык кода: SQL (Язык структурированных запросов) (sql)
pg_dumpall -U postgres> c: \ pgbackup \ all.sql
Параметры программы pg_dumpall аналогичны параметрам программы pg_dump .Эта команда пропускает параметр -W , чтобы не вводить пароль для каждой отдельной базы данных.
Как сделать резервную копию определений объектов базы данных
Иногда вы хотите сделать резервную копию только определений объектов базы данных, а не данных. Это полезно на этапе тестирования, когда вы не хотите перемещать тестовые данные в действующую систему.
Для резервного копирования объектов во всех базах данных, включая роли, табличные пространства, базы данных, схемы, таблицы, индексы, триггеры, функции, ограничения, представления, владения и привилегии, используйте следующую команду:
Язык кода: CSS (css)
pg_dumpall --schema -only> c: \ pgdump \ definitiononly.sql
Если вы хотите создать резервную копию только определения роли, используйте следующую команду:
Язык кода: CSS (css)
pg_dumpall --roles-only> c: \ pgdump \ allroles.sql
Если вы хотите создать резервную копию определения табличных пространств, используйте следующую команду:
Язык кода: CSS (css)
pg_dumpall --tablespaces-only> c: \ pgdump \ allroles.sql
Дополнительная информация
Было ли это руководство полезным?
Как получить работающее и полное резервное копирование и тестирование БД PostgreSQL
Я надеялся, что смогу получить четкий ответ о том, как обеспечить создание полной резервной копии Postgres, как в случае с MS SQL Server, а затем позаботиться об осиротевших пользователях.
Судя по тому, что я читал, и это могло быть неправильно, найти хороший блог PostgreSQL было непросто, поэтому, пожалуйста, не стесняйтесь рекомендовать мне некоторые из них, мне нужно выяснить, как это приложение работает, чтобы я мог доверять своим резервным копиям и Слони репликация. У меня был разработчик, восстановивший резервную копию, которую я взял с PgadminIII, через custom , directory и tar при выборе OID s, но он сказал, что две из них не загрузились, tar загрузились, но это было только каталог, а не данные.Я действительно в замешательстве.
- Я использую PGAdminIII, у него есть опции
pg_dumpиpg_dumpall. Я хочу вернуть всего , что мне нужно, чтобы протестировать восстановление этой базы данных где-нибудь и убедиться, что да, все данные, которые нам нужны, и наша резервная копия в порядке. В конце концов, я хочу написать сценарий автоматического восстановления, но по одному дню.
pg_dumpall , по-видимому, имеет параметр -globals , который должен резервировать все, но справка для pg_dumpall показывает -g, --globals-only дамп только глобальных объектов, без баз данных , не - -globals вариант.
Я думал, что pg_dumpall , по крайней мере, сделает резервную копию внешних ключей, но даже это кажется «вариантом». Согласно документации, даже с pg_dumpall мне нужно использовать параметр -o для резервного копирования внешних ключей, я не могу представить, когда я не хотел бы создавать резервные копии внешних ключей, и это будет иметь больше смысла по умолчанию параметры.
- Как мне позаботиться о пользователях-сиротах и убедиться, что у меня все есть? Я действительно хотел бы восстановить свой файл резервной копии на другом сервере и убедиться, что все работает.Если у кого-то есть предложения, как сделать настоящую резервную копию в PostgreSQL и восстановить, я был бы очень признателен.
У меня был сервер PostgreSQL, но я до сих пор не могу понять, почему приложение не выполняет резервное копирование OID s по умолчанию! Кажется, что в 99,9% случаев вы этого захотите.
ОБНОВЛЕНИЕ 1:
В документации Postgres упоминается, что опция globals , которую я искал, кажется, является опцией по умолчанию в этой версии, но для нее по-прежнему нужна опция -o .Если кто-то может проверить или дать мне пример команды для восстановления единой базы данных в другом месте со всем, что ей нужно, я был бы признателен.
Edit: сайт просит показать уникальность этого вопроса, отредактировав мой вопрос. Этот вопрос поднимает проблему и дает ясность в отношении OID в резервных копиях, разницы между глобальными и неглобальными, а также рекомендации по тестированию восстановления, чтобы убедиться, что резервная копия является хорошей, а не просто резервной копией. Благодаря ответам я смог выполнить резервное копирование, выяснить глобальные / oids и каждую ночь запускать тестовый процесс восстановления на Postgres с использованием заданий cron.Спасибо за помощь!
PostgreSQL Complete Database Backup — администраторы баз данных Stack Exchange
На этот вопрос уже есть ответ :
Закрыт 4 года назад.
Я пытался понять, как я могу полностью сделать резервную копию моей базы данных PostgreSQL.Я не видел ресурсов, которые объясняли бы, как сделать полную резервную копию.
Мне известны утилиты pg_dump и pg_dumpall. Синтаксис прост, но детали не очень понятны.
Похоже, что pg_dump поддерживает только «некоторые» таблицы для конкретной базы данных и никакой информации о конфигурации. Я предполагаю, что такие вещи, как разрешения и многое другое, не копируются. Таким образом, в случае полной переустановки базы данных PostgreSQL резервное копирование дампа не будет работать без значительной ручной настройки и настройки.
pg_dumpall выполняет резервное копирование еще нескольких вещей, чем pg_dump, но опять же в документации Postgres не содержится четкой информации о том, что еще не включено в резервную копию и что необходимо сделать резервную копию в дополнение к.
Мне нужно создать резервную копию всей информации о конфигурации PostgreSQL, таблиц, индексов, разрешений, схем и т. Д. В случае полной катастрофы, при условии, что я переустановлю ту же версию PostgreSQL, я не должен придется что-либо перенастраивать.
Мне наплевать, например, если индексы перестраиваются с нуля, если в резервной копии уже хранятся индексы…. подобные вещи для меня не имеют значения … Я просто хочу, чтобы база данных была в том же состоянии после восстановления, что и во время резервного копирования.
Я был бы признателен, если бы кто-нибудь мог составить список вещей, которые необходимо скопировать, чтобы получить полную резервную копию. Конечно, я был бы признателен, если бы вы порекомендовали некоторые инструменты вместе с некоторыми процедурами для различных вещей в списке. Пожалуйста, объясните, какие элементы из общего списка охватывают рекомендуемый вами инструмент и процедуру.
резервных копий PostgreSQL: что такое pg_dumpall?
PostgreSQL — это система управления базами данных с открытым исходным кодом, которую можно использовать для хранения или взаимодействия с данными любого приложения или веб-сайта.Если вы используете базу данных PostgreSQL для хранения информации о своем веб-сайте или приложении, важно, чтобы вы знали об инструментах или утилитах резервного копирования для PostgreSQL, чтобы защитить базу данных от потери данных. В этой статье мы рассмотрим некоторые утилиты PostgreSQL для резервного копирования ваших баз данных и их восстановления.
УстановкаPostgreSQL включает в себя утилиты резервного копирования, называемые pg_dump и pg_dumpall, для создания логических резервных копий ваших баз данных PostgreSQL. Это стандартные утилиты для создания переносимых резервных копий баз данных PostgreSQL.Мы также можем использовать эти инструменты для резервного копирования любых удаленных баз данных PostgreSQL.
Предварительные требования
Прежде чем мы начнем это руководство, убедитесь, что на вашем компьютере установлен PostgreSQL. Кроме того, у вас должно быть разрешение на чтение всей информации в базе данных.
Резервное копирование с использованием pg_dump
В этом примере мы будем запускать все команды от имени пользователя «postgres», который является пользователем по умолчанию для базы данных PostgreSQL и имеет необходимые разрешения для выполнения команд резервного копирования.Выполните следующую команду, чтобы переключить пользователя на postgres.
$ sudo su - postgres
Теперь вы можете использовать следующую команду для резервного копирования любой отдельной базы данных:
$ pg_dump mydb> /tmp/backups/postgres/mydb.sql
Приведенная выше команда является очень общей. Эта команда сгенерирует файл резервной копии в текстовом формате, который подходит для небольших баз данных, в которых меньше объектов. Но для больших баз данных это не подходит.Теперь взгляните на следующую команду:
$ pg_dump -U -W -F t mydb> /tmp/backups/postgres/mydb.tar
Рассмотрим эти флаги подробнее:
- -U параметр может использоваться для указания пользователя, который будет использоваться для подключения к удаленному серверу. Параметр
- -W запросит у пользователя пароль перед подключением к удаленному серверу.
- -F параметр определяет формат выходного файла резервной копии. Он может иметь несколько значений, как показано ниже.
- p: обычный текст SQL (по умолчанию)
- т: деготь
- d: каталог в формате архива
- c: Любой пользовательский формат архива
Утилита pg_dump — это не что иное, как клиентская программа.Следовательно, его можно запустить и из удаленной системы, если у вас есть доступ к серверу базы данных. Вы можете использовать параметр -h, чтобы указать строку хоста, и параметр -p, чтобы указать номер порта, на котором работает сервер PostgreSQL:
$ pg_dump -U-h -p >
Вы можете запустить следующую команду, чтобы увидеть список всех доступных опций pg_dump:
$ pg_dump -?
Резервное копирование с помощью pg_dumpall
Командаpg_dump может одновременно выполнять резервное копирование любой базы данных.Что, если мы хотим сделать резервную копию всех баз данных, которые есть на сервере PostgreSQL? Для этого есть два варианта.
- Выполните команду pg_dump для каждой базы данных по очереди.
- Используйте другой инструмент, предоставляемый PostgreSQL, под названием pg_dumpall, чтобы сделать резервную копию всех баз данных.
Выполните следующую команду, чтобы сделать резервную копию всех баз данных с помощью pg_dumpall:
$ pg_dumpall -F t> /tmp/backups/postgres/all_dbs.tar
Все параметры команды pg_dumpall аналогичны команде pg_dump.Вы также можете использовать эту команду для создания резервных копий только схем базы данных.
Резервное копирование только определений схемы
$ pg_dumpall - только схема> /tmp/backups/postgres/schemas/all_dbs.sql
Резервное копирование только определений ролей
$ pg_dumpall - только роли> /tmp/backups/postgres/roles/all_dbs.sql
Резервное копирование только определений табличных пространств
$ pg_dumpall - только tablespaces> /tmp/backups/postgres/tablespaces/all_dbs.sql
Однако иногда pg_dumpall может быть плохим вариантом для создания резервных копий по сравнению с командой pg_dump.
Недостатки команды pg_dumpall
- Команда pg_dumpall создает резервные копии каждой базы данных одну за другой в последовательном порядке, что может занять много времени, если ваши базы данных большие. Вот почему вы не можете выполнять параллельное восстановление баз данных. В случае команды pg_dump вы можете начать процесс восстановления, как только будет сгенерирован один файл резервной копии базы данных, что позволит вам запустить процесс резервного копирования и восстановления одновременно.
- Создание резервной копии всех баз данных вместе требует больше времени, чем резервное копирование одной базы данных, поэтому это может привести к увеличению времени простоя вашего сервера.
Восстановление дампа базы данных PostgreSQL
Мы можем импортировать дампы PostgreSQL двумя способами.
Восстановите базу данных с помощью psql
Если вы создали резервную копию, используя параметр по умолчанию, который представляет собой простой текстовый файл SQL, вы можете восстановить свою базу данных напрямую, используя следующую команду psql ::
$ psql -U <ИМЯ ПОЛЬЗОВАТЕЛЯ> <ИМЯ БД> <<ИМЯ РЕЗЕРВНОЙ КОПИИ> .sql
Например, вы можете восстановить только что созданный дамп так:
$ psql -U postgres new_dbПеред тем, как запустить указанную выше команду, убедитесь, что новая пустая база данных уже создана, поскольку эта команда не создаст новую базу данных, если она не существует. Вы можете запустить следующую команду, чтобы создать новую базу данных.
$ createdb -T template0 new_dbЕще одна вещь, которую следует сделать перед восстановлением базы данных, - это создать всех зависимых пользователей, которые владеют какими-либо объектами внутри базы данных.
Восстановите базу данных с помощью pg_restore
При создании резервной копии с помощью pg_dump или pg_dumpall, если вы выберете любой вариант формата, отличный от значения по умолчанию, вам придется использовать утилиту pg_restore для восстановления ваших баз данных.
$ pg_restore -d new_db /tmp/backups/postgres/mydb.tar -c -U postgresВот список некоторых опций, которые можно использовать с вышеуказанной командой:
- -c - удалить объекты базы данных перед ее воссозданием
- -C - Для создания новой базы данных для восстановления
- -F - предоставить формат файла резервной копии
- -e - для выхода из процесса при обнаружении какой-либо ошибки
Вы можете использовать следующую команду, чтобы увидеть все доступные параметры:
$ pg_restore -?Заключение
Для любой системы управления базами данных очень важно иметь правильные решения для резервного копирования или восстановления резервных копий.К счастью, PostgreSQL предоставляет встроенные функции для резервного копирования и восстановления баз данных. Если вы планируете использовать эти инструменты для создания резервных копий ваших баз данных PostgreSQL, обязательно проверяйте свои резервные копии через регулярные промежутки времени, восстанавливая их в некоторые фиктивные базы данных. Таким образом, его можно использовать для восстановления ваших баз данных во время кризиса без каких-либо проблем.
Резервное копирование всех баз данных в PostgreSQL
Введение
Резервное копирование базы данных - одна из наиболее важных задач при любом типе администрирования базы данных.Регулярное резервное копирование гарантирует, что любые данные, потерянные из-за повреждения, сбоев или нарушений, могут быть успешно восстановлены. В этом руководстве объясняется, как реализовать встроенные инструменты и параметры администрирования PostgreSQL, используемые для резервного копирования всей базы данных в PostgreSQL.
Предварительные требования для резервного копирования всей базы данных в PostgreSQL
- Сервер PostgreSQL должен быть правильно установлен, настроен и запущен.
Загрузите PostgreSQL для систем Linux и Windows здесь
Как использовать команду PostgreSQL pg_dump
Команду
pg_dumpнеобходимо запустить в терминале компьютера, на котором установлена база данных, и в командной строке на компьютере, где хранится база данных.Для резервного копирования базы данных PostgreSQL используется следующий код:
1
pg_dump -U dbusername -W -F t dbname> /desired/derictory/dump_file_name.tar
Как использовать формат расширения резервного копирования PostgreSQL
Для хранения резервной копии базы данных PostgreSQL можно использовать несколько форматов или расширений. Примеры включают:
- Формат
.tarдля tarball- Модель
.bakдля сжатого двоичного формата- Формат
.sqlдля дампа открытого текстаОбщие сведения о различных параметрах резервного копирования PostgreSQL pg_admin
Следующие параметры также могут использоваться для предоставления дополнительных инструкций при выполнении команды
pg_dump:
- Параметр
-Uуказывает конкретного пользователя, подключающегося к базе данных PostgreSQL.
Параметр
-Wтребует от пользователя ввода правильного пароля при подключении к серверу PostgreSQL.Параметр
-Fможет использоваться файлом резервной копии, как описано в разделе «Формат расширения резервной копии PostgreSQL» выше.Как сделать резервную копию одной базы данных в PostgreSQL
Понимая, как
pg_dumpможет помочь в выполнении резервного копирования базы данных, в этом разделе будет рассказано, как именно использовать командуpg_dumpдля резервного копирования базы данных.Сначала подключитесь к базе данных PostgreSQL с помощью интерактивной программы терминала PostgreSQL
psql.Затем перечислите текущую базу данных PostgreSQL в системе полностью, используя команду PostgreSQL\ l.Выполнить следующие команды в указанной последовательности:
Теперь выполните команду
\ l.Результат должен выглядеть следующим образом:
Отсюда решение о том, какую базу данных следует копировать, можно принять с помощью команды
testdatabase.Теперь введите команду
\ q, чтобы выйти из сеанса базы данных, а затем выполните следующий код в командной строке:
1
pg_dump -U risa testdatabase> / Users / risa / documents / demo_single_backup.sql;
Приведенный выше код инструктирует команду
pg_dumpсохранить резервную копию от имени пользователяrisaпо следующему пути:/Users/risa/documents/demo_single_backup.sqlИзображение ниже должно быть видно при переходе в указанный каталог:
Как сделать резервную копию всей базы данных в PostgreSQL
В предыдущем разделе рассказывалось, как сделать резервную копию одной базы данных PostgreSQL. В этом разделе объясняется, как сделать резервную копию всей информации, существующей в базе данных в PostgreSQL.Это достигается с помощью команды PostgreSQL
pg_dumpall, которая позволяет одновременно резервировать всю базу данных. Однако обратите внимание, что есть некоторые предостережения, которые следует принять во внимание перед использованием этого подхода.
Хотя очень удобно иметь возможность экспортировать всю базу данных сразу, использование файла сценария запрещает выполнение параллельного восстановления. Это означает, что некоторым процессам потребуется больше времени, чем обычно, для выполнения обратного действия, выполненного таким образом.
Помимо того, что дамп базы данных требует больше времени, нет способа определить, какой дамп для какой базы данных выполняется, пока процесс продолжается.
Синтаксис команды
pg_dumpallследующий:
1
pg_dumpall -U имя пользователя> /desired/derictory/dump_file_name.tar
Теперь выполните следующую команду для резервного копирования всей существующей базы данных в PostgreSQL:
1
pg_dump -U risa> / Users / risa / documents / demo_all_database_backup.sql;
Обратите внимание, что синтаксис для
pg-dumpallиpg_dumpпохож, но не идентичен. Однако обратите внимание, что опция-W, которая указываетpg_dumpзапрашивать пароль, использовалась как , а не .Результат выполнения команды
pg_dumpall:На приведенном выше изображении сравниваются два файла, которые были созданы в этом руководстве: один для одной резервной копии базы данных, а другой - для нескольких резервных копий базы данных.
Заключение
В этом руководстве объясняется, как создать резервную копию всей базы данных в PostgreSQL с помощью встроенных инструментов PostgreSQL
Обновлениеpg_dumpиpg_dumpall. В статье конкретно рассказывается, как использовать команду PostgreSQL pg_dump и использовать формат расширения резервного копирования PostgreSQL. В руководстве также объясняются параметры резервного копирования PostgreSQL pg_admin и способы резервного копирования как одной, так и нескольких баз данных в PostgreSQL. При выполнении резервного копирования помните, что синтаксис дляpg-dumpallиpg_dumpпохож, но не идентичен.PostgreSQL с использованием pg_dumpall - Блог о производительности баз данных Percona
Авинаш Валларапу2019-03-18T10: 59: 50-04: 00Существует несколько подходов к оценке необходимости обновления PostgreSQL. В этом сообщении блога мы рассмотрим вариант обновления базы данных postgres с помощью pg_dumpall. Поскольку этот инструмент также можно использовать для резервного копирования кластеров PostgreSQL, он также является допустимым вариантом для обновления кластера. Мы рассмотрим преимущества и недостатки этого подхода и покажем вам шаги, необходимые для обновления.
Это первая из серии «Обновление или миграция устаревшего PostgreSQL на более новые версии PostgreSQL», серия , в которой мы будем изучать различные способы выполнения обновления или миграции postgres. Кульминацией сериала станет практический веб-семинар, который будет показан 17 апреля (вы можете зарегистрироваться здесь).
Мы начинаем это путешествие с того, что предоставим вам наиболее простой способ продолжить обновление или миграцию PostgreSQL: перестроив всю базу данных из логической резервной копии.
Определение объема
Давайте определим, что мы подразумеваем под обновлением или миграцией PostgreSQL с помощью pg_dumpall.
Если вам нужно выполнить обновление PostgreSQL на одном сервере базы данных, мы будем называть это обновлением на месте или просто обновлением. В то время как процедура, которая включает в себя миграцию вашего сервера PostgreSQL с одного сервера на другой, в сочетании с обновлением со старой версии (скажем, 9.3) до более новой версии PostgreSQL (скажем, PG 11.2), может считаться миграцией.
Есть два способа выполнить это требование с помощью логических резервных копий:
- Использование pg_dumpall
- Использование pg_dumpall + pg_dump + pg_restore
Мы будем обсуждать здесь первый вариант (pg_dumpall), а обсуждение второго варианта оставим для нашей следующей публикации.
pg_dumpall
pg_dumpall можно использовать для получения дампа всего кластера базы данных в текстовом формате, включая все базы данных в кластере. Это единственный метод, который можно использовать для резервного копирования глобальных объектов, таких как пользователи и роли в PostgreSQL.
Конечно, у этого подхода к обновлению PostgreSQL есть свои преимущества и недостатки путем перестройки кластера базы данных с помощью pg_dumpall.
Преимущества использования pg_dumpall для обновления сервера PostgreSQL:
- Хорошо подходит для небольшого кластера базы данных.
- Обновление можно выполнить с помощью всего нескольких команд.
- Устраняет раздувание всех таблиц и сжимает таблицы до их абсолютных размеров.
Недостатки использования pg_dumpall для обновления сервера PostgreSQL:
- Не лучший вариант для баз данных огромного размера, так как это может привести к увеличению времени простоя.(Несколько ГБ или ТБ).
- Невозможно использовать параллельный режим. Резервное копирование / восстановление может использовать только один процесс.
- Требуется вдвое больше места на диске, так как это предполагает временное создание копии кластера базы данных для обновления на месте.
Давайте посмотрим на этапы выполнения обновления с помощью pg_dumpall:
- Установите новые двоичные файлы PostgreSQL на целевой сервер (который может быть таким же, как исходный сервер базы данных, если это обновление на месте).
- Для ОС семейства RedHat # yum install postgresql11 * Или же - В ОС Ubuntu / Debian # apt install postgresql11
- Для ОС семейства RedHat
# yum install postgresql11 *
или
- В ОС Ubuntu / Debian
# apt install postgresql11
- Завершите все операции записи на сервер базы данных, чтобы избежать потери данных / несоответствия между старой и новой версиями после обновления.
- Если вы выполняете обновление на том же сервере, создайте кластер, используя новые двоичные файлы в новом каталоге данных, и запустите его, используя порт, отличный от исходного. Например, если более старая версия PostgreSQL работает на порту 5432, запустите новый кластер на порту 5433. Если вы обновляете и переносите базу данных на другой сервер, создайте новый кластер, используя новые двоичные файлы на целевом сервере - кластер может нет необходимости запускать другой порт, отличный от порта по умолчанию, если это не ваше предпочтение.
$ / usr / pgsql-11 / bin / initdb -D каталог_новых_данных $ cd new_data_directory $ echo «порт = 5433» >> postgresql.auto.conf $ / usr / pgsql-11 / bin / pg_ctl -D начало_каталога_новых_данных
$ / usr / pgsql-11 / bin / initdb -D new_data_directory
$ cd new_data_directory
$ echo «port = 5433» >> postgresql.auto.conf
$ / usr / pgsql-11 / bin -D начало_каталога_новых_данных
- У вас может быть установлено несколько расширений в кластере PostgreSQL старой версии.Получите список всех расширений, созданных на исходном сервере базы данных, и установите их для новых версий. Вы можете исключить те, которые получаете с модулем contrib по умолчанию. Чтобы просмотреть список расширений, созданных и установленных на сервере базы данных, вы можете выполнить следующую команду.
$ psql -d имя_бд -c "\ dx"
$ psql -d имя_бд -c "\ dx"
Обязательно проверьте все базы данных в кластере, поскольку расширения, которые вы видите в одной базе данных, могут не совпадать со списком расширений, созданных в другой базе данных.- Подготовьте файл postgresql.conf для нового кластера. Тщательно подготовьте это, просмотрев существующий файл конфигурации сервера postgres более старой версии.
- Используйте pg_dumpall, чтобы сделать резервную копию кластера и восстановить ее в новом кластере.
- Команда на выгрузку всего кластера в файл. $ / usr / pgsql-11 / bin / pg_dumpall> /tmp/dumpall.sql - Команда для восстановления файла дампа в новый кластер (при условии, что он работает на порту 5433 того же сервера).$ / usr / pgsql-11 / bin / psql -p 5433 -f /tmp/dumpall.sql
- Команда на выгрузку всего кластера в файл.
$ / usr / pgsql-11 / bin / pg_dumpall> /tmp/dumpall.sql
- Команда для восстановления файла дампа в новый кластер (при условии, что он работает на порту 5433 того же сервера).
$ / usr / pgsql-11 / bin / psql -p 5433 -f /tmp/dumpall.sql
Обратите внимание, что я использовал новый pg_dumpall из новых двоичных файлов, чтобы сделать резервную копию.
Другой, более простой способ - использовать PIPE, чтобы не тратить время на создание файла дампа. Просто добавьте имя хоста, если вы выполняете обновление и миграцию.
$ pg_dumpall -p 5432 | psql -p 5433 Или же $ pg_dumpall -p 5432 -h исходный_сервер | psql -p 5433 -h целевой_сервер
$ pg_dumpall -p 5432 | psql -p 5433
Или
$ pg_dumpall -p 5432 -h исходный_сервер | psql -p 5433 -h целевой_сервер
- Запустите ANALYZE, чтобы обновить статистику каждой базы данных на новом сервере.
- Перезапустите сервер базы данных, используя тот же порт, что и у источника.
Наша следующая статья из этой серии предоставляет аналогичный способ обновления вашего сервера PostgreSQL, в то же время обеспечивая некоторую гибкость для продолжения изменений, подобных описанным выше. Следите за обновлениями!
-
Связанные
Изображение основано на фотографии Серджио Ортеги на UnsplashАвтор
Авинаш Валларапу
Авинаш Валларапу присоединился к Percona в мае 2018 года.До прихода в Percona Ави работал архитектором баз данных в OpenSCG в течение 2 лет и в течение 10 лет руководил администратором баз данных в Dell в таких технологиях баз данных, как PostgreSQL, Oracle, MySQL и MongoDB. Он провел несколько лекций и тренингов по PostgreSQL. У него хороший опыт выполнения проверок работоспособности архитектуры и миграции в среды PostgreSQL.
Фернандо Лаударес Камаргос
Фернандо Лаударес Камаргос присоединился к Percona в начале 2013 года, проработав 8 лет в канадской компании, специализирующейся на предоставлении услуг на основе технологий с открытым исходным кодом.Опыт работы Фернандо включает архитектуру, развертывание и обслуживание ИТ-инфраструктур на основе Linux, программного обеспечения с открытым исходным кодом и уровня виртуализации серверов. От базовых сервисов, таких как DHCP и DNS, до систем управления идентификацией, но также включая процедуры резервного копирования, инструменты управления конфигурацией и тонкие клиенты. Сейчас он сосредоточен на вселенной MySQL, MongoDB и PostgreSQL с особым интересом к пониманию тонкостей систем баз данных и регулярно вносит свой вклад в этот блог.Вы можете прочитать другие его статьи здесь.
Джобин Августин
Джобин Августин является экспертом по PostgreSQL и сторонником открытого исходного кода и имеет более 19 лет опыта работы в качестве консультанта, архитектора, администратора, писателя и инструктора по PostgreSQL, Oracle и другим технологиям баз данных. Он всегда был активным участником сообществ Open Source, и его основная сфера деятельности - производительность и оптимизация баз данных. Он участвует в различных проектах с открытым исходным кодом, ведет активный блогер и любит писать код на C ++ и Python.Джобин имеет степень магистра компьютерных приложений и присоединился к Percona в 2018 году в качестве старшего инженера службы поддержки. До прихода в Percona он 2 года проработал в OpenSCG в качестве архитектора и был частью основной команды BigSQL, полного предложения по распространению PostgreSQL. До своей работы в OpenSCG Джобин работал в Dell в качестве старшего советника по базам данных в течение 10 лет и 5 лет в TCS / CMC.
Николай Ихалайнен
Николай пришел в Percona в декабре 2010 года, проработав несколько лет в самом популярном кинотеатре в России.Пока он был там, Николай и небольшая команда разработчиков отвечали за масштабирование сайта до уровня, который теперь обслуживает более миллиона уникальных посетителей в день. До этого он работал в нескольких других компаниях, включая NetUp, которая предоставляет решения для биллинга ISP и IPTV, и eHouse, старейшую российскую компанию электронной коммерции. Николай имеет большой опыт как в системном администрировании, так и в программировании. Его опыт включает обширную практическую работу с широким спектром технологий, включая SQL, MySQL, PHP, C, C ++, Python, Java, XML, настройку параметров ОС (Linux, Solaris), методы кэширования (e.g., memcached), RAID, файловые системы, SMTP, POP3, Apache, сетевые и сетевые форматы данных и многие другие. Он является экспертом в области масштабируемости, производительности и надежности системы.
Справочная страница Ubuntu: pg_dumpall - извлечение кластера базы данных PostgreSQL в файл сценария
Предоставлено: postgresql-client-9.5_9.5.2-1_amd64НАИМЕНОВАНИЕpg_dumpall - извлечь кластер базы данных PostgreSQL в файл скриптаОБЗОРpg_dumpall [ вариант подключения ...] [ option ...]ОПИСАНИЕpg_dumpall - утилита для записи («дампинга») всех баз данных PostgreSQL кластера. в один файл сценария. Файл сценария содержит команды SQL, которые можно использовать в качестве входных данных для psql (1) для восстановления баз данных. Он делает это, вызывая pg_dump (1) для каждой базы данных в кластер. pg_dumpall также выгружает глобальные объекты, общие для всех баз данных. (pg_dump не сохраняет эти объекты.) В настоящее время сюда входит информация о базе данных пользователи и группы, табличные пространства и свойства, такие как разрешения на доступ, которые применяются к базы данных в целом. Поскольку pg_dumpall читает таблицы из всех баз данных, вам, скорее всего, придется подключиться как суперпользователя базы данных, чтобы произвести полный дамп. Также вам понадобится суперпользователь привилегии для выполнения сохраненного сценария, чтобы иметь возможность добавлять пользователей и группы, и для создания баз данных. Скрипт SQL будет записан на стандартный вывод.Используйте параметр [-f | file] или оболочку операторы, чтобы перенаправить его в файл. pg_dumpall необходимо несколько раз подключиться к серверу PostgreSQL (один раз для каждой базы данных). Если вы используете аутентификацию по паролю, он будет запрашивать пароль каждый раз. Удобно в таких случаях используйте файл ~ / .pgpass. См. Раздел 31.15, «Файл паролей» в документация для получения дополнительной информации.ОПЦИИСледующие параметры командной строки управляют содержимым и форматом вывода. -а - только данные Выгрузите только данные, а не схему (определения данных). -c - чистая Включите команды SQL для очистки (удаления) баз данных перед их воссозданием. DROP команд для ролей и табличных пространств. -f имя_файла --file = имя_файла Отправить вывод в указанный файл. Если это не указано, используется стандартный вывод. -г - только глобальные Дамп только глобальных объектов (ролей и табличных пространств), без баз данных. -o --oids Дамп идентификаторов объектов (OID) как часть данных для каждой таблицы. Используйте эту опцию, если ваше приложение каким-то образом ссылается на столбцы OID (например, во внешнем ключе ограничение). В противном случае эту опцию использовать не следует. -O - не владелец Не выводите команды для установки владения объектами в соответствии с исходной базой данных.От по умолчанию, pg_dumpall выдает ALTER OWNER или SET SESSION AUTHORIZATION операторов для установки владение созданными элементами схемы. Эти операторы не сработают, если сценарий запускается, если он не запущен суперпользователем (или тем же пользователем, которому принадлежат все объекты в сценарии). Сделать скрипт, который может быть восстановлен любым пользователем, но даст это право собственности пользователя на все объекты, указать -O . -r - только ролики Дамп только ролей, без баз данных или табличных пространств. -с - только схема Выгружать только определения объекта (схему), но не данные. -S имя пользователя --superuser = имя пользователя Укажите имя пользователя суперпользователя, которое будет использоваться при отключении триггеров. Это актуально только если --disable-triggers . (Обычно это лучше не указывать, а вместо этого запустите получившийся скрипт от имени суперпользователя.) -т - только табличные пространства Дамп только табличных пространств, без баз данных или ролей. -v - словесно Задает подробный режим. Это заставит pg_dumpall выводить время начала / остановки в файл дампа и сообщения о ходе выполнения до стандартной ошибки. Также будет включен подробный вывод в pg_dump. -В - версия Распечатайте версию pg_dumpall и выйдите.-х - без привилегий --no-acl Запретить сброс прав доступа (команды предоставления / отзыва). - двоичное обновление Эта опция предназначена для использования утилит обновления на месте. Его использование для других целей не рекомендуется и не поддерживается. Поведение опции может измениться в будущих выпусках без предупреждения. - вставки-колонны - атрибуты-вставки Вывести данные в виде команд INSERT с явными именами столбцов (INSERT INTO таблица ( столбец , ...) ЗНАЧЕНИЯ ...). Это сделает восстановление очень медленным; в основном это полезно для изготовления дампы, которые можно загружать в базы данных, отличные от PostgreSQL. - отключение котировки в долларах Эта опция отключает использование долларовых кавычек для тел функций и заставляет их заключаться в кавычки с использованием стандартного строкового синтаксиса SQL. - отключение-триггеры Эта опция актуальна только при создании дампа только с данными. Он указывает pg_dumpall включить команды для временного отключения триггеров в целевых таблицах, пока данные перезагружаются.Используйте это, если у вас есть проверки ссылочной целостности или другие триггеры. в таблицах, которые вы не хотите вызывать во время перезагрузки данных. В настоящее время команды, выдаваемые для --disable-triggers , должны выполняться от имени суперпользователя. Так, вы также должны указать имя суперпользователя с -S , или, желательно, будьте осторожны при запуске получившийся скрипт как суперпользователь. - если существует Используйте условные команды (например, добавьте предложение IF EXISTS) для очистки баз данных и других объекты.Этот параметр недопустим, если не указан также --clean . - вставки Вывести данные в виде команд INSERT (вместо COPY ). Это сделает восстановление очень медленным; в основном это полезно для создания дампов, которые могут быть загружены в базы данных, отличные от PostgreSQL. Обратите внимание, что восстановление может полностью завершиться неудачно, если вы изменили порядок столбцов. В --column-insertts безопаснее, хотя и медленнее. --lock-wait-timeout = тайм-аут Не ждите бесконечно, чтобы получить блокировки разделяемой таблицы в начале дампа. Вместо этого выполнить сбой, если невозможно заблокировать таблицу в течение указанного времени ожидания . Тайм-аут может должен быть указан в любом из форматов, принятых в SET statement_timeout . Допустимые значения варьируются в зависимости от версии сервера, с которого выполняется дамп, но целое число миллисекунды принимаются всеми версиями начиная с 7.3. Этот параметр игнорируется, когда дамп с сервера до 7.3. - этикеток без защиты Не сбрасывайте защитные наклейки. - без табличных пространств Не выводите команды для создания табличных пространств и не выбирайте табличные пространства для объектов. С участием эта опция, все объекты будут созданы в любом табличном пространстве, используемом по умолчанию во время восстановить. - данные таблицы без регистрации Не выгружайте содержимое незарегистрированных таблиц.Эта опция не влияет на то, не выгружаются определения таблиц (схемы); он только подавляет сброс таблицы данные. --цитировать все идентификаторы Принудительное цитирование всех идентификаторов. Это может быть полезно при сбросе базы данных для переход на будущую версию, в которой могли быть добавлены дополнительные ключевые слова. - использование-установка-авторизация-сеанс Вывод стандартного SQL SET SESSION AUTHORIZATION команд вместо ALTER OWNER команд для определения права собственности на объект.Это делает дамп более совместимым со стандартами, но в зависимости от истории объектов в дампе может не восстановиться должным образом. -? - справка Показать справку об аргументах командной строки pg_dumpall и выйти. Следующие параметры командной строки управляют параметрами подключения к базе данных. -d соединитель --dbname = connstr Задает параметры, используемые для подключения к серверу, в виде строки подключения.Видеть Раздел 31.1.1, «Строки подключения», в документации для получения дополнительной информации. Параметр называется --dbname для согласованности с другими клиентскими приложениями, но поскольку pg_dumpall необходимо подключиться ко многим базам данных, имя базы данных в соединении строка будет проигнорирована. Используйте параметр -l, чтобы указать имя базы данных, используемой для дампа глобальные объекты и выяснить, какие другие базы данных следует выгружать. -h хост --host = хост Задает имя хоста компьютера, на котором работает сервер базы данных.Если значение начинается с косой черты, оно используется как каталог для сокета домена Unix. В по умолчанию берется из переменной среды PGHOST , если она установлена, иначе домен Unix попытка подключения к сокету. -l имя_бд --database = dbname Задает имя базы данных, к которой нужно подключиться для сброса глобальных объектов и обнаружение, какие другие базы данных следует сбросить.Если не указано иное, postgres будет использоваться база данных, а если она не существует, будет использоваться template1. -p порт --port = порт Задает TCP-порт или расширение файла локального сокета домена Unix, на котором сервер прослушивает соединения. По умолчанию используется переменная среды PGPORT , если она установлена, или встроенное значение по умолчанию. -U имя пользователя --username = имя пользователя Имя пользователя для подключения. -w - без пароля Никогда не запрашивайте пароль. Если сервер требует аутентификации по паролю и пароль недоступен другими способами, такими как файл .pgpass, соединение попытка не удастся. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет пользователей. присутствует для ввода пароля. -W - пароль Заставьте pg_dumpall запрашивать пароль перед подключением к базе данных.Эта опция никогда не является существенной, поскольку pg_dumpall автоматически запрашивает пароль, если сервер требует аутентификации по паролю. Однако pg_dumpall потратит впустую попытка подключения, обнаруживающая, что серверу нужен пароль. В некоторых случаях это стоит набрать -W , чтобы избежать лишних попыток подключения. Обратите внимание, что запрос пароля будет появляться снова для каждой базы данных, которая будет выгружена. Обычно лучше создать ~ /.pgpass, чем полагаться на ввод пароля вручную. --role = имя роли Задает имя роли, которая будет использоваться для создания дампа. Эта опция заставляет pg_dumpall введите команду SET ROLE rolename после подключения к базе данных. Это полезно, когда аутентифицированный пользователь (указанный как -U ) не имеет прав, необходимых для pg_dumpall, но может переключиться на роль с необходимыми правами.Некоторые установки имеют политику против входа непосредственно в качестве суперпользователя, и использование этой опции позволяет дампам быть сделано без нарушения политики.ОКРУЖАЮЩАЯ СРЕДАPGHOST PGOPTIONS PGPORT PGUSER Параметры подключения по умолчанию Эта утилита, как и большинство других утилит PostgreSQL, также использует переменные среды поддерживается libpq (см. раздел 31.14, «Переменные среды», в документации).ПРИМЕЧАНИЯПоскольку pg_dumpall вызывает внутри себя pg_dump, некоторые диагностические сообщения будут относиться к pg_dump. После восстановления целесообразно запустить ANALYZE для каждой базы данных, чтобы оптимизатор статистика. Вы также можете запустить vacuumdb -a -z для анализа всех баз данных. pg_dumpall требует, чтобы все необходимые каталоги табличных пространств существовали до восстановления; в противном случае создание базы данных не удастся для баз данных в расположениях, отличных от расположения по умолчанию.ПРИМЕРЫЧтобы выгрузить все базы данных: $ pg_dumpall > db.out Чтобы перезагрузить базы данных из этого файла, вы можете использовать: $ psql -f db.out postgres (Неважно, к какой базе данных вы подключаетесь, поскольку файл сценария, созданный pg_dumpall будет содержать соответствующие команды для создания и подключения к сохраненному базы данных.